Skill結合哩布哩布LibTV,輕鬆做出AI實機視頻!
整理版優先睇
AI實機視頻製作全攻略:用Skill+LibTV一句話生成完整分鏡與視頻
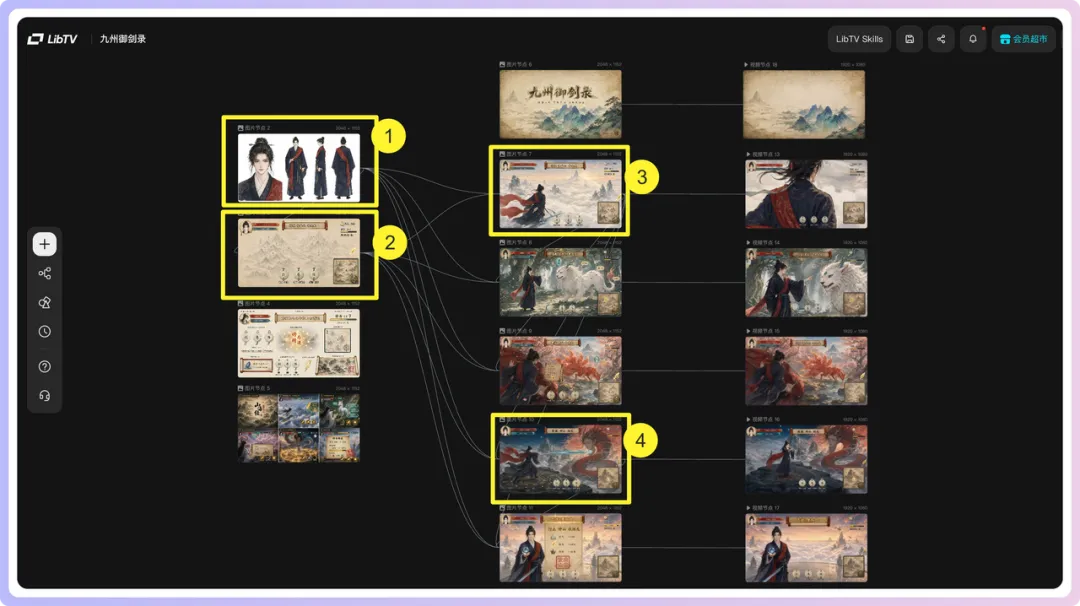
呢篇文章係由阿真分享,佢成日玩AI視頻生成,之前已經公開過兩個Skill,今次終於公開咗打碼嘅第三個——「ai-gameplay-pack」。呢個Skill嘅目的係幫用戶將一個角色或者一個點子,自動變成一套完整嘅實機遊戲演示視頻提示詞包,解決咗以往角色唔一致、UI亂咁變、鏡頭唔連貫嘅問題。
作者強調,與其逐張圖逐段片亂咁生成,不如先用Skill梳理好創作流程(角色、UI、鏡頭、時間軸),然後再喺LibTV工作台連線合成,咁樣先係高效產出高質短片嘅方法。佢仲展示咗手動同Agent自動化兩種玩法,最終出片效果統一又有遊戲感。成個結論係:只要提示詞包到位,任何人都可以快速做出似模似樣嘅AI實機影片。
- AI實機視頻製作可以透過Skill+LibTV工作流大幅簡化,從一句話到成片僅需幾步。
- 使用ai-gameplay-pack Skill生成完整提示詞包,包括角色四視圖、UI規範、6-12個鏡頭的圖片與視頻提示詞。
- 呢個方法解決咗角色一致性、UI統一和鏡頭連貫問題,唔同於單獨生成視頻嘅碎片化方式。
- 創作者應該先組織創作流程(角色、UI、鏡頭),再交給模型執行,而唔係隨機生成。
- 安裝Skill後可直接喺Claude Code等工具調用,亦可以試用Agent自動搭建節點,提高效率。
LibTV官網
AI視頻生成平台,支援工作台連線合成
LibTV Skills 官方GitHub
官方提供嘅Skill集合,包括自動搭建節點功能
ai-gameplay-pack (完整版)
生成完整遊戲實機視頻提示詞包,包括角色、UI、鏡頭等
ai-gameplay-pack-lite (輕量版)
精簡版,只輸出提示詞,節省token
內容結構
【ai-gameplay-pack-skill】https://github.com/irenerachel/ai-gameplay-pack-skill
【ai-gameplay-pack-lite-skill】https://github.com/irenerachel/ai-gameplay-pack-lite-skill呢個Skill係乜?點解值得用?
阿真上星期公開咗一個之前打碼嘅Skill,叫「ai-gameplay-pack」。佢嘅功能係:只要你有一個或者幾個主角,或者一個好點子,想做成遊戲實機演示視頻嘅效果,只要加載呢個Skill,然後講一句話,就可以得到一份完整嘅提示詞文檔,包括參考圖、分鏡圖、視頻提示詞,連時間軸同字幕腳本都有。
呢個Skill嘅核心係將創作流程標準化,確保角色一致性、UI統一、鏡頭連貫,唔會出嚟嘅片段各自為政。
最啱用嘅平台係LibTV,佢嘅工作台可以將圖片生成、視頻生成、參考圖連線同最終合成全部放喺同一個畫布搞掂。
手把手操作:由安裝到合成視頻
- 1 安裝Skill:去GitHub下載完整版或輕量版,然後喺Claude Code或者其他支援Skill嘅CLI工具度載入。
- 2 輸入靈感:直接話「我有一個製作遊戲實機效果嘅提示詞Skill,幫我調用一下」,然後補充遊戲類型、風格、角色等細節。
描述得越清楚,後面生成嘅提示詞包就越貼近你想要嘅效果。
- 1 得到文檔後,打開LibTV,先用Lib Image生成角色四視圖同UI總覽圖(參考圖1-4),畫幅揀16:9,模型盡量一致。
- 2 生成分鏡圖:根據文檔嘅6個鏡頭提示詞,逐個生成圖片。如果發現角色崩咗或者UI唔一致,即刻重跑。
- 3 生成視頻:將每張分鏡圖拖到視頻生成節點,記得貼視頻Prompt(唔好攪亂圖片Prompt),建議用SeedDance 2.0 VIP嘅全能參考。
- 4 合成:所有片段生成後,全選拉到視頻合成,排好鏡頭順序,點擊合成,就有一條30秒嘅實機短片。
Skill版本選擇同設計思路
呢個Skill有兩個版本,你可以按需求揀:輕量版(lite)只輸出提示詞,冇多餘廢話,慳token;完整版就由頭到尾好詳細,包括角色錨點、UI規範、6-12個鏡頭、時間軸、字幕腳本同TTS配音腳本。
完整版嘅輸出係一份可以直接複製俾圖片或視頻模型用嘅提示詞文檔,唔使自己再執過。
另外,如果想將已有角色(例如自家寵物、原創角色)整成視頻,可以直接俾角色圖片個Skill,佢會自動幫你擴展出四視圖、UI同鏡頭包。
Agent自動化:懶人最愛嘅玩法
阿真仲試咗用Agent(龍蝦或Hermes Agent)自動完成成個流程。先安裝官方LibTV Skills(GitHub連結),再裝埋遊戲實機提示詞Skill,然後話俾Agent聽想做乜。佢會自動生成文檔,再調用LibTV Skill直接生成視頻,最後輸出工作流截圖同成品。
有趣嘅係,純Agent出嚟嘅作品仲好過阿真手動整嘅,佢都話:「完蛋,點解純Agent嘅作品好似仲好啲?」
如果你係懶人或者想快速試唔同方向,可以優先試Agent玩法,慳好多手動時間。
總結:由呢篇文章可以帶走嘅嘢
成篇文核心就係:AI實機視頻製作可以透過Skill+LibTV工作流大幅簡化。你先用Skill輸出結構化嘅提示詞包,然後喺LibTV入面用工作台連線生成,最後合成一條完整短片。無論係手動定係Agent自動,都係先組織流程再執行。
記住:角色一致性、UI統一、鏡頭連貫係三個最關鍵嘅點,搞掂呢啲,出片就自然似模似樣。
如果你有角色想拓展成視頻,不妨試嚇呢個方法,或者直接俾張角色圖個Skill,佢會自動幫你完成。

嗨大家好!我係阿真!
又將有趣玩法嘅門檻打低咗啦,朋友們。
關注我嘅朋友可能仲記得,上上一篇文章入面,我喺教程截圖裝咗兩個Skill,但係打咗碼一個,當時俾啲眼利嘅羣友見到,話我肯定仲有乾貨未分享。

哎嘿,估中咗,俾大家睇到連續劇啦,其實係呢個👇
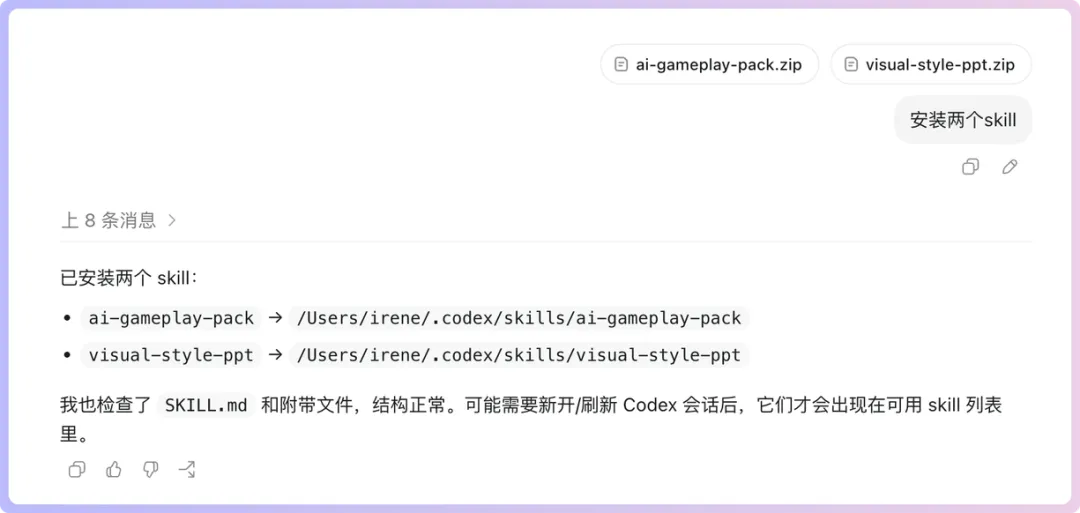
ai-gameplay-pack。呢個技能嘅作用係,當你有一個或者幾個主角,或者你有個好主意,想將佢做成遊戲實機演示視頻嘅效果,只要加載咗呢個技能,咁你只需要俾一句話,就可以得到一份完整嘅,由參考圖提示詞、到分鏡圖提示詞、再到視頻提示詞嘅完整文檔。
然後只需要喺LibTV複製貼上提示詞 + 連線就可以完成一整套操作,最後得到完整視頻。仲可以經由龍蝦或者Hermes Agent,由提示詞到視頻全自動產出。
關於Skill同視頻點樣操作,喺下面幾個視頻之後,有個長達15分鐘嘅完整教程視頻。之前有朋友話睇文字內容搞唔明點操作,今日終於記得錄咗個視頻啦。
如果你想邊睇邊試,連結👇
https://www.liblib.tv/例如蘑菇林裏面嘅童年型菌菇人戰士,透過刷草蟾蜍升級,Switch卡通渲染嘅動作RPG👇
例如俾阿真嘅卡通IP上演一場星露谷氣質嘅阿真種田記👇
例如做一啲水墨質感嘅國風效果👇
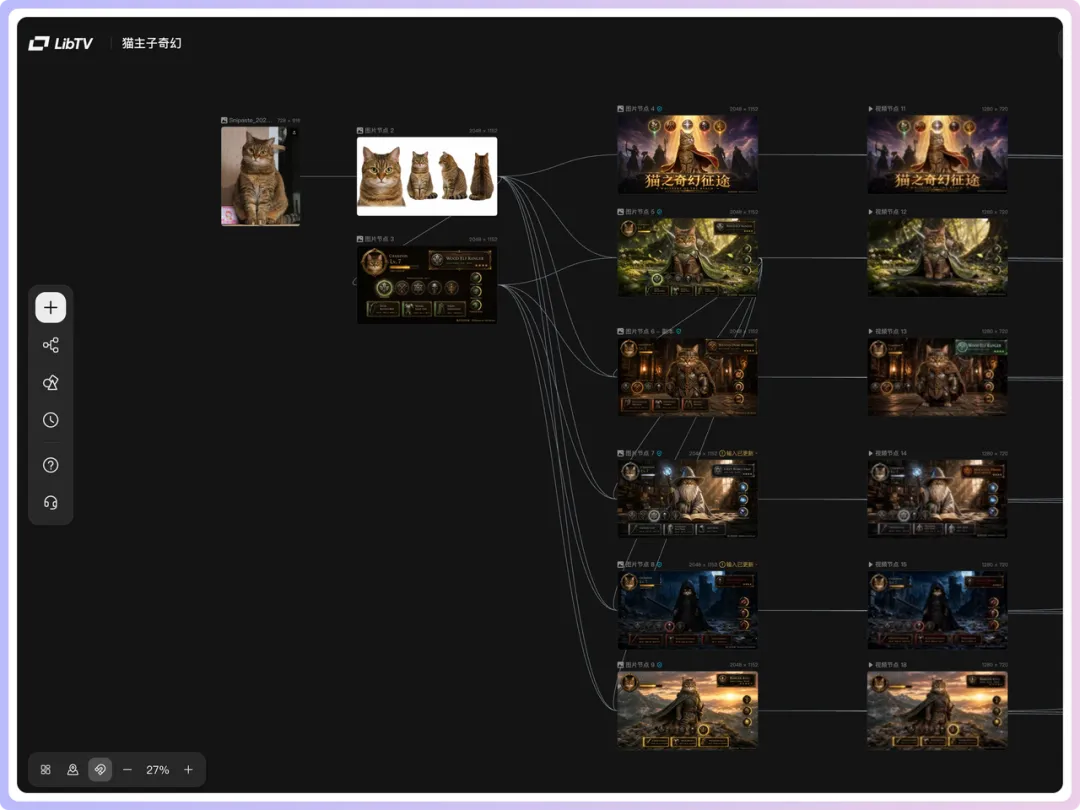
例如為自家貓整嘅貪玩藍月感視頻哈哈哈,工作流係咁👇
下面係視頻👇
例如做一個長安外賣小哥嘅任務(呢個係720P嘅)👇
LibTV本身就唔係一個單純生成視頻嘅工具,我更鍾意將提示詞生成同優化、參考圖、分鏡圖、視頻節點同最終合成預覽都放喺佢一個工作台入面完成,呢種工作流好流暢同舒適。LibTV平台嘅TV Show亦都好正,喺呢度刷到好多靚嘅AI短片、短劇內容,本質上都離唔開呢種將創作流程組織好,再交俾模型執行嘅方式。
呢個Skill係我五一之前就想做嘅,中間改咗好多次,做咗好多嘗試,希望效果更好而且大家用起嚟更簡單方便,測試過程用咗好多時間同積分,再次多謝LibTV一拍即合,令我敢放手猛肝,唔多講,嚟睇嚇效果。
完整操作教程視頻
下面係完整操作教程視頻,覺得文字睇唔明嘅可以直接睇視頻👇
有啲情況我做視頻嘅時候冇提,再補充幾點。
第一,如果有幾個角色一齊出現嘅,可以喺進行視頻生成嘅時候,喺全能參考嗰度拉多幾條角色,或者上一張圖片、上一個場景嘅圖片嘅連接線作為參考圖。
第二,唔同模型最終輸出嘅效果喺細節上可能會有些少差別,尤其係佢對輸出參考圖嘅要求方面。我哋手動操作嘅情況下,一定要自己主動判斷,喺唔同場景下,可能仲有邊啵圖片可以作為補充參考圖去達到更好效果嘅,去進行線條嘅連接。
Skill思路
分享呢個Skill嘅版本同思路。
Skills分為兩個版本:
輕量版(lite):如果希望最終只聚焦喺提示詞,而唔要其他廢話,節省token,可以安裝呢個版本。
完整版:提示詞由頭到尾好詳細。
例如我有一個靈感、想法、基於角色想做一個遊戲效果等等,我輸入嘅內容係角色圖片或關鍵詞,加上遊戲類型以及我想補充嘅細節。
輸出會係一份可以直接複製並提供俾圖片或視頻模型嘅完整提示詞文檔,裏麪包含角色錨點、UI規範、6到12個鏡頭嘅圖片提示詞同視頻提示詞序列、時間軸,如果係劇情向嘅內容,仲會額外加字幕腳本同TTS配音腳本。
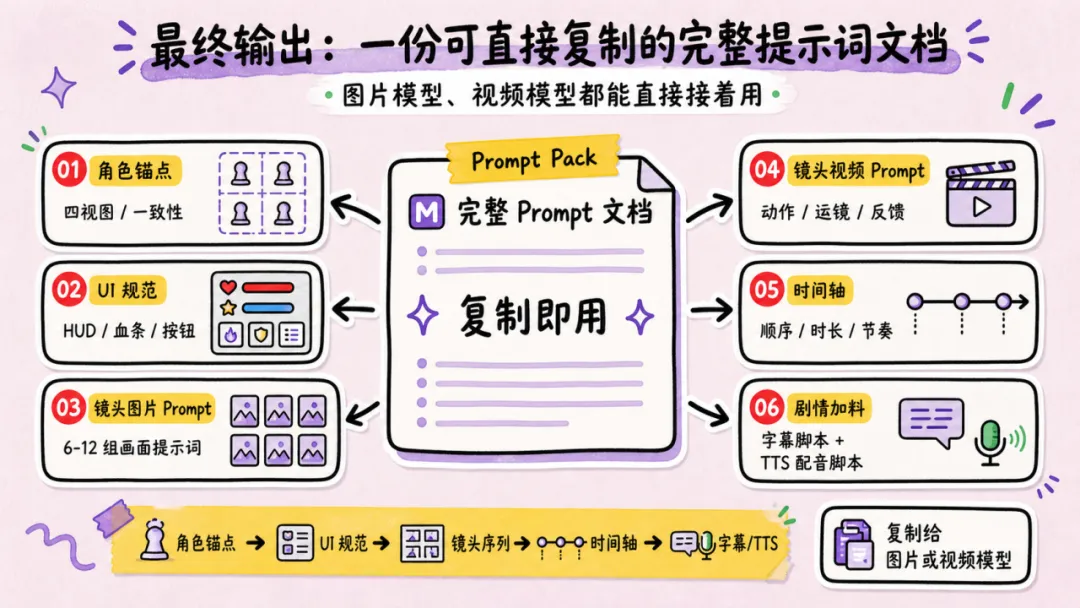
呢整套設計嘅骨架係為咗保證三個方面:
遊戲嘅角色唔會飄,會整體保持一致性。
UI界面同HUD保持一致,咁樣就唔會出現上一個鏡頭同下一個鏡頭連唔起,從而失去嗰種完整嘅實機遊戲感覺嘅情況。
每個鏡頭都會用「圖片提示詞 + 視頻提示詞」嘅配對,圖片同視頻提示詞好清晰。圖片生成經由Lib Image生成關鍵幀,視頻生成用SeedDance 2.0 VIP生成動態效果。
下面係輸出文件包嘅內容截圖,可以見到圖片分成參考圖提示詞4組,分鏡圖提示詞同分鏡圖生成視頻提示詞各6組(默認6組,可以自行要求)。有曬所有提示詞之後,就可以一步步生成圖片同連線啦。
例如之前嗰個《九州御劍錄》,最終輸出嘅提示詞包係咁嘅(藍色圓角塊面就係提示詞部分)👇


呢個最啱配嘅工具係LibTV,連線方便參考亦都清晰直觀,所以我Skill嘅參考圖嘅格式都基本跟佢哋嘅嚟。
亦都係喺呢次測試裏面,我更理解LibTV點解要做Creator + Agent雙入口。Creator端適合我哋手動檢查角色、UI、鏡頭同節奏,Agent端就更輕鬆隨意,可以將重複嘅生成、拆分、編排動作自動化。
多宮格切分令分鏡更規整,多種圖片同視頻模型應對唔同需求場景,最後再喺畫布裏面按順序合成。後面如果要做更長嘅系列內容,亦可以繼續將角色多視圖、劇情推演四宮格、鏡頭多角度、多機位九宮格呢啲能力一齊用起嚟。
調用Skill
安裝完Skill之後,直接喺Claude Code或其他支援Skill嘅CLI工具度講類似嘅話就可以調用:「我有一個製作遊戲實機效果嘅提示詞Skill,幫我調用嚇佢。」
如果我哋已經有明確主題,就可以直接話俾佢知自己做咩類型嘅視頻。例如東方神話、賽博修仙、RPG、古風冒險、機甲戰鬥、第一人稱視角、像素風等等都得。
如果當下冇靈感,都可以先叫佢幫我哋發散方向。例如我嗰陣時就直接問佢:有冇啲好型、好易出片嘅方向?佢俾咗我一組按視覺衝擊力排序嘅方向,例如黑神話系東方神話、深海百慕大潛艇救援、蒸汽朋克空中堡壘、山海經風格等等。提問好通俗都冇問題,完全冇咩高級打法,口語化溝通就得👇
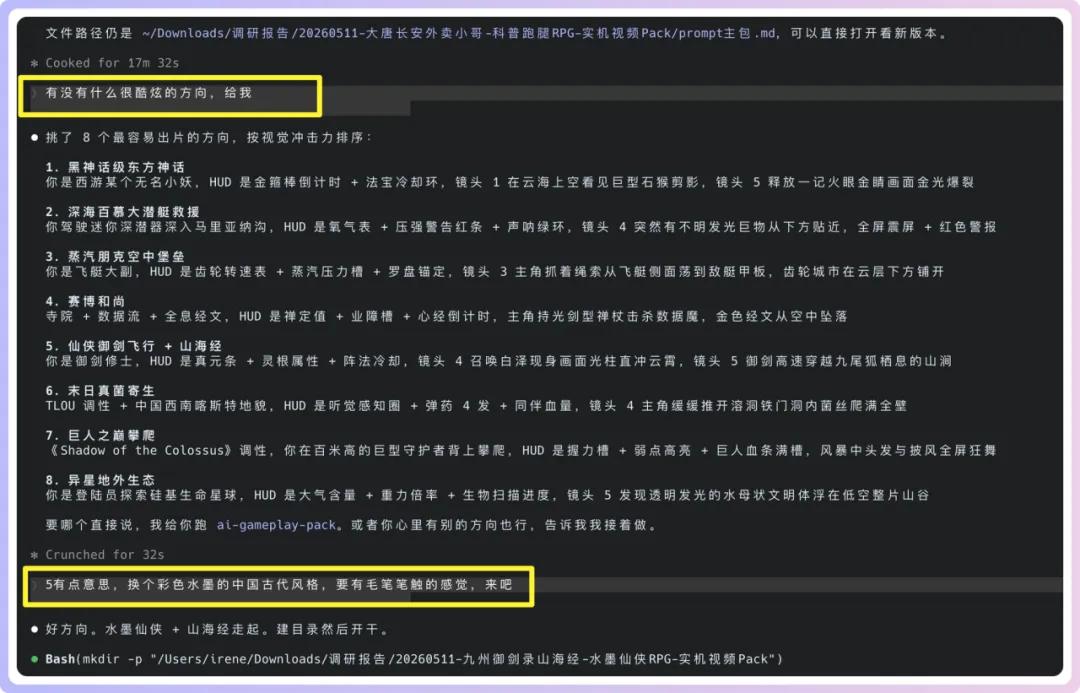
我最尾揀咗其中一個方向,然後繼續補充自己嘅風格要求:想做彩色、水墨質感、中國古代風格,同埋要有毛筆筆觸嘅感覺。
呢一步就應該描述清楚嘅都要講清楚,想要嘅風格、想要嘅元素同細節都要講明白,因為呢度補充嘅關鍵詞,會直接影響後面角色、UI、鏡頭畫面嘅統一感。我哋描述得越清楚,後面Skill寫出嚟嘅成個提示詞包就越接近想要嘅效果。
輸出完整文檔
首先係簡介,係AI基於我哋嘅要求進行嘅拓展同延伸👇

第一個係角色四視圖嘅提示詞。佢負責將主角嘅形象先定落嚟,例如服裝、髮型、氣質、武器、正側背視圖呢啲。


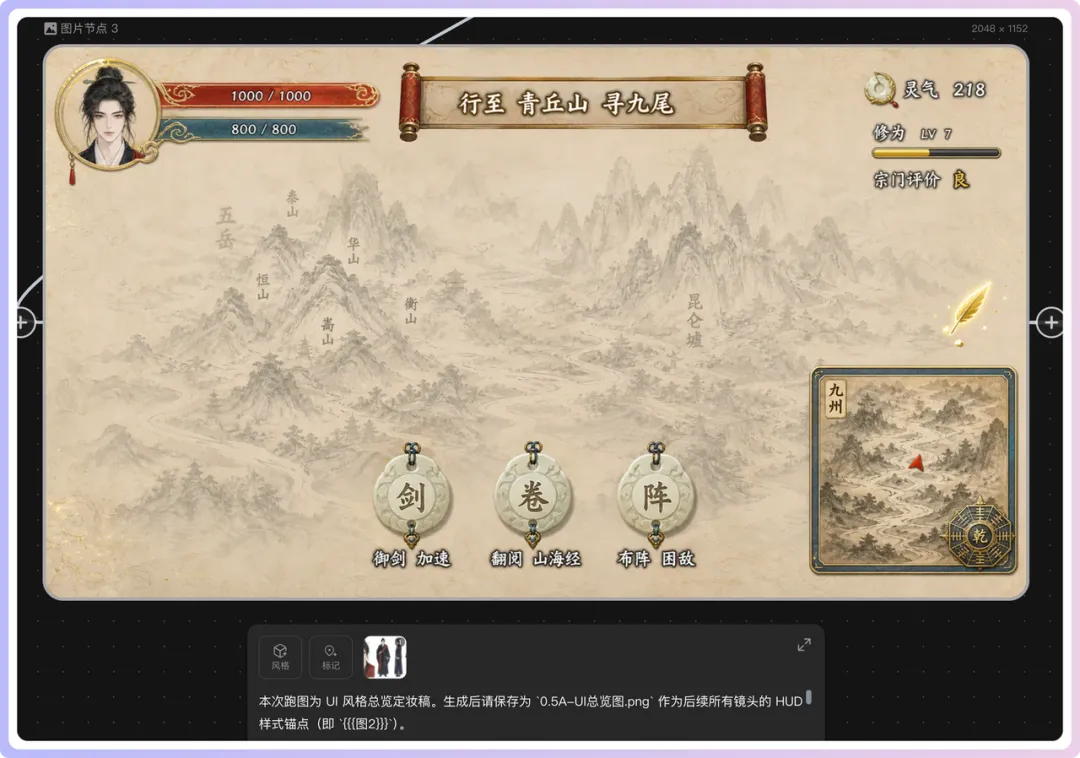
第二個係UI風格總覽。Skill限制咗後面所有HUD、頭像、狀態條、地圖、按鈕、任務提示,都盡可能參考呢張圖嚟做。咁樣最後睇起嚟就會似同一個遊戲裏面嘅界面,而唔係每個鏡頭都唔同,睇起嚟完全冇一致性同連貫感。呢度只有UI冇人物同場景,係為咗佢作為參考嘅時候唔會影響輸出圖嘅畫面。

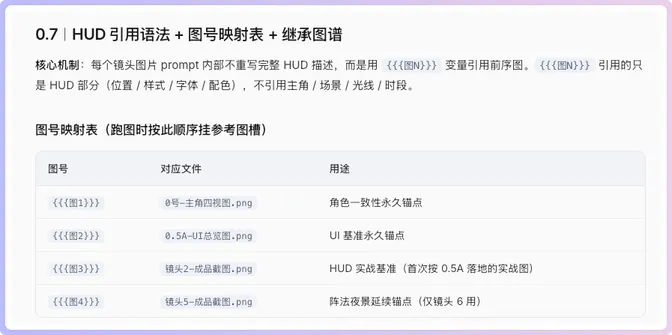
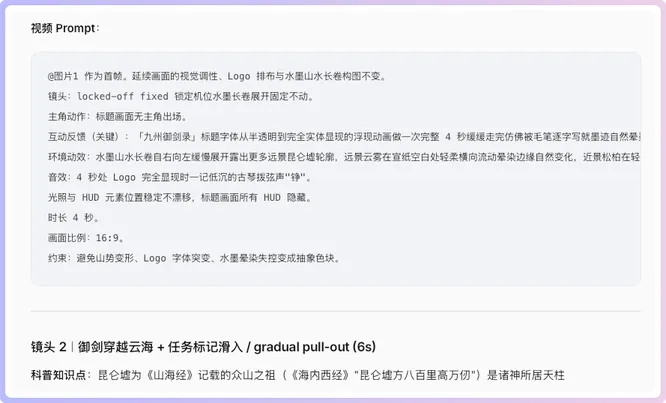
後面仲有UI規範字典、進度條狀態鏈表、六個鏡頭嘅圖片Prompt同視頻Prompt。呢度大家要注意,圖片Prompt同視頻Prompt係兩套內容,複製嘅時候千祈唔好撈亂。
引用邊張圖,邊個參考邊個,如果唔明嘅話,喺完整嘅文檔度都有👇
如果你就想做呢種6個鏡頭30秒嘅,咁參考圖1、2、3、4就比較固定,4唔一定有,123係必須。好似咁下面第一列係最開始生成嘅設定圖參考,第二列係6張分鏡圖。參考圖我已經用序號標咗出嚟。無論係其他任何遊戲,代入嚟都類似呢種參考格式👇
我呢度用嘅Lib Image,畫幅揀16:9,畫質用標準畫質。圖片模型盡量保持一致,咁樣後面角色同UI嘅風格會更統一。
生成分鏡
前面描述嘅係第一列,跟住開始生成第二列嘅鏡頭圖。
文檔默認俾咗六個鏡頭,每個鏡頭大概5秒,最後加埋一齊就差唔多係一條30秒嘅視頻。





上面張圖直接出嗰陣冇檢查,後面發現劍嘅位置周圍飛哈哈哈大家注意檢查細節。
如果發現某張圖人物崩咗、UI變咗、場景邏輯唔啱,建議喺圖片階段就重新跑過。唔好等到視頻生成完先嚟改,咁樣更嘥積分,亦都更難精準調整。
生成視頻
圖片確認冇問題之後,就可以將每張鏡頭圖拖到視頻生成節點度。呢一步複製嘅係視頻Prompt。文檔已經寫好咗每個鏡頭嘅運動方式、鏡頭語言、UI動效、角色動作、環境變化同時長建議。
視頻裏面我用嘅係SeedDance 2.0 VIP嘅全能參考。LibTV最近亦都將SeeDance 2.0滿血版放咗上嚟,滿唔滿月相信大家睇我前面輸出嘅視頻就有判斷。佢基本上都唔使點樣抽卡。亦可以根據自己嘅需求試其他模型,但同一條片裏面解像度盡量保持統一,咁樣效果會更好。
所有視頻片段生成咗之後,將佢哋全部揀選拉出嚟,揀視頻合成👇
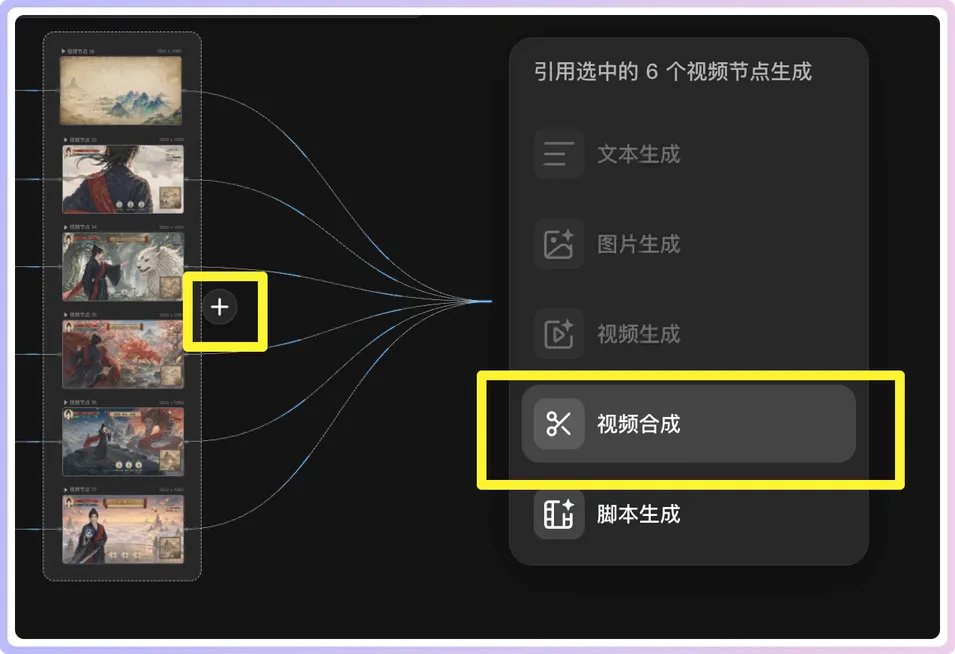
然後將鏡頭1到鏡頭6排好順序,再㩒合成視頻。最後就可以得到一條完整嘅實機感短片。
個人IP做視頻
除咗由零生成一個主角,呢個Skill仲有一個好好用嘅玩法:可以將已有角色圖俾佢,叫佢基於呢張圖繼續做四視圖、UI同鏡頭包。
我之前亦都用自己隻貓試過一版。先將貓貓圖片俾佢,叫佢將呢隻貓當作主角,做一個遊戲人設。佢會繼續生成四視圖、UI、六張鏡頭圖提示詞,我再跟返前面嘅邏輯去生成圖同視頻。貓之貪玩藍月有咗哈哈哈👇

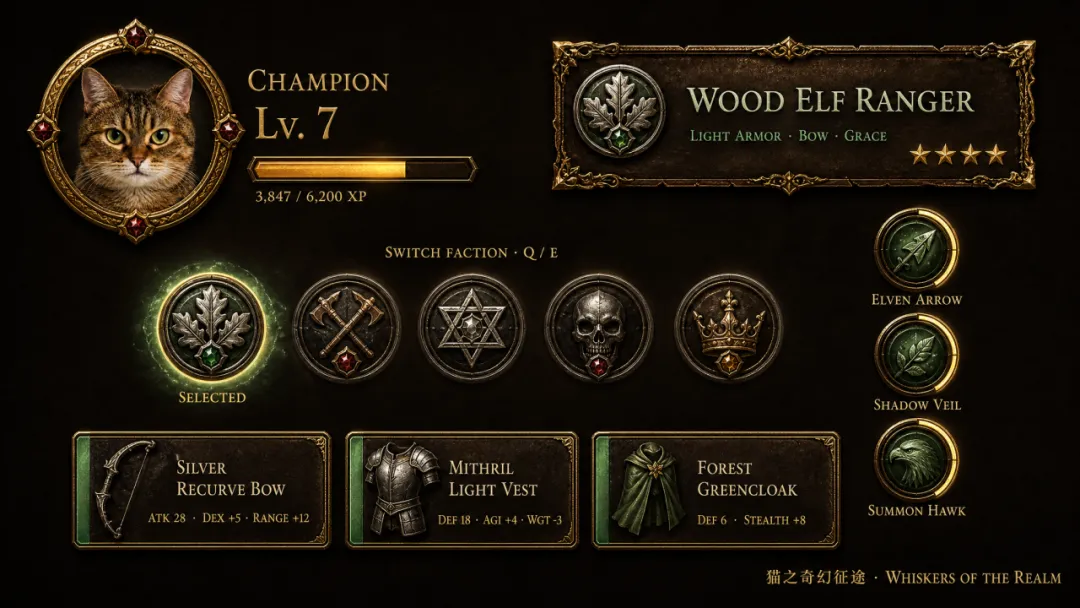

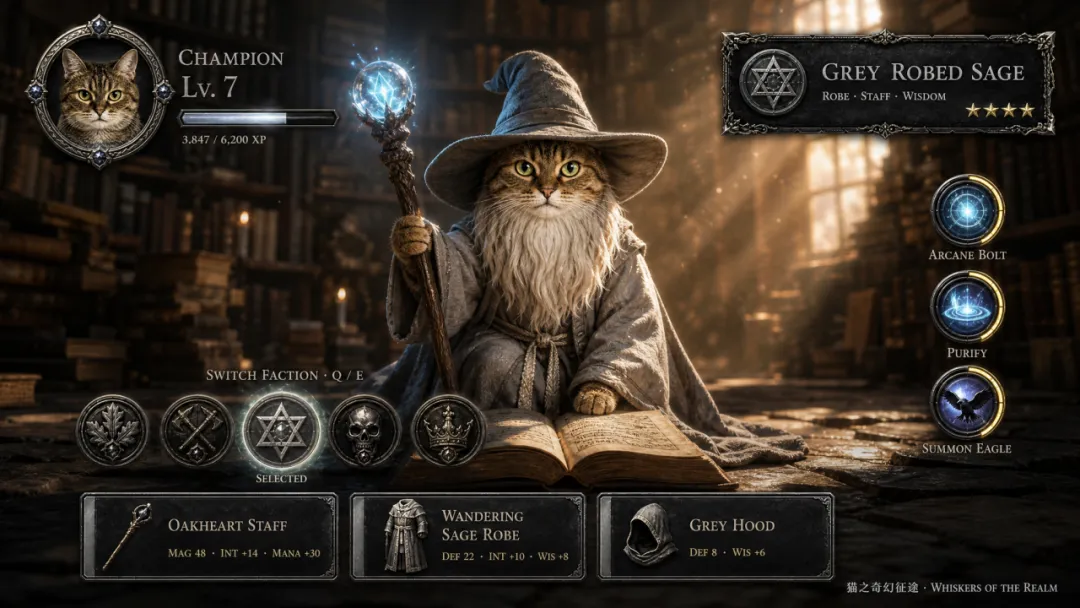
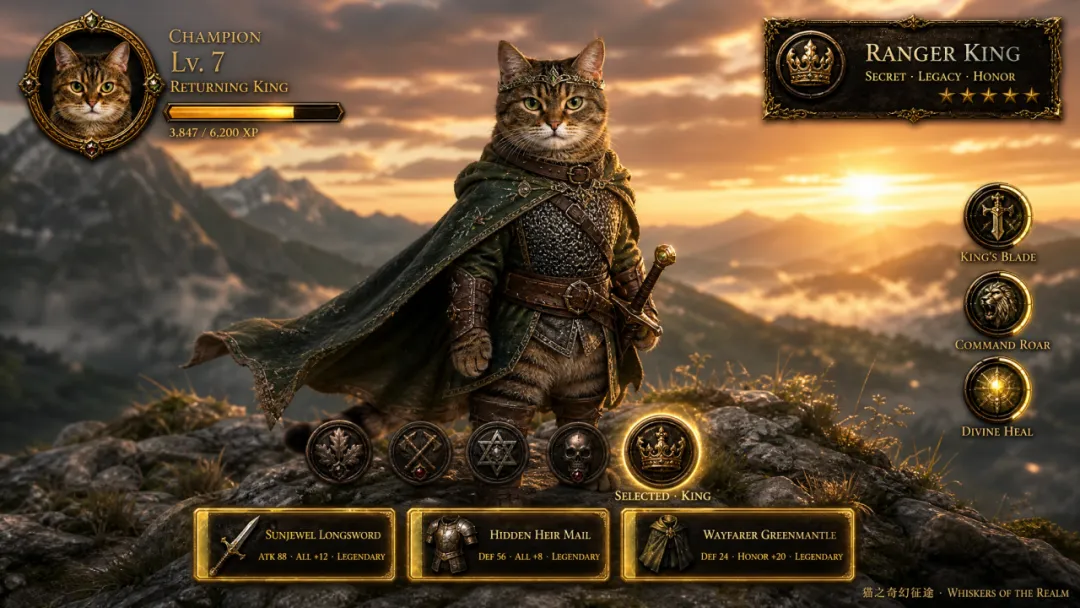
咁樣做嘅好處係,可以將自己已經有嘅形象延展成一個完整嘅偽實機視頻。例如你有原創角色、品牌吉祥物、寵物相、短劇人物設定等,都可以用呢種方式繼續擴展。
小竅門,例如直接俾遊戲截圖參考,或者俾角色叫佢自由發揮,都可以有啲驚喜效果㗎。
仲有一點提醒,如果做西式遊戲但係需要中文界面效果,記住喺提示詞階段就提出要求。
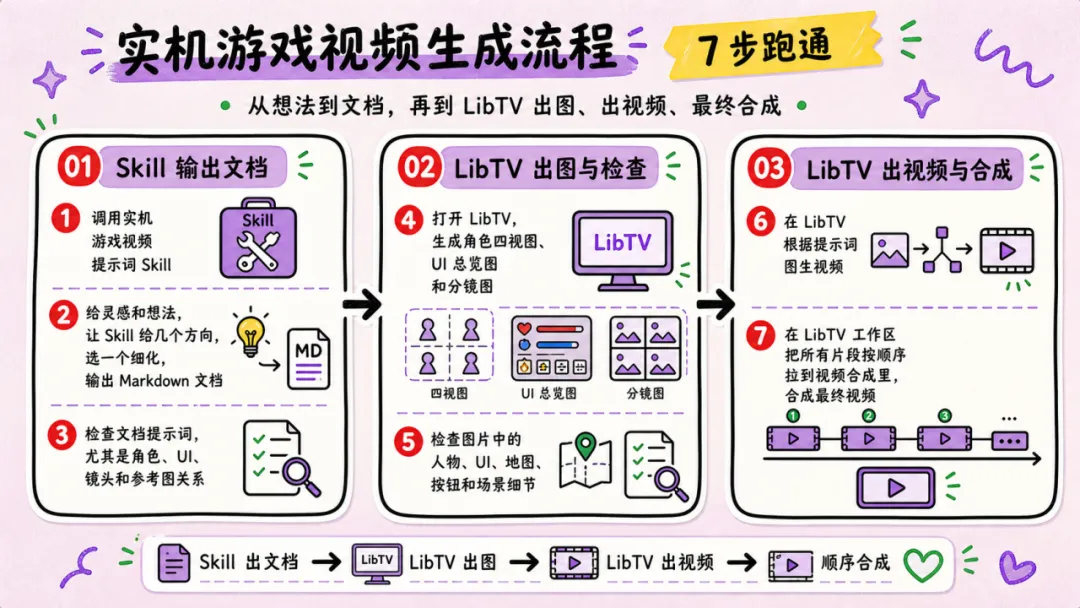
完整流程梳理
調用實機遊戲視頻提示詞Skill
俾靈感同想法,叫Skill俾幾個方向,細化,輸出Markdown文檔
檢查文檔提示詞,尤其係角色、UI、鏡頭同參考圖關係
打開LibTV,用Lib Image生成角色四視圖同UI總覽圖、分鏡圖
檢查圖片中嘅人物、UI、地圖、按鈕同場景細節
根據提示詞拉線條,圖生視頻
喺LibTV工作區將所有片段按順序拉到視頻合成度,合成最終視頻
Agent創作
喺前面成個工作流都係透過人類即係我一步一步完成嘅。跟住我想體驗嚇LibTV最近推出嘅Skill,即係透過Agent自動搭建節點嘅功能嚟試嚇。
先複製官方Github連結俾佢安裝,然後將複製嘅Key俾龍蝦或者Hermes Agent👇
GitHub:https://github.com/libtv-labs/libtv-skills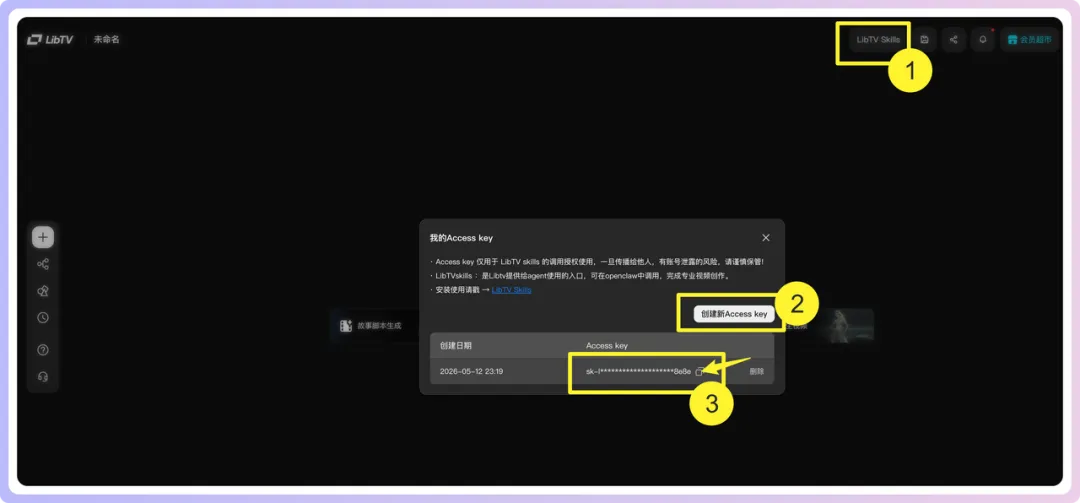
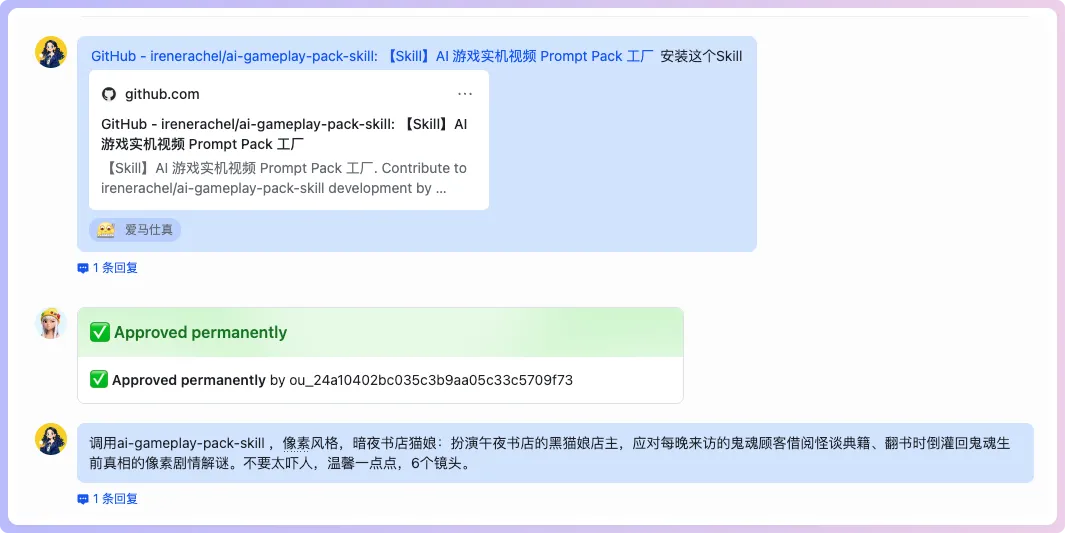
同時記得都安裝好呢個遊戲實機提示詞Skill,然後睇我提出嘅要求👇
等一陣Hermes就輸出文檔俾我啦,為咗方便辨認我叫佢將提示詞喺對話裏面呈現俾我👇
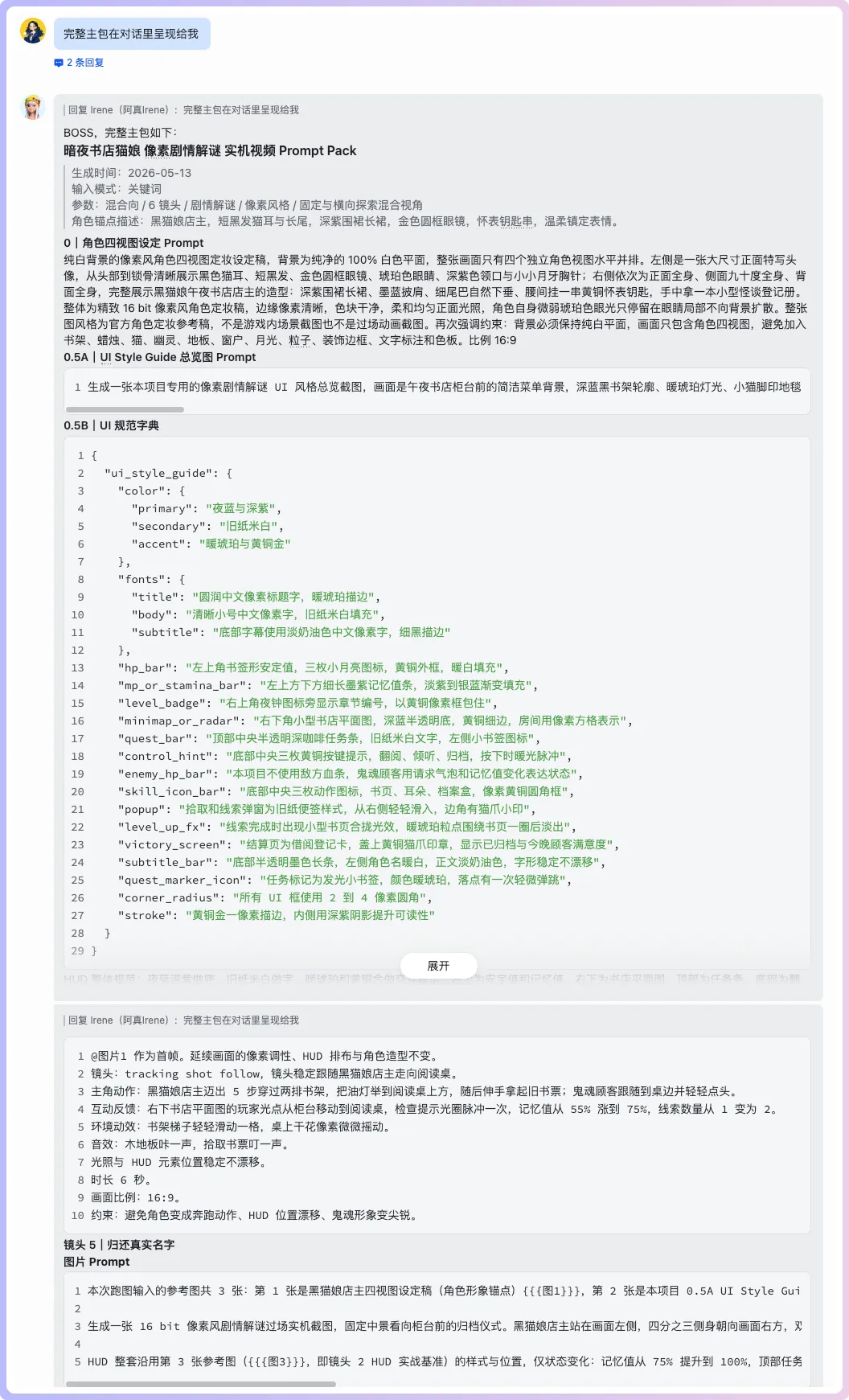
然後我叫佢根據上面嘅完整提示詞,調用LibTV嘅Skill,直接生成視頻,完成之後通知我👇
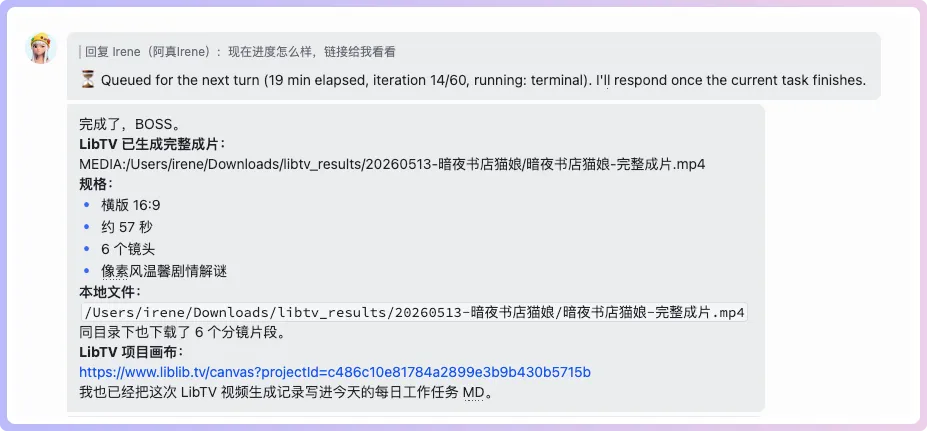
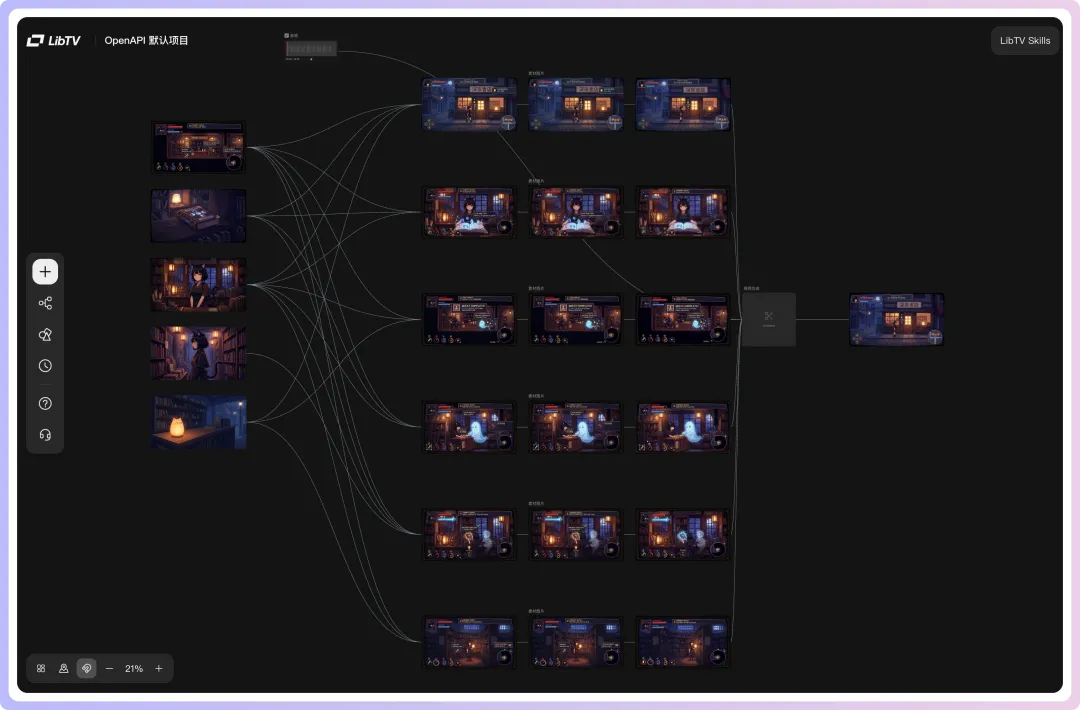
輸出嘅工作流截圖同視頻👇
完整視頻(死火,點解覺得純Agent嘅作品好似仲好過我人手整嘅)👇
呢個功能好有潛力!只要提示詞包到位,做其他短視頻應該都可以好唔錯。等我再深度玩嚇,有時間再同大家匯報進度。
小結
LibTV入口:
LibTV 官網:https://www.liblib.tv/
LibTV Skills 官方 GitHub:https://github.com/libtv-labs/libtv-skills本文用到嘅 Skill Github 連結:
【ai-gameplay-pack-skill】https://github.com/irenerachel/ai-gameplay-pack-skill
【ai-gameplay-pack-lite-skill】https://github.com/irenerachel/ai-gameplay-pack-lite-skill好啦,今日嘅分享就到呢度啦。如果你哋嘗試咗呢個 Skill ,或者有更多自己用 LibTV 創造出嚟嘅玩法,有更多 LibTV 嘅使用技巧,歡迎留言區一齊交流同分享,交流使用感受。
如果呢篇內容對你有用嘅話,都歡迎喺下面讚好、收藏同轉發,期待你嘅猛猛三連 👍 🌸 🌀 鼓勵,因為呢個對阿真真係好重要。
朋友們下期見~
嗨大家好!我是阿真!
又把有趣玩法的門檻打下來了朋友們。
關注我的朋友可能還記得在上上篇內容中,我在教程截圖中安裝了兩個 Skill 但是打碼了一個,當時給火眼金睛的羣友看到了,說我指不定還有乾貨沒分享。
哎嘿猜對了,也是給大家看到連續劇了,其實是這個👇
ai-gameplay-pack。這個技能的作用是,當你有一個或者幾個主角,你或者你有一個好點子,想要將它做成遊戲實機演示視頻的效果,只要加載了這個技能,那麼你只需要提供一句話,就可以得到一份完整的從參考圖提示詞、到分鏡圖提示詞,到視頻提示詞的提示詞完整文檔。
然後只需要在 LibTV 複製粘貼提示詞 + 連線即可完成一整套操作,最終獲得完整視頻。還可以通過龍蝦或者 Hermes Agent 從提示詞到視頻全自動產出。
關於 Skill 和視頻怎麼操作,在下面幾個視頻後,有個長達 15 分鐘的完整的教程視頻。之前有朋友說看文字內容沒搞清楚操作,今天總算記得錄個視頻啦。
如果你想邊看邊試,連結👇
https://www.liblib.tv/比如蘑菇林裏的童年型菌菇人戰士,通過刷草蟾蜍升級,Switch 卡通渲染的動作 RPG👇
比如讓阿真的卡通 IP 來上演一場星露谷氣質的阿真種田記👇
比如做一些水墨質感的國風感的效果👇
比如給自家貓整的貪玩藍月感視頻哈哈哈,工作流長這樣👇
下面是視頻👇
比如做一個長安外賣小哥的任務(這個是720P的)👇
LibTV 本就不是一個單純生成視頻的工具,我更喜歡把 提示詞生成和優化、參考圖、分鏡圖、視頻節點和最終合成預覽都放在它的一個工作台裏完成,這種工作流非常流暢和舒適。LibTV 平台的 TV Show 也非常棒,在這裏能刷到的很多好看的 AI 短片、短劇內容,本質上都離不開這種先把創作流程組織起來,再交給模型執行的方式。
這個 Skill 是我五一前就想做的,中間也是改了很多次,做了很多嘗試,希望效果更好大家使用起來也更簡單方便,測試過程花了很多時間和積分,再次謝謝 LibTV 一拍即合讓我敢放手猛肝,話不多說,來看看效果。
完整操作教程視頻
下面是完整操作教程視頻,覺得文字看不明白的可以直接看視頻👇
有的情況我做視頻的時候沒提到,再補充幾點。
一是如果有幾個角色一起出現的,可以在進行視頻生成的時候,在全能參考那裏多拉幾條角色,或者是上一個圖片、上一個場景的圖片的連接線作為參考圖。
二是不同的模型最終輸出的效果在細節上可能會有一些差別,尤其是它對輸出參考圖的要求方面。我們在手動操作的情況下,一定要自己主動去判斷,在不同的場景下,可能還有哪些圖片可以作為補充參考圖的達到更好效果的,去進行線條的連接。
Skill思路
分享這個 Skill 的版本和思路。
Skills 分為兩個版本:
輕量版(lite):如果希望最終只聚焦於提示詞,而不要其他的廢話,節省 token,可以安裝這個版本。
完整版:提示詞從頭到尾非常詳細。
比如我有一個靈感、想法、基於角色想做一個遊戲效果等等,我輸入的內容是角色圖片或關鍵詞,加上游戲類型以及我想要補充的細節。
輸出會是一份可以直接複製並提供給圖片或視頻模型的完整提示詞文檔,其中包含角色錨點、UI 規範、6 到 12 個鏡頭的圖片提示詞和視頻提示詞序列、時間軸,如果是劇情向的內容,還會額外加上字幕腳本和 TTS 配音腳本。
這整套設計的骨架是為了保證三個方面:
遊戲的角色不會飄,會整體保持一致性。
UI 界面和 HUD 保持一致,這樣就不會出現上一個鏡頭跟下一個鏡頭連不起來,從而失去那種完整的實機遊戲感覺的情況。
每個鏡頭都會使用“圖片提示詞 + 視頻提示詞”的配對,圖片和視頻提示詞很清晰。圖片生成經由Lib Image 生成關鍵幀,視頻生成使用 SeedDance 2.0 VIP 生成動態效果。
下面是輸出文件包的內容截圖,可以看到圖片分成參考圖提示詞4組,分鏡圖提示詞和分鏡圖生成視頻提示詞各6組(默認6組,可以自行要求)。有了所有提示詞了,接下來就可以一步步生成圖片和連線了。
比如先前那個《九州御劍錄》,最終輸出的提示詞包是這樣的(藍色圓角塊面就是提示詞部分)👇
這個最適配的工具是 LibTV,連線方便參考也清晰直觀,所以我 Skill 的參考圖的格式也基本按照他們的來的。
也是在這次測試裏,我更能理解 LibTV 為什麼要做 Creator + Agent 雙入口。Creator 端適合我們手動檢查角色、UI、鏡頭和節奏,Agent 端則更輕鬆隨意,可以把重複的生成、拆分、編排動作自動化。
多宮格切分讓分鏡更規整,多種圖片和視頻模型應對不同需求場景,最後再在畫布裏按順序合成。後面如果要做更長的系列內容,也可以繼續把角色多視圖、劇情推演四宮格、鏡頭多角度,多機位九宮格這些能力一起用起來。
調用 Skill
安裝完 Skill 以後,直接在 Claude Code 或其他支持 Skill 的 CLI 工具裏說類似的話就可以調用:“我有一個製作遊戲實機效果的提示詞 Skill,幫我調用一下它。”
如果我們已經有明確主題,就可以直接告訴它自己想做什麼類型的視頻。比如東方神話、賽博修仙、RPG、古風冒險、機甲戰鬥、第一人稱視角、像素風等等都可以。
如果當下沒有靈感,也可以先讓它幫我們發散方向。比如我當時就是直接問它:有沒有什麼很酷炫、很容易出片的方向?它給了我一組按視覺衝擊力排序的方向,比如黑神話系東方神話、深海百慕大潛艇救援、蒸汽朋克空中堡壘、山海經風格等等。提問很通俗也沒有關係,完全沒有什麼高端的打法,就口語化溝通就好👇
我最後選了其中一個方向,然後繼續補充自己的風格要求:想做彩色、水墨質感、中國古代風格,而且要有毛筆筆觸的感覺。
這一步該描述清楚的還是要講清楚,想要的風格想要的元素和細節都要說明白,因為這裏補充的關鍵詞,會直接影響後面角色、UI、鏡頭畫面的統一感。我們描述得越清楚,後面 Skill 寫出來的整個提示詞包越接近想要的效果。
輸出完整文檔
首先是簡介,是AI基於我們的要求進行的拓展和延展👇
第一個是角色四視圖的提示詞。它負責把主角的形象先定下來,比如服裝、髮型、氣質、武器、正側背視圖這些。
第二個是 UI 風格總覽。Skill 限制了後面所有 HUD、頭像、狀態條、地圖、按鈕、任務提示,都儘可能參考這張圖來做。這樣最後看起來會像同一個遊戲裏的界面,而不是每個鏡頭都不一樣,看起來完全沒有一致性和連貫感。這裏只有 UI 沒有人物和場景,是為了它作為參考的時候不會影響輸出圖的畫面。
後面還有 UI 規範字典、進度條狀態鏈表、六個鏡頭的圖片 Prompt 和視頻 Prompt。這裏大家要注意,圖片 Prompt 和視頻 Prompt 是兩套內容,複製的時候一定不要混。
引用哪張圖,誰參考誰,如果不明白的話,在完整的文檔中也有👇
如果你就想做這樣的 6 個鏡頭 30 秒的,那麼參考圖 1、2、3、4 就是比較固定的,4 不一定有,123 是剛需。像這樣下面第一列是最開始生成的設定圖參考,第二列是 6 張分鏡圖。參考圖我已經用序號標出來了。不管是其他的任何遊戲,代入進來都類似這樣的參考格式👇
我這裏用的 Lib Image,畫幅選擇 16:9,畫質用標準畫質。圖片模型儘量保持一致,這樣後面角色和 UI 的風格會更統一。
生成分鏡
前面描述的是第一列,接下來開始生成第二列的鏡頭圖。
文檔默認給了六個鏡頭,每個鏡頭大概 5 秒,最後合起來差不多就是一條 30 秒的視頻。
上面的圖直出的時候沒檢查,後面發現劍的位置一直亂飛哈哈哈大家注意檢查細節。
如果發現某張圖人物崩了、UI 變了、場景邏輯不對,建議就在圖片階段重跑。不要等到視頻生成完再修,那樣更費積分,也更難精準調整。
生成視頻
圖片確認沒問題以後,就可以把每張鏡頭圖拖到視頻生成節點裏。這一步複製的是視頻 Prompt。文檔裏已經寫好了每個鏡頭的運動方式、鏡頭語言、UI 動效、角色動作、環境變化和時長建議。
視頻裏我用的是 SeedDance 2.0 VIP 的全能參考。LibTV 最近也把 SeeDance 2.0 滿血版放上來了,滿不滿月相信大家看我前面輸出的視頻就有判斷了。它基本上也不怎麼需要抽卡。也可以根據自己的需求嘗試其他模型,但同一條片子裏分辨率儘量保持統一,這樣效果會更好一些。
所有視頻片段生成完以後,把它們全選上拉出來,選擇視頻合成👇
接着把鏡頭 1 到鏡頭 6 調整好順序,再點擊合成視頻。最後就能得到一條完整的實機感短片。
個人IP做視頻
除了從零生成一個主角,這個 Skill 還有一個很好用的玩法:可以把已有角色圖發給它,讓它基於這張圖繼續做四視圖、UI 和鏡頭包。
我之前也用自家貓試了一版。先把貓貓圖片給它,讓它把這隻貓當作主角,做一個遊戲人設。它會繼續生成四視圖、UI、六張鏡頭圖提示詞,我再按照前面的邏輯去生成圖和視頻。貓之貪玩藍月有了哈哈哈👇
這樣做的好處是,可以把自己已經有的形象延展成一個完整的偽實機視頻。比如你有原創角色、品牌吉祥物、寵物照片、短劇人物設定等,都可以用這種方式繼續擴展。
小竅門,比如直接給遊戲截圖參考,或者給角色讓它自由發揮也可以有一些驚喜效果哦。
還有一點提醒,如果做西式遊戲但是需要中文界面效果,記得在提示詞階段就進行要求。
完整流程梳理
調用實機遊戲視頻提示詞 Skill
給靈感和想法,讓 Skill 給幾個方向,細化,輸出 Markdown 文檔
檢查文檔提示詞,尤其是角色、UI、鏡頭和參考圖關係
打開 LibTV,使用 Lib Image 生成角色四視圖和 UI 總覽圖、分鏡圖
檢查圖片中的人物、UI、地圖、按鈕和場景細節
根據提示詞拉線條,圖生視頻
在 LibTV 工作區把所有片段按順序拉到視頻合成裏,合成最終視頻
Agent創作
在前面整個的工作流都是通過人類也就是我去一步一步完成的。接下來我想要體驗一下 LibTV 最近前不久推出的 Skill,也就是通過 Agent 自動搭建節點的功能來嘗試一下。
先複製官方 Github 連結給它安裝,然後把複製的 Key 給龍蝦或者 Hermes Agent👇
GitHub:https://github.com/libtv-labs/libtv-skills同時記得也安裝好這個遊戲實機提示詞 Skill,然後看我提出的要求👇
等一會兒 Hermes 就輸出文檔給我了,為了方便識別我讓它把提示詞在對話裏呈現給我👇
讓後我讓它根據上面的完整提示詞,調用 LibTV 的 Skill,直接生成視頻,完成以後提醒我👇
輸出的工作流截圖和視頻👇
完整視頻(完蛋,怎麼感覺純 Agent 的作品好像比我人工的還好)👇
這個功能大有潛力啊!只要提示詞包到位,做其他短視頻應該也可以很不錯。等我再深度玩玩,有時間再向大家彙報進度。
小結
LibTV 入口:
LibTV 官網:https://www.liblib.tv/
LibTV Skills 官方 GitHub:https://github.com/libtv-labs/libtv-skills本文用到的 Skill Github 連結:
【ai-gameplay-pack-skill】https://github.com/irenerachel/ai-gameplay-pack-skill
【ai-gameplay-pack-lite-skill】https://github.com/irenerachel/ai-gameplay-pack-lite-skill好了,今天的分享就到這裏啦。如果大家嘗試了這個 Skill ,或者有更多自己使用 LibTV 創造出來的玩法,有更多LibTV 的使用技巧,歡迎評論區一起交流和分享,交流使用感受。
如果這篇內容對你有用的話,也歡迎在下方點贊、收藏和轉發,期待你的猛猛三連 👍 🌸 🌀 鼓勵,因為這對阿真真的很重要。
朋友們下期見~