Hermes Agent 工具系統實戰解析:40+ 工具為什麼不用配置表
整理版優先睇
Hermes Agent 嘅工具系統:自註冊、單例註冊表,40+工具唔使配置表就管理得井井有條
呢篇文章係術哥對 Hermes Agent(Nous Research 開源嘅自進化 AI Agent 框架)工具系統嘅深度拆解。術哥係專注 AI 編程同智能體嘅技術實踐者,佢翻曬源碼同社區討論,發現呢個系統嘅設計好值得琢磨:一個單例註冊表、AST 分析自動發現、import 即註冊嘅機制,將 40+ 內置工具管理得井井有條。文章旨在解答『點解 Hermes 可以咁快擴張到 14.9 萬 Star』,並畀出源碼層面嘅實證。
整體結論係:呢套架構唔係複雜嘅設計模式,而係『每個工具自己管自己,註冊表統一收口』嘅簡單思路。正因為簡單,所以好擴展、好調試、好理解。術哥從 4 層調用鏈、ToolRegistry 核心結構、自註冊模式、工具調度流程、Toolset 分組組合,到最佳實踐,逐層拆解,話畀你聽點解呢個系統咁高效。
如果你正在整 Agent 框架,或者想畀 Hermes 寫自定義工具,呢篇文嘅源碼分析同實踐建議可以直接用嚟參考。術哥特別提醒:工具邊界要清晰、結果大小要控制、錯誤要用結構化 JSON 返回、check_fn 一定要加——呢啲細節決定咗 Agent 系統嘅穩定度。
- 結論:import 即註冊模式令新增工具唔使改任何配置文件,自動發現同註冊,開發效率極高。
- 方法:ToolRegistry 單例統一管理所有工具嘅 Schema、handler、可用性檢查,分層清晰,無交叉依賴。
- 差異:相比其他框架需要手動註冊或配置表,Hermes 用 AST 分析自動導入有註冊嘅模塊,減低維護成本。
- 啟發:工具邊界設計(一個工具做一件事)、結果大小控制(100K chars)、錯誤處理(結構化 JSON)等做法值得借鏡。
- 可行動點:寫自定義工具時,直接用 registry.register() 註冊,配合 check_fn 檢查依賴,唔使搞複雜繼承或裝飾器。
內容結構
tools/*.py ← 各工具文件(模塊導入時自注冊) ↓ register()tools/registry.py ← 單例註冊中心(ToolRegistry) ↓ get_definitions() / dispatch()model_tools.py ← 編排層(發現 + Schema 提供 + 調度) ↓ resolve_toolset()toolsets.py ← Toolset 定義(工具分組、組合) ↓run_agent.py/cli.py ← 入口(消費工具定義,驅動 Agent Loop)4 層調用鏈:各層職責獨立
Hermes Agent 嘅工具系統分成 4 層,每一層職責清晰,冇交叉依賴,亦冇上帝類。由底層嘅 tools/*.py 工具文件、registry.py 單例註冊中心、model_tools.py 編排層、toolsets.py 工具集定義,到最上層嘅 run_agent.py/cli.py 入口,各層各管各嘅。
- tools/*.py:每個工具文件喺模塊末尾直接調用 registry.register(),import 就自動註冊。
- registry.py:ToolRegistry 單例,集中管理所有工具嘅 Schema、handler、check_fn,提供發現同調度接口。
- model_tools.py:編排層,負責工具發現、提供 Schema 畀模型,同埋調度 dispatch()。
- toolsets.py:定義工具分組組合,支援 includes 遞歸同鑽石依賴去重。
單例註冊表 + import 即註冊
核心係 ToolRegistry 模塊級單例,每個工具註冊成 ToolEntry 對象,包含 name、toolset、schema、handler、check_fn、requires_env 等字段。註冊時有防護機制:唔同 toolset 嘅同名工具會被拒絕,除非係 MCP 工具刷新或顯式 override。呢個設計防止插件意外覆蓋內置工具。
自註冊模式靠 discover_builtin_tools() 實現:先用 AST 分析 .py 文件,淨係 import 嗰啲模塊頂層有 registry.register() 調用嘅文件。新增工具文件完全唔使改任何註冊表或配置,放喺 tools/ 目錄下就會被自動發現。
從 Function Call 到結果:參數強轉、異步橋接、錯誤脱敏
- 1 Agent Loop 收到模型 Function Call,調用 handle_function_call()。
- 2 coerce_tool_args() 進行參數類型強轉,例如將 string '42' 轉做 integer,將 bare value 轉做 array。
- 3 執行 pre_tool_call hook(插件攔截),然後 registry.dispatch() 路由到對應 handler。
- 4 如果工具係異步(is_async=True),用 _run_async() 橋接:CLI 主線程用持久化事件循環,工作線程每線程一個循環,避免「Event loop is closed」錯誤。
- 5 執行後置 hook 同 transform_tool_result,最後返回 JSON 字符串。
錯誤處理方面,工具執行出錯唔會拋異常,而係返回結構化 JSON。dispatch() 裏面 catch Exception,用 _sanitize_tool_error() 剝離 XML 標籤、CDATA 等 framing token,防止幹擾模型上下文。呢個細節顯示 Hermes 團隊對安全嘅重視。
Toolset 分組組合:用 includes 複用,按場景分類
toolsets.py 定義咗 TOOLSETS 字典,每個 toolset 包含 tools(直接工具)同 includes(組合其他 toolset)。支援遞歸解析同鑽石依賴去重。例如 hermes-gateway 組合咗所有平台工具集,平台之間共享核心工具列表但唔會重複。
運行時可以用 create_custom_toolset() 動態創建,同靜態定義完全等價。最佳實踐係按場景分組,例如 'debugging' 組合 'web' 同 'file','safe' 組合 'web'、'vision'、'image_gen' 但排除 terminal。
- 工具邊界設計:一個工具做一件事,例如 read_file、write_file、patch、search_files 獨立,唔用 action 參數。
- 結果大小控制:設置 max_result_size_chars(默認 100,000),防止撐爆上下文窗口。
- 錯誤處理模式:用 tool_error() 返回結構化 JSON,唔好拋異常。
- check_fn 必須加:依賴外部狀態嘅工具(如 Docker、API Key)一定要提供 check_fn,避免模型調用失敗浪費 Token。
- MCP 集成:MCP 工具動態註冊到 registry,toolset 名為 mcp-<server_name>,同內置工具完全等價。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 120 篇,Hermes Agent 最佳實戰「2026」系列第 3 篇
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注喺 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
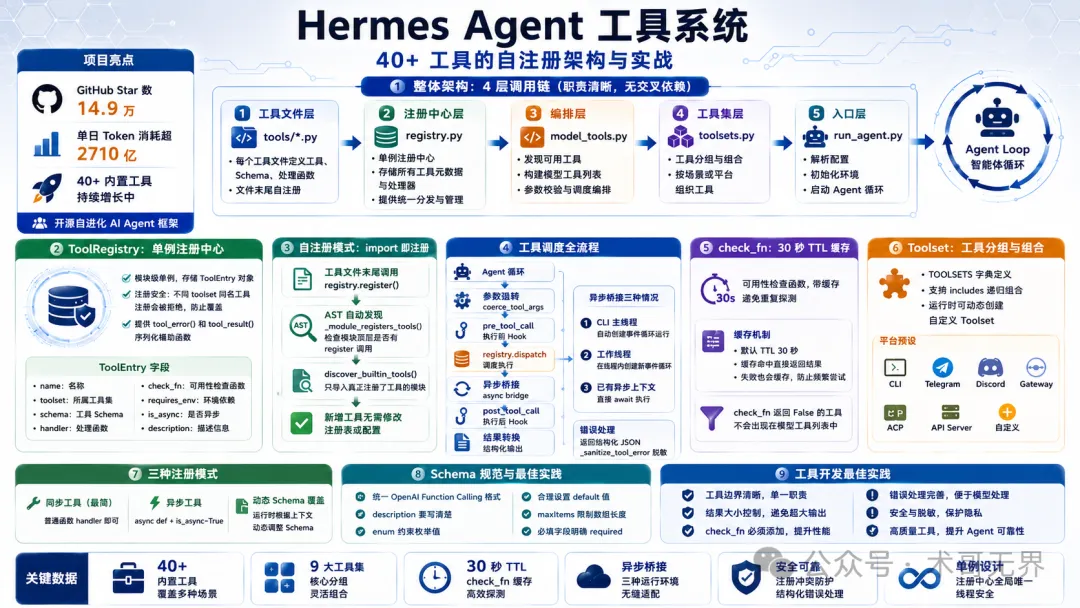
圖 1:Hermes Agent 工具系統全景
GitHub 上一個唔夠一年嘅項目,Star 數衝到 14.9 萬。2026 年 5 月 9 日,佢嘅單日 Token 消耗超過 2710 億,喺 OpenRouter 排行榜上首次登頂。
呢個係 Hermes Agent - Nous Research 開源嘅自進化 AI Agent 框架。我睇咗一圈源碼同社區討論,發現佢工具系統嘅設計相當值得研究:一個單例註冊表、AST 分析自動發現、import 即註冊嘅機制,將 40+ 內置工具管理得井井有條。
說明:本文內容係基於 Hermes Agent 源碼(NousResearch/hermes-agent)同官方文檔分析整理而成,源碼分析係基於筆者本地倉庫版本。文中嘅配置模板同參數建議僅供參考,實際效果請以你嘅業務數據同環境測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
呢篇文章就拆解下佢嘅 Tools & Toolsets 系統,睇下呢套架構到底係點運作嘅。
1. 整體架構:4 層調用鏈
Hermes Agent 嘅工具系統分成 4 層,每一層職責清晰:
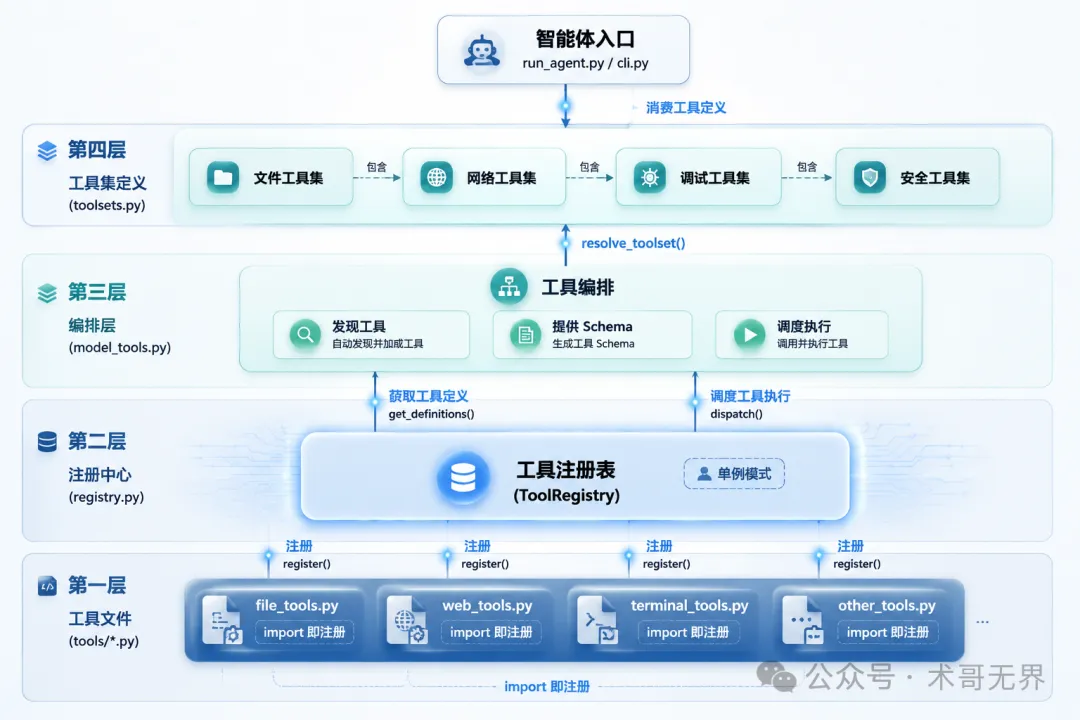
圖 2:Hermes Agent 工具系統 4 層架構
tools/*.py ← 各工具文件(模塊導入時自注冊)
↓ register()
tools/registry.py ← 單例註冊中心(ToolRegistry)
↓ get_definitions() / dispatch()
model_tools.py ← 編排層(發現 + Schema 提供 + 調度)
↓ resolve_toolset()
toolsets.py ← Toolset 定義(工具分組、組合)
↓
run_agent.py/cli.py ← 入口(消費工具定義,驅動 Agent Loop)
呢 4 層各管各嘅。tools/*.py 淨係負責註冊自己,registry.py 淨係負責存取,model_tools.py 做編排調度,toolsets.py 負責分組組合。冇交叉依賴,亦冇上帝類。
2. ToolRegistry:一個單例管曬所有工具
2.1 核心數據結構
tools/registry.py 係整個工具系統嘅中樞。核心類 ToolRegistry,模塊級單例:
# 模塊級單例
registry = ToolRegistry()
每個工具註冊入嚟,存嘅係 ToolEntry 對象。源碼入面嘅定義:
class ToolEntry:
__slots__ = (
"name", "toolset", "schema", "handler", "check_fn",
"requires_env", "is_async", "description", "emoji",
"max_result_size_chars", "dynamic_schema_overrides",
)
每個字段用嚟做咩:
name | |
toolset | file、web) |
schema | |
handler | |
check_fn | |
requires_env | |
is_async | |
max_result_size_chars | |
dynamic_schema_overrides |
2.2 註冊安全機制
register() 方法有一套防護邏輯,源碼入面寫得好清楚:
def register(self, name, toolset, schema, handler, ..., override=False):
existing = self._tools.get(name)
if existing and existing.toolset != toolset:
# MCP-to-MCP 允許覆蓋(服務器刷新場景)
both_mcp = (existing.toolset.startswith("mcp-")
and toolset.startswith("mcp-"))
if both_mcp:
pass# 允許
elif override:
pass# 顯式允許(插件場景)
else:
# 拒絕 - 防止意外覆蓋內置工具
logger.error("Tool registration REJECTED: ...")
return
講白咗就係:唔同 toolset 嘅同名工具註冊會被拒絕。除非你係 MCP 工具刷新,或者顯式傳咗 override=True。呢個設計防止咗插件或 MCP 服務器不小心覆蓋內置工具。
2.3 兩個輔助函數
源碼入面仲提供咗 tool_error() 和 tool_result() 兩個序列化輔助函數,唔使每個 handler 都手寫 json.dumps():
def tool_error(message, **extra) -> str:
result = {"error": str(message)}
if extra:
result.update(extra)
return json.dumps(result, ensure_ascii=False)
def tool_result(data=None, **kwargs) -> str:
if data is not None:
return json.dumps(data, ensure_ascii=False)
return json.dumps(kwargs, ensure_ascii=False)
用起嚟好簡潔:return tool_error("file not found") 或者 return tool_result({"content": text})。
3. 自註冊模式:import 即註冊
呢個係 Hermes 工具系統入面好有意思嘅設計。
3.1 模塊級註冊
每個工具文件喺模塊尾直接調用 registry.register()。模塊俾人 import 嘅時候,Python 執行模塊級代碼,註冊就自動完成咗。
拿 tools/file_tools.py 舉例(源碼尾,第 1169-1172 行):
from tools.registry import registry, tool_error
registry.register(name="read_file", toolset="file", schema=READ_FILE_SCHEMA,
handler=_handle_read_file, check_fn=_check_file_reqs,
emoji="📖", max_result_size_chars=100_000)
registry.register(name="write_file", toolset="file", schema=WRITE_FILE_SCHEMA,
handler=_handle_write_file, check_fn=_check_file_reqs,
emoji="✍️", max_result_size_chars=100_000)
registry.register(name="patch", toolset="file", schema=PATCH_SCHEMA,
handler=_handle_patch, check_fn=_check_file_reqs,
emoji="🔧", max_result_size_chars=100_000)
registry.register(name="search_files", toolset="file", schema=SEARCH_FILES_SCHEMA,
handler=_handle_search_files, check_fn=_check_file_reqs,
emoji="🔎", max_result_size_chars=100_000)
四個文件操作工具,四行註冊代碼。冇任何裝飾器、冇繼承、冇配置文件。直來直去。
3.2 AST 分析 + 動態導入
但問題嚟咗:邊個嚟 import 呢啲文件?
答案在 discover_builtin_tools() 函數入面。佢唔係冇條件 import 所有 .py 文件,而係先用 AST 分析,只導入真正註冊咗工具嘅模塊:
def discover_builtin_tools(tools_dir=None):
tools_path = Path(tools_dir) or Path(__file__).resolve().parent
module_names = [
f"tools.{path.stem}"
for path in sorted(tools_path.glob("*.py"))
if path.name not in {"__init__.py", "registry.py", "mcp_tool.py"}
and _module_registers_tools(path) # AST 分析
]
for mod_name in module_names:
importlib.import_module(mod_name) # 觸發自注冊
_module_registers_tools() 嘅判斷邏輯:解析 .py 文件嘅 AST,檢查模塊頂層係咪存在 registry.register(...) 調用。只睇模塊頂層,唔深入函數體 - 咁樣輔助模塊唔會俾人誤識別。
呢個設計有一個好處:新增工具文件完全唔需要修改任何註冊表或配置。只要文件入面有 registry.register() 調用,佢就會俾人自動發現同註冊。
4. 工具調度全流程
由模型發起 Function Call 到攞到結果,中間經歷咗呢啲步驟:
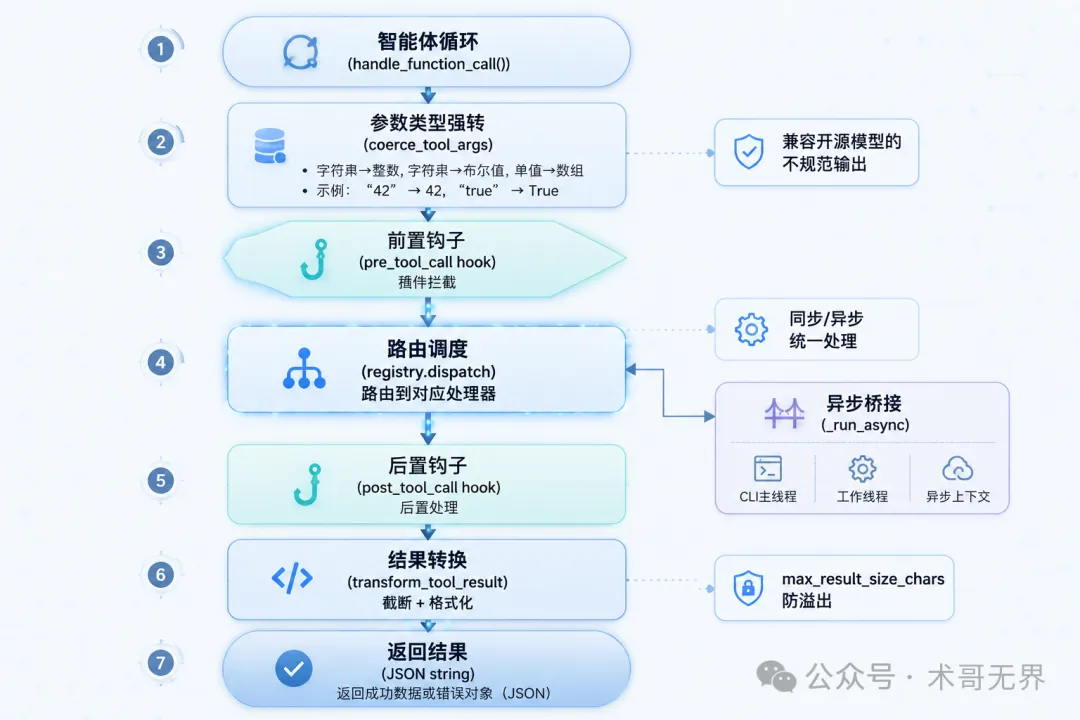
圖 3:Hermes Agent 工具調度全流程
Agent Loop → handle_function_call()
↓
coerce_tool_args() # 參數類型強轉
↓
pre_tool_call hook # 插件攔截
↓
registry.dispatch() # 路由到處理器
↓
async bridge (_run_async) # 異步橋接(如果需要)
↓
post_tool_call hook # 後置處理
↓
transform_tool_result # 結果轉換
↓
返回 JSON 字符串
4.1 參數類型強轉
LLM 返回嘅參數類型成日同 Schema 對唔上。例如 Schema 聲明 integer,模型返回字符串 "42"。coerce_tool_args() 處理呢啲常見唔匹配:
"42"→42(string → integer)"true"→True(string → boolean)"https://a.com"→["https://a.com"](bare value → array,當 Schema 期望 array)JSON 字符串 "['a','b']"→['a', 'b'](解析嵌套結構)
仲支持 union type 同 nullable。源碼註釋入面寫得好直接:**Open-weight models (DeepSeek, Qwen, GLM) sometimes emit {"urls": "https://a.com"} when the tool expects {"urls": ["https://a.com"]}**。
4.2 異步橋接
_run_async() 係同步上下文入面跑異步工具嘅關鍵。源碼入面分咗三種情況:
CLI 主線程:用持久化事件循環(避免 asyncio.run()反覆創建/銷燬循環導致 "Event loop is closed" 錯誤)工作線程(例如 delegate_task 嘅線程池):每線程一個持久化循環 已有異步上下文(例如 gateway):新建獨立線程運行,帶 300s 超時保護
呢個設計解決咗一個實際問題:緩存嘅 httpx/AsyncOpenAI 客戶端綁定喺事件循環上,循環一關,GC 清理時就會報錯。持久化循環令客戶端一直有效。
4.3 錯誤處理
工具執行出錯唔會拋異常,而係返回結構化錯誤 JSON。registry.dispatch() 入面嘅邏輯:
try:
if entry.is_async:
return _run_async(entry.handler(args, **kwargs))
return entry.handler(args, **kwargs)
except Exception as e:
raw = f"Tool execution failed: {type(e).__name__}: {e}"
sanitized = _sanitize_tool_error(raw) # 脱敏處理
return json.dumps({"error": sanitized})
_sanitize_tool_error() 會剝離結構性 framing token(XML 標籤、CDATA、代碼圍欄),防止錯誤信息入面嘅特殊內容幹擾模型嘅上下文理解。呢個細節說明 Hermes 團隊喺安全上花咗唔少心思。
5. check_fn:可用性檢查嘅 30 秒緩存
有啲工具依賴外部狀態。例如終端工具需要檢查 Docker daemon 係咪喺度運行,瀏覽器工具需要 Playwright 二進制文件,web 工具需要 API Key。
check_fn 就係做呢樣嘢嘅 - 一個零參函數,返回 bool:
def check_vision_requirements():
"""檢查視覺分析所需依賴"""
try:
import some_vision_lib
return True
except ImportError:
return False
但每次調用都去探測外部狀態好浪費。所以 Hermes 加咗 30s TTL 緩存:
_CHECK_FN_TTL_SECONDS = 30.0
_check_fn_cache: Dict[Callable, tuple[float, bool]] = {}
def _check_fn_cached(fn):
now = time.monotonic()
cached = _check_fn_cache.get(fn)
if cached and (now - cached[0]) < _CHECK_FN_TTL_SECONDS:
return cached[1] # 命中緩存
try:
value = bool(fn())
except Exception:
value = False # 異常 = 不可用
_check_fn_cache[fn] = (now, value)
return value
30 秒嘅 TTL 選擇亦有講究 - 用戶通過 hermes tools enable 改配置,大概 30 秒內生效。太短浪費資源,太長用戶體驗差。
get_definitions() 返回 Schema 嘅時候會過濾:check_fn 返回 False 嘅工具唔會出現喺畀模型嘅工具列表入面。咁樣模型就唔會調用一個實際不可用嘅工具。
6. Toolset:工具分組同組合
6.1 基本結構
toolsets.py 裏的 TOOLSETS 字典定義咗所有工具集。每個工具集包含 tools(直接包含嘅工具名)同 includes(組合嘅其他工具集):
TOOLSETS = {
"web": {
"description": "Web research and content extraction tools",
"tools": ["web_search", "web_extract"],
"includes": []
},
"debugging": {
"description": "Debugging and troubleshooting toolkit",
"tools": ["terminal", "process"],
"includes": ["web", "file"] # 組合其他 toolset
},
"safe": {
"description": "Safe toolkit without terminal access",
"tools": [],
"includes": ["web", "vision", "image_gen"] # 純組合,無直接工具
},
}
includes 支持遞歸解析和鑽石依賴(去重)。例如 hermes-gateway 包含咗所有平台工具集,各平台又都包含核心工具列表,但最終解析出嚟唔會重複。
6.2 平台預設
源碼入面有一個 _HERMES_CORE_TOOLS 列表,70+ 個核心工具名,各平台共享:
hermes-cli | |
hermes-telegramhermes-discord 等 | |
hermes-gateway | |
hermes-acp | |
hermes-api-server |
每個平台預設嘅核心工具列表一樣,分別在於各平台可能追加自己嘅專屬工具。例如 hermes-discord 追加了 discord 和 discord_admin 工具,hermes-feishu 追加咗飛書文檔相關工具。
6.3 運行時創建自定義 Toolset
create_custom_toolset() 允許喺運行時動態創建工具集:
from toolsets import create_custom_toolset
create_custom_toolset(
name="my_workflow",
description="Custom workflow toolset",
tools=["my_tool", "web_search"],
includes=["file"] # 組合 file toolset
)
創建後同其他靜態定義嘅 Toolset 完全等價。
7. 三種工具註冊模式:源碼實戰
7.1 同步工具(最簡模式)
以 read_file 為例,來自 tools/file_tools.py:
from tools.registry import registry, tool_error
READ_FILE_SCHEMA = {
"name": "read_file",
"description": "Read file contents...",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path to read"},
"offset": {"type": "integer", "description": "Starting line number", "default": 1},
"limit": {"type": "integer", "description": "Max lines to return", "default": 500},
},
"required": ["path"]
}
}
def _handle_read_file(args, **kw):
tid = kw.get("task_id") or"default"
return read_file_tool(
path=args.get("path", ""),
offset=args.get("offset", 1),
limit=args.get("limit", 500),
task_id=tid
)
registry.register(
name="read_file",
toolset="file",
schema=READ_FILE_SCHEMA,
handler=_handle_read_file,
check_fn=_check_file_reqs,
emoji="📖",
max_result_size_chars=100_000,
)
要點:handler 接收 args 字典和 **kwargs(task_id 等上下文信息),返回 JSON 字符串。
7.2 異步工具
web_extract 係異步工具嘅代表,來自 tools/web_tools.py:
registry.register(
name="web_extract",
toolset="web",
schema=WEB_EXTRACT_SCHEMA,
handler=lambda args, **kw: web_extract_tool(
args.get("urls", [])[:5] if isinstance(args.get("urls"), list) else [],
"markdown"),
check_fn=check_web_api_key,
requires_env=_web_requires_env(),
is_async=True, # 標記為異步
emoji="📄",
max_result_size_chars=100_000,
)
唯一分別就係 is_async=True。框架嘅 _run_async() 會自動處理同步/異步橋接,handler 本身唔需要關心調用上下文。
7.3 動態 Schema 覆蓋
delegate_task 嘅 Schema 需要根據運行時配置動態調整(例如最大併發子 Agent 數)。源碼入面嘅做法:
def _build_dynamic_schema_overrides() -> dict:
"""每次 get_definitions() 調用時執行,返回要覆蓋的 Schema 字段"""
overrides_params = {**DELEGATE_TASK_SCHEMA["parameters"]}
overrides_params["properties"] = {
k: dict(v) for k, v in
DELEGATE_TASK_SCHEMA["parameters"]["properties"].items()
}
overrides_params["properties"]["tasks"]["description"] = (
_build_tasks_param_description() # 讀取當前配置
)
return {
"description": _build_top_level_description(),
"parameters": overrides_params,
}
registry.register(
name="delegate_task",
...,
dynamic_schema_overrides=_build_dynamic_schema_overrides,
)
dynamic_schema_overrides 係一個零參回調,喺 get_definitions() 俾人調用時執行。返回嘅字典會淺合併到原始 Schema 上。咁樣模型見到嘅工具描述始終同當前配置一致。
8. Schema 設計規範
睇下源碼入面嘅 Schema 定義,有幾個值得留意嘅規範:
8.1 Schema 結構
統一跟隨 OpenAI Function Calling 格式:
{
"name": "search_files",
"description": "Search file contents or find files by name...",
"parameters": {
"type": "object",
"properties": {
"pattern": {"type": "string", "description": "Regex pattern..."},
"target": {
"type": "string",
"enum": ["content", "files"],
"default": "content"
},
"limit": {"type": "integer", "default": 50},
},
"required": ["pattern"]
}
}
8.2 設計要點
由源碼嘅 Schema 定義入面可以提煉出幾個原則:
description 要寫清楚。search_files 嘅 description 足足有 3 行,解釋咗兩種搜索模式同各自嘅行為。模型靠呢個描述決定幾時調用工具、傳咩參數。
enum 約束枚舉值。target 參數用 enum: ["content", "files"] 而唔係自由文本,減少模型誤調用。
合理設置 default。limit 嘅 default 係 50,唔係冇限制返回。offset 嘅 default 係 0。呢啲默認值喺模型冇指定參數時生效。
maxItems 限制數組長度。web_extract 的 urls 參數設置咗 maxItems: 5,防止模型一次傳太多 URL。
9. 最佳實踐
基於源碼分析同社區反饋,總結幾條實踐建議:
9.1 工具邊界設計
一個工具做一件事。源碼入面 read_file、write_file、patch、search_files 係四個獨立工具,而唔係一個 file_operation 工具帶 action 參數。咁樣 Schema 更清晰,模型嘅調用準確率更高。
9.2 結果大小控制
設置 max_result_size_chars。file_tools.py 入面設嘅係 100,000 字符(約 25-35K tokens)。冇呢個限制,一個工具返回嘅結果可能直接撐爆上下文窗口。社區反饋中"上下文窗口溢出"係高頻問題,合理控制返回大小係關鍵。
9.3 錯誤處理模式
用 tool_error() 返回結構化錯誤,唔好拋異常。源碼入面每個 handler 都係咁做嘅:
def _handle_write_file(args, **kw):
if not args.get("path"):
return tool_error("write_file: missing required field 'path'...")
if "content" not in args:
return tool_error("write_file: missing required field 'content'...")
# ...
9.4 check_fn 必須加
依賴外部狀態嘅工具一定要提供 check_fn。如果唔加,工具會出現喺模型可用嘅工具列表入面,但調用時必然失敗。模型會反覆重試,浪費 Token。社區反饋入面 MCP 服務器連接超時、Docker 權限拒絕呢類問題好常見,check_fn 可以提前暴露呢啲狀態。
9.5 Toolset 組合策略
按場景分組,用 includes 組合複用。源碼入面 debugging 工具集組合咗 web 和 file,因為調試時成日需要搜索錯誤信息 + 讀取文件。safe 工具集組合咗 web、vision、image_gen,排除咗 terminal - 適合唔需要執行命令嘅場景。
9.6 MCP 集成
Hermes 支持 MCP 協議擴展外部工具。MCP 工具動態註冊到 registry,toolset 名為 mcp-<server_name>。配置支持三種傳輸方式:
mcp_servers:
filesystem:
command:"npx"
args:["-y","@modelcontextprotocol/server-filesystem","/tmp"]
timeout:120
remote_api:
url:"https://my-mcp-server.example.com/mcp"
headers:
Authorization:"Bearer sk-..."
MCP 工具同內置工具喺 registry 入面完全等價,check_fn、dispatch()、get_definitions() 都用同一套邏輯。
總結
Hermes Agent 嘅工具系統做啱咗幾件事:
import 即註冊。新增工具文件唔需要修改任何註冊邏輯,只要文件入面有 registry.register() 調用就會俾人自動發現。
單例註冊表。所有工具嘅 Schema、handler、可用性檢查集中喺一個地方管理,冇散落各處嘅字典同配置。
分層清晰。註冊、發現、編排、分組各層獨立,修改一層唔影響其他層。
防禦性設計。註冊隔離、錯誤脱敏、Schema 清洗、參數強轉、結果截斷...源碼入面周圍都係防呆措施。
講到底,呢套架構唔係咩複雜嘅設計模式,就係"每個工具自己管自己,註冊表統一收口"嘅思路。但正因為佢簡單,所以容易擴展、容易調試、容易理解。14.9 萬 Star 唔係白嚟嘅。
如果你都喺度做 Agent 框架或者幫 Hermes 寫自定義工具,呢套註冊表模式值得參考。
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發俾需要嘅朋友,我哋下一期再見!敬請期待!
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 120 篇,Hermes Agent 最佳實戰「2026」系列第 3 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
圖 1:Hermes Agent 工具系統全景
GitHub 上一個不到一年的項目,Star 數衝到了 14.9 萬。2026 年 5 月 9 日,它的單日 Token 消耗超過 2710 億,在 OpenRouter 排行榜上首次登頂。
這是 Hermes Agent - Nous Research 開源的自進化 AI Agent 框架。翻了一圈源碼和社區討論,我發現它工具系統的設計相當值得琢磨:一個單例註冊表、AST 分析自動發現、import 即註冊的機制,把 40+ 內置工具管理得井井有條。
說明:本文內容基於 Hermes Agent 源碼(NousResearch/hermes-agent)和官方文檔分析整理而成,源碼分析基於筆者本地倉庫版本。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
這篇文章就拆解一下它的 Tools & Toolsets 系統,看看這套架構到底怎麼運作的。
1. 整體架構:4 層調用鏈
Hermes Agent 的工具系統分成 4 層,每一層職責清晰:
圖 2:Hermes Agent 工具系統 4 層架構
tools/*.py ← 各工具文件(模塊導入時自注冊)
↓ register()
tools/registry.py ← 單例註冊中心(ToolRegistry)
↓ get_definitions() / dispatch()
model_tools.py ← 編排層(發現 + Schema 提供 + 調度)
↓ resolve_toolset()
toolsets.py ← Toolset 定義(工具分組、組合)
↓
run_agent.py/cli.py ← 入口(消費工具定義,驅動 Agent Loop)
這 4 層各管各的。tools/*.py 只管註冊自己,registry.py 只管存取,model_tools.py 做編排調度,toolsets.py 負責分組組合。沒有交叉依賴,也沒有上帝類。
2. ToolRegistry:一個單例管所有工具
2.1 核心數據結構
tools/registry.py 是整個工具系統的中樞。核心類 ToolRegistry,模塊級單例:
# 模塊級單例
registry = ToolRegistry()
每個工具註冊進來,存的是 ToolEntry 對象。源碼裏的定義:
class ToolEntry:
__slots__ = (
"name", "toolset", "schema", "handler", "check_fn",
"requires_env", "is_async", "description", "emoji",
"max_result_size_chars", "dynamic_schema_overrides",
)
每個字段幹什麼用:
name | |
toolset | file、web) |
schema | |
handler | |
check_fn | |
requires_env | |
is_async | |
max_result_size_chars | |
dynamic_schema_overrides |
2.2 註冊安全機制
register() 方法有一套防護邏輯,源碼裏寫得很清楚:
def register(self, name, toolset, schema, handler, ..., override=False):
existing = self._tools.get(name)
if existing and existing.toolset != toolset:
# MCP-to-MCP 允許覆蓋(服務器刷新場景)
both_mcp = (existing.toolset.startswith("mcp-")
and toolset.startswith("mcp-"))
if both_mcp:
pass# 允許
elif override:
pass# 顯式允許(插件場景)
else:
# 拒絕 - 防止意外覆蓋內置工具
logger.error("Tool registration REJECTED: ...")
return
說白了就是:不同 toolset 的同名工具註冊會被拒絕。除非你是 MCP 工具刷新,或者顯式傳了 override=True。這個設計防止了插件或 MCP 服務器不小心覆蓋內置工具。
2.3 兩個輔助函數
源碼裏還提供了 tool_error() 和 tool_result() 兩個序列化輔助函數,省得每個 handler 都手寫 json.dumps():
def tool_error(message, **extra) -> str:
result = {"error": str(message)}
if extra:
result.update(extra)
return json.dumps(result, ensure_ascii=False)
def tool_result(data=None, **kwargs) -> str:
if data is not None:
return json.dumps(data, ensure_ascii=False)
return json.dumps(kwargs, ensure_ascii=False)
用起來很簡潔:return tool_error("file not found") 或者 return tool_result({"content": text})。
3. 自注冊模式:import 即註冊
這是 Hermes 工具系統裏面很有意思的設計。
3.1 模塊級註冊
每個工具文件在模塊末尾直接調用 registry.register()。模塊被 import 的時候,Python 執行模塊級代碼,註冊就自動完成了。
拿 tools/file_tools.py 舉例(源碼末尾,第 1169-1172 行):
from tools.registry import registry, tool_error
registry.register(name="read_file", toolset="file", schema=READ_FILE_SCHEMA,
handler=_handle_read_file, check_fn=_check_file_reqs,
emoji="📖", max_result_size_chars=100_000)
registry.register(name="write_file", toolset="file", schema=WRITE_FILE_SCHEMA,
handler=_handle_write_file, check_fn=_check_file_reqs,
emoji="✍️", max_result_size_chars=100_000)
registry.register(name="patch", toolset="file", schema=PATCH_SCHEMA,
handler=_handle_patch, check_fn=_check_file_reqs,
emoji="🔧", max_result_size_chars=100_000)
registry.register(name="search_files", toolset="file", schema=SEARCH_FILES_SCHEMA,
handler=_handle_search_files, check_fn=_check_file_reqs,
emoji="🔎", max_result_size_chars=100_000)
四個文件操作工具,四行註冊代碼。沒有任何裝飾器、沒有繼承、沒有配置文件。直來直去。
3.2 AST 分析 + 動態導入
但問題來了:誰來 import 這些文件?
答案在 discover_builtin_tools() 函數里。它不是無條件 import 所有 .py 文件,而是先用 AST 分析,只導入真正註冊了工具的模塊:
def discover_builtin_tools(tools_dir=None):
tools_path = Path(tools_dir) or Path(__file__).resolve().parent
module_names = [
f"tools.{path.stem}"
for path in sorted(tools_path.glob("*.py"))
if path.name not in {"__init__.py", "registry.py", "mcp_tool.py"}
and _module_registers_tools(path) # AST 分析
]
for mod_name in module_names:
importlib.import_module(mod_name) # 觸發自注冊
_module_registers_tools() 的判斷邏輯:解析 .py 文件的 AST,檢查模塊頂層是否存在 registry.register(...) 調用。只看模塊頂層,不深入函數體 - 這樣輔助模塊不會被誤識別。
這個設計有一個好處:新增工具文件完全不需要修改任何註冊表或配置。只要文件裏有 registry.register() 調用,它就會被自動發現和註冊。
4. 工具調度全流程
從模型發起 Function Call 到拿到結果,中間經歷了這些步驟:
圖 3:Hermes Agent 工具調度全流程
Agent Loop → handle_function_call()
↓
coerce_tool_args() # 參數類型強轉
↓
pre_tool_call hook # 插件攔截
↓
registry.dispatch() # 路由到處理器
↓
async bridge (_run_async) # 異步橋接(如果需要)
↓
post_tool_call hook # 後置處理
↓
transform_tool_result # 結果轉換
↓
返回 JSON 字符串
4.1 參數類型強轉
LLM 返回的參數類型經常和 Schema 對不上。比如 Schema 聲明 integer,模型返回字符串 "42"。coerce_tool_args() 處理這些常見不匹配:
"42"→42(string → integer)"true"→True(string → boolean)"https://a.com"→["https://a.com"](bare value → array,當 Schema 期望 array)JSON 字符串 "['a','b']"→['a', 'b'](解析嵌套結構)
還支持 union type 和 nullable。源碼註釋裏寫得很直接:**Open-weight models (DeepSeek, Qwen, GLM) sometimes emit {"urls": "https://a.com"} when the tool expects {"urls": ["https://a.com"]}**。
4.2 異步橋接
_run_async() 是同步上下文裏跑異步工具的關鍵。源碼裏分了三種情況:
CLI 主線程:用持久化事件循環(避免 asyncio.run()反覆創建/銷燬循環導致 "Event loop is closed" 錯誤)工作線程(如 delegate_task 的線程池):每線程一個持久化循環 已有異步上下文(如 gateway):新建獨立線程運行,帶 300s 超時保護
這個設計解決了一個實際問題:緩存的 httpx/AsyncOpenAI 客戶端綁定在事件循環上,循環一關,GC 清理時就會報錯。持久化循環讓客戶端一直有效。
4.3 錯誤處理
工具執行出錯不會拋異常,而是返回結構化錯誤 JSON。registry.dispatch() 裏的邏輯:
try:
if entry.is_async:
return _run_async(entry.handler(args, **kwargs))
return entry.handler(args, **kwargs)
except Exception as e:
raw = f"Tool execution failed: {type(e).__name__}: {e}"
sanitized = _sanitize_tool_error(raw) # 脱敏處理
return json.dumps({"error": sanitized})
_sanitize_tool_error() 會剝離結構性 framing token(XML 標籤、CDATA、代碼圍欄),防止錯誤信息裏的特殊內容干擾模型的上下文理解。這個細節說明 Hermes 團隊在安全上花了不少心思。
5. check_fn:可用性檢查的 30 秒緩存
有些工具依賴外部狀態。比如終端工具需要檢查 Docker daemon 是否在跑,瀏覽器工具需要 Playwright 二進制文件,web 工具需要 API Key。
check_fn 就是幹這個的 - 一個零參函數,返回 bool:
def check_vision_requirements():
"""檢查視覺分析所需依賴"""
try:
import some_vision_lib
return True
except ImportError:
return False
但每次調用都去探測外部狀態很浪費。所以 Hermes 加了 30s TTL 緩存:
_CHECK_FN_TTL_SECONDS = 30.0
_check_fn_cache: Dict[Callable, tuple[float, bool]] = {}
def _check_fn_cached(fn):
now = time.monotonic()
cached = _check_fn_cache.get(fn)
if cached and (now - cached[0]) < _CHECK_FN_TTL_SECONDS:
return cached[1] # 命中緩存
try:
value = bool(fn())
except Exception:
value = False # 異常 = 不可用
_check_fn_cache[fn] = (now, value)
return value
30 秒的 TTL 選擇也有講究 - 用戶通過 hermes tools enable 改配置,大概 30 秒內生效。太短浪費資源,太長用戶體驗差。
get_definitions() 返回 Schema 的時候會過濾:check_fn 返回 False 的工具不會出現在給模型的工具列表裏。這樣模型就不會調用一個實際不可用的工具。
6. Toolset:工具分組與組合
6.1 基本結構
toolsets.py 裏的 TOOLSETS 字典定義了所有工具集。每個工具集包含 tools(直接包含的工具名)和 includes(組合的其他工具集):
TOOLSETS = {
"web": {
"description": "Web research and content extraction tools",
"tools": ["web_search", "web_extract"],
"includes": []
},
"debugging": {
"description": "Debugging and troubleshooting toolkit",
"tools": ["terminal", "process"],
"includes": ["web", "file"] # 組合其他 toolset
},
"safe": {
"description": "Safe toolkit without terminal access",
"tools": [],
"includes": ["web", "vision", "image_gen"] # 純組合,無直接工具
},
}
includes 支持遞歸解析和鑽石依賴(去重)。比如 hermes-gateway 包含了所有平台工具集,各平台又都包含核心工具列表,但最終解析出來不會重複。
6.2 平台預設
源碼裏有一個 _HERMES_CORE_TOOLS 列表,70+ 個核心工具名,各平台共享:
hermes-cli | |
hermes-telegramhermes-discord 等 | |
hermes-gateway | |
hermes-acp | |
hermes-api-server |
每個平台預設的核心工具列表一樣,區別在於各平台可能追加自己的專屬工具。比如 hermes-discord 追加了 discord 和 discord_admin 工具,hermes-feishu 追加了飛書文檔相關工具。
6.3 運行時創建自定義 Toolset
create_custom_toolset() 允許在運行時動態創建工具集:
from toolsets import create_custom_toolset
create_custom_toolset(
name="my_workflow",
description="Custom workflow toolset",
tools=["my_tool", "web_search"],
includes=["file"] # 組合 file toolset
)
創建後和其他靜態定義的 Toolset 完全等價。
7. 三種工具註冊模式:源碼實戰
7.1 同步工具(最簡模式)
以 read_file 為例,來自 tools/file_tools.py:
from tools.registry import registry, tool_error
READ_FILE_SCHEMA = {
"name": "read_file",
"description": "Read file contents...",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path to read"},
"offset": {"type": "integer", "description": "Starting line number", "default": 1},
"limit": {"type": "integer", "description": "Max lines to return", "default": 500},
},
"required": ["path"]
}
}
def _handle_read_file(args, **kw):
tid = kw.get("task_id") or"default"
return read_file_tool(
path=args.get("path", ""),
offset=args.get("offset", 1),
limit=args.get("limit", 500),
task_id=tid
)
registry.register(
name="read_file",
toolset="file",
schema=READ_FILE_SCHEMA,
handler=_handle_read_file,
check_fn=_check_file_reqs,
emoji="📖",
max_result_size_chars=100_000,
)
要點:handler 接收 args 字典和 **kwargs(task_id 等上下文信息),返回 JSON 字符串。
7.2 異步工具
web_extract 是異步工具的代表,來自 tools/web_tools.py:
registry.register(
name="web_extract",
toolset="web",
schema=WEB_EXTRACT_SCHEMA,
handler=lambda args, **kw: web_extract_tool(
args.get("urls", [])[:5] if isinstance(args.get("urls"), list) else [],
"markdown"),
check_fn=check_web_api_key,
requires_env=_web_requires_env(),
is_async=True, # 標記為異步
emoji="📄",
max_result_size_chars=100_000,
)
唯一區別就是 is_async=True。框架的 _run_async() 會自動處理同步/異步橋接,handler 本身不需要關心調用上下文。
7.3 動態 Schema 覆蓋
delegate_task 的 Schema 需要根據運行時配置動態調整(比如最大併發子 Agent 數)。源碼裏的做法:
def _build_dynamic_schema_overrides() -> dict:
"""每次 get_definitions() 調用時執行,返回要覆蓋的 Schema 字段"""
overrides_params = {**DELEGATE_TASK_SCHEMA["parameters"]}
overrides_params["properties"] = {
k: dict(v) for k, v in
DELEGATE_TASK_SCHEMA["parameters"]["properties"].items()
}
overrides_params["properties"]["tasks"]["description"] = (
_build_tasks_param_description() # 讀取當前配置
)
return {
"description": _build_top_level_description(),
"parameters": overrides_params,
}
registry.register(
name="delegate_task",
...,
dynamic_schema_overrides=_build_dynamic_schema_overrides,
)
dynamic_schema_overrides 是一個零參回調,在 get_definitions() 被調用時執行。返回的字典會淺合併到原始 Schema 上。這樣模型看到的工具描述始終和當前配置一致。
8. Schema 設計規範
翻看源碼中的 Schema 定義,有幾個值得注意的規範:
8.1 Schema 結構
統一遵循 OpenAI Function Calling 格式:
{
"name": "search_files",
"description": "Search file contents or find files by name...",
"parameters": {
"type": "object",
"properties": {
"pattern": {"type": "string", "description": "Regex pattern..."},
"target": {
"type": "string",
"enum": ["content", "files"],
"default": "content"
},
"limit": {"type": "integer", "default": 50},
},
"required": ["pattern"]
}
}
8.2 設計要點
從源碼的 Schema 定義中可以提煉出幾個原則:
description 要寫清楚。search_files 的 description 足有 3 行,解釋了兩種搜索模式和各自的行為。模型靠這個描述決定什麼時候調用工具、傳什麼參數。
enum 約束枚舉值。target 參數用 enum: ["content", "files"] 而不是自由文本,減少模型誤調用。
合理設置 default。limit 的 default 是 50,不是無限制返回。offset 的 default 是 0。這些默認值在模型沒指定參數時生效。
maxItems 限制數組長度。web_extract 的 urls 參數設置了 maxItems: 5,防止模型一次傳太多 URL。
9. 最佳實踐
基於源碼分析和社區反饋,總結幾條實踐建議:
9.1 工具邊界設計
一個工具做一件事。源碼裏 read_file、write_file、patch、search_files 是四個獨立工具,而不是一個 file_operation 工具帶 action 參數。這樣 Schema 更清晰,模型的調用準確率更高。
9.2 結果大小控制
設置 max_result_size_chars。file_tools.py 裏設的是 100,000 字符(約 25-35K tokens)。沒有這個限制,一個工具返回的結果可能直接撐爆上下文窗口。社區反饋中"上下文窗口溢出"是高頻問題,合理控制返回大小是關鍵。
9.3 錯誤處理模式
用 tool_error() 返回結構化錯誤,不要拋異常。源碼裏每個 handler 都是這麼做的:
def _handle_write_file(args, **kw):
if not args.get("path"):
return tool_error("write_file: missing required field 'path'...")
if "content" not in args:
return tool_error("write_file: missing required field 'content'...")
# ...
9.4 check_fn 必須加
依賴外部狀態的工具一定要提供 check_fn。如果不加,工具會出現在模型可用的工具列表裏,但調用時必然失敗。模型會反覆重試,浪費 Token。社區反饋裏 MCP 服務器連接超時、Docker 權限拒絕這類問題很常見,check_fn 可以提前暴露這些狀態。
9.5 Toolset 組合策略
按場景分組,用 includes 組合複用。源碼裏 debugging 工具集組合了 web 和 file,因為調試時經常需要搜索錯誤信息 + 讀取文件。safe 工具集組合了 web、vision、image_gen,排除了 terminal - 適合不需要執行命令的場景。
9.6 MCP 集成
Hermes 支持 MCP 協議擴展外部工具。MCP 工具動態註冊到 registry,toolset 名為 mcp-<server_name>。配置支持三種傳輸方式:
mcp_servers:
filesystem:
command:"npx"
args:["-y","@modelcontextprotocol/server-filesystem","/tmp"]
timeout:120
remote_api:
url:"https://my-mcp-server.example.com/mcp"
headers:
Authorization:"Bearer sk-..."
MCP 工具和內置工具在 registry 裏完全等價,check_fn、dispatch()、get_definitions() 都用同一套邏輯。
總結
Hermes Agent 的工具系統做對了幾件事:
import 即註冊。新增工具文件不需要修改任何註冊邏輯,只要文件裏有 registry.register() 調用就會被自動發現。
單例註冊表。所有工具的 Schema、handler、可用性檢查集中在一個地方管理,沒有散落各處的字典和配置。
分層清晰。註冊、發現、編排、分組各層獨立,修改一層不影響其他層。
防禦性設計。註冊隔離、錯誤脱敏、Schema 清洗、參數強轉、結果截斷...源碼裏到處是防呆措施。
說到底,這套架構不是什麼複雜的設計模式,就是"每個工具自己管自己,註冊表統一收口"的思路。但正因為它簡單,所以好擴展、好調試、好理解。14.9 萬 Star 不是白來的。
如果你也在做 Agent 框架或者給 Hermes 寫自定義工具,這套註冊表模式值得參考。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!