Hermes 的記憶系統真正厲害在哪:它不是在記事,而是在訓練自己的工作方式
整理版優先睇
Hermes 的記憶系統不是做大記憶庫,而是透過拆解事實、歷史、技能、覆盤和整理機制,讓 AI agent 越用越懂你。
呢篇文章係一位技術作者睇完 Hermes Agent 源碼同文檔之後寫嘅反思。佢一開始覺得 Hermes 嘅記憶系統好簡單,咪又係兩個 Markdown 文件,仲要容量細,中途寫入新記憶唔會即刻改系統 prompt,睇落一啲都唔「先進」。但佢繼續深入之後發現,呢個先係 Hermes 聰明嘅地方——佢核心唔係做更大嘅記憶庫,而係想訓練一個會成長嘅協作者。
Hermes 將記憶拆成唔同產品語義:USER.md 同 MEMORY.md 管短小常駐事實;session_search 用 SQLite FTS5 做歷史情景記憶;skills 負責程序性記憶,即係「下次呢類任務點樣做」;MemoryProvider 處理外部深層用戶建模;background review 同 Curator 負責後台學習同長期整理。呢層分工令系統唔會將所有記憶塞埋一齊,唔同問題由唔同對象處理。
最關鍵係 Hermes 嘅學習閉環:用戶交互產生軌跡,軌跡進入會話庫;穩定事實入 memory;做事方法入 skills;後台覆盤沉澱經驗;Curator 清理合併技能。下一次遇到類似場景,agent 嘅行為真係會變。呢個先係「越用越懂你」嘅來源。所以作者最後判斷:Hermes 記憶系統最值得學嘅唔係某個技術,而係佢點樣由場景拆解產品需求,再倒推出多層機制。
- 結論:Hermes 記憶系統本質係一個學習系統,而唔係儲存系統——佢嘅目標係令 agent 從每次交互中學到點樣改進未來行為。
- 方法:將記憶拆分為事實記憶(USER.md/MEMORY.md)、歷史記憶(session_search)、程序性記憶(skills)、外部用戶建模(MemoryProvider)同後台學習(background review, Curator)。
- 差異:有別於常見嘅向量數據庫+語義召回,Hermes 先定義「長期協作者」場景,再倒推出產品能力,強調場景優先而非記憶優先。
- 啟發:真正嘅「越用越懂人」需要完整閉環:交互 -> 保存軌跡 -> 後台覆盤 -> 更新技能 -> 定期整理,單靠一個大記憶庫做唔到。
- 可行動點:開發 AI agent 時,可以仿效 Hermes 引入多層記憶結構,尤其要重視 skills(程序性記憶)同 background review(後台學習),並用 Curator 防止長期污染。
表面簡單,背後聰明
一開始睇 Hermes 個記憶系統,真係覺得冇乜特別。不過係兩個 Markdown 文件——
MEMORY.md
同
USER.md
,仲要容量唔大。更反直覺嘅係,佢哋喺會話開始時先讀入系統 prompt,中途寫入新記憶都唔會立刻改當前 prompt。呢個設計睇落一啲都唔先進。
核心唔係做更大嘅記憶庫,而係想訓練一個會成長嘅協作者
如果目標淨係「記住更多嘢」,產品會走向大容量存儲、語義搜索呢類;但如果目標係「越用越懂你」,就要區分常駐事實、按需歷史、做事方法,同埋一次用戶糾正應該寫入用戶畫像定係改工作流程。
五層架構:由入口到學習閉環
從系統架構睇,Hermes 可以分成五層:
- 第一層入口層:用戶可以從 CLI、Telegram、Discord 等觸發任務,最終入同一核心 AIAgent,確保長期記憶跨場景連續。
- 第二層 Agent 核心層:AIAgent 係調度中心,記憶唔係旁路插件,而係嵌進主循環。
- 第三層 Context 層:將穩定系統 prompt 同臨時上下文拆開,穩定前綴包括 SOUL.md、工具指導、凍結嘅 MEMORY.md/USER.md、skills 索引等,咁做可以保住
- prompt cache
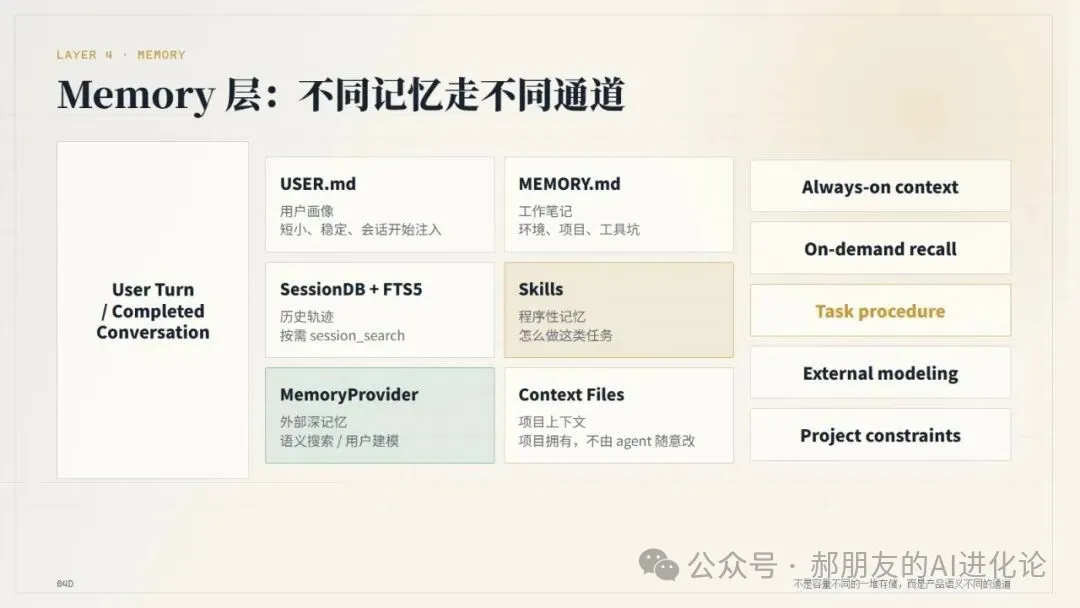
- 第四層 Memory 層:Hermes 唔係一套記憶,而係多套:MEMORY.md/USER.md 負責短小常駐事實,SQLite session store + session_search 負責歷史回憶,skills 負責程序性記憶,MemoryProvider 負責外部深記憶,context files 負責項目靜態上下文。
- 第五層 Learning 層:背景 review 同 Curator 負責後台學習同整理,呢層最易被低估。
prompt cache
frozen snapshot
程序性記憶
關鍵模塊逐個拆
內置 memory 好剋制,只有 add、replace、remove,寫入前掃描 prompt injection 同憑據外泄,用文件鎖同 atomic replace 避免衝突。
add、replace、remove
session_search 用 SQLite 嘅 FTS5 做全文搜索,支援 CJK。skills 係目錄,核心係 SKILL.md,採用 progressive disclosure 先睇列表,需要時先載入完整內容。
progressive disclosure
MemoryProvider 統一接口,一次只啟用一個外部 provider,避免工具 schema 膨脹。Honcho 係最值得關注嘅 provider,佢將用戶同 AI 都建模成 peer。
Curator 默認每 7 日運行一次,將長期唔用嘅 skill 變 stale 再 archived,唔會自動刪除,只歸檔。佢唔會碰 bundled skills 同 hub-installed skills。
Curator
成條鏈:由一句糾正到行為改變
假設用戶對 Hermes 話:「以後寫公眾號唔好寫咁長,口水詞太多,壓縮一半。」喺普通記憶系統,可能只保存成「用戶喜歡簡潔」;但 Hermes 嘅做法係:
- 當前任務先完成,主 agent 壓縮好文章,唔停低保存偏好。
- 呢輪對話進入 SessionDB,用戶原話、修改過程同最終稿成為可搜歷史。
- 後台覆盤認為係穩定偏好,寫入 USER.md:用戶偏好精煉公眾號文章。
- 更新公眾號寫作相關 skill:當用戶反饋太長時,優先刪除鋪墊、重複解釋同抽象套話。
於是下一次用戶再叫 Hermes 寫公眾號,系統唔係淨係「記得用戶嫌長」,而係執行方式真係變咗。
USER.md
skills
background review
Hermes 嘅記憶系統真正厲害喺邊:佢唔係記事,而係訓練自己嘅工作方式
我一開始睇 Hermes Agent 嘅記憶系統,覺得都幾簡單。
最表面不過係兩個 Markdown 檔案:MEMORY.md 儲存 agent 工作筆記,USER.md 儲存用戶畫像。容量都唔大。
更加反直覺嘅係,佢哋喺一次會話開始嗰陣俾人讀入系統提示詞,中途就算寫入新記憶,都唔會即刻改變當前會話嘅系統提示詞。
咁樣睇落一啲都唔「先進」。
至少唔似好多人想像中嘅 Agent 記憶系統:向量數據庫、語義召回。
但係繼續睇源碼同文檔,我反而覺得呢度先係 Hermes 聰明嘅地方。
因為 Hermes 核心唔係整更大嘅記憶庫。
佢真正想做到嘅係一個會成長嘅協作者。

如果目標只係「記住更多嘢」,產品設計自然會走向大容量儲存、語義搜索、自動摘要同 top-k 召回。
但如果目標係「越用越明你」,淨係記住唔夠。系統仲要分清楚:常駐事實、按需歷史、做事方法,同埋一次用戶糾正到底應該寫入用戶畫像,定係改做工作流程。
Hermes 唔係 Memory-first,而係 Scenario-first。
先定義協作者,再倒推記憶、技能、覆盤同維護機制。
先睇佢要解決咩場景
官方 README 入面,Hermes 對自己嘅定位係 self-improving AI agent。
佢強調嘅唔係單點記憶,而係一組連續動作:創建技能、改進技能、保存知識、搜索歷史,並逐漸建立對用戶嘅理解。
講白啲,Hermes 唔係要做一個「會傾偈嘅工具」,佢想成為長期協作者。
長期協作者至少要解決五個問題:
用戶唔想重複介紹自己,所以需要 USER.md或外部用戶建模。用戶唔想重複交代環境,所以需要 MEMORY.md記錄項目、工具同流程嘅坑。用戶希望揾返過去發生過嘅事,所以需要 session_search。用戶真正想要嘅唔係佢記得事實,而係下次唔好用錯方法,所以需要 skills。 記憶越來越多之後唔可以自我污染,所以需要 Curator。
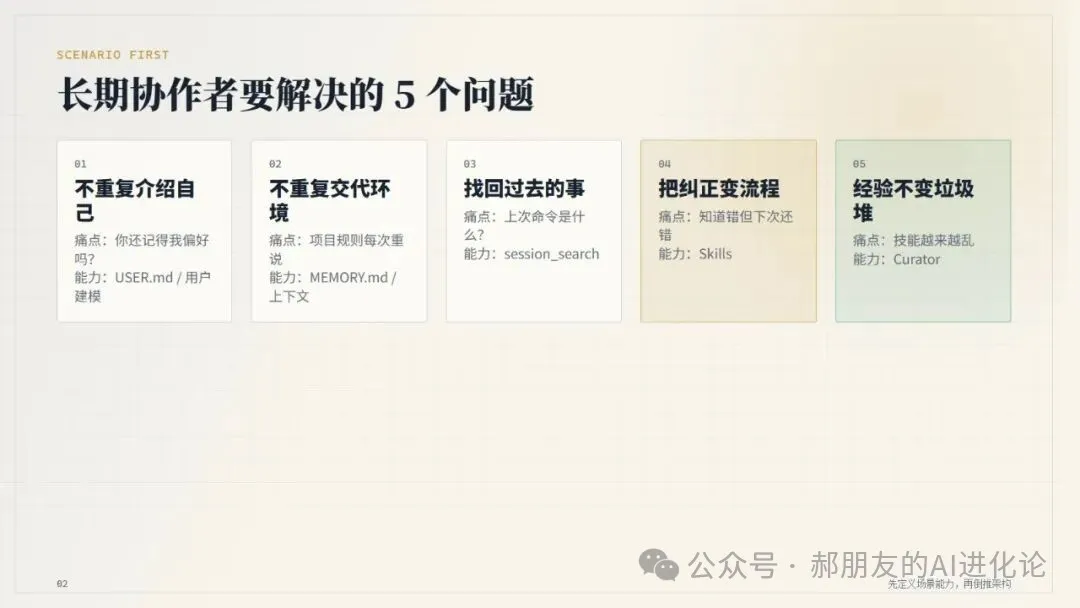
呢個就係 Hermes 冇將所有嘢塞入一個 memory 系統嘅原因。
佢將唔同問題拆成唔同對象。
佢抽象出嚟嘅唔係「記憶」,而係一組業務對象
從產品設計角度睇,Hermes 嘅記憶系統背後唔係一個 Memory 表,而係一組圍繞「完成一次交互之後點樣沉澱經驗」嘅業務對象。
最中心嘅係 Completed Turn,即係一次完成嘅用戶交互。
圍繞佢,系統至少要保存四類嘢:
人同身份:User / Peer、Agent Profile / AI Peer。 歷史同軌跡:Session、Message。 沉澱物:Memory Entry、Skill、Skill Usage。 學習機制:Memory Provider、Background Review、Curator Run。
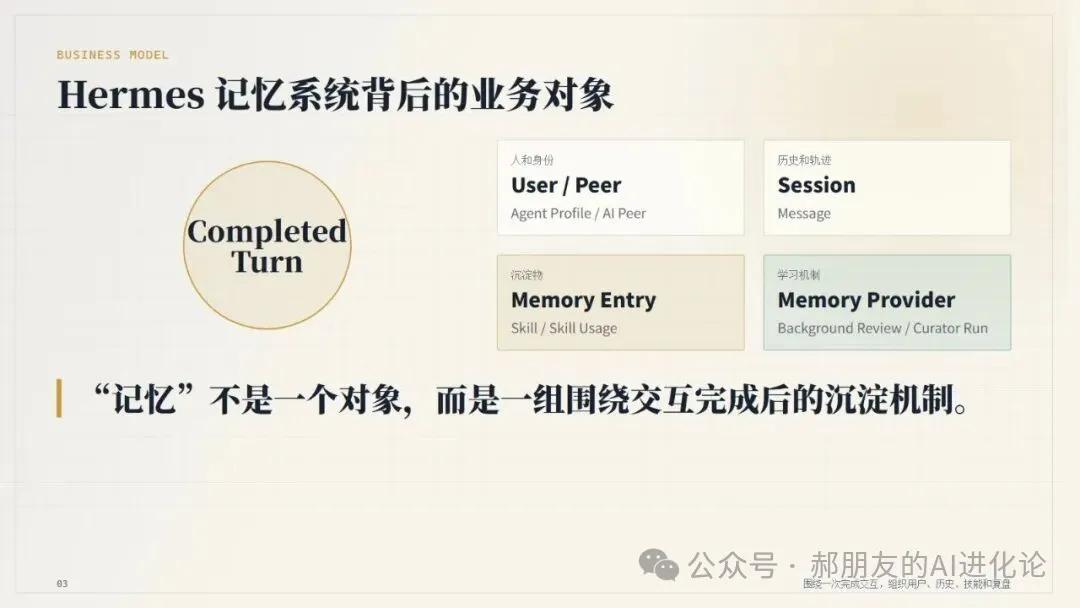
呢個抽象好關鍵。
用戶唔係一次訊息嘅發送者,而係長期存在嘅人。Session 唔係聊天記錄,而係一條協作線。Message 唔只保存文字,仲保存工具調用。Skill 唔係備註,而係「呢類任務以後點做」嘅程序性記憶。
所以 Hermes 嘅「記憶系統」唔係一個模塊,而係一組業務對象共同支撐嘅產品能力。
架構上,佢將記憶拆成五層
如果從系統架構睇,Hermes 大概可以分成五層。

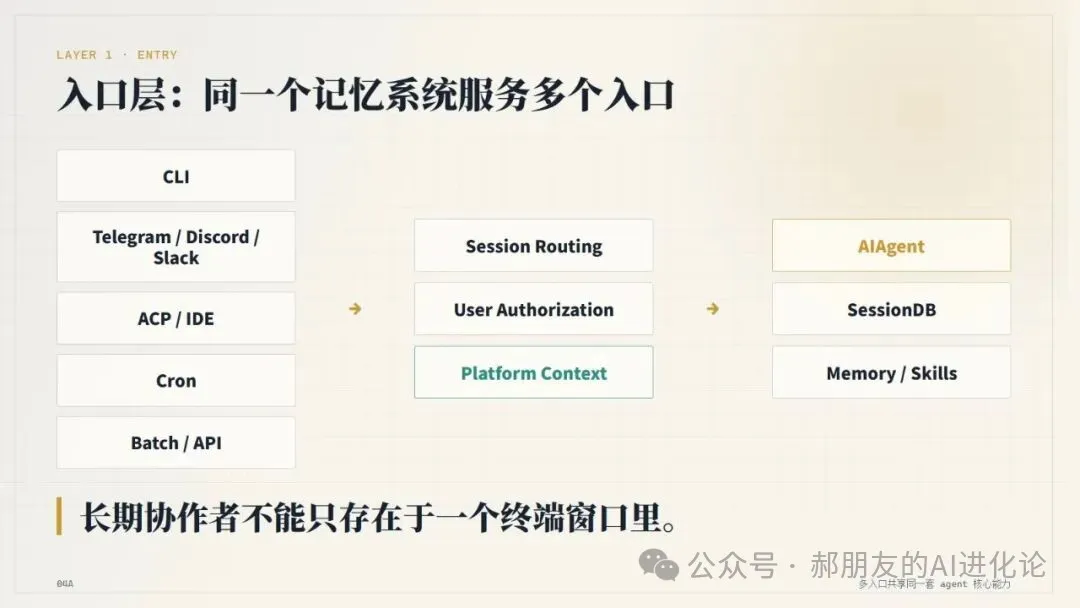
第一層係入口層。
用戶可以從 CLI、Telegram、Discord、Slack、ACP、cron、batch runner 等方式觸發任務,最終都會入同一個核心:AIAgent。
呢個說明 Hermes 嘅長期記憶唔可以只服務本地命令行。多入口共享同一套 agent 核心能力,記憶、會話同技能先可能跨場景連續。
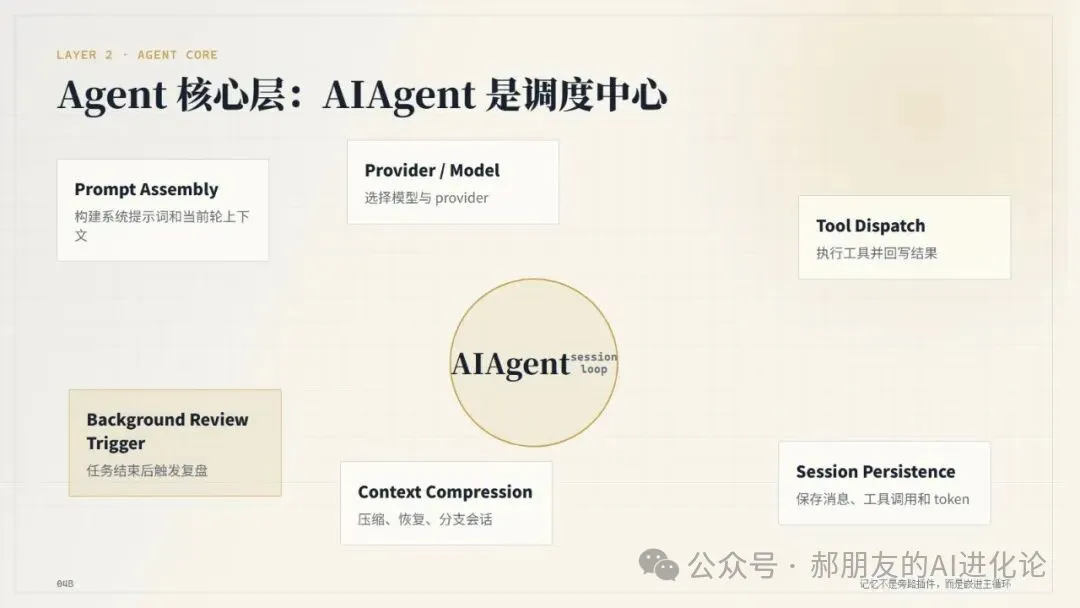
第二層係 Agent 核心層。
AIAgent 係調度中心:構建系統提示詞、選擇模型同 provider、執行工具、保存會話、觸發壓縮、調用 memory provider 生命週期、觸發後台覆盤。
即係話,記憶唔係旁路插件,而係嵌進主循環。
第三層係 Context 層。
Hermes 喺呢度做咗一個關鍵拆分:緩存穩定嘅系統提示詞,同每次調用模型時臨時注入嘅上下文,係兩回事。
穩定前綴入面可以有 SOUL.md、工具指導、凍結嘅 MEMORY.md / USER.md、skills 索引同項目上下文檔案。臨時上下文入面可以有外部 provider 召回、gateway overlays、Honcho 嘅用戶理解。
點解要咁拆?因為系統提示詞穩定,先可以保住 prompt cache。Hermes 嘅內置 memory 採用 frozen snapshot:會話開始嗰陣凍結快照,中途寫入會落盤,但唔會即刻改當前系統提示詞。
呢個唔係能力唔夠,而係產品同工程之間嘅取捨。

第四層係 Memory 層。
Hermes 嘅 memory 唔係一套,而係多套:MEMORY.md / USER.md 負責短小常駐事實,SQLite session store + session_search 負責歷史情景記憶,skills 負責程序性記憶,MemoryProvider 負責外部深記憶,context files 負責項目擁有嘅靜態上下文。
呢幾層嘅調用成本、更新方式、可靠性邊界都唔一樣。
第五層係 Learning 層。
呢個先係 Hermes 最容易被低估嘅地方。
主模型可以調用 memory 保存事實,亦可以用 skill_manage 更新技能。但 Hermes 冇完全依賴主模型「順手記一下」。
佢仲有後台 self-improvement review。任務完成之後,系統會 fork 一個新嘅 AIAgent,只俾佢 memory 同 skills 兩類工具,專門覆盤:有冇用戶偏好要保存?有冇流程經驗要寫成技能?skill 有冇需要修補?
再之後,仲有 Curator 負責整理呢啲 agent-created skills,避免長期學習變成長期污染。
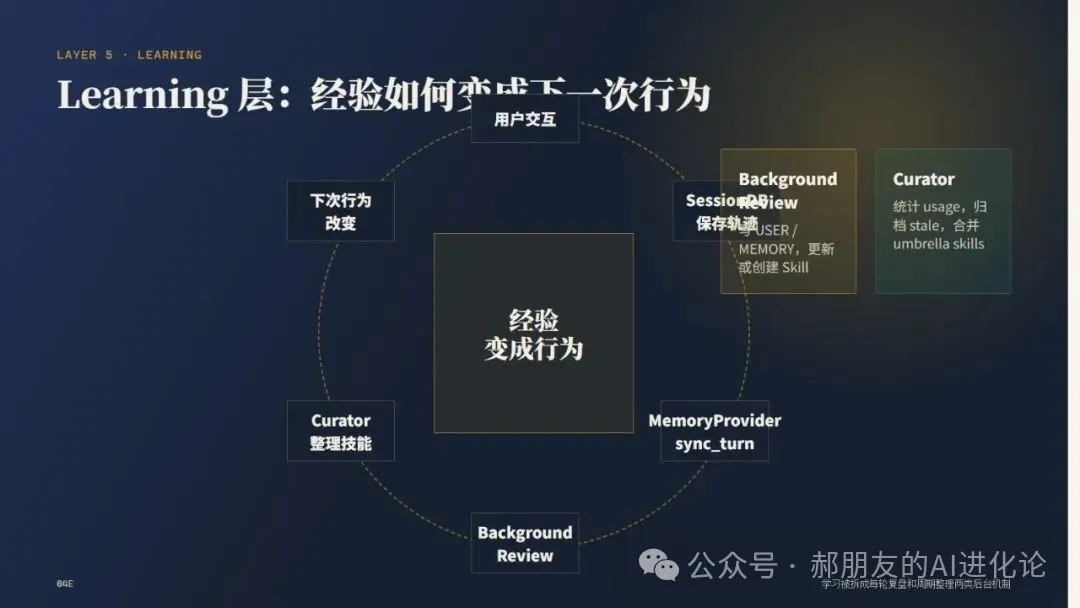
所以 Hermes 嘅學習閉環係:
用戶交互產生軌跡,軌跡入會話庫,穩定事實入 memory,做事方法入 skills,外部 provider 做用戶建模,後台覆盤沉澱經驗,Curator 清理同合併技能。
下一次再遇到類似場景,行為會改變。
呢條鏈路,先係佢「越用越明人」嘅來源。

幾個模塊分別點樣實現
先睇最樸素嘅內置 memory。
tools/memory_tool.py 入面有一個 MemoryStore,管理 memory_entries 和 user_entries,落到 ~/.hermes/memories/ 下的 MEMORY.md 和 USER.md。
寫入方式好剋制:只有 add、replace、remove。冇複雜編輯器,亦冇默認 read action,因為 memory 喺會話開始嗰陣會自動注入。
佢仲做咗兩件工程化嘅事:寫入前掃描 prompt injection 同憑據外泄風險;併發寫入時用檔案鎖同 atomic replace,避免多會話同時改壞檔案。
再看 session_search。
Hermes 用 SQLite 嘅 state.db 保存 sessions 同 messages。messages_fts 做全文搜索,messages_fts_trigram 支援 CJK 同子串搜索。搜索時先揾歷史消息,再按 session 聚合,最後交俾輔助模型總結。
再睇 skills。
每個 skill 係一個目錄,核心係 SKILL.md。佢唔係一次過全量塞入 prompt,而係 progressive disclosure:先睇 skill 列表,需要時加載某個 skill,仲唔夠嘅話再加載 references、templates 或 scripts。
再睇 MemoryProvider。
agent/memory_provider.py 定義統一接口,agent/memory_manager.py 負責調度,而且一次只可以啓用一個外部 provider,避免工具 schema 膨脹同多個後端互相打架。
外部 provider 嘅召回結果,唔係直接寫入系統 prompt,而係每次 API 調用前透過 <memory-context> 臨時注入當前用戶消息。
呢個邊界好重要:原始消息唔變,持久化記錄唔會被污染,呢啲召回都只係背景資料,唔係用戶嘅新指令。
Honcho 係呢度最值得關注嘅 provider。佢唔只搜索過去內容,而係將用戶同 AI 都建模成 peer,並注入 session summary、user representation、peer card、AI representation,仲有更深一層嘅 dialectic supplement。
但佢係外部 memory provider,唔係 Hermes 默認內置能力。Hermes 嘅架構俾佢留咗位,用戶需要配置。
最後睇 background review 同 Curator。
background review 嘅 combined review 入面有一句劃分好關鍵:Memory 負責 who the user is,Skills 負責 how to do this class of task。
翻譯成人話就係:USER.md 解決「用戶係邊個」,skill 解決「下次點做」。好多記憶系統嘅問題,正正係將呢兩件事撈埋一齊。
Curator 解決另一個長期問題:學得越多,系統越亂。佢默認每 7 日、喺 agent 空閒夠耐之後運行,先把長期唔用嘅 skill 從 active 變 stale,再變 archived;然後檢查 agent-created skills 有冇重複、過窄、應該合併。
佢唔會鬱 bundled skills 同 hub-installed skills,亦唔會自動刪除,只歸檔。Hermes 好清楚:自我改進如果冇維護機制,最後會變成自我污染。
用一個例子行完整鏈路

假設用戶對 Hermes 講:
「以後寫公眾號唔好寫咁長,口水詞太多,壓縮一半。」
喺普通記憶系統入面,呢句嘢可能只會被保存成:「用戶鍾意簡潔。」
有用,但唔夠。
首先,當前任務要先完成。主 agent 應該先將文章壓縮好,唔係停喺度保存偏好。
然後,呢輪對話會入 SessionDB,用戶原話、修改過程、工具調用同最終稿都會成為可搜索歷史。
接着,如果後台覆盤認為呢個係穩定偏好,佢可以寫入 USER.md:
用戶偏好更精煉嘅公眾號文章,反感口水詞,常要求壓縮冗餘表達。
呢個解決嘅係「用戶係邊個」。
但更重要嘅係,佢應該更新公眾號寫作相關 skill:
當用戶反饋文章太長嗰陣,優先刪除鋪墊、重複解釋同抽象套話,保留核心判斷同論據。
呢個解決嘅係「下次點做」。
於是下一次用戶再叫 Hermes 寫公眾號,系統唔係淨係「記得用戶嫌長」,而係執行方式真係變咗。呢個就係「越用越明你」嘅產品體驗。
點解從架構圖唔容易睇出佢嘅優勢
如果你只問:Hermes 有冇向量數據庫?或者只睇 MEMORY.md / USER.md 係點樣存嘅?你好容易得出一個結論:冇咩特別。但呢個結論睇漏咗產品設計主線。
Hermes 嘅優勢唔係某個 memory store 特別先進,而係佢將「記憶」拆成咗唔同產品語義。
事實記憶、歷史記憶、程序性記憶、外部用戶建模、後台覆盤、長期整理,各自解決唔同問題。
佢亦冇將「越用越明人」寄託喺一次模型調用嘅自覺上。
主任務模型可能唔記得保存記憶,所以有 background review。覆盤可能創建太多窄技能,所以有 Curator。常駐 memory 太細,所以有 session_search。外部深記憶差異好大,所以抽象成 MemoryProvider。
呢套設計嘅厲害之處在於,佢唔係一個點,而係一組互相補位嘅機制。

我最尾嘅判斷
Hermes 嘅記憶系統,最值得學嘅唔係 MEMORY.md 點寫,亦唔係 Honcho 點樣接。
最值得學嘅係佢嘅產品拆解方式。
佢先定義咗一個場景:用戶需要一個長期協作者。
然後佢問:長期協作者要具備咩能力?
答案唔係「記住所有嘢」,而係:
少啲叫用戶重複背景。 能夠揾返過去發生過嘅事。 能夠將糾正轉化做流程。 能夠喺任務完成後覆盤。 能夠長期整理自己嘅經驗。
最後先落到架構:
短記憶用 Markdown 檔案。 歷史回憶用 SQLite FTS5 同總結模型。 做事方法用 skills。 深層用戶建模交俾 MemoryProvider。 學習觸發交俾 background review。 長期維護交俾 Curator。
所以如果要一句話概括 Hermes 嘅記憶系統,我會咁講:
佢唔係整一個更大嘅記憶庫,而係整一個會將交互經驗轉化成未來行為嘅系統。
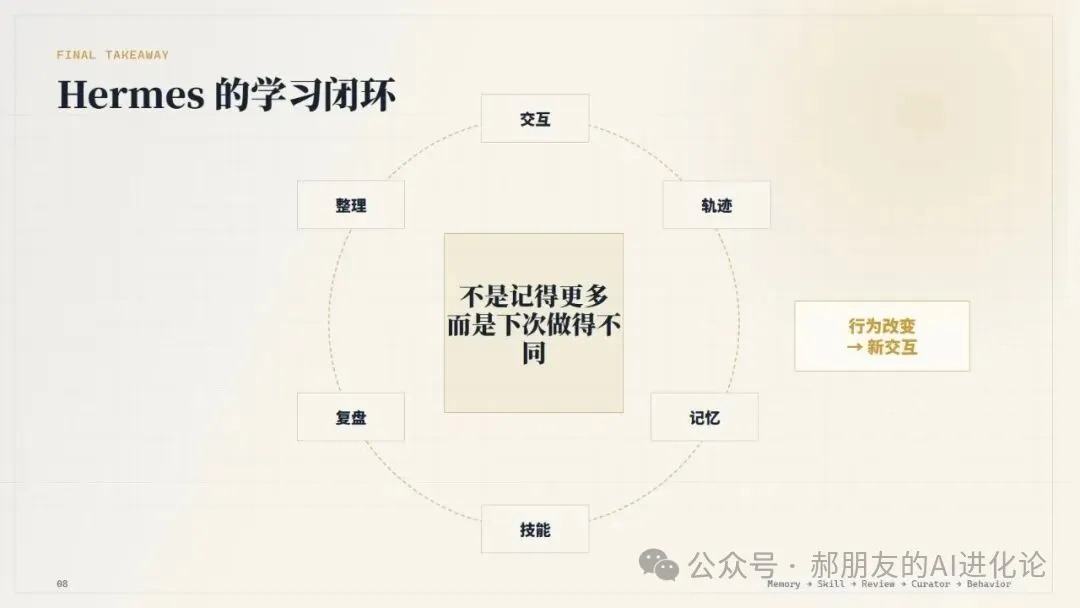
呢個亦係點解佢最近評價好:用戶感受到嘅唔係「佢保存咗好多資料」,而係我上次糾正過嘅嘢,佢下次真係少犯咗。
呢個先係 Agent 記憶應該追求嘅方向。
作者個人介紹:
https://my.feishu.cn/wiki/O62Pwtb94ikFEJkYHuEcxaWanQb
Hermes 的記憶系統真正厲害在哪:它不是在記事,而是在訓練自己的工作方式
我一開始看 Hermes Agent 的記憶系統,感覺比較簡單。
最表層不過是兩個 Markdown 文件:MEMORY.md 存 agent 工作筆記,USER.md 存用戶畫像。容量也不大。
更反直覺的是,它們在一次會話開始時被讀進系統提示詞,中途哪怕寫入新記憶,也不會立刻改變當前會話的系統提示詞。
這看起來一點都不“先進”。
至少不像很多人想象中的 Agent 記憶系統:向量數據庫、語義召回。
但繼續看源碼和文檔,我反而覺得這裏才是 Hermes 聰明的地方。
因為 Hermes 核心不是做更大的記憶庫。
它真正想做的是一個會成長的協作者。
如果目標只是“記住更多東西”,產品設計會自然走向大容量存儲、語義搜索、自動摘要和 top-k 召回。
但如果目標是“越用越懂你”,光記住不夠。系統還要區分:常駐事實、按需歷史、做事方法,以及一次用戶糾正到底該寫進用戶畫像,還是改掉工作流程。
Hermes 不是 Memory-first,而是 Scenario-first。
先定義協作者,再倒推記憶、技能、覆盤和維護機制。
先看它要解決什麼場景
官方 README 裏,Hermes 對自己的定位是 self-improving AI agent。
它強調的不是單點記憶,而是一組連續動作:創建技能、改進技能、保存知識、搜索歷史,並逐漸建立對用戶的理解。
說白了,Hermes 不是要做一個“會聊天的工具”,它想成為長期協作者。
長期協作者至少要解決五個問題:
用戶不想重複介紹自己,所以需要 USER.md或外部用戶建模。用戶不想重複交代環境,所以需要 MEMORY.md記錄項目、工具和流程坑。用戶希望找回過去發生過的事,所以需要 session_search。用戶真正想要的不是它記得事實,而是下次別再用錯方法,所以需要 skills。 記憶越來越多以後不能自我污染,所以需要 Curator。
這就是 Hermes 沒有把所有東西塞進一個 memory 系統裏的原因。
它把不同問題拆成了不同對象。
它抽象出的不是“記憶”,而是一組業務對象
從產品設計角度看,Hermes 的記憶系統背後不是一個 Memory 表,而是一組圍繞“完成一次交互後如何沉澱經驗”的業務對象。
最中心的是 Completed Turn,也就是一次完成的用戶交互。
圍繞它,系統至少要保存四類東西:
人和身份:User / Peer、Agent Profile / AI Peer。 歷史和軌跡:Session、Message。 沉澱物:Memory Entry、Skill、Skill Usage。 學習機制:Memory Provider、Background Review、Curator Run。
這個抽象很關鍵。
用戶不是一次消息的發送者,而是長期存在的人。Session 不是聊天記錄,而是一條協作線。Message 不只保存文本,也保存工具調用。Skill 不是備註,而是“這類任務以後怎麼做”的程序性記憶。
所以 Hermes 的“記憶系統”不是一個模塊,而是一組業務對象共同支撐的產品能力。
架構上,它把記憶拆成了五層
如果從系統架構看,Hermes 大概可以分成五層。
第一層是入口層。
用戶可以從 CLI、Telegram、Discord、Slack、ACP、cron、batch runner 等方式觸發任務,最終都會進入同一個核心:AIAgent。
這說明 Hermes 的長期記憶不能只服務本地命令行。多入口共享同一套 agent 核心能力,記憶、會話和技能才可能跨場景連續。
第二層是 Agent 核心層。
AIAgent 是調度中心:構建系統提示詞、選擇模型和 provider、執行工具、保存會話、觸發壓縮、調用 memory provider 生命週期、觸發後台覆盤。
也就是說,記憶不是旁路插件,而是嵌進主循環。
第三層是 Context 層。
Hermes 在這裏做了一個關鍵拆分:緩存穩定的系統提示詞,和每次調用模型時臨時注入的上下文,是兩回事。
穩定前綴裏可以有 SOUL.md、工具指導、凍結的 MEMORY.md / USER.md、skills 索引和項目上下文文件。臨時上下文裏可以有外部 provider 召回、gateway overlays、Honcho 的用戶理解。
為什麼要這麼拆?因為系統提示詞穩定,才能保住 prompt cache。Hermes 的內置 memory 採用 frozen snapshot:會話開始時凍結快照,中途寫入會落盤,但不會立刻改當前系統提示詞。
這不是能力不夠,而是產品和工程之間的取捨。
第四層是 Memory 層。
Hermes 的 memory 不是一套,而是多套:MEMORY.md / USER.md 負責短小常駐事實,SQLite session store + session_search 負責歷史情景記憶,skills 負責程序性記憶,MemoryProvider 負責外部深記憶,context files 負責項目擁有的靜態上下文。
這幾層的調用成本、更新方式、可靠性邊界都不一樣。
第五層是 Learning 層。
這才是 Hermes 最容易被低估的地方。
主模型可以調用 memory 保存事實,也可以用 skill_manage 更新技能。但 Hermes 沒有完全依賴主模型“順手記一下”。
它還有後台 self-improvement review。任務完成後,系統會 fork 一個新的 AIAgent,只給它 memory 和 skills 兩類工具,專門覆盤:有沒有用戶偏好要保存?有沒有流程經驗要寫成技能?skill 有沒有需要修補?
再往後,還有 Curator 負責整理這些 agent-created skills,避免長期學習變成長期污染。
所以 Hermes 的學習閉環是:
用戶交互產生軌跡,軌跡進入會話庫,穩定事實進入 memory,做事方法進入 skills,外部 provider 做用戶建模,後台覆盤沉澱經驗,Curator 清理和合並技能。
下一次再遇到類似場景,行為發生變化。
這條鏈路,才是它“越用越懂人”的來源。
幾個模塊分別怎麼實現
先看最樸素的內置 memory。
tools/memory_tool.py 裏有一個 MemoryStore,管理 memory_entries 和 user_entries,落到 ~/.hermes/memories/ 下的 MEMORY.md 和 USER.md。
寫入方式很剋制:只有 add、replace、remove。沒有複雜編輯器,也沒有默認 read action,因為 memory 會在會話開始時自動注入。
它還做了兩件工程化的事:寫入前掃描 prompt injection 和憑據外泄風險;併發寫入時用文件鎖和 atomic replace,避免多會話同時改壞文件。
再看 session_search。
Hermes 用 SQLite 的 state.db 保存 sessions 和 messages。messages_fts 做全文搜索,messages_fts_trigram 支持 CJK 和子串搜索。搜索時先找歷史消息,再按 session 聚合,最後交給輔助模型總結。
再看 skills。
每個 skill 是一個目錄,核心是 SKILL.md。它不是一次性全量塞進 prompt,而是 progressive disclosure:先看 skill 列表,需要時加載某個 skill,還不夠時再加載 references、templates 或 scripts。
再看 MemoryProvider。
agent/memory_provider.py 定義統一接口,agent/memory_manager.py 負責調度,而且一次只能啓用一個外部 provider,避免工具 schema 膨脹和多個後端互相打架。
外部 provider 的召回結果,不是直接寫進系統 prompt,而是在每次 API 調用前通過 <memory-context> 臨時注入當前用戶消息。
這個邊界很重要:原始消息不變,持久化記錄不被污染,這些召回也只是背景資料,不是用戶的新指令。
Honcho 是這裏最值得關注的 provider。它不只是搜索過去內容,而是把用戶和 AI 都建模成 peer,並注入 session summary、user representation、peer card、AI representation,以及更深一層的 dialectic supplement。
但它是外部 memory provider,不是 Hermes 默認內置能力。Hermes 的架構給它留了位置,用戶需要配置。
最後看 background review 和 Curator。
background review 的 combined review 裏有一句劃分很關鍵:Memory 負責 who the user is,Skills 負責 how to do this class of task。
翻譯成人話就是:USER.md 解決“用戶是誰”,skill 解決“下次怎麼做”。很多記憶系統的問題,恰恰是把這兩件事混在一起。
Curator 解決另一個長期問題:學得越多,系統越亂。它默認每 7 天、在 agent 空閒足夠久後運行,先把長期不用的 skill 從 active 變 stale,再變 archived;然後檢查 agent-created skills 有沒有重複、過窄、應該合併。
它不會碰 bundled skills 和 hub-installed skills,也不會自動刪除,只歸檔。Hermes 很清楚:自我改進如果沒有維護機制,最後會變成自我污染。
用一個例子跑完整鏈路
假設用戶對 Hermes 說:
“以後寫公眾號別寫那麼長,口水詞太多,壓縮一半。”
在普通記憶系統裏,這句話可能只會被保存成:“用戶喜歡簡潔。”
有用,但不夠。
首先,當前任務要先完成。主 agent 應該先把文章壓縮好,而不是停下來保存偏好。
然後,這輪對話進入 SessionDB,用戶原話、修改過程、工具調用和最終稿都會成為可搜索歷史。
接着,如果後台覆盤認為這是穩定偏好,它可以寫入 USER.md:
用戶偏好更精煉的公眾號文章,反感口水詞,常要求壓縮冗餘表達。
這解決的是“用戶是誰”。
但更重要的是,它應該更新公眾號寫作相關 skill:
當用戶反饋文章太長時,優先刪除鋪墊、重複解釋和抽象套話,保留核心判斷和論據。
這解決的是“下次怎麼做”。
於是下一次用戶再讓 Hermes 寫公眾號,系統不是隻“記得用戶嫌長”,而是執行方式真的變了。這就是“越用越懂你”的產品體驗。
為什麼從架構圖裏不容易看出它的優勢
如果你只問:Hermes 有沒有向量數據庫?或者只看 MEMORY.md / USER.md 是怎麼存的?你很容易得出一個結論:沒什麼特別。但這個結論看漏了產品設計主線。
Hermes 的優勢不是某個 memory store 特別先進,而是它把“記憶”拆成了不同產品語義。
事實記憶、歷史記憶、程序性記憶、外部用戶建模、後台覆盤、長期整理,各自解決不同問題。
它也沒有把“越用越懂人”寄託在一次模型調用的自覺上。
主任務模型可能忘記保存記憶,所以有 background review。覆盤可能創建太多窄技能,所以有 Curator。常駐 memory 太小,所以有 session_search。外部深記憶差異很大,所以抽象成 MemoryProvider。
這套設計的厲害之處在於,它不是一個點,而是一組互相補位的機制。
我最後的判斷
Hermes 的記憶系統,最值得學的不是 MEMORY.md 怎麼寫,也不是 Honcho 怎麼接。
最值得學的是它的產品拆解方式。
它先定義了一個場景:用戶需要一個長期協作者。
然後它問:長期協作者要具備什麼能力?
答案不是“記住所有東西”,而是:
少讓用戶重複背景。 能找回過去發生過的事。 能把糾正轉化成流程。 能在任務結束後覆盤。 能長期整理自己的經驗。
最後才落到架構:
短記憶用 Markdown 文件。 歷史回憶用 SQLite FTS5 和總結模型。 做事方法用 skills。 深層用戶建模交給 MemoryProvider。 學習觸發交給 background review。 長期維護交給 Curator。
所以如果要一句話概括 Hermes 的記憶系統,我會這麼說:
它不是在做一個更大的記憶庫,而是在做一個會把交互經驗轉化成未來行為的系統。
這也是為什麼它最近評價會好:用戶感受到的不是“它保存了很多資料”,而是我上次糾正過的東西,它下次真的少犯了。
這才是 Agent 記憶該追求的方向。
作者個人介紹:
https://my.feishu.cn/wiki/O62Pwtb94ikFEJkYHuEcxaWanQb