LLM Wiki:讓AI真正幫你“維護”個人知識庫,而不是每次提問都臨時搜索
整理版優先睇
LLM Wiki 將 Andrej Karpathy 理念落地,讓 AI 幫你自動維護個人知識庫,實現知識複利增長
呢篇文章介紹一個開源桌面應用 LLM Wiki,基於 Andrej Karpathy 嘅理念:唔好每次叫 AI 臨時 RAG,而係等佢增量構建並持續維護一個持久化嘅 Markdown 知識庫。作者引用 GitHub 項目 nashsu/llm_wiki,詳細講解呢個工具點樣將抽象概念變成跨平台 App,大大降低門檻。
文章背景係現代人信息過載,讀咗好多嘢但需要時揾唔到關鍵資訊;用 ChatGPT 呢類工具每次都要從零開始,知識無法真正積累。LLM Wiki 嘅解法係讓 AI 做「專屬知識管理員」,自動將資料轉化為結構化、互相連結嘅 Wiki,並支援增量更新。整體結論係呢個工具方向好正確,唔係 AI 幫你搜,而係幫你建、幫你連、幫你維護。
作者同時指出優勢(真正積累、人機分工清晰、本地可控)同侷限(Token 成本、依賴模型質量、學習曲線),並畀咗實用建議。適合對知識管理、個人第二大腦感興趣嘅朋友試用。
- LLM Wiki 將 Karpathy 理念工程化,讓 AI 從「臨時助手」變成「長期知識夥伴」,持續維護結構化知識庫,避免每次查詢從零開始。
- 核心方法係智能攝入:支援 PDF、網頁、文件夾等格式,利用兩步思維鏈先分析再生成頁面,並用 SHA256 增量緩存慳 token。
- 自動構建知識圖譜,用四信號相關度模型加 Louvain 算法發現知識聚類,可視化展示「驚奇連接」同知識缺口。
- 人機分工清晰:AI 負責整理、連結、找缺口;人類掌控方向、做最終判斷,並通過 Lint 功能定期健康檢查。
- 立即行動:下載安裝、創建項目、配置 LLM API、導入資料,之後每週花 15-30 分鐘 Review 同 Lint,即可逐步累積知識複利。
LLM Wiki 專案
GitHub 倉庫,包含安裝包、文檔、源碼,支援 Mac/Windows/Linux
背景與核心理念:唔好再臨時 RAG 啦
成日畀信息過載折磨嘅我哋,係咪試過讀咗大量書同文章,存咗一堆筆記,但需要時揾唔到關鍵資訊?用 ChatGPT 或者 Notion AI 問完,答案都係「基於當前上下文」臨時生成,感覺知識永遠積累唔到。呢個就係 Andrrej Karpathy 提出 LLM Wiki 理念嘅原因:唔好次次都叫 AI 從原始文檔臨時檢索,而係等佢增量構建並維護一個持久化嘅 Markdown 知識庫。人類提供資料同方向,AI 負責整理、連結、更新同發現缺口。
Karpathy 嘅核心洞見:知識要編譯一次,持續維護,避免每次查詢從零開始
nashsu/llm_wiki 呢個開源項目就係將呢個抽象理念變成跨平台桌面 App(Mac/Windows/Linux),極大降低門檻。項目更新活躍,已經有唔少功能同社區反饋。
核心功能:從攝入到圖譜,再到查詢維護
LLM Wiki 嘅智能攝入(Ingest)支援 PDF、網頁、文件夾、DOCX、Markdown 等多種格式,仲有 Chrome 一鍵剪藏。佢用兩步思維鏈:先分析(提取實體、概念、與現有知識嘅關聯同矛盾),再生成頁面。
- SHA256 增量緩存:文件冇變就跳過,節省 token 同時間。
- 持久化隊列:支援暫停、重試、崩潰恢復,進度實時可見。
- 多模態支援:自動提取 PDF 圖片,用視覺模型生成描述並關聯。
系統比單次 prompt 更重要:增量緩存同持久化隊列確保知識庫持續累積
自動構建知識圖譜方面,使用四信號相關度模型(直接 wikilink、來源重疊、Adamic-Adar、類型親和),結合 Louvain 社區檢測算法自動發現知識聚類。圖譜可視化清晰,可以見到「驚奇連接」同知識缺口(孤立頁面、稀疏社區等),仲可以一鍵觸發 Deep Research 進行自動補全。
查詢同維護方面,聊天界面支援多對話、引用面板同保存到 Wiki。Lint 功能會定期健康檢查矛盾、孤兒頁、過時資訊。Async Review 系統標記需要人工判斷嘅內容,唔會阻塞流程。Deep Research 仲可以自動搜索並攝入結果。
Lint 功能係「知識衞生」嘅關鍵,避免 AI 放養導致資料混亂
點樣上手:5-10 分鐘起步
首先去 GitHub Releases 下載對應系統嘅安裝包(.dmg/.msi/.deb/AppImage),直接安裝。開咗之後新建項目,揀模板(研究、閲讀、個人成長等),系統會自動生成 purpose.md 同 schema.md 文檔。
Purpose 係 Wiki 嘅靈魂,寫得越清楚,AI 生成嘅相關性越高
然後喺 Settings 填 API Key(支援 OpenAI、Anthropic、Ollama、本地模型等),可選開向量搜索同 Web Search。接著導入資料:可以喺 Sources 面板匯入檔案或文件夾,或者直接將檔案掉到 raw/sources/ 目錄(支援自動監聽),亦可以用 Chrome 擴展一鍵剪藏網頁。
AI 會自動生成 wiki 頁面、更新 index.md、overview.md、log.md,並加上交叉引用。之後日常使用就係喺 Chat 提問、瀏覽知識圖譜、處理 Review 面板嘅待辦事項,定期運行 Lint 維護。有價值嘅對話可以保存為新 Wiki 頁面,形成 Compounding(複利增長)。整個 Wiki 文件夾係標準 Obsidian Vault,可直接用 Obsidian 瀏覽編輯。
每日使用只係「問問題 + 睇圖譜 + 做 Review」,維護成本好低
優勢同侷限:並唔係完美,但方向好正
最大優勢係真正積累:知識編譯一次,持續維護,避免每次查詢從零開始。人類同 AI 分工清晰:AI 做苦活(整理、連結、找缺口),人類保留方向同最終判斷。本地優先、資料喺自己手,兼容 Obsidian,私隱友好,仲支援本地模型。
超越傳統筆記:唔係靜態存儲,而係動態、圖譜化、帶智能洞察嘅知識網絡
不過都有潛在侷限:初次大量攝入會消耗較多 API 調用,建議分批或用本地模型;輸出質量取決於所用 LLM,複雜領域可能要人工校正;界面雖然友好,但要發揮最大價值,需要理解 purpose/schema 設定同定期 Lint;呢個工具適合深度知識管理(研究、學習、專業領域),日常瑣事用傳統筆記可能更有效率。
使用建議:點樣發揮最大效果
- 1 精心定義 Purpose:呢個係 Wiki 嘅靈魂,清晰寫下目標同關鍵問題,顯著提升 AI 生成嘅相關性。
- 2 定期維護:每週花 15-30 分鐘 Review 同 Lint,唔好畀 AI 完全放養。
- 3 結合 Obsidian:用 Obsidian 嘅圖譜同插件增強瀏覽體驗。
- 4 Agent 集成:如果你用 Claude Code 等,接入 skill 後,編程同研究流程會更順滑。
- 5 成本控制:優先試本地模型(Ollama),重要項目先用強力雲模型。
- 6 迭代優化:根據使用反饋更新 schema,等 AI 越來越懂你嘅思維方式。
最後提醒:最缺嘅唔係更多工具,而係讓已有知識真正複利變現嘅能力
成日俾資訊過載折磨嘅我哋,你有冇試過咁樣:讀咗好多書、論文、文章,存咗一堆筆記同PDF,但係真係要用嗰陣就揾唔到關鍵資訊?用ChatGPT、Notion AI問嘢嘅時候,答案成日都係「根據當下上文下理」臨時生成,覺得知識永遠都冇辦法真正累積?
最近發現一個將Andrej Karpathy方法論徹底工程化嘅開源項目:LLM Wiki,社區反應幾好。佢唔係一個AI傾偈工具,而係令LLM成為你嘅「專屬知識管理員」:自動將資料轉化成結構化、互相連結、持續更新嘅個人Wiki。
由Karpathy理念到實用桌面App
大神Karpathy提出嘅LLM Wiki核心理念係:唔好俾LLM每次都喺原始文件度「臨時RAG」,而係俾佢增量構建並維護一個持久化嘅Markdown知識庫。人類提供資料同方向,AI負責整理、連結、更新同埋發現缺口。同時,Wiki完全兼容Obsidian,可以直接打開使用。
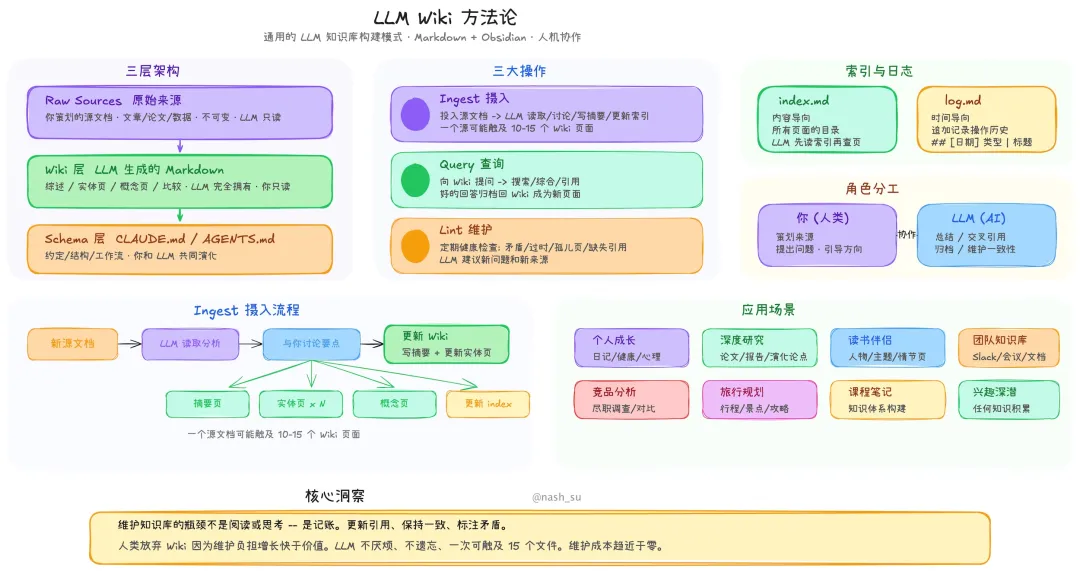
nashsu/llm_wiki項目將呢個抽象理念進一步變成咗跨平台桌面應用程式(Mac/Windows/Linux),極大降低咗門檻。項目更新比較活躍,已經積累咗豐富功能同社區回饋。
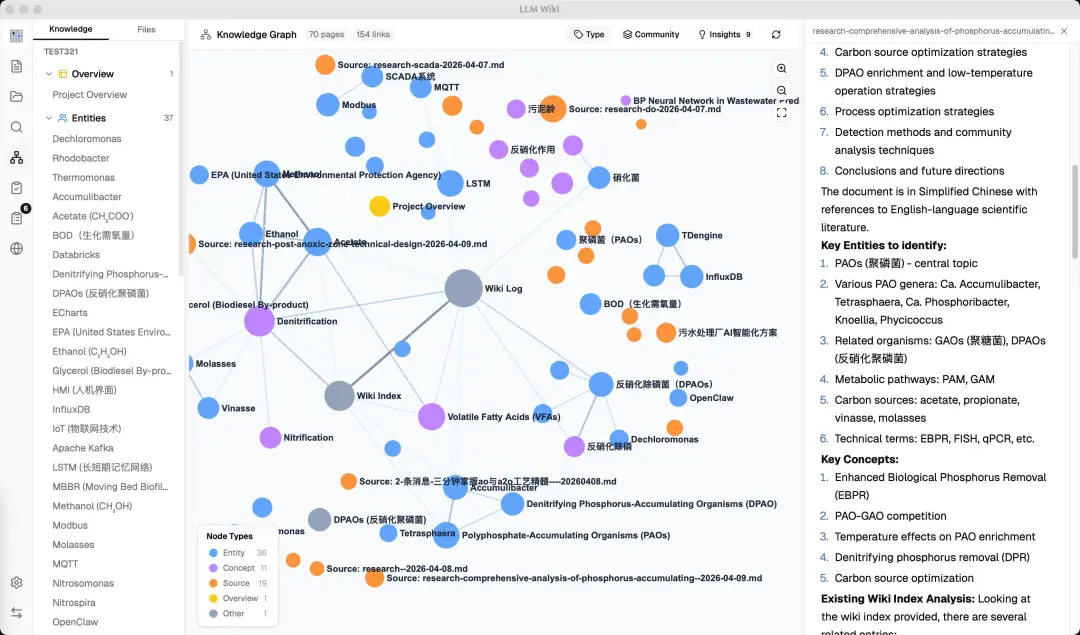
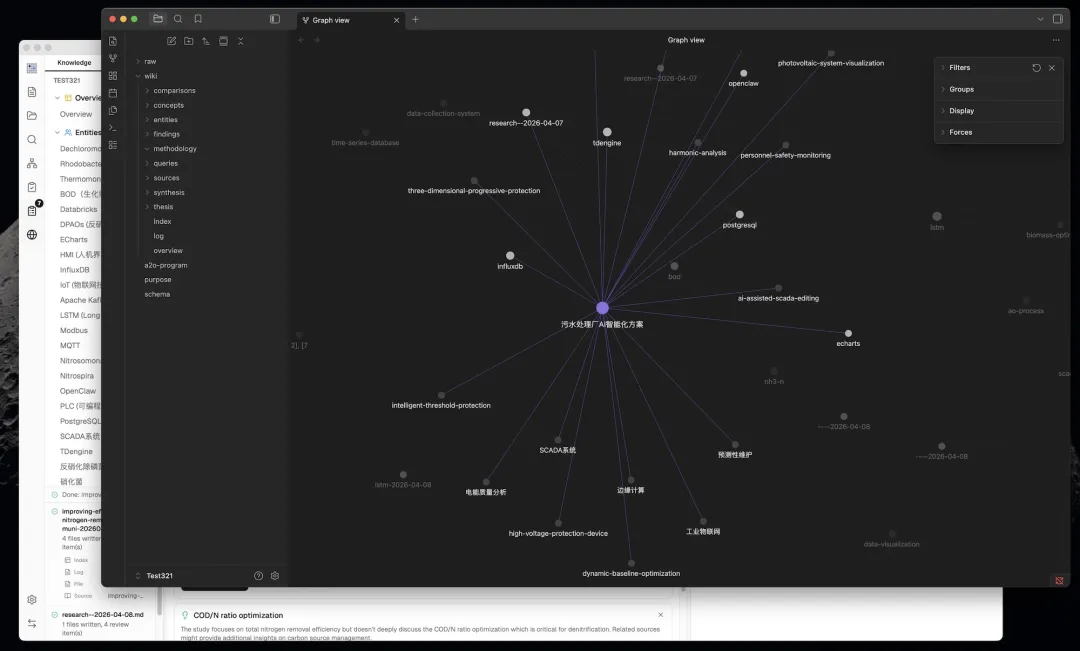
核心功能亮點(由實用角度睇)
1. 智能攝入(Ingest)
支援PDF、網頁、文件夾、DOCX、Markdown等多種格式,仲支援Chrome一鍵剪藏。
採用兩步思維鏈:先分析(提取實體、概念、同現有知識嘅關聯/矛盾),再生成頁面。◦ SHA256增量緩存:文件冇變就跳過,節省token同時間。 ◦ 持久化隊列:支援暫停、重試、崩潰恢復,進度即時可見。 ◦ 多模態支援:自動提取PDF圖片,用視覺模型生成描述並關聯。 2. 自動構建知識圖譜
使用四信號相關度模型(直接wikilink、來源重疊、Adamic-Adar、類型親和),結合Louvain社區檢測算法自動發現知識聚類。
圖譜可視化清晰,睇到「驚奇連接」同知識缺口(孤立頁面、稀疏社區等),可以一鍵觸發Deep Research進行自動補全。
3. 查詢同維護 ◦ 聊天界面支援多對話、引用面板、保存到Wiki。 ◦ Lint功能會定期健康檢查矛盾、孤兒頁、過時資訊。 ◦ Async Review系統:AI標記需要人工判斷嘅內容,唔會阻塞流程。 ◦ Deep Research:AI生成搜索主題,透過Tavily等工具搜索並自動攝入結果。 4. 開放集成
內置本地HTTP API(127.0.0.1:19828),支援Agent接入。一行命令就可以安裝skill到Claude Code等,令你嘅Coding Agent直接讀寫Wiki。
項目結構比較清晰,可以直接導出/用Obsidian打開。
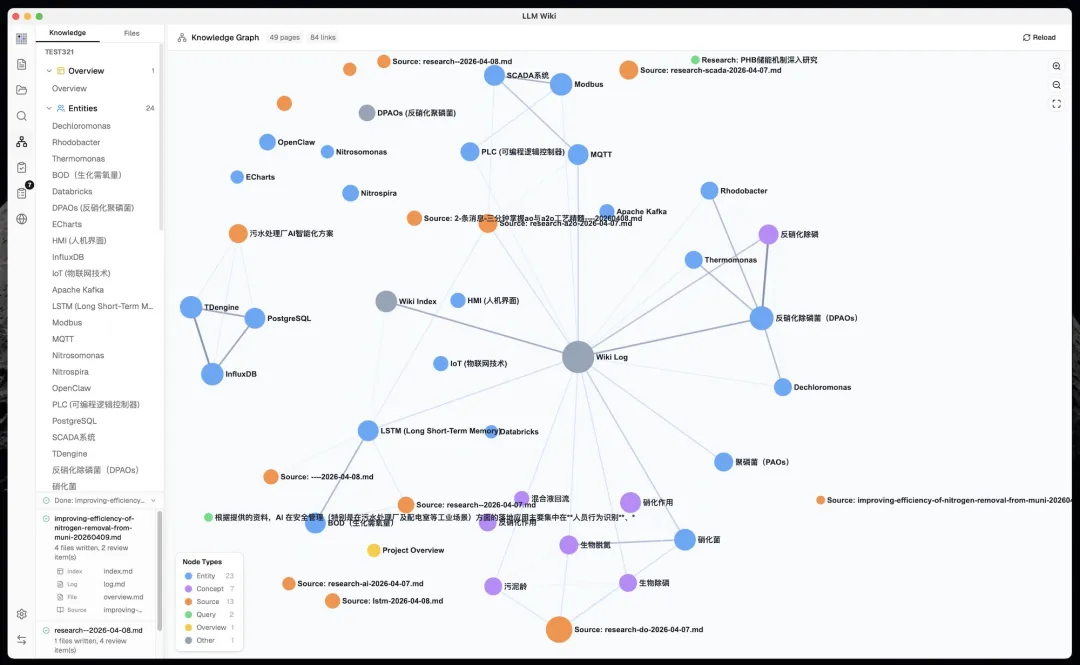
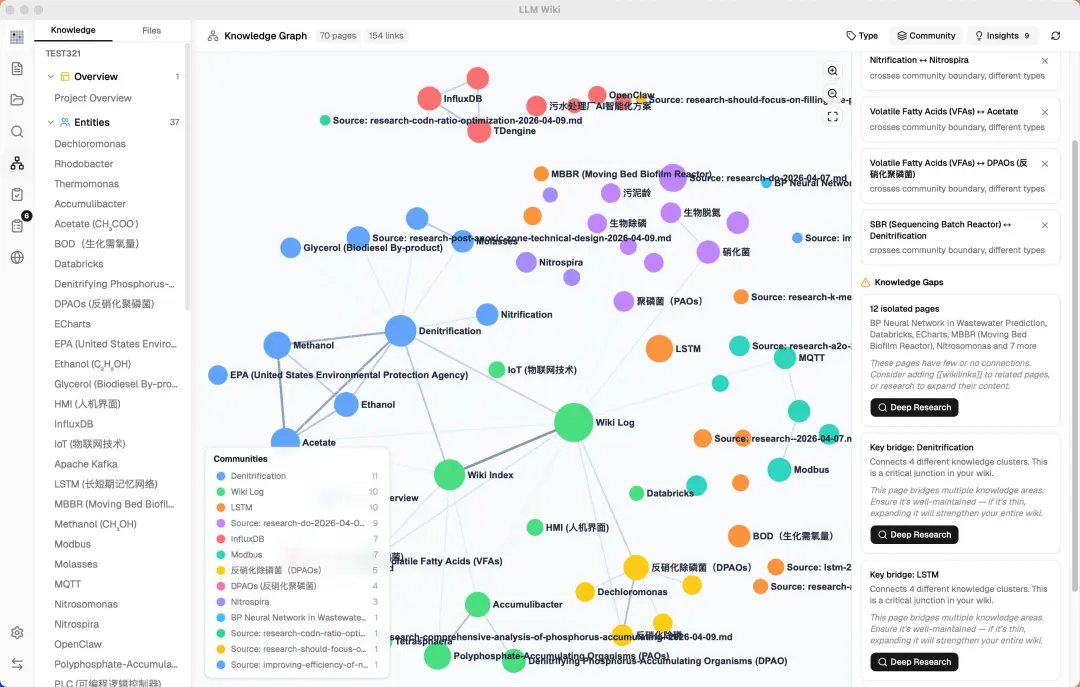
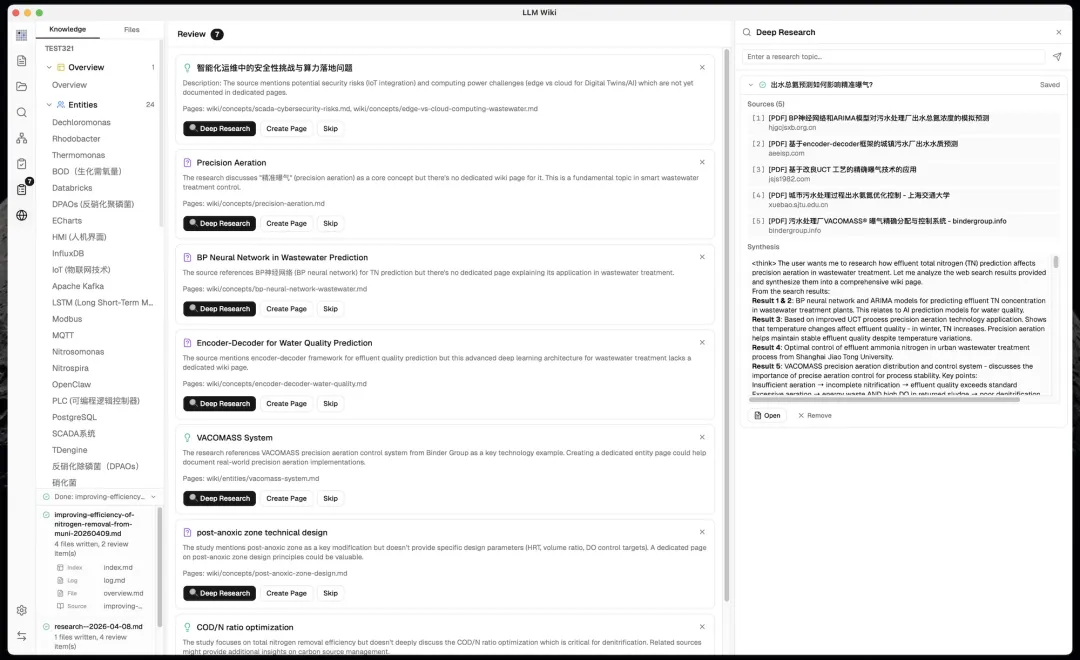
點樣上手使用(5-10分鐘起步)
1. 下載安裝:去GitHub Releases下載對應系統安裝包(.dmg/.msi/.deb/AppImage),直接執行安裝就得。 2. 創建項目:啟動之後新建項目,選擇模板(研究、閲讀、個人成長等),會自動生成 purpose.md 同 schema.md 文檔。 3. 配置LLM:喺Settings度填寫API Key(支援OpenAI、Anthropic、Ollama、本地模型等各種方式)。可以揀開啓向量搜索同Web Search。 4. 導入資料: ◦ Sources面板導入文件/文件夾。 ◦ 或者將文件掟到項目目錄嘅 raw/sources/(支援自動監聽)。◦ Chrome擴展一鍵剪藏網頁。 5. 睇住構建:Activity面板即時顯示進度。AI會生成wiki頁面、更新index.md、overview.md、log.md,並加入交叉引用。 6. 日常使用: ◦ 喺Chat度提問,答案會引用具體頁面。 ◦ 瀏覽知識圖譜發現連接。 ◦ Review面板處理待辦事項。 ◦ 定期執行Lint維護健康。 ◦ 有價值對話可以保存做新Wiki頁面,從而繼續 compounding(複利增長/累積)。
成個Wiki文件夾就係標準嘅Obsidian Vault,可以隨時用熟悉嘅工具瀏覽、編輯。
分析:優勢同侷限
優勢:
• 真正累積:知識編譯一次,持續維護,避免每次查詢「從零開始」。長期使用之下,Wiki會越來越智能、連貫。 • 人類+AI分工清晰:AI做苦工(整理、連結、揾缺口),人類保留方向把控同最終判斷。 • 本地優先、可控:數據喺本地,兼容Obsidian,私隱友好,支援本地模型。 • 超越傳統筆記:唔係靜態儲存,而係動態、圖譜化、帶智能洞察嘅知識網絡。
潛在侷限:
• Token成本:初次大量攝入會消耗較多API調用,建議分批或用本地模型。 • 依賴模型質量:輸出質量取決於所用LLM,複雜領域可能需要人工校正。 • 學習曲線:界面友好,但要發揮最大價值,仲需要理解purpose/schema嘅設定同定期Lint。 • 唔係萬能:適合需要深度知識管理嘅領域(例如研究、學習、專業領域),日常瑣事可能用傳統筆記更高效。
整體嚟講,佢唔係為咗「替代」Notion或Obsidian,而係一個將AI真正融入知識管理流程嘅進化版工具。
使用建議(令效果最大化)
• 精心定義Purpose:呢個係Wiki嘅「靈魂」,清晰寫低目標、關鍵問題,可以顯著提升AI生成嘅相關性同深度。 • 定期維護:每星期花15-30分鐘Review同Lint,唔好俾AI完全「放養」。 • 結合Obsidian:用Obsidian嘅圖譜、插件增強瀏覽體驗。 • Agent集成:如果你用Claude Code等,接入skill之後,編程/研究流程會更順暢。 • 成本控制:可以優先嘗試Ollama本地模型,重要項目先用強力雲模型。 • 迭代優化:根據使用回饋更新schema,令AI越來越明白你嘅思考方式。
最後:AI時代知識管理嘅正確打開方式
喺資訊爆炸嘅時代,我哋最缺嘅唔係更多工具,而係令已有知識真正複利變現嘅能力。LLM Wiki將Karpathy嘅洞見變成咗可落地嘅產品,令AI由「臨時助手」變成咗一個「長期知識夥伴」。呢個工具仲未係完美無缺,但方向非常正確,唔係AI幫你搜,而係AI幫你建、幫你連、幫你維護。喺AI時代更好地「管理自己嘅大腦」。
推薦對知識管理、個人第二大腦、研究學習感興趣嘅朋友去試試,項目地址:
https://github.com/nashsu/llm_wiki
(本文基於公開GitHub資訊同項目文檔整理,觀點僅供參考。開源項目發展迅速,建議以最新版本為準。)
常年被信息過載折磨的我們,你是否也有過這種經歷:讀了大量書、論文、文章,存了一堆筆記和PDF,但真正需要時卻找不到關鍵信息?用ChatGPT、Notion AI提問時,答案總是“基於當前上下文”臨時生成,感覺知識永遠無法真正積累?
最近發現一個把Andrej Karpathy方法論徹底工程化的開源項目:LLM Wiki,社區反響不錯。它不是一個AI聊天工具,而是讓LLM成為你的“專屬知識管理員”:自動把資料轉化為結構化、相互連結、持續更新的個人Wiki。
從Karpathy理念到實用桌面App
大神Karpathy提出的LLM Wiki核心理念是:不要讓LLM每次都從原始文檔“臨時RAG”,而是讓它增量構建並維護一個持久化的Markdown知識庫。人類提供資料和方向,AI負責整理、連結、更新和發現缺口。同時,Wiki完全兼容Obsidian,可直接打開使用。
nashsu/llm_wiki項目把這個抽象理念進一步變成了跨平台桌面應用(Mac/Windows/Linux),極大降低了門檻。項目更新比較活躍,已經積累了豐富功能和社區反饋。
核心功能亮點(從實用角度看)
1. 智能攝入(Ingest)
支持PDF、網頁、文件夾、DOCX、Markdown等多種格式,還支持Chrome一鍵剪藏。
採用兩步思維鏈:先分析(提取實體、概念、與現有知識的關聯/矛盾),再生成頁面。◦ SHA256增量緩存:文件沒變就跳過,節省token和時間。 ◦ 持久化隊列:支持暫停、重試、崩潰恢復,進度實時可見。 ◦ 多模態支持:自動提取PDF圖片,用視覺模型生成描述並關聯。 2. 自動構建知識圖譜
使用四信號相關度模型(直接wikilink、來源重疊、Adamic-Adar、類型親和),結合Louvain社區檢測算法自動發現知識聚類。
圖譜可視化清晰,能看到“驚奇連接”和知識缺口(孤立頁面、稀疏社區等),可以一鍵觸發Deep Research進行自動補全。3. 查詢與維護 ◦ 聊天界面支持多對話、引用面板、保存到Wiki。 ◦ Lint功能會定期健康檢查矛盾、孤兒頁、過時信息。 ◦ Async Review系統:AI標記需要人工判斷的內容,不會阻塞流程。 ◦ Deep Research:AI生成搜索主題,通過Tavily等工具搜索並自動攝入結果。 4. 開放集成
內置本地HTTP API(127.0.0.1:19828),支持Agent接入。一行命令就能安裝skill到Claude Code等,讓你的Coding Agent直接讀寫Wiki。
項目結構比較清晰,可直接導出/用Obsidian打開。
如何上手使用(5-10分鐘起步)
1. 下載安裝:去GitHub Releases下載對應系統安裝包(.dmg/.msi/.deb/AppImage),直接運行安裝即可。 2. 創建項目:啓動後新建項目,選擇模板(研究、閲讀、個人成長等),會自動生成 purpose.md 和 schema.md 文檔。 3. 配置LLM:在Settings中填寫API Key(支持OpenAI、Anthropic、Ollama、本地模型等各種方式)。可選開啓向量搜索和Web Search。 4. 導入資料: ◦ Sources面板導入文件/文件夾。 ◦ 或把文件扔到項目目錄的 raw/sources/(支持自動監聽)。◦ Chrome擴展一鍵剪藏網頁。 5. 觀看構建:Activity面板實時顯示進度。AI會生成wiki頁面、更新index.md、overview.md、log.md,並添加交叉引用。 6. 日常使用: ◦ 在Chat中提問,答案會引用具體頁面。 ◦ 瀏覽知識圖譜發現連接。 ◦ Review面板處理待辦事項。 ◦ 定期運行Lint維護健康。 ◦ 有價值對話可保存為新Wiki頁面,從而繼續 compounding(複利增長/積累)。
整個Wiki文件夾就是標準的Obsidian Vault,可以隨時用熟悉工具瀏覽、編輯。
分析:優勢與侷限
優勢:
• 真正積累:知識編譯一次,持續維護,避免每次查詢“從零開始”。長期使用下,Wiki會越來越智能、連貫。 • 人類+AI分工清晰:AI幹苦活累活(整理、連結、找缺口),人類保留方向把控和最終判斷。 • 本地優先、可控:數據在本地,兼容Obsidian,隱私友好,支持本地模型。 • 超越傳統筆記:不是靜態存儲,而是動態、圖譜化、帶智能洞察的知識網絡。
潛在侷限:
• Token成本:初次大量攝入會消耗較多API調用,建議分批或用本地模型。 • 依賴模型質量:輸出質量取決於所用LLM,複雜領域可能需人工校正。 • 學習曲線:界面友好,但要發揮最大價值,仍需理解purpose/schema的設定和定期Lint。 • 不是萬能:適合需要深度知識管理的領域(如研究、學習、專業領域),日常瑣事可能用傳統筆記更高效。
總體來說,它不是為了“替代”Notion或Obsidian,而是一個把AI真正融入知識管理流程的進化版工具。
使用建議(讓效果最大化)
• 精心定義Purpose:這是Wiki的“靈魂”,清晰寫下目標、關鍵問題,能顯著提升AI生成的相關性和深度。 • 定期維護:每週花15-30分鐘Review和Lint,別讓AI完全“放養”。 • 結合Obsidian:用Obsidian的圖譜、插件增強瀏覽體驗。 • Agent集成:如果你用Claude Code等,接入skill後,編程/研究流程會更絲滑。 • 成本控制:可以優先嚐試Ollama本地模型,重要項目再上強力雲模型。 • 迭代優化:根據使用反饋更新schema,讓AI越來越懂你的思維方式。
最後:AI時代知識管理的正確打開方式
在信息爆炸的時代,我們最缺的不是更多工具,而是讓已有知識真正複利變現的能力。LLM Wiki把Karpathy的洞見變成了可落地的產品,讓AI從“臨時助手”變成了一個“長期知識夥伴”。這個工具還不是完美無缺,但方向非常正確,不是AI幫你搜,而是AI幫你建、幫你連、幫你維護。在AI時代更好地“管理自己的大腦”。
推薦對知識管理、個人第二大腦、研究學習感興趣的朋友去試試,項目地址:
https://github.com/nashsu/llm_wiki
(本文基於公開GitHub信息和項目文檔整理,觀點僅供參考。開源項目發展迅速,建議以最新版本為準。)