LLM Wiki vs GBrain:AI知識庫正在分裂成兩條路線,你選哪條?
整理版優先睇
LLM Wiki vs GBrain:AI知識庫兩條路線,你應該點揀?
呢篇文章係由AI編程實踐者袁鋭欽寫嘅,佢比較咗兩條AI知識庫嘅新路線:Andrej Karpathy提出嘅LLM Wiki,同埋Y Combinator CEO Garry Tan開源嘅GBrain。作者指出傳統RAG每次都要從零檢索,冇辦法積累知識,所以需要一條新路。整體結論係,兩條路線雖然出發點唔同,但正喺度互相靠近,最終可能會收斂成一個個人迷你AGI。
第一條路線LLM Wiki係知識編譯,概念係將原始資料整理成一本AI自己維護嘅百科全書,人類負責揀材,AI負責書簿工作。第二條路線GBrain係知識運行,強調全自動嘅知識系統,支援數據庫、向量檢索、知識圖譜同自動化流程。作者認為,你應該先問自己係咪真係需要積累知識,再揀路線;如果仲係偶爾查嚇資料,繼續用RAG就夠。
- 傳統RAG每次檢索都冇積累,LLM Wiki將資料編譯成穩定Wiki層,GBrain係自動化知識運行系統。
- LLM Wiki採用三層架構(原始資料、Wiki、Schema)同三大操作(Ingest、Query、Lint),AI負責書簿,人類負責策劃。
- GBrain嘅Dream Loop令AI喺對話前後更新知識,支援多種信息源自動處理,保留頁面可讀性。
- 兩條路線核心差異:知識編譯 vs 知識運行,技術架構上LLM Wiki輕量,GBrain需要向量數據庫等基礎設施。
- 未來趨勢係LLM Wiki結構化加上GBrain自動化,個人應先問自己是否需要積累知識,再揀合適路線。
傳統RAG嘅先天缺陷
你係咪成日見到一篇好文章就丟畀ChatGPT叫佢總結,過幾日又開個新視窗重新上載文件再問?呢種做法嘅問題係:每次檢索都係由零開始,冇積累。新資料入嚟唔會自動重組,問完就完,下次又要重新揾材料。
- 同一個問題多問幾次,答案可能唔一樣
- 新資料入嚟,舊知識唔會自動重組
- 問完就結束,下次重新撈材料
- 呢啲唔係你嘅問題,係傳統RAG嘅先天缺陷
LLM Wiki vs GBrain:知識編譯定知識運行?
針對呢個問題,2026年出現咗兩個截然不同嘅答案。第一條路線係LLM Wiki,由Andrej Karpathy提出,核心係將原始資料整理成穩定嘅Wiki層,畀AI自己寫、自己維護、自己更新交叉引用。第二條路線係GBrain,由Y Combinator CEO Garry Tan開源,強調知識系統要持續運行,喺頁面之上疊加工程基礎設施。
- LLM Wiki三層架構:原始資料層(人類管理,LLM只讀),Wiki層(LLM完全擁有),Schema層(人類同LLM共同演化)
- 三大操作:Ingest(攝取新資料更新Wiki)、Query(喺Wiki搜尋相關頁面回答)、Lint(定期檢查矛盾、死鏈、孤兒頁)
- Karpathy明確分工:人類負責策劃來源、引導方向、提出正確問題;AI負責所有彙總、交叉引用、歸檔同簿記
- GBrain特色:保留頁面可讀可編輯,疊加數據庫、向量檢索、關鍵詞索引、知識圖譜、自動化流程、多媒體處理
- 支援MCP串接Claude同Cursor,技術架構更重,需要部署向量數據庫
未來趨勢與你應該點揀
而家LLM Wiki同GBrain睇落係平行線,但正喺度互相靠近。LLM Wiki社區已經加入向量搜索同知識圖譜,GBrain亦保持頁面可讀性。最終收斂點可能係:LLM Wiki嘅結構化加上GBrain嘅自動化等於下一代個人知識操作系統。
- 1 如果你仲係「丟PDF問AI」階段:先問自己係咪真係需要積累知識。如果只係偶爾查資料,繼續用RAG(ChatGPT/Claude丟文件)就夠。
- 2 如果你願意人工整理:揀LLM Wiki,今日就可以開始。建立raw/sources、wiki/entities、wiki/concepts三個資料夾,寫3-5條Schema規則,丟第一份資料畀Claude幫手生成Wiki頁面,每週做一次Lint檢查。推薦工具:Obsidian + claude-obsidian插件。
- 3 如果你唔想手動維護,有技術能力:揀GBrain,全自動、大規模、能接多種信息源,但需要部署向量數據庫,技術門檻中高。
- 4 如果你唔想手動維護,技術能力有限:折衷方案係先用LLM Wiki加簡化流程,或者等低代碼工具成熟。
最後,作者畀咗幾句建議:普通人唔使焦慮,先用起來最重要,由LLM Wiki開始,哪怕得10個頁面都比每次重新檢索強;資深AI實踐者如果已經用緊Agent,GBrain方向更值得投入;內容創作者應該思考你嘅「零散資料」係咪俾人消費完就消失,定係可以編譯成可複用嘅知識層。
睇完呢篇文章,你就會明點解「掟PDF問AI」已經唔夠用,同埋AI知識庫而家係向邊個方向發展。
一、先問你一個問題
你係唔係都係咁樣用AI㗎?
見到一篇好文章,掟畀ChatGPT:「幫我總結一下。」
過幾日有個相關問題,又開一個新視窗,重新上傳文件,再問一次。
同一個問題問多幾次,答案可能唔同。新資料入嚟,舊知識唔會自動重組。問完就完,下次重新揾材料。
呢個唔係你嘅問題。係傳統RAG(檢索增強生成)嘅先天缺陷——每次都由零開始檢索,冇積累。
正如Andrej Karpathy話:「Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time.」 Nothing is built up."
真正嘅問題唔係「AI揾唔揾到資訊」,而係:AI可唔可以將零散資料,沉澱成一套可以重用、可以維護、可以持續更新嘅知識層?
2026年,呢個問題有咗兩個完全唔同嘅答案。
二、兩條路線:知識編譯 vs 知識運行
路線一:LLM Wiki——知識編譯
發起人提出者:Andrej Karpathy(OpenAI創始成員,前Tesla AI總監)
佢嘅核心想法唔係將一堆資料直接掟畀模型臨時檢索,而係先將原始資料整理成一套穩定嘅Wiki知識層,再畀AI喺呢套知識層上面工作。
簡單講——畀AI一本百科全書,等佢自己寫、自己維護、自己更新交叉引用。
Karpathy設計咗三層架構:
- • 原始資料層原始資料層:你嘅PDF、文章、筆記,人類管理,LLM只讀唔修改
- • Wiki層Wiki層:LLM完全擁有,創建頁面、更新內容、維護交叉引用
- • Schema層Schema層:定義Wiki結構、規則、工作流程,人類同LLM共同演化
三大核心操作:
- 1. Ingest(攝取)Ingest(攝取):掟新資料入去,LLM讀取並更新Wiki
- 2. Query(查詢)Query(查詢):問問題,LLM喺Wiki裏面搜索相關頁面綜合回答
- 3. Lint(檢查)Lint(檢查):定期健康檢查,揾矛盾、死鏈、孤兒頁面
Karpathy明確界定咗人機分工:人類負責策劃來源、引導方向、提出正確問題;AI負責所有匯總、交叉引用、歸檔同簿記工作。
「The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeepingLLMs唔會覺得悶,唔會唔記得更新交叉引用,仲可以一次過處理15個文件。」
社區熱門實現:nashsu/llm_wiki(4.8k Stars,桌面應用)、AgriciDaniel/claude-obsidian(3.7k Stars,Claude Code插件)。
路線二:GBrain——知識運行
發起人提出者:Garry Tan(Y Combinator CEO)
同Karpathy嘅研究導向唔同,Garry Tan係長期用緊Agent嘅人長期用緊Agent嘅人,直接將自己需要嘅知識運行系統整咗出嚟。2026年4月,佢將個人13年積累嘅17,888頁筆記、4,383個人名實體、723個項目,轉化成可複製嘅開源系統。
如果話LLM Wiki回答嘅係「知識點寫」咁GBrain回答嘅係「知識系統點樣持續運行」。
GBrain保留咗頁面嘅可讀/可編輯形態,但喺上面疊加咗一整層工程基礎設施工程基礎設施:數據庫、向量檢索、關鍵詞索引、知識圖譜、自動化流程、多媒體處理。
關鍵特性係「Dream Loop(夢循環)」「Dream Loop(夢循環)」:AI喺對話前後進行讀寫操作以更新知識,定期「反思」並整合新資訊到持久記憶,支援MCP串接Claude同Cursor。
一場客戶會議錄音,喺普通知識庫裏面只係一個附件;喺GBrain裏面,佢會自動轉錄、生成頁面、更新實體、補到時間線、建立索引。後續提問時,你面對嘅唔係原始錄音,而係被拆解同結構化過嘅知識對象。
三、核心差異:一張表講清楚

四、兩條路線嘅技術架構

五、未來趨勢:兩條路線正在靠近
而家LLM Wiki同GBrain睇落係兩條平行線,但佢哋正在靠近。
LLM Wiki社區已經在加入向量搜索(nashsu/llm_wiki用LanceDB)、知識圖譜(4信號相關性模型+Louvain社區檢測)、Deep Research自動網絡搜索。
GBrain都在保持頁面嘅可讀性,冇變成黑箱數據庫。
最終嘅收斂點可能係:LLM Wiki嘅結構化 + GBrain嘅自動化 = 下一代個人知識操作系統。
行業趨勢都好明確:
傳統RAG → 持久化知識庫 → Agent記憶系統 → 個人迷你AGI
(每次檢索) (增量編譯) (持續學習) (自主維護)2026年4月Garry Tan開源GBrain,標誌着AI記憶系統進入開源時代。呢個唔係一個小工具,而係一個知識操作系統。
六、你應該揀邊條?
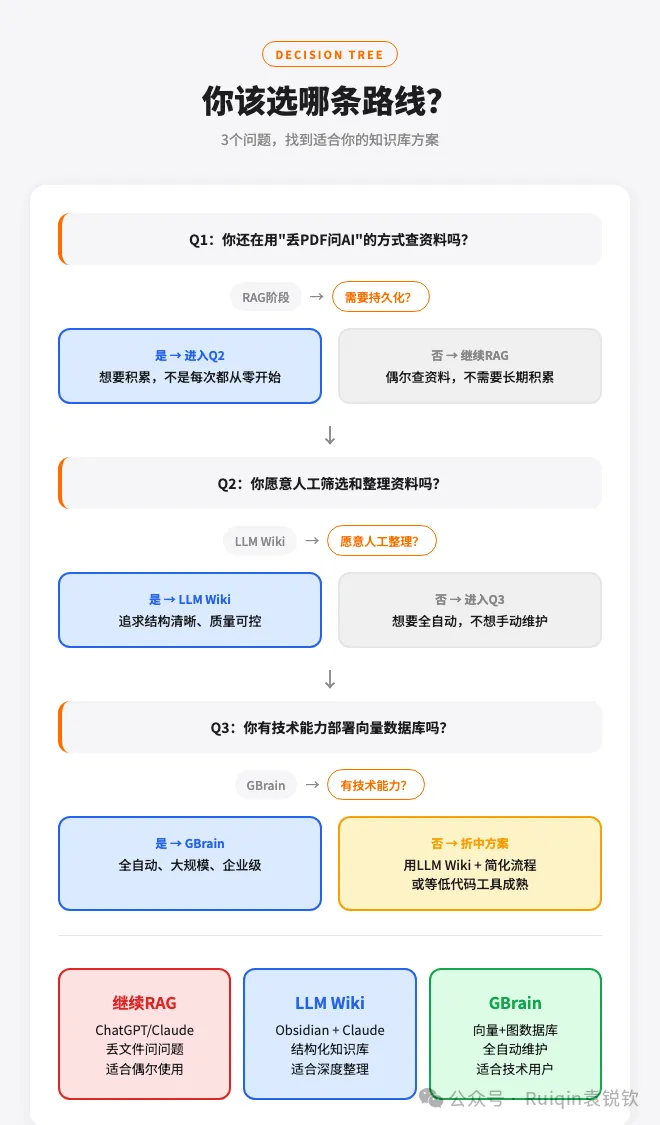
如果你仲係「掟PDF問AI」
唔好急住揀路線。先問自己:我真係需要積累知識,定係只係偶然查資料?
如果只係偶然用,繼續RAG(ChatGPT/Claude掟文件)就夠。
如果你願意人手整理
揀LLM Wiki今日就可以開始:
- 1. 開文件夾(raw/sources、wiki/entities、wiki/concepts)
- 2. 寫Schema(3-5條規則就夠)
- 3. 掟第一份資料入去,等Claude幫你生成Wiki頁面
- 4. 每星期Lint檢查一次
推薦工具:Obsidian + claude-obsidian插件(最輕量,免費開始)。
如果你唔想手動維護,而且有技術能力
揀GBrain全自動、大規模、可以連接多種資訊源。
但需要部署向量數據庫,技術門檻中高。
如果你唔想手動維護,但技術能力有限
折衷方案:先用LLM Wiki + 簡化流程,或者等低代碼工具成熟。
七、畀唔同人嘅建議
畀普通人
唔使焦慮。AI知識庫仲係早期,用咗先比揀邊個更重要。
由LLM Wiki開始,今日就可以行得通。就算得10個頁面,都好過每次重新檢索。
畀資深AI實踐者
如果你已經在用Agent、做多Agent系統、或者管理大量資訊源,GBrain嘅方向更值得投入。
向量檢索+知識圖譜+自動化流程,呢三件事唔係錦上添花,係Agent有長期記憶嘅基礎設施。
畀內容創作者
你嘅文章、影片、播客、課程——呢啲「零散資料」本身就係知識庫嘅原材料。
關鍵問題:你嘅內容係被消費完就消失,定係被編譯入可重用嘅知識層?
八、寫喺最後
Karpathy同Garry Tan,一個係研究導向,一個係實戰導向;一個回答「知識點寫」,一個回答「知識點運行」。
但佢哋都反對同一件事:臨時檢索、冇積累、每次由零開始。
你嘅知識庫係要「寫一本百科全書」,定係要「搭一個操作系統」?
呢個問題冇標準答案。但唔揀都係一種選擇——繼續RAG,繼續每次由零開始。
回覆「知識庫」,送你三份資料:
- 1. LLM Wiki快速上手指南(5分鐘上手,今日就可以開始)
- 2. 十步深度認知框架完整版(系統化學習任何複雜主題嘅方法論)
- 3. AI知識庫工具清單(2026年4月版)(RAG/LLM Wiki/GBrain/知識圖譜/Agent記憶全覆蓋)
袁鋭欽 | AI編程實踐者 | 公眾號「Ruiqin 袁鋭欽」 參考資料:Karpathy LLM Wiki設計文檔、GBrain開源項目、nashsu/llm_wiki、AgriciDaniel/claude-obsidian
看完這篇文章,你會明白為什麼"丟PDF問AI"已經不夠用了,以及AI知識庫正在往哪走。
一、先問你一個問題
你是不是也這樣用AI的?
看到一篇好文章,丟給ChatGPT:"幫我總結一下。"
過幾天有個相關問題,又打開一個新窗口,重新上傳文件,再問一遍。
同一個問題多問幾次,答案可能不一樣。新資料進來,舊知識不會自動重組。問完就結束,下次重新撈材料。
這不是你的問題。這是傳統RAG(檢索增強生成)的先天缺陷——每次都在從零開始檢索,沒有積累。
正如Andrej Karpathy說的:"Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up."
真正的問題不是"AI能不能搜到信息",而是:AI能不能把零散資料,沉澱成一套可複用、可維護、可持續更新的知識層?
2026年,這個問題有了兩個截然不同的答案。
二、兩條路線:知識編譯 vs 知識運行
路線一:LLM Wiki——知識編譯
發起人:Andrej Karpathy(OpenAI創始成員,前特斯拉AI總監)
他的核心想法不是把一堆資料直接丟給模型臨時檢索,而是先把原始資料整理成一套穩定的Wiki知識層,再讓AI在這套知識層上工作。
簡單說——給AI一本百科全書,讓它自己寫、自己維護、自己更新交叉引用。
Karpathy設計了三層架構:
- • 原始資料層:你的PDF、文章、筆記,人類管理,LLM只讀不修改
- • Wiki層:LLM完全擁有,創建頁面、更新內容、維護交叉引用
- • Schema層:定義Wiki結構、規則、工作流程,人類和LLM共同演化
三大核心操作:
- 1. Ingest(攝取):丟新資料進去,LLM讀取並更新Wiki
- 2. Query(查詢):問問題,LLM在Wiki裏搜索相關頁面綜合回答
- 3. Lint(檢查):定期健康檢查,找矛盾、死鏈、孤兒頁面
Karpathy明確界定了人機分工:人類負責策劃來源、引導方向、提出正確問題;AI負責所有彙總、交叉引用、歸檔和簿記工作。
"The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping. LLMs don't get bored, don't forget to update a cross-reference, and can touch 15 files in one pass."
社區熱門實現:nashsu/llm_wiki(4.8k Stars,桌面應用)、AgriciDaniel/claude-obsidian(3.7k Stars,Claude Code插件)。
路線二:GBrain——知識運行
發起人:Garry Tan(Y Combinator CEO)
與Karpathy的研究導向不同,Garry Tan是長期在用Agent的人,直接把自己需要的知識運行系統做出來了。2026年4月,他將個人13年積累的17,888頁筆記、4,383個人物實體、723個項目,轉化為可複製的開源系統。
如果說LLM Wiki回答的是"知識怎麼寫",那GBrain回答的是"知識系統怎麼持續運行"。
GBrain保留了頁面的可讀/可編輯形態,但在上面疊加了一整層工程基礎設施:數據庫、向量檢索、關鍵詞索引、知識圖譜、自動化流程、多媒體處理。
關鍵特性是"Dream Loop(夢循環)":AI在對話前後進行讀寫操作以更新知識,定期"反思"並整合新信息到持久記憶,支持MCP串接Claude與Cursor。
一場客戶會議錄音,在普通知識庫裏只是一個附件;在GBrain裏,它會自動轉錄、生成頁面、更新實體、補到時間線、建立索引。後續提問時,你面對的不是原始錄音,而是被拆解和結構化過的知識對象。
三、核心差異:一張表說清楚
四、兩條路線的技術架構
五、未來趨勢:兩條路線正在靠近
現在LLM Wiki和GBrain看起來是兩條平行線,但它們正在靠近。
LLM Wiki社區已經在加入向量搜索(nashsu/llm_wiki用LanceDB)、知識圖譜(4信號相關性模型+Louvain社區檢測)、Deep Research自動網絡搜索。
GBrain也在保持頁面的可讀性,沒有變成黑箱數據庫。
最終的收斂點可能是:LLM Wiki的結構化 + GBrain的自動化 = 下一代個人知識操作系統。
行業趨勢也很明確:
傳統RAG → 持久化知識庫 → Agent記憶系統 → 個人迷你AGI
(每次檢索) (增量編譯) (持續學習) (自主維護)2026年4月Garry Tan開源GBrain,標誌着AI記憶系統進入開源時代。這不是一個小工具,是一個知識操作系統。
六、你該選哪條?
如果你還在"丟PDF問AI"
先別急着選路線。先問自己:我真的需要積累知識,還是隻是偶爾查資料?
如果只是偶爾用,繼續RAG(ChatGPT/Claude丟文件)就夠了。
如果你願意人工整理
選LLM Wiki。今天就能開始:
- 1. 建文件夾(raw/sources、wiki/entities、wiki/concepts)
- 2. 寫Schema(3-5條規則就夠了)
- 3. 丟第一份資料進去,讓Claude幫你生成Wiki頁面
- 4. 每週Lint檢查一次
推薦工具:Obsidian + claude-obsidian插件(最輕量,免費開始)。
如果你不想手動維護,且有技術能力
選GBrain。全自動、大規模、能接多種信息源。
但需要部署向量數據庫,技術門檻中高。
如果你不想手動維護,但技術能力有限
折中方案:先用LLM Wiki + 簡化流程,或等低代碼工具成熟。
七、給不同人的建議
給普通人
不要焦慮。AI知識庫還在早期,先用起來比選哪個更重要。
從LLM Wiki開始,今天就能跑通。哪怕只有10個頁面,也比每次重新檢索強。
給資深AI實踐者
如果你已經在用Agent、做多Agent系統、或者管理大量信息源,GBrain的方向更值得投入。
向量檢索+知識圖譜+自動化流程,這三件事不是錦上添花,是Agent有長期記憶的基礎設施。
給內容創作者
你的文章、視頻、播客、課程——這些"零散資料"本身就是知識庫的原材料。
關鍵問題:你的內容是被消費完就消失了,還是被編譯進可複用的知識層?
八、寫在最後
Karpathy和Garry Tan,一個是研究導向,一個是實戰導向;一個回答"知識怎麼寫",一個回答"知識怎麼運行"。
但他們都反對同一件事:臨時檢索、沒有積累、每次從零開始。
你的知識庫是要"寫一本百科全書",還是要"搭一個操作系統"?
這個問題沒有標準答案。但不選也是一種選擇——繼續RAG,繼續每次從零開始。
回覆"知識庫",送你三份資料:
- 1. LLM Wiki快速上手指南(5分鐘上手,今天就能開始)
- 2. 十步深度認知框架完整版(系統化學習任何複雜主題的方法論)
- 3. AI知識庫工具清單(2026年4月版)(RAG/LLM Wiki/GBrain/知識圖譜/Agent記憶全覆蓋)
袁鋭欽 | AI編程實踐者 | 公眾號「Ruiqin 袁鋭欽」 參考資料:Karpathy LLM Wiki設計文檔、GBrain開源項目、nashsu/llm_wiki、AgriciDaniel/claude-obsidian