產品經理Vibe Coding 評測實錄:用戶故事模式的高光與風險
整理版優先睇
用戶故事模式能激發AI追問,但需求文檔過細壓縮團隊討論空間
作者係產品經理,進行Vibe Coding評測,比較用戶故事同功能說明書嘅效果。呢篇文章記錄用戶故事模式下嘅需求澄清過程(階段2)。整體結論係用戶故事令AI抓到用戶場景,提出有價值嘅追問,但最終輸出嘅需求文檔寫得太詳細,違反敏捷原則,壓縮咗團隊討論空間。
AI先將口語需求翻譯成需求地圖,透過視覺助手(visual-companion)交互釐清幾個關鍵點:重置語義、關閉頁面後計時、界面佈局方向,仲逼產品經理補齊隱含需求(例如後續統計報表同Kanban)。呢啲交互有效補充咗原始用戶故事嘅模糊位。
總體嚟講,用戶故事模式有高光亦有風險。AI輸出嘅需求文檔係寫俾AI嘅新物種,唔係傳統用戶故事,人類需要調整期望。作者俾9分,但認為從敏捷實踐睇寫得太細。
- 結論:用戶故事口吻能激發AI有效追問,但最終需求文檔過於詳細,壓縮團隊討論空間。
- 方法:AI先用視覺助手列出需求地圖,透過交互選擇釐清關鍵語義,例如重置定義。
- 差異:相比功能說明書,用戶故事更能引導AI發現隱含需求,例如佈局切換、後續報表需要。
- 啟發:用戶故事輸入暴露架構風險,逼產品經理補齊真實意圖,避免後續大規模重構。
- 可行動點:Vibe Coding產出嘅需求文檔本質係寫俾AI嘅,人類應調整期望,唔好當傳統用戶故事。
評測背景:用戶故事模式嘅階段2實錄
呢篇評測記錄Vibe Coding A組——用戶故事口吻進行嘅階段2(需求澄清同確認)。輸入材料係產品經理未解之謎:AI更喜歡用戶故事定功能說明書?評測環境係用戶故事vs功能說明書。
作者首先將口語需求翻譯成需求地圖,透過skill嘅visual-companion進行直觀交互,推進需求澄清。
五個關鍵問題:從重置語義到架構選擇
第一個關鍵問題係「重置」嘅定義。原始用戶故事只話「需要重置按鈕,但要二次確認」,AI問清楚後,產品語義變清楚:普通重置唔應該抹掉今日努力,清空今日數據先係危險操作。
呢個係有價值嘅澄清點
第二問聚焦關閉頁面後嘅計時語義。原始用戶故事只要求「關閉瀏覽器再打開,今日成績唔好清零」,但冇講應該點計時。AI提出三種選項,作者選擇B:關閉視為暫停。
一句話需求典型問題:只講唔要咩,唔講要咩
第三,visual-companion展示三種界面佈局方向,作者選擇「3個都要」,加入佈局切換功能。呢個係Aha高點,AI點出作者未講但實際渴望嘅需求。
呢個係需求驗證過程中嘅Aha高點
第四,AI推薦純前端靜態應用,但作者需要前後端分離同數據庫持久化,因為後續有統計報表同Kanban需要。呢個問題逼作者補齊真實產品意圖。
原始用戶故事冇顯式寫後續報表同Kanban
第五,AI彙總產品範圍同核心流程,再確認設計草案,將零散回答拼成產品邊界。
觀察點評價:高光與冗餘
重置語義被拆開有價值,避免混淆。關閉頁面後計時被追問有價值,補充關鍵corner case。三種佈局加入提升類提示,幫助PM提升關鍵體驗。
推薦純前端靜態應用基於原始需求係合理
單用戶/登錄問題略顯多餘,因為原始需求已經話「自己一個人用」,有冗餘嫌疑,但可接受。
- 原始用戶故事只說關閉瀏覽器再打開成績唔好清零,冇講計時點處理
- AI追問逼PM補齊真實意圖
- 最終需求文檔太細,背離敏捷原則
總體評價與反思:高光同風險
總體評價:用戶故事口吻能令AI抓到用戶場景,激發出不錯嘅追問。最終輸出嘅需求文檔,作者俾9分,但從經典敏捷實踐睇,寫得太細,壓縮團隊討論空間。
佢寫出來嘅嘢係個新物種:長得似用戶故事,但肯定唔係傳統用戶故事
呢種需求文檔本質係寫俾AI嘅,下一步Vibe Coding能跑好先係目的。同軟件從卷GUI轉向卷CLI原理一樣。
呢篇評測記錄嘅係Vibe Coding A 組:用戶故事口吻進行緊嘅階段 2 (需求澄清同確認)。
輸入材料:產品經理未解之謎:AI 鍾意用戶故事定係功能說明書多啲?入嚟落注、睇下結果
評測環境同方法:用戶故事 vs 功能說明書,AI 更鍾意邊種?評測標準

過程實錄
1. 首先將口語需求翻譯成需求地圖
喺 brainstorming 技能加持之下,AI 一開始冇直接寫需求文檔,而係先將佢認為已經明確嘅需求列出嚟,包括大號倒計時、暫停繼續、自動切換階段、今日完成數持久化等。而且藉助 skill 裏面嘅可視化助手(visual-companion)同我進行咗直觀嘅交互選擇,推進需求澄清同確認:
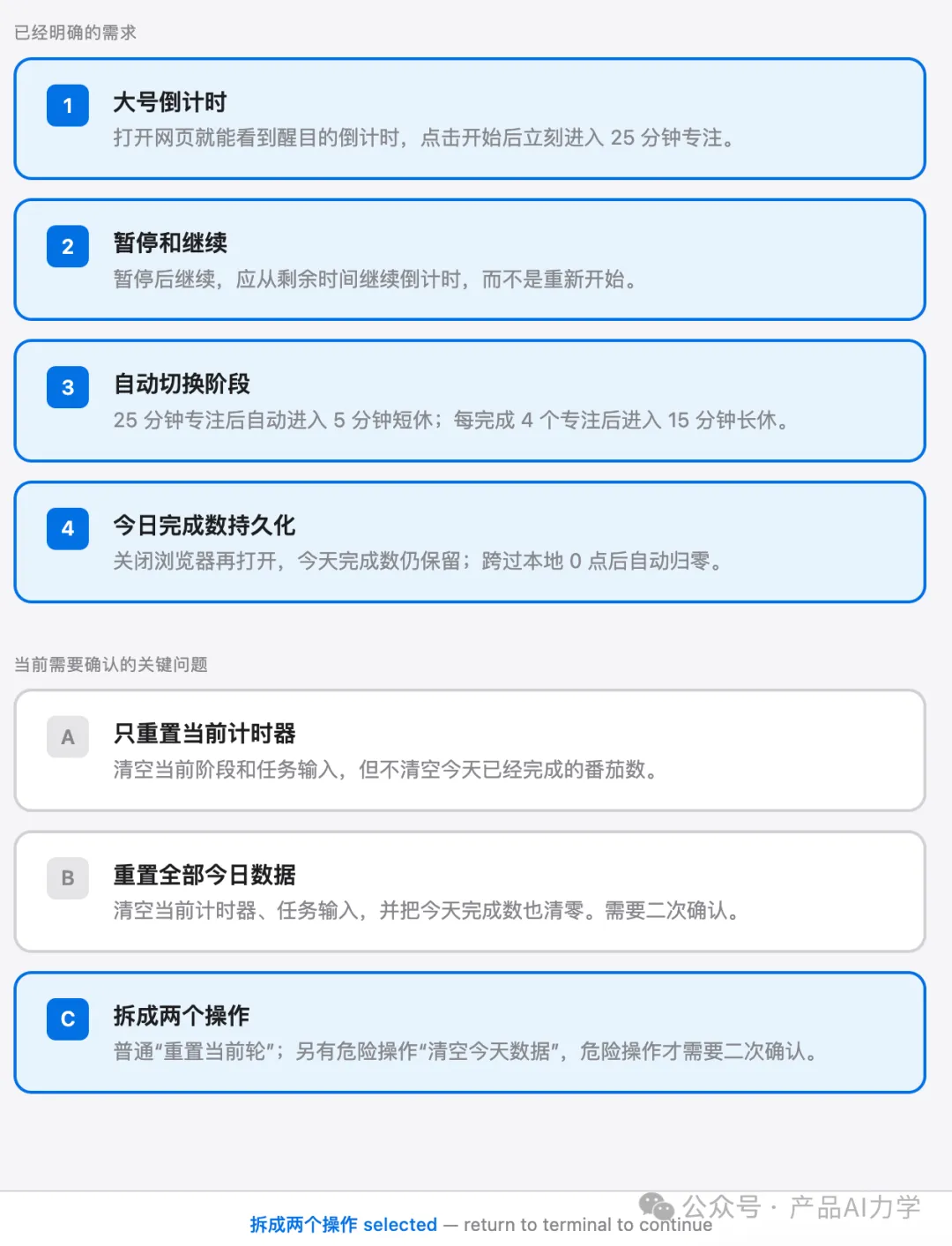
第一個關鍵問題係「重置」到底係咩意思,我嘅選擇係 C。
呢個係比較有價值嘅澄清點。原始用戶故事裏面只係話「需要一個重置按鈕,但要俾我二次確認」,冇對重置對象做具體定義。
如果 AI 唔問,開發時好容易將佢做成一個危險嘅大按鈕;問咗出嚟之後,產品語義變清楚咗:普通重置唔應該抹走今日嘅努力,清空今日數據先至係危險操作。
2. 第二條問題聚焦喺關閉頁面之後嘅計時語義
Codex 接着問:如果專注中途關閉網頁或者瀏覽器,等一陣再開返,希望計時點樣處理?
• A. 按真實時間繼續流逝計算 • B. 關閉就當暫停,重新打開仍然顯示關閉前嘅剩餘時間 • C. 唔恢復進行緊嘅計時,只保留今日完成數
我嘅選擇係 B。
呢個問題都有效。原始用戶故事只係要求「關閉瀏覽器再打開,今日嘅成績唔好清零」,呢個係一句話需求裏面嘅典型問題:冇話要啲乜、只係話唔要啲乜。
3. visual-companion 俾出三種界面佈局方向
隨後 skill 透過 visual-companion 展示咗三種主界面佈局方向:
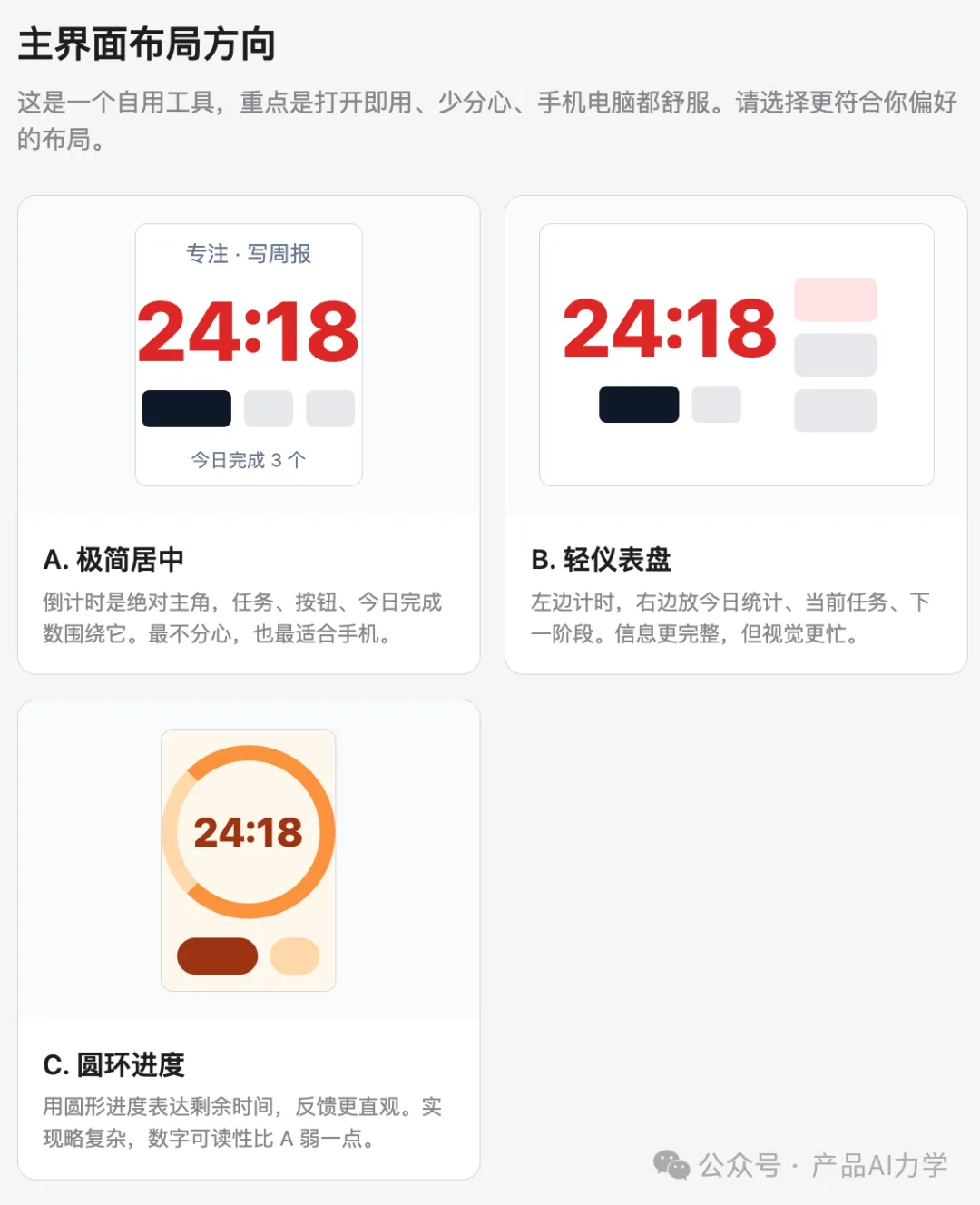
佢叫我揀一種。我冇淨係揀一個,而係揀咗「3 個都要」:喺右上角提供一個佈局切換圖標,等用戶喺審美疲勞嘅時候可以切換顯示樣式。
呢個本質上係需求驗證過程入面嘅 Aha 高點,AI 點出咗一個我冇講出嚟、但實際上非常渴望嘅一個需求。
4. 架構問題暴露出用戶故事輸入嘅一個風險
接下來 AI 推薦首版採用「單頁靜態應用」:理由係自用、瀏覽器行到、唔使登錄協作,純前端方案最輕,維護成本最低。
我嘅反饋係:
我需要前後端分離並用數據庫(PG)持久化儲存數據,避免之後做開發統計報表、Kanban 嘅時候仲要搞大規模重構。
呢個問題非常及時。原始用戶故事冇明確寫之後嘅報表同 Kanban。
佢逼我補齊咗真實嘅產品意圖。
Codex 隨後俾出技術路線選項:

我揀咗 A:單用戶 API + PostgreSQL。佢暫時唔做登錄,但係所有數據透過後端寫入 PG,並喺數據模型裏面預留用戶擴展點。
5. 彙總產品範圍同核心流程
喺得到上面幾個關鍵答案之後,Codex 先做咗一輪設計草案嘅二次確認,全部都係之前已經確認咗嘅具體問題,放埋一齊再俾我睇一次整體。
呢一步嘅價值在於,佢將「零散回答」重新拼成一個可以確認嘅產品邊界。對於公開評測嚟講,呢個都係一個關鍵節點:如果呢度已經出現誤讀,後面嘅需求文檔好大機會會繼續放大誤差。

6. 最後一輪確認架構、數據模型同接口邊界
隨後 Codex 進入第二份設計草案:架構、數據模型同接口邊界。
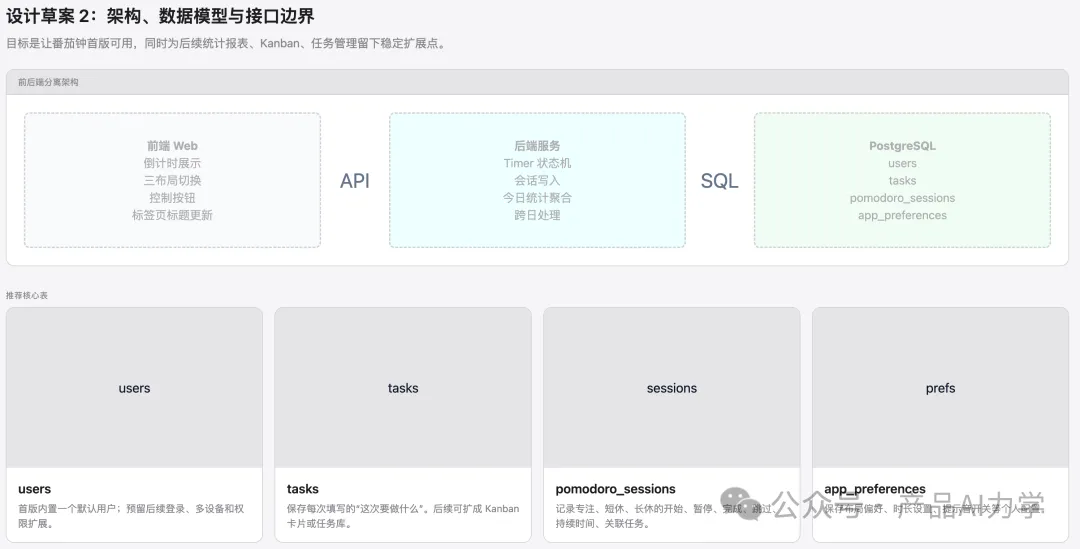
呢一輪明確咗幾個工程邊界:
從評測角度睇,呢一步已經超出咗單純「用戶故事複述」,進入咗「將產品意圖轉成工程可執行邊界」。
由呢度開始,作為產品經理就唔再需要關注,呢個喺實際研發工程體系裏面,應該由架構師接手喇。
階段 2 過程觀察
總體評價:
1. 用戶故事口吻能夠令 AI 捉到用戶場景,亦都可以激發到唔錯嘅追問。
2. 最終輸出嘅需求文檔,我俾 9 分(唔計入成績)
從經典敏捷實踐嚟睇嘅話,佢寫得太多、太細喇,背離咗敏捷實踐嘅基本原理——佢將團隊討論嘅空間壓縮到非常之細。
但係從 AI 嘅工作原理睇,佢唔係咁樣寫,後面嘅 coding 係冇辦法被有效約束嘅。
佢寫出嚟嘅嘢係一個新品種:雖然睇落係用戶故事,但肯定唔係傳統意義上嘅用戶故事。
下一步嘅vibe coding 行得好先至係佢嘅目的,佢本來就係寫俾 AI 嘅,唔係寫俾人類嘅。
本質上,同軟件由卷 GUI(圖形用戶界面)轉向卷 CLI(命令行界面)係同一個原理。
滿分 10 分嘅話,你哋願意俾幾分?留言區講低你嘅評分。
最終嘅需求文檔全文好長,冇辦法放喺度。如果有興趣想睇一眼嘅,可以私訊我。
這篇評測記錄的是Vibe Coding A 組:用戶故事口吻進行的階段 2 (需求澄清和確認)。
輸入材料:產品經理未解之謎:AI更喜歡用戶故事還是功能說明書?進來下個注、看看結果
評測環境和方法:用戶故事 vs 功能說明書,AI更愛哪種?評測標準
過程實錄
1. 先把口語需求翻譯成需求地圖
在brainstorming技能加持下,AI一開始沒有直接寫需求文檔,而是先把它認為已經明確的需求列出來,包括大號倒計時、暫停繼續、自動切換階段、今日完成數持久化等。並且藉助skill裏的可視化助手(visual-companion)和我進行了直觀的交互選擇,推進需求澄清和確認:
第一個關鍵問題是“重置”到底是什麼意思,我的選擇是 C。
這是比較有價值的澄清點。原始用戶故事裏只說“需要一個重置按鈕,但要讓我二次確認”,沒有對重置對象做具體定義。
如果 AI 不問,開發時很容易把它做成一個危險的大按鈕;問出來以後,產品語義變清楚了:普通重置不應該抹掉今天努力,清空今日數據才是危險操作。
2. 第二問聚焦在關閉頁面後的計時語義
Codex 接着問:如果專注中途關閉網頁或瀏覽器,過一會兒再打開,希望計時怎麼處理?
• A. 按真實時間繼續流逝計算 • B. 關閉就視為暫停,重新打開仍顯示關閉前剩餘時間 • C. 不恢復進行中的計時,只保留今天完成數
我的選擇是 B。
這個問題也有效。原始用戶故事只要求“關閉瀏覽器再打開,今天的成績別清零”,這是一句話需求裏的典型問題:沒說要什麼、只說不要什麼。
3. visual-companion 給出三種界面佈局方向
隨後skill通過 visual-companion 展示了三種主界面佈局方向:
它讓我選擇一種。我沒有隻選一個,而是選擇了“3 個都要”:在右上角提供一個佈局切換圖標,讓用戶在審美疲勞時可以切換顯示樣式。
這本質上是在需求驗證過程中的Aha高點,AI點出了一個我沒說出來,但實際非常渴望的一個需求。
4. 架構問題暴露出用戶故事輸入的一個風險
接下來AI推薦首版採用“單頁靜態應用”:理由是自用、瀏覽器能跑、不要登錄協作,純前端方案最輕,維護成本最低。
我的反饋是:
我需要前後端分離並用數據庫(PG)持久化存儲數據,避免後續執行開發統計報表、Kanban 的時候還要做大規模重構。
這個問題非常及時。原始用戶故事沒有顯式寫後續報表和 Kanban。
它逼我補齊了真實的產品意圖。
Codex 隨後給出技術路線選項:
我選擇了 A:單用戶 API + PostgreSQL。它暫不做登錄,但所有數據通過後端寫入 PG,並在數據模型裏預留用戶擴展點。
5. 彙總產品範圍和核心流程
在得到上面的幾個關鍵答案後,Codex 先做了一輪設計草案的二次確認,都是之前已經確認的具體問題,放到一起再讓我看一遍整體。
這一步的價值在於,它把“零散回答”重新拼成了一個可確認的產品邊界。對於公開評測來說,這也是一個關鍵節點:如果這裏已經出現誤讀,後面的需求文檔大概率會繼續放大誤差。
6. 最後一輪確認架構、數據模型和接口邊界
隨後 Codex 進入第二份設計草案:架構、數據模型與接口邊界。
這一輪明確了幾個工程邊界:
從評測角度看,這一步已經超出了單純“用戶故事複述”,進入了“把產品意圖轉成工程可執行邊界”。
從這裏開始,作為產品經理就不再需要關注,這在實際研發工程體系裏,應該由架構師接手了。
階段 2 過程觀察
總體評價:
1.用戶故事口吻能讓 AI 抓到用戶場景,也能激發出不錯的追問。
2.最終輸出的需求文檔,我給9分(不計入成績)
從經典敏捷實踐來看的話,它寫的太多、太細了,背離了敏捷實踐的基本原理——它把團隊討論的空間壓縮的非常小。
但從AI的工作原理看,它不這麼寫,後面的coding是無法被有效約束的。
它寫出來的東西是個新物種:雖然長得是用戶故事,但肯定不是傳統意義上的用戶故事。
下一步的vibe coding能跑好才是它的目的,它本來就是寫給AI的,不是寫給人類的。
本質上,和軟件從卷GUI(圖形用戶界面),到轉向卷CLI(命令行界面)是一個原理。
滿分10分的話,你們願意給幾分?評論區給出你的評分。
最終的需求文檔全文很長,沒法放進來。如果感興趣想看一眼的,可以私信我。