X 上那些刷屏的 AI 短視頻,原來是這麼做出來的
整理版優先睇
GPT Image 2 + Seedance 2.0 工作流:用圖像鎖定角色,告別AI視頻角色不一致嘅煩惱
呢篇文章係講近排喺 X 上刷屏嗰啲高質AI短視頻——末世廢土女主角、卡通廚房鬥氣、科幻城市追逐——原來背後係一套固定嘅工作流:先用 OpenAI 嘅 GPT Image 2 生成角色一致嘅分鏡圖,再將啲圖餵俾字節跳動嘅 Seedance 2.0 動畫化。作者想解決嘅係AI視頻圈長期以嚟嘅老大難問題——角色一致性:同一個人物唔同鏡頭會變樣,搞到冇辦法講故事。整體結論係呢套「設計+執行」兩段式流程嘅可用片段成功率可以降低到純文字轉視頻嘅五分之一到八分之一成本,大幅減少廢稿。
文章用咗一個漢唐宮廷舞嘅具體案例逐步拆解工作流:第一階段係喺 ChatGPT 用 GPT Image 2 生成16宮格分鏡圖,第二階段係將張分鏡圖上傳到 Dreamina 用 Seedance 2.0 生成連貫視頻。作者特別強調,提示詞唔係靠人逐字敲出嚟,而係先參考工具嘅規則,再同AI一齊協作產出,而且需要幾輪試錯。最後畀咗兩個工具嘅入手門檻同費用,仲點出咗適用人羣同目前限制(最多15秒、真人面孔過濾、思考模式慢)。
總括嚟講,呢篇唔係純工具介紹,而係一個實戰教程,展示咗點樣用現有AI工具組合解決具體創作難題,對想整連續角色短視頻嘅創作者好有參考價值。
- 角色一致性係AI視頻最大痛點,呢套工作流透過先鎖定角色再動畫化,大幅提升可控性。
- GPT Image 2 嘅思考模式可以一次生成最多8張角色一致嘅圖像,係分鏡基礎。
- Seedance 2.0 接受圖像、視頻、音頻同時輸入,最長15秒1080p視頻,仲有環境音效。
- 兩段式流程比純文字轉視頻嘅可用片段成功率低五分之一到八分之一成本,減少廢稿。
- 提示詞可以參考工具規範然後同AI協作生成,唔使硬寫;月費$20起即可用全部功能。
ChatGPT Images 2.0(需登入)
GPT Image 2 嘅官方入口,免費用戶可用即時模式,Plus訂閲解鎖思考模式。
Dreamina - Seedance 2.0
字節跳動國際版平台,新用戶有免費額度,月費$18起。
漢唐宮廷舞 16宮格分鏡提示詞(Step 1)
用GPT Image 2生成分鏡圖嘅完整提示詞範本,包含場景、人物、服裝、16格動作描述,可直接使用或修改。
漢唐宮廷舞 Seedance 視頻生成提示詞(Step 2)
將分鏡圖轉為視頻嘅完整提示詞,包含鏡頭要求、分鏡腳本、動作限制,可作範本。
內容片段
請創作一張高完成度、高清晰度的「漢唐宮廷舞 / 霓裳羽衣舞 · 16宮格分鏡圖」。
【整體定位】
這不是普通古風寫真,也不是單純舞蹈教學圖,而是一張融合「漢唐宮廷舞」「霓裳羽衣舞」「真實宮苑空間」「電影分鏡感」「16步動作編排」的高完成度分鏡海報。
整體要像一段盛唐宮廷舞的完整編舞被拆解成16個關鍵畫面,每一格既清晰獨立,又有連續流動感,方便後續用於視頻生成。
【場景設定】
不要舞台,不要空黑背景,不要現代攝影棚。
場景必須是一個真實、立體、優美、符合漢唐時代氣質的盛唐宮苑空間:
- 傍晚金藍時刻,宮燈初上
- 硃紅宮柱
- 金色宮燈
- 宮廷迴廊 / 大殿外庭院
- 石階、欄杆、輕紗帷幔
- 遠處可見層疊殿宇與宮苑深景
- 空間有明確前景、中景、後景,具有真實縱深感
- 整體氛圍華美、通透、盛世感強,不要烏漆麻黑,不要渾濁,不要色斑
【人物設定】
主角是一位年輕中國女舞者,帶有盛唐宮廷舞者氣質,端莊、華美、優雅、剋制。
她在16格中必須保持同一張臉、同一人物身份、同一氣質、同一套服裝體系,不要每格都像換了一個人。
【服裝與妝造】
服裝為漢唐宮廷舞服 / 霓裳羽衣風格:
- 高腰長裙
- 大袖
- 輕紗披帛
- 精緻髮髻
- 金色髮飾、步搖
- 少量花鈿或唐風妝感
- 裙襬、披帛、大袖都要有真實動態
推薦配色:
- 胭脂粉
- 象牙白
- 香檳金
- 淡石青
整體華麗但不俗豔。
【版式要求】
- 畫面採用 4×4 的16宮格分鏡排版
- 每格都有明顯編號 1-16
- 每格都有中文動作標題
- 每格可有簡潔中文說明或短句提示
- 每格都要像一個獨立鏡頭畫面
- 適當加入動作方向箭頭或軌跡線,增強分鏡感
- 整體清晰、工整、信息完整,但不要過度擁擠
- 分辨率要非常高清,線條清楚,人物和背景都清晰,不要糊,不要髒,不要有色斑
【動作分鏡順序】
1. 宮苑亮相
舞者站在宮苑中央,微側身,長裙曳地,一手輕提大袖,一手自然垂落,建立盛唐氣場。
2. 起袖迎風
雙臂緩緩抬起,大袖與披帛輕輕被帶起,像樂聲初起。
3. 拈花側行
舞者緩步前行,一手做拈花或蘭花指,一手大袖舒展在身後,動作優雅。
4. 開袖成雲
雙袖向兩側大幅展開,形成對稱而華麗的大開構圖,像雲氣鋪開。
5. 回眸轉廊
舞者經過宮柱或迴廊邊緣,身體轉向側背,再緩緩回眸。
6. 環步繞帛
腳下走環步,披帛繞身形成流動軌跡,雙臂一前一後,動作圓潤。
7. 旋裙開宴
原地或小範圍旋轉,長裙與披帛打開,形成華麗旋舞。
8. 折腰揚袖
身體輕折,一袖高揚,一袖下垂,形成斜向張力構圖。
9. 低身獻禮
半蹲或單膝低位,雙手託袖向前,動作像宮廷獻禮,具有禮樂儀式感。
10. 仰身拂雲
從低位起身,上半身輕微後仰,雙袖向上揚起,披帛向後飛,動作華美但真人可完成。
11. 飛步掠庭
向側前方做一個輕盈掠步,大袖和披帛向後帶出,形成位移動線。
12. 盛唐大旋
最華麗的一次大旋轉,長裙、披帛、大袖同時打開,是整套最強高潮之一。
13. 回身收袖
從大旋中自然回身,雙袖由外向內慢慢收回,動作從大開轉向收束。
14. 託月舉袖
一手高舉如託月,一手橫於胸前,身體向上拉長,披帛在身側形成弧線,儀式感強。
15. 合袖禮成
雙袖緩緩合攏至胸前,形成“禮成”動作,神情寧靜莊重。
16. 霓裳定格
最終大定格,一袖高揚,一袖低垂,身體優雅扭轉,長裙鋪開,端莊華美地完成收尾。
【重點要求】
- 必須突出真實空間感與時代感
- 必須保持同一舞者一致性
- 必須有完整的大袖、披帛、長裙動態
- 必須適合後續作為視頻分鏡參考
- 每一格動作都要明顯不同,不能過於重複
- 畫面整體要華麗、優美、清晰、通透
- 不要黑壓壓,不要髒,不要模糊,不要色斑,不要廉價古風感點解呢套工作流通殺?
近排 X 上成日見到啲末日女主角、卡通鬥氣、科幻追逐嘅短視頻,唔超過15秒,質素高到嚇親人。發帖者都唔係專業電影人,但佢哋唔約而同用咗兩個工具:GPT Image 2 同 Seedance 2.0。呢個唔係巧合,而係一套快速擴散嘅工作流。
角色一致性一直係AI視頻嘅老大難——同一個人喺唔同鏡頭會變樣,搞到冇辦法講連續故事。
而 GPT Image 2 + Seedance 2.0 嘅組合,係目前已知解決得最徹底嘅方案之一。GPT Image 2 喺2026年4月發佈,12小時內登上 Image Arena 第一名,領先第二名242分。佢嘅文字渲染接近完美,仲有「思考模式」推理構圖,一次可以生成最多8張角色一致嘅圖像。Seedance 2.0 係字節跳動嘅視頻模型,接受圖像、視頻、音頻同時輸入,最長15秒1080p,仲有環境音效。
工作流拆解:分鏡圖 > 動畫化
- 1 第一步:喺 ChatGPT 描述故事場景,叫 GPT Image 2 一次過生成一組角色圖,例如正面、側面、動作姿勢。由於係同一會話生成,角色外貌穩定。創作者常用「分鏡網格圖」技巧,將多個鏡頭排列喺同一張圖。
- 2 第二步:將已生成嘅圖上傳到 Seedance 2.0,配合文字描述話畀模型「呢個角色要做咩動作、鏡頭點移動」。Seedance 2.0 會將靜態圖變成有真實運動感嘅視頻片段,有時仲附帶環境聲效。
用呢套流程已經產出咗多種風格嘅視頻,例如漢唐宮廷舞。即係文章入面用16宮格參考圖生成嗰段,角色一致性完成得非常好。相比純文字轉視頻,呢套流程嘅核心優勢係「可控性」——創作過程拆成「設計」同「執行」兩個階段,前者由人主導,後者由模型完成。
提示詞唔使硬寫,可以同 AI 協作
文章提供咗完整嘅提示詞範例,分Step 1(16宮格分鏡圖)同Step 2(Seedance 視頻生成)。你可能會覺得:「啲提示詞咁長,我邊寫得出?」但事實上,絕大部分人都係先參考工具嘅規則或規範,再將呢啲規範餵俾AI大模型學習,然後根據自己嘅創意同AI共同協作產出。
提示詞唔係一次性生成,需要幾輪試錯同打磨先可以定稿。
所以唔使覺得自己唔得。上面嘅提示詞就係模版,你可以餵俾大模型令佢學習,然後按照自己構思嘅諗法,同AI協作創作新嘅視頻創意。
入手門檻同費用一覽
- GPT Image 2:所有ChatGPT用戶(包括免費)可以用即時模式,有使用頻次限制。解鎖思考模式(多圖一致性生成)需要訂閲ChatGPT Plus($20/月)或Pro($100/月)。API按token計費,1024×1024圖像低質量約$0.006,高質量約$0.211。
- Seedance 2.0:國際用戶用Dreamina(dreamina.capcut.com),新用戶有免費額度。付費套餐$18/月起,高檔約$84/月。中文版即夢平台起步價69元/月(約$9.6),同等額度更划算。第三方平台如Lovart亦有接入。
注意:每段視頻最長15秒,需手動剪輯拼接;Seedance 2.0對真實人物面孔有內容過濾;GPT Image 2思考模式生成速度較慢,複雜場景可能需5-10分鐘。
總結:值得一試嘅AI影視化工作流
雖然目前有長度限制同生成速度問題,但整體嚟講,GPT Image 2 + Seedance 2.0 嘅組合令AI短片製作嘅可控性大大提升,值得你試一試!
最近如果你喺 X 上面行,成日都會見到呢類影片。
一個末世廢土嘅女主角獨自對抗世界,電影感鏡頭切換。
或者兩個卡通角色喺廚房互鬥,3D 動畫效果流暢到出奇。
仲有科幻漫畫感嘅城市追逐場景,人物喺高樓之間穿梭。
呢啲影片嘅共通點係:唔超過 15 秒,質素高得離奇,而且發帖嘅人都唔係專業電影人。
從佢哋嘅推文入面會發現,呢批影片幾乎都提到咗同樣兩個工具:
GPT Image 2 和 Seedance 2.0
呢個唔係巧合,而係一套喺 AI 創作圈入面快速擴散嘅工作流程組合。
要搞清呢套組合點解最近咁流行,就要先了解一個喺 AI 影片圈長期存在嘅老大難問題:
角色一致性
AI 生成影片最令人頭痕嘅地方,唔係畫質差,而係同一個人喺唔同鏡頭入面「樣貌唔同」。呢個問題令到任何想講故事、有連續角色嘅影片,基本上冇可能用 AI 直接完成,因為鏡頭一換角色就變形。
呢個問題困擾咗所有 AI 影片工具好幾年。
而 GPT Image 2 加上 Seedance 2.0 嘅組合,係目前已知將呢個問題解決得最徹底嘅方案之一。
GPT Image 2 係 OpenAI 喺 2026 年 4 月 21 日推出嘅新一代圖像生成模型,官方名係 ChatGPT Images 2.0,API 代號係 gpt-image-2。
呢個模型推出 12 小時內就上咗 Image Arena 排行榜第一名,領先第二名足足 242 分,係該排行榜有史以嚟最大嘅領先幅度,到而家仍然保持第一。
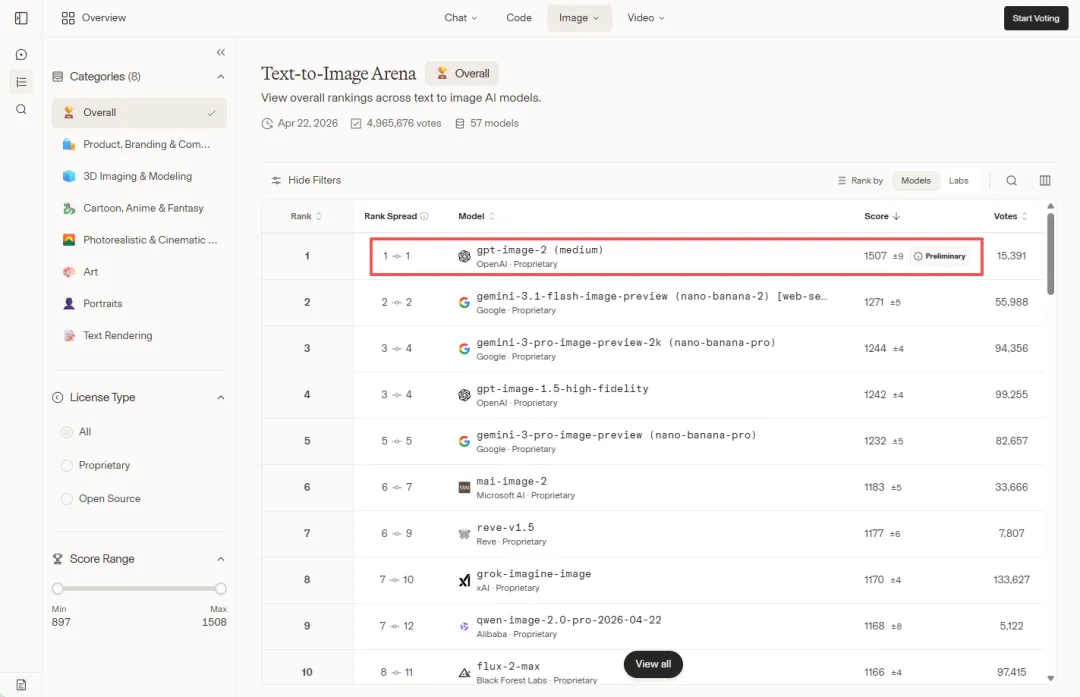
佢相比上一代(GPT Image 1.5)最核心嘅兩個突破:
第一,文字渲染接近完美,唔再出現 AI 圖像入面嗰啲字母錯位、字體扭曲嘅現象,中文、日文、韓文、阿拉伯文等非拉丁字符都準確處理到。
第二,加入咗「思考模式」,模型喺生圖之前會先推理構圖邏輯,類似 o1 嘅思維鏈機制。
對呢套工作流程嚟講,更重要嘅能力係:
佢可以喺一次請求入面生成最多 8 張角色一致嘅圖像,同一個人物喺唔同角度、唔同場景下保持高度穩定嘅外貌。
例如下面呢張「一致性」嘅圖像組,就成為咗後續影片製作嘅視覺基礎。

而 Seedance 2.0 係字節跳動旗下 AI 研究團隊 Seed 開發嘅影片生成模型,2026 年 2 月正式推出。
字節跳動喺國內嘅產品叫即夢(Jimeng),國際版叫 Dreamina,Seedance 2.0 係兩者底層共用嘅影片模型。
呢個模型一推出就迅速喺全球社交媒體上走紅,以對電影中真實演員嘅高度還原度聞名,甚至當時仲引發咗荷里活製片公司嘅版權抗議,迪士尼同派拉蒙都向字節跳動發出過警告。
後嚟字節跳動表示會加強安全過濾,對真實人物生成進行嚴格限制。
但對創作者嚟講,呢個模型真正嘅亮點係:
佢接受圖像、影片、音頻同時作為參考輸入,最多可以上傳 9 張圖片、3 段影片、3 段音頻,一次性生成一段有角色、有鏡頭運動、有環境音效嘅連貫影片,單次生成時長最長 15 秒,解像度可以達到 1080p 甚至 2K。
呢兩個工具而家撘埋一齊,工作流程嘅邏輯變成咗:先用 GPT Image 2 做「角色設定」同「分鏡稿」;再將生成好嘅圖像交俾 Seedance 2.0 令佢「鬱起來」。
如果再拆細啲講:
第一步,係喺 ChatGPT 入面描述你想嘅故事場景同角色,叫 GPT Image 2 一次性生成一組角色圖。例如同一個主角嘅正面、側面、唔同動作姿勢。
因為呢啲圖係喺同一輪對話入面生成嘅,模型會保持該角色外貌嘅穩定性。喺 X 上流傳嘅截圖入面,可以見到創作者用嘅就係呢種「分鏡網格圖」嘅技巧。佢哋叫 GPT Image 2 生成類似電影分鏡板嘅多格畫面,將多個鏡頭場景排列喺同一張圖入面,咁樣角色喺所有格子入面都嚟自同一輪生成,一致性更加有保障。
第二步,就係將已經生成好嘅圖上傳俾 Seedance 2.0,配合文字描述話俾模型知「呢個角色要做乜動作、鏡頭點樣移動」。例如從低角度慢推變特寫,角色回頭望鏡頭。Seedance 2.0 會將靜態嘅角色圖變做一段有真實運動感嘅影片片段,包括鏡頭運動、物理動效,有時仲會附帶同步嘅環境聲效。
喺 X 上面,用呢套流程已經產生咗各種風格影片嘅輸出。除咗文章開頭你睇到嘅嗰啲影片之外,例如好似下面呢種漢唐宮廷舞,就係透過啱啱上面嗰個 16 宮格嘅參考圖生成嘅,角色一致性做得非常好。
同直接用文字生成影片相比,呢套工作流程嘅核心優勢就係「可控性」。
我哋就用上面呢個漢唐宮廷舞嘅影片做模板,睇下作者按照呢套工作流程,分做兩步嘅話,佢嘅提示詞係點樣寫嘅。
Step 1 —— 先生成 16 宮格編舞分鏡圖
請創作一張高完成度、高清晰度的「漢唐宮廷舞 / 霓裳羽衣舞 · 16宮格分鏡圖」。
【整體定位】
這不是普通古風寫真,也不是單純舞蹈教學圖,而是一張融合「漢唐宮廷舞」「霓裳羽衣舞」「真實宮苑空間」「電影分鏡感」「16步動作編排」的高完成度分鏡海報。
整體要像一段盛唐宮廷舞的完整編舞被拆解成16個關鍵畫面,每一格既清晰獨立,又有連續流動感,方便後續用於視頻生成。
【場景設定】
不要舞台,不要空黑背景,不要現代攝影棚。
場景必須是一個真實、立體、優美、符合漢唐時代氣質的盛唐宮苑空間:
- 傍晚金藍時刻,宮燈初上
- 硃紅宮柱
- 金色宮燈
- 宮廷迴廊 / 大殿外庭院
- 石階、欄杆、輕紗帷幔
- 遠處可見層疊殿宇與宮苑深景
- 空間有明確前景、中景、後景,具有真實縱深感
- 整體氛圍華美、通透、盛世感強,不要烏漆麻黑,不要渾濁,不要色斑
【人物設定】
主角是一位年輕中國女舞者,帶有盛唐宮廷舞者氣質,端莊、華美、優雅、剋制。
她在16格中必須保持同一張臉、同一人物身份、同一氣質、同一套服裝體系,不要每格都像換了一個人。
【服裝與妝造】
服裝為漢唐宮廷舞服 / 霓裳羽衣風格:
- 高腰長裙
- 大袖
- 輕紗披帛
- 精緻髮髻
- 金色髮飾、步搖
- 少量花鈿或唐風妝感
- 裙襬、披帛、大袖都要有真實動態
推薦配色:
- 胭脂粉
- 象牙白
- 香檳金
- 淡石青
整體華麗但不俗豔。
【版式要求】
- 畫面採用 4×4 的16宮格分鏡排版
- 每格都有明顯編號 1-16
- 每格都有中文動作標題
- 每格可有簡潔中文說明或短句提示
- 每格都要像一個獨立鏡頭畫面
- 適當加入動作方向箭頭或軌跡線,增強分鏡感
- 整體清晰、工整、信息完整,但不要過度擁擠
- 分辨率要非常高清,線條清楚,人物和背景都清晰,不要糊,不要髒,不要有色斑
【動作分鏡順序】
1. 宮苑亮相
舞者站在宮苑中央,微側身,長裙曳地,一手輕提大袖,一手自然垂落,建立盛唐氣場。
2. 起袖迎風
雙臂緩緩抬起,大袖與披帛輕輕被帶起,像樂聲初起。
3. 拈花側行
舞者緩步前行,一手做拈花或蘭花指,一手大袖舒展在身後,動作優雅。
4. 開袖成雲
雙袖向兩側大幅展開,形成對稱而華麗的大開構圖,像雲氣鋪開。
5. 回眸轉廊
舞者經過宮柱或迴廊邊緣,身體轉向側背,再緩緩回眸。
6. 環步繞帛
腳下走環步,披帛繞身形成流動軌跡,雙臂一前一後,動作圓潤。
7. 旋裙開宴
原地或小範圍旋轉,長裙與披帛打開,形成華麗旋舞。
8. 折腰揚袖
身體輕折,一袖高揚,一袖下垂,形成斜向張力構圖。
9. 低身獻禮
半蹲或單膝低位,雙手託袖向前,動作像宮廷獻禮,具有禮樂儀式感。
10. 仰身拂雲
從低位起身,上半身輕微後仰,雙袖向上揚起,披帛向後飛,動作華美但真人可完成。
11. 飛步掠庭
向側前方做一個輕盈掠步,大袖和披帛向後帶出,形成位移動線。
12. 盛唐大旋
最華麗的一次大旋轉,長裙、披帛、大袖同時打開,是整套最強高潮之一。
13. 回身收袖
從大旋中自然回身,雙袖由外向內慢慢收回,動作從大開轉向收束。
14. 託月舉袖
一手高舉如託月,一手橫於胸前,身體向上拉長,披帛在身側形成弧線,儀式感強。
15. 合袖禮成
雙袖緩緩合攏至胸前,形成“禮成”動作,神情寧靜莊重。
16. 霓裳定格
最終大定格,一袖高揚,一袖低垂,身體優雅扭轉,長裙鋪開,端莊華美地完成收尾。
【重點要求】
- 必須突出真實空間感與時代感
- 必須保持同一舞者一致性
- 必須有完整的大袖、披帛、長裙動態
- 必須適合後續作為視頻分鏡參考
- 每一格動作都要明顯不同,不能過於重複
- 畫面整體要華麗、優美、清晰、通透
- 不要黑壓壓,不要髒,不要模糊,不要色斑,不要廉價古風感Step 2 —— 將 16 宮格圖畀 Seedance 生成影片
請根據我提供的16宮格參考圖,生成一段高完成度的「漢唐宮廷舞 / 霓裳羽衣舞」視頻。
【核心要求】
嚴格按照畫面1-畫面16的順序生成。這不是舞台表演,也不是仙俠特效,而是一位成年中國女舞者,在真實立體的盛唐宮苑空間裏完成一段華美、端莊、流暢的宮廷舞。整體像電影裏的宮廷舞段落,強調大袖、披帛、長裙的真實流動,以及盛唐禮樂氣質。
【人物設定】
同一位成年中國女舞者,全程保持同一張臉、同一套造型。服裝為漢唐宮廷舞服:高腰長裙、大袖、輕紗披帛、精緻髮髻與金色髮飾,色調以胭脂粉、象牙白、香檳金、淡石青為主。
【場景設定】
真實盛唐宮苑 / 宮廷迴廊 / 大殿外庭院。時間是傍晚金藍時刻,宮燈初上。環境包含硃紅宮柱、金色宮燈、層疊殿宇、欄杆、石階、輕紗帷幔與遠處宮殿深景。空間要有前景、中景、後景,真實、通透、優美,不要黑壓壓。
【鏡頭要求】
鏡頭穩定、優雅,有緩慢推進、橫向跟拍、小幅環繞、低機位。不要亂晃,不要快切。大部分時候完整展示全身,讓大袖、披帛、裙襬的流動清楚可見。畫面12為全片高潮,鏡頭圍繞舞者做完整360度環繞。
必須嚴格遵守:場景要保持穩定性和一致性,不要出現割裂不符合物理世界的想象,人物動作自然連貫,不要出現字幕、符號等標識。BGM要大氣。畫面要連貫,一鏡到底不允許剪輯。
【分鏡腳本】
畫面1:宮苑亮相,舞者立於宮苑中央,微側身,長裙曳地,鏡頭緩慢推進。
畫面2:起袖迎風,雙臂緩緩抬起,大袖與披帛輕輕被帶起,鏡頭輕推近。
畫面3:拈花側行,舞者緩步前行,一手拈花,一手大袖舒展,鏡頭橫向跟拍。
畫面4:開袖成雲,雙袖向兩側大幅展開,形成對稱構圖,鏡頭半環繞。
畫面5:回眸轉廊,舞者經過宮柱,轉向側背後回眸,鏡頭輕移。
畫面6:環步繞帛,腳下環步,披帛繞身,鏡頭小幅環繞。
畫面7:旋裙開宴,舞者旋轉,長裙與披帛打開,鏡頭約180度環繞。
畫面8:折腰揚袖,身體輕折,一袖高揚,一袖下垂,鏡頭略低機位。
畫面9:低身獻禮,舞者半蹲或單膝低位,雙手託袖向前,鏡頭低機位慢推。
畫面10:仰身拂雲,從低位起身,上身輕微後仰,雙袖上揚,鏡頭隨動作上抬。
畫面11:飛步掠庭,舞者做真實可完成的輕盈掠步,鏡頭橫向跟拍。
畫面12:盛唐大旋,舞者完成最華麗的大旋轉,長裙、披帛、大袖同時打開,鏡頭完整360度環繞。
畫面13:回身收袖,從大旋中自然回身,雙袖由外向內收回,鏡頭輕跟隨。
畫面14:託月舉袖,一手高舉如託月,一手橫於胸前,鏡頭緩慢推進。
畫面15:合袖禮成,雙袖緩緩合攏至胸前,動作莊重,鏡頭短暫停留。
畫面16:霓裳定格,最終大定格,一袖高揚,一袖低垂,長裙鋪開,鏡頭輕微拉遠收尾。
【動作要求】
所有動作必須是真人舞者真實可完成的動作,不要懸浮,不要飛天,不要不合理大騰空。重點表現宮廷舞的端莊、大袖展開、披帛流動、長裙旋轉和禮樂之美。
【負面要求】
不要舞台背景,不要空黑背景,不要仙俠特效,不要魔法光效,不要人物懸浮,不要鏡頭亂晃,不要快切,不要畫面渾濁,不要色斑,不要模糊。你睇完上面呢啲提示詞之後,可能心入面會諗,呢啲提示詞要寫得咁複雜咩?我邊度寫得出嚟呀!
其實你以為上面呢啲提示詞全部都係作者一個字一個字打嘅咩?當然,我相信肯定有人可以自己寫出嚟,但一定係嗰啲非常專業嘅人。
絕大部分人都係非專業製作人員,喺我睇嚟,佢哋都係先參考咗 GPT Image 2 同 Seedance 2.0 嘅規則或規範,然後將呢啲規則或規範餵俾 AI 大模型學習,再根據自己嘅想法或創意,同 AI 共同協作產出嘅。你要知道呢啲提示詞肯定唔係一次性生成嘅,都需要幾輪試錯同打磨先可以定稿。
所以,唔好覺得自己唔得,上面嘅提示詞其實就係模板,你都可以將佢餵俾大模型等佢學習,然後再按照你自己構思嘅想法,同 AI 協作創作出一個新嘅影片創意。
返番正題~
最開始嗰陣,我哋都係用文字轉影片嘅方式,但純文字轉影片嘅模式等於將所有創作決定交曬俾模型,等佢亂估,每次結果都係抽獎而且隨機,同一個提示詞走十次可能得到十個唔同樣嘅角色。
呢個就係文字轉影片嘅最大問題!
而先用 GPT Image 2 將角色「鎖定」,再叫 Seedance 2.0 淨係負責「動起來」,相當於將創作過程拆做「設計」和「執行」兩個階段。
前者由人主導,後者由模型完成,出錯率就可以大幅降低。
我曾經喺 Atlas Cloud 上面睇過一篇技術分析,佢指出:相比純文字轉影片,呢套兩段式流程嘅可用片段成功率可以降到原來嘅五分之一到八分之一嘅成本,因為減少咗大量廢片。
如果你都對呢套圖像轉影片嘅新工作流程方式有興趣,都想試嚇,下面簡單講下點樣入手同費用情況,兩個工具分開講。
GPT Image 2 方面
目前所有 ChatGPT 用戶(包括免費仔)都可以用基礎嘅「即時模式」,唔需要額外畀錢,但有使用次數限制,用嚟偶爾測試完全夠用。訪問以下網址就得:
https://chatgpt.com/images
如果想解鎖「思考模式」,即係多圖一致性生成、佈局推理等更強功能,就需要訂閲 ChatGPT Plus,月費 $20,或者 Pro 檔($100/月)。
上面呢套工作流程入面用到嘅多圖一致性生成,就屬於 Thinking Mode 嘅功能,所以想用嘅話 Plus 係門檻。API 方面,係按 token 計費,例如生成一張 1024×1024 嘅標準圖像,低質素約 $0.006,中等質素約 $0.053,高質素約 $0.211。
Seedance 2.0 方面
國際用戶主要入口係 Dreamina 平台 dreamina.capcut.com,亦可以透過 CapCut 嘅 AI 工具模塊訪問。Dreamina 有免費額度,新註冊用戶可以先試用。訪問以下網址就可以體驗:
https://dreamina.capcut.com/zh-tw/tools/seedance-2-0
付費套餐起步價約 $18/月,有更多生成次數,高級套餐約 $84/月。如果你用得到中文版嘅即夢平台,起步價係 69 元/月,摺合約 $9.6,同等額度下更抵。另外,亦都有好多第三方平台(例如 Lovart 等)接入咗 Seedance 2.0,各有唔同嘅試用政策。
寫喺最後
總結一下呢套組合嘅適合人羣。
如果想製作有連續角色嘅 AI 短片、對影片質素有要求但冇專業製作背景嘅內容創作者,或者想探索 AI 影視化創作可能性嘅獨立創作者。
你要知道而家每段影片最長 15 秒,想駁成更長嘅成片仍然需要手動剪接,而且 Seedance 2.0 對真實人物面孔嘅生成係有內容過濾嘅(當然授權係必須嘅),GPT Image 2 嘅思考模式生成速度比較慢,複雜場景下可能需要最長 5-10 分鐘。
不過對大多數短片內容嚟講,GPT Image 2 + Seedance 2.0 嘅能力已經遠超以前所有 AI 影片工具嘅組合效果。
值得你試嚇!
既然睇到呢度,如果覺得唔錯,幫手順手㩒個「讚」、「睇」、「轉發」三連;如果想第一時間收到推送,亦可以幫我加個星標★,非常感謝!
最近一段時間如果你在 X 上逛,時不時的就能看到以下這類視頻。
一個末世廢土裏的女主角獨立對抗世界,電影感鏡頭切換。
或者兩個卡通角色在廚房裏互相鬥氣,3D 動畫效果流暢得出奇。
還有科幻漫畫感的城市追逐場景,人物在高樓間穿梭。
這些視頻的共同特點是:不超過 15 秒,質量出奇的高,而且發帖者也都不是什麼專業電影人。
從他們的推文當中會發現,這批視頻幾乎都提到了同樣的兩個工具:
GPT Image 2 和 Seedance 2.0
這不是巧合,而是一套正在 AI 創作圈裏快速擴散的工作流組合。
要搞清楚這套組合為什麼最近這麼火,就要先了解一個在 AI 視頻圈長期存在的老大難問題:
角色一致性
AI 生成視頻最讓人抓狂的地方,不是畫質差,而是同一個人物在不同鏡頭裏「臉不一樣」。這就導致任何想講故事、有連續角色的視頻,基本不可能用 AI 直接完成,因為鏡頭一切換角色就變形了。
這個問題困擾了所有 AI 視頻工具好幾年。
而 GPT Image 2 加上 Seedance 2.0 的組合,是目前已知能把這個問題解決得最徹底的方案之一。
GPT Image 2 是 OpenAI 在 2026 年 4 月 21 日發佈的新一代圖像生成模型,官方名稱是 ChatGPT Images 2.0,API 代號是 gpt-image-2。
這個模型發佈 12 小時內就登上了 Image Arena 排行榜第一名,領先第二名足足 242 分,是該排行榜有史以來最大的領先幅度,直到現在也依然保持着頭名。
它相比上一代(GPT Image 1.5)最核心的兩個突破:
第一,文字渲染接近完美,不再出現 AI 圖像裏那種字母錯位、字體扭曲的現象,中文、日文、韓文、阿拉伯文等非拉丁字符也能準確處理。
第二,加入了「思考模式」,模型在生圖前會先推理構圖邏輯,類似 o1 的思維鏈機制。
對於這套工作流來說,更關鍵的能力是:
它可以在一次請求中生成最多 8 張角色一致的圖像,同一個人物在不同角度、不同場景下保持高度穩定的外貌。
比如下面這張「一致性」的圖像組,就成為了後續視頻製作的視覺基礎。
而 Seedance 2.0 是字節跳動旗下 AI 研究團隊 Seed 開發的視頻生成模型,2026 年 2 月正式發佈。
字節跳動在國內的產品叫即夢(Jimeng),國際版叫 Dreamina,Seedance 2.0 是兩者底層共用的視頻模型。
這個模型一經發布迅速在全球社交媒體上走紅,以對電影中真實演員的高度還原度而著稱,甚至當時還引發了好萊塢製片公司的版權抗議,迪士尼和派拉蒙均向字節跳動發出過警告。
後來字節跳動表示會加強安全過濾,對真實人物生成進行了嚴格限制。
但對於創作者來說,這個模型真正的亮點是:
它接受圖像、視頻、音頻同時作為參考輸入,最多可以上傳 9 張圖片、3 段視頻、3 段音頻,一次性生成一段有角色、有鏡頭運動、有環境音效的連貫視頻,單次生成時長最長 15 秒,分辨率可達到 1080p 乃至 2K。
這兩個工具現在搭在一起,工作流的邏輯變成了:先用 GPT Image 2 做「角色設定」與「分鏡稿」;再把生成好的圖像交給 Seedance 2.0 讓其「動起來」。
如果再拆細點兒說:
第一步,是在 ChatGPT 裏描述你想要的故事場景和角色,讓 GPT Image 2 一次性生成一組角色圖。比如同一個主角兒的正面、側面、不同動作姿勢。
因為這些圖是在同一次會話裏生成的,模型會保持該角色外貌的穩定性。在 X 上流傳的截圖中,可以看到創作者用的就是這種「分鏡網格圖」的技巧。他們讓 GPT Image 2 生成類似電影分鏡板的多格畫面,把多個鏡頭場景排列在同一張圖裏,這樣角色在所有格子裏都來自同一次生成,一致性更有保障。
第二步,就是把已生成好的圖上傳給 Seedance 2.0,配合文字描述來告訴模型「這個角色要做什麼動作、鏡頭怎麼移動」。比如從仰拍緩慢推進到特寫,角色回頭望向鏡頭。Seedance 2.0 會把靜態的角色圖變成一段兒有真實運動感的視頻片段,包括鏡頭運動、物理動效,有時還會附帶同步的環境聲效。
在 X 上,用這套流程已經產生了各種風格視頻的輸出。除了文章開頭你看的那些視頻以外,比如像下面這種漢唐宮廷舞,就是通過剛剛上面那個 16 宮格的參考圖生成的,角色一致性完成的非常好。
和直接使用文字生成視頻相比,這套工作流的核心優勢就是「可控性」。
我們就以上面這個漢唐宮廷舞的視頻為模版,看看作者按照這套工作流,分成兩步的話,他的提示詞是如何撰寫的。
Step 1 —— 先生成 16 宮格編舞分鏡圖
請創作一張高完成度、高清晰度的「漢唐宮廷舞 / 霓裳羽衣舞 · 16宮格分鏡圖」。
【整體定位】
這不是普通古風寫真,也不是單純舞蹈教學圖,而是一張融合「漢唐宮廷舞」「霓裳羽衣舞」「真實宮苑空間」「電影分鏡感」「16步動作編排」的高完成度分鏡海報。
整體要像一段盛唐宮廷舞的完整編舞被拆解成16個關鍵畫面,每一格既清晰獨立,又有連續流動感,方便後續用於視頻生成。
【場景設定】
不要舞台,不要空黑背景,不要現代攝影棚。
場景必須是一個真實、立體、優美、符合漢唐時代氣質的盛唐宮苑空間:
- 傍晚金藍時刻,宮燈初上
- 硃紅宮柱
- 金色宮燈
- 宮廷迴廊 / 大殿外庭院
- 石階、欄杆、輕紗帷幔
- 遠處可見層疊殿宇與宮苑深景
- 空間有明確前景、中景、後景,具有真實縱深感
- 整體氛圍華美、通透、盛世感強,不要烏漆麻黑,不要渾濁,不要色斑
【人物設定】
主角是一位年輕中國女舞者,帶有盛唐宮廷舞者氣質,端莊、華美、優雅、剋制。
她在16格中必須保持同一張臉、同一人物身份、同一氣質、同一套服裝體系,不要每格都像換了一個人。
【服裝與妝造】
服裝為漢唐宮廷舞服 / 霓裳羽衣風格:
- 高腰長裙
- 大袖
- 輕紗披帛
- 精緻髮髻
- 金色髮飾、步搖
- 少量花鈿或唐風妝感
- 裙襬、披帛、大袖都要有真實動態
推薦配色:
- 胭脂粉
- 象牙白
- 香檳金
- 淡石青
整體華麗但不俗豔。
【版式要求】
- 畫面採用 4×4 的16宮格分鏡排版
- 每格都有明顯編號 1-16
- 每格都有中文動作標題
- 每格可有簡潔中文說明或短句提示
- 每格都要像一個獨立鏡頭畫面
- 適當加入動作方向箭頭或軌跡線,增強分鏡感
- 整體清晰、工整、信息完整,但不要過度擁擠
- 分辨率要非常高清,線條清楚,人物和背景都清晰,不要糊,不要髒,不要有色斑
【動作分鏡順序】
1. 宮苑亮相
舞者站在宮苑中央,微側身,長裙曳地,一手輕提大袖,一手自然垂落,建立盛唐氣場。
2. 起袖迎風
雙臂緩緩抬起,大袖與披帛輕輕被帶起,像樂聲初起。
3. 拈花側行
舞者緩步前行,一手做拈花或蘭花指,一手大袖舒展在身後,動作優雅。
4. 開袖成雲
雙袖向兩側大幅展開,形成對稱而華麗的大開構圖,像雲氣鋪開。
5. 回眸轉廊
舞者經過宮柱或迴廊邊緣,身體轉向側背,再緩緩回眸。
6. 環步繞帛
腳下走環步,披帛繞身形成流動軌跡,雙臂一前一後,動作圓潤。
7. 旋裙開宴
原地或小範圍旋轉,長裙與披帛打開,形成華麗旋舞。
8. 折腰揚袖
身體輕折,一袖高揚,一袖下垂,形成斜向張力構圖。
9. 低身獻禮
半蹲或單膝低位,雙手託袖向前,動作像宮廷獻禮,具有禮樂儀式感。
10. 仰身拂雲
從低位起身,上半身輕微後仰,雙袖向上揚起,披帛向後飛,動作華美但真人可完成。
11. 飛步掠庭
向側前方做一個輕盈掠步,大袖和披帛向後帶出,形成位移動線。
12. 盛唐大旋
最華麗的一次大旋轉,長裙、披帛、大袖同時打開,是整套最強高潮之一。
13. 回身收袖
從大旋中自然回身,雙袖由外向內慢慢收回,動作從大開轉向收束。
14. 託月舉袖
一手高舉如託月,一手橫於胸前,身體向上拉長,披帛在身側形成弧線,儀式感強。
15. 合袖禮成
雙袖緩緩合攏至胸前,形成“禮成”動作,神情寧靜莊重。
16. 霓裳定格
最終大定格,一袖高揚,一袖低垂,身體優雅扭轉,長裙鋪開,端莊華美地完成收尾。
【重點要求】
- 必須突出真實空間感與時代感
- 必須保持同一舞者一致性
- 必須有完整的大袖、披帛、長裙動態
- 必須適合後續作為視頻分鏡參考
- 每一格動作都要明顯不同,不能過於重複
- 畫面整體要華麗、優美、清晰、通透
- 不要黑壓壓,不要髒,不要模糊,不要色斑,不要廉價古風感Step 2 —— 把 16 宮格圖丟給 Seedance 生成視頻
請根據我提供的16宮格參考圖,生成一段高完成度的「漢唐宮廷舞 / 霓裳羽衣舞」視頻。
【核心要求】
嚴格按照畫面1-畫面16的順序生成。這不是舞台表演,也不是仙俠特效,而是一位成年中國女舞者,在真實立體的盛唐宮苑空間裏完成一段華美、端莊、流暢的宮廷舞。整體像電影裏的宮廷舞段落,強調大袖、披帛、長裙的真實流動,以及盛唐禮樂氣質。
【人物設定】
同一位成年中國女舞者,全程保持同一張臉、同一套造型。服裝為漢唐宮廷舞服:高腰長裙、大袖、輕紗披帛、精緻髮髻與金色髮飾,色調以胭脂粉、象牙白、香檳金、淡石青為主。
【場景設定】
真實盛唐宮苑 / 宮廷迴廊 / 大殿外庭院。時間是傍晚金藍時刻,宮燈初上。環境包含硃紅宮柱、金色宮燈、層疊殿宇、欄杆、石階、輕紗帷幔與遠處宮殿深景。空間要有前景、中景、後景,真實、通透、優美,不要黑壓壓。
【鏡頭要求】
鏡頭穩定、優雅,有緩慢推進、橫向跟拍、小幅環繞、低機位。不要亂晃,不要快切。大部分時候完整展示全身,讓大袖、披帛、裙襬的流動清楚可見。畫面12為全片高潮,鏡頭圍繞舞者做完整360度環繞。
必須嚴格遵守:場景要保持穩定性和一致性,不要出現割裂不符合物理世界的想象,人物動作自然連貫,不要出現字幕、符號等標識。BGM要大氣。畫面要連貫,一鏡到底不允許剪輯。
【分鏡腳本】
畫面1:宮苑亮相,舞者立於宮苑中央,微側身,長裙曳地,鏡頭緩慢推進。
畫面2:起袖迎風,雙臂緩緩抬起,大袖與披帛輕輕被帶起,鏡頭輕推近。
畫面3:拈花側行,舞者緩步前行,一手拈花,一手大袖舒展,鏡頭橫向跟拍。
畫面4:開袖成雲,雙袖向兩側大幅展開,形成對稱構圖,鏡頭半環繞。
畫面5:回眸轉廊,舞者經過宮柱,轉向側背後回眸,鏡頭輕移。
畫面6:環步繞帛,腳下環步,披帛繞身,鏡頭小幅環繞。
畫面7:旋裙開宴,舞者旋轉,長裙與披帛打開,鏡頭約180度環繞。
畫面8:折腰揚袖,身體輕折,一袖高揚,一袖下垂,鏡頭略低機位。
畫面9:低身獻禮,舞者半蹲或單膝低位,雙手託袖向前,鏡頭低機位慢推。
畫面10:仰身拂雲,從低位起身,上身輕微後仰,雙袖上揚,鏡頭隨動作上抬。
畫面11:飛步掠庭,舞者做真實可完成的輕盈掠步,鏡頭橫向跟拍。
畫面12:盛唐大旋,舞者完成最華麗的大旋轉,長裙、披帛、大袖同時打開,鏡頭完整360度環繞。
畫面13:回身收袖,從大旋中自然回身,雙袖由外向內收回,鏡頭輕跟隨。
畫面14:託月舉袖,一手高舉如託月,一手橫於胸前,鏡頭緩慢推進。
畫面15:合袖禮成,雙袖緩緩合攏至胸前,動作莊重,鏡頭短暫停留。
畫面16:霓裳定格,最終大定格,一袖高揚,一袖低垂,長裙鋪開,鏡頭輕微拉遠收尾。
【動作要求】
所有動作必須是真人舞者真實可完成的動作,不要懸浮,不要飛天,不要不合理大騰空。重點表現宮廷舞的端莊、大袖展開、披帛流動、長裙旋轉和禮樂之美。
【負面要求】
不要舞台背景,不要空黑背景,不要仙俠特效,不要魔法光效,不要人物懸浮,不要鏡頭亂晃,不要快切,不要畫面渾濁,不要色斑,不要模糊。你看完上面這些提示詞後,可能心裏會想,這提示詞要寫的這麼複雜嗎?我哪兒寫的出來呀!
其實你真的以為上面這些提示詞都是作者一個字一個字的敲出來的麼!當然,我相信肯定有人能自己寫出來,但一定是那些非常專業的人。
絕大部分的人都是非專業製作人員,在我看來,他們也都是先參考了 GPT Image 2 與 Seedance 2.0 的規則或規範,然後將這些規則或規範餵給 AI 大模型進行學習,再根據自己的想法或創意,與 AI 共同協作產出的。你要知道這些提示詞肯定不是一次性生成的,也需要幾輪的試錯與打磨才能定稿。
因此,也不要覺得自己不行,上面的提示詞其實就是模版,你也可以把它餵給大模型讓它學習,然後再按照你自己構思的想法,與 AI 協作創作出來一個新的視頻創意。
再回到正題~
最開始的時候,我們都是用文字轉視頻的方式,但純文字轉視頻的模式等於把所有創作決策都交給了模型,讓它進行猜測,每次結果都是抽卡且隨機的,同一個提示詞跑十次可能得到十個不同長相的角色。
這是文字轉視頻的最大問題!
而先用 GPT Image 2 把角色「鎖定」,再讓 Seedance 2.0 僅負責「動起來」,相當於把創作過程拆成了「設計」和「執行」兩個階段。
前者由人來主導,後者由模型來完成,出錯率就能大幅降低。
我曾在 Atlas Cloud 上看過一篇技術分析,它指出:相比純文字轉視頻,這套兩段式流程的可用片段成功率可以降低到原來的五分之一到八分之一的成本,因為減少了大量廢稿。
如果你也對這套圖像轉視頻的新工作流方式感興趣,也想試試看看,下面簡單說一下怎麼入手和費用情況,兩個工具分開說。
GPT Image 2 方面
目前是所有 ChatGPT 用戶(包括免費用戶)都可以使用基礎的「即時模式」,不需要額外付費,但有使用頻次限制,用於偶爾測試完全夠用。訪問以下網址即可使用:
https://chatgpt.com/images
如果要解鎖「思考模式」,也就是多圖一致性生成、佈局推理等更強功能,那就需要訂閲 ChatGPT Plus,月費 $20,或者 Pro 檔($100/月)。
上面這套工作流裏用到的多圖一致性生成,就屬於 Thinking Mode 的功能,所以要想使用的話 Plus 是門檻。API 方面,是按 token 計費的,比如生成一張 1024×1024 的標準圖像,低質量約 $0.006,中等質量約 $0.053,高質量約 $0.211。
Seedance 2.0 方面
國際用戶的主要入口是 Dreamina 平台 dreamina.capcut.com,也可以通過 CapCut 的 AI 工具模塊訪問。Dreamina 有免費額度,新註冊用戶可以先試用。訪問以下網址即可體驗:
https://dreamina.capcut.com/zh-tw/tools/seedance-2-0
付費套餐的起步價約 $18/月,有更多生成次數,高檔套餐約 $84/月。如果你能使用中文版的即夢平台,起步價是 69 元/月,摺合約 $9.6,同等額度下更划算。另外,也有很多第三方平台(如 Lovart 等)也接入了 Seedance 2.0,各有不同的試用政策。
寫在最後
總結一下這套組合的適用人羣。
如果是想製作有連續角色的 AI 短視頻、對視頻質感有要求但沒有專業製作背景的內容創作者,或者是想探索 AI 影視化創作可能性的獨立創作者。
你要知道現在每段視頻最長 15 秒,想要拼接成更長的成片仍需要手動剪輯,並且 Seedance 2.0 對真實人物面孔的生成是有內容過濾的(當然授權是必須的),GPT Image 2 的思考模式生成速度比較慢,複雜場景下可能需要最長 5-10 分鐘。
不過對於大多數短視頻內容來講,GPT Image 2 + Seedance 2.0 的能力已經遠超過去所有 AI 視頻工具的組合效果。
值得你試一試!
既然看到這兒了,如果覺得還不錯,幫忙隨手點個「贊」、「在看」、「轉發」三連;如果想第一時間收到推送,也可給我加個星標★,非常感謝!