一文講清 LLM、Chatbot 與 Agent 的關係
整理版優先睇
LLM、Chatbot同Agent嘅分別:大腦、對話外殼同執行體
呢篇文章主要拆解LLM、Chatbot同Agent呢三個成日撈亂嘅概念。作者由底層能力講到產品形態,再講到執行能力,幫讀者搞清楚佢哋嘅本質分工。作者指出,三者唔係互相取代,而係層層疊加:LLM係能力底座,Chatbot係交互外殼,Agent係能夠調用工具完成任務嘅執行體。
文章先解釋LLM嘅工作機制——基於預測生成文本,訓練經過預訓練、指令微調同強化學習三步。然後講Chatbot點樣將LLM包裝成可對話產品,核心包括提示詞、上下文同會話管理。最後詳細介紹Agent嘅工具系統同閉環流程,強調Agent需要具備自主規劃、環境操作同自我修正能力。整體結論係:理解呢條鏈路,可以更清楚判斷產品係咪真正具備執行能力。
作者仲提到Agent嘅發展趨勢,指出雖然Agent好熱,但成本、系統障礙同穩定性仍然係現實限制,佢更似係下一代軟件形態嘅雛形。總括嚟講,呢篇文章提供咗一個清晰嘅框架,幫讀者喺AI產品選型或理解能力時有個可靠嘅參考架構。
- LLM係基於預測嘅文本生成模型,訓練三步:預訓練(建立知識)、指令微調(學會應答)、強化學習(對齊人類偏好)。
- Chatbot係將LLM包裝成對話產品嘅關鍵,核心係提示詞(系統同用戶)、上下文(歷史+約束)同會話管理(截斷/保存)。
- Agent透過工具系統延伸模型能力,典型閉環:聲明工具→模型決策→外部執行→整合結果。真正拉開差距嘅係工具系統完整度。
- 三者關係:LLM係底座,Chatbot係交互形態,Agent係執行形態。很多產品表面係Agent,背後離唔開LLM;Chatbot接上工具亦會向Agent靠攏。
- Agent係下一代默認形態嘅雛形,但現實限制包括高昂成本、舊系統障礙同執行結果不穩,未係終局答案。真正值得關注嘅係軟件默認具備理解任務同自動執行嘅能力。
三層架構:LLM、Chatbot同Agent嘅根本分別
如果將今日嘅AI應用拆開,可以分成三層:LLM係「大腦」,Chatbot係「對話外殼」,Agent係「能調用工具完成任務嘅執行體」。呢三個詞經常被撈亂用,但放喺同一張框架圖入面,好多討論會清楚好多。
三層關係
尤其係Agent再次升温嘅當下,好多人一接觸AI就會俾一連串名詞包圍:大模型、聊天機器人、智能體、自動化助手……聽落都似一回事,實際分工完全唔同。先將呢三層關係睇清楚,後面無論係理解產品、做選型,定係判斷一項能力到底靠乜實現,都會輕鬆唔少。
分工完全唔同
LLM:所有能力嘅底層引擎
LLM本質係基於「預測」嘅文本生成模型。佢唔係好似人咁先理解世界再組織語言,而係喺已知知識同當前輸入基礎上,預測接下來最可能出現嘅詞,再不斷往後續寫。核心三步:
- 1 輸入:將背景信息同問題交俾模型
- 2 預測:模型基於訓練中學到嘅語言規律進行預測
- 3 輸出:將預測結果組織成一段回答返回
預測能力
訓練路線通常概括成三步:預訓練、指令微調、強化學習。
- 預訓練:將海量文本交俾模型,建立基礎認識
- 指令微調:令模型學會提問、回答同高質量輸出
- 強化學習:透過反饋機制對齊,形成更穩定嘅回答能力
預訓練
指令微調
強化學習
預訓練解決「知道世界上有乜」,指令微調解決「知道點樣答」,強化學習解決「知道點樣答得更似一個好結果」。底層算法Transformer係算力同算法底座。
Transformer
Chatbot:將LLM變成可對話產品
大多數普通用戶第一次接觸AI,其實係接觸Chatbot。佢哋將LLM包裝成可以持續對話、管理歷史記錄、調參數嘅交互界面。核心有三個概念:提示詞、上下文、會話。
對話產品
- 1 提示詞:分為系統提示詞(產品側最高規則)同用戶提示詞(用戶輸入),模型最終收到嘅係整段組織好嘅上下文。
- 2 上下文:包含當前問題、歷史問答、系統約束同背景信息。模型靠佢判斷你講乜,但本質唔係永久記憶,而係將相關歷史一併送進本輪推理。
- 3 會話:上下文嘅容器。歷史越長對話越豐富,但模型上下文窗口有限,需要做截斷、清理、歸檔或開新話題。
提示詞
上下文
會話
從產品結構睇,早期Chatbot由用戶界面、模型配置、會話管理三部分組成。LLM決定「能否答」,Chatbot決定「好不好用」。
用戶界面
模型配置
會話管理
Agent:由對話進化到執行
Chatbot最大嘅侷限係停留在「對話」層。Agent嘅價值,就係將模型從「會說」推進到「會做」。為咗實現呢點,系統需要俾模型準備工具,並話俾佢知每個工具嘅用途、參數同輸出。
工具
調用外部世界
整個過程可以概括成四段:
- 1 聲明工具:定義每個工具嘅能力同參數
- 2 模型決策:模型理解任務後決定調用邊個工具
- 3 外部執行:外部程式接到指令後真正執行
- 4 整合結果:模型將原始結果整合成自然最終答覆
一個更完整嘅Agent,通常至少要有三種能力:自主規劃、環境操作、自我修正。呢亦係Agent同Chatbot嘅關鍵差異——前者追求將事做完,後者更擅長將話講清。
- 自主規劃:面對複雜任務時先拆目標、排步驟
- 環境操作:真係去瀏覽頁面、讀寫文件、運行流程
- 自我修正:遇到問題時調整策略繼續嘗試
數字員工
任務執行者
三者關係:層層疊加,唔係取代
用一句最直白嘅話總結:LLM係能力底座,Chatbot係交互形態,Agent係執行形態。三者唔係互相替代,而係層層疊加。
能力底座
交互形態
執行形態
- 冇LLM,後兩者就缺少推理同生成能力。
- 冇Chatbot,普通用戶好難舒服咁使用模型能力。
- 冇Agent,模型再會講,都好難真正介入現實工作流。
從趨勢睇,Agent正快速進入大眾視野,唔少通用型同垂直型Agent出現。但高昂成本、舊系統高牆、執行結果唔穩定依然係現實限制。Agent似係下一代軟件形態嘅雛形,唔係終局答案。真正值得關注嘅係,當熱潮退去,越來越多人唔會再強調「呢個係Agent」,而係軟件默認具備理解任務、調用工具、自動執行嘅能力。
下一代默認形態
如果將今日嘅 AI 應用拆開嚟睇,其實可以分成三層:LLM 係「大腦」,Chatbot 係「對話外殼」,Agent 就係「可以調用工具完成任務嘅執行體」。呢三個詞成日俾人撈亂用,但一旦放喺同一張框架圖入面,好多討論都會清楚好多。
尤其係而家 Agent 又再升温,好多人一接觸 AI,就會俾一串名詞包圍:大模型、聊天機械人、智能體、自動化助手……聽落好似差唔多,實際上分工完全唔同。先搞清楚呢三層關係,之後無論係理解產品、做選擇,定係判斷一項能力到底靠咩實現,都會輕鬆好多。
一、LLM:所有能力嘅底座
LLM,亦即係大語言模型,本質上係一種基於「預測」嘅文字生成模型。佢並唔係好似人咁先理解世界再組織語言,而係喺已有知識同當前輸入嘅基礎上,預測接下來最有可能出現嘅詞,再不斷往後續寫。
如果將佢嘅工作過程拆開嚟睇,核心就係三步:輸入、預測、輸出。你將背景資訊同問題交俾模型,模型基於訓練中學到嘅語言規律進行預測,再將預測結果組織成一段回答返俾你。無論係傾偈、寫作、總結,定係程式碼補全,底層都離唔開呢套機制。
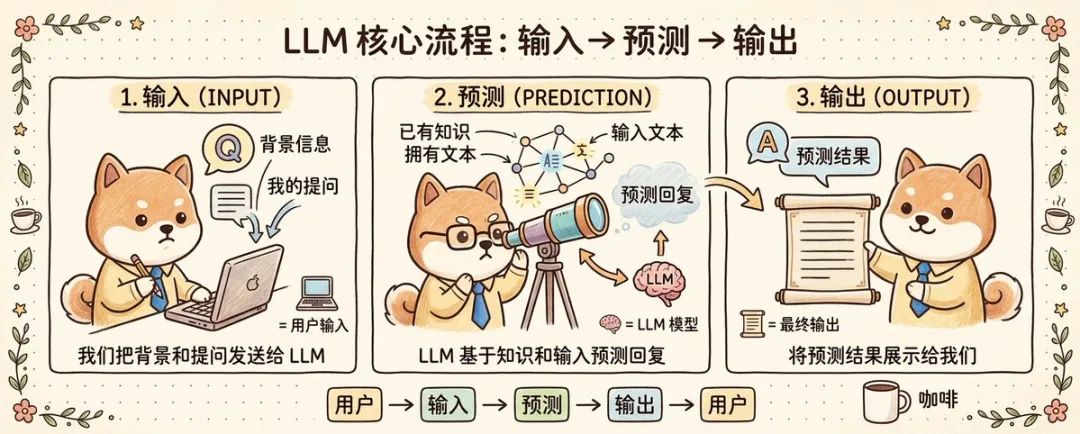
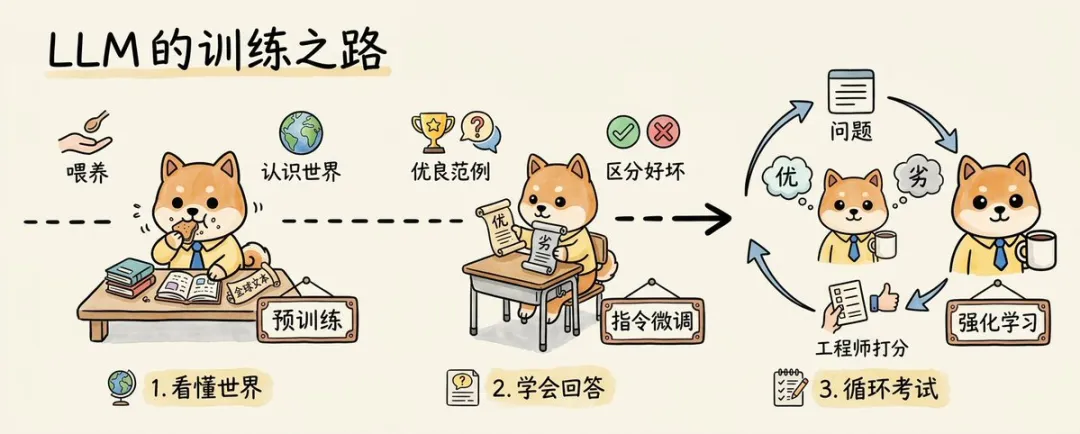
好多人跟住會問:既然佢咁勁,呢種「預測能力」係點練出嚟㗎?主流路線通常都可以概括成三步:預訓練、指令微調、強化學習。
預訓練階段,工程師會將海量文字交俾模型,等佢先對世界建立一個基本認識;到咗指令微調階段,重點唔再只係「讀過好多內容」,而係要模型學識咩叫提問、咩叫回答、咩叫高質量輸出;再之後,透過強化學習呢類機制不斷俾回饋,等模型喺一次次對齊同糾偏入面,逐漸形成更穩定嘅回答能力。
換句話講,預訓練解決嘅係「知道世界上有啲咩」,指令微調解決嘅係「知道應該點樣答」,強化學習解決嘅係「知道點樣答得更似一個好結果」。明白咗呢三步,就明白點解今日嘅大模型睇落越嚟越識講嘢、越嚟越識配合任務。
至於底層演算法,而家主流 AI 系統背後普遍都繞唔開 Transformer。佢唔單止支撐 LLM,亦都支撐好多圖像、影片等生成模型。將呢一層睇成「算力同演算法底座」,會更容易理解後面 Chatbot 同 Agent 點解都建立喺佢之上。
二、Chatbot:將大模型變成可以對話嘅產品
大多數普通用戶第一次接觸 AI,其實接觸到嘅唔係「裸 LLM」,而係 Chatbot。各種網頁版聊天產品、桌面版問答窗口,本質上都屬於呢一類:佢哋將大模型包裝成一個可以持續對話、可以管理歷史記錄、可以調整參數嘅互動界面。
例如常見嘅模型網頁版,用戶見到嘅係一個對話框、一個歷史會話列表,以及一啲模型切換同參數設定入口。呢啲嘢本身唔係模型,但佢哋決定咗用戶點樣用模型、模型點樣接收上下文,以及對話點樣被保存同繼續。
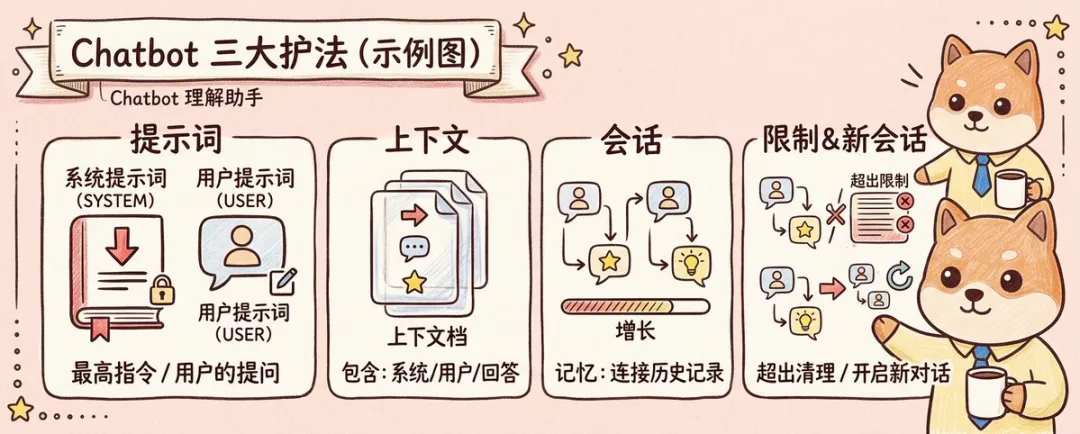
要理解 Chatbot,可以先捉住三個核心概念:提示詞、上下文、會話。
提示詞分為系統提示詞同用戶提示詞。系統提示詞通常優先級更高,好似產品方面俾模型設定嘅最高規則;用戶提示詞就係用戶喺對話框入面提出嘅問題同指令。模型最終收到嘅,並唔係得你眼前輸入嘅嗰一句,而係成段被組織好嘅上下文。
上下文入面通常會包含當前問題、歷史問答、系統約束,以及必要嘅背景資訊。模型依賴呢份上下文嚟判斷你講緊咩、你延續緊邊條話題、佢之前俾過你咩回答。亦正因為咁,AI 傾偈睇落好似「有記憶」,但本質上並唔係永久記憶,而係將相關歷史一併送入咗今輪推理。
而會話,就係呢啲上下文嘅容器。歷史內容越長,會話越豐富;但模型嘅上下文窗口係有限嘅,冇可能無限堆疊所有歷史,所以 Chatbot 往往需要做截斷、清理、歸檔,或者俾用戶開一個新話題。
從產品結構嚟睇,早期 Chatbot 大致由三個部分組成:用戶界面、模型配置、會話管理。用戶界面解決「點樣用」,模型配置解決「用邊個模型、調咩參數」,會話管理解決「歷史點樣保存、刪除、修改同切換」。
亦正因為有咗呢一層,大模型先真正由實驗室能力變成大眾日常可以用嘅軟件形態。換句話講,LLM 決定「答唔答得到」,Chatbot 決定「好用唔好用」。
三、Agent:唔止識傾偈,仲可以做到件事
Chatbot 最大嘅侷限係,佢主要停留喺「對話」層。佢可以解釋、建議、整理、陪你推演,但如果唔俾佢連接外部世界嘅能力,佢通常冇辦法真正幫你打開網頁、調用服務、讀寫檔案、執行腳本。
Agent 嘅價值,就係將模型由「識講」推進到「識做」。為咗實現呢點,系統需要畀模型準備工具,並話俾佢知每個工具可以做咩、需要咩參數、輸出係點樣。模型理解任務之後,決定幾時調用邊個工具;外部程式接到指令之後真正執行;結果再返到模型嗰邊,由模型將原始結果整合成更自然嘅最終答覆。
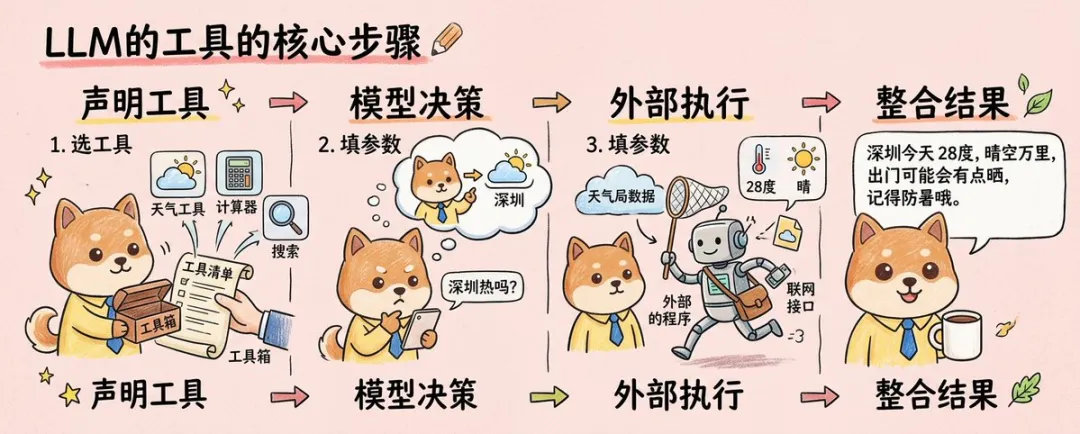
成個過程可以概括成四段:聲明工具、模型決策、外部執行、整合結果。例如當用戶問「深圳今日熱唔熱」,模型發現自己嘅知識唔係實時嘅,於是選擇天氣工具、提取「深圳」呢個參數、觸發外部查詢,再將返回嘅數據組織成一句似人話嘅回答。呢個先係 Agent 嘅基本工作閉環。
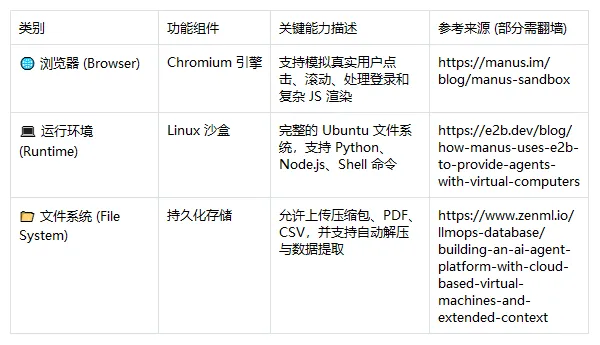
如果繼續向前睇,真正拉開差距嘅唔係「識唔識得調用一個接口」,而係工具系統係咪夠完整。以 Manus 呢類產品為代表,Agent 往往唔止可以查一個結果,仲可以圍繞瀏覽網頁、運行代碼、處理檔案、整理資料等多個環節連續工作。工具一旦豐富,模型就唔再只係問答器,而更像一個可以調用環境資源嘅執行體。
所以,而家再區分 Chatbot 同 Agent,關鍵已經唔只係「識唔識用工具」。更重要嘅分別在於:佢可唔可以將任務閉環完成。
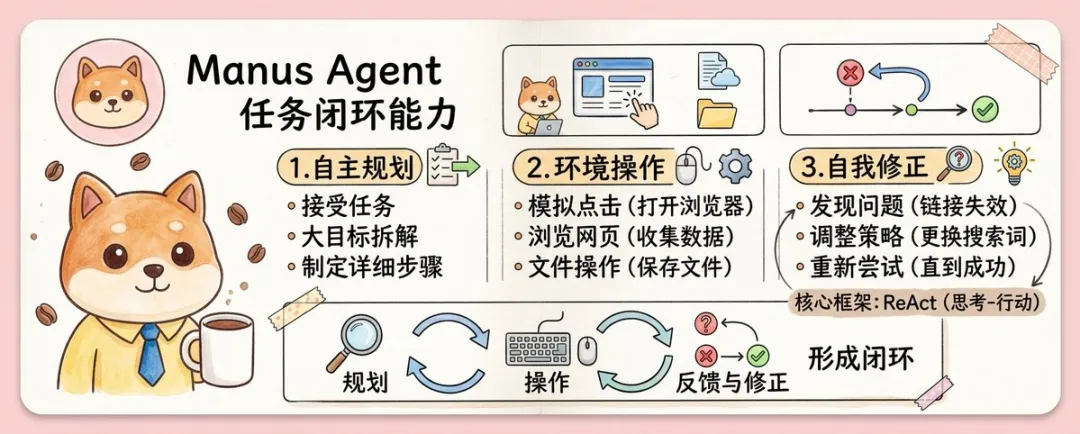
一個更完整嘅 Agent,通常至少要有三種能力:自主規劃、環境操作、自我修正。面對複雜任務時,佢唔係即刻俾出一段答案,而係先拆目標、排步驟;執行過程中,佢要真係去瀏覽頁面、讀寫檔案、運行流程;一旦遇到網頁打唔開、資訊唔齊、路徑失效等問題,佢仲要識得調整策略,繼續嘗試,而唔係第一時間停喺報錯度。
呢個亦都係點解 Agent 睇落更接近「數碼員工」或「任務執行者」,而 Chatbot 更像「隨傳隨到嘅對話助手」。前者追求做到件事,後者更擅長講清楚嘢。
四、點樣理解三者嘅關係
如果用一句最直白嘅話總結:LLM 係能力底座,Chatbot 係互動形態,Agent 係執行形態。
• 冇 LLM,後兩者就缺少推理同生成能力。 • 冇 Chatbot,普通用戶好難舒服咁用模型能力。 • 冇 Agent,模型再識講,都好難真正介入現實工作流程。
因此,呢三者唔係互相取代,而係層層疊加。好多產品表面睇係賣緊「Agent」,實際上背後依然離唔開 LLM;好多傾偈產品睇落只係 Chatbot,但如果接上工具,亦會開始向 Agent 靠攏。行業入面概念之所以越嚟越容易混淆,正正係因為產品邊界喺度融合緊。
五、Agent 會唔會成為下一代默認形態
從趨勢睇,Agent 確實係快速進入大眾視野。無論係通用型 Agent,定係設計、編程、研究、文檔等垂直型 Agent,都係說明一個方向:軟件唔再只係俾人㩒開同操作,佢開始可以代表用戶去規劃、去執行、去回收結果。
但呢個唔代表 AGI 已經到咗。高昂嘅使用成本、舊互聯網系統嘅高牆、執行結果嘅唔穩定同唔可重複,依然係現實限制。亦即係話,Agent 好熱,唔等於一切都已經成熟;佢更像係下一代軟件形態嘅雛形,而唔係終局答案。
真正值得關注嘅,可能唔係「Agent 呢個詞仲可以火幾耐」,而係當呢股熱潮退去之後,越來越多軟件會默認具備理解任務、調用工具、自動執行嘅能力。到嗰陣時,人哋可能唔會再頻繁強調「呢個係 Agent」,就好似今日好少人特登強調「呢個係互聯網軟件」一樣。
結語
如果你啱啱開始接觸 AI,最值得先記住嘅唔係一堆名詞,而係一條好簡單嘅鏈路:LLM 負責生成同推理,Chatbot 負責承載對話體驗,Agent 負責將模型能力延伸到真實任務。
將呢條鏈路諗清楚,再睇各種新產品,你會更容易判斷佢到底只係一個傾偈界面,定係已經具備真正嘅執行能力;亦更容易知道,自己當前需要嘅究竟係一個可以陪你討論問題嘅助手,定係一個可以落場幫你做嘢嘅系統。
如果把今天的 AI 應用拆開看,其實可以分成三層:LLM 是“大腦”,Chatbot 是“對話外殼”,Agent 則是“能調用工具完成任務的執行體”。這三個詞經常被混着用,但一旦放到同一張框架圖裏,很多討論都會清楚很多。
尤其是在 Agent 再次升温的當下,很多人一接觸 AI,就會被一連串名詞包圍:大模型、聊天機器人、智能體、自動化助手……聽起來都像一回事,實際分工卻完全不同。先把這三層關係看明白,後面無論是理解產品、做選型,還是判斷一項能力到底靠什麼實現,都會輕鬆不少。
一、LLM:所有能力的底座
LLM,也就是大語言模型,本質上是一種基於“預測”的文本生成模型。它並不是像人一樣先理解世界再組織語言,而是在已有知識和當前輸入的基礎上,預測接下來最可能出現的詞,再不斷往後續寫。
如果把它的工作過程拆開來看,核心就是三步:輸入、預測、輸出。你把背景信息和問題交給模型,模型基於訓練中學到的語言規律進行預測,再把預測結果組織成一段回答返回給你。無論是聊天、寫作、總結,還是代碼補全,底層都離不開這一套機制。
很多人接着會問:既然它這麼強,這種“預測能力”是怎麼練出來的?主流路線通常也可以概括成三步:預訓練、指令微調、強化學習。
預訓練階段,工程師會把海量文本交給模型,讓它先對世界建立一個基礎認識;到了指令微調階段,重點不再只是“讀過很多內容”,而是讓模型學會什麼叫提問、什麼叫回答、什麼叫高質量輸出;再往後,通過強化學習這類機制不斷給出反饋,讓模型在一次次對齊和糾偏中,逐漸形成更穩定的回答能力。
換句話說,預訓練解決的是“知道世界上有什麼”,指令微調解決的是“知道該怎麼答”,強化學習解決的是“知道怎樣答得更像一個好結果”。理解了這三步,也就理解了為什麼今天的大模型看起來越來越會說、越來越會配合任務。
至於底層算法,當前主流 AI 系統背後普遍都繞不開 Transformer。它不僅支撐 LLM,也支撐很多圖像、視頻等生成模型。把這一層看成“算力和算法底座”,會更容易理解後面 Chatbot 和 Agent 為什麼都建立在它之上。
二、Chatbot:把大模型變成可對話產品
大多數普通用戶第一次接觸 AI,其實接觸到的不是“裸 LLM”,而是 Chatbot。各種網頁端聊天產品、桌面端問答窗口,本質上都屬於這一類:它們把大模型包裝成了一個可以持續對話、可以管理歷史記錄、可以調參數的交互界面。
比如常見的模型網頁端,用戶看到的是一個聊天框、一個歷史會話列表,以及一些模型切換和參數設置入口。這些東西本身不是模型,但它們決定了用戶如何使用模型、模型如何接收上下文,以及對話如何被保存和繼續。
要理解 Chatbot,可以先抓住三個核心概念:提示詞、上下文、會話。
提示詞分成系統提示詞和用戶提示詞。系統提示詞通常優先級更高,像是產品側給模型設定的最高規則;用戶提示詞則是用戶在聊天框裏提出的問題和指令。模型最終收到的,並不只是你眼前輸入的那一句,而是整段被組織好的上下文。
上下文裏通常會包含當前問題、歷史問答、系統約束,以及必要的背景信息。模型依賴這份上下文來判斷你在說什麼、你延續的是哪條話題、它之前給過你什麼回答。也正因為如此,AI 聊天看起來像“有記憶”,但本質上並不是永久記憶,而是把相關歷史一併送進了本輪推理。
而會話,就是這些上下文的容器。歷史內容越長,會話越豐富;但模型上下文窗口是有限的,不可能無限堆疊所有歷史,所以 Chatbot 往往需要做截斷、清理、歸檔,或者讓用戶另開一個新話題。
從產品結構上看,早期 Chatbot 大體由三部分組成:用戶界面、模型配置、會話管理。用戶界面解決“怎麼用”,模型配置解決“用哪個模型、調什麼參數”,會話管理解決“歷史如何保存、刪除、修改和切換”。
也正因為有了這一層,大模型才真正從實驗室能力變成了大眾可以日常使用的軟件形態。換句話說,LLM 決定“能不能答”,Chatbot 決定“好不好用”。
三、Agent:不只會聊,還能把事做完
Chatbot 最大的侷限是,它主要停留在“對話”層。它可以解釋、建議、整理、陪你推演,但如果不給它連接外部世界的能力,它通常沒法真正替你打開網頁、調用服務、讀寫文件、執行腳本。
Agent 的價值,就在於把模型從“會說”推進到“會做”。為了實現這一點,系統需要給模型準備工具,並告訴它每個工具能做什麼、需要什麼參數、輸出長什麼樣。模型在理解任務後,決定何時調用哪個工具;外部程序接到指令後真正執行;結果再回到模型側,由模型把原始結果整合成更自然的最終答覆。
整個過程可以概括成四段:聲明工具、模型決策、外部執行、整合結果。比如當用戶問“深圳今天熱嗎”,模型發現自己的知識不是實時的,於是選擇天氣工具、提取“深圳”這個參數、觸發外部查詢,再把返回的數據組織成一句像人話的回答。這才是 Agent 的基本工作閉環。
如果繼續往前看,真正拉開差距的不是“會不會調一個接口”,而是工具系統是否足夠完整。以 Manus 這類產品為代表,Agent 往往不僅能查一個結果,還能圍繞瀏覽網頁、運行代碼、處理文件、整理資料等多個環節連續工作。工具一旦豐富,模型就不再只是問答器,而更像一個能夠調用環境資源的執行體。
所以,今天再區分 Chatbot 和 Agent,關鍵已經不只是“會不會使用工具”。更重要的差別在於:它能不能把任務閉環完成。
一個更完整的 Agent,通常至少要有三種能力:自主規劃、環境操作、自我修正。面對複雜任務時,它不是立刻給出一段答案,而是先拆目標、排步驟;執行過程中,它要真的去瀏覽頁面、讀寫文件、運行流程;一旦遇到網頁打不開、信息不全、路徑失效等問題,它還得能調整策略,繼續嘗試,而不是第一時間停在報錯上。
這也是為什麼 Agent 看上去更接近“數字員工”或“任務執行者”,而 Chatbot 更像“隨叫隨到的對話助手”。前者追求把事做完,後者更擅長把話講清。
四、怎麼理解三者的關係
如果用一句最直白的話總結:LLM 是能力底座,Chatbot 是交互形態,Agent 是執行形態。
• 沒有 LLM,後兩者就缺少推理和生成能力。 • 沒有 Chatbot,普通用戶很難舒服地使用模型能力。 • 沒有 Agent,模型再會說,也很難真正介入現實工作流。
因此,這三者不是互相替代,而是層層疊加。很多產品表面看是在賣“Agent”,實際背後依然離不開 LLM;很多聊天產品看起來只是 Chatbot,但如果接上工具,也會開始向 Agent 靠攏。行業裏概念之所以越來越容易混淆,恰恰是因為產品邊界正在融合。
五、Agent 會不會成為下一代默認形態
從趨勢看,Agent 確實正在快速進入大眾視野。無論是通用型 Agent,還是設計、編程、研究、文檔等垂直型 Agent,都在說明一個方向:軟件不再只是被點開和操作,它開始能代表用戶去規劃、去執行、去回收結果。
但這不意味着 AGI 已經到來。高昂的使用成本、舊互聯網系統的高牆、執行結果的不穩定和不可重複,依然是現實限制。也就是說,Agent 很熱,不等於一切都已經成熟;它更像是下一代軟件形態的雛形,而不是終局答案。
真正值得關注的,也許不是“Agent 這個詞還能火多久”,而是當這股熱潮退去之後,越來越多軟件會默認具備理解任務、調用工具、自動執行的能力。到那時,人們可能不會再頻繁強調“這是 Agent”,就像今天很少有人特意強調“這是互聯網軟件”一樣。
結語
如果你剛開始接觸 AI,最值得先記住的不是一堆名詞,而是一條很簡單的鏈路:LLM 負責生成與推理,Chatbot 負責承載對話體驗,Agent 負責把模型能力延伸到真實任務。
把這條鏈路想清楚,再去看各種新產品,你會更容易判斷它到底只是一個聊天界面,還是已經具備了真正的執行能力;也更容易知道,自己當前需要的究竟是一個能陪你討論問題的助手,還是一個能下場替你幹活的系統。