Skill 最佳實踐:五種設計模式+六步打磨法(含完整實戰過程和源碼)
整理版優先睇
Skill 開發嘅核心係灌入團隊內部知識,而唔係靠提示詞技巧。
呢篇文章出自一位叫熊貓 Jay 嘅開發者,佢因為一次用 AI 做售前工時估算時,兩次結果差成倍(157 vs 71人天),差啲令公司蝕錢。佢被銷售同客戶催到炆,決定做一套系統化嘅 Skill 嚟告別呢種混亂。
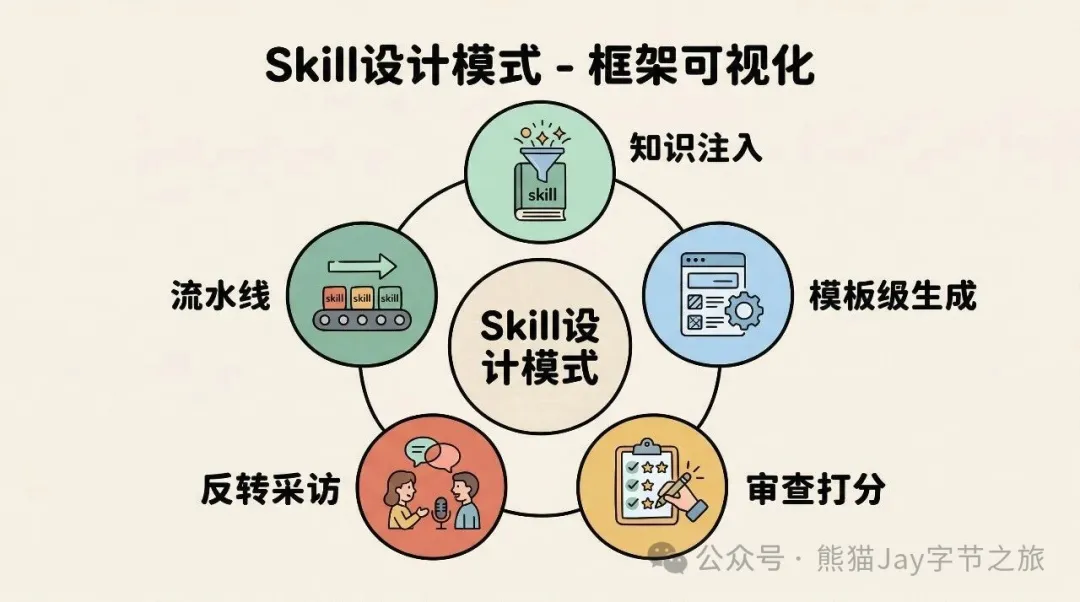
文章先介紹 Google 總結嘅五種 Skill 設計模式:知識注入型(將專業知識打包成 references)、模板生成型(固定輸出格式)、審查打分型(按清單檢查)、反轉採訪型(先問清楚再做)、流水線型(分階段執行)。作者指出呢啲模式可以組合使用,而唔係互斥。
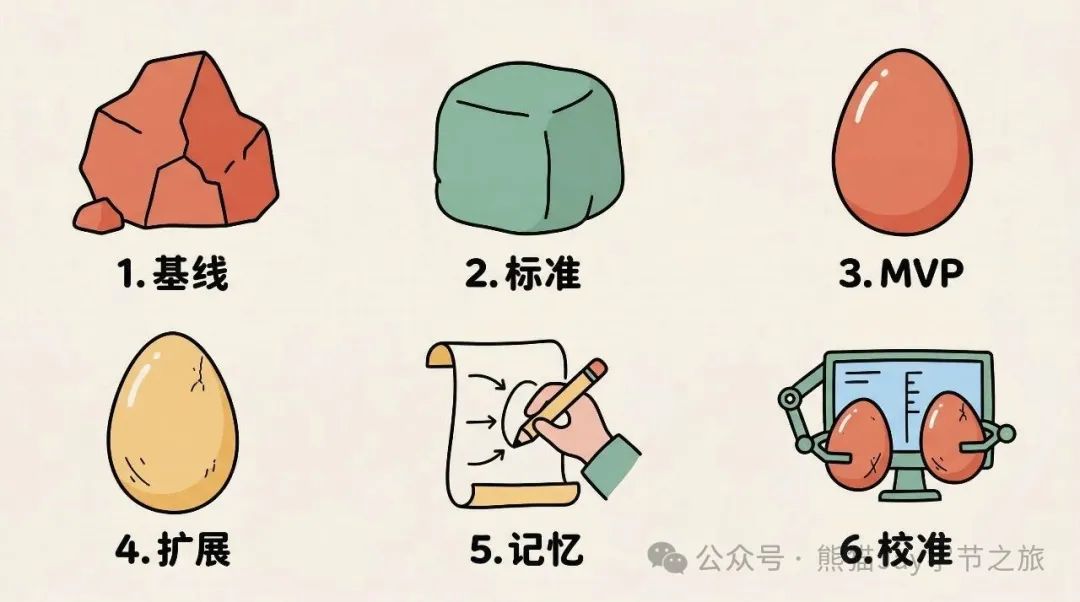
之後作者提出一套「評測驅動」嘅六步打磨法:先建立基線(直接裸跑 AI 睇下錯咩)、定義驗收標準、寫 MVP 版本、逐步擴展(每加一條規則都要對應一個測試)、加上記憶同自檢、上線後持續校準。成個方法論嘅核心係「讓失敗告訴你該寫咩」,而唔係硬估。
- 五種設計模式(知識注入、模板生成、審查打分、反轉採訪、流水線)可以按需組合,流水線做主骨架,其他模式嵌入關鍵環節。
- 六步打磨法核心係「評測驅動」:先用基線暴露問題,再定義驗收標準,寫 MVP 逐個解決,唔好一次過加好多規則。
- 成功嘅 Skill 唔係靠提示詞技巧,而係靠灌入 AI 永遠估唔到嘅團隊內部知識,例如模塊地圖、踩坑規則、員工能力矩陣。
- 實戰案例中,售前工時 Skill 將需求拆成四步流水線(分析→開發文檔→匹配資源→輸出報告),並嵌入子 Skill 同 references,最終穩定輸出兼自動生成 Word。
- 作者提醒:每加一條新規則都要對應一個測試用例,唔好盲目堆積;上線後要持續觀察誤觸發、漏文件等信號,形成閉環改進。
售前工時評估 Skill 源碼
完整嘅 Skill 源碼開源喺 GitHub,包含 SKILL.md 同相關 references 檔案。
開頭故事同五種 Skill 設計模式
作者開頭分享一個親身經歷:用 AI 做售前工時估算,兩次結果差成倍(157 vs 71人天),差啲令公司蝕錢。呢件事促使佢決心開發一套系統化嘅 Skill,杜絕呢種唔穩定嘅情況。
- 1 知識注入型(Tool Wrapper):將專業經驗包成 references 文件,解決 AI 通用知識唔夠精準嘅問題。
- 2 模板生成型(Generator):喺 assets/ 放輸出模板,解決輸出格式唔一致嘅問題。
- 3 審查打分型(Reviewer):將檢查清單放 references,定義審查流程,適合需要按固定標準評估嘅場景。
- 4 反轉採訪型(Inversion):反轉交互方向,等 AI 先問清楚至動手,避免信息不足下亂做。
- 5 流水線型(Pipeline):將任務拆成嚴格階段,每步有輸入輸出同檢查點,適合步驟多、唔可以跳步嘅複雜任務。
最簡單嘅模式係知識注入型,任何 Markdown 檔案都得,完全冇編程門檻。
反轉採訪型喺實際使用中被嚴重低估,大多數 Skill 失敗嘅原因就係 AI 喺信息不全下直接執行。
六步打磨法:評測驅動嘅系統化方法
作者提出「評測驅動」嘅打磨方法,核心係「唔好估 Skill 該寫咩,讓失敗話畀你知該寫咩」。方法共六步,每一步都針對實際問題。
- 1 建立基線:直接叫 Claude 或 DeepSeek 裸跑任務,記錄邊啲環節唔穩定、邊啲輸入會理解錯、邊度自作聰明。
- 2 定義驗收標準:按基線發現嘅問題設計 3-5 個測試用例,每個有明確通過/失敗標準。
- 3 寫最小版本(MVP):先寫誤觸發場景做防線,定義最短成功路徑,保持單一職責。
- 4 通過測試後逐步擴展:補充邊界場景、格式定義、示例,每加一條規則都要有測試支撐。
- 5 加記憶同驗收標準:用日誌檔案記錄執行結果,令 Skill 知道上次做咗咩;寫明成功/失敗標準等 AI 自檢。
- 6 上線後持續校準:觀察誤觸發、漏文件、重複讀取等信號,發現新問題就返去第二步補測試用例。
呢個打磨過程建議先用 Claude Code 執行,因為執行過程透明,睇到 AI 每一步讀咩檔案、卡喺邊度。
五分鐘測試:如果 DeepSeek 可以喺 5 分鐘內穩定輸出結果,大概唔需要寫 Skill;否則就係 Skill 嘅切入點。
實戰案例:售前工時評估 Skill 嘅完整開發過程
作者用自己嘅真實案例將六步法具體演繹一次。場景係售前工時評估,經常被催到 '奪命連環催',以前要成日熬通宵。
- 1 定義四條驗收標準:需求分析要關聯真實模塊、人員要出真實姓名同技能等級、工時要有代碼層面依據、報告結構固定七章。
- 2 MVP 版本:寫一個 SKILL.md 鎖死四步流程(需求分析→開發文檔→匹配資源→輸出報告)同七章模板,解決格式問題。
- 3 注入內部知識:將系統模塊地圖(module-structure.md)同影響範圍規則庫(impact_rules.md)放入 references,令 AI 識別需求牽涉邊個模塊、有咩坑。
- 4 補充員工能力矩陣:將員工嘅角色、技能等級、負責模塊整理成 employee-data.md,並封裝成子 Skill,令 AI 可以精準匹配人員。
- 5 加入代碼掃描步驟:令 AI 搜尋涉及模塊嘅源碼,分析現有代碼可複用程度,令工時估算有實質依據。
關鍵一步係將模塊地圖同規則庫抽成獨立子 Skill,因為呢啲能力之後可以複用,唔只係為工時評估而設。
作者仲製作咗一個 Word 生成腳本(generate_word_report.py),確保每次輸出排版一致,唔使 AI 自由發揮。
最後,Skill 上線後持續校準,發現新問題(例如客戶需求太簡略時 AI 會腦補),就補返約束「信息不足先列待確認項,唔好自行補全」。最終對比好明顯:冇 Skill 要半日至幾日、格式唔同、人員亂編、工時拍腦袋;有 Skill 只需 10-15 分鐘、七章固定、精準匹配、工時有代碼依據。
整個過程中最值錢嘅唔係流程或模板,而係模塊地圖、踩坑規則庫、員工能力矩陣——呢啲 AI 永遠估唔到嘅內部知識。
開源同總結:越早開始,複利越大
作者將售前工時評估嘅完整 Skill 源碼開源喺 GitHub(連結見 resources),希望幫到遇到類似問題嘅人。佢強調 Skill 填嘅唔係技術嘅坑,而係「理解」嘅坑。你教畀 AI 嘅每一條規則,都喺度縮緊「佢做到嘅」同「你想要嘅」之間嘅距離。
最後,作者叫大家幫手點讚、轉發、關注,並預告往期精選文章,包括 Claude Code、MCP、Skills 全套教程,同埋 10 個 AI 編程技巧。
我用 AI 差點讓公司虧了一個項目。
事情是這樣的:客戶着急要一份軟件需求的工時報價,銷售一個小時催了我三遍。
我人都被催麻了,差點想罵人。
於是,我讓 AI 快速跑了兩遍,一次 157 人天,一次 71 人天。
差了一倍。
後來我仔細看了下,如果拿着 71 人天的結果去報價,項目鐵定虧。
真的,不禁後背發涼。
這次,我先安撫住客戶和銷售,決定做一套 Skill 出來,告別這種奪命連環催的狀態。
最後,同樣的需求,每次跑出來的結果穩定、資源真實、格式統一,而且只需要 10 分鐘。
今天,我把這套方法論和完整源碼開源出來(見文末)。
一、五種常見的 Skill 設計模式
在講方法論之前,我們先來了解下 Google 總結出的五種常見 Skill 設計模式。
我在自己的實踐中也驗證了這幾種模式的有效性,這裏結合我的理解,做一個拆解。
模式一:知識注入型(Tool Wrapper)
解決什麼問題:AI 的通用知識不夠精準,需要注入「只有你知道的」專業知識。
核心思路:把你的專業經驗打包成 references 文件,AI 在需要時自動加載,按你的標準來做事。
舉個例子:
你讓 AI 幫你寫小紅書文案,但它寫出來的風格總是不對:要麼太正式,要麼太浮誇。
你可以把自己過去點贊量最高的 10 篇文案放進 references/,再在 SKILL.md 裏寫「模仿這些文案的風格」,AI 就會照着你的調性來寫。
實際的 SKILL.md 長什麼樣?
就是一個 Markdown 文件,沒有任何編程門檻。這是最簡單的模式,適合入門練手。
模式二:模板生成型(Generator)
解決什麼問題:AI 每次生成的輸出格式不一致,結構飄忽不定。
核心思路:在 assets/ 裏放一個輸出模板,讓 AI 按模板結構往裏填內容,而不是自由發揮。
舉個例子:
你每天要寫日報,格式固定:今日完成 / 明日計劃 / 阻塞項。
每次讓 AI 寫,格式都不一樣。
那我們可以放一個日報模板進去,讓 AI 做填空題,這樣,輸出會穩定得多。
同樣的思路,可以用在技術報告、項目週報、產品需求文檔,以及任何有固定格式要求的重複性產出。
注意,模板越具體越好。別寫 “請生成報告”,而是給出每個章節的標題和填寫要求。
模式三:審查打分型(Reviewer)
解決什麼問題:你需要 AI 按照一套固定標準去檢查、評估某個東西。
核心思路:把檢查清單放在 references/ 裏,SKILL.md 定義審查流程:加載清單 → 逐項檢查 → 按嚴重程度分類 → 輸出結構化報告。
舉個例子:
你寫完一篇公眾號文章,想讓 AI 幫你檢查:
我們可以把這些檢查項做成 checklist 放進去,AI 就變成了你的私人編輯。
這個模式最靈活的地方在於:換一份 checklist,就變成完全不同的審查工具。同樣的骨架,放代碼規範進去就是代碼審查,放安全標準進去就是漏洞掃描。
關鍵要求 AI 不只說 “這裏有問題”,還要說 “為什麼是問題” 和 “怎麼改”。
模式四:反轉採訪型(Inversion)
解決什麼問題:AI 總是在信息不足的情況下急着動手,結果做出來的東西和你想要的偏差很大。
核心思路:翻轉交互方向——不是你提需求 AI 馬上執行,而是 AI 先當採訪者,問清楚再動手。
舉個例子:
你說「幫我規劃一個日本旅行」,AI 二話不說就給你列了 7 天行程。
但它不知道你只有 5 天假、預算有限、帶着老人不能暴走、而且最想去的是温泉不是東京。
如果 Skill 要求 AI 先問:去幾天?預算多少?同行人是誰?有沒有必去的地方?
問完再規劃,結果好幾倍。
看起來多了一輪對話,實際上省了後面反覆返工的時間。
這個模式在實際使用中被嚴重低估了。
大多數 Skill 失敗的原因不是流程寫得不好,而是 AI 在 信息不全 的情況下就直接開始執行了。

模式五:流水線型(Pipeline)
解決什麼問題:任務複雜、步驟多,AI 容易跳步或遺漏關鍵環節。
核心思路:把任務拆成嚴格的階段,每個階段有明確的輸入、輸出和檢查點。上一步沒通過驗證,不允許進入下一步。
舉個例子:
你用 AI 寫公眾號文章的完整流程:先確定選題方向 → 列大綱讓你確認 → 寫初稿 → 自檢(標題吸引力、開頭鈎子、排版規範)→ 生成終稿。
如果你沒確認大綱,AI 不能開始寫正文;如果自檢沒通過,不能輸出終稿。
每一步之間有明確的「關卡」。
這是最重型的模式,只在任務確實複雜時使用,簡單任務不要過度設計。
怎麼選?一個簡單的決策樹:
最後一個重要提醒:這五種模式不是互斥的,它們完全可以組合。
一個流水線型的 Skill 可以在第一步用反轉模式收集需求,在最後一步用審查模式做質量檢查。
記得設計 Skill 的時候,先確定主模式,再看是否需要在某個環節嵌入其他模式。
二、進階:如何系統化地打磨一個 Skill
我想說:“能用”和“好用” 的 Skill 之間,隔着一道巨大的鴻溝。
很多人寫完 Skill 之後的做法是:跑一遍,效果不好,就憑直覺改幾句描述、加幾條約束,再跑一遍……
如此反覆,改了十幾版,也說不清楚到底是變好了還是變差了。
問題出在哪?
沒有參照物,也沒有衡量標準。
下面我介紹一套「評測驅動」的打磨方法論。核心思路是:不要猜 Skill 該寫什麼,讓失敗告訴你該寫什麼。
第一步:建立基線,發現問題
在寫任何 Skill 之前,可以考慮先讓 DeepSeek、Claude 直接做一遍你需要完成的任務。
這一步的目的是為了發現問題:就像醫生開藥之前先做體檢,你得先知道"病"在哪。
重點觀察三件事:
把這些問題一條條記下來,這就是你的 Skill 需要解決的真實缺口,也是後面所有測試用例的來源。

這裏有一個簡單的判斷標準,大家習慣叫它「五分鐘測試」:
如果 DeepSeek 就能在 5 分鐘內給出穩定的結果,你大概率不需要為這件事寫 Skill;
如果 5 分鐘內搞不定、或者結果時好時壞,那才是 Skill 真正的切入點。

第二步:定義驗收標準
這一步反直覺,但非常關鍵。大多數人的做法是:先寫 Skill → 然後想怎麼測試。
但正確的順序是反過來:先定義「什麼算做對了」,再寫 Skill 去達標。
具體做法:
為什麼要這麼做?
因為沒有測試約束的 Skill,本質上是在放大 AI 行為的不確定性。
你加的每一條規則,如果不知道它在解決什麼問題,就可能會繼續製造新的問題。

第三步:寫最小版本的 Skill
現在才開始寫 Skill。
但注意,不要試圖一次覆蓋所有情況,寫能通過測試標準的 MVP 版本。
重點做三件事:
這個階段的 Skill 會很簡陋,但它是有針對性的。
每一條規則都是在回應一個真實的失敗案例,而不是憑經驗預判。

第四步:通過測試後,再逐步擴展
最短路徑跑通了,再一點點增加覆蓋範圍:
核心紀律:每增加一條新規則,都必須對應一個測試用例。 沒有測試支撐就加規則,等於在 Skill 裏埋盲區。
同樣重要的是知道什麼時候該停。
規則太多反而會讓 AI 行為變得不可預測——它在多條指令之間糾結,結果哪條都執行不好。如果你的 Skill 已經穩定通過所有測試,就別再往裏塞東西了。
第五步:給 Skill 加上記憶和驗收標準
當 Skill 的核心邏輯穩定之後,補上兩個讓它從「能用」變成「好用」的東西:
記憶:在 Skill 目錄下放一個日誌文件,每次執行完追加記錄,下次執行前先讀。
這讓 Skill 知道上次做了什麼,避免重複產出。
哪怕只是一個簡單的文本文件,效果也天差地別。
但注意不要把記憶文件寫成流水賬。
長期記憶是有 token 上限的,只記錄反覆出現的模式和真正重要的經驗,不要什麼都往裏塞。
驗收標準:明確寫出什麼算成功、什麼算失敗。
這不只是給你看的,也是給 AI 看的。AI 可以用這些標準做自檢,在提交最終結果前先自查一遍。
第六步:上線後持續校準
測試用例只能覆蓋你已知的問題,但是,真實場景中一定會冒出新的情況。
Skill 上線後,重點觀察這幾個信號:
每發現一個新問題,就回到第二步,補一個測試用例,再改 Skill。
這是一個持續轉動的閉環,不是一次性工程。
如果要在龍蝦裏使用 Skill,一個建議:這六步的打磨過程,建議先在 Claude Code 裏完成。
Claude Code 的執行過程是透明的,你能看見 AI 每一步讀了什麼文件、調了什麼工具、在哪個環節卡住了。
因為 OpenClaw 封裝更深,Skill 跑不好時,你分不清是 Skill 的問題還是環境的問題。
在 Claude Code 裏調到滿意,再交給 OpenClaw 穩定運行。
三、實戰案例:售前工時評估 Skill
前面講了方法論,可能還是有點抽象。這裏用我自己的一個真實案例,把六步串一遍。
場景其實開頭已經介紹過了。這裏給大家再感受下那種緊迫感:
PS:1個小時內,奪命三連催。
這種場景不是第一次了。售前評估幾乎永遠是急活。客戶催銷售,銷售催你,每次都是熬大夜,熬出來的。
流程每次都一樣:拆需求 → 匹配人 → 算工時 → 套模板。
流程固定、輸入不同、反覆發生,這就是 Skill 該乾的事。
所以,這件事,已經到了讓我非做不可的地步了。

第一步:建立基線,發現問題
我沒有一上來就寫 Skill。先讓扔給 Claude 測試一下,把客戶需求原文扔給它,說「幫我出一份工時評估報告」。
結果能出來,但問題一堆:

我發現 Claude 需求分析太泛,不瞭解我們的模塊結構和技術棧,分析全是正確的廢話。
而且,它也不知道團隊有誰、誰擅長什麼,給了一堆角色,但是有些角色我們甚至沒有。
後來我嘗試生成兩次後,發現每次格式都不一樣:無論是樣式,還是內容框架。

最可怕的是兩次的人天相差巨大,幾乎翻了一倍。第一次 157 人天,第二次 71 人天。

後來我基於 Skill 生成的版本和裸跑版本做了對比,內部認真分析了一下。
如果一不小心拿到第二次的人天,項目得虧麻了。
總結下來就是 6 個字:有框架,沒質量。

第二步:定義驗收標準
把基線建立時暴露的四個問題,翻譯成驗收標準:
後面每改一版,都用同一段需求跑一遍,對着這四條逐項檢查。
不用複雜的測試框架,手動過一遍就行,但有了「通過/不通過」標準,改起來就不是盲調了。
當然這裏也可以做一個自動檢查報告的 Skill,把這些驗證標準寫進去,讓 AI 自動運行。
第三步:MVP 版本 Skill
第一版就是一個 SKILL.md:
它只做了兩件事:
1)鎖死工作流程:
把評估拆成四步流水線:需求分析 → 生成開發文檔 → 匹配資源 → 輸出報告。
每步的輸入輸出寫清楚,嚴格按照預定的步驟執行。
2)定輸出模板:
七章報告模板寫死在 SKILL.md 裏,按模板填內容,不允許 AI 自由發揮。
驗證標準第 4 條立刻通過。但前三條還是不行:AI 依然在造數據。
沒關係,最小版本的目標不是滿分,先完成再完美。
第四步:補充 AI 不知道的上下文
骨架確定後,該解決 AI 造數據的問題了。
這時候我發現:要補充的資料其實早就有了。
員工能力矩陣、模塊結構文檔、踩坑規則庫,都是過去管理中沉澱下來的,只是每次都想不起來要餵給 AI。
PS:主要還是太繁瑣,文件分散在各地,搜索成本太高。
1、內部知識注入(解決「分析太泛」)
最開始測試時,AI 的需求分析為什麼只是浮於表面?
因為它只看到客戶那段話,不知道在我們系統裏會牽動哪些模塊、踩到哪些坑。
那麼接下來,我給它灌輸內部知識。
但我沒有把這些所有資料直接塞進主 Skill。“需求轉開發文檔”這個步驟,未來一定會單獨使用。
不是每次都可能出現「評估工時」這個場景,有時候,內部的簡單需求也需要變成結構化的開發任務。
所以我把它抽成了獨立的子 Skill req-to-dev-doc,主 Skill 調用它,其他場景直接複用。
寫 Skill 時多想一步:這個能力是隻服務當前流程,還是本身就有獨立價值?
如果是後者,拆出來,未來你會感謝自己的。

主 Skill:
需求轉開發文檔 Skill:
我解讀下,這次優化,我將兩份關鍵文檔放進 req-to-dev-doc 的 references 裏:
1)系統模塊地圖(module-structure.md):
這份文檔就像一張寶藏地圖,包含系統幾十個模塊的基礎介紹、相關對象實體、各個模塊之間的依賴關係、變更風險和紅線。
我挑了一個脱敏簡化後,且大家熟知的“定時任務”模塊給大家看下:
這份文檔,除了幫助 AI 快速建立業務認知之外,也能有效地防止 AI 犯一些基本的錯誤。
比如你改了A模塊,它會告訴你要同步檢查 B、C、D模塊。
並且會禁止你做一些內部總結提到的危險操作。
這些事情,交給 AI 是猜不出來的。
2)影響範圍規則庫(impact_rules.md):
前面的模塊地圖,解決了“需求落在哪裏?怎麼避免犯錯?”
而這份規則庫,則解決了”容易漏做什麼?怎麼按照有效路徑排查問題?”
團隊踩坑沉澱的規則,分三層:
有了這兩份資料,AI 不再泛泛地寫“可能影響其他模塊”。
而是相對精確命中規則:”命中 L0-7(歷史數據兼容)、L1-9(數據結構腳本)“,逐條列出必查項和迴歸清單。

這樣拆得越細,後面估工時越準。
備註:這個規則庫也不是一成不變的,我還設計了一個 FAQ Skill 來反哺規則庫,這樣團隊運轉中高頻發生的問題和總結,就會自動落到規則中,形成高效閉環。
小結一下,這一步的本質就是:用內部知識把模糊的客戶需求,翻譯成精確的開發任務。
2、補充「員工能力矩陣」(解決「資源虛構」)
這次,我把團隊所有人的角色、技能等級整理成 employee-data.md。
考慮到匹配資源在未來也可能被複用,所以單獨封裝了一個 Skill:/dev-doc-match-resource。並且在主 Skill 中調用它。
主 Skill:
資源匹配 Skill:
但第一版只寫了角色和等級,AI 匹配還是不夠精準:不知道誰熟悉哪個具體模塊。
於是迭代中,我又補了一列「業務領域」,精確到每個人熟悉的業務模塊。
補完後,AI 輸出的不再是「高級開發 1 名,QA 1 名」。
而是「小明(精通系統底層/導入中心)負責核心引擎,小李(熟悉化工模塊)負責業務適配」。
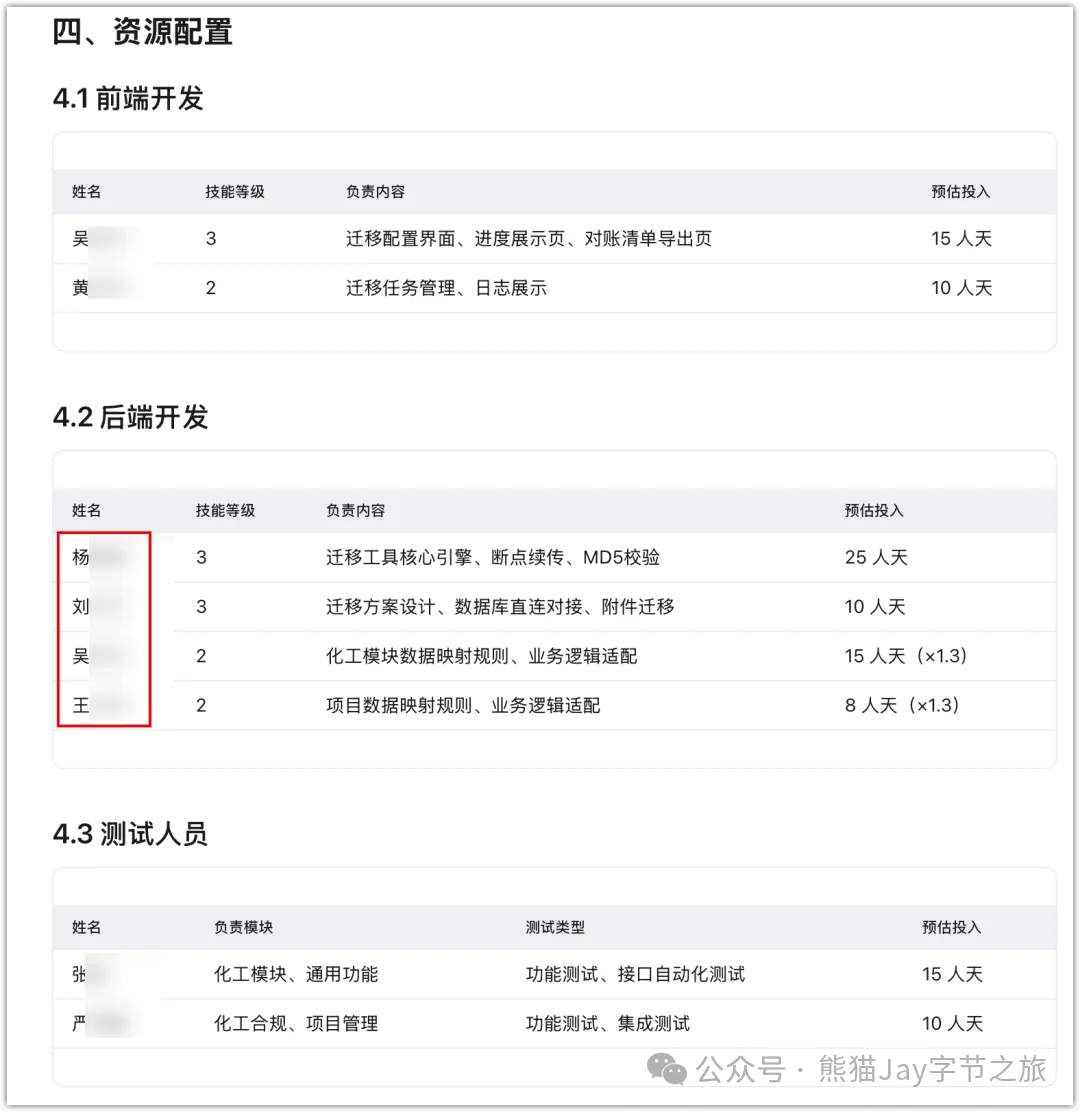
驗證標準第 2 條通過。
如下是我整理的一份模板,大家需要可以自取:
補充能力矩陣,有兩個重要的作用:

3、基於項目代碼掃描
我認為這是非常關鍵的一次優化。
和普通 AI 聊天工具最大的區別在於:它是基於我的項目代碼本身進行評估的。
從而讓 AI 搜索需求涉及的模塊,思考:
「能複用多少」和「要增加多少」都寫進報告,這樣工時終於有了更可靠的代碼層面的依據。
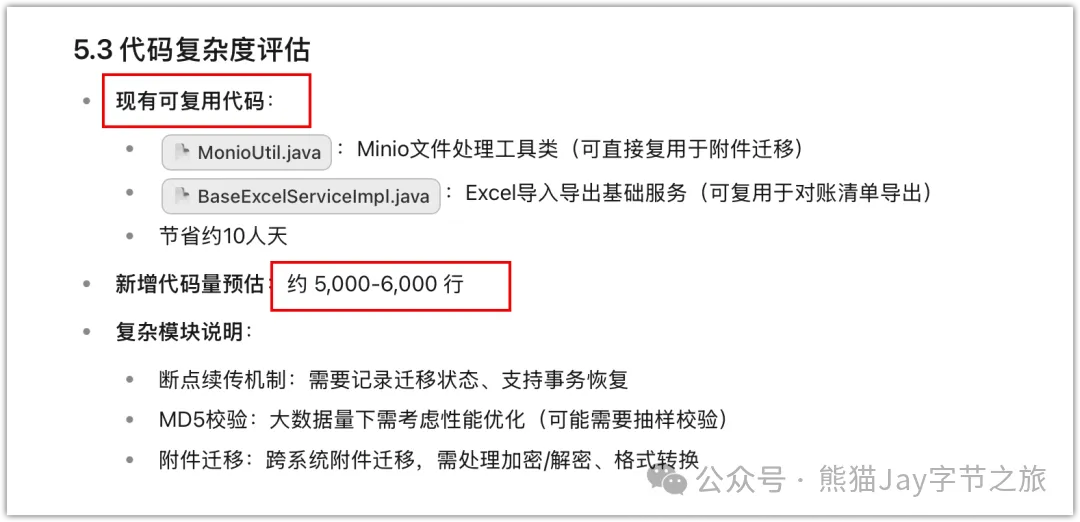
驗證標準第 3 條通過。
到這裏,四條驗證標準全部通過。

第五步:加驗收標準和腳本
1、驗收標準寫進 Skill
SKILL.md 末尾加了自檢清單,AI 輸出前先自查:結構、數據的一致性、風險是否預留了。
如果自檢不過就自動修改,不用我再次指揮 AI 進行返工。
2、加了 Word 生成腳本
基本上,客戶要 Word,不是 Markdown。
每次讓 AI 轉格式,排版都不一樣,這種確定性任務不該讓 AI 自由發揮。
所以我讓 AI 寫了一個 generate_word_report.py 放 scripts/ 裏,AI 填數據,腳本管排版,從此每次都一樣。

第六步:上線後持續校準
後續又跑了幾個需求,發現新問題:客戶需求描述太簡略時,AI 會「腦補」過度,生成客戶沒提的功能。
補了一條約束:「如果原始需求信息不足,先列待確認項,不要自行補全」
下一步,我打算把過去項目計劃的信息收集一下。
這樣每個項目的預估工時和實際工時都有了,再讓 AI 進行「類比估算」,基於歷史項目計劃數據推算結果將更加準確。
最終效果對比
回看整個過程,完美對應六步打磨法:
沒有一步到位,每一次改動都是在回應一次失敗。
這就是「評測驅動」的核心:不要猜該寫什麼,先發現問題,讓它告訴你該寫什麼。
整個過程中最值錢的,不是流程,不是模板。
而是那些「只有我們團隊知道」的經驗和規則:模塊地圖、踩坑規則庫、員工能力矩陣。
這恰恰印證了前面的原則:提供 AI 不知道的上下文。
對照五種設計模式,這個 Skill 不是單一模式,而是四種模式的組合:
| 流水線型 | |
| 知識注入型 | |
| 模板生成型 | |
| 審查打分型 |
五種模式不是互斥的,而是可以組合的。
先用流水線定骨架,在關鍵環節嵌入知識注入、模板生成和審查打分,各司其職。
這可能是我發現的最好用的 Skill 開發路徑了。
四、Skill 開源
我將工時評估的完整 Skill 源碼開源了。
如果覺得有用,記得幫我點個Star,感謝~
五、寫在最後
還記得開頭那組數字嗎?157 vs 71。
差距不是因為 AI 不行,而是沒人告訴它該怎麼做。
模塊地圖、踩坑規則、團隊能力矩陣。這些 AI 永遠猜不到的東西,才是 Skill 真正值錢的部分。

Skill 填的不是技術的坑,是「理解」的坑。
你教給 AI 的每一條規則,都在縮小「它能做的」和「你想要的」之間的距離。
總之,這件事,越早開始,複利越大。
謝謝你看我的文章,如果覺得不錯,幫忙點贊、轉發、關注三連吧~
我是 🐼熊貓 Jay,我們下次再見~
往期精選:
最適合新手的 Claude Code、MCP、Skills 全套教程
從混亂到可控:我最受益的 10 個 AI 編程技巧(含提示詞)