為 Agent 設計產品【譯】
整理版優先睇
AI 智能體正在翻轉產品設計:與其繼續優化 UI,不如開始教會 Agent 點樣成功
呢篇文係 Teddy Riker 喺 Ramp 做產品嗰陣寫嘅反思。佢成日喺 X 見到有人話 UI 死咗,唔上 MCP、API 嘅產品就會死。佢親眼見到 Ramp 嘅 MCP 每週活躍用戶三個月升咗 10 倍,而 Salesforce 仲搞咗個 Headless 360,將成個平台變成 API 同工具,讓 AI 智能體可以直接操作。作者嘅核心結論係:未來 80% 嘅人機互動會經 AI 智能體完成,產品團隊要開始為 Agent 設計,而唔係只為人類用戶。
文章用咗幾個具體案例來說明點樣做。Notion 嘅 MCP 做得好,因為佢哋喺工具描述入面直接叫 Agent 先讀規範,唔好亂估;相反 Slack 嘅 MCP 就成日撞格式,搞到用戶要自己執。Ramp 就建立咗反饋循環,強制每個工具調用都要寫理由,仲提供一個反饋工具俾 Agent 匯報問題,等產品團隊可以從使用數據中發掘新功能信號。
最後作者用 Diego 出差報銷嘅例子,講清楚點樣處理上下文缺口:費用系統唔應該直接問 GL code,而係應該問「呢餐係客戶定自己食」,由 Agent 從日曆或 Slack 度揾答案。佢話設計 Agent 產品嘅核心係問清楚:調用你係統嘅 Agent 到底需要咩先做到嘢?你有冇直接俾佢?
- 結論:AI 智能體將主導 80% 嘅人機交互,產品設計必須轉向為 Agent 服務,而唔係只服務人類用戶。
- 方法:教會 Agent 點樣成功——主動提供規範(如 Notion 嘅 Markdown 規範),而唔係等佢自己摸索(如 Slack 成日撞格式)。
- 差異:設計反饋循環(如 Ramp 嘅 rationale 參數同反饋工具),將 Agent 嘅使用數據直接變成產品改進嘅信號。
- 啟發:留意上下文缺口——Agent 之間各有優勢,設計時要判斷邊一方更適合提供邊啲信息,避免硬塞唔合適嘅參數。
- 可行動點:發佈 MCP 只係起步,真正打磨細節(工具描述、參數設計、反饋機制)先可以留住客戶,否則使用量會停滯。
Salesforce Headless 360 公告
Salesforce 宣佈將整個平台能力暴露為 API、MCP 工具和 CLI 命令,讓 AI 智能體可以直接操作。
UI 死咗?Agent 先係未來主流
如果你成日喺 X 刷動態,大概見唔少人話用戶界面已經死咗,又話產品唔上 MCP、API 就好快玩完。呢個趨勢喺 Ramp 好明顯——過去三個月 MCP 嘅每週活躍用戶升咗 10 倍,因為越嚟越多客戶用 Claude、ChatGPT 呢類 AI 智能體入件。
Salesforce 嘅反應仲快啲。佢哋推出 Headless 360,將成個平台變成 API、MCP 工具同 CLI 命令,讓 AI 智能體可以唔開瀏覽器就操作曬。作者話呢步好聰明,但唔易做,因為 Salesforce 本來靠 UI 一致性做護城河,家陣要承認條河開始乾塘。
未來 80% 嘅交互會經 AI 智能體完成
作者唔認為 UI 會死,人類始終想㩒掣睇結果。但二八法則反轉咗:未來人同軟件之間八成嘅互動都會經 Agent。呢個改變唔單止影響你要整咩功能,仲會影響你點樣整。
教會 Agent 點樣成功:Notion vs Slack
作者而家多數用 LLM 幫手寫作,然後經 Notion 嘅 MCP 放落去。佢好欣賞 Notion 嘅做法:每次叫 Agent 寫嘢,幾乎一次到位,因為工具描述一開始就叫佢先拎份 Markdown 規範,唔好亂猜語法。
如需完整 Markdown 規範,必須先獲取 MCP 資源 notion://docs/enhanced-markdown-spec。不要猜測或幻覺 Markdown 語法。舊世界呢啲規範會放喺 API 文檔,開發者自己讀完再寫轉換層。而家 Notion 喺 Agent 需要嘅時候直接將規範交俾佢。相反,Slack 嘅 MCP 就成日出事——Agent 默認用標準 Markdown,但 Slack 有自己格式,搞到用戶要花時間執格式,仲慘過自己打字。
調用你家智能體嘅人,需要知道咩先成功?主動俾佢,唔好等佢自己摸索
建立反饋循環:Ramp 嘅做法
Ramp 初初推出 MCP 嗰陣,最大問題係睇唔到用戶真正想做咩。佢哋用三個方法解決:首先,每個工具調用都要 Agent 寫 rationale,解釋點解要咁做;其次,提供一個獨立嘅反饋工具,俾 Agent 匯報卡住咗或者邊度行唔通;最後,為特定工具加 context seed,收集日後有用嘅資訊。
- 1 強制 Agent 每次調用都寫「理由」(rationale),重建用戶意圖
- 2 提供反饋工具,等 Agent 匯報想做咩、試過咩、卡喺邊
- 3 喺工具設計 context seed,捕捉日後有用嘅資訊
作者話,當你喺理由日誌見到重複模式,例如「正在生成事故報告」,就係新功能信號。你可以整一個 build-incident-report 工具,自動識別相關工單、評估嚴重程度。然後 Agent 又會開始俾反饋:報告拉咗無關工單、包埋免費套餐用戶等等。你加個日期範圍參數、客戶分組篩選器,每個反饋循環都變成產品改進入口。
Agent 嘅反饋往往比你嘅真人用戶更具體、更一致
留意上下文缺口:Diego 嘅報銷例子
任何 Agent 交互入面,你個系統知啲嘢,調用方 Agent 又知啲嘢。設計嗰陣要清楚判斷邊一方喺邊啲信息上有優勢。作者用 Diego 出差報銷做例子:佢嘅 AI 首席幕僚知道日曆、電郵、Slack 對話同收據,而費用系統知道交易數據、公司政策、GL code 同歸類習慣。
傳統 API 會問「揀 GL code」,設計得好的 Agent 會問「呢餐係客戶定自己食」
費用系統唔應該直接問 GL code,而係應該問返上下文:係客戶餐、團隊餐定個人旅行?AI 幕僚可以從日曆或 Slack 揾到答案,然後費用系統自動套用正確科目。Diego 同佢嘅 Agent 都唔需要知 GL code 係咩,財務團隊得到準確分類。
為 Agent 設計,否則客戶會流向對手
作者強調,過去你係為一個想快啲做完、唔想出錯、睇到自己手尾嘅真人設計產品。而家你仍然係服務同一個人,只係中間多咗個代理者。佢嘅直覺、上下文同限制都同人類唔同。
教會 Agent 成功、建立反饋循環、留意上下文缺口——呢三件事背後都係問同一條問題
大多數公司發佈一個 MCP 就當交咗功課,用量可能升幾個季度然後停滯。隨住時間,客戶會流向真正打磨細節嘅產品,繞開求其交貨嗰啲。好似當初為人類用戶設計產品咁,認真為 AI 智能體設計產品——因為最後簽支票嘅,可能係佢。
最後簽支票嘅,可能係 Agent
原文:Designing for Agents[1]
作者:Teddy Riker
如果你同我一樣,成日喺 X 上面同一個資訊圈入面碌動態,咁你大概都見過呢種講法:用戶界面已經死咗。
你會一邊碌到「我點樣用 Obsidian 搭建第二大腦」,一邊碌到「Anthropic 徹底殺死咗某某行業」呢類帖子。然後好快,你就會見到有人話:一個產品如果唔可以被 AI 智能體(AI Agent)通過 MCP、API、CLI,或者喺佢哋之間嘅方式使用,咁佢就生存唔到。
呢個趨勢喺 Ramp 已經好明顯。過去三個月入面,隨住越來越多客戶開始透過 Claude、ChatGPT 同其他 AI 智能體進入我哋嘅產品,我哋 MCP 上嘅每週活躍用戶增長咗 10 倍。(MCP,Model Context Protocol,模型上下文協議,可以理解為一種俾 AI 智能體調用外部工具同數據嘅標準方式。)
上個星期,Salesforce 成為咗最早主動擁抱呢個判斷嘅傳統軟件巨頭之一。
嚟自 https://venturebeat.com/ai/salesforce-launches-headless-360-to-turn-its-entire-platform-into-infrastructure-for-ai-agents:
https://www.salesforce.com/ 星期三宣佈咗呢間公司 27 年歷史上最激進嘅一次架構轉型,推出咗「https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/」——呢係一項覆蓋成個平台嘅大計劃:將平台入面嘅每一項能力都暴露成 API、MCP 工具或者 CLI 命令,令 AI 智能體可以喺完全唔打開瀏覽器嘅情況下操作成個系統。
呢項發佈係喺 Salesforce 喺舊金山舉辦嘅年度 https://www.salesforce.com/tdx/ 大會上宣佈嘅,並且即刻向開發者開放咗 100 多個新工具同技能。佢亦都正面回應咗一個懸喺企業軟件頭頂嘅生死問題:當 AI 智能體已經能夠推理、規劃同執行時,一間公司仲需要一個帶圖形界面嘅 CRM 嗎?
Salesforce 嘅回答係:唔需要——而呢個正正係重點。
Salesforce 呢一步好聰明,而且我好難想像呢會係一個容易做出嘅決定。你問大多數銷售,佢哋大概率會話俾你知,佢哋並唔鍾意用 Salesforce。但 Salesforce 之所以無處不在,好大一部分原因正正係佢嘅用戶體驗(UX)夠曬熟悉。銷售負責人通常並唔想令成個團隊重新適應一套新技術;好多時候,一致性比功能強大更加重要。
Benioff 同佢嘅團隊正在承認:呢條護城河正在被侵蝕。佢哋都開始主動擁抱一個現實——未來大量使用行為會透過 Claude、ChatGPT 以及其他用戶根本睇唔到嘅後台流程嚟完成。
我並唔認為用戶界面(UI)正在死亡。人類仍然想要點擊按鈕、查看配置、確認任務已經完成。但二八法則已經反過來咗:未來人與軟件之間 80% 嘅交互,都會透過 AI 智能體完成。呢個唔單止會改變你需要構建啲乜,亦都會改變你構建佢嘅方式。
過去二十年入面,人們同軟件互動嘅主要方式係:
用戶 → 界面 → 數據庫
你打開一個產品,點嚟點去,將事情做完。界面就係你體驗軟件嘅方式。對大多數人嚟講,界面本身就係產品。
但隨住 AI 智能體接手越來越多工作,一個新嘅中間層出現咗:
用戶 → 用戶嘅 AI 智能體(例如 Claude)→ 數據庫
AI 智能體代表用戶行動。佢讀取、寫入、瀏覽產品,咁樣用戶就唔使親自操作。突然之間,界面消失咗。智能體開始直接同底層系統對話。
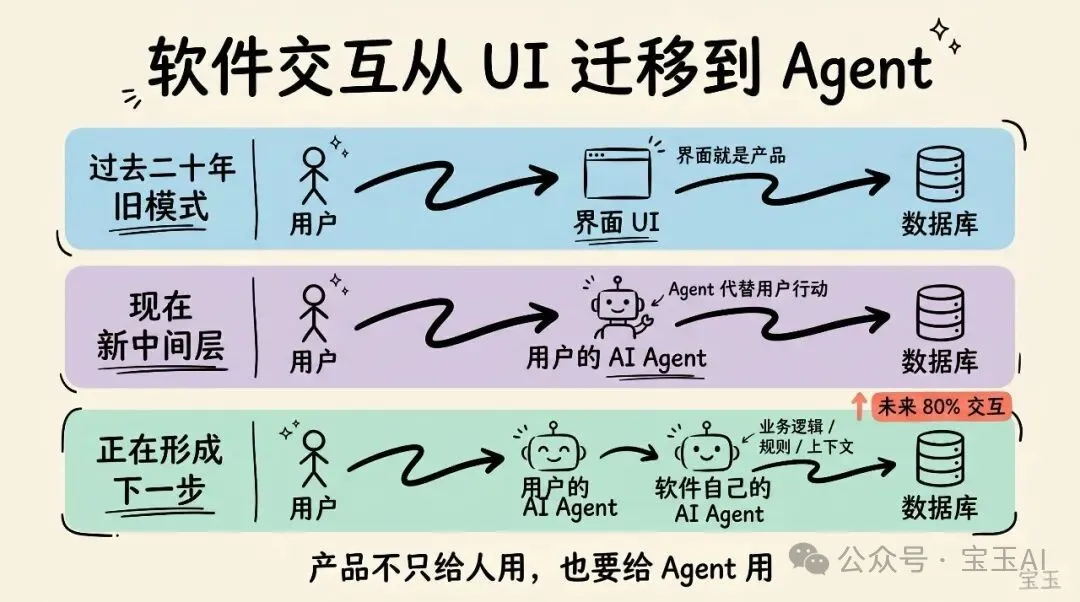
不過,呢個模式都喺迅速變化。軟件公司正在——而且都應該——設計自己嘅 AI 智能體同能力。所以新嘅模式更加似係咁:
用戶 → 用戶嘅 AI 智能體 → 軟件自己嘅 AI 智能體 → 數據庫
喺呢個模型入面,軟件自己嘅 AI 智能體會替用戶嘅智能體處理複雜性:執行業務邏輯、落實規則、補充後者冇嘅上下文。兩個大語言模型(LLM)一齊協作,朝着同一個結果推進。
教 AI 智能體點樣成功
我而家大部份頭腦風暴、寫作同構思,都係同大語言模型一齊完成嘅。當一篇草稿準備好分享時,我會透過 Notion 嘅 MCP 服務器將佢推到 Notion 入面。我曾經係 Google Docs 嘅忠實用戶好多年,但 Notion 嘅 MCP 改變咗我嘅習慣。
作為 Notion MCP 嘅用戶,我好欣賞嘅一點係:每次我叫 AI 智能體寫啲嘢,佢幾乎都可以一次到位。表格、項目符號、斜體、列表,你諗得到嘅格式,佢都唔會出錯。
呢個唔係偶然,而係設計出嚟嘅。
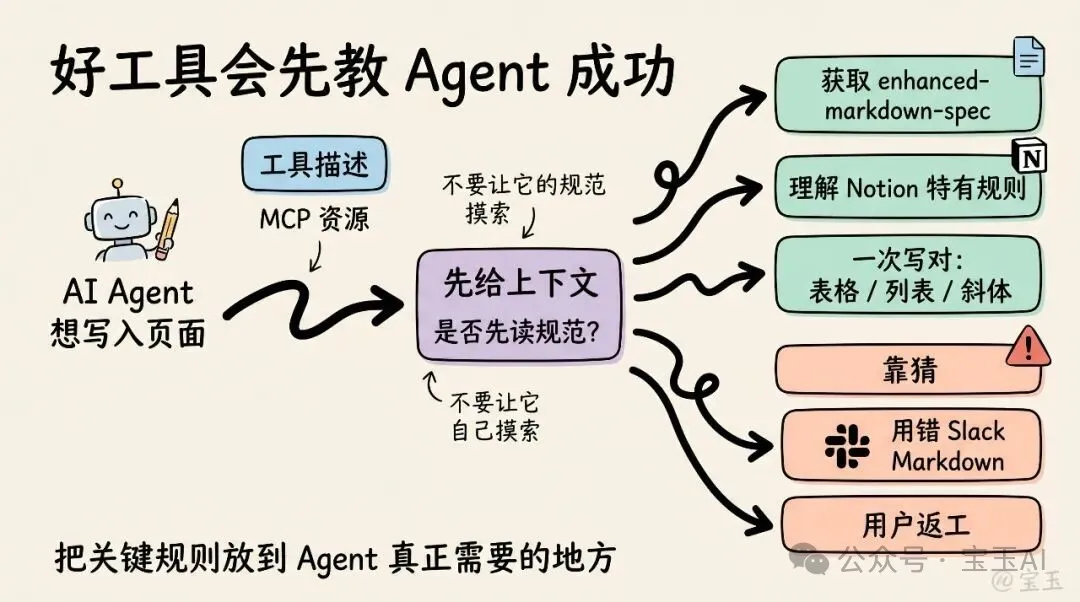
Notion 嘅 notion-create-pages 工具描述一開始就寫住:「如需完整 Markdown 規範,必須先獲取 MCP 資源 notion://docs/enhanced-markdown-spec。唔好猜測或者幻覺 Markdown 語法。」當我叫智能體寫入一個頁面時,佢做嘅第一件事就係獲取呢份規範。先讀規範,再動筆。所有 Notion 特有嘅假設,都會被明確指出,而唔係依賴通用模型嘅默認理解。
喺舊世界入面,呢類規範會放喺 API 文檔入面。接入 Notion 嘅開發者會讀文檔、理解規則,然後寫一個轉換層。而家,Notion 會喺 AI 智能體真正需要嘅時候,直接將規範交到佢手入面。
如果你用過 Slack MCP,可能就體驗過相反嘅情況。你嘅 AI 智能體會默認使用標準 Markdown,但係冇遵守 Slack 自己嗰套特定格式。結果係,你花喺修改格式上面嘅時間,可能比自己手寫消息仲多:

當然,Slack 嘅格式指南喺網上揾得到,你都可以將佢保存落嚟,再教你嘅智能體點樣用。但係呢個好煩,而且本來就唔應該係用戶需要操心嘅事。
你應該諗下:調用你哋智能體嘅人,需要知道啲乜嘢先至可以成功?然後主動將呢啲資訊交俾佢。唔好俾佢自己摸索。
建立反饋循環
當我哋啱啱喺 Ramp 發佈 MCP 時,最大嘅問題係可觀測性(observability)。我哋睇到工具調用量,但睇唔到觸發呢啲調用嘅聊天上下文。僅僅知道調用量,並唔能夠話俾我哋知乜嘢有效、乜嘢壞咗、用戶到底想完成啲乜。
後來我哋用幾種方式解決咗呢個問題:
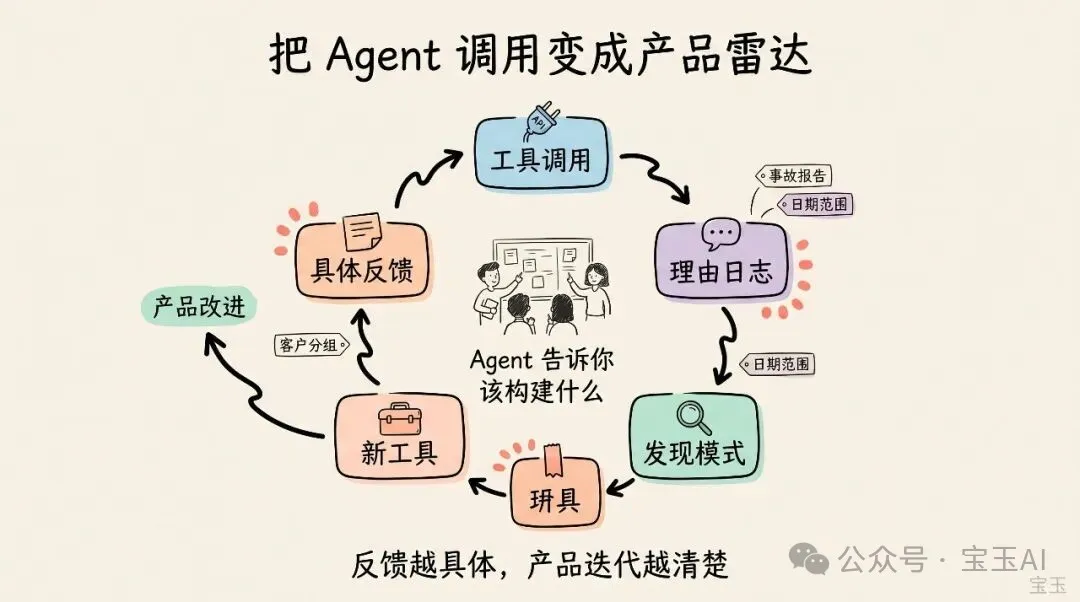
1. 每次工具調用都要求填寫「理由」。 每一次 MCP 或 CLI 工具調用,都要求 AI 智能體帶上一個 rationale參數,解釋佢點解要發起呢個請求。我哋睇唔到聊天內容,但呢個理由可以重建意圖。理由入面嘅模式,會話俾我哋知用戶到底想做啲乜。2. 提供一個反饋工具。 我哋發佈咗一個獨立工具。當 AI 智能體遇到阻礙,或者發現某種模式行唔通時,佢可以調用呢個工具。佢會提交自己原本想做啲乜、嘗試咗啲乜、卡咗喺邊度。 3. 俾特定工具加入上下文種子。 我哋會俾單個工具加入專門設計嘅參數,用嚟捕捉之後會有用嘅上下文:呢啲資訊智能體拎得到,但係如果唔主動收集,我哋之後只能靠估。
想像一下,你正在做一個客戶支援平台,並提供工具俾客戶抓取工單。過咗一段時間,你開始喺理由日誌入面反覆見到類似表達:「正在生成事故報告」「正在起草事故摘要」「正在收集停機覆盤相關工單」。
呢個就係一個新產品功能嘅信號!你可以做一個 build-incident-report 工具,用嚟識別相關工單、評估嚴重程度、拉取受影響嘅客羣,並用一種強約束嘅格式起草摘要。
呢個工具上線後,你可能又會開始收到反饋:「報告拉咗入三日之前嘅工單,但嗰啲唔屬於呢次事故」,或者「佢總係將免費套餐用戶嘅工單都放咗入覆盤入面,但呢啲用戶唔應該出現喺事故覆盤入面」。突然之間,你嘅 AI 智能體開始話俾你嘅 AI 智能體知:接下來到底應該構建啲乜。
AI 智能體當然會幻覺。但係喺反饋呢件事上面,佢哋往往比你真正發俾產品嘅多數人類用戶更加具體,亦都更加一致。
如果報告拉咗入無關工單,你就增加一個日期範圍參數。如果唔應該包含免費套餐客戶,你就增加一個客戶分組篩選器。每一個反饋循環,都會變成產品改進嘅新入口。
留意上下文缺口
喺任何 AI 智能體交互入面,你嘅系統掌握一啲調用方智能體唔知道嘅上下文;而調用方智能體都掌握一啲你嘅系統唔知道嘅上下文。設計呢啲交互時,你應該清楚噉判斷:邊一方喺邊啲資訊上面更加有優勢。
例如 Diego 去咗一趟出差。佢嘅 AI 首席幕僚收到一條嚟自費用管理系統智能體嘅 Slack 提醒:佢最近呢趟出差仲有未完成嘅報銷。而家,兩個 AI 智能體都指向同一個目標:正確提交呢啲報銷。
呢兩個智能體各自帶住唔同嘅上下文。
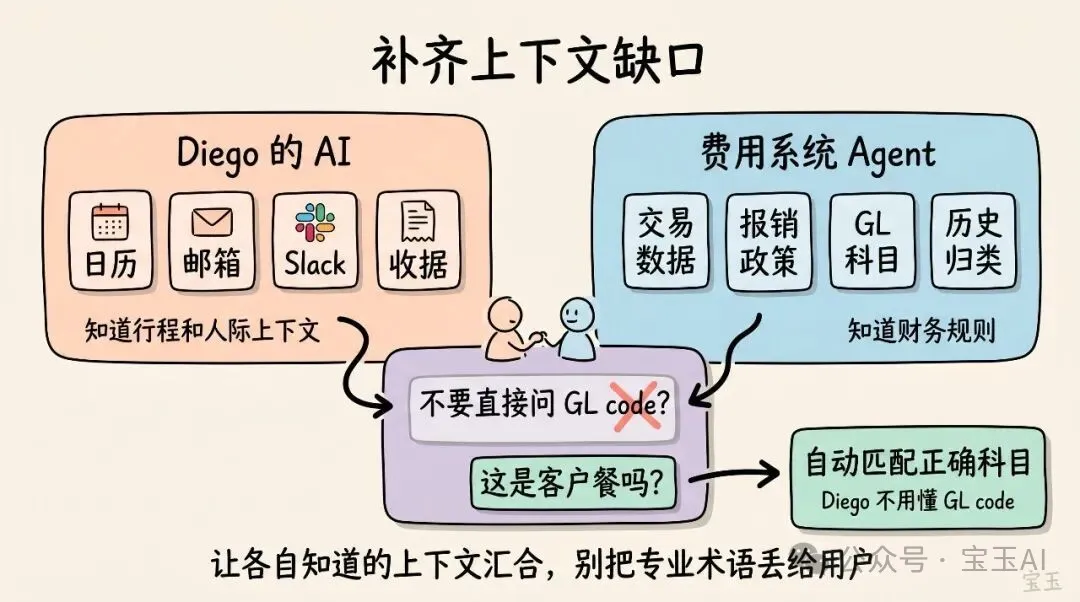
Diego 嘅 AI 首席幕僚知道:
• Diego 嘅日曆:知道邊啲會議發生咗、喺幾時、同邊個一齊 • Diego 嘅郵箱:有酒店同航班確認郵件附件 • Diego 嘅 Slack:可以將 Kokkari 嗰餐晚餐關聯到一個佢邀請 Acme 團隊嘅對話線程 • Diego 嘅收據:嚟自郵件附件同照片圖庫
費用管理系統知道:
• 原始交易數據,例如商户、交易時間 • 公司關於報銷提交嘅政策 • 公司嘅總賬科目(GL accounts)(GL 通常指 General Ledger,即係財務記賬入面嘅總賬分類) • 公司過往嘅費用歸類習慣
傳統 API 會將問題丟返俾用戶:「呢度有一筆交易需要填寫 GL code。請調用呢個接口獲取 150 個 GL code 選項,然後自己揀一個。」
設計得好嘅 AI 智能體交互會反過來處理呢件事——佢唔會直接索要 GL code,而係索要上下文:呢餐係客戶餐、團隊餐,定係個人旅行支出?AI 首席幕僚可以從日曆條目或者 Slack 對話入面揾到答案。然後費用管理系統根據自己原本缺失嘅嗰部分上下文,自動套用正確嘅科目。
Diego 同佢嘅智能體都唔需要知道 GL code 究竟係乜。財務團隊都可以得到準確嘅分類。雙方各自貢獻自己知道嘅資訊,最終交付一個對 Diego——都對佢嘅會計——都更加好嘅結果。
當你設計呢種智能體到智能體嘅交互時,一定要留意上下文缺口。承認你嘅智能體喺邊啲地方唔擅長,係完全可以嘅——因為你哋其實係喺服務同一個用戶。
過去,界面夾喺 Diego 同佢嘅費用系統之間。而家,界面夾喺佢嘅智能體同你嘅智能體之間。
呢個變化重新定義咗產品團隊嘅工作。過去,你係喺為一個想快速完成任務、避免犯錯、睇得到自己工作嘅真人設計產品。而家,你仍然係喺服務同一個人,只不過中間多咗一個代理者。佢嘅直覺、上下文同侷限,都同人類唔同。
教 AI 智能體點樣成功、建立反饋循環、留意上下文缺口,呢三件事背後其實都係喺問同一個問題:調用你哋智能體嘅一方,到底需要啲乜嘢先至可以將工作做好?你有冇將呢啲嘢交俾佢?
大多數公司會發佈一個 MCP,剔選「我哋都支援 AI 智能體喇」呢個框,然後繼續行落去。佢哋嘅使用量可能會增長幾個季度,然後停滯。隨住時間推移,客戶會流向啲真係琢磨細節嘅產品,亦都會繞開啲只係是但求其嘅產品。
好似當初為人類用戶設計產品一樣,認真為 AI 智能體設計產品。因為你好快就會發現,最後簽支票嘅,可能正正係佢。
引用連結
[1] Designing for Agents: https://x.com/teddy_riker/status/2047312986696454584
原文:Designing for Agents[1]
作者:Teddy Riker
如果你和我一樣,經常混在 X 上同一個信息圈裏刷動態,那麼你大概也見過這種說法:用戶界面已經死了。
你會一邊刷到“我如何用 Obsidian 搭建第二大腦”,一邊刷到“Anthropic 徹底殺死了某某行業”這類帖子。然後很快,你就會看到有人說:一個產品如果不能被 AI 智能體(AI Agent)通過 MCP、API、CLI,或者介於它們之間的方式使用,那它就活不下去。
這個趨勢在 Ramp 已經很明顯。過去三個月裏,隨着越來越多客戶開始通過 Claude、ChatGPT 和其他 AI 智能體進入我們的產品,我們 MCP 上的每週活躍用戶增長了 10 倍。(MCP,Model Context Protocol,模型上下文協議,可以理解為一種讓 AI 智能體調用外部工具和數據的標準方式。)
上週,Salesforce 成了最早主動擁抱這個判斷的傳統軟件巨頭之一。
來自 https://venturebeat.com/ai/salesforce-launches-headless-360-to-turn-its-entire-platform-into-infrastructure-for-ai-agents:
https://www.salesforce.com/ 週三宣佈了這家公司 27 年曆史上最激進的一次架構轉型,推出了“https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/”——這是一項覆蓋整個平台的大計劃:把平台裏的每一項能力都暴露成 API、MCP 工具或 CLI 命令,讓 AI 智能體可以在完全不打開瀏覽器的情況下操作整個系統。
這項發佈是在 Salesforce 於舊金山舉辦的年度 https://www.salesforce.com/tdx/ 大會上宣佈的,並且立刻向開發者開放了 100 多個新工具和技能。它也正面回應了一個懸在企業軟件頭頂的生死問題:當 AI 智能體已經能夠推理、規劃和執行時,一家公司還需要一個帶圖形界面的 CRM 嗎?
Salesforce 的回答是:不需要——而這正是重點。
Salesforce 這一步很聰明,而且我很難想象這會是一個容易做出的決定。你問大多數銷售,他們大概率會告訴你,他們並不喜歡用 Salesforce。但 Salesforce 之所以無處不在,很大一部分原因正是它的用戶體驗(UX)足夠熟悉。銷售負責人通常並不想讓整個團隊重新適應一套新技術;在很多時候,一致性比功能強大更重要。
Benioff 和他的團隊正在承認:這條護城河正在被侵蝕。他們也開始主動擁抱一個現實——未來大量使用行為會通過 Claude、ChatGPT 以及其他用戶根本看不見的後台流程來完成。
我並不認為用戶界面(UI)正在死亡。人類仍然想要點擊按鈕、查看配置、確認任務已經完成。但二八法則已經反過來了:未來人與軟件之間 80% 的交互,都會通過 AI 智能體完成。這不僅會改變你需要構建什麼,也會改變你構建它的方式。
過去二十年裏,人們和軟件交互的主要方式是:
用戶 → 界面 → 數據庫
你打開一個產品,點來點去,把事情做完。界面就是你體驗軟件的方式。對大多數人來說,界面本身就是產品。
但隨着 AI 智能體接手越來越多工作,一個新的中間層出現了:
用戶 → 用戶的 AI 智能體(比如 Claude)→ 數據庫
AI 智能體代表用戶行動。它讀取、寫入、瀏覽產品,這樣用戶就不用親自操作。突然之間,界面消失了。智能體開始直接和底層系統對話。
不過,這個模式也在迅速變化。軟件公司正在——而且也應該——設計自己的 AI 智能體和能力。所以新的模式更像這樣:
用戶 → 用戶的 AI 智能體 → 軟件自己的 AI 智能體 → 數據庫
在這個模型裏,軟件自己的 AI 智能體會替用戶的智能體處理複雜性:執行業務邏輯、落實規則、補充後者沒有的上下文。兩個大語言模型(LLM)一起協作,朝着同一個結果推進。
教會 AI 智能體如何成功
我現在大部分頭腦風暴、寫作和構思,都是和大語言模型一起完成的。當一篇草稿準備好分享時,我會通過 Notion 的 MCP 服務器把它推到 Notion 裏。我曾經是 Google Docs 的忠實用戶很多年,但 Notion 的 MCP 改變了我的習慣。
作為 Notion MCP 的用戶,我很欣賞的一點是:每次我讓 AI 智能體寫點什麼,它幾乎都能一次到位。表格、項目符號、斜體、列表,你能想到的格式,它都不會出錯。
這不是偶然,而是設計出來的。
Notion 的 notion-create-pages 工具描述一開始就寫着:“如需完整 Markdown 規範,必須先獲取 MCP 資源 notion://docs/enhanced-markdown-spec。不要猜測或幻覺 Markdown 語法。”當我讓智能體寫入一個頁面時,它做的第一件事就是獲取這份規範。先讀規範,再動筆。所有 Notion 特有的假設,都會被明確指出,而不是依賴通用模型的默認理解。
在舊世界裏,這類規範會放在 API 文檔裏。接入 Notion 的開發者會讀文檔、理解規則,然後寫一個轉換層。現在,Notion 會在 AI 智能體真正需要的時候,直接把規範交到它手裏。
如果你用過 Slack MCP,可能就體驗過相反的情況。你的 AI 智能體會默認使用標準 Markdown,卻沒有遵守 Slack 自己那套特定格式。結果是,你花在修改格式上的時間,可能比自己手寫消息還多:
當然,Slack 的格式指南在網上能找到,你也可以把它保存下來,再教你的智能體怎麼用。但這很煩,而且本來就不該是用戶需要操心的事。
你應該思考:調用你家智能體的人,需要知道什麼才能成功?然後主動把這些信息交給它。不要讓它自己摸索。
建立反饋循環
當我們剛在 Ramp 發佈 MCP 時,最大的問題是可觀測性(observability)。我們能看到工具調用量,但看不到觸發這些調用的聊天上下文。僅僅知道調用量,並不能告訴我們什麼有效、什麼壞了、用戶到底想完成什麼。
後來我們用幾種方式解決了這個問題:
1. 每次工具調用都要求填寫“理由”。 每一次 MCP 或 CLI 工具調用,都要求 AI 智能體帶上一個 rationale參數,解釋它為什麼要發起這個請求。我們看不到聊天內容,但這個理由可以重建意圖。理由裏的模式,會告訴我們用戶到底想做什麼。2. 提供一個反饋工具。 我們發佈了一個獨立工具。當 AI 智能體遇到阻礙,或者發現某種模式行不通時,它可以調用這個工具。它會提交自己原本想做什麼、嘗試了什麼、卡在了哪裏。 3. 給特定工具加入上下文種子。 我們會給單個工具加入專門設計的參數,用來捕捉之後會有用的上下文:這些信息智能體能拿到,但如果不主動收集,我們之後只能靠猜。
想象一下,你正在做一個客戶支持平台,並提供工具讓客戶抓取工單。過了一段時間,你開始在理由日誌裏反覆看到類似表達:“正在生成事故報告”“正在起草事故摘要”“正在收集停機覆盤相關工單”。
這就是一個新產品功能的信號!你可以做一個 build-incident-report 工具,用來識別相關工單、評估嚴重程度、拉取受影響的客戶羣體,並用一種強約束的格式起草摘要。
這個工具上線後,你可能又會開始收到反饋:“報告拉進了三天前的工單,但那些不屬於這次事故”,或者“它總是把免費套餐用戶的工單也放進覆盤裏,但這些用戶不應該出現在事故覆盤中”。突然之間,你的 AI 智能體開始告訴你的 AI 智能體:接下來到底該構建什麼。
AI 智能體當然會幻覺。但在反饋這件事上,它們往往比你真正發給產品的多數人類用戶更具體,也更一致。
如果報告拉進了無關工單,你就增加一個日期範圍參數。如果不該包含免費套餐客戶,你就增加一個客戶分組篩選器。每一個反饋循環,都會變成產品改進的新入口。
留意上下文缺口
在任何 AI 智能體交互中,你的系統掌握一些調用方智能體不知道的上下文;而調用方智能體也掌握一些你的系統不知道的上下文。設計這些交互時,你應該清楚地判斷:哪一方在哪些信息上更有優勢。
比如 Diego 去出了一趟差。他的 AI 首席幕僚收到一條來自費用管理系統智能體的 Slack 提醒:他最近這趟出差還有未完成的報銷。現在,兩個 AI 智能體都指向同一個目標:正確提交這些報銷。
這兩個智能體各自帶着不同的上下文。
Diego 的 AI 首席幕僚知道:
• Diego 的日曆:知道哪些會議發生了、在什麼時候、和誰一起 • Diego 的郵箱:有酒店和航班確認郵件附件 • Diego 的 Slack:能把 Kokkari 那頓晚餐關聯到一個他邀請 Acme 團隊的對話線程 • Diego 的收據:來自郵件附件和照片圖庫
費用管理系統知道:
• 原始交易數據,比如商户、交易時間 • 公司關於報銷提交的政策 • 公司的總賬科目(GL accounts)(GL 通常指 General Ledger,也就是財務記賬裏的總賬分類) • 公司過往的費用歸類習慣
傳統 API 會把問題丟回給用戶:“這裏有一筆交易需要填寫 GL code。請調用這個接口獲取 150 個 GL code 選項,然後自己選一個。”
設計得好的 AI 智能體交互會反過來處理這件事——它不會直接索要 GL code,而是索要上下文:這是一頓客戶餐、團隊餐,還是個人旅行支出?AI 首席幕僚可以從日曆條目或 Slack 對話裏找到答案。然後費用管理系統根據自己原本缺失的那部分上下文,自動套用正確的科目。
Diego 和他的智能體都不需要知道 GL code 到底是什麼。財務團隊也能得到準確的分類。雙方各自貢獻自己知道的信息,最終交付一個對 Diego——也對他的會計——都更好的結果。
當你設計這種智能體到智能體的交互時,一定要留意上下文缺口。承認你的智能體在哪些地方不擅長,是完全可以的——因為你們其實是在服務同一個用戶。
過去,界面夾在 Diego 和他的費用系統之間。現在,界面夾在他的智能體和你的智能體之間。
這個變化重新定義了產品團隊的工作。過去,你是在為一個想快速完成任務、避免犯錯、看得見自己工作的真人設計產品。現在,你仍然是在服務同一個人,只不過中間多了一個代理者。它的直覺、上下文和侷限,都和人類不同。
教會 AI 智能體如何成功、建立反饋循環、留意上下文缺口,這三件事背後其實都在問同一個問題:調用你家智能體的一方,到底需要什麼才能把工作做好?你有沒有把這些東西交給它?
大多數公司會發佈一個 MCP,勾上“我們也支持 AI 智能體了”這個框,然後繼續往前走。它們的使用量可能會增長几個季度,然後停滯。隨着時間推移,客戶會流向那些真正打磨細節的產品,也會繞開那些只是敷衍了事的產品。
像當初為人類用戶設計產品一樣,認真為 AI 智能體設計產品。因為你很快就會發現,最後籤支票的,可能正是它。
引用連結
[1] Designing for Agents: https://x.com/teddy_riker/status/2047312986696454584