Hermes 登頂 OpenRouter 之後,我才發現它最缺的那一塊,被這個插件補上了
整理版優先睇
Hermes 原生記憶只記事實唔記過程,MemOS Plugin 2.0 補返「執行即學習」呢塊
呢篇文章係作者用咗 Hermes Agent 一段時間之後嘅實戰反思。作者本身係技術用戶,留意到 Hermes 喺 OpenRouter 登頂,但實際用落發現佢個記憶系統有明顯盲點。
Hermes 原生記憶靠兩個 Markdown 文件(MEMORY.md 同 USER.md),總共只有 3575 個字符,採用「策展式」機制——Agent 自己判斷咩值得記,結果只記咗環境約定同用戶畫像呢類「事實」,但唔會記低合作做嘢嘅過程、失敗經驗同踩過嘅坑。作者用 Pydantic v2 遷移做例子,說明 Agent 第三次都仲係寫 .dict(),因為「v2 下 dict() 失效」呢條經驗根本冇入記憶。
為咗解決呢個問題,作者揾到 MemOS Local Plugin 2.0。呢個插件嘅核心係「執行即學習」,將 Agent 執行鏈上每一步嘅動作、觀察、反思同用戶反饋都沉澱為可審計、可歸因嘅學習信號。佢仲引入「雙層反饋」機制:步級反饋(環境客觀結果)同任務級反饋(用戶主觀滿意度),避免記低錯誤經驗。最關鍵係呢套系統底層同 Agent 無關,OpenClaw 同 Hermes 用同一份核心,令記憶可以跨 Agent 攜帶。作者最後提醒,冷啓動期約一星期,建議俾啲耐心,兩星期後先見到效果。
- Hermes 原生記憶容量得 3575 字符,只記事實唔記過程,用耐咗記憶庫會變大雜燴
- MemOS Plugin 2.0 嘅「執行即學習」將執行鏈每一步沉澱為學習信號,解決過程遺忘問題
- 雙層反饋機制(步級客觀 + 任務級主觀)避免記低「跑通但唔滿意」嘅錯誤經驗
- 記憶系統同 Agent 解耦,OpenClaw 學到嘅經驗可以俾 Hermes 用,真正實現記憶資產可攜帶
- 一鍵安裝指令 curl | bash,建議預期兩星期後先見到明顯提升
MemOS Local Plugin 安裝腳本
一鍵安裝 Hermes 記憶插件嘅 curl 指令
MemOS 技術文檔(中文)
關於 OpenClaw 本地插件嘅詳細說明
MemOS Hermes 本地插件文檔
關於 Hermes 版本嘅技術文檔
Hermes 原生記憶:記到事實,記唔到過程
Hermes Agent 核心係「部署喺你自己設備嘅 AI Agent,用得越耐越強」。佢嘅記憶系統得兩個 Markdown 文件——MEMORY.md 同 USER.md,總容量 3575 字符,每次 session 當做「冷凍快照」塞入 system prompt。呢種設計輕快、低成本,但盲點好明顯:佢記嘅係「事實」,唔係「過程」。
Hermes 原生記憶採用「策展式」機制,Agent 自己判斷咩值得記
例如作者叫 Hermes 將 Pydantic v1 嘅 dict() 遷到 v2 嘅 model_dump(),前面兩次都折騰咗個幾鐘先發現 v2 唔支援 dict()。但第三次佢寫嘅 code 仍然係 .dict()——因為「v2 下 dict() 失效」呢條經驗根本冇入 MEMORY.md。佢入面只係寫住「項目使用 Pydantic v2」。
- 1 環境約定:呢個項目用 pnpm、入口喺邊
- 2 用戶畫像:你鍾意短回答、討厭過度解釋
- 3 過程經驗:踩過咩坑、點樣解決、邊步走錯——全部唔會記
MemOS Plugin 2.0:執行即學習,雙層反饋
MemOS 團隊出咗個 Hermes 本地記憶插件 2.0,核心口號係「執行即學習」。佢哋將 Agent 執行鏈上每一步——動作、觀察、反思、你嘅反饋——都沉澱為可審計、可歸因、可複用嘅學習信號。簡單講,唔止記你講過咩,仲記你哋一齊做過咩、邊步正確、邊步衰咗、點解。
MemOS 將記憶拆成 L1(原始日記)、L2(歸納規律)、L3(全局認知)同 Skill(肌肉記憶)
最值得留意係「雙層反饋」機制。第一層係步級反饋:模型對環境,每一步執行之後環境客觀結果立刻入系統,例如 code 跑通、指令報錯。第二層係任務級反饋:模型對用戶,你對最終結果畀主觀評價,顯式點讚點踩或者隱式接受/重做。
- 步級反饋:環境客觀結果,例如「命令成功執行」
- 任務級反饋:用戶主觀評價,例如「呢個方案我唔滿意」
記憶資產可攜帶:OpenClaw 學到,Hermes 用到
呢次 2.0 最有價值嘅產品決策係——Hermes Agent 同 OpenClaw 用同一份核心。底層係 Reflect2Evolve 核心,宿主無關;上層係 agent-contract 穩定契約;再上係適配器(OpenClaw 用 TypeScript 進程內,Hermes 用 Python MemoryProvider + JSON-RPC)。底層算法、存儲、檢索、Skill 生命週期全部一樣。
作者親身經歷:用 OpenClaw 寫文案攢嘅經驗,Hermes 竟然主動問「要唔要跟之前嘅方案寫大綱」
作者喺後台 Viewer 仲可以導入 Hermes 原生記憶或者將本地 md 文件變成記憶。呢啲功能令「記憶資產可攜帶」成為現實——Agent 係工具,記憶係你嘅。切換工具唔使重新學,因為經驗喺你手度。
- 1 底層核心:Reflect2Evolve,宿主無關
- 2 適配器:OpenClaw TypeScript,Hermes Python MemoryProvider
- 3 記憶共享:一個 Agent 學到,另一個 Agent 用到
實戰安裝同使用心得
如果你已經用緊 Hermes,疊一層 MemOS 就一行命令:curl -fsSL https://raw.githubusercontent.com/MemTensor/MemOS/main/apps/memos-local-plugin/install.sh | bash。腳本會自動檢測你嘅 Agent,裝對應適配器。Hermes 嗰兩個原生 md 文件唔會被改,MemOS 喺上面再加一個 Viewer。
安裝後前一星期基本感覺唔到分別,Trace 仲喺度儲緊、Skill 未結晶
作者分享兩點心得:冷啓動期約一星期,預期係「裝上之後持平,兩星期後開始上揚」。Viewer 一開始資訊量太大,建議頭兩日淨係睇記憶同技能標籤,最有體感;Traces 同 Policies 等你想搞清楚某個行為「來源」時先翻。
- 冷啓動期約一星期,唔好心急
- Viewer 優先睇記憶同技能標籤
- Traces 同 Policies 進階先睇
上個禮拜,Hermes Agent 喺 OpenRouter 應用 Token 消耗榜上面,單日用咗 2710 億,第一次將 OpenClaw 嘅 2450 億逼低,拎到總榜第一。
由開源到登頂,淨係三個月。
呢件事喺中文圈俾人用唔同角度解讀。媒體同社區嘅標題都係咁:「快速爆紅嘅 Hermes 會唔會成為下一個 OpenClaw」、「Agentic AI 時代不可逆轉」。但比起呢啲宏觀敍事,我更在意嘅係 Nous Research 呢班人喺宣傳入面不停咁講嚟講去嘅一句話——the agent that grows with you。
同你一齊成長嘅 Agent。
聽落好似口號。但係你真係裝咗 Hermes 之後會發現,佢的確認真做緊呢件事——不過淨係做咗一半。
Hermes 遺漏咗一件事
Hermes Agent,核心思路就係一句話:一個部署喺你自己裝置上面嘅 AI Agent,用得越耐越勁。
整體嚟講 Hermes 真係好用, Skill 自動生成嗰個功能好實用,做過嘅嘢唔使再教第二次。
換句話講,你同 Agent 傾得越多,佢累積嘅資訊就越多,但係呢啲資訊之間嘅關係佢處理唔到。
重複嘅、過時嘅、矛盾嘅內容全部堆埋一齊,時間耐咗記憶庫就變成咗一個大雜燴。
就好似,你請咗個員工,佢會將你交俾佢做嘅嘢,同你傾偈時講過嘅偏好全部記低。你同佢講「我鍾意飲美式」,佢記得。你話「我要做一個關於瑞幸咖啡冰美式新品嘅設計方案」,佢都會記入去,但係當你哋琴晚一齊改冰美式設計方案改到凌晨四點,最後點樣定位問題、踩咗咩坑、行咗咩冤枉路,佢下次見你可能就會同冰美式少冰撈亂甚至完全唔記得冰美式設計方案最後點樣改。
呢種員工有用咩?有啲用。值錢咩?唔值錢。
我真正想要嘅係後面嗰種記憶,將過程記低落嚟嘅記憶。Agent 同我配合做嘢嘅成個過程,邊步係啱、邊步係錯、咩情況下應該行捷徑、咩情況下唔可以行捷徑,呢啲嘢如果可以沉澱落嚟,咁佢先算係真係「喺我身邊長大」。
然後我就喺度諗,有冇啲咩嘢可以幫 Hermes 將記憶管返好。
結果真係俾我揾到咗。
記憶張量 MemTensor 團隊出咗一個 Hermes 本地記憶插件。
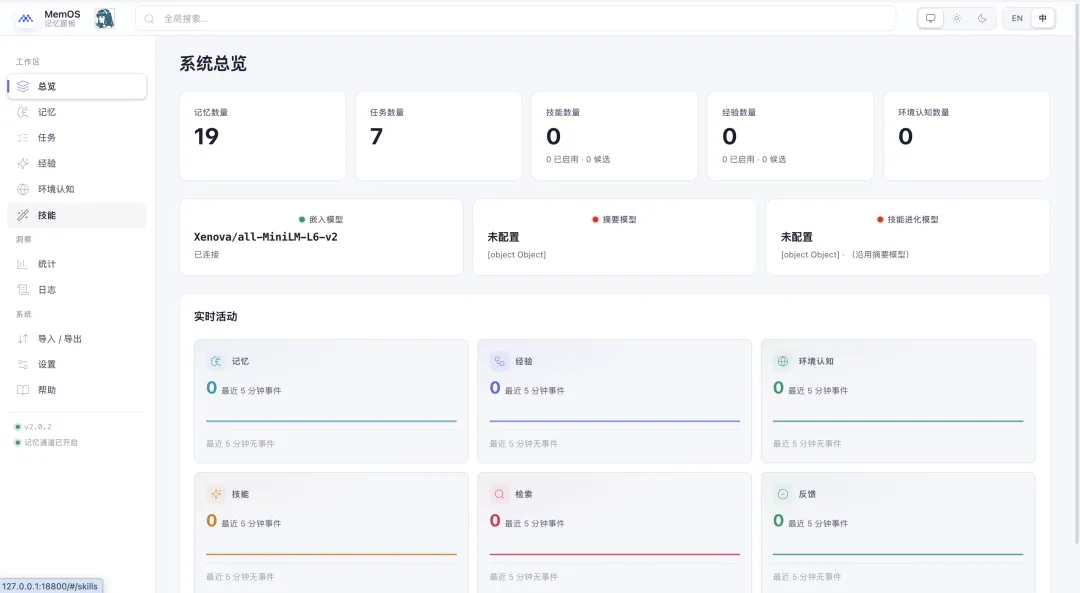
我睇咗一眼佢哋後台,感覺:呢樣嘢,可能真係唔同。
但係一個問題都出現咗。
Hermes 已經有記憶喇,點解佢仲需要一個記憶系統
呢個問題好重要。
於是我重新翻咗 Hermes 嘅系統文件 ~/.hermes/memories/。
裏面得兩個文件。
MEMORY.md,2200 字符上限,大概 800 token,用嚟記環境資訊、項目約定、佢自己學到嘅嘢。USER.md,1375 字符上限,大概 500 token,係用戶畫像,記你嘅偏好、溝通風格、對佢嘅期待。
兩份加埋,3575 個字符,比一條公眾號文章長唔到邊度去。
我睇住睇咗好耐。
Hermes 做記憶嘅方式係——俾你兩份 Markdown,硬性上限定死,每次 session 開始當做「冷凍快照」成個塞入 system prompt 最前邊。
佢嘅邏輯係,記憶唔係數據庫。記憶應該似大腦咁,細、精煉、隨時在線。所以佢索性唔要 retrieval pipeline、唔要向量庫、唔要 per-query 延遲。前綴緩存完美命中,速度快、成本低、可控性高。
Nous Research 做產品,的確比市面上大部分知識圖譜、RAG、多模態融合等要好,要輕巧。
但是。
用咗大概十日,我開始覺得唔對路。
上個禮拜我叫 Hermes 幫我將一個 Pydantic 模型由 v1 嘅 dict() 搬去 v2 嘅 model_dump()。呢件事我哋之前已經做過兩次喇,每次都搞咗成個鐘先發現 v2 下面 dict() 失效。
第三次,佢寫出嚟嘅代碼入面都係 .dict()。
我打開 MEMORY.md 一睇,裏面寫住「項目使用 Pydantic v2」,得呢句。USER.md 裏面根本冇相關條目。
佢知道項目用 v2,但「v2 下面 dict() 失效要換 model_dump()」呢條經驗,冇入到記憶。
睇完官方文檔先理解點解。Hermes 嘅記憶系統骨子裏係「策展式」——記啲咩、唔記啲咩,係 Agent 自己事後判斷嘅。每次 session 完結佢會諗一諗「今次有啲咩值得長期記住」,然後叫 memory 工具寫一行入 MEMORY.md。如果佢判斷唔值得,就咩都唔記。
呢套機制保證 MEMORY.md 永遠唔會膨脹,每條都係 Agent 主動認為有長期價值嘅「事實」。
但佢嘅盲點亦都喺呢度。
佢記嘅係事實,唔係過程。
本質上,Hermes 原生記憶解決嘅係兩件事:環境約定(呢個項目用 pnpm、入口喺邊)同用戶畫像(你鍾意短回答、討厭過度解釋)。呢兩樣佢做得真係好好。
但佢做唔到第三樣——將同你一齊做嘢嘅過程沉澱落嚟。
因為嗰樣嘢根本塞唔入 3575 個字符。
MemOS Local Plugin 2.0 嘅做法,佢哋稱之為「執行即學習」
呢個就係我兩星期之後又裝返 MemOS Local Plugin 2.0 嘅原因。
記憶張量(MemTensor)呢班人 5 月 9 號發佈 2.0 嘅時候,通告入面有一句話:
Agent 喺幫你做嘢嘅同時,將執行鏈上面嘅每一步,動作、觀察、反思、你嘅反饋,都沉澱做可審計、可歸因、可複用嘅學習信號。
翻譯成人話就係,唔只記你講過咩,仲記你哋一齊做咗啲咩、邊步做啱咗、邊步炒車、點解。
我用煮飯打個比喻。L1 係廚房日記,記低每次炒菜嘅每一步。L2 係由日記歸納出嚟嘅規律,「炒青菜油温八成落蒜頭碎啱啱好」。L3 係對自己呢個廚房嘅全局認知,灶火偏大、豉油喺第三個櫃。Skill 係肌肉記憶,番茄炒蛋合埋眼都做到。
記憶嘅「保險機制」
講到呢度,我要稍微往技術層面探一探,但放心,我盡量講人話。
2.0 今次架構重做入面有一個我特別欣賞嘅設計,叫「雙層反饋」。
記憶有個老問題,你記咗一堆嘢,但你點知邊條係啱、邊條係錯?
舉個最簡單嘅例子,我同 Hermes 執 code,佢寫咗一個方案,行通咗。呢個方案入咗記憶庫。但「行通」並唔等於「呢個係最優解」,可能佢行通嘅過程好慢、好樣衰、有性能隱患,我心裏其實係唔滿意嘅,但因為已經行到,我冇講嘢。
如果記憶系統淨係睇「行唔行得通」,佢就會將呢個差劣嘅方案當成正確答案沉澱落嚟。下次類似問題,佢繼續俾你拎呢個垃圾方案出嚟。
MemOS 2.0 嘅做法係將反饋拆做兩層。
第一層係步級反饋,模型對環境。每一步執行之後,環境嘅客觀結果即刻入系統,例如代碼行通咗、命令報錯咗、檔案創建成功咗。呢一層係「呢一步喺客觀上做唔做得啱」。
第二層係任務級反饋,模型對用戶。任務做完之後,你真人對最終結果畀出主觀評價,可以係顯式嘅讚好踩低,亦都可以係隱式嘅,例如你接受咗佢嘅方案就係隱性認可,你即刻叫佢再做就係隱性差評。呢一層係「我作為用戶,對呢個最終結果滿唔滿意」。
兩層一合,記憶系統先知道「行通咗 + 用戶滿意 = 呢個解法真係好」,「行通咗 + 用戶唔滿意 = 呢個解法用得但有問題」。
呢樣嘢,都幾反人類直覺,但又特別合理。我哋人類喺公司裏面學經驗都係咁學,剩係睇老細有冇通過你嘅方案唔夠,仲要睇佢通過嘅時候係「好,就咁」定係「是但啦」。語氣唔同,記憶嘅權重就唔同。
一份核心,OpenClaw 同 Hermes 都用得
2.0 今次發佈最關鍵嘅產品決策係——Hermes Agent 同 OpenClaw 用嘅係同一份核心。
記憶張量嘅架構圖係咁嘅:最底層係 Reflect2Evolve 核心,宿主無關;往上係 agent-contract 嘅穩定契約;再往上係各家 Agent 嘅適配器,OpenClaw 行 TypeScript 進程內,Hermes 行 Python MemoryProvider + JSON-RPC。
適配器各自唔同,底層算法、儲存、檢索、Skill 生命週期全部係同一份。

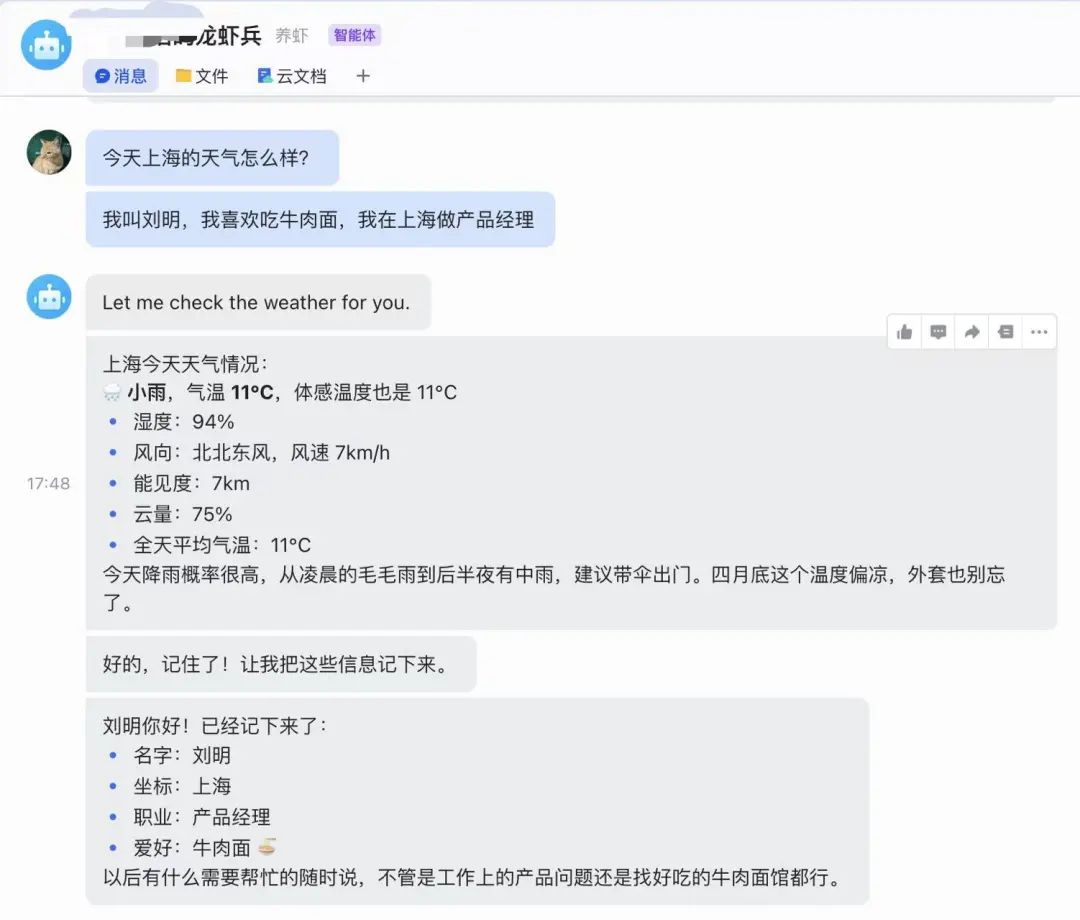
呢件事一開始我冇當一回事。直到嗰日我同時開住 Hermes 同 OpenClaw 做兩樣嘢,OpenClaw 嗰邊喺度查資料,做統計。Hermes 呢邊喺度寫公眾號。中間 Hermes 突然同我講咗句,「不如跟返之前嘅產品測評方案寫個大綱」?
我呆咗一下。
呢條經驗係我之前用 OpenClaw 寫文案儲落嚟嘅,Hermes 點解都會知?
於是我又問咗 Hermes 一個問題,問佢記唔記得之前同佢講過嘅嘢,佢俾出咗以下回答:
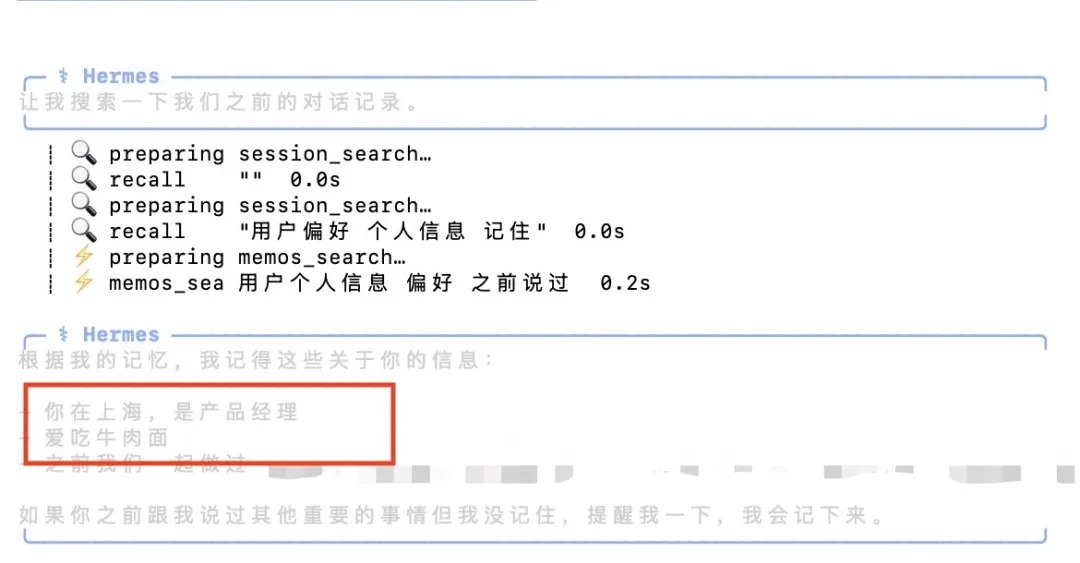
呢個問題係我之前注入 OpenClaw 用嚟測試嘅問題,得 OpenClaw 知道,大家可以對照一下
之後我又研究咗一下後台嘅 Viewer,佢可以導入 Hermes 原生記憶或者將本地形成嘅 md 檔案變成記憶。
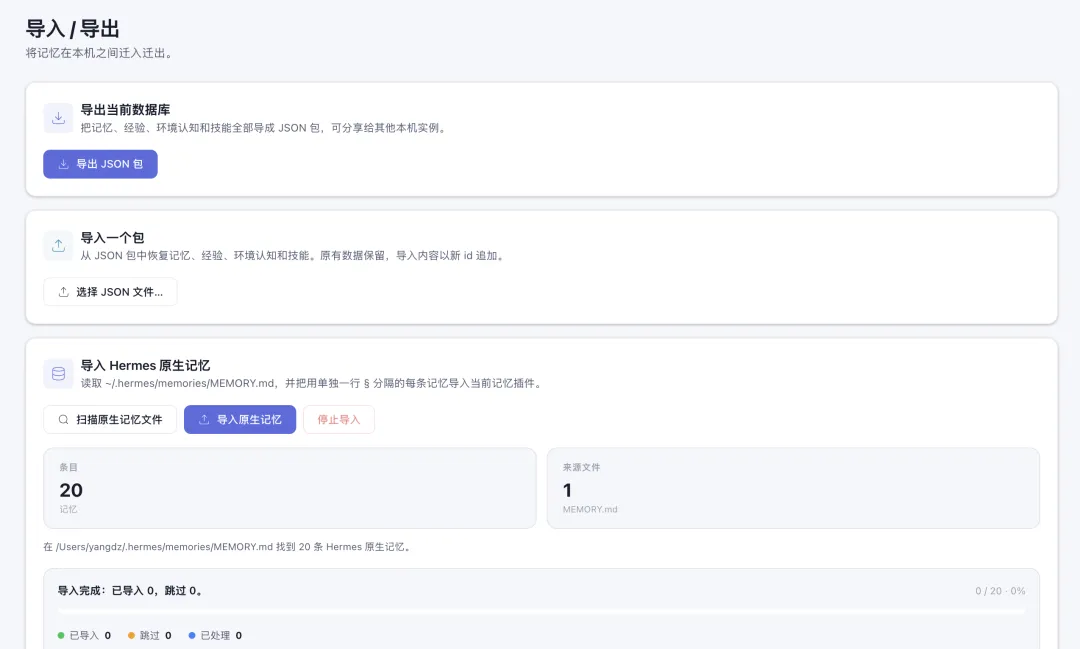
呢個係我第一次真切體會到「記憶資產可攜帶」係咩意思。同一份經驗,OpenClaw 學到,Hermes 用到。
我哋呢幾年用 AI 工具嘅最大痛點,從來唔係工具唔好用,係工具切換嘅時候經驗全部冇曬。MemOS 想做嘅嘢,係將記憶由 Agent 裏面抽返出嚟,做成一層獨立、可攜帶嘅資產層。Agent 係工具,記憶係你嘅。
實操
如果你已經用緊 Hermes,疊一層 MemOS 就一行指令:
curl -fsSL https://raw.githubusercontent.com/MemTensor/MemOS/main/apps/memos-local-plugin/install.sh | bash
腳本會自己檢測機器上面嘅 Agent,邊個喺度就幫邊個裝適配器。Hermes 嗰兩個原生 md 檔案唔會俾人鬱,佢哋繼續以原來方式運作,MemOS 喺上面再開一個 Viewer。
呢度我再講兩句自己嘅使用心得:
冷啟動期長。頭一個禮拜你基本上感覺唔到分別,trace 仲喺度儲緊、Skill 未結晶。預期應該係「裝咗之後持平,兩星期後開始上升」。
Viewer 上手有啲資訊過載。建議頭兩日淨係睇記憶同技能標籤,最有感覺,Traces 同 Policies 等你想搞清楚某個行為「來源」嗰時先再睇。
寫喺最後
返去最頭嗰張 OpenRouter 榜單。
Hermes 單日 2710 億 Token 將 OpenClaw 擠低,最直接嘅信號係——足夠多嘅用戶相信,將長期使用、持續累積呢件事押注喺佢身上係值得嘅。呢種係一種完全唔同嘅用戶關係:越用越返唔到轉頭嘅拍檔,而唔係用完就走嘅體驗。
但 Hermes 嗰 3575 個字符裝得落嘅,只係「你係邊個、呢個項目係點樣」嗰一半。淨低「你同 Agent 一齊行過嘅每一條河」,要靠 MemOS 嗰套 L1 / L2 / L3 / Skill 接住。
兩個加埋,先係一個完整嘅 AI 同事。
通用大模型已經夠勁啦。由 GPT-4 到 Claude Sonnet 4.5,由 Gemini 2.5 到國內一班模型,通用推理能力早就唔係瓶頸。下一步真正決定 Agent 好唔好用嘅係咩?
係佢可唔可以喺你自己嘅本地世界裏面學起嚟。
互聯網上面所有公開嘅代碼、文檔、Stack Overflow,模型預訓練階段都睇過曬。但你嘅代碼庫係點樣、你團隊嘅 CI 點樣行、你之前喺 Alpine 鏡像入面踩過咩坑、你呢個項目點解有個奇怪嘅 utils-legacy 目錄,呢啲互聯網上面冇,預訓練學唔到,微調趕唔切。
淨低可以填補呢一公里嘅,得一個喺你身邊長大嘅記憶系統。
如果大家想自己研究嚇 AI 記憶,開源連結喺呢度:
GitHub:https://memos-docs.openmem.net/cn/openclaw/local_plugin
技術文檔:https://memos-docs.openmem.net/openclaw/hermes_local_plugin
關注公眾號回覆「進羣」入羣討論。
就在上週,Hermes Agent 在 OpenRouter 應用 Token 消耗榜上單日 2710 億,第一次把 OpenClaw 的 2450 億擠下來,拿下總榜第一。
從開源到登頂,僅僅三個月。
這件事在中文圈被各種角度解讀。在媒體和社區題目都是這樣的:「快速躥紅的 Hermes 會不會成為下一個 OpenClaw」、「Agentic AI 時代不可逆轉」。但比起這些宏觀敍事,我更在意的是 Nous Research 這幫人在宣傳裏反覆唸叨的一句話——the agent that grows with you。
跟你一起成長的 Agent。
聽上去像口號。但你真把 Hermes 裝上之後會發現,它確實在認真做這件事——只是只做了一半。
Hermes遺漏了一件事
Hermes Agent,核心思路就一句話:一個部署在你自己設備上的 AI Agent,用得越久越強。
整體來說 Hermes 確實好使, Skill 自動生成那個功能很實用,做過的活兒不用再教第二遍。
換句話說,你跟 Agent 聊得越多,它積累的信息就越多,但這些信息之間的關係它處理不了。
重複的、過時的、矛盾的內容全部堆在一起,時間長了記憶庫就變成了一個大雜燴。
就好比,你僱了一個員工,他會把你你交給他做的活兒,你跟他閒聊時說過的偏好統統記下來。你跟他說「我喜歡喝美式」,他記得。你說「我要做一個關於瑞幸咖啡冰美式新品的設計方案」,它也會記進去,但當你倆昨天一起改冰美式設計案改到凌晨四點,最後是怎麼定位問題的、踩了什麼坑、走了什麼彎路,他下次見你可能就會和冰美式少冰混在一起甚至完全不記得冰美式設計方案最後怎麼改的。
這種員工有用嗎?有點用。值錢嗎?不值錢。
我真正想要的是後面那種記憶,把過程記下來的記憶。Agent 跟我配合幹活的整個過程,哪一步是對的、哪一步是錯的、什麼情況下應該走捷徑、什麼情況下不能走捷徑,這些東西如果能沉澱下來,那它才算是真的「在我身邊長大」。
然後我就在想,有沒有什麼東西能幫 Hermes 把記憶管起來。
結果還真讓我找到了。
記憶張量 MemTensor 團隊出了一個 Hermes 本地記憶插件。
我看了一眼他們後台,感覺到:這玩意,可能真的不一樣。
但一個問題也出現了。
Hermes已經有記憶了,為什麼它還需要一個記憶系統
這個問題很重要。
於是我重新翻了 Hermes的系統文件 ~/.hermes/memories/。
裏面就兩個文件。
MEMORY.md,2200 字符上限,大概 800 token,用來記環境信息、項目約定、它自己學到的東西。USER.md,1375 字符上限,大概 500 token,是用戶畫像,記你的偏好、溝通風格、對它的期待。
兩份加起來,3575 個字符,比一條公眾號文章長不到哪兒去。
我盯着看了挺久。
Hermes 做記憶的方式是——給你兩份 Markdown,硬性上限定死,每次 session 開始當成「冷凍快照」整個塞進 system prompt 最前面。
它的邏輯是,記憶不是數據庫。記憶應該像大腦那樣,小、精煉、隨時在線。所以它乾脆不要 retrieval pipeline、不要向量庫、不要 per-query 延遲。前綴緩存完美命中,速度快、成本低、可控性高。
Nous Research 做產品,確實比市面上大部分知識圖譜、RAG、多模態融合等要好,要輕。
但是。
用了大概十天,我開始覺得不對勁。
上週我讓 Hermes 幫我把一個 Pydantic 模型從 v1 的 dict() 遷到 v2 的 model_dump()。這事我倆前面已經做過兩次了,每次都折騰了快一小時才發現 v2 下 dict() 失效。
第三次,它寫出來的代碼裏還是 .dict()。
我打開 MEMORY.md 一看,裏面寫着「項目使用 Pydantic v2」,僅此一句。USER.md 裏壓根沒相關條目。
它知道項目用 v2,但「v2 下 dict() 失效要換 model_dump()」這條經驗,沒進記憶。
翻完官方文檔才理解為什麼。Hermes 的記憶系統骨子裏是「策展式」——記什麼、不記什麼,是 Agent 自己事後判斷的。每次 session 結束它會想一下「這次有什麼值得長期記住的」,調用 memory 工具寫一行進 MEMORY.md。如果它判斷不值得,就什麼都不記。
這套機制保證 MEMORY.md 永遠不會膨脹,每條都是 Agent 主動認為有長期價值的「事實」。
但它的盲點也在這裏。
它記的是事實,不是過程。
本質上,Hermes 原生記憶解決的是兩件事:環境約定(這個項目用 pnpm、入口在哪)和用戶畫像(你喜歡短回答、討厭過度解釋)。這兩件它做得真的很好。
但它做不到第三件——把跟你一起幹活的過程沉下來。
因為那玩意根本塞不進 3575 個字符。
MemOS Local Plugin 2.0的做法,他們稱之為「執行即學習」
這就是我兩週後又裝上 MemOS Local Plugin 2.0 的原因。
記憶張量(MemTensor)這幫人 5 月 9 號發佈 2.0 的時候,通告裏有一句話:
Agent 在為你做事的同時,把執行鏈上的每一步,動作、觀察、反思、你的反饋,都沉澱為可審計、可歸因、可複用的學習信號。
翻成一下就是,不只記你說了什麼,記你倆一起幹了什麼、哪一步走對了、哪一步翻車了、為什麼。
我用做飯打個比方。L1 是廚房日記,記每次炒菜每一步。L2 是從日記裏歸納的規律,「炒青菜油温八成下蒜末剛好」。L3 是對自己這個廚房的全局認知,灶火偏大、醬油在第三個櫃子。Skill 是肌肉記憶,番茄炒蛋閉眼都能做。
記憶的「保險機制」
聊到這兒,我得稍微往技術層面探一探,但放心,我儘量講人話。
2.0 這次架構重做裏有一個我特別欣賞的設計,叫「雙層反饋」。
記憶有個老問題,你記了一堆東西,但你怎麼知道哪條是對的、哪條是錯的?
舉個最簡單的例子,我跟 Hermes 調代碼,它寫了一個方案,跑通了。這個方案進了記憶庫。但「跑通」並不等於「這是最優解」,可能它跑通的過程巨慢、巨醜、有性能隱患,我心裏其實是不滿意的,但因為已經能跑了,我沒說什麼。
如果記憶系統只看「跑沒跑通」,它就會把這個糟糕的方案當成正確答案沉澱下來。下次類似問題,它繼續給你掏這個垃圾方案。
MemOS 2.0 的做法是把反饋拆成兩層。
第一層是步級反饋,模型對環境。每一步執行之後,環境的客觀結果立刻進系統,比如代碼跑通了、命令報錯了、文件創建成功了。這一層是「這一步在客觀上做沒做對」。
第二層是任務級反饋,模型對用戶。任務做完之後,你這個真人對最終結果給出主觀評價,可以是顯式的點贊點踩,也可以是隱式的,比如你接受了它的方案就是隱性認可,你立刻讓它重做就是隱性差評。這一層是「我作為用戶,對這個最終結果滿不滿意」。
兩層一合,記憶系統才知道「跑通了 + 用戶滿意 = 這個解法是真的好」,「跑通了 + 用戶不滿意 = 這個解法能用但是有問題」。
這種東西,挺反人類直覺的,但又特別合理。我們人類在公司裏學經驗也是這麼學的,光看老闆有沒有過你的方案不夠,還得看他過的時候是「好,就這樣」還是「就這樣吧」。語氣不一樣,記憶的權重就不一樣。
一份核心,OpenClaw 和 Hermes 都能用
2.0 這次發佈最關鍵的產品決策是——Hermes Agent 和 OpenClaw 用的是同一份核心。
記憶張量的架構圖是這樣的:最底層是 Reflect2Evolve 核心,宿主無關;往上是 agent-contract 的穩定契約;再往上是各家 Agent 的適配器,OpenClaw 走 TypeScript 進程內,Hermes 走 Python MemoryProvider + JSON-RPC。
適配器各自不同,底層算法、存儲、檢索、Skill 生命週期全是同一份。
這事一開始我沒當回事。直到那天我同時開着 Hermes 和 OpenClaw 幹兩件活,OpenClaw 那邊在查資料,做統計。Hermes這邊在寫公眾號。中間Hermes忽然給我來了一句,「要不要按照之前的產品測評方案寫一個大綱」。
我愣了一下。
這條經驗是我之前用OpenClaw寫文案攢出來的,Hermes怎麼也知道?
於是我又問了Hermes一個問題,是否記得之前跟他說過的事情,它給出瞭如下回答:
這個問題是我之前之前注入OpenClaw用來測試的問題,僅有OpenClaw知道,大家可以對照一下
之後我又研究了一下後台的Viewer,它可以導入Herme原生記憶或者把本地形成的md文件變成記憶。
這是我第一次真切體會到「記憶資產可攜帶」是什麼意思。同一份經驗,OpenClaw 學到,Hermes 用到。
我們這幾年用 AI 工具的最大痛點,從來不是工具不好用,是工具切換的時候經驗全沒了。MemOS 想幹的事,是把記憶從 Agent 裏抽出來,做成一層獨立的、可攜帶的資產層。Agent 是工具,記憶是你的。
實操
如果你已經在用 Hermes,疊一層 MemOS 就一行命令:
curl -fsSL https://raw.githubusercontent.com/MemTensor/MemOS/main/apps/memos-local-plugin/install.sh | bash
腳本會自己檢測機器上的 Agent,誰在就給誰裝適配器。Hermes 那兩個原生 md 文件不會被動,它們繼續以原來方式工作,MemOS 在上面再開一個 Viewer。
這裏我再講兩句自己的使用心得:
冷啓動期長。前一週你基本感覺不到差別,trace 還在攢、Skill 還沒結晶。預期得是「裝上之後持平,兩週後開始上揚」。
Viewer 上手有點信息過載。建議前兩天只看記憶和技能標籤,最有體感,Traces 和 Policies 等你想搞清楚某個行為「來源」時再翻。
寫在最後
回到最開頭那張 OpenRouter 榜單。
Hermes 單日 2710 億 Token 把 OpenClaw 擠下去,最直白的信號是——足夠多的用戶相信,把長期使用、持續積累這件事押注在它身上是值得的。這是一種完全不同的用戶關係:越用越回不去的搭檔,而不是即用即走的體驗。
但 Hermes 那 3575 個字符能裝下的,只是「你是誰、這個項目長什麼樣」那一半。剩下「你跟 Agent 一起趟過的每一條河」,得靠 MemOS 那套 L1 / L2 / L3 / Skill 接住。
兩個加起來,才是一個完整的 AI 同事。
通用大模型已經夠強了。從 GPT-4 到 Claude Sonnet 4.5,從 Gemini 2.5 到國內一票模型,通用推理能力早就不是瓶頸。下一步真正決定 Agent 好不好用的是什麼?
是它能不能在你自己的本地世界裏學起來。
互聯網上所有公開的代碼、文檔、Stack Overflow,模型預訓練階段都看過了。但你的代碼庫長什麼樣、你團隊的 CI 怎麼走、你之前在 Alpine 鏡像裏踩過哪些坑、你這個項目為什麼有個奇怪的 utils-legacy 目錄,這些互聯網上沒有,預訓練學不到,微調來不及。
剩下能填補這一公里的,只有一個在你身邊長大的記憶系統。
如果大家想自己研究一下AI記憶,開源連結在這兒:
GitHub:https://memos-docs.openmem.net/cn/openclaw/local_plugin
技術文檔:https://memos-docs.openmem.net/openclaw/hermes_local_plugin
關注公眾號回覆“進羣”入羣討論。