Vibe Coding數據分析時代,不要再用Excel做數據中轉了
整理版優先睇
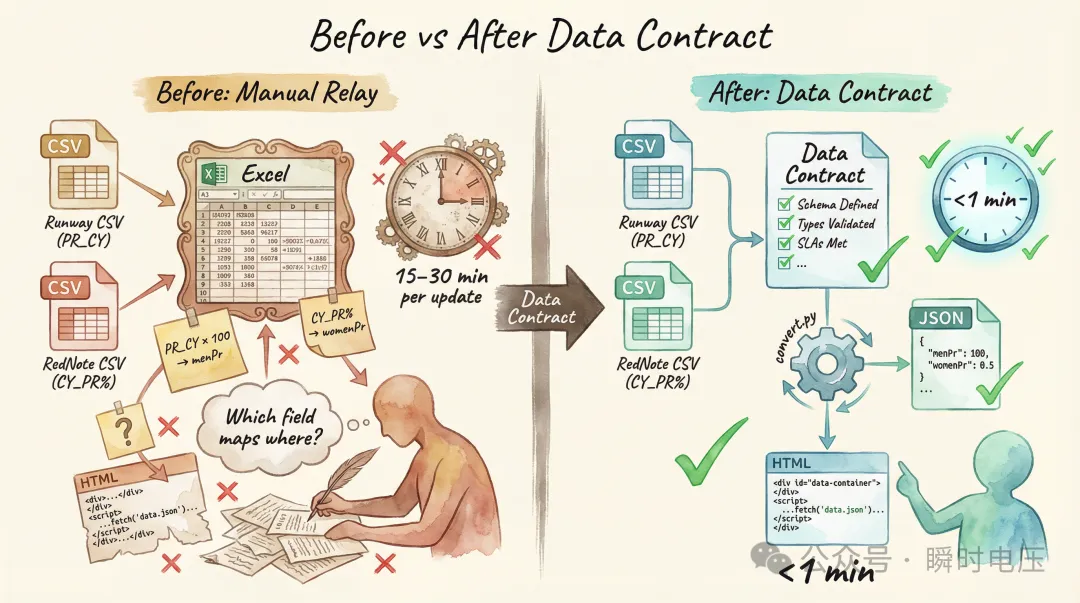
改用數據合約同自動化腳本,告別Excel中轉,將數據流從手動搬運變為一行命令
呢篇文係「Vibe Coding 覆盤手記」系列嘅第4篇,作者係一位數據分析師,正處理緊一份時尚顏色趨勢報告,數據嚟自Runway秀場同小紅書。佢原本沿用傳統做法:將兩個數據源嘅CSV提取關鍵數據,整合到Excel彙總表,再手動貼去HTML報告嘅JavaScript變數入面。每次更新數據都要重複呢條鏈路,需時15至30分鐘,而且容易出錯。
作者覆盤時先發現,呢個「標準流程」其實係最慢嘅路。當交付物由分析報告變成可交互嘅數據產品,數據嘅消費者由人變成代碼,流轉方式都要跟住變。佢提出三個核心改變:第一,砍掉Excel中間人,直接用Python腳本將CSV轉成JSON,HTML直接讀JSON渲染,更新時間縮短到一條命令唔夠1分鐘;第二,花10分鐘寫一份數據合約,用自然語言列清楚下游需要咩字段、咩類型、咩精度、上游CSV邊一列對應過嚟,等腳本同未來AI對話都唔使重新理解映射;第三,中間文件一律用文本格式(CSV/JSON),Git可以追蹤每一個數字嘅變化,Excel就做唔到。
呢篇文章唔只係技術分享,更係思維習慣嘅反思:由「畀人睇嘅彙總表」切換到「畀代碼讀嘅標準接口」。作者親身證明日日重複手動搬運係浪費時間,數據合約好簡單,只係一份字段清單加一個幾十行嘅Python腳本,但效果非常顯著。最後佢畀出三個可行動點:遇到重複格式轉換就寫轉換腳本;喺數據交接點留低字段格式清單;盡量用文本格式做中間文件。
- 核心轉變:數據消費者由人變代碼,數據流要從Excel彙總表轉為標準接口,先叫真正嘅數據產品。
- 方法:用Python腳本直接將CSV轉JSON,HTML讀JSON渲染,更新時間由15-30分鐘縮短到1分鐘內,零手動操作。
- 差異:數據合約(自然語言字段清單)取代每次教AI重新理解映射,腳本確定性高,唔會出現「上次啱下次錯」嘅問題。
- 啟發:文本格式(CSV/JSON)可畀Git追蹤每個數字變化,Excel二進制只能話「文件變咗」,出事時無從追溯。
- 可行動點:重複格式轉換手動操作時,用AI寫轉換腳本;花10分鐘寫數據合約清單;盡量用文本格式作中間文件。
內容片段
const womenData = [ { name: "Earth", hex: "#DBCCB7", menPr: 54.88, menGrowth: 11.89, womenPr: 63.35, womenGrowth: 10.13 }, { name: "Black", hex: "#000000", menPr: 30.53, menGrowth: 0.54, womenPr: 35.21, womenGrowth: 0.75 }, ...];傳統Excel中轉,每次更新都係手工搬運
作者習慣將散落嘅數據整合到Excel,呢個做法喺傳統分析冇問題,但當下游係代碼時,Excel變成咗一個昂貴嘅中間人。
- 1 第一個成本係重複勞動:每次數據更新都要從頭行一次CSV提取→Excel粘貼→AI轉寫HTML變數,而且兩個數據源嘅列名唔一樣(Runway嘅PR_CY對應HTML嘅menPr,小紅書嘅CY_PR%對應womenPr),AI每次都要重新理解映射。
- 2 第二個成本係Excel係黑盒:Git追蹤唔到入面邊個數字改咗,出錯時無從追溯。
- 3 第三個成本係精度同一致性風險:數字經Excel中轉可能丟精度,AI手動轉寫可能漏咗顏色或搞混男女裝數據,而且冇校驗機制。
一次完整數據更新耗時15-30分鐘,每次都係重新發明輪子。
數據合約唔係抽象概念,係一份字段清單加一個腳本
作者其實學過「數據合約」呢個概念,但冇實戰經驗覺得好抽象。做完項目後先明白,佢解決嘅就係佢呢兩週手動做嘅事。
- 1 第一步:寫低HTML需要嘅格式——每個顏色嘅英文名、十六進制色號、男女裝比例同增長率,保留小數位。
- 2 第二步:寫一個Python腳本,讀取CSV按合約輸出JSON,一條命令3秒完成。
- 3 第三步:HTML直接讀JSON渲染圖表,唔再需要Excel中轉同肉眼校驗。
改進後每次數據更新:重跑Notebook更新CSV,一條命令生成JSON,另一條注入HTML,總耗時唔夠1分鐘,仲有Git追蹤每個數字變化。
數據消費者變咗,你嘅流程都要跟住變
傳統數據分析思維係「將數據聚到一個地方,然後操作」,Excel彙總表係畀分析師睇嘅全景視圖。但AI輔助開發中,下游係代碼,佢唔需要排序篩選,只需要按約定格式接收數據。
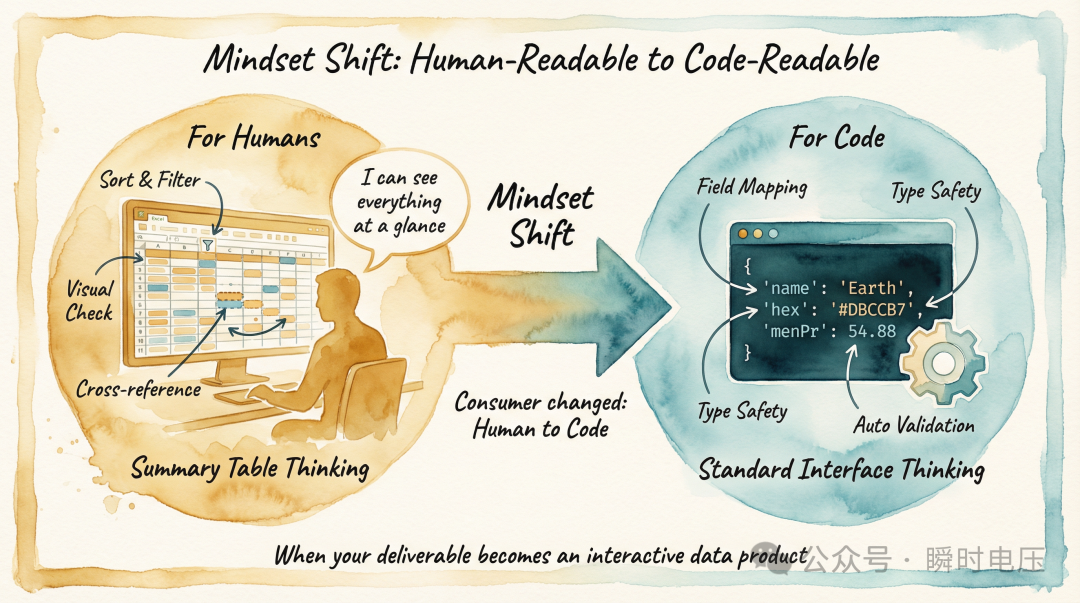
由「畀人睇嘅彙總表」到「畀代碼讀嘅標準接口」
呢個轉變唔係技術問題——寫一個CSV轉JSON腳本,AI幫手十分鐘搞得掂——而係思維習慣問題。當你嘅交付物由分析報告變成可交互嘅數據產品,數據嘅流轉方式都要跟住變。
三個步驟,即刻開始改善你嘅數據Pipeline
- 1 如果你重複做「從A格式轉成B格式」嘅手動操作,停下來,叫AI幫你寫一個轉換腳本。就算只用一次,都可靠過手動搬運。
- 2 喺數據交接點花10分鐘寫一份「我需要咩字段、咩格式」嘅清單。用自然語言,唔使正式schema。呢份就係最簡單嘅數據合約。
- 3 盡量用文本格式(CSV/JSON)做中間文件,因為Git可以追蹤每個數字嘅變化,Excel做唔到。呢個差別可以幫你省一個鐘對比時間。
呢三個行動唔複雜,但可以幫你慳返大量重複勞動,令你嘅數據Pipeline更加可靠同可追溯。
呢篇文章係「Vibe Coding 覆盤手記」系列嘅第4篇,總共5篇。
TLDR 當你嘅交付物由「分析報告」變成「可以互動嘅數據產品」,數據嘅消費者由人變成咗代碼,流轉方式都要跟住變。具體做法:① 斬咗 Excel 中間人——CSV 直接用 Python 腳本轉做 JSON,HTML 直接讀 JSON 渲染,每次數據更新由 15–30 分鐘手動搬運縮短到一條命令唔使 1 分鐘;② 花 10 分鐘寫一份數據合約——列清楚下游需要咩字段、咩類型、咩精度、上游 CSV 嘅邊一列對應過嚟(例如 Runway 嘅 PR_CY × 100 → HTML 嘅 menPr),用自然語言就得,呢份清單令腳本同未來嘅 AI 對話都唔使再重新理解映射關係;③ 中間檔案一律用文本格式——CSV 同 JSON 喺 Git 裏面可以追蹤到每一個數字嘅變化,Excel 喺 Git 眼裏永遠都只係「檔案變咗」,出錯嘅時候冇辦法追溯。核心轉變:由「畀人睇嘅匯總表」思維切換到「畀代碼讀嘅標準接口」思維。
做數據分析嘅人都有一個習慣:將散落喺各處嘅數據整合到一張 Excel 度。呢個係我返工以嚟一路做緊嘅事,冇問題,畢竟細數據整合到一個 workbook 裏面顯得好井井有條而且好容易講。但係喺新嘅時代呢個方式可能唔再適用。
今次項目係一份時尚顏色趨勢報告,數據嚟自兩個來源——Runway 秀場同小紅書。兩邊各有一條獨立嘅 Notebook 分析管線,行完之後產出十幾個 CSV 檔案。喺傳統流程入面,跟住有用部份嘅 output 我會整合到一份 Excel 度,然後用呢啲數據喺 Powerpoint 入面手動畫圖。但係今次唔同:呢啲數據最終會整合到一份互動式 HTML 報告度。
我嘅第一反應係:整一個匯總 Excel,將數據都貼過去,再叫 AI 由 Excel 度讀數,轉寫到 HTML 嘅 JavaScript 變量入面。呢個唔係標準流程咩?數據散落喺唔同地方,先匯總,再處理。我覺得呢個唔係最有效率嘅方法,但都冇覺得好奇怪,於是用返舊嘅方式繼續整合數據。
直到做完項目覆盤,我先知道呢個「標準流程」喺呢度係最慢嘅路。
呢個唔係偷懶,係專業慣性
喺傳統數據分析入面,「將數據整合到一個檔案」係最終交付前嘅標準步驟。你由唔同嘅數據庫、唔同嘅報表系統提取數據,最後匯總到一張 Excel 表度做交叉分析、做透視圖、做校驗。Excel 係分析師最熟悉嘅工具——打開就可以睇到數據全貌,可以排序篩選,可以手動核對每個數字。呢個係一種經過無數次驗證嘅工作方式。
對於一個唔識前端嘅人嚟講,叫 AI「由 Excel 度讀數據然後寫到 HTML 度」聽落完全合理。你用緊你最熟悉嘅方式組織數據,只係將最後一步——「將數據寫入代碼」——交畀 AI 嚟做。AI 負責翻譯,Excel 負責儲存,你負責校驗。分工明確,流程清楚。
呢個方案確實可以運作。我確實靠呢個方法完成咗報告。問題係,佢每次都要重新做過。
每次更新數據,都係一次手工搬運
等我將呢個流程拆開,睇嚇每次數據更新嘅時候到底發生咗啲咩。
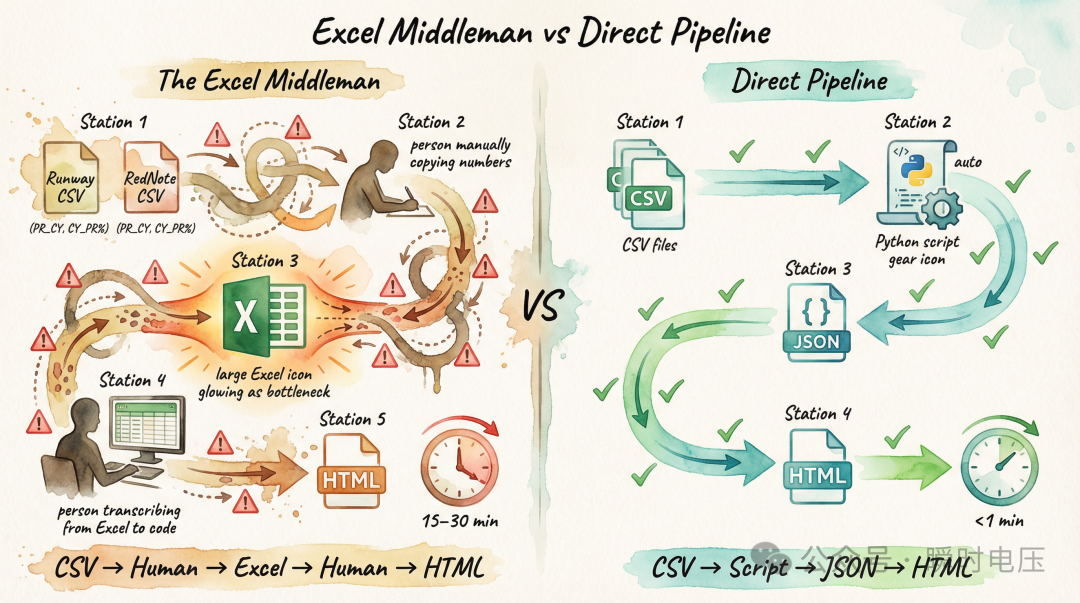
成個操作鏈係咁嘅:Notebook 產出 CSV,然後叫 AI 由 CSV 度提取關鍵數據,貼入 Excel 匯總表,再叫 AI 由 Excel 讀數、轉寫到 HTML 入面嘅 JavaScript 變量度。
每一步睇起嚟都唔難,五分鐘嘅事。但係疊加起嚟,有三個我當時冇意識到嘅隱性成本。
第一個成本係重複勞動。每次數據更新,無論改咗幾多,呢條鏈路都要由頭行一次。更麻煩嘅係,兩個數據源嘅 CSV 列名完全唔一樣。Runway 嗰邊嘅字段叫 PR_CY、PR_Growth,小紅書嗰邊叫 CY_PR%、YoY%。同一個指標——「顏色嘅出現比例」——喺兩邊有兩個唔同嘅名。每次叫 AI 做數據提取嘅時候,佢都要重新理解呢個映射關係:Runway 嘅 PR_CY 對應嘅係 HTML 度嘅 menPr,小紅書嘅 CY_PR% 對應嘅係 womenPr。(雖然今次我用非常精確嘅提示詞話畀 agent 應該由邊度去攞數,但提示詞係一次性嘅命令,之後每次數據更新都要重新再教 agent 一次,所以可複用性唔高同埋唔夠準確。) 更差嘅係,唔同嘅模型對話可能對呢個映射嘅理解唔一致。對於唔係好強嘅模型嚟講,上一個 session 搞啱咗,下一個 session 可能又搞亂。
第二個成本係 Excel 係一個黑盒。Excel 檔案係二進制格式,Git 睇唔到入面變咗咩。我呢個項目全程用 Git 做版本管理,但每次改咗 Excel 度嘅數字,git diff 只會話我知「檔案變咗」,唔會話我知「邊個數字由 54.88 變咗做 55.12」。如果某次更新出咗錯——例如某個顏色嘅數據被覆蓋咗——我根本冇辦法追溯係邊一步出嘅問題。
第三個成本係精度同一致性嘅風險。數字經過 Excel 中轉,可能會出現精度丟失。AI 手動轉寫嘅時候,可能會漏咗某個顏色,或者將男裝同女裝嘅數據搞亂。HTML 度嘅數據係咁樣:
const womenData = [
{ name: "Earth", hex: "#DBCCB7", menPr: 54.88, menGrowth: 11.89,
womenPr: 63.35, womenGrowth: 10.13 },
{ name: "Black", hex: "#000000", menPr: 30.53, menGrowth: 0.54,
womenPr: 35.21, womenGrowth: 0.75 },
...
];十幾個顏色,每個有四個數值字段,男裝女裝各一組。手動搬運一次,漏一個數字、錯一個小數點,喺肉眼校驗入面好難發現。而且冇任何校驗機制會話你知「搬錯咗」——你只能等到最終報告呈現出嚟嘅時候,靠直覺發現「呢個數字好似唔太啱」。

一次完整嘅數據更新耗時 15 到 30 分鐘。呢個時間唔算長,但問題係每次都在做同樣嘅事。每次都係重新發明輪子。
數據合約——學過但冇學識嘅概念
諷刺嘅係,「數據合約」呢個概念我喺項目開始前就學過。
當時我喺準備呢個項目嘅 pilot data 嘅時候,接觸過完整嘅分析框架,其中提到數據合約 Data Contract——上下游之間約定數據格式。聽落好有道理:你先定好數據係咩樣,上游跟呢個格式輸出,下游跟呢個格式消費,中間唔需要人工幹預。概念清楚,邏輯通順。
然後呢?冇然後。
因為冇實戰經驗,所以「數據合約」對我嚟講非常抽象,我唔知道呢個概念具體係點樣。「約定數據格式」——好,約定喺邊度?寫喺咩檔案度?用咩格式?邊個嚟執行呢個約定?呢啲問題我唔清楚。
直到做完呢個項目,同 agent 一齊覆盤嘅時候,Opus 將 Excel 流程同數據合約方案放埋一齊對比。嗰一刻我先真正理解咗呢個概念到底係解決緊咩問題——佢解決嘅,就係我呢兩週一路手動做緊嗰件事。
等我用項目嘅真實數據嚟解釋數據合約到底係咩。
第一步,寫低 HTML 需要咩格式。我嘅 HTML 報告度,1.2 頁面需要嘅數據係咁樣:每個顏色有一個英文名、一個十六進制色號、男裝嘅出現比例同增長率、女裝嘅出現比例同增長率。將呢啲寫成一份清單——字段叫咩、咩類型、保留幾位小數、數據由邊個 CSV 嘅邊一列嚟。呢份清單,就係所謂嘅「合約」。佢唔係乜嘢複雜嘅嘢,就係一張「我需要咩」嘅明細表。
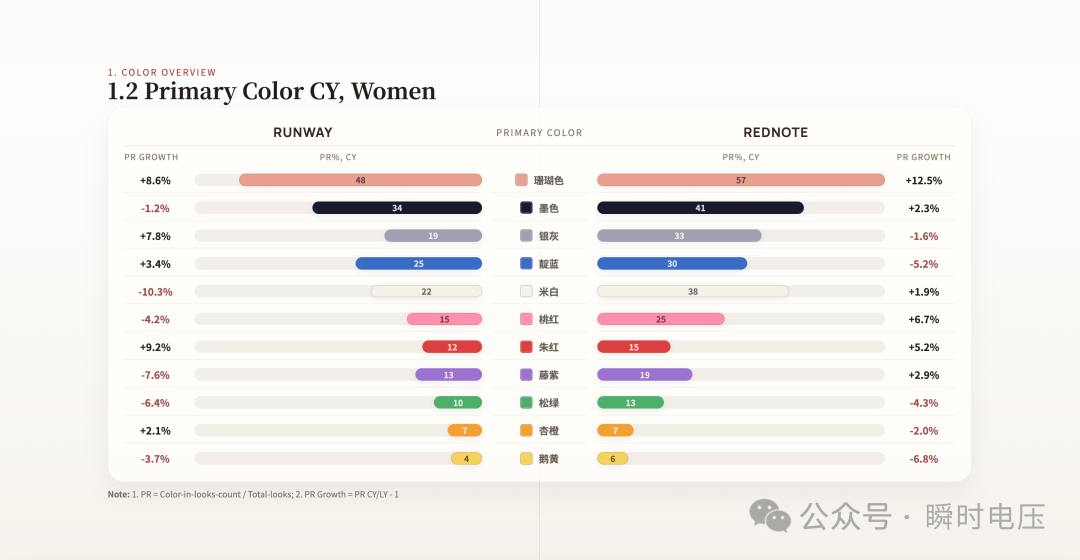
(1.2,數據已脱敏)
例如,Runway 嘅 CSV 度,字段 PR_CY 係一個 0 到 1 之間嘅小數,代表男裝嘅出現比例,需要乘以 100 轉成百分比之後對應到 HTML 嘅 menPr 字段。小紅書嘅 CSV 度,字段 CY_PR% 已經係百分比格式,直接對應到 womenPr。呢啲映射關係,以前全靠 AI 每次重新理解,而家寫喺一個檔案度,一勞永逸。
第二步,寫一個腳本自動轉換。一個 Python 腳本,讀取兩邊嘅 CSV,按合約定義嘅格式輸出一個 JSON 檔案。行一條命令,3 秒完成。腳本嘅邏輯係確定嘅——同樣嘅輸入永遠得到同樣嘅輸出,冇存在「今次 AI 理解啱咗,下次理解錯咗」嘅問題。
第三步,HTML 直接消費 JSON。數據由 CSV 變成咗標準格式嘅 JSON,HTML 頁面直接讀取呢個 JSON 渲染圖表。唔再需要 Excel 中轉,唔再需要手動轉寫,唔再需要肉眼校驗。
改進前,每次數據更新:打開 Runway 嘅 CSV 揾男裝數據,打開小紅書嘅 CSV 揾女裝數據,對齊兩邊數據貼入 Excel,由 Excel 手動轉寫成 JavaScript 陣列格式,貼到四千幾行 HTML 入面嘅正確位置。耗時 15 到 30 分鐘,仲容易出錯。
改進後,每次數據更新:重新行 Notebook 更新 CSV,行一條命令生成 JSON,行另一條命令注入到 HTML。總耗時唔使一分鐘,零手動操作。而且 JSON 係純文字檔案,Git 可以追蹤每一個數字嘅變化——邊個顏色嘅比例由 54.88 變成咗 55.12,一目瞭然。
如果要用一個比喻嚟幫助理解,數據合約就好似你平時做數據分析嗰陣嘅「字段說明文檔」。每個項目多少都會有咁樣一份嘢,記錄每個字段叫咩、由邊張表嚟、咩類型、咩意思。分別在於,傳統分析入面呢份文檔係畀人睇嘅備忘錄——你睇一眼,心中有數,然後手動操作。而數據合約係畀腳本讀嘅執行指令——腳本按照呢份清單自動完成轉換,唔需要人介入。
由「畀人睇嘅文檔」到「畀機器讀嘅接口」,就差呢一步。
由「知道」到「明咗」
好多技術概念,你「知道」同你「明咗」之間,隔住一個項目。
數據合約就係咁。項目之前我可以講出佢嘅定義:上下游之間約定數據格式。項目之後我可以畫出佢嘅樣:一份 JSON 清單,記錄字段名、類型、精度、數據來源同映射規則,配一個幾十行嘅 Python 轉換腳本。
呢個認知落差嘅背後,其實藏住一個對數據分析師嚟講更深層嘅問題。
傳統數據分析嘅思維方式係「將數據聚到一個地方,然後操作」。你由唔同嘅系統抽取數據,匯總到一張 Excel 或一個數據倉庫度,然後喺呢個集中嘅地方做分析、做可視化、做報告。Excel 匯總表就係呢個思維嘅產物——佢係一個「畀人睇嘅全景視圖」,令分析師可以一眼睇曬所有數據,做交叉比對,發現異常。
但喺 AI 輔助開發入面,你嘅「下游」唔係人類分析師,係代碼。代碼唔需要睇到數據全貌。佢唔需要一個可以排序篩選嘅 Excel 界面,唔需要手動核對數字嘅能力。佢只需要按約定嘅格式接收數據——字段名對上、類型對上、精度對上,就可以正確渲染。
由「畀人睇嘅匯總表」到「畀代碼讀嘅標準接口」,呢個係數據分析師做 vibe coding 嗰陣需要跨過嘅一道檻。佢唔係技術能力嘅問題——寫一個 CSV 轉 JSON 嘅腳本,叫 AI 幫手十分鐘就搞得掂。佢係思維習慣嘅問題:你要意識到,當你嘅交付物由「分析報告」變成「可以互動嘅數據產品」時,數據嘅消費者變咗,數據嘅流轉方式都應該跟住變。
回頭睇,我喺呢個項目度多花咗嘅時間——反覆叫 AI 由 CSV 提取數據、反覆喺 Excel 同 HTML 之間搬運數字、反覆核對有冇搬錯——本質上都係因為我用咗一個「畀人用」嘅流程去服務一個「畀代碼用」嘅需求。Excel 唔係唔好,佢喺傳統分析入面依然係最好嘅工具。但喺呢個特定嘅場景度,佢係一個昂貴嘅中間人——增加咗步驟,增加咗風險,但係冇增加任何佢擅長嘅價值。(寫到呢度,突然發現呢個咪就係 GUI 同 CLI 嘅分別:GUI 係畀人類設計嘅操作界面,但對 AI 嚟講,最適合嘅係 CLI)
呢個大概就係「知道」同「明咗」嘅分別。「知道」係聽過一個概念覺得有道理;「明咗」係喺一個真實項目度,花咗兩星期行冤枉路之後,終於明呢個概念存在嘅理由。
畀讀者嘅行動清單
1. 如果你重複緊做「由 A 格式轉做 B 格式」嘅手動操作,停低,叫 AI 幫你寫一個轉換腳本。就算呢個腳本只用一次,都比手動搬運更可靠——至少佢唔會漏咗一個數字或者搞亂一個字段。 2. 喺數據交接點花 10 分鐘寫一份「我需要咩字段、咩格式」嘅清單。唔需要用任何正式嘅 schema 語法,用自然語言寫就得——「顏色名用英文,十六進制色號帶 # 號,百分比保留兩位小數」。呢份清單就係最簡單嘅數據合約,佢令 AI 同未來嘅你都可以快速理解數據應該係點樣。 3. 儘量用文字格式(CSV、JSON)作為中間檔案,而唔係 Excel。原因好簡單:文字檔案可以被 Git 追蹤每一個數字嘅變化,而 Excel 喺 Git 眼裏永遠只係一個「檔案變咗」。當你需要追溯「上次更新到底改咗邊個數字」嗰陣,呢個分別就係慳一個鐘同花一個鐘嘅分別。
本文是"Vibe Coding 覆盤手記"系列的第 4 篇,共 5 篇。
TLDR 當你的交付物從"分析報告"變成"可交互的數據產品",數據的消費者從人變成了代碼,流轉方式也要跟着變。具體做法:① 砍掉 Excel 中間人——CSV 直接用 Python 腳本轉成 JSON,HTML 直接讀 JSON 渲染,每次數據更新從 15–30 分鐘手動搬運縮短到一條命令不到 1 分鐘;② 花 10 分鐘寫一份數據合約——列清楚下游需要什麼字段、什麼類型、什麼精度、上游 CSV 的哪一列對應過來(比如 Runway 的 PR_CY × 100 → HTML 的 menPr),自然語言就行,這份清單讓腳本和未來的 AI 對話都不再需要重新理解映射關係;③ 中間文件一律用文本格式——CSV 和 JSON 在 Git 裏能追蹤到每一個數字的變化,Excel 在 Git 眼裏永遠只是"文件變了",出錯時無從追溯。核心轉變:從"給人看的彙總表"思維切換到"給代碼讀的標準接口"思維。
做數據分析的人都有一個習慣:把散落在各處的數據整合到一張 Excel 裏。這是我工作以來一直在做的事,沒有問題,畢竟小數據整合到一個workbook中顯得well organized而且很好講。但在新的時代這個方式也許不再適用了。
本次項目是一份時尚顏色趨勢報告,數據來自兩個來源——Runway 秀場和小紅書。兩邊各有一條獨立的 Notebook 分析管線,跑完之後產出十幾個 CSV 文件。在傳統流程中,接下來有用部分的output我會整合到一份Excel中,然後用這些數據在Powerpoint中手動畫圖。但這次不一樣:這些數據最終會整合到一份交互式 HTML 報告裏。
我的第一反應是:建一個彙總 Excel,把數據都粘貼過去,再讓 AI 從 Excel 裏讀數,轉寫到 HTML 的 JavaScript 變量中。這不就是標準流程嗎?數據散落在不同地方,先彙總,再處理。我覺得這不是最高效的辦法,但也沒有覺得非常奇怪,於是沿用舊的方式繼續整合數據。
直到做完項目覆盤,我才知道這個"標準流程"在這裏是最慢的路。
這不是偷懶,是專業慣性
在傳統數據分析中,"把數據整合到一個文件"是最終交付前的標準步驟。你從不同的數據庫、不同的報表系統中提取數據,最後彙總到一張 Excel 表裏做交叉分析、做透視圖、做校驗。Excel 是分析師最熟悉的工具——打開就能看到數據全貌,能排序篩選,能手動核對每個數字。這是一種經過無數次驗證的工作方式。
對於一個不懂前端的人來說,讓 AI "從 Excel 裏讀數據然後寫到 HTML 裏"聽起來完全合理。你在用你最熟悉的方式組織數據,只是把最後一步——"把數據寫進代碼"——交給 AI 來做。AI 負責翻譯,Excel 負責存儲,你負責校驗。分工明確,流程清楚。
這個方案確實能工作。我確實靠這個方法完成了報告。問題是,它每次都要重新工作。
每次更新數據,都是一次手工搬運
讓我把這個流程拆開,看看每次數據更新時到底發生了什麼。
整個操作鏈是這樣的:Notebook 產出 CSV,然後讓 AI 從 CSV 裏提取關鍵數據,粘貼進 Excel 彙總表,再讓 AI 從 Excel 讀數、轉寫到 HTML 中的 JavaScript 變量裏。
每一步看起來都不難,五分鐘的事。但疊加起來,有三個我當時沒有意識到的隱性成本。
第一個成本是重複勞動。每次數據更新,不管改了多少,這條鏈路都要從頭走一遍。更麻煩的是,兩個數據源的 CSV 列名完全不一樣。Runway 那邊的字段叫 PR_CY、PR_Growth,小紅書那邊叫 CY_PR%、YoY%。同一個指標——"顏色的出現比例"——在兩邊有兩個不同的名字。每次讓 AI 做數據提取時,它都要重新理解這個映射關係:Runway 的 PR_CY 對應的是 HTML 裏的 menPr,小紅書的 CY_PR% 對應的是 womenPr。(雖然這次我用非常精確的提示詞告訴agent應該從哪裏去取數,但提示詞是一個一次性的命令,此後每次數據更新都需要重新再教agent一遍,所以可複用性並不高和也不夠準確。) 更糟糕的是,不同的模型對話可能對這個映射的理解還不一致。對於不是很強的模型來說,上一個 session 搞對了,下一個 session 可能又搞混。
第二個成本是 Excel 是一個黑盒。Excel 文件是二進制格式,Git 看不到裏面變了什麼。我這個項目全程在用 Git 做版本管理,但每次改了 Excel 裏的數字,git diff 只會告訴我"文件變了",不會告訴我"哪個數字從 54.88 變成了 55.12"。如果某次更新出了錯——比如某個顏色的數據被覆蓋了——我根本無從追溯是哪一步出的問題。
第三個成本是精度和一致性的風險。數字經過 Excel 中轉,可能出現精度丟失。AI 手動轉寫時,可能漏掉某個顏色,或者把男裝和女裝的數據搞混。HTML 裏的數據長這樣:
const womenData = [
{ name: "Earth", hex: "#DBCCB7", menPr: 54.88, menGrowth: 11.89,
womenPr: 63.35, womenGrowth: 10.13 },
{ name: "Black", hex: "#000000", menPr: 30.53, menGrowth: 0.54,
womenPr: 35.21, womenGrowth: 0.75 },
...
];十幾個顏色,每個有四個數值字段,男裝女裝各一組。手動搬運一次,漏一個數字、錯一個小數點,在肉眼校驗中很難發現。而且沒有任何校驗機制會告訴你"搬錯了"——你只能等到最終報告呈現出來時,靠直覺發現"這個數字好像不太對"。
一次完整的數據更新耗時 15 到 30 分鐘。這個時間不算長,但問題是每次都在做同樣的事。每次都是重新發明輪子。
數據合約——學過但沒學會的概念
諷刺的是,"數據合約"這個概念我在項目開始前就學過。
當時我在準備這個項目的pilot data的時候,接觸過完整的分析框架,其中提到了 數據合約Data Contract——上下游之間約定數據格式。聽起來很有道理:你先定好數據長什麼樣,上游按這個格式輸出,下游按這個格式消費,中間不需要人工干預。概念清楚,邏輯通順。
然後呢?沒有然後。
因為沒有實戰經驗,所以“數據合約”對我來說非常抽象,我不知道這個概念具體長什麼樣。"約定數據格式"——好,約定在哪裏?寫在什麼文件裏?用什麼格式?誰來執行這個約定?這些問題我都不清楚。
直到做完這個項目,在和agent一起復盤的時候,Opus把 Excel 流程和數據合約方案放在一起對比。那一刻我才真正理解了這個概念到底在解決什麼問題——它在解決的,就是我這兩週一直在手動做的那件事。
讓我用項目的真實數據來解釋數據合約到底是什麼。
第一步,寫下 HTML 需要什麼格式。我的 HTML 報告裏,1.2 頁面需要的數據是這樣的:每個顏色有一個英文名、一個十六進制色號、男裝的出現比例和增長率、女裝的出現比例和增長率。把這些寫成一份清單——字段叫什麼、什麼類型、保留幾位小數、數據從哪個 CSV 的哪一列來。這份清單,就是所謂的"合約"。它不是什麼複雜的東西,就是一張"我需要什麼"的明細表。
(1.2,數據已脱敏)
比如,Runway 的 CSV 裏,字段 PR_CY 是一個 0 到 1 之間的小數,代表男裝的出現比例,需要乘以 100 轉成百分比後對應到 HTML 的 menPr 字段。小紅書的 CSV 裏,字段 CY_PR% 已經是百分比格式,直接對應到 womenPr。這些映射關係,以前全靠 AI 每次重新理解,現在寫在一個文件裏,一勞永逸。
第二步,寫一個腳本自動轉換。一個 Python 腳本,讀取兩邊的 CSV,按合約定義的格式輸出一個 JSON 文件。運行一條命令,3 秒完成。腳本的邏輯是確定的——同樣的輸入永遠得到同樣的輸出,不存在"這次 AI 理解對了,下次理解錯了"的問題。
第三步,HTML 直接消費 JSON。數據從 CSV 變成了標準格式的 JSON,HTML 頁面直接讀取這個 JSON 渲染圖表。不再需要 Excel 中轉,不再需要手動轉寫,不再需要肉眼校驗。
改進前,每次數據更新:打開 Runway 的 CSV 找男裝數據,打開小紅書的 CSV 找女裝數據,對齊兩邊數據粘貼進 Excel,從 Excel 手動轉寫成 JavaScript 數組格式,粘貼到四千多行 HTML 中的正確位置。耗時 15 到 30 分鐘,還容易出錯。
改進後,每次數據更新:重跑 Notebook 更新 CSV,運行一條命令生成 JSON,運行另一條命令注入到 HTML。總耗時不到一分鐘,零手動操作。而且 JSON 是純文本文件,Git 可以追蹤每一個數字的變化——哪個顏色的比例從 54.88 變成了 55.12,一目瞭然。
如果要用一個類比來幫助理解,數據合約就像你平時做數據分析時的"字段說明文檔"。每個項目多少都會有這麼一份東西,記錄每個字段叫什麼、從哪張表來、什麼類型、什麼含義。區別在於,傳統分析中這份文檔是給人看的備忘錄——你看一眼,心裏有數,然後手動操作。而數據合約是給腳本讀的執行指令——腳本按照這份清單自動完成轉換,不需要人介入。
從"給人看的文檔"到"給機器讀的接口",就差這一步。
從"知道"到"知道了"
很多技術概念,你"知道"和你"知道了"之間,隔着一個項目。
數據合約就是這樣。項目之前我能說出它的定義:上下游之間約定數據格式。項目之後我能畫出它的樣子:一份 JSON 清單,記錄字段名、類型、精度、數據來源和映射規則,配一個幾十行的 Python 轉換腳本。
這個認知落差的背後,其實藏着一個對數據分析師來說更深層的問題。
傳統數據分析的思維方式是"把數據聚到一個地方,然後操作"。你從不同的系統抽取數據,彙總到一張 Excel 或一個數據倉庫裏,然後在這個集中的地方做分析、做可視化、做報告。Excel 彙總表就是這個思維的產物——它是一個"給人看的全景視圖",讓分析師能一眼看到所有數據,做交叉比對,發現異常。
但在 AI 輔助開發中,你的"下游"不是人類分析師,是代碼。代碼不需要看到數據全貌。它不需要一個能排序篩選的 Excel 界面,不需要手動核對數字的能力。它只需要按約定的格式接收數據——字段名對上、類型對上、精度對上,就能正確渲染。
從"給人看的彙總表"到"給代碼讀的標準接口",這是數據分析師做 vibe coding 時需要邁過的一道坎。它不是技術能力的問題——寫一個 CSV 轉 JSON 的腳本,讓 AI 幫忙十分鐘就能搞定。它是思維習慣的問題:你得意識到,當你的交付物從"分析報告"變成"可交互的數據產品"時,數據的消費者變了,數據的流轉方式也應該跟着變。
回頭看,我在這個項目裏多花的那些時間——反覆讓 AI 從 CSV 提取數據、反覆在 Excel 和 HTML 之間搬運數字、反覆核對有沒有搬錯——本質上都是因為我用了一個"給人用"的流程去服務一個"給代碼用"的需求。Excel 不是不好,它在傳統分析中依然是最好的工具。但在這個特定的場景裏,它是一個昂貴的中間人——增加了步驟,增加了風險,卻沒有增加任何它擅長的價值。(寫到這裏,突然發現這不就是GUI和CLI的區別:GUI是給人類設計的操作界面,但對AI來說,最適合的是CLI)
這大概就是"知道"和"知道了"的區別。"知道"是聽過一個概念覺得有道理;"知道了"是在一個真實項目裏,花了兩週走彎路之後,終於明白這個概念存在的理由。
給讀者的行動清單
1. 如果你在重複做"從 A 格式轉成 B 格式"的手動操作,停下來,讓 AI 幫你寫一個轉換腳本。就算這個腳本只用一次,也比手動搬運更可靠——至少它不會漏掉一個數字或搞混一個字段。 2. 在數據交接點花 10 分鐘寫一份"我需要什麼字段、什麼格式"的清單。不需要用任何正式的 schema 語法,用自然語言寫就行——"顏色名用英文,十六進制色號帶 # 號,百分比保留兩位小數"。這份清單就是最簡單的數據合約,它讓 AI 和未來的你都能快速理解數據應該長什麼樣。 3. 儘量用文本格式(CSV、JSON)作為中間文件,而不是 Excel。原因很簡單:文本文件可以被 Git 跟蹤每一個數字的變化,而 Excel 在 Git 眼裏永遠只是一個"文件變了"。當你需要追溯"上次更新到底改了哪個數字"時,這個差別就是省一小時和花一小時的區別。