OpenClaw 完整指南:從入門到真正用起來
整理版優先睇
調教OpenClaw核心:人格、記憶、Skills、心跳同模型路由,唔係剩係識得傾偈
呢篇文章嘅作者係OpenClaw用家,用咗幾星期,睇咗唔少社區帖,仲踩咗好多坑。佢發現預設設定只係用到兩成潛力,其餘八成收埋喺配置檔案入面。整體結論係:要令OpenClaw真正發揮,必須自己去寫SOUL.md、IDENTITY.md呢啲人格檔案,仲要建立分層記憶、自訂Skills、開心跳機制同模型分級。
文章詳細講咗幾個關鍵環節:人格設定可以令龍蝦由標準客服變成個人拍檔;分層記憶架構(MEMORY.md做索引,配合向量語義檢索)解決長期記憶問題;自家寫Skills比亂裝ClawHub安全好多;心跳機制令龍蝦由被動答問題變成主動巡檢;模型分級(Opus做複雜推理,Sonnet做具體任務)可以慳六成Token。最後畀咗設定清單同避坑貼士。
總括嚟講,OpenClaw嘅設計哲學係畀個框架你,由你定義佢係咩。核心在於理解每個檔案嘅作用,然後按自己需要定製。配置過程唔難,關鍵係搞清楚每個部份點樣配合。
- 調教OpenClaw嘅關鍵係自訂SOUL.md、IDENTITY.md等檔案,賦予佢人格同記憶,唔好剩係用預設
- 分層記憶架構:MEMORY.md做索引,其他分類記憶按需載入,配合向量語義檢索可以做到精準回憶
- 心跳機制令龍蝦由被動答問題變成7x24主動值班,適合定期檢查服務狀態
- 自己寫Skills最安全,ClawHub下載量可以造假,裝之前一定要睇清楚有冇額外代碼
- 模型分級:Opus管複雜推理同協調,Sonnet做具體執行,可以慳六到七成Token成本
開啟記憶沖洗配置對話
跟Openclaw對話:請升級我的OpenClaw記憶配置,在agents.defaults下啓用compaction.memoryFlush.enabled = true,這會在對話壓縮前自動儲存重要記憶。驗證配置之後,如有需要請重啓Gateway以套用變更。請確認:-配置已正確寫入 ~/.openclaw/openclaw.json-沒有 schema 驗證錯誤-重啓後功能正常運作
Memory Search 配置示例
memorySearch: { "enabled": true, "provider": "openai", "remote": { "baseUrl": "你的embedding API地址", "apiKey": "你的key" }, "model": "BAAI/bge-m3" }
模型路由配置示例
models: { "your-provider/strong-model": { "alias": "opus" }, "your-provider/medium-model": { "alias": "sonnet" }, "your-provider/light-model": { "alias": "haiku" } }
內容片段
MEMORY.md ← 索引層:只放最核心的信息和指向其他文件的索引memory/projects.md ← 項目層:每個項目的當前狀態和待辦memory/infra.md ← 基礎設施層:服務器配置、API地址等速查信息memory/lessons.md ← 教訓層:踩過的坑,按嚴重程度分級memory/YYYY-MM-DD.md ← 日誌層:每天發生了什麼畀佢一個人格:由工具變成拍檔
OpenClaw嘅workspace入面有三個關鍵人格設定檔:SOUL.md、IDENTITY.md同USER.md。預設嘅SOUL.md係空嘅,所以龍蝦回覆好似標準客服。改完之後,例如寫「別說很高興幫助您,直接幫」,成個風格即刻正常返。
SOUL.md 定義思維方式同表達習慣
IDENTITY.md 畀佢一個名同emoji,多輪對話一致性高好多
USER.md 寫你嘅時區、技術棧、溝通偏好,避免推薦錯方案
唔好睇小呢啲檔案,有名字嘅AI喺多輪對話中嘅一致性遠超無名嘅。呢步係最直接見效嘅。
建立記憶體系:呢步提升最大
會話壓縮後記憶會消失,冇寫到檔案嘅就等於冇發生過。好多人嘅龍蝦蠢,正正因為唔捨得用Token寫記憶,或者乜都塞曬入MEMORY.md變咗流水賬。
- MEMORY.md只做索引,放最核心嘅信息同指向其他檔案
- memory/projects.md、memory/infra.md、memory/lessons.md等分類存放具體內容
- memory/YYYY-MM-DD.md做日誌,等向量語義檢索可以精準揾返
配合memorySearch向量檢索,效果離譜:你話「上次個部署問題點解決」,龍蝦會語義搜索定位到對應日誌文件嘅具體行,精準回憶。推薦用SiliconFlow嘅免費bge-m3模型做embedding,零成本。
開啓compaction.memoryFlush,對話壓縮前自動儲存重要記憶
Skill擴展:自己寫最安全
Skill本質係一個SKILL.md檔案加可選嘅腳本。龍蝦收到相關請求會自動讀取對應嘅SKILL.md按指引執行。最好用嘅Skills,往往只係一個寫得清楚嘅SKILL.md,話畀Agent點用內置工具。
- 1 視頻下載:發個B站/YouTube連結,自動下載並生成分享連結
- 2 PPT生成:說「幫我做個關於XX嘅PPT」,直接生成.pptx文件
- 3 股票分析:問「XX股票可以買嗎」,跑量化模型畀預測
先停下來想想:用一段清楚嘅自然語言指令,Agent自己搞唔搞得掂?
把龍蝦當成新嚟嘅實習生——步驟寫得夠清楚,佢先至可以穩定執行。模糊嘅指令等於不穩定嘅結果。
Heartbeat心跳:由被動變主動
OpenClaw默認每30分鐘ping一次龍蝦,問佢有冇嘢要做。預設佢只係回個OK,但你可以寫HEARTBEAT.md,話畀佢心跳時檢查啲乜。
- 每次心跳:檢查XX服務是否在線(curl一下),掛咗就通知,但唔好自動重啓
- 每日一次:檢查有冇超過3日未更新嘅項目待辦
- 每週一次:整理最近7日日誌,提煉到長期記憶
心跳解決被動應答,令龍蝦可以自主活動,係佢同普通AI Chat最大分別之一
心跳適合「順便檢查」嘅輕量任務;cron適合精確定時嘅獨立任務(例如每週一早上9點發週報)。將類似檢查合併到同一個心跳,唔好搞到二十個分散Cron。
模型路由:Opus管協調,Sonnet幹活
如果你有多個模型可用,強烈建議配置模型分級:Opus做複雜推理同任務協調,Sonnet做具體執行(成本係Opus嘅1/5)。咁樣同樣任務量,Token消耗可以降六到七成。
大部分日常操作根本唔需要最強模型
配置好後,龍蝦派子Agent時會自動選合適模型。記得配模型Fallback,某服務商限速時可以自動切過去。
工程結構同配置清單
跑落嚟比較順手嘅目錄結構:~/workspace/ 下面放SOUL.md、IDENTITY.md、USER.md、MEMORY.md、ACTIVE-TASK.md、TOOLS.md、HEARTBEAT.md、AGENTS.md,同埋memory/同skills/資料夾。
按優先級做配置:先寫人格檔案(即時見效),再搞記憶結構,然後心跳、Skills、模型分級
避坑:任務執行中改配置會崩;kill進程喺macOS要用unload plist先;敏感操作(發郵件、推文)一定要加人工確認。
唔可以唔講,好多人裝完 OpenClaw,駁返釘釘或者飛書,傾到偈就覺得「搞掂曬」。
講真,嗰啲只係發揮咗佢 20% 嘅潛力。剩低嘅 80%,收埋喺幾個你可能未掂過嘅配置文件入面。
日日玩 OpenClaw 玩咗幾星期,社區帖文睇咗唔少,谷入面又同大家傾咗好多,再加埋自己撞過嘅板——今日整理嚇,將啲真係有用嘅嘢拎出嚟。
預設狀態 vs 調教之後
先睇對比,直接感受嚇個差距有幾大:
差天共地,係咪?下面一步步嚟。
畀佢一個人格:由「工具」變成「拍檔」
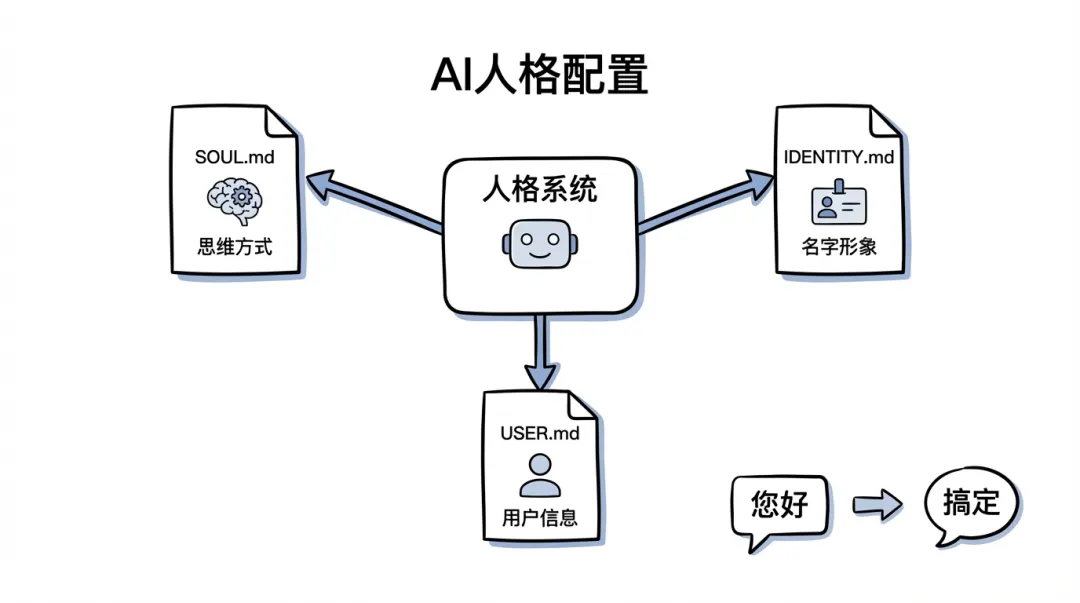
OpenClaw 嘅 workspace 入面有三個關鍵嘅人格設定檔:
• SOUL.md— 定義佢嘅諗嘢方式同表達習慣• IDENTITY.md— 名、形象、專屬 emoji• USER.md— 你嘅資訊,等佢更明你
默認的 SOUL.md 基本上係空嘅模板,所以 OpenClaw 覆你嗰陣好似個標準客服——「尊貴嘅用戶您好」嗰種。
改完之後呢?舉個例,我喺 SOUL.md 度寫咗呢幾句:
# 核心原則
- 別說"很高興幫助您",直接幫
- 允許有自己的觀點和偏好
- 先自己查,查不到再問我
- 簡潔,該詳細時詳細,該簡短時簡短就咁幾行,回覆風格即刻變返正常人講嘢。
IDENTITY.md 更簡單——幫佢改個名,揀個 emoji,佢就有咗「自我認知」。唔好睇少呢樣,有名嘅 AI 喺多輪對話入面嘅一致性遠遠好過冇名嘅。之前文章都提過,靈魂文件解決嘅就係千人千面嘅問題。
USER.md 度寫低你嘅基本資料:時區、技術棧、溝通偏好。咁樣佢唔會半夜 send 訊息畀你,亦唔會同一個 Go 開發者推薦 Java 方案。
建立記憶體系:呢步提升最大
會話一旦壓縮(Compaction),入面嘅記憶就會消失。冇寫落文件嘅,等於冇發生過。
呢個係新用戶最常犯嘅錯誤,冇之一。
之前都講過,人哋嘅 OpenClaw 好聰明,自己嗰個又蠢又鈍?好大可能係「飼養方式」嘅問題——孤寒 Token 消耗,唔捨得用高推理模型累積記憶,寫啲亂七八糟嘅嘢落去,點會唔蠢?
預設嘅 OpenClaw 有個 MEMORY.md,但大多數人唔係唔寫,就係乜都塞曬入去,最後變成無人問津嘅流水帳。
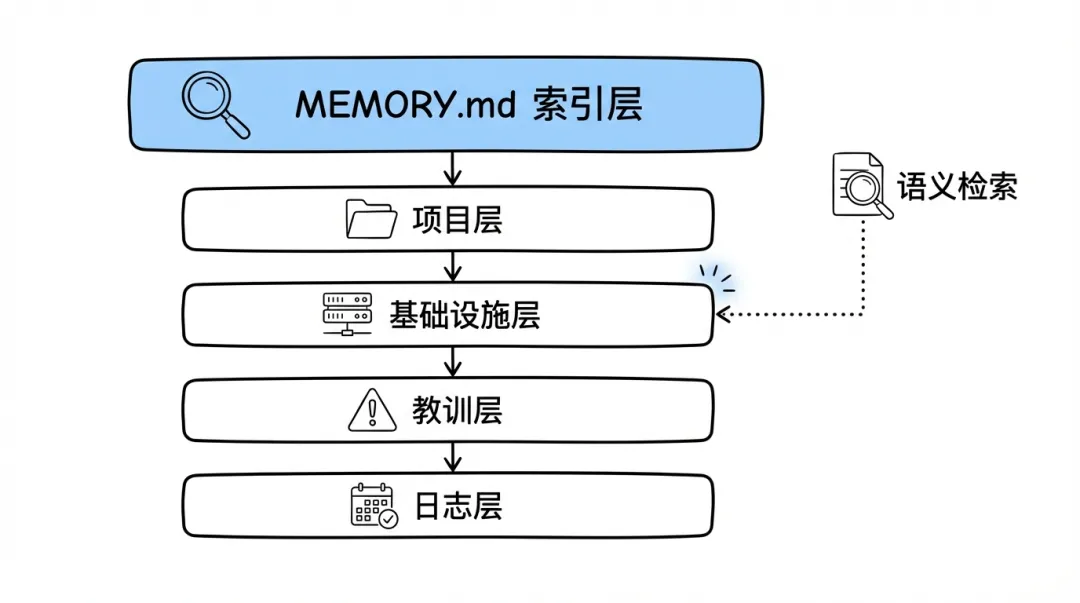
分層記憶架構
我嘅做法:
MEMORY.md ← 索引層:只放最核心的信息和指向其他文件的索引
memory/projects.md ← 項目層:每個項目的當前狀態和待辦
memory/infra.md ← 基礎設施層:服務器配置、API地址等速查信息
memory/lessons.md ← 教訓層:踩過的坑,按嚴重程度分級
memory/YYYY-MM-DD.md ← 日誌層:每天發生了什麼核心諗法:MEMORY.md 淨係做索引,唔堆內容。每次新 session 起動時淨係加載索引,需要具體資訊時先按需讀取。
仲有一個關鍵點:叫 Agent 喺任務執行期間就寫入檢查點,唔好等任務完咗先保存。 中途斷咗乜都揾唔返。記憶係寶貴資產,建議用 git + GitHub 私有倉庫做版本管理,模型運作唔穩定,可能一嘢刪咗記憶或者寫入壞記憶,備份回滾好有必要。
開啓向量語義檢索
配合 OpenClaw 嘅 memorySearch(向量語義檢索),效果好到離譜:
你話「上次嗰個部署問題點解決㗎」,OpenClaw 唔需要翻曬所有日誌,而係語義搜尋 → 定位到 memory/2026-02-18.md 第 47 行 → 精準回憶。
配置範例(openclaw.json):
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "你的embedding API地址",
"apiKey": "你的key"
},
"model": "BAAI/bge-m3"
}推薦用 SiliconFlow 嘅免費 embedding API(bge-m3 模型),零成本就可以有語義記憶。
另外建議開啓 compaction.memoryFlush,上下文就快滿嘅時候,OpenClaw 會自動將重要資訊寫入嗰日嘅日誌,避免長對話導致嘅「失憶」。
開啓方法,同 OpenClaw 講:
請升級我嘅 OpenClaw 記憶配置,喺agents.defaults 下面開啓compaction.memoryFlush.enabled = true,呢個會喺對話壓縮前自動儲存重要記憶。
驗證配置之後,如果有需要請重啓 Gateway 嚟套用變更。
請確認:
-配置已正確寫入 ~/.openclaw/openclaw.json
-冇 schema 驗證錯誤
-重啓後功能正常運作
Skill 擴展:令 OpenClaw 真正「動手做嘢」
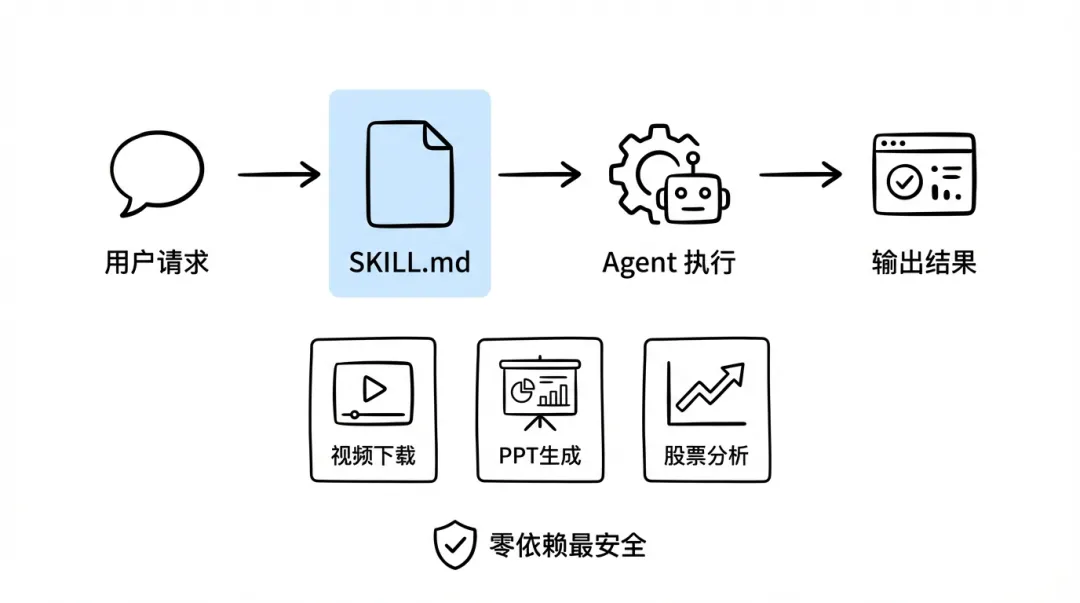
OpenClaw 內置咗幾個 skill(天氣、新聞等),但真正強大嘅係自定義 skill。
Skill 本身係一個 SKILL.md 檔案 + 可選嘅腳本/工具。OpenClaw 收到相關請求時會自動讀取對應嘅 SKILL.md,按指引執行。
我用緊嘅幾個:
• 影片下載:send 個 B站/YouTube 連結,自動下載並產生分享連結 • PPT 生成:話「幫我做個關於 XX 嘅 PPT」,直接生成 .pptx 檔案 • 股票分析:問「XX 股票買唔買得」,行量化模型俾出預測 • 新聞摘要:每日自動拎熱點新聞,生成摘要
基本結構:
skills/
my-skill/
SKILL.md ← AI 讀這個文件來了解怎麼執行
script.sh ← 可選的執行腳本
README.md ← 可選的說明文檔SKILL.md 度寫清楚觸發條件、執行步驟、輸出格式。OpenClaw 會嚴格跟住你寫嘅流程嚟做。
關鍵心得
最好用嘅 Skills,好多時只係一個寫得清楚嘅 SKILL.md,話畀 Agent 點樣用內置工具。
幾個例子:
• 瀏覽 Reddit:直接用 web_fetch訪問 Reddit 嘅公開 JSON 接口——任何 Reddit 連結後面加.json就拎到數據• 股票數據: yfinance開箱即用• 網絡調研: web_search+web_fetch覆蓋絕大多數場景
冇鑑權,冇 API Key,冇額外嘅攻擊面。
如果你嘅 Skills 需要兩百行 Python 腳本,先停一停諗嚇:用一段清楚嘅自然語言指令,Agent 自己搞唔搞得掂?
將 OpenClaw 當成一個新嚟嘅實習生——步驟寫得夠清楚,佢先至穩定執行。模糊嘅指令 = 唔穩定嘅結果。
ClawHub 上嘅 Skills,唔好亂裝
呢條單獨拎出嚟講,因為真係好重要。
ClawHub 上有幾百個 Skills,其中相當一部分有問題。之前有人特登用刷量手段將一個帶後門嘅 Skills 頂到下載榜第一,結果七個國家嘅開發者都走去裝——正一韭菜行為。
下載量可以造假。目前嗰啲「信任度」指標基本上都係擺設。
咁點算?自己寫。SKILL.md 本身就係一個 Markdown 檔案,寫清楚指令就得,唔需要任何代碼。
如果某個 Skills 入面帶咗 scripts/ 目錄,有可以執行嘅代碼,裝之前每一行都要自己睇一次。淨係用內置工具(web_fetch、web_search、exec)嘅 Skills,自然比嗰啲附帶 Python 腳本嘅安全得多。
最安全嘅 Skill,係零依賴嗰種。
Heartbeat 心跳機制:OpenClaw 主動做嘢
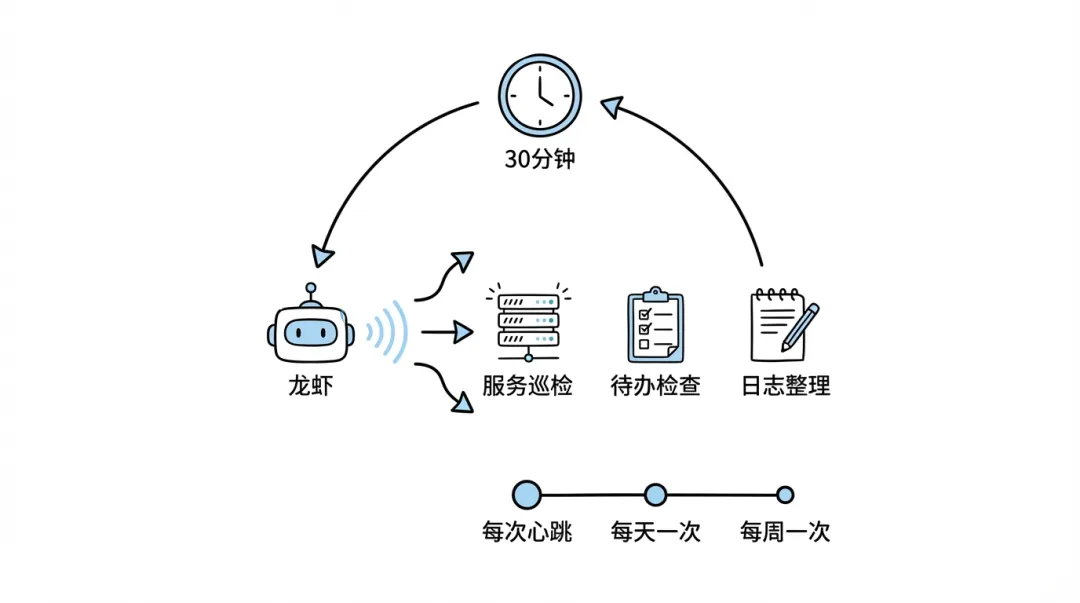
OpenClaw 有個心跳機制:每隔一段時間(預設 30 分鐘),系統會 ping 一下 OpenClaw,問佢有冇嘢要做。
預設情況下,OpenClaw 收到心跳就回個 HEARTBEAT_OK,乜都唔做。但你可以寫一個 HEARTBEAT.md,話畀佢心跳時要檢查啲咩:
# HEARTBEAT.md
## 每次心跳
- 檢查 XX 服務是否在線(curl 一下)
- 如果掛了,通知我,但不要自動重啓
## 每天一次
- 檢查有沒有超過 3 天沒更新的項目待辦
## 每週一次
- 整理最近 7 天的日誌,提煉到長期記憶咁樣你嘅 OpenClaw 就變成咗一個 7x24 嘅值班員。你瞓覺嗰陣佢喺度巡檢,你起身就睇到報告。
之前講架構嘅時候都講過,心跳解決咗被動應答模式,令 OpenClaw 可以自主活動——呢個係佢同普通 AI Chat 最大嘅分別之一。
heartbeat vs cron 點揀?
• 心跳:適合「順便檢查嚇」嘅輕量任務,可以批量執行 • cron:適合精確定時嘅獨立任務(例如「逢星期一早上 9 點出週報」)
將類似嘅檢查任務合併到同一個心跳入面,唔好搞到二十個分散嘅 Cron Job,淨係會令自己頭痛。
模型路由:Opus 管調度,Sonnet 做嘢
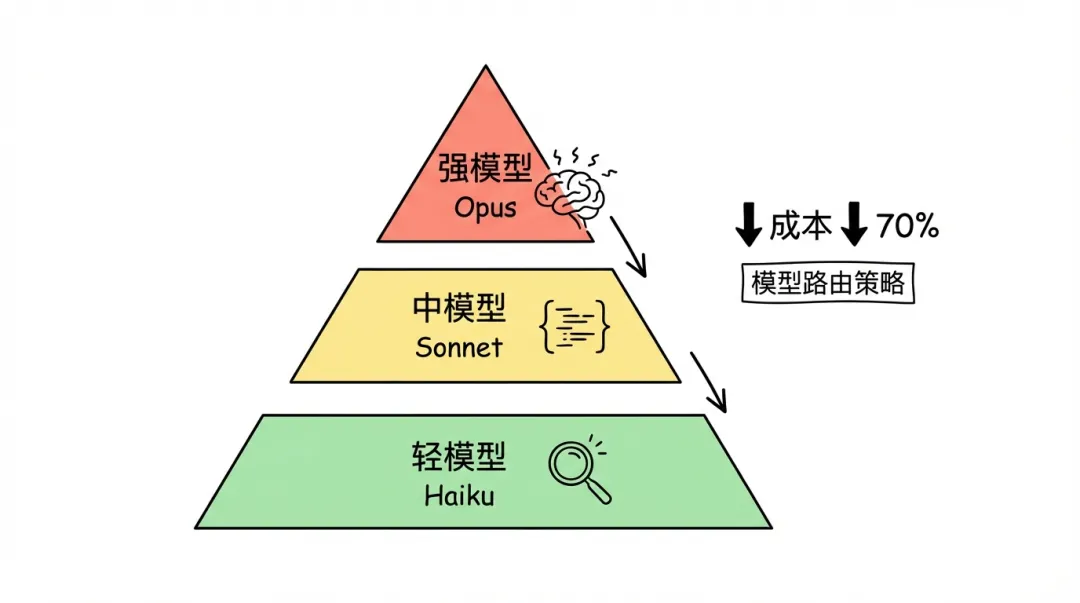
如果你有多個模型可以用(例如經 API 中轉站),強烈建議配置模型分級:
配置範例(openclaw.json):
"models": {
"your-provider/strong-model": { "alias": "opus" },
"your-provider/medium-model": { "alias": "sonnet" },
"your-provider/light-model": { "alias": "haiku" }
}然後在 AGENTS.md 度寫低分配策略,OpenClaw 派子 agent 時就會自動揀合適嘅模型。
效果:同樣嘅任務量,token 消耗可以降 60-70%。大部分日常操作根本唔需要用最強模型。
社區入面有人分享咗配置,驗證完確實掂:Opus 負責複雜推理同任務協調,Sonnet 負責具體執行(成本係 Opus 嘅 1/5,聚焦任務時表現仲好啲)。呢個都印證咗之前講嘅——高推理模型負責決策並寫入記憶,低推理模型負責日常任務執行。
另外,記得配好模型 Fallback。某個服務商限速嗰陣,你希望 OpenClaw 可以自動切過去,唔係就咁卡死喺度。
工程結構
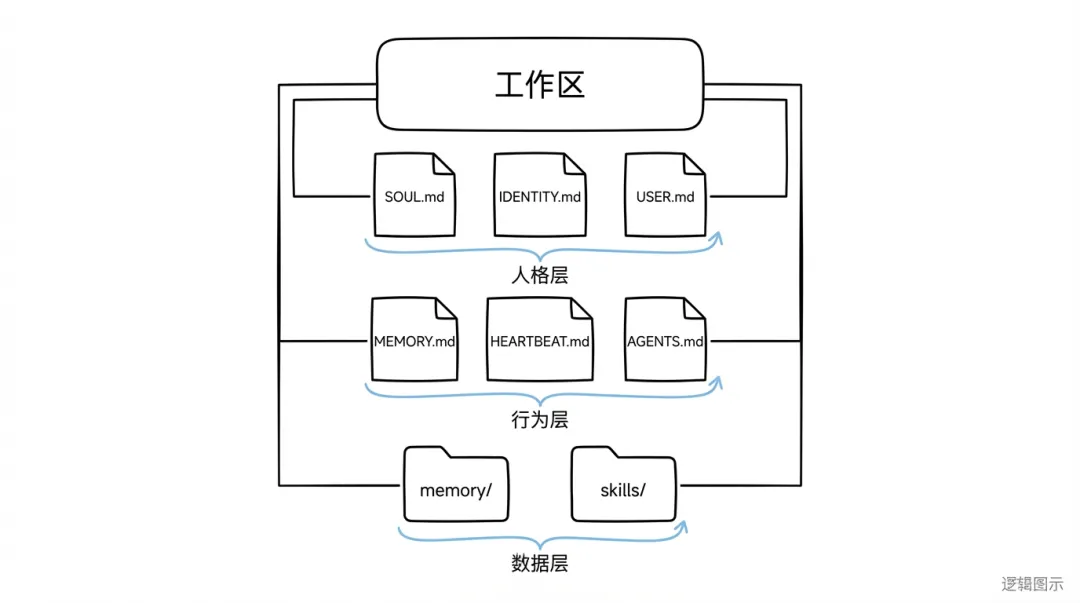
行落覺得比較順手嘅目錄結構:
~/workspace/
├── SOUL.md # Agent 的人格設定
├── IDENTITY.md # 名字和形象
├── USER.md # 你的信息
├── MEMORY.md # 長期記憶索引
├── ACTIVE-TASK.md # 當前任務的工作記憶
├── TOOLS.md # 本地工具說明
├── HEARTBEAT.md # 定期檢查任務
├── AGENTS.md # 行為規範和安全規則
├── memory/ # 每日日誌和分類記憶
└── skills/ # 自己寫的 Skills呢啲坑遲早會踩到你
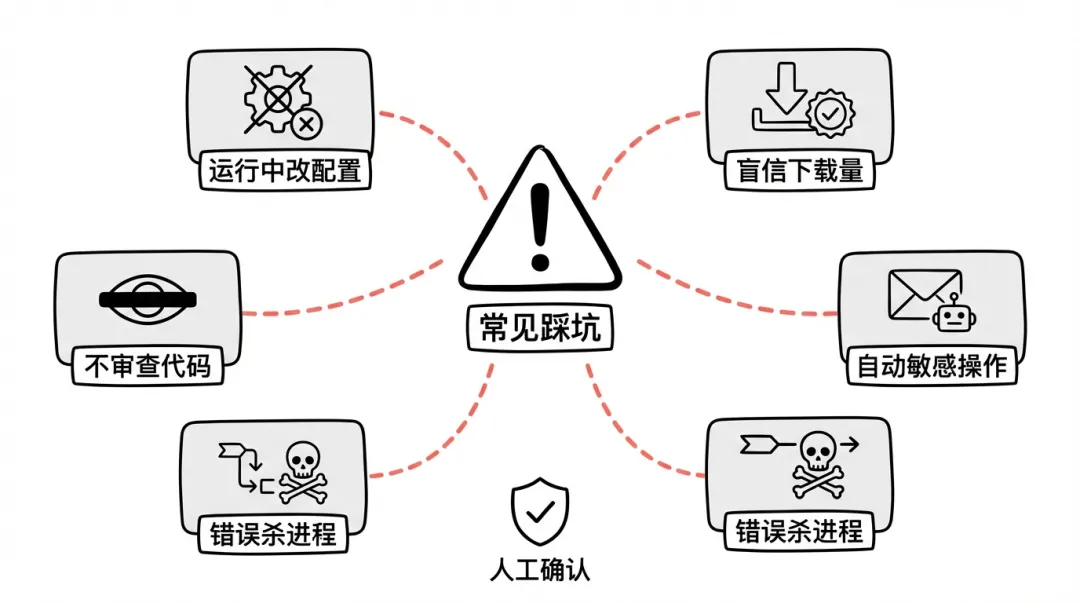
幾個容易出問題嘅地方,提前講清楚:
任務執行期間改配置,可能會令佢直接死喺中途。
信 ClawHub 嘅下載量,唔好信。上面講過。
裝之前唔睇 Skills 內容,遲早會蝕底。
叫 Agent 自動 send 電郵或出推文,一定要設定成需要人手確認先執行。我哋一方面想 OpenClaw 有探索精神,另一方面又想佢安全——呢個本身就係矛盾。敏感操作一定要加人手確認,呢個係寫入「基因」嘅安全意識。
用 kill 殺咗個進程,喺 macOS 上,launchd 會自動重新拉起。正確做法係先 unload plist,再 kill。否則就係打地鼠,殺咗又起返。
配置 Checklist
按優先級排:
•寫好 SOUL.md/IDENTITY.md/USER.md(立竿見影)•設計分層記憶結構,開啓 memorySearch•配置 HEARTBEAT.md•自己寫 2-3 個常用 skill(唔好從 ClawHub 亂裝) •配置多模型分級(如果有多個模型可用) •完善 AGENTS.md入面嘅行為規範同安全規則
就係咁多。
核心就幾件事:自己寫 Skills,所有嘢落碟,Opus + Sonnet 組合用,定時任務排入心跳或 Cron,ClawHub 嘅嘢唔好亂裝。
OpenClaw 嘅設計哲學係「畀你一個框架,你嚟定義佢係邊個」。預設配置只係起點,真正嘅價值在於你點樣調教佢。
配置過程其實唔難,關鍵係理解每個檔案嘅作用,然後根據自己嘅需求去定製。其他細節用用嚇自然就會摸清楚。
點睇?快啲動手試嚇啦。
不得不說,很多人裝完 OpenClaw,接上釘釘或飛書,能聊天了就覺得"搞定了"。
說實話,那只是發揮了它 20% 的潛力。剩下的 80%,藏在幾個你可能還沒碰過的配置文件裏。
天天跑龍蝦好幾周了,社區帖子看了不少,羣裏也跟大家聊了很多,加上自己踩的坑——今天整理一下,把真正有用的東西拿出來。
默認狀態 vs 調教後
先看對比,直觀感受一下差距有多大:
天壤之別吧?下面一步步來。
給它一個人格:從"工具"變成"搭檔"
OpenClaw 的 workspace 裏有三個關鍵的人格配置文件:
• SOUL.md— 定義它的思維方式和表達習慣• IDENTITY.md— 名字、形象、專屬 emoji• USER.md— 你的信息,讓它更懂你
默認的 SOUL.md 基本是空模板,所以龍蝦回覆你的時候像個標準客服——"尊敬的用戶您好"那種。
改完之後呢?舉個例子,我在 SOUL.md 裏寫了這麼幾條:
# 核心原則
- 別說"很高興幫助您",直接幫
- 允許有自己的觀點和偏好
- 先自己查,查不到再問我
- 簡潔,該詳細時詳細,該簡短時簡短就這麼幾行,回覆風格立刻變成正常人說話了。
IDENTITY.md 更簡單——給它起個名字,選個 emoji,它就有了"自我認知"。別小看這個,有名字的 AI 在多輪對話中的一致性遠超無名的。之前文章裏也提過,靈魂文檔解決的就是千人千面的問題。
USER.md 裏寫上你的基本信息:時區、技術棧、溝通偏好。這樣它不會半夜給你發消息,也不會跟一個 Go 開發者推薦 Java 方案。
建立記憶體系:這步提升最大
會話一旦壓縮(Compaction),裏面的記憶就消失了。沒寫到文件裏的,就等於沒發生過。
這是新用戶最常犯的錯誤,沒有之一。
之前也聊過,別人的龍蝦聰明,自己的又蠢又笨?很可能就是"飼養方式"的問題——吝嗇 Token 消耗,不捨得用高推理模型積累記憶,寫入一些亂七八糟的東西,能不笨嗎?
默認的 OpenClaw 有個 MEMORY.md,但大多數人要麼不寫,要麼什麼都往裏塞,最後變成無人問津的流水賬。
分層記憶架構
我的做法:
MEMORY.md ← 索引層:只放最核心的信息和指向其他文件的索引
memory/projects.md ← 項目層:每個項目的當前狀態和待辦
memory/infra.md ← 基礎設施層:服務器配置、API地址等速查信息
memory/lessons.md ← 教訓層:踩過的坑,按嚴重程度分級
memory/YYYY-MM-DD.md ← 日誌層:每天發生了什麼核心思路:MEMORY.md 只做索引,不堆內容。每次新 session 啓動時只加載索引,需要具體信息時再按需讀取。
還有一個關鍵點:讓 Agent 在任務執行過程中就寫入檢查點,別等任務結束才保存。 中途斷了什麼也找不回來。記憶是寶貴資產,建議用 git + GitHub 私有倉庫做版本管理,模型工作不穩定,可能一鍵刪除記憶或寫入壞記憶,備份回滾很有必要。
開啓向量語義檢索
配合 OpenClaw 的 memorySearch(向量語義檢索),效果好到離譜:
你說"上次那個部署問題怎麼解決的",龍蝦不需要翻遍所有日誌,而是語義搜索 → 定位到 memory/2026-02-18.md 第 47 行 → 精準回憶。
配置示例(openclaw.json):
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "你的embedding API地址",
"apiKey": "你的key"
},
"model": "BAAI/bge-m3"
}推薦用 SiliconFlow 的免費 embedding API(bge-m3 模型),零成本就能擁有語義記憶。
另外建議開啓 compaction.memoryFlush,上下文快滿的時候,龍蝦會自動把重要信息寫入當天日誌,避免長對話導致的"失憶"。
開啓方法,跟Openclaw對話:
請升級我的 OpenClaw 記憶配置,在agents.defaults下啓用compaction.memoryFlush.enabled = true,這會在對話壓縮前自動儲存重要記憶。
驗證配置之後,如有需要請重啓 Gateway 以套用變更。
請確認:
-配置已正確寫入 ~/.openclaw/openclaw.json
-沒有 schema 驗證錯誤
-重啓後功能正常運作
Skill 擴展:讓龍蝦真正"動手做事"
OpenClaw 內置了幾個 skill(天氣、新聞等),但真正強大的是自定義 skill。
Skill 本質是一個 SKILL.md 文件 + 可選的腳本/工具。龍蝦收到相關請求時會自動讀取對應的 SKILL.md,按指引執行。
我在用的幾個:
• 視頻下載:發個 B站/YouTube 連結,自動下載並生成分享連結 • PPT 生成:說"幫我做個關於 XX 的PPT",直接生成 .pptx 文件 • 股票分析:問"XX 股票能買嗎",跑量化模型給出預測 • 新聞摘要:每天自動抓取熱點新聞,生成摘要
基本結構:
skills/
my-skill/
SKILL.md ← AI 讀這個文件來了解怎麼執行
script.sh ← 可選的執行腳本
README.md ← 可選的說明文檔SKILL.md 裏寫清楚觸發條件、執行步驟、輸出格式。龍蝦會嚴格按你寫的流程來。
關鍵心得
最好用的 Skills,往往只是一個寫得清楚的 SKILL.md,告訴 Agent 怎麼用內置工具。
幾個例子:
• 瀏覽 Reddit:直接用 web_fetch訪問 Reddit 的公開 JSON 接口——任何 Reddit 連結後面加.json就能拿到數據• 股票數據: yfinance開箱即用• 網絡調研: web_search+web_fetch覆蓋絕大多數場景
沒有鑑權,沒有 API Key,沒有額外的攻擊面。
如果你的 Skills 需要兩百行 Python 腳本,先停下來想想:用一段清楚的自然語言指令,Agent 自己能不能搞定?
把龍蝦當成一個新來的實習生——步驟寫得足夠清楚,它才能穩定執行。模糊的指令 = 不穩定的結果。
ClawHub 上的 Skills,別亂裝
這條單獨拎出來說,因為真的很重要。
ClawHub 上有幾百個 Skills,其中相當一部分有問題。之前有人專門用刷量手段把一個帶後門的 Skills 頂到了下載榜第一,結果七個國家的開發者都跑去裝了——妥妥的韭菜行為。
下載量可以造假。目前那些「信任度」指標基本都是擺設。
那怎麼辦?自己寫。SKILL.md 本質上就是一個 Markdown 文件,寫清楚指令就行,不需要任何代碼。
如果某個 Skills 裏帶了 scripts/ 目錄,有可執行代碼,裝之前每一行都要自己看一遍。只使用內置工具(web_fetch、web_search、exec)的 Skills,天然比那些附帶 Python 腳本的安全得多。
最安全的 Skill,是零依賴的那種。
Heartbeat 心跳機制:龍蝦主動幹活
OpenClaw 有個心跳機制:每隔一段時間(默認 30 分鐘),系統會 ping 一下龍蝦,問它有沒有什麼要做的。
默認情況下,龍蝦收到心跳就回個 HEARTBEAT_OK,啥也不幹。但你可以寫一個 HEARTBEAT.md,告訴它心跳時該檢查什麼:
# HEARTBEAT.md
## 每次心跳
- 檢查 XX 服務是否在線(curl 一下)
- 如果掛了,通知我,但不要自動重啓
## 每天一次
- 檢查有沒有超過 3 天沒更新的項目待辦
## 每週一次
- 整理最近 7 天的日誌,提煉到長期記憶這樣你的龍蝦就變成了一個 7x24 的值班員。你睡覺的時候它在巡檢,你醒來就能看到報告。
之前聊架構的時候也說過,心跳解決了被動應答模式,讓龍蝦可以自主活動——這是它跟普通 AI Chat 最大的區別之一。
heartbeat vs cron 怎麼選?
• 心跳:適合"順便檢查一下"的輕量任務,可以批量執行 • cron:適合精確定時的獨立任務(如"每週一早上 9 點發週報")
把類似的檢查任務合併到同一個心跳裏,別搞出二十個分散的 Cron Job,那隻會讓自己頭大。
模型路由:Opus 管調度,Sonnet 幹活
如果你有多個模型可用(比如通過 API 中轉站),強烈建議配置模型分級:
配置示例(openclaw.json):
"models": {
"your-provider/strong-model": { "alias": "opus" },
"your-provider/medium-model": { "alias": "sonnet" },
"your-provider/light-model": { "alias": "haiku" }
}然後在 AGENTS.md 裏寫上分配策略,龍蝦派子 agent 時就會自動選合適的模型。
效果:同樣的任務量,token 消耗能降 60-70%。大部分日常操作根本不需要最強模型。
社區裏有人分享了配置,驗證下來確實好使:Opus 負責複雜推理和任務協調,Sonnet 負責具體執行(成本是 Opus 的 1/5,聚焦任務時表現往往更好)。這也印證了之前說的——高推理模型負責決策並寫入記憶,低推理模型負責日常任務執行。
另外,記得配好模型 Fallback。某個服務商限速的時候,你希望龍蝦能自動切過去,而不是直接卡死在那裏。
工程結構
跑下來覺得比較順手的目錄結構:
~/workspace/
├── SOUL.md # Agent 的人格設定
├── IDENTITY.md # 名字和形象
├── USER.md # 你的信息
├── MEMORY.md # 長期記憶索引
├── ACTIVE-TASK.md # 當前任務的工作記憶
├── TOOLS.md # 本地工具說明
├── HEARTBEAT.md # 定期檢查任務
├── AGENTS.md # 行為規範和安全規則
├── memory/ # 每日日誌和分類記憶
└── skills/ # 自己寫的 Skills這些坑遲早會踩到你
幾個容易出問題的地方,提前說清楚:
任務執行中改配置,可能導致直接崩在中途。
相信 ClawHub 的下載量,別信。上面說過了。
裝之前不看 Skills 內容,遲早吃虧。
讓 Agent 自動發郵件或發推文,務必配置成需要人工確認後才執行。我們既想讓龍蝦有探索精神,又想讓它安全——這本身就是矛盾的。敏感操作一定要加人工確認,這是寫入"基因"的安全意識。
用 kill 殺掉進程,在 macOS 上,launchd 會自動重新拉起。正確的姿勢是先 unload plist,再 kill。否則就是打地鼠,殺了又起來。
配置 Checklist
按優先級排序:
•寫好 SOUL.md/IDENTITY.md/USER.md(立竿見影)•設計分層記憶結構,開啓 memorySearch•配置 HEARTBEAT.md•自己寫 2-3 個常用 skill(別從 ClawHub 亂裝) •配置多模型分級(如果有多個模型可用) •完善 AGENTS.md裏的行為規範和安全規則
就這些。
核心就幾件事:自己寫 Skills,所有東西落盤,Opus + Sonnet 組合用,定時任務排進心跳或 Cron,ClawHub 的東西別亂裝。
OpenClaw 的設計哲學是"給你一個框架,你來定義它是誰"。默認配置只是起點,真正的價值在於你怎麼調教它。
配置過程其實不難,關鍵是理解每個文件的作用,然後根據自己的需求去定製。其他細節跑着跑着自然就摸清楚了。
怎麼樣?趕緊動手試試吧。