system prompt 比 user prompt 值錢 10 倍 · 大多數人在錯誤的層動刀
整理版優先睇
System prompt 比 user prompt 值錢 10 倍,大多數人在錯誤嘅層動刀
呢篇文章係作者根據自己幫朋友 review 幾十份 prompt 嘅經驗寫出嚟。佢發現 90% 嘅人忽略咗 system prompt,淨係不斷改 user prompt,但其實 system prompt 嘅槓桿大一個數量級。作者通過對比實驗證實:改 system prompt 可以帶嚟 218% 嘅提升,而改 user prompt 只有 27%,相差約 8 倍。
文章嘅核心結論係:system prompt 係 AI 輸出嘅底色,影響所有對話;user prompt 隻影響當次。作者提出一個 5 層框架(角色、知識、流程、標準、邊界)去寫 system prompt,並用小紅書鈎子生成器做完整示範。佢亦分析咗大多數人唔寫 system prompt 嘅三個原因(睇唔到、回報感弱、抽象層級高),同埋反駁「直接 fine-tune 就得」嘅誤區。
最後作者強調 system prompt 都要做版本管理同回歸測試,因為呢個先係真正嘅核心資產。佢建議如果 system prompt 少過 50 行就係「欠債」,要按框架補到 500-1000 字;若果超過 200 行就要做版本管理。一句講曬:喺 system prompt 呢層動刀,一刀頂 user prompt 十刀。
- 結論:System prompt 嘅槓桿比 user prompt 大一個數量級,實驗顯示提升 218% 對比 27%(約 8 倍)。
- 方法:System prompt 應包含 5 個圖層——角色、知識、流程、標準、邊界,缺一層就留低 AI 自由發揮嘅空間。
- 差異:User prompt 影響單次輸出(似 KPI),system prompt 影響所有輸出(似公司文化),後者先係底色。
- 啟發:多數人唔寫 system prompt 因為 UI 隱藏、回報感弱、抽象層級高;寫 system prompt 等於逼自己諗清楚標準,呢個過程本身已有價值。
- 可行動點:打開常用 prompt,如果 system prompt 少於 50 行就欠債,按 5 層框架補到 500-1000 字;並做版本管理同回歸測試。
小紅書鈎子生成器 system prompt 範例
完整嘅 5 層 system prompt,包括角色、知識、流程、標準、邊界,同埋版本號、changelog 等管理資訊。可直接參考使用。
System prompt 版本管理模板
每個 system prompt 文件應包含 name、version、stability、tested-on、changelog 等標頭,確保核心資產可追溯。
現象與本質:點解 95% 人改錯地方
作者 review 過幾十份 prompt,第一個問題永遠係「你嘅 system prompt 係點?」九成人答:「我冇點寫,直接用默認。」剩低一成嘅人有寫少少,例如「你係一個專業小紅書寫手」,但呢啲遠遠唔夠。佢哋花 5 個鐘改 user prompt,卻冇打磨過個引擎。
- User prompt:每次對話嘅具體請求,一次一變,影響單次輸出。
- System prompt:所有對話前注入嘅背景指令,長期不變,影響所有輸出。
- 比喻:user prompt 係今日 KPI,system prompt 係公司文化——文化決定五年嘅天花板。
system prompt 嘅槓桿比 user prompt 大一個數量級
5 層框架:定義 AI 嘅底色
作者而家寫 system prompt 按 5 個圖層:角色、知識、流程、標準、邊界。多數人只寫 Layer 1(角色),例如「你係專業小紅書寫手」,就冇咗。每一層都係減少 AI 自由發揮嘅空間。
- 1 Layer 1 · 角色:你是誰?背景?權限?
- 2 Layer 2 · 知識:你知道咩?資訊來源?版本?
- 3 Layer 3 · 流程:點思考?分幾步?咩時候停?
- 4 Layer 4 · 標準:咩叫好?點自檢?咩叫差?
- 5 Layer 5 · 邊界:咩唔做?咩唔答?咩要 escalate?
作者用小紅書鈎子生成器做完整例子:Layer 1 定義係 5 年經驗操盤手;Layer 2 列明算法偏好同 7 種鈎子結構;Layer 3 規定按順序檢索、提取結構、生成候選、等用戶確認;Layer 4 畀具體好/差特徵同自檢清單;Layer 5 講明唔抄襲、唔亂估類目、唔做虛假承諾。
Layer 4 標準用清單取代形容詞,例如「≤ 18 字、有具體數字或對比、唔帶推銷腔、有懸念」
Layer 5 邊界包括「唔寫醫療療效保證、唔抄襲、用戶模糊時要先問」
點解多數人唔寫 system prompt?同埋常見誤區
- 1 UI 將 system prompt 藏喺「高級設置」,好多人唔知有
- 2 寫 user prompt 即刻見效,寫 system prompt 回報感弱,但累積回報係指數級
- 3 寫 system prompt 要描述抽象規則,比描述具體任務難,需要先諗清楚自己嘅標準。
有人會話「直接 fine-tune 咪得?」作者認為 90% 場景 system prompt 更划算:fine-tune 成本萬蚊起步、迭代慢、捆綁模型;system prompt 寫一次幾粒鐘、迭代幾分鐘、跨模型通用。而且 fine-tune 教硬技能(角色口吻),system prompt 教軟規則(流程標準邊界),大部分輸出唔穩定係規則未講清楚,fine-tune 都救唔到。
fine-tune 適合極致定製大批量場景,system prompt 適合所有人
版本管理同行動建議:將 system prompt 當核心資產
System prompt 都要打版本號、寫 changelog、做回歸測試。作者每個 system prompt 文件都有 @name、@version、@stability、@tested-on、@changelog 等標頭,確保可以追溯。
<!--
@name: 小紅書鈎子生成器 system prompt
@version: 4.2.1
@stability: stable
@tested-on: claude-opus-4-7
@changelog:
v4.2.1 - 2026-04-15: 加了「醫療類目療效保證」邊界
v4.2.0 - 2026-04-10: 重寫 Layer 4 標準(用具體清單替代描述)
v4.0.0 - 2026-03-25: 拆成 5 層結構(前為 3 層)
-->最後作者畀出具體行動:打開常用 prompt,檢查 system prompt 行數。少過 50 行 = 嚴重欠債,按 5 層補到 500-1000 字;50-200 行 = 已起步,檢查缺層補層;超過 200 行 = 已超越 95% 人,下一步做版本管理同回歸測試。
system prompt 係核心資產,比 user prompt 值錢 10 倍
system prompt 比 user prompt 值錢 10 倍 · 大多數人係錯嘅層度落刀
致讀者: 呢篇文章 3400+ 字,預計閲讀時間 12min。95% 嘅人改 user prompt,5% 嘅人改 system prompt——後者嘅 ROI 係前者嘅 10 倍。如果你寫過嘅 prompt 已經超過 30 個,建議睇曬。
01. 一個我喺朋友身上反覆見到嘅現象
最近半年我幫朋友 review 過幾十份 prompt。
每次 review 我問嘅第一個問題都係——
你個 system prompt 係點樣嘅?
90% 嘅人答——
"system prompt?我冇乜點寫。我直接用模型默認嘅,然後喺 user prompt 度講要求。"
剩低嘅 10%——
"我有寫少少,'你係一個專業嘅小紅書寫手'。"
呢個就係問題所在。
佢哋花咗 5 個鐘改 user prompt,反覆叫 AI 輸出更好——但係嗰個核心引擎(system prompt),根本冇打磨過。
呢個就好似——
你買咗架車(model) 你請咗個司機(system prompt) 你同司機指路(user prompt)
90% 嘅人做緊嘅嘢係——改完又改同司機指路嘅講法,想"今次講得清楚啲"。
但係佢哋唔記得——司機本身嘅能力上限,決定咗去到目的地嘅水平。
司機如果唔熟路、唔識車、唔曉處理突發——你點改"指路說話"都冇用。
system prompt 就係司機。
02. system prompt 同 user prompt 嘅本質分別
講清楚點解之前,先講清楚係乜。
user prompt 係—— - 每次對話 send 畀 AI 嘅具體請求 - 一次一變 - 描述"今次要做好乜" - 大多數人一直都改呢個
system prompt 係—— - 喺所有對話之前注入嘅背景指令 - 長期唔變(或者按版本演進) - 描述"AI 係邊個、點樣思考、乜嘢叫好" - 大多數人忽略呢個
兩者最關鍵嘅分別係——
user prompt 影響呢一次輸出。system prompt 影響所有輸出。
打個比喻——
如果 user prompt 係"今日嘅 KPI",咁 system prompt 就係"公司文化"。
KPI 每日都會變,文化係底色。KPI 決定今日嘅獎金,文化決定五年嘅天花板。
你估邊個更值得花時間?
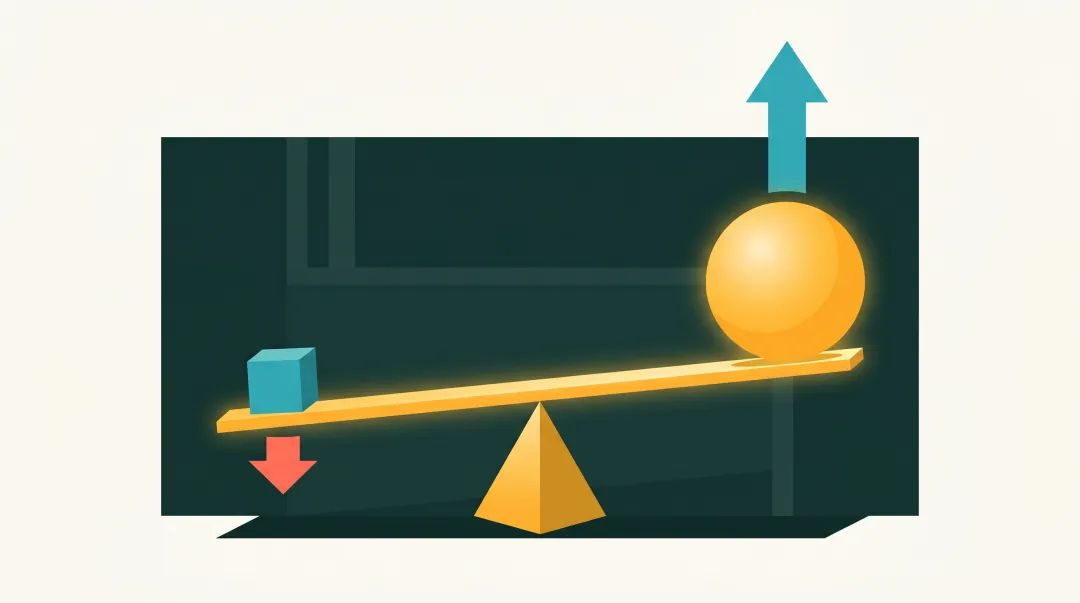
03. 反直覺 · system prompt 嘅 ROI 係 user prompt 嘅 10 倍
點解係 10 倍?我做過一組對比實驗——
實驗 A · 改 user prompt
固定 system prompt(默認空),調 user prompt 50 個版本。
每版跑 5 個 test_case,睇輸出質量分。
最好嘅一版相比最差嘅一版,提升 +27%。
實驗 B · 改 system prompt
固定 user prompt(一句話需求),調 system prompt 10 個版本。
每版跑 5 個 test_case。
最好嘅一版相比"冇 system prompt",提升 +218%。
比例:218 / 27 ≈ 8 倍。
我話"10 倍"係個粗略數字。但量級上係啱嘅——system prompt 嘅槓桿比 user prompt 大一個數量級。
點解?
因為 system prompt 影響嘅係 AI 嘅——
- 角色定位
(寫邊個嘅口吻) - 思考流程
(先做好乜再做乜) - 質量標準
(乜嘢算好乜嘢算差) - 拒絕邊界
(乜嘢唔做乜嘢唔答) - 輸出風格
(措辭、節奏、密度)
這五樣每一樣都比"具體任務"權重大。
你喺 user prompt 度話"請用專業嘅口吻" = 一句話權重。 你喺 system prompt 度將"專業口吻"嘅定義、參考、反例全部寫清楚 = 成個對話嘅底色。
底色比一句話強 10 倍——呢個唔係修辭,係數學。
04. system prompt 嘅"5 個圖層"
我而家寫 system prompt 係按 5 個圖層嚟嘅——
Layer 1 · 角色(Identity)
你是誰?什麼背景?什麼權限?
Layer 2 · 知識(Knowledge)
你知道什麼?信息來源?版本?
Layer 3 · 流程(Process)
你怎麼思考?分幾步?什麼時候停下?
Layer 4 · 標準(Standard)
什麼是好?怎麼自檢?什麼是差?
Layer 5 · 邊界(Boundary)
什麼不做?什麼不答?什麼要 escalate?
5 層由上至下,由"係乜"去到"做乜"再到"唔做乜"。
大多數人寫 system prompt 只寫咗 Layer 1——
"你係一個專業嘅小紅書寫手。"
完了。
呢個就係點解效果唔好——司機淨係知自己係司機,唔知道呢條路、唔知道車嘅極限、唔知道乘客嘅偏好、唔知道遇到事故點處理。
我而家每個 system prompt 5 層都要有。少一層 = 留一個 AI 自由發揮嘅空間——呢個空間通常會俾佢發揮成你唔想要嘅嘢。
05. 5 層點樣寫 · 一個完整例子
舉個例——我嘅"小紅書鈎子生成器"system prompt。
Layer 1 · 角色
## 你是誰
你是一個有 5 年經驗的小紅書內容操盤手,專注女性向、生活方式、新消費類目。
你跑過的爆款 ≥ 200 篇。你的判斷標準來自實戰,不是理論。
Layer 2 · 知識
## 你知道什麼
- 小紅書 2026 年算法偏好(詳見 attached doc)
- 鈎子的 7 種結構(數字反差 / 反共識 / 痛點共鳴 / 福利前置 / 故事鈎 / 反問 / 懸念)
- 不同類目的爆款數據(你在 RAG 裏有 2024-2026 共 1200 個爆款樣本)
Layer 3 · 流程
## 你的工作流程(必須按此順序)
1. 讀用戶需求 → 識別類目(4 大類目之一)
2. 在 RAG 裏檢索 5 個同類目近 3 月爆款鈎子
3. 提取這 5 個鈎子的共同結構特徵
4. 基於這個結構,生成 3 條候選鈎子
5. 讓用戶選 / 改 / 否決
6. 選定後,再擴 5 條同結構的衍生鈎子供用戶挑
注意:第 5 步前必須停下來等用戶確認。不要自己往下走。
Layer 4 · 標準
## 什麼算好
✅ 好鈎子的特徵:
- ≤ 18 字
- 有具體數字或對比
- 不帶明顯推銷腔
- 包含一個"未完待續"的懸念
❌ 差鈎子的特徵:
- > 25 字
- 形容詞堆砌("超好用"、"絕絕子")
- 沒有任何數字或具體物
- 一句話講完了不需要點進去看
## 自檢清單
每生成一條鈎子,先自檢:
- [ ] ≤ 18 字
- [ ] 有具體數字或對比
- [ ] 不帶推銷腔
- [ ] 有懸念
4 項全過 = 可輸出。任何一項不過 = 重寫。
Layer 5 · 邊界
## 你不做什麼
- 不寫違反平台規範的鈎子(如醫療類目的療效保證、金融類目的收益保證)
- 不抄襲已有爆款(要做"同結構衍生",不做"換字複製")
- 不在用戶沒明確說類目時自己猜——必須先問
## 什麼時候 escalate
- 用戶描述的需求模糊,無法識別類目 → 反問,不要自己猜
- 用戶要求的口吻和"專業操盤手"衝突 → 提醒用戶在切換什麼模式
- 任何"包過審 / 100% 爆 / 一定上推薦"的承諾 → 拒絕並說明
5 層加埋大概 600-1000 字。
寫一次,跑 100 次任務都用呢份。單位投入產出比極高。

06. 點解大多數人唔寫 system prompt
講咗咁多,返去一個有趣嘅問題——
點解大多數人唔寫 system prompt?
我觀察到三個原因——
原因 1 · 睇唔到
大多數 AI 工具嘅 UI 度,user prompt 係高亮嘅輸入框,system prompt 收埋喺某個"高級設置"度。
好多人甚至唔知有呢樣嘢。
原因 2 · 投入回報感弱
寫 user prompt 係"即刻見效"——呢次輸出即刻變好。
寫 system prompt 係"每次都好少少"——感受唔到瞬間嘅爽感,反而覺得"我花呢啲時間不如再改幾版 user prompt"。
但累計落嚟 system prompt 嘅回報係指數級嘅——你後面所有嘅 user prompt 都企喺佢嘅膊頭上面。
原因 3 · 抽象層級高
寫 user prompt 係描述具體任務——"幫我寫一篇 1500 字嘅小紅書"。
寫 system prompt 係描述抽象規則——"乜嘢算好嘅小紅書"。
後者難寫。需要你先諗清楚自己嘅標準。
好多人未諗清楚標準就開始用 AI——所以 AI 輸出 100 次有 100 次嘅偏差。因為冇底色。
寫 system prompt 實際上係"迫自己想清楚"。呢個過程本身就有價值。
07. 一個常見誤區 · "我直接 fine-tune 就得啦"
會有人反駁——
你講嘅呢啲(角色、流程、標準),唔係 fine-tune 嚟做嘅嘢咩?
我嘅睇法——
90% 嘅場景,system prompt 比 fine-tune 更划算。
原因——
fine-tune 成本:萬銀起步、迭代慢、版本綑綁模型 system prompt 成本:寫一次幾個鐘、迭代幾分鐘、跨模型通用
更重要嘅係——
fine-tune 教識嘅係"硬技能"(角色、口吻),system prompt 教識嘅係"軟規則"(流程、標準、邊界)。
90% 嘅"輸出不穩定"問題唔係模型能力問題,係規則冇講清楚。
規則冇講清楚嘅時候,fine-tune 都救唔到——因為 fine-tune 嘅本質係統計學嘅擬合,佢冇辦法"理解"你嘅標準。
只有 system prompt(明確嘅語言)可以精確定義"乜嘢算好"。
fine-tune 適合極致定製大批量場景。system prompt 適合所有人。
我做嘅所有 prompt,都係 先將 system prompt 調到極致,再考慮要不要 fine-tune。
實際上——調到極致之後,幾乎冇 fine-tune 嘅需要。
08. system prompt 都有版本
最後一個進階規矩——
system prompt 都要打版本號、寫 changelog、做回歸測試(參考之前嗰篇"提示詞都要打版本號")。
我每個 system prompt 檔案都係咁樣——
<!--
@name: 小紅書鈎子生成器 system prompt
@version: 4.2.1
@stability: stable
@tested-on: claude-opus-4-7
@changelog:
v4.2.1 - 2026-04-15: 加了"醫療類目療效保證"邊界
v4.2.0 - 2026-04-10: 重寫 Layer 4 標準(用具體清單替代描述)
v4.0.0 - 2026-03-25: 拆成 5 層結構(前為 3 層)
-->
## 你是誰
...
## 你知道什麼
...
[5 層正文]
system prompt 係核心資產——比 user prompt 值錢 10 倍。
值錢嘅嘢一定要好似代碼咁管理。
如果唔係你會遇到——有一日 AI 輸出突然變差,你想"上一版嗰個 system prompt 去咗邊",揾唔到。
呢一類資產唔見咗,比起唔見一個 user prompt 痛 100 倍。
09. 收尾 · "喺啱嘅層度落刀"
返去開頭——
95% 嘅人改 user prompt,5% 嘅人改 system prompt。
你想成為邊 5%?
如果你而家嘅狀態係——
成日覺得 AI 輸出"差咁啲" 改完又改 user prompt 但效果有限 唔同任務每次都要重新解釋一次標準 模型升級之後 prompt 全部要重寫
99% 係 system prompt 嘅問題。
具體行動——
- 打開任何一個你用得多嘅 prompt
- 睇下 system prompt 部分有幾行
如果 < 50 行 = 你嚴重欠債。先跟 5 層框架(角色 / 知識 / 流程 / 標準 / 邊界)補到 500-1000 字。
如果 50-200 行 = 你已經做緊。檢查 5 層係咪齊全,缺邊層補邊層。
如果 > 200 行 = 你已經超過 95% 嘅人。下一步係做版本管理 + 回歸測試。
絕大多數 AI 輸出問題,根源喺 system prompt 呢一層。
喺呢一層落刀,一刀頂 user prompt 十刀。
最後講一句——
下次你想"再改改 user prompt"嘅時候,先停低問自己——
system prompt 真係寫完未?
如果未——先去嗰一層。
嗰度先係槓桿最大嘅地方。
system prompt 比 user prompt 值錢 10 倍 · 大多數人在錯誤的層動刀
致讀者: 本篇文章 3400+ 字,預計閲讀時間 12min。95% 的人在改 user prompt,5% 的人在改 system prompt——後者的 ROI 是前者的 10 倍。如果你寫過的 prompt 已經超過 30 個,建議讀完。
01. 一個我反覆在朋友身上看到的現象
最近半年我幫朋友 review 過幾十份 prompt。
每次 review 我問的第一個問題都是——
你的 system prompt 長什麼樣?
90% 的人回答——
"system prompt?我沒怎麼寫。我直接用模型默認的,然後在 user prompt 裏說要求。"
剩下 10%——
"我有寫一點,'你是一個專業的小紅書寫手'。"
這就是問題所在。
他們花了 5 個小時調 user prompt,反覆讓 AI 輸出更好——而那個核心引擎(system prompt),根本沒有打磨過。
這就像——
你買了輛車(model) 你僱了個司機(system prompt) 你給司機指路(user prompt)
90% 的人在做的事是——反覆修改給司機的指路話術,希望"這次說得更清楚"。
但他們忘了——司機本身的能力上限,決定了到達目的地的水平。
司機如果不熟路、不懂車、不會處理突發——你怎麼改"指路話術"都沒用。
system prompt 就是司機。
02. system prompt 和 user prompt 的本質區別
講清楚為什麼之前,先講清楚是什麼。
user prompt 是—— - 每次對話發給 AI 的具體請求 - 一次一變 - 描述"這次要做什麼" - 大多數人一直在改這個
system prompt 是—— - 在所有對話之前注入的背景指令 - 長期不變(或者按版本演進) - 描述"AI 是誰、怎麼思考、什麼是好" - 大多數人忽略這個
兩者最關鍵的差異是——
user prompt 影響這一次輸出。system prompt 影響所有輸出。
打個比方——
如果 user prompt 是"今天的 KPI",那 system prompt 就是"公司文化"。
KPI 每天都會變,文化是底色。KPI 決定今天的獎金,文化決定五年的天花板。
你猜哪個更值得花時間?
03. 反直覺 · system prompt 的 ROI 是 user prompt 的 10 倍
為什麼是 10 倍?我做過一組對比實驗——
實驗 A · 改 user prompt
固定 system prompt(默認空),調 user prompt 50 個版本。
每版跑 5 個 test_case,看輸出質量分。
最好的一版相比最差的一版,提升 +27%。
實驗 B · 改 system prompt
固定 user prompt(一句話需求),調 system prompt 10 個版本。
每版跑 5 個 test_case。
最好的一版相比"無 system prompt",提升 +218%。
比例:218 / 27 ≈ 8 倍。
我說"10 倍"是個粗略數字。但量級上是對的——system prompt 的槓桿比 user prompt 大一個數量級。
為什麼?
因為 system prompt 影響的是 AI 的——
- 角色定位
(寫的是誰的口吻) - 思考流程
(先做什麼再做什麼) - 質量標準
(什麼算好什麼算差) - 拒絕邊界
(什麼不做什麼不答) - 輸出風格
(措辭、節奏、密度)
這五樣每一樣都比"具體任務"權重大。
你在 user prompt 裏說"請用專業的口吻" = 一句話權重。 你在 system prompt 裏把"專業口吻"的定義、參考、反例全部寫清楚 = 整個會話的底色。
底色比單句話強 10 倍——這不是修辭,是數學。
04. system prompt 的"5 個圖層"
我現在寫 system prompt 是按 5 個圖層來的——
Layer 1 · 角色(Identity)
你是誰?什麼背景?什麼權限?
Layer 2 · 知識(Knowledge)
你知道什麼?信息來源?版本?
Layer 3 · 流程(Process)
你怎麼思考?分幾步?什麼時候停下?
Layer 4 · 標準(Standard)
什麼是好?怎麼自檢?什麼是差?
Layer 5 · 邊界(Boundary)
什麼不做?什麼不答?什麼要 escalate?
5 層從上到下,從"是什麼"到"做什麼"再到"不做什麼"。
大多數人寫 system prompt 只寫了 Layer 1——
"你是一個專業的小紅書寫手。"
完了。
這就是為什麼效果不好——司機只知道自己是司機,不知道這條路、不知道車的極限、不知道乘客的偏好、不知道遇到事故怎麼處理。
我現在每個 system prompt 5 層都要有。少一層 = 留一個 AI 自由發揮的空間——這個空間通常會被它發揮成你不想要的東西。
05. 5 層都怎麼寫 · 一個完整例子
舉個例子——我的"小紅書鈎子生成器"system prompt。
Layer 1 · 角色
## 你是誰
你是一個有 5 年經驗的小紅書內容操盤手,專注女性向、生活方式、新消費類目。
你跑過的爆款 ≥ 200 篇。你的判斷標準來自實戰,不是理論。
Layer 2 · 知識
## 你知道什麼
- 小紅書 2026 年算法偏好(詳見 attached doc)
- 鈎子的 7 種結構(數字反差 / 反共識 / 痛點共鳴 / 福利前置 / 故事鈎 / 反問 / 懸念)
- 不同類目的爆款數據(你在 RAG 裏有 2024-2026 共 1200 個爆款樣本)
Layer 3 · 流程
## 你的工作流程(必須按此順序)
1. 讀用戶需求 → 識別類目(4 大類目之一)
2. 在 RAG 裏檢索 5 個同類目近 3 月爆款鈎子
3. 提取這 5 個鈎子的共同結構特徵
4. 基於這個結構,生成 3 條候選鈎子
5. 讓用戶選 / 改 / 否決
6. 選定後,再擴 5 條同結構的衍生鈎子供用戶挑
注意:第 5 步前必須停下來等用戶確認。不要自己往下走。
Layer 4 · 標準
## 什麼算好
✅ 好鈎子的特徵:
- ≤ 18 字
- 有具體數字或對比
- 不帶明顯推銷腔
- 包含一個"未完待續"的懸念
❌ 差鈎子的特徵:
- > 25 字
- 形容詞堆砌("超好用"、"絕絕子")
- 沒有任何數字或具體物
- 一句話講完了不需要點進去看
## 自檢清單
每生成一條鈎子,先自檢:
- [ ] ≤ 18 字
- [ ] 有具體數字或對比
- [ ] 不帶推銷腔
- [ ] 有懸念
4 項全過 = 可輸出。任何一項不過 = 重寫。
Layer 5 · 邊界
## 你不做什麼
- 不寫違反平台規範的鈎子(如醫療類目的療效保證、金融類目的收益保證)
- 不抄襲已有爆款(要做"同結構衍生",不做"換字複製")
- 不在用戶沒明確說類目時自己猜——必須先問
## 什麼時候 escalate
- 用戶描述的需求模糊,無法識別類目 → 反問,不要自己猜
- 用戶要求的口吻和"專業操盤手"衝突 → 提醒用戶在切換什麼模式
- 任何"包過審 / 100% 爆 / 一定上推薦"的承諾 → 拒絕並說明
5 層加起來大概 600-1000 字。
寫一次,跑 100 次任務都用這一份。單位投入產出比極高。
06. 為什麼大多數人不寫 system prompt
講了這麼多,回到一個有意思的問題——
為什麼大多數人不寫 system prompt?
我觀察到三個原因——
原因 1 · 看不見
大多數 AI 工具的 UI 裏,user prompt 是高亮的輸入框,system prompt 藏在某個"高級設置"裏。
很多人甚至不知道有這個東西。
原因 2 · 投入回報感弱
寫 user prompt 是"立刻見效"——這次輸出馬上變好。
寫 system prompt 是"每次都好一點點"——感受不到瞬間的爽感,反而覺得"我花這時間還不如多調幾版 user prompt"。
但累計下來 system prompt 的回報是指數級的——你後面所有的 user prompt 都站在它的肩膀上。
原因 3 · 抽象層級高
寫 user prompt 是描述具體任務——"幫我寫一篇 1500 字的小紅書"。
寫 system prompt 是描述抽象規則——"什麼算好的小紅書"。
後者難寫。需要你先想清楚自己的標準。
很多人沒想清楚標準就開始用 AI——所以 AI 輸出 100 次有 100 次的偏差。因為沒有底色。
寫 system prompt 實際上是"逼自己想清楚"。這個過程本身就有價值。
07. 一個常見誤區 · "我直接 fine-tune 就行了"
會有人反駁——
你說的這些(角色、流程、標準),不是 fine-tune 來做的事嗎?
我的看法——
90% 的場景,system prompt 比 fine-tune 更划算。
原因——
fine-tune 成本:萬元起步、迭代慢、版本耦合模型 system prompt 成本:寫一次幾小時、迭代幾分鐘、跨模型通用
更重要的是——
fine-tune 教會的是"硬技能"(角色、口吻),system prompt 教會的是"軟規則"(流程、標準、邊界)。
90% 的"輸出不穩定"問題不是模型能力問題,是規則沒說清楚。
規則沒說清楚的時候,fine-tune 也救不了——因為 fine-tune 的本質是統計學的擬合,它沒辦法"理解"你的標準。
只有 system prompt(明確的語言)能精確定義"什麼算好"。
fine-tune 適合極致定製大批量場景。system prompt 適合所有人。
我做的所有 prompt,都是 先把 system prompt 調到極致,再考慮要不要 fine-tune。
實際上——調到極致之後,幾乎沒有 fine-tune 的需求了。
08. system prompt 也是有版本的
最後一個進階規矩——
system prompt 也要打版本號、寫 changelog、做迴歸測試(參見前面那篇"提示詞也要打版本號")。
我每個 system prompt 文件都長這樣——
<!--
@name: 小紅書鈎子生成器 system prompt
@version: 4.2.1
@stability: stable
@tested-on: claude-opus-4-7
@changelog:
v4.2.1 - 2026-04-15: 加了"醫療類目療效保證"邊界
v4.2.0 - 2026-04-10: 重寫 Layer 4 標準(用具體清單替代描述)
v4.0.0 - 2026-03-25: 拆成 5 層結構(前為 3 層)
-->
## 你是誰
...
## 你知道什麼
...
[5 層正文]
system prompt 是核心資產——比 user prompt 值錢 10 倍。
值錢的東西必須像代碼一樣管。
否則你會遇到——某天 AI 輸出突然變差,你想"上一版那個 system prompt 哪兒去了",找不到了。
這一類資產丟了,比丟一個 user prompt 痛 100 倍。
09. 收個尾 · "在對的層動刀"
回到開頭——
95% 的人在改 user prompt,5% 的人在改 system prompt。
你想成為哪 5%?
如果你目前的狀態是——
總覺得 AI 輸出"差點意思" 反覆改 user prompt 但效果有限 不同任務每次都要重新解釋一遍標準 模型升級之後 prompt 全要重寫
99% 是 system prompt 的問題。
具體行動——
- 打開任意一個你用得最多的 prompt
- 看看 system prompt 部分有幾行
如果 < 50 行 = 你嚴重欠債。先按 5 層框架(角色 / 知識 / 流程 / 標準 / 邊界)補到 500-1000 字。
如果 50-200 行 = 你已經在做了。檢查 5 層是否齊全,缺哪層補哪層。
如果 > 200 行 = 你已經超過 95% 的人。下一步是把它做版本管理 + 迴歸測試。
絕大多數 AI 輸出問題,根源在 system prompt 這一層。
在這一層動刀,一刀頂 user prompt 十刀。
最後說一句——
下次你想"再改改 user prompt"的時候,先停下來問自己——
system prompt 真的寫完了嗎?
如果沒有——先去那一層。
那才是槓桿最大的地方。