一種新的 LLM Wiki 方法論:讓 AI 幫你建一個能活下去的知識庫
整理版優先睇
用 Obsidian 同 AI 打造一個會自己長大嘅知識庫:LLM Wiki 方法論
呢篇文章嘅作者本來用緊傳統 RAG 做知識問答,但發現每次問完之後,AI 都冇留低任何記憶,下次同一個問題又要重新解釋。佢覺得呢個係 RAG 嘅結構性問題——擅長回答,唔擅長積累。於是佢提出一個新玩法:將 AI 變成你嘅 Wiki 編輯,而唔係臨時顧問。
具體做法係用 Obsidian Web Clipper 剪下網頁內容,然後設定圖片本地化確保唔會失效,再用 Git 做版本控制,配合 Dataview、Marp 呢啲插件,令知識庫可以持續更新同查詢。作者強調,呢套方法嘅核心係將維護工作交俾 AI,人類只需決定睇咩、問咩、記低咩,AI 負責整理、歸檔、串聯。
整體結論係:只要用啱工具同流程,個人知識庫可以由「隨規模增長而崩潰」變成「近乎固定嘅維護成本」,長期運轉唔係問題。
- LLM Wiki 模式將 AI 變成持續編輯者,而非一次性搜尋引擎,解決咗 RAG 唔積累知識嘅問題。
- 用 Obsidian Web Clipper 採集內容,配合圖片本地化(Ctrl+Shift+D)確保圖片唔會失效,係最基礎嘅第一步。
- Git 版本控制係必選項,因為 AI 可以一次改動十幾個文件,冇版本歷史好難回溯。
- 圖譜視圖可以幫你發現孤島頁面同知識空白,用 Dataview 動態查詢元數據,大幅減少人工整理。
- Marp 插件可以將 Wiki 內容直接轉成幻燈片,幾分鐘就出一份像樣嘅演示文稿。
RAG 嘅天花板:問完即忘,知識無得積累
你有冇試過:同一個問題,上週問過 AI,呢週又要重新問,因為上次嘅回答完全冇留低任何痕跡?呢個就係 RAG 模式嘅天花板——佢擅長「回答」,但唔擅長「積累」。每一次對話都係一次性,AI 從文檔堆裏撈出片段、拼出答案,然後乜都冇留低。
用 RAG 處理知識嘅流程大家都熟悉:將文件上傳,提問,AI 檢索片段,組合成答案。單次使用冇問題,但佢有一個 結構性缺陷——每次查詢都係無狀態嘅。跨文檔嘅綜合性問題尤其食虧,例如問一個涉及五篇論文嘅問題,AI 要喺運行時將散落各處嘅線索實時拼湊,又慢又容易丟失細節。
工具鏈第一步:採集與本地化
第一步係喺瀏覽器安裝 Obsidian Web Clipper 擴展。打開任意網頁文章,點擊擴展圖標,選擇 Add to Obsidian,保存後文章自動轉為 Markdown 出現喺 Obsidian 裏。
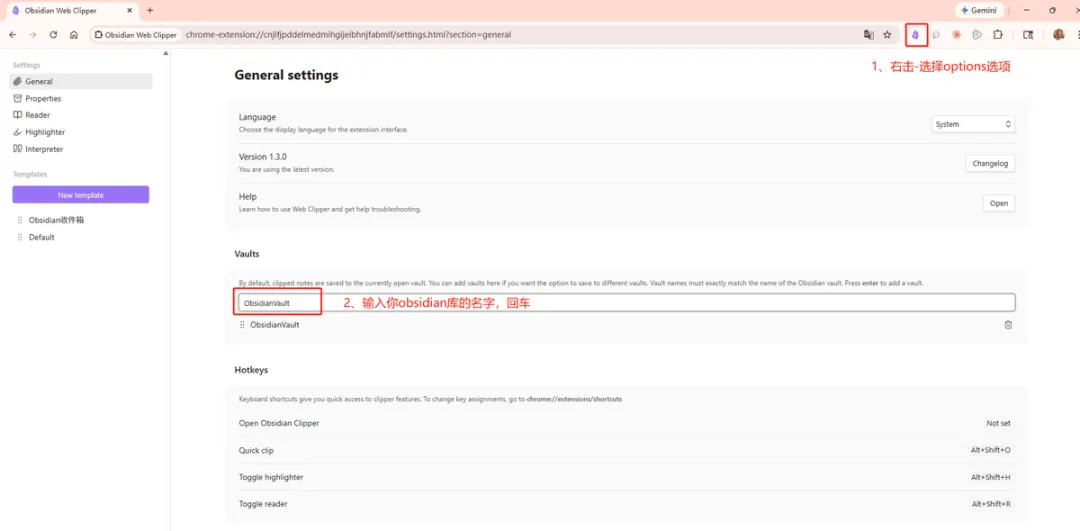
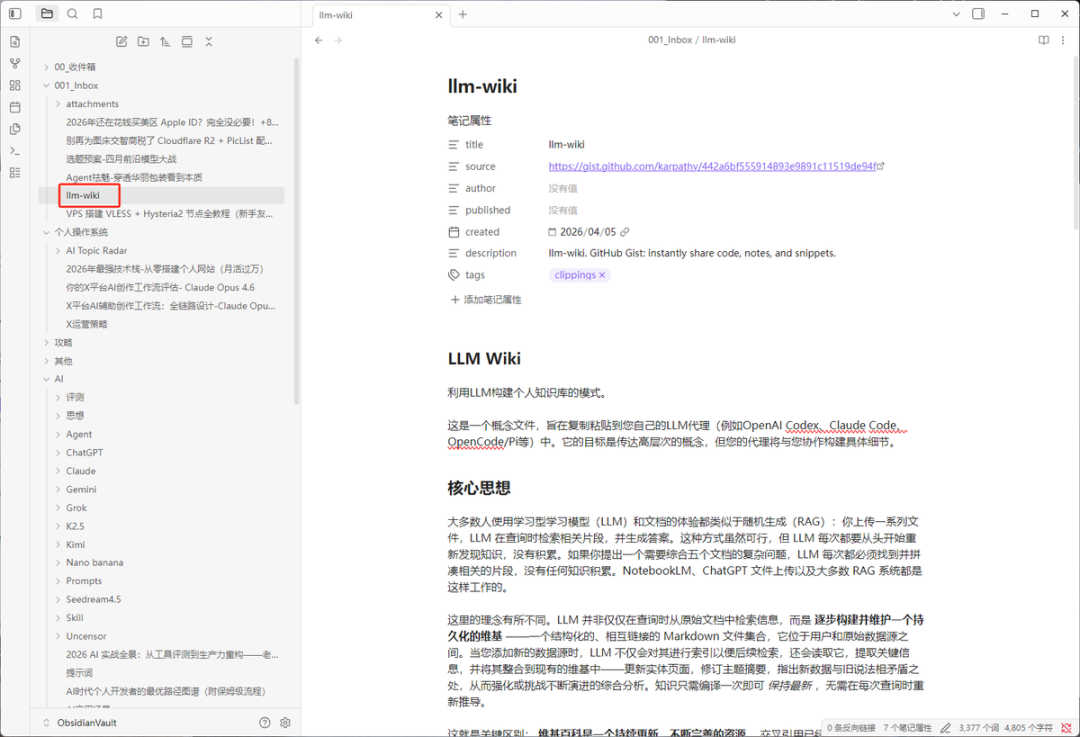
- 1 打開設置 → 文件與連結 → 附件存儲路徑 → 設為當前文件夾下嘅 attachments 子文件夾
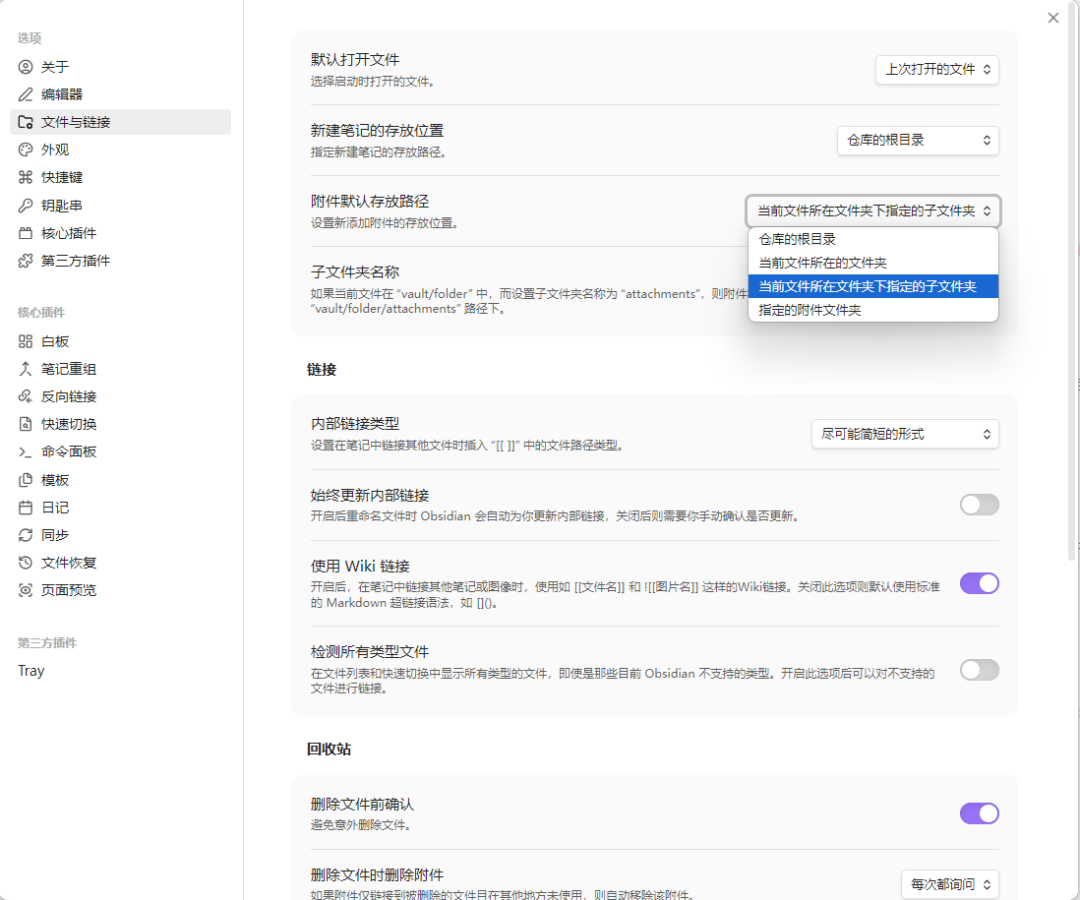
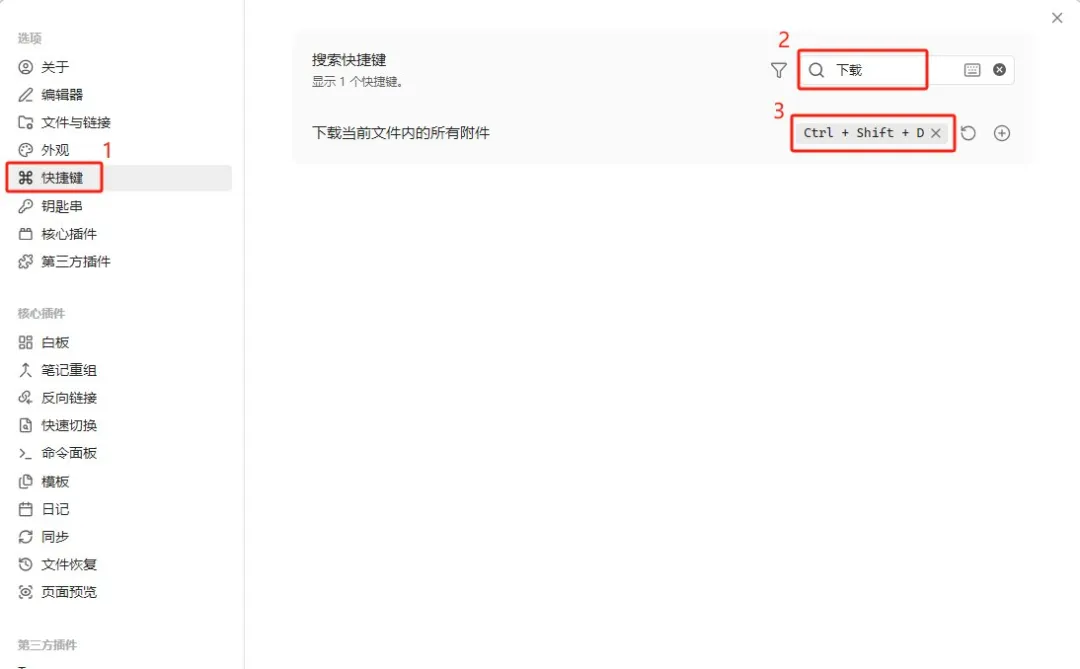
- 2 設置 → 快捷鍵 → 搜索「下載」→ 綁定快捷鍵 Ctrl+Shift+D
Web Clipper 剪落嚟嘅文章,圖片默認仲係遠程連結。呢個有兩個隱患:一係圖牀隨時可能失效,文章圖片變成一堆叉;二係 AI 無法訪問失效嘅外鏈,呢啲圖片對佢嚟講等於唔存在。解決辦法只需要配置一次:統一附件存儲路徑,然後綁定下載快捷鍵。之後每剪一篇文章,順手按一次 Ctrl+Shift+D,圖片就落到本地。呢個習慣一旦養成,知識庫裏嘅內容就真正屬於你,AI 都能完整讀取每一張圖。
進階插件:圖譜、Dataview、Marp、Git
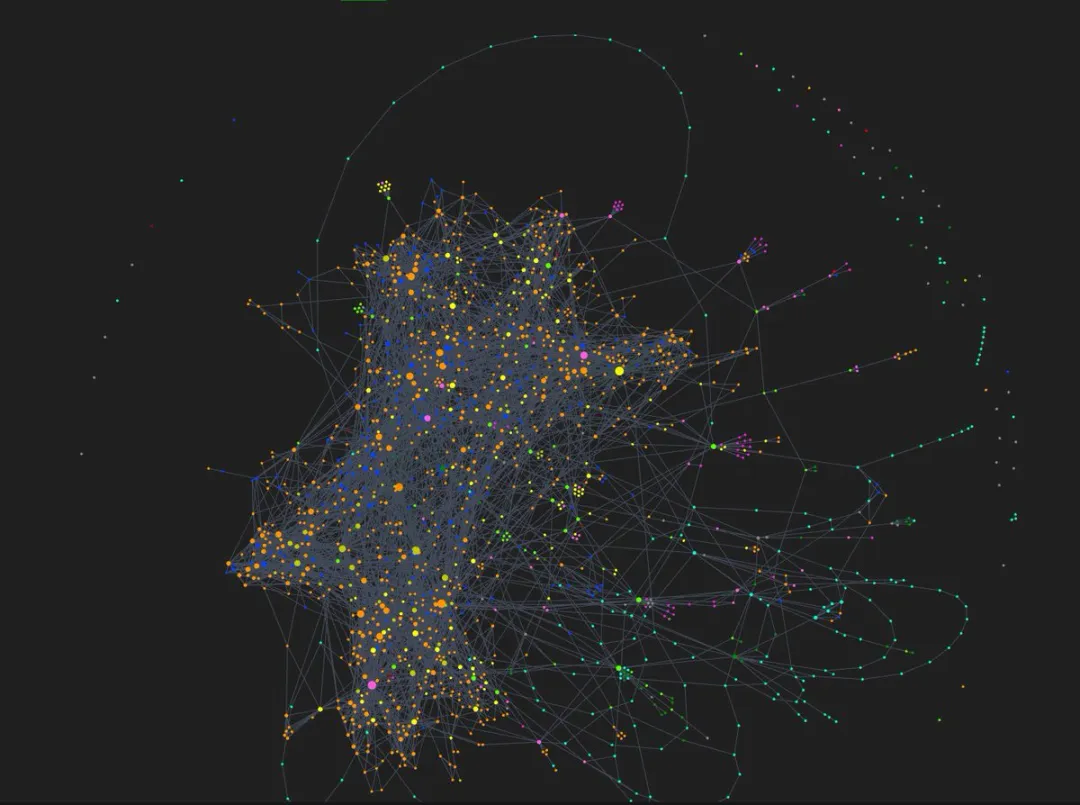
Obsidian 嘅 Graph View 係一張實時生成嘅關係地圖。每個 Wiki 頁面係一個節點,頁面之間有雙向連結嘅地方會自動連線。打開方式:點擊左側邊欄嘅圖譜圖標,或者直接按 Ctrl+G。
- 檢查孤島頁面:冇任何入鏈嘅節點懸喺圖譜邊緣,呢個頁面仲未被其他內容引用,可以叫 AI 補上交叉連結。
- 找到應該但未建立嘅頁面:一個概念如果被多個頁面提及卻冇自己嘅專頁,會以灰色幽靈節點出現——呢個就係知識庫嘅空白,值得叫 AI 補上。
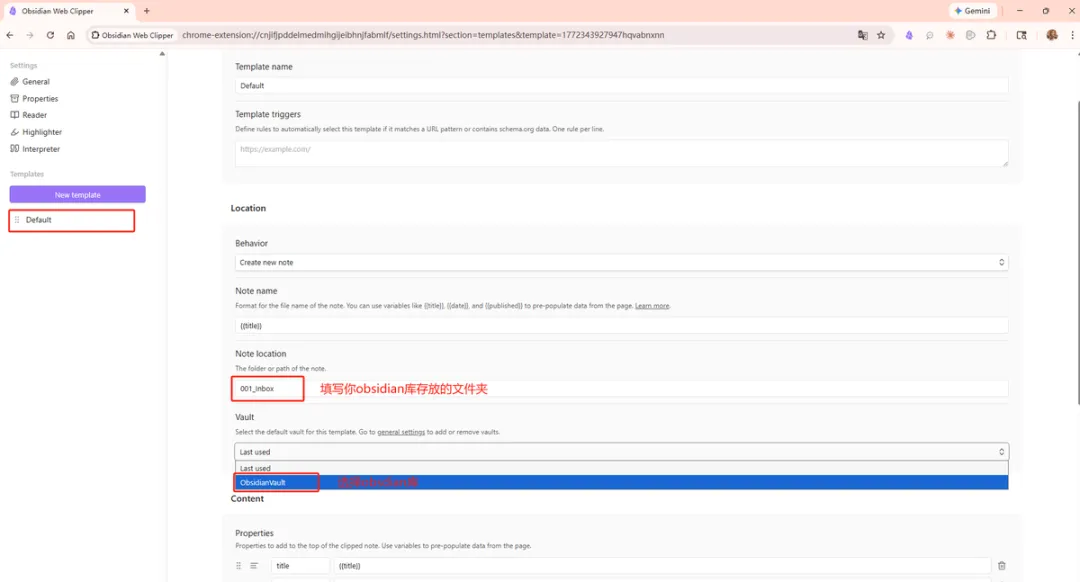
Dataview 係 Obsidian 嘅社區插件,核心能力係將 YAML frontmatter 當成數據庫字段查詢,喺頁面裏動態渲染表格同列表。配合 LLM Wiki 嘅方式係:叫 AI 喺創建或更新每個頁面時,順帶寫入結構化嘅 frontmatter,例如 type、title、date、tags。
TABLE title, date, tags
FROM "wiki/sources"
SORT date DESCMarp 係基於 Markdown 嘅幻燈片標準,喺 Obsidian 裝上 Marp Slides 插件就能本地預覽同導出。格式好簡單:文件開頭寫 marp: true,每頁之間用 --- 分隔。實際場景:將某個主題嘅 Wiki 頁面餵俾 AI,叫佢直接輸出 Marp 格式初稿,你只需調整細節,幾分鐘就出一份像樣嘅演示文稿。
呢套方法點解可以長期運轉?
知識庫做唔落去,通常唔係因為冇內容,而係因為維護太累:每加一條新知識,就要手動更新所有相關頁面嘅引用,檢查有冇矛盾,補上缺失嘅交叉連結……頁面一多,人就撐唔住。AI 喺呢件事上有結構性優勢:佢唔會因為重複勞動而厭倦,唔會漏掉需要更新嘅頁面,而且可以一次操作同時處理大量文件。
總結嚟講,Obsidian Web Clipper + 圖片本地化 + Git + Claude(或者其他 AI 模型)呢四件套就夠搭出一個真正能用、能長大、能活下去嘅個人知識庫。
你有冇遇過呢種情況:同一個問題,上個禮拜問過AI,呢個禮拜又要再問多次,因為上次嘅回答根本冇留低任何痕跡。
呢個係RAG模式嘅天花板——佢擅長「回答」,但唔擅長「累積」。每一次對話都係一次性,AI從文件堆裏面揾出片段、拼湊出答案,然後乜都冇留低。下次再問,又從頭嚟過。
轉另一種玩法:將AI變成你嘅Wiki編輯,而唔係臨時顧問。
RAG到底衰喺邊度?
用RAG處理知識嘅流程大家都熟:將文件上載入去,提問,AI檢索片段,組合成一個答案。單次使用冇問題,但佢有一個結構性缺陷——每次查詢都係無狀態嘅。
跨文件嘅綜合性問題尤其蝕底。假設你想問一個涉及五篇論文嘅問題,AI需要喺運行時將散落周圍嘅線索即時拼湊起嚟,又慢又容易漏咗細節。
LLM Wiki嘅思路反轉:唔係等你提問先至去揾,而係提早俾AI將知識整理好,寫成一組互相連結嘅Markdown頁面,持續維護,持續更新。知識喺文件裏面沉澱,而唔係喺對話裏面蒸發。
用Obsidian Web Clipper做素材採集
第一步,喺瀏覽器安裝Obsidian Web Clipper擴展。
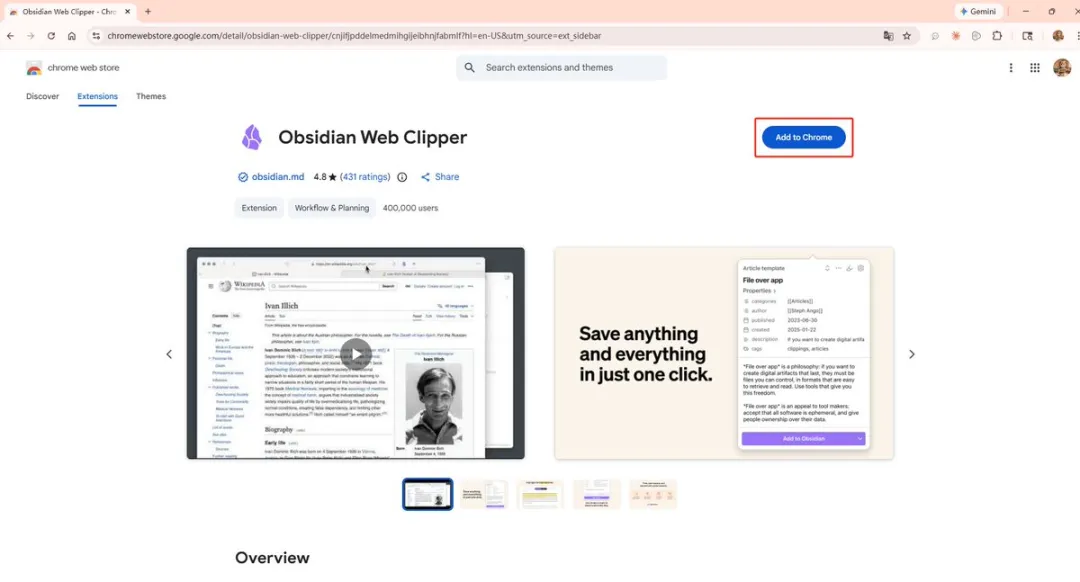
第二步,打開任意網頁文章,㩒擴展圖標,揀Add to Obsidian。
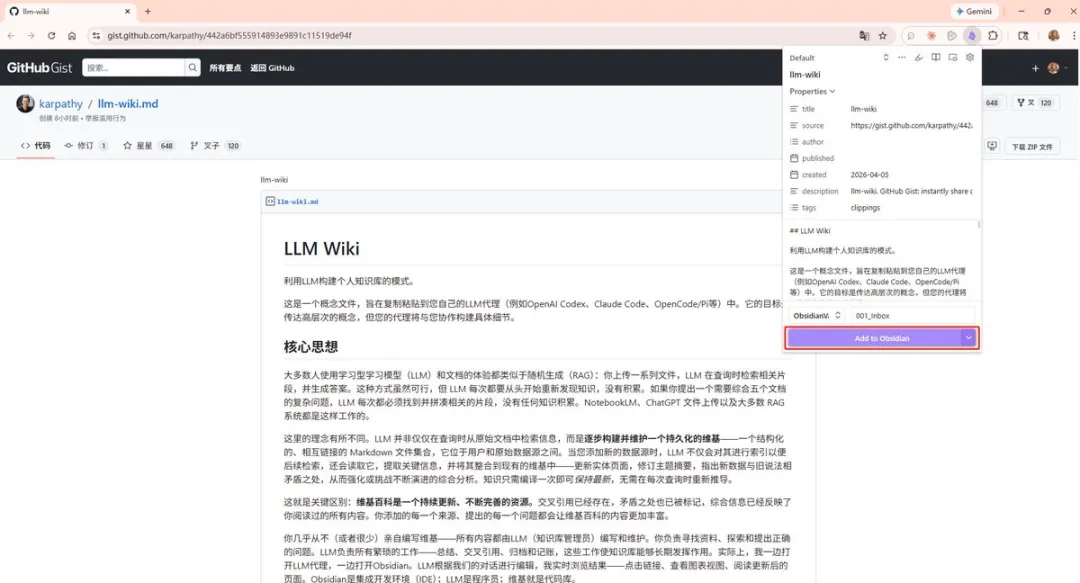
第三步,保存之後文章會自動轉做Markdown出現喺Obsidian裏面。
圖片唔本地化,遲早係計時炸彈
Web Clipper剪落嚟嘅文章,圖片預設仲係遠端連結。咁有兩個隱憂:第一係圖牀隨時可能失效,文章圖片變成一堆交叉;第二係AI無法存取失效嘅外鏈,呢啲圖片對佢嚟講等於唔存在。
解決方法只需要設定一次。
第一步:統一附件儲存路徑
打開設定 → 文件與連結 → 揾到附件儲存路徑 → 設為當前文件夾下指定嘅子文件夾,子文件夾名稱設為 attachments。
第二步:綁定下載快捷鍵
設定 → 快捷鍵 → 搜尋「下載」 → 綁定快捷鍵Ctrl+Shift+D。
之後每次剪一篇文章,順手㩒一次Ctrl+Shift+D,圖片就會落到本地。呢個習慣一旦養成,知識庫裏面嘅內容就真正屬於你,AI亦都可以完整讀取每一張圖。
圖譜視圖:令知識庫嘅健康狀況一目瞭然
Obsidian嘅Graph View係一張即時生成嘅關係地圖。每個Wiki頁面係一個節點,頁面之間凡係有雙向連結嘅地方,就會自動連上一條線。打開方法:㩒左側邊欄嘅圖譜圖標,或者直接按Ctrl+G。
呢張圖結合AI有兩個具體用途:
1. 檢查孤島頁面:沒有任何入鏈嘅節點懸喺圖譜邊緣,即係話呢個頁面仲未俾其他內容引用,叫AI去補返交叉連結。 2. 揾到應該但仲未建立嘅頁面:一個概念如果俾多個頁面提及但冇自己嘅專頁,佢會喺圖譜裏面以灰色幽靈節點嘅形式出現——呢個正正就係知識庫裏面嘅空白,值得俾AI補上。
Dataview:幫知識庫裝上自動報表
Dataview係Obsidian嘅社羣插件,核心能力係將YAML frontmatter當成數據庫字段嚟查詢,喺頁面裏面動態顯示表格同列表。安裝路徑:設定 → 第三方插件 → 社羣插件市場 → 搜尋「Dataview」 → 安裝並啓用。
同LLM Wiki配合嘅方式係:叫AI喺建立或更新每個頁面嘅時候,順便寫入結構化嘅frontmatter,例如:
type: source
title: "文章標題"
date: 2026-04-05
tags: [AI, knowledge-base]
source_count: 3有咗呢啲元數據,隨便喺邊個頁面寫一段Dataview查詢:
TABLE title, date, tags
FROM "wiki/sources"
SORT date DESC就可以自動拉出按時間排序嘅素材清單。知識庫越大,呢類查詢嘅價值就越高——人手整理費時失事嘅嘢,Dataview幾行代碼就搞掂。
Marp:Wiki內容直接變成可用嘅簡報
Marp係基於Markdown嘅簡報標準,喺Obsidian裏面裝上Marp Slides插件就可以本地預覽同匯出。安裝路徑:設定 → 社羣插件 → 搜尋「Marp Slides」 → 安裝並啓用。
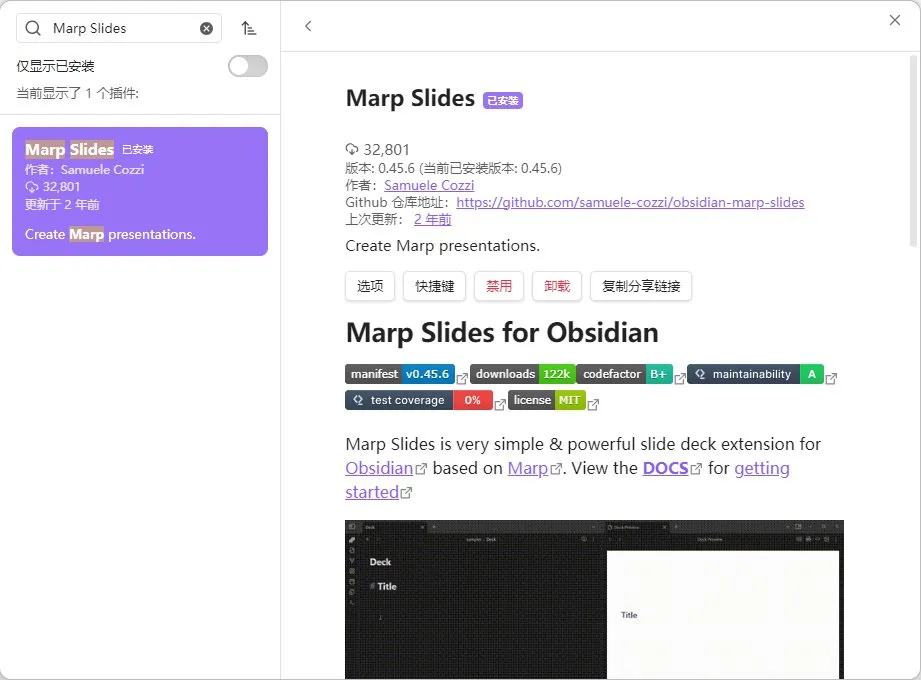
格式好簡單:檔案開頭寫 marp: true,然後每頁之間用 --- 分隔。寫完喺Obsidian裏面直接預覽,匯出支援PDF、HTML、PPTX三種格式。
實際場景:將某個主題嘅Wiki頁面餵俾AI,叫佢直接輸出Marp格式嘅初稿,你只需要調整細節,幾分鐘就可以出一份似樣嘅簡報。
Git:AI改文件,你需要一道保險
安裝路徑:設定 → 第三方插件 → 社羣插件市場 → 搜尋「git」 → 安裝並啓用。
如果Vault仲未有Git倉庫,先初始化:
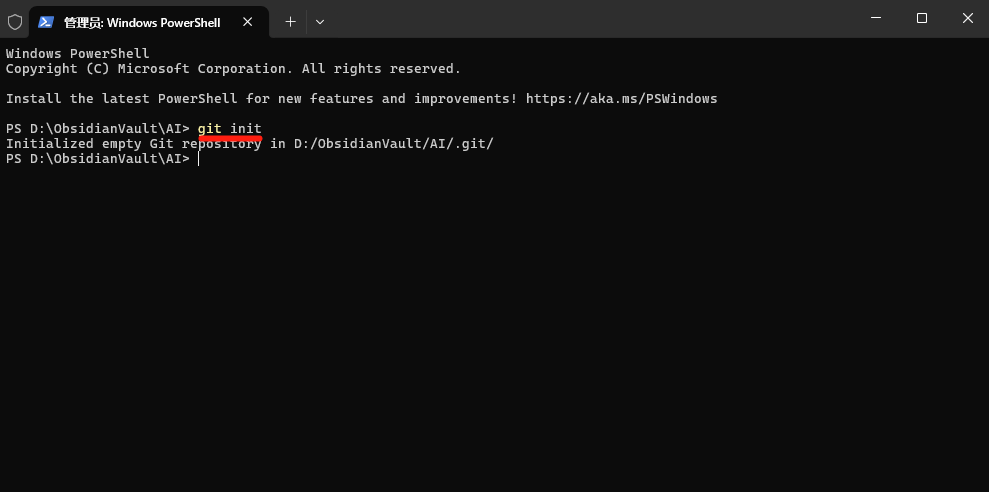
1. 打開終端機,cd到你嘅Vault目錄,執行 git init初始化倉庫。
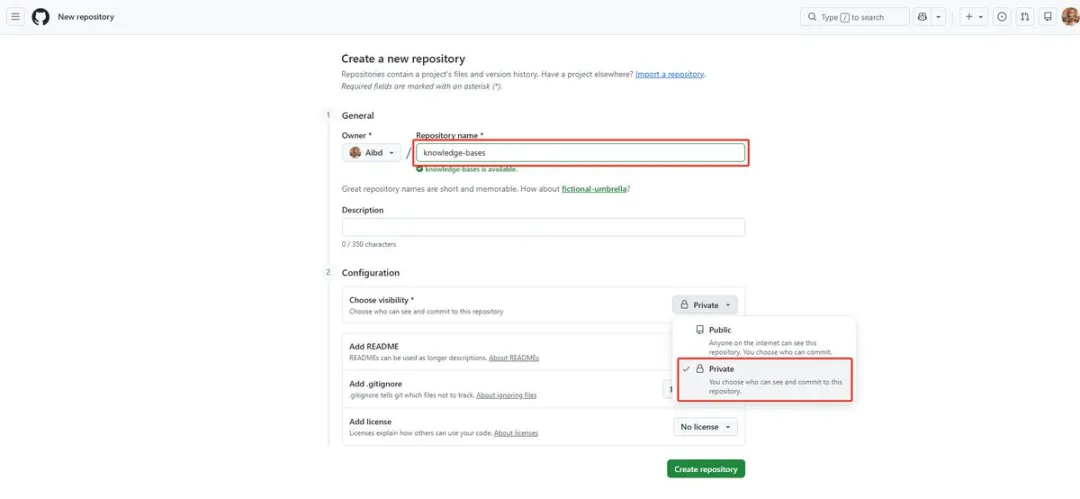
2. 喺GitHub上新建一個私有倉庫(知識庫係個人數據,唔好設成公開)。
3. 將本地倉庫推上去:
git branch -M main
git remote add origin https://github.com/你的用戶名/knowledge-bases.git
git add .
git commit -m "init: 初始化知識庫"
git push -u origin main
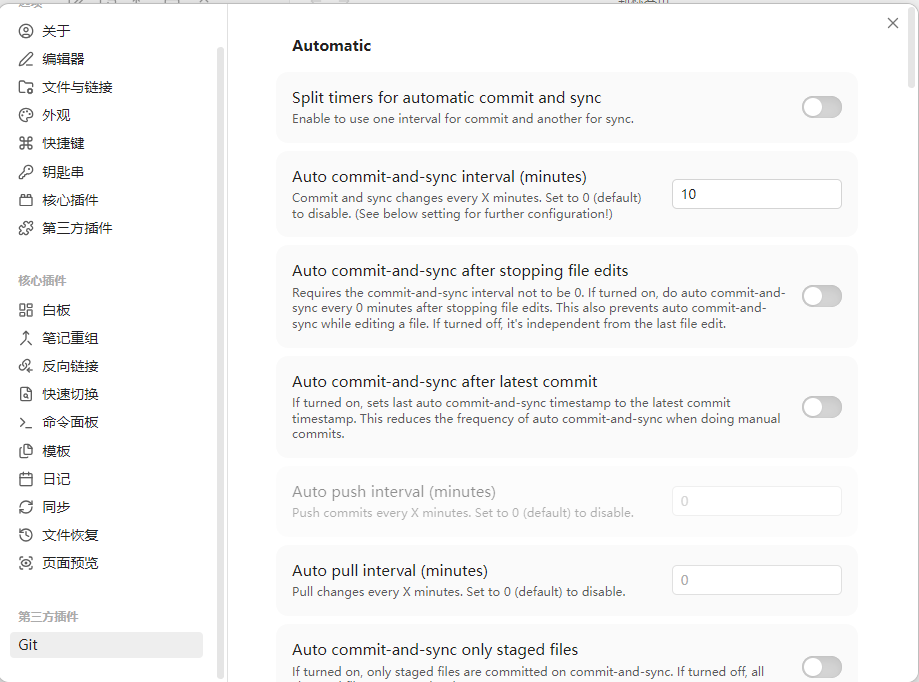
插件裝好之後,將Auto commit-and-sync interval較成10分鐘,之後唔使再理佢。
點解Git係必選項?因為AI可以一次過改動十幾個文件,一旦出錯,冇版本歷史就好難回溯。提交記錄就係一張安全網,AI嘅能力越強,呢張網就越重要。
qmd:知識庫大咗之後嘅搜尋方案
頁面數量仲少嘅時候,維護一個 index.md 作為目錄就夠用,AI靠佢就可以喺知識庫裏面揾到路。
等到頁面積累到幾百個,檢索速度開始下降,嗰時可以引入qmd——一個純本地運行嘅Markdown全文搜尋引擎。唔使急住而家就裝,等真正覺得慢咗先講。
呢套方法點解可以長期運作?
知識庫做唔落去,通常唔係因為冇內容,而係因為維護太攰:每次加一條新知識,就要手動更新所有相關頁面嘅引用,檢查有冇矛盾,補返缺失嘅交叉連結……頁面一多,人就頂唔順。
AI喺呢件事上有結構性優勢:佢唔會因為重複勞動而覺得厭倦,唔會漏咗需要更新嘅頁面,而且可以喺一次操作裏面同時處理大量文件。將呢部分工作交俾佢,維護成本就由「隨規模增長」變成近乎固定。
你需要做嘅,係決定讀啲乜、諗清楚問啲乜、判斷邊啲值得記錄。整理、歸檔、串聯呢啲事,交俾AI做。
Obsidian Web Clipper + 圖片本地化 + Git + Claude,呢四件套就夠砌出一個真正用得、可以長大、可以生存落去嘅個人知識庫。
——完——
㩒個關注,一齊學習~
你有沒有遇到過這種情況:同一個問題,上週問過 AI,這周又要重新問一遍,因為上次的回答根本沒留下任何痕跡。
這是 RAG 模式的天花板——它擅長"回答",但不擅長"積累"。每一次對話都是一次性的,AI 從文檔堆裏撈出片段、拼出答案,然後什麼都沒留下。下次再問,重頭再來。
換一種玩法:把 AI 變成你的 Wiki 編輯,而不是臨時顧問。
RAG 到底差在哪裏?
用 RAG 處理知識的流程大家都熟悉:把文件上傳進去,提問,AI 檢索片段,組合成一個答案。單次使用沒問題,但它有一個結構性缺陷——每次查詢都是無狀態的。
跨文檔的綜合性問題尤其吃虧。假設你想問一個涉及五篇論文的問題,AI 需要在運行時把散落各處的線索實時拼湊起來,既慢又容易丟失細節。
LLM Wiki 的思路反過來:不是等你提問再去找,而是提前讓 AI 把知識整理好,寫成一組互相連結的 Markdown 頁面,持續維護,持續更新。知識在文件裏沉澱,而不是在對話裏蒸發。
用 Obsidian Web Clipper 做素材採集
第一步,在瀏覽器安裝 Obsidian Web Clipper 擴展。
第二步,打開任意網頁文章,點擊擴展圖標,選擇 Add to Obsidian。
第三步,保存後文章自動轉為 Markdown 出現在 Obsidian 裏。
圖片不本地化,遲早是定時炸彈
Web Clipper 剪下來的文章,圖片默認還是遠程連結。這有兩個隱患:一是圖牀隨時可能失效,文章圖片變成一堆叉;二是 AI 無法訪問失效的外鏈,這些圖片對它來說等於不存在。
解決辦法只需要配置一次。
第一步:統一附件存儲路徑
打開設置 → 文件與連結 → 找到附件存儲路徑 → 設為當前文件夾下指定的子文件夾,子文件夾名稱設為 attachments。
第二步:綁定下載快捷鍵
設置 → 快捷鍵 → 搜索"下載" → 綁定快捷鍵 Ctrl+Shift+D。
之後每剪一篇文章,順手按一次 Ctrl+Shift+D,圖片就落到本地了。這個習慣一旦養成,知識庫裏的內容就真正屬於你,AI 也能完整讀取每一張圖。
圖譜視圖:讓知識庫的健康狀況一目瞭然
Obsidian 的 Graph View 是一張實時生成的關係地圖。每個 Wiki 頁面是一個節點,頁面之間凡是有雙向連結的地方,就會自動連上一條線。打開方式:點擊左側邊欄的圖譜圖標,或直接按 Ctrl+G。
這張圖結合 AI 有兩個具體用途:
1. 檢查孤島頁面:沒有任何入鏈的節點懸在圖譜邊緣,說明這個頁面還沒有被其他內容引用,讓 AI 去補上交叉連結。 2. 找到應該但還沒有建立的頁面:一個概念如果被多個頁面提及卻沒有自己的專頁,它會在圖譜裏以灰色幽靈節點的形式出現——這正是知識庫裏的空白,值得讓 AI 補上。
Dataview:給知識庫裝上自動報表
Dataview 是 Obsidian 的社區插件,核心能力是把 YAML frontmatter 當成數據庫字段來查詢,在頁面裏動態渲染出表格和列表。安裝路徑:設置 → 第三方插件 → 社區插件市場 → 搜索 "Dataview" → 安裝並啓用。
和 LLM Wiki 配合的方式是:讓 AI 在創建或更新每個頁面時,順帶寫入結構化的 frontmatter,例如:
type: source
title: "文章標題"
date: 2026-04-05
tags: [AI, knowledge-base]
source_count: 3有了這些元數據,隨便在哪個頁面寫一段 Dataview 查詢:
TABLE title, date, tags
FROM "wiki/sources"
SORT date DESC就能自動拉出按時間排序的素材清單。知識庫越大,這類查詢的價值就越高——人工整理費時費力的東西,Dataview 幾行代碼就搞定。
Marp:Wiki 內容直接變成可用的幻燈片
Marp 是基於 Markdown 的幻燈片標準,在 Obsidian 裏裝上 Marp Slides 插件就能本地預覽和導出。安裝路徑:設置 → 社區插件 → 搜索 "Marp Slides" → 安裝並啓用。
格式很簡單:文件開頭寫 marp: true,然後每頁之間用 --- 分隔。寫完在 Obsidian 裏直接預覽,導出支持 PDF、HTML、PPTX 三種格式。
實際場景:把某個主題的 Wiki 頁面餵給 AI,讓它直接輸出 Marp 格式的初稿,你只需要調整細節,幾分鐘就能出一份像樣的演示文稿。
Git:AI 改文件,你需要一道保險
安裝路徑:設置 → 第三方插件 → 社區插件市場 → 搜索 "git" → 安裝並啓用。
如果 Vault 還沒有 Git 倉庫,先初始化:
1. 打開終端,cd 到你的 Vault 目錄,執行 git init初始化倉庫。
2. 在 GitHub 上新建一個私有倉庫(知識庫是個人數據,不要設成公開)。
3. 把本地倉庫推上去:
git branch -M main
git remote add origin https://github.com/你的用戶名/knowledge-bases.git
git add .
git commit -m "init: 初始化知識庫"
git push -u origin main插件裝好後,把 Auto commit-and-sync interval 調成 10 分鐘,之後不用再管它。
為什麼 Git 是必選項?因為 AI 可以一次改動十幾個文件,一旦出錯,沒有版本歷史就很難回溯。提交記錄就是一張安全網,AI 的能力越強,這張網就越重要。
qmd:知識庫大了之後的搜索方案
頁面數量還少的時候,維護一個 index.md 作為目錄就夠用了,AI 靠它就能在知識庫裏找到路。
等到頁面積累到幾百個,檢索速度開始下降,這時候可以引入 qmd——一個純本地運行的 Markdown 全文搜索引擎。不用急着現在就裝,等真正感到慢了再說。
這套方法為什麼能長期運轉?
知識庫做不下去,通常不是因為沒有內容,而是因為維護太累:每加一條新知識,就要手動更新所有相關頁面的引用,檢查有沒有矛盾,補上缺失的交叉連結……頁面一多,人就撐不住了。
AI 在這件事上有結構性優勢:它不會因為重複勞動而厭倦,不會漏掉需要更新的頁面,而且可以在一次操作裏同時處理大量文件。把這部分工作交給它,維護成本就從"隨規模增長"變成了近乎固定。
你需要做的,是決定讀什麼、想清楚問什麼、判斷哪些值得記錄。整理、歸檔、串聯這些事,AI 來。
Obsidian Web Clipper + 圖片本地化 + Git + Claude,這四件套就夠搭出一個真正能用、能長大、能活下去的個人知識庫。
——END——
點點關注,一起學習~