LibTV實測,Agent們終於不再需要模仿人類來使用軟件了
整理版優先睇
LibTV 實測:用自然語言操控影片生成,Agent 時代唔再需要人手模仿操作
作者卡爾親自試玩咗 LibTV,呢個係一個基於無限畫布同節點式生成嘅 AI 影片製作平台,支援劇本、圖片、影片、音頻全鏈路製作。佢覺得之前嘅 AI 工具成日要人手模仿人類操作,好麻煩,而 LibTV 整合咗大量模型同功能,仲可以連接到 OpenClaw 用 Skill 控制,令成個流程自然好多。整體結論係 LibTV 功能全面、上手快,尤其係多角度、打光、攝像機控制呢啲直觀功能,仲有九宮格切分同影片解析成分鏡腳本,對於創作者嚟講好實用。
作者直接用 LibTV 整咗個「蒙娜麗莎出逃」短片,體驗到佢可以自動設計分鏡腳本,批量生成圖片同影片。佢特別提到呢個工具嘅靈活性,例如可以將九宮格拆開逐格修改,或者用攝像機控制精準調整角度光線。價格方面,年卡最低 39 折,作者覺得可以接受。佢認為人同 AI 會越來越融合,人類提出想法,由 AI 執行,最終由人類拍板。
- 結論:LibTV 係一個功能強大嘅 AI 影片創作平台,節點式工作流易上手,支援全鏈路製作。
- 方法:透過自然語言表達意圖,由視頻 Agent 統一編排,唔似其他工具咁要手動操作每個步驟。
- 差異:LibTV 嘅 Skill 作為中間層,可以喺 OpenClaw 用自然語言控制,唔似傳統 API 封裝 Skills 咁要自己寫腳本。
- 啟發:多角度、打光、攝像機控制等功能令非專業人士都可以精準控制畫面,大幅降低創作門檻。
- 可行動點:安裝 libtv-skills 並獲取 AccessKey,即可連接 OpenClaw 用自然語言生成影片,或者參考現有影片拆解分鏡。
libtv-skills
可連接到 OpenClaw 使用,需要安裝 GitHub 倉庫,並在網頁版獲取 AccessKey。只依賴 Python 標準庫,支持圖片和視頻上傳(200MB 以內)。
LibTV 基本體驗:節點式工作流,全鏈路製作
卡爾玩咗 LibTV 之後,第一個感覺係「好用,確實好用」。呢個平台用無限畫布加節點式生成,你只需要創建節點、拉節點、寫提示詞就行,基本上冇學習成本。佢支援劇本、圖片、影片、音頻全鏈路製作,仲可以調用目前市面上幾乎所有圖片同影片生成模型。
無限畫布 + 節點式生成
劇本、圖片、視頻、音頻全鏈路
除咗生成功能,LibTV 嘅編輯功能都好全面。例如生成圖片後,可以高清、擴圖、重繪、擦除、摳圖。其中仲有四個特別實用嘅功能:多角度、打光、攝像機控制同九宮格切分。
亮點功能:直觀操控畫面角度、光線與鏡頭
多角度功能可以透過拖拽攝像機調整拍攝角度,好直觀,而且調整幾準確。打光功能同樣可以拖拽調整光源位置同顏色,仲有預設主光源位置可以揀,最終生成圖片同設定完全一致。
拖拽調整攝像機角度
拖拽調整光源位置和顏色
攝像機控制功能內置好多相機型號、鏡頭、焦段同光圈,適合唔同場景。卡爾試咗用同一張圖同提示詞,但用唔同攝像機組合,效果明顯唔同。佢仲總結咗四組適合拍攝唔同畫面嘅鏡頭組合。
內置大量相機種類、鏡頭、焦段和光圈
九宮格切分功能解決咗以往整九宮格影片時,某個分鏡唔準確要全部重做嘅問題。而家你可以拆開九張圖,逐張修改或替換,靈活性高好多。
影片編輯與分析:拆解分鏡,二次創作
影片生成完成後,你可以繼續剪輯或高清處理。最重要嘅係「解析」功能,佢可以直接將一段影片拆成分鏡腳本,非常適合參考現有影片做二次創作。
將視頻拆成分鏡腳本
直接參考現有視頻創作
另外,生圖節點上內置咗好多提示語小功能,例如經常用到嘅修改分鏡圖片,可以直接用,唔使自己寫。
連接到 OpenClaw:用自然語言控制 libtv-skills
卡爾安裝咗 libtv-skills 之後,可以直接喺 OpenClaw 用自然語言控制 LibTV。步驟好簡單:先安裝 GitHub 上嘅 skill,然後喺網頁版賬號設置攞 AccessKey,再發畀 OpenClaw 完成配置。佢畀咗經典嘅「你過來啊」片段,得到一個 3D 動畫版本,效果唔錯。
發一段文本就能控制 LibTV
安裝 libtv-skills 並獲取 AccessKey
此外,libtv-skills 只依賴 Python 標準庫,唔需要額外安裝第三方依賴,上傳文件支援圖片同影片,大小 200MB 以內。
最後講價格:卡爾認為用 Agent 生成會用多啲模型調用次數,所以價格要合理先有人用。而家年卡最低 39 折,佢直接入咗一年。佢相信人同 AI 會越來越融合,人類提出想法,AI 執行中間過程,最終決定權永遠喺人類手中。
前兩日大家都用緊嘅libtv我終於有時間用喇,
玩咗好耐之後,我嘅感受就係好用,真係好用!
功能好齊全,支援劇本、圖片、視頻、音頻全鏈路製作,仲用緊無限畫布+節點式生成。大家平時用 AI 工具多嘅話,係好易上手㗎。
🔗 liblib.tv
重要嘅係,LibTV已經有咗自己嘅 Skill,可以連到 OpenClaw 裏面用,今次我嘅蝦又變犀利咗!
咁我今次先直接跟返我之前嘅創作習慣,喺 LibTV 度做咗一個蒙娜麗莎出逃嘅小短片,可以調用我哋目前用到嘅幾乎所有圖片同視頻生成模型。
實際上上手好快,基本上冇乜學習成本,你只需要識得創建節點、拉節點、寫提示詞進行生成就得啦。
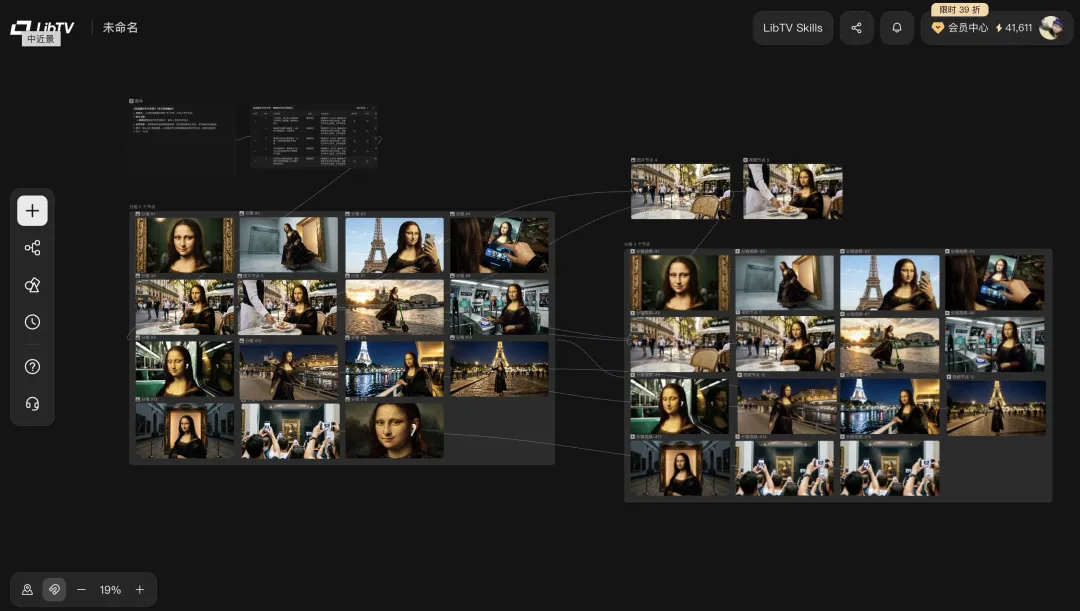
而且 LibTV 可以根據你畀嘅一個大概嘅劇情自動設計完整嘅分鏡腳本,支援一鍵批量生成分鏡圖片同批量生成視頻,做起上嚟速度好快。

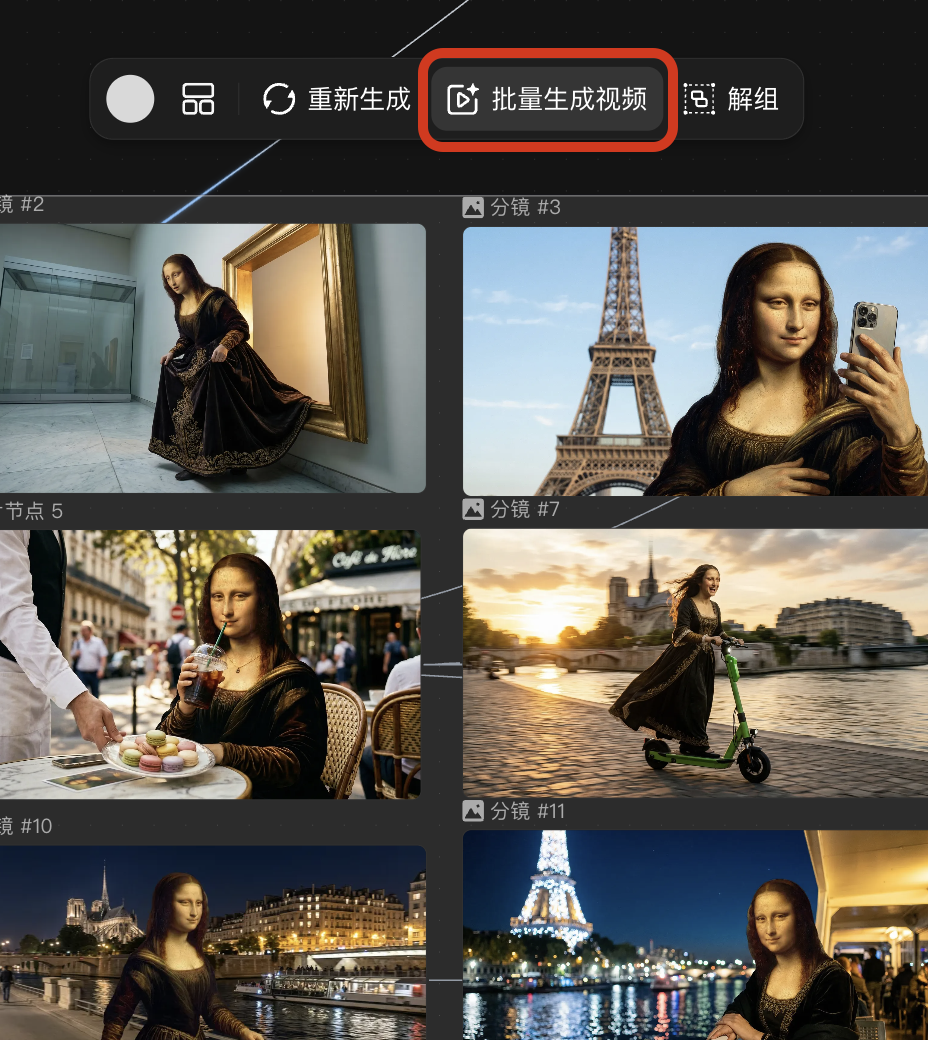
而且除咗圖片、視頻生成之外,LibTV喺圖片編輯同視頻編輯方面嘅功能都好全面。
例如我哋生成一張圖片之後,㩒落去就會發現,上面嘅功能欄入面幾乎包曬目前所有 AI 圖像編輯方面嘅功能,高清、擴圖、重繪、擦除、摳圖呢啲都有。
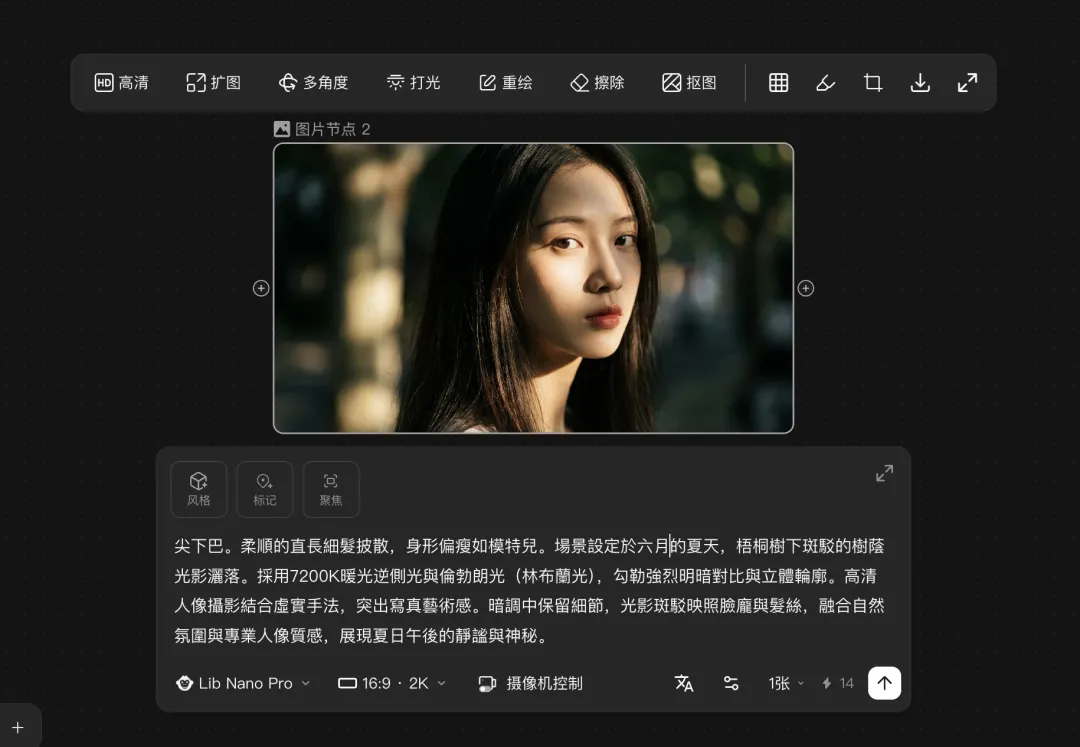
除咗呢啲生成功能之外,呢度仲有四個我個人覺得幾有趣,而且實用性都幾高嘅功能,
多角度、打光、攝像機控制同九宮格切分。
首先係多角度呢個功能,可以透過拖拽攝像機嚟調整拍攝嘅角度,咁樣就好直觀,可以好快揾到自己想拍攝嘅位置,從而得到相應嘅圖片。試咗幾次,呢個角度調整都幾精準㗎。
仲有呢個打光功能,都可以直接拖拽去調整光源嘅位置同顏色。而且如果你唔係好把握光源位置嘅話,都可以直接用佢提供嘅一啲主光源位置。透過呢個功能,我哋可以好直觀咁得到想要嘅打光角度。最終生成嘅圖片效果,同我設置嘅光源位置同顏色係完全一致嘅。
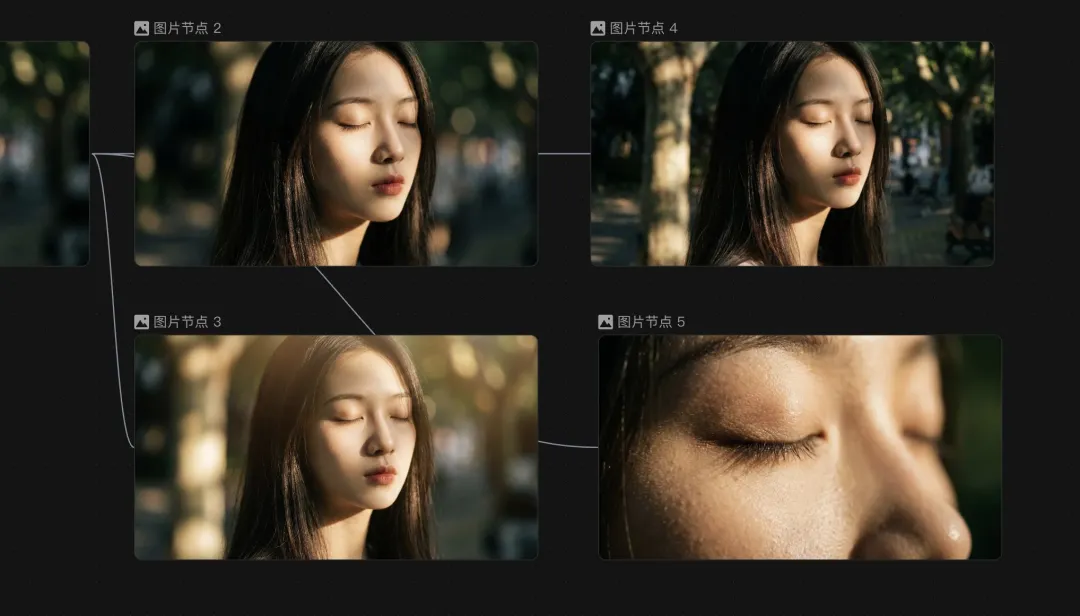
仲有呀,LibTV做咗一個攝像機控制功能,內置咗好多相機種類、鏡頭、焦段同光圈,可以適應多種場景嘅需求,
例如呢度有四張圖,就係我用同一張圖做底圖,用咗同樣嘅提示語,但係用咗唔同嘅攝像機組合嚟做出嘅圖片,攝像機鏡頭、焦段同光圈嘅唔同搭配,其實可以做出唔同嘅效果。
對於一啲好識攝像機方面專業知識嘅人嚟講特別友好,可以精準咁得到自己想要嘅光線同拍攝角度。
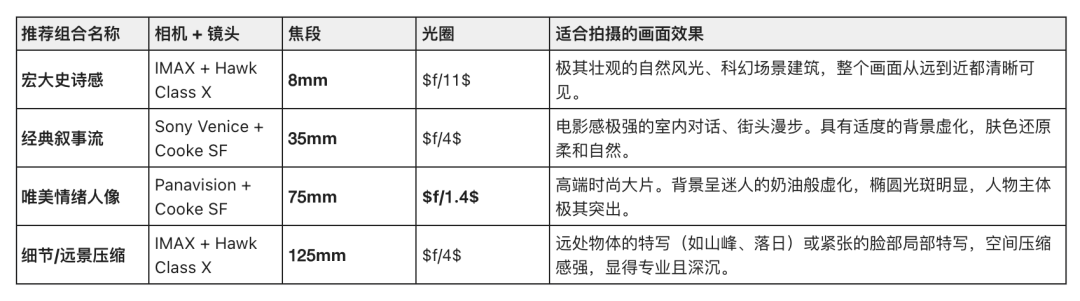
呢度我仲總結咗四組適合拍攝唔同類型畫面嘅鏡頭組合,大家有興趣可以自己去試嚇。
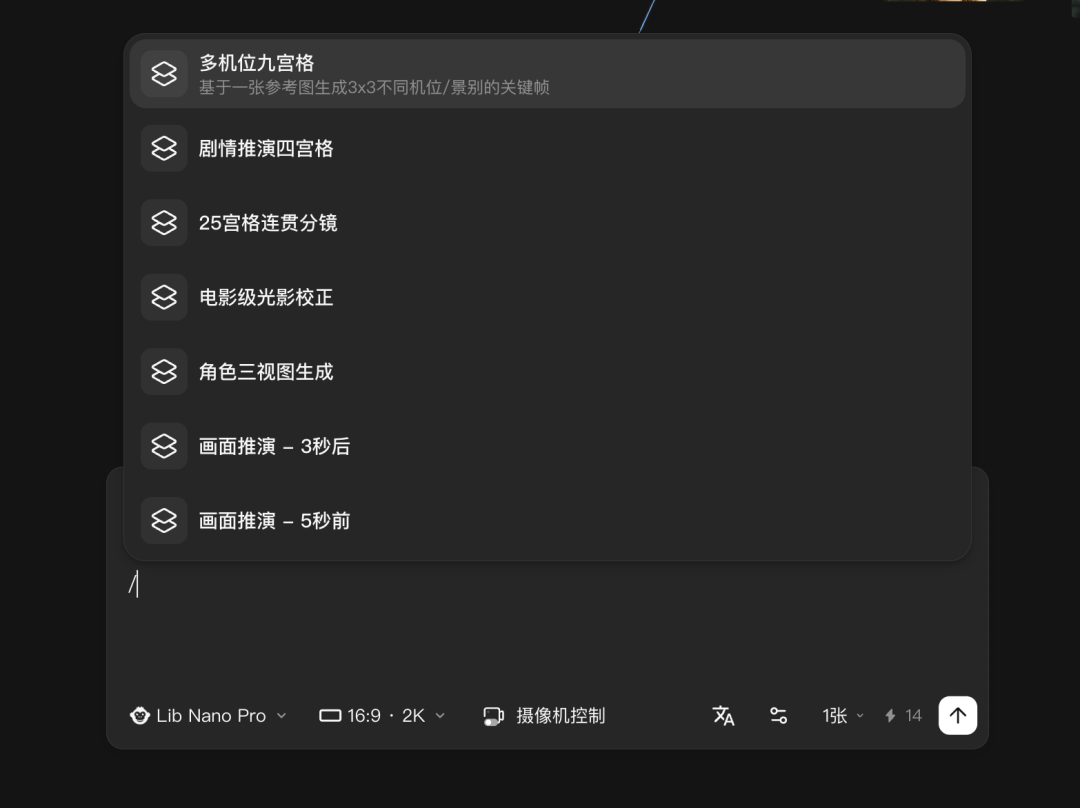
仲有一個九宮格切分嘅功能,我覺得都好有用。
之前我哋玩 AI 視頻嘅時候,成日會用到一種用九宮格去生成一整段視頻嘅玩法。但係中間成日會出現一啲問題,例如某一個分鏡可能唔係幾準確,而其他分鏡做得好好。
針對呢種情況,我哋可以直接將九宮格拆分成九張圖:你可以對每一張圖單獨去生成你想要嘅分鏡,生成後可以替換返原本完整嘅視頻入面。或者如果你對其中某一個分鏡圖唔係好滿意,或者佢有一啲 bug,你可以單獨去修改呢張圖。咁樣嘅話靈活性就更高喇。
仲有就係喺生圖節點上,LibTV 都有好多已經內置好嘅小功能。我哋喺視頻創作過程中,成日要修改部分分鏡圖片,呢幾個係我覺得會成日用嘅,咁樣已經將呢啲提示語內置成固定功能,會好方便。
咁去到視頻生成階段,一段視頻生成完成之後,你仲可以繼續對呢段視頻直接進行剪輯,或者高清處理。呢度仲有一個功能叫做解析。
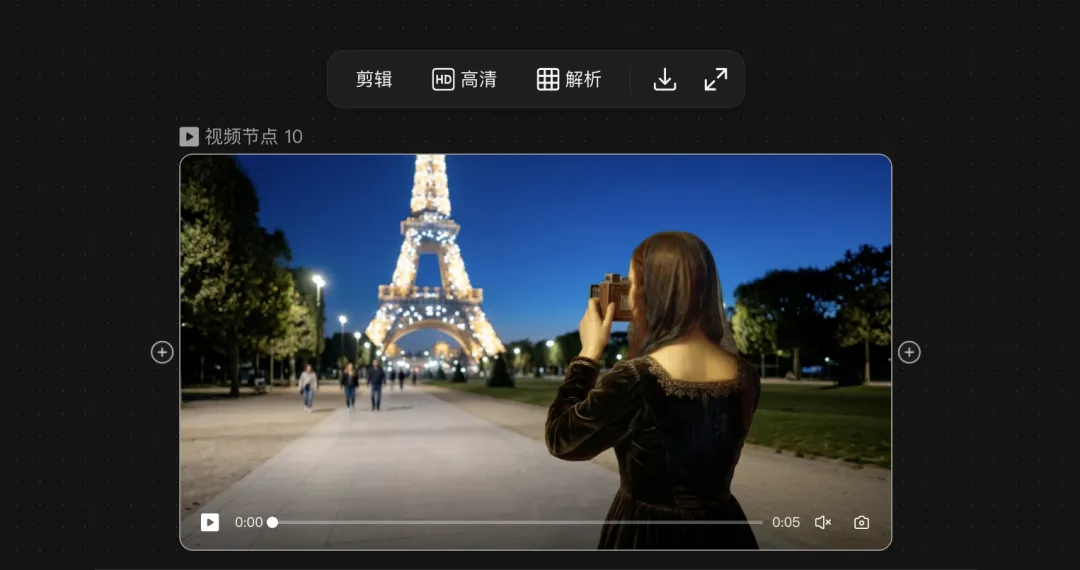
佢可以直接將一段視頻拆成分鏡腳本。咁樣嘅話,假設你有一個想參考嘅視頻創作,你可以用 LibTV 去分析佢嘅分鏡,得到分鏡腳本,然後再按照呢個腳本進行修改,生成自己嘅內容。

喺OpenClaw度用LibTV都好簡單,
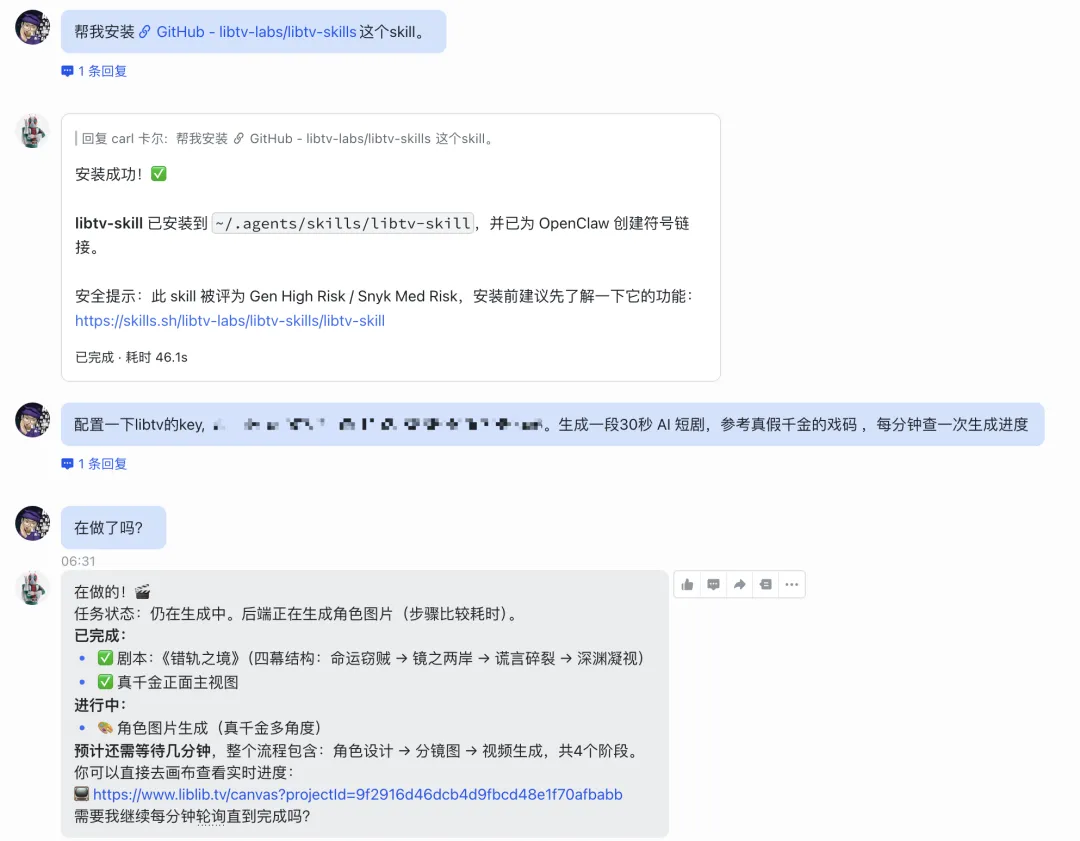
只要發一段文本就得,
幫我安裝https://github.com/libtv-labs/libtv-skills呢個skill。
然後就係喺網頁版嘅賬號設置度攞到AccessKey,再發畀OpenClaw完成配置同第一次測試。
都可以直接喺飛書上傳一個視頻,叫佢調用 LibTV 去模仿呢個視頻做一個。我呢度畀咗佢經典嘅騰哥嘅你過來啊片段,然後得到咗一個 3D 動畫版本嘅,實際上效果都幾好。
libtv-skills喺安裝完成之後發咗一個說明文檔畀我,我用GPT總結咗一下。
簡單嚟講,呢個Skills喺實現上只依賴Python標準庫,唔需要我哋電腦再額外安裝第三方依賴。上傳檔案支援圖片同視頻,大小喺200MB以內。
咁佢同我哋見到嘅封裝咗一啲視頻模型API能力嘅Skills有乜嘢唔同呢?

libtv-skills相當於一個中間層,
API封裝嘅Skills係將我哋喺網頁版上操作流程組成腳本,我哋要自己去完成提示語嘅編寫、流程推進等等。
但libtv嘅思路係盡可能俾用戶用自然語言表達意圖,由佢哋嘅視頻Agent嚟完成統一嘅編排。
最後嘅最後,
又到咗緊張刺激嘅價格環節,
用Agent生成,調用模型嘅次數係會比手動嘅平均要高,靠量嚟換審美,一次抽卡唔好,我就抽十次揀最好嘅。
所以價格唔壓低嘅話,
就好少人會用Agent直接成片㗎。
LibTV目前嘅定價係年卡最低39折,
我就直接入咗一年先踩踩坑。
而且就而家嘅趨勢嚟講,
我覺得人類同AI會變得越來越融合。
人類提出想法,
AI幫我哋去完善呢啲想法,
幫我哋執行中間嘅一啲過程。
而最終拍板成個故事走向邊一個分支嘅,
永遠都係我哋。
@ 作者 / 卡爾
最後,多謝你睇到呢度👏如果鍾意呢篇文章,不妨順手俾我哋點讚|在看|轉發|留言 📣
如果想第一時間收到推送,不妨俾我哋個星標🌟
如果你有更有趣嘅玩法,歡迎喺留言區傾嚇🤝
更多嘅內容正在不斷填坑中……

前兩天大家都在用的libtv我終於是有空用上了,
大玩特玩後,我的感受就是好用,確實好用!
功能很全,能支持劇本,圖片,視頻,音頻全鏈路製作,而且用的是無限畫布+節點式生成。大家平時用 AI 工具多的話,是非常容易上手的。
🔗 liblib.tv
重要的是,LibTV已經有了自己的 Skill,能夠連到 OpenClaw 裏面用,這下我的蝦又變厲害了!
那我這次先直接按照我之前的創作習慣,在 LibTV 裏做了一個蒙娜麗莎出逃的小短片,可以調用我們目前能用的幾乎所有圖片和視頻生成模型。
實際上上手非常快,基本上沒有什麼學習成本,你只需要會創建節點,拉節點,寫提示詞進行生成就行了。
而且 LibTV 可以根據你給的一個大概的劇情自動設計完整的分鏡腳本,支持一鍵批量生成分鏡圖片和批量生成視頻,做起來速度非常快。
而且除了圖片,視頻生成之外,LibTV在圖片編輯和視頻編輯方面的功能也非常全面。
比如我們生成一張圖片之後,點擊它會發現,上面的功能欄裏面幾乎囊括了目前所有 AI 圖像編輯方面的功能,高清,擴圖,重繪,擦除,摳圖這些都有。
除了這些生成功能之外,這裏還有四個我個人覺得比較有趣,而且實用性還挺高的功能,
多角度、打光、攝像機控制和九宮格切分。
首先是多角度這個功能,可以通過拖拽攝像機來調整拍攝的角度,這樣就非常直觀,能夠迅速找到自己想要拍攝的位置,從而得到相應的圖片。試了幾次,這個角度調整還挺精準的。
還有這個打光功能,也可以直接拖拽去調整光源的位置和顏色。而且如果你不好把握光源位置的話,也可以直接用它提供的一些主光源位置。通過這個功能,我們可以非常直觀地得到想要的打光角度。最終生成的圖片效果,與我設置的光源位置和顏色都是完全一致的。
還有啊,LibTV做了一個攝像機控制功能,內置了非常多的相機種類,鏡頭,焦段和光圈,可以適應多種場景的需求,
比如這裏有四張圖,就是我用同一張圖作為底圖,使用了同樣的提示語,但是用了不同的攝像機組合來做出的圖片,攝像機鏡頭、焦段和光圈的不同搭配,其實能夠做出不同的效果。
對於一些非常懂攝像機方面專業知識的人來說特別友好,能夠精準地得到自己想要的光線和拍攝角度。
這裏我還總結了四組適合拍攝不同類型畫面的鏡頭組合,大家感興趣可以自己去嘗試一下。
還有一個九宮格切分的功能,我覺得也很有用。
之前我們玩 AI 視頻的時候,經常會用到一種用九宮格去生成一整段視頻的玩法。但是中間經常會出現一些問題,比如某一個分鏡可能不太準確,而其他分鏡做得很好。
針對這種情況,我們可以直接把九宮格拆分成九張圖:你可以對每一張圖單獨去生成你想要的分鏡,生成後可以替換回原本完整的視頻裏。或者如果你對其中某一個分鏡圖不是很滿意,或者它有一點 bug,你可以單獨去修改這張圖。這樣的話靈活性就更高了。
再有就是在生圖節點上,LibTV 也有很多已經內置好小功能。我們在視頻創作過程中,經常會要修改部分分鏡圖片,這幾個都是我覺得會經常使用到的,這樣已經把這些提示語內置成了固定的功能,會非常方便。
那到了視頻生成階段,一段視頻生成完成之後,你還可以繼續對這段視頻直接進行剪輯,或者高清處理。這裏還有一個功能叫做解析。
它可以直接把一段視頻拆成分鏡腳本。這樣的話,假設你有一個想要參考的視頻創作,你可以用 LibTV 去分析它的分鏡,得到分鏡腳本,然後再按照這個腳本進行修改,生成自己的內容。
在OpenClaw裏用LibTV也很簡單,
只要發一段文本就行,
幫我安裝https://github.com/libtv-labs/libtv-skills這個skill。
然後就是在網頁版的賬號設置裏拿到AccessKey,再發給OpenClaw完成配置和第一次測試。
也可以直接在飛書上傳一個視頻,讓他調用 LibTV 去模仿這個視頻做一個。我這裏給了他經典的騰哥的你過來啊片段,然後得到了一個 3D 動畫版本的,實際上效果也還不錯。
libtv-skills在安裝完成後給我發了一個說明文檔,我用GPT總結了一把。
簡單來說,這個Skills在實現上只依賴Python標準庫,不需要我們電腦再額外安裝第三方依賴。上傳文件支持圖片和視頻,大小在200MB以內。
那它跟我們看到的封裝了一些視頻模型API能力的Skills有什麼不同呢?
libtv-skills相當於一箇中間層,
API封裝的Skills是把我們在網頁版上操作流程組成腳本,我們要自己去完成提示語的編寫,流程推進等等。
但libtv的思路是儘可能讓用戶用自然語言表達意圖,由他們的視頻Agent來完成統一的編排。
最後的最後,
又到了緊張刺激的價格環節,
用Agent生成,調用模型的次數是會比手動的平均要高,靠量來換審美,一次抽卡不好,我就抽十次選最好的。
所以價格不壓下來的話,
就很少有人會用Agent直接成片的。
LibTV目前的定價是年卡最低39折,
我是直接入了一年先踩踩坑。
而且就現在的趨勢來說,
我覺得人和AI會變得越來越融合。
人類提出想法,
AI幫我們去完善這些想法,
幫我們執行中間的一些過程。
而最終拍板整個故事走向哪一個分支的,
永遠都是我們。
@ 作者 / 卡爾
最後,感謝你看到這裏👏如果喜歡這篇文章,不妨順手給我們點贊|在看|轉發|評論 📣
如果想要第一時間收到推送,不妨給我個星標🌟
如果你有更有趣的玩法,歡迎在評論區聊聊🤝
更多的內容正在不斷填坑中……