【hermes保姆教程】B站視頻逐字稿自動進obsidian知識庫
整理版優先睇
用 Hermes 同 Obsidian 將 B 站視頻自動變逐字稿,從此睇片變睇書
呢篇係嬌姐寫嘅保姆級教程,佢係一個前榮耀員工、而家專注 AI 效率工具嘅研究者。佢發現成日睇完 B 站教學片覺得有用,但收藏咗之後就唔會再開,想覆盤內容又嫌重睇太麻煩。所以佢設計咗一套全自動方案:只要俾個 B 站連結,5 分鐘後 Obsidian 知識庫就會多咗篇完整逐字稿,連 23 集嘅 Claude Code 教程都可以一晚全部搞掂。整體結論係:將被動吸收嘅影片轉成主動複習嘅文字,搜尋快、易翻睇,徹底解決「睇完就忘」嘅問題。
成個流程行得通嘅關鍵係兩個工具:Hermes 做總指揮,負責下載音頻、叫 AI 轉寫、寫入筆記;Obsidian 做本地儲存,俾你永久檢索。技術門檻唔高,只要跟住步驟裝好 yt-dlp、faster-whisper,再改好 Hermes 配置文件,就可以逐條 link 或者批量處理。佢仲提供咗完整嘅 Python 腳本,連 Frontmatter 格式都寫好,基本上係 copy-paste 就用到。
嬌姐特別強調呢套方案唔係玩技術,而係改變學習習慣。把「睇片」變成「睇書」,文字可以隨時搜、隨時翻,比任何平台嘅收藏夾都可靠。最後佢順便推廣咗自己嘅付費社羣同資料包,但核心流程係免費可自學嘅。
- 核心方法:用 yt-dlp 抽音頻 → faster-whisper 轉寫文字 → 自動存入 Obsidian,全程唔使手動睇片。
- 差異優勢:轉寫完帶時間戳,逐字稿可以全文搜尋,秒揾返之前講過嘅內容,比平台收藏夾好用好多。
- 實測數據:10 分鐘片大約轉寫 3-5 分鐘(CPU small 模型),23 集片一晚搞掂。
- 啟發:呢套方案嘅精髓係將被動吸收變主動複習,文字格式令你用關鍵詞搜返任何細節。
- 可行動點:新手只要裝好 Obsidian、yt-dlp 同 faster-whisper,改好 Hermes 配置,再跟住單集實戰行一次就得。
Obsidian
本地筆記軟件,免費開源,用嚟儲存同檢索逐字稿。
Hermes
AI 助手,負責協調成個流程,需配合 Claude Code 使用。
yt-dlp
影片音頻提取工具,用嚟下載 B 站音頻。
faster-whisper
AI 轉寫工具,將語音轉成文字。
問題同方案:點解要將片變字?
你係咪成日喺 B 站睇完教學片覺得好有用,但係收咗入收藏夾之後就冇再開過?截圖截到成個相簿都係,想揾返之前講過嘅某個位就好似大海撈針。嬌姐都有呢個煩惱,佢話「視頻係被動吸收,你當時覺得明咗,關咗就忘一半」。
佢設計咗一個全自動流程:只要俾個 B 站連結,5 分鐘後 Obsidian 就會多咗篇完整逐字稿
- ① 俾 B 站 BV 號連結
- ② 自動下載音頻(yt-dlp)
- ③ AI 轉寫文字(faster-whisper)
- ④ 存入 Obsidian 知識庫,帶時間戳
- ⑤ 隨時喺 Obsidian 搜尋同翻睇
準備功夫:裝好兩大核心工具同依賴
硬件方面,任何電腦只要 8G RAM 以上就得,無論 Windows、Mac 定 Linux。軟件需要四個:Obsidian(知識庫載體)、Hermes(AI 助手大腦)、yt-dlp(音頻提取)同 faster-whisper(語音轉寫)。
- 1 裝 Obsidian:去 obsidian.md 下載,開一個新 folder 叫 zhishiku,然後喺 Obsidian 入面「打開本地倉庫」揀嗰個 folder。
- 2 裝 yt-dlp:開命令行打 `pip install yt-dlp`,然後 `yt-dlp --version` 確認有版本號。
- 3 裝 faster-whisper:打 `pip install faster-whisper`,等 2-3 分鐘,然後用 `python -c "from faster_whisper import WhisperModel; print('ok')"` 確認。
- 4 配置 Hermes:去 C:\Users\用戶名\.hermes\config.yaml,改 `wiki.path` 做你 zhishiku 嘅路徑,例如 `D:/zhishiku`。
單集實戰:一條 link 嘅完整示範
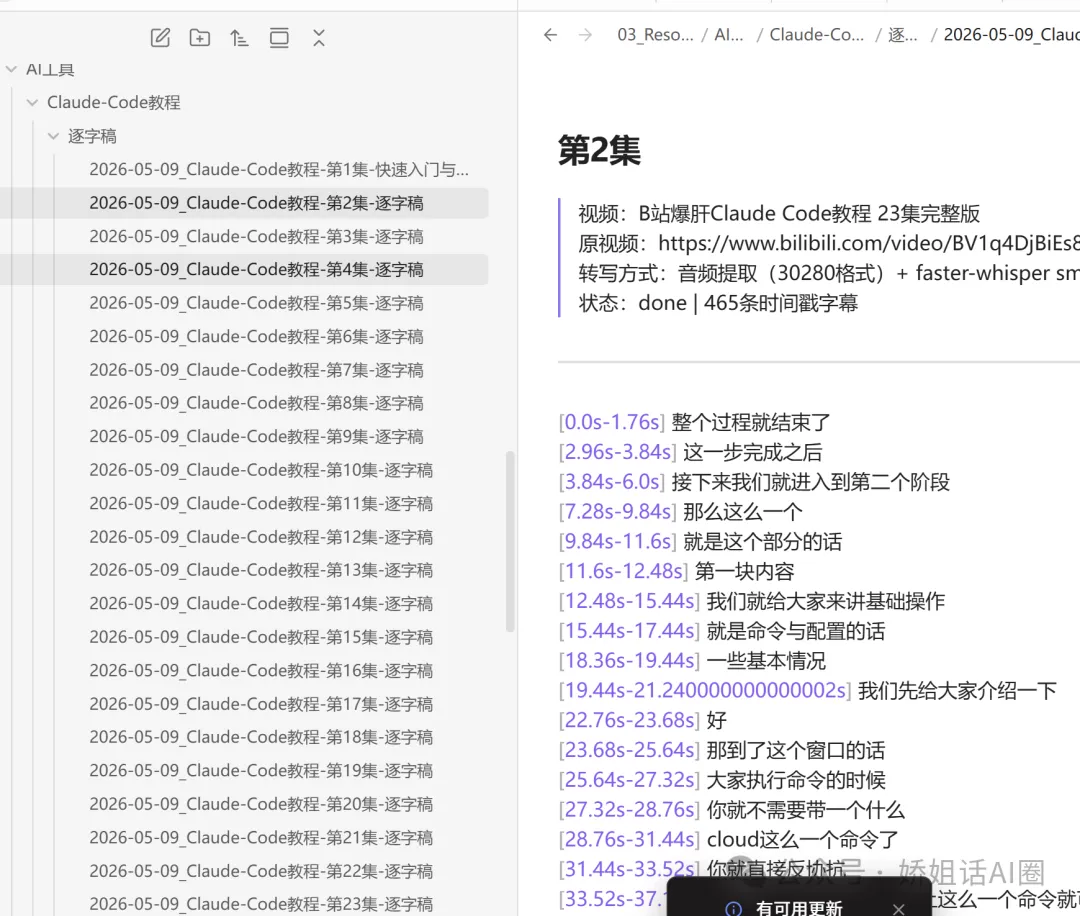
以 BV1JJ411z7LB 為例,嬌姐逐個步驟拆解。第一步係用 yt-dlp 淨係下載音頻,唔好畫面,慳位又快。
yt-dlp -f "30280" --max-filesize 100M -o "video_audio.%(ext)s" "https://www.bilibili.com/video/BV1JJ411z7LB"成功後會見到一個 .m4a 檔案。第二步係用 Python 腳本做 AI 轉寫,嬌姐提供咗一段現成嘅 `transcribe.py`,用 small 模型,CPU 運行,10 分鐘片大約要跑 3-5 分鐘。
from faster_whisper import WhisperModel
import sys
audio_path = sys.argv[1]
output_path = sys.argv[2]
model = WhisperModel('small', device='cpu')
segments, info = model.transcribe(audio_path, language='zh', beam_size=5)
with open(output_path, 'w', encoding='utf-8') as f:
for seg in segments:
f.write(f'[{seg.start:.1f}s-{seg.end:.1f}s] {seg.text}\n')
print('轉寫完成')第三步係將 output.txt 拉入 Obsidian 嘅 zhishiku folder,改埋 Frontmatter 做 `title`、`date`、`tags`、`source`,咁就永久可用。
Frontmatter 格式:```--- title: "Claude Code教程-第1集" date: 2026-05-09 tags: [B站教程, Claude-Code] source: "https://bilibili.com/video/BV1JJ411z7LB" ---```
進階玩法:批量處理同全自動化
如果你要轉成個系列,例如 23 集 Claude Code 教程,一集集做就太慢。嬌姐寫咗個 `batch_main.py` 批量腳本,會自動行曬三件事:逐集下載音頻、逐集轉寫、寫入 Obsidian,然後清理臨時檔。
import subprocess, os
for ep in range(1,24):
subprocess.run(['yt-dlp', '-f', '30280', '--max-filesize', '100M', '-o', f'p{ep}.m4a', f'https://www.bilibili.com/video/BV1JJ411z7LB?p={ep}'])
subprocess.run(['python3', 'transcribe.py', f'p{ep}.m4a', f'p{ep}.txt'])
os.remove(f'p{ep}.m4a')行完之後,23 集逐字稿就全部入咗 Obsidian。如果想再懶啲,可以將呢個流程綁落 Hermes Skills,以後只要對 Hermes 講「幫我將呢個 B 站片整成逐字稿」,佢就會自動做曬。
常見問題同注意事項
嬌姐整理咗幾個實戰常見嘅問題。第一,下載失敗可以檢查連結係咪有分集參數(例如 `?p=2`),B 站版權影片可能唔支援音頻提取,要換片。第二,轉寫速度-如果有 NVIDIA 顯卡可以開 GPU 加速,冇嘅話用 small 模型性價比最高。
第三,準確率方面,small 模型中文約 95%,少啲錯字屬正常,要 100% 準確就要人工校對或者用更大模型。第四,知識庫路徑問題:確保 Obsidian 開嘅係你自己整嘅 zhishiku folder,唔係預設嗰個。
呢套方案嘅精髓唔係技術,而係改變學習習慣:將被動睇片變成主動翻書。

先關注後閲讀,嬌姐怕失去上進嘅你
文末嬌姐整理咗openclaw所有文章連結
想了解嬌姐撳文末連結
先講呢樣嘢可以做到啲乜
你睇到一個B站教學視頻,睇完覺得有用,但係收藏咗之後從來冇再開過,cap咗一大推圖之後自己都揾唔返,想覆盤內容又懶得再睇一次。
我而家用緊呢套方案,將呢個問題徹底搞掂咗。
核心體驗:你只需要send一個B站連結,知識庫5分鐘之後就會有呢條片嘅完整逐字稿。
23集Claude Code教學,一晚全部轉曬存入Obsidian。想複習嘅時候,好似揭書咁揭出嚟睇就得。

整體架構
唔識技術都可以跳過,但係知道大概框架之後操作會更順。成個流程係咁:
① B站視頻連結
你只需要複製一個BV號連結,之後全部自動化。
② 下載音頻
跳過視頻,只攞聲音。檔案細,速度快。
③ AI轉寫
語音變文字,中文準確率大約95%。
④ 存入Obsidian知識庫
有時timestamp嘅逐字稿,自動寫入筆記軟件,永久可以搜返。
⑤ 隨時複習
打開筆記軟件,好似睇書咁揭,關鍵詞一秒就定位。
核心工具得兩個:Hermes(AI助手,負責協調成個流程)同 Obsidian(本地筆記軟件,負責儲存同搜返嘢)。
第一步:你需要準備啲乜
硬件要求:一部電腦(Windows / Mac / Linux 都得),RAM 8GB或以上。軟件清單如下:
Obsidian
用途知識庫載體,本地儲存筆記
下載obsidian.md
Claude Code
用途AI助手 Hermes嘅大腦,協調成個流程
下載claude.ai/code
yt-dlp
用途視頻音頻提取工具,淨係抓聲音唔抓畫面
安裝pip install yt-dlp
faster-whisper
用途AI轉寫工具,語音變文字
安裝pip install faster-whisper
第二步:安裝必要嘅工具
安裝 Obsidian
打開 obsidian.md,㩒「Download」,下載之後雙擊安裝 喺電腦任意位置開一個新資料夾,改名做 zhishiku打開 Obsidian → 左下角「打開本地倉庫」→ 揀啱啱嗰個資料夾
安裝 yt-dlp(音頻提取工具)
Windows 按 Win+R 輸入 cmd 打開命令提示字元;Mac 打開終端機。輸入以下指令:
pip install yt-dlp
驗證安裝係咪成功:
yt-dlp --version
見到版本號(例如 2025.05.09)就代表裝好咗。
安裝 faster-whisper(AI轉寫工具)
pip install faster-whisper
安裝包比較大,等 2–3 分鐘係正常。驗證:
python -c "from faster_whisper import
WhisperModel; print('ok')"
看到 ok 就代表裝好咗。
第三步:配置你嘅 Hermes 助手
揾到設定檔(Windows 路徑係 C:\Users\用戶名\.hermes\config.yaml),修改知識庫路徑:
YAML
skills:
config:
wiki:
path: "D:/zhishiku"
# 改做你啱啱創建嘅資料夾路徑
注意:飛書同步設定係可選項,冇飛書帳號可以 skip 呢步。
第四步:第一次實戰
以 BV 號 BV1JJ411z7LB 做例子,完整行一次流程。
4.1 提取音頻
打開命令提示字元,入到工作目錄之後執行:
Shell
yt-dlp -f "30280" \
--max-filesize 100M \
-o "video_audio.%(ext)s" \
"https://www.bilibili.com/
video/BV1JJ411z7LB"
# -f 30280:淨係下載音頻
# --max-filesize:超過100M就唔下載
行完之後會見到一個 .m4a 尾嘅音頻檔案,即係成功咗。
4.2 AI 轉寫
新建 transcribe.py,寫入以下內容:
Python
# 引入依賴
import sys
from faster_whisper import WhisperModel
audio_path = sys.argv[1]
output_path = sys.argv[2]
# small模型,中文效果好
model = WhisperModel(
'small', device='cpu')
segments, info = model.transcribe(
audio_path,
language='zh',
beam_size=5)
with open(output_path, 'w',
encoding='utf-8') as f:
for seg in segments:
f.write(
f'[{seg.start:.1f}s-
{seg.end:.1f}s]
{seg.text}\n')
print("轉寫完成")
運行轉寫:
python3 transcribe.py \
video_audio.m4a \
video_output.txt
注意:10分鐘嘅視頻大概要行 3–5 分鐘,呢步係成個流程最慢嘅,耐心等命令提示字元行完。
4.3 存入 Obsidian 知識庫
將生成嘅 video_output.txt 拉入 Obsidian 對應嘅資料夾,改返個名做:
2026-05-09_教學名-第X集-逐字稿.md
喺檔案頂部加上 Frontmatter 元資訊:
Markdown
---
title: "Claude Code教程-第1集"
date: 2026-05-09
tags: [B站教程, Claude-Code]
source: "https://bilibili.com/
video/BV1JJ411z7LB"
---
完成!你已經成功將一個B站視頻存咗入知識庫。
第五步:批量處理多個視頻(進階)
要轉 23 集,唔使一集集手動做。開新 batch_main.py,批量腳本會自動做曬三件事:
逐集叫 yt-dlp 下載音頻 叫 transcribe.py 進行轉寫 寫入 Obsidian 知識庫,清理臨時檔案
Python
# 要處理嘅集數列表
episodes = list(range(1, 24))
BV號 = "BV1JJ411z7LB"
for ep in episodes:
# 下載 → 轉寫 → 存庫
subprocess.run([...])
os.remove(f"p{ep}.m4a")
行完之後就可以去做其他嘢。23集大概跑一個夜晚,取決於視頻嘅總時長。
第六步:叫 AI 助手全自動化
配置好 skills 之後,你只需要對 Hermes 講一句:
提示:幫我將呢個B站視頻整成逐字稿:[連結]
Hermes 就會自動執行下載→轉寫→存知識庫嘅全流程,唔使手動幹預。
常見問題
Q 下載失敗咗點算?
檢查連結係咪帶分集參數(例如 ?p=2),有嘅話要帶埋先得。B站版權視頻唔支援音頻提取,要換第二條片。
Q 轉寫好慢,可唔可以快啲?
有 NVIDIA 顯示卡可以開 GPU 加速;CPU 用戶建議用 small 模型,性價比最高;medium 模型更加準確但係更慢。
Q 逐字稿有雜音/錯字點算?
small 模型中文準確率大約 95%,會有少量漏字錯字係正常。需要 100% 準確只能人手校對,或者轉用更高精度嘅模型配合核對。
Q 知識庫資料夾揾唔到?
確認 Obsidian「打開本地倉庫」指向嘅係你自己創建嘅 zhishiku 資料夾,唔係 Obsidian 默認嗰個。
最後
呢套方案嘅精髓唔係技術,而係將「睇片」變成「睇書」。
視頻係被動吸收,你嗰陣覺得明咗,熄咗片之後就唔記得一半。文字係主動複習,你想幾時睇就幾時睇,想搜咩關鍵詞一秒就定位。
23集Claude Code教學轉完存入知識庫之後,我而家揾任何內容都係秒級定位,比起喺任何平台搜收藏夾都可靠。
希望呢篇教學對你有用,有問題歡迎交流。

保姆教學已經更新到付費社羣資料包嘅文檔入面,拎咗之後即刻可以實現b站視頻自由喇。
https://fcnfwx5opw7x.feishu.cn/wiki/Ps6uwuphgidpiKkMCgrcL4WtnYb
關於微信信息嘅助手(支援羣組同私聊)
微信嘅聊天記錄其實係存在你電腦本地,有辦法將佢讀出嚟,透過 API 接口餵畀 AI。
非常之多應用場景,將微信嘅聊天記錄當做你嘅數據資產
有需要可以睇以下文章,或者私信我搭建方案

【支援一對一諮詢】我用hermes搭咗一個助手,每個人都應該用得著
關於openclaw、hermes資料包同系列文章
配套資料包
私信 kekohu 拎取,內容唔定期持續更新。
注意:付費社羣包含資料包全部內容,唔使重複購買。
hermes系列文章
持續更新,建議每篇認真閲讀
【唔推薦用官方命令】Windows 環境下安裝Hermes同遷移Openclaw嘅實操分享
告別生圖 API,我用 Hermes Skill 免費出圖無限次
清華大學 MAIC 團隊,GitHub 上已經 16.5k Star嘅一個開源項目
分享我自己喺用緊嘅Hermes Obsidian skill
【保姆教學】我用 Obsidian +hermes搭咗一個會自己整理嘅知識庫
參考劉小排嘅 BuilderPulse :我用 Hermes 發現值得睇嘅github項目
【Hermes整理】OpenClaw 變現項目地圖:6 大賽道
我將 OpenClaw 嘅 Agent 無縫遷移咗去 Hermes——就靠呢一份 Skill
參考 Hermes 優化 OpenClaw:等你嘅 AI 學識記、會覆盤、會巡檢
openclaw系列文章
openclaw系列文章
持續更新,建議每篇認真閲讀
配置與理解
唔好俾人呃,OpenClaw 可以 24 小時做嘢——但你要先做啱呢 6 件事
紅咗三個月嘅「龍蝦」,普通人裝咗真係有用咩?
用 OpenClaw 將 AI 失憶醫好:開關、精簡、外掛三步走
多 Agent 與協作
技能與工具
實戰與案例
排錯與安全
關於嬌姐
40+ IT 從業者,前榮耀員工,而家專注 AI 效率工具研究與實踐。持續輸出 OpenClaw 同 AI 工具嘅乾貨教學同落地案例,間中分享職場思考同生活感悟。
提示:覺得有用,點讚、關注、轉發,係我持續創作嘅動力。
先關注後閲讀,嬌姐怕失去上進的你
文末嬌姐整理openclaw所有文章連結
想了解嬌姐點擊文末連結
先說這東西能幹啥
你刷到一個B站教程視頻,看完之後覺得有用,但收藏了從來沒再打開過,截圖截了一大堆後來自己都找不到,想覆盤內容又懶得再看一遍。
我現在用的這套方案,把這個問題徹底幹掉了。
核心體驗:你只需要發一個B站連結,知識庫5分鐘後就有這篇視頻的完整逐字稿。
23集Claude Code教程,一晚上全部轉完存進了Obsidian。想複習的時候,像翻書一樣翻出來看就行。
整體架構
不懂技術也能跳過,但知道大概框架後面操作會更順。整個流程如下:
① B站視頻連結
你只需要複製一個BV號連結,後續全自動。
② 下載音頻
跳過視頻,只拿聲音。文件小,速度快。
③ AI轉寫
語音變文字,中文準確率約95%。
④ 存入Obsidian知識庫
帶時間戳的逐字稿,自動寫入筆記軟件,永久檢索。
⑤ 隨時複習
打開筆記軟件,像看書一樣翻閲,關鍵詞一秒定位。
核心工具只有兩個:Hermes(AI助手,負責協調整個流程)和 Obsidian(本地筆記軟件,負責存儲和檢索)。
第一步:你需要準備什麼
硬件要求:一台電腦(Windows / Mac / Linux 均可),內存 8G 以上。軟件清單如下:
Obsidian
用途知識庫載體,本地存儲筆記
下載obsidian.md
Claude Code
用途AI助手 Hermes 的大腦,協調整個流程
下載claude.ai/code
yt-dlp
用途視頻音頻提取工具,只抓聲音不抓畫面
安裝pip install yt-dlp
faster-whisper
用途AI轉寫工具,語音變文字
安裝pip install faster-whisper
第二步:安裝必要的工具
安裝 Obsidian
打開 obsidian.md,點擊「Download」,下載後雙擊安裝 在電腦任意位置新建文件夾,命名為 zhishiku打開 Obsidian → 左下角「打開本地倉庫」→ 選擇剛才那個文件夾
安裝 yt-dlp(音頻提取工具)
Windows 按 Win+R 輸入 cmd 打開命令行;Mac 打開終端。輸入以下命令:
pip install yt-dlp
驗證安裝是否成功:
yt-dlp --version
看到版本號(比如 2025.05.09)就說明裝好了。
安裝 faster-whisper(AI轉寫工具)
pip install faster-whisper
安裝包較大,等待 2–3 分鐘正常。驗證:
python -c "from faster_whisper import
WhisperModel; print('ok')"
看到 ok 就說明裝好了。
第三步:配置你的 Hermes 助手
找到配置文件(Windows 路徑為 C:\Users\用戶名\.hermes\config.yaml),修改知識庫路徑:
YAML
skills:
config:
wiki:
path: "D:/zhishiku"
# 改成你剛才創建的文件夾路徑
注意:飛書同步配置為可選項,沒有飛書賬號可跳過這步。
第四步:第一次實戰
以 BV 號 BV1JJ411z7LB 為例,完整走一遍流程。
4.1 提取音頻
打開命令行,進入工作目錄後執行:
Shell
yt-dlp -f "30280" \
--max-filesize 100M \
-o "video_audio.%(ext)s" \
"https://www.bilibili.com/
video/BV1JJ411z7LB"
# -f 30280:只下載音頻
# --max-filesize:超100M不下
跑完後會看到一個 .m4a 後綴的音頻文件,說明成功了。
4.2 AI 轉寫
新建 transcribe.py,寫入以下內容:
Python
# 引入依賴
import sys
from faster_whisper import WhisperModel
audio_path = sys.argv[1]
output_path = sys.argv[2]
# small模型,中文效果好
model = WhisperModel(
'small', device='cpu')
segments, info = model.transcribe(
audio_path,
language='zh',
beam_size=5)
with open(output_path, 'w',
encoding='utf-8') as f:
for seg in segments:
f.write(
f'[{seg.start:.1f}s-
{seg.end:.1f}s]
{seg.text}\n')
print("轉寫完成")
運行轉寫:
python3 transcribe.py \
video_audio.m4a \
video_output.txt
注意:10分鐘的視頻大概要跑 3–5 分鐘,這步是整個流程裏最慢的,耐心等待命令行跑完。
4.3 存入 Obsidian 知識庫
把生成的 video_output.txt 拖入 Obsidian 對應文件夾,重命名為:
2026-05-09_教程名-第X集-逐字稿.md
在文件頂部加上 Frontmatter 元信息:
Markdown
---
title: "Claude Code教程-第1集"
date: 2026-05-09
tags: [B站教程, Claude-Code]
source: "https://bilibili.com/
video/BV1JJ411z7LB"
---
完成!你已經成功把一個B站視頻存進了知識庫。
第五步:批量處理多個視頻(進階)
要轉 23 集,不用一集集手動來。新建 batch_main.py,批量腳本會自動完成三件事:
逐集調用 yt-dlp 下載音頻 調用 transcribe.py 進行轉寫 寫入 Obsidian 知識庫,清理臨時文件
Python
# 要處理的集數列表
episodes = list(range(1, 24))
BV號 = "BV1JJ411z7LB"
for ep in episodes:
# 下載 → 轉寫 → 存庫
subprocess.run([...])
os.remove(f"p{ep}.m4a")
運行後就可以去幹別的事了。23集大概跑一個晚上,取決於視頻總時長。
第六步:讓 AI 助手全自動化
配置好 skills 後,你只需要對 Hermes 說一句話:
提示:幫我把這個B站視頻做成逐字稿:[連結]
Hermes 就會自動執行下載→轉寫→存知識庫的全流程,無需手動干預。
常見問題
Q 下載失敗了怎麼辦?
檢查連結是否帶分集參數(如 ?p=2),有的話需要帶上。B站版權視頻不支持音頻提取,只能換視頻。
Q 轉寫很慢,能不能更快?
有 NVIDIA 顯卡可啓用 GPU 加速;CPU 用戶建議用 small 模型,性價比最高;medium 模型更準確但更慢。
Q 逐字稿有噪音/錯誤怎麼辦?
small 模型中文準確率約 95%,會有少量漏字錯字屬正常。需要 100% 準確只能人工校對,或換更高精度模型配合核驗。
Q 知識庫文件夾找不到?
確認 Obsidian「打開本地倉庫」指向的是你自己創建的 zhishiku 文件夾,而非 Obsidian 默認的文件夾。
最後
這套方案的精髓不是技術,而是把「看視頻」變成「看書」。
視頻是被動吸收,你當時覺得懂了,關掉視頻忘掉一半。文字是主動複習,你想什麼時候看就什麼時候看,想搜什麼關鍵詞一秒定位。
23集Claude Code教程轉完存進知識庫之後,我現在找任何內容都是秒級定位,比在任何平台搜索收藏夾都靠譜。
希望這篇教程對你有用,有問題歡迎交流。
保姆教程已經更新到付費社羣資料包的的文檔中,獲取後立馬可以實現b站視頻自由了。
https://fcnfwx5opw7x.feishu.cn/wiki/Ps6uwuphgidpiKkMCgrcL4WtnYb
關於微信信息的助手(支持羣聊和私聊)
微信的聊天記錄其實存在你電腦本地,有辦法把它讀出來,通過 API 接口餵給 AI。
非常多的應用場景,把微信裏的聊天記錄作為你的數據資產
有需要的可以閲讀如下文章,或私信我搭建方案
【支持一對一諮詢】我用hermes搭建了一個助手,每個人應該用得上
關於openclaw、hermes資料包和系列文章
配套資料包
私信 kekohu 獲取,內容不定期持續更新。
注意:付費社羣包含資料包全部內容,無需重複購買。
hermes系列文章
持續更新,建議每篇認真閲讀
【不推薦用官方命令】Windows 環境下安裝Hermes及遷移Openclaw的實操分享
告別生圖 API,我用 Hermes Skill 免費出圖無限次
清華大學 MAIC 團隊,GitHub 上已經 16.5k Star的一個開源項目
分享我自己在用的Hermes 的Obsidian skill
【保姆教程】我用 Obsidian +hermes搭了一個會自己整理的知識庫
借鑑劉小排的 BuilderPulse :我用 Hermes 發現值得看的github項目
【Hermes整理】OpenClaw 變現項目地圖:6 大賽道
我把 OpenClaw 的 Agent 無縫遷移到了 Hermes——就靠這一份 Skill
借鑑 Hermes 優化 OpenClaw:讓你的 AI 學會記、會覆盤、會巡檢
openclaw系列文章
openclaw系列文章
持續更新,建議每篇認真閲讀
配置與理解
別被騙,OpenClaw 可以 24 小時幹活——但你得先做對這 6 件事
火了三個月的"龍蝦",普通人裝了真的有用嗎?
用 OpenClaw 把 AI 失憶治好:開關、精簡、外掛三步走
多 Agent 與協作
技能與工具
實戰與案例
排錯與安全
關於嬌姐
40+ IT 從業者,前榮耀員工,現專注 AI 效率工具研究與實踐。持續輸出 OpenClaw 及 AI 工具的乾貨教程與落地案例,偶爾分享職場思考與生活感悟。
提示:覺得有用,點贊、關注、轉發,是我持續創作的動力。