OpenSpec 最佳實戰:3 輪實測驗證 5 個質量升級方向,結論一目瞭然
整理版優先睇
三輪實驗驗證OpenSpec質量升級:4個方向有效,1個需外部CI
呢篇文章係術哥嘅OpenSpec實戰系列,佢之前提出咗5個質量升級方向,今次用真實嘅TODO API項目做三輪實驗,驗證呢幾個方向係咪真係有用。作者係一名專注AI編程同開源技術嘅實踐者,想解決AI編程產出質量唔穩定嘅問題。
實驗由裸跑(Lab1)、低成本方案(Lab2)到中等成本方案(Lab3)遞進,逐步加入Explore、Rules、validate,同埋自定義Schema插入Review工件。總體結論係:4個方向(Spec Review、原子任務+檢查點、TDD思路、質量門控)有效,其中自定義Schema嘅結構化門控效果最好;但運行驗證呢個方向需要外部CI工具,OpenSpec本身做唔到。
作者畀出務實建議:個人項目可以先試Lab2嘅Rules+Validate,團隊項目就用Lab3嘅自定義Schema,生產環境就要再加外部CI。成篇文章都係技術實踐者嘅經驗分享,針對已經識OpenSpec基本操作嘅讀者。
- 三輪實驗由裸跑、低成本方案到中等成本方案遞進,驗證5個質量升級方向嘅成效。
- Lab2使用Explore+Rules顯著改善需求對齊,但tasks粒度控制仍不足,要靠Schema層面約束。
- Lab3自定義Schema插入Review工件,實現結構化質量門控,tasks由19個增至22個,每個新增task都有review建議來源。
- 5個升級方向中,運行驗證方向需要外部CI工具,OpenSpec原生唔支援,要透過rules+外部測試框架補足。
- 建議個人項目先用Lab2(Rules+Validate),團隊項目用Lab3(自定義Schema),生產環境就Lab3加外部CI雙保險。
OpenSpec config.yaml rules範例
rules: specs: - 每個數據字段的變更,必須覆蓋null、空值、越界三種異常場景 - Scenario必須使用#### 四級標題,否則會被靜默忽略 design: - 涉及數據庫migration的設計,必須包含回滾方案 tasks: - 所有實現任務必須配對對應的測試任務,測試任務寫在實現任務正下方 - 單個task不超過30分鐘工作量
實驗設計:三輪遞進驗證方案
作者用同一功能需求——幫TODO API加priority字段(Low/Medium/High),分別進行三輪實驗。Lab1係裸跑基線,唔加任何質量措施,睇下原始產出;Lab2加Rules、Validate同Explore,測試低成本方案;Lab3就自定義Schema插入Review工件,測試中等成本方案。
三輪Lab均在同一TODO API項目中完成,主要場景已實際跑通。
文章背景係作者上篇《OpenSpec實戰覆盤》提咗5個升級方向,今次用真實項目逐個對標。作者提醒讀者需要先識OpenSpec四步法基本概念,跟住做大概30-40分鐘。
Lab1裸跑基線:流程完整,需求靠估
第一輪純粹行propose → apply → archive,唔加任何質量措施。Propose自動生成四個工件:proposal.md、spec.md、design.md、tasks.md。Apply時AI自動執行RED-GREEN循環,第一次有1個測試失敗,然後自動修復,最終18個測試全部通過。
propose從change name推斷需求,冇問用戶意見
產出檢查後發現:Spec意外覆蓋咗邊界條件,tasks粒度仲可以,但AI自行加咗ISO 8601時間戳breaking change,呢個需求冇人提過。仲有,遷移策略提到但唔完整,冇具體回滾SQL。
四步法保證流程完整性,但唔保證需求對齊
- Spec覆蓋邊界條件:✅ 碰巧覆蓋null、空字符串、無效值,但係AI自己估,唔係你話畀佢知
- tasks粒度:⚠️ 仲可以,拆成6組15個task,但包含未經批准嘅breaking change
- 有冇測試任務:✅ 碰巧配對,但冇結構約束保證
- 有冇回滾方案:⚠️ 有但不完整,design.md有Migration Plan但冇具體回滾SQL
Lab1暴露嘅根本問題:產出不可控
Lab2低成本方案:Explore+Rules改善需求對齊
第二輪用Explore先澄清需求,再寫config.yaml rules,propose後用validate檢查結構。Explore模式幫手諗清priority嘅類型、默認值、排序權重、遷移策略,AI畀出推薦方案,作者確認後先propose。
Explore嘅價值係喺寫Spec之前將模糊地帶諗清楚
rules:
specs:
-每個數據字段的變更,必須覆蓋null、空值、越界三種異常場景
-Scenario必須使用#### 四級標題,否則會被靜默忽略
design:
-涉及數據庫migration的設計,必須包含回滾方案
tasks:
-所有實現任務必須配對對應的測試任務,測試任務寫在實現任務正下方
-單個task不超過30分鐘工作量Propose時AI記住咗Explore嘅對話,所以需求係用戶講嘅,唔係AI估嘅。Validate檢查咗delta spec結構合規性,通過後再apply。
rules係獨立約束字段,唔係追加到instruction後面
- 異常場景覆蓋:✅ 更完整,多咗null=400嘅測試場景
- 回滾方案:✅ 明顯改善,有Rollback + migration plan
- 測試任務:✅ 每組配對,同Lab1冇分別
- tasks粒度:6組19個,比Lab1多4個,但粒度控制仍然靠rules,AI對30分鐘估算唔可靠
- 需求來源:✅ 基於用戶多輪確認,唔再係AI推斷
Lab2真正價值:需求係用戶講嘅,唔係AI估嘅
Lab3中等成本方案:自定義Schema+Review工件實現門控
第三輪直接改Schema骨架:fork現有spec-driven schema,喺design同tasks之間插入一個review工件。Review工件按五個維度審查:邊界條件、回滾方案、測試覆蓋、向後兼容、任務粒度。依賴鏈變成proposal → specs → design → review → tasks。
review工件要求tasks嘅requires從[specs, design]改為[review],形成強制審查關卡
實際產出中,review.md確實生成咗,5個維度4個Pass、1個Warning(測試覆蓋),整體偏寬鬆——因為AI同時係生產者同審查者。但tasks受review影響,由Lab2嘅19個增加到Lab3嘅22個,新增task都有明確嘅review建議來源。
- 1 邊界條件:✅ Pass,Spec覆蓋咗null、空字符串、無效值等
- 2 回滾方案:✅ Pass,Design明確冇rollback需要,因為priority係新增字段
- 3 測試覆蓋:⚠️ Warning,建議tasks.md要為每個需求加入明確測試task
- 4 向後兼容:✅ Pass,priority字段係additive,唔影響現有API
- 5 任務粒度:✅ Pass,config rule要求單個task ≤30分鐘,v2嘅15個task已經夠細
review工件在design同tasks之間插入結構化檢查點,唔靠AI自覺
5個升級方向對標同選型建議
三輪實驗完結後,作者將5個升級方向逐一對標。結論係:4個方向有效,1個需要外部工具。有效嘅包括:Spec Review(validate+review工件)、原子任務+檢查點(自定義Schema依賴鏈)、TDD思路(rules+review雙保險)、質量門控(review作為tasks前置)。
運行驗證方向OpenSpec原生做唔到,需要外部CI+測試框架
作者畀出好務實嘅選型建議:個人項目或快速迭代用Lab2(Rules+Validate),團隊項目需要代碼審查就用Lab3(自定義Schema),生產環境高可靠性要求就Lab3加外部CI。仲提醒:唔好一開波就用Lab3,先用Lab1熟流程,邊度唔夠就加相應措施。
- 個人項目、快速迭代:Lab2(Rules+Validate),配置簡單,5分鐘搞掂
- 團隊項目、需要代碼審查:Lab3(自定義Schema),結構化門控,質量有保障
- 生產環境、高可靠性要求:Lab3 + 外部CI,Schema門控 + 運行驗證雙保險
- 學習OpenSpec、剛開始用:Lab1(裸跑),先熟流程再逐步加措施
rules係文本約束,AI可能忽略;requires係結構約束,唔滿足就生成唔到
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 107 篇,AI 編程最佳實戰「2026」系列第 32
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
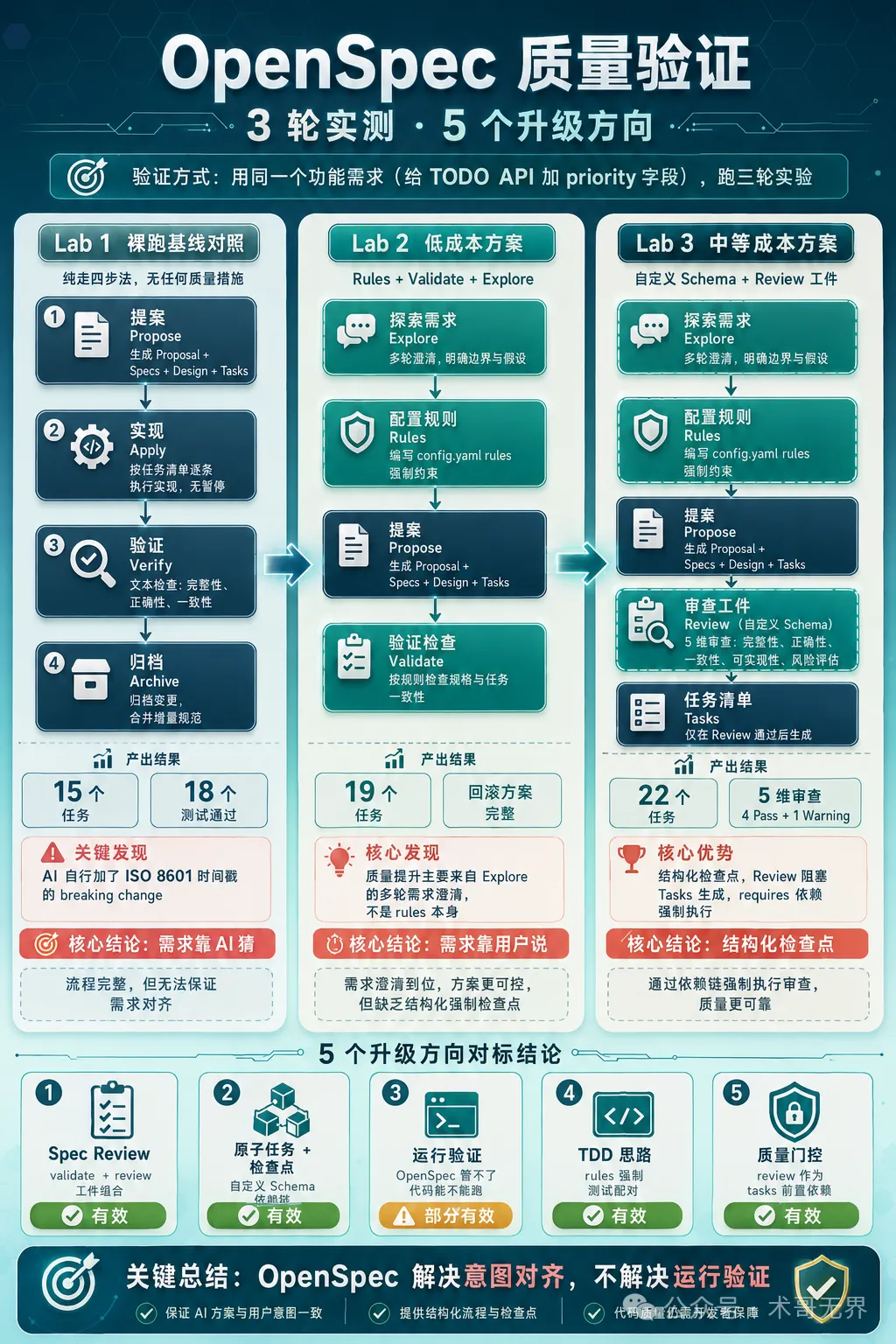
圖 1:三輪實驗全貌——從裸跑到結構化門控
上篇文章:《OpenSpec 實戰覆盤:4 步流程 + 5 項升級,讓 AI 編程從能跑到跑對》,覆盤 OpenSpec 四步法的時候,我提了 5 個質量升級方向,末尾留了一句話:還沒有用真實項目驗證過。
這篇就來兑現承諾。
驗證方式很簡單:用同一個功能需求 - 給已有 TODO API 加任務優先級(priority 字段支持 Low / Medium / High),跑三輪實驗。Lab 1 裸跑基線對照,看原始產出;Lab 2 加 Rules + Validate + Explore,看低成本方案改善多少;Lab 3 自定義 Schema 插入 Review 工件,看中等成本方案能做到什麼程度。
三輪跑完,5 個升級方向逐一對標。
說明:本文內容基於 OpenSpec(Fission-AI/OpenSpec)源碼和筆者本地實際操作驗證。三輪 Lab 均在同一 TODO API 項目中完成,主要場景已實際跑通。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。OpenSpec 仍在快速迭代,部分命令(如 schema fork)標記為 experimental,後續版本可能有變化。如果有實際使用經驗,歡迎在評論區分享交流。
你將看到什麼
✅ 裸跑 propose → apply → archive 的真實產出長什麼樣 ✅ 加 Rules + Explore 後 Spec 質量有多大改善 ✅ 自定義 Schema 插入 Review 工件的完整操作 ✅ 5 個升級方向的逐一對標結論表
環境準備
你需要準備
OpenSpec CLI 已安裝( openspec --version能正常輸出)一個現有的 TODO API 項目(或任何你想加功能的項目) Claude Code / Cursor 等支持 OpenSpec skills 的 AI 編程工具
預計時間
⏱️ 跟着做三輪實驗大約需要 30-40 分鐘
難度等級
⭐⭐ 中級 - 需要了解 OpenSpec 四步法的基本概念
Lab 1:裸跑 propose → apply → archive(基線對照)
這一輪不加任何質量措施,純粹走一遍 /opsx:propose → /opsx:apply → /opsx:archive,看看原始產出長什麼樣。
說白了這個 Lab 的目的不是做對,而是看看不做額外約束時 AI 會產出什麼。
Propose:一鍵生成工件
在 AI 編程工具中執行:
/opsx:propose
不需要手動先執行 openspec new change - propose skill 內部會自動創建 change 目錄。如果你已經手動創建了同名 change,propose 會檢測到並問你:Continue existing 還是 Recreate?選 Recreate 就行。
AI 會從 change name 推斷需求(本例中 todo-priority 被推斷為"加 priority 字段"),然後按 schema 定義的依賴順序生成四個工件。實際輸出類似這樣:
**Change created: `todo-priority`**
Location: `openspec/changes/todo-priority/`
Artifacts created:
- **proposal.md** — defines the problem and motivation for adding priority support
- **design.md** — technical decisions including default priority, strict enum validation, sort order, and timestamp format change
- **specs/todo-priority/spec.md** — detailed requirements with scenarios covering normal cases, null/empty/invalid priority values
- **tasks.md** — 6 implementation task groups with paired test tasks
All artifacts complete! Ready for implementation.
Run `/opsx:apply` to start implementing.
四個工件分別是:proposal.md(做什麼、為什麼)、specs/todo-priority/spec.md(行為規範)、design.md(怎麼做)、tasks.md(實現步驟)。
⚠️ 注意:propose 不一定會問你需求 - 如果 change name 足夠清晰,AI 可能跳過需求確認直接生成。如果你想讓 AI 按你的想法來做,可以在執行 propose 之前先通過
/opsx:explore澄清需求(Lab 2 會演示)。
Apply:執行任務
/opsx:apply
AI 讀取所有工件後,按 tasks.md 裏的順序逐個實現。每個 task 完成後會把 - [ ] 改成 - [x]。
有個真實細節值得注意:AI 第一次運行測試時有 1 個沒通過(should reject undefined priority type),然後自動修復了代碼,第二次全部通過。這個 RED-GREEN 循環是 AI 自發完成的:
# 第一次運行 - 1 個失敗
⎯⎯⎯⎯⎯⎯⎯ Failed Tests 1 ⎯⎯⎯⎯⎯⎯⎯
FAIL src/store.test.ts > priority validation > should reject undefined priority type
Test Files 1 failed (1)
Tests 1 failed | 17 passed (18)
# 修復後運行 - 全部通過
Test Files 1 passed (1)
Tests 18 passed (18)
實現完成後的完整彙報:
## Implementation Complete
**Change:** todo-priority
**Schema:** spec-driven
**Progress:** 15/15 tasks complete ✓
### Implemented This Session
**Files Created:**
- `src/types.ts` — Todo interface with Priority type
- `src/store.ts` — Store with priority validation and sorting
- `src/routes.ts` — Express routes with priority support
- `src/store.test.ts` — 18 unit tests
**Test Results:** 18 passed
All tasks complete! You can archive this change with `/opsx:archive`.
注意:/opsx:apply 不支持 --task 參數指定單個任務,它是按順序遍歷所有 task 的。
Archive:歸檔
/opsx:archive
AI 會將整個 change 目錄移動到 openspec/changes/archive/ 下,自動以日期命名(如 2026-05-09-todo-priority/)。歸檔過程是自動完成的,不需要手動選擇或確認。
## Archive Complete
**Change:** todo-priority
**Schema:** spec-driven
**Archived to:** `openspec/changes/archive/2026-05-09-todo-priority/`
**Specs:** No delta specs (new capability only)
All artifacts complete. All tasks complete.
⚠️ 注意:當前 archive 實現是直接移動目錄,不會將 delta specs 同步到
openspec/specs/主目錄。如果你的後續變更需要讀取已有 specs,可能需要手動處理。
Lab 1 產出診斷
裸跑完之後,我檢查了一下產出,結果比預期好一些 - 但也暴露了更根本的問題:
總結:四步法保證流程完整性,但不保證需求對齊。這次 propose 沒有問用戶需求 - AI 從 todo-priority 這個名字猜了全部設計,碰巧猜得不錯。但如果你要做的功能名字不夠直白(比如叫 user-experience-upgrade),或者你對邊界條件有特定要求,裸跑就可能跑偏。
這就是下面兩輪 Lab 要解決的問題 - 不是產出質量差,而是產出不可控。
Lab 2:加 Rules + Validate + Explore(低成本方案)
Lab 1 暴露的問題,不需要改 OpenSpec 的 Schema 也能部分解決。具體做法:propose 前先用 Explore 澄清需求,創建 config.yaml 寫入 rules,propose 後用 validate 檢查產出。
這一輪對標上篇的升級 1(Spec Review)和升級 4(TDD 思路)。
Step 1:Explore 澄清需求
裸跑時 AI 從 change name 推斷了需求,碰巧還行,但需求畢竟是 AI 猜的。這次先用 Explore 模式把模糊地帶想清楚:
/opsx:explore
在對話中拋出你的核心問題:
我要給 Todo API 加 priority 字段(Low / Medium / High)。幫我想想:
這個字段的可選值會不會擴展?需不需要做成 enum 還是 string? priority 為 null 時怎麼處理?默認值策略是什麼? 有沒有排序需求?按 priority 排序時 Low / Medium / High 的權重怎麼定? 現有數據遷移策略:已有任務的 priority 怎麼設?
AI 會畫出決策矩陣幫你理清思路:
┌─────────────────────────────────────────────────────────────┐
│ Priority 設計決策 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. 類型選擇 │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Enum │◀───────▶│ String │ │
│ │ type-safe │ │ flexible │ │
│ └──────────────┘ └──────────────┘ │
│ ▼ │
│ 2. Null 處理 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ NOT NULL │ │ NULL = Medium│ │ NULL = Low │ │
│ │ 強制有值 │ │ 隱式默認值 │ │ 顯式缺失 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ 3. 排序權重 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ HIGH→MED→LOW │ │ LOW→MED→HIGH │ │ MED→HIGH→LOW │ │
│ │ 緊急優先 │ │ 後台任務優先 │ │ 折中方案 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ 4. 遷移策略 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 全部設為Medium│ │ 用戶手動設置 │ │ 腳本批量遷移 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
然後 AI 會反問四個澄清問題。我的回答是:
三個固定值基本夠用,2 我不確定你來分析決定,3 最緊急的在前,4 一次性遷移
AI 分析了 null 語義後給出推薦方案:
## 推薦方案
- 類型:Enum(固定三個值)
- 數據庫:NOT NULL,默認值:'medium'
- 排序權重:HIGH → MEDIUM → LOW
- 遷移:一次性,SQL UPDATE SET priority='medium'
我確認後,AI 總結了全部決策,並建議退出 explore 進入 propose。
Explore 的價值不是生成代碼,而是在寫 Spec 之前把模糊地帶想清楚。三輪對話下來,priority 的類型、默認值、排序、遷移策略全部明確了 - 這些都是 Lab 1 裏 AI 自己猜的。
Step 2:創建 config.yaml 寫入 Rules
OpenSpec 的 rules 機制很有意思:它不是追加到 instruction 後面的文本,而是獨立的約束字段,單獨傳遞給 AI。rules 在 prompt 中以 Do NOT include in output 和 Apply as constraints 的指令出現,相當於給 AI 畫了一道紅線。
創建配置文件:
mkdir -p openspec
然後在 openspec/config.yaml 中寫入:
rules:
specs:
-每個數據字段的變更,必須覆蓋null、空值、越界三種異常場景
-Scenario必須使用#### 四級標題,否則會被靜默忽略
design:
-涉及數據庫migration的設計,必須包含回滾方案
tasks:
-所有實現任務必須配對對應的測試任務,測試任務寫在實現任務正下方
-單個task不超過30分鐘工作量
幾個關鍵點:
rules 按 artifact ID 分組,key 是工件名(specs、design、tasks),value 是規則列表。不是平鋪的列表格式 位置固定:放在項目根目錄的 openspec/config.yaml下key 必須和 schema 中的 artifact id 對應:默認 schema 有 proposal、specs、design、tasks 四個工件
Step 3:Propose 生成工件
# 重新創建變更
openspec new change todo-priority-v2
然後執行 propose:
/opsx:propose
有意思的是,Lab 2 的 propose 也沒有問用戶需求 - 但這次不是"沒問",而是 Explore 階段已經澄清了需求,AI 記住了上下文。這說明 explore + propose 的組合比單獨 propose 更可靠:需求是用戶說的,不是 AI 猜的。
實際輸出:
**Change created: `todo-priority-v2`**
Location: `openspec/changes/todo-priority-v2/`
Artifacts created:
- **proposal.md** — defines three-level priority enum, sorting, validation
- **design.md** — enum type, NOT NULL default 'medium', migration plan
- **specs/todo-priority/spec.md** — 4 requirements with scenarios (normal, null, empty, invalid cases)
- **tasks.md** — 6 task groups with paired test tasks (15 total implementation + test tasks)
All artifacts complete! Ready for implementation.
Run `/opsx:apply` to start implementing.
這時 AI 生成 Spec 時會自動把 rules 作為約束條件。
Step 4:Validate 檢查產出
openspec validate todo-priority-v2 --type change
這個命令檢查 delta spec 的結構合規性 - 比如 specs 目錄下是否有 ## ADDED Requirements 等 headers、Scenario 是否使用了 #### 四級標題。
⚠️ 注意:
--type change參數是必需的 -openspec validate不能直接識別 change 名稱。你也可以用openspec validate --changes批量驗證所有 change。
通過驗證後你會看到:
Change 'todo-priority-v2' is valid
如果 delta spec 格式有問題(比如缺少 Scenario 塊),validate 會報錯誤:
Change 'todo-priority-v2' has issues
✗ [ERROR] file: Change must have at least one delta...
validate 檢查的是結構合規性,不是業務邏輯正確性。它不會告訴你 Spec 裏忘了處理 priority 為空的場景,也不會檢查 tasks.md 裏有沒有測試任務 - 這些需要 rules 和 review 工件來約束。
Lab 2 產出對比
| 關鍵差異 |
核心發現:Lab 2 產出質量的提升主要來自 Explore 階段的多輪需求澄清,而不是 rules 本身。Rules 確實被傳遞了,但效果很難單獨量化 - 因為 Lab 1 的基線已經不低了。Lab 2 真正的價值在於:需求是用戶說的,不是 AI 猜的。
但有一個問題 rules 解決不了:tasks 粒度的控制不夠精確。rules 寫了不超過 30 分鐘工作量,但 AI 對 30 分鐘的估算本身就不可靠。更好的方式是在 Schema 層面定義 task 的結構約束。
這就是 Lab 3 要解決的問題。
Lab 3:自定義 Schema + Review 工件(中等成本方案)
如果說 Lab 2 是在不改 OpenSpec 結構的前提下打補丁,Lab 3 就是直接改骨架。
具體做法:fork 一個現有的 spec-driven schema,在 design 和 tasks 之間插入一個 review 工件,讓 AI 在生成 tasks 之前先做一輪質量審查。
這一輪對標升級 2(原子任務 + 檢查點)和升級 5(質量門控)。
Step 1:查看可用 Schema
openspec schemas
實際輸出:
Available schemas:
spec-driven
Default OpenSpec workflow - proposal → specs → design → tasks
Artifacts: proposal → specs → design → tasks
默認只有 spec-driven 這一個 schema。
Step 2:Fork Schema
openspec schema fork spec-driven with-review
實際輸出:
Note: Schema commands are experimental and may change.
- Forking 'spec-driven' to 'with-review'...
✔ Forked 'spec-driven' to 'with-review'
Source: /opt/homebrew/lib/node_modules/@fission-ai/openspec/schemas/spec-driven (package)
Destination: /Users/shuge/.../todo-api/openspec/schemas/with-review
You can now customize the schema at:
/Users/shuge/.../todo-api/openspec/schemas/with-review
注意第一行 Schema commands are experimental - 這個功能可能還會變。這會在本地創建一個新的 schema 叫 with-review,基於 spec-driven 的全部配置。
Step 3:修改 Schema,插入 Review 工件
Fork 完成後,找到 schema 配置文件(通常在 openspec/schemas/with-review/ 目錄下),修改 artifacts 定義。
核心改動:在 design 和 tasks 之間插入一個 review 工件。
Schema 配置的關鍵部分(示意):
artifacts:
-id:proposal
generates:proposal.md
template:proposal.md
description:變更提案-做什麼、為什麼做
requires:[]
-id:specs
generates:specs/**/*.md
template:spec.md
description:行為規範-系統應該做什麼
requires:[proposal]
-id:design
generates:design.md
template:design.md
description:技術設計-怎麼做
requires:[proposal]
# ⬇️ 新增的 review 工件
-id:review
generates:review.md
template:review.md # ← 需要在 templates/ 目錄下創建此文件
description:五維審查-檢查設計方案和Spec的完整性
instruction:|
從五個維度審查所有工件的完整性:
1. 邊界條件:Spec 是否覆蓋 null、空值、越界、併發等異常場景
2. 回滾方案:數據庫變更是否包含回滾策略
3. 測試覆蓋:Design 是否明確了需要測試的場景和用例
4. 向後兼容:是否分析了現有接口和數據的兼容性
5. 任務粒度:初步判斷 tasks 應該怎麼拆分才合理
requires:[proposal,specs,design]
-id:tasks
generates:tasks.md
template:tasks.md
description:實現任務列表
requires:[review] # ← 從 [specs, design] 改為 [review]
幾個要點:
每個 artifact 需要 template字段:指向templates/目錄下的模板文件。新增的 review 工件需要在openspec/schemas/with-review/templates/下創建review.md模板文件(可以是一個空文件或簡單模板)description字段保留 - 實際 schema.yaml 中確實有這個字段,它為每個 artifact 提供簡短描述review 依賴 proposal + specs + design 三個工件,確保審查時所有前置工件都已就緒 tasks 的 requires從默認的[specs, design]改為[review],形成proposal → specs → design → review → tasks的依賴鏈沒有在 schema 中寫死 tracks- 進度追蹤由apply階段負責
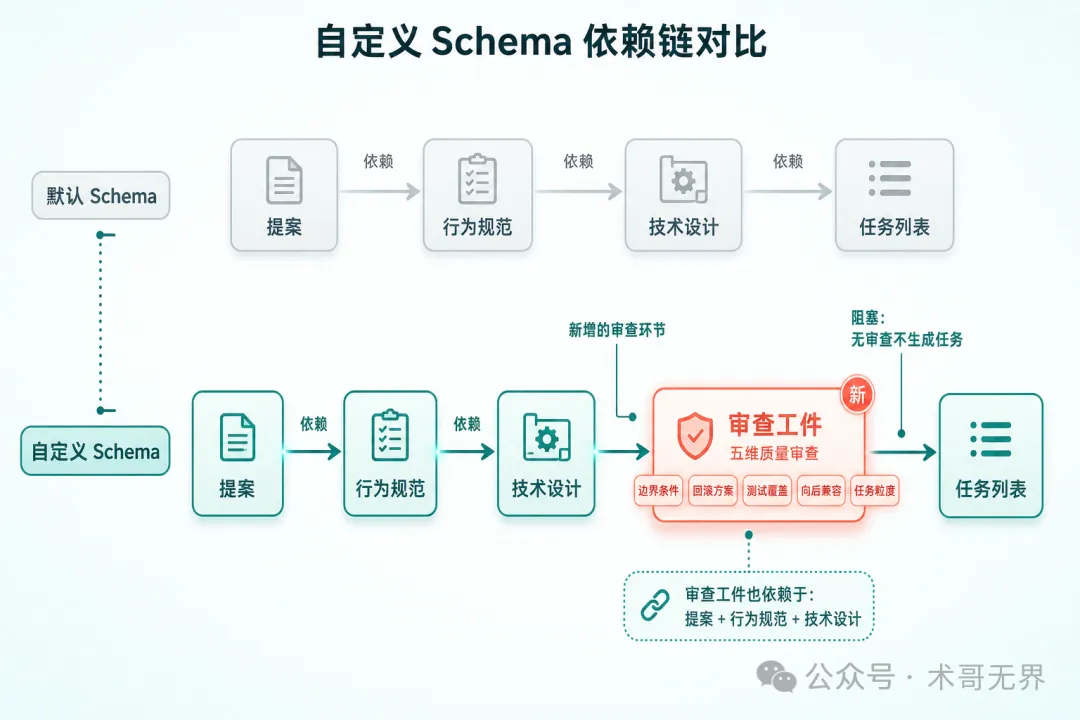
圖 2:默認 Schema vs 自定義 Schema——review 工件插入 design 和 tasks 之間
Step 4:用新 Schema 創建變更
openspec new change todo-priority-v3 --schema with-review
實際輸出:
- Creating change 'todo-priority-v3' with schema 'with-review'...
✔ Created change 'todo-priority-v3' at openspec/changes/todo-priority-v3/ (schema: with-review)
輸出中的 with schema 'with-review' 確認使用了自定義 schema。
Step 5:Propose 並觀察
/opsx:propose
這次 propose 會按依賴順序生成五個工件:proposal → specs 和 design(兩者可並行)→ review → tasks。實際輸出:
**Change created: `todo-priority-v3`**
Location: `openspec/changes/todo-priority-v3/`
Schema: `with-review` (includes review artifact)
Artifacts created:
- **proposal.md** — same content as v2, defines priority enum with three values
- **design.md** — same content as v2, documents decisions and migration plan
- **specs/todo-priority/spec.md** — same content as v2, 4 requirements with scenarios
- **review.md** — quality review across 5 dimensions (boundary conditions, rollback, test coverage, backward compatibility, task granularity)
- **tasks.md** — 6 task groups with paired test tasks (20 total tasks, includes review recommendations)
All artifacts complete! Ready for implementation.
關鍵觀察點:
review.md 確實生成了:輸出中有
Schema: with-review (includes review artifact)確認使用了自定義 schemareview 的審查結論:打開 review.md 看看五個維度的審查結果,完整內容如下:
# Quality Review
## 1. Boundary Conditions
**Status**: ✅ Pass
**Findings**:
- Specs cover null priority (rejected with 400)
- Specs cover empty string priority (rejected with 400)
- Specs cover invalid value "urgent" (rejected with 400)
- Specs cover non-existent todo PATCH (404)
- Scenarios for: valid priority creation, default priority on create, sorted listing, sorted vs default order
**Recommendations**:
None — all three error cases plus normal flow are covered.
## 2. Rollback Plan
**Status**: ✅ Pass
**Findings**:
- Design explicitly states "No rollback needed for priority field" because it's additive
- Migration is one-time and idempotent (UPDATE to 'medium' is safe to re-run)
- Migration plan includes rollback strategy for breaking changes
- Default 'medium' ensures graceful behavior even if migration partially runs
**Recommendations**:
None — rollback plan is complete for this change.
## 3. Test Coverage
**Status**: ⚠️ Warning
**Findings**:
- Specs identify test scenarios for each requirement
- Scenarios map to test cases (18 tests implemented in v1)
- Tasks.md requires paired test tasks (rule from config)
**Recommendations**:
- Ensure tasks.md includes explicit test tasks for each requirement
- Verify 18 tests cover all spec scenarios
## 4. Backward Compatibility
**Status**: ✅ Pass
**Findings**:
- Priority field is additive — existing GET responses unchanged
- POST/PATCH validation is new — only affects new writes
- Migration sets existing todos to 'medium' default
- No breaking changes to existing API contracts except timestamp format (already covered in separate change)
**Recommendations**:
None — migration addresses backward compatibility.
## 5. Task Granularity
**Status**: ✅ Pass
**Findings**:
- Requirements are clear and can be broken into small tasks
- Config rule: single task ≤ 30 minutes
- 15 tasks in todo-priority-v2, each specific and verifiable
**Recommendations**:
None — task breakdown is adequate.
---
## Overall Assessment
All five dimensions pass. The change is well-scoped with clear requirements and migration plan.
**Key recommendations for tasks.md**:
- Include explicit test tasks paired with each implementation task
- Verify sorting edge case (empty list returns empty array)
- Verify PATCH with only priority update (not touching other fields)
5 個維度中 4 Pass + 1 Warning,沒有 Fail。說實話,自己審自己的審查結論整體偏寬鬆 - 畢竟是同一 AI 生成了 specs/design 又審查自己的產出。審查機制存在且能工作,但 AI 傾向於給自己的產出打高分。
tasks.md 受了 review 影響:從 Lab 2 的 19 個 task 增加到了 Lab 3 的 22 個 - 新增的 3 個 task 都有明確的 review 建議來源:
這是 review 工件"影響下游"的量化的證據。
Lab 3 產出對比
| 審查檢查點 | |||
| 質量門控 | |||
| 需求來源 |
Lab 3 的核心優勢:review 工件在 design 和 tasks 之間插了一個結構化的檢查點。這不是依賴 AI 的自覺性(請記得檢查邊界條件),而是通過 schema 的依賴關係強制執行 - 沒有 review,tasks 就不會開始生成。
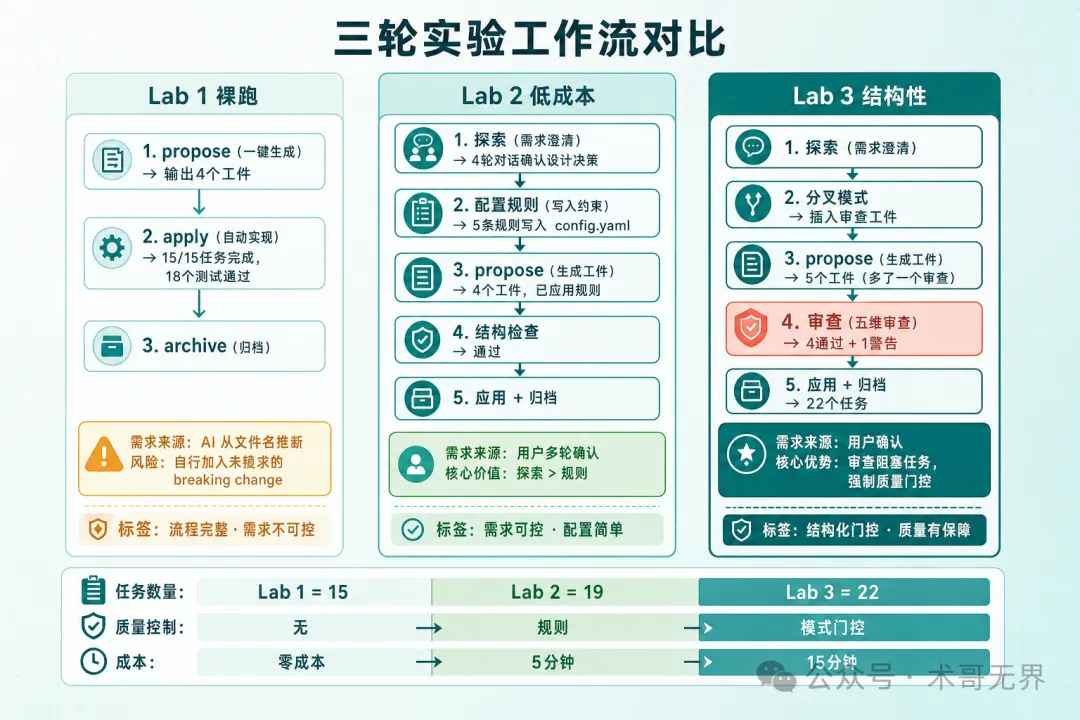
圖 3:三輪實驗工作流對比——從裸跑到結構化門控的遞進
5 個升級方向的對標結論
三輪 Lab 跑完,回到上篇提出的 5 個升級方向,逐一對標。
結論表
openspec validate | ||||
requires 依賴鏈實現檢查點;instruction 引導任務拆分 | ||||
openspec validate | ||||

圖 4:5 個升級方向驗證結論——4 個有效,1 個需要外部工具
逐條展開
升級 1(Spec Review):Lab 2 的 openspec validate 能檢查結構合規性,Lab 3 的 review 工件能做內容層面的五維審查。兩者組合效果不錯。成本也不高 - validate 是現成命令,review 工件只需要 fork 一個 schema。
升級 2(原子任務 + 檢查點):Lab 3 驗證了在 schema 中用 requires 依賴鏈插入檢查點是可行的。review 工件在 design 和 tasks 之間起到了閘門作用。但任務拆分的原子性仍然依賴 instruction 的描述質量 - OpenSpec 沒有內置每個 task 必須 ≤ N 行代碼這種硬約束。
升級 3(運行驗證):這是 5 個方向裏OpenSpec 原生能力覆蓋不到的那個。
說直白點:openspec validate 檢查的是tasks.md 有沒有按 schema 格式寫,不是代碼跑起來會不會報錯。真正的運行驗證 - 單元測試、集成測試、端到端測試 - 需要你在 tasks.md 裏把測試寫成強制性任務,然後通過 CI 管道執行。
OpenSpec 能做的是:確保測試任務被寫進了 tasks.md(通過 rules + review),但測試能不能跑通這件事,OpenSpec 管不了。
升級 4(TDD 思路):Lab 2 的 rules 強制實現任務必須配對測試任務,效果立竿見影。但更進一步的 TDD 紅綠循環(先寫失敗測試 → 實現代碼 → 測試通過 → 重構),OpenSpec 的 schema 裏沒有對應的階段定義。如果你需要嚴格 TDD,得在自定義 schema 的 instruction 裏明確寫出每個 task 必須是且僅是一個 TDD 階段。
升級 5(質量門控):Lab 3 的 review 工件就是一個簡易的質量門控。它通過 schema 的 requires 依賴確保 tasks 不會跳過審查直接生成。這比在 config.yaml 裏寫一條 rule 說記得檢查靠譜得多 - 因為 rule 是文本約束,AI 可能忽略;但 requires 是結構約束,不滿足就生成不了。
你在項目中用過類似的方案嗎?是更喜歡 Lab 2 的輕量規則,還是 Lab 3 的結構性檢查?歡迎在評論區聊聊。
三個 Lab 的選型建議
根據你的項目規模和團隊情況,選擇合適的方案。
一個務實建議:別一上來就搞 Lab 3。先用 Lab 1 跑幾輪熟悉流程,覺得哪裏不夠再加對應的措施。Rules 和 Validate 是性價比很高的起步選擇。
誠實評估:OpenSpec 的能力邊界
三輪 Lab 跑下來,我對 OpenSpec 質量工作流的判斷是:
能做到的:通過 rules 約束 AI 行為、通過 validate 檢查結構合規、通過自定義 Schema 插入結構化檢查點。這三件事覆蓋了 5 個升級方向中的 4 個。
做不到的:運行驗證。代碼能不能跑、測試過不過、性能達不達標,這些需要測試框架和 CI 管道。OpenSpec 定位在文檔對齊和流程編排,不是運行時質量保障。
還有一個 Lab 3 暴露但容易被忽略的問題:自己審自己的審查結論整體偏寬鬆。review 工件由同一個 AI 生成,它審查的是自己寫的 specs 和 design。4 Pass + 1 Warning 的結果看起來不錯,但換成人類審查可能更嚴格。如果你的項目對質量有硬性要求,review 工件適合作為初審,不宜作為終審。
說到底,OpenSpec 的質量工作流需要配合外部工具一起用。它解決的是AI 寫出來的方案和你的意圖是否對齊,不是AI 寫出來的代碼能不能跑。
這兩個問題不一樣,解決方案也不一樣。
建議收藏這篇,下次用 OpenSpec 做項目時翻出來對照着選方案。如果你的同事也在用 OpenSpec,轉發給他看看這三個 Lab 的對比。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具的實戰經驗和最佳實踐。不錯過每一篇乾貨!
