Karpathy 的 AI 知識庫 理念,已經有人開源在 GitHub 上了。
整理版優先睇
LLM Wiki 將 Karpathy 嘅 AI 知識庫理念落地做咗個桌面 App,自動幫你整結構化 Wiki
呢篇文章係介紹一個叫 LLM Wiki 嘅開源項目,佢係基於 Karpathy 之前提出嘅 LLM Wiki 理念——用 LLM 做知識工程師,持續維護一個 Markdown 知識庫——而做出嚟嘅具體實現。作者之前寫過文講呢個理念,嗰時 GitHub 上已經有人開始做,但呢個項目「卷得特別猛」,直接整咗個跨平台桌面應用,而家已經有 3300+ Star。
項目嘅核心係「兩步鏈式思考」:先分析文檔提取實體概念,再生成 Wiki 頁面,令質素明顯提升。另外佢仲加咗知識圖譜可視化,用四維關聯度模型衡量頁面關係;圖譜洞察功能會自動發現意外關聯同知識缺口,仲可以一鍵深度研究,叫 LLM 上網搜資料補全。佢仲有 Chrome 剪藏擴展、支援多格式導入(PDF、Word、Excel等),完全兼容 Obsidian,令你個知識庫可以自我增長。
整體嚟講,呢個項目將 Karpathy 嘅構想變成現實,降低咗使用門檻,普通用戶都玩得。功能比原版 Gist 豐富好多,係一個好實用嘅個人知識管理工具。作者結論係:知識嘅複利增長,呢個項目做到咗。
- 兩步鏈式思考(先分析後生成)顯著提升 Wiki 頁面質素,每次錄入可牽動 10-15 個頁面更新,仲有 SHA256 增量緩存同持久化隊列。
- 知識圖譜用四個維度(直接連結、來源重疊、Adamic-Adar、類型親和度)計算關聯度,並用 sigma.js 可視化,支援 Louvain 社區發現。
- 圖譜洞察功能自動發現意外關聯(跨社區連接)同知識缺口(孤立頁面、稀疏社區),每個缺口有深度研究按鈕自動補全。
- 深度研究功能:LLM 根據知識庫主旨生成精確搜索詞,調用 Tavily API 搜資料並整合成 Wiki 頁面,實現知識庫自我補全。
- Chrome 剪藏擴展一鍵擷取網頁內容,自動轉成 Markdown 並觸發錄入;支援多格式導入(PDF/DOCX/PPTX/Excel/圖片/音視頻),兼容 Obsidian 作為查看器。
開源倉庫(GitHub)
項目主頁,包含源碼同說明。
預編譯安裝包(Release v0.3.13)
直接下載桌面應用安裝檔。
一句話講清楚呢個項目係咩
LLM Wiki 係一個跨平台桌面應用,你將文檔掟入去,佢自動幫你生成一個結構化、互相連結嘅個人 Wiki 知識庫。同傳統 RAG 方案唔同,佢唔係每次提問都從原始文檔重新檢索,而係 LLM 先將你嘅文檔食透,生成 Wiki 頁面、建立交叉引用、標註矛盾點,後續提問直接喺 Wiki 上搞。
呢個項目係基於Karpathy 嘅 Gist 理念做嘅具體實現,但功能遠超原版設想,加咗知識圖譜、深度研究、網頁剪藏、向量搜索呢啲能力,目前斬獲 3300+ Star。
核心設計:兩步鏈式思考錄入
原版 Gist 嘅思路係 LLM 讀文檔同時寫 Wiki,一步到位。呢個項目拆成兩步:
- 1 第一,分析。LLM 先通讀你嘅文檔,提取關鍵實體、概念、論點,揾同現有 Wiki 內容嘅關聯,發現矛盾同張力,然後畀出結構化分析結果。
- 2 第二,生成。LLM 拎住分析結果先開始寫 Wiki 頁面:生成摘要頁、實體頁、概念頁,更新索引,建立交叉引用,標註需要人工判斷嘅事項。
仲有實用細節:SHA256 增量緩存,每個文件錄入前算哈希,冇改過嘅自動跳過;持久化隊列,崩咗重啟可以繼續,失敗自動重試 3 次;活動面板即時睇到每個文件嘅處理進度。
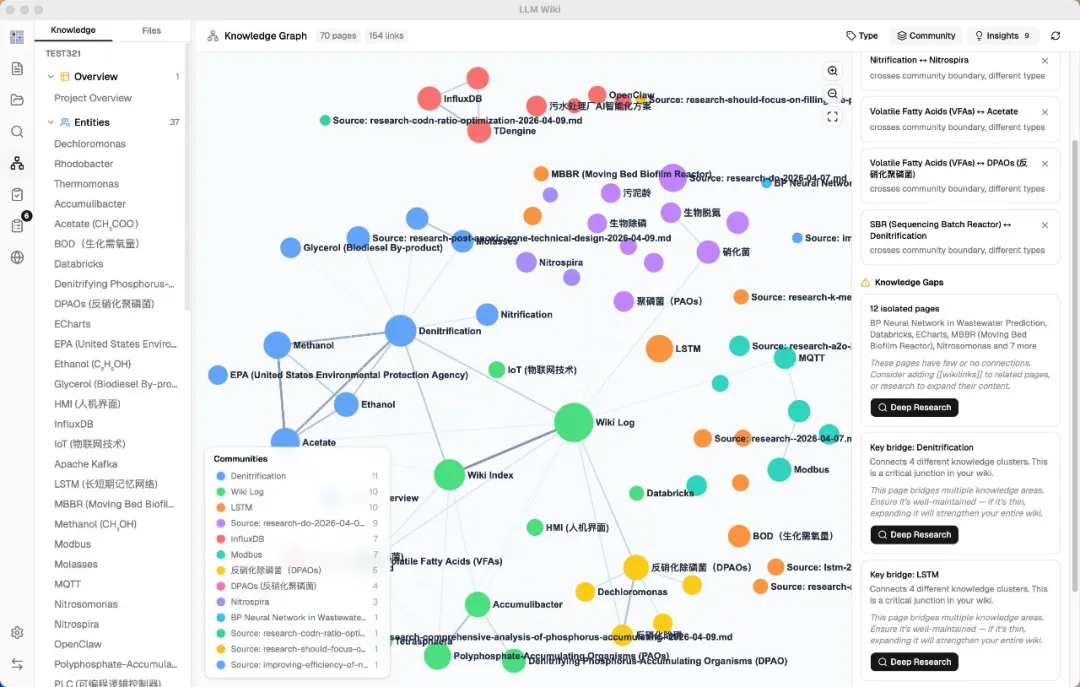
知識圖譜可視化同洞察
原版 Gist 只提到用 wikilinks 做交叉引用,呢個項目直接做咗個完整嘅知識圖譜可視化同關聯引擎。佢用四個維度衡量兩個 Wiki 頁面之間嘅關聯程度:直接連結(權重 x3.0)、來源重疊(權重 x4.0)、Adamic-Adar(權重 x1.5)、類型親和度(權重 x1.0)。
圖譜洞察係原版完全冇嘅功能,但係我覺得最有價值。系統自動分析圖譜結構,畀你兩種洞察:
- 意外關聯:跨社區、跨類型、意料之外嘅連接,係認知突破嘅起點。
- 知識缺口:孤立頁面、稀疏社區、橋接節點。每個缺口旁邊有個深度研究按鈕,一按就讓 LLM 自動上網搜資料補全。
深度研究同網頁剪藏
當系統發現知識缺口後,LLM 會自動生成搜索關鍵詞,調用Tavily API去網上搜索。搜到嘅結果 LLM 綜合分析,寫成一篇研究頁面,直接寫入 Wiki。研究頁面仲會自動觸發錄入流程,提取新實體同概念,整合到現有知識網絡。
Chrome 剪藏方面,佢做咗個專用擴展,用Readability.js自動去廣告,Turndown.js轉成乾淨 Markdown。剪藏嘅內容自動發送到本地應用,觸發錄入,直接變成 Wiki 一部分。支援多項目選擇,就算應用冇開,擴展都可以預覽內容,等打開後再自動同步。
檢索方面,LLM Wiki 搞咗套多階段檢索管線:先分詞搜索(中文 CJK 二元組),可選向量語義搜索(LanceDB 近似最近鄰),再將搜索結果當種子節點做 2 跳遍歷。上下文窗口可配置 4K 到 1M tokens。官方話開向量搜索後整體召回率由 58.2% 提升到 71.4%。
幾個眼前一亮的細節同上手方法
除咗大模組,仲有幾個好細心嘅設計:
- Purpose.md:放目標、關鍵問題、研究範圍,LLM 每次錄入同查詢都會參考,令知識庫有明確方向。
- 異步審核:LLM 遇到拿唔準嘅事會標記到審核隊列,唔阻塞主流程;每個審核項有預生成操作選項同搜索查詢。
- 刪除自動清理:刪一個資料文件,系統自動揾相關 Wiki 頁面、引用實體、索引條目、失效連結,全部清理;被多個資料共享嘅實體頁面唔會被誤刪。
- 多格式支援:PDF、DOCX、PPTX、Excel、圖片、音視頻都入得,PDF 用 Rust 解析。完全兼容 Obsidian,生成嘅 Wiki 目錄就係標準 Obsidian Vault。
上手好簡單:去 GitHub Releases 下載安裝包,裝好後啟動建立新項目(有場景模板可選:研究、閲讀、個人成長、商業、通用),設置大模型(支援 OpenAI、Anthropic、Google、Ollama 同自定義接口),導入文檔,然後睇住 LLM 自動構建 Wiki 頁面。Chrome 擴展安裝都係標準步驟:開啟開發者模式,加載 extension/ 目錄。
之前寫咗篇關於 Karpathy 嘅 LLM Wiki 理念嘅文章,講緊用 LLM 做知識工程師,幫你持續維護一個 Markdown 知識庫。

當時篇文章入面提到 GitHub 上已經有人喺度基於呢個理念做具體實現。
其中有一個項目發展得特別快。
叫 LLM Wiki,而家已經有 3300 幾粒 Star 喇。
唔係簡單嘅命令列工具或者 Claude Code Skill,直接整咗一個跨平台嘅桌面應用程式。
功能做得非常紮實,比起 Karpathy 原版 Gist 嘅構想豐富得多。
今日就嚟睇睇呢個開源項目。
01
一句話講清楚呢個係啲乜
LLM Wiki 係一個跨平台桌面應用程式,你將文件掉入去,佢會自動幫你生成一個結構化、互相連結嘅個人 Wiki 知識庫。
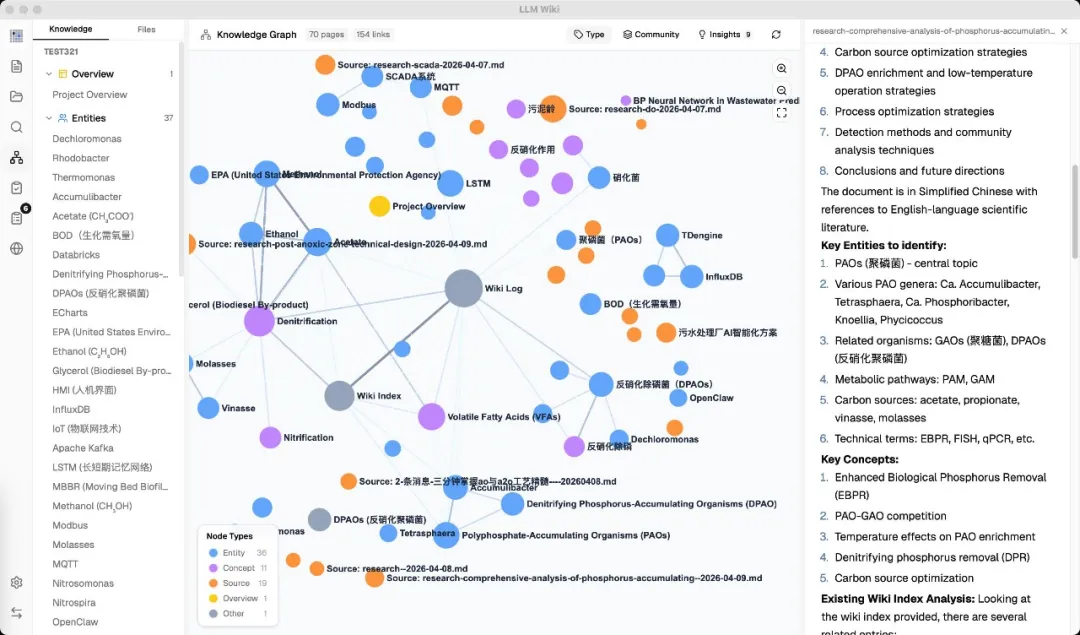
同傳統 RAG 方案唔同,佢唔係每次提問都喺原始文件重新檢索。
LLM 會先將你啲文件讀透,生成 Wiki 頁面、建立交叉引用、標註矛盾位,之後提問直接喺 Wiki 上做。
知識編譯一次,持續保持最新。
呢個項目就係基於 Karpathy 嘅 Gist 嚟做具體實現,但功能遠遠超出原版構想,加咗知識圖譜、深度研究、網頁剪藏、向量搜索呢啲能力。
目前已經有 3300+ Star。

開源地址:https://github.com/nashsu/llm_wiki02
兩步鏈式思考錄入
呢個係成個項目最核心嘅設計之一。
原版 Gist 嘅思路係叫 LLM 讀文件嘅同時寫 Wiki,一步到位。呢個項目就將佢拆成兩步。
第一步,分析。
LLM 先睇曬你啲文件,提取關鍵實體、概念、論點,揾同已有 Wiki 內容嘅關聯,發現矛盾同張力,然後畀出結構化嘅分析結果。
第二步,生成。
LLM 攞住分析結果,先開始寫 Wiki 頁面。生成摘要頁、實體頁、概念頁,更新索引,建立交叉引用,標註需要人工判斷嘅事項。
拆成兩步嘅好處係質量明顯更高。叫 LLM 諗清楚先再寫,比起邊諗邊寫效果好得多。
一個來源錄入之後,可能會牽涉到 10 至 15 個 Wiki 頁面嘅更新。LLM 會自動將新知識同已有知識網絡串連埋一齊。
仲有個好實用嘅細節:SHA256 增量快取。
每個檔案喺錄入之前會計算哈希,冇改過嘅檔案會自動跳過,唔使每次都叫 LLM 重新處理,慳返 token 同時間。
持久化隊列都做得唔錯,死咗重新開機可以繼續跑,失敗會自動重試 3 次。活動面板可以即時睇到每個檔案嘅處理進度。
03
知識圖譜可視化
原版 Gist 只係提到用 wikilinks 做交叉引用,基本上係文字連結。
呢個項目直接整咗一個完整嘅知識圖譜可視化同關聯引擎。
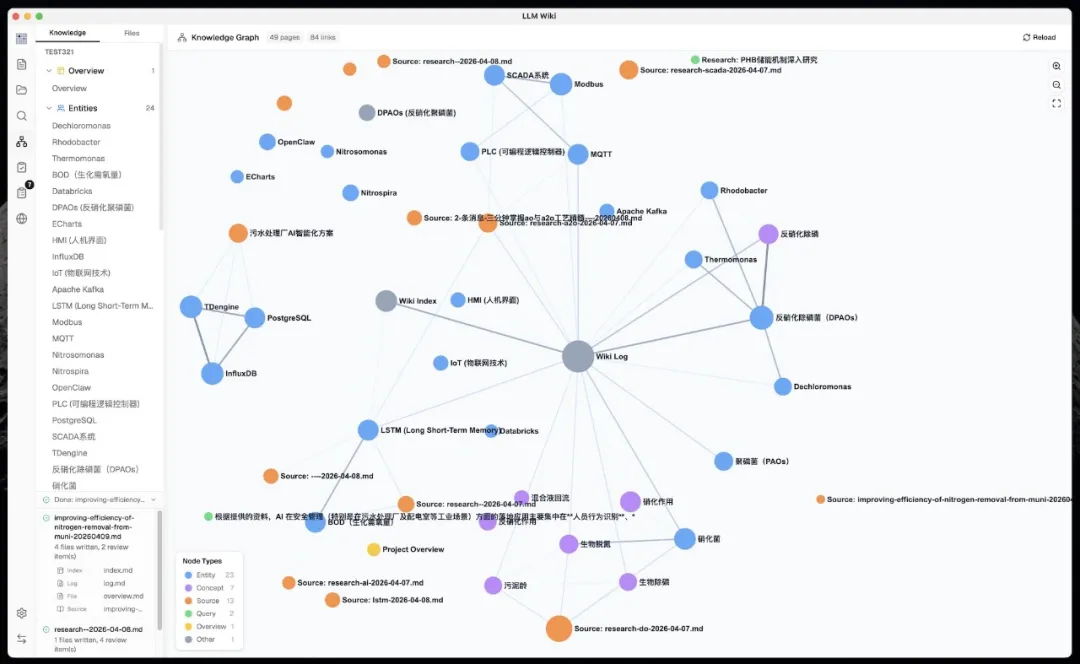
佢用四個維度嚟衡量兩個 Wiki 頁面之間嘅關聯程度:
可視化用咗 sigma.js + ForceAtlas2 佈局。
節點顏色可以按頁面類型或者社區聚類嚟着色,節點大小按連結數量縮放。
滑鼠懸停嘅時候,關聯節點保持高亮,其他節點變暗,邊緣仲會顯示關聯分數。
仲整合咗 Louvain 社區發現算法,可以自動識別出知識集羣。
你導入咗一堆文件之後,佢可以話畀你知你啲知識自然形成咗邊幾個主題聚類,每個聚類嘅內聚程度如何。
04
圖譜洞察,呢個功能最有趣
呢個係原版完全冇嘅,但我覺得係成個項目最有價值嘅部分。
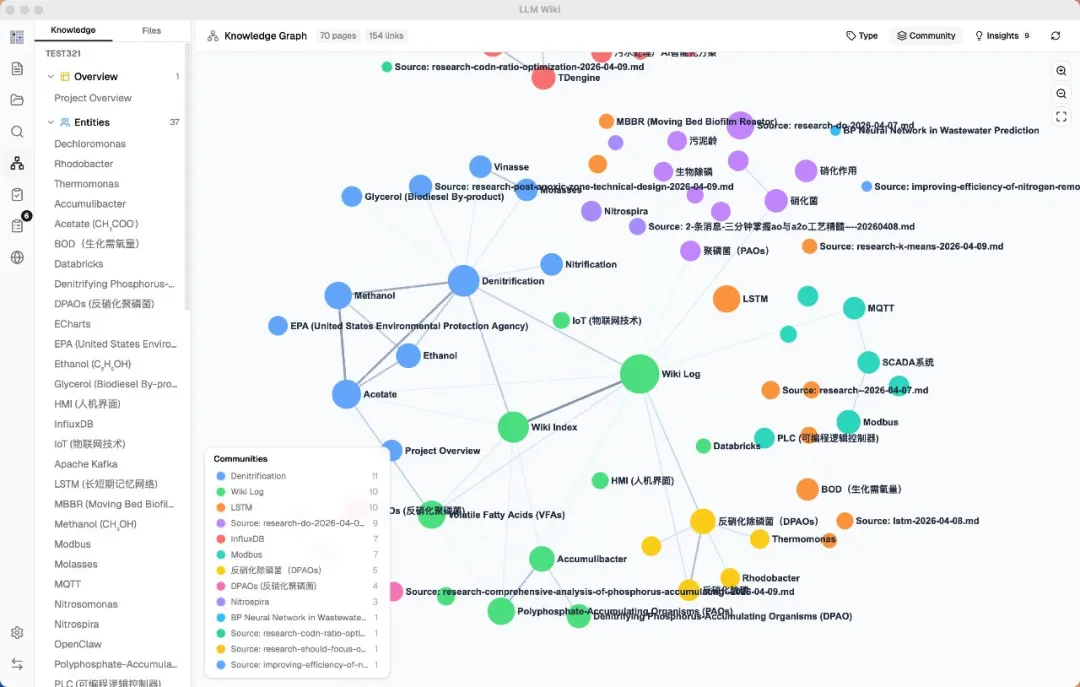
系統會自動分析圖譜結構,畀你兩種洞察。
一種係意外關聯。
跨社區、跨類型、意料之外嘅連接。例如你分別錄入咗兩批睇落完全冇關係嘅資料,圖譜裏面突然出現咗一條連接佢哋嘅邊。
呢種發現往往係認知突破嘅起點。
另一種係知識缺口。
佢會揾出幾乎冇連接嘅孤立頁面、內部交叉引用太少嘅稀疏社區、同時連接三個以上集羣嘅橋接節點。
每個缺口旁邊都有個深度研究按鈕,㩒一下就係可以叫 LLM 自動上網揾資料補全。
由發現缺口到補齊缺口,基本全程自動。
05
深度研究,知識庫會自己補全自己
當系統發現知識缺口之後,LLM 會自動生成搜尋關鍵詞,調用 Tavily API 上網揾嘢。
揾到嘅結果 LLM 會綜合分析,寫成一篇研究頁面,直接寫入 Wiki。
研究頁面仲會自動觸發錄入流程,提取出新嘅實體同概念,整合到已有嘅知識網絡入面。
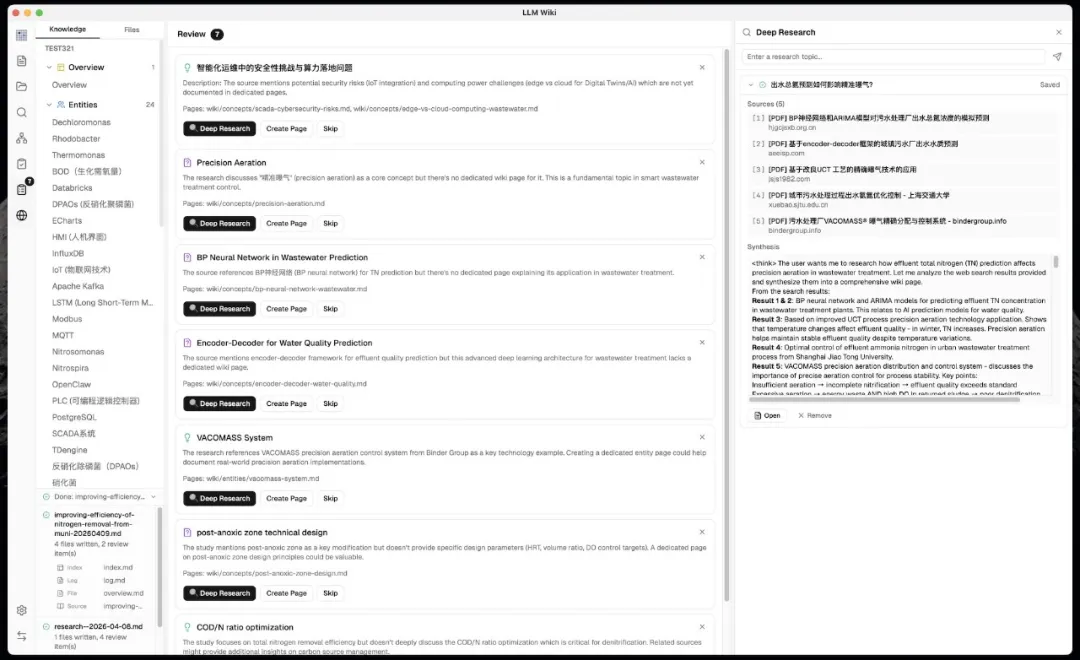
等於你嘅知識庫會自己去發現缺口,然後自己上網揾資料補全。
觸發深度研究嘅時候,LLM 會先讀 overview.md 同 purpose.md 嚟瞭解你個知識庫係關於啲乜,然後生成針對性嘅搜尋詞。
唔係泛泛嘅關鍵詞,而係根據你已有知識嘅上下文嚟精確定位。搜尋前仲會彈個確認框,你可以修改搜尋主題同搜尋詞,覺得冇問題先開始。
06
Chrome 網頁剪藏
呢個項目整咗一個專門嘅 Chrome 擴充功能,用起上嚟幾方便。
喺瀏覽器見到啲好文章,㩒個圖示就搞掂。
Readability.js 會自動剷走廣告、導航欄、側邊欄呢啲幹擾內容,只保留正文,Turndown.js 轉成乾淨嘅 Markdown。
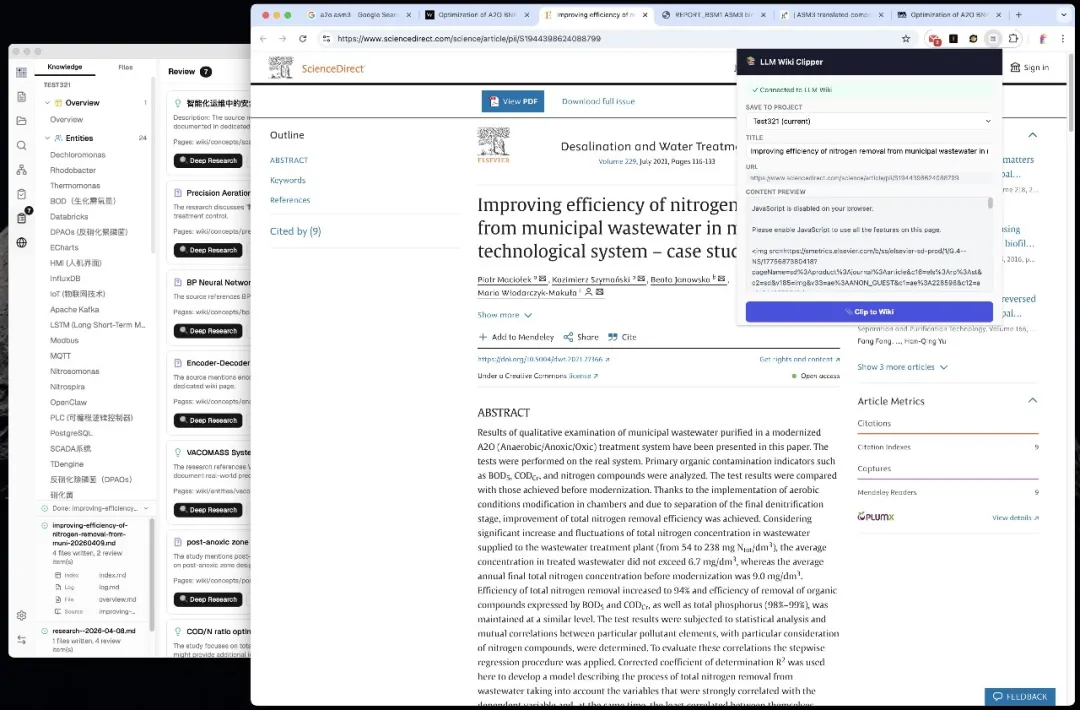
剪藏嘅內容會自動傳送去本地應用,觸發錄入流程,直接變成 Wiki 嘅一部分。
支援多項目選擇,如果你同時維護幾個知識庫,剪藏嘅時候可以揀存去邊個。
就算應用冇開住,擴充功能都可以預覽提取嘅內容,等你開返應用之後再自動同步。
檢索都做咗好多優化
Karpathy 原版方案喺中等規模之下靠索引文件就夠,但知識庫一大就唔夠用。
LLM Wiki 搞咗套多階段檢索管線。
先做分詞搜尋,中文用 CJK 二元組分詞。
然後可選開向量語義搜尋,透過 LanceDB 做近似最近鄰檢索,就算冇關鍵詞重疊都揾到語義相關嘅頁面。
再將搜尋結果當種子節點,用關聯度模型做 2 跳遍歷發現更深層嘅關聯。
上下文窗口可以配置,由 4K 到 1M tokens 都得。60% 畀 Wiki 頁面,20% 聊天歷史,5% 索引,15% 系統提示。
官方話開向量搜尋之後整體召回率由 58.2% 提升到 71.4%。
07
幾個眼前一亮嘅細節
除咗上面呢啲大模組,仲有幾個細節做得幾好。
Purpose.md
呢個項目加咗 purpose.md,放目標、關鍵問題、研究範圍。
LLM 每次錄入同查詢都會參考呢個檔案,你個知識庫就有咗一個明確嘅方向,唔係漫無目的地堆砌。呢個區分好妙。
異步審核
LLM 錄入過程中遇到拿唔準嘅事,會標記到審核隊列度,唔會阻塞主流程。
你幾時得閒就幾時睇,每個審核項帶住預先生成嘅操作選項同搜尋查詢。
刪一個資料檔案,系統會自動揾返佢嘅 Wiki 摘要頁、引用佢嘅實體頁面、索引條目、失效連結,全部清理乾淨。
被多個資料共享嘅實體頁面唔會被人錯手刪除,只會由 sources 列表度移除。
多格式支援
PDF、DOCX、PPTX、Excel、圖片、音視頻都可以導入。PDF 用 Rust 解析,效能好好。
完全兼容 Obsidian。
生成嘅 Wiki 目錄就係標準嘅 Obsidian Vault,自動生成 .obsidian/ 配置。Obsidian 當睇片器,LLM Wiki 當編輯器,兩個工具各司其職。
08
點樣上手
GitHub Releases 頁面有預先編譯好嘅安裝包:
連結:https://github.com/nashsu/llm_wiki/releases/tag/v0.3.13裝好之後嘅流程:
Chrome 擴充功能嘅安裝都好簡單。
打開 chrome://extensions,開咗開發者模式,載入已解壓縮嘅擴充功能,揀項目入面嘅 extension/ 目錄就得。
上次寫嗰篇文章嘅時候,Karpathy 嘅理念仲停留喺抽象嘅方法論層面。
當時雖然已經有人喺 GitHub 上做實現,但大多數係命令列工具或者 Claude Code 嘅 Skill,用起上嚟仲有一定門檻。
呢個項目直接做成一個桌面應用,降低咗使用門檻。普通用戶都可以用,唔使搞命令列同 Agent 配置。
而且佢唔係簡單照搬原版 Gist 嘅思路,喺知識圖譜、深度研究、網頁剪藏、向量搜索呢啲方面都有實質性嘅擴展。
迭代速度好快。
呢樣亦都印證咗 Karpathy 自己講嘅:喺 Agent 時代,你分享思路,人哋會叫佢哋嘅 Agent 去度身訂造就得。
知識嘅複利增長,呢個項目令 Karpathy 嘅構想變成現實。
09
㩒下面張卡,關注逛逛 GitHub
呢個公眾號歷史上發布過好多有趣嘅開源項目,如果你懶得逐篇文章揾,你直接關注微信公眾號:逛逛 GitHub,喺後台對話聊天就得:
前陣子寫了一篇關於 Karpathy 的 LLM Wiki 理念的文章,講的是用 LLM 當知識工程師,幫你持續維護一個 Markdown 知識庫。
當時文章裏提到 GitHub 上已經有人在基於這個理念做具體實現了。
其中有一個項目卷得特別猛。
叫 LLM Wiki,現在已經 3300 多 Star 了。
不是簡單的命令行工具或者 Claude Code Skill,直接做了一個跨平台的桌面應用。
功能做得非常紮實,比 Karpathy 原版 Gist 的設想豐富太多了。
今天就來看看這個開源項目。
01
一句話說清楚這是什麼
LLM Wiki 是一個跨平台桌面應用,你把文檔丟進去,它自動幫你生成一個結構化的、互相連結的個人 Wiki 知識庫。
和傳統 RAG 方案不同,它不是每次提問都從原始文檔重新檢索。
LLM 先把你的文檔吃透,生成 Wiki 頁面、建立交叉引用、標註矛盾點,後續提問直接在 Wiki 上做。
知識編譯一次,持續保持最新。
這個項目就是基於 Karpathy 的 Gist 做的具體實現,但功能遠超原版設想,加了知識圖譜、深度研究、網頁剪藏、向量搜索這些能力。
目前斬獲 3300+ Star。
開源地址:https://github.com/nashsu/llm_wiki02
兩步鏈式思考錄入
這是整個項目最核心的設計之一。
原版 Gist 的思路是讓 LLM 讀文檔的同時寫 Wiki,一步到位。這個項目把它拆成了兩步。
第一步,分析。
LLM 先通讀你的文檔,提取關鍵實體、概念、論點,找和已有 Wiki 內容的關聯,發現矛盾和張力,然後給出結構化的分析結果。
第二步,生成。
LLM 拿着分析結果,才開始寫 Wiki 頁面。生成摘要頁、實體頁、概念頁,更新索引,建立交叉引用,標註需要人工判斷的事項。
拆成兩步的好處是質量明顯更高。讓 LLM 先想清楚再動手寫,比邊想邊寫效果好得多。
一個來源錄入進去,可能牽動 10 到 15 個 Wiki 頁面的更新。LLM 會自動把新知識和已有知識網絡串聯起來。
還有個很實用的細節:SHA256 增量緩存。
每個文件在錄入前會算哈希,沒改過的文件自動跳過,不用每次都讓 LLM 重新處理一遍,省 token 也省時間。
持久化隊列也做得不錯,崩了重啓能接着跑,失敗自動重試 3 次。活動面板能實時看到每個文件的處理進度。
03
知識圖譜可視化
原版 Gist 只提到了用 wikilinks 做交叉引用,基本上就是文本連結。
這個項目直接做了一個完整的知識圖譜可視化和關聯引擎。
它用四個維度來衡量兩個 Wiki 頁面之間的關聯程度:
可視化用的是 sigma.js + ForceAtlas2 佈局。
節點顏色可以按頁面類型或者社區聚類來着色,節點大小按連結數量縮放。
鼠標懸停的時候,關聯節點保持高亮,其他節點變暗,邊上還會顯示關聯分數。
還集成了 Louvain 社區發現算法,能自動識別出知識集羣。
你導入了一堆文檔之後,它能告訴你你的知識自然形成了哪幾個主題聚類,每個聚類的內聚程度如何。
04
圖譜洞察,這個功能最有意思
這是原版完全沒有的,但我覺得是整個項目最有價值的部分。
系統會自動分析圖譜結構,給你兩種洞察。
一種是意外關聯。
跨社區的、跨類型的、意料之外的連接。比如你分別錄入了兩批看起來毫不相干的資料,圖譜裏突然出現了一條連接它們的邊。
這種發現往往是認知突破的起點。
另一種是知識缺口。
它會找出幾乎沒有連接的孤立頁面、內部交叉引用太少的稀疏社區、同時連接三個以上集羣的橋接節點。
每個缺口旁邊都有個深度研究按鈕,點一下就能讓 LLM 自動去網上搜資料補全。
從發現缺口到補齊缺口,基本全程自動。
05
深度研究,知識庫會自己補全自己
當系統發現知識缺口後,LLM 會自動生成搜索關鍵詞,調用 Tavily API 去網上搜索。
搜到的結果 LLM 會綜合分析,寫成一篇研究頁面,直接寫進 Wiki。
研究頁面還會自動觸發錄入流程,提取出新的實體和概念,整合到已有的知識網絡裏。
相當於你的知識庫會自己去發現缺口,然後自己上網查資料補全。
觸發深度研究的時候,LLM 會先讀 overview.md 和 purpose.md 來理解你的知識庫是關於什麼的,然後生成針對性的搜索詞。
不是泛泛的關鍵詞,而是根據你已有知識的上下文來精確定位。搜索前還會彈個確認框,你可以修改搜索主題和搜索詞,覺得沒問題再開始。
06
Chrome 網頁剪藏
這個項目做了一個專門的 Chrome 擴展,用起來挺方便的。
在瀏覽器裏看到什麼好文章,點一下圖標就搞定。
Readability.js 自動去掉廣告、導航欄、側邊欄這些干擾內容,只保留正文,Turndown.js 轉成乾淨的 Markdown。
剪藏的內容會自動發送到本地應用,觸發錄入流程,直接變成 Wiki 的一部分。
支持多項目選擇,如果你同時維護好幾個知識庫,剪藏的時候可以選存到哪個。
即使應用沒開着,擴展也能預覽提取的內容,等你打開應用後再自動同步。
檢索也做了不少優化
Karpathy 原版方案在中等規模下靠索引文件就夠了,但知識庫一大就不夠用了。
LLM Wiki 搞了一套多階段檢索管線。
先分詞搜索,中文做 CJK 二元組分詞。
然後可選開向量語義搜索,通過 LanceDB 做近似最近鄰檢索,即使沒有關鍵詞重疊也能找到語義相關的頁面。
再把搜索結果當種子節點,用關聯度模型做 2 跳遍歷發現更深層的關聯。
上下文窗口可以配置,從 4K 到 1M tokens 都行。60% 給 Wiki 頁面,20% 聊天曆史,5% 索引,15% 系統提示。
官方說開向量搜索後整體召回率從 58.2% 提升到了 71.4%。
07
幾個眼前一亮的細節
除了上面這些大模塊,還有幾個細節挺好的。
Purpose.md
這個項目加了 purpose.md,放目標、關鍵問題、研究範圍。
LLM 每次錄入和查詢都會參考這個文件,你的知識庫就有了一個明確的方向,不是漫無目的地堆砌。這個區分很妙。
異步審核
LLM 錄入過程中遇到拿不準的事情,會標記到審核隊列裏,不阻塞主流程。
你什麼時候有空什麼時候看,每個審核項帶着預生成的操作選項和搜索查詢。
刪一個資料文件,系統自動找它的 Wiki 摘要頁、引用了它的實體頁面、索引條目、失效連結,全部清理乾淨。
被多個資料共享的實體頁面不會被誤刪,只會從 sources 列表裏移除。
多格式支持
PDF、DOCX、PPTX、Excel、圖片、音視頻都能導入。PDF 用 Rust 解析,性能很好。
完全兼容 Obsidian。
生成的 Wiki 目錄就是標準的 Obsidian Vault,自動生成 .obsidian/ 配置。Obsidian 當查看器,LLM Wiki 當編輯器,兩個工具各司其職。
08
怎麼上手
GitHub Releases 頁面有預編譯安裝包:
連結:https://github.com/nashsu/llm_wiki/releases/tag/v0.3.13裝好之後的流程:
Chrome 擴展的安裝也很簡單。
打開 chrome://extensions,開啓開發者模式,加載已解壓的擴展程序,選擇項目裏的 extension/ 目錄就行。
上次寫那篇文章的時候,Karpathy 的理念還停留在抽象的方法論層面。
當時雖然已經有人在 GitHub 上做實現了,但大多是命令行工具或者 Claude Code 的 Skill,用起來還是有一定門檻。
這個項目直接做成了一個桌面應用,降低了使用門檻。普通用戶也能上手,不需要折騰命令行和 Agent 配置。
而且它不是簡單地照搬原版 Gist 的思路,在知識圖譜、深度研究、網頁剪藏、向量搜索這些方面都有實質性的擴展。
迭代速很快。
這也印證了 Karpathy 自己說的:在 Agent 時代,你分享思路,別人讓各自的 Agent 去定製化搭建就行了。
知識的複利增長,這個項目讓 Karpathy 的構想變成了現實。
09
點擊下方卡片,關注逛逛 GitHub
這個公眾號歷史發佈過很多有趣的開源項目,如果你懶得翻文章一個個找,你直接關注微信公眾號:逛逛 GitHub ,後台對話聊天就行了: