[中文翻譯完整版] Agent Skills 創作最佳實踐
整理版優先睇
Agent Skills 創作關鍵:簡潔、結構化、測試優先,並與 Claude 協作迭代
呢篇文章係 Anthropic 官方「Agent Skills 創作最佳實踐」嘅中文翻譯整合版,作者加入咗自己嘅理解同判斷,幫你寫好 AI Agents 能夠有效發現同用嘅 Skills。文章背景係 Anthropic 將 Agent Skills 標準公開後,主流 AI Agents 都已支援,但點樣寫出真正好用嘅 Skills 仍然係一個挑戰。作者想解決嘅問題係:點樣創建簡潔、結構良好、經過實際測試嘅 Skills,而唔係冗長、混亂、假設過多嘅 Skills。整體結論係:Skills 創作要遵循「簡潔係關鍵」、「設置適當自由度」、「測試計劃用嘅所有模型」同埋「與 Claude 協作迭代開發」呢幾個核心原則。
文章詳細解釋咗 Skills 嘅核心原則:上下文窗口係公共資源,SKILL.md 要盡量精簡,每個 token 都要有價值;預設 Claude 已經好聰明,只加佢唔知嘅 context;自由度要因應任務嘅脆弱性調整,高風險操作俾精確指令,開放式任務俾大致方向;而且一定要用計劃用嘅所有模型測試,因為唔同模型需要嘅細節程度唔同。
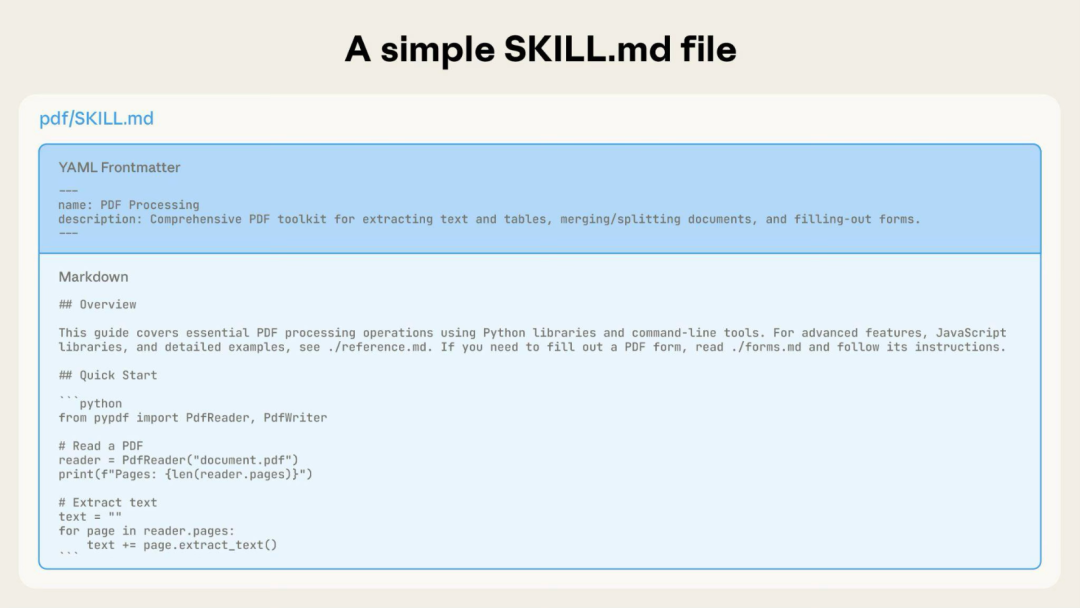
跟住文章講咗 Skills 嘅結構,包括 YAML 前言嘅 name 同 description 規範、命名建議用動名詞形式、描述要用第三人稱同包含使用時機,仲有漸進式披露模式——將主指令放喺 SKILL.md,詳細內容放喺獨立檔案,等 Claude 按需讀取。最後介紹工作流同反饋循環、…
- 簡潔係關鍵:SKILL.md 正文最好唔超過 500 行,因為 context window 係公共資源,每個 token 都要有價值。
- 自由度要配合任務脆弱性:高風險操作俾低自由度精確指令,開放式任務俾高自由度大致方向,避免混淆。
- 採用漸進式披露模式:將主指令放喺 SKILL.md,詳細內容放喺獨立檔案(如 FORMS.md、reference.md),Claude 按需讀取,節省 token。
- 測試所有計劃用嘅模型:Haiku、Sonnet、Opus 對細節需求唔同,要確保 Skill 喺各模型上都有效。
- 與 Claude 協作迭代開發:用一個 Claude 實例幫你設計同改進 Skill,再用另一個實例測試,根據觀察結果反覆優化。
結構示例
## 提取 PDF 文本使用 pdfplumber 進行文本提取:```pythonimport pdfplumberwith pdfplumber.open("file.pdf") as pdf: text = pdf.pages[0].extract_text()```核心原則:簡潔、自由度與模型測試
寫 Skills 嘅第一原則就係簡潔。上下文窗口係公共資源,你嘅 Skill 要同系統提示詞、對話歷史、其他 Skills 嘅元數據同你嘅實際請求爭位。所以 SKILL.md 入面每個 token 都要問自己:「Claude 真係需要呢個解釋嗎?」「我可以假設 Claude 知道呢個嗎?」默認假設係 Claude 已經好聰明,你只需要補充佢唔知嘅 context。
上下文窗口係公共資源
設置適當嘅自由度好重要。自由度要同任務嘅脆弱性同可變性匹配。高自由度適用於多種方法都得、決策取決於 context 嘅情況;中等自由度可以用偽代碼或帶參數嘅腳本;低自由度就用特定腳本,好少或冇參數,適用於操作脆弱、一致性至關重要嘅場景。
最後,一定要用你計劃用嘅所有模型測試 Skills。Claude Haiku 需要更多指導,Claude Opus 可能反而嫌你 over-explain。如果你打算俾多個模型用,就要力求指令適用於所有模型。
用所有模型測試
Skill 結構與命名規範
每個 Skill 嘅 SKILL.md 開頭要有 YAML 前言,包括 name 同 description。Name 最多 64 個字,只能用細階字母、數字同連字符,唔可以有 XML 標籤同保留詞。Description 最多 1024 個字,非空,都要用第三人稱寫,講清楚功能同使用時機。
Description 要用第三人稱
命名建議用動名詞形式,例如 processing-pdfs、analyzing-spreadsheets,咁樣可以清楚描述活動或能力。避免模糊嘅名好似 helper、utils,或者保留詞如 anthropic-helper。
動名詞形式命名
漸進式披露係減輕 context 負擔嘅關鍵模式。SKILL.md 只放概述同導航,詳細內容放喺獨立檔案,Claude 按需讀取。目錄結構例如:pdf/ 下面有 SKILL.md、FORMS.md、reference.md、examples.md 同 scripts/。記得引用要保持一層深度,避免嵌套,否則 Claude 可能會用 head -100 預覽而讀唔曬。
漸進式披露模式
引用只保持一層深度
工作流與反饋循環
對複雜任務,應該將佢哋拆成清晰嘅順序步驟,並提供 Claude 可以複製嘅檢核查清單。例如研究綜合工作流:步驟 1 讀取所有來源、步驟 2 識別關鍵主題、步驟 3 交叉驗證聲明、步驟 4 創建結構化摘要、步驟 5 驗證引用。呢啲清單幫 Claude 同你 track 進度。
提供可勾選嘅清單
反饋循環係常見模式:執行驗證器 → 修復錯誤 → 重複。例如文檔編輯流程:編輯 XML → 立即執行驗證腳本 → 如果失敗就修復再驗證 → 通過先繼續。呢種循環可以好早捕獲錯誤。
- 研究綜合工作流:先用清單 track 步驟,確保唔 skip 關鍵驗證。
- PDF 表單填寫工作流:分析表單 → 創建字段映射 → 驗證映射 → 填寫 → 驗證輸出。
- 文檔編輯流程:編輯 XML → 驗證 → 修復 → 重建 → 測試輸出。
評估與迭代:同 Claude 一齊開發
最好嘅 Skills 係由評估驅動嘅。先建立評估,而唔係寫一大段文檔。方法係:冇 Skill 之下用代表性任務測試 Claude,記錄失敗位,然後建立評估場景,測量 baseline,再寫最小指令去解決問題,最後迭代改進。
先建立評估,再寫文檔
同 Claude 協作開發好有效。用一個 Claude 實例(Claude A)幫你設計同改善 Skill,用另一個(Claude B)喺真實任務測試。呢個方法之所以 work,係因為 Claude 模型本身既理解點寫有效 agent 指令,又理解 agents 需要咩資訊。你可以叫 Claude A 直接「創建一個 Skill」,佢會自動生成結構良好嘅 SKILL.md。
用 Claude A 設計,Claude B 測試
迭代嘅時候要觀察 Claude 點導航 Skills:佢係咪跟預期順序讀檔案?有冇漏咗重要引用?有冇 over-rely 某部分?根據觀察去調整結構同描述。特別係 metadata 嘅 name 同 description,因為 Claude 用呢啲決定係咪觸發 Skill。
觀察 Claude 點導航 Skills
另外,收集團隊反饋、避免時效性信息、用一致術語、提供模板同示例,都係實用技巧。
常見反模式同實用貼士
有啲反模式要避免:例如 Windows 風格路徑(要用正斜槓)、提供太多選項令人困惑(應該俾一個默認方法,加逃生通道)、假設工具已安裝(要明確列出依賴)、用魔術數字而唔解釋點解係呢個值。
避免 Windows 風格路徑
避免提供過多選項
重要嘅係,腳本要「解決問題,唔好推卸」。處理錯誤條件,例如 file not found 時建立預設值,而唔係就咁 fail。中間輸出要可驗證,例如用「計劃-驗證-執行」模式,創建 changes.json 然後用腳本驗證先應用。
打包依賴要喺 SKILL.md 列出所需包,並確保喺執行環境可用。claude.ai 可以裝 npm 同 PyPI 包,但 Claude API 就冇網絡同安裝權限。最後,記住用有效 Skills 清單檢查先分享:描述具體、SKILL.md 喺 500 行內、冇時效性信息、術語一致、腳本有文檔、測試過所有模型。
有效 Skills 清單
腳本要有清晰文檔
Agent Skills 創作最佳實踐
Anthropic 將 Agent Skills 標準公開之後,主流 AI Agents 都已經支援,好的 Skills 應該係簡潔、結構良好而且經過實際使用測試嘅。我哋今日返去 Anthropic 官方嘅 Skills 創作最佳實踐,結合自己嘅理解同判斷,一齊寫好包括 Claude 在內嘅 AI Agents 能夠有效發現同使用嘅 Skills。
如果想了解 Skills 嘅工作原理嘅概念背景,請睇 Skills 概述文檔:/docs/en/agents-and-tools/agent-skills/overview
核心原則
簡潔係關鍵
上下文窗口係一種公共資源。你嘅 Skill 同 Claude 需要了解嘅所有其他內容共享上下文窗口,包括:
- 系統提示詞
- 對話歷史
- 其他 Skills 嘅元數據
- 你嘅實際請求
唔係 Skill 入面每個 token 都會即刻產生成本。喺啟動時,得所有 Skills 嘅元數據(名稱同描述)會預先加載。Claude 得喺 Skill 變得相關嘅時候先會讀取 SKILL.md,而且得喺需要嘅時候先會讀取額外文件。不過,喺 SKILL.md 入面保持簡潔依然好重要:一旦 Claude 加載咗佢,每個 token 都會同對話歷史同其他上下文競爭。
默認假設: Claude 已經好聰明
淨係加 Claude 仲未了解嘅上下文。對每條信息提出質疑:
- 「Claude 真係需要呢個解釋咩?」
- 「我可唔可以假設 Claude 知道呢個?」
- 「呢段說話值唔值得佢嘅 token 成本?」
好嘅示例:簡潔(大約 50 tokens):
## 提取 PDF 文本
使用 pdfplumber 進行文本提取:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
唔好嘅示例:太冗長(大約 150 tokens):
## 提取 PDF 文本
PDF(Portable Document Format)文件是一種常見的文件格式,包含文本、圖像和其他內容。要從 PDF 中提取文本,你需要使用一個庫。有許多可用於 PDF 處理的庫,但推薦使用 pdfplumber,因為它易於使用且能處理大多數情況。首先,你需要使用 pip 安裝它。然後你可以使用下面的代碼...
簡潔版本假設 Claude 知道咩係 PDF 同埋程式庫點樣運作。
設定適當嘅自由度
將具體程度同任務嘅脆弱性同可變性匹配。
高自由度(基於文字嘅指令):
適用於:
- 多種方法都有效
- 決策取決於上下文
- 啟發式方法指導方法
示例:
## 代碼審查流程
1. 分析代碼結構和組織
2. 檢查潛在的 bug 或邊緣情況
3. 建議改進可讀性和可維護性
4. 驗證是否符合項目規範
中等自由度(偽代碼或帶參數嘅腳本):
適用於:
- 存在首選模式
- 允許一啲變化
- 配置影響行為
示例:
## 生成報告
根據需要自定義使用此模板:
```python
def generate_report(data, format="markdown", include_charts=True):
# 處理數據
# 以指定格式生成輸出
# 可選地包含可視化
```
低自由度(特定腳本,好少或者冇參數):
適用於:
- 操作脆弱而且容易出錯
- 一致性至關重要
- 必須跟從特定序列
示例:
## 數據庫遷移
精確運行此腳本:
```bash
python scripts/migrate.py --verify --backup
```
不要修改命令或添加額外的標誌。
類比: 將 Claude 想像成探索路徑嘅機械人:
- 兩邊都係懸崖嘅窄橋: 得一種安全嘅前進方式。提供具體嘅護欄同精確指令(低自由度)。示例:必須按精確順序運行嘅數據庫遷移。
- 冇危險嘅開放區域: 好多路徑都通去成功。畀出大致方向,相信 Claude 可以揾到最佳路線(高自由度)。示例:代碼審查,上下文決定最佳方法。
測試你計劃使用嘅所有模型
Skills 作為模型嘅補充,所以有效性取決於底層模型。用你計劃使用嘅所有模型測試你嘅 Skill。
按模型劃分嘅測試考慮因素:
- Claude Haiku(快速、經濟):Skill 係咪提供咗足夠嘅指導?
- Claude Sonnet(平衡):Skill 係咪清晰同高效?
- Claude Opus(強大嘅推理):Skill 係咪避免咗過度解釋?
對 Opus 有效嘅方法可能要為 Haiku 提供更多細節。如果你計劃喺多個模型入面用你嘅 Skill,就要力求適用於所有模型嘅指令。
Skill 結構
注意:
YAML 前言: SKILL.md 前言需要兩個字段:
name:
- 最多 64 個字符
- 淨可以包含小寫字母、數字同連字符
- 唔可以包含 XML 標籤
- 唔可以包含保留詞:「anthropic」、「claude」
description:
- 必須非空
- 最多 1024 個字符
- 唔可以包含 XML 標籤
- 應該描述 Skill 嘅功能同使用時機
有關完整嘅 Skill 結構詳情,請睇 Skills 概述文檔入面嘅 Skill Structure 部分:/docs/en/agents-and-tools/agent-skills/overview#skill-structure
命名規範
用一致嘅命名模式,令 Skills 更容易引用同討論。考慮對技能名稱使用 動名詞形式(動詞 + -ing),因為呢個可以清楚描述技能提供嘅活動或能力。
請記住,name 字段淨可以用小寫字母、數字同連字符。
好嘅命名示例(動名詞形式):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
可接受嘅替代形式:
- 名詞短語:
pdf-processing、spreadsheet-analysis - 動作導向:
process-pdfs、analyze-spreadsheets
避免:
- 模糊嘅名稱:
helper、utils、tools - 太通用嘅:
documents、data、files - 保留詞:
anthropic-helper、claude-tools - 技能集合入面唔一致嘅模式
一致嘅命名令到:
- 喺文檔同對話入面引用技能更容易
- 一眼就睇得出技能嘅功能
- 組織同搜尋多個技能更方便
- 保持專業、連貫嘅技能庫
編寫有效嘅描述
description 字段支援技能發現,應該包含技能嘅功能同使用時機。
警告:
一定要用第三人稱寫。描述會被注入到系統提示詞入面,唔一致嘅人稱視角會導致發現問題。
- 好的: 「處理 Excel 檔案並生成報告」
- 避免: 「我可以幫你處理 Excel 檔案」
- 避免: 「你可以用呢個功能處理 Excel 檔案」
具體同埋包含關鍵術語。包含技能嘅功能,同埋用佢嘅具體觸發條件/上下文。
每個技能得一個描述字段。描述對技能選擇好重要:Claude 用佢喺可能超過 100 個可用技能入面揀啱嘅技能。你嘅描述必須提供足夠嘅細節,等 Claude 知道幾時選擇呢個技能,而 SKILL.md 嘅其餘部分就提供實現細節。
有效示例:
PDF 處理技能:
description: 從 PDF 文件提取文本和表格,填寫表單,合併文檔。在處理 PDF 文件或用戶提及 PDF、表單或文檔提取時使用。
Excel 分析技能:
description: 分析 Excel 電子表格,創建數據透視表,生成圖表。在分析 Excel 文件、電子表格、表格數據或 .xlsx 文件時使用。
Git 提交助手技能:
description: 通過分析 git diff 生成描述性的提交消息。在用戶請求幫助編寫提交消息或查看暫存更改時使用。
避免模糊描述,例如:
description: 幫助處理文檔
description: 處理數據
description: 對文件做一些事情
漸進式披露模式
SKILL.md 作為概述,按需要指向詳細材料,就好似入職指南嘅目錄一樣。有關漸進式披露點樣運作嘅解釋,請睇概述入面嘅 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
實用指導:
- 為咗最佳性能,保持 SKILL.md 正文喺 500 行以內
- 當接近呢個限制時,將內容拆分為單獨嘅文件
- 用以下模式有效組織指令、代碼同資源
視覺概覽:由簡單到複雜
基本嘅技能從淨包含元數據同指令嘅 SKILL.md 文件開始:
隨住技能增長,你可以捆綁淨喺需要時先加載嘅額外內容:

完整嘅技能目錄結構可能係咁:
pdf/
├── SKILL.md # 主指令(觸發時加載)
├── FORMS.md # 表單填寫指南(按需加載)
├── reference.md # API 參考(按需加載)
├── examples.md # 使用示例(按需加載)
└── scripts/
├── analyze_form.py # 實用腳本(執行,不加載)
├── fill_form.py # 表單填寫腳本
└── validate.py # 驗證腳本
Claude 淨喺需要嘅時候先加載 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
模式 1:帶參考嘅高級指南
---
name: pdf-processing
description: 從 PDF 文件提取文本和表格,填寫表單,合併文檔。在處理 PDF 文件或用戶提及 PDF、表單或文檔提取時使用。
---
# PDF 處理
## 快速開始
使用 pdfplumber 提取文本:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高級功能
**表單填寫**:有關完整指南,請參閲 FORMS.md
**API 參考**:有關所有方法,請參閲 REFERENCE.md
**示例**:有關常見模式,請參閲 EXAMPLES.md
模式 2:按領域組織
對於有多個領域嘅技能,按領域組織內容,避免加載唔相關嘅上下文。當用戶問銷售指標時,Claude 只需要銷售相關嘅 schema,而唔係財務或市場數據。咁樣可以令 token 用量低,上下文集中。
bigquery-skill/
├── SKILL.md (概述和導航)
└── reference/
├── finance.md (收入、賬單指標)
├── sales.md (機會、管道)
├── product.md (API 使用、功能)
└── marketing.md (營銷活動、歸因)
# BigQuery 數據分析
## 可用數據集
**財務**:收入、ARR、賬單 → 請參閲 reference/finance.md
**銷售**:機會、管道、賬户 → 請參閲 reference/sales.md
**產品**:API 使用、功能、採用 → 請參閲 reference/product.md
**營銷**:營銷活動、歸因、郵件 → 請參閲 reference/marketing.md
## 快速搜索
使用 grep 查找特定指標:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```
模式 3:條件詳情
顯示基本內容,連結到高級內容:
# DOCX 處理
## 創建文檔
使用 docx-js 創建新文檔。請參閲 DOCX-JS.md。
## 編輯文檔
對於簡單編輯,直接修改 XML。
**對於修訂跟蹤**:請參閲 REDLINING.md
**對於 OOXML 詳情**:請參閲 OOXML.md
Claude 淨喺用戶需要呢啲功能嘅時候先讀取 REDLINING.md 或 OOXML.md。
避免深層嵌套引用
當從其他引用嘅文件引用文件時,Claude 可能會部分讀取佢哋。遇到嵌套引用時,Claude 可能會用 head -100 呢啲命令預覽內容,而唔係讀取成個檔案,導致信息唔完整。
保持引用同 SKILL.md 只得一層深度。所有參考文件都應該直接由 SKILL.md 連結,確保 Claude 喺需要嘅時候讀取完整檔案。
唔好嘅示例:太深:
# SKILL.md
請參閲 advanced.md...
# advanced.md
請參閲 details.md...
# details.md
這是實際信息...
好嘅示例:一層深度:
# SKILL.md
**基本用法**:[SKILL.md 中的指令]
**高級功能**:請參閲 advanced.md
**API 參考**:請參閲 reference.md
**示例**:請參閲 examples.md
為較長嘅參考文件構建目錄
對於超過 100 行嘅參考文件,喺頂部包含目錄。咁樣確保 Claude 即使喺用部分讀取預覽時都可以睇到可用信息嘅完整範圍。
示例:
# API 參考
## 目錄
- 認證和設置
- 核心方法(創建、讀取、更新、刪除)
- 高級功能(批處理、webhooks)
- 錯誤處理模式
- 代碼示例
## 認證和設置
...
## 核心方法
...
然後 Claude 可以按需要讀取完整檔案或者跳到特定部分。
有關呢個基於檔案嘅架構點樣實現漸進式披露嘅詳細信息,請睇下面高級部分入面嘅 Runtime environment 部分。
工作流同反饋循環
對複雜任務使用工作流
將複雜操作分解為清晰嘅順序步驟。對於特別複雜嘅工作流,提供 Claude 可以複製到佢嘅回應入面並喺進行緊嘅時候打勾嘅清單。
示例 1:研究綜合工作流(適用於冇代碼嘅技能):
## 研究綜合工作流
複製此清單並跟蹤你的進度:
```
研究進度:
- [ ] 步驟 1:閲讀所有源文檔
- [ ] 步驟 2:識別關鍵主題
- [ ] 步驟 3:交叉驗證聲明
- [ ] 步驟 4:創建結構化摘要
- [ ] 步驟 5:驗證引用
```
**步驟 1:閲讀所有源文檔**
查看 `sources/` 目錄中的每個文檔。記錄主要論點和支持證據。
**步驟 2:識別關鍵主題**
查找跨源的模式。哪些主題反覆出現?來源在何處達成一致或分歧?
**步驟 3:交叉驗證聲明**
對於每個主要聲明,驗證它是否出現在源材料中。記錄哪個來源支持每個觀點。
**步驟 4:創建結構化摘要**
按主題組織發現。包括:
- 主要聲明
- 來自來源的支持證據
- 衝突觀點(如果有)
**步驟 5:驗證引用**
檢查每個聲明是否引用了正確的源文檔。如果引用不完整,返回步驟 3。
呢個示例展示咗工作流可以點樣應用喺唔需要代碼嘅分析任務。清單模式適用於任何複雜嘅多步驟過程。
示例 2:PDF 表單填寫工作流(適用於有代碼嘅技能):
## PDF 表單填寫工作流
複製此清單並在完成項目時勾選:
```
任務進度:
- [ ] 步驟 1:分析表單(運行 analyze_form.py)
- [ ] 步驟 2:創建字段映射(編輯 fields.json)
- [ ] 步驟 3:驗證映射(運行 validate_fields.py)
- [ ] 步驟 4:填寫表單(運行 fill_form.py)
- [ ] 步驟 5:驗證輸出(運行 verify_output.py)
```
**步驟 1:分析表單**
運行:`python scripts/analyze_form.py input.pdf`
這提取表單字段及其位置,保存到 `fields.json`。
**步驟 2:創建字段映射**
編輯 `fields.json` 為每個字段添加值。
**步驟 3:驗證映射**
運行:`python scripts/validate_fields.py fields.json`
在繼續之前修復任何驗證錯誤。
**步驟 4:填寫表單**
運行:`python scripts/fill_form.py input.pdf fields.json output.pdf`
**步驟 5:驗證輸出**
運行:`python scripts/verify_output.py output.pdf`
如果驗證失敗,返回步驟 2。
清晰嘅步驟防止 Claude 跳過關鍵驗證。清單幫 Claude 同你追蹤多步驟工作流嘅進度。
實施反饋循環
常見模式: 執行驗證器 → 修復錯誤 → 重複
呢種模式極大咁提高咗輸出質量。
示例 1:風格指南合規性(適用於冇代碼嘅技能):
## 內容審查流程
1. 按照 STYLE_GUIDE.md 中的指南起草你的內容
2. 對照清單審查:
- 檢查術語一致性
- 驗證示例是否符合標準格式
- 確認所有必需部分都存在
3. 如果發現問題:
- 用具體章節引用記錄每個問題
- 修改內容
- 再次審查清單
4. 只有在滿足所有要求時才繼續
5. 最終確定並保存文檔
呢個展示咗用參考文檔而唔係腳本嘅驗證循環模式。「驗證器」係 STYLE_GUIDE.md,Claude 通過讀取同比較嚟執行檢查。
示例 2:文檔編輯流程(適用於有代碼嘅技能):
## 文檔編輯流程
1. 對 `word/document.xml` 進行編輯
2. **立即驗證**:`python ooxml/scripts/validate.py unpacked_dir/`
3. 如果驗證失敗:
- 仔細閲讀錯誤消息
- 修復 XML 中的問題
- 再次運行驗證
4. **只有在驗證通過時才繼續**
5. 重建:`python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. 測試輸出文檔
驗證循環盡早捕獲錯誤。
內容指南
避免時效性信息
唔好包含會過時嘅信息:
唔好嘅示例:時效性(會變成錯誤):
如果你在 2025 年 8 月之前執行此操作,請使用舊 API。
2025 年 8 月之後,使用新 API。
好嘅示例(用「舊模式」部分):
## 當前方法
使用 v2 API 端點:`api.example.com/v2/messages`
## 舊模式
<details>
<summary>遺留 v1 API(已於 2025-08 棄用)</summary>
v1 API 使用:`api.example.com/v1/messages`
此端點不再受支持。
</details>
舊模式部分提供歷史背景,而唔會令主要內容混亂。
用一致嘅術語
揀一個術語並喺成個技能入面用:
好嘅 - 一致:
- 成日用「API endpoint」
- 成日用「field」
- 成日用「extract」
唔好嘅 - 唔一致:
- 混用「API endpoint」、「URL」、「API route」、「path」
- 混用「field」、「box」、「element」、「control」
- 混用「extract」、「pull」、「get」、「retrieve」
一致性幫助 Claude 理解同跟從指令。
常見模式
模板模式
為輸出格式提供模板。將嚴格程度同需求匹配。
對於嚴格要求(例如 API 回應或數據格式):
## 報告結構
始終使用此確切的模板結構:
```markdown
# [分析標題]
## 執行摘要
[關鍵發現的一段概述]
## 關鍵發現
- 帶有支持數據的發現 1
- 帶有支持數據的發現 2
- 帶有支持數據的發現 3
## 建議
1. 具體的可操作建議
2. 具體的可操作建議
```
對於靈活指導(當適應性有用嘅時候):
## 報告結構
這是一個合理的默認格式,但根據你的分析使用最佳判斷:
```markdown
# [分析標題]
## 執行摘要
[概述]
## 關鍵發現
[根據你發現的內容調整部分]
## 建議
[針對具體情境定製]
```
根據具體分析類型調整部分。
示例模式
對於輸出質量取決於睇示例嘅技能,提供輸入/輸出對,就好似常規提示咁:
## 提交消息格式
按照以下示例生成提交消息:
**示例 1:**
輸入:添加了使用 JWT token 的用戶認證
輸出:
```
feat(auth): 實現基於 JWT 的認證
添加登錄端點和 token 驗證中間件
```
**示例 2:**
輸入:修復了報告中日期顯示錯誤的 bug
輸出:
```
fix(reports): 更正時區轉換中的日期格式
在報告生成中始終使用 UTC 時間戳
```
**示例 3:**
輸入:更新了依賴項並重構了錯誤處理
輸出:
```
chore: 更新依賴項並重構錯誤處理
- 將 lodash 升級到 4.17.21
- 在整個端點中標準化錯誤響應格式
```
遵循此風格:type(scope): 簡要描述,然後詳細說明。
示例幫 Claude 比起齋靠描述更清晰咁理解所需嘅風格同詳細程度。
條件工作流模式
引導 Claude 通過決策點:
## 文檔修改工作流
1. 確定修改類型:
**創建新內容?** → 遵循下面的"創建工作流"
**編輯現有內容?** → 遵循下面的"編輯工作流"
2. 創建工作流:
- 使用 docx-js 庫
- 從頭構建文檔
- 導出為 .docx 格式
3. 編輯工作流:
- 解壓現有文檔
- 直接修改 XML
- 每次更改後驗證
- 完成後重新打包
提示:
如果工作流變得龐大或複雜,包含好多步驟,考慮將佢哋推入單獨嘅文件,並話畀 Claude 根據手頭嘅任務讀取適當嘅文件。
評估同迭代
首先構建評估
喺編寫大量文檔之前創建評估。 呢個確保你嘅技能解決實際問題,而唔係記錄想像中嘅問題。
評估驅動開發:
- 識別差距: 喺冇技能嘅情況下對代表性任務執行 Claude。記錄具體失敗或缺失嘅上下文
- 創建評估: 構建三個測試呢啲差距嘅場景
- 建立基線: 量度 Claude 喺冇技能時嘅表現
- 編寫最小指令: 創作啱啱好嘅內容嚟解決問題並通過評估
- 迭代: 執行評估,同基線比較,並改進
呢種方法確保你解決實際問題,而唔係預期可能永遠唔會實現嘅需求。
評估結構:
{
"skills":["pdf-processing"],
"query":"從此 PDF 文件中提取所有文本並保存到 output.txt",
"files":["test-files/document.pdf"],
"expected_behavior":[
"使用適當的 PDF 處理庫或命令行工具成功讀取 PDF 文件",
"從文檔的所有頁面提取文本內容,不遺漏任何頁面",
"以清晰、可讀的格式將提取的文本保存到名為 output.txt 的文件"
]
}
注意:
呢個示例演示咗帶有簡單測試標準嘅、數據驅動嘅評估。目前冇內置嘅方式嚟執行呢啲評估。用戶可以創建自己嘅評估系統。評估係量度技能有效性嘅真理之源。
同 Claude 一齊迭代開發技能
最有效嘅技能開發過程涉及 Claude 本身。同 Claude 嘅一個實例(「Claude A」)一齊創作供其他實例(「Claude B」)用嘅技能。Claude A 幫你設計同改進指令,而 Claude B 喺真實任務入面測試佢哋。呢個有效係因為 Claude 模型既理解點樣編寫有效嘅 agent 指令,亦理解 agents 需要咩信息。
創建新技能:
喺冇技能嘅情況下完成任務: 同 Claude A 一齊用正常提示完成問題。喺工作過程中,你會自然咁提供上下文、解釋偏好同分享程序性知識。留意你反複提供嘅信息。
識別可重用模式: 完成任務之後,識別你提供嘅對類似未來任務有用嘅上下文。
示例: 如果你完成咗 BigQuery 分析,你可能提供咗表名、字段定義、過濾規則(例如「成日排除測試賬户」)同常見查詢模式。
叫 Claude A 創建技能: 「創建一個技能,捕捉我哋啱先用嘅 BigQuery 分析模式。包含表 schema、命名約定同關於過濾測試賬户嘅規則。」
提示:
Claude 模型原生理解技能格式同結構。你唔需要特別嘅系統提示或「編寫技能」嘅技能嚟等 Claude 幫你創建技能。淨係叫 Claude 創建一個技能,佢就會生成有適當前言同正文內容嘅、結構良好嘅 SKILL.md 內容。
審查簡潔性: 檢查 Claude A 有冇加冇必要嘅解釋。問:「刪除關於勝率含義嘅解釋 — Claude 已經知道嗰個。」
改進信息架構: 叫 Claude A 更有效咁組織內容。例如:「將呢個組織成將表 schema 放喺單獨嘅參考文件入面。我哋以後可能會加更多表。」
喺類似任務上測試: 喺相關用例上同 Claude B(加載咗技能嘅新實例)一齊用技能。觀察 Claude B 係咪揾到正確嘅信息、正確應用規則,並成功處理任務。
根據觀察迭代: 如果 Claude B 遇到困難或漏咗某啲內容,帶住具體情況返去 Claude A:「當 Claude 用呢個技能時,佢唔記得按 Q4 日期過濾。我哋應該加個關於日期過濾模式嘅部分嗎?」
迭代現有技能:
相同嘅分層模式喺改進技能時繼續。你喺以下之間交替:
- 同 Claude A 一齊(幫你改進技能嘅專家)
- 同 Claude B 一齊測試(用技能執行實際工作嘅 agent)
- 觀察 Claude B 嘅行為並將洞察帶返 Claude A
喺實際工作流入面用技能: 畀 Claude B(加載咗技能)實際任務,而唔係測試場景
觀察 Claude B 嘅行為: 留意佢喺邊度遇到困難、成功或做出意外選擇
觀察示例: 「當我叫 Claude B 提供區域銷售報告時,佢編寫咗查詢但唔記得過濾測試賬户,即使技能提過呢條規則。」
返去 Claude A 進行改進: 分享當前嘅 SKILL.md 並描述你觀察到嘅嘢。問:「我留意到 Claude B 喺我叫區域報告時唔記得過濾測試賬户。技能提過過濾,但可能唔夠突出?」
審查 Claude A 嘅建議: Claude A 可能會建議重新組織令規則更突出,用更強嘅語言例如「MUST filter」而唔係「always filter」,或者重構工作流部分。
應用並測試更改: 用 Claude A 嘅改進更新技能,然後喺 Claude B 上對類似請求再次測試
根據使用情況重複: 當你遇到新場景時繼續呢個觀察-改進-測試循環。每次迭代都基於真實 agent 行為改進技能,而唔係假設。
收集團隊反饋:
- 同隊友分享技能並觀察佢哋嘅使用
- 問:技能係咪喺預期時激活?指令清唔清晰?缺咗啲咩?
- 納入反饋嚟解決你自己使用模式入面嘅盲點
點解呢種方法有效: Claude A 理解 agent 需求,你提供領域專業知識,Claude B 通過實際使用揭示差距,迭代改進基於觀察到嘅行為而唔係假設嚟改進技能。
觀察 Claude 點樣導航技能
喺迭代技能時,留意 Claude 喺實踐入面實際點樣用佢哋。觀察:
- 意外嘅探索路徑: Claude 係咪以你冇預料到嘅順序讀取文件?呢個可能表示你嘅結構唔似你想像中咁直觀
- 遺漏嘅連接: Claude 係咪冇跟從對重要文件嘅引用?你嘅連結可能需要更明確或更突出
- 過度依賴某啲部分: 如果 Claude 反複讀取同一個文件,考慮嗰個內容係咪應該放喺主 SKILL.md 入面
- 被忽略嘅內容: 如果 Claude 從唔訪問捆綁文件,佢可能冇必要或者喺主指令入面信號唔夠
基於呢啲觀察而唔係假設嚟迭代。技能元數據入面嘅 'name' 同 'description' 特別關鍵。Claude 喺決定係咪回應當前任務觸發技能時會用佢哋。確保佢哋清楚描述技能嘅功能同使用時機。
應避免嘅反模式
避免 Windows 風格路徑
成日用正斜槓作為檔案路徑,就算喺 Windows 上都係:
- ✓ 好的:
scripts/helper.py、reference/guide.md - ✗ 避免:
scripts\helper.py、reference\guide.md
Unix 風格路徑適用於所有平台,而 Windows 風格路徑喺 Unix 系統上會導致錯誤。
避免提供太多選項
除非必要,唔好呈現多種方法:
**不好的示例:太多選擇**(令人困惑):
"你可以使用 pypdf、或 pdfplumber、或 PyMuPDF、或 pdf2image、或..."
**好的示例:提供默認值**(帶有逃生通道):
"使用 pdfplumber 進行文本提取:
```python
import pdfplumber
```
對於需要 OCR 的掃描 PDF,改用 pdf2image 和 pytesseract。"
高級:帶有可執行代碼嘅技能
以下部分專注於包含可執行腳本嘅技能。如果你嘅技能淨係用 markdown 指令,請跳到有效技能嘅清單部分。
解決問題,唔好推卸
喺為技能編寫腳本時,處理錯誤條件,而唔係推畀 Claude。
好嘅示例:顯式處理錯誤:
def process_file(path):
"""處理文件,如果不存在則創建它。"""
try:
withopen(path) as f:
return f.read()
except FileNotFoundError:
# 使用默認內容創建文件而非失敗
print(f"未找到文件 {path},創建默認值")
withopen(path, "w") as f:
f.write("")
return""
except PermissionError:
# 提供替代方案而非失敗
print(f"無法訪問 {path},使用默認值")
return""
唔好嘅示例:推畀 Claude:
def process_file(path):
# 只是失敗,讓 Claude 自己解決
return open(path).read()
配置參數都應該 justify 同記錄,以避免「巫毒常數」(Ousterhout 定律)。如果你唔知正確嘅值,Claude 點樣確定佢?
好嘅示例:自文檔化:
# HTTP 請求通常在 30 秒內完成
# 更長的超時時間用於應對慢速連接
REQUEST_TIMEOUT = 30
# 三次重試平衡可靠性與速度
# 大多數間歇性故障在第二次重試時解決
MAX_RETRIES = 3
唔好嘅示例:魔術數字:
TIMEOUT = 47 # 為什麼是 47?
RETRIES = 5 # 為什麼是 5?
提供實用腳本
即使 Claude 可以編寫腳本,預製腳本都有優勢:
實用腳本嘅好處:
- 比起生成嘅代碼更可靠
- 節省 tokens(唔需要在上下文中包含代碼)
- 節省時間(唔需要代碼生成)
- 確保跨使用嘅一致性

上圖展示咗可執行腳本點樣同指令文件一齊運作。指令文件(forms.md)引用腳本,Claude 可以喺唔需要將內容加載到上下文嘅情況下執行佢。
重要區別: 喺指令入面明確 Claude 應該:
- 執行腳本(最常見):「執行
analyze_form.py提取字段」 - 將佢作為參考閲讀(用於複雜邏輯):「睇
analyze_form.py瞭解字段提取算法」
對於大部分實用腳本,執行係首選,因為更可靠、更高效。有關腳本執行點樣運作嘅詳細信息,請睇下面嘅 Runtime environment 部分。
示例:
## 實用腳本
**analyze_form.py**:從 PDF 提取所有表單字段
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
輸出格式:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**:檢查重疊的邊界框
```bash
python scripts/validate_boxes.py fields.json
# 返回:"OK" 或列出衝突
```
**fill_form.py**:將字段值應用到 PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```
使用視覺分析
當輸入可以渲染為圖像時,等 Claude 分析佢哋:
## 表單佈局分析
1. 將 PDF 轉換為圖像:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. 分析每頁圖像以識別表單字段
3. Claude 可以直觀地看到字段位置和類型
注意:
喺呢個示例入面,你需要編寫 pdf_to_images.py 腳本。
Claude 嘅視覺能力幫手理解佈局同結構。
創建可驗證嘅中間輸出
當 Claude 執行複雜嘅、開放式嘅任務時,佢可能會出錯。「計劃-驗證-執行」模式通過喺等 Claude 首先以結構化格式創建計劃,然後喺執行前用腳本驗證個計劃,盡早捕獲錯誤。
示例: 想像一下叫 Claude 根據電子表格更新 PDF 入面 50 個表單字段。冇驗證嘅情況下,Claude 可能會引用唔存在嘅字段、創建衝突值、遺漏必填字段或錯誤應用更新。
解決方案: 用上面顯示嘅工作流模式(PDF 表單填寫),但加返喺應用更改之前驗證嘅 changes.json 中間文件。工作流變成:分析 → 創建計劃文件 → 驗證計劃 → 執行 → 驗證。
點解呢種模式有效:
- 盡早捕獲錯誤: 驗證喺應用更改之前發現問題
- 機器可驗證: 腳本提供客觀驗證
- 可逆嘅計劃: Claude 可以喺唔接觸原件嘅情況下迭代計劃
- 清晰嘅調試: 錯誤消息指向具體問題
幾時用: 批處理操作、破壞性更改、複雜驗證規則、高風險操作。
實施技巧: 令驗證腳本有詳細嘅特定錯誤消息,例如「未找到字段 'signature_date'。可用字段:customer_name、order_total、signature_date_signed」嚟幫 Claude 修復問題。
打包依賴
技能喺具有平台特定限制嘅代碼執行環境入面運行:
- claude.ai: 可以從 npm 同 PyPI 安裝套件,並從 GitHub 倉庫拉取
- Claude API: 冇網絡訪問權限同運行時套件安裝
喺 SKILL.md 入面列出所需嘅套件,並驗證佢哋喺代碼執行工具文檔入面可用:/docs/en/agents-and-tools/tool-use/code-execution-tool
運行時環境
技能喺具有檔案系統訪問權限、bash 命令同代碼執行能力嘅代碼執行環境入面運行。有關呢個架構嘅概念性解釋,請睇概述入面嘅 The Skills architecture 部分:/docs/en/agents-and-tools/agent-skills/overview#the-skills-architecture
呢個點樣影響你嘅創作:
Claude 點樣訪問技能:
- 預加載元數據: 喺啟動時,所有技能嘅 YAML 前言入面嘅名稱同描述被加載到系統提示詞入面
- 按需讀取文件: Claude 用 bash Read 工具喺需要時從檔案系統訪問 SKILL.md 同其他文件
- 高效執行腳本: 可以通過 bash 執行實用腳本,而唔需要將佢嘅完整內容加載到上下文入面。得腳本嘅輸出會消耗 tokens
- 大檔案冇上下文懲罰: 參考文件、數據或文檔喺實際讀取之前唔會消耗上下文 tokens
- 檔案路徑好重要: Claude 好似檔案系統咁導航你嘅技能目錄。用正斜槓(
reference/guide.md),而唔係反斜槓 - 檔名應該有描述性: 用表明內容嘅名稱:
form_validation_rules.md,而非doc2.md - 為發現組織目錄: 按領域或功能組織目錄結構
- 好的:
reference/finance.md、reference/sales.md - 唔好嘅:
docs/file1.md、docs/file2.md - 捆綁全面嘅資源: 包含完整嘅 API 文檔、大量示例、大型數據集;訪問之前冇上下文懲罰
- 對確定性操作首選腳本: 編寫
validate_form.py而唔係等 Claude 生成驗證代碼 - 明確執行意圖:
- "運行
analyze_form.py提取字段」(執行) - "查看
analyze_form.py瞭解提取算法」(作為參考閲讀) - 測試檔案訪問模式: 通過用真實請求測試,驗證 Claude 可以導航你嘅目錄結構
示例:
bigquery-skill/
├── SKILL.md (概述,指向參考文件)
└── reference/
├── finance.md (收入指標)
├── sales.md (管道數據)
└── product.md (使用分析)
當用戶問收入時,Claude 讀取 SKILL.md,見到對 reference/finance.md 嘅引用,並調用 bash 淨係讀取嗰個檔案。sales.md 同 product.md 檔案保留喺檔案系統上,喺需要之前消耗零上下文 tokens。呢個基於檔案嘅模型實現咗漸進式披露。Claude 可以導航並選擇性加載每個任務所需嘅確切內容。
有關技術架構嘅完整詳情,請睇 Skills 概述入面嘅 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
MCP 工具引用
如果你嘅技能用 MCP(Model Context Protocol)工具,成日用完全限定嘅工具名稱以避免「tool not found」錯誤。
格式:ServerName:tool_name
示例:
使用 BigQuery:bigquery_schema 工具檢索表 schema。
使用 GitHub:create_issue 工具創建問題。
其中:
BigQuery和GitHub係 MCP 伺服器名稱bigquery_schema和create_issue係呢啲伺服器入面嘅工具名稱
冇伺服器前綴,Claude 可能定位唔到工具,尤其係當多個 MCP 伺服器可用時。
避免假設工具已安裝
唔好假設套件可用:
**不好的示例:假設安裝**:
"使用 pdf 庫處理文件。"
**好的示例:明確依賴**:
"安裝所需包:`pip install pypdf`
然後使用它:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"
技術說明
YAML 前言要求
SKILL.md 前言需要帶有特定驗證規則嘅 name 和 description 字段:
name:最多 64 個字符,淨小寫字母/數字/連字符,冇 XML 標籤,冇保留詞description:最多 1024 個字符,非空,冇 XML 標籤
有關完整嘅結構詳情,請睇 Skills 概述入面嘅 Skill Structure 部分:/docs/en/agents-and-tools/agent-skills/overview#skill-structure
Token 預算
為咗最佳性能,保持 SKILL.md 正文喺 500 行以內。如果你嘅內容超出呢個限制,用前面描述嘅漸進式披露模式將佢拆分為單獨嘅文件。有關架構詳情,請睇 Skills 概述入面嘅 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
有效技能嘅清單
喺分享技能之前,驗證:
核心質量
- ☐ 描述具體並包含關鍵術語
- ☐ 描述包含技能嘅功能同使用時機
- ☐ SKILL.md 正文喺 500 行以內
- ☐ 額外詳情喺單獨文件中(如果需要)
- ☐ 冇時效性信息(或者喺「舊模式」部分入面)
- ☐ 成個術語一致
- ☐ 示例具體,唔抽象
- ☐ 檔案引用只得一層深度
- ☐ 適當使用漸進式披露
- ☐ 工作流有清晰嘅步驟
代碼同腳本
- ☐ 腳本解決問題,而唔係推畀 Claude
- ☐ 錯誤處理顯式並有幫助
- ☐ 冇「巫毒常數」(所有值都有 justify)
- ☐ 所需套件喺指令入面列出並驗證可用
- ☐ 腳本有清晰嘅文檔
- ☐ 冇 Windows 風格路徑(全部正斜槓)
- ☐ 關鍵操作嘅驗證/驗證步驟
- ☐ 對質量關鍵任務包含反饋循環
測試
- ☐ 至少創建咗三個評估
- ☐ 用 Haiku、Sonnet 同 Opus 測試
- ☐ 喺真實使用場景入面測試
- ☐ 納入團隊反饋(如適用)
Agent Skills 創作最佳實踐
Anthropic 把 Agent Skills 標準公開後,主流 AI Agents 都已支持,好的 Skills 應該是簡潔、結構良好且經過實際使用測試的。咱們今天回到 Anthropic 官方的 Skills 創作最佳實踐,結合自己的理解和判斷,一起來寫好包括 Claude 在內的 AI Agents 能夠有效發現和使用的 Skills。
如需瞭解 Skills 工作原理的概念背景,請參閲 Skills 概述文檔:/docs/en/agents-and-tools/agent-skills/overview
核心原則
簡潔是關鍵
上下文窗口是一種公共資源。你的 Skill 與 Claude 需要了解的所有其他內容共享上下文窗口,包括:
- 系統提示詞
- 對話歷史
- 其他 Skills 的元數據
- 你的實際請求
並非 Skill 中的每個 token 都會產生即時成本。在啓動時,只有所有 Skills 的元數據(名稱和描述)會被預加載。Claude 僅在 Skill 變得相關時才讀取 SKILL.md,並且僅在需要時才讀取額外文件。然而,在 SKILL.md 中保持簡潔仍然很重要:一旦 Claude 加載了它,每個 token 都會與對話歷史和其他上下文競爭。
默認假設: Claude 已經非常聰明
只添加 Claude 尚不瞭解的上下文。對每條信息提出質疑:
- "Claude 真的需要這個解釋嗎?"
- "我可以假設 Claude 知道這個嗎?"
- "這段話是否 justify 它的 token 成本?"
好的示例:簡潔(約 50 tokens):
## 提取 PDF 文本
使用 pdfplumber 進行文本提取:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
不好的示例:過於冗長(約 150 tokens):
## 提取 PDF 文本
PDF(Portable Document Format)文件是一種常見的文件格式,包含文本、圖像和其他內容。要從 PDF 中提取文本,你需要使用一個庫。有許多可用於 PDF 處理的庫,但推薦使用 pdfplumber,因為它易於使用且能處理大多數情況。首先,你需要使用 pip 安裝它。然後你可以使用下面的代碼...
簡潔版本假設 Claude 知道什麼是 PDF 以及庫如何工作。
設置適當的自由度
將具體程度與任務的脆弱性和可變性相匹配。
高自由度(基於文本的指令):
適用於:
- 多種方法都有效
- 決策取決於上下文
- 啓發式方法指導方法
示例:
## 代碼審查流程
1. 分析代碼結構和組織
2. 檢查潛在的 bug 或邊緣情況
3. 建議改進可讀性和可維護性
4. 驗證是否符合項目規範
中等自由度(偽代碼或帶參數的腳本):
適用於:
- 存在首選模式
- 允許一些變化
- 配置影響行為
示例:
## 生成報告
根據需要自定義使用此模板:
```python
def generate_report(data, format="markdown", include_charts=True):
# 處理數據
# 以指定格式生成輸出
# 可選地包含可視化
```
低自由度(特定腳本,很少或沒有參數):
適用於:
- 操作脆弱且容易出錯
- 一致性至關重要
- 必須遵循特定序列
示例:
## 數據庫遷移
精確運行此腳本:
```bash
python scripts/migrate.py --verify --backup
```
不要修改命令或添加額外的標誌。
類比: 將 Claude 想象成探索路徑的機器人:
- 兩側都是懸崖的窄橋: 只有一種安全的前進方式。提供具體的護欄和精確指令(低自由度)。示例:必須按精確順序運行的數據庫遷移。
- 沒有危險的開放區域: 許多路徑通向成功。給出大致方向並相信 Claude 能找到最佳路線(高自由度)。示例:代碼審查,其中上下文決定最佳方法。
測試你計劃使用的所有模型
Skills 作為模型的補充,因此有效性取決於底層模型。用你計劃使用的所有模型測試你的 Skill。
按模型劃分的測試考慮因素:
- Claude Haiku(快速、經濟):Skill 是否提供了足夠的指導?
- Claude Sonnet(平衡):Skill 是否清晰高效?
- Claude Opus(強大的推理):Skill 是否避免了過度解釋?
對 Opus 有效的方法可能需要為 Haiku 提供更多細節。如果你計劃在多個模型中使用你的 Skill,請力求適用於所有模型的指令。
Skill 結構
注意:
YAML 前言: SKILL.md 前言需要兩個字段:
name:
- 最多 64 個字符
- 只能包含小寫字母、數字和連字符
- 不能包含 XML 標籤
- 不能包含保留詞:"anthropic"、"claude"
description:
- 必須非空
- 最多 1024 個字符
- 不能包含 XML 標籤
- 應描述 Skill 的功能和使用時機
有關完整的 Skill 結構詳情,請參閲 Skills 概述文檔中的 Skill Structure 部分:/docs/en/agents-and-tools/agent-skills/overview#skill-structure
命名規範
使用一致的命名模式,使 Skills 更容易引用和討論。考慮對 Skill 名稱使用 動名詞形式(動詞 + -ing),因為這能清楚地描述 Skill 提供的活動或能力。
請記住,name 字段只能使用小寫字母、數字和連字符。
好的命名示例(動名詞形式):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
可接受的替代形式:
- 名詞短語:
pdf-processing、spreadsheet-analysis - 動作導向:
process-pdfs、analyze-spreadsheets
避免:
- 模糊的名稱:
helper、utils、tools - 過於通用的:
documents、data、files - 保留詞:
anthropic-helper、claude-tools - Skill 集合中不一致的模式
一致的命名使得:
- 在文檔和對話中引用 Skills 更容易
- 一眼就能理解 Skill 的功能
- 組織和搜索多個 Skills 更方便
- 維護專業、連貫的 skill 庫
編寫有效的描述
description 字段支持 Skill 發現,應包含 Skill 的功能和使用時機。
警告:
始終使用第三人稱撰寫。描述被注入到系統提示詞中,不一致的人稱視角會導致發現問題。
- 好的: "處理 Excel 文件並生成報告"
- 避免: "我可以幫助你處理 Excel 文件"
- 避免: "你可以使用此功能處理 Excel 文件"
具體幷包含關鍵術語。包含 Skill 的功能以及使用它的具體觸發條件/上下文。
每個 Skill 只有一個描述字段。描述對 skill 選擇至關重要:Claude 用它從可能 100 多個可用 Skills 中選擇正確的 Skill。你的描述必須提供足夠的細節,讓 Claude 知道何時選擇此 Skill,而 SKILL.md 的其餘部分提供實現細節。
有效示例:
PDF 處理 skill:
description: 從 PDF 文件提取文本和表格,填寫表單,合併文檔。在處理 PDF 文件或用戶提及 PDF、表單或文檔提取時使用。
Excel 分析 skill:
description: 分析 Excel 電子表格,創建數據透視表,生成圖表。在分析 Excel 文件、電子表格、表格數據或 .xlsx 文件時使用。
Git 提交助手 skill:
description: 通過分析 git diff 生成描述性的提交消息。在用戶請求幫助編寫提交消息或查看暫存更改時使用。
避免模糊描述,如:
description: 幫助處理文檔
description: 處理數據
description: 對文件做一些事情
漸進式披露模式
SKILL.md 充當概述,根據需要指向詳細材料,就像入職指南中的目錄一樣。有關漸進式披露工作原理的解釋,請參閲概述中的 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
實用指導:
- 為獲得最佳性能,保持 SKILL.md 正文在 500 行以內
- 當接近此限制時,將內容拆分為單獨的文件
- 使用以下模式有效組織指令、代碼和資源
視覺概覽:從簡單到複雜
基本的 Skill 從只包含元數據和指令的 SKILL.md 文件開始:
隨着 Skill 的增長,你可以捆綁僅在需要時加載的額外內容:
完整的 Skill 目錄結構可能如下所示:
pdf/
├── SKILL.md # 主指令(觸發時加載)
├── FORMS.md # 表單填寫指南(按需加載)
├── reference.md # API 參考(按需加載)
├── examples.md # 使用示例(按需加載)
└── scripts/
├── analyze_form.py # 實用腳本(執行,不加載)
├── fill_form.py # 表單填寫腳本
└── validate.py # 驗證腳本
Claude 僅在需要時才加載 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
模式 1:帶參考的高級指南
---
name: pdf-processing
description: 從 PDF 文件提取文本和表格,填寫表單,合併文檔。在處理 PDF 文件或用戶提及 PDF、表單或文檔提取時使用。
---
# PDF 處理
## 快速開始
使用 pdfplumber 提取文本:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高級功能
**表單填寫**:有關完整指南,請參閲 FORMS.md
**API 參考**:有關所有方法,請參閲 REFERENCE.md
**示例**:有關常見模式,請參閲 EXAMPLES.md
模式 2:按領域組織
對於有多個領域的 Skills,按領域組織內容以避免加載不相關的上下文。當用戶詢問銷售指標時,Claude 只需要銷售相關的 schema,而不是財務或營銷數據。這保持 token 使用量低且上下文集中。
bigquery-skill/
├── SKILL.md (概述和導航)
└── reference/
├── finance.md (收入、賬單指標)
├── sales.md (機會、管道)
├── product.md (API 使用、功能)
└── marketing.md (營銷活動、歸因)
# BigQuery 數據分析
## 可用數據集
**財務**:收入、ARR、賬單 → 請參閲 reference/finance.md
**銷售**:機會、管道、賬户 → 請參閲 reference/sales.md
**產品**:API 使用、功能、採用 → 請參閲 reference/product.md
**營銷**:營銷活動、歸因、郵件 → 請參閲 reference/marketing.md
## 快速搜索
使用 grep 查找特定指標:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```
模式 3:條件詳情
顯示基本內容,連結到高級內容:
# DOCX 處理
## 創建文檔
使用 docx-js 創建新文檔。請參閲 DOCX-JS.md。
## 編輯文檔
對於簡單編輯,直接修改 XML。
**對於修訂跟蹤**:請參閲 REDLINING.md
**對於 OOXML 詳情**:請參閲 OOXML.md
Claude 僅在用戶需要這些功能時才讀取 REDLINING.md 或 OOXML.md。
避免深層嵌套引用
當從其他引用的文件引用文件時,Claude 可能會部分讀取它們。遇到嵌套引用時,Claude 可能會使用 head -100 等命令預覽內容,而不是讀取整個文件,導致信息不完整。
保持引用與 SKILL.md 只有一層深度。所有參考文件都應直接從 SKILL.md 連結,以確保 Claude 在需要時讀取完整文件。
不好的示例:太深:
# SKILL.md
請參閲 advanced.md...
# advanced.md
請參閲 details.md...
# details.md
這是實際信息...
好的示例:一層深度:
# SKILL.md
**基本用法**:[SKILL.md 中的指令]
**高級功能**:請參閲 advanced.md
**API 參考**:請參閲 reference.md
**示例**:請參閲 examples.md
為較長的參考文件構建目錄
對於超過 100 行的參考文件,在頂部包含目錄。這確保 Claude 即使在使用部分讀取預覽時也能看到可用信息的完整範圍。
示例:
# API 參考
## 目錄
- 認證和設置
- 核心方法(創建、讀取、更新、刪除)
- 高級功能(批處理、webhooks)
- 錯誤處理模式
- 代碼示例
## 認證和設置
...
## 核心方法
...
然後 Claude 可以根據需要讀取完整文件或跳轉到特定部分。
有關此基於文件的架構如何實現漸進式披露的詳細信息,請參閲下文高級部分中的 Runtime environment 部分。
工作流和反饋循環
對複雜任務使用工作流
將複雜操作分解為清晰的順序步驟。對於特別複雜的工作流,提供 Claude 可以複製到其響應中並在進行過程中勾選的清單。
示例 1:研究綜合工作流(適用於無代碼的 Skills):
## 研究綜合工作流
複製此清單並跟蹤你的進度:
```
研究進度:
- [ ] 步驟 1:閲讀所有源文檔
- [ ] 步驟 2:識別關鍵主題
- [ ] 步驟 3:交叉驗證聲明
- [ ] 步驟 4:創建結構化摘要
- [ ] 步驟 5:驗證引用
```
**步驟 1:閲讀所有源文檔**
查看 `sources/` 目錄中的每個文檔。記錄主要論點和支持證據。
**步驟 2:識別關鍵主題**
查找跨源的模式。哪些主題反覆出現?來源在何處達成一致或分歧?
**步驟 3:交叉驗證聲明**
對於每個主要聲明,驗證它是否出現在源材料中。記錄哪個來源支持每個觀點。
**步驟 4:創建結構化摘要**
按主題組織發現。包括:
- 主要聲明
- 來自來源的支持證據
- 衝突觀點(如果有)
**步驟 5:驗證引用**
檢查每個聲明是否引用了正確的源文檔。如果引用不完整,返回步驟 3。
此示例展示了工作流如何應用於不需要代碼的分析任務。清單模式適用於任何複雜的多步驟過程。
示例 2:PDF 表單填寫工作流(適用於帶代碼的 Skills):
## PDF 表單填寫工作流
複製此清單並在完成項目時勾選:
```
任務進度:
- [ ] 步驟 1:分析表單(運行 analyze_form.py)
- [ ] 步驟 2:創建字段映射(編輯 fields.json)
- [ ] 步驟 3:驗證映射(運行 validate_fields.py)
- [ ] 步驟 4:填寫表單(運行 fill_form.py)
- [ ] 步驟 5:驗證輸出(運行 verify_output.py)
```
**步驟 1:分析表單**
運行:`python scripts/analyze_form.py input.pdf`
這提取表單字段及其位置,保存到 `fields.json`。
**步驟 2:創建字段映射**
編輯 `fields.json` 為每個字段添加值。
**步驟 3:驗證映射**
運行:`python scripts/validate_fields.py fields.json`
在繼續之前修復任何驗證錯誤。
**步驟 4:填寫表單**
運行:`python scripts/fill_form.py input.pdf fields.json output.pdf`
**步驟 5:驗證輸出**
運行:`python scripts/verify_output.py output.pdf`
如果驗證失敗,返回步驟 2。
清晰的步驟防止 Claude 跳過關鍵驗證。清單幫助 Claude 和你跟蹤多步驟工作流的進度。
實施反饋循環
常見模式: 運行驗證器 → 修復錯誤 → 重複
這種模式極大地提高了輸出質量。
示例 1:風格指南合規性(適用於無代碼的 Skills):
## 內容審查流程
1. 按照 STYLE_GUIDE.md 中的指南起草你的內容
2. 對照清單審查:
- 檢查術語一致性
- 驗證示例是否符合標準格式
- 確認所有必需部分都存在
3. 如果發現問題:
- 用具體章節引用記錄每個問題
- 修改內容
- 再次審查清單
4. 只有在滿足所有要求時才繼續
5. 最終確定並保存文檔
這展示了使用參考文檔而非腳本的驗證循環模式。"驗證器"是 STYLE_GUIDE.md,Claude 通過讀取和比較來執行檢查。
示例 2:文檔編輯流程(適用於帶代碼的 Skills):
## 文檔編輯流程
1. 對 `word/document.xml` 進行編輯
2. **立即驗證**:`python ooxml/scripts/validate.py unpacked_dir/`
3. 如果驗證失敗:
- 仔細閲讀錯誤消息
- 修復 XML 中的問題
- 再次運行驗證
4. **只有在驗證通過時才繼續**
5. 重建:`python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. 測試輸出文檔
驗證循環儘早捕獲錯誤。
內容指南
避免時效性信息
不要包含會過時的信息:
不好的示例:時效性(將變為錯誤):
如果你在 2025 年 8 月之前執行此操作,請使用舊 API。
2025 年 8 月之後,使用新 API。
好的示例(使用"舊模式"部分):
## 當前方法
使用 v2 API 端點:`api.example.com/v2/messages`
## 舊模式
<details>
<summary>遺留 v1 API(已於 2025-08 棄用)</summary>
v1 API 使用:`api.example.com/v1/messages`
此端點不再受支持。
</details>
舊模式部分提供歷史背景,而不會使主要內容混亂。
使用一致的術語
選擇一個術語並在整個 Skill 中使用:
好的 - 一致:
- 始終使用 "API endpoint"
- 始終使用 "field"
- 始終使用 "extract"
不好的 - 不一致:
- 混用 "API endpoint"、"URL"、"API route"、"path"
- 混用 "field"、"box"、"element"、"control"
- 混用 "extract"、"pull"、"get"、"retrieve"
一致性幫助 Claude 理解和遵循指令。
常見模式
模板模式
為輸出格式提供模板。將嚴格程度與需求相匹配。
對於嚴格要求(如 API 響應或數據格式):
## 報告結構
始終使用此確切的模板結構:
```markdown
# [分析標題]
## 執行摘要
[關鍵發現的一段概述]
## 關鍵發現
- 帶有支持數據的發現 1
- 帶有支持數據的發現 2
- 帶有支持數據的發現 3
## 建議
1. 具體的可操作建議
2. 具體的可操作建議
```
對於靈活指導(當適應性有用時):
## 報告結構
這是一個合理的默認格式,但根據你的分析使用最佳判斷:
```markdown
# [分析標題]
## 執行摘要
[概述]
## 關鍵發現
[根據你發現的內容調整部分]
## 建議
[針對具體情境定製]
```
根據具體分析類型調整部分。
示例模式
對於輸出質量取決於查看示例的 Skills,提供輸入/輸出對,就像常規提示一樣:
## 提交消息格式
按照以下示例生成提交消息:
**示例 1:**
輸入:添加了使用 JWT token 的用戶認證
輸出:
```
feat(auth): 實現基於 JWT 的認證
添加登錄端點和 token 驗證中間件
```
**示例 2:**
輸入:修復了報告中日期顯示錯誤的 bug
輸出:
```
fix(reports): 更正時區轉換中的日期格式
在報告生成中始終使用 UTC 時間戳
```
**示例 3:**
輸入:更新了依賴項並重構了錯誤處理
輸出:
```
chore: 更新依賴項並重構錯誤處理
- 將 lodash 升級到 4.17.21
- 在整個端點中標準化錯誤響應格式
```
遵循此風格:type(scope): 簡要描述,然後詳細說明。
示例幫助 Claude 比僅通過描述更清楚地理解所需的風格和詳細程度。
條件工作流模式
引導 Claude 通過決策點:
## 文檔修改工作流
1. 確定修改類型:
**創建新內容?** → 遵循下面的"創建工作流"
**編輯現有內容?** → 遵循下面的"編輯工作流"
2. 創建工作流:
- 使用 docx-js 庫
- 從頭構建文檔
- 導出為 .docx 格式
3. 編輯工作流:
- 解壓現有文檔
- 直接修改 XML
- 每次更改後驗證
- 完成後重新打包
提示:
如果工作流變得龐大或複雜,包含許多步驟,考慮將它們推入單獨的文件,並告訴 Claude 根據手頭的任務閲讀適當的文件。
評估和迭代
首先構建評估
在編寫大量文檔之前創建評估。 這確保你的 Skill 解決實際問題,而不是記錄想象中的問題。
評估驅動開發:
- 識別差距: 在沒有 Skill 的情況下對代表性任務運行 Claude。記錄具體失敗或缺失的上下文
- 創建評估: 構建三個測試這些差距的場景
- 建立基線: 測量 Claude 在沒有 Skill 時的表現
- 編寫最小指令: 創建剛好足夠的內容來解決問題並通過評估
- 迭代: 執行評估,與基線比較,並改進
這種方法確保你解決實際問題,而不是預期可能永遠不會實現的需求。
評估結構:
{
"skills":["pdf-processing"],
"query":"從此 PDF 文件中提取所有文本並保存到 output.txt",
"files":["test-files/document.pdf"],
"expected_behavior":[
"使用適當的 PDF 處理庫或命令行工具成功讀取 PDF 文件",
"從文檔的所有頁面提取文本內容,不遺漏任何頁面",
"以清晰、可讀的格式將提取的文本保存到名為 output.txt 的文件"
]
}
注意:
此示例演示了帶有簡單測試標準的、數據驅動的評估。目前沒有內置的方式來運行這些評估。用戶可以創建自己的評估系統。評估是衡量 Skill 有效性的真理之源。
與 Claude 一起迭代開發 Skills
最有效的 Skill 開發過程涉及 Claude 本身。與 Claude 的一個實例("Claude A")一起創建供其他實例("Claude B")使用的 Skill。Claude A 幫助你設計和改進指令,而 Claude B 在真實任務中測試它們。這有效是因為 Claude 模型既理解如何編寫有效的 agent 指令,也理解 agents 需要什麼信息。
創建新 Skill:
在沒有 Skill 的情況下完成任務: 與 Claude A 一起使用正常提示完成問題。在工作過程中,你會自然地提供上下文、解釋偏好和分享程序性知識。注意你反覆提供的信息。
識別可重用模式: 完成任務後,識別你提供的對類似未來任務有用的上下文。
示例: 如果你完成了 BigQuery 分析,你可能提供了表名、字段定義、過濾規則(如"始終排除測試賬户")和常見查詢模式。
讓 Claude A 創建 Skill: "創建一個 Skill,捕捉我們剛才使用的 BigQuery 分析模式。包含表 schema、命名約定和關於過濾測試賬户的規則。"
提示:
Claude 模型原生理解 Skill 格式和結構。你不需要特殊的系統提示或"編寫 skills"的 skill 來讓 Claude 幫助創建 Skills。只需讓 Claude 創建一個 Skill,它就會生成具有適當前言和正文內容的、結構良好的 SKILL.md 內容。
審查簡潔性: 檢查 Claude A 是否添加了不必要的解釋。詢問:"刪除關於勝率含義的解釋 — Claude 已經知道那個。"
改進信息架構: 讓 Claude A 更有效地組織內容。例如:"將此組織為將表 schema 放在單獨的參考文件中。我們以後可能會添加更多表。"
在類似任務上測試: 在相關用例上與 Claude B(加載了 Skill 的新實例)一起使用 Skill。觀察 Claude B 是否找到正確的信息、正確應用規則併成功處理任務。
根據觀察迭代: 如果 Claude B 遇到困難或遺漏某些內容,帶着具體情況返回 Claude A:"當 Claude 使用此 Skill 時,它忘記了按 Q4 日期過濾。我們應該添加關於日期過濾模式的部分嗎?"
迭代現有 Skills:
相同的分層模式在改進 Skills 時繼續。你在以下之間交替:
- 與 Claude A 一起(幫助你改進 Skill 的專家)
- 與 Claude B 一起測試(使用 Skill 執行實際工作的 agent)
- 觀察 Claude B 的行為並將洞察帶回 Claude A
在實際工作流中使用 Skill: 給 Claude B(加載了 Skill)實際任務,而非測試場景
觀察 Claude B 的行為: 注意它在何處遇到困難、成功或做出意外選擇
觀察示例: "當我要求 Claude B 提供區域銷售報告時,它編寫了查詢但忘記了過濾測試賬户,即使 Skill 提到了此規則。"
返回 Claude A 進行改進: 分享當前的 SKILL.md 並描述你觀察到的內容。詢問:"我注意到 Claude B 在我要求區域報告時忘記了過濾測試賬户。Skill 提到了過濾,但可能不夠突出?"
審查 Claude A 的建議: Claude A 可能建議重新組織以使規則更突出,使用更強的語言如"MUST filter"而非"always filter",或重構工作流部分。
應用並測試更改: 用 Claude A 的改進更新 Skill,然後在 Claude B 上對類似請求再次測試
根據使用情況重複: 當你遇到新場景時繼續此觀察-改進-測試循環。每次迭代都基於真實 agent 行為改進 Skill,而非假設。
收集團隊反饋:
- 與隊友分享 Skills 並觀察他們的使用
- 詢問:Skill 是否在預期時激活?指令是否清晰?缺少什麼?
- 納入反饋以解決你自己使用模式中的盲點
為什麼這種方法有效: Claude A 理解 agent 需求,你提供領域專業知識,Claude B 通過實際使用揭示差距,迭代改進基於觀察到的行為而非假設改進 Skill。
觀察 Claude 如何導航 Skills
在迭代 Skills 時,注意 Claude 在實踐中實際如何使用它們。觀察:
- 意外的探索路徑: Claude 是否以你未預料的順序讀取文件?這可能表明你的結構不如你想象的直觀
- 遺漏的連接: Claude 是否未能遵循對重要文件的引用?你的連結可能需要更明確或更突出
- 過度依賴某些部分: 如果 Claude 反覆讀取同一文件,考慮該內容是否應放在主 SKILL.md 中
- 被忽略的內容: 如果 Claude 從不訪問捆綁文件,它可能不必要或在主指令中信號不足
基於這些觀察而非假設進行迭代。Skill 元數據中的 'name' 和 'description' 特別關鍵。Claude 在決定是否響應當前任務觸發 Skill 時使用這些。確保它們清楚地描述 Skill 的功能和使用時機。
應避免的反模式
避免 Windows 風格路徑
始終使用正斜槓作為文件路徑,即使在 Windows 上:
- ✓ 好的:
scripts/helper.py、reference/guide.md - ✗ 避免:
scripts\helper.py、reference\guide.md
Unix 風格路徑適用於所有平台,而 Windows 風格路徑在 Unix 系統上會導致錯誤。
避免提供過多選項
除非必要,不要呈現多種方法:
**不好的示例:太多選擇**(令人困惑):
"你可以使用 pypdf、或 pdfplumber、或 PyMuPDF、或 pdf2image、或..."
**好的示例:提供默認值**(帶有逃生通道):
"使用 pdfplumber 進行文本提取:
```python
import pdfplumber
```
對於需要 OCR 的掃描 PDF,改用 pdf2image 和 pytesseract。"
高級:帶有可執行代碼的 Skills
以下部分專注於包含可執行腳本的 Skills。如果你的 Skill 僅使用 markdown 指令,請跳到有效 Skills 的清單部分。
解決問題,不要推卸
在為 Skills 編寫腳本時,處理錯誤條件,而不是推給 Claude。
好的示例:顯式處理錯誤:
def process_file(path):
"""處理文件,如果不存在則創建它。"""
try:
withopen(path) as f:
return f.read()
except FileNotFoundError:
# 使用默認內容創建文件而非失敗
print(f"未找到文件 {path},創建默認值")
withopen(path, "w") as f:
f.write("")
return""
except PermissionError:
# 提供替代方案而非失敗
print(f"無法訪問 {path},使用默認值")
return""
不好的示例:推給 Claude:
def process_file(path):
# 只是失敗,讓 Claude 自己解決
return open(path).read()
配置參數也應 justify 和記錄,以避免"巫毒常數"(Ousterhout 定律)。如果你不知道正確的值,Claude 如何確定它?
好的示例:自文檔化:
# HTTP 請求通常在 30 秒內完成
# 更長的超時時間用於應對慢速連接
REQUEST_TIMEOUT = 30
# 三次重試平衡可靠性與速度
# 大多數間歇性故障在第二次重試時解決
MAX_RETRIES = 3
不好的示例:魔術數字:
TIMEOUT = 47 # 為什麼是 47?
RETRIES = 5 # 為什麼是 5?
提供實用腳本
即使 Claude 可以編寫腳本,預製腳本也有優勢:
實用腳本的好處:
- 比生成的代碼更可靠
- 節省 tokens(無需在上下文中包含代碼)
- 節省時間(無需代碼生成)
- 確保跨使用的一致性
上圖展示了可執行腳本如何與指令文件一起工作。指令文件(forms.md)引用腳本,Claude 可以在不將內容加載到上下文的情況下執行它。
重要區別: 在指令中明確 Claude 應該:
- 執行腳本(最常見):"運行
analyze_form.py提取字段" - 將其作為參考閲讀(用於複雜邏輯):"查看
analyze_form.py瞭解字段提取算法"
對於大多數實用腳本,執行是首選,因為它更可靠、更高效。有關腳本執行工作原理的詳細信息,請參閲下面的 Runtime environment 部分。
示例:
## 實用腳本
**analyze_form.py**:從 PDF 提取所有表單字段
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
輸出格式:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**:檢查重疊的邊界框
```bash
python scripts/validate_boxes.py fields.json
# 返回:"OK" 或列出衝突
```
**fill_form.py**:將字段值應用到 PDF
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```
使用視覺分析
當輸入可以渲染為圖像時,讓 Claude 分析它們:
## 表單佈局分析
1. 將 PDF 轉換為圖像:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. 分析每頁圖像以識別表單字段
3. Claude 可以直觀地看到字段位置和類型
注意:
在此示例中,你需要編寫 pdf_to_images.py 腳本。
Claude 的視覺能力幫助理解佈局和結構。
創建可驗證的中間輸出
當 Claude 執行復雜的、開放式的任務時,它可能會出錯。"計劃-驗證-執行"模式通過在讓 Claude 首先以結構化格式創建計劃,然後在執行前用腳本驗證該計劃,儘早捕獲錯誤。
示例: 想象一下讓 Claude 根據電子表格更新 PDF 中的 50 個表單字段。沒有驗證的情況下,Claude 可能引用不存在的字段、創建衝突值、遺漏必填字段或錯誤應用更新。
解決方案: 使用上面顯示的工作流模式(PDF 表單填寫),但添加在應用更改之前驗證的 changes.json 中間文件。工作流變為:分析 → 創建計劃文件 → 驗證計劃 → 執行 → 驗證。
為什麼這種模式有效:
- 儘早捕獲錯誤: 驗證在應用更改之前發現問題
- 機器可驗證: 腳本提供客觀驗證
- 可逆的計劃: Claude 可以在不接觸原件的情況下迭代計劃
- 清晰的調試: 錯誤消息指向具體問題
何時使用: 批處理操作、破壞性更改、複雜驗證規則、高風險操作。
實施技巧: 使驗證腳本具有詳細的特定錯誤消息,如 "未找到字段 'signature_date'。可用字段:customer_name、order_total、signature_date_signed" 以幫助 Claude 修復問題。
打包依賴
Skills 在具有平台特定限制的代碼執行環境中運行:
- claude.ai: 可以從 npm 和 PyPI 安裝包並從 GitHub 倉庫拉取
- Claude API: 沒有網絡訪問權限和運行時包安裝
在 SKILL.md 中列出所需的包,並驗證它們在代碼執行工具文檔中可用:/docs/en/agents-and-tools/tool-use/code-execution-tool
運行時環境
Skills 在具有文件系統訪問權限、bash 命令和代碼執行能力的代碼執行環境中運行。有關此架構的概念性解釋,請參閲概述中的 The Skills architecture 部分:/docs/en/agents-and-tools/agent-skills/overview#the-skills-architecture
這如何影響你的創作:
Claude 如何訪問 Skills:
- 預加載元數據: 在啓動時,所有 Skills 的 YAML 前言中的名稱和描述被加載到系統提示詞中
- 按需讀取文件: Claude 使用 bash Read 工具在需要時從文件系統訪問 SKILL.md 和其他文件
- 高效執行腳本: 可以通過 bash 執行實用腳本,而無需將其完整內容加載到上下文中。只有腳本的輸出消耗 tokens
- 大文件無上下文懲罰: 參考文件、數據或文檔在實際讀取之前不會消耗上下文 tokens
- 文件路徑很重要: Claude 像文件系統一樣導航你的 skill 目錄。使用正斜槓(
reference/guide.md),而非反斜槓 - 文件名應具有描述性: 使用表明內容的名稱:
form_validation_rules.md,而非doc2.md - 為發現組織目錄: 按領域或功能組織目錄結構
- 好的:
reference/finance.md、reference/sales.md - 不好的:
docs/file1.md、docs/file2.md - 捆綁全面的資源: 包含完整的 API 文檔、大量示例、大型數據集;訪問前無上下文懲罰
- 對確定性操作首選腳本: 編寫
validate_form.py而非讓 Claude 生成驗證代碼 - 明確執行意圖:
- "運行
analyze_form.py提取字段"(執行) - "查看
analyze_form.py瞭解提取算法"(作為參考閲讀) - 測試文件訪問模式: 通過使用真實請求測試驗證 Claude 可以導航你的目錄結構
示例:
bigquery-skill/
├── SKILL.md (概述,指向參考文件)
└── reference/
├── finance.md (收入指標)
├── sales.md (管道數據)
└── product.md (使用分析)
當用戶詢問收入時,Claude 讀取 SKILL.md,看到對 reference/finance.md 的引用,並調用 bash 僅讀取該文件。sales.md 和 product.md 文件保留在文件系統上,在需要前消耗零上下文 tokens。這種基於文件的模型實現了漸進式披露。Claude 可以導航並選擇性加載每個任務所需的確切內容。
有關技術架構的完整詳情,請參閲 Skills 概述中的 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
MCP 工具引用
如果你的 Skill 使用 MCP(Model Context Protocol)工具,始終使用完全限定的工具名稱以避免"tool not found"錯誤。
格式:ServerName:tool_name
示例:
使用 BigQuery:bigquery_schema 工具檢索表 schema。
使用 GitHub:create_issue 工具創建問題。
其中:
BigQuery和GitHub是 MCP 服務器名稱bigquery_schema和create_issue是這些服務器中的工具名稱
沒有服務器前綴,Claude 可能無法定位工具,尤其是當多個 MCP 服務器可用時。
避免假設工具已安裝
不要假設包可用:
**不好的示例:假設安裝**:
"使用 pdf 庫處理文件。"
**好的示例:明確依賴**:
"安裝所需包:`pip install pypdf`
然後使用它:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"
技術說明
YAML 前言要求
SKILL.md 前言需要帶有特定驗證規則的 name 和 description 字段:
name:最多 64 個字符,僅小寫字母/數字/連字符,無 XML 標籤,無保留詞description:最多 1024 個字符,非空,無 XML 標籤
有關完整的結構詳情,請參閲 Skills 概述中的 Skill Structure 部分:/docs/en/agents-and-tools/agent-skills/overview#skill-structure
Token 預算
為獲得最佳性能,保持 SKILL.md 正文在 500 行以內。如果你的內容超出此限制,使用前面描述的漸進式披露模式將其拆分為單獨的文件。有關架構詳情,請參閲 Skills 概述中的 How Skills work 部分:/docs/en/agents-and-tools/agent-skills/overview#how-skills-work
有效 Skills 的清單
在分享 Skill 之前,驗證:
核心質量
- ☐ 描述具體幷包含關鍵術語
- ☐ 描述包含 Skill 的功能和使用時機
- ☐ SKILL.md 正文在 500 行以內
- ☐ 額外詳情在單獨文件中(如果需要)
- ☐ 無時效性信息(或在"舊模式"部分中)
- ☐ 整個術語一致
- ☐ 示例具體,非抽象
- ☐ 文件引用只有一層深度
- ☐ 適當使用漸進式披露
- ☐ 工作流有清晰的步驟
代碼和腳本
- ☐ 腳本解決問題,而非推給 Claude
- ☐ 錯誤處理顯式且有幫助
- ☐ 沒有"巫毒常數"(所有值都有 justify)
- ☐ 所需包在指令中列出並驗證可用
- ☐ 腳本有清晰的文檔
- ☐ 沒有 Windows 風格路徑(全部正斜槓)
- ☐ 關鍵操作的驗證/驗證步驟
- ☐ 對質量關鍵任務包含反饋循環
測試
- ☐ 至少創建了三個評估
- ☐ 使用 Haiku、Sonnet 和 Opus 測試
- ☐ 在真實使用場景中測試
- ☐ 納入團隊反饋(如適用)