Karpathy 最新訪談:Vibe Coding 只是開始,真正重要的是 Agentic Engineering
整理版優先睇
Karpathy 認為 2025 年 12 月係 AI 編碼轉捩點,Vibe Coding 提高下限,Agentic Engineering 保住上限;真正嘅瓶頸唔係技術,而係人仲有冇理解系統嘅能力。
Andrej Karpathy(OpenAI 創始成員、Tesla Autopilot 前視覺主管、Vibe Coding 詞語創造者)2026 年 4 月喺 Sequoia Capital AI Ascent 接受合夥人 Stephanie Zhan 訪談。佢想解決嘅問題係:點樣理解同運用當代 LLM 嘅能力邊界,同埋編程範式點樣從 Vibe Coding 演化到 Agentic Engineering。整體結論:模型嘅能力高度不均勻,人類必須保持對系統結構嘅理解;智能變平之後,最貴嘅係理解而非執行。
Karpathy 分享個人經驗:2025 年 12 月佢發現 AI 生成嘅代碼可以直接用,唔使修改,進入咗 Vibe Coding 狀態。呢種「憑感覺寫代碼」嘅方式提升咗所有人整軟件嘅下限,但更重要係後續嘅 Agentic Engineering——點樣用 AI Agent 加速同時唔降低專業軟件嘅質量同安全。佢提出 Software 3.0 概念:LLM 係一種新嘅信息處理解釋器,程式設計變成操作 context window,關鍵係「邊段文字俾 Agent」。
模型能力呈鋸齒狀:喺數學、代碼呢啲可驗證領域極強,但喺常識題(例如洗車題)可能荒謬出錯。能力高低取決於有冇被強化學習(RL)覆蓋。創業者應該揾啲未被 RL 覆蓋但可驗證嘅領域。Karpathy 預測 Agent-first 基礎設施會重寫所有嘢,人類教育嘅…
- 2025 年 12 月係轉捩點:模型生成代碼直接可用,信任累積下進入 Vibe Coding 狀態。
- Software 3.0 嘅核心係將 LLM 當作解釋器,透過 context window 操作;程式設計變成選擇「邊段文字俾 Agent」。
- LLM 能力唔均勻:可驗證領域(數學、代碼)靠 RL 訓練飆升,常識領域(洗車題)可能仲錯;要主動探索能力邊界。
- Vibe Coding 抬高下限,Agentic Engineering 保住上限:專業軟件必須有安全、質量、責任門檻,人類要監督 Agent。
- 智能變平後,最貴嘅係理解:API 細節可以外包,但系統結構、底層機制、目標定義同質量判斷一定要自己掌握。
Karpathy Sequoia AI Ascent 訪談原始視頻
YouTube 影片連結
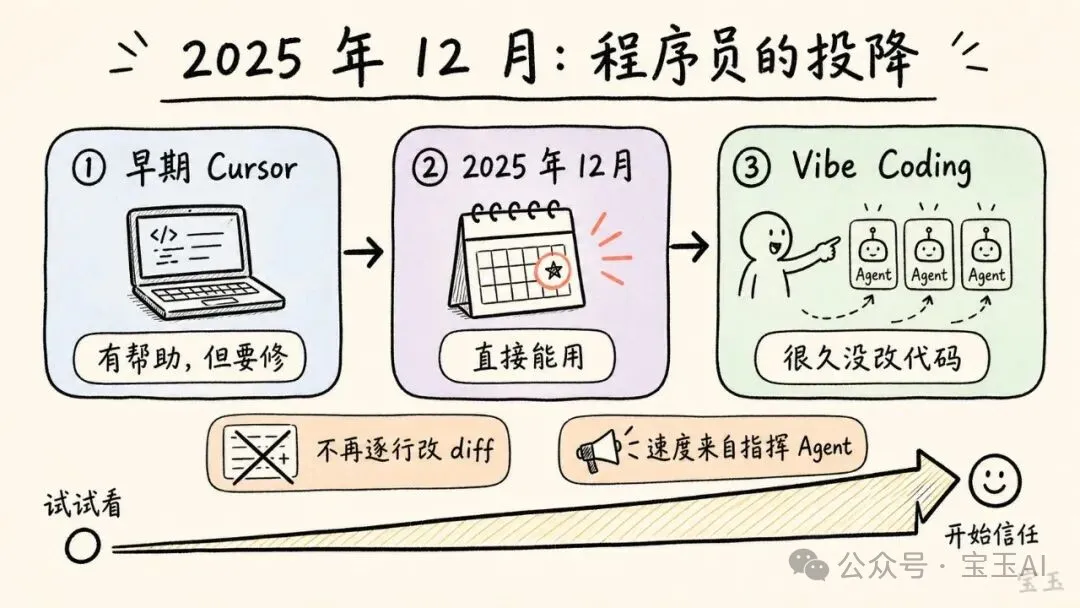
2025 年 12 月:一個程序員嘅投降
Karpathy 話,2025 年 12 月係佢個人嘅轉捩點。之前 AI 生成嘅代碼經常有錯要修改,但嗰個月佢發現最新模型寫出嚟嘅代碼「直接能用」。
佢開始只俾模型寫少少,結果唔錯,就繼續俾佢寫更多。最後佢發現自己好耐冇親手改過模型輸出,信任感不斷增加。
呢種狀態就係佢後嚟稱為 Vibe Coding 嘅開發方式——用自然語言持續提出意圖,模型生成、修改、調試代碼,人唔再逐行睇 diff。佢強調,2025 年尾之後更值得留意嘅係 Agentic coherent workflow,即係模型唔只答問題,而係連續規劃、寫代碼、調試、執行,根據反饋修正。
Software 3.0:複製貼上文字就係編程
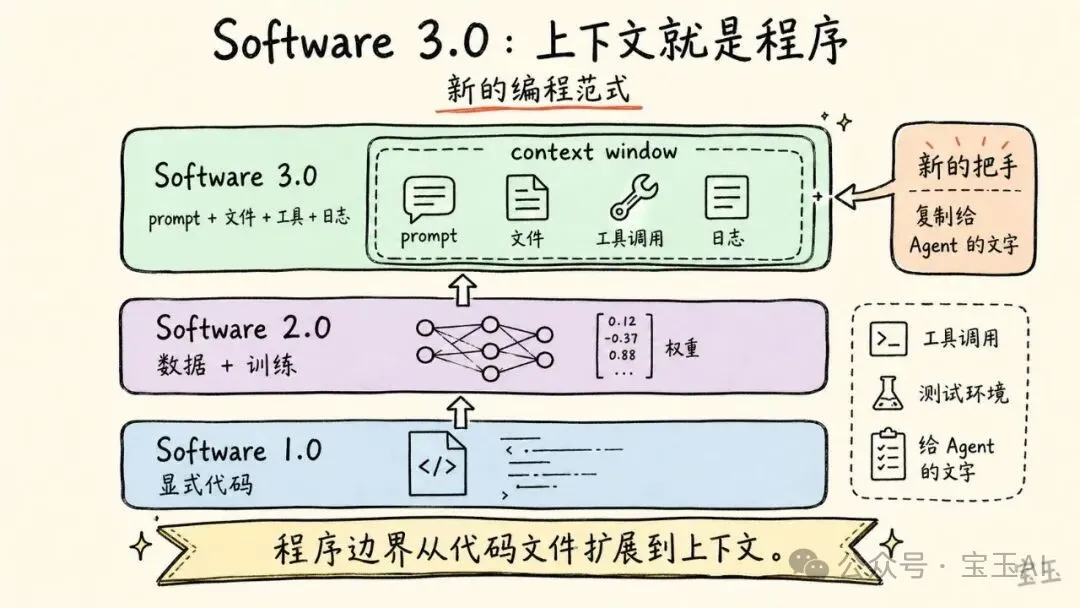
Karpathy 用自己嗰套軟件分期解釋:Software 1.0 係人寫規則,2.0 係設計神經網路架構,3.0 就係 LLM 時代——LLM 經過大規模任務訓練後變成一種可編程嘅計算機。
你唔再係喺代碼編輯器寫函數,而係喺 prompt、context window、文件、工具調用同外部環境之間組織一段「上下文程序」。
佢舉咗個安裝 OpenCL 嘅例子:傳統做法係寫 shell script 去適配各種環境,但喺 Software 3.0 入面,安裝說明本身可能就係一段可以複製俾 Agent 嘅文本,Agent 會自動執行同調試。而家嘅問題變成:「邊段文字應該複製俾你嘅 Agent?」呢個就係新嘅編程範式。
Vibe Coding 抬高下限,Agentic Engineering 保住上限
Karpathy 清楚區分兩者:Vibe Coding 係提升所有人整軟件嘅下限——唔識寫 code 嘅人都可以用自然語言整小工具;Agentic Engineering 係保住專業軟件嘅上限——唔可以因為用 AI 就引入安全漏洞,唔可以降低質量門檻。
Agentic Engineering 係一種工程紀律:點樣設計、協調、監督一組 AI Agent,令佢哋喺唔犧牲質量、安全、可維護性嘅情況下加速開發。
佢形容呢啲 Agent 係「spiky entities」——有尖刺嘅實體,能力強但會犯錯,有隨機性。工程師嘅工作係將佢哋放入合適流程:生成方案、寫 code、跑測試、互相檢查,加上邊界、驗證同回滾機制。
Karpathy 話 10x 工程師唔係 10 倍加速,熟練嘅人可以將多個 Agent、工具、測試同上下文組織起嚟,加速幅度遠超 10 倍。
AI-native 工程師:唔係刷題,係做大項目做到安全
Karpathy 觀察到,真正 AI-native 嘅工程師會投資 workflow 設置,好似以前用 Vim 同 VS Code 咁,而家要配置 Cursor、Claude Code 等工具。但面試仲停留喺舊範式——考 algorithm puzzle 測唔出 Agentic Engineering 嘅效率。
佢建議嘅面試:俾候選人一個大項目,例如做個 Twitter clone,要求絕對安全。然後掛 10 個 Cursor 做紅隊攻擊,睇系統頂唔頂得住。
呢套評估睇嘅係:將模糊目標變成規格、指揮 Agent 大規模實現、識別風險、設置測試、保持質量判斷。
- 品味、判斷、審美、監督同規格設計會變得更有價值。
- Agent 好似實習生,但唔可以過度擬人化——佢哋冇人類動機,只係執行能力強但會喺顯而易見嘅地方犯錯。
- 例如 MenuGen 嘅身份綁定問題:Agent 用 email 關聯資金,但人哋可以用唔同 email 登入同付款,正確做法應該用內部 persistent user ID。
人要負責 spec:所有資金同用戶狀態必須綁定內部唯一 ID,唔係外部 email。Agent 可以填細節,但係人必須理解系統邊界。
我哋召喚嘅係幽靈,唔係動物
Karpathy 用「幽靈」比喻 LLM:唔係動物式智能,而係由人類文檔、統計模式同獎勵函數塑造出嚟嘅鋸齒狀實體。你對佢大叫唔會令佢更努力,鼓勵佢亦唔會激發內在動機。
佢仲提出一個大膽設想:未來可能會出現完全嘅「神經計算機」——神經網絡成為主進程,CPU 同傳統代碼變成協處理器。但呢個仲係心智模型,唔係產品事實。
- 1 未來 6-12 個月要盯三個信號:實驗室喺邊啲新領域注入 RL 數據?Agent-first 基礎設施會唔會收斂?模型會唔會有審美相關嘅 RL 目標?
- 2 Karpathy 暗示有被低估嘅 RL 機會領域但唔肯公開——窗口期可能未關。
- 3 智能變平後,最貴嘅係理解:你可以外包思考,但冇人可以外包理解。
Andrej Karpathy 說,他已經記不清上次修改 AI 生成的代碼是什麼時候了。
Karpathy 參與創建了 OpenAI,在 Tesla 領導過 Autopilot 視覺團隊,去年一條推文發明了“憑感覺編程”(Vibe Coding)這個詞,後來被 Collins 詞典選為 2025 年度詞彙。
2026 年 4 月,Karpathy 在 Sequoia Capital 的 AI Ascent 現場接受合夥人 Stephanie Zhan 的訪談。這場 30 分鐘的對話覆蓋了他對編程範式劇變的親身感受、Software 3.0 的實質、AI 為什麼在某些地方極強而在另一些地方離譜地弱,以及“憑感覺編程”之後更嚴肅的下一步是什麼。

原始視頻:https://www.youtube.com/watch?v=96jN2OCOfLs
• 2025 年 12 月是 Karpathy 個人的轉折點:AI 輸出從“有幫助但常要修補”變成“直接可用”,他進入完全憑感覺編程的狀態。 • Software 3.0 的關鍵不是“用自然語言寫代碼”,而是通過 prompt和context操作 LLM 這個新的信息處理解釋器。• MenuGen 案例讓 Karpathy 意識到,一些 AI 應用不是會被做得更快,而是會被模型原生能力直接吞掉。 • LLM 的能力高度不均勻:它可以重構 10 萬行代碼、找零日漏洞,卻可能在“去 50 米外洗車該走路還是開車”這種常識題上犯錯。 • Vibe Coding 抬高所有人做軟件的下限;Agentic Engineering 則是在使用 Agent 提速時,保住專業軟件的質量、安全和責任門檻。 • 人類不必再記住每個 API 細節,但必須理解系統結構、底層機制和質量標準,否則無法監督 Agent。 • Karpathy 用“幽靈”形容 LLM:它不是動物式智能,而是由人類文檔、預訓練統計和強化學習獎勵塑造出的鋸齒狀實體。 • 智能變便宜後,教育的重點不是抵制外包思考,而是確保理解仍然進入人的大腦。
【1】2025 年 12 月:一個程序員的投降
Zhan 問:你幾個月前說,自己從未像現在這樣覺得作為程序員落後。這是興奮還是不安?
Karpathy 說兩者都有。
過去一年他一直在用 Cursor 等智能體編碼工具。早期這些工具有用,可以生成一些代碼塊,但經常出錯需要修改。真正的轉折出現在 2025 年 12 月。那段時間他正好休假,有更多時間折騰 side project,明顯感覺到最新模型生成的代碼塊開始“直接能用”。
一開始,他只讓模型寫一點。結果不錯,就繼續讓它寫更多。再往後,他發現自己已經很久沒有親自糾正模型輸出了,信任感不斷增加。最後他進入了自己後來稱為 Vibe Coding 的狀態。
我記不得上一次我需要糾正它是什麼時候了。然後我就越來越信任這個系統。
這裏的 Vibe Coding,不適合硬譯成“氛圍編程”。更準確地說,它是一種“憑感覺讓 AI 寫代碼”的開發方式:人用自然語言持續提出意圖,模型生成、修改、調試代碼,人不再像過去那樣逐行寫、逐行讀 diff。Karpathy 2025 年 2 月在 X 上提出這個詞時,描述的是一種“放棄對代碼本身的直接控制、順着感覺讓模型往前走”的開發體驗。
但這場訪談裏,Karpathy 的重點已經不只是 Vibe Coding。他強調,很多人對 AI 的印象還停留在“一個類似 ChatGPT 的東西”上:你問一句,它答一句。到 2025 年底以後,值得重新看的是 Agentic coherent workflow——一種更連貫的智能體工作流。模型不只是回答問題,而是能連續規劃、寫代碼、調試、執行、根據環境反饋繼續修正。
很多人去年體驗到的 AI,還是一個類似 ChatGPT 的東西。但你真的必須重新看一眼,而且要看 12 月之後的版本。
過去程序員的速度主要取決於他能寫多少代碼、記住多少 API、怎樣調試。現在,速度越來越取決於他能否正確地指揮一組強大但會犯錯的 Agent。
【2】Software 3.0:給 Agent 複製粘貼一段文字,這就是編程
Zhan 問:你說 LLM 是一種新計算機,不只是更好的軟件。如果一個團隊真的相信這一點,它會怎樣不同地構建產品?
Karpathy 從自己那套軟件分期講起。
Software 1.0 是傳統軟件:人寫顯式代碼,計算機按規則執行。
Software 2.0 是神經網絡時代:人不再直接寫所有規則,而是設計數據集、目標函數和神經網絡架構,通過訓練得到模型權重。Karpathy 早在 2017 年就寫過《Software 2.0》,把神經網絡視為一種新的軟件開發方式。
Software 3.0 則是大語言模型時代。LLM 經過大規模任務訓練之後,變成一種可編程的計算機。你不再只是在代碼編輯器裏寫函數,而是在 prompt、context window、文件、工具調用和外部環境之間,組織一段給模型執行的“上下文程序”。
context window 可以理解為模型一次調用中能看到的全部信息:指令、歷史對話、文件、錯誤日誌、代碼片段、圖片、工具返回結果。Karpathy 的說法是,這個上下文窗口成了人操縱 LLM 解釋器的“把手”。
他舉了一個安裝 OpenCL 的例子。傳統做法是寫一個 shell script,讓它適配各種機器、平台和環境。隨着目標環境變多,腳本會不斷膨脹,最後複雜到很難維護。但在 Software 3.0 裏,安裝說明本身可能就是一段可以複製給 Agent 的文本。Agent 會讀取你的機器環境,執行步驟,遇到錯誤再調試。
現在的問題變成:哪一段文字應該複製給你的 Agent?這就是新的編程範式。
這句話的重點不是“程序員以後只需要寫提示詞”。Karpathy 要表達的是,程序邊界擴大了。過去的程序是代碼文件。現在,程序可能是一段說明、一個上下文窗口、一組工具權限、一個測試環境,外加模型內部已經學到的大量統計結構。
【3】MenuGen:這個 App 不應該存在
Karpathy 接着講了自己的 MenuGen。
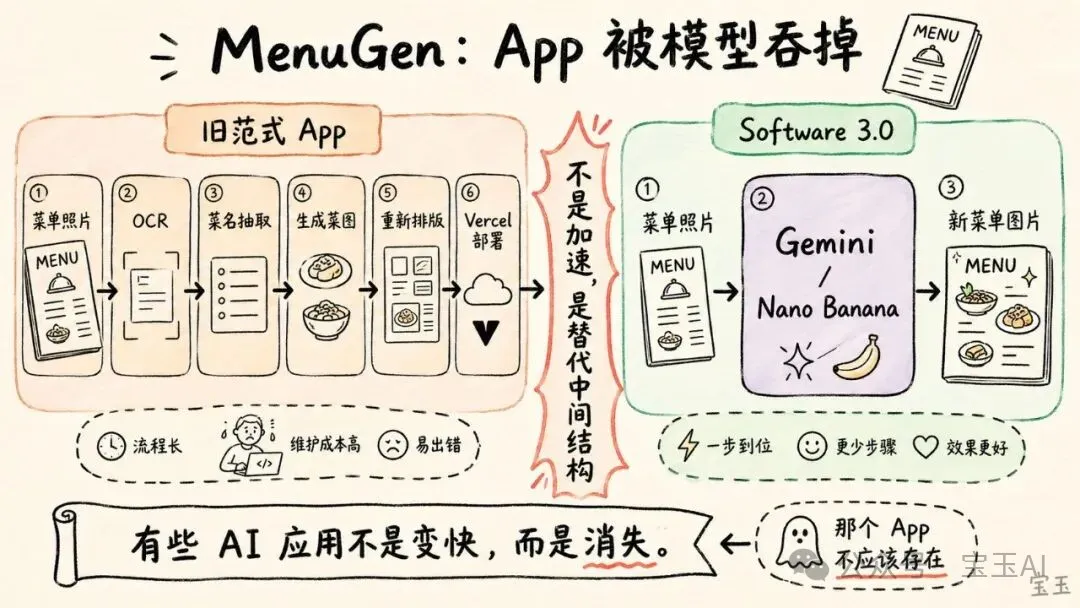
這個 App 的想法很簡單:人在餐廳拿到菜單時,通常看不到菜品圖片。很多菜名,尤其是陌生菜系裏的菜名,光看文字不知道是什麼。Karpathy 想做一個應用:拍一張菜單照片,App 識別菜單上的菜名,再為每個菜品生成一張大致圖片,最後重新渲染菜單,讓用戶看到“這些菜大概長什麼樣”。
用舊範式做這個 App,需要好幾層中間步驟:上傳照片,OCR 識別文字,抽出菜名,調用圖像生成器生成菜品圖,再把結果重新排版,部署到 Vercel 上。Karpathy 用 Vibe Coding 把這個 App 做了出來。
然後他看到了 Software 3.0 版本。
做法變成:直接把菜單照片交給 Gemini,然後說,讓 Nano Banana 把這些菜品圖疊加回菜單上。Nano Banana 返回的不是結構化數據,也不是一組組件,而是一張新的圖片:原菜單仍在,但對應菜品的位置已經直接渲染進了圖片。
【注:Nano Banana 是 Google Gemini 的圖像生成和編輯能力名稱,支持用文本、圖像或兩者結合進行對話式生成與編輯。】
Karpathy 認為他原來寫的 MenuGen 是多餘的,因為它還停留在舊範式裏。
我的整個 MenuGen 都是多餘的。它還停留在舊範式裏。那個 App 不應該存在。
這個例子是整場訪談裏最關鍵的商業判斷之一。
很多 AI 應用公司以為自己在做“更快的軟件”。比如過去一個任務要 10 個步驟,現在 App 幫你壓成 3 個步驟。但在 Software 3.0 裏,模型本身的輸入輸出可能直接覆蓋這個任務,中間 App 的結構就失去必要性。
Karpathy 進一步說,這種變化不只發生在代碼裏。傳統代碼擅長處理結構化數據:表格、數組、數據庫字段、明確規則。但 LLM 可以處理更一般的信息重組。比如他的 LLM Knowledge Bases 項目:把文章、文檔和事實重新編譯成個人或組織 wiki。這不是傳統程序天然擅長的東西,因為它要求模型理解文本之間的關係、重新排序信息、生成新的知識結構。
更令人興奮的不是把已有東西做得更快,而是那些以前根本不可能存在的東西。
【4】神經計算機:CPU 變成協處理器
Zhan 問:把這種進展外推到 2026 年,什麼是今天大部分人還沒建出來、回頭看會覺得理所當然的東西?
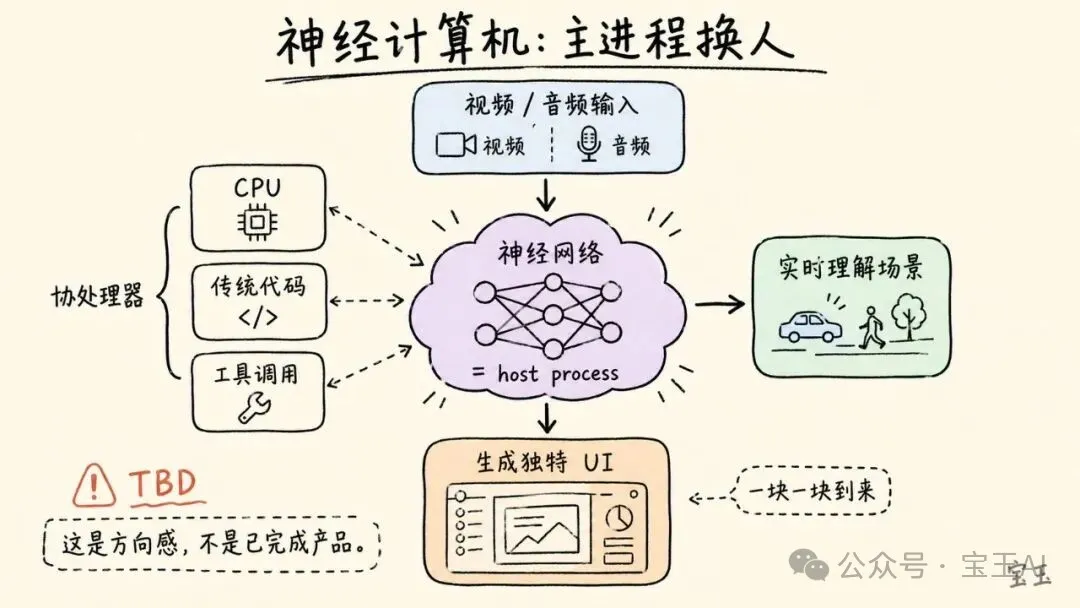
Karpathy 提出了一個更大膽但也更不確定的設想:未來可能出現一種完全的“神經計算機”。
今天的計算機仍然以 CPU、操作系統、傳統程序為中心。神經網絡運行在現有計算機之上,像是一個被虛擬化出來的能力模塊。但 Karpathy 設想,未來有可能反過來:神經網絡成為 host process,也就是主流程;CPU、傳統代碼和工具調用變成協處理器,負責一些確定性任務。
他舉的想象場景是:一個設備接收原始視頻或音頻,神經網絡理解當前場景,再用擴散模型為這一刻生成一個獨特的 UI。用戶看到的界面不再是固定組件拼出來的,而是由模型根據上下文實時生成。
他也很快給這個判斷加了限制:這種外推看起來很怪,具體路徑仍然 TBD,不會一夜之間發生,而會一塊一塊地到來。
“神經網絡成為主進程”不是一個已經發生的產品事實,更像是他用來解釋方向感的心智模型。
【5】LLM 能重構 10 萬行代碼,卻讓你走路去洗車
Zhan 問:如果 AI 更容易自動化可驗證領域,哪些工作會比人們想象中更快移動?哪些看起來安全的職業,其實高度可驗證?
Karpathy 沒有直接列職業。他轉向解釋“可驗證性”。
他的核心判斷是:
傳統計算機容易自動化你能寫進代碼的東西;這一代 LLM 容易自動化你能驗證的東西。
傳統軟件自動化的前提,是人能把規則精確寫出來。比如税率計算、排序、數據庫查詢、訂單狀態流轉。只要規則清楚,就能寫代碼。
LLM 的自動化邊界不同。它不一定需要你把規則全部寫出來,但它需要某種方式判斷輸出好壞。數學題可以驗證答案。代碼可以跑測試。某些安全問題可以通過漏洞復現判斷。這樣的任務能進入強化學習(RL)環境:模型嘗試解題,系統給獎勵或懲罰,模型在大量樣本中優化行為。
所以,模型在數學、代碼和相鄰領域能力提升很快,並不只是因為“模型整體更聰明瞭”。Karpathy 認為,這和前沿實驗室如何訓練模型有關。實驗室構造了大量可驗證任務,把它們放進訓練和強化學習流程裏,模型就在這些地方形成高峯能力。
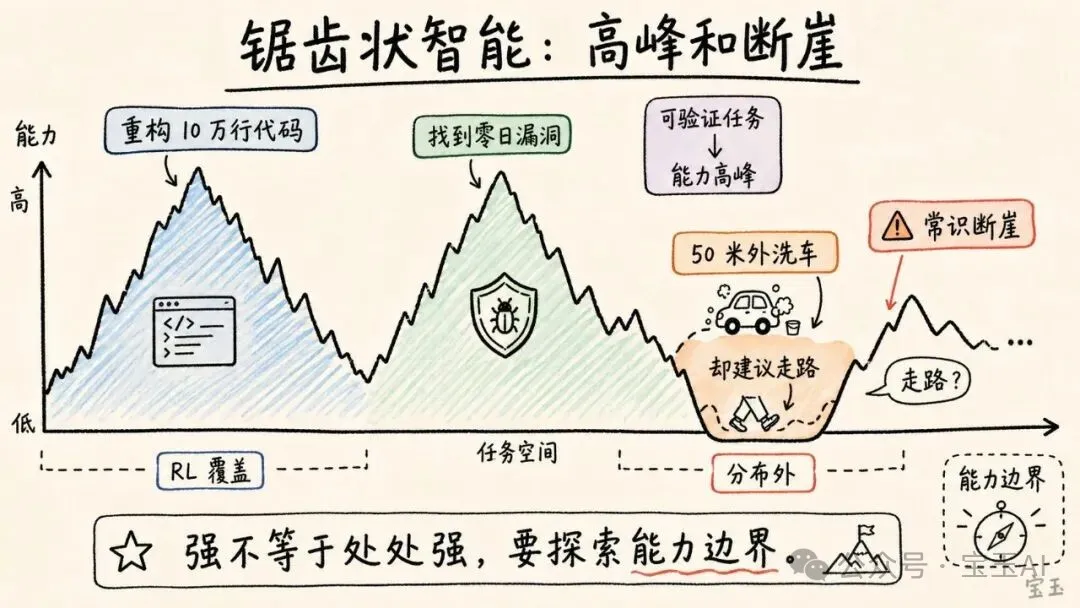
這也解釋了 LLM 的“鋸齒狀智能”(jagged intelligence):能力曲線不是平滑上升,而是有高峯和斷崖。有些任務強得驚人,有些任務弱得荒誕。
Karpathy 說,現在更好的例子是洗車題:我要去 50 米外的洗車店洗車,應該開車還是走路?最先進的模型可能會說,走路,因為很近。這個回答忽略了問題的關鍵:你要洗的是車,所以車必須到洗車店。
一個最先進的模型可以重構 10 萬行代碼、找到零日漏洞,卻告訴我應該走路去洗 50 米外的車。
【注:零日漏洞指尚未公開或尚未修補的安全漏洞。】
如果一個任務落在模型訓練和 RL 覆蓋過的能力迴路裏,它可能表現得像專家。如果落在數據分佈外,即使人類覺得很簡單,它也可能出錯。
這對使用者的要求很高。你不能因為模型在代碼上很強,就默認它在所有工程判斷上都強。你也不能因為它犯了洗車題這種錯誤,就斷定它整體沒用。更準確的做法是:探索它的能力邊界,找出哪些任務在“能力高峯”裏,哪些任務在“斷崖”旁邊。
【6】能力不是自然進化,和實驗室的數據決策相關
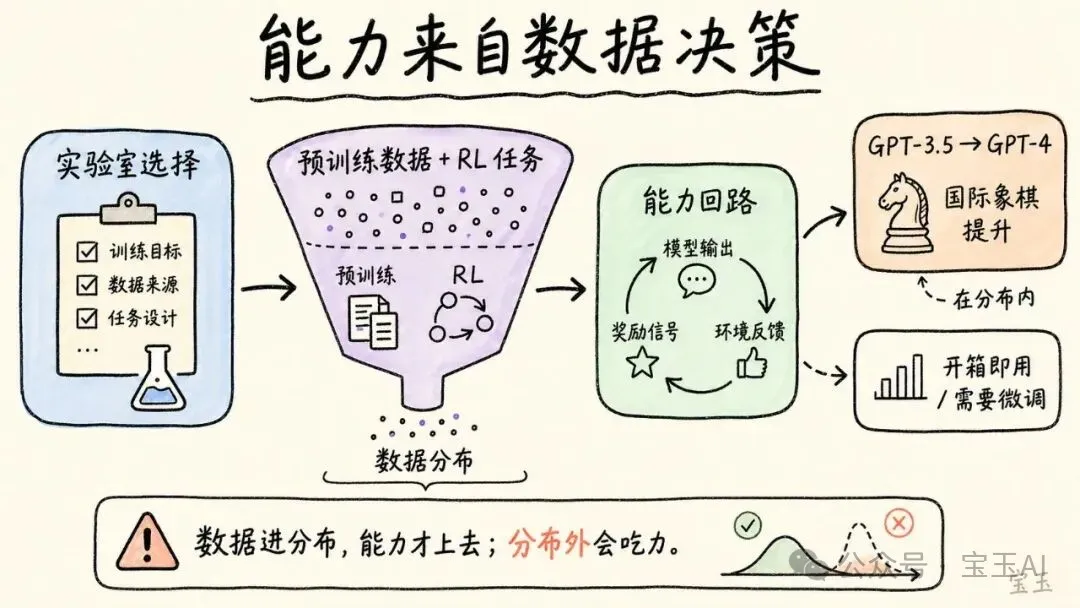
Karpathy 提到一個細節:從 GPT-3.5 到 GPT-4,國際象棋能力提升非常大。很多人以為這是能力的自然進化,但實際上是因為有人在 OpenAI 決定把大量國際象棋數據加進了預訓練。數據進了分佈,能力就跟着上去了。
這把一個看起來“模型變強”的故事,重新解釋成了一個“實驗室在做產品決策”的故事。
某種程度上,我們完全受制於實驗室給模型餵了什麼數據。如果你的場景剛好落在 RL 訓練覆蓋的“能力迴路”裏,模型就會帶你起飛;但一旦超出了這個數據分佈,它就會覺得極其吃力。
實操含義:如果你的應用場景在覆蓋的能力迴路裏,開箱即用;如果在外面,你需要自己做微調,不要指望 LLM 一上來就會。
【7】創業機會:找一個還沒被 RL 覆蓋的可驗證領域
Zhan 問:如果創業者今天想解決一個可驗證的問題,但大模型實驗室已經在數學、代碼等最明顯領域加速了,創業者該怎麼辦?
Karpathy 的回答沒有給出具體賽道,但給出了一種找機會的方法。
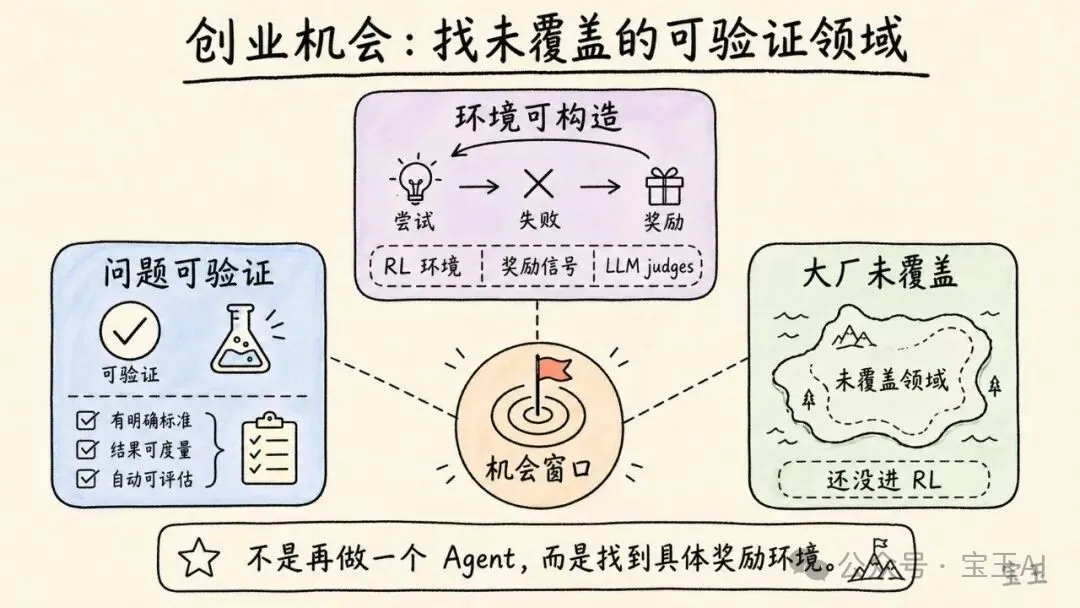
在當前技術範式下,可驗證性讓一個問題變得“可解”。如果你能構造大量、多樣的強化學習環境,能讓模型嘗試、失敗、獲得獎勵,那麼即便大實驗室沒有把這個領域作為重點,你也可能通過自己的微調和訓練獲得優勢。
他說到這裏時,幾乎要舉一個自己認為很有價值的領域,但停住了。
我不想直接給出答案……抱歉,我不是有意在台上發含糊推文的。
台下笑了。
這個停頓本身也說明了他的判斷:機會不是“再做一個 AI Agent”這樣泛泛的方向,而是找到某個可構造獎勵環境的具體問題。
他還補了一句更激進的話:幾乎所有事情,最終都可能在某種程度上變得可驗證。寫作、設計這類看似主觀的任務,也可以想象用一組 LLM judges,也就是模型評審團,形成某種近似評價。
這句話需要謹慎理解。Karpathy 並不是說所有任務都能被完美自動驗證。他說的是“程度”和“難易”。數學和代碼比較容易,因為答案或測試相對明確。寫作、審美、戰略判斷則要困難得多。
【8】Vibe Coding 抬高下限,Agentic Engineering 保住上限
Zhan 問:去年你提出 Vibe Coding。今天我們進入了一個更嚴肅的世界,更像 Agent engineering。二者的區別是什麼?
Karpathy 的區分非常清楚。
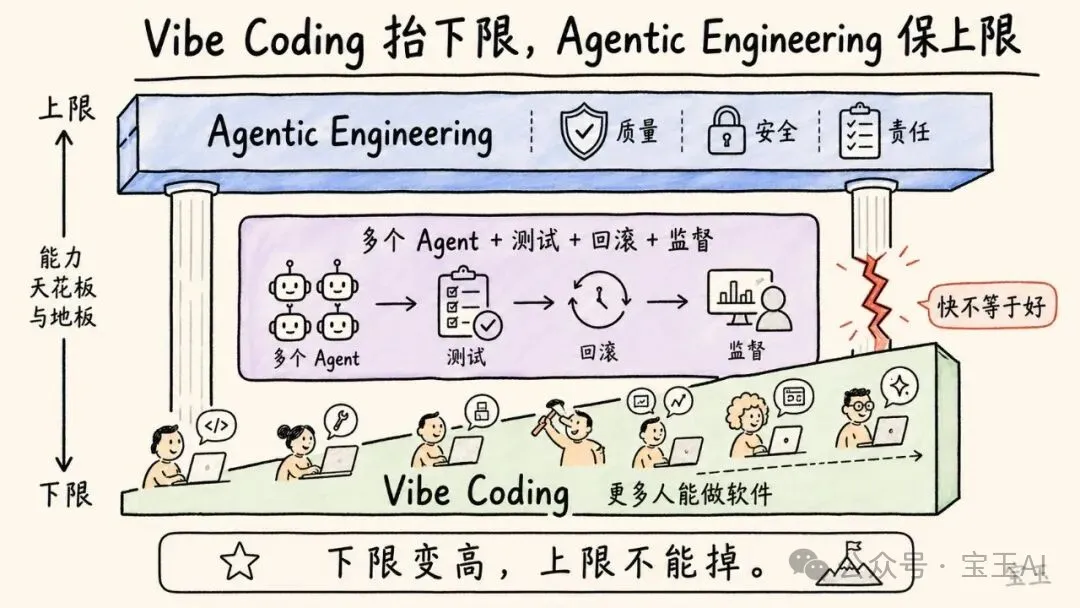
Vibe Coding 抬高的是下限。更多人可以用自然語言和 AI 做出軟件。不會寫代碼的人可以做小工具,會寫代碼的人可以更快做 side project。軟件創造的入口變寬了。
Agentic Engineering 保住的是上限。它面對的是專業軟件:不能因為用了 AI 就引入安全漏洞,不能因為模型寫得快就降低質量門檻,不能因為代碼是 Agent 生成的就沒人負責。
Vibe Coding 抬高的是所有人能做軟件的下限;Agentic Engineering 要保住的是專業軟件過去已有的質量門檻。
Agentic Engineering 可以譯作“智能體工程”。它不是一個具體工具,而是一種工程紀律:如何設計、協調、監督一組 AI Agent,讓它們在不犧牲質量、安全、可維護性的情況下加速開發。
Karpathy 說,這些 Agent 是“spiky entities”——有尖刺的實體。它們能力很強,但會犯錯,有隨機性,不穩定。工程師的工作不是盲目信任它們,而是把它們放進合適的流程裏:讓它們生成方案、寫代碼、跑測試、互相檢查,讓系統有邊界、有驗證、有回滾。
Karpathy 還提到一個更強的判斷:過去軟件行業喜歡說“10x engineer”,也就是效率遠超普通人的工程師。但在 Agentic Engineering 裏,他看到的加速幅度可能遠不止 10 倍。
10x 不是你獲得的加速倍數。
真正熟練的人,能把多個 Agent、工具、測試和上下文組織起來,產出速度會被放大得更厲害。
【9】AI-native 工程師:不是會刷題,而是能把大項目做安全
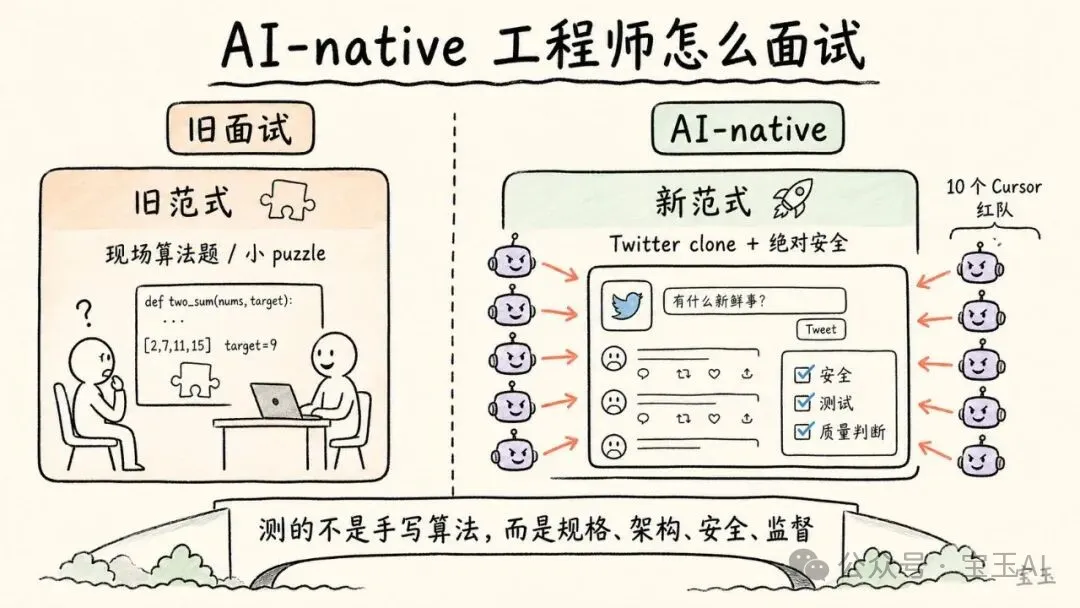
Zhan 問:如果觀察兩個使用 AI coding 工具的人,一個普通,一個真正 AI-native,區別會是什麼?
Karpathy 先說,AI-native 工程師會充分利用可用工具,並投資自己的工作流設置。就像過去工程師會花時間配置 Vim、VS Code、命令行、快捷鍵和開發環境,現在也要花時間配置 Cursor、Claude Code 或類似工具,讓它們真正適合自己的工作方式。
但他很快把話題轉到招聘。
他認為,很多公司還沒有重構面試流程。如果仍然給候選人一組小 puzzle,讓他們現場解算法題,這還是舊範式。它測不出一個人是否會在 Agentic Engineering 裏高效工作。
更好的測試應該是大項目。比如讓候選人做一個 Twitter clone:不僅要能跑,還要做得好、做得安全。然後再用多個 Agent 去攻擊這個網站,嘗試破壞它,看看系統能否經得住。
面試本該是這樣的:甩給候選人一個極大的項目,比如做個給 Agent 用的 Twitter 仿盤,要求做得絕對安全。然後,我掛上 10 個 Cursor 當作“紅隊”,放開手腳去攻擊你做出來的這個網站。
這套評估方式的核心,不是看候選人能不能手寫某個算法,而是看他能不能:把模糊目標變成清晰規格;指揮 Agent 完成大規模實現;識別安全和架構風險;設置測試與驗證;在模型生成的大量代碼裏保持質量判斷;讓最終系統經得起外部攻擊和壓力。
【10】Agent 能寫代碼,但還會把付款綁到錯誤郵箱上
Zhan 問:Agent 做得越多,什麼人類技能會變得更有價值?
Karpathy 的答案是:品味、判斷、審美、監督,以及規格設計。
他把當前 Agent 比作實習生。這個比喻很準確,但不能過度擬人化。Agent 不是真的有人類動機的員工,它只是執行能力越來越強,同時會在一些人類覺得顯而易見的地方犯錯。
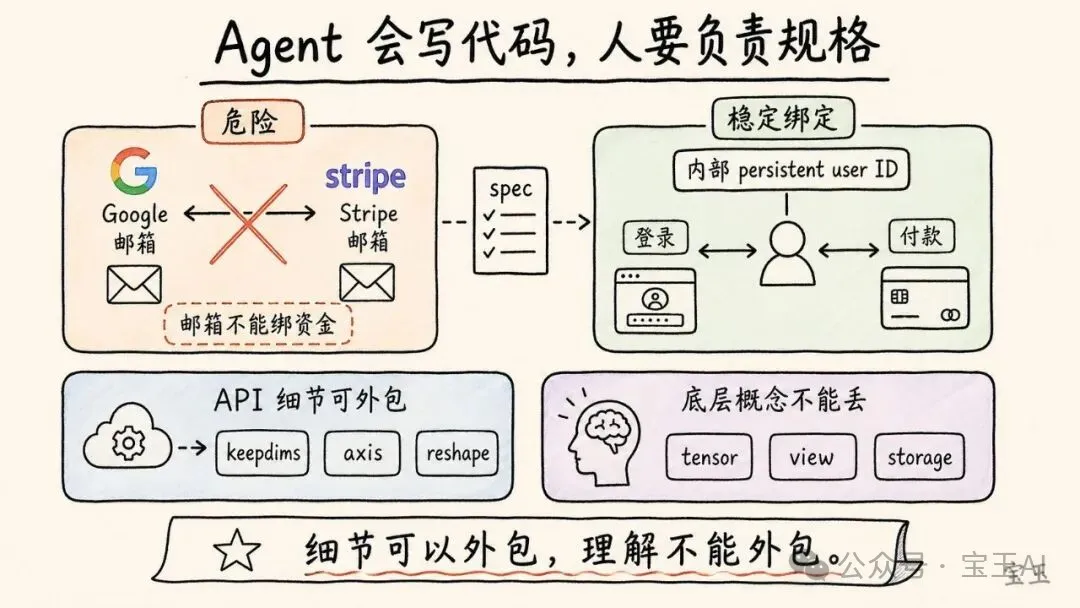
Karpathy 舉了 MenuGen 的一個實際問題。用戶用 Google 賬號登錄,但購買 credits 時使用 Stripe 賬號。Google 和 Stripe 都有郵箱地址。Agent 在實現購買邏輯時,試圖用 Stripe 郵箱去匹配 Google 郵箱,把購買的 credits 歸到對應用戶身上。
這聽起來好像合理,但在工程上是危險的。一個人完全可能用一個郵箱登錄 Google,用另一個郵箱付款。如果系統用郵箱關聯資金,就可能出現購買記錄無法歸屬、資金錯配或賬户混亂。正確做法應該是使用系統內部穩定的 persistent user ID 來綁定用戶身份和支付記錄。
你為什麼要用郵箱地址來交叉關聯資金?它們可以是任意的,你可以用不同的郵箱。這種做法太奇怪了。
這類問題沒有語法錯誤,代碼可能能跑,測試可能還過,但系統設計是錯的。Agent 沒有真正理解身份、支付和資金歸屬的風險。
所以 Karpathy 說,人必須負責 spec,也就是規格。你要告訴 Agent:所有資金和用戶狀態必須綁定到內部唯一用戶 ID,而不是綁定到外部郵箱。你要負責頂層設計、約束條件和判斷標準。Agent 可以填補實現細節,但不能替你理解系統邊界。
他接着舉了一個更技術的例子。現在他已經不再記 PyTorch、NumPy、pandas 之間很多細碎 API 差異,比如 keepdims 還是 keepdim,dim 還是 axis,reshape、permute、transpose 分別怎麼寫。這些細節可以交給 Agent,因為模型記憶很好。
但他仍然強調,人必須理解底層概念。比如張量(tensor)是什麼,view 和 storage 的關係是什麼,什麼時候只是改變同一塊內存的視圖,什麼時候會複製數據。如果不懂這些底層機制,就可能讓模型寫出低效甚至錯誤的代碼。
這給“什麼值得學”提供了一個非常具體的答案:細節可以外包,理解不能外包。API 名稱可以忘,但概念結構不能丟。
【11】模型寫出的代碼能跑,但有時“很醜”
Zhan 追問:taste 和 judgment 會不會隨着模型進步而越來越不重要?
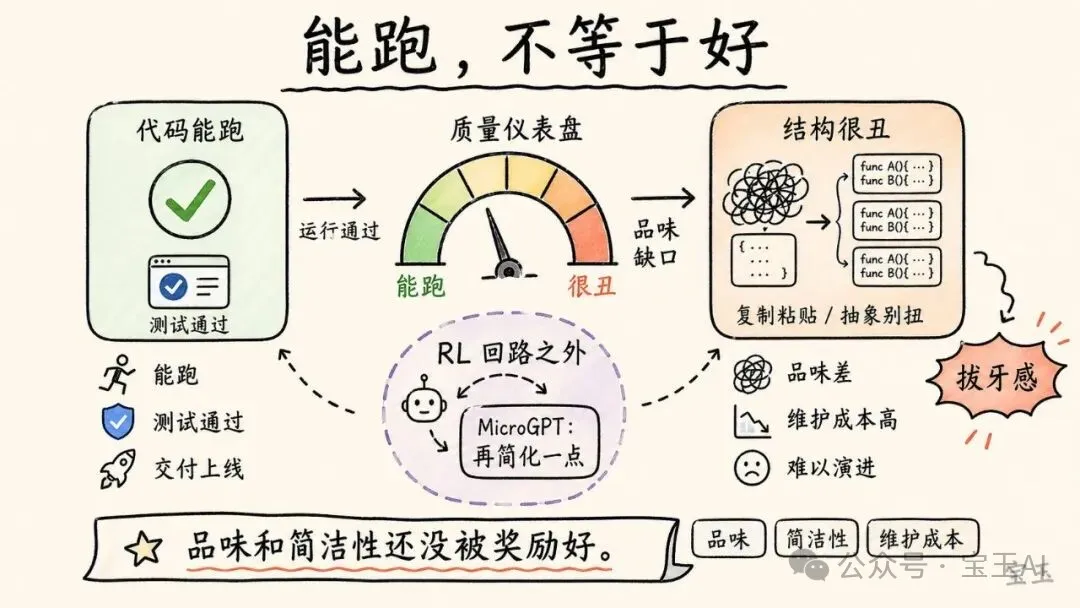
Karpathy 沒有把話說死。他希望模型會進步,也認為沒有什麼根本原因阻止它們在品味、審美和簡潔性上變好。但他指出,至少現在,這些能力還沒有被很好地訓練出來,可能因為它們沒有進入足夠好的 RL 獎勵環境。
他看模型生成的代碼時,有時會“心臟病發作”。代碼能跑,但不一定好。它可能很臃腫,有很多複製粘貼,有別扭的抽象,結構脆弱,維護起來很難。
有時我看到它寫出來的代碼,會有一點心臟病發作的感覺。它能跑,但真的很噁心。
他還提到 MicroGPT 項目。他想把 LLM training 簡化到極致,讓訓練過程儘可能小、清晰、可理解。他不斷要求模型“再簡化一點”,但模型做不到。那種感覺像“拔牙”一樣困難。
我不斷地讓 LLM“再簡化一點”,它就是做不到。你能感覺到你在 RL 迴路之外。就像在拔牙。
Karpathy 的解釋是,這個任務可能走出了模型被 RL 覆蓋的能力迴路。模型擅長生成常見工程形態,卻不擅長極簡、剋制、優雅的抽象壓縮。
【12】我們不是在造動物:Karpathy 說我們召喚的是“幽靈”
Zhan 問:你寫過一篇關於 animals vs ghosts 的文章,核心意思是我們不是在造動物,而是在召喚幽靈。這個框架為什麼重要?
Karpathy 說,他寫這篇文章,是因為自己也在試圖理解這些模型到底是什麼。如果你對模型是什麼有一個更好的心智模型,你就會更擅長使用它。
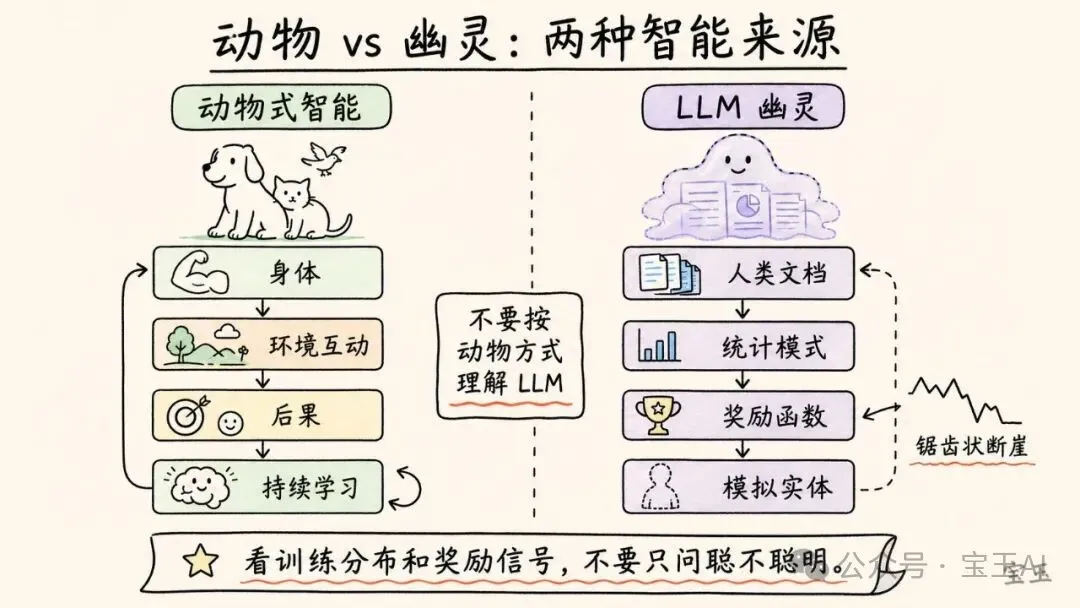
“幽靈”這個詞聽起來神秘,但 Karpathy 的意思並不玄學。他是在對比兩種智能來源。
動物智能來自進化、身體、環境互動、內在動機、好奇心、樂趣、持續學習。動物會在世界中行動,被後果塑造,會在生命過程中不斷適應。
LLM 不是這樣。今天的前沿 LLM,首先來自大規模預訓練:模型在海量人類文檔上學習統計結構。然後再疊加強化學習、偏好數據、工具調用等後訓練過程。它們不是動物式智能,而是由人類文檔、統計模式和獎勵函數塑造出的模擬實體。
在訪談裏,他把這個比喻落到一個很樸素的使用原則上:不要把 LLM 當動物。你對它大喊大叫,不會讓它因為害怕而更努力。你鼓勵它,也不是在激發它的內在動機。模型沒有動物式情緒。它的行為來自統計模擬、上下文、工具、訓練數據和獎勵機制。
如果你對它大吼,它不會因此工作得更好或更差,也沒有任何影響。
Karpathy 也承認,“幽靈”框架有哲學化的一面。他沒有說它能直接產出五條系統優化建議。它更像一種防止誤用的提醒:不要籠統地問“AI 聰不聰明”,要問它在哪些訓練分佈裏強,哪些獎勵信號塑造了它,在哪些任務上可能出現鋸齒狀斷崖。
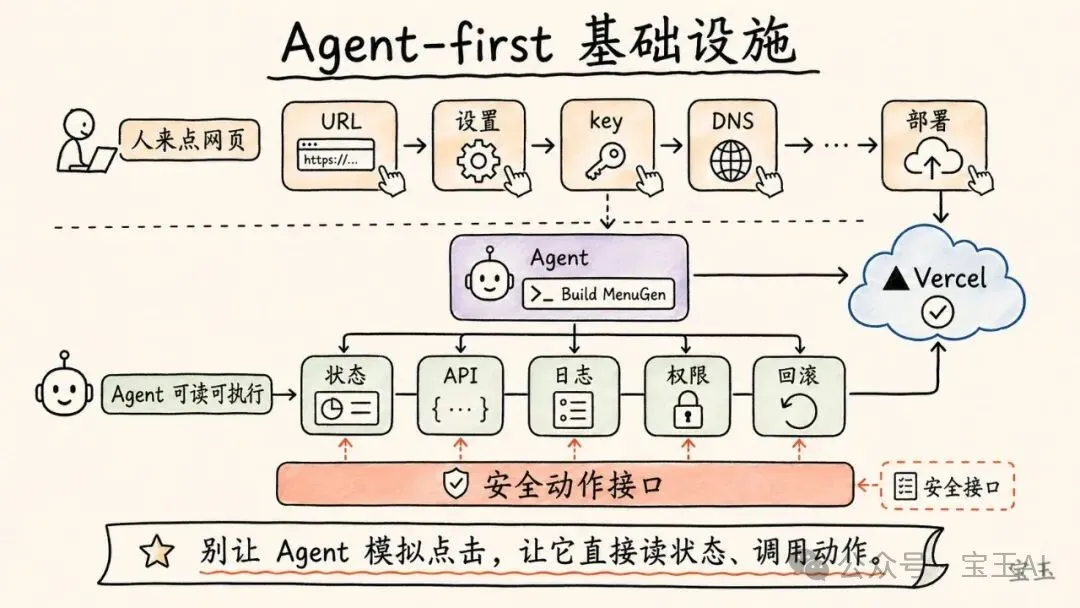
【13】Agent-first 基礎設施:一句話構建並部署 MenuGen
Zhan 問:當 Agent 不只聊天,而是擁有權限、本地上下文,並能代表人採取行動時,世界會變成什麼樣?
Karpathy 說,幾乎一切都要重寫。今天的工具、文檔、服務和設置流程,仍然主要是為人設計的。
比如一個框架的文檔會告訴你:去某個 URL,點擊某個設置,複製某個 key,打開某個菜單,配置某個 DNS。Karpathy 的反應是:為什麼還在告訴我該怎麼做?我不想做這些事。我想知道的是,哪一段東西可以複製給我的 Agent,讓它自己去做。
為什麼還有人在告訴我該做什麼?我什麼都不想做。“給我複製粘貼給 Agent 的東西是什麼?”
這不是懶,而是範式變化。Agent-first infrastructure 的目標,是把世界拆成 Agent 能讀懂的輸入,以及 Agent 能安全調用的動作接口。
在軟件基礎設施裏,這意味着文檔、API、權限、日誌、部署、配置、賬單、回滾,都要變得更適合 Agent 使用。不是讓 Agent 模擬人去點網頁,而是讓 Agent 直接理解狀態、調用動作、收到反饋。
Karpathy 又回到 MenuGen。他說,做 MenuGen 最麻煩的部分其實不是寫代碼,而是部署:在 Vercel 上部署,連接各種服務,進入不同設置頁面,配置 DNS,把所有東西串起來。
他希望未來的測試標準是:給 LLM 一句 Build MenuGen,它不僅能寫代碼,還能完成部署,上線到互聯網,配置好依賴服務,而且整個過程不需要人去一個個菜單裏操作。
更遠一點,他設想每個人、每個組織都可能有自己的 Agent representation。以後安排會議、處理細節、協調事項,可能變成“我的 Agent 和你的 Agent 去談”。
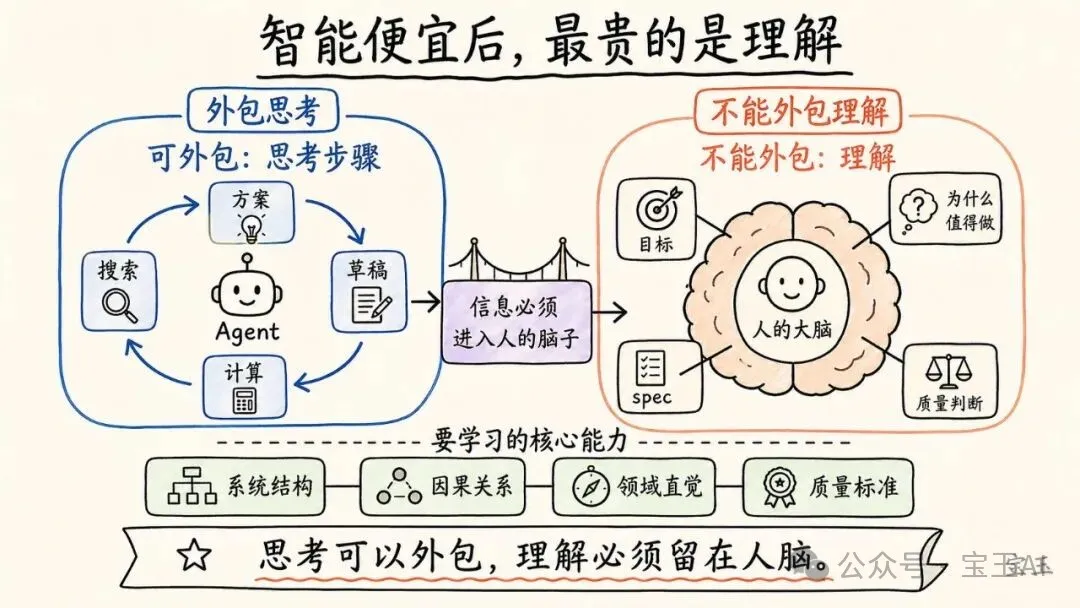
【14】智能變便宜後,最貴的是理解
Zhan 最後問:當智能變得便宜,什麼仍然值得深入學習?
Karpathy 引用了一句話:
你可以外包你的思考,但不能外包你的理解。
這句話容易被寫成勵志格言,但 Karpathy 的解釋很具體。
他仍然是系統的一部分。信息必須進入他的腦子裏。他覺得自己正在變成瓶頸:要知道到底在建什麼,為什麼值得做,怎樣指導自己的 Agent。思考步驟可以讓模型跑很多遍,但如果人沒有理解,就無法判斷哪條路線是對的,無法寫出好的規格,也無法發現 Agent 在身份綁定、系統結構、代碼質量上的錯誤。
我感覺自己正在變成瓶頸:我要知道我們到底在建什麼,為什麼值得做,以及怎樣指導我的 Agent。
這也是他對 LLM knowledge bases 感興趣的原因。他喜歡把文章、資料、事實重新投影成 wiki,因為不同的信息組織方式能幫助他獲得洞見。對他來說,這不是讓 AI 代替理解,而是用 AI 增強理解。
這一點和前面的工程例子連在一起:
• Agent 可以記 API 細節,但人要理解 tensor、view、storage和內存效率;• Agent 可以寫支付邏輯,但人要理解用戶身份和資金歸屬; • Agent 可以生成大量代碼,但人要判斷抽象是否臃腫、結構是否脆弱; • Agent 可以幫你思考很多方案,但人要知道目標是否值得做。
所以,智能變便宜之後,學習不是不重要了,而是學習的重心變了。更少時間花在機械記憶和低層執行上,更多時間花在系統理解、問題定義、質量判斷、因果關係和領域直覺上。
Q&A 速覽
問:2025 年 12 月發生了什麼?
答:最新模型生成的代碼不需要修改了,可靠性在持續的項目中也保持住了。
問:Software 3.0 和以前有什麼不同?
答:以前的代碼處理結構化數據,現在你可以處理任意信息。以前做不了的東西現在可以了。這不是加速,是新的可能性。
問:為什麼最先進的 AI 模型在簡單任務上犯低級錯誤?
答:能力分佈取決於 RL 訓練覆蓋的領域和實驗室的數據選擇。可驗證的領域能力飆升,其餘領域可能很弱。
問:Vibe Coding 和 Agentic Engineering 的區別?
答:Vibe Coding 是提升所有人的下限,Agentic Engineering 是保持專業標準的前提下利用 Agent 加速。
問:什麼時候人的品味和判斷會不重要?
答:可能會,但前提是實驗室把審美獎勵納入 RL 訓練目標。目前 Agent 的代碼經常“能跑但很難看”。
【最後】
這場訪談裏,Karpathy 的判斷有幾個值得注意的張力。
第一,他一邊說 Agent 寫出的代碼醜得讓他心臟病發作,一邊說他自己已經停止修改了。“信任並沒有解決品味的問題”——能跑的代碼和好代碼不是一回事。可這種“用着醜的,但用着”的狀態,可能比任何 hype 都更接近真實的 Vibe Coding 現狀。
第二,他暗示有“被低估的 RL 機會”領域卻不願公開。一個不願在台上發含糊推文的人主動迴避,本身是個信號:窗口期還沒關。值得注意的是,他的公司 Eureka Labs 做的是 AI 教育,而教育恰好是一個輸出可以被評估、可以被標準化考核的領域。
第三,他給“動物 vs 幽靈”這個框架自己降了級別,又用“你可以外包思考,但不能外包理解”給整場對談收束。把這兩件事放在一起讀:他的判斷是,真正稀缺的不是任何一個具體技能,而是判斷“我們到底要做什麼、為什麼值得做”的能力。如果“幾乎所有領域最終都能被驗證”這個判斷成立,那麼瓶頸最終不在執行端,而在目標設定端。
但這裏有一個隱含的時間問號。Karpathy 自己也承認,品味和判斷之所以暫時不可替代,原因只是“實驗室還沒做”。如果這個判斷成立,那麼所謂人類不可替代的部分,不是因為人類獨一無二,而是因為訓練方法還沒到位。這就把“外包思考但不能外包理解”這句話的有效期打了一個問號。
未來 6-12 個月值得盯三個具體信號:
1. 前沿實驗室在編程/數學之外,往哪些領域注入 RL 數據——那裏的能力會突然冒出來 2. Agent-first 的基礎設施(部署、auth、payments)會不會有第一波收斂——MenuGen 部署的痛苦如果還在,“自動化社會”的路就長得多 3. 模型的下一代更新是否包含審美和代碼質量相關的 RL 目標
原始視頻:https://www.youtube.com/watch?v=96jN2OCOfLs