Hermes 給我的最大啓發:上下文不是倉庫,是工作台
整理版優先睇
上下文工程比模型能力更重要:Agent 變笨通常因為上下文太亂,好 Agent 要讓信息按需出現,唔係堆積喺工作台上。
呢篇文章係作者分享佢用 Hermes Agent 嘅經驗,佢發現 Agent 用耐咗會變笨,好多時候唔係模型唔夠強,而係上下文冇管理好。作者引用多篇學術論文(Lost in the Middle、NoLiMa、Context Length Alone Hurts LLM Performance)證明長上下文會損害表現,然後拆解 Hermes 點樣透過「只保留必要信息、長期記憶外部化、沉澱成技能、子任務隔離」嚟解決問題。
作者做咗個實驗,比較 curl HTML、瀏覽器快照同 AI 搜索/抽取三種方法拎網頁內容,發現 AI 搜索嘅 token 成本只係 raw HTML 嘅 1/16,而且完成任務更乾淨。佢認為 AI 搜索嘅核心唔係揾更多資料,而係清洗上下文,令 Agent 唔使喺垃圾資訊入面揾重點。
結論係:未來 Agent 嘅差距唔只係模型,仲係上下文工程。XCrawl 呢類工具可以幫手將網頁變成乾淨、可引用、可推理嘅上下文,令 Agent 更穩定。作者建議先裝 XCrawl Skills,從抽取正文同站點地圖開始試。
- Agent 變笨主要因為上下文堆積太多雜訊,唔係模型唔夠強。
- 長上下文唔係免費午餐:即使模型完美檢索,長度增加仍會令表現下降。
- Hermes 嘅做法係將上下文當工作台管理:只留當前需要嘅信息,歷史經驗沉澱成技能,子任務各自隔離。
- 網頁係最髒嘅上下文入口,raw HTML 可以佔 66k tokens,而 AI 抽取後只需 4k tokens,而且結果更乾淨。
- XCrawl Tools 可以將網頁轉成 Markdown、JSON 等結構化資料,係 Agent 嘅清洗層,值得一試。
XCrawl Skills GitHub
用呢個連結叫 Hermes 安裝 XCrawl Skills
XCrawl 官網
申請 API Key,有免費額度
XCrawl 配置檔案
本地 ~/.xcrawl/config.json 入面放 API Key:{"XCRAWL_API_KEY": "<your_api_key>"}
Agent 變笨,好多時係上下文問題
你平時用 AI 聊天,大概都遇過呢種情況:一開始問得好順,但傾傾嚇模型開始唔對路,前面講過嘅要求佢忘記,你糾正過嘅點佢又犯,材料一多佢就重複繞圈。好多人以為係模型唔掂,要換個更強嘅,但其實更常見嘅原因係「上下文髒咗」。
上下文髒咗:Agent 唔係食得愈多資訊愈強,好多時佢變蠢係因為個腦塞咗太多唔應該睇嘅嘢。
- 1 輸出變長,Agent 解釋一堆冇必要嘅背景
- 2 目標變虛,原本嘅約束俾新信息沖淡
- 3 工具污染,網頁、JSON、日誌原樣入上下文,模型嘅注意力俾垃圾食咗。
- 1 輸出變長:Agent 解釋冇必要嘅背景,好似想證明自己好努力。
- 2 目標變虛:原本約束被新信息沖淡。
- 3 工具污染:網頁、JSON、日誌原樣入上下文,模型未開始思考先做清潔工。
長上下文唔係免費午餐
過去一年模型都喺度鬥上下文窗口,128K、200K、1M 睇落好爽,但實際上冇咁簡單。TACL 2024 嘅 Lost in the Middle 測試發現:相關資訊放喺開頭或結尾時表現最好,放中間就明顯跌。
即使係號稱支援長上下文嘅模型,相關資訊放喺中間仍然會表現下降。
ICML 2025 嘅 NoLiMa 更直接:13 個支援至少 128K 嘅模型,短上下文表現好好,但去到 32K 嗰陣有 11 個跌到短上下文基準嘅 50% 以下,GPT-4o 都從 99.3% 跌到 69.7%。仲有一篇 EMNLP Findings 2025 嘅論文講,就算模型完美檢索,只要輸入長度增加,數學、問答、代碼任務都會跌 13.9% 至 85%。
作者而家相信一個樸素判斷:少塞 token 就係優化。Agent 唔可以只靠更大窗口,佢需要上下文工程。
Hermes 點樣管理上下文
Hermes 值得睇嘅地方唔係佢識調工具,而係佢開始將上下文當成工程問題處理。作者從公開資料同自己整理嘅材料歸納咗幾層思路。
當前任務只保留必要信息,唔好揹住完整歷史走。
長期記憶要外部化,歷史經驗、項目資料、配置等唔應該常駐上下文,應該放喺 memory、文件、技能或數據庫,需要時先攞。呢點同 Claude Code 等開發 Agent 做法相似:上下文只放路徑、摘要同當前片段。
- 1 子任務隔離上下文:複雜任務拆成多個子任務,各自喺自己乾淨上下文做事,最後只將結論壓縮回主任務。好處係污染被隔離,壞處係成本上升、協調複雜。
- 2 工具結果唔可以原樣灌入對話:網頁 HTML、日誌、JSON 要清理先入上下文,唔好讓模型先做清潔工。
所以 Hermes 俾作者嘅啓發唔係記住更多,而係好 Agent 應該令資訊喺應出現嘅時候出現,唔應該出現嘅時候就唔好出現。
網頁係最易污染 Agent 嘅上下文入口
作者特別將 AI 搜索拎出嚟講,因為 Agent 做 research 時最常見動作就係查網頁。網頁本身係俾瀏覽器同人睇嘅,導航欄、廣告、頁腳、推薦內容,人識自動忽略,但模型唔會,你餵乜佢就睇乜。
作者做咗個對照實驗:用 Hermes Agent 追蹤版本更新,分別用 curl HTML、瀏覽器快照、AI 搜索/抽取拎網頁內容。
結果好誇張:curl HTML 用咗 66,334 tokens,瀏覽器快照用 8,643 tokens,AI 搜索/抽取只用 4,078 tokens,節省咗 93.9%。而且三種方法都完成到任務,但 AI 搜索嘅結果最乾淨。
- curl HTML:66,334 tokens,需要人工清洗,來源可靠但成本高。
- 瀏覽器快照:8,643 tokens,節省 87%,仍然有部分噪聲。
- AI 搜索/抽取:4,078 tokens,節省 93.9%,唔需要人工清洗,來源可靠。
XCrawl 喺呢條鏈路入面就係網頁進入上下文之前嘅清洗層,將網頁處理成 Agent 更容易用嘅材料,輸出 Markdown、JSON、links、screenshot 等。
點樣開始實戰
如果你想復現類似流程,可以先裝 XCrawl Skills,叫 Hermes 安裝呢個 GitHub 連結。然後去 XCrawl 官網申請 API Key,有免費額度。
{
"XCRAWL_API_KEY": "<your_api_key>"
}配置完之後,就可以用 search、scrape、map、crawl 呢啲 skill。作者建議先試兩個任務:
- 1 俾一個網頁,叫 Agent 只抽取正文、關鍵觀點同引用連結。
- 2 俾一個站點,叫 Agent 先 map 出 URL,再揀最相關嘅頁面 scrape。
呢兩個任務最能睇到差距:真正影響 Agent 質量嘅,通常係垃圾上下文有冇擋喺門外。
未來 Agent 嘅差距唔只係模型,都係上下文工程嘅差距。誰能讓模型少睇垃圾、多睇關鍵,誰嘅 Agent 就更穩。XCrawl 呢類工具嘅價值就係令 Agent 少睇廢話。

你平時用 AI 聊天,大概率遇到過這種情況。
剛開始問得很順。你讓它改一段話、解釋一個概念、整理一份資料,它都能接住。
但聊着聊着,它開始不對勁。
前面明明說過的要求,它忘了。你剛剛糾正過的點,它又犯了。材料一多,它開始重複、繞圈、自己發散。
這時候很多人的第一反應是:模型不行,換一個更強的。
其實不完全是。
更常見的問題是:上下文髒了。
Agent 不是吃進去的信息越多越強。很多時候,它變笨,是腦子裏塞了太多不該看的東西。
這個問題在普通聊天裏已經很明顯,到了 Hermes 這種能查網頁、調工具、跑長任務的 Agent 裏,會被放大很多倍。
所以我覺得,真要把 Agent 用好,得學一下 Hermes 背後的上下文工程做法。
Manus 和 Anthropic 之前一直講的:Context Engineering,上下文工程。
這篇文章只講一件事:Agent 變笨,很多時候不是模型不夠強,而是上下文沒有被管理。
一、Agent 的問題,很多時候是上下文問題
Hermes 這類 Agent 好用,是因為它不只是聊天。
它能拆任務,能調工具,能查網頁,能讀文件,能寫代碼。大模型從會回答問題,變成了能執行任務。
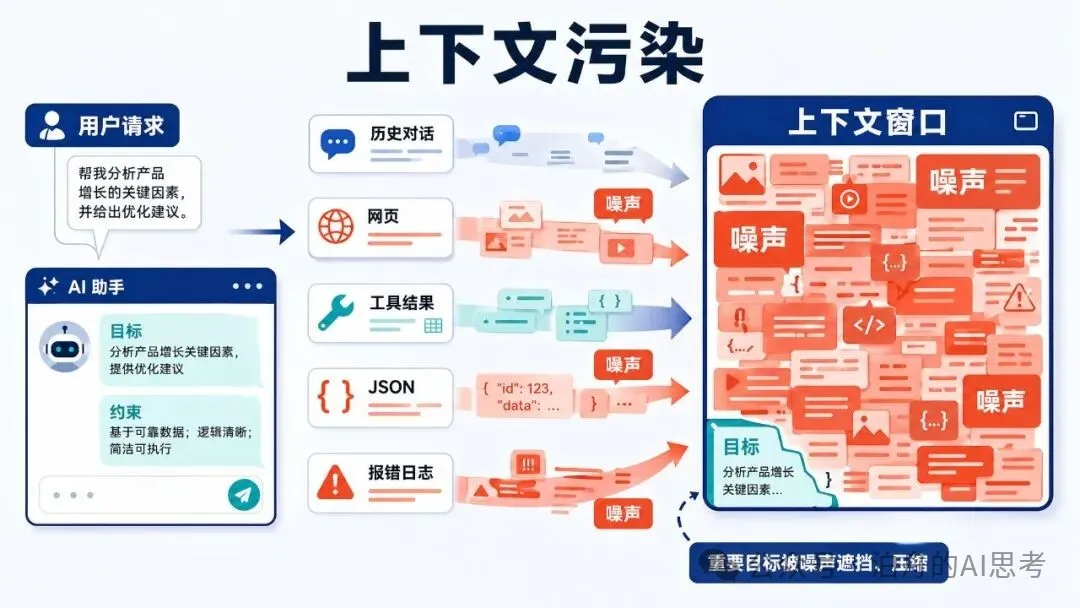
但是執行系統有一個很現實的問題:它每做一步,都會產生新的上下文。
用戶最開始的需求、系統提示詞、歷史對話、工具調用結果、網頁內容、文件內容、報錯日誌、中間總結,都會慢慢堆進來。
這些東西如果不管,模型最後看到的會是一整張亂糟糟的桌子。
我自己踩坑最多的是三類情況。
第一,輸出變長。Agent 開始解釋一堆不必要的背景,像是在證明自己很努力。
第二,目標變虛。任務做着做着,原來的約束被新信息沖淡了。
第三,工具污染。網頁、JSON、日誌、報錯原樣進上下文,模型還沒開始思考,注意力已經被垃圾內容吃掉了。
這不是玄學。
上下文就是模型當前能看到的全部信息。模型每次生成,都要在這些信息裏判斷什麼重要、什麼不重要。
所以 Context 不是資料庫。
Context 更像工作台。
資料庫可以很大,什麼都能放。工作台不行。工作台上只應該放你當前要用的工具、材料和圖紙。
如果把倉庫裏的東西全搬到工作台上,工人不會更強,只會更亂。
二、長上下文不是免費的
過去一年,很多模型都在拼上下文窗口。
128K、200K、1M,看起來很爽。好像只要窗口夠大,我們就可以把所有資料都塞進去,讓模型自己看。
但實際沒這麼簡單。
TACL 2024 的 Lost in the Middle 做過一個很有名的測試:相關信息放在長上下文的開頭或結尾時,模型表現更好;放在中間時,表現會明顯下降。哪怕是明確支持長上下文的模型,也會遇到這個問題。
這說明模型不是均勻閲讀上下文的。
NoLiMa 這個 ICML 2025 接收的工作又往前推了一步。它去掉問題和答案之間的字面匹配,讓模型必須做語義關聯檢索。結果很直接:13 個號稱至少支持 128K 上下文的模型,短上下文表現很好,但到 32K 時,11 個模型跌到短上下文強基線的 50% 以下。GPT-4o 也從 99.3% 掉到 69.7%。
還有一篇 EMNLP Findings 2025 的論文,標題更直白:Context Length Alone Hurts LLM Performance Despite Perfect Retrieval。
它控制了檢索因素。也就是說,就算模型已經能完美拿到相關信息,只要輸入長度增加,數學、問答、代碼任務上的表現仍然會下降 13.9% 到 85%。
所以我現在更願意相信一個樸素判斷:少塞 token,本身就是優化。
上下文窗口大,只代表你能塞更多東西進去,不代表模型真的能穩定用好這些東西。
Agent 想穩定,不能只靠更大的窗口。它需要上下文工程。
三、Hermes 真正值得看的,是它怎麼管理上下文
Hermes 火,不只是因為它能調工具。
更值得看的地方,是它開始把上下文當成工程問題處理。
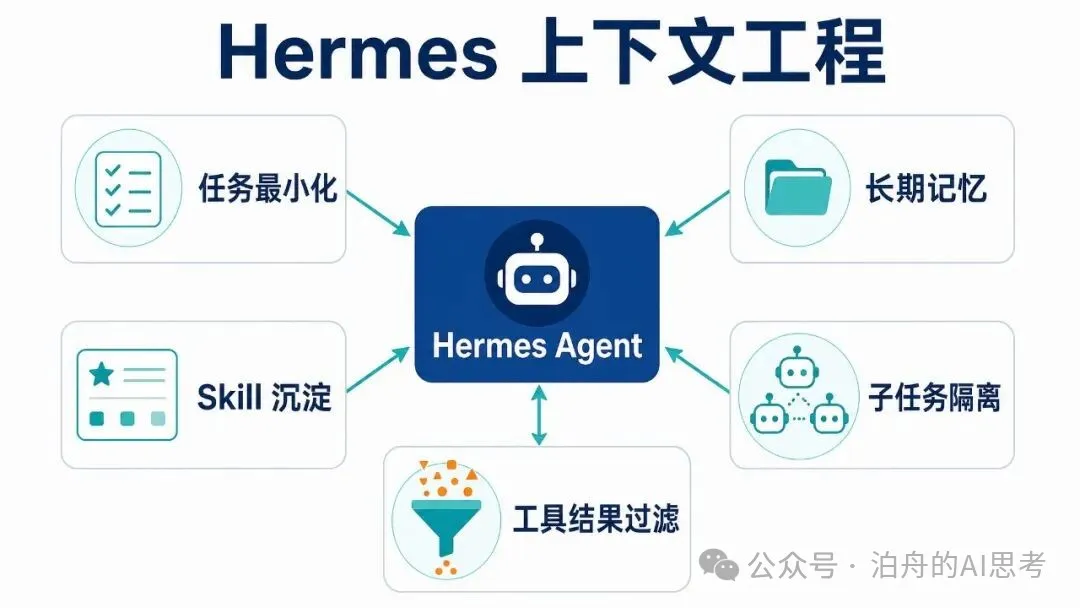
從公開資料和我這次整理的材料看,Hermes 的思路大概有幾層。
當前任務只保留必要信息。
Agent 每一步不應該都揹着完整歷史走。當前要做什麼、有哪些約束、剛才得到什麼關鍵結果,這些才是該放在工作台上的東西。
長期記憶外部化。
大量歷史經驗、項目資料、配置、長期偏好,不應該常駐上下文。更好的方式是放到 memory、文件、技能或數據庫裏,需要時再取。
這點和 Claude Code、很多開發 Agent 的做法很像:上下文裏只放路徑、摘要和當前片段。大文件、日誌、中間結果留在文件系統裏。
重複經驗沉澱成 skill。
Hermes 這類系統很有意思的一點,是會把重複出現的任務模式沉澱成技能。
這比記住一大段歷史更靠譜。
歷史對話是雜亂的,skill 是壓縮後的經驗。下次遇到同類任務,Agent 不需要重新讀一堆舊記錄,直接調用整理好的做法。
子任務隔離上下文。
複雜任務最好不要全塞進一個窗口。
Research、代碼分析、資料整理、驗證,可以拆成不同子任務。每個子任務在自己的乾淨上下文裏做事,最後只把結論壓縮回主任務。
好處很明顯:污染被隔離了。
壞處也很明顯:成本會上去,協調也更復雜。所以它適合寬度優先的複雜 research,不適合所有任務。
還有一個很容易被忽略的點:工具結果不能原樣灌進對話。
很多 Agent 的上下文失控,問題常常出在工具返回太髒。
網頁抓下來一整頁 HTML,日誌返回幾千行,API 返回一大坨 JSON。模型還沒開始做判斷,先被迫當了一遍清潔工。
所以 Hermes 給我的啓發不是讓 Agent 記住更多。
恰恰相反。
好 Agent 應該讓信息在該出現的時候出現,不該出現的時候別出現。
四、其他上下文方案:工具箱,不是銀彈
上下文工程不是單一技術。
不同入口髒法不一樣,治理方式也不一樣。
Rolling Summary 適合長對話。
它的做法很直接:舊消息太多了,就壓成摘要,然後保留摘要和最近消息。LangMem 的 SummarizationNode 是這種思路,Anthropic 也把 compaction 當成生產 Agent 的常用方案。
但是 summary 不是魔法。
摘要一定會損失細節。關鍵事實、具體文件、未解決 bug,最好用結構化字段或外部文件補強。
RAG / 向量庫適合大規模知識庫。
把知識放在上下文外,用時檢索少量材料進來。它的優勢是成本低,知識可以更新,也更適合企業文檔、產品知識庫、歷史資料。
但 RAG 不能被神化。
EMNLP Industry 2024 有一篇 RAG 和 Long Context 的對比研究,結論很剋制:資源充足時,Long Context 平均表現持續優於 RAG;RAG 的核心優勢是成本更低。
所以更穩的判斷是:RAG 適合低成本按需檢索,長上下文適合需要完整材料的任務。很多時候,混合路由更靠譜。
外部文件系統適合開發 Agent。
代碼、日誌、大文檔、中間結果,都可以放在文件裏。上下文裏只留路徑、摘要和當前必要片段。
Anthropic 在 MCP code execution 那篇文章裏給過一個很典型的例子:把工具暴露成文件樹和代碼 API 後,Agent 只讀取當前任務需要的工具定義,token 使用從 150,000 降到 2,000,節省 98.7%。
這個思路很樸素,但非常有效。
別把所有工具說明一次性塞給模型。讓它像開發者一樣,用到哪個工具,再讀哪個工具。
多 Agent 隔離適合複雜 research。
Anthropic 的多 Agent research system 是一個公開案例。lead agent 負責拆任務,subagent 各自探索不同方向,再把結果壓縮回來。
他們內部 eval 裏,多 Agent 系統比單 Agent 高 90.2%。
但這個數字不能亂用。
同一篇文章也說,多 Agent 系統大約比普通 chat 多用 15 倍 token。它適合高價值、可並行、信息量超過單窗口的複雜研究任務。對很多 coding task,依賴更強,並行空間沒那麼大。
AI 搜索 / 網頁抽取適合治理網頁入口。
網頁是 Agent 最常見的信息來源,也是最髒的上下文入口。
網頁裏有正文,也有導航、廣告、腳本、評論、推薦閲讀、版權聲明。你直接把網頁塞進上下文,本質上是在讓模型自己清垃圾。
所以 AI 搜索的價值,不是多搜一點。
它真正的價值是先渲染、過濾、抽取、結構化,再把低噪聲材料交給 Agent。
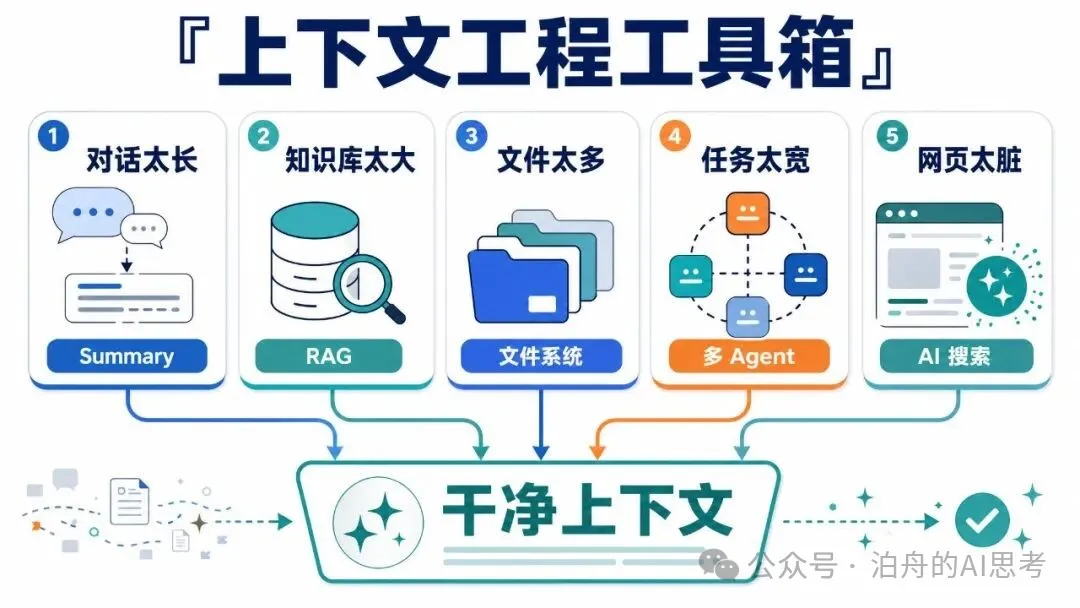
這幾個方案可以這麼記:
- • 對話太長,用 summary。
- • 知識庫太大,用 RAG。
- • 文件太多,用文件系統和按需讀取。
- • 任務太寬,用多 Agent 隔離。
- • 網頁太髒,用 AI 搜索/抽取先清洗。
五、網頁,是最容易污染 Agent 的上下文入口
為什麼我會把 AI 搜索單獨拎出來講?
因為 Agent 做 research 的時候,最常見的動作就是查網頁。
競品分析要查網頁,版本追蹤要查網頁,技術調研要查網頁,找用戶評價也要查網頁。
問題是,大多數網頁都不是給 LLM 看的。
它們是給瀏覽器和人看的。
人打開網頁,會自動忽略導航欄、廣告、頁腳和推薦內容。模型不會。你喂什麼,它就看什麼。
為了把這件事說清楚,我做了一個對照實驗。
任務很簡單:用 Hermes Agent 追蹤它自身的版本更新,從兩個頁面(騰訊雲開發者文章 + 知乎專欄)提煉 3 個核心更新點。
任務完全相同,Agent 相同,模型相同。
唯一變量是網頁獲取方式。
- 1. curl 原始 HTML:整頁 HTML 直接扔給 Agent。
- 2. 瀏覽器快照:提取頁面可見文本,過濾掉 HTML 標籤。
- 3. AI 搜索/抽取:用專門的 AI 搜索工具做結構化抽取,只把乾淨內容給 Agent。
結果差距很大。
任務:追蹤 Hermes 的版本更新,從兩個頁面提煉 3 個核心更新點
計量口徑:counted_context_tokens,也就是實際送進 Agent 上下文的網頁材料 token 數。不含系統提示、任務包裝、輸出這些固定開銷。
| 方案 | 材料 tokens | 材料字符數 | 相比 raw HTML 節省 | 完成任務 | 人工清洗 | 來源可追溯 |
|---|---|---|---|---|---|---|
| curl 原始 HTML | 66,334 | 290,023 | - | 是 | 需要 | 中 |
| 瀏覽器快照 | 8,643 | 18,726 | 87.0% | 是 | 部分 | 高 |
| AI 搜索/抽取 | 4,078 | 14,616 | 93.9% | 是 | 不需要 | 高 |
三種方案都完成了任務。
但是成本完全不是一個量級。
curl 原始 HTML ████████████████████████████████████████ 66,334 tokens
瀏覽器快照 █████ 8,643 tokens
AI 抽取 ██ 4,078 tokens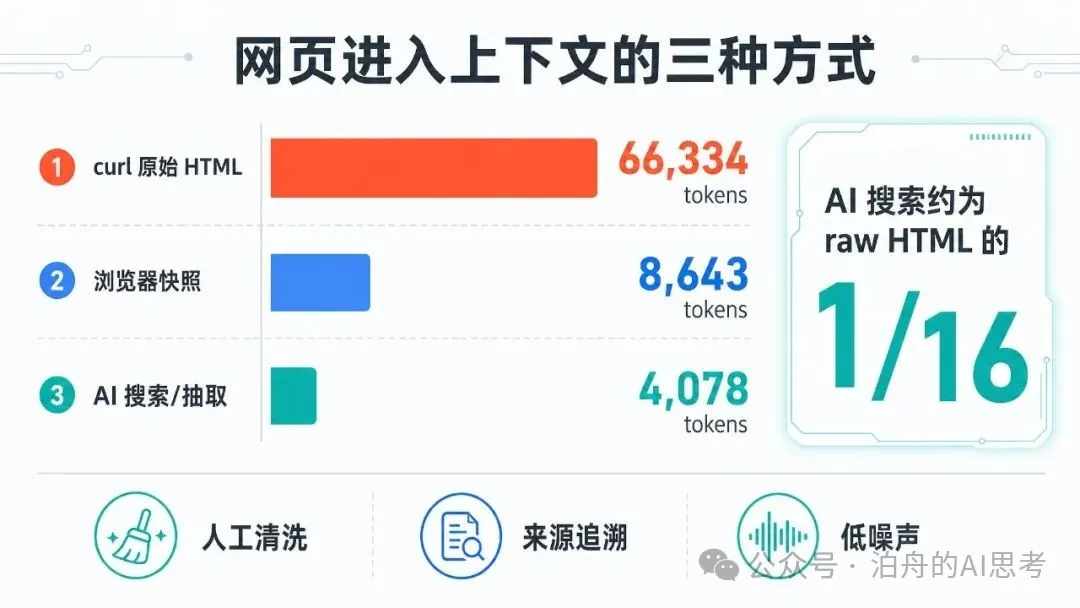
AI 搜索方案的上下文規模,只有 raw HTML 的 1/16,是瀏覽器快照的 1/2。
這個差距不是省一點錢的問題。
它直接影響 Agent 的工作狀態。
上下文越短、越乾淨,模型越容易把注意力放在真正重要的信息上。反過來,網頁噪聲越多,模型越容易被無關內容帶偏。
六、AI 搜索做的不是搜索,是上下文清洗
AI 搜索/抽取方案的本質,是把上下文工程落到了網頁入口。
它先決定 Agent 該看什麼。
Agent 拿到的應該是結構化、去噪後的信息,而不是原始 HTML 或亂七八糟的可見文本。導航欄、廣告、腳本、頁腳、推薦閲讀,這些東西不該進上下文。
然後決定什麼時候看。
任務一開始就塞所有網頁,通常會把上下文搞髒。更好的做法是,需要某個問題的答案時,再觸發搜索或抽取。
這就是 just-in-time context。
信息按需出現,不常駐。
還要控制看到多少。
整頁搬運沒有必要。頁面應該先被壓縮成可直接推理的 Markdown、JSON、links 或截圖。
比如這次實驗裏,AI 抽取返回的是這樣的結構:
{
"section_title": "自我改進的學習循環",
"content": [
"學習循環是 Hermes 與其他自託管 Agent 的根本區別。",
"工作原理:任務完成 → 模式提取 → 技能創建 → 技能完善 → 週期性提示(每 15 個任務評估一次)",
"緩存感知學習:內存架構在初始化時凍結系統提示快照,以提升緩存命中率"
]
}送進 Agent 上下文的,只有這些結構化、去噪後的信息:共 14,616 字符,約 4,078 tokens。
沒有導航欄,沒有廣告,沒有腳本,沒有冗餘 HTML。
Agent 拿到的是可以直接消費的材料,不用再當一次網頁清潔工。
最終 Hermes 給出的結論也更乾淨:
- 1. 分層記憶與可插拔內存架構
自 v0.7.0 起內存完全可插拔,支持內置、Honcho、向量存儲、自定義數據庫等後端,通過hermes memory setup切換。- 2. 自我改進學習循環與技能自動生成
Agent 完成任務後提取模式,創建 Markdown 技能文件,後續任務中複用並完善,形成“任務 → 模式提取 → 技能創建 → 技能完善”的循環。- 3. 模型無關架構與 MCP 服務器模式
一條命令切換 200+ 模型;v0.6.0+ 新增 MCP 服務器模式,可將 Hermes 暴露為 IDE/工具的 MCP 服務器。
這裏的關鍵不是答案更短。
關鍵是:來源可追溯,材料低噪聲,Agent 不用在垃圾上下文裏找重點。
七、XCrawl 在這條鏈路裏的位置
現在再看 XCrawl,就比較清楚了。
它不是一個普通網頁抓取工具。
在 Agent 工作流裏,XCrawl 更像是網頁進入上下文之前的清洗層。
你可以讓 Agent 直接用瀏覽器或 curl 抓網頁。
但這麼做的問題是,網頁會以一種很髒的形態進入上下文。
XCrawl 做的是另一件事:先把網頁處理成 Agent 更容易使用的材料。
它覆蓋幾類常見場景:
- •
search:按查詢搜索網頁,適合開放式 research。 - •
scrape:抽取單個 URL,適合文章、文檔、產品頁。 - •
map:發現站點 URL,適合先摸清網站結構。 - •
crawl:批量抓取站點內容,適合文檔站、競品站、資料庫。
輸出也更適合 Agent:
- • Markdown:保留正文語義,方便直接閲讀。
- • JSON:適合結構化提取,比如價格、版本、功能點。
- • links:保留引用和後續追蹤入口。
- • screenshot:需要視覺判斷時,可以留截圖。
所以它解決的不是能不能抓到網頁。
它解決的是:網頁抓到以後,能不能變成乾淨、可引用、可推理的上下文。
這就是為什麼我覺得 AI 搜索會變成 Agent 的基礎設施。
Agent 越強,越不能把髒數據直接塞給它。
八、怎麼在 Agent 裏用 XCrawl
如果你想復現類似流程,可以先裝 XCrawl Skills。
把這個連結發給 Hermes,讓它按 README 安裝:
https://github.com/xcrawl-api/xcrawl-skills/blob/main/README.zh-CN.md
也可以直接對 Hermes 說:
安裝這個 XCrawl Skills:https://github.com/xcrawl-api/xcrawl-skills/blob/main/README.zh-CN.md
然後去 XCrawl 官網申請 API Key:
https://www.xcrawl.com/?keyword=736zq00n
官網註冊後有免費額度,可以先跑幾個真實任務看看效果。
本地配置文件放這裏:
{
"XCRAWL_API_KEY": "<your_api_key>"
}路徑是:
~/.xcrawl/config.json配置完以後,就可以在 Agent 裏用 search、scrape、map、crawl 這些 skill。
我建議先從兩個任務開始試。
第一,給一個網頁,讓 Agent 只抽取正文、關鍵觀點和引用連結。
第二,給一個站點,讓 Agent 先 map 出 URL,再挑最相關的頁面 scrape。
這兩個任務最能看出差距。
因為你會發現,真正影響 Agent 質量的,經常是垃圾上下文有沒有擋在門外。
九、最後說人話
Hermes 讓我重新理解了 Agent。
以前我會覺得 Agent 的核心能力是推理、規劃、調工具。
現在我會再加一條:上下文控制。
上下文越多,不一定越好。
模型能力的上限,不只取決於參數,也取決於它每一步看到的材料質量。
所以未來 Agent 的差距,不只是模型差距,也會是上下文工程差距。
誰能讓模型少看垃圾、多看關鍵,誰的 Agent 就更穩。
這也是 XCrawl 這類 AI 搜索/抽取工具的價值。
它不是讓 Agent 看更多網頁。
它是讓 Agent 少看廢話。
參考來源:
- • Lost in the Middle: https://aclanthology.org/2024.tacl-1.9/
- • NoLiMa: https://arxiv.org/abs/2502.05167
- • Context Length Alone Hurts LLM Performance Despite Perfect Retrieval: https://aclanthology.org/2025.findings-emnlp.1264/
- • Effective context engineering for AI agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- • RAG or Long-Context LLMs: https://aclanthology.org/2024.emnlp-industry.66/
- • Code execution with MCP: https://www.anthropic.com/engineering/code-execution-with-mcp
- • Multi-agent research system: https://www.anthropic.com/engineering/multi-agent-research-system
- • XCrawl Skills: https://github.com/xcrawl-api/xcrawl-skills