OpenAI用8個Skill把工程師的經驗變成AI的工作手冊:扛起兩個SDK,3個月457個PR
整理版優先睇
OpenAI 用 8 個 Skill 將工程師經驗編碼成 AI 工作手冊,維護兩個 SDK 三個月合併 457 個 PR,產能提升 45%
呢篇文章係 OpenAI 公開佢哋點樣用 Codex 加 Skills 嚟維護 Agents SDK 開源項目嘅真實實踐。作者係 OpenAI 嘅工程團隊,佢哋面對兩個 SDK(Python 同 TypeScript)嘅維護壓力,想解決傳統人力維護效率低、部落知識流失嘅問題。整體結論係:透過 AGENTS.md、Skills 同 GitHub Actions 嘅組合,可以將工程師嘅經驗轉化成 AI 能夠理解同執行嘅格式,從而提升 PR 吞吐量、減少人工審查負擔,並且確保一致性。
文中詳細介紹咗 8 個 Skill 嘅設計,例如 code-change-verification、docs-sync、final-release-review 等,每個 Skill 專注一個工作流。關鍵係點樣設定條件觸發規則,喺 AGENTS.md 用自然語言定義「當改動影響運行時代碼時,執行驗證」之類嘅邏輯,令到 Codex 知道幾時用邊個 Skill。作者仲強調 description 字段嘅寫法好重要,因為佢直接影響 AI 能否正確路由。
另外,文章提出咗模型同腳本嘅分工原則:解釋、比較、報告交俾模型;確定性重複操作交俾腳本。仲有兩層測試策略(語義驗證同跨運行時測試),同埋一個「默認放行,有證據先攔」嘅發版審查流程。最後,作者將呢套方法類比成豐田生產系統嘅知識編碼化過程,認為我哋正進入「工程即散文」嘅新編程範式。
- OpenAI 用 AGENTS.md + 8 個 Skill + GitHub Actions,三個月內將兩個 SDK 嘅 PR 吞吐量提升 45%,達到 457 個 PR。
- Skill 嘅 description 要包含觸發條件(例如「when changes affect runtime code」),自然語言變成 AI 嘅控制流。
- 模型負責理解同報告,腳本負責確定性操作(如 lint、test),分開後 Skill 更可靠。
- 發版審查採用「默認放行,有證據才攔」策略,配合 final-release-review Skill 自動檢查兼容性與風險。
- 呢套方法將工程師嘅部落知識編碼成 AI 可執行嘅格式,類似 Infrastructure as Code 進化到 Engineering as Prose。
OpenAI 博客原文:Skills for Agents SDK
官方文章,詳細介紹 Skills 方法論同實踐細節。
OpenAI Agents SDK (Python)
Python 版本 SDK 倉庫。
OpenAI Agents SDK (JS)
JavaScript/TypeScript 版本 SDK 倉庫。
AGENTS.md 規範
開放標準,定義 AI 編碼工具讀取嘅行為規則。
結構示例
## Mandatory skill usage
- Use $implementation-strategy before editing runtime or API changes
- Run $code-change-verification when runtime code, tests, examples,
or build/test behavior changes
- Use $pr-draft-summary when substantial code work is ready for review三板斧:AGENTS.md + Skills + GitHub Actions
OpenAI 用三個組件構成佢哋嘅自動化工作流。AGENTS.md 係寫喺倉庫根目錄嘅「規則手冊」,話俾 Codex 知個項目嘅構建命令、測試流程同兼容性約束。Skills 係存在 .agents/skills/ 目錄下嘅工作流包,每個 Skill 係一個文件夾,裏面有 SKILL.md 說明文件,加上可選嘅腳本同參考資料。GitHub Actions 就負責將呢兩樣嘢搬上 CI 自動執行。
呢個組合將驗證、測試、發版、寫 PR 呢啲重複性工作,變成了可複用嘅自動化流程,PR 吞吐量直接升咗 45%。
8 個 Skill 各管一攤
- code-change-verification:代碼一改,自動跑格式化、lint、類型檢查、測試。
- docs-sync:檢查文檔同代碼是否同步。
- examples-auto-run:自動跑示例代碼,記錄日誌。
- final-release-review:發版前做全面審查。
- implementation-strategy:改 API 之前先評估兼容性。
- openai-knowledge:透過官方 Docs MCP 拉取最新 API 文檔。
- pr-draft-summary:自動生成分支名、PR 標題同描述。
- test-coverage-improver:找出覆蓋率缺口,建議高價值測試。
TypeScript 倉庫仲多咗 changeset-validation、integration-tests 同 pnpm-upgrade 幾個 monorepo 專屬嘅 Skill。
條件觸發:自然語言即控制流
OpenAI 喺 AGENTS.md 寫咗一組規則,例如「改 API 前必須先跑 implementation-strategy」、「改咗運行時代碼就必須跑 code-change-verification」、「代碼寫完準備提 PR 時自動用 pr-draft-summary」。呢啲規則唔係用 if/else,而係用自然語言描述,Codex 讀到就會識別觸發條件。
呢個細節揭示咗一個重要設計原則:喺 AI 工作流入面,元數據本身就係控制流。我哋正進入一個新編程範式:用自然語言編程,執行者係 AI。
模型與腳本的分工
OpenAI 提出一個好值得參考嘅原則:解釋、比較、報告交俾模型;確定性嘅重複操作交俾腳本。模型負責讀代碼、理解意圖、對比差異、生成報告;腳本負責跑 make format、make lint 呢啲 command。咁樣分開,腳本執行可靠,模型專注判斷同溝通,Skill 唔會變得又脆弱又臃腫。
模型擅長理解同推理,但每次執行 shell 命令都有不確定性;腳本執行係確定性嘅,分開之後兩邊都發揮得最好。
發版審查與信任光譜
final-release-review Skill 預設狀態係「可以發佈」,只有 diff 出現具體問題證據時先會阻塞。呢個設計同大多數團隊相反,但對快速迭代嘅開源項目更高效。背後反映嘅係對 AI 嘅信任程度:OpenAI 選擇咗光譜偏右嘅位置,建立喺完善驗證機制之上——Skill 確保每次改動經檢查,AGENTS.md 確保規則一致,CI 確保規則唔會被繞過。
代碼審查嘅分工都重新劃分:Codex 負責常規 bug、迴歸、測試覆蓋缺口;人類繼續負責架構設計、影響產品行為嘅變更、跨團隊協調。咁樣將低風險日常 PR 嘅審查瓶頸釋放出來,等人類 reviewer 集中精力喺真正需要討論嘅設計決策上。
從老師傅腦子到倉庫文件夾
文章最耐人尋味嘅係「部落知識」嘅編碼化。工程師腦入面嘅經驗——例如「呢個接口唔可以隨便改,因為三年前有個客戶依賴咗返回值順序」——以前靠口傳或者文檔,但而家可以寫成 AI 能讀、能理解、能執行嘅格式。AGENTS.md 係 Codex 嘅行為規範,SKILL.md 係工作流程序。呢個過程同豐田生產系統將老師傅知識變成標準作業,再編碼成機器人程序,係同一條路。
AGENTS.md + Skills 本質上係一種新編程:人寫規則 → AI 理解規則 → AI 寫代碼 → 機器執行代碼,由 Infrastructure as Code 進化到 Engineering as Prose。
而且呢套方案係開放標準:AGENTS.md 由 Linux Foundation 下嘅 Agentic AI Foundation 託管,Agent Skills 規範已經被 Anthropic、Microsoft、OpenAI、GitHub、Cursor 等採納。寫一次規則,多個 Agent 都可以用。
OpenAI 尋日公開咗套方法論:佢哋係點樣用 Codex + Skills 嚟維護 Agents SDK 開源項目嘅。
呢個係真係跑咗三個月、夾埋 457 個 PR 嘅生產級實踐。

三個月前,同樣嘅兩個倉庫,合併咗 316 個 PR。換句話講,引入 Skills 工作流之後,PR 吞吐量直接升咗 45%。
即係話團隊冇加人,但產出多咗接近一半。
三板斧
OpenAI 嘅方案由三個部份組成:
AGENTS.md:寫喺倉庫根目錄嘅「規則手冊」,話畀 Codex 知呢個項目嘅構建命令、測試流程、兼容性限制
Skills:存在
.agents/skills/目錄下嘅工作流包,每個 Skill 係一個文件夾,入面有 SKILL.md 說明文件,加上可選嘅腳本同參考資料GitHub Actions:將上面兩樣嘢搬去 CI 入面自動執行
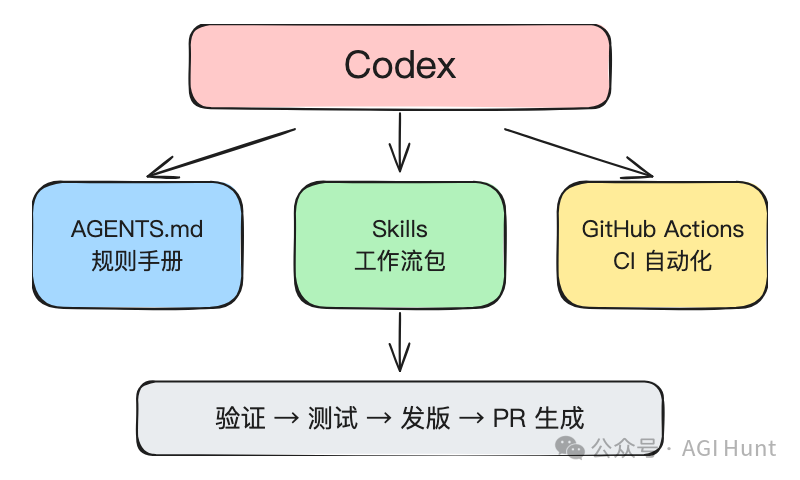
三者配合,將驗證、測試、發版、寫 PR 呢啲重複性工作,變成可重用嘅自動化流程。
8 個 Skill
Python 倉庫配咗 8 個 Skill,各自負責一範:
code-change-verification:代碼一改,自動執行格式化、lint、類型檢查、測試docs-sync:檢查文檔係咪同代碼同步examples-auto-run:自動執行範例代碼,記錄日誌final-release-review:發版前做全面審查implementation-strategy:改 API 之前先評估兼容性openai-knowledge:透過官方 Docs MCP 拉最新 API 文檔pr-draft-summary:自動生成分支名、PR 標題同描述test-coverage-improver:揾出覆蓋率缺口,建議高價值測試
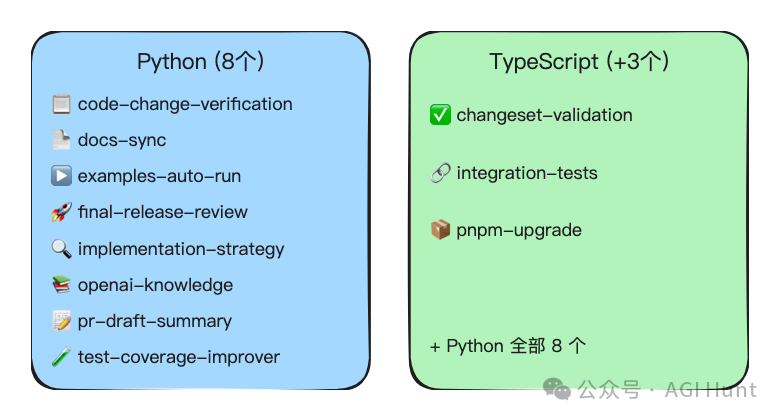
TypeScript 倉庫喺呢個基礎上,仲多咗幾個 monorepo 專屬嘅:changeset-validation 驗證變更集,integration-tests 做跨運行時嘅集成測試,pnpm-upgrade 協調工具鏈升級。
規則點樣定
淨得 Skill 唔夠,仲要話畀 Codex 知幾時要用邊個。
呢件事靠 AGENTS.md 嚟做。OpenAI 喺入面寫咗一組條件觸發規則:
## Mandatory skill usage
- Use $implementation-strategy before editing runtime or API changes
- Run $code-change-verification when runtime code, tests, examples,
or build/test behavior changes
- Use $pr-draft-summary when substantial code work is ready for review翻譯過嚟即係:改 API 前一定要先跑兼容性評估;改咗運行時代碼、測試、範例或者構建行為嘅時候一定要跑驗證;代碼寫完準備提 PR 時自動生成摘要。
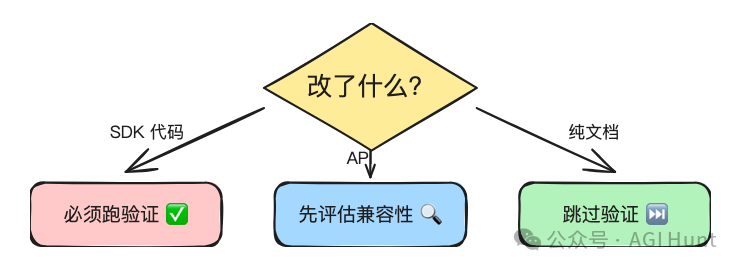
呢度嘅邏輯係:改咗 SDK 代碼?一定要跑驗證。掂到 API?先做兼容性評估。代碼寫完?自動生成 PR 描述。
純文檔改動就跳過驗證,唔浪費算力。
呢套「條件觸發」嘅設計值得留意。唔係所有改動都行曬成個流程,而係根據改動類型精準配對對應嘅 Skill。
描述即路由
Skill 嘅 SKILL.md 入面有個 description 欄位,OpenAI 發現呢個欄位嘅寫法直接決定咗 Codex 能否正確揾到並調用呢個 Skill。
佢哋畀咗一組對比:
差嘅寫法:「Run the mandatory verification stack」(執行強制驗證流程)
淨係話做咩,冇講幾時要用。
好嘅寫法:「Run the mandatory verification stack when changes affect runtime code, tests, or build/test behavior」(當改動涉及運行時代碼、測試或構建行為時,執行強制驗證流程)

多咗 when 條件,Codex 就知道咩場景下要觸發。
描述唔只係畀人睇嘅註釋,而係畀 AI 睇嘅路由規則。
呢個細節好似唔起眼,但其實揭示咗一個更大嘅設計原則:喺 AI 工作流入面,元數據本身就係控制流。
以前寫代碼,控制流靠 if/else、靠 switch/case。而家畀 AI 寫工作流,控制流靠嘅係一段自然語言描述。Codex 讀到 description 入面嘅「當改動涉及運行時代碼時」呢句話,就好似讀到一個 if 陳述式。
我哋正在進入一個新嘅編程範式:用自然語言編程,執行者係 AI。 AGENTS.md 就係呢門「新語言」嘅代碼文件。
模型同腳本嘅分工
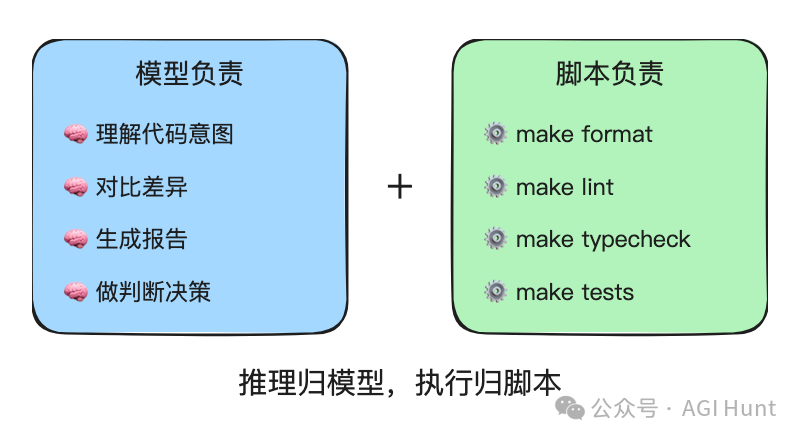
OpenAI 喺文章入面提出咗一個值得諗清楚嘅原則:解釋、比較、報告交畀模型;確定性嘅重複操作交畀腳本。
具體嚟講:
模型負責嘅嘢:讀代碼、理解意圖、對比差異、生成報告、做判斷。
腳本負責嘅嘢:執行 make format、make lint、make typecheck、make tests 呢啲命令。
點解要咁樣分?
因為模型擅長理解同推理,但每次執行 shell 命令都有不確定性(環境差異、路徑問題等等)。而腳本執行係確定性嘅,執行一百次結果都一樣。
將兩者撈亂,Skill 會變得又脆弱又臃腫。分開之後,腳本保證執行可靠,模型專注判斷同溝通。
兩層測試
集成測試係開源 SDK 嘅難點。OpenAI 設計咗一個兩層驗證策略:
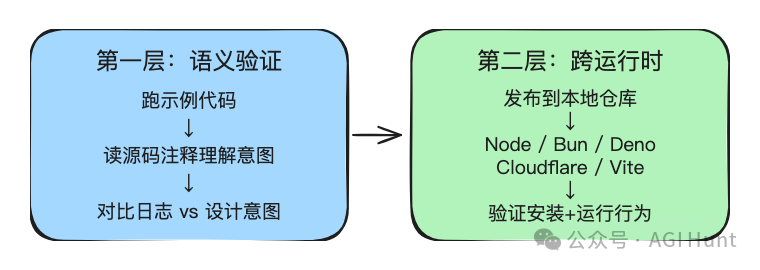
第一層:examples-auto-run
自動執行倉庫入面嘅所有範例代碼。遇到互動提示自動回答,遇到需要人手確認嘅操作自動批准。每個範例單獨記錄日誌,失敗嘅生成 rerun 文件方便重新執行。
關鍵在於驗證方式:模型會去讀每個範例嘅源碼註釋,理解呢個範例「原本想點樣做」,然後將實際運行日誌同設計意圖做對比。
呢個已經超越咗簡單嘅 pass/fail,達到咗語義級別嘅驗證。
第二層:integration-tests(TypeScript 專屬)
先將包發佈到本地嘅 Verdaccio 私有倉庫,然後喺 Node.js、Bun、Deno、Cloudflare Workers、Vite React 等唔同運行時環境下測試安裝同行為。
呢層測試嘅目的係確保發佈後嘅包同行緊嗰陣嘅行為一致。畢竟打包、發佈、安裝呢啲環節,每一步都可能出問題。
發版審查
final-release-review 呢個 Skill 淨係做一件事:將上一個 release tag 同當前 main 分支做 diff,然後逐項檢查。
檢查項包括:公共 API 嘅向後兼容性、有冇迴歸、遷移說明係咪齊全。
最終輸出一個明確嘅結論,例如:
🟢 GREEN LIGHT TO SHIP(可以發佈)
Scope: 38 files changed (+1450/-789)(變更範圍:38 個文件,新增 1450 行,刪除 789 行)
Risk: Python 3.9 support removed(風險:移除了 Python 3.9 支持)
Action: Ensure release notes clearly call out the Python 3.9 drop
(需在發佈說明中明確提及不再支持 Python 3.9)預設狀態係「可以發佈」,只有 diff 入面出現具體問題證據時先會封鎖。
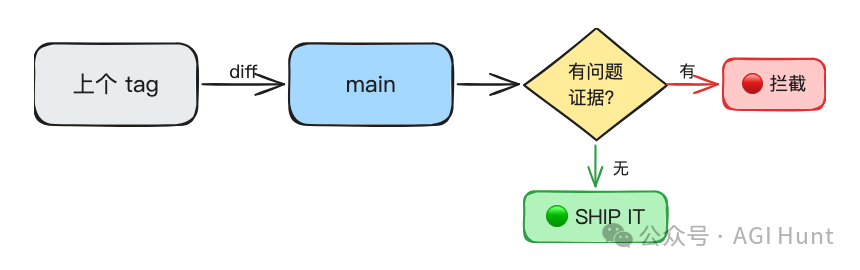
呢個設計思路同好多團隊相反。
大多數團隊嘅發版流程係「預設唔可以發,逐項確認後先放行」。OpenAI 反轉嚟:預設可以發,有證據先攔。
對於一個快速疊代嘅開源項目嚟講,後者明顯更高效。
信任光譜
呢個「預設放行」嘅選擇,背後其實藏住一個更根本嘅問題:你對 AI 嘅信任到咩程度?
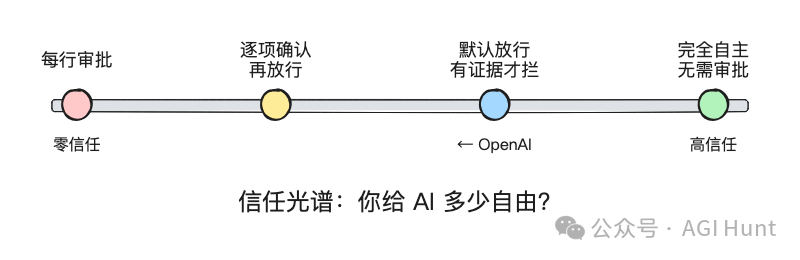
光譜最左邊係零信任:AI 寫嘅每一行代碼都要人審、每一次發版都要人批。安全,但慢到死。
中間偏左係大多數團隊而家嘅位置:AI 幫手寫代碼,但人要一條條確認,逐項放行。快少少,但瓶頸仲喺人度。
OpenAI 揀咗光譜偏右嘅位置:讓 AI 自己跑驗證、自己寫 PR、自己做發版審查,只有發現具體問題時先拉人入嚟。
就好似管理團隊咁。新嚟嘅人,你睇住佢每封電郵、每行代碼、每次提交。三個月後佢證明咗自己,你就開始淨係睇週報。半年後你連週報都唔睇,只有出問題時先介入。
OpenAI 對 Codex 嘅信任模型,就係「三個月後嘅信任」。
但要留意,呢種信任唔係盲目嘅。佢係建立喺一套完善嘅驗證機制之上:Skill 確保每次改動都經過檢查,AGENTS.md 確保檢查規則一致,GitHub Actions 確保規則唔會被繞過。
高信任嘅前提,係高質量嘅自動化保障。 檢查照樣做,只係做檢查嘅變咗 AI。
代碼審查嘅新分工
引入 Codex 之後,代碼審查嘅職責被重新劃分。
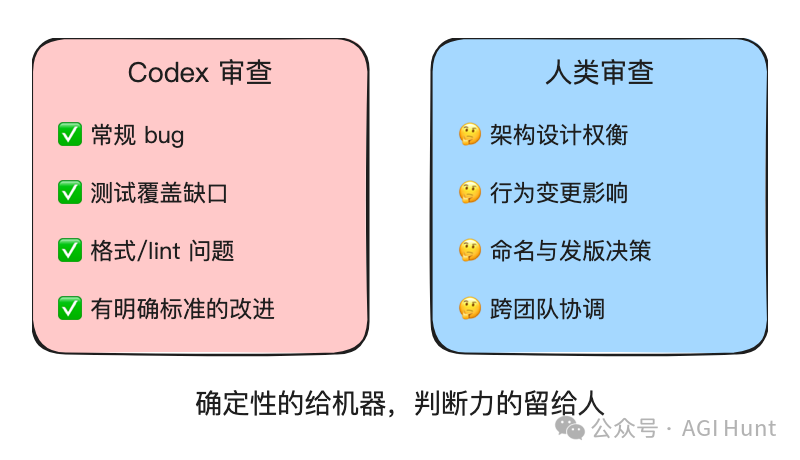
Codex 負責審查嘅:
常規 bug 同迴歸
測試覆蓋缺口
有明確正確性標準嘅常規改進
人類繼續負責嘅:
架構同設計選擇(多種合理方案時需要權衡)
影響產品預期或向後兼容性嘅行為變更
命名、遷移同發版溝通決策
跨團隊協調
簡單講:確定性嘅交畀機器,需要判斷力嘅留畀人。
呢個將審查瓶頸從低風險嘅日常 PR 釋放出嚟,等人類 reviewer 集中精力喺真正需要討論嘅設計決策上。
老師傅嘅手藝
到呢度,事實部份已經講完。但我覺得 OpenAI 呢篇博客最耐人尋味嘅嘢,唔在於具體用咗邊啲 Skill,而在於一個更深層嘅變化。
喺軟件行業,一直有種叫「部落知識」嘅嘢。
咩係部落知識?就係嗰啲淨係存在於老員工腦入面、從來冇被寫低嘅嘢。例如「呢個接口唔可以亂改,因為三年前有個客依賴咗呢個返回值嘅順序」,例如「發版前一定要先跑呢個腳本,如果唔係 CI 會死」,例如「呢個 PR 模板記得剔嗰個 checkbox,否則會漏咗 changelog」。
每個項目都有。老人知,新人唔知。老人走咗,知識就斷咗。
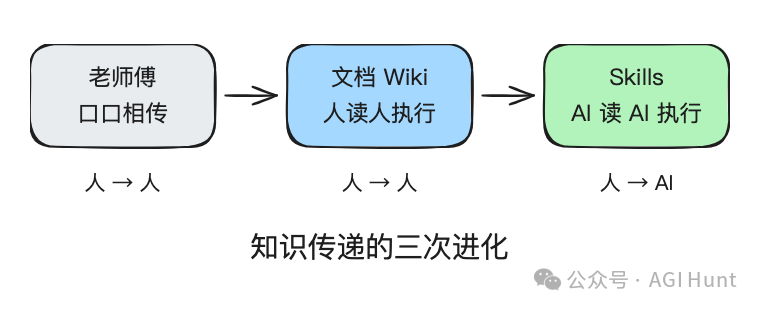
工程知識嘅傳遞經歷咗三個階段:
第一階段,口耳相傳。老師傅帶新人,手把手教。效率低,唔可以擴展,老師傅一走就玩完。
第二階段,寫成文檔。Wiki、README、Confluence,新人可以自己讀。但文檔會過時,會同代碼脱節,而且讀咗都唔一定執行得啱。
第三階段,就係 OpenAI 做緊嘅嘢。將知識寫成 AI 讀得到、理解到、執行到嘅格式。
AGENTS.md 唔止係文檔,佢係 Codex 嘅行為規範。SKILL.md 唔止係說明,佢係 Codex 嘅工作流程序。呢啲文件寫畀 AI 睇,AI 讀完就可以照做。
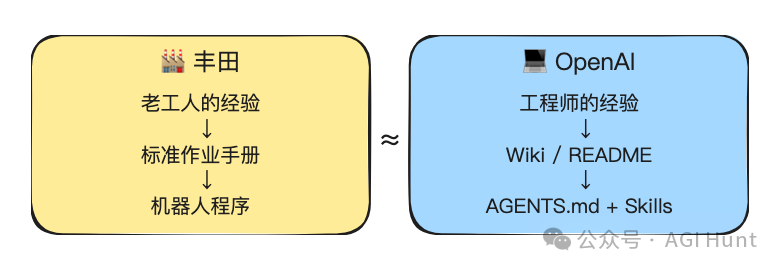
就好似豐田生產系統嘅進化咁。
1950 年代,豐田嘅生產知識全喺老工人手度。後來大野耐一將呢啲知識提煉成「標準作業」,寫成操作手冊,貼喺每個工位。任何人嚟到都可以按手冊開工,質量有保證。再後來,呢啲標準作業被編碼入機械人程式,機械人照住執行,仲精準過人。
由老工人嘅腦,到牆上嘅手冊,到機械人嘅程式。
OpenAI 正係行同一條路:由工程師嘅腦,到 Wiki 上嘅文檔,到倉庫入面嘅 Skill。
分別在於,豐田嘅機械人只可以執行固定動作,而 Codex 理解到、判斷到、靈活處理到。佢唔止係「照住做」,而係「理解咗之後做」。
開放標準
OpenAI 呢套方案唔係得 OpenAI 用得。佢背後嘅幾個組件都已經開放咗。
AGENTS.md 而家係一個開放標準,由 Linux Foundation 旗下嘅 Agentic AI Foundation 託管。OpenAI Codex、Google Jules、Cursor、Amp 等多個 AI 編碼工具都支援讀取 AGENTS.md。
Agent Skills 規範都已經開源,地址係 agentskills.io。Anthropic 最早發佈咗呢個規範,之後 Microsoft、OpenAI、Atlassian、Figma、GitHub、Cursor 等都已經採用。Claude Code 入面嘅 Skills 功能就係基於呢個規範。
咁樣一嚟,你喺 AGENTS.md 入面定義嘅規則、喺 .agents/skills/ 度寫嘅 Skill,理論上可以被多個 AI 編碼工具重用。
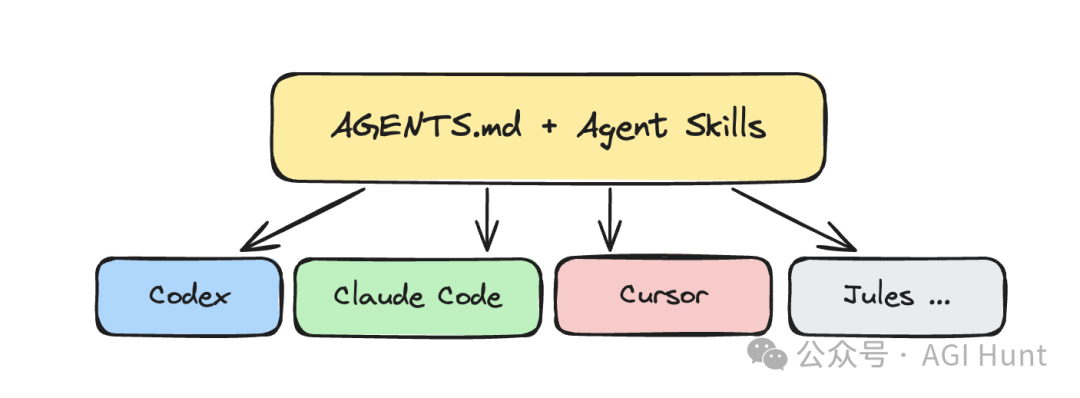
寫一次規則,多個 Agent 都用得。
新嘅編程
如果將視野拉遠啲,OpenAI 呢篇博客透露嘅唔止係「點樣維護 SDK」。
Python 包 PyPI 月下載量 1470 萬,TypeScript 包 npm 月下載量 150 萬。呢個體量嘅項目,靠純人手維護已經越來越難頂。
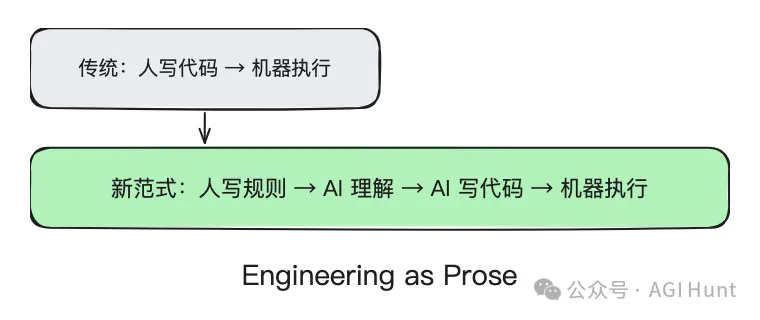
而 Skills + AGENTS.md + CI 嘅組合,本質上係一種新嘅編程。
傳統編程:人寫代碼 → 機器執行代碼。
新編程:人寫規則 → AI 理解規則 → AI 寫代碼 → 機器執行代碼。
人唔再直接話畀機器知「點樣做」,而係話畀 AI 知「要做啲咩、幾時做、做到咩標準」。AI 自己決定具體實現。
呢個同過去十年「基礎設施即代碼」(Infrastructure as Code)嘅思路異曲同工。IaC 係用代碼描述基礎設施嘅期望狀態,等工具自動達成。AGENTS.md + Skills 係用自然語言描述工程流程嘅期望行為,等 AI 自動執行。
由 Infrastructure as Code(基礎設施即代碼),到 Engineering as Prose(工程即散文)。
返去 OpenAI 嘅 Kazuhiro Sera,佢喺 X 度出咗嗰帖介紹呢篇博客時話:「希望對你哋嘅項目都有幫助。」
佢哋確實將自己食狗糧嘅過程完整公開咗。8 個 Skill 嘅設計思路、AGENTS.md 嘅寫法、description 欄位嘅踩坑經驗、模型同腳本嘅分工原則。
工程師嘅經驗變咗倉庫入面嘅一個文件夾。
而呢個文件夾,係寫畀 AI 睇嘅。
相關連結:
OpenAI 博客原文:https://developers.openai.com/blog/skills-agents-sdk OpenAI Agents SDK (Python):https://github.com/openai/openai-agents-python OpenAI Agents SDK (JS):https://github.com/openai/openai-agents-js AGENTS.md 規範:https://agents.md Agent Skills 規範:https://agentskills.io/specification Codex GitHub Action:https://developers.openai.com/codex/github-action
OpenAI 在昨天公開了一套方法論:他們是怎麼用 Codex + Skills 來維護 Agents SDK 開源項目的。
這可是真實跑了三個月、合了 457 個 PR 的生產級實踐。
三個月前,同樣的兩個倉庫,合併了 316 個 PR。換句話說,在引入 Skills 工作流之後,PR 吞吐量直接漲了 45%。
這相當於團隊沒加人,但產出多了將近一半。
三板斧
OpenAI 的方案由三個東西組成:
AGENTS.md:寫在倉庫根目錄的「規則手冊」,告訴 Codex 這個項目的構建命令、測試流程、兼容性約束
Skills:存在
.agents/skills/目錄下的工作流包,每個 Skill 是一個文件夾,裏面有 SKILL.md 說明文件,加上可選的腳本和參考資料GitHub Actions:把上面兩樣搬到 CI 裏自動跑
三者配合,把驗證、測試、發版、寫 PR 這些重複性工作,變成了可複用的自動化流程。
8 個 Skill
Python 倉庫配了 8 個 Skill,各管一攤:
code-change-verification:代碼一改,自動跑格式化、lint、類型檢查、測試docs-sync:檢查文檔是否和代碼同步examples-auto-run:自動跑示例代碼,記錄日誌final-release-review:發版前做全面審查implementation-strategy:改 API 之前先評估兼容性openai-knowledge:通過官方 Docs MCP 拉取最新 API 文檔pr-draft-summary:自動生成分支名、PR 標題和描述test-coverage-improver:找出覆蓋率缺口,建議高價值測試
TypeScript 倉庫在此基礎上,還多了幾個 monorepo 專屬的:changeset-validation 驗證變更集,integration-tests 做跨運行時的集成測試,pnpm-upgrade 協調工具鏈升級。
規則怎麼定
光有 Skill 不夠,還得告訴 Codex 什麼時候該用哪個。
這件事靠 AGENTS.md 來做。OpenAI 在裏面寫了一組條件觸發規則:
## Mandatory skill usage
- Use $implementation-strategy before editing runtime or API changes
- Run $code-change-verification when runtime code, tests, examples,
or build/test behavior changes
- Use $pr-draft-summary when substantial code work is ready for review翻譯過來就是:改 API 前必須先跑兼容性評估;改了運行時代碼、測試、示例或構建行為時必須跑驗證;代碼寫完準備提 PR 時自動生成摘要。
這裏的邏輯是:改了 SDK 代碼?必須跑驗證。碰了 API?先做兼容性評估。代碼寫完了?自動生成 PR 描述。
純文檔改動則跳過驗證,不浪費算力。
這套「條件觸發」的設計值得注意。並非所有改動都走全套流程,而是根據改動類型精準匹配對應的 Skill。
描述即路由
Skill 的 SKILL.md 裏有個 description 字段,OpenAI 發現這個字段的寫法直接決定了 Codex 能不能正確找到並調用這個 Skill。
他們給了一組對比:
差的寫法:「Run the mandatory verification stack」(執行強制驗證流程)
只說了做什麼,沒說什麼時候該用。
好的寫法:「Run the mandatory verification stack when changes affect runtime code, tests, or build/test behavior」(當改動涉及運行時代碼、測試或構建行為時,執行強制驗證流程)
多了 when 條件,Codex 就知道什麼場景下該觸發了。
描述不只是給人看的註釋,而是給 AI 看的路由規則。
這個細節看似不起眼,但其實揭示了一個更大的設計原則:在 AI 工作流中,元數據本身就是控制流。
過去寫代碼,控制流靠 if/else、靠 switch/case。現在給 AI 寫工作流,控制流靠的是一段自然語言描述。Codex 讀到 description 裏的「當改動涉及運行時代碼時」這句話,就像讀到了一個 if 語句。
我們正在進入一個新的編程範式:用自然語言編程,執行者是 AI。 AGENTS.md 就是這門「新語言」的代碼文件。
模型與腳本的分工
OpenAI 在文章中提出了一個值得細想的原則:解釋、比較、報告交給模型;確定性的重複操作交給腳本。
具體來說:
模型負責的事情:讀代碼、理解意圖、對比差異、生成報告、做判斷。
腳本負責的事情:跑 make format、make lint、make typecheck、make tests 這些命令。
為什麼要這樣分?
因為模型擅長理解和推理,但每次執行 shell 命令都有不確定性(環境差異、路徑問題等)。而腳本執行是確定性的,跑一百次結果都一樣。
把兩者混在一起,Skill 會變得既脆弱又臃腫。分開之後,腳本保證執行可靠,模型專注於判斷和溝通。
兩層測試
集成測試是開源 SDK 的難點。OpenAI 設計了一個兩層驗證策略:
第一層:examples-auto-run
自動跑倉庫裏的所有示例代碼。遇到交互式提示自動回答,遇到需要人工確認的操作自動批准。每個示例單獨記錄日誌,失敗的生成 rerun 文件方便復跑。
關鍵在於驗證方式:模型會去讀每個示例的源碼註釋,理解這個示例「本來想幹什麼」,然後把實際運行日誌和設計意圖做對比。
這已經超越了簡單的 pass/fail,達到了語義級別的驗證。
第二層:integration-tests(TypeScript 專屬)
先把包發佈到本地的 Verdaccio 私有倉庫,然後在 Node.js、Bun、Deno、Cloudflare Workers、Vite React 等不同運行時環境下測試安裝和運行行為。
這層測試的目的是確保發佈後的包和開發時的行為一致。畢竟打包、發佈、安裝這些環節,每一步都可能出幺蛾子。
發版審查
final-release-review 這個 Skill 只幹一件事:把上一個 release tag 和當前 main 分支做 diff,然後逐項檢查。
檢查項包括:公共 API 的向後兼容性、是否有迴歸、遷移說明是否齊全。
最終輸出一個明確的結論,比如:
🟢 GREEN LIGHT TO SHIP(可以發佈)
Scope: 38 files changed (+1450/-789)(變更範圍:38 個文件,新增 1450 行,刪除 789 行)
Risk: Python 3.9 support removed(風險:移除了 Python 3.9 支持)
Action: Ensure release notes clearly call out the Python 3.9 drop
(需在發佈說明中明確提及不再支持 Python 3.9)默認狀態是「可以發佈」,只有 diff 中出現具體問題證據時才會阻塞。
這個設計思路和很多團隊相反。
大多數團隊的發版流程是「默認不能發,逐項確認後才放行」。OpenAI 反過來:默認能發,有證據才攔。
對於一個快速迭代的開源項目來說,後者顯然更高效。
信任光譜
這個「默認放行」的選擇,背後其實藏着一個更本質的問題:你對 AI 的信任到什麼程度?
光譜的最左邊是零信任:AI 寫的每一行代碼都要人審、每一次發版都要人批。安全,但慢得要命。
中間偏左是大多數團隊現在的位置:AI 幫忙寫代碼,但人得一條條確認,逐項放行。稍微快一點,但瓶頸還在人身上。
OpenAI 選擇了光譜偏右的位置:讓 AI 自己跑驗證、自己寫 PR、自己做發版審查,只在發現具體問題時才把人拉進來。
這就像管理團隊。一個新人入職,你盯着他每封郵件、每行代碼、每次提交。三個月後他證明了自己,你開始只看週報。半年後你連週報都不看了,只在出問題時介入。
OpenAI 對 Codex 的信任模型,就是「三個月後的信任」。
但值得注意的是,這種信任不是盲目的。它建立在一套完善的驗證機制之上:Skill 確保每次改動都經過檢查,AGENTS.md 確保檢查規則一致,GitHub Actions 確保規則不會被繞過。
高信任的前提,是高質量的自動化保障。 檢查照樣做,只是做檢查的變成了 AI。
代碼審查的新分工
引入 Codex 之後,代碼審查的職責被重新劃分了。
Codex 負責審查的:
常規 bug 和迴歸
測試覆蓋缺口
有明確正確性標準的常規改進
人類繼續負責的:
架構和設計選擇(多種合理方案時需要權衡)
影響產品預期或向後兼容性的行為變更
命名、遷移和發版溝通決策
跨團隊協調
簡單說:確定性的給機器,需要判斷力的留給人。
這把審查瓶頸從低風險的日常 PR 上釋放出來,讓人類 reviewer 把精力集中在真正需要討論的設計決策上。
老師傅的手藝
到這裏,事實部分已經講完了。但我覺得 OpenAI 這篇博客裏最耐人尋味的東西,不在於具體用了哪些 Skill,而在於一個更深層的變化。
在軟件行業,一直有一種叫「部落知識」的東西。
什麼是部落知識?就是那些只存在於老員工腦子裏、從來沒被寫下來的東西。比如「這個接口不能隨便改,因為三年前有個客戶依賴了這個返回值的順序」,比如「發版前一定要先跑這個腳本,不然 CI 會掛」,比如「這個 PR 模板別忘了勾那個 checkbox,不然會漏掉 changelog」。
每個項目都有。老人知道,新人不知道。老人離職了,知識就斷了。
工程知識的傳遞經歷了三個階段:
第一階段,口口相傳。老師傅帶新人,手把手教。效率低,不可擴展,老師傅一走就完。
第二階段,寫成文檔。Wiki、README、Confluence,新人可以自己讀。但文檔會過時,會和代碼脱節,而且讀了也不一定能執行對。
第三階段,就是 OpenAI 正在做的事。把知識寫成 AI 能讀、能理解、能執行的格式。
AGENTS.md 不只是文檔,它是 Codex 的行為規範。SKILL.md 不只是說明,它是 Codex 的工作流程序。這些文件寫給 AI 看,AI 讀完就能照着幹。
這就像豐田生產系統的進化。
1950 年代,豐田的生產知識全在老工人手裏。後來大野耐一把這些知識提煉成了「標準作業」,寫成操作手冊,貼在每個工位上。任何人來了都能按手冊幹活,質量有保障。再後來,這些標準作業被編碼進了機器人程序,機器人照着執行,比人還精準。
從老工人的腦子,到牆上的手冊,到機器人的程序。
OpenAI 正在走同一條路:從工程師的腦子,到 Wiki 上的文檔,到倉庫裏的 Skill。
區別在於,豐田的機器人只能執行固定動作,而 Codex 能理解、能判斷、能靈活處理。它不只是在「照着做」,而是在「理解了之後做」。
開放標準
OpenAI 這套方案並不是只有 OpenAI 能用。它背後的幾個組件都已經開放了。
AGENTS.md 現在是一個開放標準,由 Linux Foundation 下的 Agentic AI Foundation 託管。OpenAI Codex、Google Jules、Cursor、Amp 等多個 AI 編碼工具都支持讀取 AGENTS.md。
Agent Skills 規範也已開源,地址是 agentskills.io。Anthropic 最早發佈了這個規範,隨後 Microsoft、OpenAI、Atlassian、Figma、GitHub、Cursor 等都已採納。Claude Code 中的 Skills 功能就是基於這個規範。
這樣一來,你在 AGENTS.md 裏定義的規則、在 .agents/skills/ 裏寫的 Skill,理論上可以被多個 AI 編碼工具複用。
寫一次規則,多個 Agent 都能用。
新的編程
如果把視野拉遠一點,OpenAI 這篇博客透露的不只是「怎麼維護 SDK」。
Python 包 PyPI 月下載量 1470 萬,TypeScript 包 npm 月下載量 150 萬。這個體量的項目,靠純人力維護已經越來越難撐住了。
而 Skills + AGENTS.md + CI 的組合,本質上是一種新的編程。
傳統編程:人寫代碼 → 機器執行代碼。
新編程:人寫規則 → AI 理解規則 → AI 寫代碼 → 機器執行代碼。
人不再直接告訴機器「怎麼做」,而是告訴 AI「該做什麼、什麼時候做、做到什麼標準」。AI 自己決定具體實現。
這和過去十年「基礎設施即代碼」(Infrastructure as Code)的思路異曲同工。IaC 是用代碼描述基礎設施的期望狀態,讓工具自動達成。AGENTS.md + Skills 是用自然語言描述工程流程的期望行為,讓 AI 自動執行。
從 Infrastructure as Code(基礎設施即代碼),到 Engineering as Prose(工程即散文)。
回到 OpenAI 的 Kazuhiro Sera,他在 X 上發了那條推介紹這篇博客時說:「希望對你們的項目也有幫助。」
他們確實把自己吃狗糧的過程完整公開了。8 個 Skill 的設計思路、AGENTS.md 的寫法、description 字段的踩坑經驗、模型和腳本的分工原則。
工程師的經驗變成了倉庫裏的一個文件夾。
而這個文件夾,是寫給 AI 看的。
相關連結:
OpenAI 博客原文:https://developers.openai.com/blog/skills-agents-sdk OpenAI Agents SDK (Python):https://github.com/openai/openai-agents-python OpenAI Agents SDK (JS):https://github.com/openai/openai-agents-js AGENTS.md 規範:https://agents.md Agent Skills 規範:https://agentskills.io/specification Codex GitHub Action:https://developers.openai.com/codex/github-action