NotebookLM 的天花板和地板,都系在 Gemini 身上
整理版優先睇
NotebookLM嘅核心能力同限制都繫於Gemini模型,用時要控源、問法同人工核實
呢排作者寫過兩篇NotebookLM文章,有讀者話可能係Gemini降智影響效果,亦有人覺得NotebookLM體驗唔錯。作者自己用咗好耐,始終覺得係個黑盒:到底用咩模型?幻覺率幾高?點樣降低?佢做咗啲調研,引用咗團隊負責人Steven Johnson嘅文章同相關論文,整理出以下見解。
NotebookLM唔係傳統RAG。團隊負責人話而家叫「source grounding」,因為佢唔似傳統RAG咁切塊向量化,而係靠Gemini超大上下文,盡量成份文檔塞入去,再生成答案兼掛引用。但文檔太多都係要檢索排序,只係Google冇公開細節。模型方面,唔係單一模型,而係按訂閲分級:免費版行Gemini 2.5 Flash,Pro版行2.5 Pro,Ultra版有Deep Think模式。2025年12月官方話切換到Gemini 3,但免費版好大機會都係Flash。
幻覺率方面,2025年論文《Not Wrong, But Untrue》測過NotebookLM幻覺率約13%,低過ChatGPT同Gemini嘅40%。作者自己實測,有時叫NotebookLM提取素材,大概十分一會張冠李戴或編出唔存在嘅場景。所以實際使用要控源(只放高質單一來源)、問法(問得越具體越好)、模型(有條件上Pro/Ultra)、同埋最終一定要人工點查引用核實。呢個先係NotebookLM最值錢嘅功能。
- NotebookLM唔係傳統RAG,而係用Gemini大上下文嘅source grounding,減少分塊損失
- 模型按訂閲分級:免費Flash、Pro、Ultra Deep Think,效果差距好大
- 幻覺率論文話13%,作者實測約10%有誤,需要小心
- 降低幻覺最有效係控源:單一高質量來源,避免二次轉載或AI總結文本
- 提問要具體,約束模型逐字引用,最後一定人工點查原文核實
NotebookLM嘅本質:唔係RAG,而係source grounding
Google NotebookLM團隊負責人Steven Johnson話,佢哋以前叫呢個做RAG,但而家改叫source grounding。原因係傳統RAG要切塊、做向量、存數據庫,再按相似度撈返最相關嘅幾段畀模型。但NotebookLM唔係咁玩,佢仗住Gemini超大上下文窗口,傾向將成份文檔塞入去——塞得落就盡量塞,然後叫模型生成答案兼掛引用號。
咁塞唔落點算?例如一次過掉幾十個大PDF入去,內部一定要做檢索排序,只係Google冇公開具體手法。呢個設計嘅好處係減少分塊帶嚟嘅語境斷裂,壞處就係依賴模型能力同上下文長度。
背後嘅模型:唔係單一,而係按訂閲分級
好多人誤會NotebookLM用單一模型,其實佢係按訂閲檔分級路由:免費版主要行Gemini 2.5 Flash系列,響應快但上下文偏細、推理弱啲;Google AI Pro升級到2.5 Pro級別;Google AI Ultra就有Deep Think慢思考模式,每日配額更高。
2025年12月官方宣佈切換到Gemini 3,但冇講明係Pro定Flash。按慣例,免費檔好大機會都係Flash。所以同一個問題,免費用戶同Pro用戶拎到嘅答案可以差好遠,因為根本唔係同一個模型作答。
幻覺率有幾高?論文13%,實測約十分之一
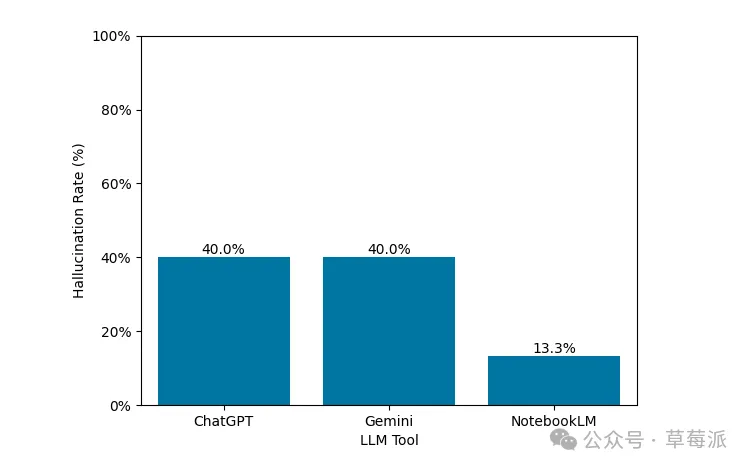
2025年論文《Not Wrong, But Untrue》測試文檔問答幻覺率:ChatGPT 40%、Gemini 40%、NotebookLM 13%。雖然樣本唔大(300份文檔、每個工具10-15個問答),但都顯示到區分度。
作者自己使用時,尤其係叫NotebookLM提取素材,有時答案帶引用但點入去會發現張冠李戴或編造唔存在嘅場景,大概十分一機會。所以幻覺問題真係存在,唔可以因為話「低」就唔理。
- 1 控源:一個Notebook只放高質量、版本明確、單一來源嘅素材,寧願少唔好多。唔好放入AI總結文本、機翻或二手轉載。
- 2 問法:問得越具體越好,例如「第3章對X嘅定義係咩?」好過「呢本書講咩?」。綜合問題要拆成子問題。用提示詞約束模型「僅基於原文逐字回答,唔好加評價、推斷或歸納」。
- 3 模型:有條件上Pro或Ultra,免費版2.5 Flash喺過度自信方面更嚴重。
- 4 複核:涉及數字、日期、人物對話一定要叫模型帶引用號,然後逐條點開核對。呢個係NotebookLM最值錢嘅功能,唔用就浪費。
實際操作:將幻覺降到最低嘅四層防線
將幻覺降到最低,按效果排:源 > 問法 > 模型 > 複核。控源係最有效一環,確保素材來源單一、優質。對於大文檔,作者做法係先洗成乾淨Markdown再上傳,太大就切開。
問法方面,越具體嘅問題,模型越冇空間自由發揮。另外用提示詞約束佢「僅基於原文逐字回答」,堵死發揮嘅路。模型層面,免費版Flash確實更易出錯,有條件就升級。
上兩個禮拜寫過兩篇關於NotebookLM嘅文章(NotebookLM vs ima:試完3個真實場景,我改觀咗, NotebookLM真係零幻覺咩?一個被忽略嘅前提),有啲讀者留言話可能係近期Gemini嚴重降智,搞到NotebookLM嘅效果唔係好理想,仲有讀者話佢仍然覺得NotebookLM嘅體驗效果比較好。
我有啲困惑,用咗NotebookLM咁耐,仍然覺得佢係個黑盒:佢用嘅模型係乜?佢嘅幻覺率有冇一個大約嘅統計?實際用嗰陣點樣將幻覺率降到最低?
帶住呢啲問題,我做咗一啲調研同分析,喺呢度分享嚇。
NotebookLM 到底係咪 RAG?
Google 嘅 NotebookLM 團隊負責人 Steven Johnson 喺《Google Engineers Deliberately Avoid Calling NotebookLM “RAG”》呢篇文章入面話:「我哋以前叫佢 RAG,而家我哋叫佢 source grounding(源文本增強)。」

點解要換個講法呢?
睇下面呢張對比表(嚟自《Architecting the Future of Research: A Technical Deep-Dive into NotebookLM and Gemini Integration》)就明曬啦。
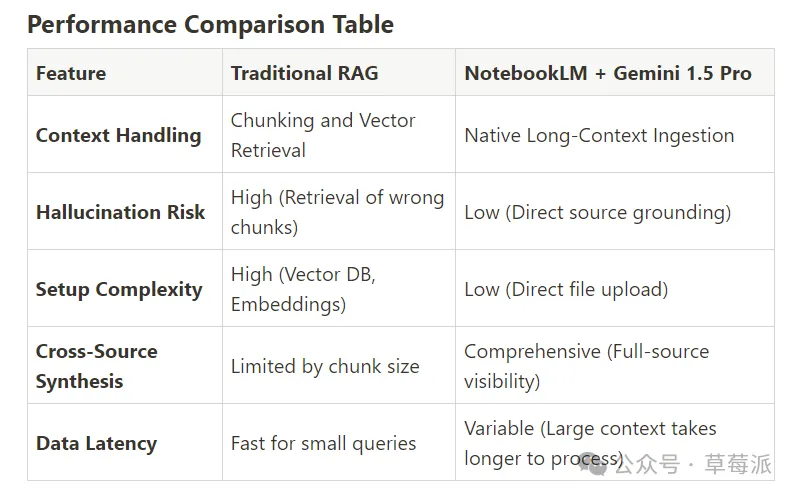
傳統 RAG 係點樣做嘢㗎?切塊、做向量、存數據庫,等你問問題嗰陣按相似度撈返最相關嗰幾段,再掉畀模型。
但 NotebookLM 唔係咁玩,佢靠住 Gemini 嘅超大上下文窗口,傾向於將你上傳嘅整份文檔塞入去——塞得落就儘量塞,再畀模型生成回答嘅同時掛上引用號。
咁塞唔落點算?例如你一嘢掉咗幾十個大 PDF 入去,佢內部肯定要做檢索同排序嘅,呢點走唔甩,只係 Google 冇公開具體點樣處理嘅。
NotebookLM 背後行嘅係邊個模型?
呢度要先糾正一個常見誤解:NotebookLM 唔係單一模型,而係按訂閲檔分級路由嘅。
免費版:主要行 Gemini 2.5 Flash 系列,反應快,但上下文窗口偏細,推理都弱啲
Google AI Pro:升級到 Gemini 2.5 Pro 級別
Google AI Ultra:包含 Deep Think 慢思考模式,每日配額亦更高
2025 年 12 月 19 日,NotebookLM 官方宣佈切換咗去 Gemini 3,但究竟係 Pro 定係 Flash 版,Google 冇明講,按慣例免費檔大概都會行 Flash 嗰條線。

同一個問題,免費用戶同 Pro 用戶拎到嘅答案可以差好遠,因為根本就唔係同一個模型喺度回答。
NotebookLM幻覺率到底有幾高
2025 年有一篇論文《Not Wrong, But Untrue: LLM Overconfidence in Document-Based Queries》專門測咗文檔問答嘅幻覺率,結果係:ChatGPT 40%,Gemini 40%,NotebookLM 13%。雖然呢個例子入面樣本唔大(300份文檔)、主題都單一(每個工具10-15個問答),但可以顯示到一啲區分度。
我自己喺用嘅過程中,有時將一份文檔掉畀NotebookLM,叫佢幫我提取素材,佢畀嘅素材有時雖然帶有引用,但㩒入去會發現佢會張冠李戴,或者作啲唔存在嘅場景,概率大概係十分之一。
實際用嗰陣點樣將幻覺降到最低
按效果排,大概係:源 > 問法 > 模型 > 複核。
先講控源,呢個係最有效嘅一環。
一個 Notebook 只放高質素、版本明確、來源單一嘅素材,寧願少都唔好多。
我試過將 AI 總結過嘅文本掉入去,結果幻覺明顯增多——機翻、自媒體二手轉載都係一樣,未經核實嘅內容入咗 Notebook 就係污染源。對於大文檔,我嘅做法係先洗成乾淨嘅 Markdown 再上傳,太大就切開先,幻覺會降低好多。
然後係問法。
「第 3 章對 X 嘅定義係乜」同「呢本書講乜」,前一個嘅回答會更準確。越具體嘅問題,模型越冇空間自由發揮。遇到綜合性嘅大問題,拆成幾個子問題逐個問。
另外,用提示詞約束佢「僅基於原文逐字回答,唔好添加任何評價、推斷或歸納」,相當於封死佢發揮嘅路。
凡是涉及數字、日期、人物對話,一定要佢帶引用號,然後逐條㩒開核對-----我就食過虧。
模型層面做到嘅有限,但差距確實存在。
有條件嘅話上 Pro 或 Ultra,免費版嘅 2.5 Flash 喺「過度自信」呢件事上確實更嚴重。
最後,當佢係研究助理就OK,佢嘅輸出唔好全部相信。真係要寫入自己作品或決策入面嘅句子,都㩒引用按鈕返去查一下原文。呢個功能其實係 NotebookLM 設計上最有價值嘅部分,唔用就浪費曬。
我自己嘅判斷
NotebookLM嘅天花板同地板都係喺 Gemini 身上。
Gemini 狀態好嘅時候,體驗確實比傳統 RAG 好一截;
Gemini 一旦降智或者轉咗模型版本,你嘅 Notebook 都跟住遭殃。
但基於對佢嘅信任,你甚至唔知道佢生成咗「不實信息」。
所以,最後一公里,仲係要靠人手核實。
多謝你睇到呢度,如果覺得有用,畀個關注,唔使迷路~
上兩週寫過兩篇關於NotebookLM的文章(NotebookLM vs ima:測完3個真實場景,我改觀了, NotebookLM真的零幻覺嗎?一個被忽略的前提),有些讀者留言說可能是近期Gemini嚴重降智,導致NotebookLM的效果不盡如人意,還有的讀者說他仍然覺得NotebookLM的體驗效果比較好。
我有點困惑,使用NotebookLM那麼久,仍然感覺它是個黑盒:它用的模型是什麼?它的幻覺率有沒有一個大概的統計?實際使用時如何把幻覺率降到最低?
帶着這些問題,我做了一些調研和分析,在這裏分享一下。
NotebookLM 到底是不是 RAG?
Google 的 NotebookLM 團隊負責人 Steven Johnson 在《Google Engineers Deliberately Avoid Calling NotebookLM “RAG”》這篇文章裏說:"我們以前叫它 RAG,現在我們稱之為 source grounding(源文本增強)。"
為什麼要換個說法呢?
看下面這張對比表(來自《Architecting the Future of Research: A Technical Deep-Dive into NotebookLM and Gemini Integration》)就明白了。
傳統 RAG 是怎麼幹活的?切塊、做向量、存數據庫,等你問問題的時候按相似度撈回最相關的那幾段,再丟給模型。
但NotebookLM 不這麼玩,它仗着 Gemini 的超大上下文窗口,傾向於把你上傳的整份文檔塞進去——能塞下就儘量塞,再讓模型生成回答的同時掛上引用號。
那塞不下怎麼辦?比如你一口氣扔了幾十個大 PDF 進去,它內部肯定要做檢索和排序的,這點跑不掉,只是 Google 沒公開具體怎麼處理的。
NotebookLM 背後跑的是哪個模型?
這裏要先糾正一個常見誤解:NotebookLM 不是單一模型,而是按訂閲檔分級路由的。
免費版:主要走 Gemini 2.5 Flash 系列,響應快,但上下文窗口偏小,推理也弱一些
Google AI Pro:升級到 Gemini 2.5 Pro 級別
Google AI Ultra:含 Deep Think 慢思考模式,每日配額也更高
2025 年 12 月 19 日,NotebookLM 官方宣佈切換到了 Gemini 3,但究竟是 Pro 還是 Flash 版, Google 沒明說,按慣例免費檔大概率走 Flash 那條線。
同一個問題,免費用戶和 Pro 用戶拿到的答案可以差很遠,因為壓根不是同一個模型在回答。
NotebookLM幻覺率到底有多高
2025 年有一篇論文《Not Wrong, But Untrue: LLM Overconfidence in Document-Based Queries》專門測了文檔問答的幻覺率,結果是:ChatGPT 40%,Gemini 40%,NotebookLM 13%。雖然這個例子裏樣本不大(300份文檔)、主題也單一(每個工具10-15個問答),但可以表明一些區分度。
我自己在使用的過程中,有時把一份文檔丟給NotebookLM,讓它幫我提取素材,它給的素材有時雖然帶有引用,但點進去會發現它會張冠李戴,或是編出不存在的場景,概率大概是十分之一。
實際使用時怎麼把幻覺降到最低
按效果排,大概是:源 > 問法 > 模型 > 複核。
先說控源,這是最有效的一環。
一個 Notebook 只放高質量、版本明確、來源單一的素材,寧願少也不要多。
我試過把 AI 總結過的文本丟進去,結果幻覺明顯增多——機翻、自媒體二手轉載也是同理,未經核實的內容進了 Notebook 就是污染源。對於大文檔,我的做法是先洗成乾淨的 Markdown 再上傳,太大就先切分,幻覺會降不少。
然後是問法。
"第 3 章對 X 的定義是什麼"和"這本書講什麼",前者的回答會更準確。越具體的問題,模型越沒有空間自由發揮。遇到綜合性的大問題,拆成幾個子問題逐個問。
另外,用提示詞約束它"僅基於原文逐字回答,不要添加任何評價、推斷或歸納",相當於堵死它發揮的路。
凡是涉及數字、日期、人物對話,務必讓它帶引用號,然後逐條點開核對-----我就吃過虧。
模型層面能做的有限,但差距確實存在。
有條件的話上 Pro 或 Ultra,免費版的 2.5 Flash 在"過度自信"這件事上確實更嚴重。
最後,把它當研究助理就好,它的輸出不要全信。真要寫進自己作品或決策裏的句子,都點引用按鈕回查一下原文。這個功能其實是 NotebookLM 設計上最值錢的部分,不用就浪費了。
我自己的判斷
NotebookLM的天花板和地板都系在 Gemini 身上。
Gemini 狀態好的時候,體驗確實比傳統 RAG 好一截;
Gemini 一旦降智或者切了模型版本,你的 Notebook 也跟着遭殃。
但基於對它的信任,你甚至不知道它生成了“不實信息”。
所以,最後一公里,還是得人工核實。
謝謝你看到這裏,如果覺得有用,點個關注,不迷路~