Playwright 自動化實戰手冊
整理版優先睇
Playwright 自動化實戰手冊:一次過掌握架構、定位、等待同埋反爬技巧
呢篇係一份面向自動化場景嘅 Playwright 速查手冊,由作者系統整理咗 Playwright 嘅核心概念、實戰配置、定位策略、等待機制、反爬技巧同異常處理。作者本身係有經驗嘅自動化工程師,寫呢篇文係為咗俾團隊一個可以快速查閲、開箱即用嘅參考,解決「寫自動化腳本成日撞到元素揾唔到、超時、反爬封鎖」呢類常見問題。整體結論係:掌握 Context 隔離、善用語義定位器、做好等待同重試機制,就可以寫出穩定可靠嘅自動化腳本。
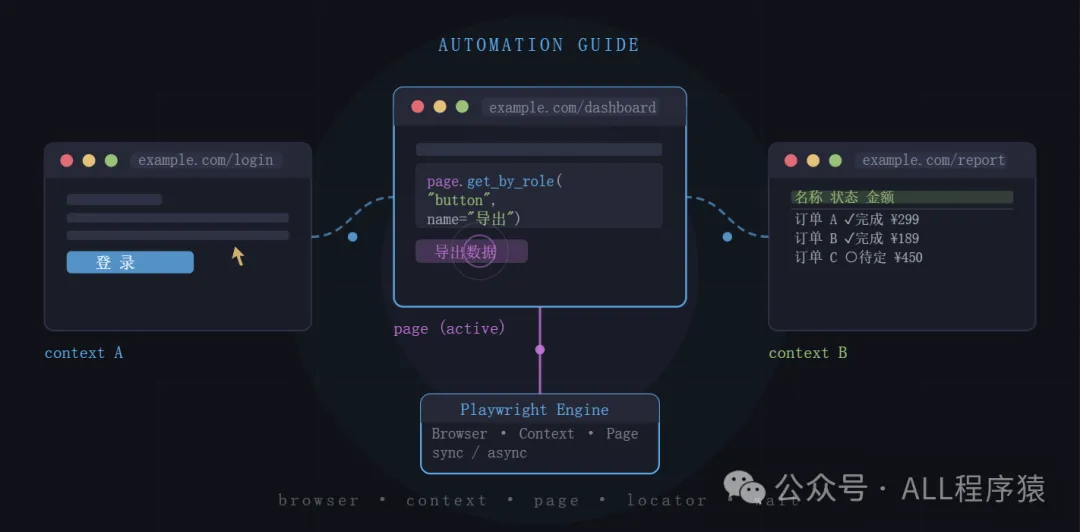
作者將成個 Playwright 使用流程拆成十幾個模塊,由最基本嘅三層架構(Browser → Context → Page)講起,再逐步深入元素定位決策樹、同步異步模式選擇、登錄態複用、iframe 同 Shadow DOM 處理等進階課題。佢特別強調 Context 嘅重要性:不同網站用不同 Context,可以避免 Cookie 同 Storage 污染;同一網站多個 Page 共享一個 Context,可以複用登錄狀態。呢個設計係 Playwright 比起 Selenium 嘅主要優勢之一。
喺定位方面,作者提出一條明確嘅優先級順序:data-testid > role > label > placeholder > text > CSS/XPath,並附上決策樹俾人快速判斷。等待機制方面,佢推介「先等 networkidle,再等關鍵元素 visible」嘅組合,確保數據加載完先操作。…
- 結論:Playwright 嘅 Context 隔離機制係穩定採集嘅關鍵,每個獨立會話應對不同場景,避免數據污染。
- 方法:元素定位優先使用語義角色(get_by_role),其次係 test ID、label、text,CSS/XPath 做兜底,提升腳本穩定性。
- 差異:同步模式適合簡單腳本,異步模式適合高併發多賬號任務,兩者選擇取決於任務規模。
- 啟發:利用 expect_response 攔截網絡數據比解析 DOM 更可靠,係高效採集嘅核心技巧。
- 可行動點:實戰必備重試模板、截圖調試、登錄狀態複用,同埋反爬注入腳本,可顯著減少腳本維護成本。
同步單任務模板
適合簡單腳本,包含 context 配置、登錄態複用、異常截圖同資源清理。
異步多賬號併發模板
適合高併發大批量任務,利用 asyncio.gather 同時處理多個賬號。
核心概念:三層架構與場景應用
Playwright 嘅架構分為 Browser、Context 同 Page 三層。Browser 係瀏覽器實例,Context 係獨立會話,相當於隔離嘅用戶環境,而 Page 就係標籤頁。記住呢條原則:唔同網站用唔同 Context,避免 Cookie 同 Storage 污染;同一網站嘅多個 Page 放喺同一個 Context,共享登錄狀態;併發採集多個賬號就用多個 Context,每個獨立登錄。
同步模式適合簡單腳本,代碼簡潔;異步模式適合高併發大批量任務,性能差距明顯。作者建議單任務用同步,多賬號用異步。
Context 隔離係 Playwright 相對於 Selenium 嘅核心優勢
- 1 不同網站用不同 Context,避免 Cookie 污染
- 2 同一網站多個 Page 共享一個 Context,複用登錄態
- 3 併發採集多個賬號:多個 Context,每個獨立登錄
元素定位:優先級決策樹與鏈式過濾
定位元素嘅穩定性直接影響腳本成功率。作者提出一條優先級順序:data-testid 最穩定,其次 get_by_role、get_by_label、get_by_placeholder、get_by_text,最後先用 CSS/XPath。
常用方法包括:get_by_role 支援 button、link、textbox、checkbox 等角色;filter 可以按文本或子元素過濾;nth 同 last 選取特定匹配項。鏈式定位可以縮小範圍,例如喺某個 form 內揾 label。
等待機制:組合策略確保操作時機準確
Playwright 多數操作自帶重試等待(默認 30 秒),但複雜場景需要顯式等待。作者推介嘅策略組合係:先 click 觸發動作,然後 wait_for_load_state('networkidle') 等網絡空閒,再 wait_for(state='visible') 確認關鍵元素出現。
- 等待頁面狀態:domcontentloaded(快)、load(所有資源)、networkidle(慢但穩)
- 等待元素狀態:visible、hidden、attached、detached
- 自定義超時:單次操作 timeout 參數或 set_default_timeout
- 固定等待係最後手段,盡量用條件等待
反爬與穩定性:隱藏特徵、模擬真人同異常處理
作者提供多種反爬技巧:--disable-blink-features=AutomationControlled 參數隱藏自動化標記;add_init_script 注入腳本覆蓋 webdriver 屬性;用 random.uniform 模擬延遲同打字速度。另外,route 可以攔截圖片、字體等資源加速加載。
異常處理方面,常見錯誤有 TimeoutError、ElementNotFound、StaleElementReference。作者提供 重試模板,用 try/except 同 time.sleep 實現最多 3 次重試。截圖調試:出錯時用 page.screenshot 留證,方便排查。
重試模板配合截圖,係實戰中最實用嘅除錯方法
- 1 隱藏自動化特徵:args 參數 + add_init_script
- 2 模擬真人:隨機延遲、打字間隔、點擊延遲
- 3 網絡攔截:route() 屏蔽圖片/媒體/字體
- 4 異常處理:重試模板 + 截圖 + 適當超時設定
完整流程模板:同步與異步實戰範例
作者提供咗兩個可直接使用嘅模板:同步單任務模板 適合簡單腳本,包含 Context 建立、登錄態複用、業務邏輯、異常截圖同資源清理;異步多賬號併發模板 用 asyncio.gather 同時處理多個賬號,每個賬號獨立 Context。
from playwright.sync_api import sync_playwright
import time
def run():
p = sync_playwright().start()
browser = p.chromium.launch(headless=True)
context = browser.new_context(storage_state='session.json', user_agent='Mozilla/5.0...')
page = context.new_page()
page.set_default_timeout(30000)
try:
page.goto('https://example.com/list', wait_until='domcontentloaded')
page.wait_for_load_state('networkidle')
# 業務邏輯
rows = page.locator("table tbody tr")
count = rows.count()
results = []
for i in range(count):
row = rows.nth(i)
results.append({
"name": row.locator("td:nth-child(1)").inner_text().strip(),
"status": row.locator("td:nth-child(2)").inner_text().strip(),
})
return results
except Exception as e:
page.screenshot(path=f"error_{int(time.time())}.png")
raise
finally:
context.close()
browser.close()
p.stop()模板入面嘅 storage_state 同 user_agent 係複用登錄態同反爬嘅關鍵
專為自動化場景而設,快速查閲,開箱即用。
目錄
核心概念:三層架構 啟動同配置 Context 同 Page 登錄狀態重用 元素定位 常用互動操作 等待機制 iframe 處理 遍歷動態列表同表格 反爬同穩定性技巧 異常處理 完整流程模板
1. 核心概念:三層架構
Playwright Engine
└── Browser(瀏覽器實例)
└── Context(獨立會話,相當於隔離的用戶環境)
└── Page(標籤頁)
記住呢個原則:
2. 啟動同配置
同步模式(腳本/簡單任務推薦)
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(
headless=True, # 生產環境用 True;調試時改 False
slow_mo=0, # 調試時設 300~500,每步之間加延遲
args=[
'--no-sandbox',
'--disable-blink-features=AutomationControlled', # 隱藏自動化特徵
]
)
異步模式(高並發/大批量任務推薦)
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
# ... 你的邏輯
await browser.close()
asyncio.run(main())
同步 vs 異步揀邊個?單任務腳本用同步,代碼更簡潔;需要並發處理多個賬號/多個頁面時用異步,性能差距好明顯。
3. Context 同 Page
創建 Context
context = browser.new_context(
no_viewport=True, # 自適應窗口(與 viewport 二選一)
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64)...',
locale='zh-CN',
timezone_id='Asia/Shanghai',
bypass_csp=True, # 繞過 CSP,調試時有用
ignore_https_errors=True, # 忽略證書錯誤(內網場景常用)
storage_state='session.json', # 加載已保存的登錄態
)
創建 Page
page = context.new_page()
# 導航
page.goto('https://example.com', wait_until='domcontentloaded')
# wait_until 選項:'load' | 'domcontentloaded' | 'networkidle' | 'commit'
# 大多數場景用 'domcontentloaded',速度更快;需要等 API 數據用 'networkidle'
# 當前 URL
print(page.url)
# 頁面標題
print(page.title())
多標籤頁處理
# 監聽新標籤頁打開事件
with context.expect_page() as new_page_info:
page.get_by_role("link", name="在新窗口打開").click()
new_page = new_page_info.value
new_page.wait_for_load_state('domcontentloaded')
# 操作 new_page...
清理資源
# 用完記得關,防止資源泄漏
context.close()
browser.close()
p.stop()
4. 登錄狀態重用
一次登錄,多次重用,避免重複行驗證碼/短信驗證流程。
第一步:登錄並保存狀態
context = browser.new_context()
page = context.new_page()
page.goto('https://example.com/login')
page.get_by_label("用戶名").fill('myuser')
page.get_by_label("密碼").fill('mypassword')
page.get_by_role("button", name="登錄").click()
page.wait_for_load_state('networkidle') # 等登錄接口完成
# 保存 cookies + localStorage
context.storage_state(path='session.json')
context.close()
第二步:後續直接加載
context = browser.new_context(storage_state='session.json')
page = context.new_page()
page.goto('https://example.com/dashboard') # 已是登錄態
注意:
session.json包含敏感信息,加入.gitignore,唔好上傳到代碼倉庫。
5. 元素定位
定位優先級(由穩到脆)
data-testid > role > label > placeholder > text > CSS/XPath
決策樹
看到一個元素
│
├─ 有 data-testid? → get_by_test_id("xxx")
│
├─ 是按鈕/連結/輸入框? → get_by_role("button/link/textbox", name="...")
│
├─ 是表單輸入框且有 <label>? → get_by_label("標籤文字")
│
├─ 輸入框有 placeholder? → get_by_placeholder("提示文字")
│
├─ 有明顯可見文本? → get_by_text("文字")
│
└─ 以上都不行 → locator("#id") / locator("xpath")
各方法示例
# 1. 按測試 ID(最穩定,需要開發配合)
page.get_by_test_id("submit-btn")
# 2. 按角色(官方最推薦)
page.get_by_role("button", name="提交")
page.get_by_role("link", name="首頁")
page.get_by_role("textbox", name="搜索")
page.get_by_role("checkbox", name="記住我")
page.get_by_role("combobox", name="城市") # <select>
# 3. 按 label / placeholder
page.get_by_label("用戶名")
page.get_by_placeholder("請輸入郵箱")
# 4. 按文本
page.get_by_text("歡迎回來")
page.get_by_text("提交", exact=True) # 精確匹配,避免誤命中
# 5. CSS / XPath(兜底)
page.locator("#submit-btn")
page.locator(".form > input[name='username']")
page.locator("//button[text()='提交']")
常用 Role 速查表
<button> | "button" |
<a> | "link" |
<input type="text"> | "textbox" |
<input type="checkbox"> | "checkbox" |
<input type="radio"> | "radio" |
<select> | "combobox" |
<li> | "listitem" |
<h1><h6> | "heading" |
<img> | "img" |
鏈式定位同過濾
# 在某個容器內查找(縮小範圍)
page.get_by_role("form").get_by_label("用戶名").fill("張三")
# 過濾包含特定文本的元素
page.get_by_role("listitem").filter(has_text="已完成").click()
# 過濾包含特定子元素的元素
page.get_by_role("listitem").filter(has=page.get_by_role("checkbox", checked=True))
# nth:獲取第 N 個匹配項(從 0 開始)
page.get_by_role("listitem").nth(0) # 第一個
page.get_by_role("listitem").last # 最後一個
定位器係"惰性"嘅
# 這行不會立即查找元素,只是定義了查找策略
button = page.get_by_role("button", name="提交")
# 直到這裏才真正查找 + 等待 + 操作
button.click()
好處:頁面刷新或者元素重新渲染之後,定位器依然有效,會自動重試。
6. 常用互動操作
點擊
page.get_by_role("button", name="提交").click()
page.get_by_role("button", name="編輯").dblclick() # 雙擊
page.get_by_role("button", name="更多").click(button="right") # 右鍵
page.get_by_role("button", name="提交").click(delay=100) # 帶延遲,防風控
文本輸入
page.get_by_label("用戶名").fill("zhangsan") # 清空後輸入(推薦)
page.get_by_label("備註").type("內容", delay=50) # 模擬真人打字速度
page.get_by_label("搜索").clear() # 清空輸入框
page.keyboard.press("Enter") # 按回車
page.keyboard.press("Control+A") # 快捷鍵
下拉框
page.locator("select#city").select_option("beijing") # 按 value
page.locator("select#city").select_option(label="北京市") # 按顯示文本
page.locator("select#tags").select_option(["tag1", "tag2"]) # 多選
複選框 / 單選框
page.get_by_label("同意協議").check()
page.get_by_label("訂閲郵件").uncheck()
is_checked = page.get_by_label("記住我").is_checked()
文件上傳
page.get_by_label("上傳文件").set_input_files("./file.pdf")
page.get_by_label("上傳文件").set_input_files(["./a.pdf", "./b.pdf"]) # 多文件
page.get_by_label("上傳文件").set_input_files([]) # 清除已選文件
獲取元素信息
text = page.get_by_role("heading").inner_text()
html = page.locator(".content").inner_html()
value = page.get_by_label("用戶名").input_value()
attr = page.locator("img").get_attribute("src")
is_visible = page.get_by_role("button").is_visible()
is_enabled = page.get_by_role("button").is_enabled()
滑鼠同滾動
# 懸停(觸發 hover 菜單)
page.get_by_role("button", name="更多").hover()
# 滾動到元素
page.get_by_text("底部內容").scroll_into_view_if_needed()
# 滾動頁面
page.mouse.wheel(0, 3000) # 向下滾動 3000px
# 拖拽
page.drag_and_drop("#source", "#target")
7. 等待機制
Playwright 大多數操作自帶重試等待(默認超時 30 秒),但複雜場景就需要顯式等待。
等待頁面狀態
page.wait_for_load_state("domcontentloaded") # DOM 解析完成(快)
page.wait_for_load_state("load") # 所有資源加載完成
page.wait_for_load_state("networkidle") # 網絡請求全部完成(慢但穩)
等待元素狀態
# 等待元素可見
page.locator(".result-list").wait_for(state="visible")
# 等待元素消失(如 loading 遮罩)
page.locator(".loading-mask").wait_for(state="hidden")
# 等待元素從 DOM 中移除
page.locator(".toast").wait_for(state="detached")
# 等待元素出現在 DOM(不一定可見)
page.locator(".data").wait_for(state="attached")
等待網絡請求
# 等待特定接口響應(用於數據加載完成的判斷)
with page.expect_response("**/api/list**") as resp_info:
page.get_by_role("button", name="查詢").click()
response = resp_info.value
data = response.json() # 直接拿接口返回數據!
直接攔截接口數據係自動化採集嘅一個強力技巧,比解析 DOM 更可靠。
固定等待(盡量少用)
page.wait_for_timeout(2000) # 等待 2 秒,最後的手段
自定義超時
# 單次操作超時
page.get_by_role("button").click(timeout=5000) # 超時 5 秒
# 全局默認超時
page.set_default_timeout(60000) # 改為 60 秒
等待策略組合(推薦模板)
# 點擊觸發數據加載後的最佳等待姿勢
page.get_by_role("button", name="查詢").click()
page.wait_for_load_state("networkidle") # 等網絡空閒
page.locator(".data-table").wait_for(state="visible") # 再確認關鍵元素
8. iframe 處理
# 通過 CSS 選擇器進入 iframe
frame = page.frame_locator("iframe#editor")
# 在 iframe 內操作,和普通 page 完全一樣
frame.get_by_role("textbox").fill("Hello World")
frame.get_by_role("button", name="保存").click()
# 操作完直接用 page 即可回到主頁面,無需顯式切換
page.get_by_role("button", name="關閉").click()
嵌套 iframe
frame = page.frame_locator("iframe#outer").frame_locator("iframe#inner")
frame.get_by_role("button", name="提交").click()
9. 遍歷動態列表同表格
正確做法:先 count,再 nth
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
name = row.locator("td:nth-child(1)").inner_text()
status = row.locator("td:nth-child(2)").inner_text()
print(f"{name}: {status}")
點解唔用
rows.all()直接遍歷?all()返回嘅係快照,如果操作過程中頁面內容變化(例如分頁、彈窗導致刷新),會出現 stale element。用nth(i)每次都重新查找,更穩陣。
操作每行並處理彈窗
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
row.get_by_role("button", name="編輯").click()
# 操作彈窗
dialog = page.locator(".modal")
dialog.wait_for(state="visible")
dialog.get_by_label("備註").fill("已處理")
dialog.get_by_role("button", name="保存").click()
dialog.wait_for(state="hidden") # 等彈窗關閉
# 下一行會自動重新查找,不受影響
點擊"加載更多"之後繼續採集
while True:
# 採集當前頁數據
items = page.get_by_role("listitem").all()
for item in items:
print(item.inner_text())
# 檢查是否還有下一頁
load_more = page.get_by_role("button", name="加載更多")
ifnot load_more.is_visible():
break
load_more.click()
# 等新內容加載完(用舊內容數量作為基準)
page.wait_for_function(f"document.querySelectorAll('li').length > {len(items)}")
10. 反爬同穩定性技巧
隱藏自動化特徵
browser = p.chromium.launch(
args=['--disable-blink-features=AutomationControlled']
)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...'
)
# 注入腳本,覆蓋 webdriver 特徵
page.add_init_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
模擬真人行為
import random, time
# 隨機延遲
time.sleep(random.uniform(1.0, 3.0))
# 打字帶延遲
page.get_by_label("搜索").type("關鍵詞", delay=random.randint(50, 150))
# 點擊加延遲
page.get_by_role("button").click(delay=random.randint(50, 200))
截圖同調試
# 出錯時截圖留證
try:
page.get_by_role("button", name="提交").click()
except Exception as e:
page.screenshot(path=f"error_{int(time.time())}.png")
raise
# 全頁截圖(包括不可見區域)
page.screenshot(path="full.png", full_page=True)
# 對特定元素截圖
page.locator(".chart").screenshot(path="chart.png")
網絡攔截(加速/Mock)
# 屏蔽圖片和媒體資源,加速加載
def block_resources(route):
if route.request.resource_type in ["image", "media", "font"]:
route.abort()
else:
route.continue_()
page.route("**/*", block_resources)
11. 異常處理
常見錯誤類型
TimeoutError | ||
ElementNotFound | ||
StaleElementReference | nth(i) 替代 all() 之後嘅元素 | |
TargetClosedError |
穩陣嘅重試模板
import time
def retry(fn, max_retries=3, delay=2):
for attempt in range(max_retries):
try:
return fn()
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"第 {attempt+1} 次失敗: {e},{delay}s 後重試...")
time.sleep(delay)
# 使用
retry(lambda: page.get_by_role("button", name="查詢").click())
12. 完整流程模板
單任務模板(同步)
from playwright.sync_api import sync_playwright
import time
def run():
p = sync_playwright().start()
browser = p.chromium.launch(headless=True)
context = browser.new_context(
storage_state='session.json', # 複用登錄態
user_agent='Mozilla/5.0...',
)
page = context.new_page()
page.set_default_timeout(30000)
try:
page.goto('https://example.com/list', wait_until='domcontentloaded')
page.wait_for_load_state('networkidle')
# 你的業務邏輯
rows = page.locator("table tbody tr")
count = rows.count()
results = []
for i in range(count):
row = rows.nth(i)
results.append({
"name": row.locator("td:nth-child(1)").inner_text().strip(),
"status": row.locator("td:nth-child(2)").inner_text().strip(),
})
return results
except Exception as e:
page.screenshot(path=f"error_{int(time.time())}.png")
raise
finally:
context.close()
browser.close()
p.stop()
if __name__ == "__main__":
data = run()
print(f"共採集 {len(data)} 條")
多賬號並發模板(異步)
import asyncio
from playwright.async_api import async_playwright
ACCOUNTS = [
{"session": "session_a.json", "name": "賬號A"},
{"session": "session_b.json", "name": "賬號B"},
]
asyncdef process_account(browser, account):
context = await browser.new_context(storage_state=account["session"])
page = await context.new_page()
try:
await page.goto("https://example.com/dashboard")
await page.wait_for_load_state("networkidle")
# ... 業務邏輯
print(f"{account['name']} 完成")
finally:
await context.close()
asyncdef main():
asyncwith async_playwright() as p:
browser = await p.chromium.launch(headless=True)
await asyncio.gather(*[
process_account(browser, acc) for acc in ACCOUNTS
])
await browser.close()
asyncio.run(main())
快速速查卡
# 導航
page.goto(url)
page.go_back() / page.go_forward() / page.reload()
# 定位
page.get_by_role("button", name="...")
page.get_by_label("...") / page.get_by_placeholder("...")
page.get_by_text("...") / page.get_by_test_id("...")
page.locator("css or xpath")
# 操作
.click() / .dblclick() / .hover()
.fill("text") / .type("text", delay=50) / .clear()
.check() / .uncheck() / .select_option("value")
.set_input_files("path")
# 獲取信息
.inner_text() / .inner_html() / .input_value()
.get_attribute("attr") / .is_visible() / .is_enabled()
# 等待
.wait_for(state="visible/hidden/attached/detached")
page.wait_for_load_state("networkidle/load/domcontentloaded")
page.wait_for_selector("css")
page.wait_for_timeout(ms)
# 截圖
page.screenshot(path="shot.png", full_page=True)
page.locator(".el").screenshot(path="el.png")
13. 執行 JavaScript
當 Playwright 嘅 Python API 滿足唔到需求時,直接喺頁面上下文執行 JS 係最後嘅利器。
基礎用法
# 執行 JS 並獲取返回值
title = page.evaluate("document.title")
scroll_y = page.evaluate("window.scrollY")
# 傳參給 JS
result = page.evaluate("(x) => x * 2", 21) # → 42
# 多行 JS
data = page.evaluate("""
() => {
const rows = document.querySelectorAll('table tr');
return Array.from(rows).map(r => r.innerText);
}
""")
操作 DOM(繞過 Playwright 限制)
# 強制修改輸入框的值(對某些 React/Vue 受控組件有效)
page.evaluate("""
(value) => {
const input = document.querySelector('#amount');
const nativeInputSetter = Object.getOwnPropertyDescriptor(
window.HTMLInputElement.prototype, 'value'
).set;
nativeInputSetter.call(input, value);
input.dispatchEvent(new Event('input', { bubbles: true }));
}
""", "9999")
# 觸發自定義事件
page.evaluate("document.querySelector('#editor').dispatchEvent(new Event('change'))")
# 滾動到頁面底部
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
evaluate vs evaluate_handle
# evaluate:返回 Python 原生值(字符串、數字、列表、字典)
count = page.evaluate("document.querySelectorAll('li').length")
# evaluate_handle:返回 JS 對象句柄(用於後續傳給其他 JS 調用)
list_handle = page.evaluate_handle("document.querySelectorAll('li')")
# 可以把 handle 傳回給 evaluate
first_text = page.evaluate("(list) => list[0].innerText", list_handle)
喺頁面加載前注入腳本
# add_init_script:每次頁面加載/刷新時都會執行,適合反檢測
page.add_init_script("""
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3] });
""")
# 也可以注入一個 JS 文件
page.add_init_script(path="./stealth.js")
14. Shadow DOM 處理
Shadow DOM 係 Web Components 嘅封裝機制,普通 CSS 選擇器穿唔透,但 Playwright 嘅大多數語義定位器(get_by_role、get_by_text 等)默認可以穿透 Shadow DOM。
推薦:直接用語義定位器
# Playwright 的 get_by_* 方法默認穿透 Shadow DOM,直接用即可
page.get_by_role("button", name="提交").click()
page.get_by_label("用戶名").fill("zhangsan")
如果必須用 CSS 選擇器
# 用 >> 穿透 Shadow DOM(舊語法,仍然有效)
page.locator("my-component >> .inner-button").click()
# 或者用 pierce/ 前綴(更明確)
page.locator("pierce/.inner-button").click()
通過 JS 訪問 Shadow Root
# 當以上方法都不行時,用 JS 訪問
text = page.evaluate("""
() => {
const host = document.querySelector('my-custom-element');
return host.shadowRoot.querySelector('.price').innerText;
}
""")
15. 對話框處理(alert/confirm/prompt)
瀏覽器原生彈窗(window.alert、window.confirm、window.prompt)會阻塞頁面,必須提前註冊監聽器處理,否則超時報錯。
自動接受所有彈窗
# 註冊監聽器,自動點"確認"
page.on("dialog", lambda dialog: dialog.accept())
# 然後觸發彈窗的操作
page.get_by_role("button", name="刪除").click()
根據類型分別處理
def handle_dialog(dialog):
print(f"彈窗類型: {dialog.type}") # alert / confirm / prompt / beforeunload
print(f"彈窗內容: {dialog.message}")
if dialog.type == "confirm":
dialog.accept() # 點確認
elif dialog.type == "prompt":
dialog.accept("我的輸入") # 輸入內容並確認
else:
dialog.dismiss() # 點取消/關閉
page.on("dialog", handle_dialog)
page.get_by_role("button", name="危險操作").click()
注意: 監聽器要在觸發彈窗之前註冊,唔係嘅話來唔切處理。
16. 文件下載
捕獲下載事件
import os
# 方法一:用 expect_download 上下文管理器(推薦)
with page.expect_download() as download_info:
page.get_by_role("button", name="導出 Excel").click()
download = download_info.value
# 保存到指定路徑
download.save_as("./exports/report.xlsx")
# 或查看臨時路徑
print(download.path()) # 臨時文件路徑
print(download.suggested_filename) # 服務器建議的文件名
批量下載
import os
os.makedirs("./downloads", exist_ok=True)
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
filename = row.locator("td:nth-child(1)").inner_text().strip()
with page.expect_download() as dl_info:
row.get_by_role("link", name="下載").click()
dl = dl_info.value
dl.save_as(f"./downloads/{filename}.pdf")
print(f"已下載: {filename}")
配置默認下載路徑
# 在 context 層面設置下載目錄
context = browser.new_context(accept_downloads=True)
# 也可以在 launch 時指定
browser = p.chromium.launch_persistent_context(
user_data_dir="./user_data",
accept_downloads=True,
downloads_path="./downloads",
)
17. Cookie 管理
讀取 Cookie
# 獲取所有 cookies
cookies = context.cookies()
for c in cookies:
print(f"{c['name']} = {c['value']}")
# 獲取特定域名的 cookies
cookies = context.cookies(["https://example.com"])
添加 / 修改 Cookie
context.add_cookies([
{
"name": "token",
"value": "abc123xyz",
"domain": "example.com",
"path": "/",
"httpOnly": True,
"secure": True,
"sameSite": "Lax",
}
])
清除 Cookie
context.clear_cookies()
導入外部 Cookie(例如從瀏覽器導出)
import json
# 假設你有從 EditThisCookie 等工具導出的 JSON
with open("cookies.json") as f:
raw = json.load(f)
# 標準化字段(不同工具導出格式可能略有不同)
cookies = [{
"name": c["name"],
"value": c["value"],
"domain": c["domain"],
"path": c.get("path", "/"),
"secure": c.get("secure", False),
"httpOnly": c.get("httpOnly", False),
} for c in raw]
context.add_cookies(cookies)
18. 代理配置
全局代理
browser = p.chromium.launch(
proxy={
"server": "http://proxy.example.com:8080",
"username": "user", # 如果代理需要認證
"password": "pass",
}
)
Context 級別代理(同一瀏覽器唔同賬號行唔同代理)
context_a = browser.new_context(proxy={"server": "http://proxy1:8080"})
context_b = browser.new_context(proxy={"server": "http://proxy2:8080"})
SOCKS5 代理
browser = p.chromium.launch(
proxy={"server": "socks5://127.0.0.1:1080"}
)
繞過特定域名(唔行代理)
browser = p.chromium.launch(
proxy={
"server": "http://proxy:8080",
"bypass": "localhost,127.0.0.1,internal.company.com"
}
)
19. 網絡攔截進階
監聽所有請求/響應(只讀,唔攔截)
# 監聽請求
page.on("request", lambda req: print(f"→ {req.method} {req.url}"))
# 監聽響應
page.on("response", lambda resp: print(f"← {resp.status} {resp.url}"))
# 只關注特定接口
def on_response(response):
if "/api/list" in response.url:
print(response.json())
page.on("response", on_response)
page.goto("https://example.com")
攔截並修改請求(Mock 數據)
def mock_api(route):
# 如果是目標接口,返回假數據
if "/api/user" in route.request.url:
route.fulfill(
status=200,
content_type="application/json",
body='{"name": "測試用戶", "role": "admin"}'
)
else:
route.continue_()
page.route("**/*", mock_api)
攔截並修改請求頭
def add_auth_header(route):
headers = {**route.request.headers, "Authorization": "Bearer my-token"}
route.continue_(headers=headers)
page.route("**/api/**", add_auth_header)
攔截並修改響應體
def modify_response(route):
# 先讓請求正常發出,拿到真實響應
response = route.fetch()
body = response.json()
# 修改數據
body["data"]["vip"] = True
# 把修改後的數據返回給頁面
route.fulfill(response=response, body=json.dumps(body))
page.route("**/api/profile", modify_response)
採集接口數據(唔解析 DOM)
collected = []
def capture_list_api(response):
if"/api/items"in response.url and response.status == 200:
data = response.json()
collected.extend(data.get("items", []))
page.on("response", capture_list_api)
# 翻頁操作,每翻一頁接口數據自動被收集
for page_num in range(1, 11):
page.goto(f"https://example.com/list?page={page_num}")
page.wait_for_load_state("networkidle")
print(f"共採集 {len(collected)} 條")
20. 分頁採集模板
按鈕翻頁(有"下一頁"按鈕)
results = []
whileTrue:
# 採集當前頁
rows = page.locator("table tbody tr")
for i in range(rows.count()):
row = rows.nth(i)
results.append({
"name": row.locator("td:nth-child(1)").inner_text().strip(),
"value": row.locator("td:nth-child(2)").inner_text().strip(),
})
# 檢查下一頁按鈕
next_btn = page.get_by_role("button", name="下一頁")
ifnot next_btn.is_visible() ornot next_btn.is_enabled():
break
next_btn.click()
page.wait_for_load_state("networkidle")
page.locator("table tbody tr").first.wait_for(state="visible")
print(f"共採集 {len(results)} 條")
URL 參數翻頁
results = []
page_num = 1
whileTrue:
page.goto(f"https://example.com/list?page={page_num}&size=50")
page.wait_for_load_state("networkidle")
rows = page.locator("table tbody tr")
count = rows.count()
if count == 0:
break# 沒有數據了
for i in range(count):
row = rows.nth(i)
results.append(row.locator("td:nth-child(1)").inner_text().strip())
# 如果返回行數小於每頁大小,說明是最後一頁
if count < 50:
break
page_num += 1
接口翻頁(直接拎 API 數據)
import json
results = []
page_num = 1
whileTrue:
with page.expect_response("**/api/list**") as resp_info:
page.goto(f"https://example.com/list?page={page_num}")
resp = resp_info.value.json()
items = resp.get("data", {}).get("list", [])
total_pages = resp.get("data", {}).get("totalPages", 1)
results.extend(items)
print(f"第 {page_num}/{total_pages} 頁,已採集 {len(results)} 條")
if page_num >= total_pages:
break
page_num += 1
21. 無限滾動採集
有啲頁面唔使翻頁,而係滾動到底部自動加載更多內容。
基礎無限滾動
results = set()
last_count = 0
no_new_count = 0# 連續幾次沒有新數據
while no_new_count < 3:
# 採集當前可見的所有項目
items = page.locator(".item-card").all()
for item in items:
results.add(item.inner_text().strip())
current_count = len(results)
if current_count == last_count:
no_new_count += 1
else:
no_new_count = 0
last_count = current_count
# 滾動到頁面底部
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
page.wait_for_timeout(1500) # 等待新內容加載
print(f"共採集 {len(results)} 條")
等待新內容出現之後再滾動(更穩定)
results = []
whileTrue:
current_items = page.locator(".item-card")
current_count = current_items.count()
# 採集當前頁的所有項
for i in range(current_count):
text = current_items.nth(i).inner_text().strip()
if text notin [r["text"] for r in results]:
results.append({"text": text})
# 滾動到最後一個元素
current_items.last.scroll_into_view_if_needed()
# 等待新內容出現(數量增加)
try:
page.wait_for_function(
f"document.querySelectorAll('.item-card').length > {current_count}",
timeout=5000
)
except:
# 超時說明沒有更多數據了
print("已到底部,採集完畢")
break
print(f"共採集 {len(results)} 條")
22. 複雜組件處理(日期選擇器/自定義下拉框)
日期選擇器
原生 <input type="date"> 直接用 fill:
page.get_by_label("開始日期").fill("2024-01-15") # 格式:YYYY-MM-DD
基於 JS 庫嘅日期選擇器(冇得直接 fill),用點擊方式操作:
# 點擊日期輸入框打開日曆
page.get_by_placeholder("選擇日期").click()
# 等待日曆彈出
page.locator(".datepicker-popup").wait_for(state="visible")
# 如果需要跳轉到特定月份
whileTrue:
month_label = page.locator(".datepicker-header .month").inner_text()
if"2024年3月"in month_label:
break
page.locator(".datepicker-prev").click()
# 點擊目標日期
page.get_by_role("gridcell", name="15").click()
更簡單嘅方案——直接用 JS 設置值:
# 找到背後隱藏的真實 input,直接設置值
page.evaluate("""
() => {
const input = document.querySelector('input[name="startDate"]');
input.value = '2024-03-15';
input.dispatchEvent(new Event('change', { bubbles: true }));
}
""")
自定義下拉框(非原生 <select>)
好多 UI 組件庫(Ant Design、Element UI 等)嘅下拉框係 <div> 模擬嘅:
# 點擊觸發下拉框展開
page.locator(".custom-select").click()
# 等待選項列表出現
page.locator(".select-dropdown").wait_for(state="visible")
# 點擊目標選項
page.get_by_role("option", name="北京市").click()
# 或者用 get_by_text 找選項
page.locator(".select-dropdown").get_by_text("北京市").click()
富文本編輯器(例如 Quill、TinyMCE)
# Quill 編輯器
editor = page.locator(".ql-editor")
editor.click()
editor.fill("這是輸入的內容")
# TinyMCE(通常在 iframe 裏)
frame = page.frame_locator("iframe#content_ifr")
frame.locator("#tinymce").fill("這是輸入的內容")
# 如果 fill 不生效,用 JS 注入
page.evaluate("""
() => {
// Quill 實例
const quill = document.querySelector('.ql-editor').__quill;
quill.setText('這是內容');
}
""")
滑塊驗證碼(拖拽類)
# 找到滑塊
slider = page.locator(".slider-btn")
box = slider.bounding_box()
# 模擬拖拽(分步移動,模擬真人)
page.mouse.move(box["x"] + box["width"] / 2, box["y"] + box["height"] / 2)
page.mouse.down()
# 分多步移動,不要一步到位
import random
target_x = box["x"] + 280# 目標位置(需根據實際調整)
current_x = box["x"] + box["width"] / 2
step = (target_x - current_x) / 20
for i in range(20):
current_x += step + random.uniform(-1, 1) # 加入隨機抖動
page.mouse.move(current_x, box["y"] + box["height"] / 2 + random.uniform(-1, 1))
page.wait_for_timeout(random.randint(10, 30))
page.mouse.up()
23. 數據導出(JSON/CSV/Excel)
導出做 JSON
import json
results = [{"name": "張三", "age": 28}, {"name": "李四", "age": 32}]
with open("output.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print("已導出 output.json")
導出做 CSV
import csv
results = [{"name": "張三", "score": 95}, {"name": "李四", "score": 87}]
with open("output.csv", "w", newline="", encoding="utf-8-sig") as f:
# utf-8-sig 讓 Excel 能正確識別中文
writer = csv.DictWriter(f, fieldnames=["name", "score"])
writer.writeheader()
writer.writerows(results)
print("已導出 output.csv")
導出做 Excel(openpyxl)
# pip install openpyxl
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment
results = [
{"名稱": "產品A", "價格": 199, "庫存": 50},
{"名稱": "產品B", "價格": 299, "庫存": 30},
]
wb = Workbook()
ws = wb.active
ws.title = "採集結果"
headers = list(results[0].keys())
# 寫表頭(加粗+背景色)
for col, header in enumerate(headers, 1):
cell = ws.cell(row=1, column=col, value=header)
cell.font = Font(bold=True)
cell.fill = PatternFill("solid", fgColor="DDEEFF")
cell.alignment = Alignment(horizontal="center")
# 寫數據
for row_idx, record in enumerate(results, 2):
for col_idx, key in enumerate(headers, 1):
ws.cell(row=row_idx, column=col_idx, value=record[key])
# 自動列寬
for col in ws.columns:
max_len = max(len(str(cell.value or"")) for cell in col)
ws.column_dimensions[col[0].column_letter].width = max_len + 4
wb.save("output.xlsx")
print("已導出 output.xlsx")
增量寫入(大量數據防止遺失)
import csv, os
OUTPUT_FILE = "output.csv"
HEADERS = ["name", "price", "url"]
# 文件不存在時寫表頭
write_header = not os.path.exists(OUTPUT_FILE)
with open(OUTPUT_FILE, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=HEADERS)
if write_header:
writer.writeheader()
# 每採集一條立即寫入,不怕中途崩潰
for item in scrape_items():
writer.writerow(item)
f.flush() # 強制刷新緩衝區
24. 調試工具
Codegen:自動生成代碼
錄製你嘅瀏覽器操作,自動生成 Playwright 代碼,好適合快速上手一個新網站。
# 錄製操作,輸出 Python 代碼
playwright codegen https://example.com --output script.py
# 指定語言
playwright codegen https://example.com --lang python
# 帶已保存的登錄態錄製
playwright codegen https://example.com --load-storage session.json
Inspector:互動式調試
# 代碼里加上這行,運行時會暫停並打開 Inspector 窗口
page.pause()
或者通過環境變量啟動:
PWDEBUG=1 python your_script.py
Inspector 入面可以:逐步執行、實時查看元素、測試定位器表達式。
Trace Viewer:事後回放
Trace 會記錄操作嘅每一步截圖、網絡請求、DOM 快照,出錯時查 trace 比起睇日誌直觀好多。
# 開啓 trace 記錄
context.tracing.start(screenshots=True, snapshots=True, sources=True)
# ... 你的操作 ...
# 保存 trace
context.tracing.stop(path="trace.zip")
# 在瀏覽器裏回放 trace
playwright show-trace trace.zip
頁面控制枱輸出
# 監聽頁面 console.log 輸出(調試 JS 邏輯很有用)
page.on("console", lambda msg: print(f"[console.{msg.type}] {msg.text}"))
# 監聽頁面報錯
page.on("pageerror", lambda err: print(f"[JS錯誤] {err}"))
25. 性能優化
按需加載資源(最有效)
# 屏蔽非必要資源,速度可以提升 2~5 倍
BLOCKED_TYPES = {"image", "media", "font", "stylesheet"}
def block_unnecessary(route):
if route.request.resource_type in BLOCKED_TYPES:
route.abort()
else:
route.continue_()
page.route("**/*", block_unnecessary)
控制並發數量
import asyncio
from playwright.async_api import async_playwright
asyncdef process_url(browser, semaphore, url):
asyncwith semaphore: # 限制同時運行的協程數
context = await browser.new_context()
page = await context.new_page()
try:
await page.goto(url)
# ... 處理邏輯
finally:
await context.close()
asyncdef main():
urls = [f"https://example.com/item/{i}"for i in range(100)]
semaphore = asyncio.Semaphore(5) # 最多 5 個併發
asyncwith async_playwright() as p:
browser = await p.chromium.launch(headless=True)
await asyncio.gather(*[process_url(browser, semaphore, url) for url in urls])
await browser.close()
asyncio.run(main())
重用 Page 而唔係每次新建
# 不好的做法:每個 URL 新建一個 page
for url in urls:
page = context.new_page()
page.goto(url)
# ...
page.close() # 也要關
# 好的做法:複用同一個 page
page = context.new_page()
for url in urls:
page.goto(url)
# ...
# 最後統一關
page.close()
注意:如果頁面跳轉後狀態有影響(例如彈窗未關閉),重用 page 可能會產生問題,按需選擇。
使用 domcontentloaded 代替 networkidle
# networkidle 要等所有請求完成,通常需要 2~5 秒
page.goto(url, wait_until="networkidle") # 慢
# domcontentloaded 只等 DOM 解析完,通常不到 1 秒
page.goto(url, wait_until="domcontentloaded") # 快
# 然後再用更精確的元素等待
page.locator(".data-table").wait_for(state="visible")
持久化 Context(保留緩存)
# launch_persistent_context 會保留磁盤緩存,重複訪問同一網站更快
context = p.chromium.launch_persistent_context(
user_data_dir="./browser_profile",
headless=True,
accept_downloads=True,
)
page = context.new_page()
# 注意:persistent context 不需要再調用 browser.new_context()
性能 Checklist
expect_response 拎接口數據,唔解析 DOM | |
面向自動化場景,快速查閲、開箱即用。
目錄
核心概念:三層架構 啓動與配置 Context 與 Page 登錄狀態複用 元素定位 常用交互操作 等待機制 iframe 處理 遍歷動態列表與表格 反爬與穩定性技巧 異常處理 完整流程模板
1. 核心概念:三層架構
Playwright Engine
└── Browser(瀏覽器實例)
└── Context(獨立會話,相當於隔離的用戶環境)
└── Page(標籤頁)
記住這條原則:
2. 啓動與配置
同步模式(腳本/簡單任務推薦)
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(
headless=True, # 生產環境用 True;調試時改 False
slow_mo=0, # 調試時設 300~500,每步之間加延遲
args=[
'--no-sandbox',
'--disable-blink-features=AutomationControlled', # 隱藏自動化特徵
]
)
異步模式(高併發/大批量任務推薦)
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
# ... 你的邏輯
await browser.close()
asyncio.run(main())
同步 vs 異步選哪個?單任務腳本用同步,代碼更簡潔;需要併發處理多個賬號/多個頁面時用異步,性能差距明顯。
3. Context 與 Page
創建 Context
context = browser.new_context(
no_viewport=True, # 自適應窗口(與 viewport 二選一)
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64)...',
locale='zh-CN',
timezone_id='Asia/Shanghai',
bypass_csp=True, # 繞過 CSP,調試時有用
ignore_https_errors=True, # 忽略證書錯誤(內網場景常用)
storage_state='session.json', # 加載已保存的登錄態
)
創建 Page
page = context.new_page()
# 導航
page.goto('https://example.com', wait_until='domcontentloaded')
# wait_until 選項:'load' | 'domcontentloaded' | 'networkidle' | 'commit'
# 大多數場景用 'domcontentloaded',速度更快;需要等 API 數據用 'networkidle'
# 當前 URL
print(page.url)
# 頁面標題
print(page.title())
多標籤頁處理
# 監聽新標籤頁打開事件
with context.expect_page() as new_page_info:
page.get_by_role("link", name="在新窗口打開").click()
new_page = new_page_info.value
new_page.wait_for_load_state('domcontentloaded')
# 操作 new_page...
清理資源
# 用完記得關,防止資源泄漏
context.close()
browser.close()
p.stop()
4. 登錄狀態複用
一次登錄,多次複用,避免重複走驗證碼/短信驗證流程。
第一步:登錄並保存狀態
context = browser.new_context()
page = context.new_page()
page.goto('https://example.com/login')
page.get_by_label("用戶名").fill('myuser')
page.get_by_label("密碼").fill('mypassword')
page.get_by_role("button", name="登錄").click()
page.wait_for_load_state('networkidle') # 等登錄接口完成
# 保存 cookies + localStorage
context.storage_state(path='session.json')
context.close()
第二步:後續直接加載
context = browser.new_context(storage_state='session.json')
page = context.new_page()
page.goto('https://example.com/dashboard') # 已是登錄態
注意:
session.json包含敏感信息,加入.gitignore,不要上傳到代碼倉庫。
5. 元素定位
定位優先級(從穩到脆)
data-testid > role > label > placeholder > text > CSS/XPath
決策樹
看到一個元素
│
├─ 有 data-testid? → get_by_test_id("xxx")
│
├─ 是按鈕/連結/輸入框? → get_by_role("button/link/textbox", name="...")
│
├─ 是表單輸入框且有 <label>? → get_by_label("標籤文字")
│
├─ 輸入框有 placeholder? → get_by_placeholder("提示文字")
│
├─ 有明顯可見文本? → get_by_text("文字")
│
└─ 以上都不行 → locator("#id") / locator("xpath")
各方法示例
# 1. 按測試 ID(最穩定,需要開發配合)
page.get_by_test_id("submit-btn")
# 2. 按角色(官方最推薦)
page.get_by_role("button", name="提交")
page.get_by_role("link", name="首頁")
page.get_by_role("textbox", name="搜索")
page.get_by_role("checkbox", name="記住我")
page.get_by_role("combobox", name="城市") # <select>
# 3. 按 label / placeholder
page.get_by_label("用戶名")
page.get_by_placeholder("請輸入郵箱")
# 4. 按文本
page.get_by_text("歡迎回來")
page.get_by_text("提交", exact=True) # 精確匹配,避免誤命中
# 5. CSS / XPath(兜底)
page.locator("#submit-btn")
page.locator(".form > input[name='username']")
page.locator("//button[text()='提交']")
常用 Role 速查表
<button> | "button" |
<a> | "link" |
<input type="text"> | "textbox" |
<input type="checkbox"> | "checkbox" |
<input type="radio"> | "radio" |
<select> | "combobox" |
<li> | "listitem" |
<h1><h6> | "heading" |
<img> | "img" |
鏈式定位與過濾
# 在某個容器內查找(縮小範圍)
page.get_by_role("form").get_by_label("用戶名").fill("張三")
# 過濾包含特定文本的元素
page.get_by_role("listitem").filter(has_text="已完成").click()
# 過濾包含特定子元素的元素
page.get_by_role("listitem").filter(has=page.get_by_role("checkbox", checked=True))
# nth:獲取第 N 個匹配項(從 0 開始)
page.get_by_role("listitem").nth(0) # 第一個
page.get_by_role("listitem").last # 最後一個
定位器是"惰性"的
# 這行不會立即查找元素,只是定義了查找策略
button = page.get_by_role("button", name="提交")
# 直到這裏才真正查找 + 等待 + 操作
button.click()
好處:頁面刷新或元素重新渲染後,定位器依然有效,會自動重試。
6. 常用交互操作
點擊
page.get_by_role("button", name="提交").click()
page.get_by_role("button", name="編輯").dblclick() # 雙擊
page.get_by_role("button", name="更多").click(button="right") # 右鍵
page.get_by_role("button", name="提交").click(delay=100) # 帶延遲,防風控
文本輸入
page.get_by_label("用戶名").fill("zhangsan") # 清空後輸入(推薦)
page.get_by_label("備註").type("內容", delay=50) # 模擬真人打字速度
page.get_by_label("搜索").clear() # 清空輸入框
page.keyboard.press("Enter") # 按回車
page.keyboard.press("Control+A") # 快捷鍵
下拉框
page.locator("select#city").select_option("beijing") # 按 value
page.locator("select#city").select_option(label="北京市") # 按顯示文本
page.locator("select#tags").select_option(["tag1", "tag2"]) # 多選
複選框 / 單選框
page.get_by_label("同意協議").check()
page.get_by_label("訂閲郵件").uncheck()
is_checked = page.get_by_label("記住我").is_checked()
文件上傳
page.get_by_label("上傳文件").set_input_files("./file.pdf")
page.get_by_label("上傳文件").set_input_files(["./a.pdf", "./b.pdf"]) # 多文件
page.get_by_label("上傳文件").set_input_files([]) # 清除已選文件
獲取元素信息
text = page.get_by_role("heading").inner_text()
html = page.locator(".content").inner_html()
value = page.get_by_label("用戶名").input_value()
attr = page.locator("img").get_attribute("src")
is_visible = page.get_by_role("button").is_visible()
is_enabled = page.get_by_role("button").is_enabled()
鼠標 & 滾動
# 懸停(觸發 hover 菜單)
page.get_by_role("button", name="更多").hover()
# 滾動到元素
page.get_by_text("底部內容").scroll_into_view_if_needed()
# 滾動頁面
page.mouse.wheel(0, 3000) # 向下滾動 3000px
# 拖拽
page.drag_and_drop("#source", "#target")
7. 等待機制
Playwright 大多數操作自帶重試等待(默認超時 30 秒),但複雜場景需要顯式等待。
等待頁面狀態
page.wait_for_load_state("domcontentloaded") # DOM 解析完成(快)
page.wait_for_load_state("load") # 所有資源加載完成
page.wait_for_load_state("networkidle") # 網絡請求全部完成(慢但穩)
等待元素狀態
# 等待元素可見
page.locator(".result-list").wait_for(state="visible")
# 等待元素消失(如 loading 遮罩)
page.locator(".loading-mask").wait_for(state="hidden")
# 等待元素從 DOM 中移除
page.locator(".toast").wait_for(state="detached")
# 等待元素出現在 DOM(不一定可見)
page.locator(".data").wait_for(state="attached")
等待網絡請求
# 等待特定接口響應(用於數據加載完成的判斷)
with page.expect_response("**/api/list**") as resp_info:
page.get_by_role("button", name="查詢").click()
response = resp_info.value
data = response.json() # 直接拿接口返回數據!
直接攔截接口數據是自動化採集的一個強力技巧,比解析 DOM 更可靠。
固定等待(儘量少用)
page.wait_for_timeout(2000) # 等待 2 秒,最後的手段
自定義超時
# 單次操作超時
page.get_by_role("button").click(timeout=5000) # 超時 5 秒
# 全局默認超時
page.set_default_timeout(60000) # 改為 60 秒
等待策略組合(推薦模板)
# 點擊觸發數據加載後的最佳等待姿勢
page.get_by_role("button", name="查詢").click()
page.wait_for_load_state("networkidle") # 等網絡空閒
page.locator(".data-table").wait_for(state="visible") # 再確認關鍵元素
8. iframe 處理
# 通過 CSS 選擇器進入 iframe
frame = page.frame_locator("iframe#editor")
# 在 iframe 內操作,和普通 page 完全一樣
frame.get_by_role("textbox").fill("Hello World")
frame.get_by_role("button", name="保存").click()
# 操作完直接用 page 即可回到主頁面,無需顯式切換
page.get_by_role("button", name="關閉").click()
嵌套 iframe
frame = page.frame_locator("iframe#outer").frame_locator("iframe#inner")
frame.get_by_role("button", name="提交").click()
9. 遍歷動態列表與表格
正確姿勢:先 count,再 nth
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
name = row.locator("td:nth-child(1)").inner_text()
status = row.locator("td:nth-child(2)").inner_text()
print(f"{name}: {status}")
為什麼不用
rows.all()直接遍歷?all()返回的是快照,如果操作過程中頁面內容變化(如分頁、彈窗導致刷新),會出現 stale element。用nth(i)每次都重新查找,更健壯。
操作每行並處理彈窗
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
row.get_by_role("button", name="編輯").click()
# 操作彈窗
dialog = page.locator(".modal")
dialog.wait_for(state="visible")
dialog.get_by_label("備註").fill("已處理")
dialog.get_by_role("button", name="保存").click()
dialog.wait_for(state="hidden") # 等彈窗關閉
# 下一行會自動重新查找,不受影響
點擊"加載更多"後繼續採集
while True:
# 採集當前頁數據
items = page.get_by_role("listitem").all()
for item in items:
print(item.inner_text())
# 檢查是否還有下一頁
load_more = page.get_by_role("button", name="加載更多")
ifnot load_more.is_visible():
break
load_more.click()
# 等新內容加載完(用舊內容數量作為基準)
page.wait_for_function(f"document.querySelectorAll('li').length > {len(items)}")
10. 反爬與穩定性技巧
隱藏自動化特徵
browser = p.chromium.launch(
args=['--disable-blink-features=AutomationControlled']
)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...'
)
# 注入腳本,覆蓋 webdriver 特徵
page.add_init_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
模擬真人行為
import random, time
# 隨機延遲
time.sleep(random.uniform(1.0, 3.0))
# 打字帶延遲
page.get_by_label("搜索").type("關鍵詞", delay=random.randint(50, 150))
# 點擊加延遲
page.get_by_role("button").click(delay=random.randint(50, 200))
截圖與調試
# 出錯時截圖留證
try:
page.get_by_role("button", name="提交").click()
except Exception as e:
page.screenshot(path=f"error_{int(time.time())}.png")
raise
# 全頁截圖(包括不可見區域)
page.screenshot(path="full.png", full_page=True)
# 對特定元素截圖
page.locator(".chart").screenshot(path="chart.png")
網絡攔截(加速/Mock)
# 屏蔽圖片和媒體資源,加速加載
def block_resources(route):
if route.request.resource_type in ["image", "media", "font"]:
route.abort()
else:
route.continue_()
page.route("**/*", block_resources)
11. 異常處理
常見錯誤類型
TimeoutError | ||
ElementNotFound | ||
StaleElementReference | nth(i) 替代 all() 後的元素 | |
TargetClosedError |
健壯的重試模板
import time
def retry(fn, max_retries=3, delay=2):
for attempt in range(max_retries):
try:
return fn()
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"第 {attempt+1} 次失敗: {e},{delay}s 後重試...")
time.sleep(delay)
# 使用
retry(lambda: page.get_by_role("button", name="查詢").click())
12. 完整流程模板
單任務模板(同步)
from playwright.sync_api import sync_playwright
import time
def run():
p = sync_playwright().start()
browser = p.chromium.launch(headless=True)
context = browser.new_context(
storage_state='session.json', # 複用登錄態
user_agent='Mozilla/5.0...',
)
page = context.new_page()
page.set_default_timeout(30000)
try:
page.goto('https://example.com/list', wait_until='domcontentloaded')
page.wait_for_load_state('networkidle')
# 你的業務邏輯
rows = page.locator("table tbody tr")
count = rows.count()
results = []
for i in range(count):
row = rows.nth(i)
results.append({
"name": row.locator("td:nth-child(1)").inner_text().strip(),
"status": row.locator("td:nth-child(2)").inner_text().strip(),
})
return results
except Exception as e:
page.screenshot(path=f"error_{int(time.time())}.png")
raise
finally:
context.close()
browser.close()
p.stop()
if __name__ == "__main__":
data = run()
print(f"共採集 {len(data)} 條")
多賬號併發模板(異步)
import asyncio
from playwright.async_api import async_playwright
ACCOUNTS = [
{"session": "session_a.json", "name": "賬號A"},
{"session": "session_b.json", "name": "賬號B"},
]
asyncdef process_account(browser, account):
context = await browser.new_context(storage_state=account["session"])
page = await context.new_page()
try:
await page.goto("https://example.com/dashboard")
await page.wait_for_load_state("networkidle")
# ... 業務邏輯
print(f"{account['name']} 完成")
finally:
await context.close()
asyncdef main():
asyncwith async_playwright() as p:
browser = await p.chromium.launch(headless=True)
await asyncio.gather(*[
process_account(browser, acc) for acc in ACCOUNTS
])
await browser.close()
asyncio.run(main())
快速速查卡
# 導航
page.goto(url)
page.go_back() / page.go_forward() / page.reload()
# 定位
page.get_by_role("button", name="...")
page.get_by_label("...") / page.get_by_placeholder("...")
page.get_by_text("...") / page.get_by_test_id("...")
page.locator("css or xpath")
# 操作
.click() / .dblclick() / .hover()
.fill("text") / .type("text", delay=50) / .clear()
.check() / .uncheck() / .select_option("value")
.set_input_files("path")
# 獲取信息
.inner_text() / .inner_html() / .input_value()
.get_attribute("attr") / .is_visible() / .is_enabled()
# 等待
.wait_for(state="visible/hidden/attached/detached")
page.wait_for_load_state("networkidle/load/domcontentloaded")
page.wait_for_selector("css")
page.wait_for_timeout(ms)
# 截圖
page.screenshot(path="shot.png", full_page=True)
page.locator(".el").screenshot(path="el.png")
13. 執行 JavaScript
當 Playwright 的 Python API 無法滿足需求時,直接在頁面上下文執行 JS 是最後的利器。
基礎用法
# 執行 JS 並獲取返回值
title = page.evaluate("document.title")
scroll_y = page.evaluate("window.scrollY")
# 傳參給 JS
result = page.evaluate("(x) => x * 2", 21) # → 42
# 多行 JS
data = page.evaluate("""
() => {
const rows = document.querySelectorAll('table tr');
return Array.from(rows).map(r => r.innerText);
}
""")
操作 DOM(繞過 Playwright 限制)
# 強制修改輸入框的值(對某些 React/Vue 受控組件有效)
page.evaluate("""
(value) => {
const input = document.querySelector('#amount');
const nativeInputSetter = Object.getOwnPropertyDescriptor(
window.HTMLInputElement.prototype, 'value'
).set;
nativeInputSetter.call(input, value);
input.dispatchEvent(new Event('input', { bubbles: true }));
}
""", "9999")
# 觸發自定義事件
page.evaluate("document.querySelector('#editor').dispatchEvent(new Event('change'))")
# 滾動到頁面底部
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
evaluate vs evaluate_handle
# evaluate:返回 Python 原生值(字符串、數字、列表、字典)
count = page.evaluate("document.querySelectorAll('li').length")
# evaluate_handle:返回 JS 對象句柄(用於後續傳給其他 JS 調用)
list_handle = page.evaluate_handle("document.querySelectorAll('li')")
# 可以把 handle 傳回給 evaluate
first_text = page.evaluate("(list) => list[0].innerText", list_handle)
在頁面加載前注入腳本
# add_init_script:每次頁面加載/刷新時都會執行,適合反檢測
page.add_init_script("""
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3] });
""")
# 也可以注入一個 JS 文件
page.add_init_script(path="./stealth.js")
14. Shadow DOM 處理
Shadow DOM 是 Web Components 的封裝機制,普通 CSS 選擇器穿不透,但 Playwright 的大多數語義定位器(get_by_role、get_by_text 等)默認可以穿透 Shadow DOM。
推薦:直接用語義定位器
# Playwright 的 get_by_* 方法默認穿透 Shadow DOM,直接用即可
page.get_by_role("button", name="提交").click()
page.get_by_label("用戶名").fill("zhangsan")
如果必須用 CSS 選擇器
# 用 >> 穿透 Shadow DOM(舊語法,仍然有效)
page.locator("my-component >> .inner-button").click()
# 或者用 pierce/ 前綴(更明確)
page.locator("pierce/.inner-button").click()
通過 JS 訪問 Shadow Root
# 當以上方法都不行時,用 JS 訪問
text = page.evaluate("""
() => {
const host = document.querySelector('my-custom-element');
return host.shadowRoot.querySelector('.price').innerText;
}
""")
15. 對話框處理(alert/confirm/prompt)
瀏覽器原生彈窗(window.alert、window.confirm、window.prompt)會阻塞頁面,必須提前註冊監聽器處理,否則超時報錯。
自動接受所有彈窗
# 註冊監聽器,自動點"確認"
page.on("dialog", lambda dialog: dialog.accept())
# 然後觸發彈窗的操作
page.get_by_role("button", name="刪除").click()
根據類型分別處理
def handle_dialog(dialog):
print(f"彈窗類型: {dialog.type}") # alert / confirm / prompt / beforeunload
print(f"彈窗內容: {dialog.message}")
if dialog.type == "confirm":
dialog.accept() # 點確認
elif dialog.type == "prompt":
dialog.accept("我的輸入") # 輸入內容並確認
else:
dialog.dismiss() # 點取消/關閉
page.on("dialog", handle_dialog)
page.get_by_role("button", name="危險操作").click()
注意: 監聽器要在觸發彈窗之前註冊,不然來不及處理。
16. 文件下載
捕獲下載事件
import os
# 方法一:用 expect_download 上下文管理器(推薦)
with page.expect_download() as download_info:
page.get_by_role("button", name="導出 Excel").click()
download = download_info.value
# 保存到指定路徑
download.save_as("./exports/report.xlsx")
# 或查看臨時路徑
print(download.path()) # 臨時文件路徑
print(download.suggested_filename) # 服務器建議的文件名
批量下載
import os
os.makedirs("./downloads", exist_ok=True)
rows = page.locator("table tbody tr")
count = rows.count()
for i in range(count):
row = rows.nth(i)
filename = row.locator("td:nth-child(1)").inner_text().strip()
with page.expect_download() as dl_info:
row.get_by_role("link", name="下載").click()
dl = dl_info.value
dl.save_as(f"./downloads/{filename}.pdf")
print(f"已下載: {filename}")
配置默認下載路徑
# 在 context 層面設置下載目錄
context = browser.new_context(accept_downloads=True)
# 也可以在 launch 時指定
browser = p.chromium.launch_persistent_context(
user_data_dir="./user_data",
accept_downloads=True,
downloads_path="./downloads",
)
17. Cookie 管理
讀取 Cookie
# 獲取所有 cookies
cookies = context.cookies()
for c in cookies:
print(f"{c['name']} = {c['value']}")
# 獲取特定域名的 cookies
cookies = context.cookies(["https://example.com"])
添加 / 修改 Cookie
context.add_cookies([
{
"name": "token",
"value": "abc123xyz",
"domain": "example.com",
"path": "/",
"httpOnly": True,
"secure": True,
"sameSite": "Lax",
}
])
清除 Cookie
context.clear_cookies()
導入外部 Cookie(如從瀏覽器導出)
import json
# 假設你有從 EditThisCookie 等工具導出的 JSON
with open("cookies.json") as f:
raw = json.load(f)
# 標準化字段(不同工具導出格式可能略有不同)
cookies = [{
"name": c["name"],
"value": c["value"],
"domain": c["domain"],
"path": c.get("path", "/"),
"secure": c.get("secure", False),
"httpOnly": c.get("httpOnly", False),
} for c in raw]
context.add_cookies(cookies)
18. 代理配置
全局代理
browser = p.chromium.launch(
proxy={
"server": "http://proxy.example.com:8080",
"username": "user", # 如果代理需要認證
"password": "pass",
}
)
Context 級別代理(同一瀏覽器不同賬號走不同代理)
context_a = browser.new_context(proxy={"server": "http://proxy1:8080"})
context_b = browser.new_context(proxy={"server": "http://proxy2:8080"})
SOCKS5 代理
browser = p.chromium.launch(
proxy={"server": "socks5://127.0.0.1:1080"}
)
繞過特定域名(不走代理)
browser = p.chromium.launch(
proxy={
"server": "http://proxy:8080",
"bypass": "localhost,127.0.0.1,internal.company.com"
}
)
19. 網絡攔截進階
監聽所有請求/響應(只讀,不攔截)
# 監聽請求
page.on("request", lambda req: print(f"→ {req.method} {req.url}"))
# 監聽響應
page.on("response", lambda resp: print(f"← {resp.status} {resp.url}"))
# 只關注特定接口
def on_response(response):
if "/api/list" in response.url:
print(response.json())
page.on("response", on_response)
page.goto("https://example.com")
攔截並修改請求(Mock 數據)
def mock_api(route):
# 如果是目標接口,返回假數據
if "/api/user" in route.request.url:
route.fulfill(
status=200,
content_type="application/json",
body='{"name": "測試用戶", "role": "admin"}'
)
else:
route.continue_()
page.route("**/*", mock_api)
攔截並修改請求頭
def add_auth_header(route):
headers = {**route.request.headers, "Authorization": "Bearer my-token"}
route.continue_(headers=headers)
page.route("**/api/**", add_auth_header)
攔截並修改響應體
def modify_response(route):
# 先讓請求正常發出,拿到真實響應
response = route.fetch()
body = response.json()
# 修改數據
body["data"]["vip"] = True
# 把修改後的數據返回給頁面
route.fulfill(response=response, body=json.dumps(body))
page.route("**/api/profile", modify_response)
採集接口數據(不解析 DOM)
collected = []
def capture_list_api(response):
if"/api/items"in response.url and response.status == 200:
data = response.json()
collected.extend(data.get("items", []))
page.on("response", capture_list_api)
# 翻頁操作,每翻一頁接口數據自動被收集
for page_num in range(1, 11):
page.goto(f"https://example.com/list?page={page_num}")
page.wait_for_load_state("networkidle")
print(f"共採集 {len(collected)} 條")
20. 分頁採集模板
按鈕翻頁(有"下一頁"按鈕)
results = []
whileTrue:
# 採集當前頁
rows = page.locator("table tbody tr")
for i in range(rows.count()):
row = rows.nth(i)
results.append({
"name": row.locator("td:nth-child(1)").inner_text().strip(),
"value": row.locator("td:nth-child(2)").inner_text().strip(),
})
# 檢查下一頁按鈕
next_btn = page.get_by_role("button", name="下一頁")
ifnot next_btn.is_visible() ornot next_btn.is_enabled():
break
next_btn.click()
page.wait_for_load_state("networkidle")
page.locator("table tbody tr").first.wait_for(state="visible")
print(f"共採集 {len(results)} 條")
URL 參數翻頁
results = []
page_num = 1
whileTrue:
page.goto(f"https://example.com/list?page={page_num}&size=50")
page.wait_for_load_state("networkidle")
rows = page.locator("table tbody tr")
count = rows.count()
if count == 0:
break# 沒有數據了
for i in range(count):
row = rows.nth(i)
results.append(row.locator("td:nth-child(1)").inner_text().strip())
# 如果返回行數小於每頁大小,說明是最後一頁
if count < 50:
break
page_num += 1
接口翻頁(直接拿 API 數據)
import json
results = []
page_num = 1
whileTrue:
with page.expect_response("**/api/list**") as resp_info:
page.goto(f"https://example.com/list?page={page_num}")
resp = resp_info.value.json()
items = resp.get("data", {}).get("list", [])
total_pages = resp.get("data", {}).get("totalPages", 1)
results.extend(items)
print(f"第 {page_num}/{total_pages} 頁,已採集 {len(results)} 條")
if page_num >= total_pages:
break
page_num += 1
21. 無限滾動採集
有些頁面不用翻頁,而是滾動到底部自動加載更多內容。
基礎無限滾動
results = set()
last_count = 0
no_new_count = 0# 連續幾次沒有新數據
while no_new_count < 3:
# 採集當前可見的所有項目
items = page.locator(".item-card").all()
for item in items:
results.add(item.inner_text().strip())
current_count = len(results)
if current_count == last_count:
no_new_count += 1
else:
no_new_count = 0
last_count = current_count
# 滾動到頁面底部
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
page.wait_for_timeout(1500) # 等待新內容加載
print(f"共採集 {len(results)} 條")
等待新內容出現後再滾動(更穩定)
results = []
whileTrue:
current_items = page.locator(".item-card")
current_count = current_items.count()
# 採集當前頁的所有項
for i in range(current_count):
text = current_items.nth(i).inner_text().strip()
if text notin [r["text"] for r in results]:
results.append({"text": text})
# 滾動到最後一個元素
current_items.last.scroll_into_view_if_needed()
# 等待新內容出現(數量增加)
try:
page.wait_for_function(
f"document.querySelectorAll('.item-card').length > {current_count}",
timeout=5000
)
except:
# 超時說明沒有更多數據了
print("已到底部,採集完畢")
break
print(f"共採集 {len(results)} 條")
22. 複雜組件處理(日期選擇器/自定義下拉框)
日期選擇器
原生 <input type="date"> 直接用 fill:
page.get_by_label("開始日期").fill("2024-01-15") # 格式:YYYY-MM-DD
基於 JS 庫的日期選擇器(無法直接 fill),用點擊方式操作:
# 點擊日期輸入框打開日曆
page.get_by_placeholder("選擇日期").click()
# 等待日曆彈出
page.locator(".datepicker-popup").wait_for(state="visible")
# 如果需要跳轉到特定月份
whileTrue:
month_label = page.locator(".datepicker-header .month").inner_text()
if"2024年3月"in month_label:
break
page.locator(".datepicker-prev").click()
# 點擊目標日期
page.get_by_role("gridcell", name="15").click()
更簡單的方案——直接用 JS 設置值:
# 找到背後隱藏的真實 input,直接設置值
page.evaluate("""
() => {
const input = document.querySelector('input[name="startDate"]');
input.value = '2024-03-15';
input.dispatchEvent(new Event('change', { bubbles: true }));
}
""")
自定義下拉框(非原生 <select>)
很多 UI 組件庫(Ant Design、Element UI 等)的下拉框是 <div> 模擬的:
# 點擊觸發下拉框展開
page.locator(".custom-select").click()
# 等待選項列表出現
page.locator(".select-dropdown").wait_for(state="visible")
# 點擊目標選項
page.get_by_role("option", name="北京市").click()
# 或者用 get_by_text 找選項
page.locator(".select-dropdown").get_by_text("北京市").click()
富文本編輯器(如 Quill、TinyMCE)
# Quill 編輯器
editor = page.locator(".ql-editor")
editor.click()
editor.fill("這是輸入的內容")
# TinyMCE(通常在 iframe 裏)
frame = page.frame_locator("iframe#content_ifr")
frame.locator("#tinymce").fill("這是輸入的內容")
# 如果 fill 不生效,用 JS 注入
page.evaluate("""
() => {
// Quill 實例
const quill = document.querySelector('.ql-editor').__quill;
quill.setText('這是內容');
}
""")
滑塊驗證碼(拖拽類)
# 找到滑塊
slider = page.locator(".slider-btn")
box = slider.bounding_box()
# 模擬拖拽(分步移動,模擬真人)
page.mouse.move(box["x"] + box["width"] / 2, box["y"] + box["height"] / 2)
page.mouse.down()
# 分多步移動,不要一步到位
import random
target_x = box["x"] + 280# 目標位置(需根據實際調整)
current_x = box["x"] + box["width"] / 2
step = (target_x - current_x) / 20
for i in range(20):
current_x += step + random.uniform(-1, 1) # 加入隨機抖動
page.mouse.move(current_x, box["y"] + box["height"] / 2 + random.uniform(-1, 1))
page.wait_for_timeout(random.randint(10, 30))
page.mouse.up()
23. 數據導出(JSON/CSV/Excel)
導出為 JSON
import json
results = [{"name": "張三", "age": 28}, {"name": "李四", "age": 32}]
with open("output.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print("已導出 output.json")
導出為 CSV
import csv
results = [{"name": "張三", "score": 95}, {"name": "李四", "score": 87}]
with open("output.csv", "w", newline="", encoding="utf-8-sig") as f:
# utf-8-sig 讓 Excel 能正確識別中文
writer = csv.DictWriter(f, fieldnames=["name", "score"])
writer.writeheader()
writer.writerows(results)
print("已導出 output.csv")
導出為 Excel(openpyxl)
# pip install openpyxl
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment
results = [
{"名稱": "產品A", "價格": 199, "庫存": 50},
{"名稱": "產品B", "價格": 299, "庫存": 30},
]
wb = Workbook()
ws = wb.active
ws.title = "採集結果"
headers = list(results[0].keys())
# 寫表頭(加粗+背景色)
for col, header in enumerate(headers, 1):
cell = ws.cell(row=1, column=col, value=header)
cell.font = Font(bold=True)
cell.fill = PatternFill("solid", fgColor="DDEEFF")
cell.alignment = Alignment(horizontal="center")
# 寫數據
for row_idx, record in enumerate(results, 2):
for col_idx, key in enumerate(headers, 1):
ws.cell(row=row_idx, column=col_idx, value=record[key])
# 自動列寬
for col in ws.columns:
max_len = max(len(str(cell.value or"")) for cell in col)
ws.column_dimensions[col[0].column_letter].width = max_len + 4
wb.save("output.xlsx")
print("已導出 output.xlsx")
增量寫入(大量數據防止丟失)
import csv, os
OUTPUT_FILE = "output.csv"
HEADERS = ["name", "price", "url"]
# 文件不存在時寫表頭
write_header = not os.path.exists(OUTPUT_FILE)
with open(OUTPUT_FILE, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=HEADERS)
if write_header:
writer.writeheader()
# 每採集一條立即寫入,不怕中途崩潰
for item in scrape_items():
writer.writerow(item)
f.flush() # 強制刷新緩衝區
24. 調試工具
Codegen:自動生成代碼
錄製你的瀏覽器操作,自動生成 Playwright 代碼,非常適合快速上手一個新網站。
# 錄製操作,輸出 Python 代碼
playwright codegen https://example.com --output script.py
# 指定語言
playwright codegen https://example.com --lang python
# 帶已保存的登錄態錄製
playwright codegen https://example.com --load-storage session.json
Inspector:交互式調試
# 代碼里加上這行,運行時會暫停並打開 Inspector 窗口
page.pause()
或者通過環境變量啓動:
PWDEBUG=1 python your_script.py
Inspector 裏可以:逐步執行、實時查看元素、測試定位器表達式。
Trace Viewer:事後回放
Trace 會記錄操作的每一步截圖、網絡請求、DOM 快照,出錯時查 trace 比看日誌直觀得多。
# 開啓 trace 記錄
context.tracing.start(screenshots=True, snapshots=True, sources=True)
# ... 你的操作 ...
# 保存 trace
context.tracing.stop(path="trace.zip")
# 在瀏覽器裏回放 trace
playwright show-trace trace.zip
頁面控制枱輸出
# 監聽頁面 console.log 輸出(調試 JS 邏輯很有用)
page.on("console", lambda msg: print(f"[console.{msg.type}] {msg.text}"))
# 監聽頁面報錯
page.on("pageerror", lambda err: print(f"[JS錯誤] {err}"))
25. 性能優化
按需加載資源(最有效)
# 屏蔽非必要資源,速度可以提升 2~5 倍
BLOCKED_TYPES = {"image", "media", "font", "stylesheet"}
def block_unnecessary(route):
if route.request.resource_type in BLOCKED_TYPES:
route.abort()
else:
route.continue_()
page.route("**/*", block_unnecessary)
控制併發數量
import asyncio
from playwright.async_api import async_playwright
asyncdef process_url(browser, semaphore, url):
asyncwith semaphore: # 限制同時運行的協程數
context = await browser.new_context()
page = await context.new_page()
try:
await page.goto(url)
# ... 處理邏輯
finally:
await context.close()
asyncdef main():
urls = [f"https://example.com/item/{i}"for i in range(100)]
semaphore = asyncio.Semaphore(5) # 最多 5 個併發
asyncwith async_playwright() as p:
browser = await p.chromium.launch(headless=True)
await asyncio.gather(*[process_url(browser, semaphore, url) for url in urls])
await browser.close()
asyncio.run(main())
複用 Page 而不是每次新建
# 不好的做法:每個 URL 新建一個 page
for url in urls:
page = context.new_page()
page.goto(url)
# ...
page.close() # 也要關
# 好的做法:複用同一個 page
page = context.new_page()
for url in urls:
page.goto(url)
# ...
# 最後統一關
page.close()
注意:如果頁面跳轉後狀態有影響(如彈窗未關閉),複用 page 可能產生問題,按需選擇。
使用 domcontentloaded 代替 networkidle
# networkidle 要等所有請求完成,通常需要 2~5 秒
page.goto(url, wait_until="networkidle") # 慢
# domcontentloaded 只等 DOM 解析完,通常不到 1 秒
page.goto(url, wait_until="domcontentloaded") # 快
# 然後再用更精確的元素等待
page.locator(".data-table").wait_for(state="visible")
持久化 Context(保留緩存)
# launch_persistent_context 會保留磁盤緩存,重複訪問同一網站更快
context = p.chromium.launch_persistent_context(
user_data_dir="./browser_profile",
headless=True,
accept_downloads=True,
)
page = context.new_page()
# 注意:persistent context 不需要再調用 browser.new_context()
性能 Checklist
expect_response 拿接口數據,不解析 DOM | |