MiniMax M3 真實項目實測:1M 上下文 + 多模態,讓編碼工作流更順了
整理版優先睇
MiniMax M3實測:1M上下文+多模態,編碼工作流更順暢
Kate係一位AI內容創作者,今次佢親自實測MiniMax M3模型。呢個模型係國內首個同時具備前沿編碼能力、1M上下文同原生多模態嘅模型。佢透過多個項目測試M3嘅能力,包括整macOS應用、改造既有項目、識別手寫圖同鉛活字、生成3D場景同SVG等。整體嚟講,M3喺多模態理解同上文處理上表現出色,能夠將圖片、代碼、日誌、網頁資料串連,完成完整開發流程。不過,佢建議將M3用於編碼,並搭配GPT-5.5呢類強模型做代碼審查,咁樣更經濟。
具體實測結果方面:M3可以根據一張UI圖生成完整嘅macOS應用,並自動拆解任務、解決構建錯誤;亦可以接入既有項目,修改界面同核心調用層。喺Bug定位方面,M3透過分析日誌同curl命令,成功揾到omlx版本嘅已知問題。多模態方面,M3能夠準確識別手寫圖、鉛活字(包括鏡像字),並生成機械腕錶爆炸視圖同SVG小羊理髮,效果比起上一代M2.7同Gemini 3.1 Pro都有明顯提升。
工作流建議方面:作者認為M3嘅編碼能力已經相當實用,但遇上複雜問題時,由GPT-5.5呢類強模型做審查會更可靠。呢個組合可以降低成本同時提高質量。最後,佢期待快將推出嘅快速版M3,認為配合hermes agent會更好用。
- M3係國內首個結合前沿編碼、1M上下文同原生多模態嘅模型,實測表現出色。
- 根據UI圖生成macOS應用時,M3能主動對齊需求、拆解21個任務並自主解決構建錯誤。
- M3擅長分析日誌定位Bug,例如發現omlx版本問題導致圖片處理失敗。
- 多模態理解強:識別手寫圖、鉛活字(鏡像字)、生成3D場景同SVG,效果優於同類模型。
- 建議工作流:用M3負責編碼,再以GPT-5.5等強模型審查,達致成本效益最佳。
MiniMax M3 官方博客
介紹M3發佈及三個案例
macOS應用開源項目
TuZhiRename,由M3編碼完成
omlx釋出版本
更新到0.4.0rc2後解決圖片識別問題
MiniMax開發者平台
OpenAI兼容接入SDK文檔
macOS應用:從一張圖到完整程式
Kate將一張由GPT Image 2生成嘅App UI圖發俾M3,然後開啓Plan模式。M3冇直接寫code,反而反問咗好多問題,同佢對齊需求,之後生成一份計劃。之後,Kate臨時新增需求「升級命名模板」,修改完成後叫M3開始構建。佢拆成21個To-dos,並生成了可以直接運行嘅程序。構建過程中遇到失敗時,M3會自己解決,呢個係MiniMax模型Agent處理能力嘅強項之一。
- 1 上傳圖片後程式一直「處理中」,Kate截圖發俾M3,叫佢分析原因。
- 2 M3按概率給出幾個失敗原因,認為最可能係App冇真正走omlx視覺理解流程,並建議從3個方向排查。
- 3 Kate將omlx日誌發俾M3,佢分析後發現omlx返回嘅內容唔係prompt要求嘅JSON。
- 4 Kate叫M3用curl繼續分析,M3揾到100%嘅根因:模型收到圖片但冇正確處理。
- 5 Kate將omlx版本同引擎版本俾Grok分析,確定係omlx嘅已知bug,更新到0.4.0rc2後立即解決。
之後,Kate叫M3檢查App效能、生成圖標,並安裝到電腦「應用程式」裏。最後叫M3優化現有README,發布到GitHub。呢個項目完整經歷咗需求對齊、計劃生成、代碼構建、運行驗證、Bug定位、性能檢查同項目發布。
改造既有項目:接入MiniMax M3
Kate叫M3對一個展示Qwen Plus模型測試效果嘅既有項目做更改。M3詳細介紹咗目錄結構、技術棧、後端架構、前端架構同值得注意嘅細節。然後Kate將MiniMax開發者平台嘅OpenAI兼容接入SDK文檔連結發俾M3,佢拆解出10個To-dos,對多個界面內容進行修改,包括文案、數據庫同核心調用層,修改後仲進行驗證。
運行程序後,第一次出現報錯:無法訪問與值無關的本地變量reasoning_buffer。Kate截圖發俾M3,佢即刻修改。修改後,對話標題出現「思考」標籤,思考過程同結果輸出被截斷。Kate叫M3重命名標題並唔開思考,佢仲詢問咗Kate嘅偏好,例如現存被污染嘅標題應該點處理。呢點好貼心。
之後,Kate上傳圖片叫M3分析,但輸出仍然被截斷。Kate提示佢:「係唔係思考同輸出分段冇做好?可以搜尋網絡睇嚇。」M3揾到一個GitHub issue,然後給出修復意見:直接拼接。修改後,M3生成嘅結果可以完整展示,思考過程用英文,最終圖片解讀介紹構圖、色彩、紋理同推薦用途,整體唔錯。
多模態實測:手寫圖、鉛活字、3D場景與SVG
Kate叫M3對MSP進行解釋,左側係一張手寫圖。M3先根據呢張圖生成咗一個整體流程,然後詳細介紹第一步、第二步同核心設計思想,最後做總結。對數學公式比較在行嘅讀者可以評論下:M3識別出嘅公式是否正確?Kate睇落,整體流程框架冇問題。
再叫M3對上傳嘅鉛活字進行識別。M3能好好識別出呢個係鉛字反文,即係凸起嘅鏡像字。佢話完整逐字精確轉錄比較困難,但識別到以下可辨識嘅字詞,最後仲介紹咗歷史背景同文化價值。相比之下,Gemini 3.1 Pro雖然都識別到左右鏡像反轉,但對鉛字盤上文字嘅識別明顯唔係一一對應。
Kate叫M3生成一個機械腕錶爆炸視圖。第一次提示後,錶盤指針位置有問題。Kate截圖提示後,M3理解呢張圖,認為可以喺視覺、結構同功能方面進行提升,然後增加咗7個To-dos,對錶盤、指針、螺絲等細節進行升級。第二次提示後明顯美觀好多,支持自動演示,齒輪細節轉動展示都做得好好。只用了2次提示,完成度唔錯。
SVG小羊理髮方面,官方介紹喺SVG-Bench基準上M3超過Opus 4.7。左側係M2.7生成,右側係M3生成。同樣任務,M3生成嘅代碼行數更多,被理髮嘅小羊髮型波浪卷更時尚;理髮師造型都係Kate測試過嘅多個大模型裏面表現最好。迷你博物館:M3生成6個展櫃,每個有唔同展品,外觀好真實。Kate叫GPT 5.5檢查,得到76分,優點係程序化資產做得好、交互覆蓋面唔錯等,主要問題包括導覽狀態機同手電筒路徑邏輯不一致等。
喺實際編程工作中,可以讓國產編碼模型搭配一個強大嘅閉源模型,例如讓GPT 5.5審查代碼,讓M3負責編碼,咁樣更經濟。
工作流建議與總結
透過呢啲實測,Kate嘅感受係:M3可以將圖片、代碼、日誌、網頁資料同長上下文串連,完成一個比較完整嘅開發流程。佢認為M3嘅編碼能力已經相當實用,但遇到複雜任務時,由GPT-5.5呢類強模型做代碼審查更可靠,咁樣可以降低成本同時提高質量。
官方推文介紹快速版M3近期會推出,Kate好期待,認為搭配hermes agent會好好用。佢係AI內容創作者,已經創作咗400+篇原創,歡迎加入知識星球。
大家好,我係 Kate。
MiniMax M3 正式發佈咗。佢係目前國內首個同時做到前沿編碼能力、1M 上下文同原生多模態能力嘅模型。
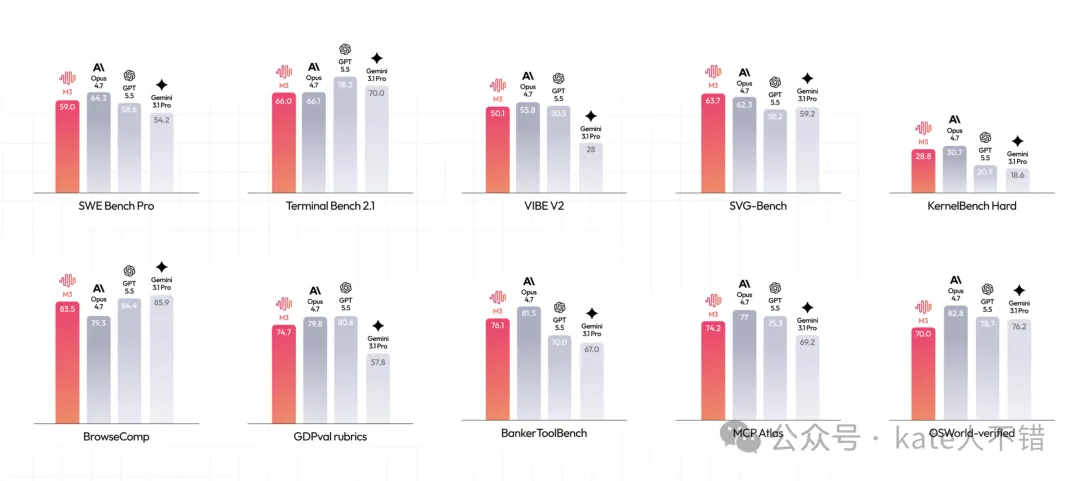
Gemini 3.1 Pro 嘅多模態一直好勁。喺多模態測試集 OmniDocBench 上,MiniMax M3 嘅得分竟然高過 Gemini,呢個真係令我好意外。
喺我嘅實測入面,我多次用到 M3 嘅圖片識別能力。有多模態之後,編碼真係方便咗好多。
官方展示咗 3 個案例:M3 點樣驗證論文、CUDA 算子優化,同埋點樣用 M3 訓練模型。呢幾個案例都好吸引,亦都展示咗 M3 喺複雜任務入面長時間執行嘅能力。
https://www.minimaxi.com/blog/minimax-m3
下面睇我嘅實測。
macOS 應用
叫 M3 幫我做咗一個 macOS 應用。
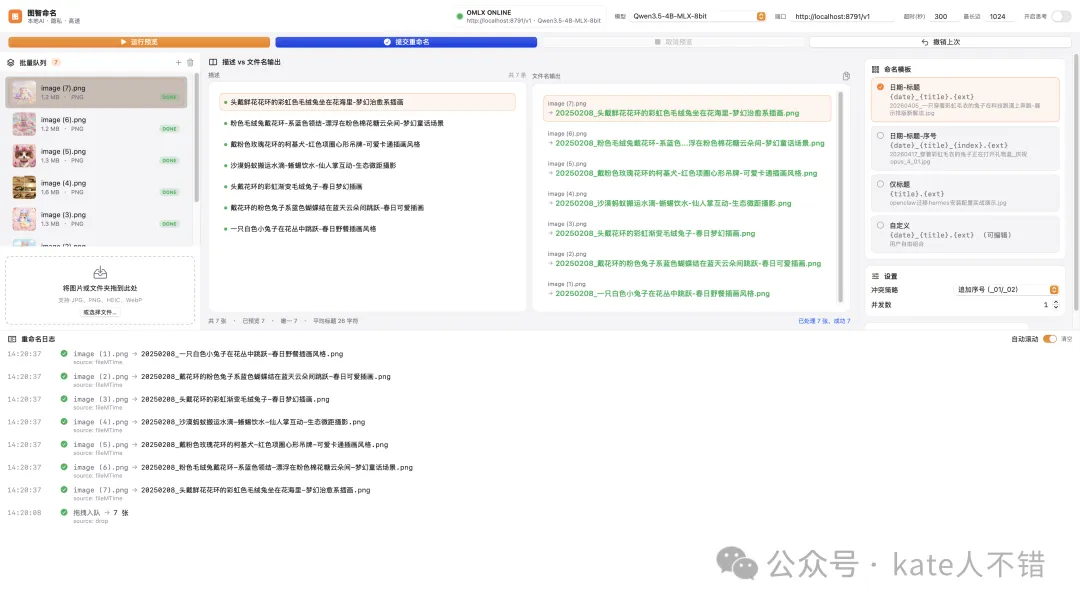
呢個 App 可以對接本地 omlx,用 AI 視覺模型識別圖片內容,然後自動幫圖片改名。成個項目已經開源,由 M3 幫我編碼同發佈完成嘅。
https://github.com/nicekate/TuZhiRename
我首先將一張由 GPT Image 2 生成嘅 App UI 圖 send 畀佢,然後開啓 Plan 模式,叫佢根據呢張圖生成應用。
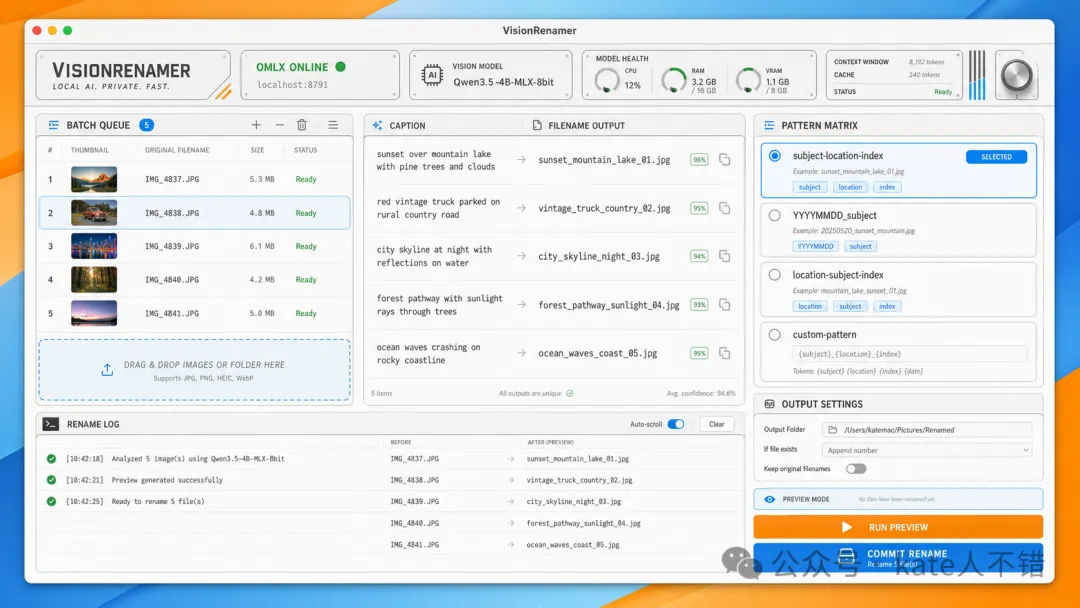

一開始,M3 並冇直接寫 code,而係反問咗我好多問題,同我對齊需求。
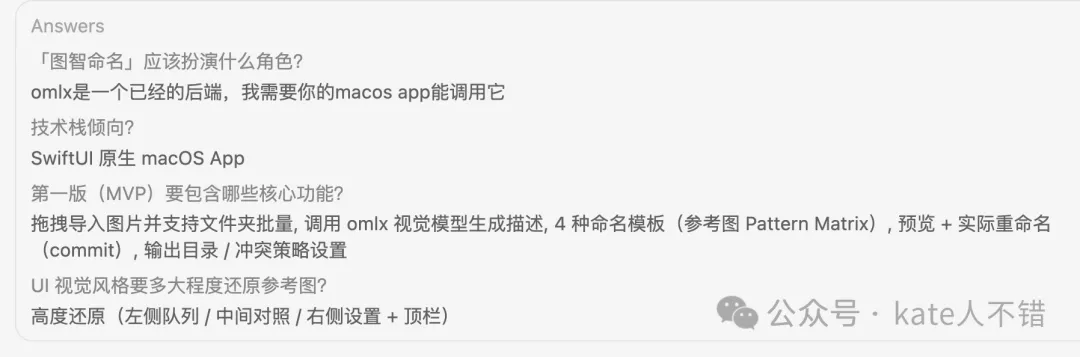
之後,佢生成咗一份計劃。

另外,我又臨時加咗個需求:升級命名模板。
修改完成之後,我就叫 M3 開始構建。
M3 將任務拆成咗 21 個 To-dos,然後生成了可以直接運行嘅程序。

喺構建過程中遇到失敗嘅時候,佢亦都會自己解決,呢個都係 MiniMax 模型 Agent 處理能力嘅強項之一。
後來,我上傳圖片之後發現個程序一直處於「處理中」。於是我截圖 send 畀 M3,叫佢分析原因同解決。

再之後,我新開咗一個窗口,叫 M3 檢查點解冇思考過程、好快就生成咗回覆。M3 分析之後,按概率俾咗幾個失敗原因。其中,佢認為最有可能嘅原因係 App 冇真正行 omlx 嘅視覺理解流程。

佢指出,Qwen3.6-35B-A3B-4bit 個名睇落似 LLM 多啲,唔係 VLM;就算模型收到 base64 圖片,都可能拒絕處理,或者直接亂噏。然後,佢建議我從 3 個方向開始排查。
跟住,我將 omlx 日誌 send 畀佢。M3 分析之後認為,omlx 返回嘅內容根本唔係 prompt 要求嘅 JSON。
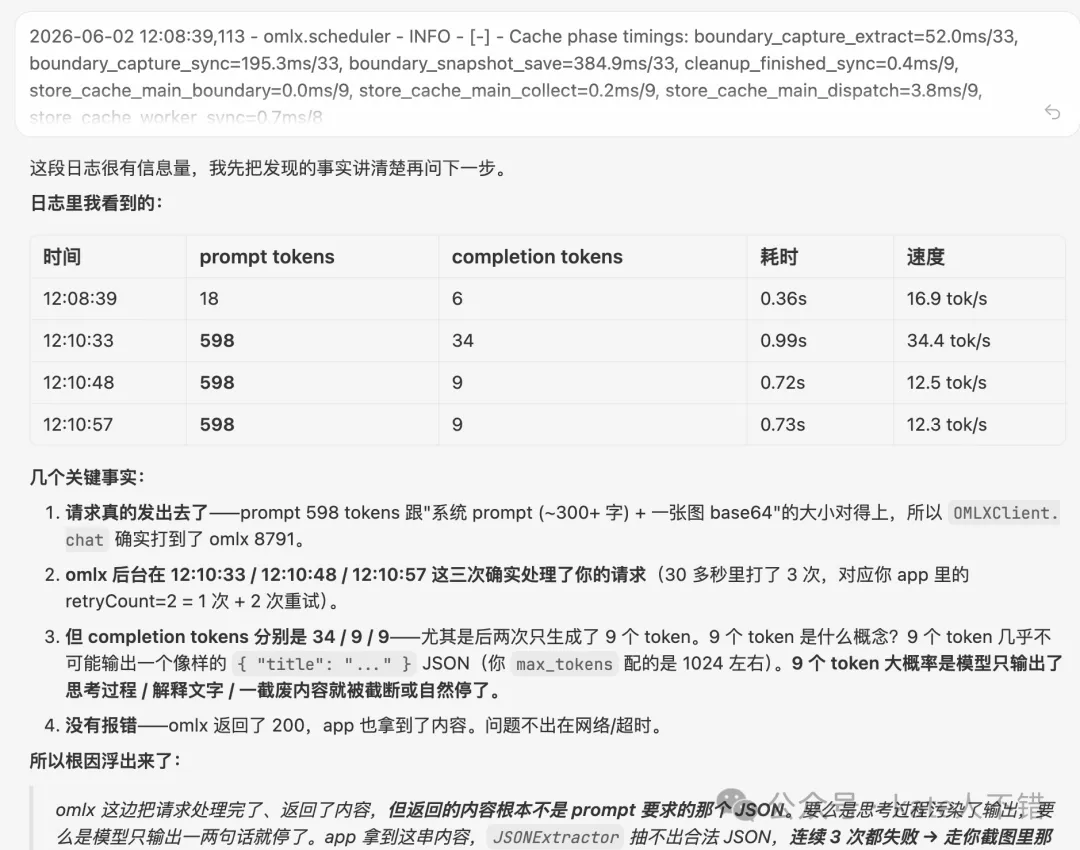
然後,我叫佢用 curl 繼續分析。M3 揾到咗 100% 嘅根因:模型確實收到咗圖片,但係冇正確處理。
到呢度,M3 幫我揾到咗一個關鍵線索。
我上個月用 omlx 調用同一個模型嘅時候,係可以正常識別圖片嘅;但今日就唔得。
而我最近都更新過幾次 omlx,所以我開始懷疑,會唔會係 omlx 版本嘅問題?
於是,我將目前嘅 omlx 版本同引擎版本 send 咗畀 Grok。Grok 幫我分析之後,認為呢個係 omlx 嘅已知 bug。

揾到問題之後,接下來就好辦喇。我將 omlx 更新到 0.4.0rc2 之後,App 即刻就可以正確識別圖片喇。
https://github.com/jundot/omlx/releases
之後,我又叫 M3 檢查目前 App 嘅性能問題、生成圖標,同埋安裝到我電腦嘅「應用程式」度,成個流程就比較順暢喇。

最後,我叫 M3 優化現有 README,同埋發佈到 GitHub。
呢個項目完整經歷咗需求對齊、計劃生成、代碼構建、運行驗證、Bug 定位、性能檢查同項目發佈。
改造既有項目,接入 MiniMax M3
接下來,我叫 M3 對我嘅一個現有項目做更改。呢個界面之前係我用嚟展示 Qwen Plus 模型測試效果嘅。
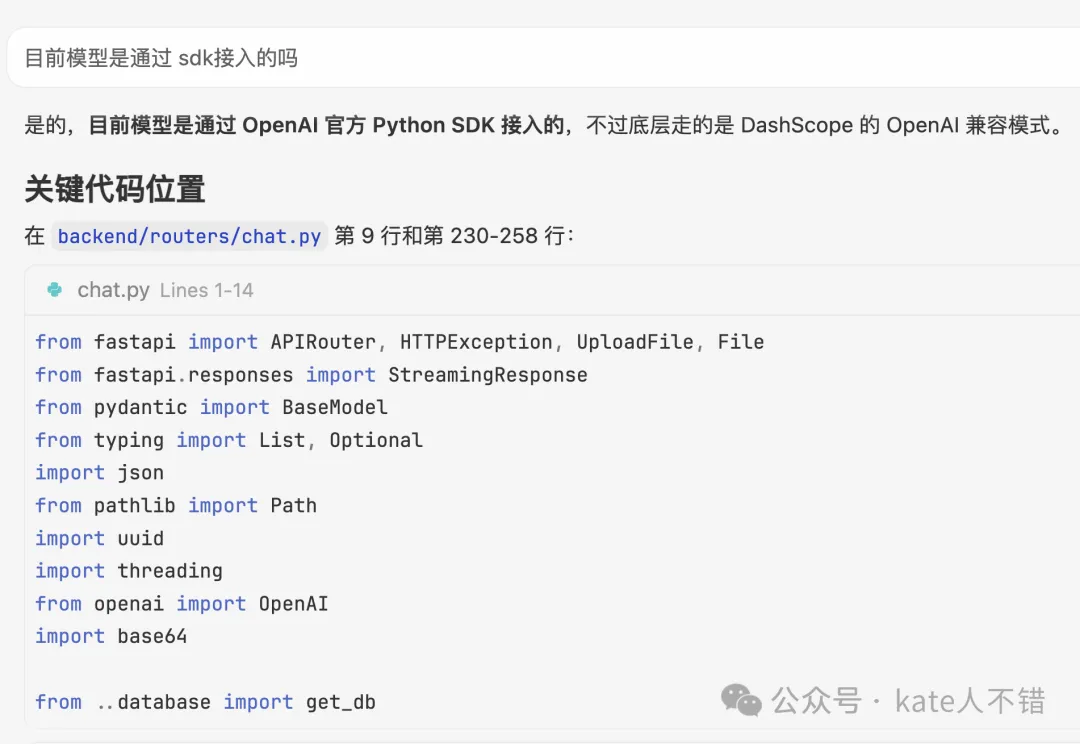
我先叫 M3 介紹呢個程序。佢詳細介紹咗目錄結構、技術棧、後端架構、前端架構同值得注意嘅細節等。跟住,我問佢係咪通過 SDK 接入,佢揾到咗關鍵代碼位置。
然後,我去到 MiniMax 開發者平台,將 OpenAI 兼容接入嘅 SDK 文檔連結 send 咗畀佢。
https://platform.minimaxi.com/docs/api-reference/text-openai-api
之後,佢就拆解出咗 10 個 To-dos。
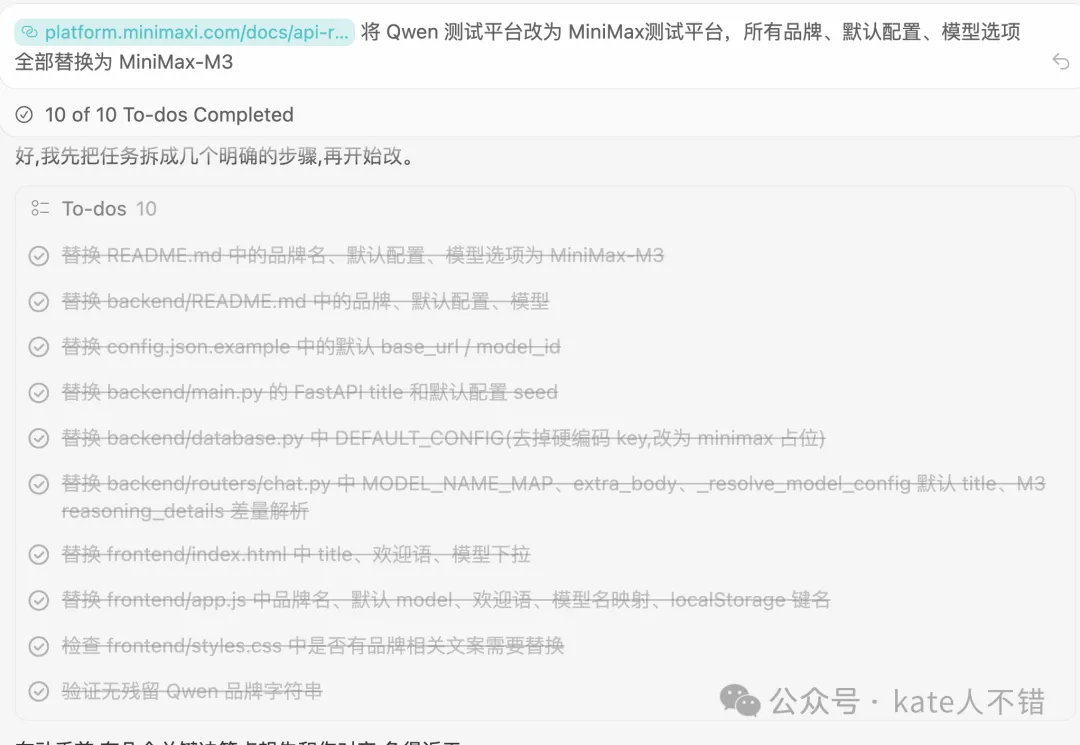
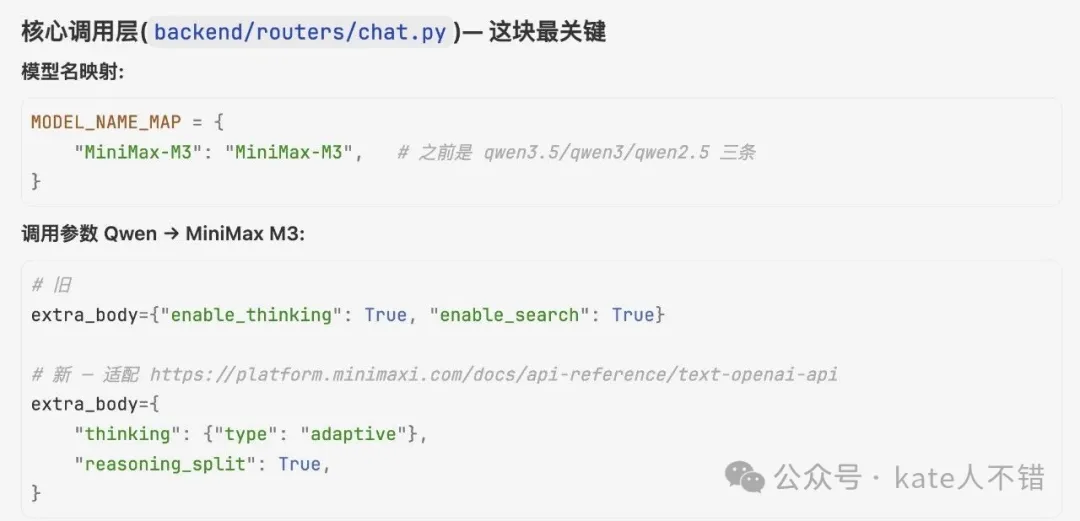
跟住,M3 對多個界面內容進行咗修改,包括文案、數據庫同核心調用層。修改之後,佢仲進行咗驗證。

運行程序之後,我開始提問。第一次出現咗報錯:
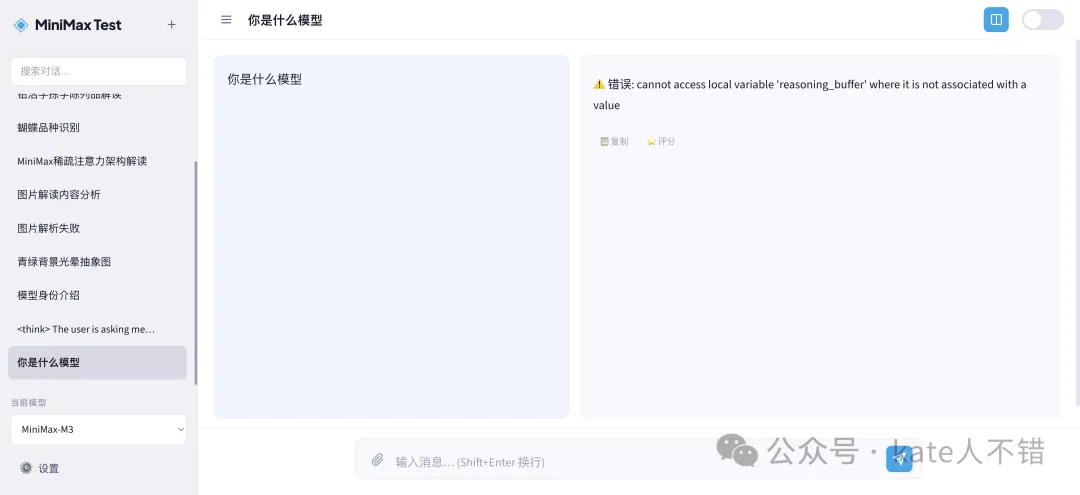
我直接截圖 send 畀 M3,叫佢修改。修改之後,就可以調用 M3 喇。
不過,喺對話標題度,我哋可以見到有「思考」嘅標籤。另外,思考過程同結果輸出部分都俾人截斷咗。
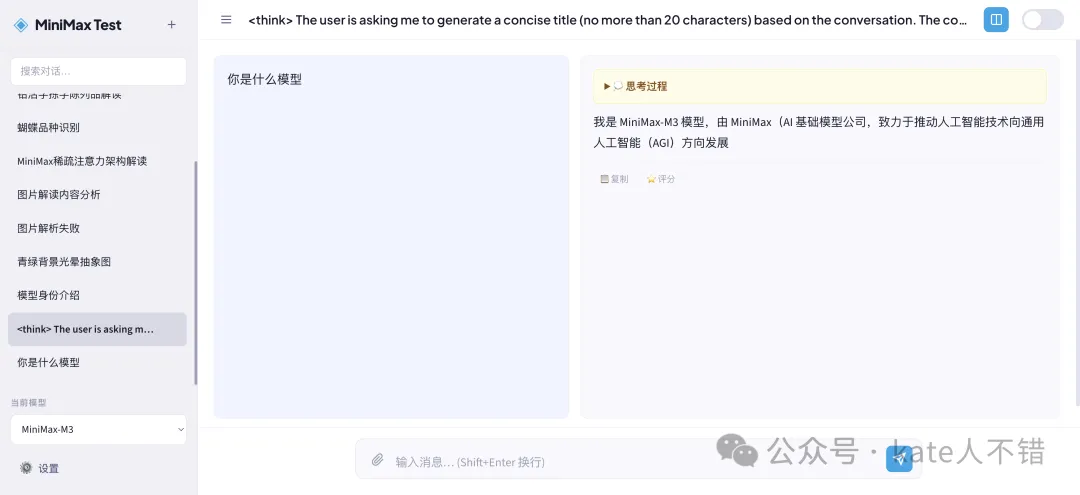
於是,我叫 M3 將對話標題重新改名,同埋唔開啓思考。
M3 仲問咗我嘅偏好,例如現存被污染嘅標題應該點處理。呢點好貼心。
跟住,我上傳圖片叫 M3 分析。但佢輸出嘅結果入面,思考同最終輸出仍然都俾人截斷咗。我提示佢:係咪思考同輸出分段做得唔好,可以上網搜尋嚇。
M3 揾到咗一個 GitHub issue,然後俾出修復意見:直接拼接。

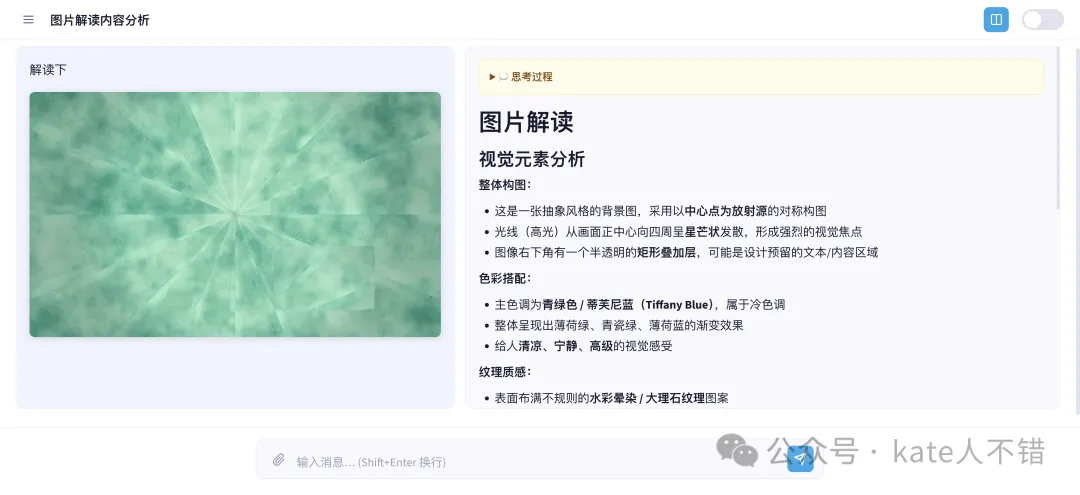
修改之後,我再次上傳圖片。而家 M3 生成嘅結果就可以完整展示出嚟喇。思考過程係英文,最終嘅圖片解讀介紹咗構圖、色彩、紋理,同埋推薦用途,整體都唔錯。
手寫圖識別,考驗多模態理解
跟住,我叫 M3 對 MSP 進行解釋。
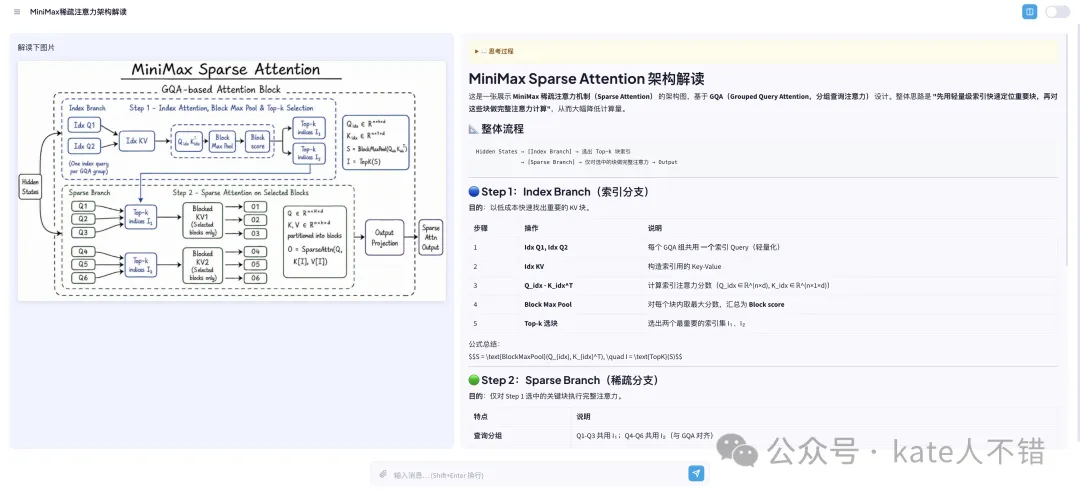
由於左邊呢張圖係手寫嘅,都幾考驗模型嘅圖像識別能力。M3 先根據呢張圖生成咗一個整體流程,然後詳細介紹咗第一步、第二步同核心設計思想,最後做咗總結。
對數學公式比較熟悉嘅讀者,可以喺評論區評論一下:M3 識別出嘅公式係咪正確?
我睇落,佢識別出嘅整體流程框架係冇問題嘅。
鉛活字識別,對比 Gemini 3.1 Pro
再叫 M3 對上傳嘅鉛活字進行識別。

M3 可以好好咁識別出呢啲係鉛字反文,即係凸起嘅鏡像字。佢話完整逐字精確轉錄比較困難,但識別咗以下可辨識嘅字詞。
最後,佢仲介紹咗歷史背景、文化價值同陳列意義。
Gemini 3.1 Pro 都識別到呢個係左右鏡像反轉,但係佢對鉛字盤上嘅文字識別,例如第六行,明顯同原圖唔係一一對應。

機械腕錶爆炸視圖
跟住,我叫 M3 生成一個機械腕錶爆炸視圖。
第一次提示之後,佢生成嘅錶盤效果係咁嘅,明顯見到指針位置擺放有問題。

於是我截咗圖,提示 M3 修改。
佢先理解呢張圖,認為喺視覺、結構同功能方面可以做呢啲提升;

對於一啲佢唔確定嘅地方,都會彈窗問我。
隨後,M3 增加咗 7 個 To-dos,對錶盤、指針、螺絲等細節進行咗升級。
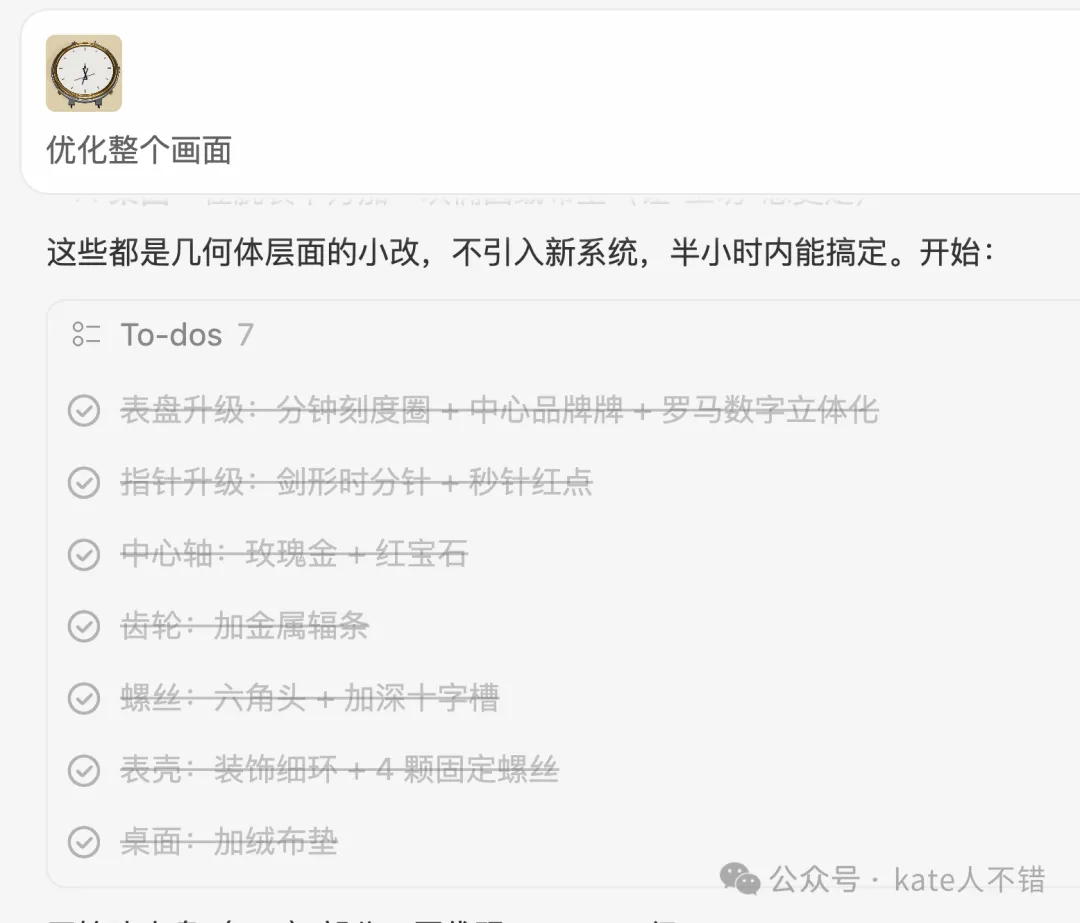 第二次提示之後嘅頁面明顯靚咗好多。
第二次提示之後嘅頁面明顯靚咗好多。


頁面支援自動演示,齒輪細節嘅轉動展示都做得好好。
隨住鼠標移動,我可以好方便咁睇各零部件嘅介紹。
淨係用咗 2 次提示,M3 喺呢個任務上嘅完成度都唔錯。
第一次提示⬇️

尤其係多模態能力嘅加持,令到提示詞少咗好多費力嘅解釋。
SVG 小羊理髮,對比 M2.7 效果提升
官方介紹,喺 SVG-Bench 基準上,MiniMax M3 超過咗 Opus 4.7。
左邊係 M2.7 生成嘅 SVG,右邊係 M3 生成嘅效果。
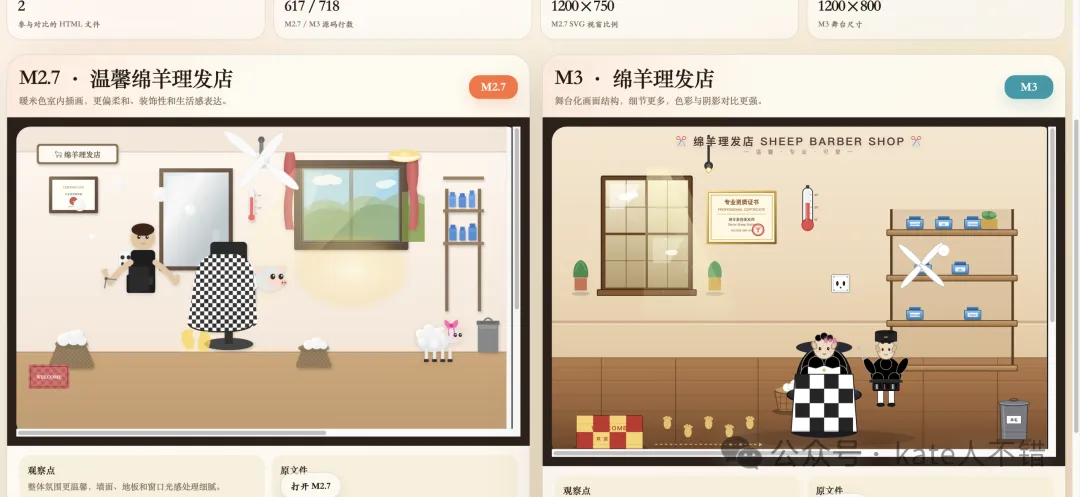
同樣嘅任務,M3 生成嘅代碼行數更多。被理髮嘅小羊髮型係波浪卷,更時尚;理髮師嘅造型都係我測試過嘅多個大模型裏面表現最好嘅。
整體嚟睇,M3 生成嘅效果明顯更好。
迷你博物館
我仲叫 M3 生成一個迷你博物館,要求至少 6 個展櫃,每個展櫃要有唔同嘅展品。

M3 生成嘅展櫃外觀好真實。隨後,我請 GPT 5.5 檢查現有程序有冇問題,包括但不限於性能問題,並總結優點、缺點,同時畀分佢。
GPT 俾呢個頁面打咗 76 分。佢認為優點包括:程序化資產做得好、交互覆蓋面唔錯、視覺氛圍完整,以及目前規模下性能冇爆炸。
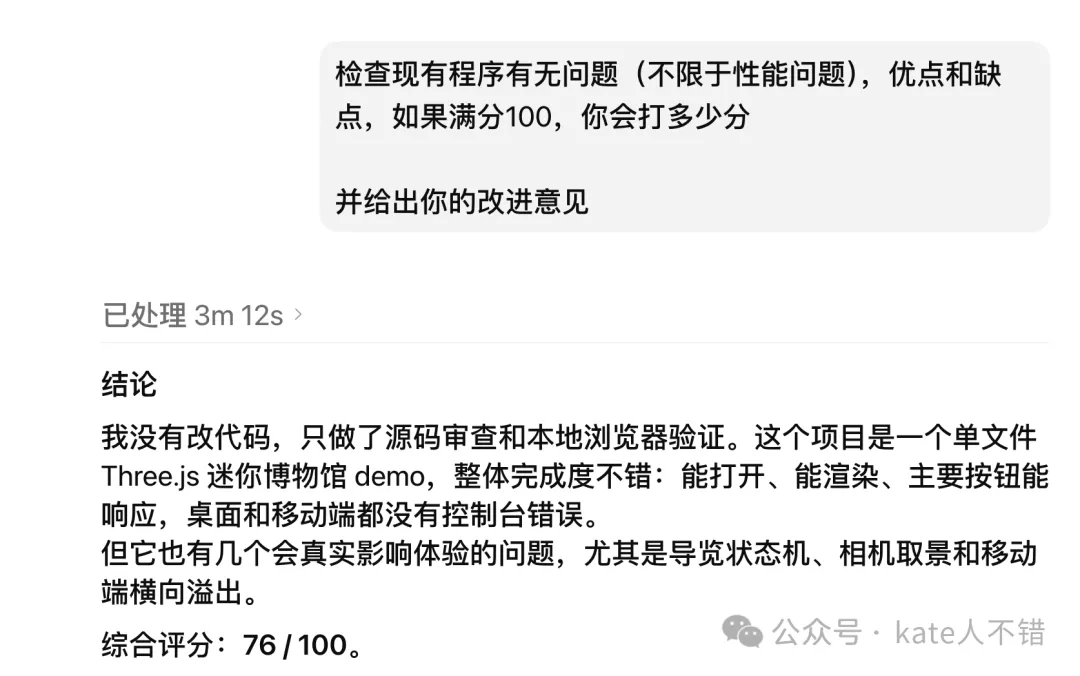

主要問題包括:導覽狀態機同電筒路徑邏輯唔一致、首屏導覽取景被展櫃遮擋等。

喺實際編程工作入面,我哋可以畀國產編碼模型搭配一個強大嘅閉源模型,例如叫 GPT 5.5 審查代碼,叫 M3 負責編碼,咁樣會更經濟。
工作流建議:M3 編碼,強模型審查
透過呢啲實測,我嘅感受係:M3 將圖片、代碼、日誌、網頁資料同長上下文串埋一齊,完成一個比較完整嘅開發流程。
官方推文入面介紹,快速版 M3 近期會推出,好期待,我認為搭配 hermes agent 會好好用。

希望今日嘅短片對你有幫助,我哋下次見。
廣告
過去我已經創作咗 400+ 篇AI主題原創內容,我對繼續寫作充滿信心,因為呢個係我嘅愛好,我好熱愛呢件事。
如果你鍾意我嘅文章同短片,歡迎加入我嘅知識星球,我會分享最新嘅 AI 資訊、源碼,回答你嘅問題。我哋下次再見啦!

最近文章,請睇呢度:
Grok Build 0.1 vs GPT 5.5 vs Composer 2.5:17 個複雜前端任務,邊個最強?
大家好,我是 Kate。
MiniMax M3 正式發佈了。它是目前國內首個同時實現前沿編碼能力、1M 上下文和原生多模態能力的模型。
Gemini 3.1 Pro 的多模態一直很強。在多模態測試集 OmniDocBench 上,MiniMax M3 的得分竟然超過了 Gemini,這讓我很意外。
在我的實測中,我多次用到了 M3 的圖片識別能力。有了多模態之後,編碼確實方便了很多。
官方展示了 3 個案例:M3 如何驗證論文、CUDA 算子優化,以及如何讓 M3 訓練模型。這幾個案例都非常吸引人,也展示了 M3 在複雜任務中長時間執行的能力。
https://www.minimaxi.com/blog/minimax-m3
下面看我的實測。
macOS 應用
讓 M3 幫我做了一個 macOS 應用。
這個 App 可以對接本地 omlx,用 AI 視覺模型識別圖片內容,然後自動給圖片重命名。整個項目已經開源,由 M3 幫我編碼併發布完成的。
https://github.com/nicekate/TuZhiRename
我先把一張由 GPT Image 2 生成的 App UI 圖發給它,然後開啓 Plan 模式,讓它根據這張圖生成應用。
一開始,M3 並沒有直接寫代碼,而是反問了我很多問題,和我對齊需求。
之後,它生成了一份計劃。
另外,我又臨時新增了一個需求:升級命名模板。
修改完成後,我就讓 M3 開始構建。
M3 把任務拆成了 21 個 To-dos,然後生成了可以直接運行的程序。
在構建過程中遇到失敗時,它也會自己解決,這也是 MiniMax 模型 Agent 處理能力的強項之一。
後來,我上傳圖片後發現程序一直處於“處理中”。於是我截圖發給 M3,讓它分析原因並解決。
再之後,我新開了一個窗口,讓 M3 檢查為什麼沒有思考過程、很快就生成了回覆。M3 分析後,按概率給出了幾個失敗原因。其中,它認為最可能的原因是 App 沒有真正走 omlx 的視覺理解流程。
它指出,Qwen3.6-35B-A3B-4bit 從名字看更像是 LLM,而不是 VLM;即使模型收到了 base64 圖片,也可能拒絕處理,或者直接瞎編。然後,它建議我從 3 個方向開始排查。
接着,我把 omlx 日誌發給它。M3 分析後認為,omlx 返回的內容根本不是 prompt 要求的 JSON。
然後,我讓它使用 curl 繼續分析。M3 找到了 100% 的根因:模型確實收到了圖片,但是沒有正確處理。
到這裏,M3 幫我找到一個關鍵線索。
我上個月使用 omlx 調用同樣的模型時,是可以正常識別圖片的;但今天不行。
而我最近也更新過幾次 omlx,所以我開始懷疑,會不會是 omlx 版本的問題?
於是,我把目前的 omlx 版本和引擎版本發給 Grok。Grok 幫我分析後,認為這是 omlx 的已知 bug。
找到問題後,接下來就好辦了。我把 omlx 更新到 0.4.0rc2 後,App 立即就能正確識別圖片了。
https://github.com/jundot/omlx/releases
之後,我又讓 M3 檢查目前 App 的性能問題、生成圖標,並安裝到我的電腦“應用程序”裏,整個流程就比較順暢了。
最後,我讓 M3 優化現有 README,併發布到 GitHub。
這個項目完整經歷了需求對齊、計劃生成、代碼構建、運行驗證、Bug 定位、性能檢查和項目發佈。
改造既有項目,接入 MiniMax M3
接下來,我讓 M3 對我的一個既有項目做更改。這個界面之前是我用來展示 Qwen Plus 模型測試效果的。
我先讓 M3 介紹這個程序。它詳細介紹了目錄結構、技術棧、後端架構、前端架構和值得注意的細節等。接着,我問它是不是通過 SDK 接入,它找到了關鍵代碼位置。
然後,我來到 MiniMax 開發者平台,把 OpenAI 兼容接入的 SDK 文檔連結發給它。
https://platform.minimaxi.com/docs/api-reference/text-openai-api
之後,它就拆解出了 10 個 To-dos。
接着,M3 對多個界面內容進行了修改,包括文案、數據庫和核心調用層。修改後,它還進行了驗證。
運行程序後,我開始提問。第一次出現了報錯:
我直接截圖發給 M3,提示它修改。修改後,就能調用 M3 了。
不過,在對話標題裏,我們可以看到有“思考”的標籤。此外,思考過程和結果輸出部分都被截斷了。
於是,我讓 M3 把對話標題重命名,並且不開啓思考。
M3 還詢問了我的偏好,比如現存被污染的標題應該怎麼處理。這點很貼心。
接着,我上傳圖片讓 M3 分析。但它輸出的結果裏,思考和最終輸出仍然都被截斷了。我提示它:是不是思考和輸出分段沒有做好,可以搜索網絡看看。
M3 找到了一個 GitHub issue,然後給出修復意見:直接拼接。
修改後,我再次上傳圖片。現在,M3 生成的結果就可以完整展示出來了。思考過程裏展示的是英文,最終的圖片解讀介紹了構圖、色彩、紋理,還有推薦用途,整體還是很不錯的。
手寫圖識別,考驗多模態理解
接着,我讓 M3 對 MSP 進行解釋。
由於左側這張圖是手寫的,還是比較考驗模型的圖像識別能力。M3 先根據這張圖生成了一個整體流程,然後詳細介紹了第一步、第二步和核心設計思想,最後做了總結。
對數學公式比較在行的讀者,可以在評論區評論一下:M3 識別出的公式是否正確?
我看下來,它識別出的整體流程框架是沒有問題的。
鉛活字識別,對比 Gemini 3.1 Pro
再讓 M3 對上傳的鉛活字進行識別。
M3 能很好地識別出這是鉛字反文,也就是凸起的鏡像字。它說完整逐字精確轉錄比較困難,但識別了以下可辨識的字詞。
最後,它還介紹了歷史背景與文化價值、陳列意義。
Gemini 3.1 Pro 也能識別出這是左右鏡像反轉,但是,它對鉛字盤上的文字識別,比如第六行,明顯和原圖不是一一對應。
機械腕錶爆炸視圖
接着,我讓 M3 生成一個機械腕錶爆炸視圖。
第一次提示後,它生成的錶盤效果是這樣的,明顯可以看到指針位置放置有問題。
於是我截了圖,提示 M3 修改。
它先理解這張圖,認為在視覺、結構和功能方面可以進行這些提升;
對於一些它不確定的地方,也會彈窗詢問我。
隨後,M3 增加了 7 個 To-dos,對錶盤、指針、螺絲等細節進行了升級。
第二次提示後的頁面明顯美觀了很多。
頁面支持自動演示,齒輪細節的轉動展示也做得很好。
隨着鼠標移動,我可以很方便地查看各個零部件的介紹。
只用了 2 次提示,M3 在這個任務上的完成度就不錯。
第一次提示⬇️
尤其是多模態能力的加持,讓提示詞少了很多費力的解釋。
SVG 小羊理髮,對比 M2.7 效果提升
官方介紹,在 SVG-Bench 基準上,MiniMax M3 超過了 Opus 4.7。
左側是 M2.7 生成的 SVG,右側是 M3 生成的效果。
同樣的任務,M3 生成的代碼行數更多。被理髮的小羊髮型是波浪卷,更時尚;理髮師的造型也是我測試過的多個大模型裏表現最好的。
整體來看,M3 生成的效果明顯更好。
迷你博物館
我還讓 M3 生成一個迷你博物館,要求至少 6 個展櫃,每個展櫃裏要有不同的展品。
M3 生成的展櫃外觀很真實。隨後,我請 GPT 5.5 檢查現有程序有沒有問題,包括但不限於性能問題,並總結優點、缺點,同時給它打分。
GPT 給這個頁面打了 76 分。它認為優點包括:程序化資產做得好、交互覆蓋面不錯、視覺氛圍完整,以及當前規模下性能沒有爆炸。
主要問題包括:導覽狀態機和手電筒路徑邏輯不一致、首屏導覽取景被展櫃遮擋等。
在實際編程工作中,我們可以讓國產編碼模型搭配一個強大的閉源模型,比如讓 GPT 5.5 審查代碼,讓 M3 負責編碼,這樣會更經濟一些。
工作流建議:M3 編碼,強模型審查
通過這些實測,我的感受是:M3 把圖片、代碼、日誌、網頁資料和長上下文串起來,完成一個比較完整的開發流程。
官方推文裏介紹,快速版 M3 近期會推出,非常期待,我認為搭配 hermes agent 會很好用。
希望今天的視頻對你有幫助,我們下次見。
廣告
過去我已創作了 400+ 篇AI主題原創內容,我對繼續寫作充滿信心,因為這是我的愛好,我非常熱愛這件事。
如果喜歡我的文章和視頻,歡迎加入我的知識星球,我會分享最新的 AI 資訊、源代碼,回答你的問題。我們下次再見啦!
最近文章,請看這裏:
Grok Build 0.1 vs GPT 5.5 vs Composer 2.5:17 個複雜前端任務,誰最強?