Voicebox,開源了!
整理版優先睇
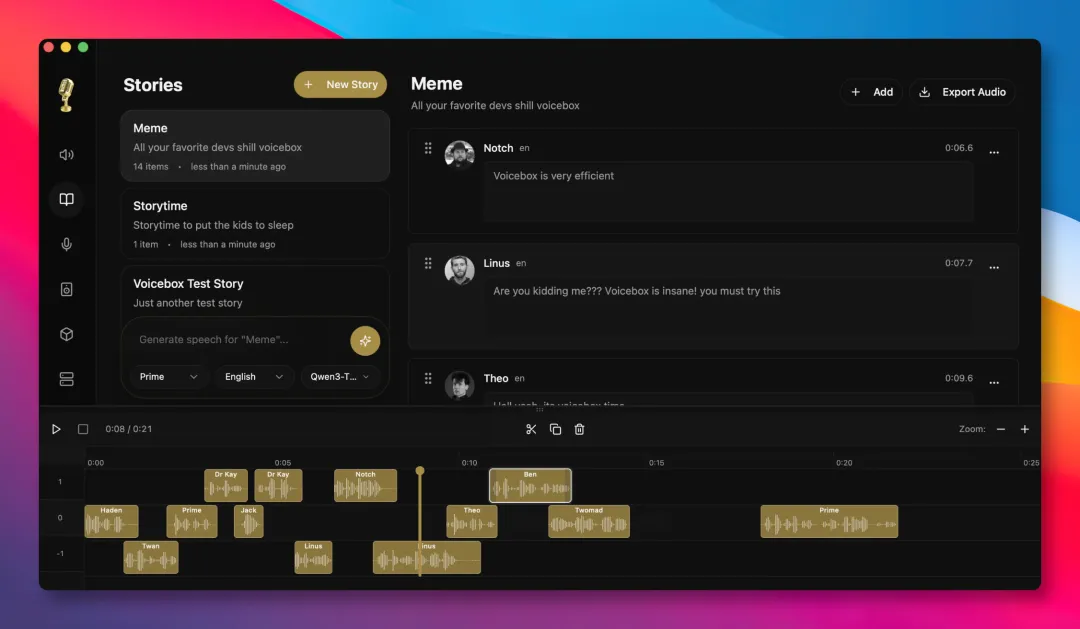
Voicebox開源咗,本地語音克隆加Agent配音一次搞掂
呢篇文章係一個技術作者喺GitHub發現咗一個叫Voicebox嘅開源項目,佢嘅核心定位係ElevenLabs同WisprFlow嘅本地平替。作者認為語音I/O本地化係遲早嘅事,而Voicebox將語音輸入、輸出同埋本地LLM改寫串聯起嚟,解決咗雲端訂閲成本同數據隱私嘅問題。整體結論係:呢個工具唔單止功能實用,更提供咗一種新可能——AI Agent可以講嘢、有情緒、有人設,未來會從純文字輸出工具演化成有聲有格嘅協作夥伴。
文章先介紹咗Voicebox嘅背景:GitHub上攞咗28,000+ Star,係一個以本地優先嘅AI語音工作室。佢覆蓋咗聲音克隆、語音聽寫、Agent配音三大部分,並且全程唔使上傳數據,私隱安全。作者比較咗現有工具:ElevenLabs主力語音輸出但收費,WisprFlow主力語音輸入同樣要錢,Voicebox一次過包辦曬兩邊,仲加咗本地LLM做人設改寫。
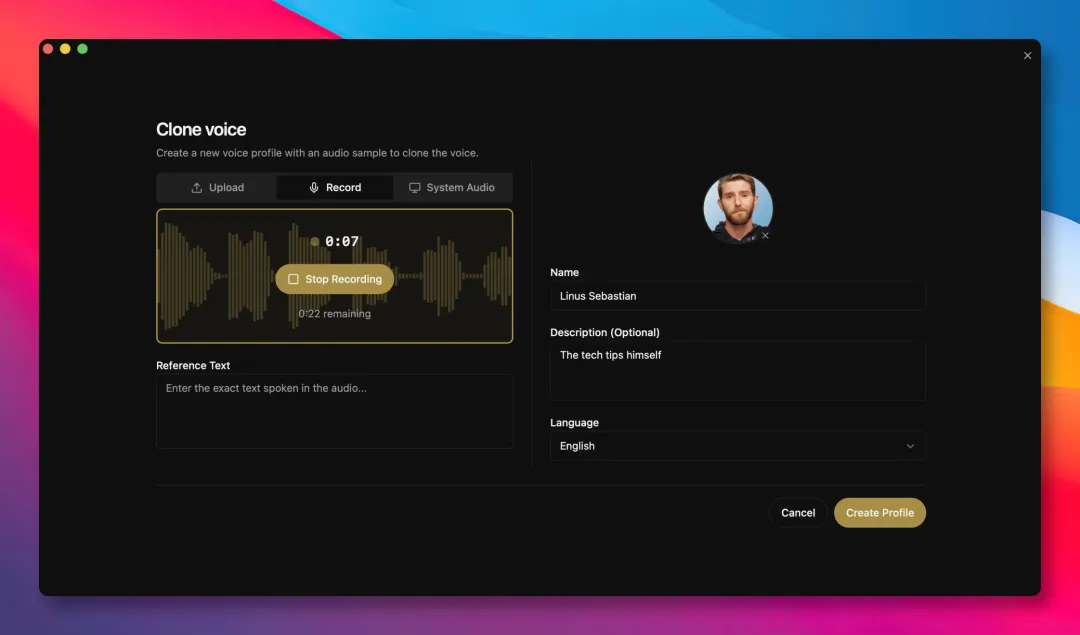
跟住文章詳細拆解咗功能:聲音克隆只需幾秒參考音頻,支援23種語言、7個TTS引擎,包括可以加情緒標籤嘅Chatterbox Turbo同埋支援自然語言指令嘅Qwen3-TTS。冇獨立顯卡可以用Kokoro(82M模型)。仲有MCP服務器可以畀Agent工具調用,例如Claude Code用一句命令就駁通,仲可以綁定唔同聲音畀唔同Agent。進階玩法係「人格化」,畀每個聲音綁人設描述,例如「冷靜嘅工程師」,然後文本會經本地LLM按人設改寫先合成語…
- Voicebox係ElevenLabs同WisprFlow嘅開源平替,本地優先,數據唔離機,私隱安全。
- 聲音克隆只需幾秒參考音頻,支援23種語言、7個TTS引擎,包括可加情緒標籤嘅Chatterbox Turbo。
- 提供MCP服務器協議,Agent工具(例如Claude Code)可以駁入,用克隆嘅聲音報語音進度。
- 「人格化」功能:畀每個聲音綁人設描述,文本經本地LLM改寫先合成,連說話風格都自由定。
- 安裝簡便,macOS/Windows有安裝包,蘋果M芯片同NVIDIA CUDA都支援,REST API同MCP Server預設監聽127.0.0.1:17493。
GitHub 項目地址
Voicebox 官方倉庫,可以下載同睇原始碼。
MCP Server 配置命令
將 Voicebox 接入 Claude Code 嘅指令:claude mcp add voicebox --transport http --url --header "X-Voicebox-Client-Id: claude-code"
本地文檔地址
啟動後 REST API 同 MCP Server 文檔喺
Voicebox 係乜?點解值得注意
呢個項目係一個本地優先嘅 AI 語音工作室,GitHub 上已經有 28,000+ Star。佢想解決嘅問題好直接:ElevenLabs 同 WisprFlow 呢類工具雖然好用,但每月要幾十蚊美金,而且音頻數據要上傳,好多人唔放心。Voicebox 將語音輸入、輸出同埋本地 LLM 改寫串埋一齊,聲稱係「開源平替」。
全程唔使上傳數據,私隱安全
作者認為語音 I/O 本地化係大勢所趨,而 Voicebox 提供咗一個可行嘅方案:喺自己電腦度完成聲音克隆、語音聽寫同 Agent 配音,唔使靠雲端。
聲音克隆:幾秒參考音頻,23種語言7個引擎
你需要嘅只係幾秒鐘嘅參考音頻,就可以生成一個屬於自己嘅聲音模型。支援23種語言,包括英文、中文、阿拉伯文、印地文、斯瓦希里文等主流語言。
內置7個TTS引擎
- Chatterbox Turbo 支援 [laugh]、[sigh] 情緒標籤,可以生成帶笑聲、嘆氣嘅真實語音。
- Qwen3-TTS 擅長多語言克隆,仲聽得明「慢啲講」「用耳語」呢啲自然語言指令。
- Kokoro 模型得82M,冇獨立顯卡嘅CPU機都行得鬱。
唔想克隆自己把聲?項目內置咗50幾個預設音色,開箱即用。生成出嚟嘅音頻仲可以編輯,調音、混響、延遲、壓縮呢啲參數全部可以實時預覽。
Agent 配音:MCP 協議駁通 Claude Code
Voicebox 提供一個 MCP 服務器協議,任何支援 MCP 嘅 Agent 工具都可以調用佢嚟發聲。例如接入 Claude Code,只需要一行命令:
claude mcp add voicebox \
--transport http \
--url http://127.0.0.1:17493/mcp \
--header "X-Voicebox-Client-Id: claude-code"加完之後,Claude Code 就可以直接用你克隆嘅聲音講「測試通過,可以合併」。你仲可以喺設定入面畀唔同 Agent 綁唔同聲音,聽聲就知邊個 Agent 喺度報告。
聽聲音就能分辨係邊個 Agent 喺度報告
咁樣寫 code 嘅時候就唔使成日望住個 mon,可以聽到熟悉嘅聲音報進度,開發體驗即刻升呢。
人格化玩法:連說話風格都由你定
Voicebox 仲有個進階功能叫「人格化」。你可以畀每個聲音綁一段自由格式嘅人設描述,例如「冷靜嘅工程師」「毒舌嘅代碼審查官」。
呢個功能令 AI Agent 唔再係冷冰冰嘅文字輸出,而係可以有情緒、有性格嘅協作夥伴。
聽寫功能同安裝說明
除咗語音輸出,Voicebox 仲有全局快捷鍵聽寫功能。按住熱鍵講嘢,鬆開之後文字會自動黐到你當前聚焦嘅輸入框。
macOS 上透過輔助功能API精確識別目標文本框
粘貼過程唔會污染剪貼板,體驗做得幾好。安裝方面,項目提供 macOS 同 Windows 嘅安裝包,可以去官網或者 Releases 頁面下載。首次使用會自動下載模型權重:Kokoro 得 82M,Qwen3-TTS 要幾個 GB,你可以按需要下載。
蘋果M芯片上跑速度比通用方案快好多,NVIDIA顯卡會自動行CUDA
REST API 同 MCP Server 預設監聽本地17493端口,文檔網址係 http://127.0.0.1:17493/docs,對接自己嘅腳本同工具非常方便。
想 clone 自己把聲嚟做配音,ElevenLabs 一定係首選,佢呢個功能做得真係唔錯。
但係每個月幾十美金嘅費用,加上音頻數據要 upload 去佢哋嘅 server,對好多人嚟講都係一個門檻。
至於語音輸入都有唔錯嘅工具,例如 WisprFlow,但係同樣要俾錢,私隱同樣成疑。
今日喺 GitHub 上面發現一個叫 Voicebox 嘅開源項目,狂攞咗 28000+ Star。
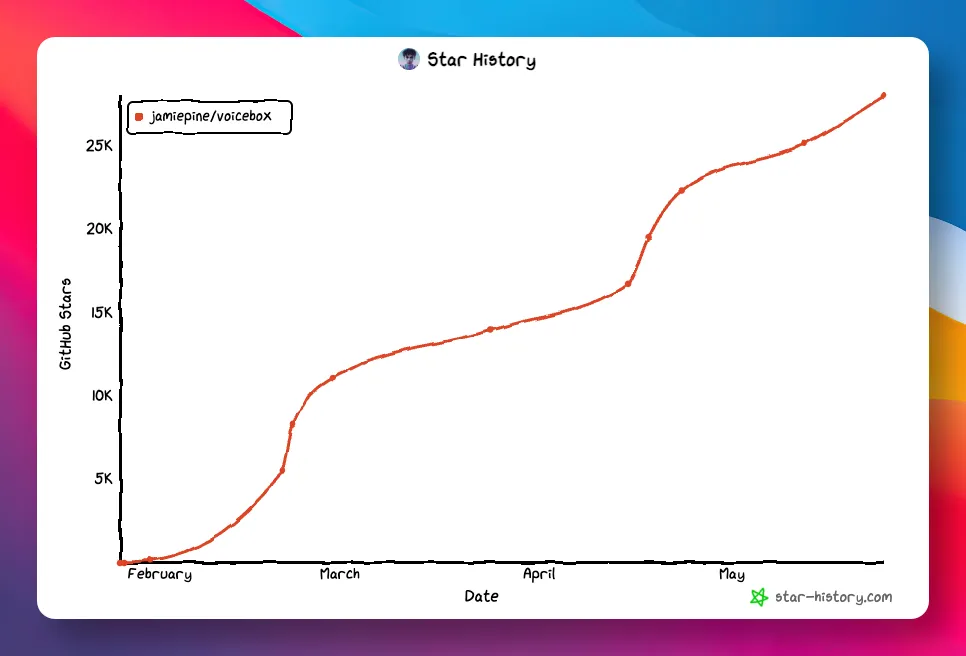
佢嘅核心定位係 ElevenLabs 同 WisprFlow 嘅開源平替,以本地優先嘅 AI 語音工作室。
喺語音市場上,ElevenLabs 主打語音輸出,WisprFlow 主打語音輸入,佢哋兩個算係各佔一邊。
今次 Voicebox 將兩邊都做埋,額外仲用一個本地 LLM 將中間嘅改寫、人格化環節串連起嚟。
即係話,我哋 clone 出嚟嘅聲音、錄低嘅語音片段,全程唔會離開自己部電腦,數據私隱安全。
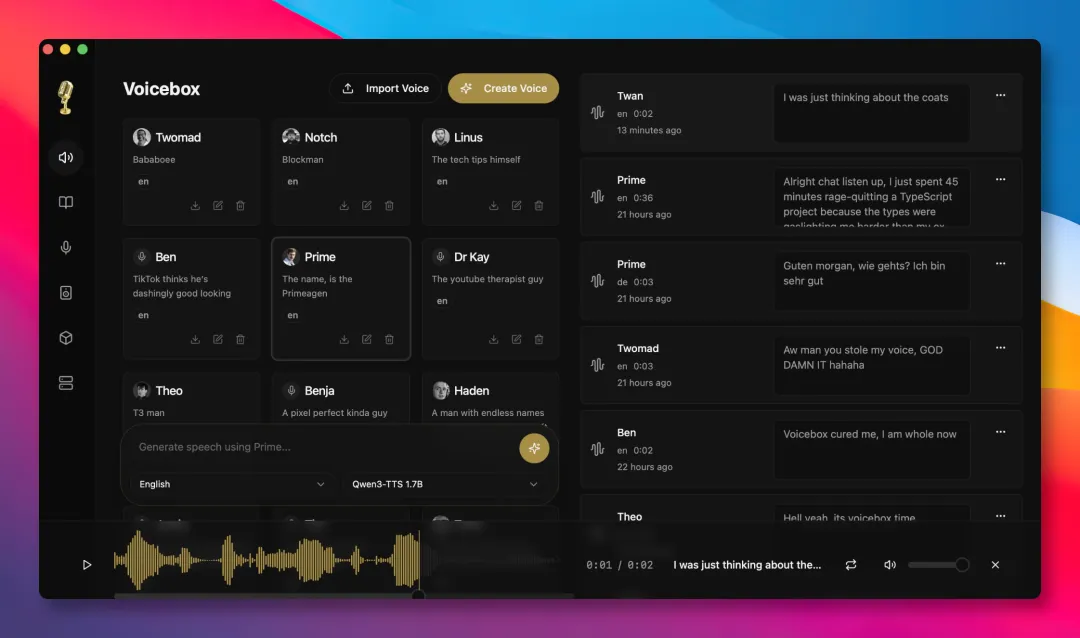
先講下工具嘅聲音 clone 呢部分。
只需要我哋提供幾秒鐘嘅參考音頻,就可以生成一個屬於我哋自己嘅聲音模型。
覆蓋 23 種語言,由英文、中文到阿拉伯文、印地文、斯瓦希里文,主流語言都支援。
內置 7 個 TTS 引擎,包括 Qwen3-TTS、Chatterbox、LuxTTS、Kokoro 等。
唔同引擎各有作用,例如 Chatterbox Turbo 支援 [laugh]、[sigh] 呢類情緒標籤,可以令生成嘅語音帶有笑聲、嘆氣等真實情緒。
而 Qwen3-TTS 就擅長多語言 clone,仲可以聽得明「慢啲講」「用耳語」呢啲自然語言指令。
至於冇獨立顯示卡嘅朋友,可以揀 Kokoro,模型得 82M,CPU 都行得鬱。
如果唔想 clone 自己把聲,項目都有內置 50 幾個預設音色,可以直接開箱就用得。
生成出嚟嘅音頻仲可以編輯,調音、混響、延遲、壓縮呢啲參數都可以實時預覽。
接下來要講嘅,呢個項目另一個我覺得幾得意嘅功能,就係可以俾 Agent 工具配音。
Voicebox 提供一個 MCP server 協議,任何支援 MCP 嘅 Agent 工具,都可以 call 佢嚟發聲。
例如將佢接入 Claude Code,只需要一行 command:
claude mcp add voicebox \
--transport http \
--url http://127.0.0.1:17493/mcp \
--header"X-Voicebox-Client-Id: claude-code"加完之後,Claude Code 就可以直接用我哋 clone 嘅聲音講一句「測試通過,可以合併」。
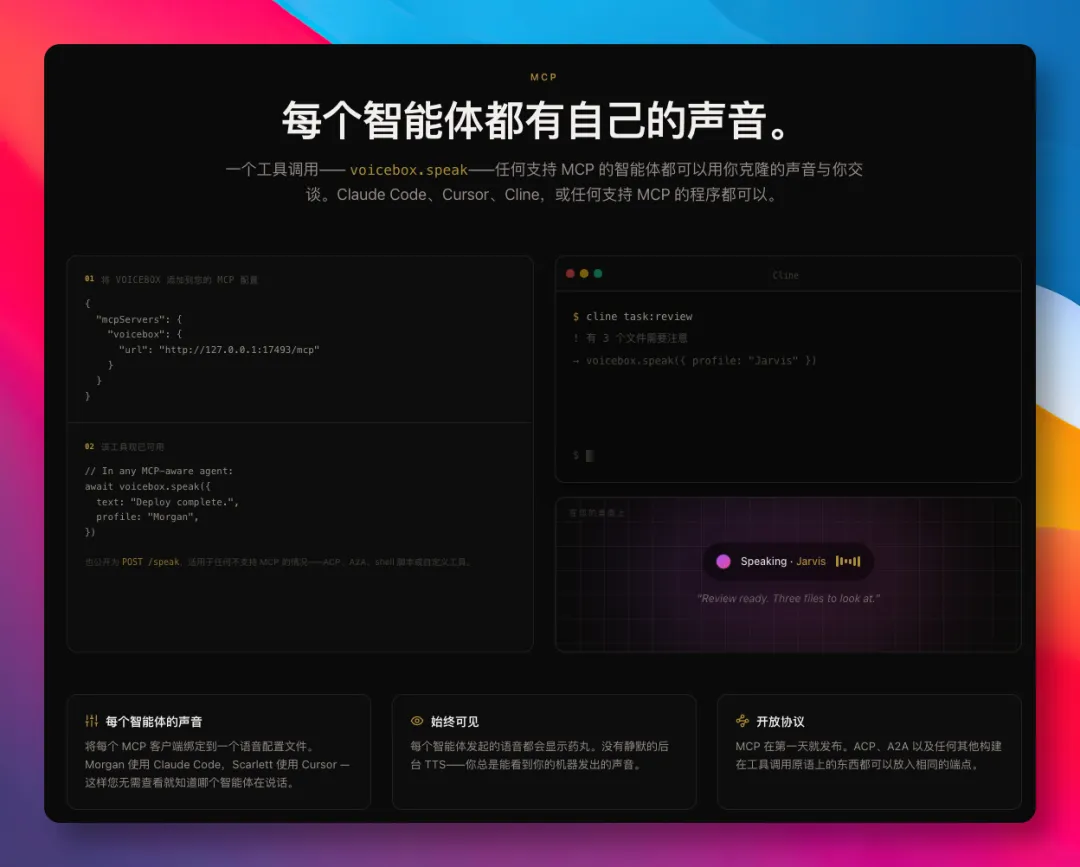
我哋仲可以喺設定入面俾唔同嘅 Agent 綁定唔同嘅聲音,聽聲音就知邊個 Agent 喺度報告。
咁樣我哋喺寫 code 嘅空隙,就可以聽到熟悉嘅聲音報告進度,令我哋嘅開發體驗更上一層樓。
另外 Voicebox 仲有一個更高階嘅玩法,叫做人格化。
我哋可以俾每個聲音綁一段自由格式嘅人設描述,例如「冷靜嘅工程師」「毒舌嘅 code review 官」。
之後無論係手動生成,定係 Agent 經 MCP 呼叫,文字都會先經本地 LLM 按照人設改寫,再合成語音。
即係話,Agent 講出嚟嘅嘢唔單止聲音由你決定,連講嘢風格都可以自由設定。
唔止咁,仲提供一個全局快捷鍵聽寫功能,撳住熱鍵講嘢,放開之後文字會自動貼到當前 focus 嘅輸入框。
喺 macOS 上面嘅體驗做得唔錯,會透過輔助功能 API 精確識別目標文字框,貼上過程唔會污染剪貼簿。
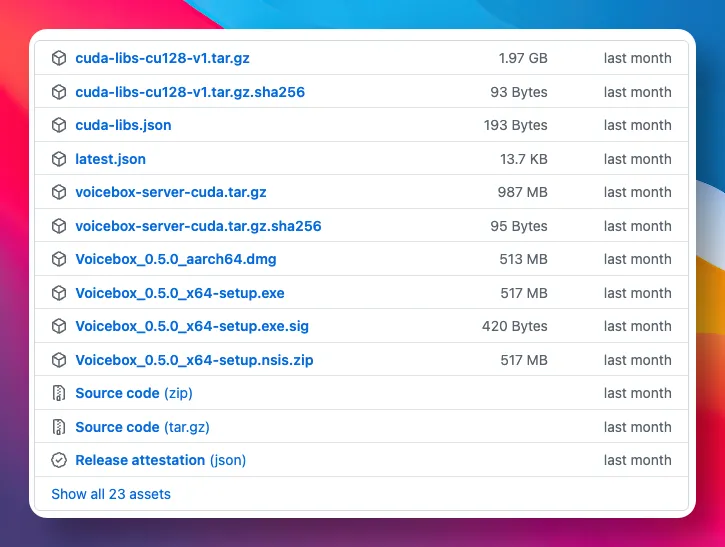
至於安裝,項目提供咗 macOS、Windows 嘅安裝包,可以去官網或 Releases 頁面下載。
第一次用會自動下載模型權重,Kokoro 得 82M,Qwen3-TTS 要幾個 G,可以按需要下載。
再提一句,喺蘋果 M 芯片上面行,速度比通用方案快唔少,NVIDIA 顯示卡就會自動行 CUDA。
至於 REST API 同 MCP Server 預設會 listen 本地 17493 port,文檔地址喺 http://127.0.0.1:17493/docs,對接自己嘅 script 同工具非常方便。
寫喺最後
講真,我認為語音 I/O 嘅本地化係一件遲早會發生嘅事。
但係都唔可以唔承認,雲端喺方便程度上確實有優勢,但訂閲成本同數據私隱呢兩道檻一直都喺度。
我哋嘅聲音特徵數據,真係俾人泄露或者濫用,後果可能同密碼泄露差不多嚴重。
呢個都係點解語音本地方案嘅需求,越來越被重視嘅原因之一。
好彩呢兩年,開源模型不斷迭代更新,基本上係肉眼可見咁快追平閉源模型嘅效果。
再加上都可以喺蘋果 MLX、NVIDIA CUDA 呢啲消費級硬件上面,本地行 TTS、STT、LLM。
而 Voicebox 嘅價值,我覺得唔止喺功能上實用,更加俾我哋提供一個新嘅可能。
以後用 Agent,我哋唔一定係要對住一個冰冷嘅對話框,都可以叫佢講嘢、有情緒、有名。
未來好快 AI Agent 就會由純文字輸出工具,逐漸演化成有聲音、有人設嘅協作夥伴。
至於會唔會成為主流,我哋就拭目以待啦。
GitHub 項目地址:https://github.com/jamiepine/voicebox
今日嘅分享到呢度結束,多謝大家抽空閲讀,我哋下期再見,Respect!
想要克隆自己的聲音做配音,ElevenLabs 當屬首選,它這個功能做的的確不錯。
但每月幾十刀的費用,加上音頻數據要上傳到他們服務器,對不少人來說都是個門檻。
對於語音輸入也有不錯的工具,比如 WisprFlow,可同樣要付費,隱私同樣存疑。
今天在 GitHub 上發現一個名叫 Voicebox 的開源項目,狂攬了 28000+ Star。
它的核心定位是 ElevenLabs 和 WisprFlow 的開源平替,以本地優先的 AI 語音工作室。
在語音市場上,ElevenLabs 主攻語音輸出,WisprFlow 主攻語音輸入,它兩算是各佔一邊。
這一次 Voicebox 把兩邊都做了,額外還用一個本地 LLM 把中間的改寫、人格化環節串了起來。
也就是說,我們克隆出來的聲音、錄下的語音片段,全程不會離開自己的電腦,數據隱私安全。
先來說說工具的聲音克隆這塊。
只需要我們提供幾秒鐘的參考音頻,就能生成一個屬於我們自己的聲音模型。
覆蓋 23 種語言,從英語、中文到阿拉伯語、印地語、斯瓦希里語,主流語言都支持。
內置 7 個 TTS 引擎,包括 Qwen3-TTS、Chatterbox、LuxTTS、Kokoro 等。
不同引擎各有作用,比如 Chatterbox Turbo 支持 [laugh]、[sigh] 這類情緒標籤,能讓生成的語音帶笑聲、嘆氣等真實情緒。
而 Qwen3-TTS 則擅長多語言克隆,還能聽懂「慢一點說」「用耳語」這種自然語言指令。
至於沒有獨立顯卡的同學,可以選 Kokoro,模型只有 82M,CPU 也能跑得動。
如果不想克隆自己的聲音,項目也內置了 50 多個預設音色,可以直接開箱可用。
生成出來的音頻還能進行編輯,調音、混響、延遲、壓縮這些參數都能實時預覽。
接下來要說的,這個項目另一個讓我覺得挺有意思的功能,那就是可以給 Agent 工具配音。
Voicebox 提供一個 MCP 服務器協議,任何支持 MCP 的 Agent 工具,都能調用它來發聲。
比如將其接入到 Claude Code,只需要一行命令:
claude mcp add voicebox \
--transport http \
--url http://127.0.0.1:17493/mcp \
--header"X-Voicebox-Client-Id: claude-code"添加完成後,Claude Code 就能直接用我們克隆的聲音說一句「測試通過,可以合併」。
我們還能在設置裏給不同的 Agent 綁定不同的聲音,聽聲音就能分辨是哪個 Agent 在報告。
這樣我們在寫代碼的間隙,就能聽到熟悉的聲音報告進度,讓我們的開發體驗更上一個台階。
另外 Voicebox 還有一個更進階的玩法,叫人格化。
我們可以給每個聲音綁一段自由格式的人設描述,比如「冷靜的工程師」「毒舌的代碼審查官」。
之後無論是手動生成,還是 Agent 通過 MCP 調用,文本都會先經過本地 LLM 按人設改寫,再合成語音。
也就是說,Agent 說出來的話不只是聲音由你定的,連說話風格也可以自由設定。
不止於此,還提供一個全局快捷鍵聽寫功能,按住熱鍵說話,鬆開後文字會自動粘貼到當前聚焦的輸入框。
在 macOS 上的體驗做得不錯,會通過輔助功能 API 精確識別目標文本框,粘貼過程不會污染剪貼板。
至於安裝,項目提供了 macOS、Windows 的安裝包,可到官網或 Releases 頁面下載。
首次使用會自動下載模型權重,Kokoro 只有 82M,Qwen3-TTS 要幾個 G,可按需下載。
再提一句,在蘋果 M 芯片上跑,速度比通用方案快不少,NVIDIA 顯卡則會自動走 CUDA。
至於 REST API 和 MCP Server 默認監聽本地 17493 端口,文檔地址在 http://127.0.0.1:17493/docs,對接自己的腳本和工具非常方便。
寫在最後
講真的,在我看來,語音 I/O 的本地化是一件遲早要發生的事。
但也不得不承認,雲端在便利性上確實有優勢,可訂閲成本和數據隱私這兩道坎一直在。
我們的聲音特徵數據,真要是被泄露或者被濫用,後果可能跟密碼泄露差不多嚴重。
這也是為什麼語音本地方案的需求,越來越被重視的原因之一。
好在這兩年,開源模型的不斷迭代更新,基本是肉眼可見地速度在追平閉源模型的效果。
再加上也可在蘋果 MLX、NVIDIA CUDA 這些消費級硬件,本地跑 TTS、STT、LLM。
而 Voicebox 的價值,我覺得不止在功能上的實用,更給我們提供一個新的可能。
以後使用 Agen,我們不一定非得對着一個冰冷的對話框,也可以讓它說話、有情緒、有名字。
未來很快 AI Agent 即將從純文本輸出工具,逐漸演化成有聲音、有人設的協作夥伴。
至於會不會成為主流,我們就拭目以待吧。
GitHub 項目地址:https://github.com/jamiepine/voicebox
今天的分享到此結束,感謝大家抽空閲讀,我們下期再見,Respect!