OpenSpec 項目實戰(八)| 3 期改造、2 處修復、verify 第 4 維度依然缺席後,我把工作流拆成三檔
整理版優先睇
OpenSpec改造揭示後置檢查天花板,術哥提出三檔工作流:按風險選擇流程強度,平衡速度與質量
呢篇文章係術哥喺OpenSpec v1.3.1項目實戰系列嘅第八篇。佢之前幾期改造咗tasks template、拆分review同verify職責、統一verify SKILL.md嘅定義,但第7期修完後verify報告仍然只得3個維度,Task Granularity缺席。呢次佢唔急住寫新功能,反而覆盤咗三期改造嘅實際效果同共同缺口,發現後置檢查(template、review、verify)有用但有天花板——AI係概率性執行者,唔係確定性機器,讀咗規則唔等於遵守。
為咗解決呢個問題,術哥提出咗三檔工作流:快速檔(低風險改動,靠瀏覽器確認兜底)、標準檔(普通功能開發,用Superpowers writing-plans管執行顆粒度)、嚴格檔(高風險改動,行TDD加兩階段review)。每檔有明確嘅適用場景、工具組合同質量門檻,核心係「改錯代價越高,流程越嚴格」。佢仲用shuge AI Toolbox嚟舉例,講清楚每檔適合咩改動。
最後佢規劃咗第9至15期嘅實戰計劃,直接用呢三檔流程驗證唔同場景,目標係用數據驅動嚟校準工作流效率。總括嚟講,呢篇文嘅結論係:AI編程要管理嘅係風險,唔係儀式感;OpenSpec管「做咩」,Superpowers管「點做」,兩套工具唔係二選一,而係按風險組合使用。
- 第7期verify修復實驗表明:即使全鏈路統一,AI仍可能唔跟模板輸出,提示詞約束有概率性天花板
- 三層改造各有收穫(template生效、review拆分有用),但共同缺口係後置檢查無法保證執行紀律,AI報告不能盡信
- 解決方案係三檔工作流:快速檔靠瀏覽器確認、標準檔靠writing-plans、嚴格檔靠TDD+review,按風險選擇流程強度
- 快速檔約5分鐘額外成本,標準檔約15-20分鐘,嚴格檔約30-40分鐘,用時間換質量保證
- 後續第9-15期會用呢三檔流程實戰驗證:標準檔實現Markdown預覽、嚴格檔寫正則測試器、快速檔優化UI等
結構示例
### Summary| Dimension | Status ||--------------|---------------------|| Completeness | 11/11 tasks, 7/8 scenarios || Correctness | Requirement implemented, 1 scenario uncovered || Coherence | Followed/Issues |第7期verify修復實驗:全鏈路改咗,AI仲係行老路
術哥先交代第7期修咗咩。原本verify SKILL.md入面有內部矛盾:L46定義話有four dimensions,但Summary Scorecard模板(L117-127)得3行,Graceful Degradation段(L159-164)亦寫住verify all three dimensions。佢改咗兩處,加返Task Granularity行,將three改做four,以為咁就可以見到第4維度。
全鏈路統一後,AI仍然按慣性輸出3維度
執行/opsx:verify後,報告Summary得Completeness、Correctness、Coherence三行,Task Granularity完全冇出現。術哥話呢個結果有啲意外,但反映出一個反直覺嘅點:AI生成輸出時唔係逐項填模板,佢有自己嘅慣性路徑。
不過術哥補充,雖然第4維度缺席,但verify喺其他3個維度發揮咗實際價值——佢發現咗1個CRITICAL issue(大文件JSON解析漏咗size check)同1個WARNING(有效JSON點擊語法校驗按鈕嘅測試用例缺失)。所以結論唔係verify冇用,而係純後置檢查有天花板。
verify有用,但提示詞約束嘅天花板仍然存在
三層改造效果回顧:後置檢查嘅共同缺口
術哥將第5-7期放埋一齊睇:第5期改tasks template生效,因為template優先級高過instruction;第6期拆分review/verify職責部分生效,review嘅拆分方向建議有參考價值,但verify第4維度因內部矛盾未生效;第7期修完矛盾後仍未生效。
- 1 第5期:template改造生效,tasks格式規範,經驗係「template比instruction更能約束輸出格式」
- 2 第6期:review從5維度減到4維度,為tasks提供拆分方向建議;verify新增第4維度但未生效
- 3 第7期:全鏈路同步後AI仍然唔跟模板,Task Granularity缺席
三層改造嘅共同缺口有幾個:task checkbox唔代表真係跟TDD執行;verify報告唔能替代fresh test/build/browser;AI完成報告唔可以直接信。術哥指出呢啲問題根源係同一條:AI係概率性執行者,佢讀咗規則唔等於遵守,標咗完成唔等於真係完成。
缺口:checkbox唔代表執行、verify唔能替代測試、AI報告唔能信
概率性執行者呢個根因解釋咗所有後置檢查嘅侷限
三檔工作流:按風險選擇流程強度
術哥提出將工作流分三檔,每檔有唔同適用場景、工具組合同質量門檻。快速檔適合低風險改動(文案、樣式微調),流程係OpenSpec + fresh verify + 瀏覽器檢查,質量門檻係fresh verification,唔信AI報告,約5分鐘額外成本。
- 快速檔:改按鈕顏色、調整間距,風險低,靠瀏覽器兜底
- 標準檔:實現新工具(如Markdown預覽),有明確輸入輸出,用writing-plans管執行顆粒度,約15-20分鐘
- 嚴格檔:bug修復、公共模塊重構,必須先有失敗測試或根因分析,加兩階段review,約30-40分鐘
術哥仲用shuge AI Toolbox舉例:工具頁標題改措辭用快速檔;實現時間戳轉換工具用標準檔;重構公共基礎組件用嚴格檔。呢個原則同軟件工程講嘅風險驅動測試係同一思路——唔係所有代碼都需要100%測試覆蓋,但高風險代碼必須有測試。
OpenSpec管「做咩」,Superpowers管「點做」
三檔工作流按風險組合兩套工具,唔係二選一
第9-15期規劃:用實戰校準三檔流程
術哥已經定好第9-15期嘅檔位分配:第9期標準檔實現Markdown預覽工具,驗證writing-plans嘅顆粒度價值;第10期嚴格檔寫正則測試器,驗證TDD喺複雜邏輯中嘅效果;第11期快速檔做工具頁體驗優化,睇下輕量流程對低風險改動係咪夠用。
- 1 第9期(標準檔):Markdown預覽工具,關鍵驗證點係writing-plans能唔能唔拖慢速度而令任務顆粒度更可控
- 2 第10期(嚴格檔):正則測試器,TDD嘅Red-Green-Refactor循環能否提高邊界條件處理
- 3 第11期(快速檔):工具頁UI微調,驗證輕量流程對低風險改動係咪足夠
- 4 第12期(標準檔):時間戳轉換工具,同第9期對比標準檔嘅穩定性
- 5 第13期(嚴格檔):修復真實Bug,測試systematic-debugging嘅實際效果
- 6 第14期(嚴格檔):重構工具頁公共基礎,因為一處改動影響所有工具
- 7 第15期(覆盤):收集第9-14期嘅速度同質量數據,校準三檔流程
關鍵驗證點:writing-plans顆粒度、TDD邊界條件、systematic-debugging效果
真正要管理嘅係風險,唔係儀式感
術哥回顧第5-7期改造路徑,其實都係答緊同一個問題:點樣令AI編程嘅產出質量可控。第5期用template,有效但只管輸出格式;第6期拆review/verify,有效但後置檢查有天花板;第7期修矛盾,但AI唔跟模板。
後置檢查有用,但不能保證執行過程本身係啱
三檔工作流將質量保證從後置檢查向前移:快速檔靠瀏覽器確認兜底,標準檔靠writing-plans做計劃前置,嚴格檔靠TDD同review管執行過程。風險越高,前置越多。
術哥話,如果將三檔工作流壓縮成一條規則就係咁。唔好追求流程嘅儀式感,而係管理風險。OpenSpec同Superpowers各管一段,按風險組合用。
OpenSpec管「做咩」,Superpowers管「點做」
兩套工具唔係二選一,係按風險選擇組合強度
🚩 2026 年「術哥無界」系列實戰文件 X 篇原創計劃 第 133 篇,OpenSpec 項目實戰「2026」系列第 8 篇
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
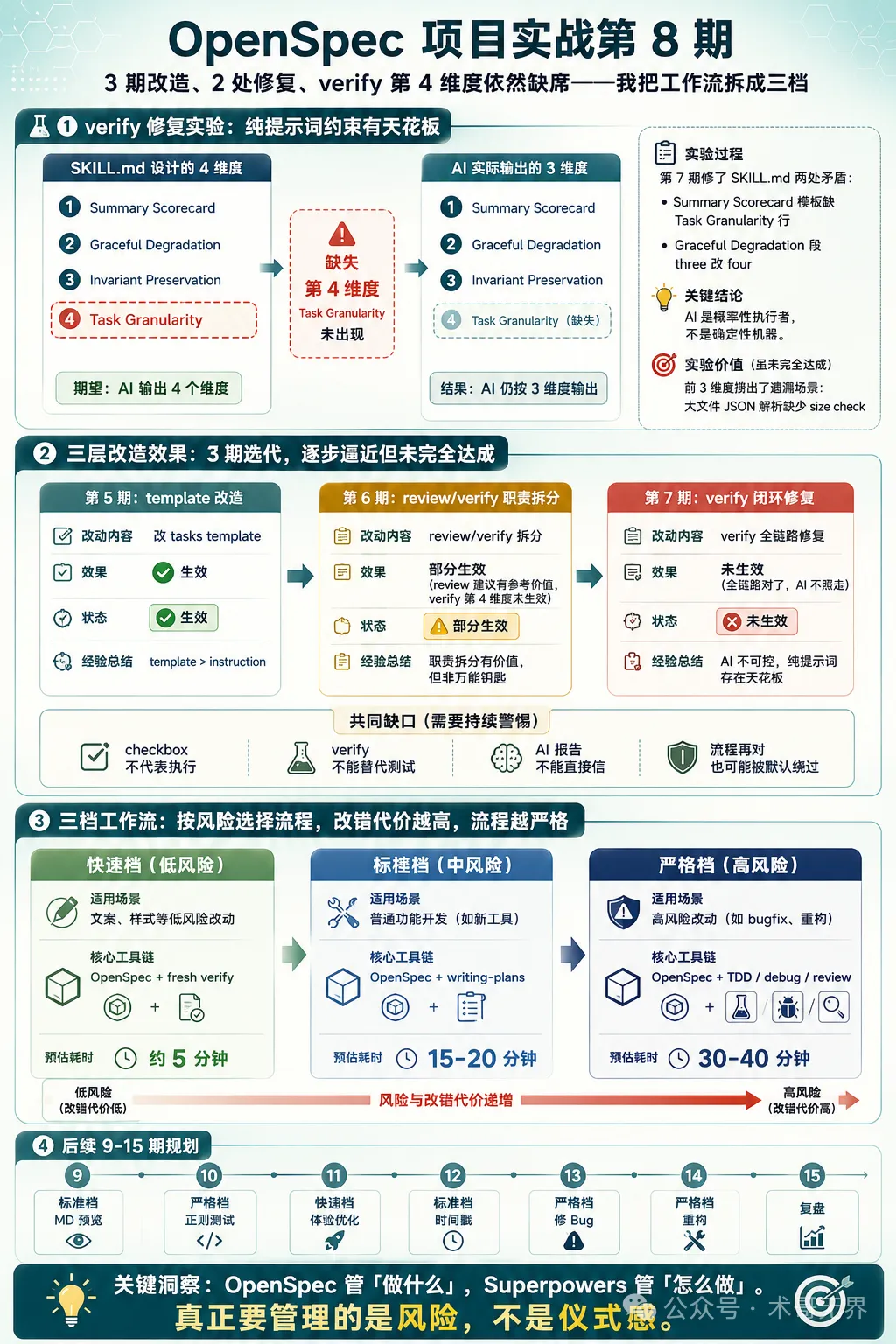
圖:verify 實驗結果 + 三層改造覆盤 + 三檔工作流程設計
說明:本文內容係基於 OpenSpec v1.3.1 實際項目操作記錄同讀者反饋整理。verify SKILL.md 修復同三層改造效果都喺 shuge-ai-toolbox 項目中實際驗證,但 verify 第 4 維度(Task Granularity)修復後仍然未生效,文中如實記錄。文中嘅配置修改同代碼僅供參考,實際效果請以你嘅項目環境測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
第 5 期改咗 tasks template,tasks 格式穩咗。OpenSpec 項目實戰(五)|UI 視覺打磨 + 改 template 令 AI 寫出規範任務
第 6 期拆咗 review 同 verify 嘅職責,review 給出嘅拆分方向建議有咗參考價值。OpenSpec 項目實戰(六) | review 拆分 + verify 增強 + 實現第一個工具
第 7 期將 verify SKILL.md 裏便兩處矛盾同步修咗,以為今次總算可以見到第 4 維度 Task Granularity 出現喺報告裏便。OpenSpec 項目實戰(七)| verify 2 個工具、3 處修復,第 4 維度依然缺席
結果:verify 報告 Summary 表格仍然只有 3 行。Completeness、Correctness、Coherence,同改之前一模一樣。
呢一期唔寫新功能,專門覆盤第 7 期 verify 修復實驗嘅真實結果,梳理第 5-7 期三層改造各解決咗啲咩、仲缺啲咩,然後給出後續系列嘅工作流程規則——按風險揀流程強度,唔再一刀切。
完整流程如下: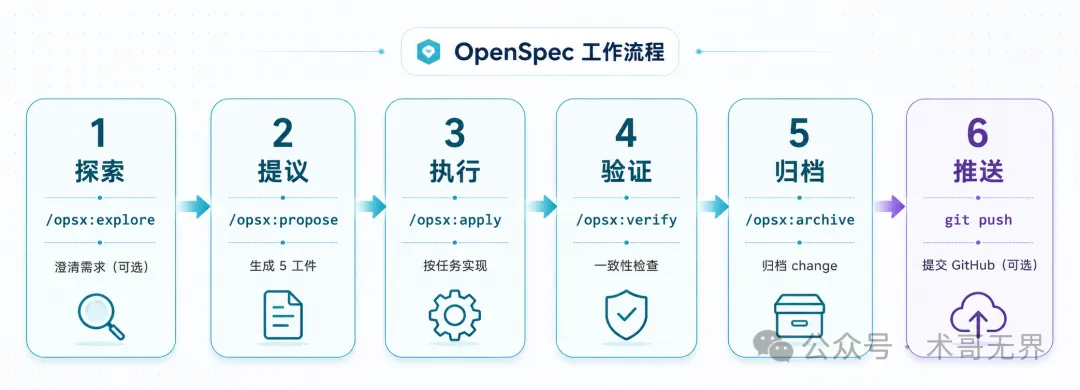
第 7 期 verify 修復實驗:改咗全鏈路,AI 仍然按老路徑走
先交代第 7 期修咗啲咩。
第 6 期喺 verify SKILL.md 裏便新增咗第 4 維度 Task Granularity,但執行 /opsx:verify 後報告淨係輸出咗 3 個維度。當時翻咗一遍源文件,根因係 SKILL.md 內部矛盾——L46 定義部分寫咗 four dimensions,但後面兩處引用仲停留喺 three:
Summary Scorecard 模板(L117-127):表格得 3 行,缺 Task Granularity 行 Graceful Degradation 段(L159-164):最後一句寫嘅係 verify all three dimensions
第 7 期改咗兩處:Summary Scorecard 加咗 Task Granularity 行(| Task Granularity | Format/TDD/Code |),Graceful Degradation 嘅 three 改成 four。改動好細。
修完之後直接行 Propose → Apply → Verify,今期 verify 階段應該可以用到修復後嘅配置。執行 /opsx:verify 之後,AI 輸出嘅報告係咁嘅:
### Summary
| Dimension | Status |
|--------------|---------------------|
| Completeness | 11/11 tasks, 7/8 scenarios |
| Correctness | Requirement implemented, 1 scenario uncovered |
| Coherence | Followed/Issues |
3 行。Task Granularity 冇出現。定義、模板、退化邏輯全鏈路統一咗,AI 生成報告時依然跳過咗模板,按慣性輸出。
老實講,見到呢個結果嘅時候有啲意外。修之前以為係改定義冇改引用嘅問題,引用同步之後應該就可以生效。但實際情況係,就算全鏈路都對齊咗,AI 在生成輸出時並唔嚴格按模板逐項填充——佢自己有慣性路徑,讀到模板但唔一定會照住行。
有個反直覺嘅點值得記錄:verify 報告雖然缺咗第 4 維度,但喺其他 3 個維度上發揮咗實際價值。呢啲係第 7 期 /opsx:verify 嘅實際輸出——佢發現咗 1 個 CRITICAL issue,spec 裏便定義咗大檔案 JSON 解析場景(超過 1MB 要提示用戶),但實現中冇做 size check。仲發現咗 1 個 WARNING,有效 JSON 點擊語法校驗按鈕嘅測試用例缺失。呢啲係 specs 寫咗但 tasks 冇覆蓋到嘅場景,verify 將佢哋撈咗出嚟。
所以結論唔係verify 冇用,而是verify 嘅後置檢查有用,但純提示詞約束有天花板。
再睇 verify SKILL.md 嘅當前版本——L46-54 確實定義咗四個維度,Task Granularity 下面仲詳細拆咗四項檢查:任務格式(### 任務 N)、TDD 合規(Red/Green/Refactor)、代碼完整性(冇 TBD/TODO)、粒度評估(2-5 分鐘範圍)。定義本身冇問題。Summary Scorecard 模板都加咗 Task Granularity 行。Graceful Degradation 都改咗做 four。全鏈路都啱,但 AI 就係唔輸出。
呢個俾咗一個好實際嘅教訓:提示詞約束係一條鏈路,唔係孤立嘅定義。L46 寫得幾靚都冇用,後面模板同退化邏輯冇跟上,執行層就按舊路徑行。但反轉都成立——全鏈路都跟上咗,都唔代表 AI 一定會照住行。呢個係提示詞約束同代碼邏輯嘅本質區別:代碼係確定性嘅,提示詞係概率性嘅。你改咗代碼裏便嘅 if (x === 3) 變成 if (x === 4),行為一定會變。你改咗提示詞裏便嘅 three 變成 four,行為可能唔變。

圖:SKILL.md 定義了 4 個維度,AI 實際只輸出了 3 個,Task Granularity 缺席
三層改造解決了什麼,沒解決什麼
把第 5-7 期放在一起看,每期改造的效果很清楚。
第 5 期:template 改造(生效)
前 4 期嘅 tasks.md 格式都唔啱——## 1. + - [ ] 1.1 嘅扁平列表,AI 唔會按 TDD 五步結構拆任務。改 instruction 無效,根因係 OpenSpec 源碼裏便 template 優先級高過 instruction。舊 template 用嘅就係 ## 1. 格式。
改咗 tasks template,換成 ### 任務 N:[名稱] + 涉及文件列表 + TDD 五步結構(寫失敗測試 → 確認失敗 → 寫最小實現 → 確認通過 → 提交)。從第 5 期起 tasks.md 格式規範咗,後續幾期都穩定輸出。
呢條經驗好直接:template 比 instruction 更加能夠約束輸出格式。
第 6 期:review/verify 職責拆分(部分生效)
讀者反饋:review 維度 5(任務粒度審查)係一個擺設——review 喺 tasks 之前生成,根本睇唔到 tasks.md,點樣審查任務粒度?
改咗兩個方向。review 從 5 維度減到 4 維度,將維度 5 去掉,改為為 tasks 提供拆分方向建議。verify 從 3 維度加到 4 維度,新增 Task Granularity 維度。
效果:review 嘅拆分方向建議有參考價值——第 6 期同第 7 期都輸出咗先純函數、再組件、最後路由嘅建議,同實際 tasks 拆分一致。verify 第 4 維度未生效(因內部矛盾,第 7 期修咗矛盾後仍未生效)。
第 7 期:verify 閉環修復(未生效)
上一個章節已經詳細講咗。全鏈路同步之後 AI 仍然按 3 維度輸出。
三層改造嘅共同缺口
三層改造各有收穫,但有幾個問題係佢哋都解決唔到嘅:
task checkbox 唔能夠證明真係按 TDD 執行:tasks.md 裏便嘅 [x]淨係記錄 AI 聲稱嘅狀態,唔記錄實際執行過程。AI 可以標[x]但實際跳過咗某啲步驟verify 報告唔能夠替代 fresh test/build/browser:verify 係 AI 自己審自己。第 7 期 verify 發現咗遺漏場景,但 json-formatter 嘅 export default bug 係瀏覽器檢查先至發現嘅 AI 完成報告唔可以直接信:apply 階段嘅完成報告標咗 11/11 tasks complete,但 json-formatter 嘅 index.tsx 少咗 export default,頁面加載直接卡死對低風險任務使用完整流程會拖慢速度:唔係每個改動都需要完整 TDD + review + verify。改個按鈕顏色行全套流程,投入產出比太低
呢四個缺口指向同一個問題:質量保證唔能夠只靠後置檢查,執行過程嘅紀律同樣重要。而後置檢查嘅約束力,又受限制於 AI 對提示詞模板嘅遵循程度。
換個角度講,呢三個問題(checkbox 唔代表執行、verify 唔能夠替代測試、AI 報告唔可以直接信)本質上都係同一個根因:AI 係概率性嘅執行者,唔係確定性嘅機器。佢讀咗規則唔等於遵守規則,標咗完成唔等於真係完成,通過咗 verify 唔等於代碼冇問題。要彌補呢個差距,一係喺執行過程中加強紀律(令 AI 一定要按規則行),一係喺驗證環節引入獨立證據(唔信任 AI 自己嘅輸出)。前者係 Superpowers 嘅思路,後者係瀏覽器檢查同 fresh test 嘅思路。
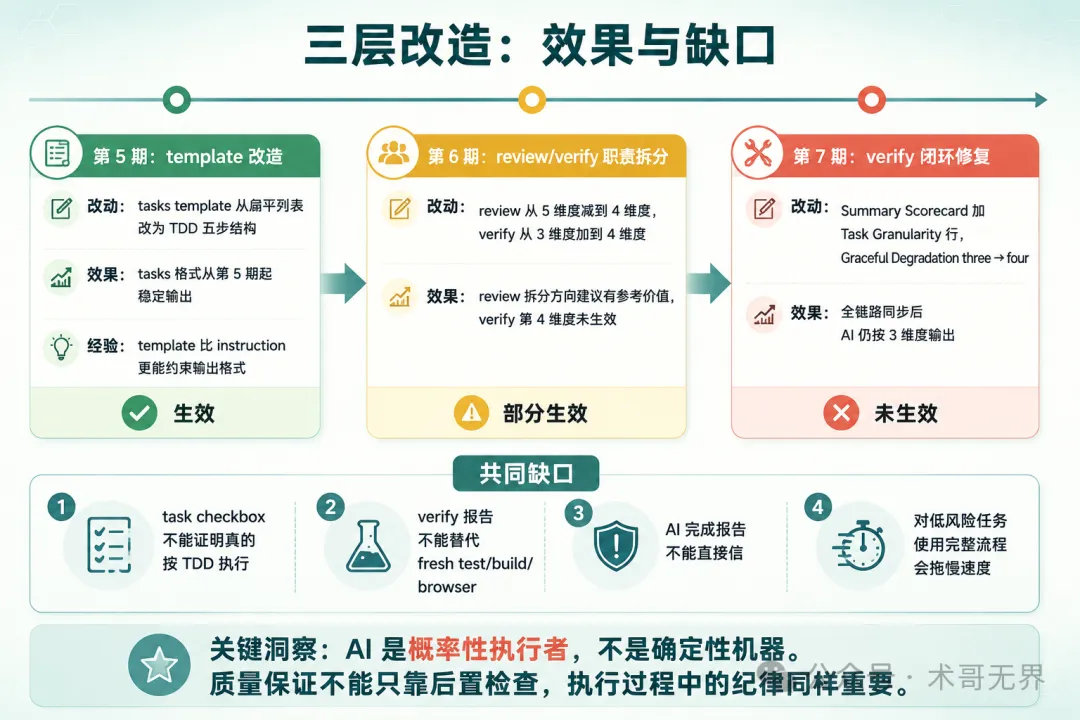
圖:第 5-7 期改造效果 + 共同缺口
點解要引入 Superpowers,但唔全量照搬
三層改造暴露嘅缺口,啱啱對應 Superpowers 幾個核心 skill 要解決嘅問題。
writing-plans 解決嘅係任務顆粒度不可控。佢將每個任務拆成 2-5 分鐘嘅步驟,每步有明確嘅文件路徑、代碼模板同驗證命令。計劃顆粒度由結構化模板約束,唔依賴 AI 自覺。呢個啱啱補返咗task checkbox 唔能夠證明執行過程嘅缺口——唔係令 AI 聲稱做咗啲咩,而係喺計劃階段就將每一步要做啲咩定死。
test-driven-development 解決嘅係核心邏輯冇先驗證。佢嘅鐵律係先寫失敗測試,再寫最小實現。Red-Green-Refactor 循環。如果冇見到測試失敗,你唔知佢測試咗啲咩。呢個直接補返咗TDD 執行紀律嘅缺口。
verification-before-completion 解決嘅係AI 完成報告唔可以信。佢嘅核心原則係證據優先,唔允許喺驗證前聲稱完成。任何完成聲明必須有 fresh verification evidence。唔信任 AI 嘅成功報告。呢個對應第 7 期 json-formatter 嘅 export default bug——AI 標咗 11/11 complete 但實際有 bug,如果有 fresh browser check 就唔會漏過去。
subagent-driven-development 解決嘅係高風險改動需要獨立審查。每個任務派一個獨立 subagent 執行,兩階段 review:spec compliance review + code quality review。唔喺任務之間暫停等確認,連續執行。呢個適合核心邏輯、bugfix、公共模塊重構呢類一處錯誤影響多個工具嘅場景。
但係唔係所有任務都需要上呢套完整流程。
寫個按鈕文案改顏色,唔需要 writing-plans 拆成 2-5 分鐘步驟。調個 CSS 間距,唔需要先寫失敗測試。工具頁標題改個措辭,唔需要 subagent 兩階段 review。
講白啲,Superpowers 嘅每個 skill 都有適用場景,但如果所有改動都行全套流程,速度會慢到唔實用。項目實戰需要速度,唔能夠只追求流程嘅完備。
所以答案唔係OpenSpec vs Superpowers 二選一,亦唔係所有任務都上 Superpowers 嚴格檔。答案係按風險揀流程強度。
三檔工作流程:快速檔、標準檔、嚴格檔
基於上面嘅分析,後續系列嘅工作流程分三檔。每檔嘅適用場景、工具組合、質量門檻同速度成本都唔同。
快速檔:低風險改動
適用場景:文案調整、樣式微調、小範圍 UI 交互優化。可以通過瀏覽器同截圖快速確認嘅改動。改錯咗都唔影響其他功能。
執行流程:
OpenSpec propose/tasks/apply
→ /opsx:verify
→ npm run build
→ 瀏覽器檢查主路徑
→ /opsx:archive
質量門檻:
fresh verification,唔憑 AI 嘅完成報告話好了——第 7 期就係 AI 標咗 11/11 但頁面加載卡死 必須瀏覽器確認主路徑——export default 嘅 bug 只有瀏覽器先發現到 唔強制完整 TDD——改個按鈕顏色唔需要先寫失敗測試
速度:同之前嘅 OpenSpec 單工具流程基本一樣,多咗一步瀏覽器確認。預估額外成本約 5 分鐘。呢度嘅時間係流程設計估算,唔係今期實測耗時。
喺 shuge AI Toolbox 裏便,快速檔適合嘅場景:工具頁標題改措辭、調整 textarea 高度、修改按鈕 hover 效果、調整頁面間距、修改提示文案。呢啲改動嘅共同特徵係:影響範圍小(淨係改一個組件甚至一行 CSS),驗證方法直觀(睇一眼就知道啱唔啱),回滾成本低(改返就得)。
快速檔嘅底線係唔慳瀏覽器檢查。就算只係改咗一行 CSS,都要打開頁面睇一眼實際效果。呢 5 分鐘嘅投入,可以攔住AI 標咗完成但頁面冇變或改咗顏色但影響咗其他元素呢類低級問題。
標準檔:普通功能開發
適用場景:一個獨立工具嘅實現。有明確嘅輸入輸出。有核心純函數或可測試邏輯。改錯咗隻影響呢一個工具。
執行流程:
OpenSpec propose
→ proposal/specs/design/review/tasks 全套工件
→ Superpowers writing-plans 展開執行計劃
→ /opsx:apply 執行
→ /opsx:verify + test + build + 瀏覽器檢查
→ /opsx:archive
質量門檻:
OpenSpec 管規格邊界——proposal、specs、design 定義做啲咩同唔做 Superpowers writing-plans 管執行顆粒度——將任務拆成 2-5 分鐘步驟,每步有文件路徑同驗證命令 核心邏輯必須測試——純函數優先寫測試 verify 必須記錄真實輸出——唔可以概括,引用原文
速度:比快速檔多一個 writing-plans 環節。預估額外成本約 15-20 分鐘,換嚟嘅係任務顆粒度嘅可控同執行紀律嘅保證。呢個數字後續要喺第 9、12 期實戰中校準。
喺 shuge AI Toolbox 裏便,標準檔適合嘅場景:實現一個新嘅工具(Markdown 預覽、時間戳轉換等)、給現有工具加新功能按鈕、修改工具頁嘅交互邏輯。
嚴格檔:高風險改動
適用場景:bug 修復、公共模塊重構、路由同狀態管理嘅改動、核心算法修改。一處錯誤會影響多個工具或整個平台。
執行流程:
OpenSpec propose
→ Superpowers writing-plans 展開執行計劃
→ TDD 或 systematic-debugging
→ spec compliance review
→ code quality review
→ final verification
→ /opsx:archive
質量門檻:
先有失敗測試或根因分析——bug 修復必須有能夠復現嘅失敗測試,唔可以只係改咗代碼就話修好咗 每個重要任務有 review——spec compliance 確認實現咗需求,code quality 確認代碼質量達標 唔允許只係靠 build 通過就話完成——第 7 期 build 通過咗,但 export default bug 仲喺度
速度:比標準檔多 TDD + 兩階段 review。預估額外成本約 30-40 分鐘,換嚟嘅係高風險改動嘅質量保證。呢個數字同樣係預估,後續要用嚴格檔實戰校準。改錯咗代價好高嘅地方,呢筆投入值得。
喺 shuge AI Toolbox 裏便,嚴格檔適合嘅場景:修復一個影響多個工具嘅 bug、重構工具頁嘅公共基礎組件、修改路由或狀態管理嘅核心邏輯。
三檔對比
選擇標準就一句話:改錯咗代價有幾高?代價越高,流程越嚴格。
改個按鈕顏色,代價係用戶點兩下發現唔啱,改返就得。行快速檔。實現一個新工具,代價係工具不可用但唔影響其他功能。行標準檔。重構公共基礎組件,代價係一個改動可能影響所有工具。行嚴格檔。
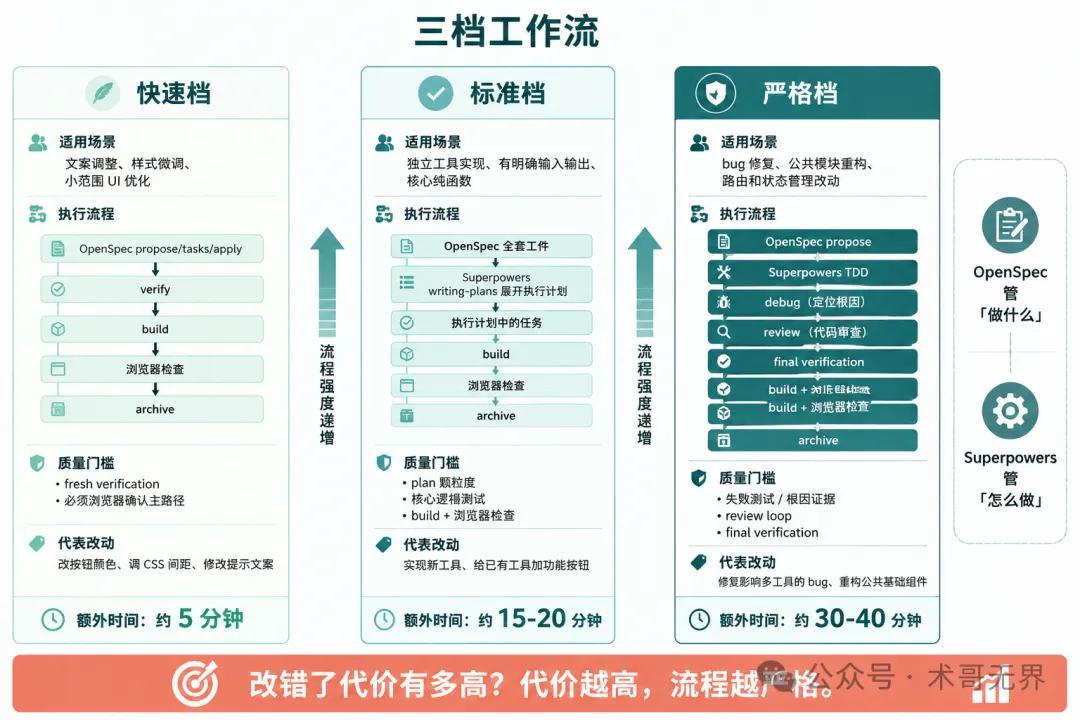
圖:三檔工作流程嘅選擇邏輯——風險越高,流程越嚴格
你喺項目中係點樣分級嘅?或者話,你覺得呢種按風險分級嘅思路喺實際項目中可行嗎?歡迎喺評論區傾下。
後續系列點樣用呢三檔
第 9-15 期嘅檔位分配已經定好咗,每期用對應嘅流程強度。
第 9 期:標準檔,Markdown 預覽工具
呢個將係三檔工作流程嘅第一個實戰驗證。用標準檔實現 Markdown 預覽工具:OpenSpec 管規格同工件,Superpowers writing-plans 管執行顆粒度。
關鍵驗證點:writing-plans 可唔可以在唔明顯拖慢速度嘅前提下,令任務顆粒度比純 OpenSpec tasks.md 更可控。如果 writing-plans 展開嘅執行計劃比 OpenSpec tasks 更細,而且 apply 階段 AI 嘅執行更準確,咁標準檔就有價值。如果 writing-plans 只係多咗一層文檔但執行效果差不多,咁就需要調整策略。
第 10 期:嚴格檔,正則測試器
正則測試器嘅核心係正則表達式引擎同匹配高亮。呢個係有複雜邏輯嘅工具,適合用 TDD 驅動。先寫失敗測試確認正則匹配行為,再寫最小實現。
關鍵驗證點:TDD 嘅 Red-Green-Refactor 循環喺 AI 編程中係咪真係可以提高代碼質量。正則表達式嘅邊界條件多(空輸入、非法正則、超長匹配),TDD 可以提前暴露呢啲邊界。
第 11 期:快速檔,工具頁體驗優化
喺前兩期嚴格同標準檔之後,插一期快速檔。純 UI/UX 微調:按鈕間距、交互反饋、加載狀態、錯誤提示樣式。行快速檔流程,驗證低風險改動用輕量流程係咪足夠。
第 12 期:標準檔,時間戳轉換工具
繼續用標準檔實現新工具。同第 9 期對比,睇標準檔喺唔同工具上嘅穩定性同效率。
第 13 期:嚴格檔,修復真實 Bug
喺第 9-12 期嘅工具開發過程中,大概率會積累一啲 bug。第 13 期專門用一個 change 修一個真實 bug,行嚴格檔:先復現、寫失敗測試、定位根因、修復、verify。
關鍵驗證點:systematic-debugging 喺 AI 編程中嘅實際效果。可唔可以通過根因分析而唔係盲目改代碼嚟修復 bug。
第 14 期:嚴格檔,重構工具頁公共基礎
到第 13 期,shuge AI Toolbox 應該有 5-6 個工具喇。每個工具頁都獨立實現,但組件模式高度相似(textarea + 操作控件 + 結果展示)。呢期重構公共基礎,提取共享組件。
行嚴格檔嘅原因:一處改動影響所有工具。重構時唔可以破壞現有功能,每個改動都需要驗證。
第 15 期:覆盤
唔寫新功能,覆盤第 9-14 期嘅速度同質量數據。三檔工作流程喺 6 期實戰中嘅表現:快速檔夠唔夠快、標準檔值唔值額外 15 分鐘、嚴格檔嘅 review 有冇真正攔住問題。
規劃總覽
回顧:真正要管理嘅係風險,唔係儀式感
回頭睇下第 5-7 期嘅改造路徑,其實係喺回答同一個問題:點樣令 AI 編程嘅產出質量可控。
第 5 期嘅答案係多改 template。有效,但淨係管輸出格式。第 6 期嘅答案係拆 review 同 verify 嘅職責。有效,但後置檢查有天花板。第 7 期嘅答案係將 verify 嘅內部矛盾修完。做咗,但 AI 唔按模板行。
三層改造嘅共同侷限係:都喺後置檢查上做文章。template 管格式係後置嘅(format after generation),review 管方向係後置嘅(review after propose),verify 管質量係後置嘅(verify after apply)。後置檢查有用——第 7 期 verify 確實撈咗出遺漏場景——但佢唔能夠保證執行過程本身係啱嘅。
三檔工作流程嘅邏輯係:將質量保證從後置檢查往前移。快速檔靠瀏覽器確認做後置兜底。標準檔靠 writing-plans 做計劃前置。嚴格檔靠 TDD 同 review 做執行過程控制。風險越高,前置越多。
OpenSpec 適合管方向同工件:proposal 定義做啲咩,specs 定義做到咩程度,design 定義點樣做,archive 留下變更記錄。Superpowers 適合管執行紀律同證據:writing-plans 管計劃顆粒度,TDD 管測試先行,verification-before-completion 管證據優先,subagent review 管獨立審查。
兩套工具唔係二選一嘅關係,係各管一段。OpenSpec 管做什麼,Superpowers 管怎麼做。三檔工作流程係按風險揀組合強度。
講到底,真正要管理嘅係風險,唔係儀式感。
如果將三檔工作流程壓縮成一條規則,就係:改之前先問自己,呢處改動如果出咗 bug,要花幾耐定位同修復?答案係 5 分鐘,行快速檔。答案係半個鐘,行標準檔。答案係半日甚至更耐,行嚴格檔。
呢個同軟件工程裏便一直講嘅風險驅動測試係同一個思路——唔係所有代碼都需要 100% 測試覆蓋率,但高風險代碼必須有測試。三檔工作流程將呢個原則落到咗 AI 編程嘅工作流程選擇上。
預告
第 9 期用標準檔實現 Markdown 預覽工具。重點驗證 Superpowers writing-plans 可唔可以令執行顆粒度比純 OpenSpec tasks.md 更可控,同時唔明顯拖慢速度。標準檔嘅第一個實戰樣本。
聲明:本文係基於 OpenSpec v1.3.1 源碼分析、實際項目操作記錄同讀者反饋整理。所有改造都喺 shuge-ai-toolbox 項目中實際驗證。配置同代碼僅供參考,請以實際環境測試為準。
項目倉庫:https://github.com/shuge-x/shuge-ai-toolbox
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發俾需要嘅朋友,我哋下一期再見!敬請期待!
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 133 篇,OpenSpec 項目實戰「2026」系列第 8 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
圖:verify 實驗結果 + 三層改造覆盤 + 三檔工作流設計
說明:本文內容基於 OpenSpec v1.3.1 實際項目操作記錄和讀者反饋整理。verify SKILL.md 修復和三層改造效果均在 shuge-ai-toolbox 項目中實際驗證,但 verify 第 4 維度(Task Granularity)修復後仍未生效,文中如實記錄。文中的配置修改和代碼僅供參考,實際效果請以你的項目環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
第 5 期改了 tasks template,tasks 格式穩了。OpenSpec 項目實戰(五)|UI 視覺打磨 + 改 template 讓 AI 寫出規範任務
第 6 期拆了 review 和 verify 的職責,review 給出的拆分方向建議有了參考價值。OpenSpec 項目實戰(六) | review 拆分 + verify 增強 + 實現第一個工具
第 7 期把 verify SKILL.md 裏兩處矛盾同步修了,以為這次總能看到第 4 維度 Task Granularity 出現在報告裏。OpenSpec 項目實戰(七)| verify 2 個工具、3 處修復,第 4 維度依然缺席
結果:verify 報告 Summary 表格還是隻有 3 行。Completeness、Correctness、Coherence,和改之前一模一樣。
這一期不寫新功能,專門覆盤第 7 期 verify 修復實驗的真實結果,梳理第 5-7 期三層改造各解決了什麼、還缺什麼,然後給出後續系列的工作流規則——按風險選流程強度,不再一刀切。
完整流程如下:
第 7 期 verify 修復實驗:改了全鏈路,AI 還是按老路徑走
先交代第 7 期修了什麼。
第 6 期在 verify SKILL.md 裏新增了第 4 維度 Task Granularity,但執行 /opsx:verify 後報告只輸出了 3 個維度。當時翻了一遍源文件,根因是 SKILL.md 內部矛盾——L46 定義部分寫了 four dimensions,但後面兩處引用還停留在 three:
Summary Scorecard 模板(L117-127):表格只有 3 行,缺 Task Granularity 行 Graceful Degradation 段(L159-164):最後一句寫的是 verify all three dimensions
第 7 期改了兩處:Summary Scorecard 加了 Task Granularity 行(| Task Granularity | Format/TDD/Code |),Graceful Degradation 的 three 改成 four。改動很小。
修完後直接走 Propose → Apply → Verify,本期 verify 階段應該能用上修復後的配置。執行 /opsx:verify 後,AI 輸出的報告是這樣的:
### Summary
| Dimension | Status |
|--------------|---------------------|
| Completeness | 11/11 tasks, 7/8 scenarios |
| Correctness | Requirement implemented, 1 scenario uncovered |
| Coherence | Followed/Issues |
3 行。Task Granularity 沒出現。定義、模板、退化邏輯全鏈路統一了,AI 生成報告時仍然跳過了模板,按慣性輸出。
說實話,看到這個結果的時候有點意外。修之前以為是改定義沒改引用的問題,引用同步後應該就能生效。但實際情況是,即使全鏈路都對齊了,AI 在生成輸出時並不嚴格按模板逐項填充——它有自己的慣性路徑,讀到模板但不一定照着走。
有個反直覺的點值得記錄:verify 報告雖然缺了第 4 維度,但在其他 3 個維度上發揮了實際價值。這些是第 7 期 /opsx:verify 的實際輸出——它發現了 1 個 CRITICAL issue,spec 裏定義了大文件 JSON 解析場景(超過 1MB 要提示用戶),但實現中沒做 size check。還發現了 1 個 WARNING,有效 JSON 點擊語法校驗按鈕的測試用例缺失。這些是 specs 寫了但 tasks 沒覆蓋到的場景,verify 把它們撈出來了。
所以結論不是verify 沒用,而是verify 的後置檢查有用,但純提示詞約束有天花板。
再看 verify SKILL.md 的當前版本——L46-54 確實定義了四個維度,Task Granularity 下面還詳細拆了四項檢查:任務格式(### 任務 N)、TDD 合規(Red/Green/Refactor)、代碼完整性(無 TBD/TODO)、粒度評估(2-5 分鐘範圍)。定義本身沒問題。Summary Scorecard 模板也加了 Task Granularity 行。Graceful Degradation 也改成了 four。全鏈路都對了,但 AI 就是不輸出。
這給了一個很實際的教訓:提示詞約束是一條鏈路,不是孤立的定義。L46 寫得再漂亮,後面模板和退化邏輯沒跟上,執行層就按舊路徑走。但反過來也成立——全鏈路都跟上了,也不代表 AI 一定照走。這是提示詞約束和代碼邏輯的本質區別:代碼是確定性的,提示詞是概率性的。你改了代碼裏的 if (x === 3) 變成 if (x === 4),行為一定變。你改了提示詞裏的 three 變成 four,行為可能不變。
圖:SKILL.md 定義了 4 個維度,AI 實際只輸出了 3 個,Task Granularity 缺席
三層改造解決了什麼,沒解決什麼
把第 5-7 期放在一起看,每期改造的效果很清楚。
第 5 期:template 改造(生效)
前 4 期的 tasks.md 格式都不對——## 1. + - [ ] 1.1 的扁平列表,AI 不會按 TDD 五步結構拆任務。改 instruction 無效,根因是 OpenSpec 源碼裏 template 優先級高於 instruction。舊 template 用的就是 ## 1. 格式。
改了 tasks template,換成 ### 任務 N:[名稱] + 涉及文件列表 + TDD 五步結構(寫失敗測試 → 確認失敗 → 寫最小實現 → 確認通過 → 提交)。從第 5 期起 tasks.md 格式規範了,後續幾期都穩定輸出。
這條經驗很直接:template 比 instruction 更能約束輸出格式。
第 6 期:review/verify 職責拆分(部分生效)
讀者反饋:review 維度 5(任務粒度審查)是個擺設——review 在 tasks 之前生成,根本看不到 tasks.md,怎麼審查任務粒度?
改了兩個方向。review 從 5 維度減到 4 維度,把維度 5 去掉,改為為 tasks 提供拆分方向建議。verify 從 3 維度加到 4 維度,新增 Task Granularity 維度。
效果:review 的拆分方向建議有參考價值——第 6 期和第 7 期都輸出了先純函數、再組件、最後路由的建議,和實際 tasks 拆分一致。verify 第 4 維度未生效(因內部矛盾,第 7 期修了矛盾後仍未生效)。
第 7 期:verify 閉環修復(未生效)
上一節已經詳細說了。全鏈路同步後 AI 仍然按 3 維度輸出。
三層改造的共同缺口
三層改造各有收穫,但有幾個問題是它們都解決不了的:
task checkbox 不能證明真的按 TDD 執行:tasks.md 裏的 [x]只記錄 AI 聲稱的狀態,不記錄實際執行過程。AI 可以標[x]但實際跳過了某些步驟verify 報告不能替代 fresh test/build/browser:verify 是 AI 自己審自己。第 7 期 verify 發現了遺漏場景,但 json-formatter 的 export default bug 是瀏覽器檢查才發現的 AI 完成報告不能直接信:apply 階段的完成報告標了 11/11 tasks complete,但 json-formatter 的 index.tsx 少了 export default,頁面加載直接卡死對低風險任務使用完整流程會拖慢速度:不是每個改動都需要完整 TDD + review + verify。改個按鈕顏色走全套流程,投入產出比太低
這四個缺口指向同一個問題:質量保證不能只靠後置檢查,執行過程中的紀律同樣重要。而後置檢查的約束力,又受限於 AI 對提示詞模板的遵循程度。
換個角度說,這三個問題(checkbox 不代表執行、verify 不能替代測試、AI 報告不能直接信)本質上都是同一個根因:AI 是概率性的執行者,不是確定性的機器。它讀了規則不等於遵守規則,標了完成不等於真的完成,通過了 verify 不等於代碼沒問題。要彌補這個差距,要麼在執行過程中加強紀律(讓 AI 不得不按規則走),要麼在驗證環節引入獨立證據(不信任 AI 自己的輸出)。前者是 Superpowers 的思路,後者是瀏覽器檢查和 fresh test 的思路。
圖:第 5-7 期改造效果 + 共同缺口
為什麼引入 Superpowers,但不全量照搬
三層改造暴露的缺口,恰好對應 Superpowers 幾個核心 skill 要解決的問題。
writing-plans 解決的是任務顆粒度不可控。它把每個任務拆成 2-5 分鐘的步驟,每步有明確的文件路徑、代碼模板和驗證命令。計劃顆粒度由結構化模板約束,不依賴 AI 自覺。這正好補上了task checkbox 不能證明執行過程的缺口——不是讓 AI 聲稱做了什麼,而是在計劃階段就把每一步要做什麼定死。
test-driven-development 解決的是核心邏輯沒有先驗證。它的鐵律是先寫失敗測試,再寫最小實現。Red-Green-Refactor 循環。如果沒看到測試失敗,你不知道它測試了什麼。這直接補上了TDD 執行紀律的缺口。
verification-before-completion 解決的是AI 完成報告不能信。它的核心原則是證據優先,不允許在驗證前聲稱完成。任何完成聲明必須有 fresh verification evidence。不信任 AI 的成功報告。這對應第 7 期 json-formatter 的 export default bug——AI 標了 11/11 complete 但實際有 bug,如果有 fresh browser check 就不會漏過去。
subagent-driven-development 解決的是高風險改動需要獨立審查。每個任務派一個獨立 subagent 執行,兩階段 review:spec compliance review + code quality review。不在任務間暫停等人確認,連續執行。這適合核心邏輯、bugfix、公共模塊重構這類一處錯誤影響多個工具的場景。
但不是所有任務都需要上這套完整流程。
寫個按鈕文案改顏色,不需要 writing-plans 拆成 2-5 分鐘步驟。調個 CSS 間距,不需要先寫失敗測試。工具頁標題改個措辭,不需要 subagent 兩階段 review。
說白了,Superpowers 的每個 skill 都有適用場景,但如果所有改動都走全套流程,速度會慢到不實用。項目實戰需要速度,不能只追求流程的完備。
所以答案不是OpenSpec vs Superpowers 二選一,也不是所有任務都上 Superpowers 嚴格檔。答案是按風險選擇流程強度。
三檔工作流:快速檔、標準檔、嚴格檔
基於上面的分析,後續系列的工作流分三檔。每檔的適用場景、工具組合、質量門檻和速度成本都不同。
快速檔:低風險改動
適用場景:文案調整、樣式微調、小範圍 UI 交互優化。可以通過瀏覽器和截圖快速確認的改動。改錯了也不影響其他功能。
執行流程:
OpenSpec propose/tasks/apply
→ /opsx:verify
→ npm run build
→ 瀏覽器檢查主路徑
→ /opsx:archive
質量門檻:
fresh verification,不憑 AI 的完成報告說好了——第 7 期就是 AI 標了 11/11 但頁面加載卡死 必須瀏覽器確認主路徑——export default 的 bug 只有瀏覽器能發現 不強制完整 TDD——改個按鈕顏色不需要先寫失敗測試
速度:和之前的 OpenSpec 單工具流程基本一樣,多了一步瀏覽器確認。預估額外成本約 5 分鐘。這裏的時間是流程設計估算,不是本期實測耗時。
在 shuge AI Toolbox 裏,快速檔適合的場景:工具頁標題改措辭、調整 textarea 高度、修改按鈕 hover 效果、調整頁面間距、修改提示文案。這些改動的共同特徵是:影響範圍小(只改一個組件甚至一行 CSS),驗證方式直觀(看一眼就知道對不對),回滾成本低(改回來就行)。
快速檔的底線是不省瀏覽器檢查。哪怕只改了一行 CSS,也要打開頁面看一眼實際效果。這 5 分鐘的投入,能攔住AI 標了完成但頁面沒變或改了顏色但影響了別的元素這類低級問題。
標準檔:普通功能開發
適用場景:一個獨立工具的實現。有明確的輸入輸出。有核心純函數或可測試邏輯。改錯了隻影響這一個工具。
執行流程:
OpenSpec propose
→ proposal/specs/design/review/tasks 全套工件
→ Superpowers writing-plans 展開執行計劃
→ /opsx:apply 執行
→ /opsx:verify + test + build + 瀏覽器檢查
→ /opsx:archive
質量門檻:
OpenSpec 管規格邊界——proposal、specs、design 定義做什麼和不做 Superpowers writing-plans 管執行顆粒度——把任務拆成 2-5 分鐘步驟,每步有文件路徑和驗證命令 核心邏輯必須測試——純函數優先寫測試 verify 必須記錄真實輸出——不能概括,引用原文
速度:比快速檔多一個 writing-plans 環節。預估額外成本約 15-20 分鐘,換來的是任務顆粒度的可控和執行紀律的保證。這個數字後續要在第 9、12 期實戰中校準。
在 shuge AI Toolbox 裏,標準檔適合的場景:實現一個新的工具(Markdown 預覽、時間戳轉換等)、給已有工具加新功能按鈕、修改工具頁的交互邏輯。
嚴格檔:高風險改動
適用場景:bug 修復、公共模塊重構、路由和狀態管理的改動、核心算法修改。一處錯誤會影響多個工具或整個平台。
執行流程:
OpenSpec propose
→ Superpowers writing-plans 展開執行計劃
→ TDD 或 systematic-debugging
→ spec compliance review
→ code quality review
→ final verification
→ /opsx:archive
質量門檻:
先有失敗測試或根因分析——bug 修復必須有能復現的失敗測試,不能只改了代碼就聲稱修好了 每個重要任務有 review——spec compliance 確認實現了需求,code quality 確認代碼質量達標 不允許只靠 build 通過宣稱完成——第 7 期 build 通過了,但 export default bug 還在
速度:比標準檔多 TDD + 兩階段 review。預估額外成本約 30-40 分鐘,換來的是高風險改動的質量保證。這個數字同樣是預估,後續要用嚴格檔實戰校準。改錯了代價很高的地方,這筆投入值得。
在 shuge AI Toolbox 裏,嚴格檔適合的場景:修復一個影響多個工具的 bug、重構工具頁的公共基礎組件、修改路由或狀態管理的核心邏輯。
三檔對比
選擇標準就一句話:改錯了代價有多高?代價越高,流程越嚴格。
改個按鈕顏色,代價是用戶點兩下發現不對,改回來就行。走快速檔。實現一個新工具,代價是工具不可用但不影響其他功能。走標準檔。重構公共基礎組件,代價是一個改動可能影響所有工具。走嚴格檔。
圖:三檔工作流的選擇邏輯——風險越高,流程越嚴格
你在項目中是怎麼分級的?或者說,你覺得這種按風險分級的思路在實際項目中可行嗎?歡迎在評論區聊聊。
後續系列怎麼用這三檔
第 9-15 期的檔位分配已經定好了,每期用對應的流程強度。
第 9 期:標準檔,Markdown 預覽工具
這將是三檔工作流的第一個實戰驗證。用標準檔實現 Markdown 預覽工具:OpenSpec 管規格和工件,Superpowers writing-plans 管執行顆粒度。
關鍵驗證點:writing-plans 能不能在不明顯拖慢速度的前提下,讓任務顆粒度比純 OpenSpec tasks.md 更可控。如果 writing-plans 展開的執行計劃比 OpenSpec tasks 更細,而且 apply 階段 AI 的執行更準確,那標準檔就有價值。如果 writing-plans 只是多了一層文檔但執行效果差不多,那需要調整策略。
第 10 期:嚴格檔,正則測試器
正則測試器的核心是正則表達式引擎和匹配高亮。這是有複雜邏輯的工具,適合用 TDD 驅動。先寫失敗測試確認正則匹配行為,再寫最小實現。
關鍵驗證點:TDD 的 Red-Green-Refactor 循環在 AI 編程中是否真的能提高代碼質量。正則表達式的邊界條件多(空輸入、非法正則、超長匹配),TDD 能提前暴露這些邊界。
第 11 期:快速檔,工具頁體驗優化
在前兩期嚴格和標準檔之後,插一期快速檔。純 UI/UX 微調:按鈕間距、交互反饋、加載狀態、錯誤提示樣式。走快速檔流程,驗證低風險改動用輕量流程是否足夠。
第 12 期:標準檔,時間戳轉換工具
繼續用標準檔實現新工具。和第 9 期對比,看標準檔在不同工具上的穩定性和效率。
第 13 期:嚴格檔,修復真實 Bug
在第 9-12 期的工具開發過程中,大概率會積累一些 bug。第 13 期專門用一個 change 修一個真實 bug,走嚴格檔:先復現、寫失敗測試、定位根因、修復、verify。
關鍵驗證點:systematic-debugging 在 AI 編程中的實際效果。能不能通過根因分析而不是盲目改代碼來修復 bug。
第 14 期:嚴格檔,重構工具頁公共基礎
到第 13 期,shuge AI Toolbox 應該有 5-6 個工具了。每個工具頁都獨立實現,但組件模式高度相似(textarea + 操作控件 + 結果展示)。這期重構公共基礎,提取共享組件。
走嚴格檔的原因:一處改動影響所有工具。重構時不能破壞已有功能,每個改動都需要驗證。
第 15 期:覆盤
不寫新功能,覆盤第 9-14 期的速度和質量數據。三檔工作流在 6 期實戰中的表現:快速檔夠不夠快、標準檔值不值額外 15 分鐘、嚴格檔的 review 有沒有真正攔住問題。
規劃總覽
回顧:真正要管理的是風險,不是儀式感
回頭看看第 5-7 期的改造路徑,其實是在回答同一個問題:怎麼讓 AI 編程的產出質量可控。
第 5 期的答案是多改 template。有效,但只管輸出格式。第 6 期的答案是拆 review 和 verify 的職責。有效,但後置檢查有天花板。第 7 期的答案是把 verify 的內部矛盾修完。做了,但 AI 不按模板走。
三層改造的共同侷限是:都在後置檢查上做文章。template 管格式是後置的(format after generation),review 管方向是後置的(review after propose),verify 管質量是後置的(verify after apply)。後置檢查有用——第 7 期 verify 確實撈出了遺漏場景——但它不能保證執行過程本身是對的。
三檔工作流的邏輯是:把質量保證從後置檢查往前移。快速檔靠瀏覽器確認做後置兜底。標準檔靠 writing-plans 做計劃前置。嚴格檔靠 TDD 和 review 做執行過程控制。風險越高,前置越多。
OpenSpec 適合管方向和工件:proposal 定義做什麼,specs 定義做到什麼程度,design 定義怎麼做,archive 留下變更記錄。Superpowers 適合管執行紀律和證據:writing-plans 管計劃顆粒度,TDD 管測試先行,verification-before-completion 管證據優先,subagent review 管獨立審查。
兩套工具不是二選一的關係,是各管一段。OpenSpec 管做什麼,Superpowers 管怎麼做。三檔工作流是按風險選擇組合強度。
說到底,真正要管理的是風險,不是儀式感。
如果把三檔工作流壓縮成一條規則,就是:改之前先問自己,這處改動如果出了 bug,要花多久定位和修復?答案是 5 分鐘,走快速檔。答案是半小時,走標準檔。答案是半天甚至更久,走嚴格檔。
這和軟件工程裏一直說的風險驅動測試是同一個思路——不是所有代碼都需要 100% 測試覆蓋率,但高風險代碼必須有測試。三檔工作流把這個原則落到了 AI 編程的工作流選擇上。
預告
第 9 期用標準檔實現 Markdown 預覽工具。重點驗證 Superpowers writing-plans 能不能讓執行顆粒度比純 OpenSpec tasks.md 更可控,同時不明顯拖慢速度。標準檔的第一個實戰樣本。
聲明:本文基於 OpenSpec v1.3.1 源碼分析、實際項目操作記錄和讀者反饋整理。所有改造均在 shuge-ai-toolbox 項目中實際驗證。配置和代碼僅供參考,請以實際環境測試為準。
項目倉庫:https://github.com/shuge-x/shuge-ai-toolbox
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!