一個skill自動化搭建LLM Wiki
整理版優先睇
用一個Skill自動化搭建LLM Wiki,告別知識管理碎片化
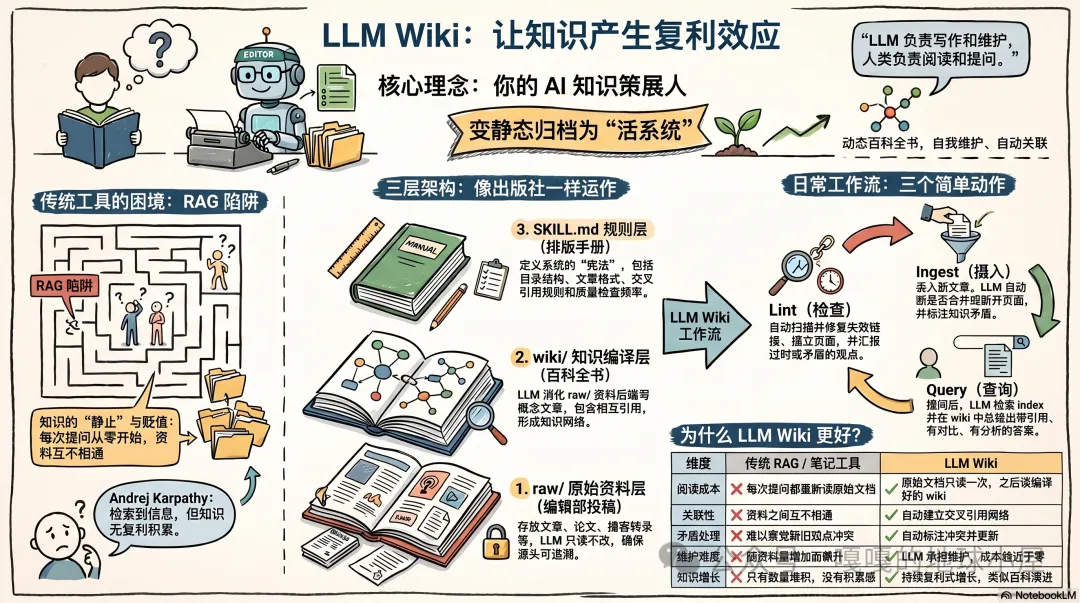
作者發現現有LLM Wiki文章多為概念,實際搭建太麻煩,於是基於一個基礎skill改造,加入Git原生集成與增量lint機制,打造出可直接用的LLM Wiki Skill。文章先點出傳統知識管理工具的結構性缺陷:靜止、貶值、互不相通,形成Andrej Karpathy所講嘅「RAG陷阱」——每次檢索都從零開始,知識無法複利積累。
LLM Wiki嘅核心思想係「讓LLM負責寫作和維護,人類負責閲讀和提問」,透過三層架構實現:raw/原始資料層(原封不動存放來源)、wiki/知識編譯層(LLM消化整理成概念文章並交叉引用)、SKILL.md規則層(定義系統「憲法」)。日常工作流只有三個動作:攝入(Ingest)、查詢(Query)、檢查(Lint),令知識庫變成一個會自我維護嘅系統。
作者指出LLM Wiki比傳統RAG更好:原始文檔只讀一次,之後讀編譯好嘅wiki;文章之間主動交叉引用;新舊矛盾自動標註;維護成本趨近零;知識持續複利式增長。Karpathy經驗:約100篇文章、40萬詞規模下,直接由LLM讀索引再深入文章效果極好,唔需要複雜嘅向量檢索。作者提供的Skill已集成Git原生支持與增量lint,讓每一次演進都有跡可循。
- LLM Wiki本質係讓LLM負責寫作維護,人類負責閲讀提問,實現知識複利增長。
- 三層架構:raw/原始資料層、wiki/知識編譯層、SKILL.md規則層;三個工作流:攝入、查詢、檢查。
- 相比傳統RAG,LLM Wiki只讀一次原始文檔,之後讀編譯好嘅wiki,主動交叉引用,自動標註衝突,維護成本趨近零。
- Karpathy經驗:約100篇文章40萬詞規模下,直接讀索引再深入文章效果極好,不需向量檢索。
- 作者提供嘅Skill附Git原生集成同增量lint機制,快速搭建個人複利式知識庫。
LLM Wiki Skill (Git原生集成)
基於LLM Wiki概念實現嘅Claude Code Skill,支援攝入、查詢、檢查三種工作流,所有修改自動提交Git,並有增量lint機制。安裝後可用自然語言或slash command操作。
你仲喺度「每次重新發現知識」?
三個月前你讀咗篇關於AI Agent架構嘅文章,覺得好有啟發,隨手收藏喺瀏覽器書籤。今日你做相關項目想找回一個觀點,點都諗唔起標題,打開收藏夾面對幾百個連結茫無頭緒,最後只好再Google搜過或重新問AI。呢個唔係你嘅問題,而係傳統知識管理工具嘅結構性缺陷。
知識係靜止嘅——放進去嗰一刻就開始貶值
筆記軟件、收藏夾、簡單文件歸檔都有共同點:資料之間互不相通,新資料不斷堆疊,舊資料漸漸沉沒。Andrej Karpathy將呢種現象稱為「RAG陷阱」:你確實能檢索到資訊,但知識本身冇產生複利式積累,每一次提問都係從零開始。
LLM Wiki:一個會自我維護嘅知識系統
LLM Wiki嘅核心思想得一句:「讓LLM負責寫作和維護,人類負責閲讀和提問。」佢將你嘅個人知識庫變成一個活的系統,你唔再係孤獨嘅圖書管理員,而有咗一位永不疲倦嘅AI策展人。
三層架構:raw/、wiki/、SKILL.md
- 1 raw/ 原始資料層:你睇到嘅文章、論文、播客轉錄稿,原封不動丟入去,LLM只讀唔改。
- 2 wiki/ 知識編譯層:LLM消化整理raw/嘅資料,寫成概念文章並相互引用,形成知識網絡。
- 3 SKILL.md 規則層:定義系統「憲法」,包括目錄結構、文章格式、交叉引用寫法、質量檢查頻率。
呢三層關係就好似出版社:raw/係編輯部收到嘅投稿堆,wiki/係印刷出來嘅百科全書,SKILL.md係排版手冊。
日常工作流:攝入、查詢、檢查
使用LLM Wiki唔需要複雜操作,日常只有三個環節。
- 1 Ingest(攝入):將好文章丟入raw/對應主題文件夾,命令LLM「攝入呢篇文章」,LLM會歸檔、判斷合併或新建、標註矛盾、更新全局索引。
- 2 Query(查詢):直接問「關於Agent嘅錯誤恢復機制,我知啲咩?」LLM會睇index.md揾相關文章,再讀具體內容,畀出帶引用、有對比、有分析嘅答案。仲可以將滿意的答案歸檔成新wiki文章。
- 3 Lint(檢查):定期叫LLM「幫我lint一下wiki」,佢會掃描整個知識庫,自動修復失效連結、補充交叉引用、報告事實矛盾或過時觀點。
點解佢好過傳統RAG?
傳統RAG每次提問都重新讀原始文檔,維護成本隨資料量增加而飆升,知識冇積累感。LLM Wiki將原始文檔只讀一次,之後讀編譯好嘅wiki,文章之間主動交叉引用,新舊矛盾自動標註。
Karpathy經驗:100篇文章、40萬詞規模下,直接由LLM讀索引再深入相關文章效果極好
唔需要複雜嘅向量檢索,維護成本趨近零,知識持續複利式增長。呢個對比好清楚:LLM Wiki係為咗複利而設計,而唔係為咗一次過檢索。
即刻試用:附Git集成嘅LLM Wiki Skill
作者基於LLM Wiki理念實現咗一個skill,加入Git原生集成同增量lint機制,令知識庫嘅每一次演進都有跡可循。你可以將佢安裝到Claude Code嘅skills目錄,從零開始培養自己嘅複利式知識庫。
安裝後即可用自然語言操作:攝入、查詢、檢查
- 1 在項目根目錄啟動會話,講「把呢篇文章加到我的wiki」,Claude會自動初始化raw/同wiki/,攝入來源,編譯文章,更新索引,提交變更,記錄日誌。
- 2 之後可以隨時問「關於X我知啲咩?」或者「幫我lint一下wiki」。
- 3 亦可用slash command:/llm-wiki-cc lint一嚇wiki
第一次使用時會自動初始化wiki,之後所有修改都會自動commit到Git,你仲可以睇返每次變化。項目地址:https://github.com/sunshine920103/llm-wiki-cc
# 將skill安裝到Claude Code skills目錄
# 在項目根目錄啟動會話
# 講:「把呢篇文章http://xxxx/加到我的wiki」
# Claude會自動初始化raw/和wiki/,攝入並編譯
# 之後隨時查詢或lint你係咪都係「每次重新發現知識」呀?
想像一下呢個場景:三個月前你睇咗一篇關於 AI Agent 架構嘅文章,當時覺得好有啟發,順手收藏咗喺瀏覽器書籤入面。
今日你做緊一個相關項目,想揾返嗰篇文章入面嘅一個觀點,但係點樣都諗唔起個標題。你打開收藏夾,面對幾百個連結,完全唔知點算。
最後你唯有再去 Google 搜一次,或者重新問一次 AI。
呢個唔係你嘅問題。係傳統知識管理工具嘅結構性缺陷。
筆記軟件、收藏夾、甚至簡單嘅文件歸檔,佢哋都有一個共通點:知識係靜止嘅。放咗入去嘅一刻,佢就開始貶值。新嘅資料不斷堆疊,舊嘅資料漸漸沉沒。
仲麻煩嘅係,資料之間互不相通——呢篇文章嘅觀點同嗰篇文章嘅觀點明明互相矛盾,但係你永遠發現唔到,因為佢哋被鎖咗喺兩個唔同嘅文件入面。
Andrej Karpathy 將呢種現象稱為「RAG 陷阱」(RAG Trap):你確實可以「檢索」到資訊,但知識本身並冇產生複利式嘅積累。每一次提問,你都係由零開始。
LLM Wiki 係咩嚟?
LLM Wiki 係一種新嘅知識管理工作流,核心思想只有一句話:
「由 LLM 負責寫作同維護,人類負責閲讀同提問。」
佢嘅本質係將你嘅個人知識庫變成一個有生命力、會自我維護嘅系統。你唔再係一個孤獨嘅圖書管理員,而係有一個永唔疲倦嘅 AI 策展人。
三層架構
成個系統好簡單,只有三個層次:
raw/原始資料層你睇到嘅文章、論文、播客轉錄稿,原封不動就噉掉入去。LLM 只讀、唔改。呢個係你嘅「證據庫」。wiki/知識編譯層LLM 將raw/裡面嘅資料消化、整理、關聯,寫成一篇篇概念文章。呢啲文章會互相引用,形成一張知識網絡。SKILL.md規則層定義成個系統嘅「憲法」:目錄結構點樣排、文章格式係咩、交叉引用點樣寫、隔幾耐檢查一次質量。
呢三層嘅關係好似一間出版社:raw/ 係編輯部收到嘅投稿堆,wiki/ 係印出嚟嘅百科全書,SKILL.md 係排版手冊。
日常工作流程:三個動作
用 LLM Wiki 唔需要複雜操作,日常只有三個環節:
1. Ingest(攝入)
見到一篇好文章?將佢掉入 raw/ 嘅對應主題文件夾,然後話畀 LLM 聽:「攝入呢篇文章。」
LLM 會:
將資料歸檔到正確位置
讀曬全文,判斷佢應該合併到現有文章,定係開一篇新文章
檢查新觀點係咪同舊知識矛盾,如果有矛盾,會明確標註出嚟
更新全局索引
index.md,令成個百科全書嘅目錄保持最新
2. Query(查詢)
當你需要了解某個主題時,直接問:
「關於 Agent 嘅錯誤恢復機制,我知道啲咩?」
LLM 唔會亂噏。佢會先讀 wiki/index.md 揾到相關文章,再讀具體內容,最後畀你一個有引用、有對比、有分析嘅答案。如果你好滿意呢個回答,仲可以叫佢將答案「歸檔」成一篇新嘅 wiki 文章。
3. Lint(檢查)
時間耐咗,wiki 入面可能會出現失效連結、孤立頁面,或者新資料推翻咗舊結論但係冇更新嘅地方。你可以定期講:
「幫我 lint 一下個 wiki。」
LLM 會掃描成個知識庫,自動修復連結、補充缺失嘅交叉引用,並彙報佢發現嘅事實矛盾或者過時嘅觀點。
點解佢比傳統 RAG 更好?
| 傳統 RAG / 筆記工具 | LLM Wiki |
|---|---|
| 每次提問都重新讀原始文檔 | 原始文檔只讀一次,之後讀編譯好嘅 wiki |
| 資料之間互不相通 | 文章之間主動建立交叉引用 |
| 新資料同舊觀點矛盾時難以察覺 | 自動標註衝突並更新相關文章 |
| 維護成本隨資料量增加而飆升 | LLM 承擔維護工作,成本趨近於零 |
| 知識冇積累感 | wiki 持續複利式增長 |
Karpathy 嘅經驗係:喺大約 100 篇文章、40 萬詞嘅規模下,直接由 LLM 讀取索引再深入相關文章嘅方式效果極好,根本唔需要複雜嘅向量檢索。
想試嚇?
如果你都想搭建自己嘅 LLM Wiki,我基於呢個理念實現咗一個 skill,並加入咗 Git 原生集成同增量 lint 機制,令知識庫嘅每一次演進都有跡可尋。
項目地址:https://github.com/sunshine920103/llm-wiki-cc
呢個 skill 幫你喺項目目錄入面自動初始化,並維護 raw/ 和 wiki/ 嘅結構,支援攝入、查詢、檢查三種工作流,並且所有修改都會自動提交到 Git。你可以將佢安裝到 Claude Code 入面,由零開始培養自己嘅複利式知識庫。
快速開始
將該 skill 安裝到你嘅 Claude Code skills 目錄。
喺項目根目錄啟動會話,然後講: 「將呢篇文章 http://xxxx/ 加入我嘅 wiki 入面。」
Claude 會初始化 raw/和wiki/,攝入來源,編譯文章,更新索引,提交變更,並記錄日誌。之後你可以隨時問: 「關於 X 我知道啲咩?」
「幫我 lint 一下 wiki。」
4. 都可以使用 slash command:
/llm-wiki-cc lint一下 wiki
第一次使用自動初始化 wiki:

你也在"每次重新發現知識"嗎?
想象一下這個場景:三個月前你讀了一篇關於 AI Agent 架構的文章,當時覺得很有啓發,隨手收藏在瀏覽器書籤裏。
今天你在做一個相關項目,想找回那篇文章裏的一個觀點,卻怎麼也想不起標題。你打開收藏夾,面對幾百個連結茫然無措。
最後你只好再去 Google 搜一遍,或者重新問一遍 AI。
這不是你的問題。這是傳統知識管理工具的結構性缺陷。
筆記軟件、收藏夾、甚至簡單的文件歸檔,它們都有一個共同點:知識是靜止的。放進去的那一刻,它就開始貶值。新的資料不斷堆疊,舊的資料漸漸沉沒。
更麻煩的是,資料之間互不相通——這篇文章裏的觀點和那篇文章裏的觀點明明相互矛盾,但你永遠發現不了,因為它們被鎖在兩個不同的文件裏。
Andrej Karpathy 把這種現象稱為"RAG 陷阱"(RAG Trap):你確實能"檢索"到信息,但知識本身並沒有產生複利式的積累。每一次提問,你都在從零開始。
LLM Wiki 是什麼?
LLM Wiki 是一種新的知識管理工作流,核心思想只有一句話:
"讓 LLM 負責寫作和維護,人類負責閲讀和提問。"
它的本質是把你的個人知識庫變成一個活的、會自我維護的系統。你不再是一個孤獨的圖書管理員,而是有了一個永不疲倦的 AI 策展人。
三層架構
整個系統非常簡單,只有三個層次:
raw/原始資料層你看到的文章、論文、播客轉錄稿,原封不動地丟進去。LLM 只讀、不改。這是你的"證據庫"。wiki/知識編譯層LLM 把raw/裏的資料消化、整理、關聯,寫成一篇篇概念文章。這些文章會相互引用,形成一張知識網絡。SKILL.md規則層定義整個系統的"憲法":目錄結構怎麼排、文章格式是什麼、交叉引用怎麼寫、多久檢查一次質量。
這三層的關係很像一家出版社:raw/ 是編輯部收到的投稿堆,wiki/ 是印刷出來的百科全書,SKILL.md 是排版手冊。
日常工作流:三個動作
使用 LLM Wiki 不需要複雜操作,日常只有三個環節:
1. Ingest(攝入)
看到一篇好文章?把它丟進 raw/ 的對應主題文件夾,然後告訴 LLM:"攝入這篇文章。"
LLM 會:
把資料歸檔到正確位置
讀完全文,判斷它應該合併到現有文章中,還是開一篇新文章
檢查新觀點是否與舊知識矛盾,如果有矛盾,會明確標註出來
更新全局索引
index.md,讓整本百科全書的目錄保持最新
2. Query(查詢)
當你需要了解某個主題時,直接問:
"關於 Agent 的錯誤恢復機制,我都知道些什麼?"
LLM 不會胡編。它會先讀 wiki/index.md 找到相關文章,再讀具體內容,最後給你一個帶引用、有對比、有分析的答案。如果你特別滿意這個回答,還可以讓它把答案"歸檔"成一篇新的 wiki 文章。
3. Lint(檢查)
時間久了,wiki 裏可能會出現失效連結、孤立頁面、或者新資料推翻舊結論但沒有更新的地方。你可以定期說:
"幫我 lint 一下 wiki。"
LLM 會掃描整個知識庫,自動修復連結、補充缺失的交叉引用,並彙報它發現的事實矛盾或過時的觀點。
為什麼它比傳統 RAG 更好?
| 傳統 RAG / 筆記工具 | LLM Wiki |
|---|---|
| 每次提問都重新讀原始文檔 | 原始文檔只讀一次,之後讀編譯好的 wiki |
| 資料之間互不相通 | 文章之間主動建立交叉引用 |
| 新資料與舊觀點矛盾時難以察覺 | 自動標註衝突並更新相關文章 |
| 維護成本隨資料量增加而飆升 | LLM 承擔維護工作,成本趨近於零 |
| 知識沒有積累感 | wiki 持續複利式增長 |
Karpathy 的經驗是:在約 100 篇文章、40 萬詞的規模下,直接由 LLM 讀取索引再深入相關文章的方式效果極好,根本不需要複雜的向量檢索。
想試試看?
如果你也想搭建自己的 LLM Wiki,我基於這個理念實現了一個skill,並加入了 Git 原生集成和增量 lint 機制,讓知識庫的每一次演進都有跡可循。
項目地址:https://github.com/sunshine920103/llm-wiki-cc
這個 skill 幫你在項目目錄裏自動初始化,並維護 raw/ 和 wiki/ 的結構,支持攝入、查詢、檢查三種工作流,並且所有修改都會自動提交到 Git。你可以把它安裝到 Claude Code 中,從零開始培養自己的複利式知識庫。
快速開始
將該 skill 安裝到你的 Claude Code skills 目錄。
在項目根目錄啓動會話,然後說: "把這篇文章http://xxxx/加到我的 wiki 裏。"
Claude 會初始化 raw/和wiki/,攝入來源,編譯文章,更新索引,提交變更,並記錄日誌。之後你可以隨時問: "關於 X 我知道些什麼?"
"幫我 lint 一下 wiki。"
4.也可以使用slash command:
/llm-wiki-cc lint一下 wiki
第一次使用自動初始化wiki: