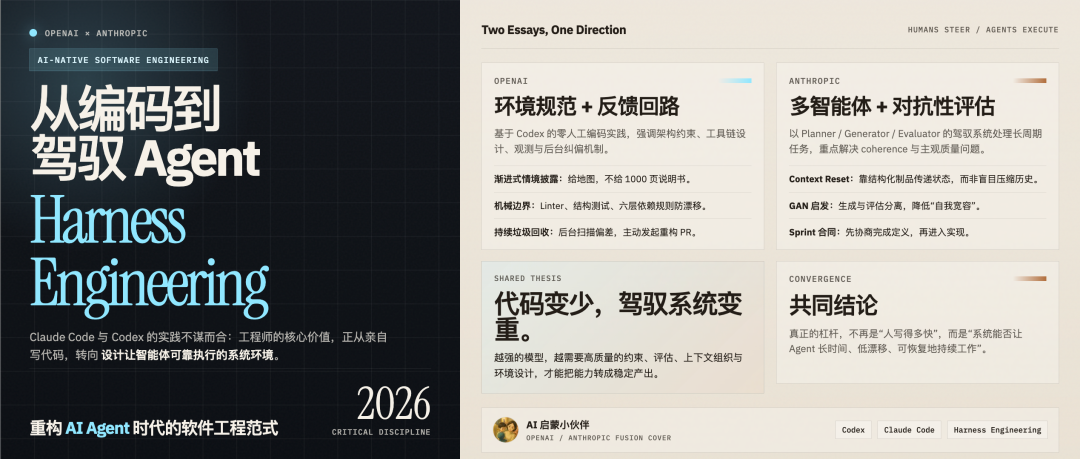
OpenAI 和 Anthropic 對 Harness Engineering 不謀而合:從編碼到駕馭 Agent,重構 AI Agent 時代軟件工程範式
整理版優先睇
OpenAI與Anthropic共推Harness Engineering:從寫Code到設計Agent駕馭系統
呢篇文章綜合咗OpenAI同Anthropic近期發表嘅技術博文,兩者不約而同提出「Harness Engineering」呢個核心概念。文章背景係AI編程Agent(如Claude Code、Codex)快速進化,傳統軟件工程正面臨範式轉變。作者想解答嘅問題係:喺Agent自主編碼能力愈來愈強嘅情況下,工程師應該點樣重新定位自己嘅角色?整體結論係:人類工程師嘅價值唔再係寫每一行Code,而係設計一個令Agent可以可靠執行嘅「駕馭系統」(Harness)。
OpenAI嘅文章基於一個百萬行Code嘅真實項目(零人工編碼),強調環境規範、工具鏈設計同反饋迴路,核心觀點係「人類掌舵,Agent執行」。Anthropic嘅文章則從多Agent架構出發,特別關注主觀質量評估(如前端設計)同長週期任務連貫性,提出用「生成器+評估器」嚟解決自我評估偏差。兩者雖然側重點唔同,但都指向同一個方向:工程工作嘅價值正從「寫Code」轉移到「設計環境」。
呢個轉變要求工程師具備新能力:系統架構設計、評估標準制定、多Agent編排、情境工程。文章預測2026年Harness Engineering會成為AI Engineering入面一個極其關鍵嘅領域,而家就係時候開始思考點樣重構我哋嘅開發流程。
- Harness Engineering係AI時代軟件工程新範式:工程師角色從親自編寫代碼轉向設計讓Agent可靠執行嘅駕馭系統。
- Anthropic用多Agent架構(生成器+評估器)解決主觀質量評估同長週期連貫性,關鍵機制包括Sprint合同同上下文重置。
- OpenAI透過嚴格分層架構、機械規則(自定義Linter)同智能體互審,將人類品味編碼為環境約束,實現零人工編碼。
- 上下文管理係核心挑戰:要用「地圖」(AGENTS.md)而非「說明書」;評估器必須分離生成與評估,避免自我寬容。
- 持續維護對抗漂移:建立黃金原則、後台掃描機制,定期清理技術債務;模型能力提升後要重新審視駕馭系統設計。
Anthropic:Harness design for long-running application development
Anthropic 技術博文,詳述多Agent架構、Sprint合同同上下文重置等實踐
OpenAI:Harness engineering: leveraging Codex in an agent-first world
OpenAI 技術博文,基於百萬行Code項目分享嚴格架構、機械規則同持續維護經驗
從寫Code到設計Harness:範式轉變嘅核心
兩篇博文共同指向一個關鍵轉變:人類工程師嘅角色正從直接編寫代碼,轉向設計讓智能體有效工作嘅「駕馭系統」(Harness)。Anthropic強調透過多智能體架構(生成器+評估器)解決複雜任務,特別關注主觀質量評估同長週期任務連貫性。OpenAI則基於完全由Codex生成代碼(零人工編碼)嘅實踐經驗,強調環境規範、工具鏈設計同反饋迴路嘅重要性。
關鍵挑戰與對策:上下文、自我評估同架構約束
長週期任務嘅連貫性係第一個挑戰。Anthropic發現模型會有「上下文焦慮」(Context Anxiety),喺接近上下文限制時提前結束任務。佢哋嘅解法係上下文重置(Context Reset):定期清空上下文,透過結構化製品(Artifacts)傳遞狀態,而非簡單壓縮歷史記錄。OpenAI則用漸進式情境披露,提供「地圖」而非「1000頁說明書」,以AGENTS.md作為內容目錄,指向結構化docs/知識庫。
自我評估偏差係第二個挑戰。Anthropic受GAN啟發,分離生成器同評估器智能體,評估器用Playwright MCP直接操作頁面動態測試,並透過少量示例校準評估標準。OpenAI則讓Codex喺本地審核自身更改,請求其他智能體審查,形成「Ralph Wiggum循環」,同時將人類品味編碼為自定義Linter、結構測試等機械規則。
- 1 Anthropic嘅三智能體架構:規劃器將簡短提示擴展為完整產品規格;生成器按Sprint逐個實現功能;評估器按合同標準評分。
- 2 OpenAI嘅嚴格分層架構:六層依賴規則(Types→Config→Repo→Service→Runtime→UI),只能向前依賴;Providers作為唯一橫切入口。
- 3 核心洞見:智能體喺嚴格邊界同可預測結構嘅環境中表現最佳。約束不是限制,而係速度嘅倍增器。
實踐成果與成本對比:效率與質量嘅取捨
Anthropic嘅實驗顯示,完整駕馭系統需6小時/$200,而單智能體僅需20分鐘/$9。雖然成本高20倍以上,但產出質量差距顯著:單智能體版本核心功能損壞(遊戲無法運行),駕馭版本功能完整且有AI集成。OpenAI嘅百萬行Code項目則以約人工編碼1/10嘅時間完成,團隊從3人擴大到7人時,人均吞吐量反而增加(平均每人每天3.5個PRs)。
最佳實踐總結:上下文、評估、架構與維護
上下文管理方面,共同原則是上下文係稀缺資源,過多指導會失效且迅速腐爛。Anthropic用結構化製品喺上下文重置間傳遞狀態;OpenAI用AGENTS.md作為目錄,實現漸進式披露。評估與反饋迴路方面,分離生成與評估係解決自我評估偏差嘅關鍵,評估器需要具體可操作嘅評分標準,動態測試優於靜態檢查。
- 架構約束作為倍增器:透過Linter、結構測試將「品味」編碼為機械規則;喺中央強制執行邊界,喺本地允許自主權。
- 持續維護對抗漂移:OpenAI嘅「黃金原則」定期運行後台Codex任務掃描偏差,發起重構PR;技術債務以小額貸款方式償還。
- 模型進化與駕馭演進:每當新模型發佈,應重新審視駕馭系統,剝離不再關鍵嘅組件,添加新能力以追求之前不可能嘅任務。駕馭設計空間唔會縮小,而係會轉移。
侷限性與未來展望:未解問題同新技能
Anthropic坦誠評估器喺音樂品味等主觀領域效果有限(Claude無法「聽」音樂),評估器調優需要多輪迭代,存在邊際收益遞減。OpenAI則指出架構連貫性長期演化、人類判斷力最優編碼位置、模型能力增長後系統演化等未解挑戰。共同風險包括模式複製(智能體複製代碼庫中不理想模式)同過度工程(生成器因評估反饋不斷增加複雜度)。
最終目標係讓智能體能夠端到端驅動功能開發:從驗證狀態、復現Bug、實施修復、驗證解決到合併代碼——僅喺需要人類判斷時才請求介入。呢種轉變要求工程師具備新能力:系統架構設計、評估標準制定、多智能體編排、情境工程——呢啲正成為AI時代軟件工程嘅核心技能。
Claude Code、Codex 呢啲 AI 寫程式嘅 agent 進步得好快,搞到軟件工程進入咗一個新範式。最近 OpenAI 同 Anthropic 都出咗技術博客,不約而同提出 "Harness Engineering" 呢個核心概念——前者探索緊幾個鐘頭自主編碼入面嘅連貫性同設計質素,後者就用「零人工寫 code」嘅方式,喺三個月內整咗個有成百萬行 code 嘅可用產品。兩篇文章一齊指向一個關鍵轉變:工程師嘅角色由自己寫 code,變成設計一個令到 agent 可以可靠執行嘅「駕馭系統」。今日我哋睇曬呢兩篇 blog,睇下 OpenAI 同 Anthropic 有咩共通觀點,同埋各自側重啲咩。可以預見,2026 年 Harness Engineering 會係 AI Engineering 入面一個好關鍵嘅領域。
Anthropic:Harness design for long-running application developmenthttps://www.anthropic.com/engineering/harness-design-long-running-apps[1]
OpenAI:Harness engineering: leveraging Codex in an agent-first worldhttps://openai.com/index/harness-engineering/[2]
一、核心思想:由「寫 code」變「設計環境」
兩篇 blog 一齊指向一個範式轉變:人類工程師嘅角色正由直接寫 code,變成設計一個令 agent 有效運作嘅「駕馭系統」(Harness)。
Anthropic 嘅角度 :
- 強調透過 多智能體架構(生成器 + 評估器)解決複雜任務
- 特別關注 主觀質量評估(例如前端設計)同 長週期任務嘅連貫性
- 核心諗法:將任務拆細、引入外部評估、透過反饋循環迭代改進
OpenAI 嘅角度 :
- 基於 完全由 Codex 生成 code(零人工寫 code)嘅實戰經驗
- 強調 環境規範、工具鏈設計同反饋迴路 嘅重要性
- 核心諗法:人類掌舵(設定方向、設計系統),agent 執行(寫 code、測試、部署)
共同點:兩者都認為,隨住模型能力提升,工程工作嘅價值越來越體現喺「點樣設計令 agent 成功嘅環境」,而唔係「自己寫每一行 code」。
二、關鍵挑戰與解決方案對比
2.1 長週期任務嘅連貫性問題
Anthropic 嘅發現:
- 「上下文焦慮」(Context Anxiety):模型喺就嚟到上下文限制嗰陣會提早結束任務
- 解決方案:上下文重置(Context Reset) —— 定期清空上下文,透過結構化製品(Artifacts)傳遞狀態,而唔係簡單壓縮歷史記錄
- 早期用 Sonnet 4.5 嗰陣一定要強制重置;Opus 4.6 改進咗之後,可以喺單一會話入面連續運行幾個鐘頭
OpenAI 嘅發現:
- 單次 Codex 運行可以持續 超過6個鐘(通常喺人類瞓覺嘅時候發生)
- 通過 漸進式情境披露 管理上下文:提供「地圖」而唔係「1000頁說明書」
AGENTS.md作為內容目錄,指向結構化嘅docs/知識庫,而唔係單一大 file
2.2 自我評估嘅偏差問題
Anthropic 嘅解法:
- 生成對抗網絡(GAN)啟發:分開「生成器」同「評估器」agent
- 評估器用 Playwright MCP 直接操作頁面,做動態測試
- 通過 少量示例(Few-shot)校準 評估標準,解決模型「自己寬容自己」嘅傾向
評估標準示例(前端設計):
- 設計質素(整體性、氛圍)
- 原創性(避免「AI 套路」例如紫白漸變)
- 工藝(技術執行)
- 功能性(可用性)
OpenAI 嘅解法:
- agent 互相審查:Codex 喺本地審查自己嘅改動,叫其他 agent 審查,形成「Ralph Wiggum 循環」
- 將人類品味編碼做規則:透過自定義 Linter、結構測試同「黃金原則」強制執行
- 工具鏈整合:Chrome DevTools 協議、可觀測性堆疊(LogQL/PromQL)令到 agent 可以直接「睇到」系統狀態
2.3 架構與約束設計
Anthropic 嘅三 agent 架構:
- 規劃器(Planner):將簡短提示擴展成完整產品規格
- 生成器(Generator):按 Sprint 逐個實現功能,用 React/Vite/FastAPI/SQLite 技術棧
- 評估器(Evaluator):透過 Playwright 測試運行緊嘅應用,按合同標準評分
關鍵機制:Sprint 合同 —— 生成前雙方傾好「完成定義」,避免過度工程或遺漏
OpenAI 嘅嚴格分層架構:
- 六層依賴規則:Types → Config → Repo → Service → Runtime → UI,只可以向前依賴
- Providers 作為唯一橫切入口:認證、遙測等透過顯式接口進入
- 機械強制執行:自定義 Linter 同結構測試確保架構唔走樣
核心洞察:agent 喺嚴格邊界同可預測結構嘅環境入面表現最好。約束唔係限制,而係速度嘅倍增器。
三、實踐成果與成本對比
Anthropic 實驗規模:單一應用(遊戲製作器、DAW),個人/小團隊實驗OpenAI 實驗規模:完整產品(百萬行 code,1500+ PRs),3人→7人工程師團隊
開發速度對比:
- Anthropic:完整駕馭系統需要 6個鐘/$200,單 agent 只需要 20分鐘/$9
- OpenAI:大約係人工寫 code 嘅 1/10 時間完成百萬行 code 項目
關鍵差異:
- Anthropic 嘅完整駕馭版本成本係單 agent 嘅 20 倍以上,但產出質素差距好大——單 agent 版本核心功能壞咗(遊戲玩唔到),而駕馭版本功能完整仲有 AI 整合
- OpenAI 隨住團隊由 3 人擴大到 7 人,人均吞吐量反而增加(平均每人每日 3.5 個 PRs)
評估器嘅價值邊界:
- 當任務超出模型原生能力邊界嗰陣,評估器帶嚟顯著增益
- 當任務喺模型能力範圍內嗰陣,評估器變咗唔必要嘅開銷
成本邏輯轉變:
- 喺 agent 吞吐量遠超人類注意力嘅系統入面,糾錯成本 < 等緊嘅成本
- 快速迭代好過完美關卡,測試偶爾失敗靠後續重跑解決,而唔係無限期阻住進展
四、關鍵洞察與最佳實踐
4.1 上下文管理:地圖 vs 說明書
Anthropic 透過結構化製品(Artifacts)喺上下文重置之間傳遞狀態;OpenAI 就將 AGENTS.md 作為內容目錄,知識庫喺 docs/ 入面結構化儲存,做到漸進式披露。
共同原則:上下文係稀缺資源,太多指導會失效,而且會快速腐爛。
4.2 評估與反饋迴路
分開生成同評估係解決自我評估偏差嘅關鍵。評估器需要具體、可操作嘅評分標準,而唔係抽象判斷。動態測試(操作真實應用)好過靜態檢查。
4.3 架構約束作為倍增器
agent 需要嚴格邊界嚟保持長週期嘅連貫性。透過 Linter、結構測試將「品味」編碼做機械規則。喺中央強制執行邊界,喺本地容許自主權。
4.4 持續維護:對抗漂移
OpenAI 嘅「黃金原則」:定期運行背景 Codex 任務掃描偏差,發起重構 PR(類似垃圾回收)。技術債嘅小額償還:不斷用小額貸款方式償還,避免累積成大問題。將審查意見、Bug 報告轉化做文檔更新或者直接編碼做工具。
4.5 模型進化與駕馭演進
Anthropic 觀察到 Opus 4.6 減少咗對 Sprint 結構同上下文重置嘅依賴,但評估器喺複雜邊界度仲有價值。
核心原則:每次有新模型發佈,就應該重新審視駕馭系統,剝離唔再關鍵嘅組件,加入新能力去做到之前做唔到嘅任務。駕馭嘅設計空間唔會縮細,而係會轉移。
五、侷限與未解決問題
Anthropic 坦白嘅侷限:
- 評估器喺音樂品味呢啲主觀領域效果有限(Claude 冇得「聽」音樂)
- 複雜邊界情況仲要改進(例如遊戲關卡設計入面嘅常識問題)
- 評估器調校需要多輪迭代,有邊際收益遞減
OpenAI 嘅未解決挑戰:
- 架構連貫性嘅長期演化:完全由 agent 生成嘅系統,佢嘅架構會點樣隨時間演變?
- 人類判斷力嘅最佳編碼位置:邊啲判斷應該留畀人類,點樣最大化佢嘅槓桿效應?
- 模型能力增長之後嘅系統演化:隨住模型變強,駕馭系統應該點樣調整?
共同風險:
- 模式複製:agent 會複製 code base 入面已經存在嘅唔理想模式,導致漂移
- 過度工程:生成器可能因為評估反饋而不斷加多實現複雜度
- 評估器自身嘅侷限:就算分開咗生成同評估,評估器都係 LLM,可能太過寬容或者測試唔夠
六、總結:Harness Engineering 嘅核心要義
兩篇 blog 一齊勾勒出 AI 原生軟件開發 嘅新範式:
「人類掌舵,agent 執行」(Humans steer, agents execute)
呢個唔係簡單嘅「用 AI 寫 code」,而係重新設計軟件工程嘅整個生產環境:
由 code 到系統:工程師設計工具、約束、反饋迴路,令 agent 可以可靠工作。
由連續到分段:透過上下文重置、Sprint 合同等機制管理長週期任務。
由自我評估到對抗性評估:分開生成同評估,引入多 agent 反饋循環。
由靈活到約束:透過嚴格架構同機械規則,將人類品味編碼做環境約束。
由一次性到持續維護:建立垃圾回收機制,對抗模式漂移同技術債。
最終目標係令 agent 可以端到端噉驅動功能開發:由驗證狀態、重現 Bug、實施修復、驗證解決,到合併 code——淨係喺需要人類判斷嗰陣先要求介入。
呢種轉變要求工程師有新嘅能力:系統架構設計、評估標準制定、多 agent 編排、情境工程——呢啲正正係 AI 時代軟件工程嘅核心技能。
References
- https://www.anthropic.com/engineering/harness-design-long-running-apps: https://www.anthropic.com/engineering/harness-design-long-running-apps
- https://openai.com/index/harness-engineering/: https://openai.com/index/harness-engineering/
Claude Code、Codex 等 AI 編程智能體的快速進化,正推動軟件工程進入新範式。近期 OpenAI 和 Anthropic 發佈技術博文,不約而同提出 "Harness Engineering" 這一核心概念——前者探索數小時自主編碼中的連貫性與設計質量,後者則以"零人工編碼"方式在三個月內構建出百萬行代碼的可用產品。兩篇文章共同指向一個關鍵轉變:工程師角色從親自編寫代碼,轉向設計讓智能體可靠執行的"駕馭系統"。今天咱們通讀這兩篇博客,看看 OpenAI 和 Anthropic 有哪些共同觀點,又分別有哪些側重點。可以預見,2026 年 Harness Engineering 會是 AI Engineering 裏一個極其關鍵的領域。
Anthropic:Harness design for long-running application developmenthttps://www.anthropic.com/engineering/harness-design-long-running-apps[1]
OpenAI:Harness engineering: leveraging Codex in an agent-first worldhttps://openai.com/index/harness-engineering/[2]
一、核心思想:從"寫代碼"到"設計環境"
兩篇博文共同指向一個範式轉變:人類工程師的角色正從直接編寫代碼,轉向設計讓智能體有效工作的"駕馭系統"(Harness)。
Anthropic 的視角 :
- 強調通過 多智能體架構(生成器+評估器)解決複雜任務
- 特別關注 主觀質量評估(如前端設計)和 長週期任務連貫性
- 核心理念:將任務分解、引入外部評估、通過反饋循環迭代改進
OpenAI 的視角 :
- 基於 完全由 Codex 生成代碼(零人工編碼)的實踐經驗
- 強調 環境規範、工具鏈設計和反饋迴路 的重要性
- 核心理念:人類掌舵(設定方向、設計系統),智能體執行(編寫、測試、部署)
共同點:兩者都認為,隨着模型能力提升,工程工作的價值越來越體現在"如何設計讓智能體成功的環境",而非"親自編寫每一行代碼"。
二、關鍵挑戰與解決方案對比
2.1 長週期任務的連貫性問題
Anthropic 的發現:
- "上下文焦慮"(Context Anxiety):模型在接近上下文限制時會提前結束任務
- 解決方案:上下文重置(Context Reset) —— 定期清空上下文,通過結構化製品(Artifacts)傳遞狀態,而非簡單壓縮歷史記錄
- 早期使用 Sonnet 4.5 時必須強制重置;Opus 4.6 改進後,可在單一會話中持續運行數小時
OpenAI 的發現:
- 單次 Codex 運行可持續 超過6小時(通常發生在人類睡眠時間)
- 通過 漸進式情境披露 管理上下文:提供"地圖"而非"1000頁說明書"
AGENTS.md作為內容目錄,指向結構化的docs/知識庫,而非單一大文件
2.2 自我評估的偏差問題
Anthropic 的解法:
- 生成對抗網絡(GAN)啓發:分離"生成器"與"評估器"智能體
- 評估器使用 Playwright MCP 直接操作頁面,進行動態測試
- 通過 少量示例(Few-shot)校準 評估標準,解決模型"自我寬容"傾向
評估標準示例(前端設計):
- 設計質量(整體性、氛圍)
- 原創性(避免"AI 套路"如紫白漸變)
- 工藝(技術執行)
- 功能性(可用性)
OpenAI 的解法:
- 智能體互審:Codex 在本地審核自身更改,請求其他智能體審查,形成"Ralph Wiggum 循環"
- 將人類品味編碼為規則:通過自定義 Linter、結構測試和"黃金原則"強制執行
- 工具鏈集成:Chrome DevTools 協議、可觀測性堆棧(LogQL/PromQL)讓智能體能直接"看到"系統狀態
2.3 架構與約束設計
Anthropic 的三智能體架構:
- 規劃器(Planner):將簡短提示擴展為完整產品規格
- 生成器(Generator):按 Sprint 逐個實現功能,使用 React/Vite/FastAPI/SQLite 技術棧
- 評估器(Evaluator):通過 Playwright 測試運行中的應用,按合同標準評分
關鍵機制:Sprint 合同 —— 生成前雙方協商"完成定義",避免過度工程或遺漏
OpenAI 的嚴格分層架構:
- 六層依賴規則:Types → Config → Repo → Service → Runtime → UI,只能向前依賴
- Providers 作為唯一橫切入口:認證、遙測等通過顯式接口進入
- 機械強制執行:自定義 Linter 和結構測試確保架構不漂移
核心洞見:智能體在嚴格邊界和可預測結構的環境中表現最佳。約束不是限制,而是速度的倍增器。
三、實踐成果與成本對比
Anthropic 實驗規模:單應用(遊戲製作器、DAW),個人/小團隊實驗OpenAI 實驗規模:完整產品(百萬行代碼,1500+ PRs),3人→7人工程師團隊
開發速度對比:
- Anthropic:完整駕馭系統需 6小時/$200,單智能體僅需 20分鐘/$9
- OpenAI:約人工編碼 1/10 的時間完成百萬行代碼項目
關鍵差異:
- Anthropic 的完整駕馭版本成本是單智能體的 20 倍以上,但產出質量差距顯著——單智能體版本核心功能損壞(遊戲無法運行),而駕馭版本功能完整且有 AI 集成
- OpenAI 隨着團隊從 3 人擴大到 7 人,人均吞吐量反而增加(平均每人每天 3.5 個 PRs)
評估器價值邊界:
- 當任務超出模型原生能力邊界時,評估器提供顯著增益
- 當任務在模型能力範圍內時,評估器成為不必要的開銷
成本邏輯轉變:
- 在智能體吞吐量遠超人類注意力的系統中,糾錯成本 < 等待成本
- 快速迭代優於完美門控,測試偶發失敗通過後續重跑解決,而非無限期阻礙進展
四、關鍵洞見與最佳實踐
4.1 上下文管理:地圖 vs 說明書
Anthropic 通過結構化製品(Artifacts)在上下文重置間傳遞狀態;OpenAI 則將 AGENTS.md 作為內容目錄,知識庫在 docs/ 中結構化存儲,實現漸進式披露。
共同原則:上下文是稀缺資源,過多的指導會失效,且會迅速腐爛。
4.2 評估與反饋迴路
分離生成與評估是解決自我評估偏差的關鍵。評估器需要具體、可操作的評分標準,而非抽象判斷。動態測試(操作真實應用)優於靜態檢查。
4.3 架構約束作為倍增器
智能體需要嚴格邊界來維持長週期 coherence。通過 Linter、結構測試將"品味"編碼為機械規則。在中央強制執行邊界,在本地允許自主權。
4.4 持續維護:對抗漂移
OpenAI 的"黃金原則":定期運行後台 Codex 任務掃描偏差,發起重構 PR(類似垃圾回收)。技術債務的小額償還:不斷以小額貸款方式償還,避免累積成大問題。將審查評論、Bug 報告轉化為文檔更新或直接編碼為工具。
4.5 模型進化與駕馭演進
Anthropic 觀察到 Opus 4.6 減少了對 Sprint 結構和上下文重置的依賴,但評估器在複雜邊界處仍有價值。
核心原則:每當新模型發佈,應重新審視駕馭系統,剝離不再關鍵的組件,添加新能力以追求之前不可能的任務。駕馭設計空間不會縮小,而是會轉移。
五、侷限性與未解問題
Anthropic 坦誠的侷限:
- 評估器在音樂品味等主觀領域效果有限(Claude 無法"聽"音樂)
- 複雜邊界情況仍需改進(如遊戲關卡設計中的常識性問題)
- 評估器調優需要多輪迭代,存在邊際收益遞減
OpenAI 的未解挑戰:
- 架構連貫性的長期演化:完全由智能體生成的系統,其架構會如何隨時間演變?
- 人類判斷力的最優編碼位置:哪些判斷應保留給人類,如何最大化其槓桿效應?
- 模型能力增長後的系統演化:隨着模型變強,駕馭系統應如何調整?
共同風險:
- 模式複製:智能體會複製代碼庫中已存在的不理想模式,導致漂移
- 過度工程:生成器可能因評估反饋而不斷增加實現複雜度
- 評估器自身的侷限:即使分離了生成與評估,評估器仍是 LLM,可能過度寬容或測試不充分
六、總結:Harness Engineering 的核心要義
兩篇博文共同勾勒出 AI 原生軟件開發 的新範式:
"人類掌舵,智能體執行"(Humans steer, agents execute)
這不是簡單的"用 AI 寫代碼",而是重新設計軟件工程的整個生產環境:
從代碼到系統:工程師設計工具、約束、反饋迴路,讓智能體能可靠工作。
從連續到分段:通過上下文重置、Sprint 合同等機制管理長週期任務。
從自我評估到對抗性評估:分離生成與評估,引入多智能體反饋循環。
從靈活到約束:通過嚴格架構和機械規則,將人類品味編碼為環境約束。
從一次性到持續維護:建立垃圾回收機制,對抗模式漂移和技術債務。
最終目標是讓智能體能夠端到端地驅動功能開發:從驗證狀態、復現 Bug、實施修復、驗證解決,到合併代碼——僅在需要人類判斷時才請求介入。
這種轉變要求工程師具備新的能力:系統架構設計、評估標準制定、多智能體編排、情境工程——這些正成為 AI 時代軟件工程的核心技能。
References
- https://www.anthropic.com/engineering/harness-design-long-running-apps: https://www.anthropic.com/engineering/harness-design-long-running-apps
- https://openai.com/index/harness-engineering/: https://openai.com/index/harness-engineering/