Nathan Lambert:GLM-5.2是開源Agent重大突破,連鎖反應將滲透進更廣泛的經濟體
整理版優先睇
GLM-5.2成為首個喺編程框架中手感極佳嘅開源Agent,打破閉源壟斷,引發經濟連鎖反應。
呢篇文章係由開源AI領域嘅重量級觀察者Nathan Lambert所寫,佢係RLHF專家,經常用第一手信源分析開源模型動態。今次佢聚焦Z.ai最新發布嘅GLM-5.2模型,認為呢個模型係開源Agent領域嘅分水嶺,效能首次追近Claude Opus 4.5同Fable等頂尖閉源模型,而且係第一個喺編程框架入面用起嚟「手感極佳」嘅開源模型。
作者指出,GLM-5.2嘅發布時機好特別,喺Anthropic因出口限制而受挫之際,Z.ai趁勢推出,成功搶奪市場注意力。佢引用多個社區測評同業界人士嘅讚賞,證明呢個模型唔單止跑分勁,實際使用體驗都好出色。對比之前嘅Kimi K2,GLM-5.2嘅突破更加具有「無法回頭」嘅性質,因為佢直接威脅到Anthropic靠Claude Code創下嘅營收增速。
整體而言,作者認為GLM-5.2標誌住開源模型與閉源模型嘅能力差距縮短到6.8個月,而且喺閉源模型被禁嘅情況下,開源模型有更多時間蠶食市場。呢種連鎖反應將滲透到更廣泛嘅經濟體,對AI產業結構同監管政策帶來深遠影響。作者同時呼籲要正視開源模型嘅管理問題,避免一刀切禁止導致未來更大嘅風險。
- GLM-5.2係首個喺編程框架中作為通用智能體使用時手感極佳嘅開源模型,效能追平頂尖閉源模型。
- Z.ai利用Anthropic受出口限制嘅時機發布,成功搶佔市場情緒同營銷優勢。
- 開源與閉源能力差距縮短至約6.8個月,GLM-5.2係DeepSeek R1之後另一個重大突破。
- 模型對Anthropic等閉源公司構成價格壓力,可能影響其創紀錄嘅營收增速。
- 開源模型嘅擴散將引發經濟連鎖反應,需要更完善嘅監管框架,避免一刀切禁止導致更大風險。
GLM-5.2嘅發布背景
呢篇文章係由開源AI領域嘅重量級觀察者Nathan Lambert所寫,佢喺RLHF領域係公認專家,經常報道開源模型動態。佢提到大約一週前,正當整個AI界因Claude Fable 5遭到出口限制而驚魂未定時,Z.ai發佈咗最新模型GLM-5.2。
反常嘅發布慣例——模型喺6月13日週六率先向GLM編程計劃會員開放,藉住Anthropic走向反開源科學嘅時代情緒大賺一筆。
按照行業命名慣例,GLM-5.2看似只係漸進式更新,但作者指出微小的版本號變動往往能跨越用戶體驗臨界點。
基準測試同訓練方式上嘅些許微調,就能開啟極其廣泛嘅新應用場景。
效能突破與社區反應
6月16日官方採用MIT協議正式發佈後,社區湧現大量測評結果,GLM-5.2嘅表現遠超預期。
Arena嘅智能體排行榜將其評為唯一一個能與OpenAI和Anthropic最新模型同台競技嘅開源模型。
以最大思考模式追平Opus 4.8嘅非思考模式,更喺Design Arena擊敗Claude Fable本尊。
- Arena智能體排行榜:唯一能與OpenAI和Anthropic最新模型競爭嘅開源模型。
- Design Arena:擊敗Claude Fable,後者係近期被封禁嘅營銷神話。
- 幾乎所有親自上手嘅研究人員都對其讚不絕口,成為社區凝聚點。
作者親自接入Claude Code工作流,配置簡單,模型底子一上手就感覺對了。
開源與閉源能力差距
作者將GLM-5.2嘅突破比作DeepSeek R1時刻,但認為呢次更加具有「無法回頭」嘅性質。
從Claude Opus 4.5發佈到GLM-5.2發佈,時間間隔204日(約6.8個月),落在美國閉源與中國開源對手之間6到9個月嘅性能時差區間。
作者原本預計呢個差距會因美國實驗室瘋狂拉高算力投入而不斷拉大,但GLM-5.2嘅出現令佢感到詫異。
Claude Fable 5嘅發佈將成為下一個決定性節點,因為佢更依賴規模同先進GPU。
經濟連鎖反應與監管挑戰
GLM-5.2對Anthropic等閉源公司構成嚴峻嘅價格壓力,可能影響其創紀錄嘅營收增速。
呢個模型對開源模型經濟體係一記超級強心針,像Fireworks、Together等推理服務廠商剛迎來又一個拐點。
- 1 價格壓力:Anthropic靠Claude Code創下嘅營收增速面臨威脅。
- 2 經濟擴散:連鎖反應滲透進更廣泛經濟體需時,但工作流正變得愈嚟愈複雜,使用不同模型進行規劃、編碼同調度。
- 3 監管難題:Mythos級別模型能力被美國裁定不宜發布,但中國開源模型狂飆突進,可能導致美國最終裁定某款開放權重模型存在安全隱患。
AI征途還有數年,下一代芯片已投產,算法突破連綿不絕,必須找出讓開源模型活下去嘅辦法。

開源AI領域嘅重量級觀察者 Nathan Lambert 話:GLM-5.2突然做到啲只有頂尖付費AI先做到嘅嘢:寫code、自動完成複雜任務。佢將呢次突破比喻成當年 DeepSeek R1 震驚世界嘅一刻。即係話,用大價錢壟斷最強AI嘅美國大公司,第一次感受到真正嘅威脅。而 GLM-5.2 行出嘅呢一步,更加似 AI 進步歷程中一扇冇得回頭嘅單向門。
Nathan Lambert 係目前 AI 開源世界最核心嘅聲音之一。
響 RLHF 領域係公認嘅專家。John Schulman(ChatGPT 聯合創辦人、前 Anthropic)公開推薦佢嘅博客作為 RLHF 進階讀物。
Interconnects Discord 有 300+ 成員,涵蓋前沿實驗室研究員、創辦人、投資者,形成獨特嘅資訊網絡。佢對開源模型嘅報道同分析響西方社區係重要嘅第一手消息來源。
Nathan Lambert啱啱寫咗一篇關於GLM5.2嘅文章,完整中文版如下:
https://www.interconnects.ai/p/glm-52-is-the-step-change-for-open

我一直密切監測緊一個能力臨界點。
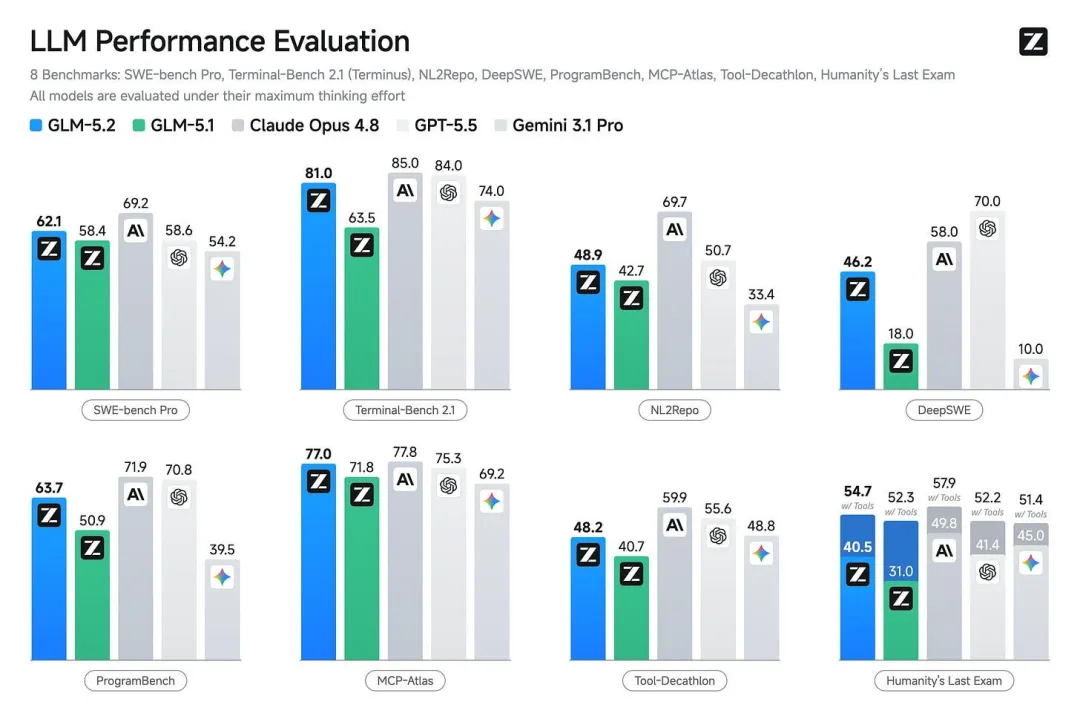
大約一個星期前,正當整個 AI 界仲因為 Claude Fable 5 受到令人震驚嘅出口限制同實質上嘅封禁而驚魂未定之際,Z.ai 發佈咗佢哋嘅最新模型:GLM-5.2。呢個模型響 6 月 13 號(星期六)以一種唔尋常嘅方式,率先向 GLM 編程計劃(GLM Coding Plan)嘅會員開放。反常嘅發佈慣例一定有原因,通常 AI 模型揀喺週末發佈,背後都有啲古古怪怪嘅原因(最出名嘅例子係 Llama 4)但係響呢次事件中,Z.ai 似乎異常興奮,打算藉助「Anthropic 走向反開源科學(對佢哋嘅 AI 研究人員採取靜默安全機制)」呢個時代情緒嘅東風大賺一筆。喺過去一兩年,中國嘅開放權重實驗室捉住咗每一個類似嘅機會,輕鬆贏咗一場又一場嘅營銷戰。
按照行業內通用嘅命名慣例,GLM-5.2 睇起嚟可能只係繼備受追捧嘅 GLM-5.1 之後嘅一次漸進式更新。到目前為止,打造咗 Kimi 系列模型嘅月之暗面(Moonshot AI)同打造咗 GLM 系列模型嘅 Z.ai,已經憑藉 AI 研究人員羣體中最受歡迎嘅開放權重模型,穩穩佔據咗口碑市場嘅頭部生態位。不過之後嘅演變,印證咗一個追蹤 AI 模型嘅經典教訓:往往微小嘅版本號變動,卻可以令 AI 模型跨越極具意義嘅用戶體驗臨界點。 基準測試同訓練方式上嘅些微調整,就可以開啟極其廣泛嘅新應用場景。
隨之而嚟係針對 GLM-5.2 緩慢而洶湧嘅口碑發酵。喺佢初次推送嘅三日後,即係 6 月 16 號,官方採用 MIT 協議嘅模型權重同發佈博客正式上線。大家可以長篇大論咁列出佢嘅技術細節——例如強勁嘅跑分成績、Z.ai 所用嘅極之熱門嘅強化學習框架(SLIME),同埋官方「始終建議喺 Max 思考強度(Max thinking effort)下使用呢個模型」嘅提示等等,但最初嘅官宣博客通常唔係重點。你大可以按兵不動,靜觀整個生態系統嘅真實反應,咁樣去判斷佢到底係咪「真傢伙」。反正,而家嘅基準測試已經半死不活喇。
6 月 16 號之後,社區湧現咗大量測評結果,GLM-5.2 嘅表現遠超預期。Arena 嘅智能體排行榜將佢評為唯一一個可以同 OpenAI 同 Anthropic 最新模型同場競技嘅開源模型(值得留意嘅係,佢以「最大思考模式」追平咗 Opus 4.8 嘅「非思考模式」)。呢個只係 GLM-5.2 喺眾多評估中將 Gemini 打到趴街嘅指標之一,不過係另一個話題喇。甚至連一個喺社區內(尤其係實際從業嘅設計師羣體中)口碑好壞參半嘅測試——Design Arena,都顯示 GLM-5.2 擊敗咗 Claude Fable 本尊——即係最近先被封禁嗰個營銷神話!
喺 AI 評論界同我所尊重嘅研究人員羣體中,幾乎所有親自上手體驗過呢個模型嘅人都對佢讚不絕口。開源模型嘅發佈可以成為社區咁清晰嘅凝聚點同討論核心,之前只發生過一次——就係 DeepSeek R1。呢個唔係我會隨便作出嘅對比;當初我將 Kimi K2 嘅發佈比喻成「DeepSeek 時刻」嗰陣,GLM-5.2 而家達到嘅高度已經遠遠超過咗。Kimi K2 之所以令人驚豔,係因為佢證明咗開源模型性能嘅大幅跨越似乎可以誕生喺中國嘅任何地方;而 GLM-5.2 行出嘅呢一步,更加似 AI 進步歷程中一扇冇得回頭嘅單向門。
Anthropic 依靠 Claude Code 實現嘅創紀錄營收增速,極其嚴重咁建立喺「佢係最好嘅模型,亦係唯一真正勝任呢項工作嘅模型」呢種認知之上。GLM-5.2 係第一個(而且之後仲會有更多)提供可信替代方案嘅開放權重模型。當中的平行映射非常清晰:正如當年嘅 DeepSeek R1 向世人展示,資源匱乏得多嘅開源實驗室,同樣可以復現 OpenAI 憑藉 o1 引領嘅思維鏈推理模型。隨住 AI 系統變得日益複雜、構建成本極其高昂——需要配套各種工具、複雜嘅集成開發框架(Harness)以及超大規模嘅模型權重——GLM-5.2 呢一刻嘅降臨,喺此之前絕對唔係理所當然。
最核心嘅一點在於,GLM-5.2 係第一個喺編程框架中作為通用智能體使用時,「手感極佳」(feels right)嘅開放權重模型。 佢係開天闢地嘅第一個。我自己喺嘗試近期一啲同類模型(例如 Kimi K2.7 或 GLM-5.1)嘅進度上本來有啲滯後,但 GLM-5.2 嘅熱度實在太高,高到我冇辦法忽視。我將佢接入咗 Claude Code 中基於 Fireworks API 嘅工作流,等佢幫我嘅後訓練(Post-training)課程寫內容(配置過程非常簡單)。中間的確遇到咗一啲小卡頓,例如 Claude Code 框架或者我嘅倉庫文檔嘗試向模型發送圖片,搞到 Fireworks API 嗰次會話直接卡死——迫我要手動清除上下文。但總體嚟講,模型嘅底子令人一上手就覺得啱,至於具體揀邊個驅動框架同雲服務商,我仲需要再微調一下。
如果你想睇更多嘅行業吹捧,可以睇嚇 Z.ai 創辦人對 Elon Musk 講嗰句:「開放權重嘅 Fable 級能力將會比 2027 年第一季更早到來」;Vercel 首席執行官發推話:「由 @zai_org 打造嘅 GLM-5.2 喺寫 code 方面嘅表現好到我發自內心感到震撼,甚至有啲震驚。呢個改變咗遊戲規則」;以及更多來自一羣我極度尊重嘅人,同埋我啱啱認識嘅圈內人士嘅評價。
咁,呢個係一個好模型,呢個又將我哋推向咗邊度?
多種趨勢正在交織作用。首先,我哋建立喺「開源與閉源能力差距」呢個基準線上嚟審視。我曾經寫過,如果開源模型能夠喺 2026 年初左右跨過「Claude Code 中 Opus 4.5」嘅能力門檻,我預計將會迎來一場「使用量嘅爆發」。而家,呢一日嚟咗。由 2025 年 11 月 24 日 Claude Opus 4.5 發佈,到 2026 年 6 月 16 日 GLM-5.2 發佈,時間間隔為 204 日——約等於 6.8 個月。呢個啱啱好落入咗好多人所主張嘅「美國閉源實驗室與中國開源對手之間存在 6 到 9 個月性能時差」嘅區間。
寫到呢度,我自己都覺得詫異。鑑於美國實驗室喺過去大約一年裏面瘋狂咁拉高算力投入,我原本預計呢個時間差距會隨住時間推移而不斷拉大。呢條軌跡上一個非常具有決定性意義嘅節點,將會係 Claude Fable 5 嘅發佈——相比於 Claude Opus 系列,佢更嚴重依賴規模(Scale),因而亦更依賴最先進嘅 GPU。不過,呢個仍然唔係一個令人滿意嘅解釋。要繼續拆解呢條發展軌跡,背後嘅複雜同微妙程度,絕對唔係我喺呢篇風向標式嘅短文裏面三言兩語可以容納得落嘅。
呢件事最直接嘅意義在於,帶俾啲瘋狂壓榨 Token 吞吐量(tokenmaxxing)、將 Anthropic 營收推向月球嘅組織內部,帶嚟咗嚴峻得多嘅價格壓力。有些人或許會預測 Anthropic 將無法達成佢哋預測嘅年度經常性收入(ARR)目標,但我認為呢種看法冇將市場對呢啲模型嘅真實需求以及不可避免嘅增長勢頭計算在內。呢個模型嘅存在,對開源模型經濟體嚟講係一記超級強心針。好似 Fireworks、Together、Thinky(通過 Tinker)、Prime Intellect 以及所有出售開源模型推理或微調服務嘅廠商,啱啱迎嚟咗又一個拐點。
呢度嘅連鎖反應滲透進更廣泛嘅經濟體(以及具體應用場景)仲需要好長一段時間。工作流正變得愈嚟愈複雜,人們開始用唔同嘅模型分別進行規劃、核心編碼以及子智能體調度。我預計呢股熱潮仲會繼續發酵——見鬼,寫低呢段話嘅時候正係星期日晚上,我已經可以預見到星期一媒體同市場嘅反應,絕對會好似當年 DeepSeek R1 發佈時一模一樣。當 Anthropic 嘅模型(擴闊範圍嚟講即係美國嘅旗艦模型)依然處於被禁狀態時,呢種技術擴散嘅發生,無異於一把插入經濟體命門深處嘅匕首。正當閉源巨頭們嘗試向住唯獨絕對前沿模型先可以解鎖嘅高毛利、高營收領域突進之際,GLM-5.2 卻得到咗充裕嘅時間,去蠶食前沿實驗室嘅經濟腹地。
呢個經濟隱憂映射咗一個喺 AI 圈子裏面已經被翻來覆去講過無數次嘅故事,因此好難講呢一次佢會喺幾時真正產生決定性影響。
感覺上更關乎 AI 發展主線嘅議題,係關於開源模型嘅監管與管控。我認為廉價智能嘅廣泛傳播係一種經濟善舉,我哋嘅默認立場理應係為開源模型喝彩;然而,呢個模型嘅發佈日期,將會令佢喺 AI 權力結構嘅認知地圖中,永久咁同 Claude Fable(並進而同 Claude Mythos)掛鈎。我哋正處於咁樣一個歷史節點:Mythos 級別嘅模型能力被美國政府裁定為「唔適宜對外公開發佈」,而中國嘅大模型製造商們卻喺所有人皆可觸達嘅普惠能力道路上狂飆突進。
呢啲趨勢線喺因果上未必直接相關,因為我哋仲唔清楚 GLM-5.2 同佢前代產品喺網絡攻防(Cyber)方面嘅具體表現差異,但佢哋嘅能力絕對係正相關。如果外界條件冇任何改變,呢個指向咗一種潛在嘅可能:美國政府最終裁定某款開放權重嘅中國模型「對公眾存在安全隱患」。呢度當然仲存在好多其他潛在推演,但唯一明確嘅係,喺梳理呢啲預案、準備我哋嘅基礎設施、以及向全社會傳達資訊方面,我哋仲有海量嘅工作要做。
要向決策者描繪並傳達「如何管理愈嚟愈強大嘅開源模型」嘅未來世界,光靠我一個人遠遠唔夠,仲需要多好多嘅同路人。人工智能嘅征途仲有數年咁耐,NVIDIA 下一代芯片已經投入量產,算法上嘅突破更加係連綿不絕。對開源模型嘅擁護者嚟講,前路感覺係一條極其狹窄嘅細縫,但我哋必須揾出令佢哋生存落去嘅辦法,絕對唔可以讓性能嘅躍升淨係變成閉源模型嘅獨腳戲。
我完全理解點解「想像一個公眾可以隨意訪問嘅 Mythos 級模型」會令人感到膽寒;但如果開源模型響今日被一刀切咁禁絕,而喺未來嘅兩年裏面,只有掌握喺一兩間公司手裏面嘅閉源模型獲得咗 10 倍甚至 100 倍嘅性能躍升——我認為到嗰陣時,我哋將會面臨遠比而家嚴重得多嘅危機。
最後我再說一句,就像文章題目所說的「連鎖反應將滲透進更廣泛的經濟體」,這句話值得好好思考一下。
--end--
最後記得⭐️我,每日都在更新:如果覺得文章仲可以嘅話可以點讚轉發推薦評論
/...@作者:你講得完全正確(YAR師)
開源AI領域的重量級觀察者 Nathan Lambert :GLM-5.2突然能做到那些只有頂尖付費AI才能做的事:寫代碼、自動完成複雜任務。他把這次突破比作當年 DeepSeek R1 震驚世界的那一刻。這意味着,花大價錢壟斷最強AI的美國大公司,第一次感受到了真正的威脅。而 GLM-5.2 邁出的這一步,更像是 AI 進步歷程中一扇無法回頭的單向門。
Nathan Lambert 是當前 AI 開源世界最核心的聲音之一。
在 RLHF 領域是公認的專家。John Schulman(ChatGPT 聯創、前 Anthropic)公開推薦他的博客作為 RLHF 進階讀物。
Interconnects Discord 有 300+ 成員,涵蓋前沿實驗室研究員、創始人、投資人,形成獨特的信息網絡。他對開源模型的報道和分析在西方社區是重要的第一手信源。
Nathan Lambert剛寫了一篇關於GLM5.2的文章,完整中文版如下:
https://www.interconnects.ai/p/glm-52-is-the-step-change-for-open
我一直在密切監測的一個能力臨界點。
大約一週前,正當整個 AI 界還在因 Claude Fable 5 遭到令人震驚的出口限制及事實上的封禁而驚魂未定時,Z.ai 發佈了他們的最新模型:GLM-5.2。這一模型在 6 月 13 日(週六)以一種不同尋常的方式,率先向 GLM 編程計劃(GLM Coding Plan)的會員開放。反常的發佈慣例總有緣由,通常 AI 模型選在週末發佈,背後都有點奇奇怪怪的原因(其中最著名的例子當屬 Llama 4)。但在本次事件中,Z.ai 似乎異常興奮,試圖藉着“Anthropic 走向反開源科學(對其 AI 研究人員採取靜默安全機制)”這一時代情緒的東風大賺一筆。在過去的一兩年裏,中國的開放權重實驗室抓住了每一個類似的機會,輕鬆贏下了一場場營銷戰。
按照行業內通用的命名慣例,GLM-5.2 看起來可能只是繼備受追捧的 GLM-5.1 之後的一次漸進式更新。時至今日,打造了 Kimi 系列模型的月之暗面(Moonshot AI)與打造了 GLM 系列模型的 Z.ai,已經憑藉 AI 研究人員羣體中最受喜愛的開放權重模型,穩穩佔據了口碑市場的頭部生態位。然而接下來的演變,印證了一個追蹤 AI 模型的經典教訓:往往微小的版本號變動,卻能讓 AI 模型跨越極具意義的用戶體驗臨界點。 基準測試和訓練方式上的些許微調,就能開啓極其廣泛的新應用場景。
隨之而來的是針對 GLM-5.2 緩慢而洶湧的口碑發酵。在其初始推送的三天後,即 6 月 16 日,官方採用 MIT 協議的模型權重和發佈博客正式上線。人們可以長篇累牘地羅列它的技術細節——比如強悍的跑分成績、Z.ai 所使用的極其熱門的強化學習框架(SLIME)、以及官方“始終建議在 Max 思考強度(Max thinking effort)下使用該模型”的提示等等,但最初的官宣博客通常不是重點。你大可按兵不動,靜觀整個生態系統的真實反應,以此來判斷它到底是不是“真傢伙”。反正,如今的基準測試已經半死不活了。
6 月 16 日之後,社區湧現出了大量測評結果,GLM-5.2 的表現遠超預期。Arena 的智能體排行榜將其評為唯一一個能與 OpenAI 和 Anthropic 最新模型同台競技的開源模型(值得注意的是,它以“最大思考模式”追平了 Opus 4.8 的“非思考模式”)。這還只是 GLM-5.2 在眾多評估中把 Gemini 吊起來打的指標之一,不過那是另一個話題了。甚至連一個在社區內(尤其是實際從業的設計師羣體中)口碑褒貶不一的測試——Design Arena,都顯示 GLM-5.2 擊敗了 Claude Fable 本尊——那個最近剛被封禁的營銷神話!
在 AI 評論界和我所尊重的研究人員羣體中,幾乎所有親自上手體驗過該模型的人都對其讚不絕口。開源模型的發佈能成為社區如此清晰的凝聚點與討論核心,此前只發生過一次——那就是 DeepSeek R1。這不是一個我會輕率作出的對比;當初我把 Kimi K2 的發佈比作“DeepSeek 時刻”時,GLM-5.2 現在達到的高度已經遠超於此。Kimi K2 之所以令人驚豔,是因為它證明了開源模型性能的大幅跨越似乎可以誕生於中國的任何地方;而 GLM-5.2 邁出的這一步,更像是 AI 進步歷程中一扇無法回頭的單向門。
Anthropic 依託 Claude Code 實現的創紀錄營收增速,極其嚴重地建立在“它是最好的模型,也是唯一真正能勝任這項工作的模型”這一認知上。GLM-5.2 是首個(且後續還會有更多)提供可信替代方案的開放權重模型。這其中的平行映射非常清晰:正如當年的 DeepSeek R1 向世人展示,資源匱乏得多的開源實驗室,同樣能夠復現 OpenAI 憑藉 o1 引領的思維鏈推理模型。隨着 AI 系統變得日益複雜、構建成本極其高昂——需要配套各種工具、複雜的集成開發框架(Harness)以及超大規模的模型權重——GLM-5.2 這一刻的降臨,在此前絕非理所當然。
最核心的一點在於,GLM-5.2 是首個在編程框架中作為通用智能體使用時,“手感極佳”(feels right)的開放權重模型。 它是開天闢地的頭一個。我個人在嘗試近期一些同類模型(如 Kimi K2.7 或 GLM-5.1)的進度上本有些滯後,但 GLM-5.2 的熱度實在高到讓我無法忽視。我把它接入了 Claude Code 中基於 Fireworks API 的工作流,讓它協助我為我的後訓練(Post-training)課程編寫內容(配置過程非常簡單)。中間確實遇到了一些小卡頓,比如 Claude Code 框架或我的倉庫文檔試圖向模型發送圖片,導致 Fireworks API 的該次會話直接卡死——迫使我手動清除上下文。但總的來說,模型的底子讓人一上手就感覺對了,至於具體選擇哪個驅動框架和雲服務商,我還需要再做些微調。
如果你想看更多的行業吹捧,可以瞧瞧 Z.ai 創始人對馬斯克說的那句:“開放權重的 Fable 級能力將比 2027 年第一季度更早到來”;Vercel 首席執行官發推稱:“由 @zai_org 打造的 GLM-5.2 在寫代碼方面的表現好到讓我發自內心地感到震撼,甚至有些震驚。這改變了遊戲規則”;以及更多來自一羣我極度尊重的人,以及我剛認識的圈內人士的評價。
那麼,這是一個好模型,這又將我們推向了何處?
多種趨勢正在交織作用。首先,讓我們建立在“開源與閉源能力差距”這一基準線上來審視。我曾寫道,如果開源模型能在 2026 年初左右邁過“Claude Code 中 Opus 4.5”的能力門檻,我預計將迎來一場“使用量的爆發”。現在,這一天來了。從 2025 年 11 月 24 日 Claude Opus 4.5 發佈,到 2026 年 6 月 16 日 GLM-5.2 發佈,時間間隔為 204 天——約合 6.8 個月。這恰好落入了很多人所主張的“美國閉源實驗室與中國開源對手之間存在 6 到 9 個月性能時差”的區間。
寫到這裏,我自己都感到詫異。鑑於美國實驗室在過去大約一年裏瘋狂拉高算力投入,我原本預計這個時間差距會隨着推移而不斷拉大。這條軌跡上一個非常具有決定性意義的節點,將是 Claude Fable 5 的發佈——相比於 Claude Opus 系列,它更嚴重依賴於規模(Scale),因而也更依賴於最先進的 GPU。不過,這仍然不是一個令人滿意的解釋。要繼續拆解這條發展軌跡,其背後的複雜與微妙程度,絕非我在這篇風向標式的短文裏三言兩語能容納得下的。
此事最直接的意義在於,給那些瘋狂壓榨 Token 吞吐量(tokenmaxxing)、把 Anthropic 營收推向月球的組織內部,帶來了嚴峻得多的價格壓力。有些人或許會預測 Anthropic 將無法達成其預測的年度經常性收入(ARR)目標,但我認為這種看法沒有把市場對這些模型的真實需求以及不可避免的增長勢頭計算在內。這一模型的存在,對開源模型經濟體而言是一記超級強心針。像 Fireworks、Together、Thinky(通過 Tinker)、Prime Intellect 以及所有出售開源模型推理或微調服務的廠商,剛剛迎來了又一個拐點。
這裏的連鎖反應滲透進更廣泛的經濟體(以及具體應用場景)還需要很長一段時間。工作流正變得愈發複雜,人們開始使用不同的模型分別進行規劃、核心編碼以及子智能體調度。我預計這股熱潮還將繼續發酵——見鬼,寫下這段話的時候正是週日晚上,我已經能預見到週一媒體和市場的反應了,絕對會像當年的 DeepSeek R1 發佈時一模一樣。當 Anthropic 的模型(擴大範圍來說即美國的旗艦模型)依然處於被禁狀態時,這種技術擴散的發生,無異於一把插入經濟體命門深處的匕首。正當閉源巨頭們試圖向着唯有絕對前沿模型才能解鎖的高毛利、高營收領域突進時,GLM-5.2 卻得到了充裕的時間,去蠶食前沿實驗室的經濟腹地。
這一經濟隱憂映射了一個在 AI 圈子裏已經被翻來覆去講過無數遍的故事,因此很難說這一次它會在何時真正產生決定性影響。
感覺上更關乎 AI 發展主線的議題,是關於開源模型的監管與管控。我認為廉價智能的廣泛傳播是一種經濟善舉,我們的默認立場理應是為開源模型喝彩;然而,該模型的發佈日期,將使其在 AI 權力結構的認知地圖中,永久地與 Claude Fable(並進而與 Claude Mythos)掛鈎。我們正處於這樣一個歷史節點:Mythos 級別的模型能力被美國政府裁定為“不宜對外公開發布”,而中國的大模型製造商們卻在所有人皆可觸達的普惠能力道路上狂飆突進。
這些趨勢線在因果上未必直接相關,因為我們尚不清楚 GLM-5.2 與其前代產品在網絡攻防(Cyber)方面的具體表現差異,但它們的能力絕對是正相關的。如果外界條件不發生任何改變,這指向了一種潛在的可能:美國政府最終裁定某款開放權重的中國模型“對公眾存在安全隱患”。此處當然還存在諸多其他潛在推演,但唯一明確的是,在梳理這些預案、準備我們的基礎設施、以及向全社會傳達信息方面,我們還有海量的工作要做。
要向決策者描繪並傳達“如何管理愈發強大的開源模型”的未來世界,光靠我一個人遠遠不夠,還需要多得多的同路人。人工智能的征途還有數年之久,英偉達下一代芯片已投入量產,算法上的突破更是連綿不絕。對開源模型的擁護者而言,前路感覺是一條極其逼仄的細縫,但我們必須找出讓它們活下去的辦法,絕不能讓性能的躍升僅僅變成閉源模型的獨角戲。
我完全理解為什麼“想象一個公眾可隨意訪問的 Mythos 級模型”會讓人感到膽寒;但如果開源模型在今天被一刀切地禁絕,而在未來的兩年裏,只有掌握在一兩家公司手裏的閉源模型獲得了 10 倍甚至 100 倍的性能躍升——我認為到那時候,我們將面臨遠比現在嚴重得多的危機。
最後我再說一句,就像文章題目所說的「連鎖反應將滲透進更廣泛的經濟體」,這句話值得好好思考一下。
--end--
最後記得⭐️我,每天都在更新:如果覺得文章還不錯的話可以點贊轉發推薦評論
/...@作者:你說的完全正確(YAR師)