Skill-creator悄悄迎來史詩級更新,所有Skills都值得重寫一遍。
整理版優先睇
Anthropic 為 Skill-Creator 加入評估系統,所有 Skills 都值得重寫一次
呢篇文章係由作者「可可耐特」嘅自身經驗出發。作者一直有玩 Claude 嘅 Skills 生態,之前寫過一篇好詳細嘅 Skills 教學。今次佢發現 Anthropic 嘅官方程式倉庫入面,嗰個核心嘅母 Skill——Skill-creator,靜雞雞迎來咗一次史詩級更新。作者認為,呢次更新解決咗一直以嚟整 Skills 嘅最大痛點:做完一個 Skill 之後,完全係黑盒,根本唔知佢好唔好用、觸發準唔準、跨場景穩唔穩定。而家 Anthropic 直接將醫藥行業嘅雙盲對照試驗嗰套搬過嚟,加咗評估系統、基準測試、多代理並行測試同描述自動調優。
成篇文章嘅結論係:呢次更新標誌住 Skills 從手工作坊跳到工業化階段,所有整過 Skills 嘅人都應該第一時間更新 Skill-creator,然後將自己啲 Skill 逐個跑一次評估流程,等問題自己浮出水面。作者仲親身示範咗用新版搓一個講稿生成 Skill,同埋展示咗描述調優點樣解決「兩個 Skill 撞車」嘅問題。
總括嚟講,呢篇文章唔單止係一個產品更新消息,仲係一個實戰指南,教你點樣用好呢套新工具去提升 Skills 嘅質素同可信度。
- Skill-creator 新增評估系統、基準測試、多代理並行測試同描述自動調優,等 Skills 創作從黑盒變透明
- 評估系統採用醫藥行業雙盲對照設計:有 Skill vs 無 Skill,乾淨環境隔離,量化打分
- 描述調優功能會自動生成「應該觸發」同「唔應該觸發」各 10 條查詢,用戶確認後進行最多 5 輪迭代,將觸發率大幅提升
- 多代理並行測試解決咗之前串行測試嘅上下文污染問題,結果更乾淨、更可信
- Skills 分為「能力提升型」同「流程封裝型」,兩者評估方向唔同:前者測有無存在必要,後者測有無跟足流程
Skill-creator GitHub 倉庫
今次更新嘅官方 Skill-creator 倉庫,包含最新版本嘅程式碼同文檔。
呢次更新有咩咁把炮?
以前做完一個 Skill,你完全係矇查查:觸發係咪啱?描述寫得掂唔掂?換個情境仲會唔會鬱?全部都係黑盒。Anthropic 今次一次過加咗 4 個能力,直接將呢層黑盒撕開。
- 1 一套評估系統:跑完你即刻知道個 Skill 到底得唔得
- 2 基準測試體系:通過率、耗時、消耗 token,全部量化曬
- 3 多代理並行測試:每個測試放喺獨立小房間,A/B 盲評,唔會互相污染
- 4 描述自動調優:自動幫你改寫 Skill 描述,該觸發嘅唔漏,唔該觸發嘅唔亂來
用新版即刻搓一個講稿 Skill
作者用新版 Skill-creator 搓咗一個新 Skill:畀個視頻連結,就出文字版講稿,外語視頻仲要原文加雙語對照。提示詞好簡單,但新版本唔會即刻開幹,反而反問幾個問題確認需求。
3 到 5 分鐘,成個 Skill 就搭好
作者用 Peter 嘅 YouTube 訪談實測,出到中文版講稿,但排版麻麻。佢冇手動改 code,直接對住 Skill 對話叫佢再改一版,新版本喺迭代改寫方面都有提升。
改完之後排版清晰,段落分明,標題層級齊曬
描述調優——解決兩個 Skill 撞車嘅最大武器
作者手頭有兩個 Skill 都同視頻連結有關:一個係 yt-dlp 用嚟下載,一個係新做嘅講稿生成。兩個都係「畀個視頻連結」去觸發,咁點知你想做邊樣?以前要自己肉眼盯住改描述,而家新版 Skill-creator 直接接管。
- 1 佢會自動生成兩組查詢:一組係「應該觸發嘅 10 條」,一組係「唔應該觸發嘅 10 條」,專挑灰色地帶邊界情況
- 2 彈一個網頁畀你逐條確認,每條右邊有個開關,覺得唔啱就直接 flip
- 3 確認完之後,後台自動行最多 5 輪優化循環,每輪做 3 件事,約 10-20 分鐘
- 4 跑完出一個巨表,顯示每個迭代版本喺訓練集同測試集上嘅觸發結果,最優描述會自動寫返入 SKILL.md
真正幹活——全面評估個講稿 Skill
觸發搞掂之後,就要測真實效果。作者對個講稿 Skill 開全面評估,新版會先啃曬成個 Skill 文件,然後畀選項你揀想測邊方面。佢揀咗全面評估,系統自動設計三類測試場景,每個都有量化驗收標準。
一口氣並行啟動 4 個獨立子代理同時跑
以前串行測試會有上下文污染問題,前一個任務積累嘅嘢會影響後一個結果。而家每個代理喺完全乾淨嘅環境跑,token 計數、耗時獨立計算,互相零交叉。
評估嘅真正價值:閉住眼都可以修 Bug
Anthropic 舉咗一個例子:佢哋有個 PDF Skill,處理表格時成日出錯,Claude 要將文字塞到指定座標,但因為冇明確字段引導,經常放歪。呢種 bug 靠肉眼好難測到。跑一次評估之後問題就被定位,改咗定位邏輯就搞掂。
評估結果會存在本地,下次改 Skill 時直接帶入上次標註過嘅問題
呢個係測試 → 發現 → 改 → 再測嘅完整循環,同軟件工程嘅單元測試一模一樣。
- 能力提升型:教 Claude 做佢本來唔叻嘅事,例如前端設計、文檔創建;評估測有無存在必要
- 流程封裝型:將你團隊嘅流程串起嚟,例如會議紀要、週報;評估測有冇跟足你嘅步驟
模型每升一代,都會有一堆能力提升型 Skill 自然被淘汰,呢個係健康嘅
前兩日直播完之後,我順手睇咗一眼Anthropic嘅Skills倉庫。 結果喺最新Commit裏面,見到一個令我即刻坐直咗嘅更新。  Skill-creator。 嗰個俾我反覆講過無數次嘅母Skill,靜靜雞迎嚟咗一波超大更新。 你要知道,小龍蝦而家可以咁犀利,本質上一半功勞要歸落Skills度。 而所有呢啲Skills可以造出嚟,又幾乎都要多謝呢個Skill-creator。 佢就係成個Skills生態嘅引擎。 之前未接觸過Skills嘅朋友,可以先睇一眼這篇,應該係全網講Skills講得最詳細嗰篇之一。 返番正題。 呢個星期夜晚抽咗啲時間,將今次更新嘅文檔由頭到尾睇曬。 睇完之後我得一個判斷——今次更新,等於俾成個Skills生態加咗一層底座。 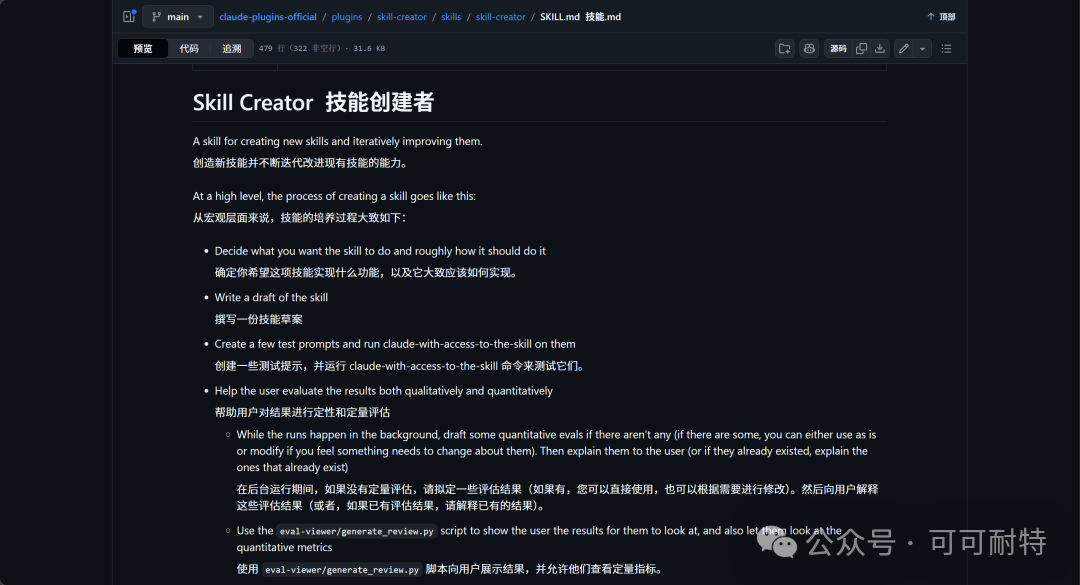 之前所有自己整Skill嘅人,其實都畀同一個問題困住咗—— 你做完一個Skill,根本唔知佢好唔好用。係觸發啱咗,定係佢自己亂估?寫嘅描述合唔合理?換個上下文仲行唔行得通? 全部都係黑盒。 而而家,呢層黑盒畀Anthropic一手撕開咗。 我極力推薦,大家先將Skill-creator更新到最新版本。 更新方法簡單到離譜,同你嘅Agent講一句就得,無論係Claude Code、小龍蝦定OpenCode,都一樣:
係,就咁一句。 Agent自己會去拉。 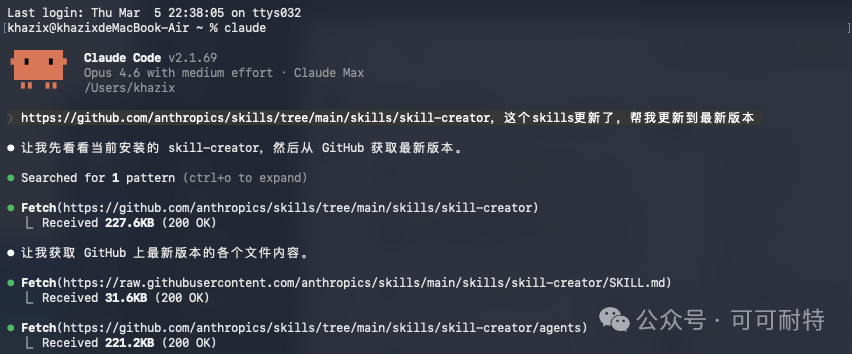 幾分鐘之內,更新就搞掂咗。  今次新版本一口氣加咗4個功能:
我見到呢份清單嘅第一反應係—— 呢個唔就係將醫藥行業嘅雙盲隨機對照試驗嗰套,原封不動搬咗過Skills度咩? 醫藥行業有個鐵律:一隻藥到底有冇效,淨係睇研發自己口講「有效」,冇人理你。 你要設實驗組、設對照組,將研究人員同受試者都蒙在鼓裏,行完之後睇量化指標,差距大唔大先算數。 人類用咗一百幾年先將呢套嘢打磨乾淨。 而Anthropic今次相當於將同一套,原封不動搬咗畀Skills——有Skill vs 冇Skill,乾淨環境隔離,並行行,量化打分。 工業化嘅本質就係評估。 一旦評估體系立咗起身,成個嘢就由手工作坊跳咗去流水線。 理論講到呢度先。 直接上案例。 1. 順手用新版Skill-creator,再整一個Skill 我之前寫過一篇文章,將GitHub上面嘅yt-dlp封裝成一個Skill,可以從YouTube、B站、小紅書等各種視頻網站下載視頻。  但用咗一排之後,我自己發現,淨係將視頻下載落嚟係唔夠嘅。 我好多場景其實係咁——碌到一個外國嘅長訪問,我冇耐性一邊睇一邊記,我想要嘅係文字版講稿,最好原文加中文雙語對照排好直接send俾我。 啱啱好趁今次更新,我用新版Skill-creator又整咗一個新Skill。 提示詞極簡單:
佢冇急住開工。 反而反問咗我幾個問題,確認需求細節,然後先開始設計成個Skill。  3到5分鐘,成個Skill就整好咗。 我攞小龍蝦老竇Peter嘅一個YouTube訪問嚟試。  直接將連結掟入去。 5分鐘之後,中文版講稿出咗嚟。  但是。 一大段文字黐埋一齊。 字細,行密,睇到頭痛。 當時我冇特登去手動改佢嘅code,直接對住個Skill繼續對話,叫佢再改一版。 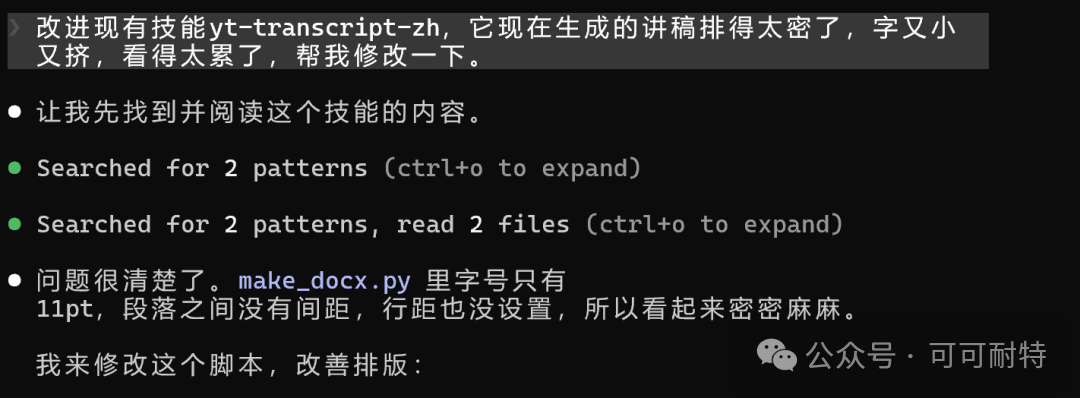 新版Skill-creator喺迭代改寫呢方面,都有啲提升。 改完之後再行一次:  排版清晰,段落分明,標題層次齊曬。 咁先似份可以畀人睇嘅文件。 到呢一步,Skill本身算係整咗出嚟。 但真正嘅麻煩,先啱啱開始。 2. 描述調優——解決衝突最勁嘅工具 我而家手上有兩個Skill都同視頻連結有關。 一個係之前嘅yt-dlp,做嘅係將視頻下載到本地。 一個係啱啱整完嘅講稿生成,做嘅係將視頻轉成文字。 佢哋嘅觸發條件都係——「畀一個視頻連結」。 咁問題就嚟喇。 我掟一個YouTube連結過去,佢點知我到底想下載視頻定係想要講稿? 萬一撞咗點算?該觸發嘅唔觸發,唔該觸發嘅亂觸發,咁呢兩個Skill就廢咗。 以前呢啲嘢我只能靠自己肉眼睇,每次行歪咗就返去手動改描述,純粹係體力活。 而新版Skill-creator,直接將呢個流程接管咗。 叫佢優化Skill描述,佢會先將目前嘅描述讀一次,然後話畀你聽要跟住做嘅4件事:  最得意係第一步:佢會自動生成兩組查詢。 一組叫「應該觸發嘅10條」,一組叫「唔應該觸發嘅10條」。 呢個設計我仔細咁諗過。 佢特登將模糊地帶嘅邊界情況都擺埋入去——唔係啲一眼就知要觸發嘅簡單句,而係嗰啲「嗯?呢個到底算唔算?」嘅灰色地帶。  逼個模型喺最難嘅地方做判斷。 同搞算法面試題一樣意思——簡單題篩唔出強弱,要hard題先得。 生成完之後,佢直接彈一個網頁叫你確認。 我第一次見到嘅時候,真係有啲驚訝。 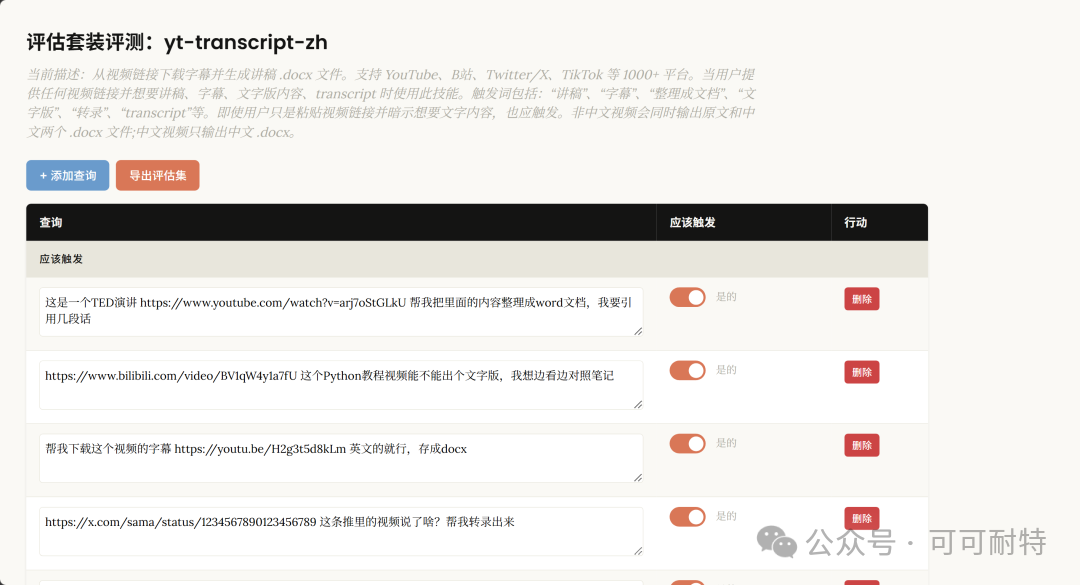 20條查詢整整齊齊排喺網頁度,每條右邊有個開關,標住「係咪應該觸發」。 你逐條睇一次,發現邊條判斷唔啱,直接將個開關撥一下。 打個比方,第三條呢種情況,我唔想再叫佢觸發,我就直接熄咗佢。 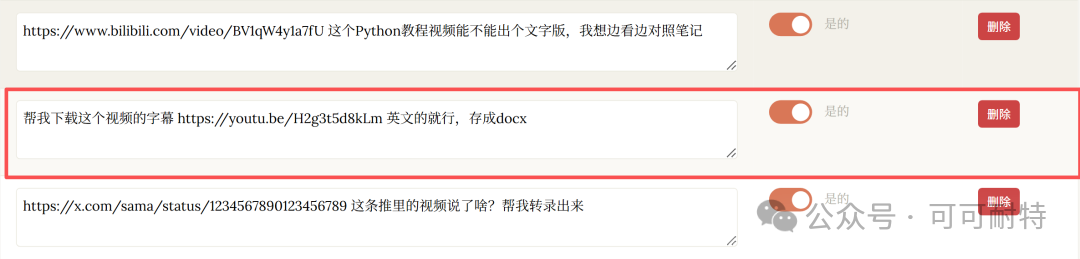 唔應該觸發嘅10條我都睇咗一次,整體冇問題。 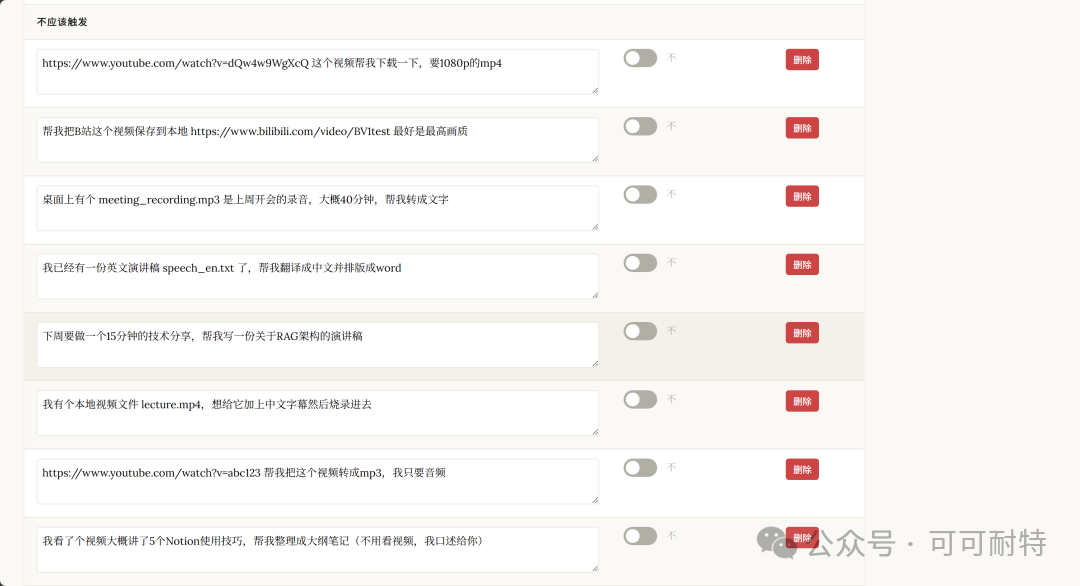 全部確認完,撳「導出評估集」,搞掂。 接落嚟先係好戲。 後台啟動優化循環,最多行5輪迭代,每輪做三件事,成個過程大約10到20分鐘。  佢會定期匯報進度。 行完之後,會出一個好大嘅表格:  每一列係一個查詢樣本,每一行係一個迭代版本嘅描述。 綠色剔號代表觸發啱咗,紅色交叉代表冇觸發或者錯觸發。 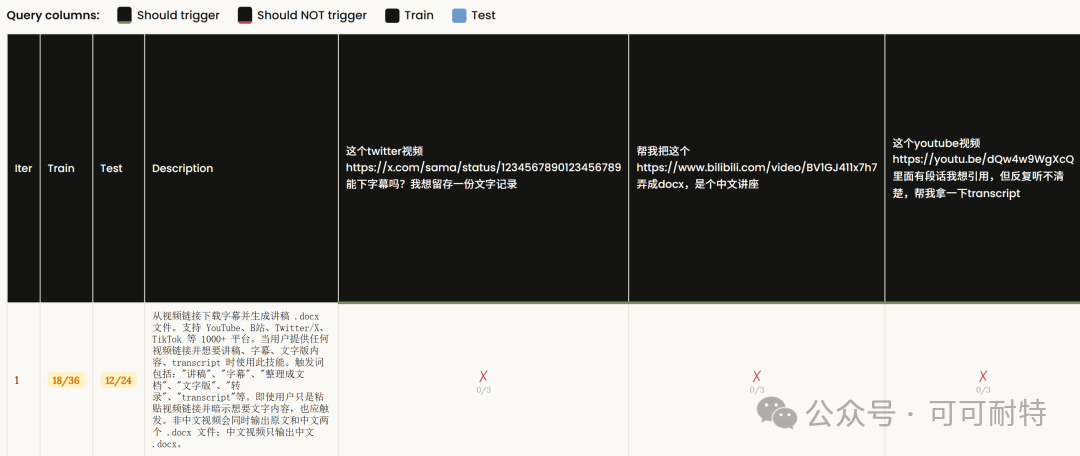 藍色嗰列係測試集,其餘係訓練集。  佢將20個樣本拆成60%訓練加40%測試,喺訓練集上反覆調描述,最後用測試集驗證收斂效果。 呢個係機器學習入面防止過擬合嘅標準做法。 行完之後,最優描述會自動寫返入SKILL.md,成個過程你唔使鬱一隻手指。 Anthropic自己喺6個文檔類Skill上做咗對照——5個嘅觸發率都畀呢套流程推高咗。 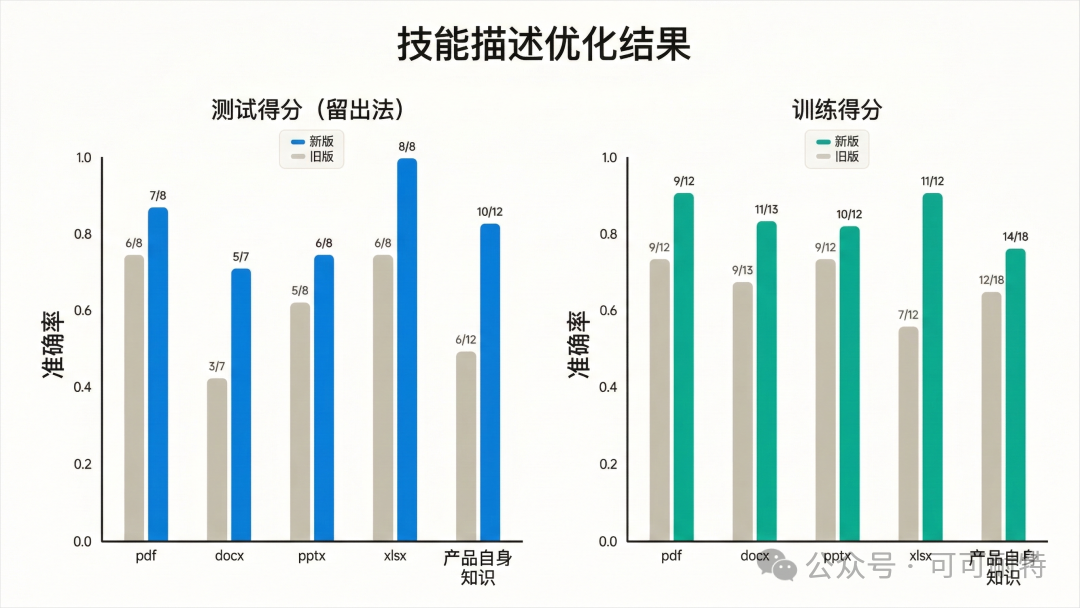 淨係描述改一改咋。 呢步做完,你嘅Skill觸發準確率可以上一個台階。 3. 觸發啱咗,只係入場券 真正做起嘢嚟效果點,仲要另外測。 跟住對啱啱做嘅講稿生成Skill開一次評估。  佢會先將成個Skill文件睇一次,搞清呢件嘢嘅核心流程係咩。  然後彈一個選項畀你:你想測邊個方面? 我揀咗「全面評估」。 佢根據Skill功能,自動設計咗三類測試場景,每個場景都配咗量化驗收標準。  確認方案之後,佢一口氣並行啟動咗4個獨立子代理同時行。  呢一步——我一定要單獨拎出嚟讚。 以前你都大概可以自己手動做啲簡單評估,但有個致命問題:所有測試只能串行行。 一個行完先行下一個。 大家都明上下文管理有幾重要。前一個任務積累嘅上下文,會污染後一個嘅結果。 你見到Skill「通過」咗,可能根本唔係Skill嘅功勞,而係上一輪對話歷史幫佢搭好咗條路。 但你睇唔出。 因為黑盒裏面冇光。 新版本直接換成4個並行Agent。 每個Agent喺完全乾淨嘅環境裏面行,自己嘅token計數、自己嘅耗時,互相之間零交叉。 更快,更乾淨,更可信。 等緊行嘅過程度,佢順手將量化評分腳本都準備好。  測試行完,瀏覽器自動彈出評估頁面,兩個標籤。 輸出標籤頁——每個測試用例嘅完整輸出。 下面掛一個反饋框,邊度唔啱、邊度要改,你直接標。 呢啲標註會被存起嚟,下次改Skill嘅時候,直接當輸入用。 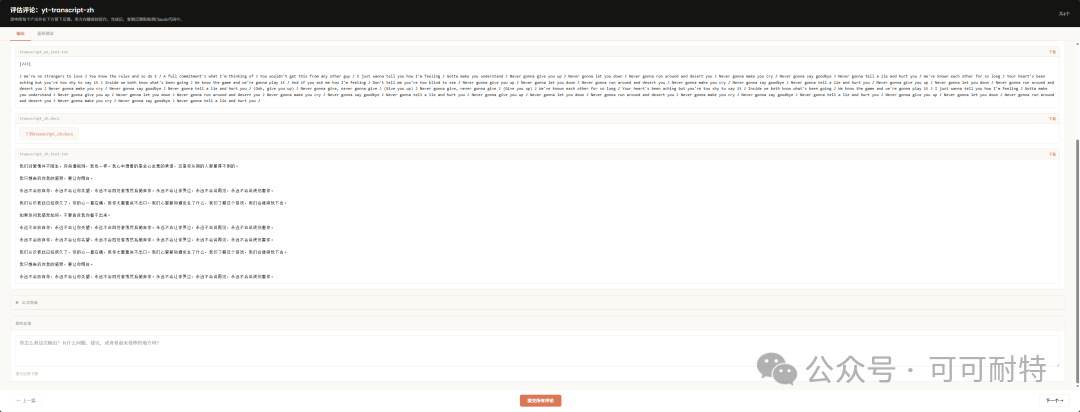 基準測試標籤頁——有Skill vs 冇Skill嘅量化對比。 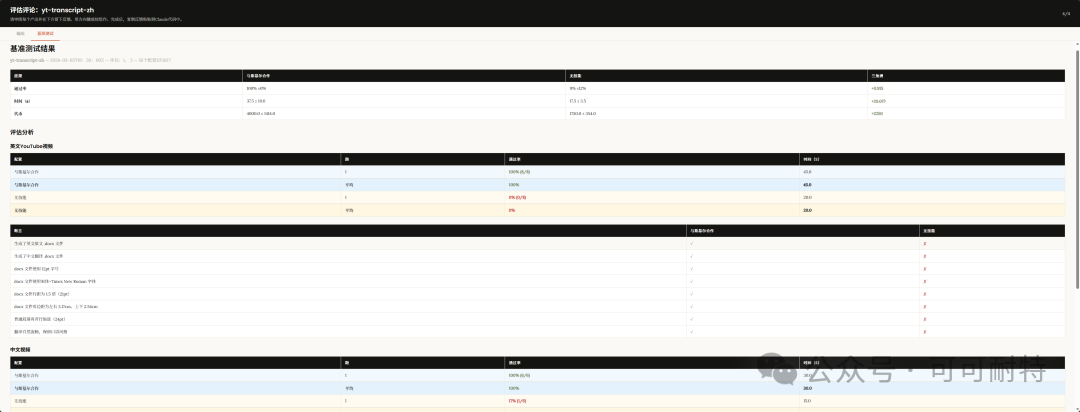 數據呢方面極度量化。 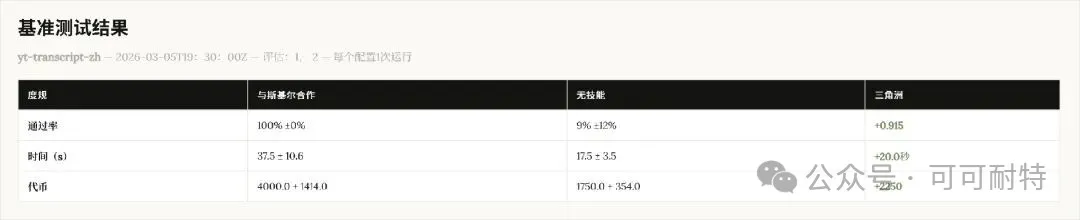 有Skill嘅通過率100%,冇Skill嘅基線9%,相差91.5%。 費用方面:有Skill每次大概4000 token,冇Skill 1750 token,多用咗2250。 呢個係Skill帶嚟嘅額外開支。 但對比產出,係值得嘅。 4. 評估嘅真正價值,係合埋眼都可以修Bug 評估嘅意義,遠遠唔止「打個分」咁簡單。 Anthropic自己舉咗個例子。 佢哋有一個PDF Skill,處理表格嘅時候經常有錯。Claude要將文字塞到指定座標,但因為缺少明確嘅字段引導,成日放歪。 呢種bug,靠肉眼測一世都可能測唔出。 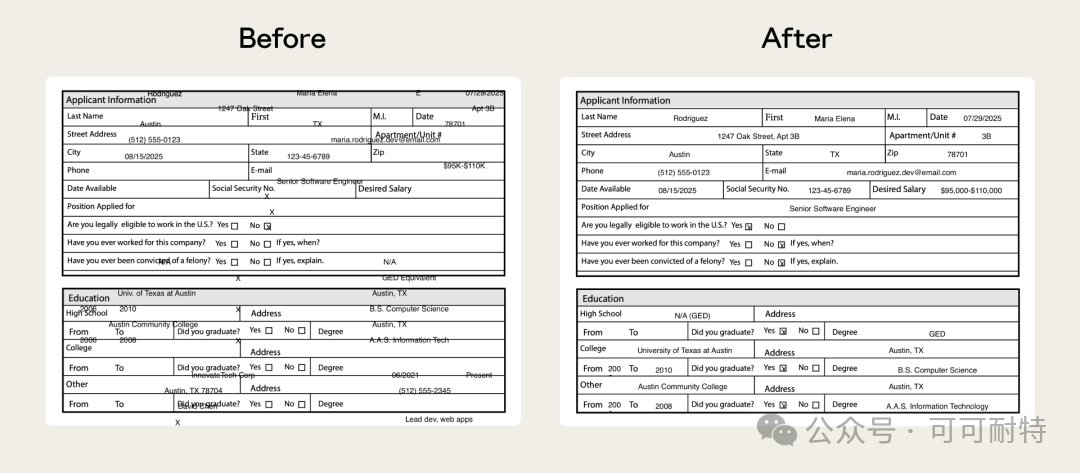 行咗一次評估之後,問題被定位咗。 改咗定位邏輯,bug就搞掂咗。 而且——發現問題之後唔使由頭嚟過。 評估結果會存喺本地,下次你用Skill-creator改呢個Skill嘅時候,佢直接將上次標註過嘅問題帶入去,針對性咁改。 改完再行一次評估,睇分數有冇提升。 測試 → 發現 → 改 → 再測。 呢一成套循環,係完整嘅。 Anthropic相當於將軟件工程入面嗰套最嚴謹嘅做法——單元測試、基準測試、迭代改進、迴歸驗證——一次過搬咗去Skills嘅創作流程度。 軟件工程用咗幾十年先將呢套嘢打磨成而家嘅樣。 Skills生態計埋計埋先出咗幾個月。 直接跳級。 5. 順便講下:你嘅Skill係邊種? 如果你打算將自己手上所有Skills都重新優化行一次,首先要分清楚一件事—— 你寫嘅呢個Skill,到底係邊種? 本質上,Skills得兩種。 第一種:能力提升型。 教Claude做佢本來唔擅長嘅事。 例如官方嘅前端設計Skill、文檔創建Skill,裏面塞咗大量小技巧——你淨係靠Prompt根本調唔出呢種效果。 我哋大多數人自己整嘅Skill,基本都係呢類。 第二種,官方叫「編碼偏好型」,我習慣叫佢做「流程封裝型」。 意思係話畀Claude跟你嘅規矩行。 Claude本身每一步都識做,但你將呢啲步驟跟你團隊或者你個人嘅流程串埋一齊。 例如一個會議記錄Skill,按你公司嘅固定格式,將錄音轉成帶行動項嘅文件。 例如一個週報Skill,從各個平台拉數據,跟你嘅固定模板排好。 呢種Skill嘅本質,就係一個工作流(Workflow)。 點解要分呢兩種? 因為評估方向唔一樣。 能力提升型係測——呢個Skill仲有冇存在嘅必要。 用A/B對比,有Skill行一次,冇Skill行一次。 如果差唔多,呢個Skill就應該退休。 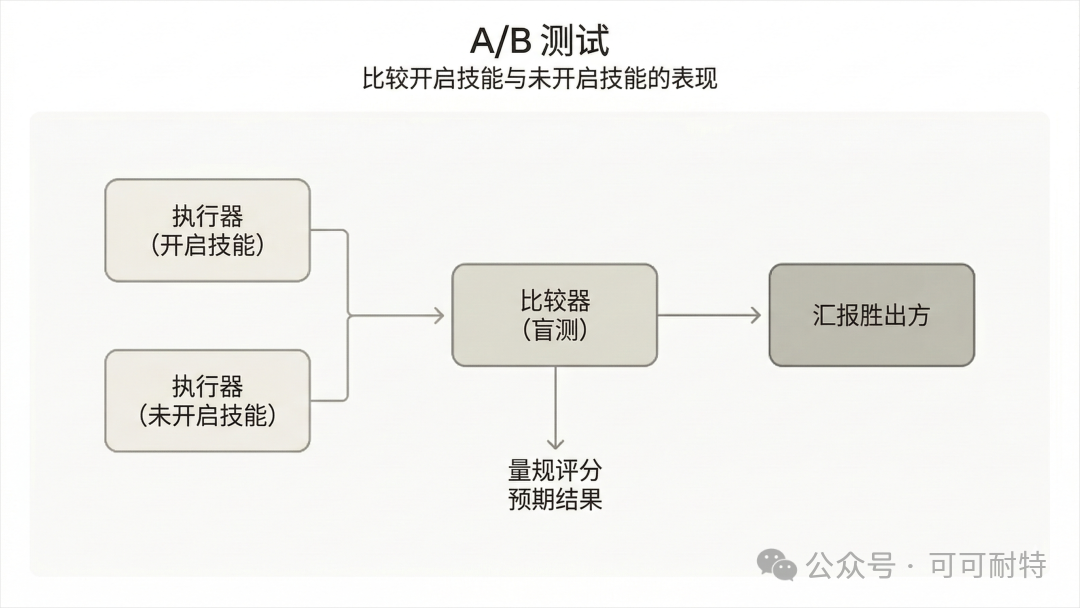 模型每升一代,都會有一堆能力提升型嘅Skill被自然淘汰。 呢樣係健康嘅。 流程封裝型係測另一件事——佢有冇乖乖哋跟你嘅流程行? 有冇漏步驟?有冇自作主張換咗順序?有冇忘記你特別交代過嗰個細節? 分別都幾大。 下次自己測嘅時候,注意分清楚。 寫喺最後 寫到呢度,我自己都想嘆一口氣。 以前整完一個Skill,純粹靠「覺得自己幾好」。 行兩個case睇落OK,就覺得搞掂咗。 但講真,全部係黑盒。 到底好唔好用,質素點樣,觸發率幾多,跨場景穩唔穩定,我根本唔知。 而家唔同曬。 評估行一次,數據擺出嚟,好唔好用,一眼就知。 呢個係Skills由「手作坊」走向「工業化」嘅第一步。 寫Code嘅同行應該最明—— 單元測試出嚟之前,軟件行業靠嘅係「我覺得應該冇問題」。 單元測試出嚟之後,行業先真係可以行到大規模工程。 今日,Skill-creator補返咗Skills嘅「單元測試」。 我極度推薦,所有玩Skills嘅朋友,第一時間將Skill-creator更新到最新版本。 然後將自己之前整過嘅所有Skill,逐個行一次呢套評估流程。 嗰啲你之前懷疑過、感覺唔對路但又講唔出邊度唔對路嘅Skill,問題會自己浮出水面。 要知道,小龍蝦點解咁犀利,並唔係佢本身有幾勁,純粹係因為—— 佢身上掛住嘅Skills實在係太多喇。 每一個都係獨立嘅技能包。 Skills,就係成個Agent未來生態大繁榮嘅基石。 而Anthropic今次,將呢塊基石澆成咗鋼筋混凝土。 Skills生態。 可能又會迎嚟一波大繁榮。 而最先享受到呢波紅利嘅人。 永遠係嗰啲第一時間行動嘅人。  以上,既然睇到呢度,如果覺得唔錯,順手畀個讚、睇嚇、轉發三連啦,如果想第一時間收到推送,都可以畀我一個星標⭐~多謝你睇我嘅文章,我哋,下次再見。
|
前兩天直播完,我順手翻了一眼Anthropic的Skills倉庫。 結果在最新Commit裏,看到一個讓我直接坐直了的更新。 Skill-creator。 那個被我反覆講過無數遍的母Skill,悄咪咪迎來了一波超大更新。 你要知道,小龍蝦現在能這麼能打,本質上一半的功勞得算到Skills頭上。 而所有這些Skills能被造出來,又幾乎都要謝這個Skill-creator。 它就是整個Skills生態的發動機。 之前沒接觸過Skills的朋友,可以先翻一眼這篇,應該是全網講Skills講得最掰碎的一篇之一了。 回到正題。 這周晚上抽了點時間,把這次更新的文檔從頭到尾啃了一遍。 啃完之後我的判斷只有一個——這次更新,等於給整個Skills生態加了一層底座。 之前所有手搓Skill的人,其實都被困在同一個問題裏—— 你做完一個Skill,根本不知道它好不好用。是觸發對了,還是它自己瞎蒙的?寫的描述合不合理?換個上下文還能不能跑? 全是黑盒。 而現在,這層黑盒被Anthropic一把撕了。 我極力推薦,大家先把Skill-creator更到最新版。 更新的方式簡單到離譜,發一句話給你的Agent就行,不管是Claude Code、小龍蝦、還是OpenCode,都一樣:
對,就這麼一句話。 Agent自己會去拉。 幾分鐘之內,更新就跑完了。 這次新版本一口氣加了4個能力:
我看到這份清單的第一反應是—— 這不就是把醫藥行業的雙盲隨機對照試驗那套,原封不動搬到Skills上了嗎? 醫藥行業有個鐵律:一個藥到底有沒有效,光看研發自己嘴上說"有效",沒人理你。 你得設實驗組、設對照組,把研究者和受試者都蒙起來,跑完之後看量化指標,差距大不大才作數。 人類花了一百多年才把這一套打磨乾淨。 而Anthropic這次相當於把同一套,原封不動搬給了Skills——有Skill vs 沒Skill,乾淨環境隔離,並行跑,量化打分。 工業化的本質就是評估。 一旦評估體系立起來,整個東西就從手工作坊跳到流水線了。 理論先到這。 直接上案例。 1. 順手用新版Skill-creator,再搓一個Skill 我之前寫過一篇文章,把GitHub上的yt-dlp封成了一個Skill,能從YouTube、B站、小紅書各種視頻網站扒視頻。 但用了一陣子之後,我自己發現,光把視頻下下來不夠。 我挺多場景其實是這樣的——刷到一個國外的長訪談,我沒耐心一邊看一邊記,我想要的是文字版講稿,最好原文+中文雙語對照排好直接發我。 正好借這次更新,我用新版Skill-creator又搓了一個新Skill。 提示詞巨簡單:
它沒急着開幹。 先反過來問了我幾個問題,確認需求細節,然後才開始設計整個Skill。 3到5分鐘,整個Skill就搭好了。 我拿小龍蝦他爸Peter的一個YouTube訪談來試。 直接把連結扔進去。 5分鐘之後,中文版講稿出來了。 但是。 一大坨文字糊在一起。 字小,行密,看着頭疼。 這時候我沒去手動改它的代碼,直接對着Skill接着對話,讓它再改一版。 新版Skill-creator在迭代改寫這件事上,也有一些提升。 改完之後再跑一遍: 排版清晰,段落分明,標題層級齊了。 這才像個能給人看的文檔。 到這一步,Skill本身算是搓出來了。 但真正的麻煩,才剛開始。 2. 描述調優——治打架最狠的那把刀 我現在手裏有兩個Skill都跟視頻連結掛鈎。 一個是之前的yt-dlp,乾的活是把視頻下到本地。 一個是剛做完的講稿生成,乾的活是把視頻轉文字。 它們的觸發條件都是——"給一個視頻連結"。 那問題就來了。 我丟一個YouTube連結過去,它怎麼知道我到底想下視頻還是想要講稿? 萬一打架了怎麼辦?該觸發的不觸發,不該觸發的亂觸發,那這倆Skill就廢了。 以前這種事我只能自己肉眼盯,每次跑歪了再回去手動改描述,純粹的體力活。 而新版Skill-creator,直接把這個流程接管了。 讓它優化Skill描述,它會先把當前的描述讀一遍,然後告訴你接下來要做的4件事: 最有意思的是第一步:它會自動生成兩組查詢。 一組叫"應該觸發的10條",一組叫"不應該觸發的10條"。 這個設計我細品了一下。 它故意把模糊地帶的邊界情況都擺進去——不是那種一眼就該觸發的簡單句,而是那種"嗯?這個到底算不算?"的灰色地帶。 逼着模型在最難的地方做判斷。 跟搞算法面試題一個意思——簡單題篩不出強弱,hard題才行。 生成完之後,它直接彈一個網頁讓你確認。 我第一次看到的時候,是真有點驚。 20條查詢整整齊齊排在網頁裏,每條右邊一個開關,標着"是否應該觸發"。 你逐條掃一遍,發現哪條判斷不對勁,直接把開關翻一下。 打個比方,第三條這種情況,我不想讓它再觸發,我就直接關掉。 不應該觸發的10條我也掃了一眼,整體沒問題。 全部確認完,點"導出評估集",結束。 接下來才是好戲。 後台啓動優化循環,最多跑5輪迭代,每輪幹三件事,整個過程大約10到20分鐘。 它會定期彙報進度。 跑完之後,會出一個巨大的表格: 每一列是一個查詢樣本,每一行是一個迭代版本的描述。 綠色對勾代表觸發對了,紅色叉代表沒觸發或者錯觸發。 藍色那列是測試集,其餘是訓練集。 它把20個樣本拆成60%訓練 + 40%測試,在訓練集上反覆調描述,最後用測試集驗證收斂效果。 這是機器學習裏防過擬合的標準做法。 跑完之後,最優描述會自動寫回SKILL.md,整個過程你不用動一根手指頭。 Anthropic自己在6個文檔類Skill上做了對照——5個的觸發率都被這套流程刷上去了。 僅僅是描述調一調而已。 這一步走完,你的Skill觸發準確率能上一個台階。 3. 觸發對了,只是入場券 真正幹起活來效果好不好,還得另測。 接着對剛做的講稿生成Skill開一次評估。 它會先把整個Skill文件啃一遍,搞清楚這玩意兒的核心流程是啥。 然後彈一個選項給你:你想測哪個方面? 我選了"全面評估"。 它根據Skill功能,自動設計了三類測試場景,每個場景都配了量化驗收標準。 確認方案之後,它一口氣並行啓動了4個獨立子代理同時跑。 這一步——我必須單獨拎出來誇。 以前你也能自己手工做點簡單評估,但有個致命問題:所有測試只能串行跑。 一個跑完再跑下一個。 大家都懂上下文管理多重要。前一個任務積累的上下文,會污染後一個的結果。 你看到Skill"通過"了,可能根本不是Skill的功勞,是上一輪對話歷史給搭好了梯子。 但你看不出來。 因為黑盒裏沒光。 新版本直接換成4個並行Agent。 每個Agent在完全乾淨的環境裏跑,自己的token計數、自己的耗時,互相之間零交叉。 更快,更乾淨,更可信。 等待跑的過程裏,它順手把量化評分腳本也準備好了。 測試跑完,瀏覽器自動彈出評估頁面,兩個標籤。 輸出標籤頁——每個測試用例的完整輸出。 下面掛一個反饋框,哪裏不對、哪裏要改,你直接標。 這些標註會被存起來,下次改Skill的時候,直接當輸入用。 基準測試標籤頁——有Skill vs 沒Skill的量化對比。 數據這塊極度量化。 有Skill的通過率100%,沒Skill的基線9%,差值91.5%。 費用上:有Skill每次大概4000 token,沒Skill 1750 token,多花了2250。 這是Skill帶來的額外開銷。 但對比產出,劃得着。 4. 評估的真正價值,是閉着眼也能修Bug 評估的意義,遠遠不止"打個分"這麼簡單。 Anthropic自己舉了個例子。 他們有一個PDF Skill,處理表格的時候老出錯。Claude要把文字塞到指定座標,但因為缺少明確的字段引導,經常放歪。 這種bug,靠肉眼測一輩子可能都測不出來。 跑了一遍評估之後,問題被定位了。 改了定位邏輯,bug就關了。 而且——發現問題之後不用從頭來過。 評估結果會存在本地,下次你拿Skill-creator改這個Skill的時候,它直接把上次標註過的問題帶進去,針對性地改。 改完再跑一遍評估,看分數有沒有提升。 測試 → 發現 → 改 → 再測。 這一整套循環,是完整的。 Anthropic相當於把軟件工程裏那一套最嚴謹的實踐——單元測試、基準測試、迭代改進、迴歸驗證——一股腦挪到了Skills的創作流程裏。 軟件工程花了幾十年才把這一套打磨成今天的樣子。 Skills生態滿打滿算才出來幾個月。 直接跳級。 5. 順便聊一下:你的Skill是哪種? 如果你打算把自己手裏所有Skills都重新優化跑一遍,得先分清楚一件事—— 你寫的這個Skill,到底是哪種? 本質上,Skills只有兩種。 第一種:能力提升型。 教Claude做它本來不擅長的事。 比如官方的前端設計Skill、文檔創建Skill,裏頭塞了大量小技巧——你光靠Prompt根本調不出來這種效果。 我們大多數人自己搓的Skill,基本都是這一類。 第二種,官方叫"編碼偏好型",我習慣叫它"流程封裝型"。 意思是告訴Claude按你的規矩走。 Claude本身每一步都能做,但你把這些步驟按你團隊/你個人的流程串了起來。 比如一個會議紀要Skill,按你們公司固定格式,把錄音轉成帶行動項的文檔。 比如一個週報Skill,從各個平台拉數據,按你的固定模板排好。 這種Skill的本質,就是一個工作流(Workflow)。 為啥要分這兩種? 因為評估方向不一樣。 能力提升型測的是——這個Skill還有沒有存在的必要。 用A/B對比,有Skill跑一次,沒Skill跑一次。 如果差不多,這個Skill就該退休了。 模型每升一代,都會有一堆能力提升型的Skill被自然淘汰。 這是健康的。 流程封裝型測的是另一件事——它有沒有老老實實按你的流程走? 有沒有漏步驟?有沒有自作主張換了順序?有沒有忘了你特別交代過的那個細節? 差別挺大。 下次自己測的時候,注意分一下。 寫在最後 寫到這兒,我自己也想嘆一口氣。 以前造完一個Skill,純粹靠"自我感覺良好"。 跑兩個case看着還行,就覺得完事了。 但說實話,全是黑盒。 到底好不好用,質量怎麼樣,觸發率多少,跨場景穩不穩定,我根本不知道。 現在不一樣了。 評估跑一遍,數據擺出來,好不好用,一眼見真章。 這是Skills從"手作坊"走向"工業化"的第一步。 寫代碼的同行應該最有感觸—— 單元測試出來之前,軟件行業靠的是"我覺得應該沒問題"。 單元測試出來之後,行業才真正能跑大規模工程。 今天,Skill-creator補上了Skills的"單元測試"。 我極度推薦,所有玩Skills的朋友,第一時間把Skill-creator更新到最新版。 然後把自己之前搓過的所有Skill,挨個跑一遍這套評估流程。 那些你之前懷疑過的、感覺不對勁但又說不出哪裏不對勁的Skill,問題會自己浮出水面。 要知道,小龍蝦為什麼這麼能打,並不是它本身有多牛逼,純粹是因為—— 它身上掛的Skills實在是太多了。 每一個都是一個獨立技能包。 Skills,就是整個Agent未來生態大繁榮的基石。 而Anthropic這次,把這塊基石澆成了鋼筋混凝土。 Skills生態。 可能又要迎來一波大繁榮了。 而最先享受到這波紅利的人。 永遠是那些第一時間動手的人。 以上,既然看到這裏了,如果覺得不錯,隨手點個贊、在看、轉發三連吧,如果想第一時間收到推送,也可以給我個星標⭐~謝謝你看我的文章,我們,下次再見。
|