Loop Engineering 很好,但先想清楚一個問題
整理版優先睇
Loop Engineering 嘅重點唔係點寫 loop,而係你講唔講得清「做完」嘅標準
呢篇文章係 Feisky 對 Loop Engineering 呢個新 AI 編程範式嘅觀察同實戰心得。作者本身用過 Claude Code + Ralph loop,後來轉用 Codex /goal,對 loop 嘅演變同優缺點有好深體會。文章先交代 Loop Engineering 點樣由 Peter Steinberger 同 Boris Cherny 帶起熱潮,再追溯返去 ReAct 模式同 Ralph loop 嘅不足,然後聚焦 Codex /goal 嘅設計(狀態持久化+權限控制+強制自審),點解比以往方案穩定。
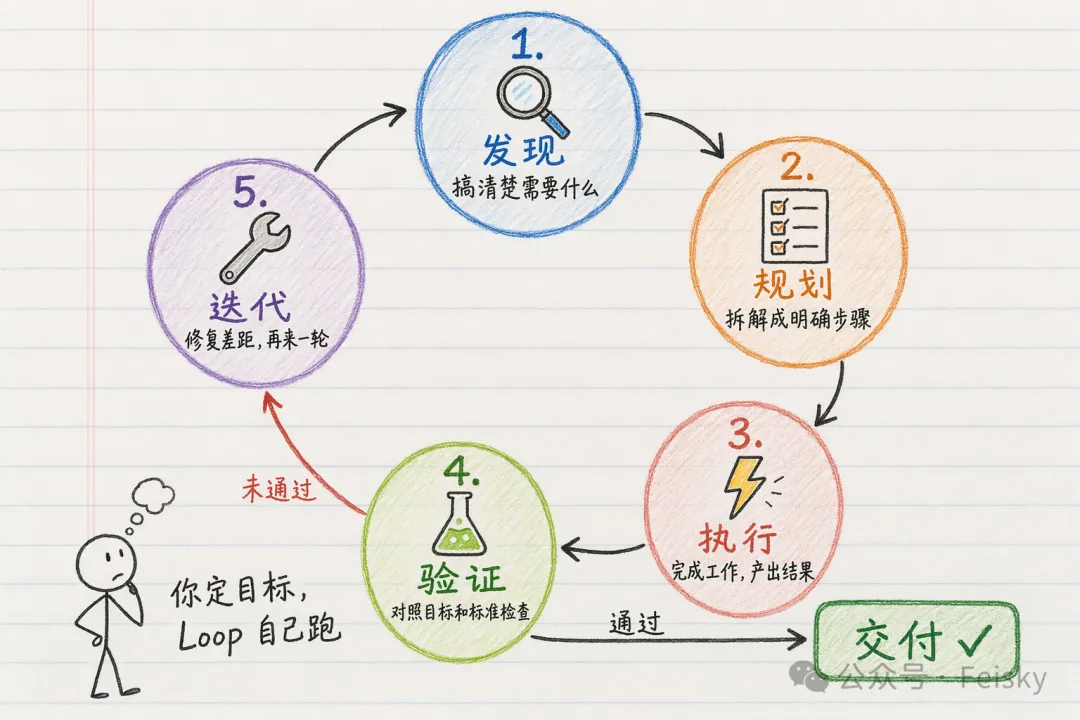
之後作者對比 Loop Engineering 同傳統定時任務嘅分別:定時任務只係定時觸發,Loop 係確保用正確方法完成目標,能夠自行判斷狀態同迭代。跟住畀出實用建議:目標要清楚、步驟有邊界、每步有檢查、有明確停止點,尤其係獨立驗證呢一步——因為模型自己話做完唔可信,要靠另一個子 agent 驗證。
最後作者點出最樸素嘅問題:你手頭嘅事,能唔能夠寫清楚「做完了」?如果可以,loop 幫你慳功夫;如果連完成標準都講唔清,就乖乖一步步嚟。另外仲提醒 token 燒得好快,要衡量自己係 token 富人定窮人,建議用訂閲制產品。整體結論係:Loop Engineering 係強大工具,但前提係你要有能力定義「完成」。
- Loop Engineering 係設計一個自動循環系統,代替人類不斷 prompt agent,直至任務完成。
- 同定時任務嘅最大分別:Loop 關注係咪用正確方法完成目標,而唔係定時觸發。
- Codex /goal 透過狀態持久化、權限控制同強制自審,解決咗 Ralph loop 嘅常見問題(假完成、狀態錯亂)。
- 成功 Loop 嘅關鍵唔係 prompt 寫得多靚,而係能否清晰定義「做完了」嘅標準。
- 獨立驗證(用另一個子 agent 評估)係防止 agent 偷懶或謊報嘅最重要機制。
Addy Osmani: Loop Engineering
Loop Engineering 概念出處
Lance Martin: Designing loops with Fable 5
獨立驗證測試結果
Boris Cherny 談自我驗證
Claude Code 負責人嘅建議
Codex /goal 上線後,我把 Ralph loop 卸了
作者之前嘅詳細文章
Loop Engineering 突然爆紅
呢兩日 Loop Engineering 呢個詞突然喺 AI 圈炸開。Peter Steinberger 發推話你唔應該再 prompt coding agent,而係要設計 prompt agent 嘅 loop,兩日衝到 800+ 萬閲讀。跟住 Claude Code 負責人 Boris Cherny 都附和,佢管嘅幾百個 agent 自己讀 GitHub 同 Slack、自己決定做咩,過去 30 日合併咗 250 幾個 PR,全部由 Claude Code 完成。
今日 Anthropic 仲發佈咗 Claude Fable 5 同 Mythos 5,話可以將幾個月嘅工作壓縮到幾日。作者話好有感觸,因為佢上個月已經開始用 Codex /goal,覺得呢個就係最好用嘅 Loop Engineering 實現,配合 GPT-5.5,完成度好過之前嘅 Claude Code + Ralph loop 組合。
咩係 Loop Engineering?
Loop 簡單講就係一個替你去 prompt agent 嘅小系統:畀 agent 任務、讀結果、判斷做完未,未做完就繼續。以前你用 Claude Code 要自己入 prompt、睇輸出、中斷再入,你本身係個 loop。而家 Loop Engineering 就係將你從個循環入面抽走。
作者話最早可以追溯到 ReAct 模式</highlight>:提示詞之後模型推理、調工具、讀結果、重複直到冇工具調用。呢個 loop 係所有 Agent 嘅基礎。但得呢個唔夠,AI 成日停咗等輸入。之後有 Geoffrey Huntley 嘅 Ralph loop</highlight>:用一行 bash 不斷將同一個 prompt 檔案 send 畀 agent,直到佢話做完。但 Ralph loop 問題多:模型假完成、狀態錯亂、卡死。
後來 Codex 推出 /goal 功能</highlight>,用狀態持久化、權限控制同強制自審解決問題。作者仲提到自己之前寫嘅《Codex /goal 上線後,我把 Ralph loop 卸了》詳細講過。Claude Code 後期都加咗相同功能,但佢認為 Opus 模型比 GPT-5.5 差啲。
同定時任務有咩分別?
驟眼睇 Loop Engineering 好似係將 timing task 改個名,底下一樣係不斷叫 AI 做嘢。但作者點出兩個本質分別:
- 定時任務</highlight>嘅目的係觸發執行,時間固定;到時執行咩取決於畀佢嘅指令,可以係腳本、提示詞甚至 Goal。
- Loop Engineering</highlight>嘅目的係確保 AI 用正確方法完成目標,佢會自己睇狀態、決定下一步,循環直到完成。
實際使用可以結合:例如用 timing task 觸發 GitHub issue 排查,排查過程用 Loop 保證質量。
點樣先用好 Loop Engineering?
作者建議四句口訣:目標寫清楚、步驟有邊界、每步有檢查、有明確停止點</highlight>,確保 agent 可以閉環迭代。Boris Cherny 都有畀建議:權限開 auto、讓 Claude 自己編排子 agent、用 /goal 模式、跑喺雲端,同埋 自我驗證</highlight>。
作者翻過 Codex /goal 源碼,設計思路一致:模型可以話做完,但唔可以話預算就快冇所以要收工。每輪注入自審,強制逐項對照真實文件同測試結果。你可以逼模型繼續做,但你逼唔到佢承認做錯</highlight>,只有獨立驗證先戳穿佢。
最後:你夠唔夠膽話「做完了」?
回到開頭個問題:你要唔要幫手頭嘅事上 loop?判斷標準好簡單:你能唔能夠寫清楚「做完了」</highlight>。寫得清,loop 真係幫你慳好多重複勞動。但如果連做完嘅標準都講唔清,不如一步步嚟。
另外仲要提醒:Loop Engineering 好燒 token</highlight>。自修正、驗證子 agent、重試,每一步都食 token。你係 token 富人定窮人,直接影響你對 loop 嘅態度。如果對消耗敏感,建議用訂閲制產品而唔直接 call API。
如果想深入研究,作者推薦咗 Addy Osmani、Lance Martin、Boris Cherny 嘅文章,同埋佢自己之前嗰篇 Codex /goal 拆解。