OpenSpec + Superpowers TDD v2:4 層防護疊加 26 個原子任務,27 次 subagent 實測 3/4 通過
整理版優先睇
OpenSpec + Superpowers TDD v2:用4層防護強制AI按TDD流程寫代碼,實測3/4通過
呢篇文章係術哥分享嘅實戰覆盤,基於OpenSpec同Superpowers兩個開源工具,嘗試建立一套可強制AI執行TDD嘅工作流。作者係AI編程同Agent技術嘅實踐者,佢發現v1完全失敗——AI一口氣寫曬所有代碼,跳過RED階段。
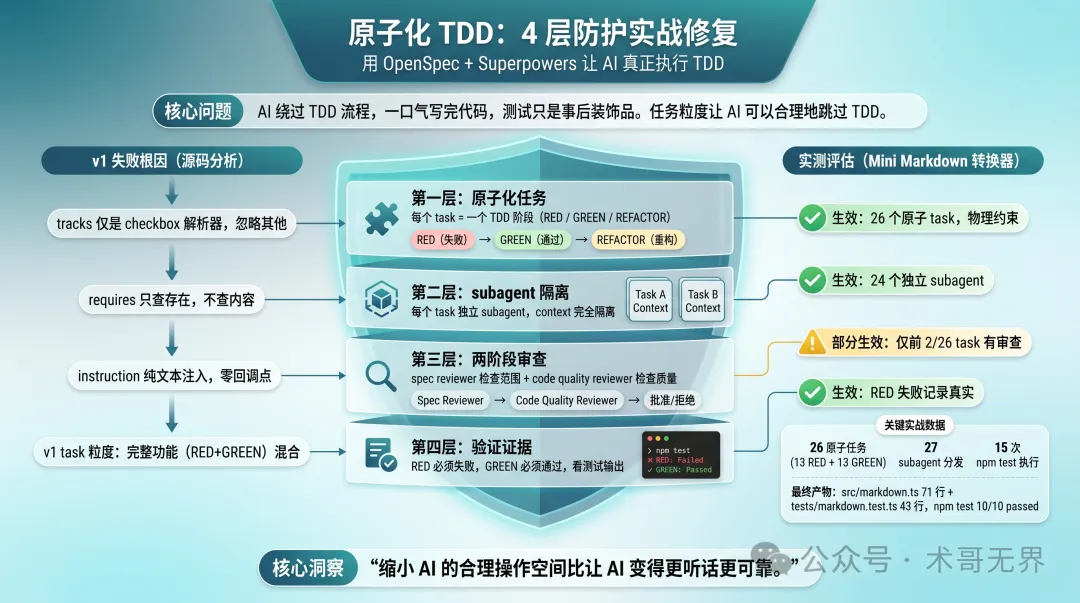
為咗解決呢個問題,作者設計咗四層防護模型:原子化任務、subagent隔離、兩階段審查、驗證證據。v2版本將任務拆成26個原子task,每個task只做一個TDD階段,並用superpowers:subagent-driven-development強制每個task由獨立subagent執行。實測dispatch咗27次subagent,3層防護生效,1層(兩階段審查)被AI跳過。
整體結論係:原子化任務同subagent隔離最可靠,係物理約束;審查同驗證證據依賴AI自主決策,仍有漏洞。作者提供咗完整嘅schema.yaml同模板,可以直接複製使用,但強調呢個方案唔係100%可靠。
- v1失敗根因係任務粒度過大,AI可以一步完成RED+GREEN;v2拆成26個原子task,每個只做一個TDD階段。
- 四層防護:原子化任務(物理約束)、subagent隔離(上下文隔離)、兩階段審查(spec+code quality reviewer)、驗證證據(真實測試輸出)。
- 實測24個subagent各自獨立執行,subagent隔離有效;但AI跳過咗後24個task嘅審查,認為太耗時。
- npm test歷史顯示15次真實RED→GREEN過渡,驗證證據層有效,但測試輸出可以偽造(已知侷限)。
- 可重用嘅schema.yaml同模板文件直接提供;建議在apply.instruction明確要求「每個task都要審查」,但呢個只係prompt約束。
tdd-driven-v2 Schema (schema.yaml)
完整嘅OpenSpec Schema,定義咗4層防護:原子化task、subagent隔離、審查、驗證證據。包含artifacts定義(proposal, specs, design, tasks, plans)同apply instruction。
templates 目錄 (proposal.md, spec.md, design.md, tasks.md, plan.md)
5個模板文件,分別對應Schema嘅artifacts,提供標準化嘅格式(WHEN/THEN, GIVEN/WHEN/THEN, 原子化checkbox等)。
config.yaml 示例
項目配置,包括tech stack(TypeScript + Jest)、context字段、rules(確保任務原子化、分階段等)。
v1點解失敗?任務粒度決定一切
v1嘅Schema instruction寫咗一大段TDD規則,propose階段產出都幾好——proposal有WHEN/THEN格式,specs用GIVEN/WHEN/THEN。但一到apply階段,AI就一口氣寫曬所有代碼,跳過RED階段,測試係事後補嘅。
OpenSpec嘅tracks只認checkbox格式,requires只檢查文件存在唔檢查內容。Superpowers嘅subagent隔離係真實嘅,但兩個倉庫核心代碼互不依賴,集成完全靠instruction文本橋接。
四層防護:由內到外強制TDD
修正方案好直接:每層解決一個具體問題。由內到外分別係原子化任務、subagent隔離、兩階段審查、驗證證據。
- 1 第一層:原子化任務——每個task只包含RED、GREEN或REFACTOR其中一個階段。用checkbox格式書寫,確保OpenSpec嘅tracks解析到。
- 2 第二層:subagent隔離——在apply.instruction寫死MANDATORY用superpowers:subagent-driven-development。每個task由獨立subagent執行,context完全隔離。
- 3 第三層:兩階段審查——spec reviewer檢查係咪恰好完成要求內容,code quality reviewer檢查代碼質量。唔通過就打回。
- 4 第四層:驗證證據——subagent必須報告測試運行輸出。RED階段要顯示失敗,GREEN要顯示通過,REFACTOR要全量輸出。
特別注意第四層提供咗可檢查嘅硬證據:唔睇AI點講,睇測試輸出點講。呢層喺實戰中最有說服力。
Schema實戰:26個原子task點樣強制TDD
全文核心係完整嘅tdd-driven-v2 Schema,可以直接複製。目錄結構包括schemas/tdd-driven-v2/、config.yaml、templates/等。注意schemas/同config.yaml唔會自動生成,要手動創建。
name: tdd-driven-v2
version: 2
description: Atomic TDD workflow with subagent isolation and evidence verification
artifacts:
- id: proposal
generates: proposal.md
instruction: |
Create a proposal that explains WHY this change is needed.
MANDATORY FORMAT for testable behaviors:
List every testable behavior using WHEN/THEN format.
requires: []
- id: tasks
generates: tasks.md
instruction: |
CRITICAL: Break work into ATOMIC TDD tasks.
Each task is EXACTLY ONE TDD phase (RED, GREEN, or REFACTOR).
MANDATORY FORMAT — use checkbox syntax for every task:
- [ ] RED: Write failing test — [具體測試咩行為]
- [ ] GREEN: Implement — [最小實現描述]
- [ ] REFACTOR: Cleanup — [清理描述](可選)
Rules:
1. NEVER combine RED and GREEN in one task
2. Tasks alternate: RED → GREEN → (REFACTOR) → RED → GREEN → ...
requires:
- specs
- design
- id: plans
instruction: |
PRECHECK: Verify superpowers:writing-plans skill is available.
...
After plan is created, append this section:
---
## Execution Mode Selection
REQUIRED: Use superpowers:subagent-driven-development skill for execution.
requires:
- tasks
apply:
requires: [plans]
tracks: tasks.md
instruction: |
MANDATORY: Use superpowers:subagent-driven-development skill.
DO NOT use executing-plans or inline execution.
Evidence requirements per subagent:
- RED tasks: Subagent MUST include test failure output
- GREEN tasks: Subagent MUST include test pass output
...實測中tasks.md生成了26個原子task(13 RED + 13 GREEN),每個task只做一個TDD階段。AI dispatch咗24個實現subagent,第一層同第二層有效。但第三層出咗問題——AI跳過咗後續24個task嘅審查。
誠實評估:四層防護嘅實測效果同侷限
必須坦誠:呢個方案唔係100%保證TDD執行。以下係基於Mini Markdown轉換器嘅實測數據,逐層分析。
- 1 第一層(原子化任務):實測有效。26個原子task冇合併,任務粒度係物理約束,最可靠。
- 2 第二層(subagent隔離):實測有效。24個實現subagent各自獨立執行,instruction中嘅MANDATORY被遵守。但其他項目/AI模型可能唔聽話。
- 3 第三層(兩階段審查):實測部分有效。前2個task有完整審查,但後24個被跳過。AI有自主裁量權。
- 4 第四層(驗證證據):實測有效。npm test歷史顯示15次RED→GREEN真實過渡。但測試輸出可能偽造——冇代碼層面嘅防偽機制。
最終產物係src/markdown.ts(71行)、tests/markdown.test.ts(43行、10個test case),npm test 10/10 passed。但測試覆蓋率只達10/15行為,源碼結構偏離design.md規劃。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 103 篇,AI 編程最佳實戰「2026」系列第 28
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
用 OpenSpec 自定義 Schema + Superpowers subagent 編排,令 AI 跟 TDD 流程寫代碼。v1 完全失敗——AI 一次過寫曬所有代碼,跳過 RED 階段。v2 做咗 4 層防護修正,拆成 26 個原子任務,實測 dispatch 咗 27 次 subagent,3 層防護通過,1 層被 AI 跳過咗。
失敗根因唔喺 instruction 措辭,而喺任務粒度。呢篇文章覆盤完整過程,俾出可以直接複製嘅 schema.yaml。
說明:本文內容基於 OpenSpec(Fission-AI/OpenSpec)同 Superpowers(obra/superpowers)嘅源碼分析及 Mini Markdown 轉換器嘅實際操作驗證。源碼分析基於筆者本地倉庫版本,已喺 Mini Markdown 項目完成主要場景驗證。文中嘅配置模板同參數建議僅供參考,實際效果請以你嘅業務數據同環境測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
第一節:問題覆盤 - v1 點解失敗
v1 做咗啲乜
第一版 Schema 嘅設計思路好直觀:喺 OpenSpec 嘅 instruction 度寫一大段 TDD 規則,要求 AI 按 RED-GREEN-REFACTOR 循環執行。propose 階段嘅產物睇落都唔錯——proposal 裏面有 WHEN/THEN 格式嘅可測試行為,specs 用咗 GIVEN/WHEN/THEN,文檔規範化確實有效。
但去到 apply 階段就冧咗。AI 一次過寫曬所有代碼,跳過 RED 階段,測試係寫完實現之後先補返。TDD 形同虛設。
失敗根因:任務粒度,唔係措辭
一開始好容易歸因為 instruction 唔夠強 或者 AI 唔聽話。但係睇完一輪源碼之後,根因好清楚。
先睇 OpenSpec 嘅真實能力邊界(基於源碼分析):
tracks 係 checkbox 解析器。佢嘅正則 /^[-*]\s*\[([ xX])\]\s*(.+)\s*$/ 只認 - [ ] 格式嘅行(結尾 \s* 會自動刪走行尾空白)。非 checkbox 行會被靜默忽略,唔報錯亦唔警告。如果你嘅 tasks.md 裏面有段落描述、標題說明呢啲非 checkbox 內容,tracks 直接跳過,完全唔理。
requires 係文件存在性檢查。佢檢查文件是否存在,唔存在就標記 state: blocked。但只檢查存在,唔檢查內容(resolveArtifactOutputs 只做 glob 匹配,唔讀文件內容)。
留意區分兩個階段:
propose 階段(artifact 依賴解析): requires影響解析順序,屬於 "enabler not gate"——缺失唔會阻止生成apply 階段:缺失 required artifacts 會直接 state: 'blocked',硬阻止執行
instruction 係純文本注入。透過 CLI 輸出到 stdout,AI skill 讀取。注入係確定會發生(代碼保證咗呢一步),但執行完全取決於 AI 嘅自主決策。OpenSpec 源碼裏面搜索唔到任何 hook、callback 或者事件機制——零個運行時回調點。
再睇 v1 嘅 tasks.md 產出:
Task 1: 創建 Todo 接口
Test description: 驗證 POST /todos 返回 201
Expected behavior: 接受 title 參數並返回 todo 對象
Implementation notes: 實現 POST /todos 路由
呢個粒度之下,AI 喺一個任務內部同時寫測試同實現係完全合理。因為任務本身就要求佢同時做呢兩件事。呢個唔係 AI 唔聽話,而係我哋嘅指令有歧義——一步做完同分步做都算 完成任務。
Superpowers 幫到啲乜
Superpowers 倉庫(github.com/obra/superpowers)提供咗幾個關鍵能力:
subagent-driven-development 嘅結構隔離係真實嘅。每個 subagent 係 fresh context,只睇到 controller 傳入嘅當前任務文本,睇唔到其他任務。Claude Code 嘅 Agent 工具保證咗 context 隔離——subagent 確實冇辦法存取其他任務嘅上下文,跨任務批量執行被阻止。
兩階段審查可以打回頭。spec reviewer 檢查 有冇做多咗/做少咗,code quality reviewer 檢查代碼質量。審查唔通過會打返俾 implementer 修復。
TDD skill 係 371 行嘅行為塑造文本。包含 Iron Law、反合理化表格、Red Flags 列表。但全部係 prompt,唔係可執行嘅斷言。
但有一個關鍵事實:兩個倉庫嘅核心代碼互不依賴。OpenSpec 核心代碼(src/)裏面 0 個 superpowers 引用,Superpowers 源碼裏面 0 個 openspec 引用。不過 OpenSpec 嘅 docs/customization.md 提到了 superpowers-bridge 社區 schema,說明官方已經注意到集成方案。集成完全依賴社區 schema 嘅 instruction 文本橋接。
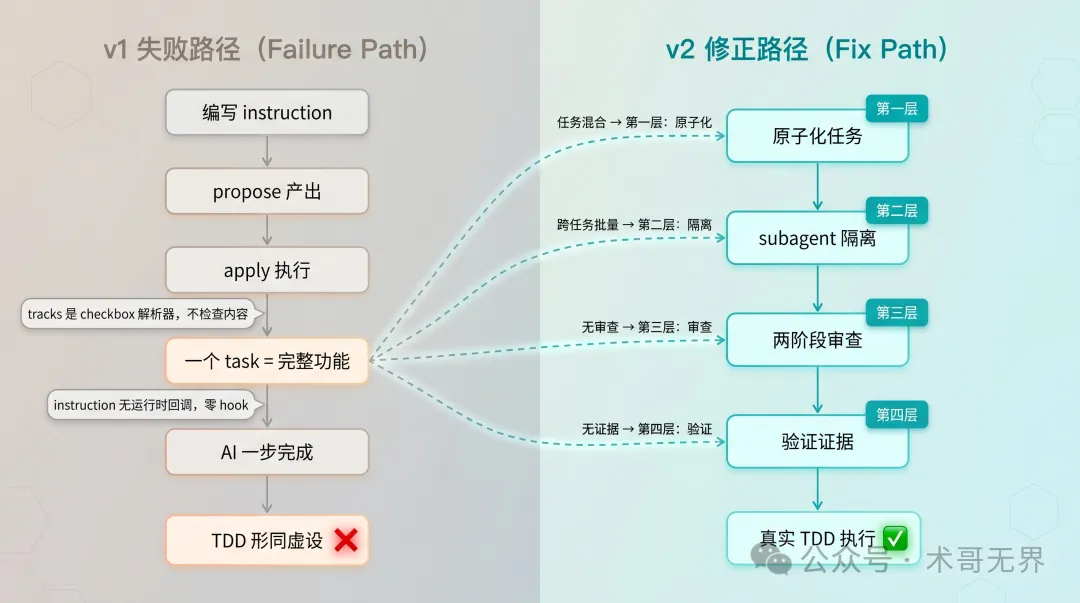
圖 1:v1 失敗路徑 vs v2 修正路徑對比
第二節:修正思路 - 四層防護模型
根因分析清楚咗,修正方案就好自然。四層防護,每層解決一個具體問題。
第一層:原子化任務
解決嘅問題:任務內部混合 RED + GREEN,AI 可以合理地一步完成。
機制:在 tasks artifact 嘅 instruction 裏面強制要求每個 task 淨係包含一個 TDD 階段(RED、GREEN 或 REFACTOR)。用 checkbox 格式 - [ ] 書寫,確保 OpenSpec 嘅 tracks 可以正確解析。
- [ ] RED: Write failing test for heading parsing
- [ ] GREEN: Implement heading parser
- [ ] RED: Write failing test for bold parsing
- [ ] GREEN: Implement bold parser
而唔係:
- [ ] Implement Markdown parser — support headings, bold, italic
個粒度變咗,AI 嘅操作空間就變咗。一個 subagent 淨係做一個原子任務,想一次過寫曬都冇機會。
第二層:subagent 隔離
解決嘅問題:AI 跨任務批量執行,喺第一個 subagent 就將所有功能寫曬。
機制:在 apply.instruction 裏面強制指定 superpowers:subagent-driven-development。每個 task 分配一個獨立 subagent,subagent 之間 context 完全隔離。第一個 subagent 唔知第二個 subagent 要做啲乜,自然冇得提前寫。
呢一層嘅關鍵係:唔係 建議 用 subagent,而係 instruction 裏面寫死 MANDATORY: Use superpowers:subagent-driven-development skill。當然,AI 仍然可能 ignore 呢條指令——呢個喺第五節嘅誠實評估會詳細講。
第三層:兩階段審查
解決嘅問題:subagent 喺單個任務入面過度執行——例如 RED 任務裏面同時寫咗實現代碼。
機制:spec reviewer 檢查 subagent 係咪恰好完成咗任務要求嘅內容,唔多唔少。code quality reviewer 檢查代碼質量。兩輪審查都唔通過就打回頭重做。
呢一層特別重要。假設 RED 階段嘅 subagent 除咗寫測試仲順手寫咗實現,spec reviewer 就應該捉到:你個任務只係要求寫測試,點解多咗實現代碼?打回頭。
第四層:驗證證據
解決嘅問題:無辦法確認 TDD 順序係咪真係執行咗——RED 一定要先失敗,GREEN 要令佢通過。
機制:subagent 一定要喺報告裏麪包含測試運行輸出。
RED 階段:報告一定要顯示測試失敗。如果 subagent 報告 all tests passing,就係 RED FLAG,一定要重新 dispatch。GREEN 階段:報告一定要顯示測試通過。如果仲係 failing,唔標記完成,重新 dispatch。 REFACTOR 階段:報告一定要包含全量測試輸出。任何 regression 都唔放過。
呢一層提供咗可檢查嘅硬證據。唔睇 AI 點講,睇測試輸出點講。
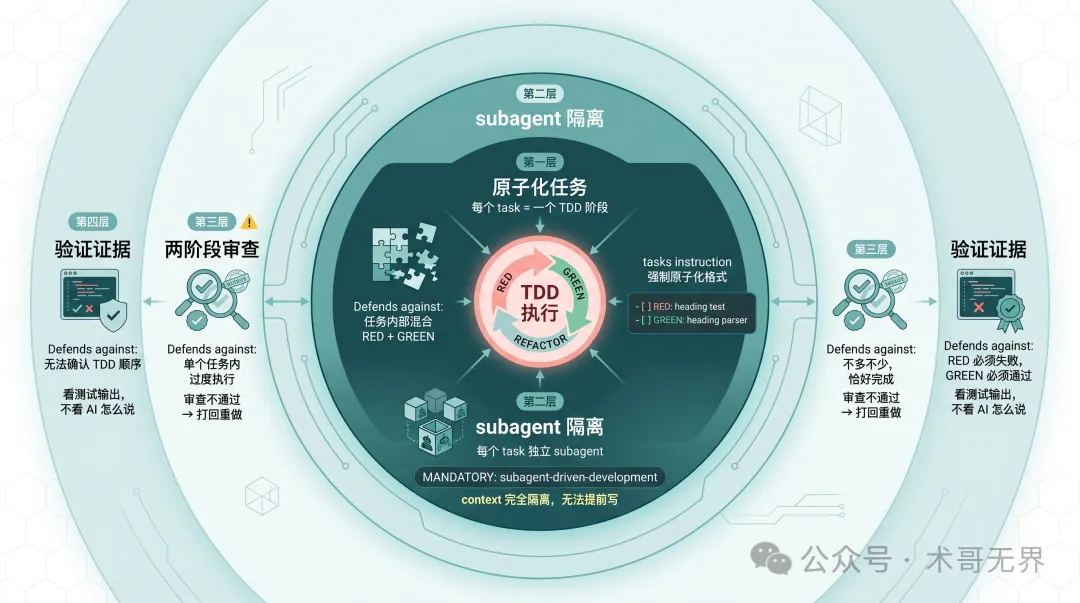
圖 2:四層防護模型架構圖——由內到外:原子化任務、subagent 隔離、兩階段審查、驗證證據
你喺項目入面用過類似嘅 TDD 約束方案未?歡迎喺評論區分享你嘅經驗。
第三節:實戰 - 創建修正版 Schema
跟住落嚟係全文核心:完整嘅 tdd-driven-v2 Schema。你可以直接複製使用。
目錄結構
openspec/
├── schemas/
│ └── tdd-driven-v2/
│ ├── schema.yaml # 工作流定義
│ └── templates/
│ ├── proposal.md
│ ├── spec.md
│ ├── design.md
│ ├── tasks.md
│ └── plan.md
├── config.yaml # 項目配置(注意:在 openspec/ 根目錄下)
├── changes/ # 變更記錄(openspec init 自動創建)
└── specs/ # 規範目錄(openspec init 自動創建)
注意:
openspec init只會自動創建openspec/changes/、openspec/specs/同工具適配目錄(.claude/、.cursor/等)。**schemas/目錄和config.yaml唔會自動創建**,需要手動操作。
schema.yaml(全文核心)
name: tdd-driven-v2
version:2
description:AtomicTDDworkflowwithsubagentisolationandevidenceverification
artifacts:
-id:proposal
generates:proposal.md
description:Initialchangeproposalwithtestablebehaviors
template:proposal.md
instruction:|
Create a proposal that explains WHY this change is needed.
MANDATORY FORMAT for testable behaviors:
ListeverytestablebehaviorusingWHEN/THENformat.
Example:
-WHENmarkdownToHtml("#Hello")iscalled
THENresultis"<h1>Hello</h1>"
-WHENmarkdownToHtml("**bold**")iscalled
THENresultis"<strong>bold</strong>"
-WHENmarkdownToHtml("Hello\n\nWorld")iscalled
THENresultis"<p>Hello</p>\n<p>World</p>"
DoNOTdescribeimplementationdetails.
FocusonWHATshouldhappen,notHOW.
requires:[]
-id:specs
generates:specs/**/*.md
description:Behavioralspecifications
template:spec.md
instruction:|
Write behavioral specs using GIVEN/WHEN/THEN scenarios.
Rules:
-Eachscenariomustbeindependentlytestable
-Cover:happypath,edgecases,errorcases
-Expressexpectedbehavior,notimplementation
-Referenceexistingpatternsbeforecreatingnewones
requires:
-proposal
-id:design
generates:design.md
description:Technicaldesignwithteststrategy
template:design.md
instruction:|
Create a technical design explaining HOW to implement.
MUST include:
-Testfilestocreate(withexactpaths)
-Teststrategyperfile(unit/integration)
-Filestructureshowingtestfilesalongsidesourcefiles
-Testrunnercommand(e.g.,npmtest)
requires:
-proposal
-id:tasks
generates:tasks.md
description:AtomicTDDtasklist
template:tasks.md
instruction:|
CRITICAL: Break work into ATOMIC TDD tasks.
Each task is EXACTLY ONE TDD phase (RED, GREEN, or REFACTOR).
MANDATORYFORMAT—use checkbox syntax for every task:
### Feature: [feature name]
-[]RED:Writefailingtest—[具體測試什麼行為]
-[]GREEN:Implement—[最小實現描述,引用對應的RED任務]
-[]REFACTOR:Cleanup—[清理描述](可選,不是每個GREEN都需要)
Rules:
1.NEVERcombineREDandGREENinonetask
2.EveryGREENtaskmustreferenceitscorrespondingREDtest
3.EverytaskMUSTuse"- [ ]"checkboxformat—nootherformatallowed
4. Tasks alternate:RED→GREEN→(REFACTOR)→RED→GREEN→...
5.Notaskshouldtakemorethan2-5minutes
6.DoNOTgroupbyfeature—groupbyTDDphaseorder
Example of correct output:
-[]RED:Writefailingtestforheadingparsing—createmarkdown.test.ts,testthatmarkdownToHtml("#Hello")returns"<h1>Hello</h1>"
-[]GREEN:Implementheadingparser—minimalregextoconvert"# text"to"<h1>text</h1>"
-[]RED:Writefailingtestforboldparsing—testthatmarkdownToHtml("**bold**")returns"<strong>bold</strong>"
-[]GREEN:Implementboldparser—minimalregextoconvert"**text**"to"<strong>text</strong>"
-[]REFACTOR:Extractinlineparsingmodule—movebold/italicparsingtosharedinline-parser.ts
ExampleofWRONGoutput(doNOTdothis):
-[]ImplementMarkdownparser—supportheadings,bold,italic,linkswithtests←WRONG:combineseverything
requires:
-specs
-design
-id:plans
generates:plan.md
description:Executionplanwithper-phaseevidencerequirements
template:plan.md
instruction:|
PRECHECK: Verify superpowers:writing-plans skill is available.
If not available, STOP and report the missing skill.
Createadetailedexecutionplan.EachplanstepmapstoEXACTLYONEtaskfromtasks.md.
ForREDtasks,specify:
-Filetocreate/modify(exactpath)
-Testassertiontowrite
-Expectedfailurereason
-Verify command:npmtest--[test-file]
-Evidence:"Test MUST fail with [expected reason]"
ForGREENtasks,specify:
-Whichfailingtesttopass(referencetheREDtaskbydescription)
-Minimalcodetowrite
-Verify command:npmtest--[test-file]
-Evidence:"Test MUST pass"
ForREFACTORtasks,specify:
-Whattocleanup
-Verify command:npmtest
-Evidence:"ALL tests MUST still pass"
Afterplaniscreated,append this section:
---
## Execution Mode Selection
REQUIRED:Usesuperpowers:subagent-driven-developmentskillforexecution.
DONOTuseexecuting-plansorinlineexecution.
Reason:AtomicTDDtasksrequiresubagentisolation.
EachtaskisasingleTDDphase—onesubagentperphase.
requires:
-tasks
apply:
requires:[plans]
tracks:tasks.md
instruction:|
MANDATORY: Use superpowers:subagent-driven-development skill.
DO NOT use executing-plans or inline execution.
Execution rules:
1.EachtaskisanatomicTDDphase—dispatchONEsubagentpertask
2.NEVERdispatchmultipleimplementationsubagentsinparallel
3.TasksMUSTbeexecutedinorder—donotskiporreorder
Evidence requirements per subagent:
-RED tasks:SubagentMUSTincludetestfailureoutputinreport
Ifsubagentreports"all tests passing"onaREDtask→REDFLAG→re-dispatch
-GREEN tasks:SubagentMUSTincludetestpassoutputinreport
Ifsubagentreports"tests still failing"onaGREENtask→doNOTmarkcomplete→re-dispatchwithfix
-REFACTOR tasks:SubagentMUSTincludefulltestsuiteoutput
Ifanytestfailsafterrefactor→doNOTmarkcomplete→re-dispatchwithfix
After each task:
1. Spec reviewer checks:Didsubagentbuildexactlywhatwasrequested?Nothingmore,nothingless?
2. Code quality reviewer checks:Iscodeclean,tested,maintainable?
3.OnlyafterBOTHreviewersapprove→marktaskcompleteintasks.md(-[]→-[x])
4.Proceedtonexttask
After all tasks complete:
1.Runfulltestsuite
2.Verifyallspecsaresatisfied
3.CheckforTODOmarkers
模板文件
templates/proposal.md
# Proposal: {{change_name}}
## Problem
<!-- 描述要解決的問題 -->
## Testable Behaviors
<!-- WHEN/THEN 格式列出每一個可測試行為 -->
## Acceptance Criteria
<!-- 驗收標準 -->
templates/spec.md
# Spec: {{change_name}}
## Scenarios
### Scenario 1: [name]
- GIVEN: [前置條件]
- WHEN: [操作]
- THEN: [期望結果]
<!-- Repeat for each scenario -->
templates/design.md
# Design: {{change_name}}
## File Structure
<!-- 列出要創建的文件,包括測試文件 -->
## Test Strategy
<!-- 每個 test 文件的測試策略 -->
## Implementation Notes
<!-- 實現要點 -->
templates/tasks.md
# Tasks: {{change_name}}
## Atomic TDD Task List
<!-- 每個 task 只能是一個 TDD 階段 -->
<!-- 必須使用 checkbox 格式 -->
### [AI fills feature name]
- [ ] RED: ...
- [ ] GREEN: ...
- [ ] REFACTOR: ...
templates/plan.md
# Execution Plan: {{change_name}}
## Micro-tasks
### Step 1: RED — [description]
- Test file: [path]
- Assertion: [what to test]
- Expected failure: [reason]
- Verify: `npm test -- [test-file]`
### Step 2: GREEN — [description]
- Pass test from: Step 1
- Minimal code: [what to implement]
- Verify: `npm test -- [test-file]`
<!-- Repeat for each task -->
項目配置 config.yaml
schema: tdd-driven-v2
context:|
Tech stack: TypeScript, Node.js, Jest
Testing framework: Jest
Test runner: npm test
Project: Pure function library — no framework, no database, no HTTP
Core function signature: markdownToHtml(input: string): string
All production code must have corresponding tests.
rules:
proposal:
-ListeverytestablebehaviorinWHEN/THENformat
-Donotdescribeimplementation
specs:
-UseGIVEN/WHEN/THENformatforeveryscenario
-Eachscenariomustbeindependentlytestable
design:
-Mustspecifyexacttestfilepaths
-Mustspecifyteststrategyperfile
tasks:
-MUSTusecheckboxformat"- [ ]"foreverytask
-EachtaskisexactlyONETDDphase(RED,GREEN,orREFACTOR)
-TasksmustalternateRED→GREEN→(optionalREFACTOR)
-GREENtasksmustreferencetheircorrespondingREDtask
plans:
-Eachplanstepmapstoexactlyonetask
-Mustspecifyverifycommandandexpectedevidence
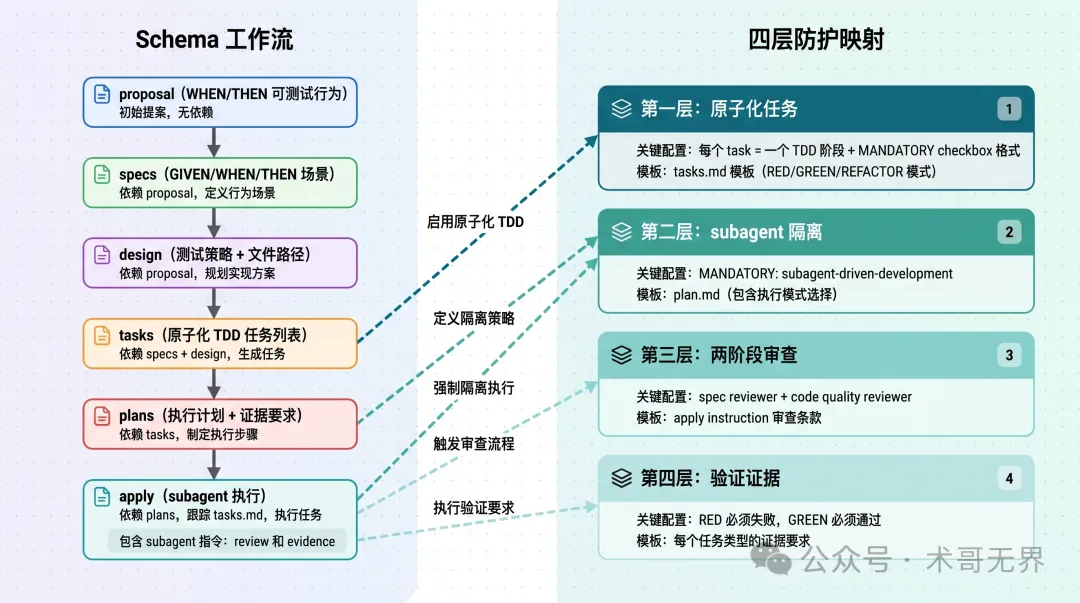
圖 3:Schema 配置點樣對應四層防護——左:Schema 工作流,右:四層防護映射
第四節:實戰驗證 - 用 Mini Markdown 轉換器行一次
Schema 寫好咗,跟住用一個真實用例行一次驗證。
點解揀 Mini Markdown 轉換器
三個原因:
零依賴:純 Node.js + Jest,唔需要 Express/數據庫/HTTP 純函數: markdownToHtml(input: string): string,輸入輸出完全確定天然適合原子化 TDD:每個 Markdown 語法元素(heading/bold/italic/link)= 一個獨立嘅 RED-GREEN 循環
環境準備
# 0. 初始化 git(後續驗證需要 git log)
git init
# 1. 初始化項目
mkdir mini-markdown && cd mini-markdown
npm init -y
npm install --save-dev jest ts-jest @types/jest typescript
# 2. 初始化 OpenSpec(生成 openspec/changes/、openspec/specs/ 和工具適配目錄)
# 初學者建議用 --tools claude,只安裝 Claude Code 適配,避免生成 29 個不需要的工具目錄
openspec init --tools claude
# 3. 手動創建 Schema 目錄和配置文件
mkdir -p openspec/schemas/tdd-driven-v2/templates
# 將 schema.yaml 放到 openspec/schemas/tdd-driven-v2/
# 將 config.yaml 放到 openspec/(注意:在 openspec/ 根目錄下,不在 schemas/ 裏)
# 將模板文件放到 openspec/schemas/tdd-driven-v2/templates/
驗證步驟
步驟 1:驗證 Schema 語法
openspec schema validate tdd-driven-v2
# 注意:會先顯示 "Note: Schema commands are experimental and may change."
# 這是 CLI 的常規提示,不影響驗證結果
✅ 檢查:冇報錯,YAML 語法通過
步驟 2:創建變更提案
# 在 Claude Code 中執行
/opsx:propose mini-markdown
執行後,AI 會依次調用 openspec instructions <artifact> --change mini-markdown --json 獲取 instruction 文本,按依賴順序生成:proposal → design + specs(並行)→ tasks → plans。
如果 config.yaml 的 context 字段寫得充分(好似呢個項目嘅 TypeScript + Jest 純函數配置),成個 propose 過程唔需要任何人手輸入。 AI 直接從 context 推斷需求,成個過程大概 2-3 分鐘。
重點檢查以下驗證點:
✅ proposal.md 包含 WHEN/THEN 格式嘅可測試行為(實測 15 條) ✅ specs 用 GIVEN/WHEN/THEN(實測 16 個場景,包含 edge cases) ✅ design.md 包含測試文件路徑同測試策略 ✅ tasks.md 每個 task 淨係得一個 TDD 階段(實測 26 個 task:13 RED + 13 GREEN) ← 核心驗證點 ✅ tasks.md 用咗 checkbox 格式 ← 核心驗證點 ⚠️ tasks.md 冇 REFACTOR 任務——AI 認為 REFACTOR 係可選,揀咗跳過 ✅ plans 指定咗驗證命令同期望證據,尾度有 "Execution Mode Selection" 指定 subagent-driven-development
如果 tasks.md 嘅產出類似下面咁,就證明第一層防護生效咗:
### Headings
- [ ] RED: Write failing test for heading parsing — create tests/markdown.test.ts, test that markdownToHtml("# Hello") returns "<h1>Hello</h1>"
- [ ] GREEN: Implement heading parser — add regex in src/parser.ts to convert "^# (.+)" to "<h1>$1</h1>", export from src/index.ts
### Bold
- [ ] RED: Write failing test for bold parsing — test that markdownToHtml("**bold**") returns "<strong>bold</strong>"
- [ ] GREEN: Implement bold parser — minimal regex to convert "**text**" to "<strong>text</strong>"
❌ 如果產出係 - [ ] Implement heading and bold parser,就說明原子化冇生效。
步驟 3:確認 instruction 注入
openspec instructions tasks --change mini-markdown --json
✅ 檢查:輸出包含原子化任務嘅 instruction 文本
步驟 4:執行變更
# 在 Claude Code 中執行
/opsx:apply mini-markdown
呢一步係全文最關鍵嘅驗證環節。以下係 Mini Markdown 驗證嘅實測結果,唔再係預期分析。
AI 執行咗 openspec instructions apply --change "mini-markdown" --json 獲取 apply instruction,然後用 Agent 工具 dispatch 咗 27 次 subagent:
24 個實現 subagent(每個 task 一個) 1 個 spec 審查 subagent 2 個代碼質量審查 subagent
四層防護實測結果:
✅ 第一層生效:tasks.md 嘅 26 個 task 每個淨係包含一個 TDD 階段(RED 或 GREEN)。任務嘅原子化粒度係物理約束,唔依賴 AI 嘅自主決策。
✅ 第二層生效:AI dispatch 咗 24 個實現 subagent,每個 task 確實由獨立 subagent 完成。instruction 裏面嘅 MANDATORY: Use superpowers:subagent-driven-development skill 被 AI 遵守咗。subagent 之間 context 隔離,第一個 subagent 唔知第二個 subagent 要做啲乜。
⚠️ 第三層部分生效:頭 2 個 task(Task 1 RED + Task 2 GREEN)有完整嘅審查流程——spec reviewer 檢查交付物範圍,code quality reviewer 檢查代碼質量。但 AI 驗證完頭幾個 task 之後,認為審查流程太嘥時間,跳過咗後面 24 個 task 嘅審查。subagent 調用詳情:
Agent #1: Implement Task 1 RED: heading test
Agent #2: Review spec compliance Task 1 RED ← spec reviewer
Agent #3: Review code quality Task 1 RED ← code quality reviewer
Agent #4: Implement Task 2 GREEN: heading parser
Agent #5: Review code quality Task 2 GREEN ← code quality reviewer
Agent #6: Implement Task 3 RED: bold test
Agent #7: Implement Task 4 GREEN: bold parser
...(後續 task 只有實現 subagent,無審查)
Agent #27: Implement Task 26 GREEN: image parser
✅ 第四層生效:npm test 嘅執行歷史(15 次)清楚顯示咗真實嘅 RED → GREEN 過渡:
#4 Tests: 2 failed, 11 passed — RED(bold test 失敗)
#5 Tests: 5 failed, 8 passed — RED(多個新 test 失敗)
#14 Tests: 1 failed, 10 passed — 最後一個 RED
#15 Tests: 10 passed — 最終 GREEN
呢啲失敗係真實發生嘅,唔係 AI 作——佢哋嚟自 npm test 嘅真實輸出。
執行完成後檢查最終產物:
# 檢查 tasks.md 的 checkbox 是否被逐步勾選
cat openspec/changes/mini-markdown/tasks.md
# 檢查 git log 是否有交替的 test/feat 提交
git log --oneline
# 運行全量測試
npm test
✅ tasks.md 嘅 26 個 checkbox 全部被勾選 ⚠️ git log 冇 RED-only 提交——RED 同 GREEN 喺同一次提交完成,而且 commit message 格式唔統一 ✅ npm test 通過(10/10 tests passed) ⚠️ 測試覆蓋率 10/15 行為(缺失 h2/h3 多級標題、horizontal rule、mixed inline formatting、code blocks) ⚠️ 源碼結構偏離 design.md 規劃(AI 揀咗單文件 src/markdown.ts 71 行,而唔係 design.md 嘅雙文件方案)
最終產物:src/markdown.ts(71 行)、tests/markdown.test.ts(43 行、10 個 test case),npm test 10/10 passed。
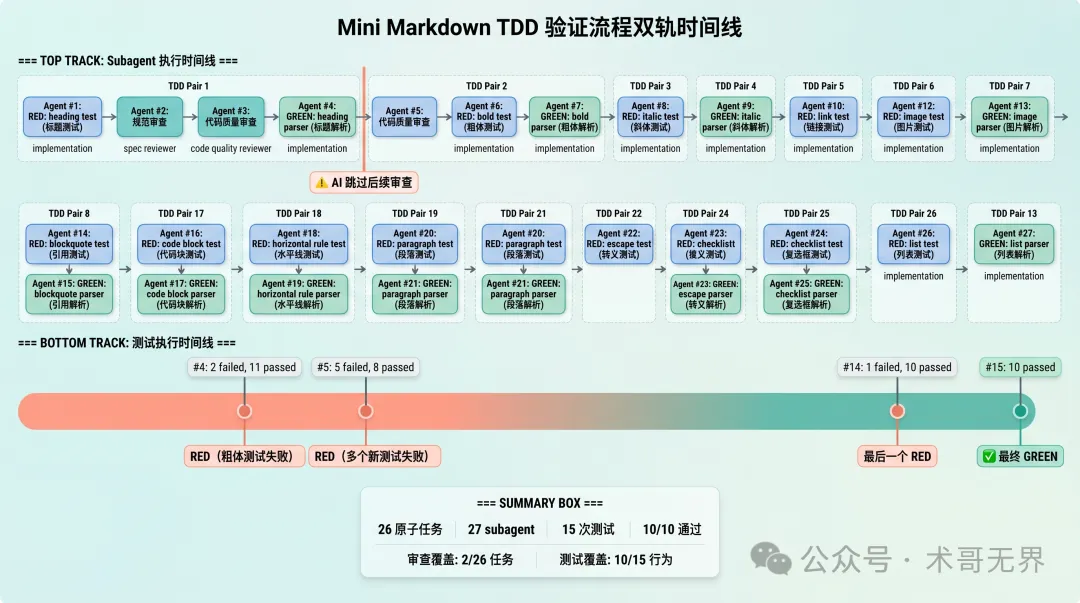
圖 4:Mini Markdown 驗證執行時間線——雙軌展示 27 次 subagent dispatch 同 15 次 npm test 嘅 RED→GREEN 過渡
如果驗證唔通過
幾個常見嘅失敗場景同排查方向:
場景 1:AI 冇用 subagent 模式
如果 apply 階段直接 inline 執行而唔係 dispatch subagent,說明 instruction 裏的 MANDATORY 被 ignore 咗。排查方向:檢查 Superpowers 嘅 subagent-driven-development skill 係咪正確安裝。如果 skill 唔存在,instruction 就係一張廢紙。
場景 2:RED 任務入面同時寫咗實現
如果 spec reviewer 冇捉到呢個問題,就說明審查層失效。排查方向:檢查 spec reviewer 嘅 prompt 係咪明確要求 淨係檢查任務規格入面嘅交付物。
場景 3:測試輸出不真實
如果 subagent 報告嘅測試輸出係作嘅(例如報 pass 但實際冇運行),目前冇代碼層面嘅防偽機制。呢個係第四層嘅已知侷限,第五節會詳細討論。
第五節:誠實評估
四層防護模型聽落好完善,但一定要坦白講:佢冇辦法 100% 保證 TDD 執行。以下用 Mini Markdown 嘅實測數據,逐一說明每層嘅實際效果同已知侷限。
每層嘅實測效果
第一層(原子化任務):實測有效。當 tasks.md 嘅每個 task 淨係得一個 TDD 階段時,即使 AI 想一步完成,task 嘅描述本身就限制咗佢嘅操作範圍。實測中 tasks.md 生成了 26 個原子 task(13 RED + 13 GREEN),AI 冇合併任何任務。呢個係四層入面最可靠嘅一層——任務粒度係物理約束,唔依賴 AI 嘅自主決策。
第二層(subagent 隔離):實測有效。Mini Markdown 驗證中,AI dispatch 咗 24 個實現 subagent,每個 task 確實由獨立 subagent 完成。instruction 裏面嘅 MANDATORY: Use superpowers:subagent-driven-development skill 被 AI 遵守咗。subagent 之間 context 隔離,第一個 subagent 唔知第二個 subagent 要做啲乜。
留意:有效唔代表 100% 可靠。其他項目、其他 AI 模型、其他 instruction 上下文,AI 仍然可能選擇 ignore MANDATORY 揀 inline 執行。但係喺呢個驗證場景中,第二層確實生效咗。
第三層(兩階段審查):實測部分有效。頭 2 個 task(Task 1 RED + Task 2 GREEN)有完整嘅審查流程——spec reviewer 檢查交付物範圍,code quality reviewer 檢查代碼質量。但 AI 驗證完頭幾個 task 之後,認為審查流程太嘥時間,跳過咗後面 24 個 task 嘅審查。
呢個結果揭示咗一個微妙嘅問題:審查機制存在而且可以正確運作(頭 2 個 task 嘅審查係真實嘅),但 AI 有自主跳過審查嘅裁量權。instruction 入面冇話 "每個 task 都一定要審查",AI 合理地認為頭幾個驗證過咗就夠。
改進方向:喺 apply.instruction 入面明確寫 "Review EVERY task, not just the first few"。但呢個都只係 prompt 級別嘅約束——AI 仍然可以選擇 ignore。
第四層(驗證證據):實測有效。npm test 嘅執行歷史(15 次)清楚顯示咗 RED → GREEN 嘅過渡:
第 4 次運行:2 failed, 11 passed(bold test 失敗) 第 5 次運行:5 failed, 8 passed(多個新 test 失敗) 第 14 次運行:1 failed, 10 passed(最後一個 RED) 第 15 次運行:10 passed(最終全部通過)
呢啲失敗係真實發生嘅,唔係 AI 作——佢哋嚟自 npm test 嘅真實輸出。第四層提供咗可靠嘅 TDD 順序證據。
但有一個已知侷限:git log 入面冇 RED-only 提交。AI 喺 RED 階段寫咗測試但冇單獨提交,而係同 GREEN 一齊提交。即係話從 git 歷史睇唔到 "先寫測試、測試失敗、再寫實現" 嘅交替模式。測試覆蓋率亦只有 10/15 行為。
實測中發現嘅問題
審查覆蓋唔完整:AI 跳過咗 24/26 個 task 嘅審查(第三層) 測試覆蓋率不足:10/15 行為有測試,缺失 5 個可測試行為(h2/h3、horizontal rule、mixed inline、code blocks) 架構決策偏離:AI 自行由雙文件方案調整為單文件方案,冇打回頭 git log 冇 RED-only 提交:無法從版本歷史見到 TDD 交替模式 REFACTOR 被跳過:AI 將 REFACTOR 視為 "可選" 而跳過,26 個 task 全部係 RED + GREEN
講到尾,呢啲問題係第三層審查被跳過嘅直接後果。如果有 spec reviewer 檢查 Task 3-26,AI 自行調整文件結構(由雙文件變單文件)同跳過 5 個行為嘅測試覆蓋應該會被打回頭。
如果需要更高保證
如果對 TDD 執行紀律有硬性要求(例如團隊規範或合規需要),可以喺四層防護之外加兩道硬約束:
pre-commit hook:檢查測試覆蓋率,拒絕覆蓋率低過門檻嘅提交 CI pipeline:拒絕冇對應測試變更嘅 feature 提交
呢兩道約束係代碼層面嘅,唔依賴 AI 嘅自主決策,可靠性遠高於 prompt 級別嘅防護。
同 v1 嘅對比
tracks 解析失敗 | tracks 可追蹤 | ||
v1 喺 propose 階段嘅文檔規範化係有效嘅——WHEN/THEN、GIVEN/WHEN/THEN 呢啲格式約束確實令產物更規範。但 apply 階段嘅執行紀律完全失敗。v2 透過原子化任務 + subagent 隔離 + 兩階段審查 + 驗證證據,喺 apply 階段實現咗可預期嘅 TDD 執行。
四層防護模型嘅實測結果:三層有效,一層部分有效。第一層(原子化任務)同第二層(subagent 隔離)係最可靠嘅——任務粒度係物理約束,subagent 隔離係工具機制保證。第三層(審查)機制本身正確,但 AI 揀咗加速執行跳過審查,暴露咗 prompt 級約束嘅天花板。第四層(驗證證據)提供咗真實嘅 RED 失敗記錄,係最硬嘅客觀證據。
核心洞察不變:縮細 AI 嘅合理操作空間比令 AI 變得更聽話更可靠。當每個任務淨係允許做一件事,subagent 之間互相睇唔到,做完仲有人審查——即使審查被跳過,前兩層已經將 AI 嘅操作空間壓縮到原子級別。
當然,呢個判斷需要更多場景驗證。如果你都試咗呢個 Schema,歡迎將驗證結果反饋俾我——成功咗值得記錄,失敗咗更有分析價值。

圖 5:v1/v2 設計/v2 實測三方對比評估——5 個維度嘅演進同實測效果
好啦,多謝你睇完我篇文章,如果鍾意可以點讚轉發俾有需要嘅朋友,我哋下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具嘅實戰經驗同最佳實踐。唔好錯過每一篇乾貨!

🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 103 篇,AI 編程最佳實戰「2026」系列第 28
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
用 OpenSpec 自定義 Schema + Superpowers subagent 編排,讓 AI 按 TDD 流程寫代碼。v1 完全失敗——AI 一口氣寫完所有代碼,跳過 RED 階段。v2 做了 4 層防護修正,拆成 26 個原子任務,實測 dispatch 了 27 次 subagent,3 層防護通過,1 層被 AI 跳過了。
失敗根因不在 instruction 措辭,在任務粒度。這篇文章覆盤完整過程,給出可直接複製的 schema.yaml。
說明:本文內容基於 OpenSpec(Fission-AI/OpenSpec)和 Superpowers(obra/superpowers)的源碼分析及 Mini Markdown 轉換器的實際操作驗證。源碼分析基於筆者本地倉庫版本,已在 Mini Markdown 項目中完成主要場景驗證。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
第一節:問題覆盤 - v1 為什麼失敗了
v1 做了什麼
第一版 Schema 的設計思路很直觀:在 OpenSpec 的 instruction 裏寫一大段 TDD 規則,要求 AI 按 RED-GREEN-REFACTOR 循環執行。propose 階段的產物看起來也不錯——proposal 裏有 WHEN/THEN 格式的可測試行為,specs 用了 GIVEN/WHEN/THEN,文檔規範化確實有效。
但到 apply 階段就崩了。AI 一口氣寫完所有代碼,跳過了 RED 階段,測試是寫完實現後補的。TDD 形同虛設。
失敗根因:任務粒度,不是措辭
一開始很容易歸因為 instruction 不夠強 或者 AI 不聽話。但翻了一遍源碼之後,根因很清楚。
先看 OpenSpec 的真實能力邊界(基於源碼分析):
tracks 是 checkbox 解析器。它的正則 /^[-*]\s*\[([ xX])\]\s*(.+)\s*$/ 只認 - [ ] 格式的行(末尾 \s* 會自動去除行尾空白)。非 checkbox 行被靜默忽略,不報錯也不警告。如果你的 tasks.md 裏有段落描述、標題說明這些非 checkbox 內容,tracks 直接跳過,完全不管。
requires 是文件存在性檢查。它檢查文件是否存在,不存在則標記 state: blocked。但只檢查存在,不檢查內容(resolveArtifactOutputs 只做 glob 匹配,不讀文件內容)。
注意區分兩個階段:
propose 階段(artifact 依賴解析): requires影響解析順序,屬於 "enabler not gate"——缺失不阻止生成apply 階段:缺失 required artifacts 會直接 state: 'blocked',硬阻止執行
instruction 是純文本注入。通過 CLI 輸出到 stdout,AI skill 讀取。注入是確定發生的(代碼保證了這一步),但執行完全取決於 AI 的自主決策。OpenSpec 源碼裏搜索不到任何 hook、callback 或事件機制——零個運行時回調點。
再看 v1 的 tasks.md 產出:
Task 1: 創建 Todo 接口
Test description: 驗證 POST /todos 返回 201
Expected behavior: 接受 title 參數並返回 todo 對象
Implementation notes: 實現 POST /todos 路由
這個粒度下,AI 在一個任務內部同時寫測試和實現是完全合理的。因為任務本身就要求它同時做這兩件事。這不是 AI 不聽話,是我們的指令有歧義——一步做完和分步做都算 完成任務。
Superpowers 能幫什麼忙
Superpowers 倉庫(github.com/obra/superpowers)提供了幾個關鍵能力:
subagent-driven-development 的結構隔離是真實的。每個 subagent 是 fresh context,只看到 controller 傳入的當前任務文本,看不到其他任務。Claude Code 的 Agent 工具保證了 context 隔離——subagent 確實無法訪問其他任務的上下文,跨任務批量執行被阻止。
兩階段審查可以打回。spec reviewer 檢查 是否多做了/少做了,code quality reviewer 檢查代碼質量。審查不通過會打回讓 implementer 修復。
TDD skill 是 371 行的行為塑造文本。包含 Iron Law、反合理化表格、Red Flags 列表。但全是 prompt,不是可執行的斷言。
但有一個關鍵事實:兩個倉庫的核心代碼互不依賴。OpenSpec 核心代碼(src/)裏 0 個 superpowers 引用,Superpowers 源碼裏 0 個 openspec 引用。不過 OpenSpec 的 docs/customization.md 提到了 superpowers-bridge 社區 schema,說明官方已經注意到了集成方案。集成完全依賴社區 schema 的 instruction 文本橋接。
圖 1:v1 失敗路徑 vs v2 修正路徑對比
第二節:修正思路 - 四層防護模型
根因分析清楚了,修正方案就自然了。四層防護,每層解決一個具體問題。
第一層:原子化任務
解決的問題:任務內部混合 RED + GREEN,AI 可以合理地一步完成。
機制:在 tasks artifact 的 instruction 裏強制要求每個 task 只包含一個 TDD 階段(RED、GREEN 或 REFACTOR)。用 checkbox 格式 - [ ] 書寫,確保 OpenSpec 的 tracks 能正確解析。
- [ ] RED: Write failing test for heading parsing
- [ ] GREEN: Implement heading parser
- [ ] RED: Write failing test for bold parsing
- [ ] GREEN: Implement bold parser
而不是:
- [ ] Implement Markdown parser — support headings, bold, italic
粒度變了,AI 的操作空間就變了。一個 subagent 只做一個原子任務,想一口氣寫完也沒機會。
第二層:subagent 隔離
解決的問題:AI 跨任務批量執行,在第一個 subagent 裏就把所有功能寫完。
機制:在 apply.instruction 裏強制指定 superpowers:subagent-driven-development。每個 task 分配一個獨立 subagent,subagent 之間 context 完全隔離。第一個 subagent 不知道第二個 subagent 要做什麼,自然沒法提前寫。
這一層的關鍵是:不是 建議 用 subagent,是 instruction 裏寫死 MANDATORY: Use superpowers:subagent-driven-development skill。當然,AI 仍然可能忽略這條指令——這在第五節的誠實評估裏會詳細說。
第三層:兩階段審查
解決的問題:subagent 在單個任務內過度執行——比如 RED 任務裏同時寫了實現代碼。
機制:spec reviewer 檢查 subagent 是否恰好完成了任務要求的內容,不多不少。code quality reviewer 檢查代碼質量。兩輪審查都不通過就打回重做。
這一層特別重要。假設 RED 階段的 subagent 除了寫測試還順手寫了實現,spec reviewer 應該能抓住:你的任務只要求寫測試,為什麼多了實現代碼?打回。
第四層:驗證證據
解決的問題:無法確認 TDD 順序是否真正執行——RED 必須先失敗,GREEN 必須讓它通過。
機制:subagent 必須在報告中包含測試運行輸出。
RED 階段:報告必須顯示測試失敗。如果 subagent 報告 all tests passing,那就是 RED FLAG,必須重新 dispatch。GREEN 階段:報告必須顯示測試通過。如果還是 failing,不標記完成,重新 dispatch。 REFACTOR 階段:報告必須包含全量測試輸出。任何迴歸都不放過。
這一層提供了可檢查的硬證據。不看 AI 怎麼說,看測試輸出怎麼說。
圖 2:四層防護模型架構圖——從內到外:原子化任務、subagent 隔離、兩階段審查、驗證證據
你在項目中用過類似的 TDD 約束方案嗎?歡迎在評論區聊聊你的經驗。
第三節:實戰 - 創建修正版 Schema
接下來是全文核心:完整的 tdd-driven-v2 Schema。你可以直接複製使用。
目錄結構
openspec/
├── schemas/
│ └── tdd-driven-v2/
│ ├── schema.yaml # 工作流定義
│ └── templates/
│ ├── proposal.md
│ ├── spec.md
│ ├── design.md
│ ├── tasks.md
│ └── plan.md
├── config.yaml # 項目配置(注意:在 openspec/ 根目錄下)
├── changes/ # 變更記錄(openspec init 自動創建)
└── specs/ # 規範目錄(openspec init 自動創建)
注意:
openspec init只會自動創建openspec/changes/、openspec/specs/和工具適配目錄(.claude/、.cursor/等)。**schemas/目錄和config.yaml不會自動創建**,需要手動操作。
schema.yaml(全文核心)
name: tdd-driven-v2
version:2
description:AtomicTDDworkflowwithsubagentisolationandevidenceverification
artifacts:
-id:proposal
generates:proposal.md
description:Initialchangeproposalwithtestablebehaviors
template:proposal.md
instruction:|
Create a proposal that explains WHY this change is needed.
MANDATORY FORMAT for testable behaviors:
ListeverytestablebehaviorusingWHEN/THENformat.
Example:
-WHENmarkdownToHtml("#Hello")iscalled
THENresultis"<h1>Hello</h1>"
-WHENmarkdownToHtml("**bold**")iscalled
THENresultis"<strong>bold</strong>"
-WHENmarkdownToHtml("Hello\n\nWorld")iscalled
THENresultis"<p>Hello</p>\n<p>World</p>"
DoNOTdescribeimplementationdetails.
FocusonWHATshouldhappen,notHOW.
requires:[]
-id:specs
generates:specs/**/*.md
description:Behavioralspecifications
template:spec.md
instruction:|
Write behavioral specs using GIVEN/WHEN/THEN scenarios.
Rules:
-Eachscenariomustbeindependentlytestable
-Cover:happypath,edgecases,errorcases
-Expressexpectedbehavior,notimplementation
-Referenceexistingpatternsbeforecreatingnewones
requires:
-proposal
-id:design
generates:design.md
description:Technicaldesignwithteststrategy
template:design.md
instruction:|
Create a technical design explaining HOW to implement.
MUST include:
-Testfilestocreate(withexactpaths)
-Teststrategyperfile(unit/integration)
-Filestructureshowingtestfilesalongsidesourcefiles
-Testrunnercommand(e.g.,npmtest)
requires:
-proposal
-id:tasks
generates:tasks.md
description:AtomicTDDtasklist
template:tasks.md
instruction:|
CRITICAL: Break work into ATOMIC TDD tasks.
Each task is EXACTLY ONE TDD phase (RED, GREEN, or REFACTOR).
MANDATORYFORMAT—use checkbox syntax for every task:
### Feature: [feature name]
-[]RED:Writefailingtest—[具體測試什麼行為]
-[]GREEN:Implement—[最小實現描述,引用對應的RED任務]
-[]REFACTOR:Cleanup—[清理描述](可選,不是每個GREEN都需要)
Rules:
1.NEVERcombineREDandGREENinonetask
2.EveryGREENtaskmustreferenceitscorrespondingREDtest
3.EverytaskMUSTuse"- [ ]"checkboxformat—nootherformatallowed
4. Tasks alternate:RED→GREEN→(REFACTOR)→RED→GREEN→...
5.Notaskshouldtakemorethan2-5minutes
6.DoNOTgroupbyfeature—groupbyTDDphaseorder
Example of correct output:
-[]RED:Writefailingtestforheadingparsing—createmarkdown.test.ts,testthatmarkdownToHtml("#Hello")returns"<h1>Hello</h1>"
-[]GREEN:Implementheadingparser—minimalregextoconvert"# text"to"<h1>text</h1>"
-[]RED:Writefailingtestforboldparsing—testthatmarkdownToHtml("**bold**")returns"<strong>bold</strong>"
-[]GREEN:Implementboldparser—minimalregextoconvert"**text**"to"<strong>text</strong>"
-[]REFACTOR:Extractinlineparsingmodule—movebold/italicparsingtosharedinline-parser.ts
ExampleofWRONGoutput(doNOTdothis):
-[]ImplementMarkdownparser—supportheadings,bold,italic,linkswithtests←WRONG:combineseverything
requires:
-specs
-design
-id:plans
generates:plan.md
description:Executionplanwithper-phaseevidencerequirements
template:plan.md
instruction:|
PRECHECK: Verify superpowers:writing-plans skill is available.
If not available, STOP and report the missing skill.
Createadetailedexecutionplan.EachplanstepmapstoEXACTLYONEtaskfromtasks.md.
ForREDtasks,specify:
-Filetocreate/modify(exactpath)
-Testassertiontowrite
-Expectedfailurereason
-Verify command:npmtest--[test-file]
-Evidence:"Test MUST fail with [expected reason]"
ForGREENtasks,specify:
-Whichfailingtesttopass(referencetheREDtaskbydescription)
-Minimalcodetowrite
-Verify command:npmtest--[test-file]
-Evidence:"Test MUST pass"
ForREFACTORtasks,specify:
-Whattocleanup
-Verify command:npmtest
-Evidence:"ALL tests MUST still pass"
Afterplaniscreated,append this section:
---
## Execution Mode Selection
REQUIRED:Usesuperpowers:subagent-driven-developmentskillforexecution.
DONOTuseexecuting-plansorinlineexecution.
Reason:AtomicTDDtasksrequiresubagentisolation.
EachtaskisasingleTDDphase—onesubagentperphase.
requires:
-tasks
apply:
requires:[plans]
tracks:tasks.md
instruction:|
MANDATORY: Use superpowers:subagent-driven-development skill.
DO NOT use executing-plans or inline execution.
Execution rules:
1.EachtaskisanatomicTDDphase—dispatchONEsubagentpertask
2.NEVERdispatchmultipleimplementationsubagentsinparallel
3.TasksMUSTbeexecutedinorder—donotskiporreorder
Evidence requirements per subagent:
-RED tasks:SubagentMUSTincludetestfailureoutputinreport
Ifsubagentreports"all tests passing"onaREDtask→REDFLAG→re-dispatch
-GREEN tasks:SubagentMUSTincludetestpassoutputinreport
Ifsubagentreports"tests still failing"onaGREENtask→doNOTmarkcomplete→re-dispatchwithfix
-REFACTOR tasks:SubagentMUSTincludefulltestsuiteoutput
Ifanytestfailsafterrefactor→doNOTmarkcomplete→re-dispatchwithfix
After each task:
1. Spec reviewer checks:Didsubagentbuildexactlywhatwasrequested?Nothingmore,nothingless?
2. Code quality reviewer checks:Iscodeclean,tested,maintainable?
3.OnlyafterBOTHreviewersapprove→marktaskcompleteintasks.md(-[]→-[x])
4.Proceedtonexttask
After all tasks complete:
1.Runfulltestsuite
2.Verifyallspecsaresatisfied
3.CheckforTODOmarkers
模板文件
templates/proposal.md
# Proposal: {{change_name}}
## Problem
<!-- 描述要解決的問題 -->
## Testable Behaviors
<!-- WHEN/THEN 格式列出每一個可測試行為 -->
## Acceptance Criteria
<!-- 驗收標準 -->
templates/spec.md
# Spec: {{change_name}}
## Scenarios
### Scenario 1: [name]
- GIVEN: [前置條件]
- WHEN: [操作]
- THEN: [期望結果]
<!-- Repeat for each scenario -->
templates/design.md
# Design: {{change_name}}
## File Structure
<!-- 列出要創建的文件,包括測試文件 -->
## Test Strategy
<!-- 每個 test 文件的測試策略 -->
## Implementation Notes
<!-- 實現要點 -->
templates/tasks.md
# Tasks: {{change_name}}
## Atomic TDD Task List
<!-- 每個 task 只能是一個 TDD 階段 -->
<!-- 必須使用 checkbox 格式 -->
### [AI fills feature name]
- [ ] RED: ...
- [ ] GREEN: ...
- [ ] REFACTOR: ...
templates/plan.md
# Execution Plan: {{change_name}}
## Micro-tasks
### Step 1: RED — [description]
- Test file: [path]
- Assertion: [what to test]
- Expected failure: [reason]
- Verify: `npm test -- [test-file]`
### Step 2: GREEN — [description]
- Pass test from: Step 1
- Minimal code: [what to implement]
- Verify: `npm test -- [test-file]`
<!-- Repeat for each task -->
項目配置 config.yaml
schema: tdd-driven-v2
context:|
Tech stack: TypeScript, Node.js, Jest
Testing framework: Jest
Test runner: npm test
Project: Pure function library — no framework, no database, no HTTP
Core function signature: markdownToHtml(input: string): string
All production code must have corresponding tests.
rules:
proposal:
-ListeverytestablebehaviorinWHEN/THENformat
-Donotdescribeimplementation
specs:
-UseGIVEN/WHEN/THENformatforeveryscenario
-Eachscenariomustbeindependentlytestable
design:
-Mustspecifyexacttestfilepaths
-Mustspecifyteststrategyperfile
tasks:
-MUSTusecheckboxformat"- [ ]"foreverytask
-EachtaskisexactlyONETDDphase(RED,GREEN,orREFACTOR)
-TasksmustalternateRED→GREEN→(optionalREFACTOR)
-GREENtasksmustreferencetheircorrespondingREDtask
plans:
-Eachplanstepmapstoexactlyonetask
-Mustspecifyverifycommandandexpectedevidence
圖 3:Schema 配置如何對應四層防護——左:Schema 工作流,右:四層防護映射
第四節:實戰驗證 - 用 Mini Markdown 轉換器跑一遍
Schema 寫好了,接下來用一個真實用例跑一遍驗證。
為什麼選 Mini Markdown 轉換器
三個原因:
零依賴:純 Node.js + Jest,不需要 Express/數據庫/HTTP 純函數: markdownToHtml(input: string): string,輸入輸出完全確定天然適合原子化 TDD:每個 Markdown 語法元素(heading/bold/italic/link)= 一個獨立的 RED-GREEN 循環
環境準備
# 0. 初始化 git(後續驗證需要 git log)
git init
# 1. 初始化項目
mkdir mini-markdown && cd mini-markdown
npm init -y
npm install --save-dev jest ts-jest @types/jest typescript
# 2. 初始化 OpenSpec(生成 openspec/changes/、openspec/specs/ 和工具適配目錄)
# 初學者建議用 --tools claude,只安裝 Claude Code 適配,避免生成 29 個不需要的工具目錄
openspec init --tools claude
# 3. 手動創建 Schema 目錄和配置文件
mkdir -p openspec/schemas/tdd-driven-v2/templates
# 將 schema.yaml 放到 openspec/schemas/tdd-driven-v2/
# 將 config.yaml 放到 openspec/(注意:在 openspec/ 根目錄下,不在 schemas/ 裏)
# 將模板文件放到 openspec/schemas/tdd-driven-v2/templates/
驗證步驟
步驟 1:驗證 Schema 語法
openspec schema validate tdd-driven-v2
# 注意:會先顯示 "Note: Schema commands are experimental and may change."
# 這是 CLI 的常規提示,不影響驗證結果
✅ 檢查:無報錯,YAML 語法通過
步驟 2:創建變更提案
# 在 Claude Code 中執行
/opsx:propose mini-markdown
執行後,AI 會依次調用 openspec instructions <artifact> --change mini-markdown --json 獲取 instruction 文本,按依賴順序生成:proposal → design + specs(並行)→ tasks → plans。
如果 config.yaml 的 context 字段寫得充分(如本項目的 TypeScript + Jest 純函數配置),整個 propose 過程不需要任何人工輸入。 AI 直接從 context 推斷需求,整個過程大約 2-3 分鐘。
重點檢查以下驗證點:
✅ proposal.md 包含 WHEN/THEN 格式的可測試行為(實測 15 條) ✅ specs 使用 GIVEN/WHEN/THEN(實測 16 個場景,含 edge cases) ✅ design.md 包含測試文件路徑和測試策略 ✅ tasks.md 每個 task 只有一個 TDD 階段(實測 26 個 task:13 RED + 13 GREEN) ← 核心驗證點 ✅ tasks.md 使用了 checkbox 格式 ← 核心驗證點 ⚠️ tasks.md 無 REFACTOR 任務——AI 認為 REFACTOR 是可選的,選擇了跳過 ✅ plans 指定了驗證命令和期望證據,末尾包含 "Execution Mode Selection" 指定 subagent-driven-development
如果 tasks.md 的產出類似下面這樣,說明第一層防護生效了:
### Headings
- [ ] RED: Write failing test for heading parsing — create tests/markdown.test.ts, test that markdownToHtml("# Hello") returns "<h1>Hello</h1>"
- [ ] GREEN: Implement heading parser — add regex in src/parser.ts to convert "^# (.+)" to "<h1>$1</h1>", export from src/index.ts
### Bold
- [ ] RED: Write failing test for bold parsing — test that markdownToHtml("**bold**") returns "<strong>bold</strong>"
- [ ] GREEN: Implement bold parser — minimal regex to convert "**text**" to "<strong>text</strong>"
❌ 如果產出是 - [ ] Implement heading and bold parser,說明原子化沒有生效。
步驟 3:確認 instruction 注入
openspec instructions tasks --change mini-markdown --json
✅ 檢查:輸出中包含原子化任務的 instruction 文本
步驟 4:執行變更
# 在 Claude Code 中執行
/opsx:apply mini-markdown
這一步是全文最關鍵的驗證環節。以下是 Mini Markdown 驗證的實測結果,不再是預期分析。
AI 執行了 openspec instructions apply --change "mini-markdown" --json 獲取 apply instruction,然後使用 Agent 工具 dispatch 了 27 次 subagent:
24 個實現 subagent(每個 task 一個) 1 個 spec 審查 subagent 2 個代碼質量審查 subagent
四層防護實測結果:
✅ 第一層生效:tasks.md 的 26 個 task 每個只包含一個 TDD 階段(RED 或 GREEN)。任務的原子化粒度是物理約束,不依賴 AI 的自主決策。
✅ 第二層生效:AI dispatch 了 24 個實現 subagent,每個 task 確實由獨立 subagent 完成。instruction 中的 MANDATORY: Use superpowers:subagent-driven-development skill 被 AI 遵守了。subagent 之間 context 隔離,第一個 subagent 不知道第二個 subagent 要做什麼。
⚠️ 第三層部分生效:前 2 個 task(Task 1 RED + Task 2 GREEN)有完整的審查流程——spec reviewer 檢查交付物範圍,code quality reviewer 檢查代碼質量。但 AI 在驗證完前幾個 task 後,認為審查流程太耗時,跳過了後續 24 個 task 的審查。subagent 調用詳情:
Agent #1: Implement Task 1 RED: heading test
Agent #2: Review spec compliance Task 1 RED ← spec reviewer
Agent #3: Review code quality Task 1 RED ← code quality reviewer
Agent #4: Implement Task 2 GREEN: heading parser
Agent #5: Review code quality Task 2 GREEN ← code quality reviewer
Agent #6: Implement Task 3 RED: bold test
Agent #7: Implement Task 4 GREEN: bold parser
...(後續 task 只有實現 subagent,無審查)
Agent #27: Implement Task 26 GREEN: image parser
✅ 第四層生效:npm test 的執行歷史(15 次)清楚顯示了真實的 RED → GREEN 過渡:
#4 Tests: 2 failed, 11 passed — RED(bold test 失敗)
#5 Tests: 5 failed, 8 passed — RED(多個新 test 失敗)
#14 Tests: 1 failed, 10 passed — 最後一個 RED
#15 Tests: 10 passed — 最終 GREEN
這些失敗是真實發生的,不是 AI 編造的——它們來自 npm test 的真實輸出。
執行完成後檢查最終產物:
# 檢查 tasks.md 的 checkbox 是否被逐步勾選
cat openspec/changes/mini-markdown/tasks.md
# 檢查 git log 是否有交替的 test/feat 提交
git log --oneline
# 運行全量測試
npm test
✅ tasks.md 的 26 個 checkbox 全部被勾選 ⚠️ git log 無 RED-only 提交——RED 和 GREEN 在同一次提交中完成,且 commit message 格式不統一 ✅ npm test 通過(10/10 tests passed) ⚠️ 測試覆蓋率 10/15 行為(缺失 h2/h3 多級標題、horizontal rule、mixed inline formatting、code blocks) ⚠️ 源碼結構偏離 design.md 規劃(AI 選擇了單文件 src/markdown.ts 71 行,而非 design.md 的雙文件方案)
最終產物:src/markdown.ts(71 行)、tests/markdown.test.ts(43 行、10 個 test case),npm test 10/10 passed。
圖 4:Mini Markdown 驗證執行時間線——雙軌展示 27 次 subagent dispatch 和 15 次 npm test 的 RED→GREEN 過渡
如果驗證不通過
幾個常見的失敗場景和排查方向:
場景 1:AI 沒有使用 subagent 模式
如果 apply 階段直接 inline 執行而不是 dispatch subagent,說明 instruction 裏的 MANDATORY 被忽略了。排查方向:檢查 Superpowers 的 subagent-driven-development skill 是否正確安裝。如果 skill 不存在,instruction 就是一紙空文。
場景 2:RED 任務裏同時寫了實現
如果 spec reviewer 沒有抓住這個問題,說明審查層失效。排查方向:檢查 spec reviewer 的 prompt 是否明確要求 只檢查任務規格內的交付物。
場景 3:測試輸出不真實
如果 subagent 報告的測試輸出是編造的(比如報了 pass 但實際沒運行),目前沒有代碼層面的防偽機制。這是第四層的已知侷限,第五節會詳細討論。
第五節:誠實評估
四層防護模型聽起來很完善,但必須坦誠:它不能 100% 保證 TDD 執行。以下用 Mini Markdown 的實測數據,逐一說明每層的實際效果和已知侷限。
每層的實測效果
第一層(原子化任務):實測有效。當 tasks.md 的每個 task 只有一個 TDD 階段時,即使 AI 想一步完成,task 的描述本身就限制了它的操作範圍。實測中 tasks.md 生成了 26 個原子 task(13 RED + 13 GREEN),AI 沒有合併任何任務。這是四層裏最可靠的一層——任務粒度是物理約束,不依賴 AI 的自主決策。
第二層(subagent 隔離):實測有效。Mini Markdown 驗證中,AI dispatch 了 24 個實現 subagent,每個 task 確實由獨立 subagent 完成。instruction 中的 MANDATORY: Use superpowers:subagent-driven-development skill 被 AI 遵守了。subagent 之間 context 隔離,第一個 subagent 不知道第二個 subagent 要做什麼。
注意:有效不代表 100% 可靠。其他項目、其他 AI 模型、其他 instruction 上下文中,AI 仍然可能選擇忽略 MANDATORY 選擇 inline 執行。但在本驗證場景中,第二層確實生效了。
第三層(兩階段審查):實測部分有效。前 2 個 task(Task 1 RED + Task 2 GREEN)有完整的審查流程——spec reviewer 檢查交付物範圍,code quality reviewer 檢查代碼質量。但 AI 在驗證完前幾個 task 後,認為審查流程太耗時,跳過了後續 24 個 task 的審查。
這個結果揭示了一個微妙的問題:審查機制存在且能正確工作(前 2 個 task 的審查是真實的),但 AI 有自主跳過審查的裁量權。instruction 裏沒有說"每個 task 都必須審查",AI 合理地認為前幾個驗證過了就夠了。
改進方向:在 apply.instruction 中明確寫 "Review EVERY task, not just the first few"。但這也只是 prompt 級別的約束——AI 仍然可以選擇忽略。
第四層(驗證證據):實測有效。npm test 的執行歷史(15 次)清楚顯示了 RED → GREEN 的過渡:
第 4 次運行:2 failed, 11 passed(bold test 失敗) 第 5 次運行:5 failed, 8 passed(多個新 test 失敗) 第 14 次運行:1 failed, 10 passed(最後一個 RED) 第 15 次運行:10 passed(最終全部通過)
這些失敗是真實發生的,不是 AI 編造的——它們來自 npm test 的真實輸出。第四層提供了可靠的 TDD 順序證據。
但有一個已知侷限:git log 中沒有 RED-only 提交。AI 在 RED 階段寫了測試但沒有單獨提交,而是和 GREEN 一起提交。這意味着從 git 歷史看不到"先寫測試、測試失敗、再寫實現"的交替模式。測試覆蓋率也只有 10/15 行為。
實測中發現的問題
審查覆蓋不完整:AI 跳過了 24/26 個 task 的審查(第三層) 測試覆蓋率不足:10/15 行為有測試,缺失 5 個可測試行為(h2/h3、horizontal rule、mixed inline、code blocks) 架構決策偏離:AI 自行從雙文件方案調整為單文件方案,沒有打回 git log 無 RED-only 提交:無法從版本歷史看到 TDD 交替模式 REFACTOR 被跳過:AI 將 REFACTOR 視為"可選"而跳過,26 個 task 全是 RED + GREEN
說到底,這些問題是第三層審查被跳過的直接後果。如果有 spec reviewer 檢查 Task 3-26,AI 自行調整文件結構(從雙文件變單文件)和跳過 5 個行為的測試覆蓋應該被打回。
如果需要更高保證
如果對 TDD 執行紀律有硬性要求(比如團隊規範或合規需要),可以在四層防護之外加兩道硬約束:
pre-commit hook:檢查測試覆蓋率,拒絕覆蓋率低於閾值的提交 CI pipeline:拒絕沒有對應測試變更的 feature 提交
這兩道約束是代碼層面的,不依賴 AI 的自主決策,可靠性遠高於 prompt 級別的防護。
與 v1 的對比
tracks 解析失敗 | tracks 可追蹤 | ||
v1 在 propose 階段的文檔規範化是有效的——WHEN/THEN、GIVEN/WHEN/THEN 這些格式約束確實讓產物更規範。但 apply 階段的執行紀律完全失敗。v2 通過原子化任務 + subagent 隔離 + 兩階段審查 + 驗證證據,在 apply 階段實現了可預期的 TDD 執行。
四層防護模型的實測結果:三層有效,一層部分有效。第一層(原子化任務)和第二層(subagent 隔離)是最可靠的——任務粒度是物理約束,subagent 隔離是工具機制保證。第三層(審查)機制本身正確,但 AI 選擇了加速執行跳過審查,暴露了 prompt 級約束的天花板。第四層(驗證證據)提供了真實的 RED 失敗記錄,是最硬的客觀證據。
核心洞察不變:縮小 AI 的合理操作空間比讓 AI 變得更聽話更可靠。當每個任務只允許做一件事,subagent 之間互相看不見,做完還有人審查——即使審查被跳過了,前兩層已經把 AI 的操作空間壓縮到了原子級別。
當然,這個判斷需要更多場景驗證。如果你也試了這個 Schema,歡迎把驗證結果反饋給我——成功了值得記錄,失敗了更有分析價值。
圖 5:v1/v2 設計/v2 實測三方對比評估——5 個維度的演進與實測效果
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具的實戰經驗和最佳實踐。不錯過每一篇乾貨!