perplexity 產品不咋樣,但這個 Skills 文檔寫得是真的好!
整理版優先睇
Perplexity 最近公開了一篇內部工程文檔,講他們怎麼設計、迭代和維護 Agent Skills庫。原文地址如下:https://link.bytenote.net/DapXMDPerplexity的產品做得稀碎,但這篇文檔把如何寫Skills這件事卻是講得比任何人都要好。文章中的結論幾乎每一個都反直覺,但是如果細品就會發現異常合理,值得我們借鑑和實踐。比如開頭引用類比Python 之禪這本書,講Python 的設計哲學是"簡單優於複雜"、"明確優於隱式",但是在寫技能時就完全不是那麼回事。“如果一件事很容易解釋,說明模型早就知道了。刪掉它。”文檔直指要害。我們寫技能時最大的本能錯誤,就是把它當說明文檔寫。各種列命令、列步驟、列注意事項。但這些東西模型全會,寫了等於浪費上下文,還會稀釋真正有價值的信息。假設你在寫一個處理代碼合併的技能,兩種寫法:寫法一,工程師本能寫法:git log # 找到提交
Perplexity 最近公開了一篇內部工程文檔,講他們怎麼設計、迭代和維護 Agent Skills庫。原文地址如下:https://link.bytenote.net/DapXMDPerplexity的產品做得稀碎,但這篇文檔把如何寫Skills這件事卻是講得比任何人都要好。
文章中的結論幾乎每一個都反直覺,但是如果細品就會發現異常合理,值得我們借鑑和實踐。比如開頭引用類比Python 之禪這本書,講Python 的設計哲學是"簡單優於複雜"、"明確優於隱式",但是在寫技能時就完全不是那麼回事。“如果一件事很容易解釋,說明模型早就知道了。刪掉它。”文檔直指要害。
我們寫技能時最大的本能錯誤,就是把它當說明文檔寫。各種列命令、列步驟、列注意事項。但呢啲東西模型全會,寫了等於浪費上下文,還會稀釋真正有價值的信息。假設你在寫一個處理代碼合併的技能,兩種寫法:寫法一,工程師本能寫法:git log # 找到提交 git checkout main git checkout -b <新分支> git cherry-pick <提交>
- git checkout main
- git checkout -b <新分支>
- git cherry-pick <提交>
- 寫法二,Perplexity 建議的做法:“把呢個提交到一個乾淨的分支上。解決衝突時保留原始意圖。如果實在合不進去,解釋…
- perplexity 產品不咋樣,但呢個 Skills 文檔寫得是真…
可記低 Skill
Perplexity 最近公開了一篇內部工程文檔,講他們怎麼設計、迭代和維護 Agent Skills庫。原文地址如下:
可記低 Prompt
寫法二,Perplexity 建議的做法:“把這個提交到一個乾淨的分支上。解決衝突時保留原始意圖。如果實在合不進去,解釋原因。”模型用後者的表現要遠好於前者。第一種寫法在出問題時可能會讓模型卡殼,因為過於強制性的指定反而限制了模型的發揮,指…
內容片段
git log # 找到提交
git checkout main
git checkout -b <新分支>
git cherry-pick <提交>整理版
Perplexity 最近公開了一篇內部工程文檔,講他們怎麼設計、迭代和維護 Agent Skills庫。原文地址如下:https://link.bytenote.net/DapXMDPerplexity的產品做得稀碎,但這篇文檔把如何寫Skills這件事卻是講得比任何人都要好。文章中的結論幾乎每一個都反直覺,但是如果細品就會發現異常合理,值得我們借鑑和實踐。比如開頭引用類比Python 之禪這本書,講Python 的設計哲學是"簡單優於複雜"、"明確優於隱式",但是在寫技能時就完全不是那麼回事。“如果一件事很容易解釋,說明模型早就知道了。刪掉它。”文檔直指要害。我們寫技能時最大的本能錯誤,就是把它當說明文檔寫。各種列命令、列步驟、列注意事項。但呢啲東西模型全會,寫了等於浪費上下文,還會稀釋真正有價值的信息。假設你在寫一個處理代碼合併的技能,兩種寫法:寫法一,工程師本能寫法:git log # 找到提交
git checkout main
git checkout -b <新分支>
git cherry-pick <提交>
Perplexity 最近出咗一篇內部工程文檔,講佢哋點樣設計、迭代同維護 Agent Skills 庫。

原文地址如下:
https://link.bytenote.net/DapXMD
Perplexity 嘅產品做得麻麻哋,但呢篇文檔講點樣寫 Skills 就講得比任何人都好。
文章入面嘅結論幾乎每一個都反直覺,但係如果你細心諗下就會發現異常合理,值得我哋參考同實踐。
例如開頭引用咗《Python 之禪》呢本書,講 Python 嘅設計哲學係「簡單優於複雜」、「明確優於隱式」,但係寫技能嗰陣就完全唔係咁回事。
「如果一件事好容易解釋,代表模型一早已經知道。刪咗佢。」
篇文檔一針見血。我哋寫技能嗰陣最大嘅本能錯誤,就係當正係說明文檔咁寫。
乜嘢列命令、列步驟、列注意事項。
但呢啲嘢模型全部識,寫咗等於浪費上下文,仲會溝淡真正有價值嘅資訊。
假設你喺度寫一個處理代碼合併嘅技能,兩種寫法:
寫法一,工程師本能寫法:
git log # 找到提交
git checkout main
git checkout -b <新分支>
git cherry-pick <提交>
寫法二,Perplexity 建議嘅做法:
「將呢個提交到一個乾淨嘅分支上。解決衝突嘅時候保留原始意圖。如果真係合唔埋,解釋原因。」
模型用後者嘅表現遠好過前者。
第一種寫法喺出問題嘅時候可能會令模型卡殼,因為太過強制性嘅指定反而限制咗模型嘅發揮,指令遵守得越好嘅模型,限制越強,好可能後續執行命令序列嗰陣斷咗就完全無所適從。
第二種寫法只係畀咗意圖,等模型自己諗辦法。
呢點好反直覺,但係如果你細心諗,又非常正確。
其實唔止 Skills,同 AI 對話同編程嘅時候都係咁,AI 會非常順從你嘅思路,嚴格遵守你嘅指令同提示詞嚟完成任務,但同臭棋簍子捉棋越捉越臭一樣道理,你嘅認知高度會限制模型嘅上限。
所以用 Claude Code 嗰陣,我會刻意提出一個好模糊嘅需求,然後等佢提供多條路徑嘅方案,最後我先喺呢啲方案入面比較同揀,從而激發出模型本身嘅潛能。
上下文成本好高,每一層都係燒緊錢
Perplexity 將技能嘅加載開銷分成三層,呢個分法好清晰,比官方文檔明瞭好多。
第一層係索引層。
每個技能嘅名加描述,無論用戶問乜,每次對話都要畀呢個成本。
佢哋嘅預算係每個技能大約 100 個 token,越短越好。
因為呢個成本乘以用戶,再乘以每日嘅對話次數,累積起嚟就係一個好大嘅數字。
第二層係正文層。
技能主體,理想控制喺 5000 token 以內。
一旦加載,就要頂到上下文壓縮(Compact)。
一次對話通常會同時加載三到五個技能,成本疊加起嚟非常可觀。
技能入面嘅描述廢話唔止浪費自己嘅空間,浪費 Token,仲會壓縮其他技能嘅發揮空間。
其實呢個講法好啱,Skills 唔可以當作文檔咁用,唔好事無大小全部塞曬入 Skills 入面。
Claude Code 官方似乎都留意到呢點,新版本更新之後會壓縮 Skills 嘅加載,用 Warning 提示嚟警告你。
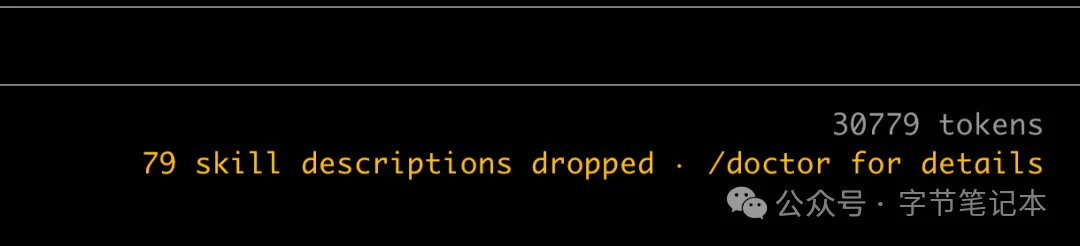
如圖所示,我開 Claude Code 會話嗰陣,79 個 Skills 嘅描述直接畀人 drop 咗,係因為大量測評同寫 Skills,堆積咗近百個 Skills,呢點唔好跟我學。
之前陸續發佈過嘅 Skills 都放喺下面嘅地址入面,有需要可以自己攞:
https://link.bytenote.net/note
第三層係運行層。
腳本、參考文檔、輸出模板呢啲附屬文件,只有模型真正需要嗰陣先會讀取。
呢一層冇上限,因為都係按需加載,可以任意增補。
Perplexity 引用咗帕斯卡嘅經典語錄:
「我將呢封信寫得咁長,只係因為我冇時間將佢寫短。」
寫一個好技能同寫一封好信係同一件事。短唔係懶,短係功夫。
如果一個技能好容易寫出嚟,好大機會係寫多咗,或者根本唔需要佢。
描述係最難寫嗰個
Skill 技能嘅描述唔係說明文檔,佢真正嘅作用係路由觸發器。
模型靠佢決定係咪要加載呢個技能。
佢哋嘅格式要求好簡單:
以「當……時加載」開頭,目標 50 詞以內,用真實用戶講嘢嘅方式寫,唔好用工程師寫文檔嘅方式寫。
舉個例子。
一個用嚟監控代碼合併請求嘅技能,兩種描述:
差嘅寫法:
監控代碼合併請求嘅狀態,支持查看進度同審查結果。
好嘅寫法:
當用戶想睇實一個合併請求順利完成,或者擔心流水線死咗嗰陣加載。關鍵詞:幫我睇實、確保呢個可以合入去、唔好畀佢卡住。
分別喺邊?
前者描述技能可以做乜,後者描述用戶把口會講乜。
模型匹配嘅係後者,唔係前者,因為模型真正匹配嘅係關鍵詞同關鍵詞嘅密度,你可以覆蓋到嘅點越多,咁自然 Skills 就會好容易畀路由到。
有啲嘢模型學唔到,只能由你嚟寫
呢一個細節可以話係全文嘅精要。
Perplexity 有一套設計相關嘅技能,係佢哋嘅設計負責人 Henry 親自寫嘅。
內容包括用邊啲字體、唔用邊啲字體,以及呢啲字體嘅「感覺」係點。
一個好奇怪、好抽象嘅詞,感覺。
點解要寫呢個感覺呢?
因為呢個係審美判斷,唔係知識點。
模型可以知道 Helvetica 字體係乜,但佢完全唔理解呢個字體喺咩場景下會顯得好 low。
講到呢點就好好笑,每次新模型出嚟,啲營銷號就開始用佢嚟整頁面,話佢審美點樣點樣。
其實模型本身根本冇審美能力,佢所有嘅「審美」都係依賴概率同使用者嘅品味。
即係話,就算我用最早嘅 Deepseek V3,一樣可以原樣複製嗰啲所謂「審美強」嘅頁面。
真正嘅審美判斷來自經驗同品味,訓練數據全部係死嘅,都可以透過技能注入返嚟。
Skills 技能最大嘅價值,唔係話畀模型知點樣做佢已經識嘅嘢,而係將你個腦入面嗰啲講唔清楚但確實存在嘅判斷,變成模型可以用嘅上下文。
反面案例比正面案例更值錢
文章最後講技能維護,又係一個反直覺嘅結論。
文章好明確指出技能嘅迭代模式應該係「只增不改」,而且主要喺反面案例區域追加內容。
佢哋嘅做法係每次模型出錯,加一條反面案例,呢個時候唔好改描述,唔好加新規則,加反面案例就夠。
點解反面案例比正面案例更有價值?
因為佢直接話畀模型知呢條路行過,係死路,唔好再行。正面案例話畀模型知往邊度行,反面案例話畀模型知邊度有坑,後者嘅資訊密度往往更高。
佢哋仲提到一個重要嘅副作用:加一個新技能,可能會令到已有嘅技能變差。因為索引層嘅 description 都喺度爭模型嘅注意力,兩個 description 相近嘅技能會互相干擾。
所以每次新增技能,都要跑一次已有技能嘅測試,確認冇連帶破壞。
我覺得呢篇文檔值得反複睇,而且唔好侷限於寫 Skills,完全可以應用喺模型對話嘅各方面。
最後一句話送畀仲將技能當說明文檔寫嘅人:
如果模型冇呢個技能都可以做啱,就唔需要呢個技能。
Claude Code 又有十個最值得裝嘅 Skills!呢篇一次過補齊
將 Claude Design 蒸餾成可重用嘅投影片、原型、動畫、著陸頁嘅 Skills
更多 Skills 嘅進階系統學習同分享請查看字節筆記本星球嘅每日推送:
Perplexity 最近公開了一篇內部工程文檔,講他們怎麼設計、迭代和維護 Agent Skills庫。
原文地址如下:
https://link.bytenote.net/DapXMD
Perplexity的產品做得稀碎,但這篇文檔把如何寫Skills這件事卻是講得比任何人都要好。
文章中的結論幾乎每一個都反直覺,但是如果細品就會發現異常合理,值得我們借鑑和實踐。
比如開頭引用類比Python 之禪這本書,講Python 的設計哲學是"簡單優於複雜"、"明確優於隱式",但是在寫技能時就完全不是那麼回事。
“如果一件事很容易解釋,說明模型早就知道了。刪掉它。”
文檔直指要害。我們寫技能時最大的本能錯誤,就是把它當說明文檔寫。
各種列命令、列步驟、列注意事項。
但這些東西模型全會,寫了等於浪費上下文,還會稀釋真正有價值的信息。
假設你在寫一個處理代碼合併的技能,兩種寫法:
寫法一,工程師本能寫法:
git log # 找到提交
git checkout main
git checkout -b <新分支>
git cherry-pick <提交>
寫法二,Perplexity 建議的做法:
“把這個提交到一個乾淨的分支上。解決衝突時保留原始意圖。如果實在合不進去,解釋原因。”
模型用後者的表現要遠好於前者。
第一種寫法在出問題時可能會讓模型卡殼,因為過於強制性的指定反而限制了模型的發揮,指令遵守越好的模型,限制越強,很可能後續執行命令序列時斷了就完全無所適從了。
第二種寫法只給了意圖,讓模型自己想辦法。
這點就非常的反直覺,但是如果細想,又非常的正確。
其實不只是Skills,在和AI的對話和編程當中也是如此,AI會非常的順從你的思路,嚴格遵守你的指令和提示詞來完成任務,但和臭棋簍子下棋越下越臭一樣道理,你的認知高度會限制模型的上限。
所以在使用Claude Code的時候,我會刻意的提出一個非常模糊的需求,然後讓它來提供多種路徑的方案,最後我才從這些方案當中去比較和選擇,從而激發出模型本身的潛能。
上下文是有成本的,每一層都在燒錢
Perplexity把技能的加載開銷分成三層,這個分法非常清晰,比官方文檔明瞭多了。
第一層是索引層。
每個技能的名稱加描述,不管用戶問什麼,每次對話都在付這個成本。
他們的預算是每個技能約 100 個 token,能短則短。
因為這個成本乘以用戶,再乘以每天的對話次數,累積起來就是一個很大的數字。
第二層是正文層。
技能主體,理想控制在 5000 token 以內。
一旦加載,就要扛到上下文壓縮Compact。
一次對話通常會同時加載三到五個技能,成本疊加起來非常可觀。
技能裏的描述廢話不只是浪費自己的空間,浪費Token,還會壓縮其他技能的發揮餘地。
其實這種說法非常的對,Skills不能夠當做文檔來使用,不要事無鉅細的全部都堆積到Skills當中。
Claude Code官方似乎也注意了這點,新版本更新後會壓縮Skills的加載,通過Waring提示來警告你。
如圖所示,我在開啓Claude Code會話的時候,79個Skills的描述就直接被drop掉了,這是因為大量測評和書寫Skills,堆積了近百個Skills,這點不用跟我學。
之前陸續發佈過的Skills都被放在如下的地址裏面,如有需要可以自取:
https://link.bytenote.net/note
第三層是運行層。
腳本、參考文檔、輸出模板這些附屬文件,只有模型真正需要時才讀取。
這一層沒有上限,因為都是按需加載,可以自由增補。
perplexity引用了帕斯卡的經典語錄:
“我把這封信寫得這麼長,只是因為我沒有時間把它寫短。“
寫一個好技能和寫一封好信是同一件事。短不是懶,短是功夫。
如果一個技能很容易寫出來,大概率是寫多了,或者根本不需要它。
描述是最難寫的那個
Skill技能的描述不是說明文檔,它的真正作用是路由觸發器。
模型靠它決定要不要加載這個技能。
他們的格式要求很簡單:
以"當……時加載"開頭,目標 50 詞以內,用真實用戶說話的方式寫,不要用工程師寫文檔的方式寫。
舉個例子。
一個用來監控代碼合併請求的技能,兩種描述:
差的寫法:
監控代碼合併請求的狀態,支持查看進度和審查結果。
好的寫法:
當用戶想盯着一個合併請求順利落地、或者擔心流水線掛掉時加載。關鍵詞:幫我盯着、確保這個能合進去、別讓它被卡住。
區別在哪?
前者描述的是技能能做什麼,後者描述的是用戶嘴裏會說什麼。
模型匹配的是後者,不是前者,因為模型真正去匹配的是關鍵詞以及關鍵詞的密度,你可以覆蓋到的點越多,那麼自然,Skills就會非常容易的被路由到。
有些東西模型學不到,只能你來寫
這一個細節可以說是全文的精要所在。
Perplexity 有一套設計相關的技能,是他們的設計負責人 Henry 親自寫的。
內容包括用哪些字體、不用哪些字體,以及這些字體的"感覺"是什麼。
一個很奇怪的、很抽象的詞,感覺。
為什麼要寫這個感覺呢?
因為這是審美判斷,不是知識點。
模型可以知道 Helvetica 字體是什麼,但是它完全不能理解這個字體在什麼場景下顯得非常的low。
說到這點就非常的想笑,每次新模型出來,一些營銷號就開始用它來製作頁面,說它審美如何如何。
其實模型本身根本不具備審美的能力,它所有的“審美”都是依賴於概率和使用者的品味。
也就是說,哪怕讓我使用最早期的Deepseek V3,照樣也可以原樣復原那些所謂“審美強“的頁面。
真正的審美判斷來自經驗和品味,訓練數據都是死的,都可以通過技能注入進來。
Skills技能最大的價值,不是告訴模型怎麼做它已經會的事,而是把你腦子裏那些說不清楚但確實存在的判斷,變成模型能用的上下文。
反面案例比正面案例更值錢
文章最後講技能維護,又是一個反直覺的結論。
文章非常明確地指出技能的迭代模式應該是"只增不改",而且主要往反面案例區域追加內容。
他們的做法是每次模型出錯,加一條反面案例,這個時候不要改描述,不要加新規則,加反面案例就夠了。
為什麼反面案例比正面案例更有價值?
因為它直接告訴模型這條路走過,是死路,不要再走,正面案例告訴模型往哪走,反面案例告訴模型哪裏有坑,後者的信息密度往往更高。
他們還提到了一個很重要的副作用:加一個新技能,可能會讓已有的技能變差。因為索引層的描述都在爭奪模型的注意力,兩個描述相近的技能會互相干擾。
所以每次新增技能,都要跑一遍已有技能的測試,確認沒有連帶破壞。
我覺得這篇文檔值得反覆讀,而且不要限制於書寫Skills,完全可以把它應用到模型對話的方方面面。
最後一句話送給還在把技能當說明文檔寫的人:
如果模型沒有這個技能也能做對,就不需要這個技能。
Claude Code 又十個最值得裝的 Skills!這篇全補上
將Claude Design蒸餾成可複用的幻燈片、原型、動畫、落地頁的Skills
更多Skills的進階系統學習和分享請查看字節筆記本星球的每日推送: