Vibe Coding多個對話框如何承接的小技巧,以及其它
整理版優先睇
Vibe Coding多對話框承接:用交接備忘錄與持久化文件解決AI失憶
呢篇文章係一位數據分析師嘅Vibe Coding覆盤手記最後一篇。佢用AI同自己嘅前端能力,喺兩個半星期內完成咗一份4394行嘅交互式報告,總共同AI對話咗47次。但最大問題係:每次開新對話,AI都唔記得之前傾過啲乜,佢要重新解釋項目背景、數據結構、設計決定,好似次次都要重新培訓AI咁,浪費大量時間。
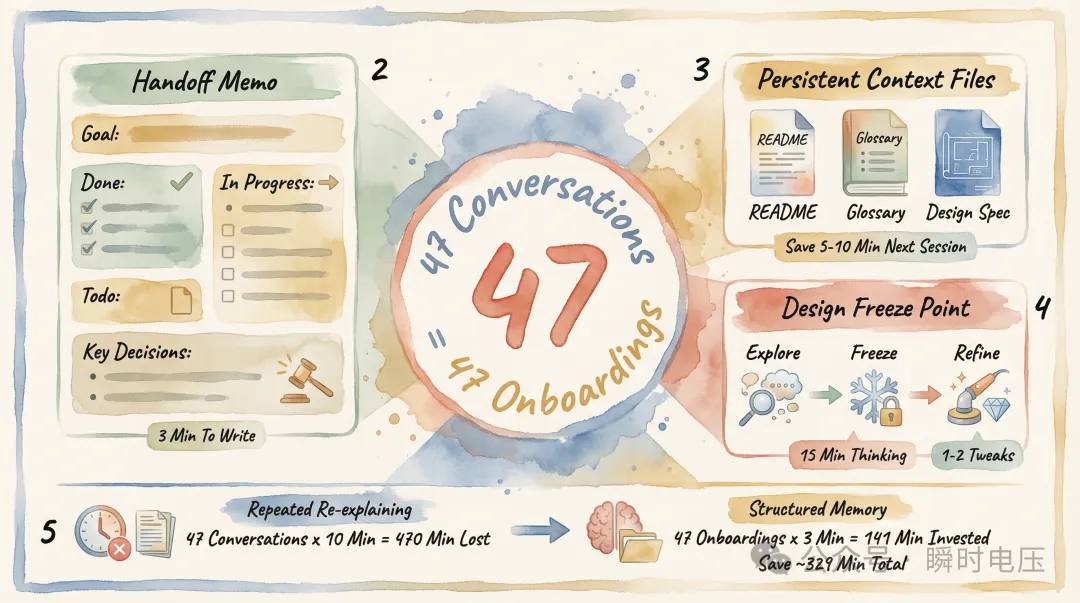
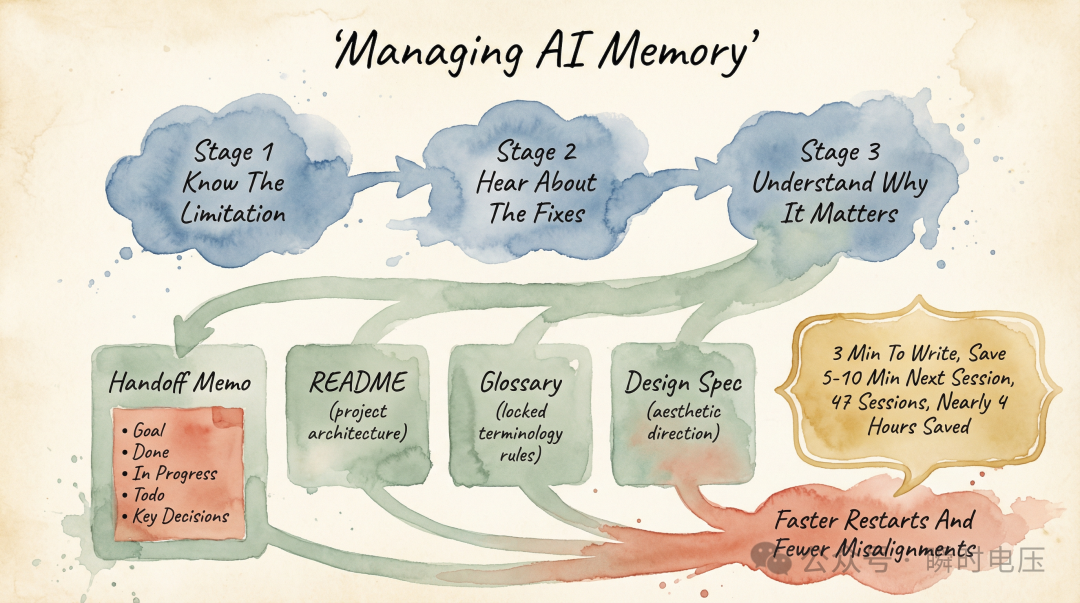
作者總結咗幾個核心解法:每個session完結前叫AI寫一份「交接備忘錄」,記錄目標、已完成、進行中、待辦同關鍵決策,下一個session引用呢份文件就可以快速恢復上下文;同時維護幾個「持久化上下文」文件,例如README、術語表同設計規範,呢啲文件唔會隨對話關閉而消失。另外,佢提議喺項目前三分之一設立「設計凍結點」,避免因為AI生成得太快而不斷「再睇多次」,最後浪費時間。成個教訓係:AI唔會主動提醒你做好流程管理,但一個真實項目就會逼你學識。
- 每個session結束叫AI寫交接備忘錄,包含目標、已完成、進行中、待辦、關鍵決策,新對話開頭引用,每次慳5–10分鐘。
- 維護持久化上下文文件(README、術語表、設計規範),文件唔會消失,每個新對話都可以引用,相當於AI嘅長期記憶。
- 項目前1/3設設計凍結點,鎖定大方向,之後只做微調,避免無限探索浪費時間。
- 術語對齊應該喺項目初期鎖定,用一份術語表列清邊啲詞喺咩語境點用,邊啲詞唔鬱得,唔好等到最後一日先緊急救火。
- 模塊化開發係降低複雜度嘅最優解:每個頁面獨立開發,用合併腳本生成單文件,之後所有修改都簡單好多。
47次入職培訓:AI失憶嘅真正成本
作者同AI對話咗47次,但每次開新對話,AI都好似新嚟嘅同事——唔知項目做咩、數據結構係點、報告分幾多章節。佢知道AI有上下文限制,甚至聽過啲技巧,例如喺上下文就滿嘅時候叫AI整理要點,但成個項目入面一個都冇用。
- 1 第1次對話:AI幫佢理清Runway秀場數據同RedNote社媒數據嘅結構同關聯。
- 2 第47次對話:AI反問佢「你嘅數據結構係點?」——完全忘記咗之前傾過嘅內容。
- 3 每次新對話要花5–10分鐘重建上下文,47次加埋就將近4個鐘,而寫交接備忘錄總時間唔超過2個鐘。
交接備忘錄:讓記憶脱離對話框
每個session結束時叫AI寫一份交接備忘錄
內容包括目標、已完成、進行中、待辦同關鍵決策。3分鐘生成,下一個session開頭引用,AI幾秒鐘就恢復上下文。
佢仲建議維護幾個「持久化上下文」文件:README描述項目架構,術語表鎖定規範(邊啲詞喺咩語境點用),設計規範記錄美學方向。呢啲文件唔會隨對話關閉而消失,每個新session都可以引用。
設計凍結點:AI太快,人類要識停
AI 10分鐘出一版,但連睇五版仲未決定,50分鐘就係浪費
作者喺項目最後幾日仲喺度做字體對比,離交付得返兩三日,設計方向都未凍結。AI可以無限生成變體,人類決策節奏跟唔上佢嘅生產速度。
- 1 項目前1/3自由探索,乜方向都可以試。
- 2 1/3處凍結大方向,之後只喺凍結框架內做微調。
- 3 唔好等最後幾日先做設計決定,否則所有微調壓縮到最後兩日。
術語對齊:最貴嘅後期修改
項目最後兩日先決定要將所有「Color」改做「Colorway」,仲要調整章節標題措辭、加結論文字。一日之內做咗5個版本,每次AI要喺4394行代碼入面逐個判斷邊啲「Color」要改、邊啲(例如JavaScript變量名colorData、CSS類名.color-card)唔鬱得。
呢啲本應喺項目啟動時用一兩個鐘鎖定
- 一份術語表——列清楚邊啲詞喺咩語境點表述,邊啲詞唔鬱得。
- 一份頁面框架文件——每個頁面嘅標題、副標題、結論位置都預先佔位。
- 呢兩份文件係給自己嘅checklist,亦係每個新AI對話嘅參考錨點。
Vibe Coding嘅經驗法則
AI嘅速度優勢唔應該繞過思考
10分鐘出一個頁面,但如果方向未諗清楚,呢10分鐘嘅產出可能喺後續修改花你兩個鐘。
畀AI嘅上下文越精確,產出越好
- 畀200行文件加一份設計規範,精確理解、精確修改。
- 畀4000行文件加一句「改一下」,AI喺海量代碼入面摸索,改錯位嘅機會大幅上升。
- 上下文質量決定產出質量。
產出文檔要剋制:AI好擅長生成文檔,但唔係所有嘢都值得文檔化
一個項目真正需要嘅文檔好少:一個README說明項目做咩,一個schema說明數據長咩樣。多了唔係加分,係噪音。
呢篇係「Vibe Coding 覆盤手記」系列嘅第 5 篇,亦都係最後一篇。
TLDR 47 次 AI 對話 = 47 次入職培訓,解決方法係令記憶脱離對話框。要做三件事:① 每個 session 完結之後叫 AI 寫交接備忘錄——目標、已完成、進行中、待辦、關鍵決策,3 分鐘搞掂,下個 session 開頭引用佢嚟恢復上下文,每次都慳返 5–10 分鐘重複交代嘅時間;② 維護幾個「持久化上下文」檔案——README 描述項目架構,術語表鎖定規範(邊啲詞喺咩語境點用),設計規範記錄美學方向,呢啲檔案唔會因為對話關閉而消失,每個新 session 都可以引用;③ 喺項目頭 1/3 位置設「設計凍結點」——前期自由探索,1/3 位置鎖定大方向,之後淨係喺框架入面微調。AI 10 分鐘出一版令「睇多陣」冇成本,但係連睇五版都仲未決定嘅話,50 分鐘就係浪費。先用 15 分鐘諗清楚評判標準,再叫 AI 出方案,一兩次微調就可以定稿。
呢個項目我同 AI 對話咗 47 次。第 1 次對話,AI 幫我理清咗數據結構——Runway 時裝騷數據有咩字段、RedNote 社交媒體數據點樣組織、兩個數據源之間點樣關聯。第 47 次對話,AI 問我:「你嘅數據結構係點樣㗎?」
我知道 AI 對話有上下文限制。我知道對話框關閉之後記錄會流失。我甚至聽講過一啲保持上下文嘅技巧——例如喺上下文就嚟滿嘅時候叫 AI 將對話重點整理成一個檔案,新開對話時引用呢個檔案嚟恢復記憶;又例如叫 AI 喺每次回答尾度加一個特定字符,當呢個字符消失,就代表上下文已經被壓縮,要新開一個對話。
但係知道還知道,呢次項目裏面我一個都冇用。
結果就係:47 次入職培訓。每一個新對話,我都要重新話俾 AI 知呢個項目做啲乜、數據係點樣、報告分幾多個章節。有時講得詳細,恢復得算準確;有時趕進度講得求其,AI 就按自己嘅理解嚟,產出同之前嘅 session 風格唔一致,又要花時間對齊。
47 個 session 嘅真相
47 呢個數字聽落好似產出好多。攤開嚟睇嚇做咗啲乜:數據分析、設計探索、代碼實現、文檔撰寫、術語修改、字體對比、封面設計——乜都有。問題唔在於做咗啲乜,而在於呢啲嘢之間冇清晰嘅階段劃分。數據分析未完全收尾就走咗去做頁面設計;頁面未定稿,又開咗一個 session 去寫項目文檔。
有啲 session 嘅產出返轉頭睇令人哭笑不得。有一個 Notebook 嘅輸出,我叫 AI 寫咗 7 個檔案嚟描述——數據字典、字段說明、輸出格式、使用指南。一個 Notebook,真係需要 7 份文檔?AI 好擅長生成文檔,你話「幫我寫個說明」,佢就可以寫幾千字。但係「識寫」唔代表「應該寫」。呢 7 個檔案後來我一個都冇再開過。
有啲設計探索發生得太遲。項目最後幾日,我仲喺度做字體方案對比——AI 幫我整咗 Mockup A、B、C 三個版本。距離交貨淨返兩三日,設計方向都未凍結(題外話:因為呢次項目係第一次嘗試,有啲 slides 係邊做邊加落去嘅,所以到最後幾日仲喺度做 mockup playground 都好正常)。呢個唔係 AI 嘅問題——你話「再試一版」,佢十分鐘就俾你。問題係人類決策節奏追唔上佢嘅生產速度。越容易出新版本,越傾向於「睇多陣」,而唔係喺某個時間點做決定向前行。
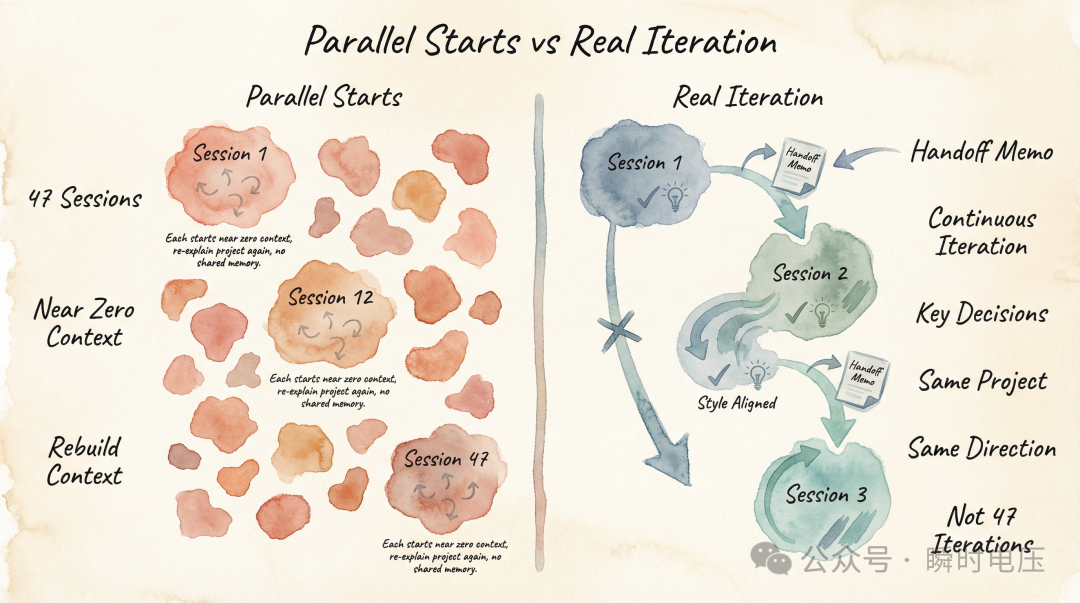
但係呢啲都唔係最核心嘅問題。最核心嘅問題係:47 個 session 之間冇記憶傳遞。我喺 Session 12 同 AI 討論咗半個鐘,敲定咗一套術語規範——報告標題用「Colorway」而唔係「Color」、章節名用特定嘅措辭、男裝用青綠色系女裝用暖棕色系。呢啲決策喺 Session 12 嘅上下文裏面清清楚楚。然後 Session 13 嘅 AI 對呢啲嘢一無所知。我唔得不重新講一次,或者——更常見嘅情況——我唔記得講,AI 就按自己嘅默認方式嚟,產出嘅嘢同 Session 12 嘅約定唔一致。
47 次對話,唔係 47 次迭代。迭代意味住喺前一個版本嘅基礎上向前行。呢 47 次更加似係 47 個平行嘅起點,每次都接近從零嘅上下文開始,靠我把口描述去恢復已經決定過嘅嘢。
術語對齊——最貴嘅後期修改
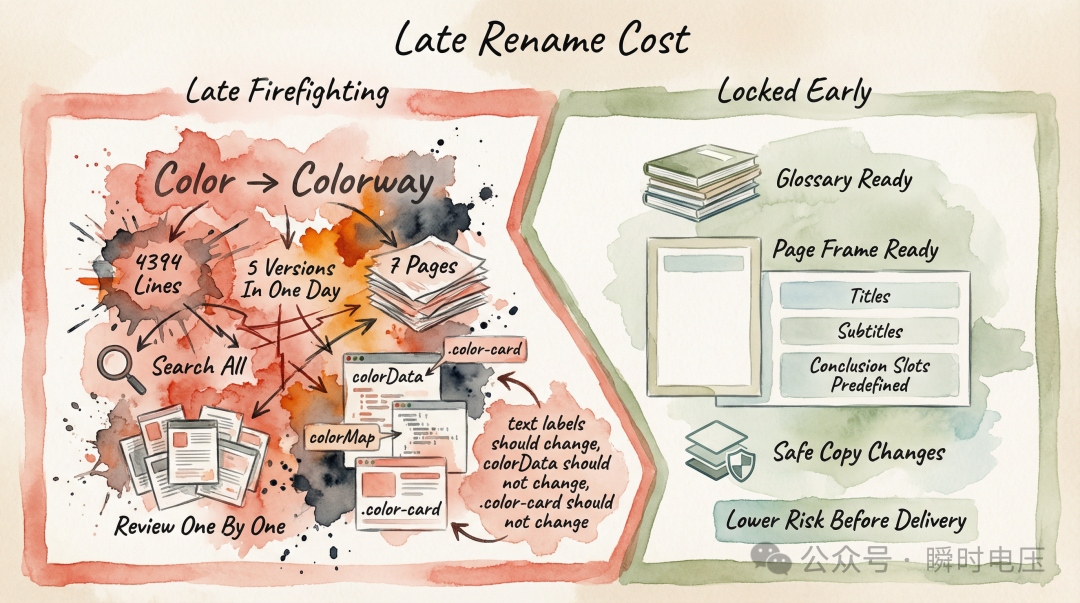
第二篇講過,項目臨近交貨時要將所有面向用戶嘅「Color」改成「Colorway」。呢度我想詳細講講呢件事到底有幾貴。
需求係最後兩日先確定嘅:除咗 Color 改 Colorway,仲有章節標題措辭調整、每個頁面加結論文字。一日之內,我整咗 5 個版本。
每次術語修改,AI 都需要喺 4394 行代碼入面做全文搜索。但係唔係所有「Color」都應該改。標題文字裏面嘅要改;JavaScript 變量名裏面嘅 colorData、colorMap 唔可以改,改咗代碼就會壞;CSS 類名裏面嘅 .color-card 都唔可以改,改咗樣式就會冇。AI 需要逐個判斷,如果判斷錯咗——改埋變量名,頁面交互就會突然唔 work,我仲要返轉頭揾問題。(不過好彩,我之前提過,用嘅模型好強所以呢個問題冇出現過)
呢啲本來應該喺項目啟動時用一兩個鐘鎖定。一份術語表——列清楚邊啲詞喺咩語境點樣表述,邊啲詞唔可以鬱。一份頁面框架檔案——每個頁面嘅標題、副標題、結論位置都預先佔位。呢兩份檔案一方面係俾自己嘅 checklist,另一方面係每個新 AI 對話嘅參考錨點。有咗佢哋,術語修改可以喺任何時候平穩執行,而唔係交貨前一日變成緊急救火。
但係項目啱啱開始嘅時候,邊個會覺得「術語」值得用一個鐘去鎖定呢?「做嚇做嚇就定啦」——結果「做嚇做嚇」就到咗最後一日。
設計凍結——幾時應該停止探索
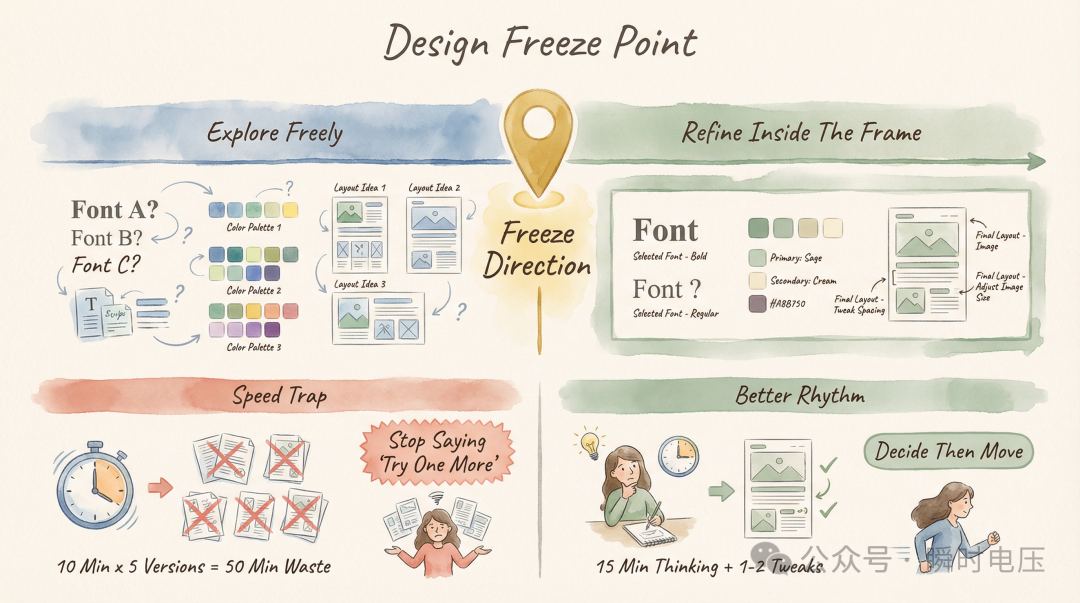
AI 可以無限生成變體。你話「再試一版」,佢即刻俾你一版。字體轉一轉?嚟啦。配色調整嚇?好㗎。佈局由左右改成上下?冇問題。佢嘅速度令「睇多陣」呢件事好似冇成本——至少表面睇係咁。
但係你嘅時間唔係無限嘅。
項目最後幾日,我仲喺度做字體方案對比。Summary 頁面嘅標題用咩字體?AI 幫我整咗三個 Mockup,各有各好,好彩我唔係選擇困難症,如果唔係好難做決定。
設計探索本身冇錯,尤其喺項目前期,你需要嘗試唔同方向揾到啱嘅感覺。錯嘅係時間點——距離交貨得返三日,字體方案都未敲定。後續所有基於字體嘅微調——間距、行高、字號比例——都壓縮咗喺最後兩日。
後來覆盤嗰陣 AI 教咗我一個「設計凍結點」嘅概念:項目前三分之一自由探索,咩方向都可以試;三分之一位置凍結大方向;後面三分之二隻喺凍結框架入面做微調。呢個唔係死板嘅教條,而係一個提醒——提醒自己喺某個時間點停低做決定,而唔係一路「睇多陣」。
AI 嘅速度優勢唔應該繞過思考。10 分鐘出一版,表面睇效率好高。但係連睇五版都仲未決定嘅話,50 分鐘就係浪費。先用 15 分鐘諗清楚——目標用戶係邊個、品牌調性係乜、邊啲元素唔可以妥協——帶住明確標準去睇 AI 嘅產出,一兩次微調就可以定稿。思考唔係慢,而係快嘅前提。
知道 AI 會失憶,同真正管理好佢嘅記憶,之間隔住啲乜
關於 AI 對話嘅上下文限制,我嘅認知經過咗三個階段。
第一個階段,係知道有限制。每個 AI 對話有上下文窗口,對話框熄咗之後所有記錄流失,下次重新開始。呢個係用過 AI 嘅人都幾乎知道嘅基本常識。我知道。
第二個階段,係聽講過解法。一種係喺上下文就嚟滿嘅時候叫 AI 將對話重點整理成檔案,新對話入面引用呢個檔案嚟恢復上下文。另一種更巧妙:叫 AI 喺每次回答尾度加一個特定字符,例如一個藍色圓點。字符仲喺度,代表上下文完整;字符消失咗,代表上下文已被壓縮,要新開對話。呢啲方法我都覺得好聰明。
第三個階段,係知道點解要用。呢個階段係喺項目結束之後先到嚟。
成個項目過程中,呢啲技巧我一個都冇用。原因好簡單:多對話視窗多線程工作時唔記得咗。每次 session 做完,個腦諗緊下一件事,例如隔籬對話框中圖表顏色未調、數據要更新、封面設計未開始。開新對話,講需求,叫 AI 做。邊有時間寫交接檔案呢?
直到項目結束後覆盤,我先專登問 AI:「如果上下文就嚟滿,應該點做?」佢俾咗我一個「交接備忘錄」方案:每個 session 結束時,叫 AI 將工作狀態寫成一份簡短備忘錄——目標、已完成、進行中、待辦、關鍵決策。下一個 session 開頭引用呢份備忘錄,AI 幾秒鐘之內就可以恢復上下文。
返轉頭睇,唔整理上下文會浪費好多時間。每個新對話都要花五到十分鐘重建上下文,而且靠我嘅記憶恢復——可能唔記得某個決策,可能遺漏某個約束,AI 基於唔完整嘅上下文產出自然都唔完整。一份備忘錄三分鐘就可以生成,精準度遠高於事後嘅口頭回憶。47 個 session,每個慳返 5 分鐘就係差唔多 4 個鐘,而生成備忘錄嘅總時間大概唔超過 2 個鐘。
呢個同第四篇講嘅數據合約係同一個故事嘅唔同章節。數據合約,我喺項目開始前就學過呢個概念,但冇喺項目入面用——因為「冇痛過就唔會真係去用」。交接備忘錄都一樣:技巧早就知道,但冇經歷過 47 次重複建立上下文嘅痛苦,就唔會覺得佢重要。Vibe coding 嘅學習曲線唔在於學識新概念,而在於透過真實項目體會到呢啲概念點解存在。
如果重新嚟過,我會咁樣做:每個 session 完結叫 AI 寫交接備忘錄;新 session 開頭引用備忘錄恢復上下文。更好嘅做法係一路維護幾個「持久化上下文」檔案——README 描述項目架構,術語表鎖定規範,設計規範記錄美學方向。呢啲檔案唔會因為對話關閉而消失,每個新 session 都可以引用,相當於俾 AI 一套唔會流失嘅長期記憶。
Vibe Coding 嘅經驗法則
做完呢個項目,返轉頭睇呢 47 個 session、30 次提交、4394 行代碼,有幾條經驗我覺得值得記低。
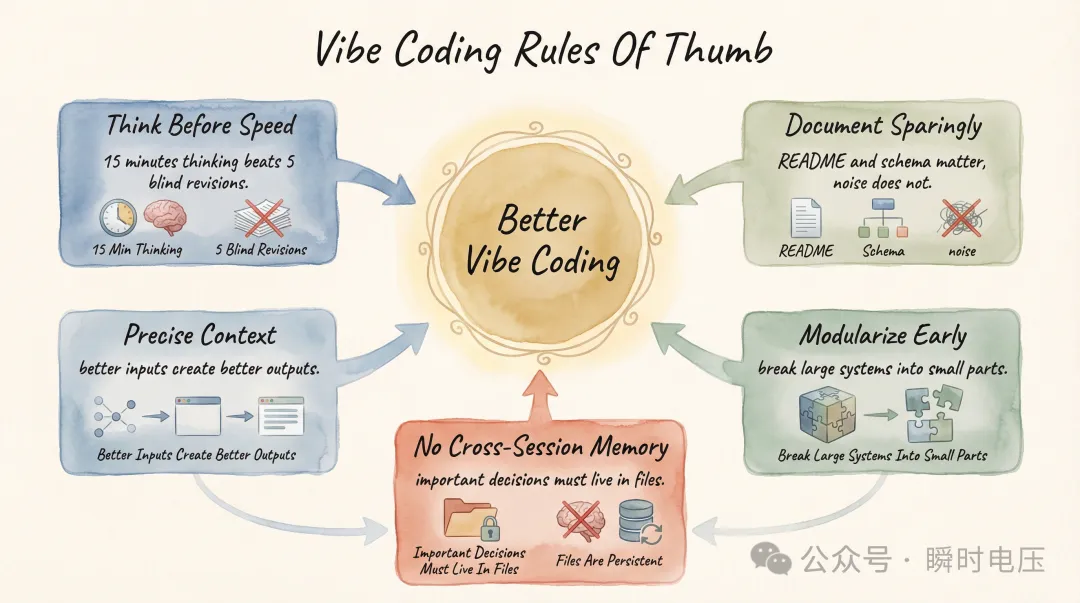
AI 嘅速度優勢唔應該繞過思考。 10 分鐘出一個頁面,表面睇效率好高。但係如果方向未諗清楚,呢 10 分鐘嘅產出可能喺後續修改入面花咗你 2 個鐘。
俾 AI 嘅上下文越精確,產出越好。 你俾佢 200 行檔案加一份設計規範,同俾佢 4000 行檔案加一句「改嚇」,結果天淵之別。前者精確理解、精確修改;後者喺海量代碼入面摸索,改錯位置嘅機率大幅上升。上下文質量決定產出質量。
AI 唔會記住跨 session 嘅約定。 第 12 個對話敲定嘅設計規範,第 13 個對話一個字都唔知。所有重要嘅約定——術語、風格、數據格式——都要寫入檔案。檔案係持久嘅,對話係臨時嘅。唔好靠對話記憶傳遞任何你唔願意從頭解釋一次嘅資訊。
模塊化開發係目前最優解。 第二篇講過,如果每個頁面獨立開發、最後用一個 50 行嘅合併腳本生成單檔案,後續所有嘅修改、除錯、維護都會簡單好多。呢個合併腳本大概係成個項目入面投入產出比最高嘅一件事——用 10 分鐘叫 AI 寫,慳返後面幾日喺 4000 行檔案入面大海撈針嘅時間。模塊化表面睇係一個工程概念,但佢嘅本質係「將大問題拆成小問題」,呢個思路對數據分析師嚟講其實唔陌生。
產出文檔要剋制。 AI 好擅長生成文檔,但唔係所有嘢都值得被文檔化。7 個檔案描述 1 個 Notebook 嘅輸出,呢個唔係嚴謹,係浪費。一個項目真正需要嘅文檔好少:一個 README 說明項目做咗啲乜,一個 schema 說明數據係點樣。多咗唔係加分,係噪音——下次打開項目面對 20 個檔案,反而更難揾到你需要嘅資訊。
系列結語
返轉頭睇呢個系列講咗啲乜。
第二篇,唔知前端規範——唔知模塊化、公共組件、CSS 變量,搞咗個 4394 行嘅巨石檔案。第三篇,唔知 Git 規範——冇 .gitignore、用檔案名管版本、commit message 寫「refine」,78 個原始檔嘅項目膨脹到 2.7 GB。第四篇,以為舊方法就係好方法——用 Excel 做數據中轉,學過數據合約但冇用。第五篇,知道新方法但冇用——聽講過交接備忘錄,一個都冇實踐。
呢四種「炒車」嘅共通點係:全部都唔係 AI 能力嘅問題,而係用 AI 嘅人嘅問題。
AI 識寫前端代碼,但唔會主動話俾你知應該模塊化。AI 識管 Git,但唔會喺第一日提醒你建立 .gitignore。AI 識生成轉換腳本,但如果你唔問,佢就唔會話「你唔需要 Excel 中轉」。AI 係一個極之強大嘅執行者,但佢嘅產出質量取決於你嘅輸入質量——你嘅問題越精確,佢嘅回答越好;你嘅流程越清晰,佢嘅執行越高效。
兩個半禮拜,47 次 AI 對話,一個唔識寫前端嘅數據分析師,交出咗一份 4394 行嘅互動式報告。如果重新嚟一次,我大概會用更少嘅對話、更短嘅代碼、更清晰嘅流程,做出同樣甚至更好嘅嘢。
Vibe coding 嘅門檻好低——有 AI 就可以開始。但係要將佢做好嘅門檻唔低:你需要一啲工程常識、一啲流程紀律、同埋「喺動手前諗多一步」嘅習慣。呢啲嘢 AI 唔會主動教你,但一個項目會。
本文是"Vibe Coding 覆盤手記"系列的第 5 篇,也是最後一篇。
TLDR 47 次 AI 對話 = 47 次入職培訓,解法是讓記憶脱離對話框。三件事:① 每個 session 結束讓 AI 寫交接備忘錄——目標、已完成、進行中、待辦、關鍵決策,3 分鐘生成,下個 session 開頭引用它恢復上下文,每次省 5–10 分鐘重複交代;② 維護幾個"持久化上下文"文件——README 描述項目架構、術語表鎖定規範(哪些詞在什麼語境怎麼用)、設計規範記錄美學方向,這些文件不隨對話關閉而消失,每個新 session 都可以引用;③ 在項目前 1/3 處設"設計凍結點"——前期自由探索,1/3 處鎖定大方向,之後只在框架內微調。AI 10 分鐘出一版讓"再看看"毫無成本,但連看五版還拿不定主意,50 分鐘就是浪費。先花 15 分鐘想清楚評判標準,再讓 AI 出方案,一兩次微調就能定稿。
這個項目我和 AI 對話了 47 次。第 1 次對話,AI 幫我理清了數據結構——Runway 秀場數據有哪些字段、RedNote 社媒數據怎麼組織、兩個數據源之間如何關聯。第 47 次對話,AI 問我:"你的數據結構是什麼樣的?"
我知道 AI 對話有上下文限制。我知道對話框關閉後記錄會丟失。我甚至聽說過一些保持上下文的技巧——比如在上下文快滿時讓 AI 把對話要點整理成一個文件,新開對話時引用這個文件來恢復記憶;又比如讓 AI 在每次回答末尾加一個特定字符,當這個字符消失,就說明上下文已經被壓縮了,該新開一個對話。
但知道歸知道,這次項目裏我一個都沒用。
結果就是:47 次入職培訓。每一個新對話,我都要重新告訴 AI 這個項目做什麼、數據長什麼樣、報告分幾個章節。有時候說得詳細,恢復得還算準確;有時候趕進度說得潦草,AI 就按自己的理解來,產出和之前的 session 風格不一致,又要花時間對齊。
47 個 session 的真相
47 這個數字聽起來產出不少。展開看看都做了什麼:數據分析、設計探索、代碼實現、文檔撰寫、術語修改、字體對比、封面設計——什麼都有。問題不在於做了什麼,而在於這些事情之間沒有清晰的階段劃分。數據分析還沒完全收尾,就跳去做頁面設計了;頁面還沒定稿,又開了一個 session 去寫項目文檔。
有些 session 的產出回頭看讓人哭笑不得。有一個 Notebook 的輸出,我讓 AI 寫了 7 個文件來描述——數據字典、字段說明、輸出格式、使用指南。一個 Notebook,真的需要 7 份文檔?AI 很擅長生成文檔,你說"幫我寫個說明",它能洋洋灑灑幾千字。但"能寫"不代表"該寫"。這 7 個文件後來我一個都沒再打開過。
有些設計探索發生得太晚。項目最後幾天,我還在做字體方案對比——AI 幫我做了 Mockup A、B、C 三個版本。離交付只剩兩三天了,設計方向還沒凍結(題外話:因為這次項目是第一次嘗試,有一些slides是邊做邊加進去的,所以到最後幾天還在做mockup playground也很正常)。這不是 AI 的問題——你說"再試一版",它十分鐘就給你。問題是人類決策節奏跟不上它的生產速度。越容易出新版本,越傾向於"再看看",而不是在某個時間點做出決定往前走。
但這些都不是最核心的問題。最核心的問題是:47 個 session 之間沒有記憶傳遞。我在 Session 12 和 AI 討論了半小時,敲定了一套術語規範——報告標題用"Colorway"而不是"Color"、章節名用特定的措辭、男裝用青綠色系女裝用暖棕色系。這些決策在 Session 12 的上下文裏清清楚楚。然後 Session 13 的 AI 對此一無所知。我不得不重新說一遍,或者——更常見的情況——我忘了說,AI 就按自己的默認方式來了,產出的東西和 Session 12 的約定不一致。
47 次對話,不是 47 次迭代。迭代意味着在前一版的基礎上往前走。這 47 次更像是 47 次平行的起點,每次都從接近零的上下文開始,靠我的口頭描述去恢復那些已經決定過的事情。
術語對齊——最貴的後期修改
篇 2 講過,項目臨近交付時需要把所有面向用戶的"Color"改成"Colorway"。這裏我想展開講講這件事到底有多貴。
需求是最後兩天才確定的:除了 Color 改 Colorway,還有章節標題措辭調整、每個頁面加結論文字。一天之內,我做了 5 個版本。
每次術語修改,AI 都需要在 4394 行代碼裏做全文搜索。但不是所有的"Color"都該改。標題文字裏的要改;JavaScript 變量名裏的 colorData、colorMap 不能改,改了代碼就壞了;CSS 類名裏的 .color-card 也不能改,改了樣式就丟了。AI 需要逐個判斷,如果判斷錯了——把一個變量名也改了,頁面交互就會突然不工作,我還得回去定位問題。(不過幸運的是,我之前提到過,用的模型很強所以這個問題沒有出現過)
這些本應在項目啓動時用一兩個小時鎖定。一份術語表——列清楚哪些詞在什麼語境下怎麼表述,哪些詞不能動。一份頁面框架文件——每個頁面的標題、副標題、結論位置都預先佔位。這兩份文件既是給自己的 checklist,也是每個新 AI 對話的參考錨點。有了它們,術語修改可以在任何時候平穩執行,而不是交付前一天變成緊急救火。
但項目剛開始的時候,誰會覺得"術語"值得花一個小時去鎖定呢?"做着做着就定了"——結果"做着做着"就到了最後一天。
設計凍結——什麼時候該停止探索
AI 可以無限生成變體。你說"再試一版",它立刻給你一版。字體換一換?來了。配色調一調?好的。佈局從左右改成上下?沒問題。它的速度讓"再看看"這件事變得毫無成本——至少看起來毫無成本。
但你的時間不是無限的。
項目最後幾天,我還在做字體方案對比。Summary 頁面的標題用什麼字體?AI 幫我做了三個 Mockup,各有各的好,還好我不是選擇困難症,不然很難做決定。
設計探索本身不是錯,尤其在項目前期,你需要嘗試不同方向找到對的感覺。錯的是時間點——離交付只剩三天了,字體方案還沒敲定。後續所有基於字體的微調——間距、行高、字號比例——都被壓縮到了最後兩天。
後來覆盤時agent教了我一個"設計凍結點"的概念:項目前三分之一自由探索,什麼方向都可以試;三分之一處凍結大方向;後面三分之二隻在凍結框架內做微調。這不是死板的教條,而是一個提醒——提醒自己在某個時間點停下來做決定,而不是一直"再看看"。
AI 的速度優勢不應該繞過思考。10 分鐘出一版,看起來效率很高。但連看五版還拿不定主意,50 分鐘就是浪費。花 15 分鐘先想清楚——目標用戶是誰、品牌調性是什麼、哪些元素不可妥協——帶着明確標準去看 AI 的產出,一兩次微調就能定稿。思考不是慢,是快的前提。
知道 AI 會失憶,和真正管好它的記憶,隔着什麼
關於 AI 對話的上下文限制,我的認知經過了三個階段。
第一個階段,是知道有限制。每個 AI 對話有上下文窗口,對話框關掉之後所有記錄丟失,下次重新開始。這是用過 AI 的人幾乎都知道的基本常識。我知道。
第二個階段,是聽說過解法。一種是在上下文快滿時讓 AI 把對話要點整理成文件,新對話中引用這個文件來恢復上下文。另一種更巧妙:讓 AI 在每次回答末尾加一個特定字符,比如一個藍色圓點。字符還在,說明上下文完整;字符消失了,說明上下文已被壓縮,該新開對話了。這些方法我都覺得很聰明。
第三個階段,是知道為什麼要用。這個階段是在項目結束之後才到來的。
整個項目過程中,這些技巧我一個都沒用。原因很簡單:多對話窗口多線程工作時忘記了。每次 session 做完,腦子裏想的是下一件事,比如隔壁對話框中圖表顏色還沒調、數據要更新、封面設計還沒開始。開新對話,說需求,讓 AI 做。哪有時間寫交接文件?
直到項目結束後覆盤,我才專門問 AI:"如果上下文快滿了,應該怎麼辦?"它給了我一個"交接備忘錄"方案:每個 session 結束時,讓 AI 把工作狀態寫成一份簡短備忘錄——目標、已完成、進行中、待辦、關鍵決策。下一個 session 開頭引用這份備忘錄,AI 幾秒鐘內就能恢復上下文。
回頭看,不整理上下文會浪費很多時間。每個新對話都要花五到十分鐘重建上下文,而且靠我的記憶恢復——可能忘了某個決策,可能遺漏某個約束,AI 基於不完整的上下文產出自然也不完整。一份備忘錄三分鐘就能生成,精確度遠高於事後的口頭回憶。47 個 session,每個省 5 分鐘就是將近 4 小時,而生成備忘錄的總時間大概不超過 2 小時。
這和篇 4 講的數據合約是同一個故事的不同章節。數據合約,我在項目開始前就學過這個概念,但沒有在項目中用上——因為"沒有痛過就不會真的去用"。交接備忘錄也一樣:技巧早就知道,但沒有經歷過 47 次重複建立上下文的痛苦,就不會覺得它重要。Vibe coding 的學習曲線不在於學會新概念,而在於通過真實項目體會到這些概念為什麼存在。
如果重來,我會這樣做:每個 session 結束讓 AI 寫交接備忘錄;新 session 開頭引用備忘錄恢復上下文。更好的做法是始終維護幾個"持久化上下文"文件——README 描述項目架構,術語表鎖定規範,設計規範記錄美學方向。這些文件不會隨對話關閉而消失,每個新 session 都可以引用,相當於給 AI 一套不會丟失的長期記憶。
Vibe Coding 的經驗法則
做完這個項目,回頭看這 47 個 session、30 次提交、4394 行代碼,有幾條經驗我覺得值得記下來。
AI 的速度優勢不應該繞過思考。 10 分鐘出一個頁面,感覺效率很高。但如果方向沒想清楚,這 10 分鐘的產出可能在後續修改中花掉你 2 個小時。
給 AI 的上下文越精確,產出越好。 你給它 200 行文件加一份設計規範,和給它 4000 行文件加一句"改一下",結果天差地別。前者精確理解、精確修改;後者在海量代碼裏摸索,改錯位置的概率大幅上升。上下文質量決定產出質量。
AI 不會記住跨 session 的約定。 第 12 個對話敲定的設計規範,第 13 個對話一個字都不知道。所有重要的約定——術語、風格、數據格式——都要寫進文件。文件是持久的,對話是臨時的。不要靠對話記憶傳遞任何你不願意從頭解釋一遍的信息。
模塊化開發是目前最優解。 篇 2 講過,如果每個頁面獨立開發、最後用一個 50 行的合併腳本生成單文件,後續所有的修改、調試、維護都會簡單得多。這個合併腳本大概是整個項目中投入產出比最高的一件事——花 10 分鐘讓 AI 寫,省下後面幾天在 4000 行文件裏大海撈針的時間。模塊化看起來是一個工程概念,但它的本質是"把大問題拆成小問題",這個思路對數據分析師來說其實並不陌生。
產出文檔要剋制。 AI 很擅長生成文檔,但不是所有東西都值得被文檔化。7 個文件描述 1 個 Notebook 的輸出,這不是嚴謹,是浪費。一個項目真正需要的文檔很少:一個 README 說明項目做了什麼,一個 schema 說明數據長什麼樣。多了不是加分,是噪音——下次打開項目面對 20 個文件,反而更難找到你需要的信息。
系列結語
回頭看這個系列講了什麼。
篇 2,不知道前端規範——不知道模塊化、公共組件、CSS 變量,做成了 4394 行的巨石文件。篇 3,不知道 Git 規範——沒有 .gitignore、用文件名管版本、commit message 寫"refine",78 個源文件的項目膨脹成 2.7 GB。篇 4,以為舊方法就是好方法——用 Excel 做數據中轉,學過數據合約卻沒用上。篇 5,知道新方法但沒有用——聽說過交接備忘錄,一個都沒付諸實踐。
這四種"翻車"的共同點是:都不是 AI 能力的問題,而是使用 AI 的人的問題。
AI 能寫前端代碼,但不會主動告訴你該模塊化。AI 能管 Git,但不會在第一天提醒你創建 .gitignore。AI 能生成轉換腳本,但你不問它就不會說"你不需要 Excel 中轉"。AI 是一個極其強大的執行者,但它的產出質量取決於你的輸入質量——你的問題越精確,它的回答越好;你的流程越清晰,它的執行越高效。
兩週半,47 次 AI 對話,一個不會寫前端的數據分析師,交付了一份 4394 行的交互式報告。如果重來一次,我大概會用更少的對話、更短的代碼、更清晰的流程,做出同樣甚至更好的東西。
Vibe coding 的門檻很低——有 AI 就能開始。但把它做好的門檻不低:你需要一些工程常識、一些流程紀律、以及"在動手前多想一步"的習慣。這些東西 AI 不會主動教你,但一個項目會。