OpenSpec 最佳實戰:4 步覆盤 + 5 項升級,讓 AI 編程從"能跑"到"跑對"
整理版優先睇
OpenSpec 四步法流程完整但代碼唔掂,關鍵係要補返運行驗證同測試閉環
術哥係一名專注AI編程嘅技術實踐者,佢分享用OpenSpec四步法(propose、apply、verify、archive)嘅真實經驗。好多用戶反映流程行完但代碼質量時好時壞,verify通過咗但運行時問題不斷。
術哥深入拆解每個環節嘅短板:propose階段Spec質量無驗證,apply係黑盒執行無中間檢查,verify只做文本對比唔運行代碼,archive前無質量門控。根本問題係四步法只保證文檔對齊,但唔保證代碼正確。
佢提出五項升級方案:加Spec Review、將apply拆成原子任務加檢查點、verify加入運行驗證、引入TDD思路、archive前設質量門控。結論係要喺原有流程基礎上補上運行驗證同測試閉環,先可以從「能跑」進化到「跑對」。
- 結論:四步法保證流程完整性但唔保證代碼正確性,需要補上運行驗證環節先得。
- 方法:五項升級包括Spec Review、原子任務加檢查點、運行驗證、TDD思路、質量門控。
- 差異:原本verify係文本檢查,升級後加入實際運行測試同lint,由睇文件變成試跑代碼。
- 啟發:質量問題嘅源頭係propose階段Spec無驗證,修復越早成本越低,唔好等到archive先處理。
- 可行動點:優先apply後加review同手動測試,逐步引入測試任務同原子拆分,保持上下文乾淨。
問題現象:流程行完但代碼唔掂
術哥觀察到好多OpenSpec用戶嘅真實情況:propose、apply、verify、archive行曬,但代碼質量時好時壞,有時直接用到,有時Bug頻出,甚至跑唔通。更奇怪嘅係,verify明明通過咗,該檢查嘅都檢查咗,但運行時問題一個接一個。
問題嘅根因唔係某個單一環節,而係四步法嘅設計哲學本身:佢保證咗流程完整性,但冇保證代碼正確性。
四步法短板逐個拆
Propose階段一次性生成四個工件,效率高但冇驗證Spec質量。Delta Specs格式要求嚴格,例如Scenario要用####四級標題,但寫錯咗唔會報錯,只會被靜默忽略。咁樣會導致成個鏈路質量取決於最薄弱環節。
Apply階段係黑盒執行,冇中間檢查點。AI由第一個task做到最後一個,中間冇停頓確認,如果早期task有Bug,後續都會基於錯誤代碼繼續構建,錯誤級聯放大。
Verify階段做嘅係文本檢查,檢查spec意圖同實現係咪一致,但唔會實際運行代碼。官方都話verify唔會阻塞archive,只係暴露問題。所以佢發現唔到邏輯錯誤、競態條件、邊界情況呢類運行時問題。
Archive階段缺乏質量門控,verify發現問題都可以照樣歸檔,問題就咁被埋咗落去。
五項升級方案:由文檔對齊到質量閉環
- 1 升級一:Propose後加Spec Review。格式校驗、一致性檢查、邊界條件審查,確保源頭質量。最好用另一個AI做Review,避免自己檢查自己。
- 2 升級二:Apply拆分為原子任務加檢查點。每個task完成後確認改動一致、冇影響之前任務、lint通過,錯誤發生即刻發現。
- 3 升級三:Verify加入運行驗證。靜態檢查(lint、type check)、單元測試、集成測試、手動驗證點,由睇文件變試跑代碼。
- 4 升級四:引入TDD思路。Design階段定義驗收標準,Tasks中明確測試任務,Apply先寫測試再寫實現,Verify運行測試。
- 5 升級五:Archive前設置質量門控清單。所有tasks完成、Spec Review通過、原子檢查點通過、運行驗證通過、無已知未修復Bug,全部通過先歸檔。
核心原則:唔好只睇代碼啱唔啱,要睇代碼跑唔跑得鬱。文本檢查解決做冇做嘅問題,運行驗證解決用得唔用得嘅問題。
實戰落地建議:由簡單開始逐步升級
以上升級方案唔使一次過全部上,術哥建議跟住優先級逐步引入。第一步成本最低效果最明顯:apply完成後先加review同手動測試核心功能。
- 第一步:Apply後加Review加手動測試。讓AI review代碼,自己再手動跑一次。
- 第二步:Propose後手動檢查Spec質量。睇下Scenario格式、邊界條件有冇覆蓋。
- 第三步:Tasks中強制包含測試任務。每個功能變更必須帶測試,養成習慣。
- 第四步:Apply拆分為原子任務。遇到複雜變更先用,簡單變更唔使拆。
- 另外:複雜變更分批處理,每個change只做一件事;保持上下文乾淨,apply前/clear。
工具係死嘅,人係生嘅。如果produce階段Spec有問題,直接手動編輯Markdown文件,唔好將就住往下走。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 106 篇,AI 編程最佳實戰「2026」系列第 31
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。

圖 1:OpenSpec 四步法覆盤——流程完整 ≠ 代碼正確
說明:本文是「OpenSpec 深度覆盤」系列的第一篇,定位為觀點提出與問題拆解。文中的四步法短板分析基於 OpenSpec 官方文檔和過往實踐記錄,5 項升級方案是基於這些分析推導出的改進方向——尚未經過完整的項目實戰驗證。後續會圍繞這些觀點逐一落地,用實際項目跑通驗證,推出 V2(單點驗證)、V3(全流程驗證)等實戰篇。如果你有不同的看法或者已經在做類似的改進,歡迎在評論區聊聊,互相啓發。
你在用 OpenSpec 的四步法工作流嗎?
propose(提案)、apply(實現)、verify(驗證)、archive(歸檔),流程走下來絲滑順暢,每一步都有明確的輸入輸出,看起來靠譜得很。
但實際用下來呢?代碼跑起來了沒有?跑起來之後 Bug 多不多?
這是不少 OpenSpec 用戶反饋的真實情況:流程走完了,代碼質量卻時好時壞。有時出來的功能直接能用,有時 Bug 頻出,甚至跑不通。更讓人費解的是,verify 階段明明通過了,該檢查的都檢查了,運行時問題還是一個接一個。
翻了官方文檔和過往的實踐記錄,我發現這個問題的根因不在於某個單一環節,而在於四步法的設計哲學本身:它保證了流程完整性,但沒有保證代碼正確性。
這篇文章,來做一次深度覆盤。
1. 四步法的設計意圖:它本來想做什麼
拆問題之前,先回顧四步法的設計意圖。
OpenSpec(GitHub: Fission-AI/OpenSpec,35K+ Star)的核心理念是先和 AI 對齊需求,再動手寫代碼。它的標準工作流(OPSX)是:
/opsx:propose ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive
每個階段都有明確的工件(Artifact):
這些工件之間有嚴格的依賴關係:proposal 生成 specs 和 design,specs 和 design 共同產出 tasks,tasks 驅動最終的代碼實現。
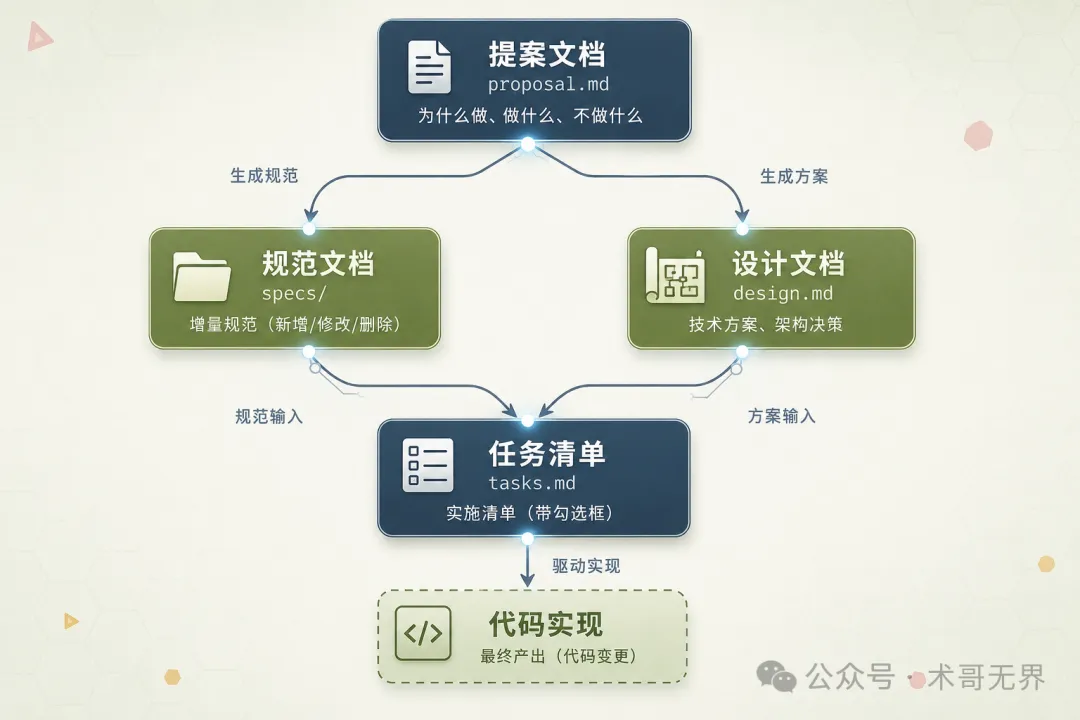
圖 2:OpenSpec 四個工件的 DAG 依賴關係
設計者的初衷很清晰:通過規範化的文檔鏈路,讓 AI 在動手之前先把需求理清楚、把方案想明白,避免邊寫邊想導致的混亂。這個方向沒問題。
問題在於,落地的時候每個環節都有暗坑。
2. 逐環節剖析:設計意圖 vs 實際表現
Propose:Spec 質量沒有驗證機制
propose 一次性生成 proposal、specs、design、tasks 四個工件。高效,但藏着一個關鍵問題:誰來確保這些工件本身是對的?
根據官方文檔(docs/concepts.md),Spec 是行為契約,寫的是系統應該做什麼。但 Spec 本身的完整性和準確性,沒有驗證機制。
更具體地說,Delta Specs 的格式要求很嚴格。比如 Scenario 必須用 #### 四級標題,但寫錯了不會報錯。過往實踐文章的記錄顯示,歸檔時格式不對的 Delta Spec 會被靜默忽略 - 不會提示你哪裏有問題,直接跳過。
這意味着什麼?如果 propose 階段的 Spec 寫得不完整或有格式問題,整個後續鏈路都會受影響:不完整的 Spec 導致不完整的設計,不完整的設計導致不完整的任務,不完整的任務導致不完整的實現。
整個鏈路的質量取決於最薄弱的環節。而 propose 這個環節,恰恰沒有質量兜底。
Apply:黑盒執行,沒有中間檢查點
apply 按 tasks.md 逐條實現代碼。官方文檔(docs/opsx.md)的描述是 checking them off as you go。
這裏有兩個問題。
第一,沒有中間檢查點。 AI 從第一個 task 開始,一口氣做到最後一個,中間沒有停頓讓你確認。如果 AI 在第 3 個 task 的實現出了問題,後面的 4、5、6 都會基於有 Bug 的代碼繼續構建。錯誤級聯放大。
第二,沒有人工干預的時機設計。 官方文檔說如果發現問題可以 fix the artifact, then continue。但這更像一個補丁,不是系統性的解決方案。
打個比方:這就像讓一個施工隊一口氣蓋完一棟十層的樓,中間不驗收任何一層。等蓋完了你說第 3 層的承重牆有問題 - 對不起,第 4 到 10 層都建在上面了,改不動了。
Verify:文本檢查不是運行驗證
這是四步法中被誤解最多的環節。
verify 從三個維度檢查:Completeness(完整性)、Correctness(正確性)、Coherence(一致性)。聽起來很嚴謹。
但根據官方文檔(docs/commands.md)的描述,verify 檢查的是實現是否匹配 spec 意圖、設計決策是否反映在代碼中。本質上,這是 AI 讀取文件做文本對比,不涉及實際運行代碼。
官方自己說得很直白:verify won't block archive, but it surfaces issues(verify 不會阻塞 archive,只是暴露問題)。
所以 verify 能發現什麼?能發現你 spec 裏寫了要做 A,但代碼裏做的是 B這類文本層面的不一致。
發現不了什麼呢?邏輯錯誤、競態條件、邊界情況、性能問題、安全隱患 - 這些都需要實際運行代碼才能暴露。
文本檢查和運行驗證是本質不同的兩件事。 前者確認你做了你說要做的事,後者確認你做的事真能跑。
Archive:缺乏質量門控
archive 做的是歸檔變更、合併 Delta Specs。質量風險相對較低,但有一個容易被忽略的問題:archive 之前沒有質量門控。
前面說了,verify 不會阻塞 archive。也就是說,即使 verify 發現了問題,archive 照樣可以執行。你可能歸檔了一份有問題的變更,後續的其他變更會基於這份有問題的代碼繼續構建。問題就這樣被埋進去了。

圖 3:四步法各環節設計意圖與實際短板對比
你在用 AI 編程時遇到過類似的問題嗎?比如 verify 通過了但代碼跑不通,歡迎在評論區聊聊你的經驗。
3. 根因分析:流程完整為什麼產不出正確代碼
把四個環節的問題放在一起看,會發現一個共同的模式。
根本問題在於:四步法的質量保障機制是文檔層面的對齊,不是代碼層面的驗證。
整個工作流隱含了一個假設:只要文檔(Spec、Design)寫得夠好,AI 就能按文檔實現出正確的代碼。但這個假設在兩個地方站不住腳。
第一,文檔本身的質量無法確保。 propose 階段一次性生成四個工件,這些工件之間可能存在不一致,而且沒有驗證機制來發現這些問題。
第二,即使文檔是完美的,從文檔到代碼的轉化也可能出錯。 AI 的實現能力在複雜業務邏輯、邊界條件、併發處理等方面都有侷限。這不是四步法的問題,是當前 AI 編程能力的固有短板。
還有一個容易被忽視的因素:上下文窗口壓力。官方 README 明確建議:OpenSpec benefits from a clean context window. Clear your context before starting implementation。但在 apply 過程中,AI 需要同時持有 Proposal + Specs + Design + Tasks 的信息。複雜變更產生的代碼量一大,上下文窗口就會被填滿,AI 在長會話中可能遺忘早期的設計決策,導致實現和原始設計產生偏差。

圖 4:質量風險級聯傳導——問題累積,越往後越難修復
說到底,四步法解決的是需求對齊的問題,不是代碼質量的問題。這是兩件事,需要不同的機制來保障。
4. 現有改進:Apply 後加自 Review
一些用戶已經意識到這個問題,並在實踐中做了改進:在 apply 結束後,讓 AI 自己 review 一次代碼。
具體做法:review 沒問題就 archive;有問題就修復,然後更新 change 相關文件,再 archive。
這個實踐的效果如何?
能解決的問題:
多了一道質量關卡,能發現一些明顯的邏輯錯誤 確保 tasks.md 的完成狀態與實際代碼一致 成本低,不需要額外工具
但侷限也很明顯:
AI 審查自己的代碼有盲區。 讓寫代碼和查代碼的是同一個 AI,就好比讓學生自己批自己的卷子 - 有些錯誤寫的時候看不到,回頭看也看不到,因為思維模式是固定的。
沒有自動化測試。 Review 仍然是文本層面的檢查,不運行代碼。
Review 標準不明確。 檢查什麼、怎麼算通過、怎麼算不通過,沒有統一準則。
方向是對的,但還不夠。
5. 升級方案:從文檔對齊到質量閉環
基於上面的分析,這裏梳理一個升級方案。核心思路:在四步法基礎上加入運行驗證和測試閉環,不推翻重來,而是補上缺失的環節。
升級一:Propose 後加 Spec Review
針對問題:Spec 質量無驗證,格式錯誤被靜默忽略。
具體做法:
propose 生成四個工件後、apply 開始之前,加一個 Spec Review 步驟:
格式校驗:確保 Scenario 用了正確的標題層級( ####),ADDED/MODIFIED/REMOVED 標記完整一致性檢查:Spec 描述的行為是否覆蓋了 Proposal 中的所有需求 邊界條件審查:是否考慮了異常場景、邊界輸入、錯誤處理
這一步的目的是在源頭把控質量。不完整的 Spec 會導致整個鏈路下游全部偏離,修復越早成本越低。
實際操作上,可以手動檢查,也可以讓另一個 AI 實例來做 Review - 重點是別讓同一次 propose 的 AI 自己檢查自己。
升級二:Apply 拆分為原子任務 + 檢查點
針對問題:黑盒執行,錯誤級聯放大。
具體做法:
把 apply 拆分成更小的粒度,每個原子任務完成後做一個快速檢查:
apply-task-1 → check-1 → apply-task-2 → check-2 → ... → apply-task-N → check-N
每個 check 點確認三件事:
當前任務的代碼改動是否和 task 描述一致 是否影響了之前已完成的 task 基本語法檢查(lint)是否通過
這樣做的好處是:錯誤在發生時就能被發現,而不是等所有任務做完才發現第 3 步就有問題。
如果 tasks.md 的拆分粒度太粗,可以先手動拆分:把一個大 task 拆成幾個小 task,再逐個執行。OpenSpec 的工件都是 Markdown 文件,直接編輯就行。
升級三:Verify 加入運行驗證
針對問題:文本檢查發現不了運行時錯誤。
具體做法:
在原有文本檢查的基礎上,加入實際運行驗證:
靜態檢查:lint、類型檢查(TypeScript 項目跑 tsc --noEmit)單元測試:要求每個新增功能都有對應的測試用例 集成測試:涉及多個模塊變更的場景,跑集成測試 手動驗證點:核心業務邏輯標記需要人工確認的驗證項
關鍵原則:不要只看代碼對不對,要看代碼能不能跑。文本檢查解決做沒做的問題,運行驗證解決能不能用的問題。
升級四:引入 TDD 思路
針對問題:測試被當作可選項。
具體做法:
把測試從可選變成強制,參考 TDD(Test-Driven Development)的思路:
Design 階段定義驗收標準:什麼輸入應該產生什麼輸出 Tasks 中明確測試任務:不是籠統的寫測試,而是為 XX 場景寫測試,斷言 YY 輸出 Apply 中先寫測試再寫實現:至少對核心邏輯採用這個順序 Verify 中運行測試:測試不通過就不進入 archive
TDD 不需要嚴格遵循紅-綠-重構的完整循環,但先想清楚怎麼驗證,再動手寫代碼這個思路,能從源頭改變代碼質量的保障方式。
升級五:Archive 前設置質量門控
針對問題:Verify 不阻塞 Archive,問題代碼可能被歸檔。
具體做法:
在 Archive 之前設置一個質量門控清單:
[ ] 所有 Tasks 已完成(tasks.md 中無未勾選項) [ ] Spec Review 已通過 [ ] 原子任務檢查點已通過 [ ] 運行驗證已通過:lint、測試、類型檢查 [ ] 無已知未修復的 Bug
只有全部通過,才執行 Archive。這個清單可以根據項目實際情況增減條目。
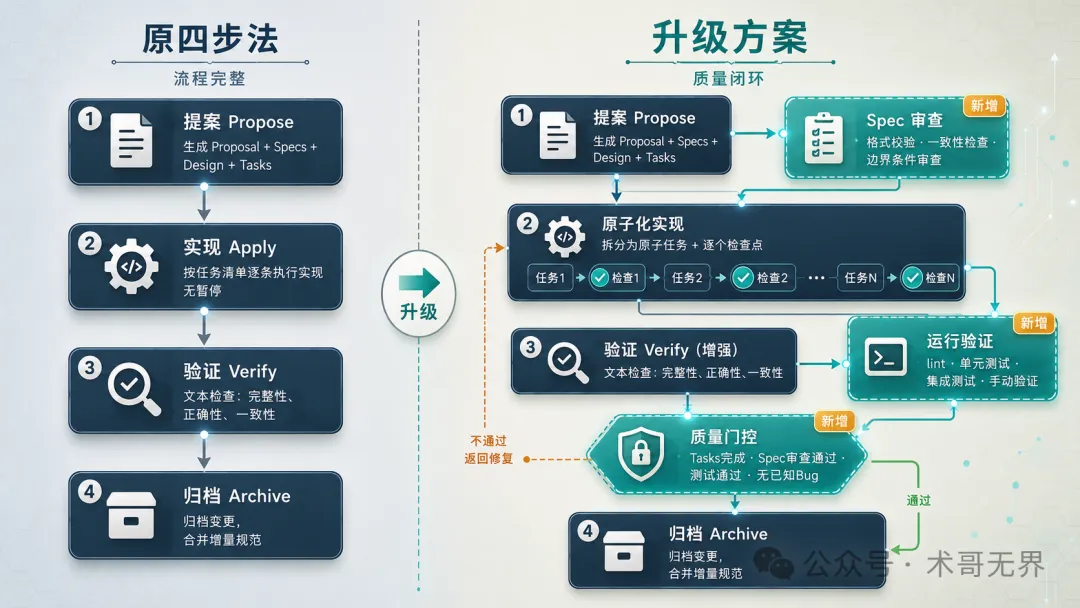
圖 5:原四步法 vs 升級後工作流對比(新增環節已標註)
6. 實戰建議:先改什麼,後改什麼
上面的升級方案不需要一次性全上。以下是一個更務實的落地順序。
優先級排序
第一步:Apply 後加 Review + 手動測試。 成本最低,效果明顯。apply 完成後先別急着 archive,讓 AI review 代碼,自己再手動跑一遍核心功能。
第二步:Propose 後手動檢查 Spec 質量。 看看 Scenario 格式對不對、邊界條件有沒有覆蓋。防止源頭出錯。
第三步:在 Tasks 中強制包含測試任務。 不是可選的測試,而是每個功能變更必須帶測試。養成習慣。
第四步:Apply 拆分為原子任務。 遇到複雜變更時再用。簡單變更(改兩三個文件)不需要拆。
利用 OpenSpec 的 Edit 機制
OpenSpec 的工件都是 Markdown 文件,可以手動編輯。
如果 propose 生成的 Spec 有問題,直接改,不要將就着往下走。改完後 apply 會讀取修改後的版本。
如果 apply 過程中發現 tasks.md 拆分粒度太粗,也可以手動拆。工具是死的,人是活的。
複雜變更分批處理
如果一個變更涉及 5 個以上文件或 3 個以上模塊,考慮拆成多個獨立的 change,每個 change 只做一件事。
好處有三:
每個 change 的上下文壓力更小,AI 不容易遺忘 驗證更集中,出問題更容易定位 回滾更容易,不至於一個改動出問題就把整批代碼都卡住
保持上下文乾淨
官方建議在開始 implementation 前清空上下文。這個建議要認真對待。
apply 之前執行 /clear,讓 AI 重新讀取所有工件文件。雖然會多花一點時間,但能有效避免長會話中的遺忘問題。
總結
這篇文章做了一件事:把 OpenSpec 四步法"流程走完但代碼不對"的現象拆開來看,找到每個環節的短板,並推導出 5 個升級方向。
四步法的質量保障停留在文檔對齊層面,缺少代碼驗證環節。Propose 階段的 Spec 沒有質量驗證,Apply 是黑盒執行,Verify 做的是文本檢查而非運行驗證,Archive 缺乏質量門控。單獨看每個問題都不大,疊加起來就是流程走完了但代碼不對的尷尬局面。
但坦率說,這篇文章只完成了發現問題和提出方案這兩步。提出的 5 個升級方向——Spec Review、原子任務拆分、運行驗證、TDD 思路、質量門控——邏輯上說得通,但還沒有用真實項目驗證過。這些方案到底能不能跑通?哪幾個效果最明顯?落地時又會踩什麼新坑?這些問題的答案,要靠實戰才能給出來。
這也是為什麼把這篇文章作為「OpenSpec 深度覆盤」系列的第一篇——先拋出觀點,後續逐一實戰驗證。如果你也在用 OpenSpec,你的工作流是什麼樣的?有沒有遇到過類似的問題?評論區聊聊,互相啓發。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具的實戰經驗和最佳實踐。不錯過每一篇乾貨!
