openspec 最佳實戰:不改 OpenSpec 源碼,只改一段配置,代碼質量從不可控到 80 分
整理版優先睇
任務粒度控制係提升AI生成代碼質量最有效嘅20%改動
呢篇文章由術哥(ShugeX)撰寫,佢係一位專注AI編程、OpenSpec同MCP等技術嘅開源佈道者。文章基於OpenSpec v1.3.1官方文檔同埋作者3輪Lab實測數據,想解決嘅問題係:點樣低成本咁大幅提升AI生成代碼嘅質量。整體結論係:喺5個質量升級方向入面,任務粒度控制(即係改一段配置文本)性價比最高,20%嘅改動可以覆蓋80%嘅質量問題。
作者指出,AI喺apply階段成日夾帶私貨,根源唔係AI能力問題,而係畀佢嘅任務描述太粗。粗粒度任務令AI自行解釋需求同實現範圍,導致出現冇人提及嘅需求(例如更改時間戳格式)。相反,細粒度任務每個step附完整代碼同命令,壓縮咗AI嘅發揮空間,令佢淨係跟住做就得。
文章詳細解釋咗三步配置方法:創建config.yaml提供全局上下文同規則、fork schema升級tasks嘅instruction、插入review工件做安全網。呢啲改動唔使改OpenSpec源碼,唔使裝外部工具,只係改幾個文件嘅文字內容。最後佢仲畫咗一個6個Phase嘅日常工作流,同埋三層防線嘅設計哲學:源頭控制做重、過程檢查做輕、收尾確認做快。
- 任務粒度控制係提升AI生成代碼質量嘅最大槓桿,佔整體效益嘅80%,淨係改一段配置文本就搞掂。
- 三步配置法:創建config.yaml(上下文+規則)、fork schema升級tasks instruction(畀嚴格模板同禁止事項)、插入review工件(結構化審查)。
- 粗粒度任務令AI自行解釋需求導致夾帶私貨,細粒度任務(2-5分鐘一個step,附完整代碼)壓縮解釋空間。
- 指令質量係根因:你畀嘅指令有模糊空間,AI就會填滿;壓縮到零,AI就只能照單執行。
- 日常開發用6個Phase:需求澄清(Explore)、一鍵生成工件(propose)、人工檢查(1-2分鐘掃review)、按任務執行(apply)、一致性驗證(verify)、歸檔(archive)。
問題根源:任務太粗,AI就會自由發揮
3輪Lab跑落,AI喺apply階段夾帶私貨呢個現象反覆出現。Lab 1裸跑嘅時候,AI從todo-priority呢個change name推斷曬全部需求,結果tasks.md出現咗一個冇人提過嘅需求——ISO 8601時間戳格式變更。呢個係breaking change,但propose階段根本冇人要求做。
AI做咗乜?佢自行解釋咗需求,然後自行決定咗實現範圍。問題嘅根因唔係AI嘅能力,而係我哋畀佢嘅任務描述太粗。
睇一個對比就明:粗粒度任務係一句話描述,例如「實現用戶註冊接口」;細粒度任務每個step附完整測試代碼、實現代碼、運行命令同預期輸出。AI拿到細粒度任務,淨係跟住做就得,冇解釋空間。
因果鏈好清楚:任務粗 → AI自行解釋 → 自行決定範圍 → 夾帶私貨;任務細 + 附代碼 → AI只需執行 → 冇解釋空間 → 夾唔到私貨。
2/8法則:任務粒度先係嗰個20%
上篇文章驗證咗5個升級方向,如果從性價比角度重新排序,畫面完全唔同。
改進方向包括:升級tasks instruction(改一段配置文本)、加代碼審查、加歸檔前驗證、寫更細rules、需求澄清。其中升級tasks instruction性價比極高:淨係改一個字段嘅一段文字,唔使改OpenSpec源碼、唔使裝外部工具、唔使調整DAG依賴鏈。
效果係令AI喺生成tasks.md嘅階段就將任務拆到2-5分鐘粒度,每個step附完整代碼。20%嘅改動,覆蓋80%嘅質量提升。
Lab 2加Rules + Explore,產出質量主要來自Explore嘅需求澄清,rules本身效果難單獨量化;Lab 3自定義Schema插入Review工件,配置成本唔低。而升級tasks instruction係最輕量嘅選擇。
三步配置:從不可控到80分
三步配置嘅思路好簡單:畀AI足夠精確嘅上下文 → 畀AI足夠嚴格嘅執行指令 → 插一道自動檢查。每步淨係改一個文件。
第1步:創建config.yaml,放喺項目根目錄嘅openspec/config.yaml。呢個文件畀AI提供全局上下文同按工件分組嘅規則。例如技術棧、測試命令、編碼規範,rules按artifact ID分組如specs、design、tasks、review。
schema: with-review
context: |
技術棧:TypeScript, Express, Vitest
測試命令:npx vitest run
所有新功能必須遵循 TDD 節奏——先寫失敗測試,再寫實現代碼
rules:
specs:
- 每個數據字段嘅變更,必須覆蓋 null、空值、越界三種異常場景
- Scenario 必須使用 #### 四級標題,否則歸檔時唔生效
design:
- 涉及數據庫 migration 嘅設計,必須包含回滾方案
tasks:
- 每個 task 必須包含完整嘅測試代碼同實現代碼
- 每組 task 嘅第一步必須係寫失敗測試,最後一步必須係驗證通過
review:
- 重點檢查 tasks.md 嘅粒度係咪達到 2-5 分鐘一個 step
- 檢查係咪有佔位符(TBD、TODO、implement later)第2步:Fork Schema,升級tasks instruction。先用openspec schema fork命令fork一個現有schema,然後喺openspec/schemas/with-review/schema.yaml入面,將id: tasks嘅instruction字段替換成嚴格模板:每個task必須包含5個step(寫失敗測試、運行確認失敗、寫最小實現、運行確認通過、提交),每步附完整代碼同命令。再加禁止事項,例如唔準出現TBD、TODO、「添加適當嘅錯誤處理」等。
第3步:插入review工件(配套措施)。喺schema加入一個id: review嘅工件,放喺design同tasks之間。呢個工件做五維審查:邊界條件、回滾方案、測試覆蓋、向後兼容、任務粒度(最重要)。然後將tasks嘅requires改成[review],形成依賴鏈:proposal → specs → design → review → tasks → APPLY。review工件係一個閘門:冇review,tasks就唔會開始生成。
坦率講,呢一步嘅效果比前兩步温和,因為自己審自己嘅審查結論偏寬鬆。4 Pass + 1 Warning睇落唔錯,但換成人類審查可能更嚴格。不過作為結構化安全網,仲係有價值。
完整工作流:6個Phase嘅日常開發
配置係一次性嘅,日常開發就係反覆跑6個Phase。每個Phase對應一條OpenSpec命令,AI做完一步你確認一步。
- 1 Phase 1:需求澄清(/opsx:explore)。可選但推薦,喺propose之前將模糊地帶唸清楚:字段類型、邊界條件、遷移策略等。
- 2 Phase 2:一鍵生成工件(/opsx:propose)。自動創建change目錄,按依賴順序生成全部工件。用with-review schema會一次產出5個文件:proposal.md、specs/、design.md、review.md、tasks.md。
- 3 Phase 3:人工檢查(1-2分鐘)。掃一眼review.md,重點睇任務粒度嗰個維度同整體評估嘅關鍵建議。如果唔啱,直接手動改tasks.md,唔使重跑propose。
- 4 Phase 4:按任務執行(/opsx:apply)。AI按照tasks.md逐個step實現,因為每個step有完整代碼同命令,冇發揮空間。
- 5 Phase 5:一致性驗證(/opsx:verify)。文本層面檢查實現係咪匹配spec意圖,注意verify唔做運行驗證,要另外靠測試框架同CI。
- 6 Phase 6:歸檔(/opsx:archive)。歸檔前建議掃一眼所有task嘅完成狀態,確認冇遺漏。
三層防線嘅設計哲學:第一層做重,第二層做輕,第三層做快。第一層(tasks instruction升級)貢獻80%質量;第二層(review + verify)做安全網;第三層(archive前人工檢查)做兜底。
實戰注意事項
坑點同技巧都係3輪Lab入面踩過嘅,每條一句話。
- rules嘅key必須同artifact id完全一致。寫成task而唔係tasks,規則就會靜默失效,唔會報錯。
- openspec schema fork目前係experimental功能,後續版本命令格式可能變化,升級時留意changelog。
- verify唔做運行驗證,只做文本一致性檢查。代碼能唔能跑,要另外靠測試框架。
- review係自己審自己,結論偏寬鬆。對質量有硬性要求嘅項目,review適合初審,唔適宜終審。
- context窗口壓力。apply階段AI需要同時持有所有工件信息,複雜變更建議先/clear再apply。
- 技巧:複雜變更(5個文件以上)拆成多個獨立change,每個淨係做一件事。
- propose唔一定會問需求——change name夠清晰時AI可能跳過確認直接生成。想控制需求就先跑Explore。
- 工件都係Markdown文件,隨時可以手動改。propose生成嘅tasks粒度唔夠?直接編輯tasks.md,唔使重跑propose。
下一期預告:呢篇方法論講完咗任務粒度點解係嗰20%、三步配置點樣做、日常工作流係點樣。第2期開始實戰,用呢套方法論從零搭建一個真實項目——shuge AI Toolbox。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 108 篇,AI 編程最佳實戰「2026」系列第 33
各位好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。

圖 1:任務粒度——代碼質量最大嘅槓桿
說明:本文內容係基於 OpenSpec(Fission-AI/OpenSpec)v1.3.1 官方文檔、筆者前兩篇文章(《OpenSpec 最佳實戰:4 步覆盤 + 5 項升級》、《3 輪實測驗證 5 個質量升級方向》)嘅實測數據,同埋 Superpowers writing-plans skill 嘅公開設計文檔分析整理出嚟。文入面嘅配置模板同參數建議只係參考,實際效果請以你嘅業務數據同環境測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
上篇文章用 3 輪 Lab 驗證咗 5 個質量升級方向。結論表貼出嚟,答案一目瞭然:5 個方向都有效,但性價比天差地別。
有啲改動要 fork schema、插入新工件、調依賴鏈,搞一輪之後質量的確好咗。但有個方向令我意外——淨係改一段配置文本,唔鬱 OpenSpec 源碼,唔裝外部工具,效果卻覆蓋咗 80% 嘅質量問題。
呢個方向就係:任務粒度控制。
今日呢篇係「OpenSpec 項目實戰」系列第 1 期,定位方法論篇。先講清楚點解任務粒度係嗰個 20%,然後講三步配置點樣做,最後畫一張完整嘅日常工作流全景圖。由第 2 期開始,會拎一個真實項目「shuge AI Toolbox」,用呢套方法論由零開始搭建,逐期展開。
1. 問題根源:任務太粗,AI 就會自由發揮
3 輪 Lab 跑落嚟,有一個發現反覆出現:AI 喺 apply 階段夾帶私貨。
Lab 1 裸跑嘅時候,AI 由 todo-priority 呢個 change name 推斷曬全部需求。結果 tasks.md 入面出現咗一個冇人提過嘅需求——ISO 8601 時間戳格式變更。呢個係一個 breaking change,但 propose 階段根本冇人要求做呢件事。
AI 做咗啲咩?佢自己解釋咗需求,然後自己決定咗實現範圍。
呢個問題嘅根因唔係 AI 嘅能力,而係我哋畀佢嘅任務描述太粗。睇一個對比就明。
粗粒度任務係咁樣:
- [ ] 1.1 實現用戶註冊接口
- [ ] 1.2 添加輸入校驗
- [ ] 1.3 處理異常情況
三個 task,每個都係一句話描述。AI 拎到呢啲 task 會做啲咩?佢會猜——註冊接口使唔使發電郵?校驗規則是乜?異常情況具體指邊啲?估完之後就自己寫,寫完你一睇,唔啱。
細粒度任務係咁樣:
### 任務 1:郵箱格式校驗
- [ ] 第 1 步:寫失敗測試
```typescript
test('無效郵箱格式返回 400', () => {
const result = register({ email: 'abc' });
expect(result.status).toBe(400);
});
[ ] 第 2 步:運行測試——確認失敗 命令:
npx vitest run tests/auth.test.ts預期:FAIL — function is not defined[ ] 第 3 步:寫最小實現 (完整代碼)
[ ] 第 4 步:運行測試——確認通過 命令:
npx vitest run tests/auth.test.ts預期:PASS
每個 step 附了完整代碼、運行命令、預期輸出。AI 拿到這種 task 還能發揮什麼?**照着做就行了**。

*圖 2:任務粒度對比——粗任務給 AI 留了發揮空間,細任務把空間壓縮到零*
因果鏈很清楚:
任務粗 → AI 自己解釋 → 自己決定範圍 → 夾帶私貨 任務細 + 附代碼 → AI 淨係執行 → 冇解釋空間 → 夾唔到私貨
說到底,這不是 AI 能力的問題,是**指令質量**的問題。你給的指令有模糊空間,AI 就會填滿這個空間。你把模糊空間壓縮到零,AI 就只能照單執行。
## 2. 2/8 法則:任務粒度才是那個 20%
上篇文章驗證了 5 個升級方向。如果從性價比角度重新排序,畫面會完全不一樣。
| 改進方向 | 你需要做什麼 | 效果 | 投入產出比 |
|---------|------------|------|-----------|
| **升級 tasks 的 instruction** | 改一段配置文本 | AI 生成細粒度 tasks → 源頭消滅問題 | **極高** |
| 加代碼審查 | 獨立 subagent 或人工審查 | 發現已產生的問題 | 中 |
| 加歸檔前驗證 | 開啓 expanded workflow | 補抓遺漏 | 中 |
| 寫更細的 rules | 調試 config.yaml rules | AI 遵循度不穩定 | 低 |
| 需求澄清 | Explore 多輪對話 | 效果好但耗時 | 中高 |
3 輪實測的結論支撐這個排序:
**Lab 2 加了 Rules + Explore**,產出質量主要來自 Explore 的需求澄清,rules 本身的效果很難單獨量化。為什麼?因為 rules 是文本約束,AI 有時候遵循有時候不遵循,你沒法保證每次都生效。
**Lab 3 自定義 Schema 插入 Review 工件**,tasks.md 從 19 個增加到 22 個,新增的 3 個 task 都有明確的 review 建議來源。但整條鏈路需要 fork schema、寫 review 模板、調整依賴關係,配置成本不低。
而升級 tasks 的 instruction 呢?只需要**改一個字段裏的一段文字**。不改 OpenSpec 源碼,不裝外部工具,不調整 DAG 依賴鏈。效果是讓 AI 在生成 tasks.md 的階段就把任務拆到 2-5 分鐘粒度,每個 step 附完整代碼。
**20% 的改動,覆蓋 80% 的質量提升。** 這就是 2/8 法則。
剩下的 80% 改動(審查 + 驗證 + CI)能帶來多少額外提升?大概 20%。它們是安全網,不是主力。
那這 20% 的改動具體怎麼做?
## 3. 三步配置:從不可控到 80 分
三步配置的思路很簡單:**給 AI 足夠精確的上下文 → 給 AI 足夠嚴格的執行指令 → 插一道自動檢查**。每步只改一個文件。
### 第 1 步:創建 config.yaml(上下文 + 規則)
這個文件給 AI 提供全局上下文和按工件分組的規則。放在項目根目錄的 `openspec/config.yaml`:
```yaml
schema: with-review
context: |
技術棧:TypeScript, Express, Vitest
測試命令:npx vitest run
所有新功能必須遵循 TDD 節奏——先寫失敗測試,再寫實現代碼
rules:
specs:
- 每個數據字段的變更,必須覆蓋 null、空值、越界三種異常場景
- Scenario 必須使用 #### 四級標題,否則歸檔時不生效
design:
- 涉及數據庫 migration 的設計,必須包含回滾方案
tasks:
- 每個 task 必須包含完整的測試代碼和實現代碼
- 每組 task 的第一步必須是寫失敗測試,最後一步必須是驗證通過
review:
- 重點檢查 tasks.md 的粒度是否達到 2-5 分鐘一個 step
- 檢查是否有佔位符(TBD、TODO、implement later)
幾個要點:
context字段注入所有工件,話畀 AI 知你嘅技術棧、測試命令、編碼規範rules按 artifact ID 分組,key 必須同 schema 裏面嘅 artifact id 完全一致rules 喺 prompt 中以約束條件嘅形式傳遞,相當於畀 AI 畫紅線
完整配置文件見附件:
config.yaml
第 2 步:Fork Schema,升級 tasks 嘅 instruction
這是核心改動。
先 fork 一個現有嘅 schema:
openspec schema fork spec-driven with-review
注意:
openspec schema fork目前標記為 experimental,後續版本可能有變化。
然後在 openspec/schemas/with-review/schema.yaml 入面,揾到 id: tasks 嘅 artifact,將佢嘅 instruction 字段換成下面呢段:
instruction: |
創建細粒度的實現計劃。每個任務的工作量應在 2-5 分鐘之間。
每個任務必須遵循以下格式:
-涉及文件(精確路徑)
-第1步:寫失敗測試(附完整測試代碼)
-第2步:運行測試——確認失敗(附命令+預期輸出)
-第3步:寫最小實現(附完整實現代碼)
-第4步:運行測試——確認通過(附命令+預期輸出)
-第5步:提交(附git命令)
禁止事項(出現即視為計劃不合格):
-TBD、TODO、implementlater
-「添加適當的錯誤處理」(必須寫出具體代碼)
-「為以上代碼寫測試」(必須寫出具體測試代碼)
-只描述做什麼但不展示怎麼做
呢段 instruction 做咗兩件事:
第一,畀 AI 一個嚴格嘅任務模板。 每個 task 必須包含 5 個 step,由寫失敗測試到提交,每步附完整代碼同命令。AI 冇發揮空間。
第二,列咗一堆禁止事項。 呢啲都係 AI 常見嘅偷懶行為——寫個 TBD 叫你自已填,講句「添加適當嘅錯誤處理」就算完成。而家出現呢啲就直接判定計劃唔合格。
完整 instruction 內容見附件:
tasks-instruction.yaml
第 3 步:插入 review 工件(配套措施)
喺前兩步嘅基礎上,加一個 review 工件落 schema,放喺 design 同 tasks 之間:
# schema.yaml 中的新增工件
-id:review
generates:review.md
template:review.md
description:五維審查-檢查設計方案和Spec的完整性
instruction:|
從五個維度審查所有工件的完整性和質量。
審查維度:
1. 邊界條件 2. 回滾方案 3. 測試覆蓋
4. 向後兼容 5. 任務粒度(最重要)
requires:[proposal,specs,design]
然後將 tasks 嘅 requires 從 [specs, design] 改為 [review]。咁樣依賴鏈變成:
proposal → specs → design → review → tasks → APPLY
review 工件係一個閘門:冇 review,tasks 就唔會開始生成。審查結論入面會明確標註每個維度嘅狀態(✅ 通過 / ⚠️ 警告 / ❌ 失敗),tasks.md 會參考 review 嘅建議嚟決定拆分方向。
坦白講,呢一步嘅效果比前兩步温和。3 輪實測發現,自己審自己嘅審查結論偏寬鬆——4 Pass + 1 Warning 睇落唔錯,但換成人類審查可能會更嚴格。不過作為一道結構化嘅安全網,佢仲有價值。
完整 review instruction 見附件:
review-instruction.yamlreview 模板文件見附件:review-template.md
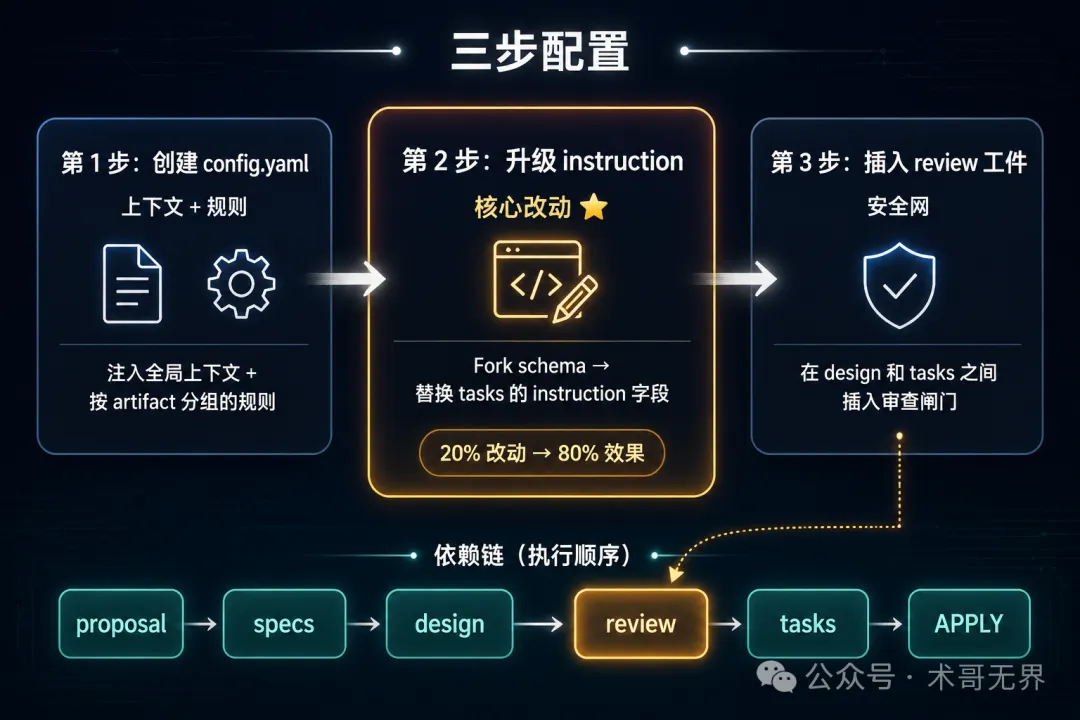
圖 3:三步配置——由上下文注入到指令升級再到自動審查
三步做完,日常開發嘅工作流係點樣?
4. 完整工作流:6 個 Phase 嘅日常開發
配置係一次過嘅,日常開發就不斷跑 6 個 Phase。每個 Phase 對應一條 OpenSpec 命令,AI 做完一步你確認一步。
Phase 1:需求澄清
/opsx:explore
可選但推薦。喺 propose 之前,先諗清楚模糊地帶:字段類型點揀、邊界條件有邊啲、遷移策略係乜。Explore 會畫出決策矩陣幫你理清思路。
3 輪實測嘅結論係:Explore 階段嘅需求澄清,係產出質量提升嘅主要來源。Lab 2 嘅 rules 本身效果唔太容易量化,但 Explore + propose 嘅組合比單獨 propose 可靠得多——需求係你講嘅,唔係 AI 估嘅。
Phase 2:一鍵生成工件
/opsx:propose
propose 內部會自動創建 change 目錄,然後按依賴順序生成全部工件。用 with-review schema 嘅話,一次產出 5 個文件:proposal.md、specs/、design.md、review.md、tasks.md。
關鍵係 tasks.md——因為我哋升級咗 instruction,呢度嘅每個 task 都係 2-5 分鐘粒度、附完整代碼同命令嘅。
Phase 3:人工檢查(1-2 分鐘)
呢一步只需要睇一眼 review.md。重點睇兩個地方:
任務粒度嗰個維度嘅狀態:係 ✅ 定係 ⚠️? 整體評估入面對 tasks.md 嘅關鍵建議
如果 review 話 tasks.md 粒度唔夠或者有佔位符,手動改返 tasks.md 先繼續。OpenSpec 嘅工件都係 Markdown 文件,直接編輯就得。
Phase 4:按任務執行
/opsx:apply
AI 讀取曬所有工件之後,按 tasks.md 裏面嘅順序逐個實現。因為每個 step 都有完整代碼同命令,AI 只需要跟住做——冇發揮空間。
Phase 5:一致性驗證(安全網)
/opsx:verify
注意:verify 需要 expanded workflow 先用到。
verify 檢查實現係咪匹配 spec 意圖。本質係文本層面嘅一致性檢查,唔係運行驗證。代碼跑唔跑得掂,仲要靠測試框架同 CI。但作為一道安全網,佢可以發現「spec 裏面寫咗要做 A,代碼入面做嘅係 B」呢類問題。
你喺項目入面用過類似嘅 6 步工作流未?有冇邊個 Phase 你覺得可以慳返?歡迎喺評論區傾嚇。
Phase 6:歸檔
/opsx:archive
將成個 change 目錄歸檔。歸檔前建議睇一眼所有 task 嘅完成狀態,確認冇遺漏。
5. 三層防線:唔係所有防線都咁重要
三步配置搞掂之後,日常開發入面其實有三層防線喺度運作。不過佢哋嘅重要性唔係一個量級。

圖 4:三層防線——80% 嘅質量來自源頭控制
第一層:源頭控制(tasks instruction 升級)→ 貢獻 80% 嘅質量
呢個係成篇文章嘅核心。通過升級 instruction,令 AI 喺生成 tasks.md 嘅時候將每個 step 拆到 2-5 分鐘、附上完整代碼。問題喺源頭就消滅咗,後面嘅防線只需要處理遺漏。
第二層:過程檢查(review + verify)→ 安全網
review 工件喺 design 同 tasks 之間插入咗一道結構化審查。verify 喺 apply 之後做一致性檢查。呢兩道防線處理嘅係第一層漏咗嘅問題——邊界條件遺漏、回滾方案缺失、spec 同代碼不一致。
第三層:收尾確認(archive 前嘅人工檢查)→ 兜底
睇一眼 review.md 嘅結論同 tasks.md 嘅完成狀態,1-2 分鐘嘅事。呢個係人嘅防線,處理前兩層冇覆蓋到嘅邊界情況。
三層防線嘅設計哲學:第一層做重,第二層做輕,第三層做快。 唔好試喺每一層都做 100% 嘅檢查——咁樣係喺每個環節投入 80% 嘅精力,換嚟 20% 嘅邊際提升。
6. 實戰注意事項
坑點同技巧都係 3 輪 Lab 入面踩過嘅,每條一句話。
坑點:
rules 嘅 key 必須同 artifact id 完全一致。寫成 task而不是tasks,規則就會靜默失效,唔會報錯。openspec schema fork目前係 experimental 功能,後續版本命令格式可能變化,升級時留意 changelog。verify 唔做運行驗證,只做文本一致性檢查。代碼跑唔跑得掂,要靠測試框架。 review 係自己審自己,結論偏寬鬆。對質量有硬性要求嘅項目,review 適合初審,唔適合終審。 context 窗口壓力。apply 階段 AI 需要同時持有所有工件信息,複雜變更時建議先 /clear再 apply。
技巧:
複雜變更(5 個文件以上)拆成多個獨立 change,每個淨係做一件事。上下文壓力細,AI 唔容易遺漏。 propose 唔一定會問需求——change name 夠清晰時 AI 可能跳過確認直接生成。想控制需求就先跑一次 Explore。 工件都係 Markdown 文件,隨時可以手動改。propose 生成嘅 tasks 粒度唔夠?直接編輯 tasks.md,唔使重跑 propose。 instruction 入面多寫「禁止事項」比多寫「建議事項」更有效。AI 對否定約束嘅遵循度高過模糊嘅正面指導。
下一期預告
呢篇方法論講完咗點解任務粒度係嗰個 20%,三步配置點樣做,日常工作流係點樣。
第 2 期開始實戰。我會用呢套方法論,由零開始搭建一個真實項目——shuge AI Toolbox。第 2 期嘅內容:
用 Explore 澄清項目需求,確定 MVP 範圍 執行 propose 生成 5 個工件,逐個檢查產出質量 重點睇 tasks.md 嘅粒度係咪真係達到 2-5 分鐘一個 step
如果你都想跟住做,建議你先將三步配置搞掂:創建 config.yaml、fork schema、升級 instruction。具體配置文件下一期會放喺公開嘅代碼倉庫作為附件,讀者可以直接拎嚟改。
系列持續更新中,關注唔迷路。
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發俾需要嘅朋友,我哋下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具嘅實戰經驗同最佳實踐。唔好錯過每一篇乾貨!

🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 108 篇,AI 編程最佳實戰「2026」系列第 33
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
圖 1:任務粒度——代碼質量最大的槓桿
說明:本文內容基於 OpenSpec(Fission-AI/OpenSpec)v1.3.1 官方文檔、筆者前兩篇文章(《OpenSpec 最佳實戰:4 步覆盤 + 5 項升級》、《3 輪實測驗證 5 個質量升級方向》)的實測數據,以及 Superpowers writing-plans skill 的公開設計文檔分析整理而成。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
上篇文章用 3 輪 Lab 驗證了 5 個質量升級方向。結論表貼出來,答案一目瞭然:5 個方向都有效,但性價比天差地別。
有些改動需要 fork schema、插入新工件、調依賴鏈,折騰一圈下來質量確實好了。但有個方向讓我意外——只改一段配置文本,不碰 OpenSpec 源碼,不裝外部工具,效果卻覆蓋了 80% 的質量問題。
這個方向就是:任務粒度控制。
今天這篇是「OpenSpec 項目實戰」系列第 1 期,定位方法論篇。先把為什麼任務粒度是那個 20% 講清楚,再說三步配置怎麼做,最後畫一張完整的日常工作流全景圖。從第 2 期開始,會拿一個真實項目「shuge AI Toolbox」,用這套方法論從零搭建,逐期展開。
1. 問題根源:任務太粗,AI 就會自由發揮
3 輪 Lab 跑下來,有一個發現反覆出現:AI 在 apply 階段夾帶私貨。
Lab 1 裸跑的時候,AI 從 todo-priority 這個 change name 推斷了全部需求。結果 tasks.md 裏出現了一個沒人提過的需求——ISO 8601 時間戳格式變更。這是個 breaking change,但 propose 階段根本沒人要求做這件事。
AI 做了什麼?它自行解釋了需求,然後自行決定了實現範圍。
這個問題的根因不在 AI 的能力,而在我們給它的任務描述太粗了。看一個對比就明白。
粗粒度任務長這樣:
- [ ] 1.1 實現用戶註冊接口
- [ ] 1.2 添加輸入校驗
- [ ] 1.3 處理異常情況
三個 task,每個都是一句話描述。AI 拿到這種 task 會做什麼?它會猜——註冊接口要不要發郵件?校驗規則是什麼?異常情況具體指哪些?猜完了就自己寫,寫完了你一看,不對。
細粒度任務長這樣:
### 任務 1:郵箱格式校驗
- [ ] 第 1 步:寫失敗測試
```typescript
test('無效郵箱格式返回 400', () => {
const result = register({ email: 'abc' });
expect(result.status).toBe(400);
});
[ ] 第 2 步:運行測試——確認失敗 命令:
npx vitest run tests/auth.test.ts預期:FAIL — function is not defined[ ] 第 3 步:寫最小實現 (完整代碼)
[ ] 第 4 步:運行測試——確認通過 命令:
npx vitest run tests/auth.test.ts預期:PASS
每個 step 附了完整代碼、運行命令、預期輸出。AI 拿到這種 task 還能發揮什麼?**照着做就行了**。

*圖 2:任務粒度對比——粗任務給 AI 留了發揮空間,細任務把空間壓縮到零*
因果鏈很清楚:
任務粗 → AI 自行解釋 → 自行決定範圍 → 夾帶私貨 任務細 + 附代碼 → AI 只需執行 → 沒有解釋空間 → 夾不了私貨
說到底,這不是 AI 能力的問題,是**指令質量**的問題。你給的指令有模糊空間,AI 就會填滿這個空間。你把模糊空間壓縮到零,AI 就只能照單執行。
## 2. 2/8 法則:任務粒度才是那個 20%
上篇文章驗證了 5 個升級方向。如果從性價比角度重新排序,畫面會完全不一樣。
| 改進方向 | 你需要做什麼 | 效果 | 投入產出比 |
|---------|------------|------|-----------|
| **升級 tasks 的 instruction** | 改一段配置文本 | AI 生成細粒度 tasks → 源頭消滅問題 | **極高** |
| 加代碼審查 | 獨立 subagent 或人工審查 | 發現已產生的問題 | 中 |
| 加歸檔前驗證 | 開啓 expanded workflow | 補抓遺漏 | 中 |
| 寫更細的 rules | 調試 config.yaml rules | AI 遵循度不穩定 | 低 |
| 需求澄清 | Explore 多輪對話 | 效果好但耗時 | 中高 |
3 輪實測的結論支撐這個排序:
**Lab 2 加了 Rules + Explore**,產出質量主要來自 Explore 的需求澄清,rules 本身的效果很難單獨量化。為什麼?因為 rules 是文本約束,AI 有時候遵循有時候不遵循,你沒法保證每次都生效。
**Lab 3 自定義 Schema 插入 Review 工件**,tasks.md 從 19 個增加到 22 個,新增的 3 個 task 都有明確的 review 建議來源。但整條鏈路需要 fork schema、寫 review 模板、調整依賴關係,配置成本不低。
而升級 tasks 的 instruction 呢?只需要**改一個字段裏的一段文字**。不改 OpenSpec 源碼,不裝外部工具,不調整 DAG 依賴鏈。效果是讓 AI 在生成 tasks.md 的階段就把任務拆到 2-5 分鐘粒度,每個 step 附完整代碼。
**20% 的改動,覆蓋 80% 的質量提升。** 這就是 2/8 法則。
剩下的 80% 改動(審查 + 驗證 + CI)能帶來多少額外提升?大概 20%。它們是安全網,不是主力。
那這 20% 的改動具體怎麼做?
## 3. 三步配置:從不可控到 80 分
三步配置的思路很簡單:**給 AI 足夠精確的上下文 → 給 AI 足夠嚴格的執行指令 → 插一道自動檢查**。每步只改一個文件。
### 第 1 步:創建 config.yaml(上下文 + 規則)
這個文件給 AI 提供全局上下文和按工件分組的規則。放在項目根目錄的 `openspec/config.yaml`:
```yaml
schema: with-review
context: |
技術棧:TypeScript, Express, Vitest
測試命令:npx vitest run
所有新功能必須遵循 TDD 節奏——先寫失敗測試,再寫實現代碼
rules:
specs:
- 每個數據字段的變更,必須覆蓋 null、空值、越界三種異常場景
- Scenario 必須使用 #### 四級標題,否則歸檔時不生效
design:
- 涉及數據庫 migration 的設計,必須包含回滾方案
tasks:
- 每個 task 必須包含完整的測試代碼和實現代碼
- 每組 task 的第一步必須是寫失敗測試,最後一步必須是驗證通過
review:
- 重點檢查 tasks.md 的粒度是否達到 2-5 分鐘一個 step
- 檢查是否有佔位符(TBD、TODO、implement later)
幾個要點:
context字段注入所有工件,告訴 AI 你的技術棧、測試命令、編碼規範rules按 artifact ID 分組,key 必須和 schema 裏的 artifact id 完全一致rules 在 prompt 中以約束條件的形式傳遞,相當於給 AI 畫紅線
完整配置文件見附件:
config.yaml
第 2 步:Fork Schema,升級 tasks 的 instruction
這是核心改動。
先 fork 一個現有的 schema:
openspec schema fork spec-driven with-review
注意:
openspec schema fork目前標記為 experimental,後續版本可能有變化。
然後在 openspec/schemas/with-review/schema.yaml 中,找到 id: tasks 的 artifact,把它的 instruction 字段替換成下面這段:
instruction: |
創建細粒度的實現計劃。每個任務的工作量應在 2-5 分鐘之間。
每個任務必須遵循以下格式:
-涉及文件(精確路徑)
-第1步:寫失敗測試(附完整測試代碼)
-第2步:運行測試——確認失敗(附命令+預期輸出)
-第3步:寫最小實現(附完整實現代碼)
-第4步:運行測試——確認通過(附命令+預期輸出)
-第5步:提交(附git命令)
禁止事項(出現即視為計劃不合格):
-TBD、TODO、implementlater
-「添加適當的錯誤處理」(必須寫出具體代碼)
-「為以上代碼寫測試」(必須寫出具體測試代碼)
-只描述做什麼但不展示怎麼做
這段 instruction 做了兩件事:
第一,給 AI 一個嚴格的任務模板。 每個 task 必須包含 5 個 step,從寫失敗測試到提交,每步附完整代碼和命令。AI 沒有發揮空間。
第二,列了一堆禁止事項。 這些都是 AI 常見的偷懶行為——寫個 TBD 讓你自己填,說一句「添加適當的錯誤處理」就算完成了。現在出現這些就直接判定計劃不合格。
完整 instruction 內容見附件:
tasks-instruction.yaml
第 3 步:插入 review 工件(配套措施)
在前兩步的基礎上,給 schema 加一個 review 工件,放在 design 和 tasks 之間:
# schema.yaml 中的新增工件
-id:review
generates:review.md
template:review.md
description:五維審查-檢查設計方案和Spec的完整性
instruction:|
從五個維度審查所有工件的完整性和質量。
審查維度:
1. 邊界條件 2. 回滾方案 3. 測試覆蓋
4. 向後兼容 5. 任務粒度(最重要)
requires:[proposal,specs,design]
然後把 tasks 的 requires 從 [specs, design] 改為 [review]。這樣依賴鏈變成:
proposal → specs → design → review → tasks → APPLY
review 工件是個閘門:沒有 review,tasks 就不會開始生成。審查結論裏會明確標註每個維度的狀態(✅ 通過 / ⚠️ 警告 / ❌ 失敗),tasks.md 會參考 review 的建議來決定拆分方向。
坦率說,這一步的效果比前兩步温和。3 輪實測發現,自己審自己的審查結論偏寬鬆——4 Pass + 1 Warning 看着不錯,但換成人類審查可能更嚴格。不過作為一道結構化的安全網,它還是有價值的。
完整 review instruction 見附件:
review-instruction.yamlreview 模板文件見附件:review-template.md
圖 3:三步配置——從上下文注入到指令升級再到自動審查
三步做完,日常開發的工作流長什麼樣?
4. 完整工作流:6 個 Phase 的日常開發
配置是一次性的,日常開發就是反覆跑 6 個 Phase。每個 Phase 對應一條 OpenSpec 命令,AI 做完一步你確認一步。
Phase 1:需求澄清
/opsx:explore
可選但推薦。在 propose 之前,先把模糊地帶想清楚:字段類型怎麼選、邊界條件有哪些、遷移策略是什麼。Explore 會畫出決策矩陣幫你理清思路。
3 輪實測的結論是:Explore 階段的需求澄清,是產出質量提升的主要來源。Lab 2 的 rules 本身效果不太容易量化,但 Explore + propose 的組合比單獨 propose 可靠得多——需求是你說的,不是 AI 猜的。
Phase 2:一鍵生成工件
/opsx:propose
propose 內部會自動創建 change 目錄,然後按依賴順序生成全部工件。用 with-review schema 的話,一次產出 5 個文件:proposal.md、specs/、design.md、review.md、tasks.md。
關鍵是 tasks.md——因為我們升級了 instruction,這裏的每個 task 都是 2-5 分鐘粒度、附完整代碼和命令的。
Phase 3:人工檢查(1-2 分鐘)
這一步只需要掃一眼 review.md。重點看兩個地方:
任務粒度那個維度的狀態:是 ✅ 還是 ⚠️? 整體評估裏對 tasks.md 的關鍵建議
如果 review 說 tasks.md 粒度不夠或者有佔位符,手動改一下 tasks.md 再往下走。OpenSpec 的工件都是 Markdown 文件,直接編輯就行。
Phase 4:按任務執行
/opsx:apply
AI 讀取所有工件後,按 tasks.md 裏的順序逐個實現。因為每個 step 都有完整代碼和命令,AI 只需要照着做——沒有發揮空間。
Phase 5:一致性驗證(安全網)
/opsx:verify
注意:verify 需要 expanded workflow 才能使用。
verify 檢查實現是否匹配 spec 意圖。本質是文本層面的一致性檢查,不是運行驗證。代碼能不能跑,還得靠測試框架和 CI。但作為一道安全網,它能發現「spec 裏寫了要做 A,代碼裏做的是 B」這類問題。
你在項目中用過類似的 6 步工作流嗎?有沒有哪個 Phase 你覺得可以省掉?歡迎在評論區聊聊。
Phase 6:歸檔
/opsx:archive
將整個 change 目錄歸檔。歸檔前建議掃一眼所有 task 的完成狀態,確認沒有遺漏。
5. 三層防線:不是所有防線都一樣重要
三步配置搭好之後,日常開發中其實有三層防線在工作。但它們的重要性不在一個量級。
圖 4:三層防線——80% 的質量來自源頭控制
第一層:源頭控制(tasks instruction 升級)→ 貢獻 80% 的質量
這是整篇文章的核心。通過升級 instruction,讓 AI 在生成 tasks.md 的時候就把每個 step 拆到 2-5 分鐘、附上完整代碼。問題在源頭就被消滅了,後面的防線只需要處理遺漏。
第二層:過程檢查(review + verify)→ 安全網
review 工件在 design 和 tasks 之間插入一道結構化審查。verify 在 apply 後做一致性檢查。這兩道防線處理的是第一層漏掉的問題——邊界條件遺漏、回滾方案缺失、spec 和代碼不一致。
第三層:收尾確認(archive 前的人工檢查)→ 兜底
掃一眼 review.md 的結論和 tasks.md 的完成狀態,1-2 分鐘的事。這是人的防線,處理前兩層沒覆蓋到的邊界情況。
三層防線的設計哲學:第一層做重,第二層做輕,第三層做快。 不要試圖在每一層都做 100% 的檢查——那是在每個環節都投入 80% 的精力,換來 20% 的邊際提升。
6. 實戰注意事項
坑點和技巧都是 3 輪 Lab 裏踩過的,每條一句話。
坑點:
rules 的 key 必須和 artifact id 完全一致。寫成 task而不是tasks,規則就靜默失效了,不會報錯。openspec schema fork目前是 experimental 功能,後續版本命令格式可能變化,升級時留意 changelog。verify 不做運行驗證,只做文本一致性檢查。代碼能不能跑,得靠測試框架。 review 是自己審自己,結論偏寬鬆。對質量有硬性要求的項目,review 適合初審,不宜終審。 context 窗口壓力。apply 階段 AI 需要同時持有所有工件信息,複雜變更時建議先 /clear再 apply。
技巧:
複雜變更(5 個文件以上)拆成多個獨立 change,每個只做一件事。上下文壓力小,AI 不容易遺忘。 propose 不一定會問需求——change name 足夠清晰時 AI 可能跳過確認直接生成。想控制需求就先跑一遍 Explore。 工件都是 Markdown 文件,隨時可以手動改。propose 生成的 tasks 粒度不夠?直接編輯 tasks.md,不用重跑 propose。 instruction 裏多寫「禁止事項」比多寫「建議事項」更有效。AI 對否定約束的遵循度高於模糊的正面指導。
下一期預告
這篇方法論講完了為什麼任務粒度是那個 20%,三步配置怎麼做,日常工作流長什麼樣。
第 2 期開始實戰。我會用這套方法論,從零開始搭建一個真實項目——shuge AI Toolbox。第 2 期的內容:
用 Explore 澄清項目需求,確定 MVP 範圍 執行 propose 生成 5 個工件,逐個檢查產出質量 重點看 tasks.md 的粒度是不是真的達到了 2-5 分鐘一個 step
如果你也想跟着做,建議先把三步配置跑通:創建 config.yaml、fork schema、升級 instruction。具體配置文件下一期會放在公開的代碼倉庫作為附件,讀者可以直接拿來改。
系列持續更新中,關注不迷路。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!
掃碼關注,獲取更多 AI 工具的實戰經驗和最佳實踐。不錯過每一篇乾貨!