Karpathy的AI知識庫方法很好用,但不一定適合你
整理版優先睇
Karpathy嘅LLM wiki方法最啱學習研究,內容創作同企業場景要改或唔適用
呢篇文章係蔡蔡分享佢對Andrej Karpathy嘅LLM wiki方法嘅實戰體會。Karpathy提出一個核心思路:與其每次叫AI去原始資料揾答案,不如叫AI幫你將知識編譯成一個持續維護嘅wiki。蔡蔡跟住試咗,發現呢套方案喺學習研究場景真係神器,但喺內容創作同企業知識庫場景就唔係咁掂。
先講學習場景。Karpathy嘅方法可以直接照搬:用Obsidian加Claude Code,建立Raw、Wiki、Schema三層結構,由AI自動將外部資料整理成關聯wiki,仲可以定期查詢同整理。呢個方法嘅好處係持續積累、反覆查閲、強調關聯,維護成本低,好啱個人學習同研究。
但內容創作場景就唔同。蔡蔡指出,創作人嘅知識庫應該以自己嘅Output為核心,而唔係Input。因為AI要學嘅係「我點諗」,唔係「我睇咗啲乜」。直接照搬Karpathy方案可能會生成「看似啱但其實有偏差」嘅內容,所以要人工把關。至於企業場景,LLM wiki暫時唔適合大組織,因為規模上限、權限管理同引用精確性都有問題,反而RAG方案更成熟。總括來講,冇最好嘅工具,只有最適合你場景嘅工具。
- 核心方法:LLM wiki三層結構(Raw、Wiki、Schema),搭配Obsidian同Claude Code,自動建立關聯知識庫,從攝入到查詢到整理。
- 學習場景直接照搬:持續積累、反覆查閲、強調關聯,維護成本低,啱曬個人學習同研究。
- 內容創作場景需調整:知識庫應以Output為核心,而唔係Input,而且要人工把關AI生成內容,確保代表你嘅觀點。
- 企業場景限制:規模上限(索引可能超出上下文)、權限管理不足、引用精確性問題(幻覺寫入wiki影響後續查詢)。
- 可行動點:學習場景直接複製Karpathy方案;創作場景借鑑結構但要改;企業小團隊可用RAG-over-wiki,大組織仍要用RAG。
Karpathy LLM-wiki指南
Andrej Karpathy嘅原始Gist,講解LLM wiki嘅結構同用法。
Obsidian Web Clipper
官方配套嘅剪存工具,支援將文章、論文、YouTube影片一鍵剪存到Obsidian。
Obsidian Clipper CN (蔡蔡自製插件)
基於官方Web Clipper做嘅中文內容增強插件,解決B站等中文網站剪存問題。
學習場景:直接複製Karpathy方案
Karpathy嘅LLM wiki方法喺學習研究場景幾乎可以原樣照搬。核心係三層結構:Raw層(原始資料)、Wiki層(整理後嘅知識頁)、Schema層(規則文件)。配搭Obsidian同Claude Code,就可以由零開始建立一個持續維護嘅知識庫。
呢套方案之所以好用,係因為佢做到持續積累、反覆查閲、強調關聯。一次整理,長期受益。而且唔單止用喺論文研究,仲可以用喺書籍閲讀、個人目標追蹤等場景。
創作場景:按個人知識庫調整
如果你係內容創作者,唔可以直接照搬Karpathy方案。因為你嘅知識庫結構可能同佢唔同。蔡蔡自己就用IPO結構:Input(輸入)→ Processing(加工)→ Output(輸出)。
- 學習場景重點係將外部知識內化,wiki係終點。
- 創作場景重點係將個人思考外化,wiki只係中間站。
- AI生成嘅wiki內容可能「看似啱但同你觀點有偏差」,所以要人工把關,確保佢代表「你」嘅知識。
所以創作場景嘅做法係:借鑑LLM wiki嘅結構,但將核心資料換成自己嘅Output,並且每次生成同更新都做人工審查。
企業場景:LLM wiki暫時唔適合大組織
LLM wiki爆火後好多人話RAG已死,但蔡蔡認為小團隊可以,大組織仲未得。雖然wiki唔駛向量數據庫、唔駛做嵌入,但簡單有簡單嘅代價。
- 規模上限:wiki太龐大時,index.md會超出上下文,要用RAG方式檢索。
- 權限管理:冇RBAC方案,唔適合大型組織嘅分權控制。
- 引用精確性:LLM可能幻覺出錯誤關聯,寫入wiki後會污染後續查詢結果。
企業場景建議:小團隊或大組織嘅細部門可以用LLM wiki;大規模仍然要依靠成熟嘅RAG方案,配合向量數據庫同權限控制。
哈囉各位精神股東們,我係蔡蔡!
前排,大神 Andrej Karpathy 出咗兩條 tweet,分享佢點樣做 LLM 知識庫。
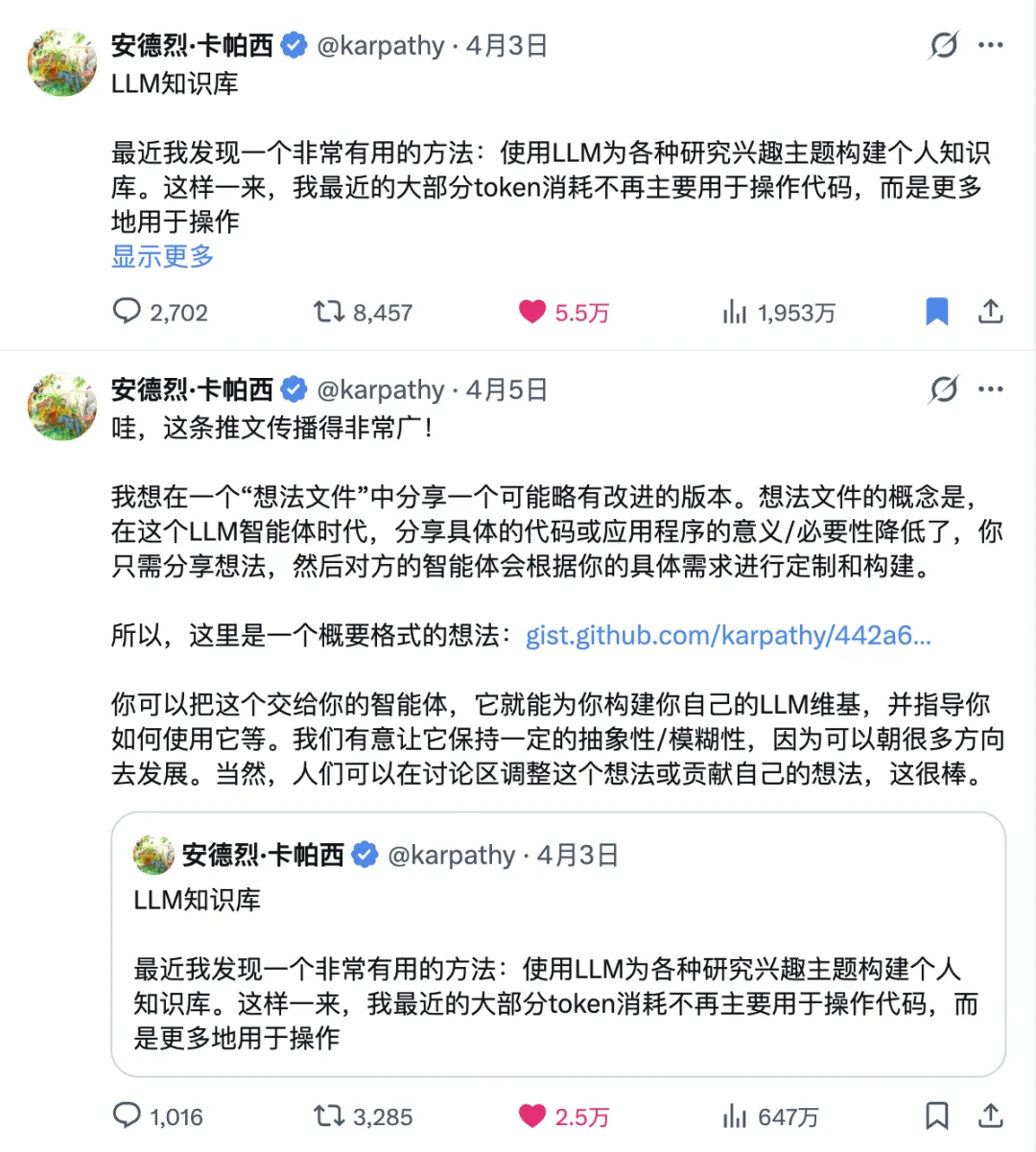
佢嘅核心思路其實好簡單:
與其每次叫 AI 去原始資料度揾答案,不如叫 AI 幫你將知識編譯成一個持續維護嘅 wiki。
呢句聽落幾啱。
但我自己試咗試,同幾個朋友傾完,發現一個問題——
LLM wiki 對學習研究場景係神器,但係喺內容創作場景同企業知識庫場景就未必。
今日就同大家傾下呢件事。
01 學習/研究場景:可以直接用
如果你係學習、研究某個領域,Karpathy 呢套方案幾乎可以原樣照搬。因為呢個就係大神自己最開始嘅應用場景。
呢套方案本身唔複雜,三層結構:Raw 層、Wiki 層,同埋 Schema 層。
乾講呢三層概念太乾,我直接由頭行個案例俾大家睇更直觀。
中間用到兩個工具:Obsidian、Claude Code。呢度假設大家都已經裝咗 Claude Code 同識用(亦可以用你哋常用嘅其他 AI 編程工具,例如 Codex、Cursor、Qoder、Trae 等)。
打開 Obsidian,撳【創建】,喺指定文件夾下創建一個新倉庫。
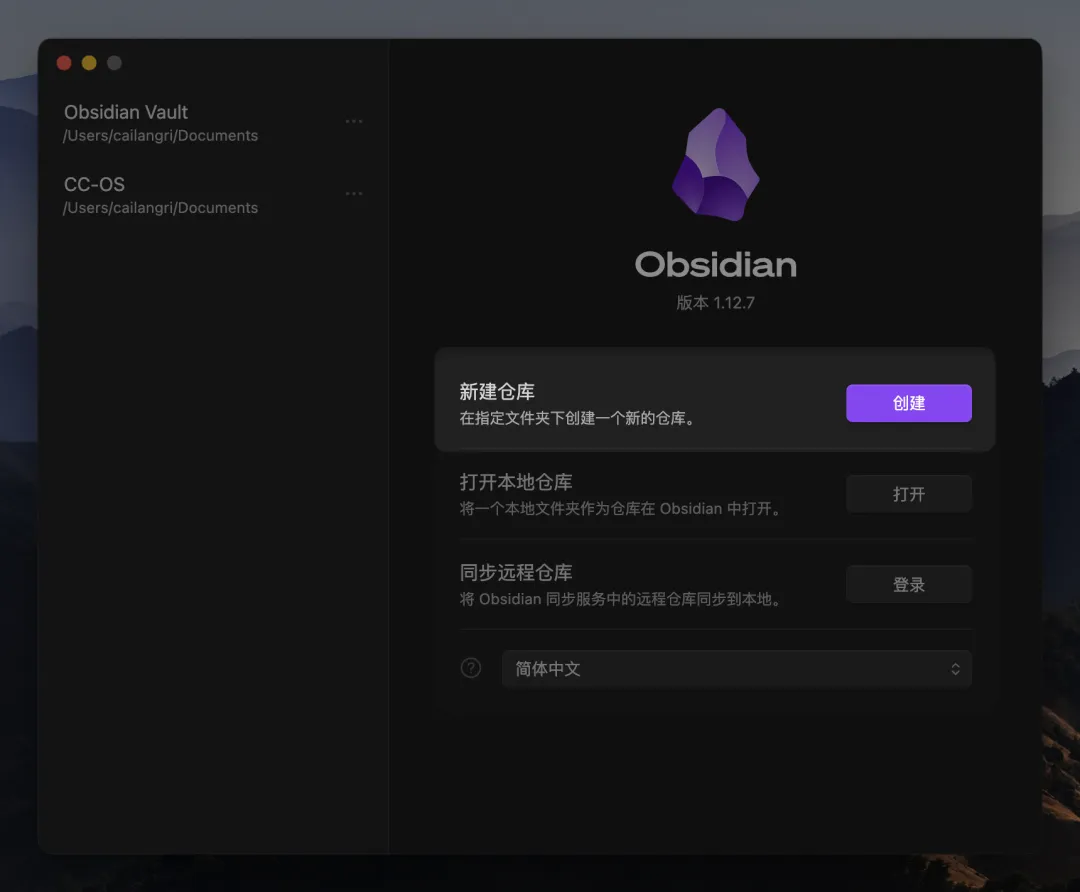
呢個就係你之後嘅知識庫大本營,雖然而家仲空盪盪。唔緊要,繼續下一步
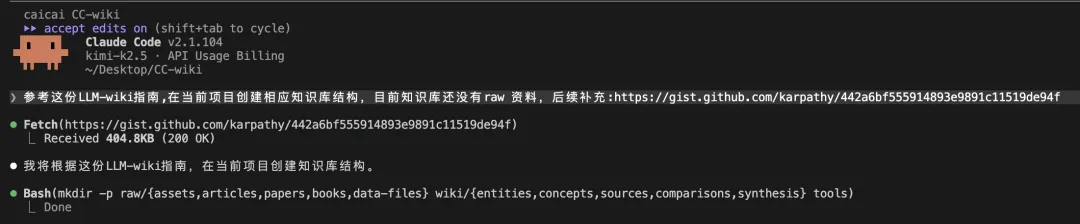
用 Claude Code 打開啱先喺 Obsidian 創建嘅文件夾,然後將 Karpathy 嘅 llm-wiki.md 連結掟俾 Claude Code。
參考這份LLM-wiki指南,在當前項目創建相應知識庫結構,目前知識庫還沒有raw 資料,後續補充:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
註:對新手嚟講,最方便嘅方法係用 IDE 打開然後執行 Claude Code
跟住 Claude Code 就會根據 LLM-wiki 創建相應嘅知識庫結構,首次創建嘅目錄包括:raw、wiki、schema ,當然佢哋而家都仲係空嘅。
例如我最近要研究 harness engineering,就可以將自己揾到嘅博客、論文等資料,全部以 markdown 格式掟到 raw 呢個文件夾下。
保存資料有個更方便嘅方法,就係用官方配套嘅 Obsidian Web Clipper,支援將你睇到嘅好文章、論文同 YouTube 片文稿,一鍵剪存到 Obsidian 中。
🔗:https://github.com/obsidianmd/obsidian-clipper
不過目前 Obsidian Web Clipper 唔支援 B 站片嘅剪存,我原本喺官方項目提咗 PR 合併,不過冇通過,Obsidian CEO 駁回嘅原因係:Obsidian Web Clipper 只會處理經過 Defuddle 處理後嘅內容。
後來我就諗住喺 Defuddle 項目上提交 PR,但係因為冇辦法喺本地驗證自己嘅 PR 係咪成功,所以最後冇提交,改為基於 Obsidian Web Clipper 做咗個中文內容增強嘅插件,大家有需要可以直接使用。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
跟住話俾 Claude Code 知要攝入 raw 文件夾新加嘅資料。
攝入 raw 文件夾新添加的文章
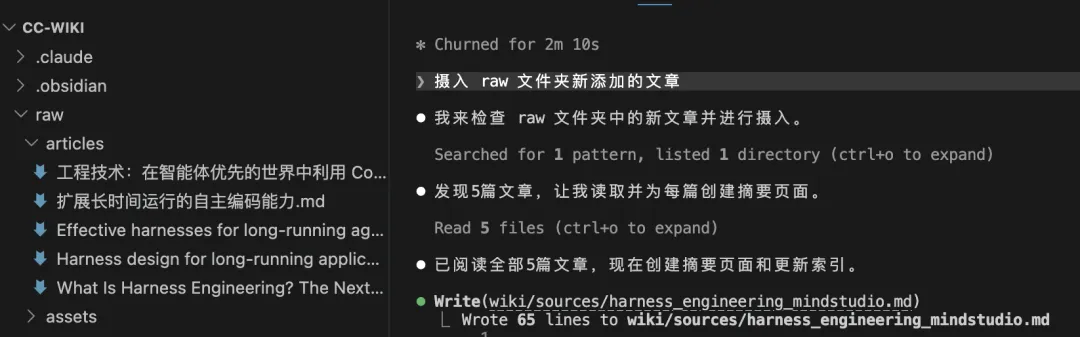
AI 就會根據呢啲原始資料,自動生成一系列 Markdown 文件,所有文件都放喺 wiki 呢個文件夾下。
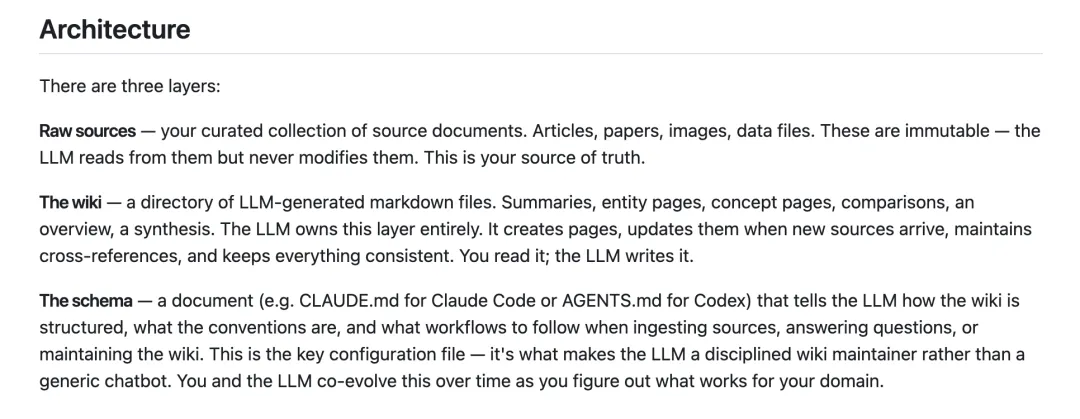
文件嘅內容可能係某個概念、人物、產品、專題、摘要、索引、操作歷史等等,其中有三個好重要嘅文件,包括:
index.md:內容目錄,佢會按類別組織,每篇 wiki 單行摘要,方便你快啲瀏覽。
log.md:時間線記錄,幾時睇咗咩、更新咗邊啲頁面。
schema(通常係 CLAUDE.md 或 AGENTS.md):就係規則文檔,話俾 AI 知點樣組織 wiki、點樣命名文件、點樣交叉引用等,之後你可以自定義調整。
所有文件唔係散亂嘅,彼此之間會用連結關聯起嚟。
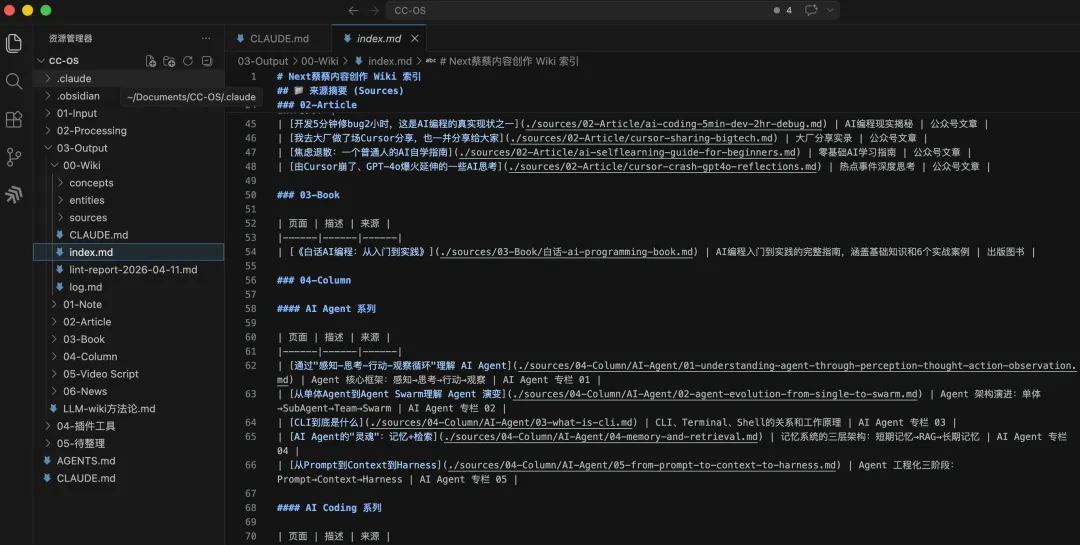
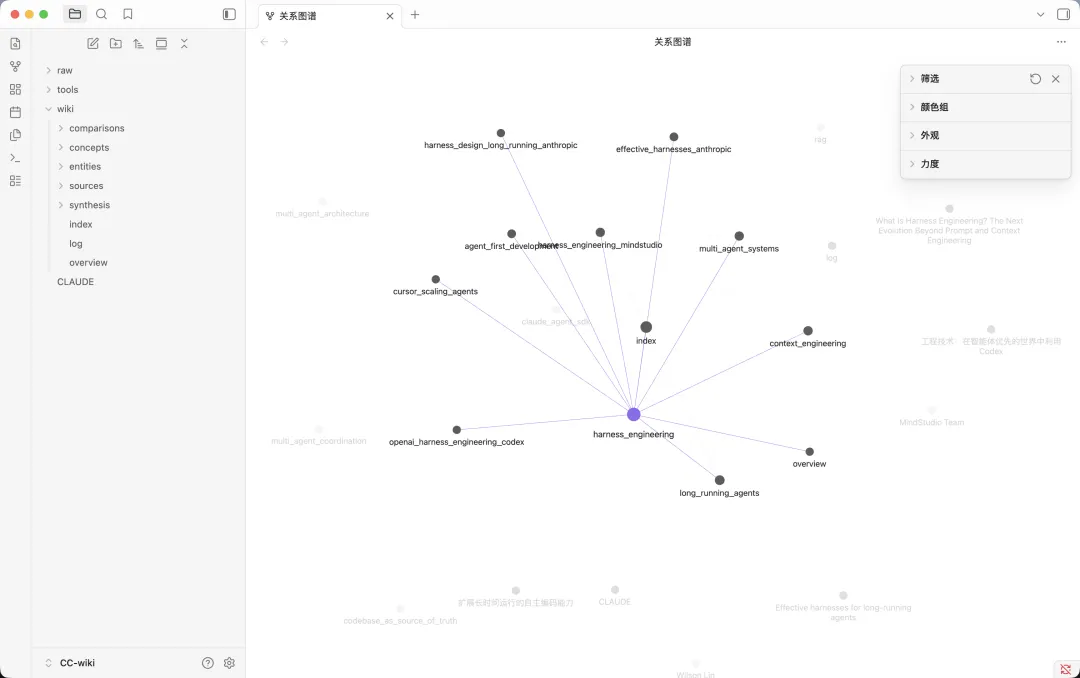
呢種關聯喺 IDE 入面可能唔夠直觀,
但係喺 Obsidian 入面,係咁樣一張知識圖譜,你隨時可以睇唔同知識點、唔同資料之間嘅關聯。
以上就係由 0 到 1 搭建 LLM-wiki,並且完成初步內容攝取嘅全過程。
但係你以為 LLM-wiki 就到曬頂,仲未。完整嘅 LLM-wiki 工作流仲包括之後嘅 Query(查詢)和 Lint(整理)
Query 就係你有問題可以直接問 AI,AI 會去讀相關頁面,進行綜合回答。答得好,仲可以將結論寫返入 wiki,即係你嘅知識會越積越厚。
Lint 就係定期叫 AI 檢查一次,睇成個知識庫有冇矛盾、有冇孤立頁面、連結有冇斷,保證你嘅知識庫唔會因為資料越多就越亂。
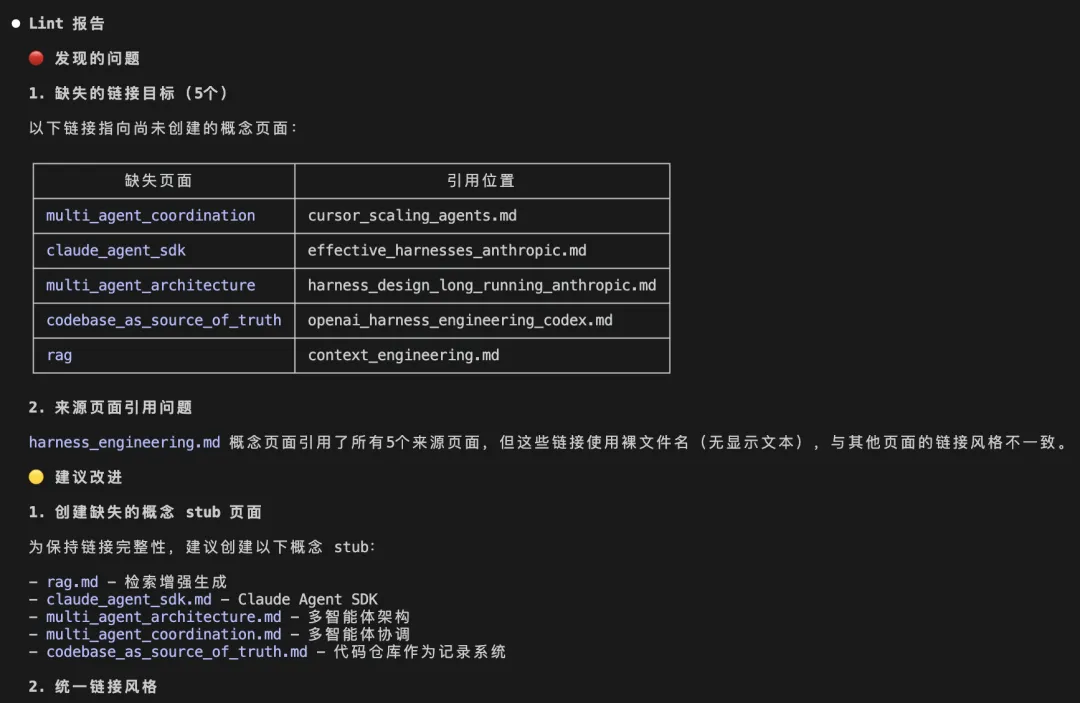
呢個就係 LLM-wiki 嘅完整工作流:由攝入到查詢再到整理。
呢套方案之所以對學習研究咁好用,係因為佢可以 持續積累、反覆查閲、強調關聯。
你今日讀一篇論文,下星期讀另一篇,兩個月後突然發現——呢兩篇講嘅係同一個嘢嘅唔同側面。
如果冇 wiki,你要靠記憶去揾。有咗 wiki,LLM 會自動幫你將關聯標出嚟。
而且 wiki 維護成本低,一次整理,長期受益。
呢套方案仲可以用喺書籍閲讀、個人目標追蹤等方面,大家有興趣嘅話我喺下期分享。
02 內容創作場景:根據個人知識庫調整
雖然 LLM-wiki 喺學習研究場景特別好用,但係如果你係做內容創作嘅,直接照搬 Karpathy 嘅方案可能會出問題。
問題出喺邊?
你嘅知識庫結構可能唔一樣。
Karpathy 嘅 wiki 係由 raw 到 wiki,核心係將外部資訊進行結構化關聯。
但係內容創作者嘅知識庫通常唔係呢個邏輯。例如我自己嘅知識庫係經典嘅 IPO 結構:Input(輸入)→ Processing(加工)→ Output(輸出)。
Input:我睇嘅書、文章、影片、新聞
Processing:我嘅想法、筆記、草稿
Output:我發布嘅碎片想法、文章、書籍、影片、專欄
如果我想令 AI 更加好咁理解我嘅思想同風格,應該餵俾佢嘅唔係 Input,而係 Output。
點解?因為 Input 係人哋嘅嘢,Output 先係我嘅嘢。AI 要學嘅係「我點樣諗」,唔係「我睇咗啲咩」。
所以內容輸出嘅場景下,我嘅 wiki 核心應該係基於 Output 嘅歷史內容,而唔係基於 Input 嘅原始資料。
當然,Input 都可以用 LLM-wiki 嘅方法去學習同消化,最後經過 Processing 再變成我自己嘅 Output。
呢個就係學習場景同內容場景嘅根本區別:
學習場景:重點係將外部知識內化,wiki 係終點。
創作場景:重點係將個人思考外化,wiki 只係中間站。
創作場景仲要注意一點,就係佢可能會自動生成一啲「睇落對但實際上同你嘅觀點有偏差」嘅內容。所以喺 wiki 每次嘅生成同更新環節,我哋仲要睇住,確保佢代表嘅係「你」嘅知識,而唔係「AI 估嘅你」。
03 企業知識庫:LLM wiki 可能唔適用
最後,簡單傾下企業場景。
LLM wiki 爆紅之後,有不少關於 RAG 已死嘅論調,仲有人認為佢可以取代 RAG 做企業知識庫。
我嘅觀點係:小團隊可以,大組織仲未得。
雖然 wiki 聽落比 RAG 簡單好多,唔使搞向量數據庫,唔使做嵌入,每次新增仲可以自己更新。
但係簡單有簡單嘅代價。
首先係佢目前支援嘅規模上限好明顯。Karpathy 自己嘅 wiki 係 100 篇文章、40 萬字,呢個已經係唔細嘅體量。當 wiki 膨脹到幾百上千個文檔時,index.md 可能會超出上下文窗口,你都要壓縮、分片、或者引入檢索——呢個就變成 RAG-over-wiki 了,唔再係純粹嘅 LLM wiki。
其次係權限管理,企業級 RAG 結合向量數據庫通常有更成熟嘅 RBAC(基於角色嘅權限訪問控制)方案,但 LLM-wiki 冇呢樣嘢,所以目前更多隻可以用喺小團隊或大組織嘅小部門中。
仲有一個致命問題:引用精確性。
企業場景對來源追溯要求好高。RAG 可以話俾用戶知「呢個結論來自第幾頁第幾段」,但完全由 LLM 維護嘅 wiki 可能會幻覺出一個概念之間嘅錯誤關聯。當呢個錯誤寫入 wiki,就會影響之後所有查詢。
寫在最後
Karpathy 嘅 LLM wiki 確實係好嘢,但要分場景。
學習研究場景,直接照搬,非常好用。
內容輸出場景,參考結構,人工把關。
企業知識庫,小規模可用,大規模都係要用 RAG。
講到底,冇最好嘅工具,只有最適合你場景嘅工具。
哈嘍各位精神股東們,我是蔡蔡!
前段時間,大神 Andrej Karpathy 發了個兩條推特,分享他是怎麼做 LLM 知識庫的。
他的核心思路其實很簡單:
與其每次讓 AI 去原始資料裏翻答案,不如讓 AI 幫你把知識編譯成一個持續維護的 wiki。
這話聽起來挺對。
但我自己試了試,又跟幾個朋友聊完,發現一個問題——
LLM wiki 對學習研究場景是神器,但在內容創作場景和企業知識庫場景則不一定。
今天就是和大家聊聊這事兒。
01 學習/研究場景:可以直接用
如果你是在學習、研究某個領域,Karpathy 這套方案幾乎可以原樣複製。因為這就是大神自己最開始的應用場景。
這套方案本身並不複雜,三層結構:Raw 層、Wiki 層,以及 Schema 層。
硬講這三層概念太過乾巴,我直接從頭跑個案例給大家看更直觀。
中間用到兩個工具:Obsidian、Claude Code。這裏默認大家都已經安裝 Claude Code 並且會使用(也可以用你們常用的其它 AI 編程工具,如 Codex、Cursor、Qoder、Trae 等)。
打開 Obsidian,點擊【創建】,在指定文件夾下創建一個新的倉庫。
這就是你接下來的知識庫大本營了,雖然現在還空空如也。沒關係,繼續下一步
用 Claude Code 中打開剛才在 Obsidian 創建的文件夾,然後把 Karpathy 的 llm-wiki.md 連結丟給 Claude Code。
參考這份LLM-wiki指南,在當前項目創建相應知識庫結構,目前知識庫還沒有raw 資料,後續補充:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
注:對新手來說,最方便的方法是用 IDE 打開然後運行 Claude Code
接着 Claude Code 就會根據 LLM-wiki 創建相應的知識庫結構,首次創建的目錄包括:raw、wiki、schema ,當然它們現在都還是空的。
比如我最近要研究 harness engineering,就可以將自己找到的博客、論文等資料,都以 mardown 的格式丟到 raw 這個文件夾下。
保存資料有個更方便的方法,就是用官方配套的 Obisidian Web Clipper,支持將你看到的好的文章、論文以及 YouTube 視頻文稿,一鍵剪存到 Obisidian 中。
🔗:https://github.com/obsidianmd/obsidian-clipper
不過目前 Obisidian Web Clipper 不支持 B 站視頻的剪存,我原本在官方項目中提了 PR 合併,不過沒通過,Obsidian CEO 駁回的原因是:Obisidian Web Clipper 只處理從 Defuddle 處理後的內容。
後來我就想着在 Defuddle 項目上提交 PR,但由於沒法在本地驗證自己的 PR 是否成功,所以最後沒提交,而是基於 Obisidian Web Clipper 做了箇中文內容增強的插件,大家有需要可以直接使用。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
接着告訴 Claude Code 攝入 raw 文件夾新添加的資料。
攝入 raw 文件夾新添加的文章
AI 就會根據這些原始資料,自動生成系列 Markdown 文件,所有文件都放 wiki 這個文件夾下。
文件的內容可能某個概念、人物、產品、專題、摘要、索引、操作歷史等等,其中有三個很重要的文件,包括:
index.md:內容目錄,它會按類別組織,每篇 wiki 單行摘要,方便你快速瀏覽。
log.md:時間線記錄,什麼時候讀了什麼、更新了哪些頁面。
schema(一般是 CLAUDE.md 或 AGENTS.md):就是規則文檔,告訴 AI 怎麼組織 wiki、怎麼命名文件、怎麼交叉引用等,後續你可以做自定義調整。
所有文件並不是散亂的,彼此之間會用連結關聯起來。
這種關聯在 IDE 中可能不夠直觀,
但在 Obsidian 中,是這麼一張知識圖譜,你隨時可以查看不同知識點、不同資料之間的關聯。
以上就是從 0 到 1 搭建 LLM-wiki ,並且完成初步內容攝取的全過程。
但你以為 LLM-wiki 這就到頭了,還沒有。完整的 LLM-wiki 工作流還包括後續的 Query(查詢)和 Lint(整理)
Query 就是你有問題可以直接問 AI,AI 會去讀相關頁面,進行綜合回答。回答得好,還可以把結論寫回 wiki,也就是你的知識是越攢越厚的。
Lint 則是定期讓 AI 檢查一遍,看整個知識庫有沒有矛盾、有沒有孤立頁面、連結有沒有斷,保證你的知識庫不會因為資料越多就越亂。
這就是 LLM-wiki 的完整工作流:從攝入到查詢再到整理。
這套方案之所以對學習研究這麼好用,是因為它可以 持續積累、反覆查閲、強調關聯。
你今天讀一篇論文,下週讀另一篇,兩個月後突然發現——這兩篇講的是一個東西的不同側面。
如果沒有 wiki,你得靠記憶去翻。有了 wiki,LLM 會自動幫你把關聯標出來。
而且 wiki 維護成本低,一次整理,長期受益。
這套方案還可以用在書籍閲讀、個人目標追蹤等方面,大家感興趣的話我在下期分享。
02 內容創作場景:根據個人知識庫調整
雖然 LLM-wiki 在學習研究場景特別好使,但如果你是做內容創作的,直接照搬 Karpathy 的方案可能會出問題。
問題出在哪?
你的知識庫結構可能不一樣。
Karpathy 的 wiki 是從 raw 到 wiki,核心是把外部信息進行結構化關聯。
但內容創作者的知識庫通常不是這個邏輯。比如我自己的知識庫是經典的 IPO 結構:Input(輸入)→ Processing(加工)→ Output(輸出)。
Input:我看的書、文章、視頻、新聞
Processing:我的想法、筆記、草稿
Output:我發佈的碎片想法、文章、書籍、視頻、專欄
如果我想讓 AI 更好地理解我的思想和風格,應該餵給它的不是 Input,而是 Output。
為什麼?因為 Input 是別人的東西,Output 才是我的東西。AI 要學的是“我怎麼想”,不是“我看了什麼”。
所以內容輸出的場景下,我的 wiki 核心應該是基於 Output 的歷史內容,而不是基於 Input 的原始資料。
當然,Input 也可以用 LLM-wiki 的方法去學習和消化,最後經過 Processing 再變成我自己的 Output。
這就是學習場景和內容場景的根本區別:
學習場景:重點是把外部知識內化,wiki 是終點。
創作場景:重點是把個人思考外化,wiki 只是中間站。
創作場景還要注意一個點,就是它可能會自動生成一些“看起來對但實際上和你的觀點有所偏差”的內容。所以在 wiki 每次的生成和更新環節,我們還是要做個把關,確保它代表的是“你”的知識,不是“AI 猜的你”。
03 企業知識庫:LLM wiki 可能不適用
最後,簡單聊聊企業場景。
LLM wiki 爆火後,有不少關於 RAG 已死的論調,還有人認為它可以替代 RAG 做企業知識庫。
我的觀點是:小團隊可以,大組織還不行。
雖然 wiki 聽起來比 RAG 簡單多了,不用搞向量數據庫,不用做嵌入,每次新增還能自己更新。
但簡單有簡單的代價。
首先是它目前支持的規模上限很明顯。Karpathy 自己的 wiki 是 100 篇文章、40 萬字,這已經是個不小的體量了。當 wiki 膨脹到幾百上千個文檔時,index.md 可能就會超出上下文窗口,你還是得壓縮、分片、或者引入檢索——這就變成 RAG-over-wiki 了,不再是純粹的 LLM wiki。
其次是權限管理,企業級 RAG 結合向量數據庫通常有更成熟的 RBAC(基於角色的權限訪問控制)方案,但 LLM-wiki 沒有這東西,所以目前更多隻能用在小團隊或大組織的小部門中。
還有一個致命問題:引用精確性。
企業場景對來源追溯要求很高。RAG 可以告訴用戶“這個結論來自第幾頁第幾段”,但完全由 LLM 維護的 wiki 可能會幻覺出一個概念之間的錯誤關聯。當這個錯誤寫進 wiki,就會影響後續所有查詢。
寫在最後
Karpathy 的 LLM wiki 確實是個好東西,但得分場景。
學習研究場景,直接照搬,非常好用。
內容輸出場景,借鑑結構,人工把關。
企業知識庫,小規模可用,大規模還是得用 RAG。
說到底,沒有最好的工具,只有最適合你場景的工具。