MCP 和 Skills 到底什麼區別?一篇文章說清楚
整理版優先睇
MCP 係連接外部系統嘅 USB 協議,Skills 係封裝專業知識同本地工作流程嘅應用程式,兩者唔係競爭,而係互補,建議優先學 Skills。
呢篇文章出自一位 AI 開發者,佢收到網友私信問「MCP 係咪已經過時?而家應該全部用 Skills?」。作者理解呢種焦慮,因為 AI 工具圈成日有新嘢出嚟,每次就有人話舊嘢已死。佢透過分析 MCP 同 Skills 嘅定位同技術本質,釐清兩者區別。
MCP(Model Context Protocol)由 Anthropic 開源,目標係統一 AI 連接工具嘅標準,類似 USB-C 統一充電接口,將 M×N 問題變成 M+N 問題,大幅降低開發成本。但 MCP 有一個嚴重問題:上下文爆炸——每個 MCP Server 會將所有工具定義預加載入上下文,一個 GitHub MCP Server 就食 18,000 tokens,連接 7 個 Server 未開始對話就用咗 67,000 tokens。Anthropic 雖然推出咗 Tool Search 補丁,但只係治標。
Skills 採用另一種設計哲學——漸進式披露(Progressive Disclosure):元數據只需 100 tokens,完整指令相關時先加載,參考文檔按需讀取。仲可以自帶可執行腳本(Python、Bash、JS),腳本執行唔會入上下文,只返回結果。呢個設計天然避開上下文問題,效率更高。作者結論:MCP 適合連接遠程服務、對外暴露 API;Skills 適合內部團隊嘅本地工作流同專業知識。隨住 Skills 生態成熟,MCP 嘅角色會收窄到…
- MCP 係 USB 協議,Skills 係應用程式:MCP 定義 AI 與外部世界嘅連接標準,Skills 將專業知識同工作流程打包成操作手冊。
- Skills 採用漸進式披露,解決知識太多問題:啟動時只加載元數據(約 100 tokens),需要時先讀完整指令,按需加載參考資料,大幅節省上下文。
- Skills 可自帶腳本執行,零上下文成本:複雜流程封裝成腳本後,AI 只需一次調用,腳本代碼同中間結果都唔會入上下文,最終結果先入。
- MCP 嘅致命問題係上下文爆炸:所有工具定義預加載,簡單問題成本被放大幾千倍,連接 3 個以上 Server 準確性明顯下降。
- 選擇指南:團隊內部用 Skills,對外公開用 MCP;本地文件操作、瀏覽器自動化等用 Skills + 內置工具;只有連接遠程 API 或 SaaS 先需要 MCP。
內容結構
my-skill/├──
SKILL.md # 核心指令├── scripts/ # 可執行腳本│ ├── validate.py│ ├── generate.sh│ └── process.js├── references/ # 參考文檔└── assets/ # 模板、配置文件問題源起:MCP 定 Skills,點揀好?
有位網友私信問作者:「MCP 係咪已經過時?而家應該全部用 Skills?」呢條問題好多人都有共鳴。AI Agent 工具圈隔兩個禮拜就出新嘢,每次新嘢一出就有人話舊嘅「已死」。
MCP 同 Skills 唔係功能差異,而係分發方式差異:Skills 係俾自己人用,MCP 係俾全世界用。
作者用一個比喻:如果你係賣服務嘅公司,以 Skills 方式發佈要叫用戶複製 SKILL.md 到指定目錄,用戶未必敢安裝;但 MCP 方式就係「輸入呢個 URL」或者「直接同 AI 講幫我用呢個服務」,方便得多。
MCP:AI 世界嘅 USB 協議,但上下文代價好大
2024 年 11 月 Anthropic 開源 MCP,目標係定義一套標準協議,令任何 AI 都可以即插即用地連接任何工具,將 M×N 問題變成 M+N 問題。
但 MCP 有一個嚴重副作用:吃掉上下文窗口。
真實數據:GitHub MCP Server 有 27 個工具,消耗約 18,000 tokens;Playwright MCP Server 21 個工具,消耗約 13,600 tokens。有開發者配咗 7 個 MCP Server,未開始對話就無咗 67,000 tokens,佔窗口 33%。
Anthropic 推出咗 Tool Search 功能做補丁:MCP 工具按需發現,從 77,000 tokens 降到 8,700 tokens。但呢個只係治標,問題根源係 MCP 設計假設「把所有工具擺出來畀 AI 揀」,工具一多就撐唔住。
Skills:漸進式披露 + 腳本執行,更慳上下文
Skills 採用漸進式披露(Progressive Disclosure)設計哲學。想像請新員工:唔會第一日就曬所有流程,而係逐級畀資訊。
- 1 第一層:元數據(啟動時加載)——只有名稱同簡短描述,每個 Skill 約 100 tokens,100 個都係 10,000 tokens。
- 2 第二層:完整指令(相關時加載)——當 AI 判斷 Skill 同任務相關,先讀取完整 SKILL.md,建議 5,000 tokens 以內。
- 3 第三層:參考資料(需要時加載)——詳細技術文檔、API 說明,用幾多 load 幾多,理論上無限。
一個 Skill 可以打包整套 API 文檔,但只要任務唔需要,就永遠唔會佔用上下文。
Skills 另一殺手鐧:自帶可執行腳本。典型文件夾結構:SKILL.md、scripts/(Python、Bash、JS)、references/、assets/。當 AI 運行腳本時,腳本代碼本身唔會加載入上下文,只有執行結果返回。
真實案例:發佈 X Article 兩種方案對比
王樹義老師開發咗 x-article-publisher-skill,用 Playwright MCP 將 Markdown 自動發佈到 X Article。但 Playwright MCP 有 22 個工具,工具定義佔 8,000-10,000 tokens,每次瀏覽器交互仲要返回 accessibility tree 快照,搞到一篇文章消耗 50,000+ tokens。
作者改進版本 baoyu-post-to-x 用 Skills + Chrome CDP 腳本,直接繞過 MCP。
腳本自己解析 Markdown、操作瀏覽器、填充內容、保存草稿,只返回最終結果「發佈成功,草稿連結:xxx」。AI 只需要調用一次腳本,上下文消耗可能只有幾百 tokens。
選擇指南:問自己三個問題
1. 邊個用?內部團隊用 Skills,外部用戶用 MCP。
2. 點樣分發?接受「放文件到某目錄」就用 Skills;希望用戶直接輸入 URL 就用 MCP。
3. 解決咩問題?編碼領域知識、定義工作流程用 Skills;連接外部服務、對外暴露 API 用 MCP。
最佳實踐係兩者配合:用 Skills 編碼領域知識,用 MCP 連接外部服務。
隨住 Skills 生態成熟,MCP 會收窄到「遠程連接」核心場景。對於開發者,優先用 Skills 封裝工作流程,複雜邏輯用腳本,只在必須連遠程系統時先用 MCP。如果只能揀一個學,揀 Skills:更輕量、更高效、更容易上手。
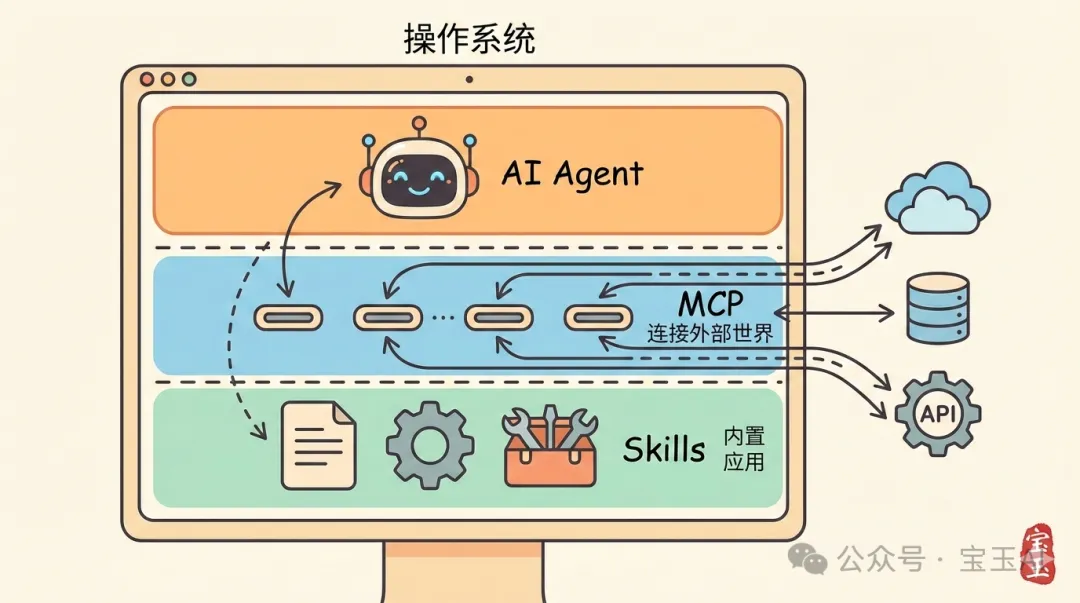
一句話解釋 MCP 同 Skills 嘅分別:如果 AI Agent 係操作系統,MCP 就係 USB 協議,Skills 就係應用程式。
一位開發者嘅困惑
有位網友私信問我:「MCP 係咪已經過時咗?而家應該全部用 Skills?」
呢個問題可能好多人都有好奇心。我理解呢種焦慮。AI Agent 工具圈每隔兩星期就會出現新嘢,每次新嘢一出,就有人話舊嘅『已死』。
鍾意 Skills 嘅人可能會諗:我寫個腳本自己用,做咩搞到咁複雜?我只係想編碼一下我嘅工作流程,等 AI 可以理解我哋團隊嘅做事方式,Skills 寫起嚟好簡單,放個文件就得,何必搞咁多嘢整個 MCP Server?
鍾意 MCP 嘅人就會覺得:我要做一個服務,等所有人都可以用,唔止我自己,唔止我團隊。我要等用戶輸入一個 URL 就用得,甚至將來咩都唔使裝,直接問 AI『幫我訂機票』就得。
仔細睇其實呢兩班人嘅需求完全唔同。唔係功能上嘅分別,而係分發方式嘅分別。Skills 係俾自己人用嘅,MCP 係俾全世界用嘅。

想像你係一間賣服務嘅公司。你服務嘅安裝說明點樣寫?如果你係用 Skills 嘅方式發佈,說明就要講清楚『將 SKILL.md 檔案複製到指定目錄』,可能仲需要特定腳本嘅執行權限,用戶都未必敢安裝。但如果係『輸入呢個 URL』或者『直接同 AI 講幫我用呢個服務』,亦都唔需要喺你部機安裝個 nodejs/python,咁就好得多。
但淨係理解定位都唔夠。呢兩個嘢喺技術層面有本質上嘅分別,直接影響你嘅使用體驗同成本。
MCP:AI 世界嘅 USB 協議
仲記得十年前嘅充電線嗎?蘋果用 Lightning,Android 用 Micro USB,筆記本用各種奇形怪狀嘅電源頭。出一次門,個袋塞滿五六條線。
AI 行業喺 2024 年之前都係咁。
你想等 Agent 讀取 GitHub 倉庫?寫一套對接代碼。想等 ChatGPT 查數據庫?再寫一套。想等 Cursor 發 Slack 訊息?又係一套。10 個 AI 應用要連 20 個工具,理論上需要 200 個定製集成。每間公司都不斷重複造輪子,開發者苦不堪言。
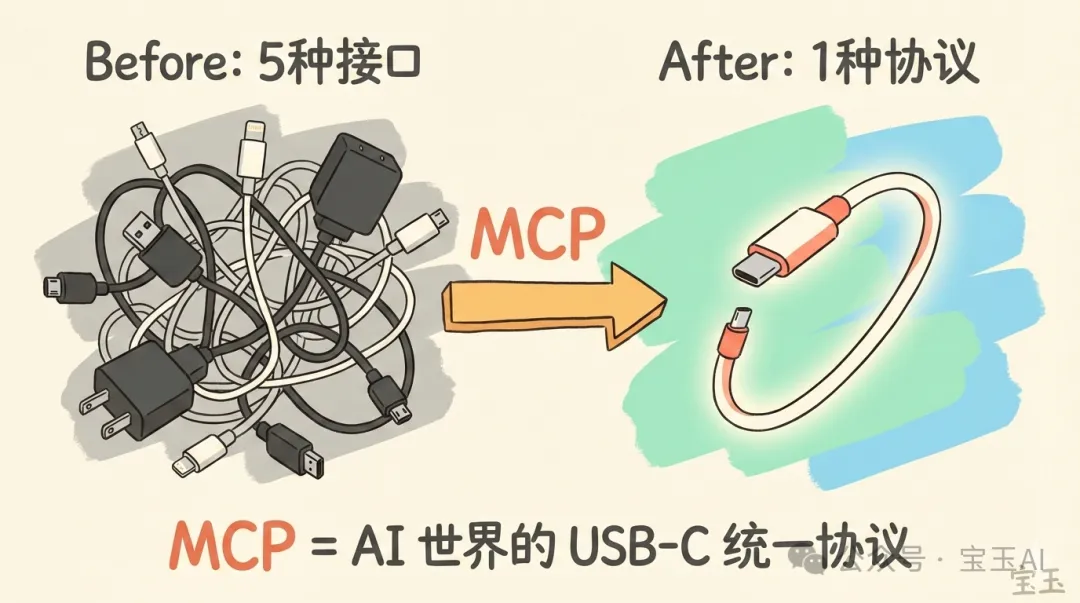
2024 年 11 月,Anthropic 開源咗 MCP(Model Context Protocol,模型上下文協議)。佢做嘅嘢,同 USB-C 統一充電接口一模一樣:定義一套標準協議,等任何 AI 都可以即插即用地連接任何工具。
有咗 MCP,10 個 AI 應用 + 20 個工具 = 30 個 MCP 實現,而唔係 200 個定製集成。數學上叫將 M×N 問題變成咗 M+N 問題,實踐中意味住開發成本斷崖式下降。
MCP 嘅致命問題:上下文爆炸
但 MCP 有一個嚴重嘅副作用:食曬你嘅上下文窗口。
每個 MCP Server 連接到 AI 時,必須將所有工具嘅定義(名稱、描述、參數、示例)一次過塞入上下文。一個工具嘅定義大概 500-800 tokens,一個 MCP Server 通常有 10-20 個工具。
嚟睇幾個真實數據:
• GitHub MCP Server:27 個工具,消耗約 18,000 tokens • Playwright MCP Server:21 個工具,消耗約 13,600 tokens • mcp-omnisearch:20 個工具,消耗約 14,200 tokens
有開發者配咗 7 個 MCP Server,仲未開始對話,上下文就已經被食咗 67,000 tokens——佔 AI 上下文窗口嘅 33%。更誇張嘅案例係 82,000 tokens,佔 41%。
呢個意味住啲咩?你問 AI『2+2 等於幾』,佢回答『4』只需要 5 個 token,但工具定義已經消耗咗 15,000 tokens。簡單問題嘅成本被放大咗 3000 倍。

更差嘅係,當上下文被工具定義塞滿之後,AI 揀錯工具、傳錯參數嘅機會率會明顯上升。實際操作中,連接 2-3 個以上嘅 MCP Server,工具使用準確性就會明顯下降。
Claude Code 嘅解法:Tool Search
Anthropic 意識到咗呢個問題。2025 年 1 月,Claude Code 推出咗 Tool Search 功能:
• MCP 工具唔再預先加載,而係按需要發現 • 當工具定義超過上下文嘅 10% 時自動啓用 • AI 需要用某個工具時,先搜尋再加載
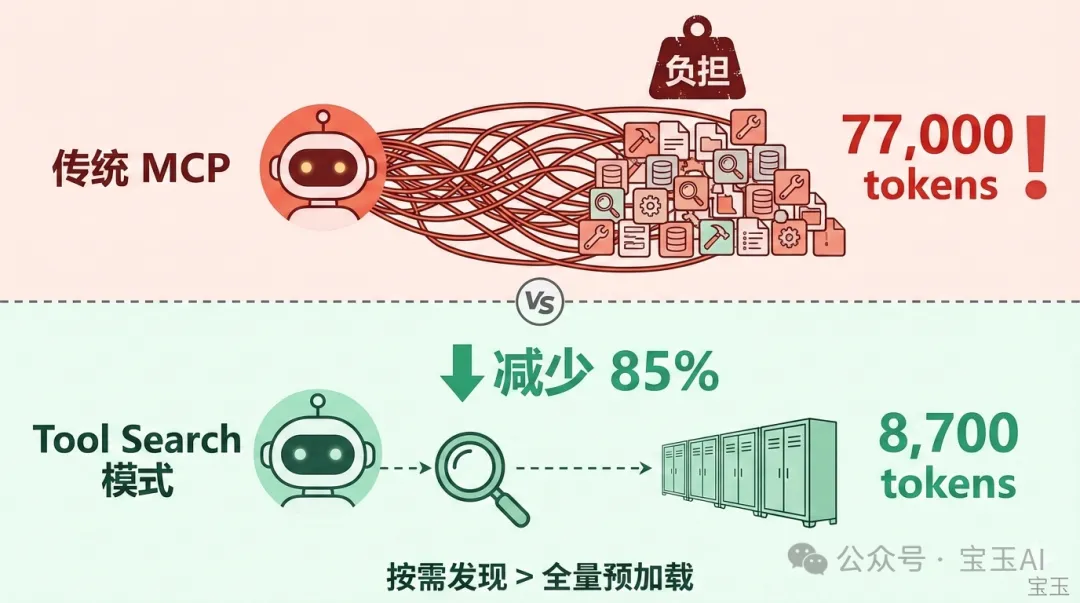
效果立竿見影:由 77,000 tokens 降到 8,700 tokens,減少 85%。
但呢個只係喺度幫 MCP 打補丁。問題嘅根源在於:MCP 嘅設計假設係『將所有工具擺出嚟等 AI 揀』,呢個喺工具數量少嘅時候冇問題,工具多咗就頂唔順。
Skills:漸進式披露嘅操作手冊
Skills 由一開始就採用咗唔同嘅設計哲學:漸進式披露(Progressive Disclosure)。
點樣理解呢?
想像你請咗個新員工。傳統做法係入職第一日將公司所有流程文件、規章制度、操作手冊全部打印出嚟堆喺佢枱面,呢個就係 MCP 嘅做法。而 Skills 嘅做法係:先俾一份簡短嘅崗位說明,等佢遇到具體問題時,先話佢知去揭邊本手冊嘅邊一頁。
技術上,Skills 係咁樣實現嘅:
第一層:元數據(啟動時載入)
• 只有名稱同簡短描述 • 每個 Skill 約 100 tokens • 裝 100 個 Skill 都只係佔 10,000 tokens
第二層:完整指令(相關時載入)
• 當 AI 判斷某個 Skill 同任務相關時,先會讀取完整嘅 SKILL.md • 建議控制在 5,000 tokens 以內
第三層:參考資料(需要時載入)
• 詳細嘅技術文件、API 說明、示例代碼 • 按需要讀取,用幾多載入幾多 • 理論上可以包含無限內容
呢個意味住:一個 Skill 可以打包整套 API 文件、完整嘅數據字典、幾百頁嘅參考手冊,但只要任務唔需要,呢啲內容就永遠唔會佔用上下文。
Skills 嘅殺手鐧:自帶腳本
Skills 仲有一個好多人忽略嘅能力:佢可以自帶可執行腳本。
一個典型嘅 Skill 文件夾結構係咁樣:
my-skill/
├── SKILL.md # 核心指令
├── scripts/ # 可執行腳本
│ ├── validate.py
│ ├── generate.sh
│ └── process.js
├── references/ # 參考文檔
└── assets/ # 模板、配置文件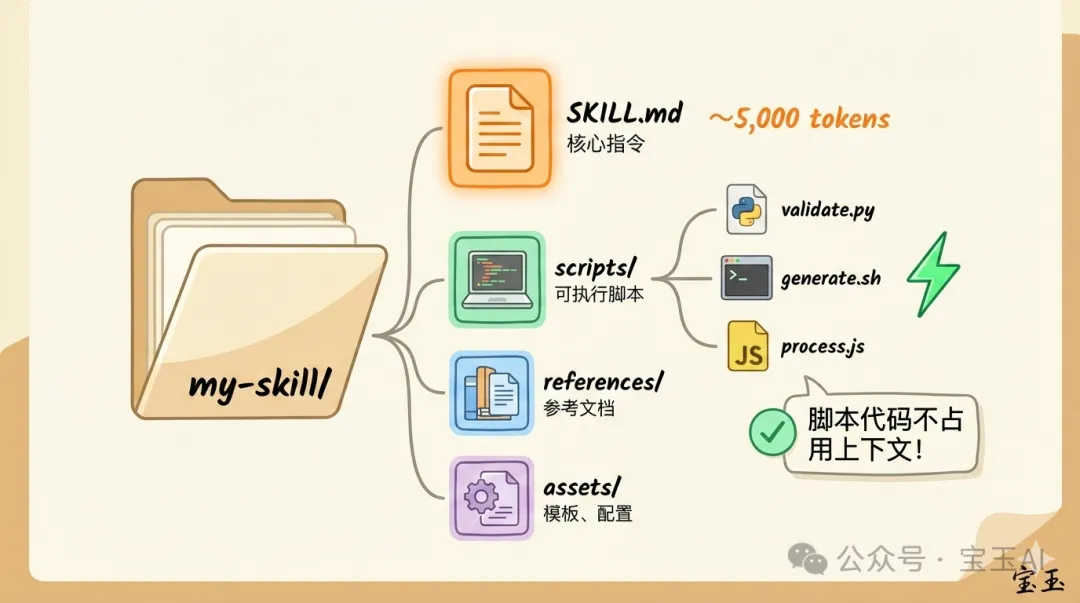
關鍵嚟啦:當 AI 運行 scripts/validate.py 時,腳本代碼本身唔會載入到上下文,只有執行結果會返回。
呢個係咩概念?
假設你有一個 500 行嘅 Python 腳本,用來處理 PDF 表單。用傳統方式,AI 一係自己寫代碼(消耗大量 tokens 生成),一係讀取你嘅腳本再執行(腳本內容佔用上下文)。而用 Skills,AI 直接運行預先寫好嘅腳本,成個過程可能只係消耗 50 tokens 嘅輸出結果。
腳本執行 = 零上下文成本 + 確定性結果
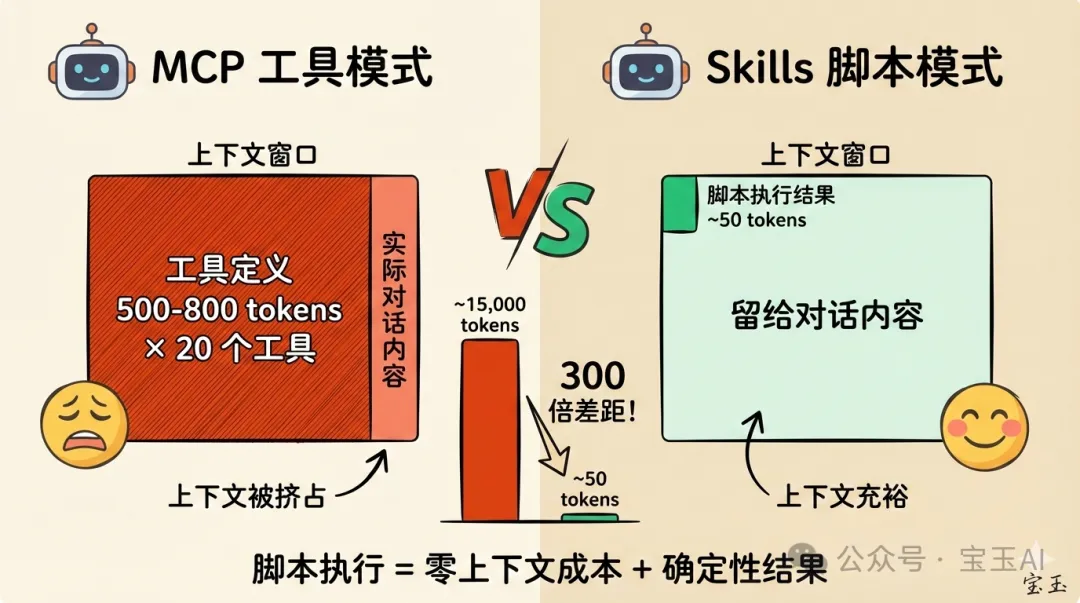
更重要嘅係:呢啲腳本通過 Agent 內置嘅 bash 工具執行,唔需要 MCP。
Skills 支援嘅腳本語言包括 Python、Bash、JavaScript 等,基本上你係統行到嘅都用得。呢個意味住:
• 文件讀寫?Skill 腳本攪掂 • 數據處理?Skill 腳本攪掂 • 格式轉換?Skill 腳本攪掂 • 本地 API 調用?Skill 腳本攪掂
MCP vs Skills:幾時需要啲咩?
而家我哋可以重新審視呢兩個概念嘅定位啦。
| 類比 | ||
| 核心能力 | ||
| 工具來源 | ||
| 上下文消耗 | ||
| 網絡訪問 | ||
| 分發方式 | ||
| 適用場景 |
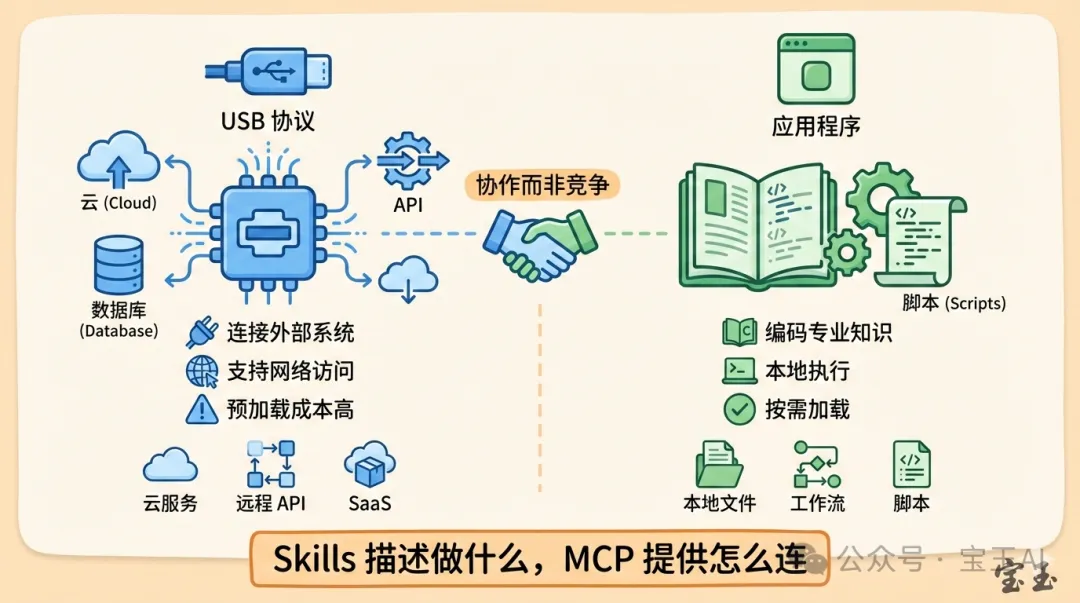
有一句話講得好精闢:
Skills 描述工作流程,MCP 提供執行引擎。但好多時候,操作系統自帶嘅引擎就夠用。
呢個就好似 GitHub Actions:工作流文件(相當於 Skills)定義咗構建、測試、部署嘅步驟,但實際執行嘅仲係 bash 命令。YAML 就好似菜譜,寫清楚先放油、再落葱、最後翻炒,但菜譜本身唔會煮餸,真正落廚嘅係廚師。
問題係:Agent 呢個『操作系統』本身就自帶咗 bash、read、write 等基礎工具。對於大量本地任務,Skills + 內置工具就搞得掂,根本唔需要額外嘅 MCP Server。
仲有個比喻我覺得好貼切:Skills 好似 Slack 裏面嘅斜槓指令(slash commands)。你公司 Slack 裏面可能有幾十個 slash commands,大部分你從來未用過,但對特定嘅人特定嘅場景好有用。呢個就係 Skills 嘅定位:內部工具,按需要使用。
但你唔可能將 slash commands 賣俾外部用戶。要對外,就要用 MCP。
隨住 Skills 普及,MCP 嘅需求會大幅減少
呢個係一個正在發生嘅趨勢。
諗嚇,幾時你先真正需要 MCP?
需要 MCP 嘅場景:
• 連接遠程 CRM 系統獲取客戶數據 • 調用第三方 SaaS API(Slack、Notion、Jira) • 查詢雲端數據庫 • 訪問需要認證嘅外部服務 • 做一個服務等外部用戶都用得
唔需要 MCP 嘅場景:
• 讀寫本地文件 → bash + Skill 腳本 • 處理 PDF/Word/Excel → Skill 腳本 • 運行代碼分析 → Skill 腳本 • 執行 Git 操作 → Skill 腳本 • 生成圖表同可視化 → Skill 腳本 • 優化自己或團隊嘅工作流
事實上,Anthropic 嘅工程博客提到:佢哋用『代碼執行 + MCP』嘅方法,將一個 150,000 token 嘅工作流壓縮到得返 2,000 tokens——核心思路就係等 AI 寫代碼調用工具,而唔係預先載入所有工具定義。
呢個正正就係 Skills 嘅設計方向:用腳本封裝能力,用漸進式披露管理知識,最大限度減少上下文消耗。
將來嘅格局可能會係咁樣:
• 少數通用 MCP Server 處理遠程連接(數據庫、雲 API、SaaS 集成) • 大量 Skills 編碼專業知識同本地工作流 • 兩者在必要時協作,但 Skills 會承擔絕大部分『教 AI 點樣做嘢』嘅工作
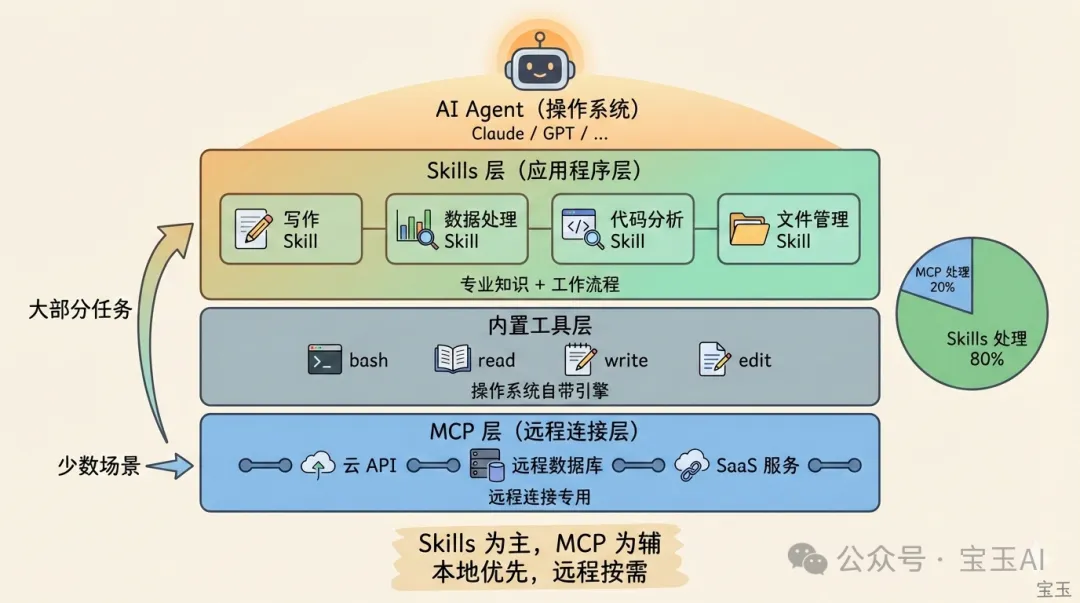
一個真實案例:自動發佈 X Article
呢個係一個真實發生嘅演進過程,完美展示咗由 MCP 到 Skills 嘅轉變。
需求: 將 Markdown 文章自動發佈到 X(Twitter)嘅長文功能 X Article。
方案一:Playwright MCP
王樹義老師開發咗 x-article-publisher-skill,流程係咁樣:
Markdown 文件
↓
Python 腳本解析(提取標題、圖片位置、HTML)
↓
Playwright MCP 操作瀏覽器
↓
X Articles 編輯器(自動化填充)
↓
保存草稿提示詞好簡潔,功能亦都好強大。但問題嚟啦:上下文消耗得好快。
Playwright MCP 有 22 個工具,淨係工具定義就佔用約 8,000-10,000 tokens。更慘嘅係,每次瀏覽器交互,MCP 都要返回頁面嘅 accessibility tree(無障礙樹)快照——呢個係為咗等 AI 理解當前頁面狀態。一個複雜頁面嘅快照可能就係幾千 tokens。
發佈一篇文章,可能需要:打開頁面、等載入、點擊編輯器、貼上內容、上傳圖片、調整位置、儲存草稿……每一步都係一次 MCP 交互,每一次交互都喺度消耗上下文。
結果:一篇文章發完,上下文可能已經用咗 50,000+ tokens。
方案二:Skills + CDP 腳本(我嘅改進版本)
我將 Playwright MCP 部分完全改咗做腳本,做咗個 baoyu-post-to-x:
baoyu-post-to-x/
├── SKILL.md # 簡短的使用說明
└── scripts/
└── x-article.ts # 核心腳本,使用 Chrome CDP核心變化:
1. 腳本直接調用 Chrome CDP(Chrome DevTools Protocol),繞過 MCP 2. 傳入 Markdown 文件路徑,腳本自己解析內容 3. 腳本自己完成所有瀏覽器操作:打開頁面、填充內容、上傳圖片、儲存草稿 4. 只返回最終結果俾 Agent:『發佈成功,草稿連結:xxx』
成個過程,AI 只需要做一件事:調用腳本,傳入文件路徑。
上下文消耗:可能只有幾百 tokens。
點解差距咁大?
| 工具定義 | ||
| 每次交互 | ||
| AI 參與度 | ||
| 總消耗 |
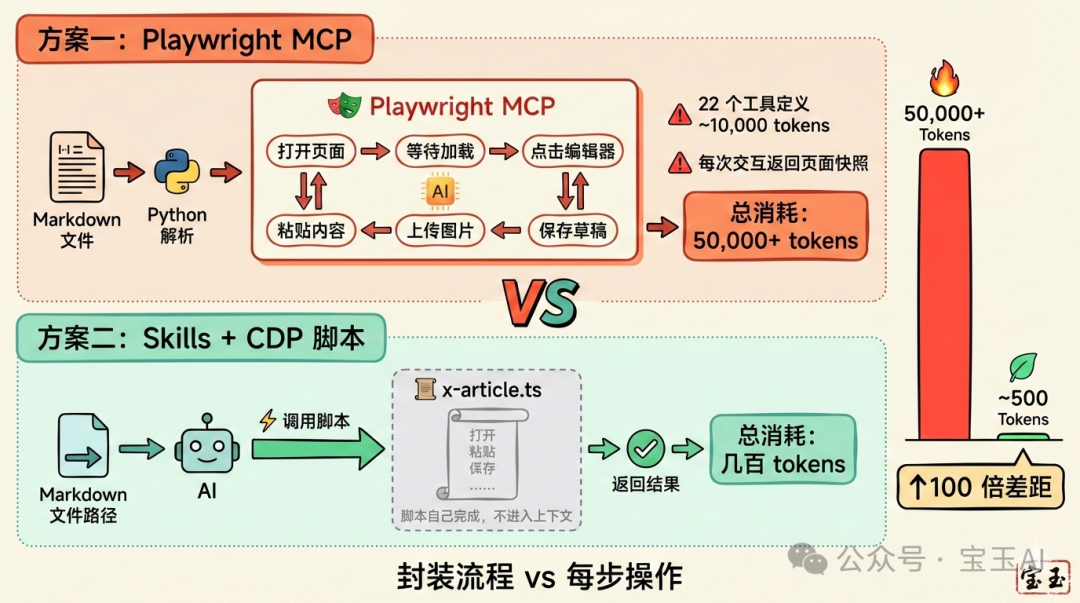
關鍵洞察:MCP 嘅設計係等 AI 一步步操作,每一步都要理解、決策、執行。而腳本嘅設計係將成個流程封裝起來,AI 只需要講『開始』同埋『結束』。
呢個就係點解即使 MCP 支援咗 Tool Search(按需要載入工具),上下文問題都冇根本解決——因為工具定義只係一部分,真正嘅大頭係交互過程中產生嘅中間結果。
而 Skills 嘅腳本執行模式,天然避開咗呢個問題:腳本代碼唔進入上下文,中間過程唔進入上下文,只有最終結果進入上下文。
寫在最後:回到嗰個私信
所以我俾嗰位讀者嘅回覆係咁樣:
MCP 未死。Skills 都好有用。佢哋解決嘅係唔同問題。
MCP 係 USB 協議,定義咗 AI 同外部世界嘅連接標準;Skills 係應用程式,將專業知識同工作流程打包成 AI 能理解嘅操作手冊。
Skills 嘅兩大殺手鐧——漸進式披露同腳本執行——等佢可以獨立完成大量任務,唔依賴 MCP。
漸進式披露解決咗『知識太多』嘅問題:AI 唔需要一次過載入所有資訊,用到咩就載入咩。
腳本執行解決咗『交互太多』嘅問題:複雜流程封裝成腳本,AI 只需要一次調用,中間過程唔佔用上下文。
到底點樣揀?問自己三個問題:
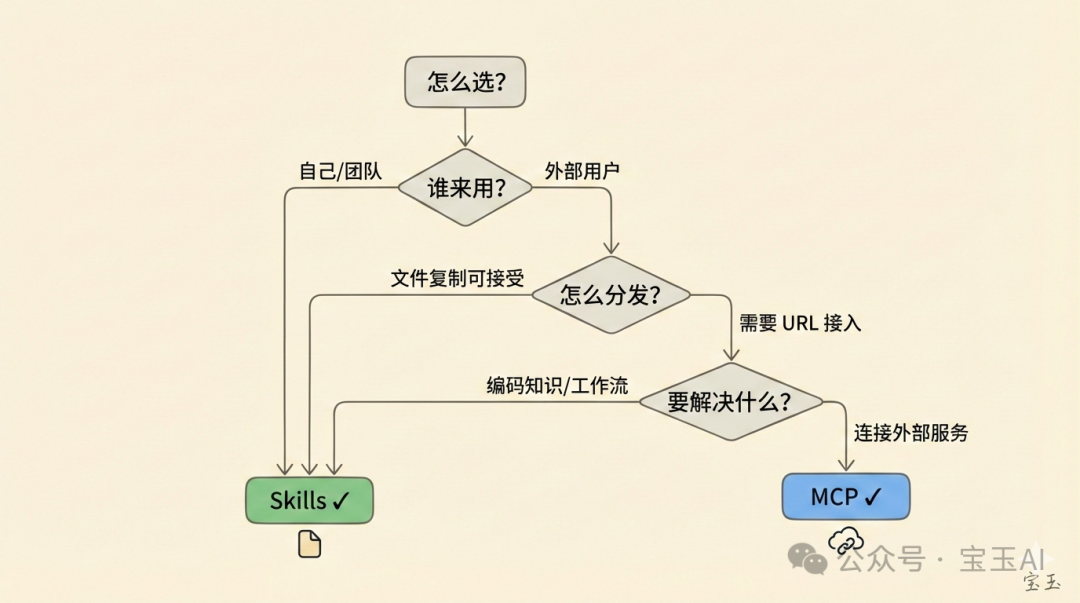
1. 邊個來用? 如果只有你自己或者團隊內部用,Skills 就夠啦。如果要俾外部用戶或客戶用,MCP 係必選項。 2. 點樣分發? 如果可以接受『將文件放到某個目錄』呢種安裝方式,用 Skills。如果希望用戶輸入 URL 就用得,用 MCP。 3. 要解決咩問題? 如果係編碼領域知識、定義工作流程,Skills 更友好。如果係連接外部服務、對外暴露 API,MCP 先做到。
最佳實踐係兩者配合使用:用 Skills 編碼你嘅領域知識,用 MCP 連接外部服務。 例如你哋公司有一套特定嘅工作流程,先查呢個系統,再查嗰個系統,按某個順序處理。呢種領域知識用 Skills 寫出來,等 AI 理解。但具體連接嗰啲系統嘅能力,靠 MCP 提供。兩層配合,各司其職。
隨住 Skills 生態成熟,MCP 嘅角色會收窄到『遠程連接』呢個核心場景——需要實時訪問外部 API、需要認證嘅 SaaS 服務、需要跨網絡嘅數據庫連接。而本地文件操作、瀏覽器自動化、數據處理呢啲任務,Skills + 內置工具就搞得掂,而且效率更高。
對於開發者:優先使用 Skills 封裝工作流程,複雜邏輯用腳本而唔係等 AI 一步步操作,只有喺必須連接遠程系統時先用 MCP。
Skills 同 MCP 唔係競爭關係,而係唔同層次嘅能力。但如果你只可以揀一個先學,揀 Skills。佢更輕量、更高效、更容易上手,可以解決日常遇到嘅大部分問題。
一句話解釋 MCP 和 Skills 的區別:如果 AI Agent 是操作系統,MCP 就是 USB 協議,Skills 就是應用程序。
一位開發者的困惑
有位網友私信問我:“MCP 是不是已經過時了?現在應該全用 Skills?”
這個問題可能很多人都好奇。我理解這種焦慮。AI Agent 工具圈每隔兩週就會冒出新東西,每次新東西出來,就有人喊舊的“已死”。
對於喜歡 Skills 的人可能會想:我寫個腳本自己用,幹嘛搞那麼複雜?我就是要編碼一下我的工作流程,讓 AI 能理解我們團隊的做事方式,Skills 寫起來簡單,放個文件就行,何必折騰 MCP Server?
喜歡 MCP 的人則會認為:我要做一個服務,讓所有人都能用,不只是我自己,不只是我團隊。我要讓用戶輸入一個 URL 就能用,甚至未來什麼都不用裝,直接問 AI“幫我訂機票”就行。
仔細看其實這兩撥人的需求完全不一樣。不是功能差異,是分發方式的差異。Skills 是給自己人用的,MCP 是給全世界用的。
想象你是一家賣服務的公司。你服務的安裝說明怎麼寫?如果你是以 Skills 的方式發佈,說明就要說清楚“把 SKILL.md 文件複製到特定目錄”,可能還需要特定腳本的運行權限,用戶都不一定敢安裝。但如果是“輸入這個 URL”或者“直接跟 AI 說幫我用這個服務”,也不需要你在本機安裝個 nodejs/python,那就好多了。
但光理解定位還不夠。這兩個東西在技術層面有本質區別,直接影響你的使用體驗和成本。
MCP:AI 世界的 USB 協議
還記得十年前的充電線嗎?蘋果用 Lightning,安卓用 Micro USB,筆記本用各種奇形怪狀的電源頭。出門一趟,包裏塞滿五六根線。
AI 行業在 2024 年之前也是這樣。
你想讓 Agent 讀取 GitHub 倉庫?寫一套對接代碼。想讓 ChatGPT 查數據庫?再寫一套。想讓 Cursor 發 Slack 消息?又是一套。10 個 AI 應用要連 20 個工具,理論上需要 200 個定製集成。每家都在重複造輪子,開發者苦不堪言。
2024 年 11 月,Anthropic 開源了 MCP(Model Context Protocol,模型上下文協議)。它做的事情,和 USB-C 統一充電接口一模一樣:定義一套標準協議,讓任何 AI 都能即插即用地連接任何工具。
有了 MCP,10 個 AI 應用 + 20 個工具 = 30 個 MCP 實現,而不是 200 個定製集成。數學上叫把 M×N 問題變成了 M+N 問題,實踐中意味着開發成本斷崖式下降。
MCP 的致命問題:上下文爆炸
但 MCP 有一個嚴重的副作用:吃掉你的上下文窗口。
每個 MCP Server 連接到 AI 時,必須把所有工具的定義(名稱、描述、參數、示例)一次性塞進上下文。一個工具的定義大概 500-800 tokens,一個 MCP Server 通常有 10-20 個工具。
來看幾個真實數據:
• GitHub MCP Server:27 個工具,消耗約 18,000 tokens • Playwright MCP Server:21 個工具,消耗約 13,600 tokens • mcp-omnisearch:20 個工具,消耗約 14,200 tokens
有開發者配了 7 個 MCP Server,還沒開始對話,上下文就被吃掉了 67,000 tokens——佔 AI 上下文窗口的 33%。更誇張的案例是 82,000 tokens,佔 41%。
這意味着什麼?你問 AI“2+2 等於幾”,它回答“4”只需要 5 個 token,但工具定義已經消耗了 15,000 tokens。簡單問題的成本被放大了 3000 倍。
更糟糕的是,當上下文被工具定義擠佔後,AI 選錯工具、傳錯參數的概率會顯著上升。實踐中,連接 2-3 個以上的 MCP Server,工具使用準確性就會明顯下降。
Claude Code 的解法:Tool Search
Anthropic 意識到了這個問題。2025 年 1 月,Claude Code 推出了 Tool Search 功能:
• MCP 工具不再預加載,而是按需發現 • 當工具定義超過上下文的 10% 時自動啓用 • AI 需要用某個工具時,先搜索再加載
效果立竿見影:從 77,000 tokens 降到 8,700 tokens,減少 85%。
但這只是在給 MCP 打補丁。問題的根源在於:MCP 的設計假設是“把所有工具擺出來讓 AI 挑”,這在工具數量少的時候沒問題,工具多了就撐不住。
Skills:漸進式披露的操作手冊
Skills 從一開始就採用了不同的設計哲學:漸進式披露(Progressive Disclosure)。
怎麼理解呢?
想象你招了個新員工。傳統做法是入職第一天把公司所有流程文檔、規章制度、操作手冊全部打印出來堆在他桌上,這就是 MCP 的做法。而 Skills 的做法是:先給一份簡短的崗位說明,等他遇到具體問題時,再告訴他去翻哪本手冊的哪一頁。
技術上,Skills 是這樣實現的:
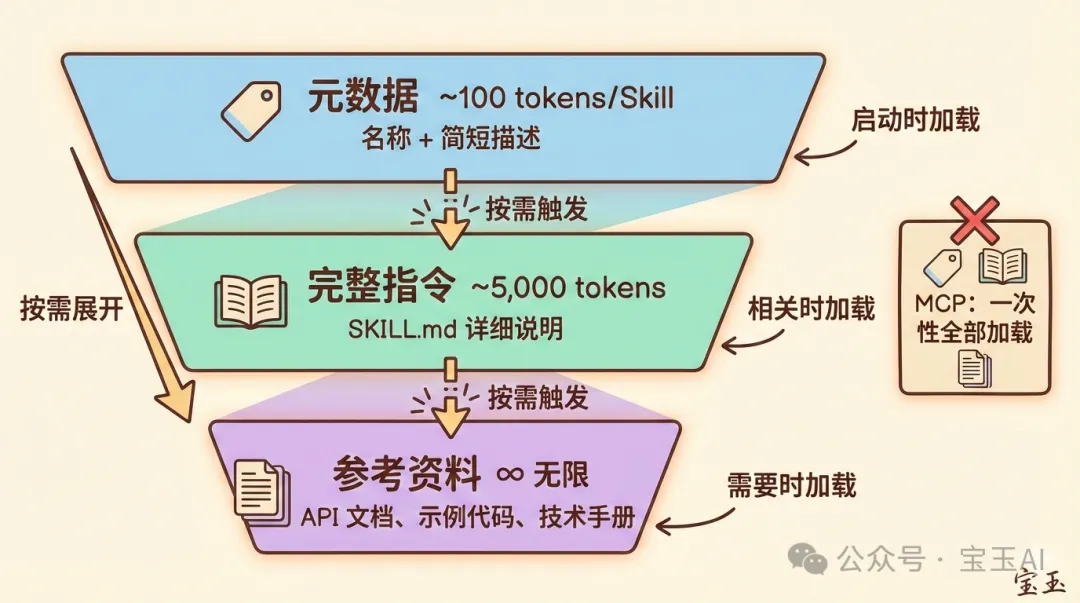
第一層:元數據(啓動時加載)
• 只有名稱和簡短描述 • 每個 Skill 約 100 tokens • 裝 100 個 Skill 也只佔 10,000 tokens
第二層:完整指令(相關時加載)
• 當 AI 判斷某個 Skill 與任務相關時,才讀取完整的 SKILL.md • 建議控制在 5,000 tokens 以內
第三層:參考資料(需要時加載)
• 詳細的技術文檔、API 說明、示例代碼 • 按需讀取,用多少加載多少 • 理論上可以包含無限內容
這意味着:一個 Skill 可以打包整套 API 文檔、完整的數據字典、幾百頁的參考手冊,但只要任務不需要,這些內容就永遠不會佔用上下文。
Skills 的殺手鐧:自帶腳本
Skills 還有一個很多人忽略的能力:它可以自帶可執行腳本。
一個典型的 Skill 文件夾結構是這樣的:
my-skill/
├── SKILL.md # 核心指令
├── scripts/ # 可執行腳本
│ ├── validate.py
│ ├── generate.sh
│ └── process.js
├── references/ # 參考文檔
└── assets/ # 模板、配置文件關鍵來了:當 AI 運行 scripts/validate.py 時,腳本代碼本身不會加載到上下文,只有執行結果會返回。
這是什麼概念?
假設你有一個 500 行的 Python 腳本,用來處理 PDF 表單。用傳統方式,AI 要麼自己寫代碼(消耗大量 tokens 生成),要麼讀取你的腳本再執行(腳本內容佔用上下文)。而用 Skills,AI 直接運行預寫好的腳本,整個過程可能只消耗 50 tokens 的輸出結果。
腳本執行 = 零上下文成本 + 確定性結果
更重要的是:這些腳本通過 Agent 內置的 bash 工具執行,不需要 MCP。
Skills 支持的腳本語言包括 Python、Bash、JavaScript 等,基本上你係統能跑的都能用。這意味着:
• 文件讀寫?Skill 腳本搞定 • 數據處理?Skill 腳本搞定 • 格式轉換?Skill 腳本搞定 • 本地 API 調用?Skill 腳本搞定
MCP vs Skills:什麼時候需要什麼?
現在我們可以重新審視這兩個概念的定位了。
| 類比 | ||
| 核心能力 | ||
| 工具來源 | ||
| 上下文消耗 | ||
| 網絡訪問 | ||
| 分發方式 | ||
| 適用場景 |
有一句話說得很精闢:
Skills 描述工作流程,MCP 提供執行引擎。但很多時候,操作系統自帶的引擎就夠用了。
這就像 GitHub Actions:工作流文件(相當於 Skills)定義了構建、測試、部署的步驟,但實際執行的還是 bash 命令。YAML 就像菜譜,寫清楚先放油、再下葱、最後翻炒,但菜譜本身不會做菜,真正掌勺的是廚師。
問題是:Agent 這個“操作系統”本身就自帶了 bash、read、write 等基礎工具。對於大量本地任務,Skills + 內置工具就能完成,根本不需要額外的 MCP Server。
還有個類比我覺得很貼切:Skills 像 Slack 裏的斜槓指令(slash commands)。你公司 Slack 裏可能有幾十個 slash commands,大部分你從來沒用過,但對特定的人特定的場景很有用。這就是 Skills 的定位:內部工具,按需使用。
但你不可能把 slash commands 賣給外部用戶。要對外,得用 MCP。
隨着 Skills 普及,MCP 的需求會大幅減少
這是一個正在發生的趨勢。
想想看,什麼時候你真正需要 MCP?
需要 MCP 的場景:
• 連接遠程 CRM 系統獲取客戶數據 • 調用第三方 SaaS API(Slack、Notion、Jira) • 查詢雲端數據庫 • 訪問需要認證的外部服務 • 做一個服務讓外部用戶都能用
不需要 MCP 的場景:
• 讀寫本地文件 → bash + Skill 腳本 • 處理 PDF/Word/Excel → Skill 腳本 • 運行代碼分析 → Skill 腳本 • 執行 Git 操作 → Skill 腳本 • 生成圖表和可視化 → Skill 腳本 • 優化自己或團隊的工作流
事實上,Anthropic 的工程博客提到:他們用“代碼執行 + MCP”的方法,把一個 150,000 token 的工作流壓縮到了 2,000 tokens——核心思路就是讓 AI 寫代碼調用工具,而不是預加載所有工具定義。
這正是 Skills 的設計方向:用腳本封裝能力,用漸進式披露管理知識,最大限度減少上下文消耗。
未來的格局可能是這樣的:
• 少數通用 MCP Server 處理遠程連接(數據庫、雲 API、SaaS 集成) • 大量 Skills 編碼專業知識和本地工作流 • 兩者在必要時協作,但 Skills 會承擔絕大部分“教 AI 怎麼做事”的工作
一個真實案例:自動發佈 X Article
這是一個真實發生的演進過程,完美展示了從 MCP 到 Skills 的轉變。
需求: 把 Markdown 文章自動發佈到 X(Twitter)的長文功能 X Article。
方案一:Playwright MCP
王樹義老師開發了 x-article-publisher-skill,流程是這樣的:
Markdown 文件
↓
Python 腳本解析(提取標題、圖片位置、HTML)
↓
Playwright MCP 操作瀏覽器
↓
X Articles 編輯器(自動化填充)
↓
保存草稿提示詞很簡潔,功能也很強大。但問題來了:上下文消耗得飛快。
Playwright MCP 有 22 個工具,光工具定義就佔用約 8,000-10,000 tokens。更要命的是,每次瀏覽器交互,MCP 都要返回頁面的 accessibility tree(無障礙樹)快照——這是為了讓 AI 理解當前頁面狀態。一個複雜頁面的快照可能就是幾千 tokens。
發佈一篇文章,可能需要:打開頁面、等待加載、點擊編輯器、粘貼內容、上傳圖片、調整位置、保存草稿……每一步都是一次 MCP 交互,每一次交互都在消耗上下文。
結果:一篇文章發完,上下文可能已經用掉 50,000+ tokens。
方案二:Skills + CDP 腳本(我的改進版本)
我把 Playwright MCP 部分完全改成了腳本,做成了 baoyu-post-to-x:
baoyu-post-to-x/
├── SKILL.md # 簡短的使用說明
└── scripts/
└── x-article.ts # 核心腳本,使用 Chrome CDP核心變化:
1. 腳本直接調用 Chrome CDP(Chrome DevTools Protocol),繞過 MCP 2. 傳入 Markdown 文件路徑,腳本自己解析內容 3. 腳本自己完成所有瀏覽器操作:打開頁面、填充內容、上傳圖片、保存草稿 4. 只返回最終結果給 Agent:“發佈成功,草稿連結:xxx”
整個過程,AI 只需要做一件事:調用腳本,傳入文件路徑。
上下文消耗:可能只有幾百 tokens。
為什麼差距這麼大?
| 工具定義 | ||
| 每次交互 | ||
| AI 參與度 | ||
| 總消耗 |
關鍵洞察:MCP 的設計是讓 AI 一步步操作,每一步都要理解、決策、執行。而腳本的設計是把整個流程封裝起來,AI 只需要說“開始”和“結束”。
這就是為什麼即使 MCP 支持了 Tool Search(按需加載工具),上下文問題也沒有根本解決——因為工具定義只是一部分,真正的大頭是交互過程中產生的中間結果。
而 Skills 的腳本執行模式,天然避開了這個問題:腳本代碼不進入上下文,中間過程不進入上下文,只有最終結果進入上下文。
寫在最後:回到那個私信
所以我給那位讀者的回覆是這樣的:
MCP 沒死。Skills 也很有用。它們解決的是不同問題。
MCP 是 USB 協議,定義了 AI 與外部世界的連接標準;Skills 是應用程序,把專業知識和工作流程打包成 AI 能理解的操作手冊。
Skills 的兩大殺手鐧——漸進式披露和腳本執行——讓它能獨立完成大量任務,不依賴 MCP。
漸進式披露解決了“知識太多”的問題:AI 不需要一次性加載所有信息,用到什麼加載什麼。
腳本執行解決了“交互太多”的問題:複雜流程封裝成腳本,AI 只需要一次調用,中間過程不佔用上下文。
到底怎麼選?問自己三個問題:
1. 誰來用? 如果只有你自己或者團隊內部用,Skills 就夠了。如果要給外部用戶或客戶用,MCP 是必選項。 2. 怎麼分發? 如果可以接受“把文件放到某個目錄”這種安裝方式,用 Skills。如果希望用戶輸入 URL 就能用,用 MCP。 3. 要解決什麼問題? 如果是編碼領域知識、定義工作流程,Skills 更友好。如果是連接外部服務、對外暴露 API,MCP 才能做到。
最佳實踐是兩者配合使用:用 Skills 編碼你的領域知識,用 MCP 連接外部服務。 比如你們公司有一套特定的工作流程,先查這個系統,再查那個系統,按某個順序處理。這種領域知識用 Skills 寫出來,讓 AI 理解。但具體連接那些系統的能力,靠 MCP 提供。兩層配合,各司其職。
隨着 Skills 生態成熟,MCP 的角色會收窄到“遠程連接”這個核心場景——需要實時訪問外部 API、需要認證的 SaaS 服務、需要跨網絡的數據庫連接。而本地文件操作、瀏覽器自動化、數據處理這些任務,Skills + 內置工具就能搞定,而且效率更高。
對於開發者:優先用 Skills 封裝工作流程,複雜邏輯用腳本而非讓 AI 一步步操作,只在必須連接遠程系統時才用 MCP。
Skills 和 MCP 不是競爭關係,而是不同層次的能力。但如果你只能選一個先學,選 Skills。它更輕量、更高效、更容易上手,能解決日常遇到的大部分問題。