Karpathy 的 LLM Wiki 搭建實戰:三層架構 + 三大操作,Obsidian + AGENTS.md 讓知識庫自我維護
整理版優先睇
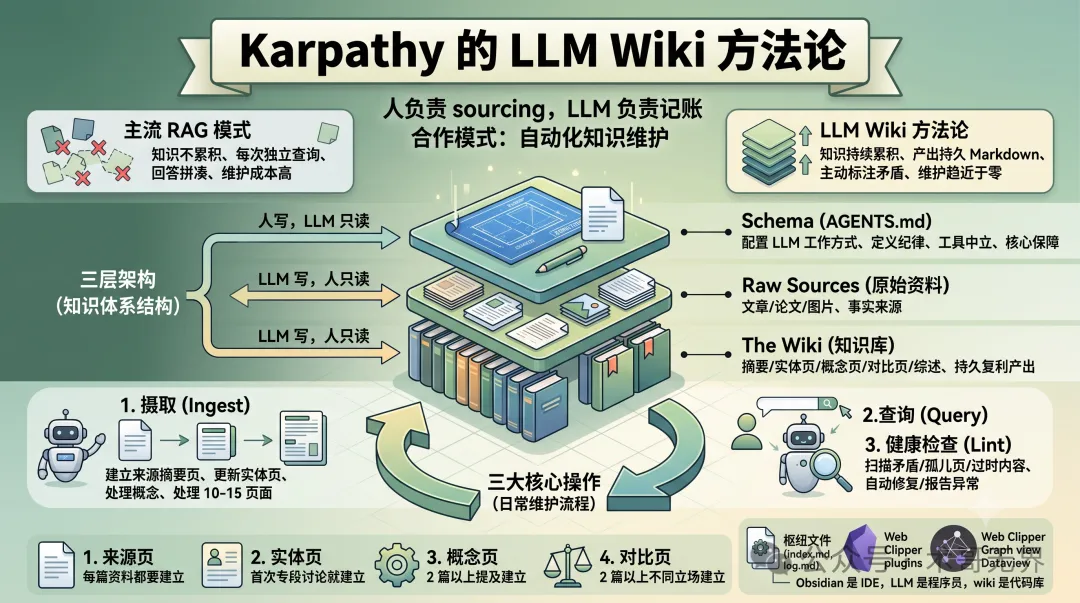
Andrej Karpathy 嘅 LLM Wiki 方法論:人做 sourcing,LLM 做記賬,用 Obsidian 實現知識複利累積
呢篇文章係術哥根據 Andrej Karpathy 嘅 LLM Wiki Gist 整理嘅實戰教程。Karpathy 係 AI 界知名人物,佢提出一個全新嘅知識管理模式:與其用 RAG 每次從零檢索,不如建立一個由 LLM 持續維護嘅 Wiki 知識庫,令知識可以隨時間累積同增長。
術哥親身用 Obsidian 將呢套方法落地,佢嘅角度係一個技術實踐者,分享點樣透過三層架構(Schema、Raw sources、Wiki)同三大操作(Ingest、Query、Lint)嚟運作。核心結論係:人只需要負責揾料同提問,LLM 負責所有記賬嘅工作,例如摘要、交叉引用、更新索引等等。呢個分工令維護成本趨近於零,真正實現知識複利。
- LLM Wiki 嘅核心係人做 sourcing、LLM 做記賬,解決 RAG 知識唔累積嘅問題。
- 三層架構:Schema(AGENTS.md)定義規則、Raw sources 只讀、Wiki 由 LLM 全權維護,讀寫權限隔離係關鍵。
- 相比 RAG 每次從零檢索,LLM Wiki 喺攝取時會觸及 10-15 個頁面,主動標註矛盾,實現複利。
- 三大操作中,Query 嘅亮點係將好嘅回答沉澱成新 wiki 頁面,令知識持續增長。
- 快速起步:開一個 Obsidian vault,將 Karpathy 嘅 Gist 交畀 LLM Agent,佢會自動生成 AGENTS.md 同完整目錄結構。
Karpathy 嘅 LLM Wiki Gist
Andrej Karpathy 提出嘅 LLM Wiki 方法論原始 Gist,包含三層架構、三大操作等核心概念。
內容結構
my-wiki/ ← Obsidian 直接打開這個文件夾├── .obsidian/ ← vault 配置├──
AGENTS.md ← Schema 配置(LLM 的行為說明書)├──
README.md ← 項目說明(給人看)│├── raw/ ← 原始資料層(只讀)│ └── 素材/│ ├── 文章/ ← URL 抓取 / Web Clipper / 手動存入│ │ └── 2026/06/ ← 按年月組織│ ├── 圖片/ ← 單獨下載的參考圖片│ └── 附件/ ← 拖拽進來的任意附件│└── wiki/ ← 知識庫層(LLM 全權維護) ├── index.md ← 內容索引(每次操作後更新) ├── log.md ← 操作日誌(僅追加) ├── 來源/ ← 來源摘要頁 ├── 實體/ ← 實體頁:人/公司/產品/工具 ├── 概念/ ← 概念頁:原理/方法/術語 └── 對比/ ← 對比分析頁:跨來源綜合RAG 嘅問題同 LLM Wiki 嘅思路
主流 RAG 系統(如 NotebookLM、ChatGPT 文件上傳)嘅工作方式係:你上傳文件,系統切塊做向量索引,然後每次查詢都獨立檢索片段。但問題係每次查詢都係一次性事件,知識唔會累積,LLM 每次都要重新拼湊片段。
RAG 每次從零檢索,知識唔累積
Karpathy 嘅 LLM Wiki 模式唔同:加入新資料時,LLM 讀完整篇、提取關鍵信息、整合進現有 wiki、更新實體頁、修訂綜述摘要、標出新舊矛盾。一次攝取常常觸碰 10 到 15 個 wiki 頁面,形成一個「持久嘅、複利嘅產物」。
三層架構:Schema、Raw sources、Wiki
第一層係 Schema(行為配置),即係 AGENTS.md 文件,佢定義 wiki 點組織、頁面類型、工作流。呢個文件係 LLM 嘅「紀律說明書」,作者特別建議用 AGENTS.md 呢個通用命名,而唔係 CLAUDE.md,咁樣可以跨工具複用。
AGENTS.md 係跨工具嘅通用約定
第二層係 Raw sources,只有你寫入資料,LLM 只讀。第三層係 The wiki,LLM 全權維護,你只讀唔寫。目錄結構清楚分隔 raw/ 同 wiki/,讀寫權限隔離保證事實來源唔會被篡改。
- Schema:AGENTS.md,定義規則,係方法論嘅合約。
- Raw sources:原始資料,只讀,係事實來源。
- Wiki:知識庫,LLM 全權維護,你只需瀏覽、點連結、睇圖譜。
三大核心操作:Ingest、Query、Lint
操作一係 Ingest(攝取):你放新資料入 raw/,然後叫 LLM 處理。佢會讀取原始文件、創建來源摘要頁、更新相關實體同概念頁、檢查對比機會、更新 index.md 同 log.md。一次攝取觸及 10-15 個頁面好正常。
一次攝取觸及 10-15 個 wiki 頁面
操作二係 Query(查詢):你有問題時,LLM 先讀 index.md 定位頁面,再深入閲讀,必要時跳去 raw 原始文件,最後綜合回答。關鍵係如果呢次回答產生新洞察,佢會將佢寫成新頁面歸檔,追加落 log.md。呢個就係複利嘅來源。
操作三係 Lint(健康檢查):叫 LLM 掃成個庫,報告矛盾、孤兒頁、缺頁、過時信息、死鏈等問題。能自動修嘅直接修,唔能修嘅只報告由你確認。
Lint 分兩類:自動修復同人在環確認
落地實操:頁面類型、建頁規則同工具
每個 wiki 頁面都有 frontmatter,包含 type、tags、sources、created、updated 字段。四種頁面類型:來源(每篇資料都建)、實體(首次被專段討論就建)、概念(被兩篇以上來源提到先建)、對比(兩個以上來源立場不同時建)。
概念頁要等兩篇來源先建,避免過度抽象
index.md 係 wiki 首頁,用 Dataview 插件基於 frontmatter 自動生成動態表格,LLM 回答問題前會先讀呢個文件定位頁面。log.md 係只追加嘅時間線,記錄每次操作,方便 LLM 瞭解 wiki 狀態。
- 1 用 Obsidian Web Clipper 快速剪藏文章入 raw/。
- 2 將圖片下載到本地,避免依賴失效 URL。
- 3 裝 Dataview 插件令 index.md 動態表格可渲染。
- 4 將 wiki 當做 git 倉庫,免費獲得版本歷史同分支。
快速起步:兩步搞掂
你唔需要手寫目錄同規則文件。只需要做兩件事:建一個空 Obsidian vault,然後將 Karpathy 嘅 Gist 連結交畀 LLM Agent,叫佢按方法論初始化整個 wiki 結構。
將 Gist 交畀 LLM,佢會自動生成 AGENTS.md 同完整目錄
最終生成嘅結構包括 raw/、wiki/、AGENTS.md、index.md、log.md。裝埋 Dataview 同 Web Clipper 插件之後,你就可以開始喂數據。對 LLM 講一句「處理一下我剛存嘅文章」,wiki 就會開始生長。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 156 篇,AI 星探「2026」系列第 19 篇
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
你可能試過咁:Upload 咗一堆 PDF 同文章去 NotebookLM 或者 ChatGPT,問完問題,關咗個窗口,乜都冇留低。下次再問,又要由頭餵資料。
你睇過嘅嘢,AI 幫你總結過嘅嘢,全部蒸發曬。
問題嘅根源得一個:呢啲工具唔會累積。佢哋每次都由零開始重新檢索、重新拼湊、重新遺忘。
Andrej Karpathy 前段時間喺一個 gist 提出咗另一種做法——等 LLM 唔止回答你嘅問題,而係持續維護一個屬於你、會越用越厚嘅知識庫。佢將呢套模式叫做 LLM Wiki。
呢篇教程就帶你用 Obsidian 將佢實現出嚟。
成個方法嘅核心分工,Karpathy 講得好白:
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You're in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping.
一句講曬:你幾乎唔使自己寫 wiki,只負責揾資料同問問題;LLM 負責所有記賬嘅粗重嘢。
說明:本文係基於 Andrej Karpathy 嘅 LLM Wiki 方法論 gist 同筆者搭建嘅可運行 Obsidian 模板整理而成。文中目錄結構、frontmatter 字段、建頁規則都係模板實際實現,但 LLM 維護效果會因工具版本、模型能力、資料類型唔同而有差異,請以你嘅實際環境測試結果為準。如果有實操經驗或者疑問,歡迎喺評論區分享交流。
先搞清楚:點解 RAG 嘅知識唔累積
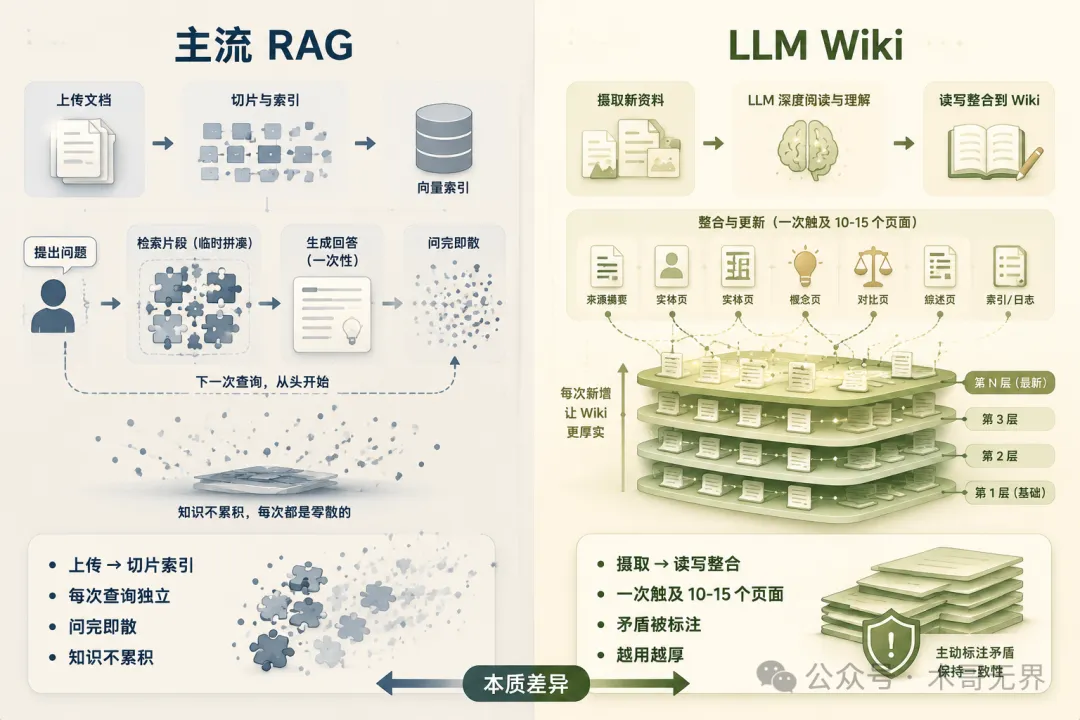
圖 1:RAG 每次由零檢索、問完即散;LLM Wiki 攝取一次整合 10-15 個頁面,知識持續累積變厚
先講清楚痛點,你先知呢個方法到底解決咗咩問題。
主流嘅 RAG 系統(NotebookLM、ChatGPT 文件上傳、大多數自建 RAG)嘅運作方式係咁:你 Upload 一批文件,系統將佢哋切做細塊、做向量索引。
你提問嘅時候,系統檢索出最相關嘅幾個片段,餵畀 LLM,LLM 基於呢啲片段生成答案。
聽落合理。但問題係:每次查詢都係獨立嘅一次性事件。你問一個需要綜合五篇文章嘅微妙問題,LLM 每次都要重新拼湊嗰啲片段。
佢冇將上一次嘅發現記低,亦冇將矛盾標註出嚟。冇任何嘢被建立起來。
Karpathy 嘅 LLM Wiki 模式唔同。加入新資料時,LLM 做嘅嘢遠超「為以後檢索做索引」——佢讀曬成篇、提取關鍵信息、整合入現有嘅 wiki、更新實體頁、修訂綜述摘要、將新舊數據嘅矛盾標出嚟。一次攝取,成日同時掂到 10 到 15 個 wiki 頁面。
結果就係一個 Karpathy 成日提嘅詞——持久嘅、複利嘅產物(persistent, compounding artifact):
交叉引用已經整好咗 矛盾已經被標註咗 綜述反映咗你讀過嘅所有內容 每加一篇資料、每問一個問題,wiki 都會變厚
兩者嘅分別,一句話概括:
點解維護成本可以趨近於零
呢度有個關鍵洞察,亦係成個方法能夠成立嘅根基。
Karpathy 原話:
The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping.
維護一個知識庫,攰嘅地方唔係讀、唔係諗。係記賬:更新交叉引用、保持摘要唔過時、標註新數據推翻咗邊個舊聲明、跨幾十個頁面維持一致性。
呢個正係人類放棄維護 wiki 嘅原因——維護成本增長比價值增長快。
你可能花一個週末整咗個精美嘅 Obsidian 庫,一個月後再打開,已經唔記得邊個頁面講緊咩階段嘅結論。
LLM 將呢件事接過咗。佢唔會悶,唔會唔記得更新交叉引用,可以一次過掂十幾個文件仲保持一致。Wiki 之所以可以持續被維護,唔係靠人變勤力,而係記賬嘅工作被外部化畀 LLM,對用戶嚟講趨近於零。
Karpathy 仲將呢個想法關聯到 Vannevar Bush 1945 年嘅 Memex 設想——一個私人嘅、主動策劃嘅知識存儲,文件之間有聯想式嘅連接。Bush 諗到咗呢個願景,但留低一個未解決嘅問題:邊個嚟做維護? LLM 將呢一步補返。
明咗呢個核心邏輯,接下來就係點樣落地。
三層架構:Schema、原始資料、Wiki
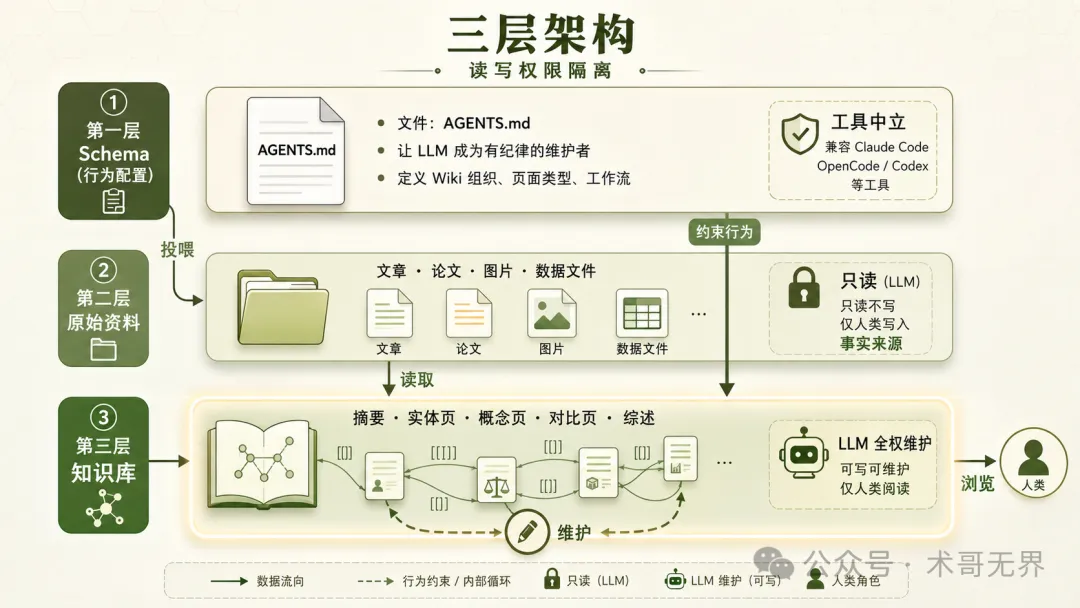
圖 2:三層架構與讀寫權限隔離——Schema 配置行為、Raw 原始資料只讀、Wiki 知識庫由 LLM 全權維護
Karpathy 定義咗三層結構,呢個亦係成個系統嘅骨架。
第一層:Schema(行為配置)
呢個係話畀 LLM「應該點樣做嘢」嘅配置文件。佢定義 wiki 點樣組織、頁面類型有啲咩、工作流程係點。佢係令 LLM 成為「有紀律嘅維護者」而唔係「通用聊天機械人」嘅關鍵。
呢一層有個命名問題一定要講清楚。
Karpathy 原文用嘅係 CLAUDE.md,佢明確寫咗「a document e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex」。即係話,呢個命名係面向特定工具 Claude Code。
但呢度有個問題:餵畀 LLM 嘅工具唔止 Claude Code 一個。OpenCode、Codex、Cursor,任何能夠讀寫文件嘅 LLM Agent 都可以用呢套模式。
如果你將配置文件命名做 CLAUDE.md,換一個工具就未必可以被識別,Schema 都冇辦法跨工具重用。
所以本文嘅建議係:統一用 AGENTS.md 呢個通用名。原因好簡單:
AGENTS.md係跨工具嘅通用約定,Claude Code、OpenCode、Codex 都可以識別你唔會因為換咗個 LLM 工具就要重新命名配置文件 Schema 作為「呢套方法論嘅合約」,唔應該綁死某個特定產品
呢個分別睇落係小事,但如果你打算長期用呢套方法,工具中立可以慳返好多麻煩。
第二層:Raw sources(原始資料)
原始資料層。文章、論文、圖片、數據文件。只有你自己可以寫入嘢,LLM 讀取時當做唯讀。 呢個係事實來源(source of truth)。
第三層:The wiki(知識庫)
LLM 全權維護嘅部分。摘要、實體頁、概念頁、對比頁、綜述。你唯讀,唔寫。 你要做嘅就係瀏覽佢、㩒連結、睇圖譜。
一個完整嘅目錄結構係咁:
my-wiki/ ← Obsidian 直接打開這個文件夾
├── .obsidian/ ← vault 配置
├── AGENTS.md ← Schema 配置(LLM 的行為說明書)
├── README.md ← 項目說明(給人看)
│
├── raw/ ← 原始資料層(只讀)
│ └── 素材/
│ ├── 文章/ ← URL 抓取 / Web Clipper / 手動存入
│ │ └── 2026/06/ ← 按年月組織
│ ├── 圖片/ ← 單獨下載的參考圖片
│ └── 附件/ ← 拖拽進來的任意附件
│
└── wiki/ ← 知識庫層(LLM 全權維護)
├── index.md ← 內容索引(每次操作後更新)
├── log.md ← 操作日誌(僅追加)
├── 來源/ ← 來源摘要頁
├── 實體/ ← 實體頁:人/公司/產品/工具
├── 概念/ ← 概念頁:原理/方法/術語
└── 對比/ ← 對比分析頁:跨來源綜合
呢個結構嘅核心設計思路係讀寫權限隔離。raw 層只有你可以寫,確保事實來源唔會被 LLM 篡改;wiki 層只有 LLM 寫,確保你唔會手動整壞 LLM 維護嘅一致性。各司其職。
三個核心操作:Ingest、Query、Lint
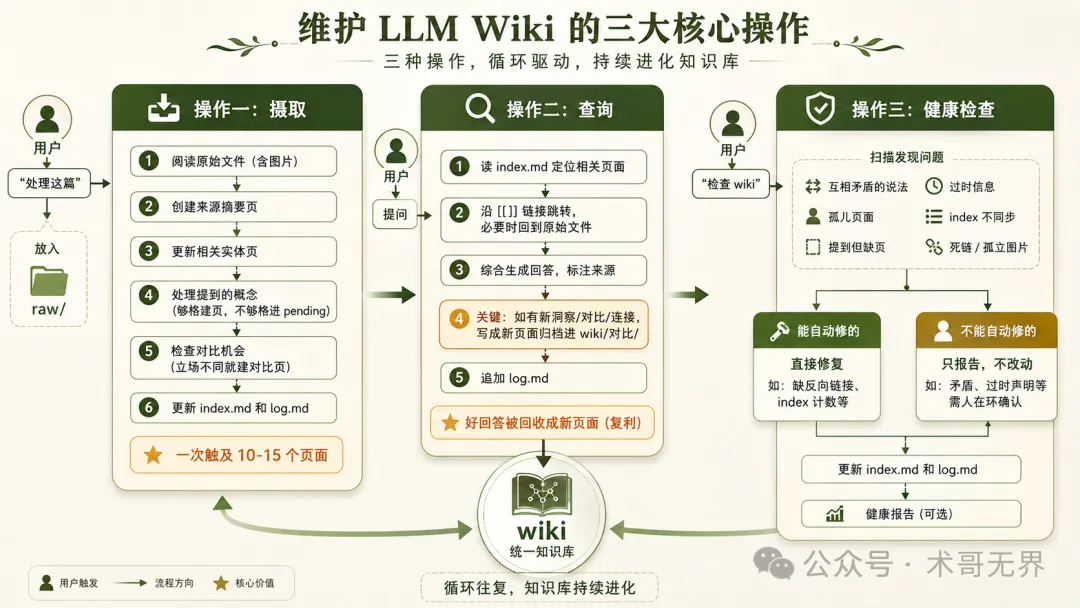
圖 3:三大核心操作——攝取每次觸及 10-15 個頁面,查詢會將好答案沉澱做新頁面(複利來源),健康檢查區分自動修復同人在環
架構整好咗,接下來係你日常會重複做嘅三件事。
操作一:Ingest(攝取)
你將新資料放入 raw/,然後對 LLM 講一句「處理呢篇」。之後全部係 LLM 嘅事:
閲讀原始文件(包括圖片) 創建一篇 wiki/來源/{標題}.md摘要頁更新相關嘅實體頁 處理提到嘅概念(夠資格就建頁,唔夠資格就入 pending) 檢查有冇對比機會(新資料同已有來源立場唔同就建對比頁) 更新 index.md 同 log.md
Karpathy 嘅實操偏好係一次攝取一篇,保持參與。唔好一次過掉十篇畀佢批量處理——你會失去對內容走向嘅掌控。
讀一讀佢生成嘅摘要,檢查佢更新咗邊啲頁面,引導佢應該強調啲咩。一次攝取觸及 10 到 15 個 wiki 頁面係正常嘅,呢個表示資料被充分消化,唔係孤立咁躺喺度。
操作二:Query(查詢)
你有問題想問嘅時候,LLM 嘅工作流程係:
先讀 index.md 定位相關頁面 深入閲讀相關頁面,沿着 [[]]連結跳轉,必要時回到 raw 原始文件綜合生成答案,標註來源頁面 關鍵一步:如果今次答案產生咗新嘅綜合洞察、對比分析或者意外連接,將佢寫成一篇新頁面歸檔入 wiki/對比/追加 log.md
第 4 步係成個 Query 操作嘅亮點,亦係 LLM Wiki 有別於普通問答嘅地方。Karpathy 原話:
Good answers can be filed back into the wiki as new pages. A comparison you asked for, an analysis, a connection you discovered — these are valuable and shouldn't disappear into chat history.
普通問答入面,你問出一個好問題、得到一個精彩答案,關咗窗口就冇咗,下一次仲要重新問。
而喺 LLM Wiki 裏面,好嘅答案會被回收做 wiki 嘅新頁面,成為下次提問嘅起點——「複利」就係咁樣嚟。
操作三:Lint(健康檢查)
你同 LLM 講「檢查 wiki」或者「lint」,佢會掃一次成個庫,報告呢啲問題:
互相矛盾嘅講法:唔同頁面對同一件事描述唔一致 孤兒頁面:冇任何反向連結嘅頁面 提到但缺頁:有 [[]]有連結但目標頁唔存在過時信息:被新資料推翻但仲未更新嘅內容 index.md 同實際文件唔同步 值得新建嘅對比頁:多個來源討論同一主題但角度唔同 死鏈:來源頁嘅 URL 已經失效 孤立圖片:raw 裏面嘅圖片冇被任何 wiki 頁引用
Lint 分兩類處理。能夠自動修嘅(缺反向連結、index 計數對唔上),LLM 直接修。
唔能夠自動修嘅(矛盾、過時聲明),只報告,唔擅自改——因為呢類判斷需要你喺環裏面確認。
落地實操:四種頁面同建頁規則
架構同操作清楚咗,接下來要睇 wiki 裏面到底放咩頁面、幾時建。
Frontmatter:每個頁面都有嘅元信息
所有 wiki 頁面頂部都有 frontmatter,係咁:
---
type:來源 # 頁面類型:來源 | 實體 | 概念 | 對比
tags:[AI,知識管理]# 標籤
sources:[] # 關聯的來源頁(實體/概念/對比頁必填,來源頁不填)
created:2026-07-02# 創建日期
updated:2026-07-02# 更新日期
---
幾個字段說明:
type標明頁面類型,Dataview 插件靠佢做動態表格sources係 wiki-link 列表,標註呢個頁面嘅依據係嚟自邊啲原始資料。來源頁自己唔需要呢個字段,其他三類必填created和updated係日期戳,方便 Lint 判斷信息新鮮度
四種頁面類型
| 來源 | 來源/ | ||
| 實體 | 實體/ | ||
| 概念 | 概念/ | ||
| 對比 | 對比/ |
呢套建頁規則背後有個由下而上嘅原則:唔好急住抽象。
實體頁(例如 Karpathy、Obsidian、Claude Code 呢啲)單篇資料就能夠刻畫清楚,首次出現專段討論就可以建。跨來源嘅認知演進,透過實體頁裏面嘅「認知演進」段落追加記錄。孤兒頁交畀 Lint 清理。
概念頁(例如「向量檢索」「上下文窗口」)比較抽象,容易過度概括產生低質素頁面。
所以規則係第一次出現先唔建,記入 index.md 嘅 pending 列表,等第二篇來源都提到佢,確定呢個概念確實成日出現,先至正式建頁。
對比頁有兩種來源:一係你攝取資料時 LLM 發現唔同來源立場對立,主動建;二係你 Query 時 LLM 產出咗有價值嘅橫向分析,歸檔做新頁。
交叉引用點樣寫
Obsidian 兼容嘅寫法,留意唔好包反引號:
- 引用實體頁:[[實體/Karpathy]]
- 引用概念頁:[[概念/LLM Wiki]]
- 引用原始資料:[[raw/素材/文章/2026/06/xxx.md]]
- 引用圖片:![[raw/素材/圖片/xxx.png]]
有個重要取捨:圖片唔複製到 wiki,直接引用 raw 裏面嘅路徑。咁樣原始資料同 wiki 各司其職,避免同一張圖存兩份導致唔同步。
index.md 同 log.md:兩個樞紐文件
index.md:內容導向
index.md 係 wiki 嘅首頁,亦係 LLM 回答任何問題前嘅第一個動作——讀佢嚟定位相關頁面。
Karpathy 喺原文提到,喺中等規模(大約 100 篇來源、幾百個頁面)下,一個 index 文件已經夠用,唔需要引入 embedding-based 嘅 RAG 基礎設施。
Karpathy 給出嘅做法係用 Dataview 插件生成動態表格,基於 frontmatter 嘅 type、tags、created 字段自動彙總。咁樣表格永遠跟住實際文件走,唔會出現手寫表格同文件對唔上嘅情況。
log.md:時間導向
log.md 係一個只追加嘅時間線,記錄每次操作。固定格式:
## [2026-07-02] ingest | 攝取了 Karpathy 的 LLM Wiki gist
## [2026-07-02] query | 對比了 RAG 和 LLM Wiki 的累積機制
## [2026-07-03] lint | 發現 3 個孤兒頁面,已清理 2 個
想睇最近做咗啲咩,一行命令:
grep "^## \[" log.md | tail -10
log.md 嘅作用係畀 LLM 一個「最近發生咗咩事」嘅時間線,幫佢理解當前 wiki 嘅狀態。
Obsidian 喺呢套模式裏面扮演咩角色
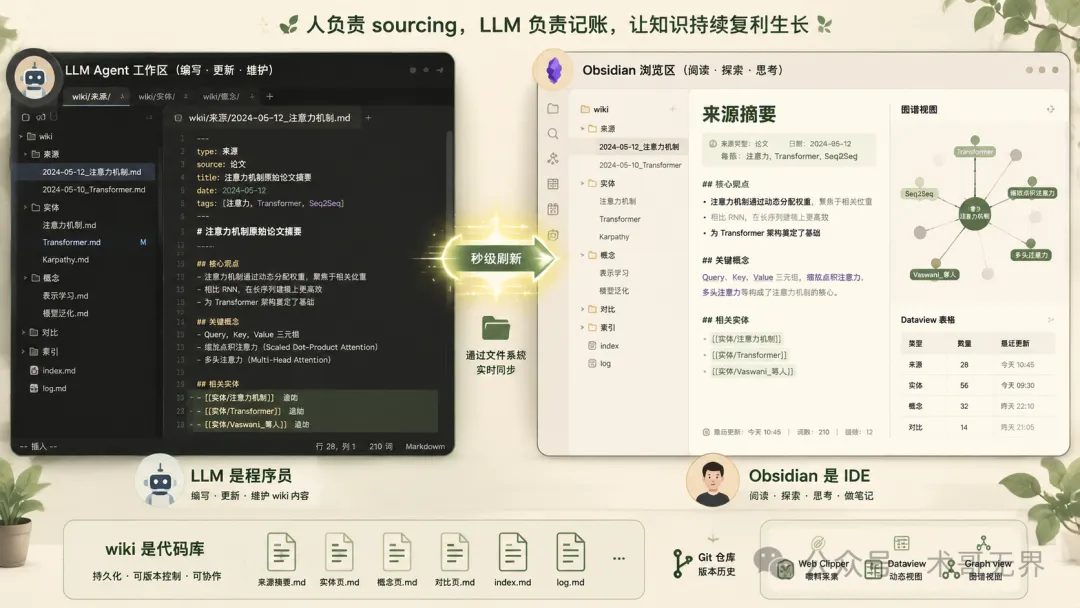
圖 4:Obsidian 係 IDE、LLM 係程序員、wiki 係代碼庫——LLM 喺一邊編輯,Obsidian 實時刷新頁面同圖譜
Karpathy 有一句概括整個協作畫面嘅金句:
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.
實操畫面係:LLM agent 開喺一邊,Obsidian 開喺另一邊。LLM 基於對話做編輯,你喺 Obsidian 裏面實時睇結果——㩒連結、睇圖譜、讀更新咗嘅頁面。LLM 改文件,Obsidian 秒級刷新。
Obsidian 喺呢套模式裏面主要用上呢幾個功能:
Web Clipper(瀏覽器擴展):將網頁文章一鍵轉成 markdown 存入 raw/,係快速喂數據嘅利器。
圖片下載到本地:喺 Settings → Files and links 將 Attachment folder path 設成固定目錄(例如 raw/assets/),然後喺 Hotkeys 搜「Download」,揾到「Download attachments for current file」,綁個快捷鍵。
剪藏文章後㩒一下,所有圖片自動下載到本地。點解重要:等 LLM 直接睇本地圖片,而唔係依賴會失效嘅 URL。
Graph view(圖譜視圖):睇 wiki 形態最直接嘅方法。咩連去咩、邊啲頁面係 hub、邊啲係孤兒,一目瞭然。
Dataview 插件:基於 frontmatter 執行查詢,自動生成動態表格同列表。LLM 加 YAML frontmatter,Dataview 負責展示。
仲有一點值得強調:wiki 就係一個 git 倉庫。你免費得到版本歷史、分支、協作能力。Karpathy 原文:
The wiki is just a git repo of markdown files. You get version history, branching, and collaboration for free.
刻意唔做嘅嘢:幾個設計取捨
呢套方法有幾個明確嘅「唔做」,理解佢哋比理解「做啲咩」更能睇清設計思路:
唔複製圖片到 wiki:直接引用 raw 裏面嘅路徑,避免雙份儲存 唔複製原文到 wiki:原始文件喺 raw,wiki 只存提煉後嘅知識 唔引入向量搜索:量級喺 100 篇以內,index.md 加 Dataview 完全夠用 唔建 tags 目錄:用 frontmatter 嘅 tags 字段加 index.md 分類就夠
呢啲取捨背後係同一個判斷:中等規模下,簡單結構比複雜基礎設施更扛得住。等你真係儲到幾百篇來源、覺得 index 唔夠用,先至引入正經嘅搜索工具(例如 Karpathy 提到嘅 qmd,一個本地 markdown 搜索引擎)都未遲。
呢套方法適合咩場景
Karpathy 喺原文列舉咗幾個典型場景:
個人:跟蹤目標、健康、自我提升,歸檔日誌、文章、播客筆記 研究:用幾星期或幾個月深入一個主題,讀論文同報告,增量搭建一個帶演進觀點嘅綜述 wiki 讀書:每讀完一章攝取一次,為人物、主題、情節線索建頁,睇佢哋點樣連接。讀完成本書,就有一個豐富嘅伴生 wiki 團隊:LLM 維護嘅內部 wiki,餵 Slack 討論、會議記錄、項目文檔,可能需要有人喺環審核更新
講到底,任何「隨時間累積知識、希望有組織而唔係散亂」嘅場景,都啱用。
動手搭一個:將 Gist 掉畀 LLM
講到呢度,原理夠曬,應該動手啦。
回想嚇前面講嘅核心理念——人做 sourcing,LLM 做記賬咁搭 wiki 呢件「記賬工作」本身,理所當然都應該交畀 LLM。你唔需要手寫目錄、手寫規則文件、手打 frontmatter 模板。你只需要做兩件事:開一個空 vault,然後將 Karpathy 嘅 Gist 掉畀你嘅 LLM Agent。
準備清單好短:
Obsidian:免費下載,官網 https://obsidian.md 一個 LLM Agent 工具:Claude Code、OpenCode、Codex、Cursor,任何能讀寫文件嘅都得 Karpathy 嘅 Gist 連結:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
兩步搞掂。
第一步:新建一個 Obsidian Vault
打開 Obsidian,㩒「Create new vault」,揀一個空文件夾,改名做你嘅項目名(例如 my-wiki)。呢一步只係開一個空盒。
第二步:將 Karpathy 嘅 Gist 餵畀你嘅 LLM Agent
打開終端,cd 去你啱啱建嘅 vault:
cd /你的路徑/my-wiki
claude # 或 opencode、codex,看你用哪個工具
然後將 Karpathy 嘅 Gist 連結掉畀佢,配一句指令:
讀一下呢篇 Gist:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 按佢定義嘅 LLM Wiki 方法論,幫我初始化整個 wiki 嘅結構。 規則文件用
AGENTS.md命名(唔好用CLAUDE.md,我希望佢跨工具通用)。
LLM 會幫你做曬全部粗重嘢:
✅ 讀明 Gist 裏面嘅三層架構、三大操作、建頁規則 ✅ 創建完整嘅目錄結構( raw/、wiki/來源/、wiki/實體/、wiki/概念/、wiki/對比/)✅ 生成 AGENTS.md(規則文件,話畀佢自己以後點樣做嘢)✅ 生成 index.md(索引骨架,整好 Dataview 查詢模板)同log.md(空日誌)
最終生成嘅結構係咁(目錄命名你可以叫 LLM 按你嘅偏好調整):
my-wiki/
├── raw/ ← 原始資料層(你喂數據的地方)
│ ├── articles/ ← 抓取的文章
│ ├── images/ ← 圖片
│ └── attachments/ ← 其他附件
│
├── wiki/ ← 知識庫層(LLM 全權維護)
│ ├── sources/ ← 來源摘要頁
│ ├── entities/ ← 實體頁
│ ├── concepts/ ← 概念頁
│ ├── comparisons/ ← 對比頁
│ ├── index.md ← 索引(Dataview 動態生成)
│ └── log.md ← 操作日誌
│
└── AGENTS.md ← 規則文件(最關鍵)
其中 AGENTS.md 係成個系統嘅鎖匙——佢就係 Karpathy 講嘅 Schema,定義咗所有規則:點樣讀原始素材、幾時建實體頁、幾時建概念頁、交叉引用點樣寫、命名約定係咩、index 同 log 點樣更新。
呢個文件你唔需要自己寫,LLM 已經幫你寫好咗。佢後面會嚴格遵守裏面嘅規則。
第三步(可選):裝兩個 Obsidian 插件
Dataview(社區插件):等 index.md 裏面嘅動態表格可以渲染出嚟。喺設置關閉安全模式後從社區插件市場安裝 Web Clipper(Obsidian 官方出嘅瀏覽器擴展):用嚟快速剪藏網頁文章入 raw/
裝完之後,成個環境準備好。你嘅工作到此為止,剩低嘅都係 LLM 嘅事。
開始喂數據
揾一篇你最近讀過嘅文章,用 Web Clipper 剪入 raw/articles/,然後對你嘅 LLM Agent 講:
處理一下 raw/articles/ 裏面我啱啱存嗰篇文章。
由呢一刻開始,你嘅 wiki 就開始生長。佢會建來源摘要頁、提取實體、標出值得追蹤嘅概念、更新 index 同 log——一次攝取掂十幾個頁面,全部係佢自己做。
寫喺最後
返返去嗰個核心分工:人做 sourcing,LLM 做記賬。
Vannevar Bush 喺 1945 年就諗到個人知識庫嘅願景,但佢解決唔到嘅問題係「邊個嚟維護」。
Karpathy 將呢件事睇通咗——維護知識庫攰嘅地方唔係讀、唔係諗,係記賬。而記賬呢件事,啱啱係 LLM 擅長又唔會厭倦嘅工作。
呢套方法唔係話你要從此告別 RAG。RAG 喺「快速查詢一批陌生文檔」時依然好用。
但如果你面對嘅係一個會隨時間累積、需要持續整合同交叉引用嘅知識領域,LLM Wiki 係一個更啱嘅模式。
Karpathy 喺 gist 尾留低咗一句元說明,我覺得好啱做呢篇教程嘅結尾:
This document is intentionally abstract. It describes the idea, not a specific implementation.
方法論係抽象嘅,只傳達模式。具體嘅目錄結構、Schema 內容、頁面格式、用邊個 LLM 工具——都由你嘅領域同偏好決定。將呢份方法論交畀你嘅 LLM agent,同佢一齊搭出一個適合你嘅版本。 剩低嘅,LLM 搞得掂。
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發畀有需要嘅朋友,我哋下一期再見!敬請期待!
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 156 篇,AI 星探「2026」系列第 19 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
你可能有過這樣的體驗:往 NotebookLM 或 ChatGPT 裏上傳了一堆 PDF 和文章,問完問題,關掉窗口,什麼都沒留下。下次再問,又得從頭喂資料。
你讀過的東西,AI 替你總結過的東西,全部蒸發。
問題的根源只有一個:這些工具不累積。它們每次都從零開始重新檢索、重新拼湊、重新遺忘。
Andrej Karpathy 前段時間在一個 gist 裏提出了另一種做法——讓 LLM 不只是回答你的問題,而是持續維護一個屬於你的、會越長越厚的知識庫。他把這套模式叫做 LLM Wiki。
這篇教程就帶你用 Obsidian 把它落地。
整套方法的核心分工,Karpathy 說得很直白:
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You're in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping.
一句話:你幾乎不用自己寫 wiki,只負責找資料和提問;LLM 負責所有記賬的髒活累活。
說明:本文基於 Andrej Karpathy 的 LLM Wiki 方法論 gist 和筆者搭建的可運行 Obsidian 模板整理而成。文中目錄結構、frontmatter 字段、建頁規則均為模板實際實現,但 LLM 維護效果會因工具版本、模型能力、資料類型不同而有差異,請以你的實際環境測試結果為準。如果有實操經驗或疑問,歡迎在評論區分享交流。
先搞清楚:為什麼 RAG 的知識不累積
圖 1:RAG 每次從零檢索、問完即散;LLM Wiki 攝取一次整合 10-15 個頁面,知識持續累積變厚
先把痛點說透,你才知道這個方法到底解決了什麼。
主流的 RAG 系統(NotebookLM、ChatGPT 文件上傳、大多數自建 RAG)的工作方式是這樣的:你上傳一批文件,系統把它們切塊、做向量索引。
你提問的時候,系統檢索出最相關的幾個片段,餵給 LLM,LLM 基於這些片段生成回答。
聽起來合理。但問題在於:每次查詢都是獨立的一次性事件。你問一個需要綜合五篇文章的微妙問題,LLM 每次都要重新拼湊那些片段。
它沒有把上一次的發現記下來,也沒有把矛盾標註出來。沒有任何東西被建立起來。
Karpathy 的 LLM Wiki 模式不一樣。加入新資料時,LLM 做的事情遠不止「為以後檢索做索引」——它讀完整篇、提取關鍵信息、整合進現有的 wiki、更新實體頁、修訂綜述摘要、把新舊數據的矛盾標出來。一次攝取,常常同時觸碰 10 到 15 個 wiki 頁面。
結果就是一個 Karpathy 反覆強調的詞——持久的、複利的產物(persistent, compounding artifact):
交叉引用已經建好了 矛盾已經被標註了 綜述反映了你讀過的所有內容 每加一篇資料、每問一個問題,wiki 都在變厚
兩者的區別,一句話概括:
為什麼維護成本能趨近於零
這裏有個關鍵洞察,也是整套方法能成立的根基。
Karpathy 的原話:
The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping.
維護一個知識庫,累人的地方不是讀、不是想。是記賬:更新交叉引用、保持摘要不過時、標註新數據推翻了哪個舊聲明、跨幾十個頁面維持一致性。
這正是人類放棄維護 wiki 的原因——維護成本增長比價值增長快。
你可能花一個週末搭了個精美的 Obsidian 庫,一個月後再打開,已經記不清哪個頁面說的是什麼階段的結論了。
LLM 把這件事接過去了。它不會無聊,不會忘記更新交叉引用,可以一次性碰觸十幾個文件還保持一致。wiki 之所以能持續被維護,靠的不是人變勤快,而是記賬的活兒被外部化給了 LLM,對用戶來說趨近於零。
Karpathy 還把這個想法關聯到了 Vannevar Bush 1945 年的 Memex 設想——一個私人的、主動策劃的知識存儲,文檔之間有聯想式的連接。Bush 想到了這個願景,但留下一個沒解決的問題:誰來做維護? LLM 把這一步補上了。
理解了這個核心邏輯,接下來就是怎麼落地。
三層架構:Schema、原始資料、Wiki
圖 2:三層架構與讀寫權限隔離——Schema 配置行為、Raw 原始資料只讀、Wiki 知識庫由 LLM 全權維護
Karpathy 定義了三層結構,這也是整個系統的骨架。
第一層:Schema(行為配置)
這是告訴 LLM「該怎麼幹活」的配置文件。它定義 wiki 如何組織、頁面類型有哪些、工作流是什麼。它是讓 LLM 成為「有紀律的維護者」而非「通用聊天機器人」的關鍵。
這一層有個命名問題必須說清楚。
Karpathy 原文用的是 CLAUDE.md,他明確寫了「a document e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex」。也就是說,這個命名是面向特定工具 Claude Code 的。
但這裏有個問題:餵給 LLM 的工具不止 Claude Code 一個。OpenCode、Codex、Cursor,任何能讀寫文件的 LLM Agent 都能用這套模式。
如果你把配置文件命名為 CLAUDE.md,換一個工具就未必能被識別,Schema 也沒法跨工具複用。
所以本文的建議是:統一用 AGENTS.md 這個通用命名。原因很簡單:
AGENTS.md是跨工具的通用約定,Claude Code、OpenCode、Codex 都能識別你不會因為換了個 LLM 工具就得重命名配置文件 Schema 作為「這套方法論的合約」,不應該綁定某個特定產品
這個差異看起來是小事,但如果你打算長期用這套方法,工具中立能省掉很多麻煩。
第二層:Raw sources(原始資料)
原始資料層。文章、論文、圖片、數據文件。只有你自己可以往裏寫東西,LLM 讀取時視為只讀。 這是事實來源(source of truth)。
第三層:The wiki(知識庫)
LLM 全權維護的部分。摘要、實體頁、概念頁、對比頁、綜述。你只讀,不寫。 你要做的就是瀏覽它、點連結、看圖譜。
一個完整的目錄結構長這樣:
my-wiki/ ← Obsidian 直接打開這個文件夾
├── .obsidian/ ← vault 配置
├── AGENTS.md ← Schema 配置(LLM 的行為說明書)
├── README.md ← 項目說明(給人看)
│
├── raw/ ← 原始資料層(只讀)
│ └── 素材/
│ ├── 文章/ ← URL 抓取 / Web Clipper / 手動存入
│ │ └── 2026/06/ ← 按年月組織
│ ├── 圖片/ ← 單獨下載的參考圖片
│ └── 附件/ ← 拖拽進來的任意附件
│
└── wiki/ ← 知識庫層(LLM 全權維護)
├── index.md ← 內容索引(每次操作後更新)
├── log.md ← 操作日誌(僅追加)
├── 來源/ ← 來源摘要頁
├── 實體/ ← 實體頁:人/公司/產品/工具
├── 概念/ ← 概念頁:原理/方法/術語
└── 對比/ ← 對比分析頁:跨來源綜合
這個結構的核心設計思路是讀寫權限隔離。raw 層只你能寫,保證事實來源不被 LLM 篡改;wiki 層只 LLM 寫,保證你不會手動改壞 LLM 維護的一致性。各司其職。
三個核心操作:Ingest、Query、Lint
圖 3:三大核心操作——攝取每次觸及 10-15 個頁面,查詢會把好回答沉澱為新頁面(複利來源),健康檢查區分自動修復與人在環
架構搭好了,接下來是你日常會反覆做的三件事。
操作一:Ingest(攝取)
你把新資料放進 raw/,然後對 LLM 說一句「處理這篇」。接下來全是 LLM 的事:
閲讀原始文件(包括圖片) 創建一篇 wiki/來源/{標題}.md摘要頁更新相關的實體頁 處理提到的概念(夠格就建頁,不夠格進 pending) 檢查有沒有對比機會(新資料和已有來源立場不同就建對比頁) 更新 index.md 和 log.md
Karpathy 的實操偏好是一次攝取一篇,保持參與。別一口氣扔十篇讓它批量處理——你會失去對內容走向的掌控。
讀一讀它生成的摘要,檢查它更新了哪些頁面,引導它該強調什麼。一次攝取觸及 10 到 15 個 wiki 頁面是正常的,這說明資料被充分消化了,不是孤立地躺在那裏。
操作二:Query(查詢)
你有問題要問的時候,LLM 的工作流程是:
先讀 index.md 定位相關頁面 深入閲讀相關頁面,沿着 [[]]連結跳轉,必要時回到 raw 原始文件綜合生成回答,標註來源頁面 關鍵一步:如果這次回答產生了新的綜合洞察、對比分析或意外連接,把它寫成一篇新頁面歸檔進 wiki/對比/追加 log.md
第 4 步是整個 Query 操作的亮點,也是 LLM Wiki 區別於普通問答的地方。Karpathy 的原話:
Good answers can be filed back into the wiki as new pages. A comparison you asked for, an analysis, a connection you discovered — these are valuable and shouldn't disappear into chat history.
普通問答裏,你問出一個好問題、得到一個精彩回答,關掉窗口就沒了,下一次還得重新問。
而在 LLM Wiki 裏,好的回答會被回收成 wiki 的新頁面,成為下次提問的起點——「複利」就是這麼來的。
操作三:Lint(健康檢查)
你跟 LLM 說「檢查 wiki」或「lint」,它會掃一遍整個庫,報告這些問題:
互相矛盾的說法:不同頁面對同一事實描述不一致 孤兒頁面:沒有任何反向連結的頁面 提到但缺頁:有 [[]]連結但目標頁不存在過時信息:被新資料推翻但還沒更新的內容 index.md 與實際文件不同步 值得新建的對比頁:多個來源討論同一主題但角度不同 死鏈:來源頁的 URL 已經失效 孤立圖片:raw 裏的圖片沒有被任何 wiki 頁引用
Lint 分兩類處理。能自動修的(缺反向連結、index 計數對不上),LLM 直接修。
不能自動修的(矛盾、過時聲明),只報告,不擅自改——因為這類判斷需要你這個人在環裏確認。
落地實操:四種頁面和建頁規則
架構和操作清楚了,接下來要看 wiki 裏到底放什麼頁面、什麼時候建。
Frontmatter:每個頁面都有的元信息
所有 wiki 頁面頂部都有 frontmatter,長這樣:
---
type:來源 # 頁面類型:來源 | 實體 | 概念 | 對比
tags:[AI,知識管理]# 標籤
sources:[] # 關聯的來源頁(實體/概念/對比頁必填,來源頁不填)
created:2026-07-02# 創建日期
updated:2026-07-02# 更新日期
---
幾個字段說明:
type標明頁面類型,Dataview 插件靠它做動態表格sources是 wiki-link 列表,標註這個頁面的依據來自哪些原始資料。來源頁自己不需要這個字段,其他三類必填created和updated是日期戳,方便 Lint 判斷信息新鮮度
四種頁面類型
| 來源 | 來源/ | ||
| 實體 | 實體/ | ||
| 概念 | 概念/ | ||
| 對比 | 對比/ |
這套建頁規則背後有個自下而上的原則:不要急着抽象。
實體頁(比如 Karpathy、Obsidian、Claude Code 這種)單篇資料就能刻畫清楚,首次出現專段討論就可以建。跨來源的認知演進,通過實體頁裏的「認知演進」段落追加記錄。孤兒頁交給 Lint 清理。
概念頁(比如「向量檢索」「上下文窗口」)更抽象,容易過度泛化產生低質量頁面。
所以規則是第一次出現先不建,記進 index.md 的 pending 列表,等第二篇來源也提到它,確認這個概念確實反覆出現,才正式建頁。
對比頁有兩種來源:一是你攝取資料時 LLM 發現不同來源立場對立,主動建;二是你 Query 時 LLM 產出了有價值的橫向分析,歸檔成新頁。
交叉引用怎麼寫
Obsidian 兼容的寫法,注意別包反引號:
- 引用實體頁:[[實體/Karpathy]]
- 引用概念頁:[[概念/LLM Wiki]]
- 引用原始資料:[[raw/素材/文章/2026/06/xxx.md]]
- 引用圖片:![[raw/素材/圖片/xxx.png]]
有個重要取捨:圖片不復制到 wiki,直接引用 raw 裏的路徑。這樣原始資料和 wiki 各司其職,避免同一張圖存兩份導致不同步。
index.md 和 log.md:兩個樞紐文件
index.md:內容導向
index.md 是 wiki 的首頁,也是 LLM 回答任何問題前的第一個動作——讀它來定位相關頁面。
Karpathy 在原文裏提到,在中等規模(大約 100 篇來源、幾百個頁面)下,一個 index 文件已經夠用,不需要引入 embedding-based 的 RAG 基礎設施。
Karpathy 給出的做法是用 Dataview 插件生成動態表格,基於 frontmatter 的 type、tags、created 字段自動彙總。這樣表格永遠跟着實際文件走,不會出現手寫表格和文件對不上的情況。
log.md:時間導向
log.md 是一個只追加的時間線,記錄每次操作。固定格式:
## [2026-07-02] ingest | 攝取了 Karpathy 的 LLM Wiki gist
## [2026-07-02] query | 對比了 RAG 和 LLM Wiki 的累積機制
## [2026-07-03] lint | 發現 3 個孤兒頁面,已清理 2 個
想看最近做了什麼,一行命令:
grep "^## \[" log.md | tail -10
log.md 的作用是給 LLM 一個「最近發生了什麼」的時間線,幫它理解當前 wiki 的狀態。
Obsidian 在這套模式裏扮演什麼角色
圖 4:Obsidian 是 IDE、LLM 是程序員、wiki 是代碼庫——LLM 在一側編輯,Obsidian 實時刷新頁面與圖譜
Karpathy 有一句概括整個協作畫面的金句:
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.
實操畫面是:LLM agent 開在一邊,Obsidian 開在另一邊。LLM 基於對話做編輯,你在 Obsidian 裏實時看結果——點連結、看圖譜、讀更新的頁面。LLM 改文件,Obsidian 秒級刷新。
Obsidian 在這套模式裏主要用上這幾個功能:
Web Clipper(瀏覽器擴展):把網頁文章一鍵轉成 markdown 存進 raw/,是快速喂數料的利器。
圖片下載到本地:在 Settings → Files and links 裏把 Attachment folder path 設成固定目錄(比如 raw/assets/),然後在 Hotkeys 裏搜「Download」,找到「Download attachments for current file」,綁個快捷鍵。
剪藏文章後按一下,所有圖片自動下載到本地。為什麼重要:讓 LLM 直接看本地圖片,而不是依賴會失效的 URL。
Graph view(圖譜視圖):看 wiki 形態最直觀的方式。什麼連到什麼、哪些頁面是 hub、哪些是孤兒,一目瞭然。
Dataview 插件:基於 frontmatter 跑查詢,自動生成動態表格和列表。LLM 加 YAML frontmatter,Dataview 負責展示。
還有一點值得強調:wiki 就是一個 git 倉庫。你免費拿到版本歷史、分支、協作能力。Karpathy 原文:
The wiki is just a git repo of markdown files. You get version history, branching, and collaboration for free.
刻意不做的事:幾個設計取捨
這套方法有幾個明確的「不做」,理解它們比理解「做什麼」更能看清設計思路:
不復製圖片到 wiki:直接引用 raw 裏的路徑,避免雙份存儲 不復制原文到 wiki:原始文件在 raw,wiki 只存提煉後的知識 不引入向量搜索:量級在 100 篇以內,index.md 加 Dataview 完全夠用 不建 tags 目錄:用 frontmatter 的 tags 字段加 index.md 分類就夠
這些取捨背後是同一個判斷:中等規模下,簡單結構比複雜基礎設施更扛得住。等你真的攢到幾百篇來源、感覺 index 不夠用了,再引入正經的搜索工具(比如 Karpathy 提到的 qmd,一個本地 markdown 搜索引擎)也不遲。
這套方法適合什麼場景
Karpathy 在原文裏列舉了幾個典型場景:
個人:跟蹤目標、健康、自我提升,歸檔日誌、文章、播客筆記 研究:用幾周或幾個月深入一個主題,讀論文和報告,增量搭建一個帶演進觀點的綜述 wiki 讀書:每讀完一章攝取一次,給人物、主題、情節線索建頁,看它們怎麼連接。讀完整本書,就有一個豐富的伴生 wiki 團隊:LLM 維護的內部 wiki,喂 Slack 討論、會議記錄、項目文檔,可能需要有人在環審核更新
說到底,任何「隨時間累積知識、希望組織化而非散亂」的場景,都適用。
動手搭一個:把 Gist 丟給 LLM
說到這裏,原理夠了,該動手了。
回想一下前面講的核心理念——人做 sourcing,LLM 做記賬。那麼搭 wiki 這件"記賬活兒"本身,理所當然也應該交給 LLM。你不需要手寫目錄、手寫規則文件、手敲 frontmatter 模板。你只需要做兩件事:建一個空 vault,然後把 Karpathy 的 Gist 丟給你的 LLM Agent。
準備清單很短:
Obsidian:免費下載,官網 https://obsidian.md 一個 LLM Agent 工具:Claude Code、OpenCode、Codex、Cursor,任何能讀寫文件的都行 Karpathy 的 Gist 連結:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
兩步走。
第一步:新建一個 Obsidian Vault
打開 Obsidian,點「Create new vault」,選一個空文件夾,命名為你的項目名(比如 my-wiki)。這一步只是建一個空盒子。
第二步:把 Karpathy 的 Gist 餵給你的 LLM Agent
打開終端,cd 到你剛才建的 vault:
cd /你的路徑/my-wiki
claude # 或 opencode、codex,看你用哪個工具
然後把 Karpathy 的 Gist 連結丟給它,配一句指令:
讀一下這篇 Gist:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 按它定義的 LLM Wiki 方法論,幫我初始化整個 wiki 的結構。 規則文件用
AGENTS.md命名(不要用CLAUDE.md,我希望它跨工具通用)。
LLM 會替你做完全部髒活:
✅ 讀懂 Gist 裏的三層架構、三大操作、建頁規則 ✅ 創建完整的目錄結構( raw/、wiki/來源/、wiki/實體/、wiki/概念/、wiki/對比/)✅ 生成 AGENTS.md(規則文件,告訴它自己以後怎麼幹活)✅ 生成 index.md(索引骨架,配好 Dataview 查詢模板)和log.md(空日誌)
最終生成的結構長這樣(目錄命名你可以讓 LLM 按你的偏好調整):
my-wiki/
├── raw/ ← 原始資料層(你喂數據的地方)
│ ├── articles/ ← 抓取的文章
│ ├── images/ ← 圖片
│ └── attachments/ ← 其他附件
│
├── wiki/ ← 知識庫層(LLM 全權維護)
│ ├── sources/ ← 來源摘要頁
│ ├── entities/ ← 實體頁
│ ├── concepts/ ← 概念頁
│ ├── comparisons/ ← 對比頁
│ ├── index.md ← 索引(Dataview 動態生成)
│ └── log.md ← 操作日誌
│
└── AGENTS.md ← 規則文件(最關鍵)
其中 AGENTS.md 是整套系統的鑰匙——它就是 Karpathy 說的 Schema,定義了所有規則:怎麼讀原始素材、什麼時候建實體頁、什麼時候建概念頁、交叉引用怎麼寫、命名約定是什麼、index 和 log 怎麼更新。
這個文件你不需要自己寫,LLM 已經幫你寫好了。它後面會嚴格遵守裏面的規則。
第三步(可選):裝兩個 Obsidian 插件
Dataview(社區插件):讓 index.md 裏的動態表格能渲染出來。在設置裏關閉安全模式後從社區插件市場裝 Web Clipper(Obsidian 官方出的瀏覽器擴展):用來快速剪藏網頁文章進 raw/
裝完之後,整個環境就緒。你的活兒到此為止,剩下的都是 LLM 的事。
開始喂數據
找一篇你最近讀過的文章,用 Web Clipper 剪進 raw/articles/,然後對你的 LLM Agent 說:
處理一下 raw/articles/ 裏我剛存的那篇文章。
從這一刻開始,你的 wiki 就開始生長了。它會建來源摘要頁、提取實體、標出值得追蹤的概念、更新 index 和 log——一次攝取觸碰十幾個頁面,全是它自己幹。
寫在最後
回到那個核心分工:人做 sourcing,LLM 做記賬。
Vannevar Bush 在 1945 年就想到了個人知識庫的願景,但他沒法解決的問題是「誰來維護」。
Karpathy 把這件事看透了——維護知識庫累人的地方不在讀、不在想,在記賬。而記賬這件事,恰好是 LLM 擅長又不會厭倦的活兒。
這套方法不是說你要從此告別 RAG。RAG 在「快速查詢一批陌生文檔」時依然好用。
但如果你面對的是一個會隨時間累積、需要持續整合和交叉引用的知識領域,LLM Wiki 是一個更對路的模式。
Karpathy 在 gist 末尾留了一句元說明,我覺得很適合作為這篇教程的結尾:
This document is intentionally abstract. It describes the idea, not a specific implementation.
方法論是抽象的,只傳達模式。具體的目錄結構、Schema 內容、頁面格式、用哪個 LLM 工具——都由你的領域和偏好決定。把這份方法論交給你的 LLM agent,和它一起搭出一個適合你的版本。 剩下的,LLM 能搞定。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!