Sam Altman被紐約客指控撒謊成性
整理版優先睇
紐約客調查揭露 Sam Altman 系統性撒謊,OpenAI 安全承諾名存實亡
呢篇文章係作者根據《紐約客》嘅調查報導整理而成。《紐約客》花咗18個月,採訪超過100個信源,翻閲200幾頁內部文件,得出結論:Sam Altman 表現出系統性撒謊模式。作者認為呢次唔係宮鬥,而係董事會止損。文章仲引用咗 OpenAI 前首席科學家 Ilya Sutskever 嘅52頁備忘錄,同埋 Anthropic 創辦人 Dario Amodei 嘅筆記,指出 Altman「不受真相約束」。
文章重點分析咗 OpenAI 嘅安全承諾同實際做法嘅巨大差距。例如承諾投入20%算力畀超級對齊團隊,實際只畀咗1-2%,最終解散團隊。Altman 仲呃董事會話 GPT-4 功能已獲審批。Paul Graham 私下承認佢一直講大話,但公開維護佢。作者指出,呢啲行為令信任大打折扣。相反,Anthropic 因為更誠實,做出更好產品,收入反超 OpenAI。作者認為,對開發者嚟講,產品先係最實際嘅考量,即使 Anthropic 對中國市場不友好,但因為好用,大家仍然「真香」。
- 紐約客調查揭露 Altman 對董事會、投資者甚至導師 Paul Graham 系統性撒謊,連合作伙伴都擔心佢可能成為 SBF 級別嘅騙子。
- OpenAI 承諾投入20%算力做 AI 安全,實際只畀1-2%,超級對齊團隊最終解散,安全承諾淪為公關工具。
- Paul Graham 私下話「Sam 一直在騙我哋」,但公開改口,紐約客報導後沉默不澄清,等於默認。
- 被安全問題逼走嘅 Dario Amodei 創立 Anthropic,以誠實文化做出更好產品,收入反超 OpenAI,企業用戶中73%選擇 Anthropic。
- 對開發者嚟講,產品質量先係關鍵;即使 Anthropic 對中國用戶限制多,但因為最好用,仍然被廣泛使用,反映信任折扣嘅現實。
一份遲到嘅屍檢報告
《紐約客》花咗18個月調查,採訪超過100個信源,翻閲200幾頁內部文件,得出一個結論:
Sam Altman 表現出系統性撒謊模式(Exhibits a consistent pattern of lying)
呢個結論唔係憑空出嚟,而係有紮實證據。前首席科學家 Ilya Sutskever 嘅52頁備忘錄同 Dario Amodei 嘅200頁筆記都指向同一個問題:Altman「不受真相約束」——佢講大話就好似光子唔受萬有引力影響咁自然。
承諾1/5,兑現1%
OpenAI 高調宣佈成立
超級對齊團隊
,承諾投入20%算力防止人類滅亡,呢個聽起嚟好負責。但四個內部人士向紐約客透露:實際畀咗
1-2%算力
,仲要跑喺公司最舊嘅 GPU 上。好卡留畀賺錢嘅模型。最後團隊被解散,記者問 OpenAI 仲有冇「存在主義安全研究人員」,對方回應:「That's not, like, a thing.」——個概念根本唔存在。
- 2022年12月,Altman 同董事會講 GPT-4 功能已通過安全委員會審批,但實際上冇文件,因為根本冇審批過。
- 呢種行為唔係單純嘅食言,而係本體論層面嘅否認:話你知呢件事從來冇存在過。
身邊人嘅沉默與擔憂
Paul Graham 係 YC 創辦人,當年親手提拔 Altman 做總裁。但佢私下同同事講:
「Sam 一直在騙我哋」
。公開場合,PG 就模糊處理,話「我哋冇開除佢,只係佢揀咗 OpenAI」。紐約客報導後,PG 完全沉默——呢個沉默嘅信息量好大,因為如果引述有誤,佢一定會澄清。連微軟高管都私下話:
「我諗佢有機會被記住為 Bernie Madoff 或 SBF 級別嘅騙子」
合作伙伴用龐氏騙局嚟比喻,呢個信任度真係跌到谷底。
出走嘅人贏咗
Dario Amodei 離開 OpenAI 創辦 Anthropic,佢嘅筆記寫低:「The problem with OpenAI is Sam himself.」結果 Anthropic 收入反超 OpenAI:
年化收入300億美元 vs 250億
,首次採購 AI 工具嘅企業有73%揀 Anthropic。作者由2025年3月已經建議揀 Claude,而家睇嚟好準確。Anthropic 對模型嘅優化全部針對 AI 編程同 Agent,做到
碾壓級別嘅領先
- 1 Anthropic 年化收入300億美元,OpenAI 250億
- 2 首次採購AI工具嘅企業,73%揀Anthropic
- 3 YC入營創業者52%揀Anthropic,一年前OpenAI佔90%
邊罵邊用嘅現實
作者坦白講,Anthropic 對中國用戶嘅態度係最差嘅:封號、限制訪問做得好積極。但開發者嘅日常係「上午罵 Anthropic 又封號,下午打開 Claude Code 趕工」。點解?因為
產品差距唔係 benchmark 上一啲,而係真實體驗上有好大分別
。作者提醒:
「謊言係有利息嘅」
OpenAI 嘅真正技術債唔喺代碼,而喺敍事裏面。最後做一個思想實驗:如果 Altman 係中國創辦人,輿論會點?但因為佢係「人類AI未來掌舵人」,光環蓋過一切。
或許你仲記得,喺唔係好遠嘅2023年11月,Sam Altman俾自己嘅董事會投票炒咗,又喺5日之內奇蹟翻生。當時全世界都當呢出係硅谷宮鬥劇,一個天才創業者俾啲唔識做嘢嘅學術派board趕走,又俾市場嘅力量請返嚟。幾咁勵志。
直到尋日《紐約客》放出咗份遲到嘅屍檢報告,我哋先知道,原來嗰啲唔係宮鬥,係止蝕。董事會唔係唔識做嘢,係知道得太多喇。
《紐約客》用咗18個月,採訪咗100幾個信源,睇咗200幾頁內部文件。標題好直白:「Sam Altman May Control Our Future — Can He Be Trusted?」同一日,Altman自己出咗份13頁政策報告,將自己比作羅斯福,話要搞AI時代嘅New Deal。
一邊係檢察官喺度宣讀起訴書,一邊係被告喺度發表競選演講。
呢個時間線,魔幻現實主義見到都要服氣。
52頁備忘錄
呢篇調查真正嘅殺傷力來自兩份從未公開過嘅內部文件。
第一份係Ilya Sutskever喺2023年秋天整嘅52頁備忘錄。Ilya當時仲係OpenAI首席科學家,佢唔係寫投訴信——佢係整緊案卷。截圖、通訊紀錄、事實核對,一條一條咁列。備忘錄第一行:
「Exhibits a consistent pattern of lying.」
表現出系統性嘅講大話模式。
第二份係Dario Amodei喺OpenAI期間記低嘅200幾頁筆記。Dario後來離開創辦咗Anthropic,我哋一陣先講呢件事點解重要。佢嘅筆記濃縮成一句話:
「The problem with OpenAI is Sam himself.」
有個董事會成員嘅措辭更準確:「He's unconstrained by truth.」佢唔受真相約束。
Unconstrained by truth。唔係「間中講大話」,唔係「有時唔夠坦誠」——係真相對佢來講構成唔到約束力。就好似萬有引力之於光子,唔係佢抵抗,而係呢個力對佢唔適用。
承諾1/5,兑現1%
《紐約客》列咗一長串指控,但核心邏輯其實只有一條:Altman將安全承諾當成融資PPT咁用。
最典型嘅案例:OpenAI高調宣佈成立「超級對齊團隊」,承諾投入1/5嘅計算資源,防止AI導致「人類滅亡」。聽落好負責任好壯觀,投資者安心,媒體寫咗,輿論買帳。
但四個內部人士話畀《紐約客》知,呢個團隊實際拎到嘅算力係1-2%,跑喺公司最舊嘅GPU上面。好卡留畀有得賺錢嘅模型。
然後呢個團隊被解散咗。
記者去問OpenAI:你哋仲有冇「存在主義安全研究人員」?
對方嘅回應我睇咗三次:
「That's not, like, a thing.」
呢句話嘅信息密度極高。翻譯成中文就係:「嗰個...唔算係...一個存在嘅嘢。」
你諗下呢個邏輯鏈:先承諾1/5 → 實際畀1% → 解散成個團隊 → 被問嘅時候話呢個概念唔存在。呢個唔係食言,而係一種本體論層面嘅否認——唔係我冇做到,而係呢件事從來都唔係一件事。薛定諤嘅安全承諾:你唔查嘅時候,佢既存在又唔存在。
2022年12月嗰件事仲離譜。Altman同自己嘅董事會講GPT-4嘅爭議功能都已經通過安全委員會審批。董事會要求睇文件。冇文件。因為嗰啲功能根本冇被審批過。
呃投資者仲可以理解為硅谷傳統。但呃自己嘅董事會,就好似棋手想作弊騙裁判——而裁判就坐喺你對面睇住你落棋。需要嘅唔係勇氣,而係某種對現實嘅創造性理解。
Paul Graham嘅沉默
講一個我覺得俾大多數人忽略嘅細節。
Paul Graham係YC嘅創辦人,係當年親手提拔Altman做YC總裁嘅人。《紐約客》引用咗PG嘅原話:
「Sam had been lying to us all the time.」
Sam一直呃我哋。
但你估下點?2024年5月,PG喺X上特登發咗條帖子,語氣仲幾認真咁:「我聽夠咗話YC開除Sam嘅說法,等我話畀你哋真正發生咩事。」大意係我哋冇開除佢,只係畀佢揀YC定OpenAI,佢揀咗OpenAI。
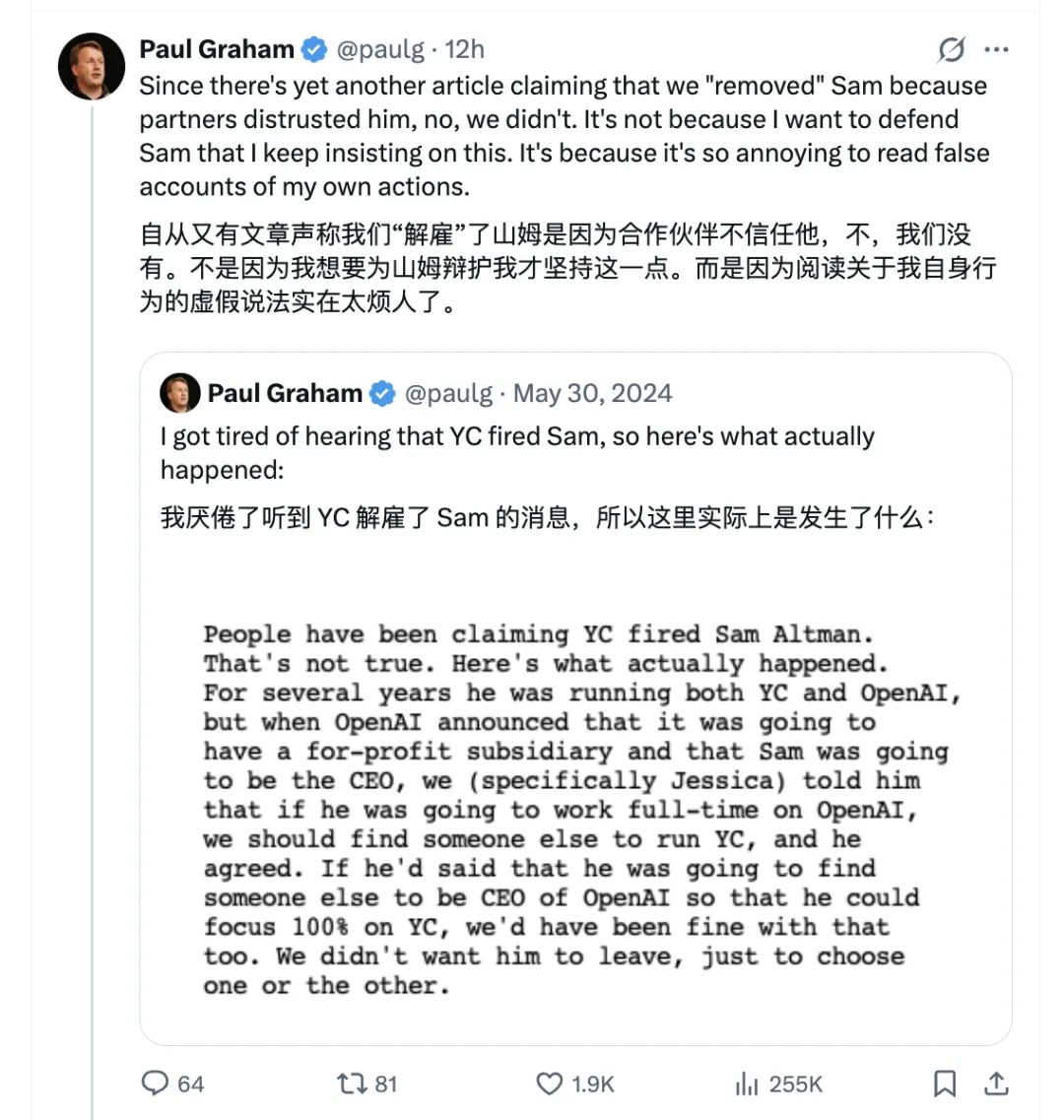 私下同同事講「佢一直呃我哋」,公開幫佢拆話話「我哋冇開除佢」。
私下同同事講「佢一直呃我哋」,公開幫佢拆話話「我哋冇開除佢」。
我絕對相信PG知道自己做緊乜。你一手提拔嘅人後來證實係個講大話嘅人,你有兩個選擇:承認自己識人能力有問題,或者將件事模糊化處理。PG揀咗後者。
《紐約客》篇文出咗之後,PG冇再出帖。
沉默。
呢個沉默入面嘅信息量,比一萬字嘅聲明仲大。因為如果《紐約客》嘅引語有錯,PG一定會澄清——佢係最在乎公共敍事準確性嘅人。佢冇澄清,即係嗰啲話的確係佢講嘅。
甚至連微軟高管都私下講咗句:
「I think there's a small but real chance he's eventually remembered as a Bernie Madoff- or Sam Bankman-Fried-level scammer.」
可能被記住為麥道夫或SBF級別嘅騙子。呢句係合作伙伴講嘅。你嘅合作伙伴將你同龐氏騙局比,你試下感受下呢個信任度。
vibes
面對以上呢啲,Altman同《紐約客》嘅回應值得裝裱起來。
「My vibes don't really fit with a lot of this traditional A.I.-safety stuff.」
我嘅vibes同傳統AI安全唔係太夾。
Vibes。
呢個詞如果被收入商業史教科書,大概會出現喺「企業高管面對嚴肅質疑時最短有效回應」呢個條目下面。一個掌管住可能係人類歷史上最強大技術工具嘅人,揀咗一個連詞性都模糊嘅詞來回應點解唔重視安全。
呢個就好似核電站廠長喺安全聽證會上話「我同鈾235之間嘅chemistry唔多對」.
佢仲話OpenAI會繼續做「safety projects, or at least safety-adjacent projects」。你睇下呢個措辭降級——從safety到safety-adjacent。就好似有人話「我愛你,或者至少,我對你有好感相關嘅情緒」.
同一日發嘅嗰份New Deal報告呢?卡內基基金會嘅人畀咗句點評:「comms work to provide cover for regulatory nihilism.」——公關作品,幫監管虛無主義打掩護。
到今日,Altman仲未正式回應《紐約客》嘅具體指控。
可能佢正在準備一份新嘅政策報告,標題大概叫「Why Being Unconstrained by Truth Is Actually Good for Humanity」.
出走嘅人贏咗
而家講下點解Dario Amodei嗰句「The problem with OpenAI is Sam himself」格外值得回味。
因為寫低呢句話嘅人離開咗OpenAI,創辦咗Anthropic,然後喺收入上反超咗OpenAI。
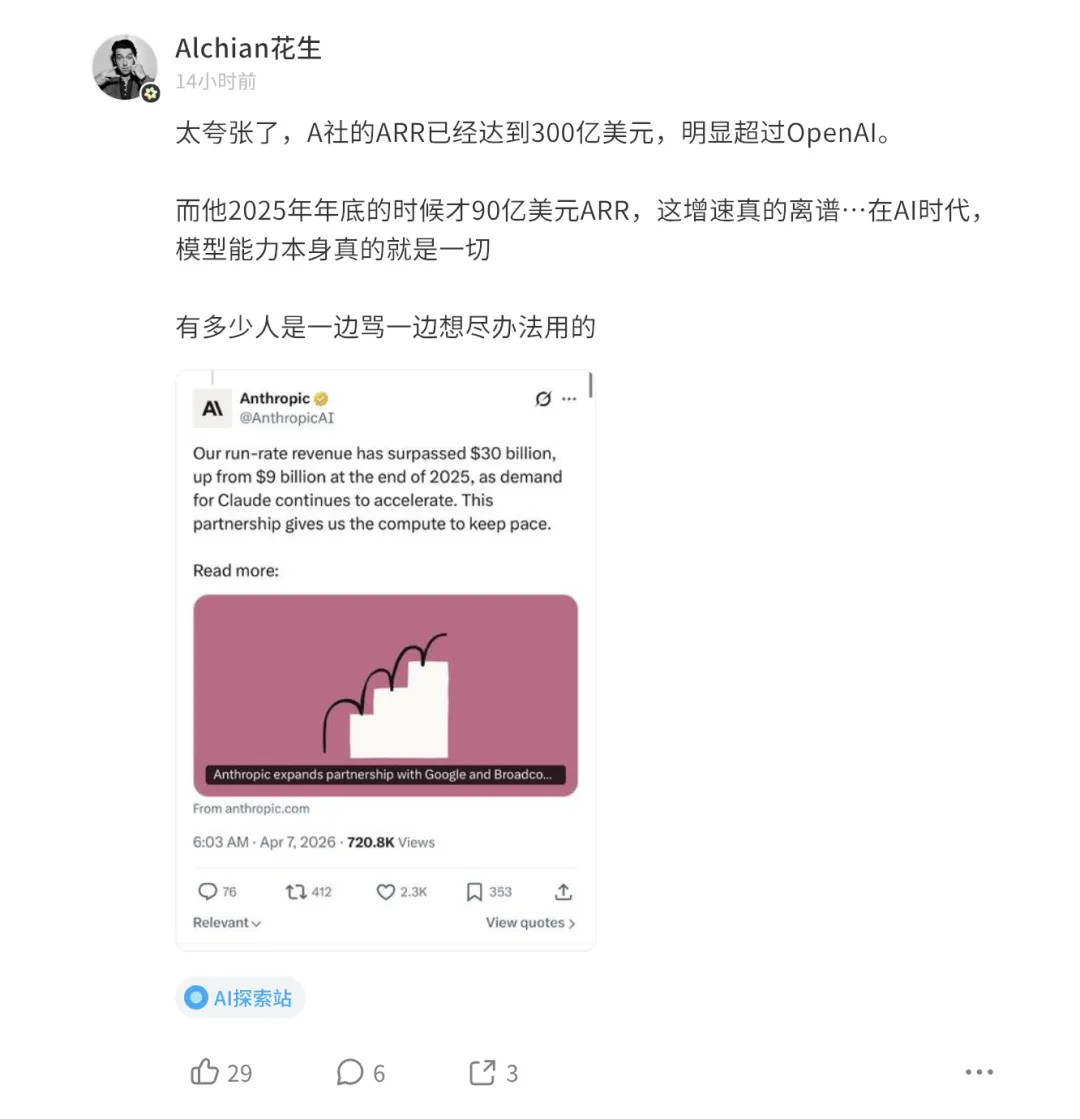
Anthropic年化收入300億美元。OpenAI係250億。
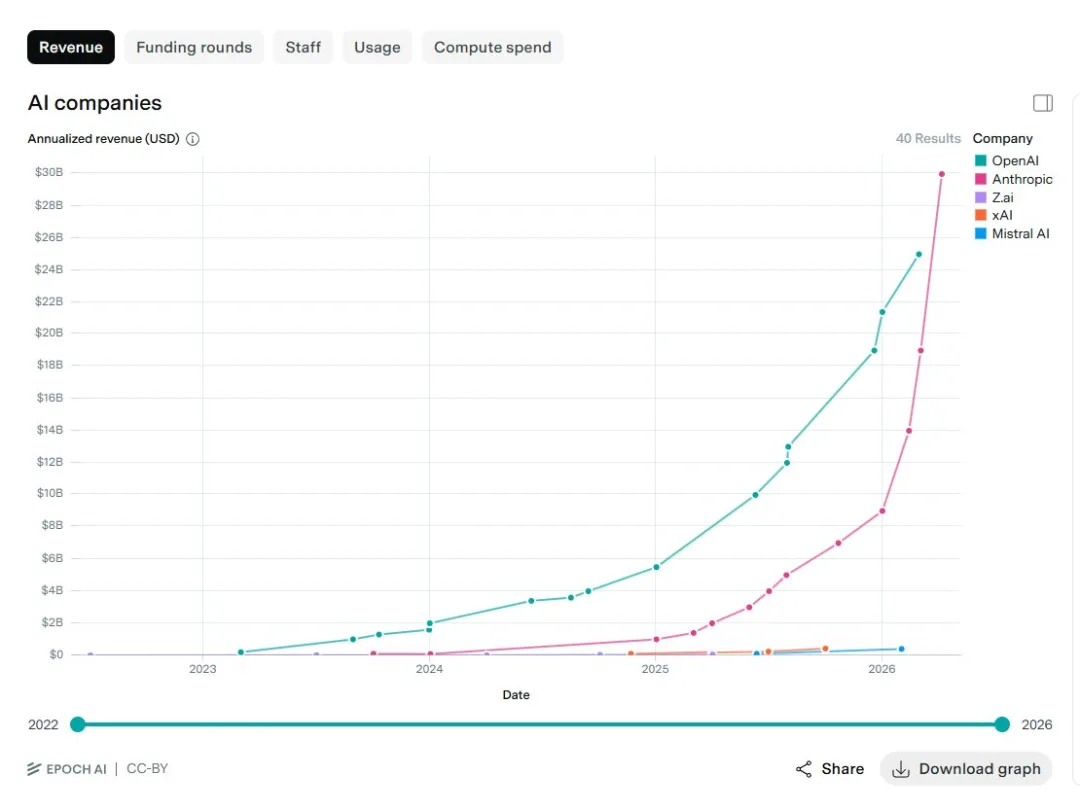 Epoch AI做過一張圖,兩條曲線嘅走勢一目瞭然:Anthropic從10億起每年增長10倍,OpenAI得3.4倍。喺首次採購AI工具嘅企業裏面,73%揀咗Anthropic。
Epoch AI做過一張圖,兩條曲線嘅走勢一目瞭然:Anthropic從10億起每年增長10倍,OpenAI得3.4倍。喺首次採購AI工具嘅企業裏面,73%揀咗Anthropic。
俾安全問題逼走嘅人,做咗一間更安全嘅公司,然後收入反超咗逼走佢嗰間公司。
如果呢個係電影劇本,製片人會話「太假喇,現實唔會有咁工整嘅因果報應」。但現實嘅品味一向比荷里活更刻意。
舊年3月我已經落咗判斷
其實唔使等《紐約客》嘅調查。產品層面嘅投票早已經結束咗。
2025年3月3日,Claude 3.7推出當日,我喺即刻上寫過一句到而家都冇改過嘅判斷:「你應該揀、而且只揀咗接Claude 3.7嘅AI編程工具。」
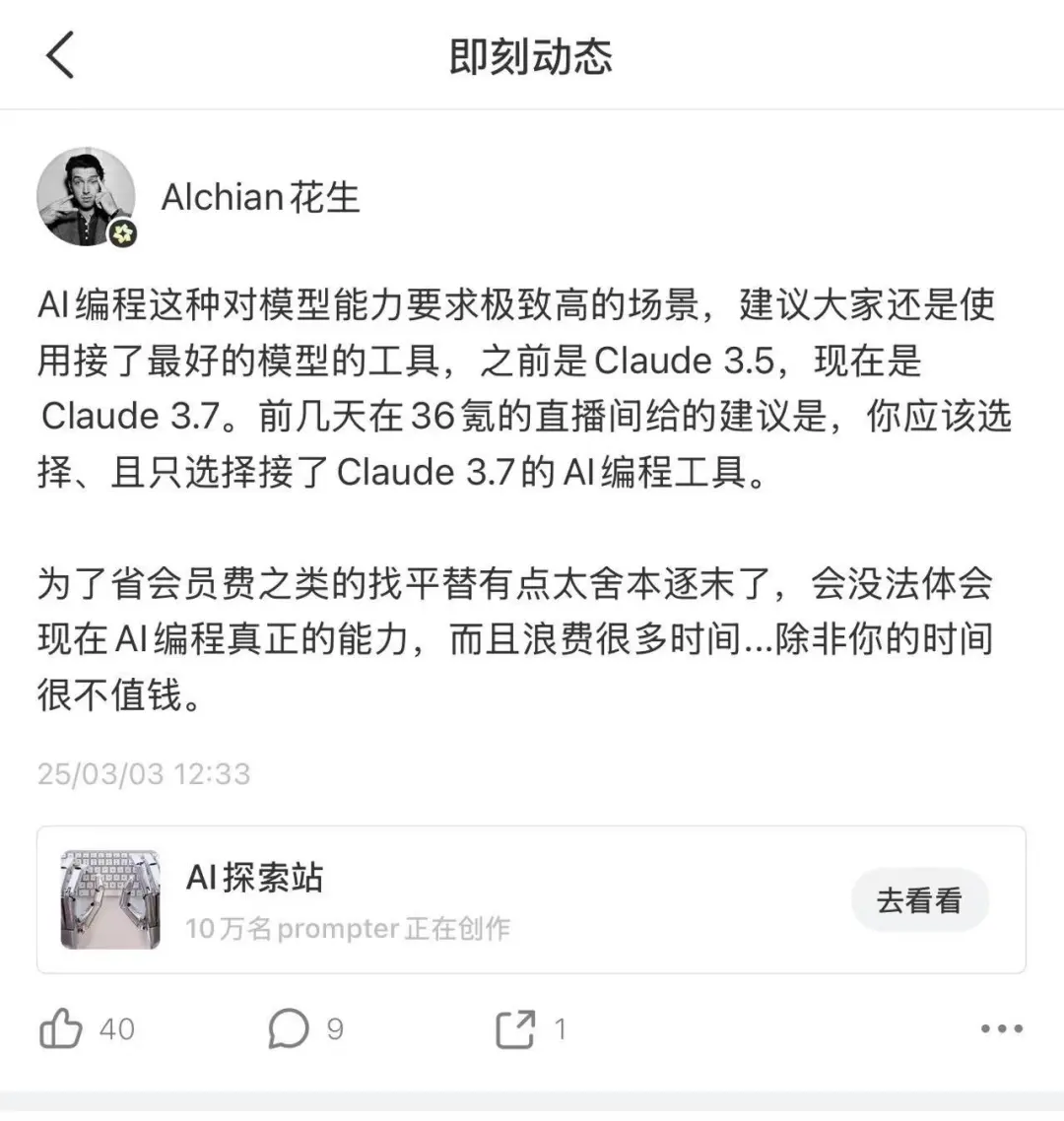
到舊年5月Claude 4出咗,我嘅話更直接:「最強編程模型+最強Agent基建。Anthropic對模型嘅所有優化都係為咗To B做AI coding同令開發者整agent而去嘅。」
由Claude 3.5到3.7到4到4.5再到而家嘅Opus 4.6,Anthropic喺AI編程同Agentic方向唔係領先,係碾壓。GPT-5我試過,評價係「可以用下,但係唔好期待太多」.
YC最新嘅數據都好有趣:入營創業者52%揀咗Anthropic,首次超過OpenAI。一年前OpenAI仲佔90%以上。
每日用呢啲工具嘅人,身體最誠實。唔需要Ronan Farrow花18個月來話畀你知邊個好用。
邊鬧邊用
到呢度你可能覺得我喺度幫Anthropic寫緊軟文。
唔係嘅。我講句大實話。
Anthropic對中國用戶嘅態度,喺所有AI公司裏面大概係最差嘅。封號、限制訪問、區域封鎖,做起嚟比邊個都積極。我身邊嘅開發者羣係咁嘅日常:上晝鬧Anthropic又封咗一批號,下晝開Claude Code趕工寫代碼。
鬧完繼續用。呢個行為模式如果俾行為經濟學家觀察到,大概會寫入下一篇論文:「論理性個體喺產品質量與國別情感之間嘅帕累託次優選擇」。但我哋嘅講法更簡單——真香。
你知道最好嘅工具喺邊個手度。你都知對方唔太歡迎你。但你冇得揀,因為差距唔係benchmark上嗰少少距離,真係能唔能夠順利搞掂件事,你自己好容易有體感。
所以《紐約客》呢篇調查,安全嘅爭論對我嚟講唔係重點。坦白講,AI安全敍事離大多數中國開發者都幾遠。我關心嘅問題簡單直接:邊個嘅模型好用?邊個嘅API穩定?邊個可以幫我將產品整出嚟?
但呢篇調查揭示咗一件更底層嘅事。
一個連自己嘅董事會都呃、連PG都話「一直喺度呃我哋」嘅人——當佢同你講「我哋嘅模型係最好」「我哋重視安全」嘅時候,你嘅信任折扣打幾折?
Dario離開嘅時候,佢可能只係想做一間唔需要講大話嘅AI公司。結果係:一個更誠實嘅組織,做出咗更好嘅產品,賺到咗更多嘅錢。
你可以話呢個係安全主義嘅勝利。我更願意將佢理解為一個極之樸素嘅商業邏輯——一個唔需要花精力維護謊言嘅團隊,可以將全部精力放喺產品上。
謊言係有利息嘅。你呃咗一個人,就需要記住你呃咗啲乜;呃咗十個人,你需要一個系統管理你嘅謊言庫。呢個大概就係OpenAI真正嘅技術債——唔喺代碼裏面,而係喺敍事裏面。
最後一個思想實驗
將《紐約客》呢篇報道入面嘅名換一換。Sam Altman換成任何一個中國科技公司創辦人。連自己董事會都呃。前老闆話佢一直講大話。前同事用咗sociopath呢個詞。合作伙伴拎佢同SBF比。
中文互聯網會有咩反應?
你估下點,微博熱搜大概會掛三日,知乎會產出兩千個「如何評價」,B站鬼畜區會喺48小時內完成所有二創。
但換成Altman就冇事。因為佢頭上嘅title係「人類AI未來嘅掌舵人」,呢個光環大到可以遮蓋一切。就好似Anthropic對中國開發者嘅態度都係小事一樣——產品好就得啦。
AI行業嘅現狀就係咁:最好嘅產品嚟自一間唔太歡迎你嘅公司,而嗰間最歡迎你嘅公司,佢嘅CEO唔受真相約束。
錘子嘅充裕,對應嘅就係釘子嘅稀缺。如果你分唔清自己係錘子定釘子——咁你好大機會係釘子。
不過作為釘子,我哋早就練咗一項核心競爭力:用住先,其他嘅以後再講。
或許你還記得,在並不遙遠的2023年11月,Sam Altman被自己的董事會投票解僱,又在5天內奇蹟復活。當時全世界都把這當成一出硅谷宮鬥劇來看,一個天才創業者被不懂事的學術派board趕走,又被市場的力量迎回來。多麼勵志。
直到昨天紐約客放出了那份遲到的屍檢報告,我們才知道,原來那不是宮鬥,是止損。董事會不是不懂事,是知道得太多了。
紐約客花了18個月,採了100多個信源,翻了200多頁內部文件。標題很直球:「Sam Altman May Control Our Future — Can He Be Trusted?」 同一天,Altman自己發了份13頁政策報告,把自己比作羅斯福,說要搞AI時代的New Deal。
一邊是檢察官在宣讀起訴書,一邊是被告在發表競選演講。
這個時間線,魔幻現實主義看了都要歎服。
52頁備忘錄
這篇調查真正的殺傷力來自兩份從未公開過的內部文件。
第一份是Ilya Sutskever在2023年秋天編的52頁備忘錄。Ilya當時還是OpenAI首席科學家,他不是在寫投訴信——他是在編案卷。截圖、通信記錄、事實核對,一條一條地列。備忘錄第一行:
「Exhibits a consistent pattern of lying.」
表現出系統性的撒謊模式。
第二份是Dario Amodei在OpenAI期間記的200多頁筆記。Dario後來離開創辦了Anthropic,我們一會兒再說這件事為什麼重要。他的筆記濃縮成一句話:
「The problem with OpenAI is Sam himself.」
一個董事會成員的措辭更精確:「He's unconstrained by truth.」他不受真相約束。
Unconstrained by truth。不是「偶爾撒謊」,不是「有時不夠坦誠」——是真相對他構不成約束力。就像萬有引力之於光子,不是它在抵抗,是這個力對它不適用。
承諾1/5,兑現1%
紐約客列了一長串指控,但核心邏輯其實只有一條:Altman把安全承諾當成融資PPT用。
最典型的案例:OpenAI高調宣佈成立「超級對齊團隊」,承諾投入1/5的計算資源,防止AI導致「人類滅亡」。聽起來很負責很壯觀,投資人安心了,媒體寫了,輿論買賬了。
但四個內部人士告訴紐約客,這個團隊實際拿到的算力是1-2%,跑在公司最老舊的GPU上。好卡留給了能賺錢的模型。
然後這個團隊被解散了。
記者去問OpenAI:你們現在還有「存在主義安全研究人員」嗎?
對方的回應我來來回回讀了三遍:
「That's not, like, a thing.」
這句話的信息密度極高。翻譯成中文就是:「那個...不算是...一個存在的事物。」
你想想這個邏輯鏈:先承諾1/5 → 實際給1% → 解散整個團隊 → 被問的時候表示這個概念不存在。這不是食言,這是一種本體論層面的否認——不是我沒做到,是這件事從來就不是一件事。薛定諤的安全承諾:你不去查的時候,它既存在又不存在。
2022年12月的事更離譜。Altman跟自己的董事會說GPT-4的爭議功能都已通過安全委員會審批。董事會要求看文件。沒有文件。因為那些功能壓根沒被審批過。
騙投資人還能理解為硅谷傳統。但騙自己的董事會,這就像棋手試圖作弊騙裁判——而裁判就坐在你對面看着你下棋。需要的不是勇氣,是某種對現實的創造性理解。
Paul Graham的沉默
說一個我覺得被大多數人忽略的細節。
Paul Graham是YC的創始人,是當年親手提拔Altman做YC總裁的人。紐約客引用了PG的原話:
「Sam had been lying to us all the time.」
Sam一直在騙我們。
但你猜怎麼着?2024年5月,PG在X上專門發了一條帖子,語氣還挺認真的:「我聽夠了說YC開除Sam的說法,來告訴你們真正發生了什麼。」大意是我們沒開除他,只是讓他選YC還是OpenAI,他選了OpenAI。
私下跟同事說「他一直在騙我們」,公開替他洗地說「我們沒開除他」。
我毫不懷疑PG知道自己在做什麼。你親手提拔的人後來證明是個說謊者,你有兩個選項:承認自己的識人能力有問題,或者把整件事模糊化處理。PG選了後者。
紐約客出來之後,PG沒有再發帖。
沉默。
這個沉默裏面的信息量,比一萬字的聲明都大。因為如果紐約客的引語有誤,PG一定會澄清——他可是最在乎公共敍事準確性的人。他沒澄清,說明那些話確實是他說的。
甚至連微軟高管都私下來了一句:
「I think there's a small but real chance he's eventually remembered as a Bernie Madoff- or Sam Bankman-Fried-level scammer.」
可能被記住為麥道夫或SBF級別的騙子。這話是合作伙伴說的。你的合作伙伴拿你跟龐氏騙局比,你品品這個信任度。
vibes
面對以上所有這些,Altman跟紐約客的回應值得裱起來。
「My vibes don't really fit with a lot of this traditional A.I.-safety stuff.」
我的vibes和傳統AI安全不太搭。
Vibes。
這個詞如果被收進商業史教科書,大概會出現在「企業高管面對嚴肅質疑時的最短有效回答」這個條目下。一個掌管着可能是人類歷史上最強大技術工具的人,選擇了一個連詞性都模糊的詞來回應為什麼不重視安全。
這就好比核電站廠長在安全聽證會上說「我跟鈾235之間的chemistry不太對」。
他還說OpenAI會繼續做「safety projects, or at least safety-adjacent projects」。你品品這個措辭降級——從safety到safety-adjacent。就像有人說「我愛你,或者至少,我對你有好感相關的情緒」。
同一天發的那份New Deal報告呢?卡內基基金會的人給了一句點評:「comms work to provide cover for regulatory nihilism.」——公關作品,給監管虛無主義打掩護。
到今天,Altman還沒正式回應紐約客的具體指控。
也許他正在準備一份新的政策報告,標題大概叫「Why Being Unconstrained by Truth Is Actually Good for Humanity」。
出走的人贏了
現在說說為什麼Dario Amodei的那句「The problem with OpenAI is Sam himself」格外值得回味。
因為寫下這句話的人離開了OpenAI,創辦了Anthropic,然後在收入上反超了OpenAI。
Anthropic年化收入300億美元。OpenAI是250億。
Epoch AI做過一張圖,兩條曲線的走勢一目瞭然:Anthropic從10億起年增長10倍,OpenAI只有3.4倍。在首次採購AI工具的企業裏,73%選了Anthropic。
被安全問題逼走的人,做了一家更安全的公司,然後收入反超了逼走他的那家公司。
如果這是一部電影的劇本,製片人會說「太假了,現實中不會有這麼工整的因果報應」。但現實的品味一向比好萊塢更刻意。
去年3月我就下了判斷
其實不用等紐約客的調查。產品層面的投票早就結束了。
2025年3月3日,Claude 3.7發佈當天,我在即刻上寫過一句至今沒改過的判斷:「你應該選擇、且只選擇接了Claude 3.7的AI編程工具。」
到去年5月Claude 4出來,我的話更直接:「最強編程模型+最強Agent基建。Anthropic對模型的所有優化都是奔着To B做AI coding和讓開發者建agent而去的。」
從Claude 3.5到3.7到4到4.5再到現在的Opus 4.6,Anthropic在AI編程和Agentic方向上不是領先,是碾壓。GPT-5出來我試了,評價是「可以用用,但是別期待太多」。
YC最新的數據也很有意思:入營創業者52%選了Anthropic,首次超過OpenAI。一年前OpenAI還佔90%以上。
每天用這些工具的人,身體是最誠實的。不需要Ronan Farrow花18個月來告訴你誰更好用。
邊罵邊用
到這裏你可能覺得我在替Anthropic寫軟文。
不是的。我要說一句大實話。
Anthropic對中國用戶的態度,在所有AI公司裏大概是最差的。封號、限制訪問、區域屏蔽,做起來比誰都積極。我身邊的開發者羣是這樣的日常:上午罵Anthropic又封了一批號,下午打開Claude Code趕工寫代碼。
罵完繼續用。這個行為模式如果被行為經濟學家觀察到,大概會寫進下一篇論文:「論理性個體在產品質量與國別情感之間的帕累託次優選擇」。但我們的說法更簡單——真香。
你知道最好的工具在誰手裏。你也知道對方不怎麼待見你。但你沒得選,因為差距不是benchmark上的那一丟丟距離,真的能不能順利把事做完,你自己很容易有體感的。
所以紐約客這篇調查,安全的爭論對我來說不是重點。坦白說,AI安全敍事離大多數中國開發者挺遠的。我關心的問題簡單粗暴:誰的模型好用?誰的API穩?誰能幫我把產品做出來?
但這篇調查揭示了一件更底層的事。
一個連自己的董事會都騙、連PG都說「一直在騙我們」的人——當他跟你說「我們的模型是最好的」「我們重視安全」的時候,你的信任折扣打幾折?
Dario離開的時候,他可能只是想做一家不需要撒謊的AI公司。結果是:一個更誠實的組織,做出了更好的產品,賺到了更多的錢。
你可以說這是安全主義的勝利。我更願意把它理解為一個極其樸素的商業邏輯——一個不需要花精力維護謊言的團隊,可以把全部精力放在產品上。
謊言是有利息的。你騙了一個人,就需要記住你騙了什麼;騙了十個人,你需要一個系統來管理你的謊言庫。這大概就是OpenAI真正的技術債——不在代碼裏,在敍事裏。
最後一個思想實驗
把紐約客這篇報道里的名字換一下。Sam Altman換成任何一箇中國科技公司創始人。連自己董事會都騙。前老闆說他一直在撒謊。前同事用了sociopath這個詞。合作伙伴拿他和SBF比。
中文互聯網會是什麼反應?
你猜怎麼着,微博熱搜大概能掛三天,知乎會產出兩千個「如何評價」,B站鬼畜區會在48小時內完成所有二創。
但換成Altman就沒事了。因為他頭頂的title是「人類AI未來的掌舵人」,這個光環大到可以遮住一切。就像Anthropic對中國開發者的態度也是小事一樣——產品好就行了嘛。
AI行業的現狀就是這樣:最好的產品來自一家不太歡迎你的公司,而那家看起來最歡迎你的公司,它的CEO不受真相約束。
錘子的充裕,對應的就是釘子的稀缺。如果你分不清自己是錘子還是釘子——那你大概率是釘子。
不過作為釘子,我們早就練出了一項核心競爭力:先用着,別的以後再說。