PRD 越寫越長,AI 還是做歪——它缺的不是細節,而是這套模板信息
整理版優先睇
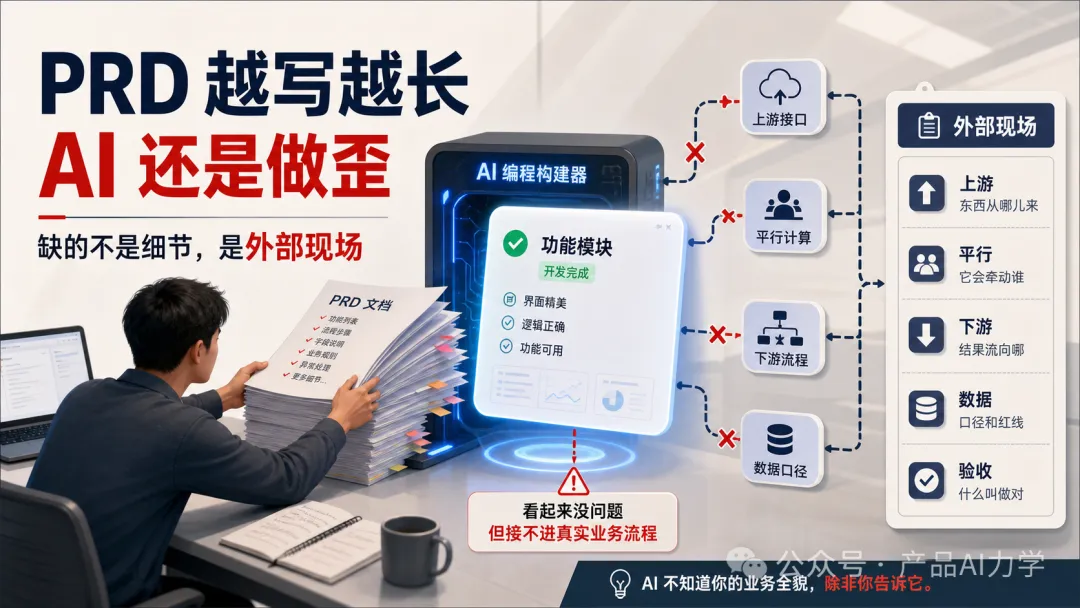
AI做歪唔係因為你PRD唔夠長,而係佢從來唔知你公司系統點咬合
呢篇文章出自一位有實戰經驗嘅產品經理,佢發現每次叫AI做功能,單獨跑就好順,但一接入真實業務流程就斷——接口對唔上、數據計錯、下流卡死。佢想解決嘅問題係:點解AI做完嘅功能整合唔到產品,反推唔到可用PRD?
佢嘅結論係:問題唔喺AI笨,亦唔喺PRD唔夠詳細,而係有一類關鍵信息AI從來冇接觸過——即係你公司系統之間嘅接口、數據標準、業務邏輯呢類「外部現場」。呢啲嘢AI再聰明都估唔到,得靠產品經理親手填補。
作者將AI嘅「記憶」分成四種來源:項目說明書、自動記憶、項目現場、同埋最容易被忽略嘅業務上下文。前三種大部分工具已經幫你搞掂,第四種先係產品經理真正嘅主場。佢提出一個一頁模板,幫你喺開新功能前用十分鐘整理呢啲「AI唔知嘅事」,包括上游、平行、下游、數據邊界同一句驗收標準。最後佢指出,雖然大型組織好難標準化呢套做法,但個人完全可以自己維護一套,成為「超級個體」。
- AI開發完嘅功能整合失敗,主因係業務上下文(接口、數據、流程)完全冇傳遞俾AI,唔係PRD唔夠長。
- AI記憶有四個來源:項目說明書(CLAUDE.md)、自動記憶(工具自動學)、項目現場(代碼理解)、業務現場(要人話佢知)。
- 產品經理最不可替代嘅工作係填補第四個空白:寫清楚上游接口、平行影響、下游動作、數據標準同合規紅線。
- 實用模板包含五個部分:上游、平行、下游、數據與邊界、一句話驗收,每次開功能前花10分鐘填好。
- 即使大公司好難標準化上下文工程,個人產品經理都可以自己整一套,放喺項目根目錄或者做成Skills,大幅提升AI產出可用率。
功能外部現場模板
# 呢個功能嘅「外部現場」(AI唔知、要我話佢知) ## 上游:嘢從邊度嚟 - 佢依賴邊啲上游接口/數據?邊個產生嘅、咩樣? ## 平行:佢會牽動邊個 - 呢個改動會影響邊啲並行模塊/計算?(最易漏、最易出事) ## 下游:佢產出後流向邊度 - 做完之後,結果俾邊個用、觸發咩後續動作? ## 數據與邊界 - 關鍵字段/口徑有冇統一標準? - 邊啲係合規/風控紅線,唔可以擅自處理? ## 一句話驗收 - 呢個功能「做啱」嘅標準係咩?(用業務話講)
結構示例
# 這個功能的"外部現場"(AI 不知道、必須我告訴它的)## 上游:東西從哪兒來- 它依賴哪些上游接口/數據?誰產生的、長什麼樣?## 平行:它會牽動誰- 這個改動會影響到哪些並行的模塊/計算?(最容易漏,也最容易出事)## 下游:它產出後流向哪- 做完之後,結果給誰用、觸發什麼後續動作?## 數據與邊界- 關鍵字段/口徑有沒有統一標準?- 哪些是合規/風控紅線,不能擅自處理?## 一句話驗收- 這個功能"做對了"的標準是什麼?(用業務話說,不用技術話)Vibe Coding 做完嘅功能,點解一接入就死?
你有冇遇過呢種情況:你講清楚需求,等AI做咗個功能。佢做完,自己行起嚟好順,你都幾滿意。但一接入真實業務流程——接口對唔上、數據計錯、下一環斷咗。仲慘嘅係:出事前你完全睇唔出。佢行得好哋哋、界面似模似樣,但就係整合唔到產品,更加反推唔到可用嘅PRD。
分清四種記憶來源,先知自己要管邊種
AI喺一個項目上可以依靠嘅「記憶」,通常有四種來源。認清楚,你先知道自己真正應該管邊一種。
- 1 第一種:你立嘅規矩(項目說明書)。即係 CLAUDE.md / AGENTS.md 呢類文件——呢個項目係咩、邊個可以掂、邊個唔掂得、佢應該點同你配合。工具俾你文件,內容你嚟寫。網上模板同教學好多,唔多講。
- 2 第二種:佢自己儲嘅偏好(自動記憶)。你反覆糾正佢「唔好貼大段代碼、用大白話」,佢會自己記低,下次帶上。呢層基本唔使你操心——確認佢開咗、可以睇到就得。
- 3 第三種:佢對現有項目嘅理解(項目現場)。開新對話,佢要先「讀懂而家嘅代碼係咩樣」。Qoder 嘅知識引擎有「知識卡片+對話記憶+Repo Wiki」;Codex、Claude就用更直接嘅方法:每次開新對話,自己重讀一次項目現場同 docs。都唔使你管。
- 4 第四種:佢從來唔知道嘅事——呢個先係你嘅主場。無論你係 vibe coding 反推 PRD,定直接寫 PRD,真正決定產品經理產出好壞嘅,係呢樣嘢。
第四種記憶——業務現場嘅判斷——係產品經理最不可替代嘅價值
舉個例:我要做一張出庫單,而家係第三個迭代。前兩個迭代佢做咗咩,我唔使話佢知(佢自己讀到)。但我一定要話佢知:上游——領料流程俾出庫單嘅接口有邊啲;平行——出庫會影響嘅可用量點計、行邊個接口;下游——出庫之後會計點記賬。呢啲嘢,AI 再聰明都估唔到——佢根本唔知道你公司套系統係點咬合嘅。
實操:寫一頁「佢唔知道嘅事」
下面呢個模板,係你每次開新功能/新迭代之前,用十分鐘就可以填好、然後餵俾AI嘅嘢。你可以先投入少少精力試嚇,然後持續完善。
- 上游:嘢從邊度嚟——佢依賴邊啲上游接口/數據?邊個產生、咩樣?
- 平行:佢會牽動邊個——呢個改動會影響邊啲並行模塊/計算?(最容易漏,亦最容易出事)
- 下游:佢產出後流向邊度——做完之後,結果俾邊個用、觸發咩後續動作?
- 數據與邊界——關鍵字段/口徑有冇統一標準?邊啲係合規/風控紅線,唔可以擅自處理?
- 一句話驗收——呢個功能「做啱」嘅標準係咩?(用業務話講,唔用技術話)
佢幫你慳落嘅,係後面來回返工、仲指唔出問題嘅嗰啲夜晚。
呢個模板嘅核心係迫使你諗清楚系統之間嘅咬合關係
點解公司做唔到,但你做到
你一定會問:呢套嘢,難道公司唔應該統一搞一套咩?我可以肯定話你知:好多公司都想搞。呢套嘢有個正經名,叫 Context Engineering(上下文工程),早就同 Spec-Driven Development、Harness Engineering 融埋一齊。但對於一個大型研發組織,要搞成一套人人用得嘅標準,幾乎冇可能:成本極高、難度極大,Agent 能力或者 DevOps 一次迭代,都可能令巨額投入打水漂。
殘酷真相係:好多公司嘅研發體系根本冇唯一標準答案,而係有無數非標答案
接口同數據嘅標準、原則、規範,只存在ISO同CMMI認證嘅文件裏面,從來唔喺研發人員嘅日常工作入面,更加唔喺產品入面。但對個人就完全可行。你要做嘅唔多:將自己嘅工作方法、全局規格放喺根目錄或者抽象成 Skills,你負責嘅一畝三分地,邊界、集成要求、數據標準都可以蒸餾出嚟。你更加唔使計較其他二千人係咪都咁做。
你有冇遇到過呢種情況:
你將需求講清楚,叫 AI 做咗個功能。佢做曬,自己行起嚟都幾順,你睇落都幾滿意。但一旦將佢接入你哋真實嘅業務流程——接口對唔到、數計錯、或者行到下一步就斷咗。
更唔抵嘅係:出問題之前,你完全睇唔出佢行得好好哋、界面都有板有眼,但就係集成唔到落產品,更加唔可能反推得出可用嘅PRD。
產品經理嘅 Vibe Coding (下): PRD 寫法徹底改咗
結論先擺喺度:問題唔係 AI 蠢,亦唔係你 PRD 唔夠長。係有一類資訊,佢從來就唔知。
先將「記憶」拆開:四種來源,前三種工具幫你搞掂咗
AI 喺一個項目上要靠嘅「記憶」,通常有四種來源。先認清楚,你先知自己真正要理邊一種。
第一種:你定嘅規矩(項目說明書)。
就是 CLAUDE.md / AGENTS.md 呢類文件——呢個項目係乜、邊個可以鬱、邊個唔可以鬱、佢要點樣同你配合。工具俾你文件,內容你嚟寫。網上模板同教程好多,我哋唔多講。
第二種:佢自己積落嘅偏好(自動記憶)。 你反覆糾正佢「唔好貼大段代碼、用大白話」,佢會自己記低做筆記,下次帶埋。呢層基本唔使你操心——確認佢開咗、可以睇就得。工具記唔住,你就換工具,有啲工具默認唔開,你用之前瞭解清楚就得。
第三種:佢對已有項目嘅理解(項目現場)。 舊項目新開對話,佢要先「讀明而家嘅代碼係點樣」。Qoder 嘅知識引擎有「知識卡片 + 對話記憶 + Repo Wiki」。Codex、Claude 採用了更粗暴同大大力嘅方式:每次開新對話,佢哋會自己先重讀一次項目現場同 docs。都唔使你管。
第四種:佢從來唔知嘅事——呢個先係你嘅主場
無論你係vibe coding反推PRD,定係直接寫PRD,真正決定產品經理產出好壞嘅,係呢種嘢。舉個例子:
我要做一個出庫單,而家係第 3 個迭代。前兩個迭代佢做咗啲乜,我不用話俾佢知(佢自己讀得到)。但我必須話俾佢知:
• 上游——領料流程俾出庫單嘅接口有邊啲; • 平行——出庫會影響嘅可用量係點樣計嘅、行邊個接口; • 下游——出庫之後會計點樣記賬。
呢啲嘢,AI 再聰明都估唔到——佢根本唔知你公司呢套系統係點樣咬合嘅。
呢個其實根本唔係「AI 失憶」,係佢從來冇過呢段記憶。
而喺呢段空白度填嘢,正正係產品經理最唔可以取代嘅價值——你唔係喺度寫代碼,你係喺度交付業務現場嘅判斷。
實操:寫一頁「佢唔知嘅事」
下面呢張模板,係你每次開一個新功能/新迭代之前,花十分鐘就可以填好、然後餵俾 AI ——你可以先投入少少精力試試,然後再持續完善:
# 這個功能的"外部現場"(AI 不知道、必須我告訴它的)
## 上游:東西從哪兒來
- 它依賴哪些上游接口/數據?誰產生的、長什麼樣?
## 平行:它會牽動誰
- 這個改動會影響到哪些並行的模塊/計算?(最容易漏,也最容易出事)
## 下游:它產出後流向哪
- 做完之後,結果給誰用、觸發什麼後續動作?
## 數據與邊界
- 關鍵字段/口徑有沒有統一標準?
- 哪些是合規/風控紅線,不能擅自處理?
## 一句話驗收
- 這個功能"做對了"的標準是什麼?(用業務話說,不用技術話)佢幫你慳返嘅係你後面來回返工、仲指唔出問題嘅嗰啲夜晚。
最後:點解呢件事公司做唔到,你反而可以
你一定會問:呢套嘢,難道公司唔應該統一搞一套咩?
我可以肯定咁話你知:好多公司想搞。
呢套嘢有個正經名,叫 Context Engineering(上下文工程),早就同 Spec-Driven Development 、Harness Engineering 融合咗一齊。
但對一個大型研發組織,將佢做成一 set 人人都用得嘅標準,幾幾乎冇可能:成本極高、難度極大,Agent 能力或者Devops嘅一次迭代,都有可能令巨額投入打水漂。
更加殘酷嘅真相係:好多公司嘅研發體系,根本冇唯一嘅標準答案,而係有無數嘅非標答案:接口同數據嘅標準、原則、規範,只存在於ISO同CMMI認證嘅文件度,從來都唔喺研發人員嘅日常工作中,更加唔喺產品度。
而對個人咁就完全可行。你要做嘅唔多:將自己嘅工作方法、全局規格放喺根目錄或者抽象成skills,你負責嘅一畝三分地,邊界、集成要求、數據標準都可以蒸餾出嚟。你更加唔需要計較其他2000人係咪都係咁做。

所以,我一直認為:研發工程體系化咁切到 AI模式,仲有好長嘅路,好多公司甚至早就將自己嘅路堵死咗;但每個產品經理,維護一套自己嘅 AI 工作模式、喺組織入面成為「超級個體」,今日就可以開始。
試嚇上面嘅模板,對比一下vibe coding或者PRD嘅產出質量同可用率。
你有沒有遇到過這種情況:
你把需求講清楚,讓 AI 做了個功能。它做完了,自己跑起來也挺順,你看着挺滿意。可一旦把它接進你們真實的業務流程——要麼接口對不上,要麼數算錯了,要麼走到下一環就斷了。
更憋屈的是:出問題之前,你完全沒看出來。它跑得好好的、界面也像模像樣,但就是集成不進產品,更不可能反推出能用的PRD。
產品經理的 Vibe Coding (下): PRD 寫法徹底改了
結論先擺這兒:問題不在 AI 笨,也不在你 PRD 不夠長。是有一類信息,它從來就不知道。
先把"記憶"拆開:四種來源,前三種工具替你扛了
AI 在一個項目上能依靠的"記憶",通常有四種來源。先認清楚,你才知道自己真正該管哪一種。
第一種:你立的規矩(項目說明書)。
就是 CLAUDE.md / AGENTS.md 這類文件——這個項目是什麼、誰能動、誰不能動、它該怎麼跟你配合。工具給你文件,內容你來寫。網上模板和教程很多,我們不多說。
第二種:它自己攢的偏好(自動記憶)。 你反覆糾正它"別貼大段代碼、用大白話",它會自己記成小本本,下次帶上。這層基本不用你操心——確認它開着、能查看就行。工具記不住,你就換工具,有的工具默認不開,你用之前瞭解清楚就行。
第三種:它對已有項目的理解(項目現場)。 老項目新開對話,它得先"讀懂現在的代碼長什麼樣"。Qoder 的知識引擎有「知識卡片 + 對話記憶 + Repo Wiki」。Codex、Claude 採用了更粗暴和勢大力沉的方式:每次開新對話,它們會自己先重讀一遍項目現場和 docs。也不用你管。
第四種:它從來不知道的事——這才是你的主場
無論你是vibe coding反推PRD,還是直接寫PRD,真正決定產品經理產出好壞的,是這種東西。舉個例子:
我要做一個出庫單,現在是第 3 個迭代。前兩個迭代它做了什麼,我不用告訴它(它自己讀得到)。但我必須告訴它:
• 上游——領料流程給出庫單的接口有哪些; • 平行——出庫會影響的可用量是怎麼算的、走哪個接口; • 下游——出庫之後會計怎麼記賬。
這些東西,AI 再聰明也猜不到——它壓根不知道你公司這套系統是怎麼咬合的。
這其實根本不是"AI 失憶",是它從來沒有過這段記憶。
而往這段空白裏填東西,正是產品經理最不可替代的價值——你不是在寫代碼,你是在交付業務現場的判斷。
實操:寫一頁"它不知道的事"
下面這張模板,是你每開一個新功能/新迭代前,花十分鐘就能填、然後餵給 AI ——你可以先投入一點精力試試,然後再持續完善:
# 這個功能的"外部現場"(AI 不知道、必須我告訴它的)
## 上游:東西從哪兒來
- 它依賴哪些上游接口/數據?誰產生的、長什麼樣?
## 平行:它會牽動誰
- 這個改動會影響到哪些並行的模塊/計算?(最容易漏,也最容易出事)
## 下游:它產出後流向哪
- 做完之後,結果給誰用、觸發什麼後續動作?
## 數據與邊界
- 關鍵字段/口徑有沒有統一標準?
- 哪些是合規/風控紅線,不能擅自處理?
## 一句話驗收
- 這個功能"做對了"的標準是什麼?(用業務話說,不用技術話)它省下的是你後面來回返工、還指不出問題的那些夜晚。
最後:為什麼這事公司做不了,你卻可以
你一定會問:這套東西,難道公司不該統一搞一套嗎?
我可以肯定地告訴你:很多公司想搞。
這套東西有個正經名字,叫 Context Engineering(上下文工程),早就和 Spec-Driven Development 、Harness Engineering 融到了一起。
但對一個大型研發組織,把它做成一套人人能用的標準,幾乎不可能:成本極高、難度極大,Agent 能力或者Devops的一次迭代,都有可能讓鉅額投入打水漂。
更殘酷的真相是:很多公司的研發體系,根本沒有唯一的標準答案,而是有無數的非標答案:接口和數據的標準、原則、規範,只存在於ISO和CMMI認證的文件裏,從來都不在研發人員的日常工作中,更不在產品裏。
而對個人則完全可行。你要做的不多:把自己的工作方法、全局規格放根目錄或者抽象成skills,你負責的一畝三分地,邊界、集成要求、數據標準都可以蒸餾出來。你更不需要計較其他2000人是不是也這麼幹。
所以,我一直認為:研發工程體系化地切到 AI模式,還有很長的路,很多公司甚至早就把自己的路堵死了;但每個產品經理,維護一套自己的 AI 工作模式、在組織裏成為"超級個體",今天就能開始。
試試上面的模板,對比一下vibe coding或者PRD的產出質量和可用率。