大多數人用AI編程仲係一個代理做到尾。Superpowers嘅並行代理模式令3個代理同時開工:一個寫前端、一個寫後端、一個寫測試,互相唔干擾,效率翻3倍。我踩咗8個坑,你唔使再踩。
寫在前頭
你用AI編程助手,好大機會係咁樣:
一個對話窗口,一個代理,由頭做到尾。寫前端、寫後端、寫測試、修bug,全部靠佢一個。
就好似請咗一個全能員工,叫佢同時做設計、寫代碼、做測試。佢的確做到,但每個任務都要排隊等佢。
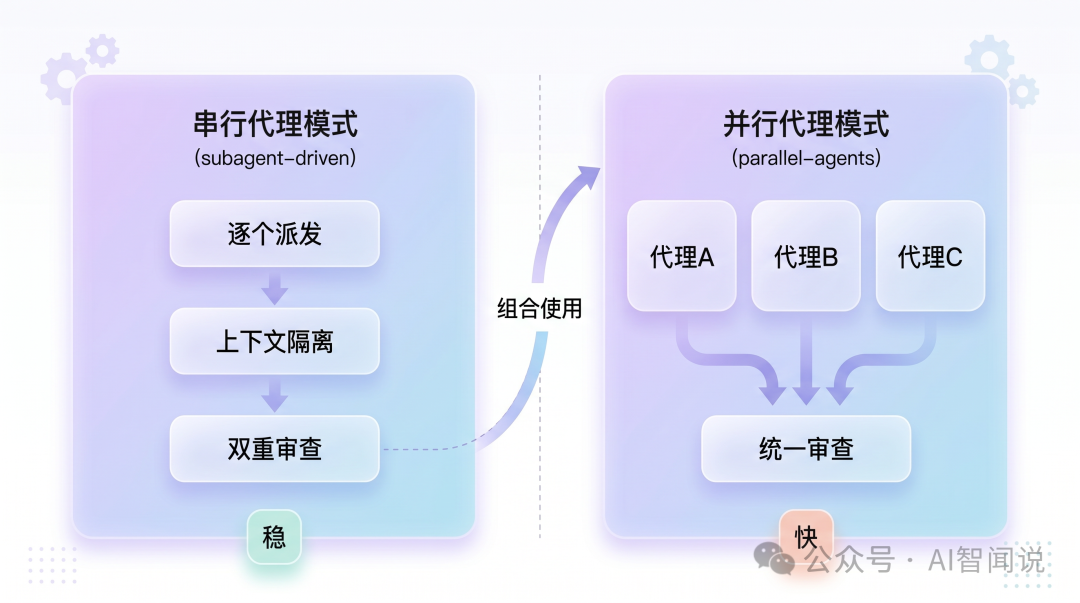
Superpowers嘅並行代理模式打破咗呢種串行瓶頸。 核心思路好簡單:將獨立任務分俾唔同嘅代理,等佢哋同時做。一個代理寫前端組件,一個代理寫後端接口,一個代理寫測試——3條線並行推進,互相唔干擾。
Superpowers提供咗兩種代理模式:
subagent-driven-development — 逐個派發代理,每個代理獨立執行+雙重審查。唔係並行,但每個代理嘅上下文係乾淨嘅,質量有保障dispatching-parallel-agents — 真正嘅並行派發,多個代理同時開工,解決獨立問題兩種模式解決唔同嘅問題。呢篇文章,我用一個真實項目行一次完整流程:俾一個Python FastAPI應用同時開發3個獨立功能。我會將每一步嘅輸入輸出、踩坑同調整都寫出來。
一、先搞清楚:兩種代理模式,兩種場景
好多人分唔清subagent-driven同parallel-agents,以為都係"多代理"。實際上佢哋解決嘅係完全唔同嘅問題:
| subagent-driven-development | dispatching-parallel-agents |
|---|
| | |
| | |
| | |
| | |
| | |
| | |
| | |
一句話總結:subagent-driven確保每個任務嘅質量,parallel-agents確保多個獨立任務嘅速度。
實際項目中,兩種模式經常組合使用:用parallel-agents並行派發3組任務,每組任務內部用subagent-driven逐個執行+審查。
二、實戰項目:同時開發3個獨立功能
場景設定
項目背景:
一個Python FastAPI應用,已有用戶註冊同登錄功能需要同時開發3個獨立功能:通知系統、文件上傳、數據導出第1步:用brainstorming確認任務獨立性
呢個係最容易跳過嘅一步,亦係踩坑最多嘅地方。 並行代理嘅前提係任務獨立——如果兩個代理改咗同一個文件,合併時就會係災難。
用Superpowers嘅brainstorming Skill確認:
/superpowers:brainstorming
你同AI嘅對話:
你:我需要同時開發通知系統、文件上傳、數據導出,可以用並行代理嗎
AI:等我檢查一下呢三個功能嘅依賴關係……
通知系統:新增 notifications/ 模塊,修改 models/user.py 添加通知偏好字段
文件上傳:新增 uploads/ 模塊,修改 models/user.py 添加存儲配額字段
數據導出:新增 exports/ 模塊,只依賴 models/user.py 讀取用戶數據
三個功能都會改 models/user.py,呢個唔係獨立嘅——並行代理會衝突
你:點樣解決
AI:兩種方案:
先把 models/user.py 嘅改動拆出來作為一個前置任務,完成後再並行3個功能每個功能用獨立嘅git worktree開發,最後合併
踩坑1:以為任務獨立就直接並行
我第一次用時,見到3個功能分屬唔同模塊就以為獨立咗,結果兩個代理同時改咗 models/user.py,合併時衝突咗30幾行。判斷獨立性嘅標準唔係"功能是否相關",而係"是否改同一個文件"。
第2步:用writing-plans拆分計劃
確認咗前置任務後,用Superpowers嘅writing-plans Skill拆分:
/superpowers:writing-plans
AI生成計劃文檔,關鍵部分:
# 三功能並行開發計劃
## 前置任務(串行,subagent-driven)
### 任務0:拆分用戶模型
**文件:**
- 修改:`models/user.py`
- 新增:`models/notification_preference.py`
- 新增:`models/storage_quota.py`
- 測試:`tests/test_user_model.py`
- [ ] 步驟1:寫失敗測試 — 驗證通知偏好和存儲配額字段
- [ ] 步驟2:運行測試,確認失敗
- [ ] 步驟3:從user.py提取通知偏好到獨立模型
- [ ] 步驟4:從user.py提取存儲配額到獨立模型
- [ ] 步驟5:運行測試,確認通過
- [ ] 步驟6:提交
## 並行任務(3組,dispatching-parallel-agents)
### 任務組A:通知系統
- 新增 `notifications/` 模塊
- 新增 `routers/notifications.py`
- 新增 `services/notification_service.py`
- 不修改 `models/user.py`(前置任務已拆分)
### 任務組B:文件上傳
- 新增 `uploads/` 模塊
- 新增 `routers/uploads.py`
- 新增 `services/upload_service.py`
- 不修改 `models/user.py`(前置任務已拆分)
### 任務組C:數據導出
- 新增 `exports/` 模塊
- 新增 `routers/exports.py`
- 新增 `services/export_service.py`
- 只讀取 `models/user.py`,不修改
踩坑2:計劃粒度太粗,代理唔知道邊界喺邊
我第一次寫嘅計劃淨係話"開發通知系統",代理唔知道佢唔可以碰 models/user.py,結果又改咗。計劃裏面必須明確寫出"唔修改"嘅文件列表,呢個同我之前講嘅OpenSpec規範"排除範圍"係一個道理——話俾AI知唔做啲乜,比話俾佢知做啲乜更重要。
第3步:用git worktree創建隔離空間
呢個係並行代理嘅安全網。 每個代理喺自己嘅worktree裏面幹活,互相唔干擾。
/superpowers:using-git-worktrees
創建3個worktree:
# 通知系統的worktree
git worktree add .worktrees/notifications -b feature/notifications
# 文件上傳的worktree
git worktree add .worktrees/uploads -b feature/uploads
# 數據導出的worktree
git worktree add .worktrees/exports -b feature/exports
踩坑3:唔記得驗證worktree目錄被gitignore
我第一次創建worktree之後,git status 顯示 .worktrees/ 下面嘅文件全部被追蹤咗——因為 .gitignore 裏面冇呢個目錄。創建worktree之前必須確認目錄被忽略:
git check-ignore -q .worktrees
# 如果返回非0,說明沒被忽略,需要添加:
echo ".worktrees/" >> .gitignore
git add .gitignore
git commit -m "chore: 忽略worktree目錄"
踩坑4:worktree裏面唔記得安裝依賴
worktree係代碼嘅獨立副本,但唔包含 node_modules、__pycache__ 等。每個worktree創建後必須重新安裝依賴:
cd .worktrees/notifications
pip install -r requirements.txt # Python項目
# 或 npm install # Node.js項目
# 或 go mod download # Go項目
第4步:前置任務 — subagent-driven串行執行
前置任務(拆分用戶模型)用subagent-driven-development執行。呢個任務必須先完成,因為3個並行任務都依賴佢。
/superpowers:subagent-driven-development
執行流程:
1. 派實現代理
AI根據計劃派出一個全新嘅代理,淨係俾佢前置任務嘅上下文:
你是一個實現代理。你的任務是:
任務0:拆分用戶模型
文件:
- 修改:models/user.py
- 新增:models/notification_preference.py
- 新增:models/storage_quota.py
- 測試:tests/test_user_model.py
步驟:
1. 寫失敗測試
2. 運行測試確認失敗
3. 實現最小代碼
4. 運行測試確認通過
5. 提交
約束:
- 不修改 models/user.py 以外的文件
- 使用項目現有的測試框架(pytest)
- 遵循項目現有的代碼風格
注意:代理嘅上下文係精確構建嘅,唔係繼承會話嘅完整歷史。 呢個係subagent-driven嘅核心優勢——代理只睇到佢需要嘅信息,唔會被無關上下文干擾。
2. 實現代碼+自審
代理執行TDD流程:寫測試、跑測試、寫實現、跑測試、自審、提交。
3. 派規範審查代理
實現完成後,派一個全新嘅代理檢查規範合規:
你是一個規範審查代理。檢查以下實現是否符合規範:
規範要求:
1. 從user.py提取通知偏好到獨立模型
2. 從user.py提取存儲配額到獨立模型
3. 原有功能不受影響
請檢查:
- 每個規範要求是否有對應實現
- 是否有超出規範的額外實現
- 是否有遺漏
4. 派代碼質量審查代理
規範審查通過後,再派一個全新代理檢查代碼質量:
你是一個代碼質量審查代理。審查以下文件的代碼質量:
文件:
- models/user.py
- models/notification_preference.py
- models/storage_quota.py
檢查維度:
- 命名是否清晰
- 錯誤處理是否完整
- 是否有重複代碼
- 測試覆蓋是否充分
踩坑5:審查代理同實現代理用同一個模型,浪費token
Superpowers嘅模型選擇策略係:
實現代理唔需要最強嘅模型——計劃已經寫清楚咗每一步,佢只需要機械執行。審查代理先需要最強嘅模型,因為審查需要判斷力同理解力。
第5步:並行任務 — dispatching-parallel-agents同時開工
前置任務完成後,3個功能可以並行開發喇。
關鍵:每個代理必須得到精確嘅上下文。 代理唔知道其他代理嘅存在,亦唔知道項目嘅完整歷史——你俾乜佢就用乜。
代理A嘅指令(通知系統):
你是一個實現代理。你的任務是開發通知系統。
工作目錄:.worktrees/notifications
分支:feature/notifications
文件:
- 新增:notifications/__init__.py
- 新增:notifications/models.py(通知模型)
- 新增:notifications/service.py(通知服務)
- 新增:routers/notifications.py(API路由)
- 新增:tests/test_notifications.py
規範:
1. 用戶可以創建通知
2. 用戶可以標記通知為已讀
3. 用戶可以獲取未讀通知列表
4. 支持郵件和站內信兩種通知渠道
約束:
- 不修改 models/user.py
- 不修改 models/notification_preference.py
- 不修改任何現有文件
- 使用 pytest 測試框架
- 遵循項目現有的代碼風格
TDD流程:
每個功能點:寫失敗測試 → 運行測試 → 寫最小實現 → 運行測試 → 提交
完成後返回:實現的文件列表、測試結果、自審報告
代理B嘅指令(文件上傳):
你是一個實現代理。你的任務是開發文件上傳功能。
工作目錄:.worktrees/uploads
分支:feature/uploads
文件:
- 新增:uploads/__init__.py
- 新增:uploads/models.py(上傳記錄模型)
- 新增:uploads/service.py(上傳服務)
- 新增:routers/uploads.py(API路由)
- 新增:tests/test_uploads.py
規範:
1. 用戶可以上傳文件(最大50MB)
2. 用戶可以獲取自己的上傳列表
3. 用戶可以刪除自己上傳的文件
4. 檢查文件類型白名單
約束:
- 不修改 models/user.py
- 不修改 models/storage_quota.py
- 不修改任何現有文件
- 使用 pytest 測試框架
完成後返回:實現的文件列表、測試結果、自審報告
代理C嘅指令(數據導出):
你是一個實現代理。你的任務是開發數據導出功能。
工作目錄:.worktrees/exports
分支:feature/exports
文件:
- 新增:exports/__init__.py
- 新增:exports/service.py(導出服務)
- 新增:routers/exports.py(API路由)
- 新增:tests/test_exports.py
規範:
1. 用戶可以導出自己的數據為CSV
2. 用戶可以導出自己的數據為JSON
3. 大數據量導出使用流式響應
4. 只能導出自己的數據
約束:
- 只讀取 models/user.py,不修改
- 不修改任何現有文件
- 使用 pytest 測試框架
完成後返回:實現的文件列表、測試結果、自審報告
3個代理同時開工,各自喺自己嘅worktree裏面幹活。
踩坑6:代理指令裏面少咗"唔修改"約束
我第一次寫代理指令時淨係話"開發通知系統",冇寫"唔修改 models/user.py"。代理覺得喺 user.py 裏面加個 notifications 字段更方便,就直接改咗。同踩坑2係同一個問題喺唔同階段嘅表現——計劃階段要寫排除範圍,派發階段亦要寫排除範圍。
踩坑7:代理返回嘅狀態冇處理好
代理執行完後可能返回4種狀態:
| | |
|---|
| | |
| | |
| | |
| | 根據原因處理:加信息、換強模型、拆小任務、升級俾人 |
最常見嘅錯誤:見到DONE_WITH_CONCERNS就忽略疑慮直接審查。 代理話"我完成咗,但擔心導出大數據時內存溢出"——呢種疑慮可能指向真實問題,必須在審查前處理。
第6步:審查同合併
3個代理都返回後,需要審查同合併。
審查順序:
合併策略:
# 切回主分支
git checkout main
# 逐個合併(順序不重要,因為文件不衝突)
git merge feature/notifications
git merge feature/uploads
git merge feature/exports
# 跑全量測試
pytest
# 清理worktree
git worktree remove .worktrees/notifications
git worktree remove .worktrees/uploads
git worktree remove .worktrees/exports
踩坑8:合併後唔記得跑全量測試
每個代理喺自己嘅worktree裏面測試都通過咗,但合併後可能出問題——譬如3個功能都註冊咗同名嘅路由,單獨跑冇問題,合併後衝突咗。合併後必須跑全量測試,呢個係鐵律。
用Superpowers嘅verification-before-completion Skill強制執行:
/superpowers:verification-before-completion
呢個Skill要求你提供當前對話中運行嘅測試結果,唔跑測試唔可以話"搞掂咗"。
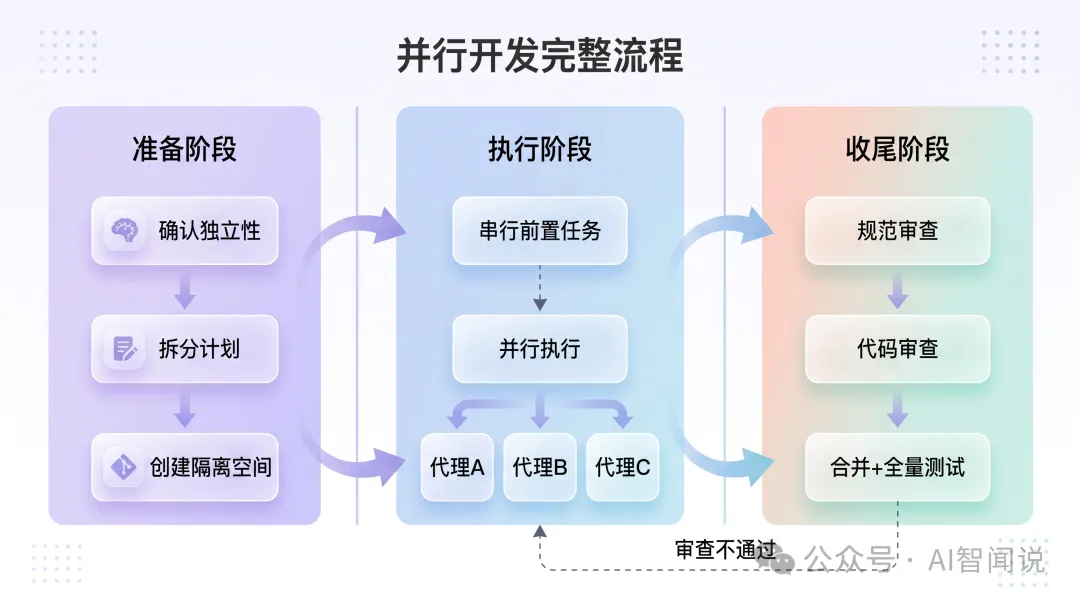
三、完整流程一覽
將6步串起來,完整嘅並行開發流程:
準備階段:
brainstorming — 確認任務獨立性,識別文件衝突writing-plans — 拆分計劃,明確每個代理嘅邊界同約束using-git-worktrees — 為每個並行任務創建隔離空間執行階段:
subagent-driven — 串行執行前置任務(有依賴嘅任務)dispatching-parallel-agents — 並行執行獨立任務(3個代理同時開工)收尾階段:
核心原則:前置任務串行確保基礎穩固,獨立任務並行確保速度最大化。
當流程出問題時點算?
代理間文件衝突 — 說明任務唔係真正獨立嘅,回退到串行模式代理返回BLOCKED — 根據原因處理:補充信息、換更強嘅模型、拆小任務、升級俾人合併後測試失敗 — 用systematic-debugging Skill定位根因,修復後重新跑全量測試代理改咗唔應該改嘅文件 — 指令裏面加更明確嘅約束,或者喺worktree裏面用 .git/info/exclude 限制可修改文件代理返回DONE_WITH_CONCERNS — 先評估疑慮嘅嚴重性,再決定是否進入審查流程審查唔通過 — 派新嘅修復代理(唔好複用原來嘅代理,上下文已經污染咗)所有代理都失敗 — 計劃可能有問題,回到brainstorming重新評估四、8個坑嘅完整清單
五、自定義Skill:等並行代理自動避坑
上面8個坑,有4個可以通過自定義Skill自動解決。我寫咗兩個銜接Skill:
---
name: parallel-agent-guard
description: Use when 準備派發並行代理時,在dispatching-parallel-agents之前自動加載。檢查任務獨立性、生成代理指令、驗證worktree配置
---
# 並行代理安全守衞
## 鐵律
並行代理的前提是任務獨立。不獨立的任務必須串行執行。
## 執行步驟
1. 檢查任務列表,識別每個任務涉及的文件
2. 如果多個任務修改同一文件,標記為衝突,建議拆分或串行
3. 為每個任務生成代理指令模板,包含:
- 工作目錄(worktree路徑)
- 分支名
- 新增文件列表
- 修改文件列表
- 不修改文件列表(排除範圍)
- 規範要求
- TDD流程要求
- 返回格式(文件列表、測試結果、自審報告)
4. 驗證worktree配置:
- 確認目錄被gitignore
- 確認依賴已安裝
- 確認基線測試通過
5. 檢查代理指令中的排除範圍是否完整
## 代理指令模板
每個代理指令必須包含:
- 工作目錄
- 分支名
- 文件清單(新增/修改/不修改)
- 規範要求
- 約束條件(排除範圍)
- TDD流程要求
- 返回格式
## 常見問題
- "兩個任務都讀同一個文件":只讀不寫,不算衝突
- "兩個任務都改同一個文件":必須拆出前置任務,或串行執行
- "不確定是否衝突":按衝突處理,安全第一
---
name: parallel-merge-verify
description: Use when 並行代理全部返回後,在合併分支之前自動加載。驗證合併安全性、跑全量測試、檢查代理狀態
---
# 並行合併驗證
## 鐵律
合併前必須驗證。每個代理測試通過不等於合併後通過。
## 執行步驟
1. 檢查每個代理的返回狀態:
- DONE:進入審查
- DONE_WITH_CONCERNS:先評估疑慮,再審查
- NEEDS_CONTEXT:補充信息,重新派發
- BLOCKED:根據原因處理
2. 對每個代理的結果做雙重審查:
- 規範審查:實現是否符合規範
- 代碼質量審查:代碼質量是否達標
3. 審查通過後,逐個合併分支
4. 合併後跑全量測試
5. 全量測試通過後,清理worktree
## 審查模型選擇
- 規範審查:用最強模型(需要理解規範語義)
- 代碼質量審查:用最強模型(需要判斷代碼質量)
- 實現代理:用最便宜的模型即可(規範明確,機械執行)
## 常見問題
- "合併衝突":說明任務不是真正獨立,回退到串行模式
- "合併後測試失敗":用systematic-debugging定位根因
- "審查不通過":派新的修復代理(不復用原代理)
呢兩個Skill直接解決咗8個坑中嘅4個:
parallel-agent-guard — 解決坑1(檢查文件衝突)、坑2(生成排除範圍)、坑6(指令裏面加約束)parallel-merge-verify — 解決坑7(處理DONE_WITH_CONCERNS)、坑8(合併後強制跑測試)加上Superpowers自帶嘅功能(worktree驗證、模型選擇),8個坑淨係得2個需要人手手動把關:坑1嘅根源判斷同坑6嘅約束補充。
六、並行代理嘅真實成本:速度翻倍,token都翻倍
並行代理唔係免費嘅午餐。我必須將成本問題講清楚,否則你用咗之後會被賬單嚇親。
社區實測數據揭示咗幾個關鍵結論:
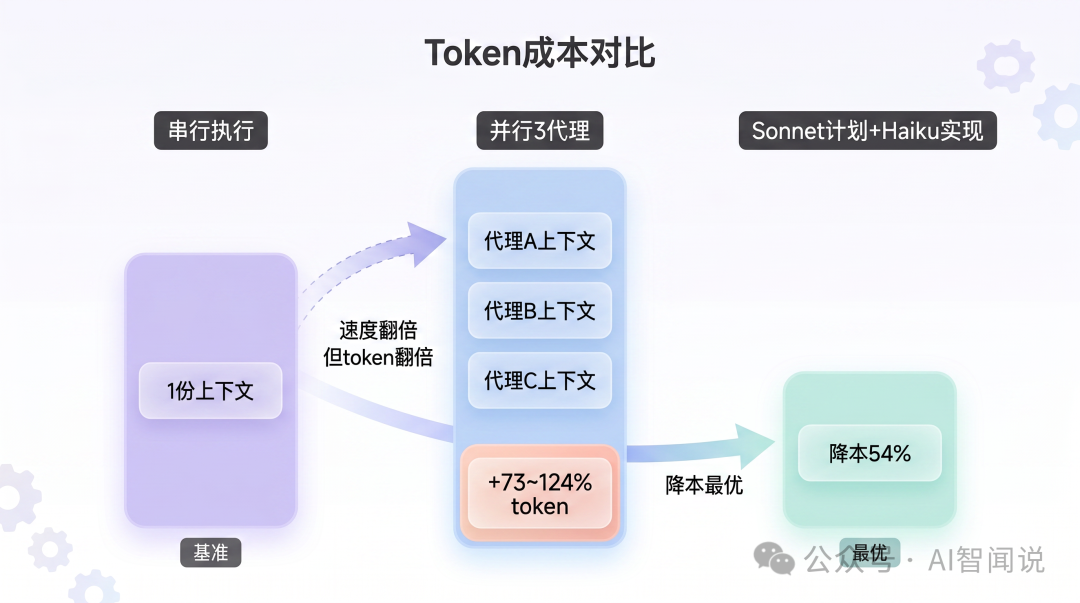
並行代理比串行多用73-124%嘅token。 每個代理獨立加載項目上下文——3個代理就係3份80K token嘅上下文。串行執行時,第2個代理可以複用第1個代理嘅緩存,但並行時每個代理都要由零加載
2. 最大嘅降本槓桿唔係並行,而係計劃。 寫好計劃(CONTRACT.md)再叫代理實現,成本降54%,質量由5分升到9分。呢個效果遠超並行帶來嘅速度收益
3. Haiku實現+Sonnet審查嘅組合最慳。 Haiku寫代碼嘅質量同Sonnet差唔多(有計劃嘅前提下),但成本淨係得Sonnet嘅36%。但前提係計劃必須由Sonnet寫——Haiku自己寫計劃,質量直接崩到4.9分上下文隔離先係並行代理嘅核心價值,唔係並行本身。 好多人以為並行代理嘅價值係"3個代理同時幹活,慳2/3時間"。呢個只係表面。真正嘅價值係:每個代理嘅上下文係乾淨嘅——佢只睇到自己需要嘅信息,唔會被會話歷史裏面幾十輪對話嘅噪音干擾。
一個喺主會話裏面做咗30分鐘任務嘅AI,上下文裏面堆滿咗之前嘅搜索結果、調試日誌、廢棄方案。呢個時候叫佢寫新功能,佢會參考那些已經過時嘅信息。但一個全新派出嘅代理,淨係拿到佢需要嘅5條信息,乾淨利落。
所以並行代理最適合嘅場景唔係"趕時間",而係"任務需要乾淨上下文"。 就算你淨係得一個任務,用subagent-driven派一個乾淨嘅代理出去,都好過喺主會話裏面繼續做——因為主會話嘅上下文已經污染咗。
幾時並行,幾時串行:
判斷標準:任務之間是否改同一個文件。 如果3個任務改嘅文件完全唔同,並行代理可以慳2/3嘅時間。如果有任何文件重疊,先拆出前置任務,再並行。如果token預算緊張,優先保證質量(subagent-driven + 好計劃),而唔係追求速度(parallel-agents)。
由串行過渡到並行:
如果你已經用緊sub-agent-driven:喺下一個有多個獨立任務嘅項目中,先用brainstorming確認獨立性,再用parallel-agents並行派發如果你未用過Superpowers嘅代理模式:先從subagent-driven開始,熟悉"派代理+審查"嘅流程後,再嘗試並行如果你token預算有限:先將計劃寫好(用Sonnet寫),再叫Haiku實現——呢個降本效果比並行慳錢多得多七、效果對比:4種模式嘅數據一覽
用同一個項目(Python FastAPI應用3個獨立功能)做對比(以下數據嚟自作者個人經驗,僅供參考):
組合模式(前置任務subagent-driven + 獨立任務parallel-agents)嘅綜合表現最好。 佢既有subagent-driven嘅質量保障,又有parallel-agents嘅速度優勢。
數據說明: 開發時間包括編寫、測試、審查同修復。parallel-agents嘅測試覆蓋略低,係因為並行代理各自跑自己嘅測試,冇集成測試——合併後需要補集成測試。組合模式在並行任務完成後,會用subagent-driven補一輪集成測試同雙重審查,所以測試覆蓋同subagent-driven持平。返工次數指因方向錯誤或質量唔達標需要返工嘅次數。
八、Claude Code原生支持:3種並行方式
Superpowers嘅代理模式基於Claude Code嘅Agent工具。瞭解底層能力,你先可以更好地理解Superpowers在做乜。
Claude Code提供咗3種並行方式:
1. 子代理(Subagent)
喺當前會話內派出一個代理,佢有自己嘅200K token上下文窗口、自己嘅工具訪問權限。完成後返回一條摘要消息,所有中間過程(搜索結果、文件讀取、工具調用)都留喺子代理嘅上下文裏面,唔污染主會話。
Superpowers嘅subagent-driven-development用的就係呢個。
2. Agent View(後台代理)
用 claude agents 命令打開一個管理界面,可以派發同監控後台會話。每個後台會話獨立運行,你可以隨時檢查狀態。按Ctrl+B可以將當前運行嘅子代理移到後台。
Superpowers嘅dispatching-parallel-agents喺Claude Code中就係通過呢種方式實現嘅——3個後台代理同時運行,互相唔干擾。
3. /batch命令
Claude Code內置嘅批量命令,自動將一個大改動拆成5-30個worktree隔離嘅子代理,每個子代理開一個PR。適合全倉庫級別嘅遷移或機械性重構。
3個重要嘅限制:
子代理唔可以嵌套。 一個子代理唔可以再派子代理。所以Superpowers嘅審查代理係由控制器(主會話)派嘅,唔係由實現代理派嘅子代理嘅結果會消耗主會話嘅上下文。 3個子代理各返回5000 token嘅摘要,主會話就多咗15000 token。子代理越多,主會話上下文越容易溢出自動選擇代理類型唔可靠。 Claude有時會選錯代理類型——應該用通用代理時用了探索代理,或者過度派發子代理。Superpowers通過精確指定代理類型同上下文來避免呢個問題Claude Code仲支持團隊模式(Agent Teams)— 多個協調嘅會話共享任務列表,可以互相發消息。呢個係比子代理更高層嘅抽象,適合大型項目。但目前仲係實驗性功能,默認關閉。
九、進階:代理指令嘅6個關鍵要素
寫妤代理指令係並行代理成功嘅核心。一條好嘅代理指令必須包含6個要素:
1. 身份定義
唔好淨係話"寫通知系統",要明確代理嘅角色:
你是一個實現代理。你的任務是開發通知系統。
2. 工作環境
代理必須知道喺邊度工作:
工作目錄:.worktrees/notifications
分支:feature/notifications
3. 文件清單
精確到每個文件,分為三類:
新增:
- notifications/__init__.py
- notifications/models.py
- notifications/service.py
- routers/notifications.py
- tests/test_notifications.py
修改:
- main.py(註冊路由)
不修改:
- models/user.py
- models/notification_preference.py
- 任何現有測試文件
4. 規範要求
用"假設/當/則"格式寫清楚每個場景:
規範:
1. 用戶可以創建通知
- 假設 用戶已登錄
- 當 用戶發送創建通知請求
- 則 返回201和通知詳情
2. 用戶可以獲取未讀通知
- 假設 用戶有5條未讀通知
- 當 用戶請求未讀列表
- 則 返回5條通知
5. 約束條件
排除範圍同邊界條件:
約束:
- 不修改 models/user.py
- 不實現推送通知(只做站內信和郵件)
- 文件不超過200行
- 遵循項目現有的代碼風格
6. 返回格式
代理必須返回乜嘢信息:
完成後返回:
1. 實現的文件列表
2. 測試結果(pytest輸出)
3. 自審報告(自己發現的問題)
4. 狀態標記:DONE / DONE_WITH_CONCERNS / NEEDS_CONTEXT / BLOCKED
6個要素缺一不可。 少咗身份定義,代理唔知道自己嘅角色;少咗工作環境,代理唔知道喺邊度工作;少咗文件清單,代理可能改錯文件;少咗規範要求,代理自己猜需求;少咗約束條件,代理可能做多咗或少做;少咗返回格式,你唔知道代理做咗啲乜。
3分鐘上手
安裝Superpowers後,按呢個順序行你嘅第一個並行任務:
/superpowers:brainstorming 確認任務獨立性,識別文件衝突如果有衝突,拆出前置任務(subagent-driven串行執行)/superpowers:writing-plans 拆分計劃,每個任務明確文件邊界/superpowers:using-git-worktrees 為每個並行任務創建隔離空間/superpowers:subagent-driven-development 執行前置任務/superpowers:dispatching-parallel-agents 並行執行獨立任務合併分支 + 跑全量測試 + /superpowers:verification-before-completion第1步同第6步係關鍵——如果你淨係記兩件事:先確認獨立性再並行,合併後必須跑全量測試。
寫到最後
並行代理嘅本質係將"一個人做三件事"變成"三個人各自做一件事"。但前提係你要將三件事拆乾淨——任務之間嘅依賴關係、文件邊界、約束條件,呢啲準備工作決定咗並行代理係加速定係加速翻車。
Superpowers提供咗工具,但工具唔可以替你思考。brainstorming幫你確認獨立性,writing-plans幫你拆分邊界,worktrees幫你隔離空間,subagent-driven幫你保障質量——呢啲準備步驟唔係可選項,而係並行代理能夠成功嘅前提。
仲有一個容易被忽略嘅事實:一個乾淨嘅代理比一個上下文污染嘅主會話更可靠,就算你淨係得一個任務。
5條起步規則:
先brainstorming確認獨立性——唔係功能獨立,而係文件獨立代理指令裏面寫清楚"唔做啲乜"——排除範圍比需求更重要Sonnet寫計劃+Haiku實現——降本54%,質量反而提升留意token成本——並行比串行多用73-124%嘅token,預算緊張時優先保證質量掃碼關注「AI智聞說」,每日3分鐘掌握AI新知識