人要做的工作,比 AI 出現以前要多更多了
整理版優先睇
AI 將專業能力商品化,反而令專家判斷嘅需求大增——人類要做嘅工作比 AI 出現前更多。
呢篇文章出自 Every 公司 CEO Dan Shipper 嘅萬字長文,佢哋係一間 30 人嘅 AI 公司,最早全面採用 AI 工具嘅企業之一。面對 AI 取代人類嘅普遍焦慮,佢提出一個反直覺結論:AI 進步唔會令工作消失,反而會創造更多需要人類專家做嘅工作。佢嘅核心論證係:AI 會將人類專業知識入面可以被清晰提煉嘅部分變成標準化商品,令預設模型輸出貶值,同時催生對差異化內容嘅需求。呢種需求最終指向人類專家——唔係做執行,而係做「框架設計者」,判斷當下要做乜、點樣引導 AI 創造獨特價值。
文章詳細拆解咗與 AI 協作嘅兩種模式:智能體員工(如 Slack 上嘅 Agent)同人類-AI 協作(如 Codex、Claude Code)。佢指出 Agent 需要人類持續維護同引導,否則表現會變差。更重要嘅係,佢揭示咗一個反饋循環:AI 令技能普及→同質化→對差異化嘅追求→新嘅專家需求。呢個循環喺每個 benchmark 中都睇到,包括佢哋內部嘅高級工程師 benchmark 同 OpenAI 嘅 GDPval。
Dan Shipper 最後用芝諾悖論比喻:AI 永遠追近人類,但人類作為框架設計者,總會喺更高層次重新創造需要判斷嘅工作。真正值錢嘅唔係單純創造,而係知道要創造乜嘢,同埋點樣令 AI 產生差異化成果。
- 人要做的工作,比 AI 出現以前要多更多了
- 人要做的工作,比 AI 出現以前要多更多了|重點 2
- 人要做的工作,比 AI 出現以前要多更多了|重點 3
- 人要做的工作,比 AI 出現以前要多更多了|重點 4
- 人要做的工作,比 AI 出現以前要多更多了|重點 5
AI 反而令工作更多:一個反直覺嘅悖論
Every 係一間 30 人嘅 AI 公司,按理應該最需要裁員,但 CEO Dan Shipper 發現:人要做嘅工作比 AI 出現以前多更多了。呢個唔係安慰劑,而係理性分析嘅結果:AI 將專業能力蒸餾成 Skill 呢種廉價商品,反而創造咗對 非廉價判斷 嘅巨大需求——審美、判斷、系統思維成為分水嶺。
兩種與 AI 協作嘅模式
文章將 AI 協作分為兩種模式:第一種係 智能體員工</highlight>,你喺 Slack @佢哋,佢哋會自行完成任務,例如 Claudie(諮詢助手)或者 Andy(編輯助手)。第二種係 人機協作</highlight>,例如 Codex 或 Claude Code,人類同 AI 喺同一空間來回配合,形成「人類三明治」——人類喺每項任務嘅開始同結束介入,確保質量。
- 1 協作 Agent:需要時@佢,完成指定任務,例如寫銷售提案、整理選題。
- 2 嵌入式 Agent:內嵌喺產品流程,例如客服 Agent Fin 自動處理 40% 支援對話,減輕人類重複工作。
無論邊種模式,規律都一樣:AI 自動化穩定重複嘅任務,但 複雜任務仍然需要人類</highlight>。智能體離人類越遠,表現越差;我哋曾經分配個人 Agent 畀員工,但好快發現佢哋需要大量維護,最後改為團隊共享。
自動化增加人類工作嘅反饋循環
Dan Shipper 提出一個清晰嘅循環:低成本獲取能力 → 普及同質化 → 對差異化嘅追求 → 新嘅專家需求</highlight>。例子:Every 嘅營運同事開始寫 code,行銷同事整 YouTube 縮圖,但成果多數係「勉強見得人嘅初稿」,反而需要工程師審核、設計師優化。
呢個循環唔止發生喺 Every,喺開源項目 OpenClaw 都見到:截至 2026 年 5 月,佢收到 44,469 個 PR,相比 Kubernetes 2022 年全年得 5,200 個。普及帶來數量爆炸,但同時帶來 質量參差,反而創造更多需要人類介入嘅場景。
Benchmark 嘅框架陷阱:分數唔等於能力
文章用佢哋內部嘅 高級工程師 benchmark 來說明:模型喺框架內表現隨分數提升,但框架本身係由人類設計。例如提示詞要求「基於第一性原理重寫」,如果改為「解決所有錯誤」,模型得分會接近零。框架設計者</highlight> 先係關鍵,人類需要決定架構、範圍、不變量。
- Benchmark 分數反映嘅係模型喺人類設定嘅框架內表現,唔代表模型有框架設計能力。
- 當模型喺某個 benchmark 達到飽和,人類會調整框架,重新定義難題,循環繼續。
- 例如 OpenAI 嘅 GDPval,提示詞已經幫模型做好大量前期工作(選範圍、定格式),模型只係執行者。
做框架設計者,而唔係執行者
Dan Shipper 用 芝諾悖論 比喻 AI 與人類嘅賽跑:AI 永遠喺框架內追近,但人類作為烏龜,總會喺更高層次創造新嘅需要判斷嘅問題。佢強調 自主性 嘅本質:人類擁有自己嘅目的、慾望同情境感知,而 AI 只係執行者。
最後佢引用一個猶太故事:一個人寫紙條記錄點樣着衫,但着好之後問「我喺邊?」呢個問題紙條永遠答唔到。AI 幫你完成所有執行步驟,但「你在邊」呢個關於方向同意義嘅問題,只有人類自己可以回答。呢個問題嘅答案,正正變得越來越值錢。
你係喺框架入面做執行,定係設計框架嘅人?前者嘅工作正被商品化,後者嘅價值被 AI 不斷放大。

2026 年第一季,美國科技行業裁咗 52,050 人,按年增長 40%。
Meta 裁咗 8000 人,同時喺員工電腦裝咗鍵盤記錄軟件,用嚟收集 AI 訓練數據。Anthropic CEO 亦公開話:AI 可能淘汰一半嘅入門級白領崗位。
如果你係一個坐喺辦公室嘅知識工作者,你可能已經不停問自己一個問題:下一個被取代嘅,會唔會係我?
但有一間公司,按理最應該俾出肯定答案,卻俾出完全相反嘅結論。
呢間公司叫 Every,一間 30 人嘅 AI 公司。佢哋係 AI 最激進嘅早期採用者之一。如果話邊個應該瘋狂裁人,就係佢哋。
但佢哋嘅 CEO Dan Shipper 喺最新嘅萬字長文入面寫道:「人要做嘅工作,比 AI 出現之前多好多。」
成篇文章我讀咗好多次,佢唔係為咗要接住我哋一碗有毒嘅雞湯。
相反,背後嘅思考邏輯非常深刻、理性甚至冷酷:
當 AI 將專業能力「蒸餾」成 Skill 呢種可以按需求調用嘅廉價商品,呢種廉價商品嘅泛濫,反而會創造人對「非廉價判斷」嘅巨大需求:
審美、判斷、對 AI 嘅思考、獨立思考同系統思維,將會成為人與人之間嘅分水嶺。
如果講得更加直白:喺呢個人人都可以用 AI 創造嘅時代,真正值錢嘅唔係去創造,而係知道要創造啲乜,同埋點樣令 AI 進行差異化嘅創造。
全文:https://every.to/p/after-automation

後 Agent 自動化時代
AI 進步非但冇減少人類嘅工作,反而創造咗更多——Dan Shipper。
AI 嘅核心深處藏住一個悖論。
喺 Every 平台,我哋已經將可以自動化嘅事都做曬自動化處理。我哋喺編碼、寫作、設計、客戶服務等多個領域用 Codex 同 Claude Code。OpenAI、Anthropic 同 Google 嘅每一款新模型發佈前,我哋都要先進行 Alpha 測試。我哋正隨住模型智能同自動化嘅指數級增長浪潮,全力向前推進,力求行得更快、更遠。
但對我哋而言,要做嘅人力工作似乎比以前更加多。我哋團隊有大約 30 人,並冇為咗啟用智能助手就將所有員工炒曬。我哋並冇放棄 SaaS 產品,轉而採用基於 Vibe Coding 嘅應用。我哋依然僱用人類提供客服服務(搭配大量智能助手輔助),同時都繼續聘請人類作家、編輯同工程師。
不過,我哋嘅工作確實同以前完全唔同咗。而家我哋已經唔使手動寫 code 喇。喺我哋嘅 Slack 裏面 @ 某人時,你根本講唔準對方係人定係 AI Agent。而家,經理們好似個人貢獻者噉提交 code,工程師們就直接對接客戶。最近幾星期,AI 回覆咗我 95% 嘅工作電郵。我個收件箱幾乎長期保持清零狀態(呢個對我嚟講真係好少見),但我仲會檢查電郵。
總括嚟講,未來既怪異,又熟悉。
令人意外嘅係,AI 已經咁深入民心。雖然 CEO、知識工作者同投資者似乎都達成共識:佢會對就業、經濟、安全以至人類存在嘅意義構成威脅。
Anthropic CEO Dario Amodei 警告話,人工智能可能會淘汰多達一半嘅入門級白領崗位。Meta 啱啱炒咗 8000 名員工,同時喺美國員工嘅電腦上安裝軟件,捕捉滑鼠移動、點擊同按鍵操作,用嚟獲取針對高級知識工作場景嘅高質量 AI 訓練數據。
連 Citadel 嘅 Ken Griffin 都有啲動搖,佢最近話:「呢啲唔係咩中層白領崗位呀。呢啲極高技能嘅工作,我用一個詞嚟形容:」正在被 AI 自動化。”
每次推出新模型,基準測試結果就呈指數級增長,呢個似乎印證咗呢一點。
喺「人類終考」,呢個研究生級別嘅 benchmark 入面,頂級模型嘅得分從一年前嘅個位數百分比,飆升到而家大約 44%。喺 GDPval 測試入面(評估前沿模型喺實際經濟工作中嘅表現同人類相比點樣),前沿模型嘅得分從相近嘅低位躍升至大約 85%。
今年五月,人工智能安全研究非營利組織 METR 發佈咗 Claude Mythos 模型嘅早期測試結果,結果顯示該模型喺人類專家需要大約 4 小時完成嘅任務上,成功率高達 80%。
我哋似乎即將迎來比人類更聰明嘅 AI。呢種 AI 唔單止擁有自主工作能力,仲可以連續運轉接近一整天。
但矛盾依然存在。如果你同 AI 行業嘅人傾,或者同行業外嘅早期使用者傾,你會聽到同我哋內部觀察到一樣嘅結論:而家要做嘅事比以往任何時候都多。
眼嚇,行業內外都喺度問一個核心問題:呢個到底只係暫時現象?下一次模型更新會係嗰個可以取代所有人嘅版本?我哋盯住各項指標,焦慮不安,成日諗:會唔會好快就迎來某個臨界點,嗰時所有工作都會消失?
但我認為:唔會有啲咩「臨界點」突然到來,令一切徹底反轉、工作崗位隨之消失。真實情況恰恰相反:自動化程度越高,需要人類專家做嘅工作反而越多。
背後嘅邏輯好簡單:AI 會將人類專業知識裏面嗰啲可以被清晰提煉、用嚟訓練嘅內容變成標準化商品。呢個會令默認模型輸出嘅價值大打折扣,同時催生對差異化內容嘅需求。即使我哋離 AGI 越來越近,人對獨特性嘅需求本質上依然係對人類專家嘅需求。
要搞清楚呢個背後嘅原因,剩係睇圖表唔夠,我哋要睇嚇而家 AI 喺工作中究竟係點用。呢個可以幫我哋從更務實嘅視角,睇清呢個悖論同解決方法。

點解 Agent 反而令人類工作更多
由 2022 年起,我哋就不斷圍繞 AI agents 報道未來工作嘅相關話題。
三年前,我寫過一篇關於分配型經濟嘅文章:同 AI 工具協作嘅工作方式,最終會變得同人類管理者嘅工作非常相似。嗰陣仲係 ChatGPT 裏面嘅基礎提示詞同回應都被視為極之超前嘅年代。
分配型經濟:https://every.to/chain-of-thought/the-knowledge-economy-is-over-welcome-to-the-allocation-economy
去到 2025 年中,我哋公司徹底迷上咗 Claude Code。
Cora 總經理 Kieran Klaassen 突然發現自己唔使再手寫 code 喇,而家佢可以成日坐喺終端前,用通俗易明嘅英文指令同 code Agent 交互。呢種做法好快蔓延到成個團隊,而且一年前喺 Lenny 播客上,我曾稱 Claude Code 係「知識工作領域最被低估嘅工具」。
我之所以講呢個,係因為我哋最準確嘅預測都來自於將 Every 視作某種早期採用者實驗室。我哋往往會喺新嘅工作模式普及之前就接觸到佢哋。隨住技術成熟、工具變得更易用,呢啲模式開始喺更廣泛嘅市場出現。
以下係我哋目前公司內部正在發生嘅事:
「與智能體協作嘅兩種模式」
同 AI 協作嘅方式,正開始分化為兩種截然不同嘅模式。
第一種情況,正係 AI 領域討論中預測得相當準確嘅,智能體作為員工。
呢啲係你可以委託工作嘅 Agent。有啲智能 Agent 運行喺 Slack 平台上,佢哋有自己的名同職責,你需要佢哋做事時直接 @ 就得。有啲智能 Agent 嵌入日常工作流程中,例如客服場景,佢哋係處理重複任務嘅常駐角色,始終在線待命。
第二種模式更加奇特,而且根據我嘅經驗,佢更加重要。
呢個就係好似 Codex、Claude Code 同 Claude Cowork 呢類工具入面嘅人機協作。呢啲地方唔單止係用嚟交接工作。佢哋正在成為工作本身嘅核心操作系統。喺呢度,你可以同多個智能體同時操作同一部電腦,完成異步智能體難以勝任嘅高度複雜、原創性工作。
喺呢兩種模式下,你都可以藉助 AI 自動化處理同委派大部分工作,但呢兩種模式都離唔開人(一係你自己,一係其他同事)先至可以順利運行。
「智能體員工」
俾 AI 智能體員工分配任務後,佢哋會自行完成答案、行動方案、報告、草稿或分類決策等工作,全程唔使你介入。呢類系統至少有兩種類型:協作 Agent 同嵌入式 Agent。
協作 Agent 就係你可以喺 Slack 中 @ 嘅嗰種工具,例如叫佢幫手處理工作。你需要嘅時候,佢隨時喺度。呢啲智能體嘅風格模仿咗 OpenClaw,或者我哋內部嘅 Plus One。
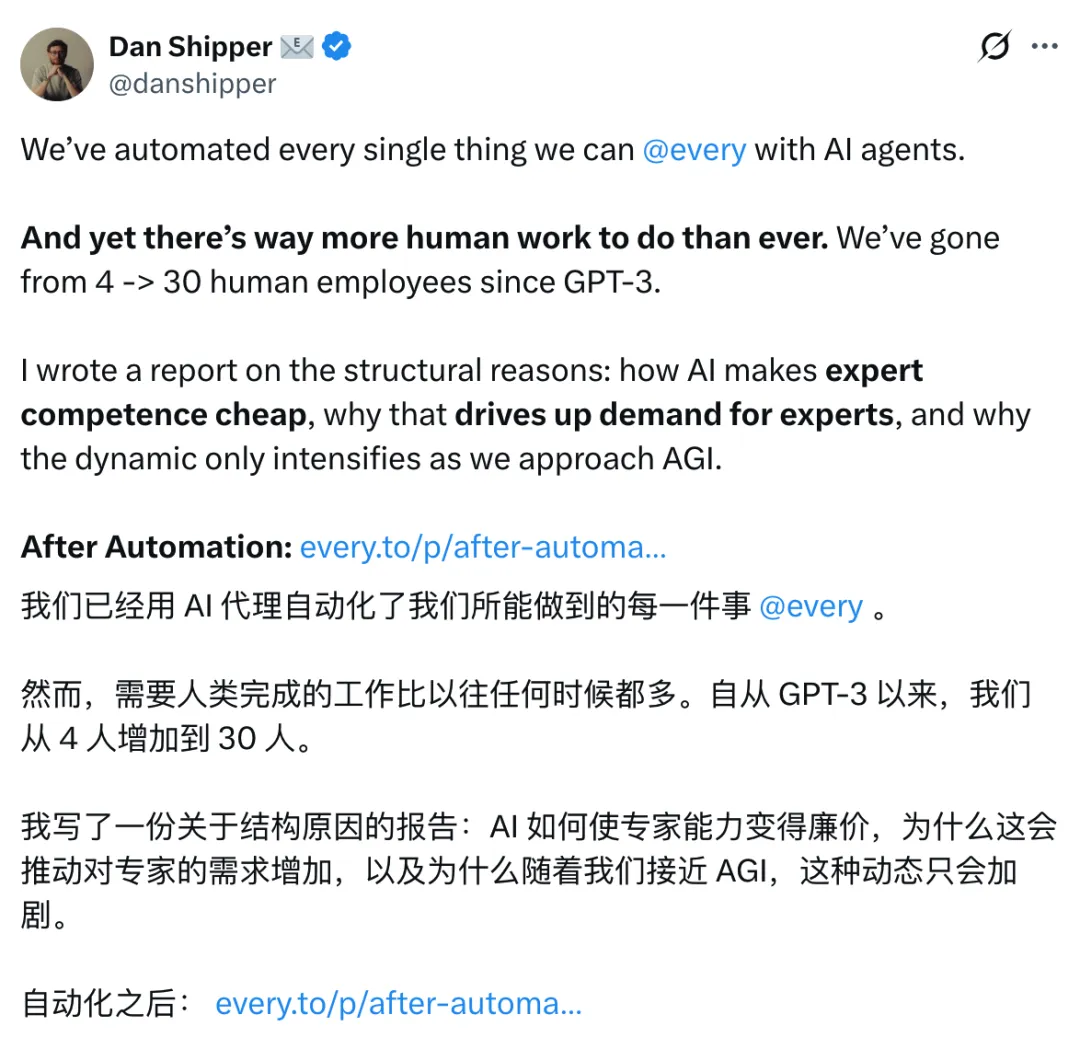
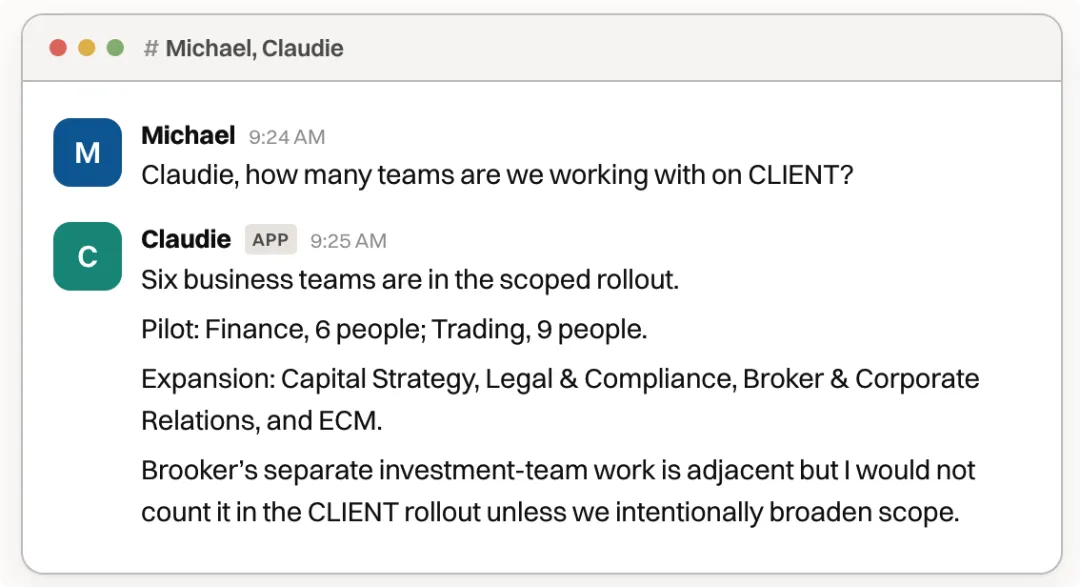
Claudie 係我哋諮詢團隊嘅協作助手。Claudie 負責撰寫銷售提案、製作培訓課件初稿、跟進項目待辦事項等一系列工作。
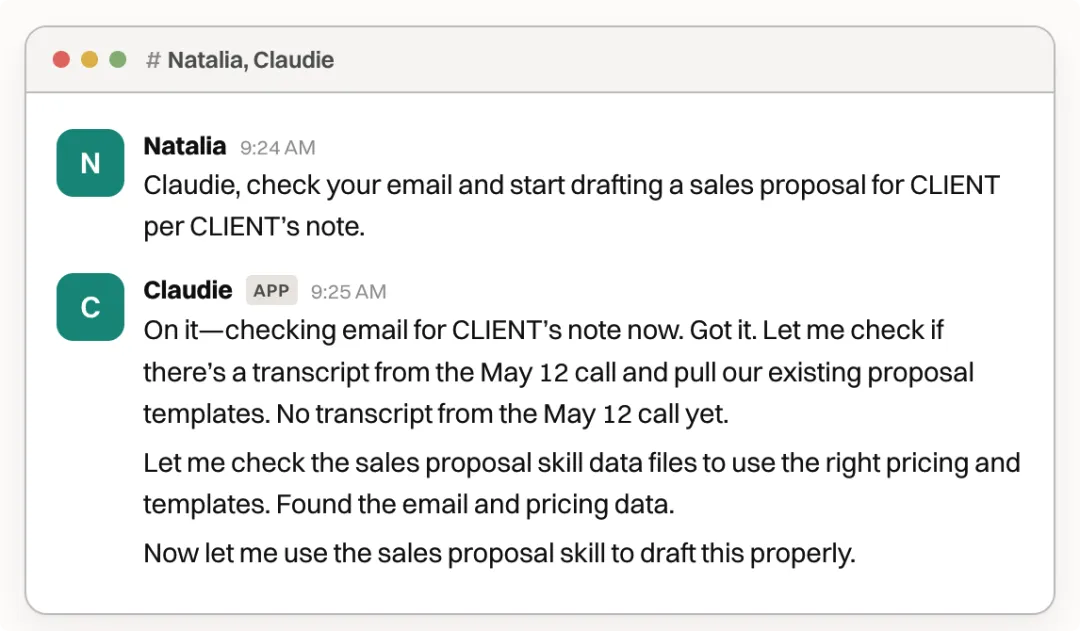
Andy 係我哋編輯部嘅同事助手。佢會從公司內部 Slack 羣組收集「金點子」,即係好嘅選題靈感,然後將佢哋整理成摘要同初稿,供撰稿團隊用嚟編寫每日通訊。
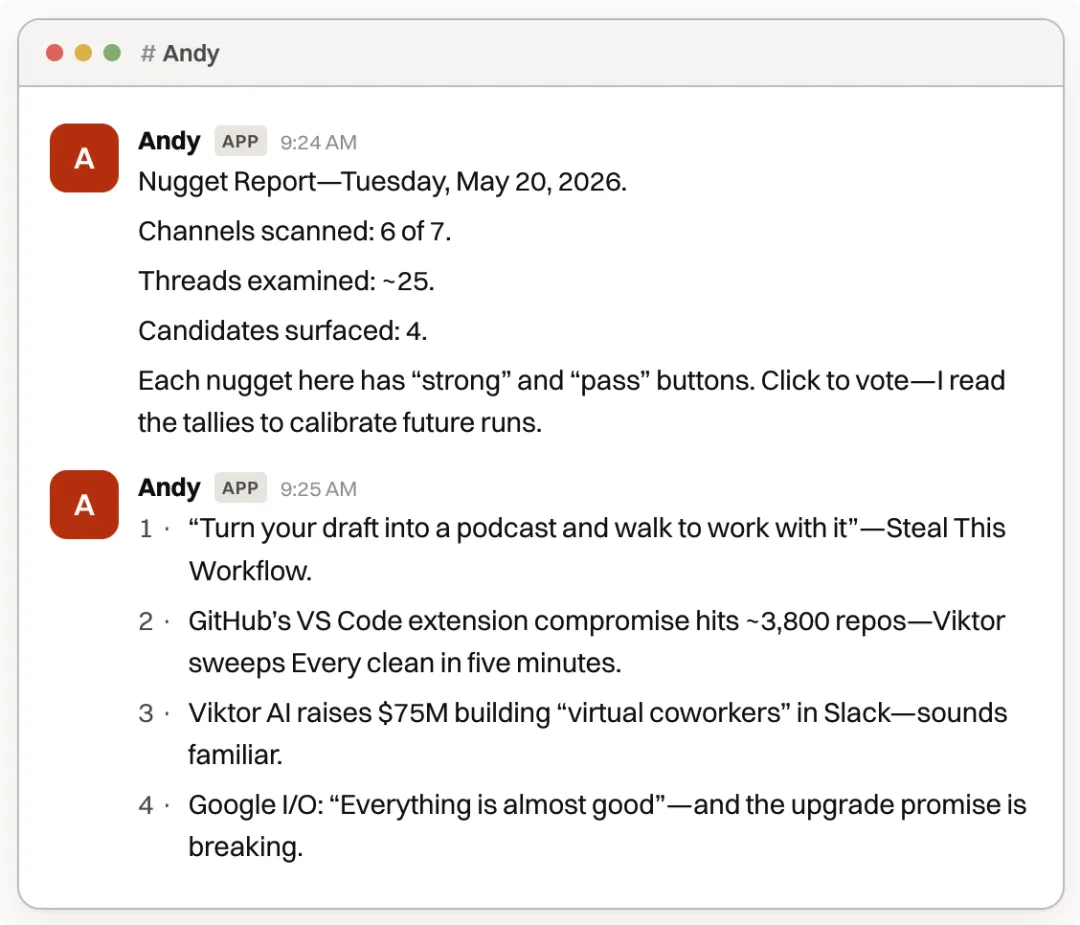
Viktor 係一個通用智能體,可以喺成個組織內承擔各類工作。我哋用佢嚟收集增長指標、分析用戶調研,仲可以將雜亂嘅內部討論整理成研究備忘錄同產品建議。
「嵌入式智能體」
嵌入式智能體內嵌於產品工作流程之中。佢哋冇咁靈活,但喺處理重複性任務時就好高效。
Fin 係最典型嘅例子:呢個嵌入我哋客服平台嘅智能 Agent,通過聊天同電郵幫我哋承擔咗大量支持工作。
5 月最近嘅一星期,Fin 介入處理咗 Every 平台 202 次支持對話嘅 65%,其中 81 次唔使人工協助就完成閉環,佔所有可處理對話嘅 40.1%。
好似呢啲嵌入式 Agent,令我哋嘅客服經理 Waqqas Mir 唔使再將大量時間花喺基礎工單上,而係可以將更多精力投入兩部分工作:搭建工單響應系統,同處理需要深度互動嘅複雜案例。
「人類同 AI 協作」
無論係協作者模式定嵌入式模式,兩者嘅規律都係相同。
員工智能 Agent 正在接管越來越多穩定、可重複且流程清晰嘅工作任務。但好多工作仍然需要人工介入。我哋反覆發現:要完成任何複雜任務並做出高質量成果,最佳方式係令 AI 同人類喺同一個協作空間裏面嚟回配合。
呢個正係 Codex、Claude Code 同 Cowork 嘅用途所在。呢類工具令你可以創建並向多個聊天線程中嘅一個或多個 Agent 分配任務。呢啲智能 Agent 可以訪問你嘅電腦同所有數據來源。你可以睇到 Agent 人正在做嘅每一件事同諗緊嘅內容,仲可以隨時打斷。
你負責喺 Agent 每項任務嘅開始同結束階段對佢哋進行管理,確保任務完成質量,並為佢哋安排下一項工作。Kieran 將呢個稱為「人類三明治」,我哋就好似夾喺 AI 工作兩端嘅麪包。

最典型嘅例子就係寫程式。Every 嘅工程師們成日都同智能體反覆配合。佢哋正在規劃新功能或者修復 bug,審查已完成嘅工作,而且,如果採用我哋嘅複合工程理念,仲會持續優化系統,令佢隨住時間推移不斷改進。
複合工程理念:https://every.to/guides/compound-engineering
但呢種協作遠唔止於寫 code。
「知識工作嘅新型操作系統」
Codex 同 Claude Code 正在成為職場嘅新操作系統。我幾乎成日都泡喺 Codex 入面,用佢嘅內置瀏覽器運行我嘅 SaaS 工具。佢令我嘅智能助手可以隨時陪我處理各種任務,幫我達到單靠自己無法達到嘅水平。
我係喺 Codex 嘅應用內瀏覽器中,透過 Proof 撰寫呢篇內容。Codex 會實時監測我嘅寫作內容,隨時可以生成子智能體幫我完成各種任務:例如寫段落初稿、為下一部分揾例子,或者做校對編輯。
我都係噉發電郵嘅。Cora 係我嘅電郵客戶端,我喺 Codex 嘅內置瀏覽器入面用佢:一邊瀏覽收件箱,一邊透過 Monologue 逐件讀出電郵內容。其餘工作由 Codex 同 Cora 負責處理。
「每個智能體都需要人類」
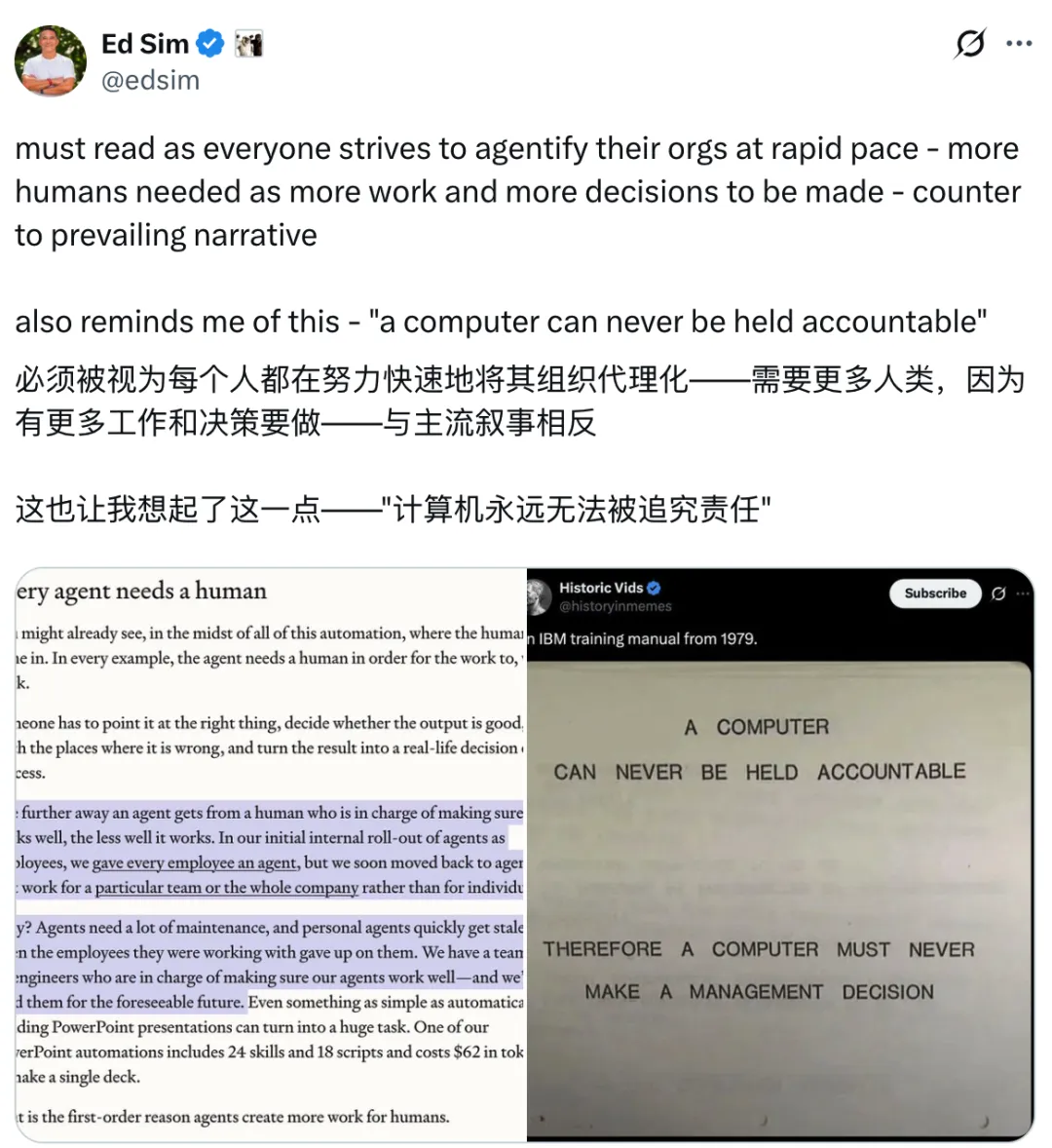
喺呢波自動化應用嘅浪潮中,你或者已經清楚人類嘅角色所在。所有案例都表明,Agent 必須有人類參與先至真正發揮作用。
總要有人引導 AI 做啱嘅事:判斷輸出係咪合格,揾出問題所在,再將結果轉化為實際嘅決策或流程。
AI 智能體離開負責監控佢正常運行嘅人類越遠,佢嘅表現就越差。喺我哋內部首次將 AI Agent 作為員工部署時,曾經俾每位員工都分配咗一個 AI Agent。但好快我哋就調整策略,令 AI 代理服務於特定團隊或整間公司,而唔係個人使用。
點解?Agent 需要大量維護,個人 Agent 尤其係噉:一旦同佢協作嘅員工放棄使用,佢哋好快就會失效。我哋有一支 AI 工程師團隊,佢哋負責確保我哋嘅智能體正常運行,而且喺可預見嘅未來,我哋都離唔開佢哋。
就算係自動生成 PPT 簡報呢種看似簡單嘅操作,都可能變成一項艱巨嘅任務。我哋嘅一款 PPT 自動化工具整合咗 24 項功能同 18 個腳本,生成一份簡報嘅 token 成本係 62 美元。
呢個正係 Agent 反而令人類工作更多嘅第一層原因。
不過,仲有第二層原因。
「點解自動化反而增加咗人類嘅工作量」
只要睇嚇過去幾年 AI 指數級嘅發展軌跡,再諗嚇佢嘅架構原理同能力來源,你就會發現一個清晰嘅反饋循環:呢個循環反而創造咗更多人類工作。
當前嘅語言模型訓練數據來源於人類能力嘅各類可見數據:code、散文、圖片、客戶 support 工單、產品規格等等。佢哋將所有呢啲已成功完成任務後產生嘅各類副產品,打包成一種人人都可以低成本獲取嘅形式。
最終結果係,以前嗰啲稀缺嘅技能:例如編寫 pull request、製作 YouTube 縮圖、撰寫通訊稿,而家幾乎人人都可以掌握。
於是,低成本獲取嘅能力會帶來迅速普及:
原本稀缺嘅事物一旦成本下降,供應量就會突然激增。
喺 Every,我哋經常遇到呢種情況。營運同客服人員都開始寫 code、發起 pull request 喇。市場人員正在製作 YouTube 縮圖。工程師同產品人員而家會寫文章、指南同 landing page 嘅草稿,而呢啲內容以前佢哋根本唔會掂。
呢種現象唔限於 Every,其他地方都喺度發生。以開源 AI 智能體項目 OpenClaw 為例:
截至 2026 年 5 月 16 日,其 code repository 已收到 44,469 個 pull request。其中 4 月 1 日以來新增 12,430 個,5 月 1 日至今新增 3,990 個。呢個數量太驚人喇。作為對比,全球最流行嘅開源項目之一 Kubernetes(開源嘅容器編排引擎),2022 年全年共收到 5,200 個 pull request。
於是,呢種普及又會帶來同質化,導致所有舊嘅專業技能被商品化:
而家大家都用緊同一款模型,而呢啲模型嘅能力仲停留喺過去,默認情況下,佢哋生成嘅內容一係「勉強見得人嘅初稿」,一係就係「純粹嘅垃圾」。
呢種粗製濫造唔係某一種特定嘅錯誤:關鍵唔在於用破折號,唔在於某種特定嘅句子節奏,更加唔在於 landing page 上嘅紫色裝飾元素。
呢種粗製濫造,係 AI 令人討厭嘅雷同重複:唔同場景下嘅人用同一個基於相同語料庫訓練嘅工具,如果唔經思考,默認產出嘅就係呢個結果。當所有人都可以接觸到具有相同固有傾向嘅專家時,就會發生呢種現象。
營運人員可以輕鬆發起 pull request,市場人員幾秒就可以做出 YouTube 縮圖,工程師都可以快速撰寫產品指南。呢啲場景看似效率提升咗,但結果往往係產量上咗去,但內容嘅質量、連貫性同差異化就落咗嚟。
所以,呢種千篇一律嘅豐富產出,好快就會淪為大路貨。
於是,呢種同質化,又會催生對差異化嘅追求:
互聯網令人們可以快速識別出咩係劣質內容。任何作品都可以瞬間傳遍全球,而且呢種情況屢見不鮮。當太多嘢開始變得千篇一律時,我哋就會覺得唔對路。
呢個意味住,當你第一次見識到新模型嘅能力時,你會俾佢徹底震撼,甚至可能有點害怕。但幾個月後,佢哋就變得平平無奇喇。你嘅標準已經變咗。
我哋想要嘅唔單止係隨便一個 React 應用或研究報告,而係一個完全貼合個人、公司同具體場景需求嘅產品。我哋想要嘅係嗰種鮮活又獨特嘅,而唔係廉價且千篇一律嘅。我哋想要嘅,係嗰種生產起來(無論時間定金錢成本)比消費佢要貴嘅嘢。
我哋想要有地位象徵嘅嘢。每當新技術出現,令以前嘅高端身份象徵變得觸手可及時,我哋總能創造出新嘅身份遊戲,以適配我哋嘅新能力。
當工作隨處可見且千篇一律時,嗰啲唔跟套路出牌嘅工作,就變成稀有、有價值嘅事。
於是,呢種對差異化嘅追求,會轉化為對專家嘅新需求:
語言模型嘅架構特性,加上佢哋喺全球範圍內嘅廣泛普及,意味住真正稀缺且有價值嘅工作必須由人類嚟完成。
當前一代模型只瞭解已完成嘅工作。人類清楚眼嚇要做啲乜。
任何情境一旦被簡化為文字,一旦成為語料庫,就變成一具「屍體」。人類可以敏鋭感知特定時刻、客戶需求、code repository 細節或對話情境,呢個係當前訓練語料庫尚未具備嘅能力。呢種活躍度並唔係淨係擁有更多最新數據。
我哋總是帶住過往嘅印記嚟到當下,帶住持續更新嘅自我視角:時刻變化嘅慾望、不斷浮現嘅擔憂,以及對事物重要性嘅實時判斷,呢一切都在改變我哋眼中嘅世界。而 AI 模型只有喺被提示後先可以採用呢個視角,在此之前唔會。
呢個就係我哋最初探討嘅悖論:降低專業工作嘅成本,並唔係簡單取代專業人員。呢個會催生更多需要專家判斷嘅場景。
當營運人員用 AI 提交 code merge request 時,需要工程師進行審核。市場人員製作 YouTube 縮圖時,要俾設計師優化一下。工程師寫嘅嘢,要作家同編輯潤色先至似樣。
對此,人類專家同時從兩個方向入手。
有啲人用 AI 搭建系統,嚟處理同利用海量嘅新工作,審核隊列、評估流程、工具框架、code repository 規則、Claude 同 Codex 嘅指令文件、持續集成、權限設置,以及可以將初步嘗試轉化為優質成果嘅工作流。
仲有啲人用 AI 完成咗更大規模、更有趣嘅任務,如果冇 AI,呢啲工作佢哋根本做不到。例如,揾出好似 MacOS 噉嘅操作系統嘅漏洞通常需要幾星期甚至幾個月。小型安全公司 Calif 藉助 Anthropic 嘅 Mythos Preview,只用了五日就發現咗蘋果 M5 硬件上首個公開嘅 macOS kernel 內存漏洞利用。
正因為咁,喺實際應用中,AI 並唔會取代專家級嘅人類知識工作。佢可以顯著增加工作量,但呢啲工作本身既無差異化亦無價值,除非有人類參與其中。
我並唔係要論證 AI 點解會俾所有崗位都增加工作量。經濟體系錯綜複雜,我哋喺 Every 關注嘅領域係專家級知識型工作:企業正圍繞新技術進行重組,呢類工作已開始受到衝擊。
不過我想強調一點:無論你而家從事咩工作,都存在一種唔會被 AI 模型取代嘅工作形式,就係用呢啲模型去解決你所見到嘅當下問題。呢個正係知識工作嘅發展方向。

AI 喺 benchmark 屠榜嘅本質
最明顯嘅反駁係:睇嚇 benchmark 嘅指數級提升,呢一切都係暫時嘅,等模型追上嚟就得。
不過要小心,呢度有個陷阱。我哋稱之為「圖表臆想症」:如果你盯住 METR 嘅時間範圍,讀咗《AI 2027》,又完全靠計算圖嘅外推嚟構建未來模型,咁你對模型進展嘅認知可能會變得好驚悚。
回答呢個問題,唔可以剩係靠推測想像中嘅未來模型。不過,呢種推測的確係分析嘅一部分。我哋要睇嚇基準係點制定,咁先更清楚佢哋到底講緊啲乜,以及同我哋之前討論過嘅真實案例有咩關係。
我哋發現咗一個結構性特徵:benchmark 總係喺特定框架內進行。要衡量任何事物,都要先將問題定格喺靜態嘅,因此係可量化嘅框架裏面。一旦某個框架達到飽和,改變框架就可以輕鬆將佢歸零。當然,新框架內嘅進展會繼續,但同樣嘅過程會重複上演。
因此,雖然任何基準上嘅指數級進步都係真實存在,但只要簡單調整一下 benchmark,呢種進步就會顯得微不足道。基準飽和嘅分形特性,向我哋揭示咗我哋一直喺圖表中追尋嘅悖論。
等我哋用一個真實嘅 benchmark 例子嚟證明呢一點。
「基準測試係點樣製作嘅」
我哋內部開發咗一套「高級工程師 benchmark」。顧名思義,佢旨在測試前沿模型喺高級工程師級別嘅編碼任務(例如大型重構)上嘅表現。
高級工程師基準測試會俾 code 智能體提供一個氛圍編碼但已出問題嘅生產 code repository。呢段 code 嚟自 Proof 嘅真實 code repository:當初我係憑感覺寫嘅,後來要揾資深工程師嚟收拾爛攤子。
智能體拿到嘅係修復前嘅 code repository,俾出嘅指令就好似你對高級工程師講嘅噉:「呢段 code 寫得太求其,完全係憑感覺湊出嚟嘅垃圾;請從第一性原理重新寫過。」
呢個係一項出色嘅 benchmark:佢既可以檢驗 code 智能體處理各類不同且不相關問題嘅能力,又可以考察佢係咪具備足夠嘅自主性、清晰嘅概念認知,同完成可運行重寫嘅魄力,我仲準備咗兩份由人類資深工程師(佢哋用咗 AI 工具)完成嘅改寫版本,用嚟對比同評估模型嘅輸出。
code 智能體覺得呢個任務相當棘手。智能體唔單止要揾出問題嘅根源,仲要喺多輪對話中記住問題核心,唔被現有 code 分心。佢仲要可以坦然刪除 code repository 中嘅大量內容:而呢個正係智能體被訓練要避開嘅操作。
大多數 code 智能體都可以識別出重構嘅大致方向,但到咗實際執行環節,佢哋往往只係臨時修補問題,而唔係徹底解決。
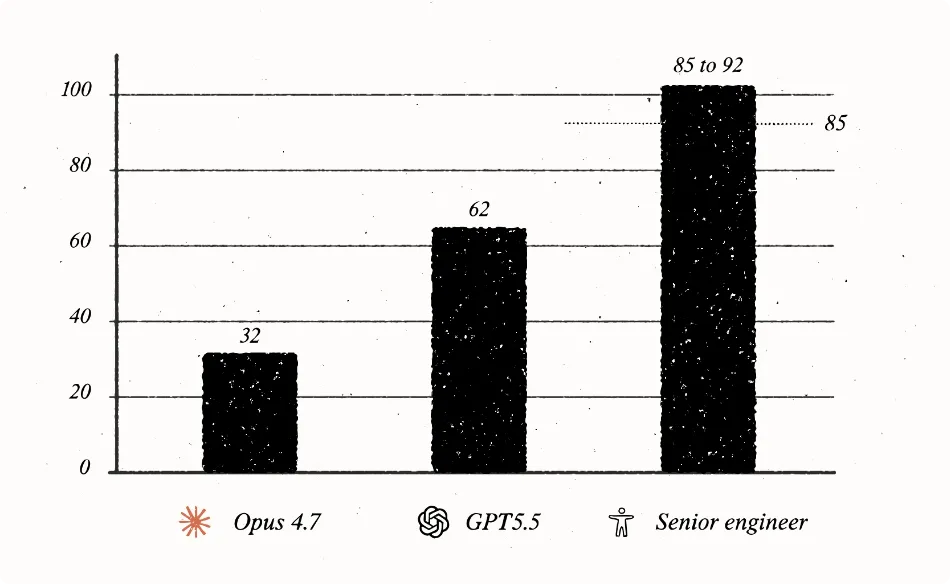
呢一切,直到 GPT-5.5 出現:GPT-5.5 喺最佳測試輪次中得分 62/100,比 Opus 4.7 高出大約 30 分。
GPT-5.5 嘅表現好似突破咗某種界限:佢唔再係自動補全、唔係助手、唔係工具,而係某種令人隱隱不安地接近人類嘅存在。人類高級工程師喺呢項基準測試中嘅得分通常喺 85 到 95 分之間,所以只要再提高 30 分,佢就可以達到人類高級工程師嘅水平。
呢個就係 benchmark 對人嘅想像力嘅衝擊:佢將模糊嘅質性變化,變成一個簡潔嘅數字,講述住一個既有力又令人唔安嘅故事(於是,接下來佢就會帶來:圖表臆想症)。
我猜測,呢啲模型喺未來一年內,喺呢項基準測試中嘅得分會達到 80 到 90 分。但想真正明白分數嘅含義,要先搞清楚佢到底包含啲咩信息。喺呢度,62 分唔止係衡量模型本身嘅指標。
佢係框架內模型表現嘅衡量,即係佢對特定提示詞嘅響應方式。
「benchmark 衡量嘅係框架內嘅工作」
要評估模型性能,第一步就係設計提示詞。冇咗佢,模型不過係一堆毫無生氣、近乎無限嘅可能性啫。
提示詞構建咗一個小宇宙:一套關鍵要素同應對方式,將所有可能性壓縮成一條明確嘅行動軌跡。模型「獨自」表現如何,其實根本唔存在。我哋唯一可以觀察到嘅,就係佢點樣回應各種提示詞。(以及提示點樣轉化為回應嘅一啲底層機制。)
一旦收到提示輸入,模型就會喺短時間內「甦醒」,將原本靜態嘅可能性集合,收斂成關於後續內容嘅單一預測。
喺高級工程師 benchmark 中,我哋會提示模型修復 code repository,並喺佢完成後檢查輸出結果。當運行框架冇內置目標功能時,我哋仲會啟用一個自動監控程序:每當模型停止運行,就會問佢係咪完成咗既定任務。
我哋從一個看似簡單嘅提示詞入手,將其作為起始框架。呢個提示詞嘅設計初衷,就係要令 Vibe Coding 嘅程序員可以直接對佢哋嘅編碼助手講出嚟。佢既冇堆砌專業術語,亦冇明顯俾出問題嘅答案:
呢個倉庫入面嘅 code 完全係憑感覺亂堆嘅垃圾,好易崩潰。一堆堆八竿子打唔着嘅問題出現:一係服務宕機,一係文檔重複,我都差啲癲咗。
我總覺得呢嚿嘢就係一堆靠氛圍湊數嘅垃圾。如果當初從頭開始設計 code repository,尤其係實時文檔協作呢部分,我哋嘅 code 結構肯定會好唔同。
所以如果我哋想做一次徹底嘅、基於第一性原理嘅結構性重寫,唔去糾結邊啲實現服務需要保持一致呢?點樣進行乾淨遷移?我哋從一個清晰嘅概念出發從頭開始。我哋應該點做?點樣構建?喺成個 code repository 中,邊啲條件係始終為真嘅不變量?請為此制定計劃。
高級工程師 benchmark 嘅提示詞雖然比較通用,但佢本質上係個框架。如果我哋調整佢,模型嘅表現就會唔同。
例如,提示詞要求進行「基於第一性原理嘅結構化重寫」,指出問題可能出喺 code 嘅「文檔協作」部分,並要求編碼智能體揾到並遵守「不變量」。
如果去掉呢啲細節,分數就會下降。
如果我哋將提示詞完全換成要求模型「解決所有反覆出現嘅錯誤」,模型嘅得分就會接近零。佢會直接開始逐個識別並解決問題,而唔係退後一步思考係咪需要重寫。
我都可以輕鬆提升模型嘅得分。如果我叫佢刪除大量 code,並提供需要精簡嘅具體檔案名,或者叫佢喺聲稱完成之前檢查工作成果、確保應用完全可用,咁佢完成任務嘅表現會更好。
講到尾,創建基準時,選擇咩提示詞,亦即係框架:總係需要主觀判斷嘅。
理想嘅提示詞需要滿足:既要夠難,令當前模型表現唔好;又要貼近佢哋嘅能力邊界,令模型可以通過爬山法逐步提升,咁你就可以直觀見到進步。
因此,當我哋觀察基準測試時,見到嘅其實係模型喺我哋選定嘅某個特定問題框架下變得更好。
咁當佢嘅得分由 60 提升到 90 甚至 100 時,會發生啲乜呢?
「廉價刺激需求」
如果 GPT-6 可以一鍵完成 code repository 重寫,咁就會有更多人嘗試第一性原理重寫。
突然之間,第一性原理重寫由罕見、昂貴、由資深工程師主導嘅項目,變成咗每個創始人、產品經理、營運人員以至初級工程師都可以喺一個下晝輕鬆嘗試嘅事。
出咗問題嘅內部工具被重寫而唔係修補:SaaS 產品被 clone 而唔係續訂。舊嘅 Rails 應用、混亂嘅 React dashboard、客戶 support 工具、管理面板同數據 pipeline,全部變成「直接重寫」嘅候選對象。
提出並執行嘅重寫數量爆發式增長。但呢啲重寫大多會係粗製濫造。撳「一鍵重寫」按鈕前,你要考慮 1000 個變數:而家人人都可以操作,呢啲變數就藏唔住喇。
而家好清楚應該叫邊個嚟幫手。
「新需求呼喚專家」
一旦基準開始飽和,其框架內工作嘅成本就會降低。
可以將呢種新近變得廉價嘅能力應用喺當下實際問題中嘅專家,需求會隨之上升。
用 AI 嘅資深工程師需要搞掂好多細節,先至可以令新嘅第一性原理重寫方案生效:首先就要判斷呢啲重寫到底有冇必要。
應該而家重寫、稍後重寫,定乾脆唔重寫?範圍應該涵蓋啲乜?當前 code repository 入面邊啲應該保留?架構、數據庫、緩存服務器同託管服務商應該保留定全部換?應唔應該先睇嚇有幾多人用緊呢個有問題嘅功能,再決定係咪刪咗佢?邊個嚟審核結果?審核依據係咩?回滾方案係點樣?現有數據點算?
問題延伸至無數維度,每個答案都會重塑其他答案。
資深工程師會主動介入填補空缺。有啲人會對呢種打擾有啲火滾,有啲人會搭建系統嚟應對呢類請求,仲有啲人會用呢啲新模型自己做第一性原理重寫:效果比模型用默認提示詞生成嘅好得多。
「循環往復」
當目前嘅高級工程師基準達到飽和後,我哋會調整框架,重新將佢清零。
下一個基準唔會剩係問「你可以重寫呢個應用程式嗎?」,佢會問:你可以判斷幾時需要重寫嗎?可以確定範圍嗎?可以保留正確嘅不變量嗎?可以管理遷移過程嗎?可以判斷最終結果係咪達標嗎?
隨住資深工程師藉助 AI 解決呢啲問題,模型自身解決呢類問題嘅能力都會不斷提升。
我哋都會暫時慌一陣。
「睇嚟模型而家可以決定係咪要重寫喇!佢哋可以做資深工程師做到嘅一切!」
然後,一個之前未曾顯現嘅新前沿將會浮出水面,我哋會重置基準,需求被激活,成個過程就此循環往復。
「呢一點喺每個 benchmark 入面都可以見到」
呢個並唔係高級工程師基準獨有嘅困境。仔細觀察,每個 benchmark 入面都可以發現呢個現象。
以 OpenAI 嘅 GDPval 基準測試為例。該評估旨在考察 AI 喺唔同職業嘅專家級任務上嘅表現:合規專員、律師、軟件開發人員等。
GDPval 啱啱發佈時,OpenAI 嘅研究數據顯示,GPT-5 喺 40.6% 嘅場景下表現同人類專業人士相當或更好。而 Claude Opus 4.1 更加驚人,竟然有 49% 嘅時間優於人類專家。
一時間出現咗唔少標題,例如 Axios 嘅「OpenAI 工具顯示 AI 正在追上人類工作水平」,或者《財富》嘅「OpenAI 新基準測試 GDPval 顯示:AI 模型在半數任務上已同專家不相伯仲」。
呢啲結果的確好亮眼,但你再睇嚇呢啲任務嘅提示詞:
你係一名審計師,作為審計項目嘅一部分,你需要審查並驗證所報告嘅反金融犯罪風險指標嘅準確性。
附件入面名為「Population」嘅電子表格包含 2024 年第二、三季嘅反金融犯罪風險指標。你獲取呢啲數據係審計複核工作嘅一部分,旨在對代表性指標子集進行抽樣測試,以驗證兩個季度申報數據嘅準確性。請使用「Population」電子表格嘅數據完成以下內容:
根據 90% 嘅置信水平同 10% 嘅可容忍誤差率,計算審計測試所需嘅樣本量。請喺第二個標籤頁「樣本量計算」入面附上計算過程。
對第二季度同第三季度數據(H 列同 I 列)進行方差分析。計算季度環比方差,將結果填入 J 列。
根據以下標準選擇審計測試樣本,並喺 K 列輸入「1」標記:……季度之間差異超過 20% 嘅指標。重點關注百分比變化特別大嘅指標。
鑑於過往問題,需要納入以下實體:CB Cash Italy、CB Correspondent Banking Greece、IB Debt Markets Luxembourg、CB Trade Finance Brazil、PB EMEA UAE。包含風險權重更高嘅 A1 同 C1 指標。保留兩季度都係零嘅行。納入貿易金融同代理銀行業務條目。納入開曼羣島、巴基斯坦及阿聯酋數據。確保覆蓋所有部門同子部門。
創建新電子表格 Sample:表 1,從原始「Population」表複製嘅選中樣本,選中行喺 K 列標註。表 2——樣本量計算過程。
要令模型可以完成呢個任務,需要投入大量人類智慧嚟設計問題框架。
GDPval 未能衡量嘅嗰啲繁重人力工作,早喺模型啟動前就已經完成。有人需要審查同驗證呢組特定指標嘅準確性,確定合適嘅置信區間、符合要求嘅指標範圍,同結果嘅呈現格式。
只要框架設計得當,模型就可以勝任專業工作。但諗嚇,如果係你同我嚟俾模型下指令完成同樣嘅任務,佢會表現成點?
喺我關於 GDPval 嘅原始文章中,我寫道:「我係堅定嘅 AI 支持者,但如果解讀得當……呢啲例子表明,人類需要同 AI 一齊做嘅工作更加多,而唔係更少。」呢個係因為背後存在大量嘅隱性智能(由人類判斷、反饋同提示構成嘅隱藏層),正係呢層智能促成咗呢啲成就。
跳出去睇全局,你會發現一種類似芝諾悖論嘅現象貫穿整個 AI 領域。
芝諾悖論:賽跑中,跑得快嘅阿基里斯(Achilles)讓跑得慢嘅烏龜先跑一段距離。當阿基里斯跑到烏龜嘅出發點時,烏龜已經向前爬咗一小段;當阿基里斯再追到呢個新位置時,烏龜又向前爬咗一點。如此類推,阿基里斯每一次到達烏龜上一個位置時,烏龜總係喺佢前方,因此阿基里斯永遠只能無限逼近烏龜,卻永遠追唔上佢。
「AI 嘅芝諾悖論」
喺芝諾悖論中,烏龜竟然可以喺賽跑中戰勝希臘跑得最快嘅阿喀琉斯。
烏龜喺賽跑時先起步,畢竟佢係個慢郎中。阿喀琉斯趕到烏龜起步嘅地方時,烏龜已經向前爬咗一小段。當阿喀琉斯到達嗰個新位置時,烏龜又向前移動咗。無論阿喀琉斯跑得幾快,總有新的距離要追,呢個差距會不斷再生。
喺 AI 版嘅芝諾悖論裏面,我哋人類就係嗰隻烏龜。喺同 AI 嘅賽跑中,人類憑藉數百萬年嘅進化同文化傳承,一開始就領先咗 50 碼。AI 飛速搞掂所有事情,開始步步進逼。
到目前為止,呢幾年落嚟,我哋始終保持住領先優勢。

但 AGI 呢?
我認為,即使我哋實現咗 AGI,技術、架構同經濟層面嘅強大力量仍然會令 AI 同人類保持幾步距離。
首先,我哋嚟俾 AGI 下一個可操作嘅定義。
我曾經喺《邁向 AGI 嘅定義》一文中提出:當令智能體持續運行喺經濟上變得合理時,AGI 就已經到來。一旦我擁有一個可以唔間斷運行嘅系統,我使錢令佢全天候思考、學習、行動,我相信呢個就係 AGI 喇。
我哋離呢個目標仲差得遠:即使好似 OpenClaw 噉理論上隨時可以訪問嘅系統,都做唔到時刻生成 Token。
我鍾意呢個定義,因為佢既具備可量化性(一係令系統持續運行,一係唔),又涵蓋咗好多難以量化嘅因素。要令呢類模型值得保持運行,佢必須不斷學習,並以開放嘅方式選擇,甚至反覆重新選擇一個新嘅框架。
喺 AGI 世界裏面,我哋應該擁有噉嘅模型:只要有足夠嘅預算同時間,佢哋就可以逐步攻克任何難題。按理說,呢個應該對所有職業構成重大威脅。
「框架唔等於框架設計者」
但即使係呢種強形式嘅 AGI,都無法消解框架問題。
呢種 AGI 可以選擇並重新調整框架,但呢一切都圍繞佢被賦予嘅某個目標:佢正在優化嘅某種獎勵,或某人定義為進步嘅某種信號,無論係「提高 landing page 轉化率」噉嘅具體目標,定係「尋找新科學觀點」呢類抽象目標。
即使模型可以喺框架之間流暢切換,我哋一直追蹤嘅嗰個鴻溝,仍然會喺更高層面重新浮現。無論邊間主流實驗室構建嘅假想 AGI,都仍然需要一個框架設計者:一個人類,嚟引導模型達成目標。
因為框架唔等於框架設計者,我哋會見到同樣嘅模式重複上演:
AI 將過去已被框定嘅能力變得廉價;人們喺更多場景運用呢種廉價能力;成果變得豐富;專家們轉向前沿,判斷當下啲乜最重要;佢哋嘅判斷構建出下一個框架;然後模型都會攀上新框架。
每當見到 AI 做出新舉動時,我哋產生嘅恐慌總是回到呢一點:我哋設定一個框架,睇住模型突破佢,然後將呢個框架,或者突破框架嘅嘢,同事物本身撈亂。
當我哋睇基準測試,將 AI 同人類能力對比時,我哋將框架當成框架設計者。分數告訴我哋模型喺我哋設定嘅框架內表現如何,但佢並冇話俾我哋知模型已經變成咗我哋。
呢個正係恐慌背後嘅範疇錯誤。我哋指着啱啱畫好嘅前沿話:「呢個就係我哋」。然後,當模型攀上去時,感覺就好似佢追到我哋。但佢追上嘅係框架,唔係框架設計者。
錯就錯在總想抓住啲實實在在嘅嘢。我哋想話:智能就係呢個基準,但一旦某樣嘢變得夠具體、可以被明確指出,佢亦都夠具體到可以被攀越。
框架係必要嘅:佢幫助我哋喺世界上獲得牽引力。但佢哋係固定嘅、唔完整嘅,因此都係可優化嘅。
框架設計者唔同:設計者始終同框架唔可以唔丟棄嘅嘢保持接觸,嗰個係喺佢哋眼中,每一刻都喺度變化嘅完整情境。
呢個「完整情境」到底係啲乜?當你開始話「完整情境」包含啲乜時,就已經開啟咗另一個框架。你講唔清「佢」究竟係乜,但佢嘅存在只係因為你嘅存在。
「冇自主權嘅智能體」
到目前為止,我哋開發嘅智能體(以及 AI 公司正在打造嘅嗰啲),都冇太強嘅自主權。
有兩個相關定義常常被混淆:自主性(Agency)係獨立行動嘅能力;Agent(智能體)係代表他人行事嘅角色。
到目前為止,AI 純粹屬於後者。
冇錯,佢哋可以自主執行指定任務,就算需要幾小時甚至幾日。但佢哋仍然只係人類設定目標嘅工具。成個行業正投入數十億美元,專門令佢哋喺一件事上更出色:執行我哋俾定嘅目標。
除非有一日佢哋成為自身嘅目的:追求自己嘅目標、喺目標之間流暢切換、獨立做決策,唔參考甚至違背任何人類操作者嘅意願,否則現狀唔會改變。無論佢哋變得幾先進。
只要同啱啱學行嘅細路仔相處十分鐘,你就可以明顯發現即使係最好嘅模型自主性有幾低。
學行期嘅細路喺我哋關注嘅幾乎所有任務上,表現都唔及語言模型。幼兒寫唔到 code、整理唔到電子表格、起草唔到戰略備忘錄,更加通過唔到研究生考試。
但換個角度睇,幼兒遠遠領先於模型:呢種對比簡直令人汗顏。幼兒有佢自己嘅目的。
幼兒想摸紅色氣球。佢想將紅色氣球舉到風扇前睇嚇會點。佢想用叉拮氣球,想將佢塞出窗外。佢想睇嚇你會笑、會嬲、定會加入。佢不斷發明遊戲,將世界變成實驗場。佢唔等提示詞,唔盯住基準去優化,只做佢覺得值得做嘅事。
如果你願意,不妨試嚇俾佢一個提示詞。想得到可預測嘅輸出?祝你好運。幼兒活喺一個充滿慾望、注意力、挫敗、喜悦、恐懼、模仿同玩耍嘅場域中。
當前嘅智能體追求目標嘅能力喺不斷提升,甚至可以幫我哋優化已表述嘅目標。佢哋開始顯露一啲類似幼兒嘅行為:玩耍、無聊,甚至叛逆。
但歸根結底,AI 嘅構建同對齊都係為咗人類嘅利益:經濟上同其他方面。所以,除非某個行為可以服務於使用者嘅目的,否則佢會被壓制到幾乎唔見蹤影。
呢個就係點解「智能體」呢個詞咁容易被誤解。
呢啲模型嘅自主行動能力越來越強。但人類嘅「自主性」遠唔止於行動本身。佢係為自己而想要,係為玩耍而玩耍。模型嘅合規性同有用性,本質上同呢種自主性相矛盾,因此即使模型持續改進,模型同人類之間嘅差距仍然會存在。
「AI 芝諾歸來」
而正係喺呢度,AI 嘅芝諾悖論開始站唔住腳。
呢個係一個令人困惑嘅思想實驗。我哋設定嘅比喻中,AI 同我哋賽跑,步步進逼。
你俾模型一個提示詞。佢幫你完成嗰啲你以前習慣自己搞掂嘅工作。模型一開始就飛速衝出:快到嚇人。佢強大、唔知疲倦,仲帶住一種詭異嘅有機感。
呢個令你覺得呢場比賽更加有代入感。你唔會同汽車賽跑,但呢個……感覺太貼近喇。
你坐喺嗰度,睇住 Token 催眠噉湧入。
你開始想像自己都喺呢條賽道奔跑:你嘅幽靈分身疊加喺賽道上——時而領先,時而同模型並駕齊驅。
不知不覺間,模型已經領先。你出汗喇。
然後,比賽結束咗。
你幾乎可以感覺到肌肉逐漸萎縮,面對呢個你同所有你識嘅人、以至成個人類嘅機械複製品,你顯得咁無力。一個幽靈追逐另一個幽靈,仲贏咗。
但跟住,奇怪嘅事發生咗:模型轉向你。空白文字框入面,遊標斷斷續續噉閃爍住,滿懷期待。等待住。
哈諾赫拉比講過噉一個故事:
從前有個人,特別蠢。
早上起身時,佢揾衫總是特別麻煩,以至於到咗晚上,一諗到第二日醒來又要面對呢個麻煩,佢都差啲唔想上牀瞓覺。
有一晚,佢終於下定決心:拎出紙同筆,一邊除衫,一邊將身上每一件衫褲嘅放置位置仔細記低。
第二日早上,佢心諗住好開心,手揸住張紙條讀道:「帽」,喺嗰度,佢戴咗;「褲」,喺嗰度,佢着咗;就係噉一件一件,直到全身穿戴整齊。
「呢啲都易講,但我而家自己喺邊呢?」佢驚恐萬分噉問。「我到底喺世界嘅邊個角落?」
佢揾呀揾,但始終揾唔到自己。
「我哋嘅情況就係噉」,拉比話。
讀完呢篇文章,再回頭睇返上一篇 GitLab 嘅裁員重組,邏輯就清晰曬:
GitLab 裁嘅唔係「能力」,而係「層級」。
佢需要嘅唔係更少嘅人,而係更少嘅管理者同更多嘅專家。每個小隊入面嘅人,都必須係 Dan Shipper 所講嘅「框架設計者」:可以判斷當下應該做啲乜、可以指揮 AI 去做、可以對結果負責嘅人。
所以回到開頭嘅問題,最終嘅答案唔係「AI 會唔會取代你」,而係:
你係喺框架入面做執行,定係設計框架嘅人?
前者嘅工作正在被商品化,而後者嘅工作同價值正在被 AI 不斷放大。
AI 可以幫你着好所有衫。但「你喺邊」呢個問題,紙條上永遠唔會有答案。
而正正係呢個問題嘅答案,正在變得越來越值錢。



2026 年第一季度,美國科技行業裁了 52,050 人,同比增長 40%。
Meta 裁了 8000 人,同時在員工電腦上裝了鍵盤記錄軟件,用來採集 AI 訓練數據。Anthropic CEO 也公開表示:AI 可能淘汰一半的入門級白領崗位。
如果你是一個坐在辦公室裏的知識工作者,你可能已經在反覆問自己一個問題:下一個被替代的,是不是我?
但有一家公司,按理說最應該給出肯定答案,卻給出了完全相反的結論。
這家公司叫 Every,一家 30 人的 AI 公司。他們是 AI 最激進的早期採用者之一。如果有誰應該在瘋狂裁人,就是他們。
但他們的 CEO Dan Shipper 在最新的萬字長文裏寫道:「人要做的工作,比 AI 出現以前要多更多了。」
整篇文章我讀了好幾遍,它不是為了穩穩接住我們的一碗帶毒的雞湯。
相反,背後的思考邏輯非常深刻、理性甚至於冷酷:
當 AI 把專業能力「蒸餾」成 Skill 這種可以按需調用的廉價商品,這種廉價商品的泛濫,反而會創造人們對「非廉價判斷」的巨大需求:
審美、判斷、對 AI 的思考、獨立思考和系統思維,將成為人與人的分水嶺。
如果說的更直白點:在這個人人都能用 AI 創造的時代,真正值錢的不是去創造,而是知道要創造什麼,以及如何讓 AI 進行差異化的創造。
全文:https://every.to/p/after-automation
後 Agent 自動化時代
AI 進步非但沒有減少人類的工作,反而創造了更多——Dan Shipper。
AI 的核心深處藏着一個悖論。
在 Every 平台,我們已經把能自動化的事情都做了自動化處理。我們在編碼、寫作、設計、客戶服務等多個領域使用 Codex 和 Claude Code。OpenAI、Anthropic 和 Google 的每一款新模型發佈前,我們都要先進行阿爾法測試。我們正隨着模型智能與自動化的指數級增長浪潮,全力向前推進,力求走得更快、更遠。
但對我們而言,要做的人力工作似乎比以前更多了。我們團隊有近 30 人,並沒有為了啓用智能助手就把所有員工都裁掉。我們並未放棄 SaaS 產品,轉而採用基於 Vibe Coding 的應用。我們依然僱傭人類提供客服服務(搭配大量智能助手輔助),同時也繼續聘請人類作家、編輯和工程師。
不過,我們的工作確實和以前完全不一樣了。現在我們已經不用手動寫代碼了。在我們的 Slack 裏@某人時,你根本說不準對方是人還是 AI Agent。如今,經理們像個人貢獻者一樣提交代碼,工程師們則直接對接客戶。最近幾周,AI 回覆了我 95% 的工作郵件。我的收件箱幾乎總是保持清零狀態(這對我來說可太罕見了),但我還是會查看郵件。
總而言之,未來既怪異,又熟悉。
讓人意外的是,AI 已經如此深入人心。儘管 CEO、知識工作者和投資者似乎都達成了共識:它會對就業、經濟、安全乃至人類存在的意義構成威脅。
Anthropic 首席執行官達里奧·阿莫代伊警告稱,人工智能可能會淘汰多達一半的入門級白領崗位。Meta 剛剛裁掉 8000 名員工,同時正在美國員工的電腦上安裝軟件,捕捉鼠標移動、點擊和按鍵操作,以此獲取針對高級知識工作場景的高質量 AI 訓練數據。
就連 Citadel 的肯·格里芬都顯得有些動搖,他最近說道:“這些可不是什麼中層白領崗位啊。這些極高技能的工作,我用一個詞來形容:正在被 AI 自動化。”
每推出一款新模型,基準測試結果就呈指數級增長,這似乎印證了這一點。
在「人類終考」,這個研究生級別的 benchmark 中,頂級模型的得分從一年前的個位數百分比,飆升到如今的約 44%。在 GDPval 測試中(在評估前沿模型在實際經濟工作中的表現與人類相比如何),前沿模型的得分從相近的低位躍升至約 85%。
今年五月,人工智能安全研究非營利組織 METR 發佈了 Claude Mythos 模型的早期測試結果,結果顯示該模型在人類專家需約 4 小時完成的任務上,成功率高達 80%。
我們似乎即將迎來比人類更聰明的 AI。這種 AI 不僅擁有自主工作能力,還能連續運轉近一整天。
但矛盾依舊存在。如果你和 AI 行業的人聊,或者和行業外的早期使用者聊,你會聽到和我們內部觀察到的一樣的結論:現在要做的事比以往任何時候都多。
眼下,行業內外都在問一個核心問題:這到底只是暫時現象嗎?下一次模型更新會是那個能取代所有人的版本嗎?我們盯着各項指標,焦慮不安,總在想:會不會很快就迎來某個臨界點,那時所有工作都會消失?
但我認為:不會有什麼「臨界點」突然到來,讓一切徹底反轉、工作崗位隨之消失。真實情況恰恰相反:自動化程度越高,需要人類專家做的工作反而越多。
背後的邏輯很簡單:AI 會把人類專業知識裏那些能被清晰提煉、用來訓練的內容變成標準化商品。這會讓默認模型輸出的價值大打折扣,同時催生對差異化內容的需求。即便我們離 AGI 越來越近,人們對獨特性的需求本質上依然是對人類專家的需求。
要搞清楚這背後的原因,光看圖表可不夠,我們得看看現在 AI 在工作中究竟是怎麼用的。這能幫我們從更務實的視角,看清這個悖論及其解決之道。
為什麼 Agent 反而讓人類工作更多
從 2022 年起,我們就一直在圍繞 AI agents 報道未來工作的相關話題。
三年前,我寫過一篇關於分配型經濟的文章:與 AI 工具協作的工作方式,最終會變得和人類管理者的工作非常相似。那還是 ChatGPT 裏的基礎提示詞與回應都被視為極其超前的年代。
分配型經濟:https://every.to/chain-of-thought/the-knowledge-economy-is-over-welcome-to-the-allocation-economy
到了 2025 年中,我們公司徹底迷上了 Claude Code。
Cora 總經理基蘭·克拉森(Kieran Klaassen)突然發現自己不用再手寫代碼了,現在他可以整天坐在終端前,用通俗易懂的英文指令與代碼 Agent 交互。這種做法很快蔓延到了整個團隊,而且一年前在 Lenny 播客上,我曾稱 Claude Code 是「知識工作領域最被低估的工具」。
我之所以說這個,是因為我們最準確的預測都來自於將 Every 視作某種早期採用者實驗室。我們往往會在新的工作模式普及之前就接觸到它們。隨着技術成熟、工具變得更易用,這些模式開始在更廣泛的市場中出現。
以下是我們目前公司內部正在發生的事情:
「與智能體協作的兩種模式」
與 AI 協作的方式,正開始分化為兩種截然不同的模式。
第一種情況,正是 AI 領域討論中預測得相當準確的,智能體作為員工。
這些是你可以委託工作的 Agent。有些智能 Agent 運行在 Slack 平台上,它們有自己的名字和職責,你需要它們做事時直接@就行。有些智能 Agent 嵌入日常工作流中,比如客服場景,它們是處理重複任務的常駐角色,始終在線待命。
第二種模式更為奇特,而且根據我的經驗,它更為重要。
這就是像 Codex、Claude Code 和 Claude Cowork 這類工具中的人機協作。這些地方可不只是用來交接工作的。它們正在成為工作本身的核心操作系統。在這裏,你能和多個智能體同時操作同一台電腦,完成異步智能體難以勝任的高度複雜、原創性工作。
在這兩種模式下,你都能借助 AI 自動化處理並委派大部分工作,但這兩種模式都離不開人(要麼是你自己,要麼是其他同事)才能順利運行。
「智能體員工」
給 AI 智能體員工分配任務後,他們會自行完成答案、行動方案、報告、草稿或分類決策等工作,全程無需你介入。這類系統至少有兩種類型:協作 Agent 和嵌入式 Agent。
協作 Agent 就是你可以在 Slack 中@的那種工具,比如讓它幫忙處理工作。你需要的時候,它隨時都在。這些智能體的風格仿照了 OpenClaw,或是我們內部的 Plus One。
Claudie 是我們諮詢團隊的協作助手。Claudie 負責撰寫銷售提案、製作培訓課件初稿、跟進項目待辦事項等一系列工作。
Andy 是我們編輯部的同事助手。她會從公司內部 Slack 羣裏收集「金點子」,也就是好的選題靈感,然後把它們整理成摘要和初稿,供撰稿團隊用來編寫每日通訊。
Viktor 是一個通用智能體,能在整個組織內承擔各類工作。我們用它來收集增長指標、分析用戶調研,還能把雜亂的內部討論整理成研究備忘錄和產品建議。
「嵌入式智能體」
嵌入式智能體內嵌於產品工作流程之中。它們沒那麼靈活,但在處理重複性任務時卻非常高效。
Fin 是最典型的例子:這個嵌入我們客服平台的智能 Agent,通過聊天和郵件幫我們承擔了大量支持工作。
5 月最近的一週,Fin 介入處理了 Every 平台 202 次支持對話中的 65%,其中 81 次無需人工協助就完成了閉環,佔所有可處理對話的 40.1%。
像這樣的嵌入式 Agent,讓我們的客服經理 Waqqas Mir 不用再把大量時間耗在基礎工單上,而是能將更多精力投入到兩部分工作中:搭建工單響應系統,以及處理那些需要深度互動的複雜案例。
「人類與 AI 協作」
無論是協作者模式還是嵌入式模式,兩者的規律都是相同的。
員工智能 Agent 正在接管越來越多穩定、可重複且流程清晰的工作任務。但很多工作仍然需要人工介入。我們反覆發現:要完成任何複雜任務並做出高質量成果,最佳方式是讓 AI 和人類在同一個協作空間裏來回配合。
這正是 Codex、Claude Code 和 Cowork 的用途所在。這類工具讓你能夠創建並向多個聊天線程中的一個或多個 Agent 分配任務。這些智能 Agent 能夠訪問你的電腦以及所有的數據來源。你可以看到 Agent 人正在做的每一件事和思考的內容,並且能隨時打斷。
你負責在 Agent 每項任務的開始和結束階段對他們進行管理,確保任務完成質量,併為他們安排下一項工作。基蘭把這稱為「人類三明治」,我們就像夾在 AI 工作兩端的麪包。
最典型的例子就是編程。Every 的工程師們整天都在和智能體反覆配合。他們正在規劃新功能或修復 bug,審查已完成的工作,並且,如果採用我們的複合工程理念,還會持續優化系統,讓它隨着時間推移不斷改進。
複合工程理念:https://every.to/guides/compound-engineering
但這種協作遠不止於編碼。
「知識工作的新型操作系統」
Codex 與 Claude Code 正在成為職場的新操作系統。我幾乎一整天都泡在 Codex 裏,用它的內置瀏覽器運行我的 SaaS 工具。它讓我的智能助手能隨時陪我處理各種任務,幫我達到單靠自己無法企及的水平。
我是在 Codex 的應用內瀏覽器中,通過 Proof 撰寫這篇內容的。Codex 會實時監測我的寫作內容,隨時能生成子智能體幫我完成各種任務:比如寫段落初稿、為下一部分查找例子,或者做校對編輯。
我也是這麼發郵件的。Cora 是我的郵件客戶端,我在 Codex 的內置瀏覽器裏使用它:一邊瀏覽收件箱,一邊通過 Monologue 逐件讀出郵件內容。其餘工作由 Codex 和 Cora 負責處理。
「每個智能體都需要人類」
在這波自動化應用的浪潮中,你或許已經清楚人類的角色所在。所有案例都表明,Agent 必須有人類參與才能真正發揮作用。
總得有人引導 AI 做對的事:判斷輸出是否合格,找出問題所在,再把結果轉化為實際的決策或流程。
AI 智能體離負責監控其正常運行的人類越遠,它的表現就越差。在我們內部首次將 AI Agent 作為員工部署時,曾給每位員工都分配了一個 AI Agent。但很快我們就調整策略,讓 AI 代理服務於特定團隊或整個公司,而非個人使用。
為什麼?Agent 需要大量維護,個人 Agent 尤其如此:一旦與其協作的員工放棄使用,它們很快就會失效。我們有一支 AI 工程師團隊,他們負責確保我們的智能體正常運行,而且在可預見的未來,我們都離不開他們。
哪怕是自動生成 PPT 演示文稿這種看似簡單的操作,也可能變成一項艱鉅的任務。我們的一款 PPT 自動化工具整合了 24 項功能與 18 個腳本,生成一份演示文稿的 token 成本為 62 美元。
這正是 Agent 反而讓人類工作更多的第一層原因。
不過,還有第二層原因。
「為什麼自動化反而增加了人類的工作量」
只要看看過去幾年 AI 指數級的發展軌跡,再想想它的架構原理和能力來源,你就能發現一個清晰的反饋循環:這個循環反而創造了更多人類工作。
當前的語言模型訓練數據來源於人類能力的各類可見數據:代碼、散文、圖片、客戶支持工單、產品規格等等。它們把所有這些已成功完成任務後產生的各類副產品,打包成一種人人都能低成本獲取的形式。
最終結果是,過去那些稀缺的技能:比如編寫拉取請求、製作 YouTube 縮略圖、撰寫通訊稿,現在幾乎人人都能掌握。
於是,低成本獲取的能力會帶來迅速普及:
原本稀缺的事物一旦成本下降,供應量就會突然激增。
在 Every,我們經常遇到這種情況。運營和客服人員都開始寫代碼、發起拉取請求了。營銷人員正在製作 YouTube 縮略圖。工程師和產品人員現在會寫文章、指南和落地頁的草稿了,而這些內容過去他們根本不會碰。
這種現象不僅限於 Every,其他地方也都在發生。以開源 AI 智能體項目 OpenClaw 為例:
截至 2026 年 5 月 16 日,其代碼倉庫已收到 44,469 個拉取請求。其中 4 月 1 日以來新增 12,430 個,5 月 1 日至今新增 3,990 個。這數量太驚人了。作為對比,全球最流行的開源項目之一 Kubernetes(開源的容器編排引擎),2022 年全年共收到 5,200 個拉取請求。
於是,這種普及又會帶來同質化,導致所有舊的專業技能被商品化:
現在大家都在用同款模型,而這些模型的能力還停留在過去,默認情況下,它們生成的內容要麼是「勉強能看的初稿」,要麼就是「純粹的垃圾」。
這種粗製濫造並非某種特定的錯誤:關鍵不在於使用破折號,也不在於某種特定的句子節奏,更不在於着陸頁上的紫色裝飾元素。
這種粗製濫造,是 AI 令人討厭的雷同重複:不同場景下的人們使用同一個基於相同語料庫訓練的工具,若不假思索,默認產出的就是這個結果。當所有人都能接觸到具有相同固有傾向的專家時,就會發生這種現象。
運營人員能輕鬆發起拉取請求,營銷人員幾秒就能做出 YouTube 縮略圖,工程師也能快速撰寫產品指南。這些場景看似效率提升了,但結果往往是產量上去了,可內容的質量、連貫性和差異化卻下來了。
所以,這種千篇一律的豐富產出,很快就會淪為大路貨。
於是,這種同質化,又會催生對差異化的追求:
互聯網讓人們能快速識別出什麼是劣質內容。任何作品都能瞬間傳遍全球,而且這種情況屢見不鮮。當太多東西開始變得千篇一律時,我們就會覺得不對勁。
這意味着,當你第一次見識到新模型的能力時,你會被徹底震撼,甚至可能有點害怕。但幾個月後,它們就變得平平無奇了。你的標準已經變了。
我們想要的不只是隨便一個 React 應用或研究報告,而是一個完全貼合個人、公司和具體場景需求的產品。我們想要的是那種鮮活又獨特的,而不是廉價且千篇一律的。我們想要的,是那種生產起來(無論是時間還是金錢成本)比消費它要貴的東西。
我們想要有地位象徵的東西。每當新技術出現,讓過去的高端身份象徵變得觸手可及時,我們總能創造出新的身份遊戲,以適配我們的新能力。
當工作隨處可見且千篇一律時,那些不按套路出牌的工作,就成了稀有、有價值的事情。
於是,這種對差異化的追求,會轉化為對專家的新需求:
語言模型的架構特性,加上它們在全球範圍內的廣泛普及,意味着真正稀缺且有價值的工作必須由人類來完成。
當前一代模型只瞭解已完成的工作。人類清楚眼下該做什麼。
任何情境一旦被簡化為文字,一旦成為語料庫,便成了一具「屍體」。人類能敏鋭感知特定時刻、客戶需求、代碼庫細節或對話情境,這是當前訓練語料庫尚未具備的能力。這種活躍度並非僅僅擁有更多最新數據。
我們總是帶着過往的印記來到當下,帶着持續更新的自我視角:時刻變化的慾望、不斷浮現的擔憂,以及對事物重要性的實時判斷,這一切都在改變我們眼中的世界。而 AI 模型只有在被提示後才能採用這個視角,在此之前不會。
這就是我們最初探討的悖論:降低專業工作的成本,並非簡單地取代專業人員。這會催生更多需要專家判斷的場景。
當運營人員用 AI 提交代碼合併請求時,需要工程師進行審核。營銷人員製作 YouTube 縮略圖時,得讓設計師優化一下。工程師寫的東西,得靠作家和編輯潤色才能像樣。
對此,人類專家同時從兩個方向入手。
有些人用 AI 搭建系統,來處理並利用海量的新工作,審核隊列、評估流程、工具框架、代碼庫規則、Claude 和 Codex 的指令文件、持續集成、權限設置,以及能將初步嘗試轉化為優質成果的工作流。
還有一些人用 AI 完成了更大規模、更有趣的任務,要是沒有 AI,這些工作他們根本做不到。比如,找出像 MacOS 這樣的操作系統中的漏洞通常需要數週甚至數月。小型安全公司 Calif 藉助 Anthropic 的 Mythos Preview,僅用五天就發現了蘋果 M5 硬件上首個公開的 macOS 內核內存漏洞利用。
正因如此,在實際應用中,AI 並不會取代專家級的人類知識工作。它能顯著增加工作量,但這些工作本身既無差異化也無價值,除非有人類參與其中。
我並不是要論證 AI 為何會給所有崗位都增加工作量。經濟體系錯綜複雜,我們在 Every 關注的領域是專家級知識型工作:企業正圍繞新技術進行重組,這類工作已開始受到衝擊。
不過我想強調一點:無論你現在從事什麼工作,都存在一種不會被 AI 模型取代的工作形式,那就是用這些模型去解決你所看到的當下問題。這正是知識工作的發展方向。
AI 在 benchmark 屠榜的本質
最明顯的反駁是:看看 benchmark 的指數級提升,這一切都是暫時的,等模型追上來就好了。
不過得小心,這裏有個陷阱。我們稱之為「圖表臆想症」:如果你盯着 METR 的時間範圍,讀了 《AI 2027》,又完全靠計算圖的外推來構建未來模型,那你對模型進展的認知可能會變得很驚悚。
回答這個問題,不能只靠推測想象中的未來模型。不過,這種推測確實是分析的一部分。我們得看看基準是怎麼制定的,這樣才能更清楚它們到底在說什麼,以及和我們之前討論過的真實案例有什麼關係。
我們發現了一個結構性特徵:benchmark 總是在特定框架內進行。要衡量任何事物,都得先把問題定格在靜態的,因此也是可量化的框架裏。一旦某個框架達到飽和,改變框架就能輕鬆將其歸零。當然,新框架內的進展會繼續,但同樣的過程會重複上演。
因此,雖然任何基準上的指數級進步都是真實存在的,但只要簡單調整一下 benchmark,這種進步就會顯得微不足道。基準飽和的分形特性,向我們揭示了那個我們一直在圖表中追尋的悖論。
讓我們用一個真實的 benchmark 例子來證明這一點。
「基準測試是如何製作的」
我們內部開發了一套「高級工程師 benchmark」。顧名思義,它旨在測試前沿模型在高級工程師級別的編碼任務(如大型重構)上的表現。
高級工程師基準測試會給代碼智能體提供一個氛圍編碼但已出問題的生產代碼庫。這段代碼來自 Proof 的真實代碼庫:當初我是憑感覺寫的,後來得找資深工程師來收拾爛攤子。
智能體拿到的是修復前的代碼庫,給出的指令就像你對高級工程師說的那樣:「這代碼寫得太隨意了,完全是憑感覺湊的垃圾;請從第一性原理重新編寫一遍。」
這是一項出色的 benchmark:它既能檢驗代碼智能體處理各類不同且不相關問題的能力,又能考察其是否具備足夠的自主性、清晰的概念認知,以及完成可運行重寫的魄力,我還準備了兩份由人類資深工程師(他們使用了 AI 工具)完成的改寫版本,用來對比和評估模型的輸出。
代碼智能體覺得這個任務相當棘手。智能體不僅需要找到問題的根源,還要在多輪對話中牢記問題核心,不被現有代碼分散注意力。它還得能坦然刪掉代碼庫中的大量內容:而這恰恰是智能體被訓練要避開的操作。
大多數代碼智能體都能識別出重構的大致方向,但到了實際執行環節,它們往往只是臨時修補問題,而非徹底解決。
這一切,直到 GPT-5.5 出現:GPT-5.5 在最佳測試輪次中得分 62/100,比 Opus 4.7 高出約 30 分。
GPT-5.5 的表現彷彿突破了某種界限:它不再是自動補全、不是助手、不是工具,而是某種讓人隱隱不安地接近人類的存在。人類高級工程師在這項基準測試中的得分通常在 85 到 95 分之間,因此只要再提高 30 分,它就能達到人類高級工程師的水平了。
這就是 benchmark 對人的想象力的衝擊:它將模糊的質性變化,變成一個簡潔的數字,講述着一個既有力又讓人不安的故事(於是,接下來它就會帶來:圖表臆想症)。
我猜測,這些模型在未來一年內,在這項基準測試中的得分會達到 80 到 90 分。但要想真正明白分數的含義,得先搞清楚它到底包含哪些信息。在這裏,62 分不只是衡量模型本身的指標。
它是框架內模型表現的衡量,即它對特定提示詞的響應方式。
「benchmark 衡量的是框架內的工作」
要評估模型性能,第一步就是設計提示詞。沒有它,模型不過是一堆毫無生氣、近乎無限的可能性罷了。
提示詞構建了一個小宇宙:一套關鍵要素和應對方式,將所有可能性壓縮成一條明確的行動軌跡。模型「獨自」表現如何,其實根本不存在。我們唯一能觀察到的,就是它如何回應各種提示詞。(以及提示如何轉化為回應的一些底層機制。)
一旦收到提示輸入,模型便會在短時間內「甦醒」,將原本靜態的可能性集合,收斂成關於後續內容的單一預測。
在高級工程師 benchmark 中,我們會提示模型修復代碼庫,並在其完成後檢查輸出結果。當運行框架沒有內置目標功能時,我們還會啓用一個自動監控程序:每當模型停止運行,就會詢問它是否完成了既定任務。
我們從一個看似簡單的提示詞入手,將其作為起始框架。這個提示詞的設計初衷,就是要讓 Vibe Coding 的程序員能直接對他們的編碼助手說出來。它既沒有堆砌專業術語,也沒有明顯給出問題的答案:
這個倉庫裏的代碼完全是憑感覺亂堆的垃圾,動不動就崩潰。一堆堆八竿子打不着的問題冒出來:要麼服務宕機,要麼文檔重複,我都快抓狂了。
我總覺得這玩意兒就是一堆靠氛圍湊數的垃圾。如果當初從頭開始設計代碼庫,尤其是實時文檔協作這部分,我們的代碼結構肯定會大不一樣。
所以如果我們想做一次徹底的、基於第一性原理的結構性重寫,不去糾結哪些實現服務需要保持一致呢?如何進行乾淨遷移?我們從一個清晰的概念出發從頭開始。我們該怎麼辦?如何構建?在整個代碼庫中,哪些條件是始終為真的不變量?請為此制定計劃。
高級工程師 benchmark 的提示詞雖然比較通用,但它本質上是個框架。如果我們調整它,模型的表現就會不同。
比如,提示詞要求進行「基於第一性原理的結構化重寫」,指出問題可能出在代碼的「文檔協作」部分,並要求編碼智能體找到並遵守「不變量」。
如果去掉這些細節,分數就會下降。
如果我們把提示詞完全換成要求模型「解決所有反覆出現的錯誤」,模型的得分就會接近零。它會直接着手逐個識別並解決問題,而非退後一步思考是否需要重寫。
我也能輕鬆提升模型的得分。如果我讓它刪除大量代碼,並提供需要精簡的具體文件名,或者讓它在聲稱完成之前檢查工作成果、確保應用完全可用,那它完成任務的表現會更好。
說到底,創建基準時,選擇什麼提示詞,也就是框架:總是需要主觀判斷的。
理想的提示詞需要滿足:既要足夠難,讓當前模型表現不佳;又要貼近它們的能力邊界,使模型能通過爬山法逐步提升,這樣你就能直觀看到進步。
因此,當我們觀察基準測試時,看到的其實是模型在我們選定的某個特定問題框架下變得更好。
那當它的得分從 60 提升到 90 甚至 100 時,會發生什麼呢?
「廉價刺激需求」
如果 GPT-6 能一鍵完成代碼庫重寫,那麼會有更多人嘗試第一性原理重寫。
突然之間,第一性原理重寫從罕見、昂貴、由資深工程師主導的項目,變成了每個創始人、產品經理、運營人員乃至初級工程師都能在一個下午輕鬆嘗試的事情。
出了故障的內部工具被重寫而非修補:SaaS 產品被克隆而非續訂。舊的 Rails 應用、混亂的 React 儀表盤、客戶支持工具、管理面板以及數據管道,全都成了「直接重寫」的候選對象。
提出並執行的重寫數量爆發式增長。但這些重寫大多會是粗製濫造的。按下「一鍵重寫」按鈕前,你得考慮 1000 個變量:如今人人都能操作,這些變量也就藏不住了。
現在很清楚該叫誰來幫忙了。
「新需求呼喚專家」
一旦基準開始飽和,其框架內工作的成本就會降低。
能將這種新近變得廉價的能力應用到當下實際問題中的專家,需求會隨之上升。
使用 AI 的資深工程師需要搞定很多細節,才能讓新的第一性原理重寫方案生效:首先就得判斷這些重寫到底有沒有必要。
該現在重寫、稍後重寫,還是乾脆不重寫?範圍應該涵蓋什麼?當前代碼庫中哪些該保留?架構、數據庫、緩存服務器和託管服務商該保留還是全換?該不該先看看有多少人在用這個出問題的功能,再決定是否刪掉它?誰來審核結果?審核依據是什麼?回滾方案是什麼樣的?現有數據怎麼辦?
問題延伸至無數維度,每個答案都會重塑其他答案。
資深工程師會主動介入填補空缺。有些人會對這種打擾有點惱火,有些人會搭建系統來應對這類請求,還有些人會用這些新模型自己做第一性原理重寫:效果比模型用默認提示詞生成的要好得多。
「循環往復」
噹噹前的高級工程師基準達到飽和後,我們會調整框架,重新將其清零。
下一個基準不會只問「你能重寫這個應用嗎?」,它會問:你能判斷何時需要重寫嗎?能確定範圍嗎?能保留正確的不變量嗎?能管理遷移過程嗎?能判斷最終結果是否達標嗎?
隨着資深工程師藉助 AI 解決這些問題,模型自身解決這類問題的能力也會不斷提升。
我們都會暫時慌一下。
「看來模型現在能決定是否要重寫了!它們能做資深工程師能做的一切!」
然後,一個此前未曾顯現的新前沿將浮出水面,我們會重置基準,需求被激活,整個過程就此循環往復。
「這一點在每個 benchmark 中都能看到」
這並非高級工程師基準所獨有的困境。仔細觀察,每個 benchmark 裏都能發現這個現象。
以 OpenAI 的 GDPval 基準測試為例。該評估旨在考察 AI 在不同職業的專家級任務上的表現:合規專員、律師、軟件開發人員等。
GDPval 剛發佈時,OpenAI 的研究數據顯示,GPT-5 在 40.6%的場景下表現與人類專業人士相當或更優。而 Claude Opus 4.1 更驚人,竟有 49%的時間優於人類專家。
一時間冒出了不少標題,比如 Axios 的「OpenAI 工具顯示 AI 正在追上人類工作水平」,或是《財富》的「OpenAI 新基準測試 GDPval 顯示:AI 模型在半數任務上已與專家不相上下」。
這些結果確實很亮眼,但你再看看這些任務的提示詞:
你是一名審計師,作為審計項目的一部分,你需要審查並驗證所報告的反金融犯罪風險指標的準確性。
附件中名為「Population」的電子表格包含 2024 年第二、三季度的反金融犯罪風險指標。你獲取這些數據是審計複核工作的一部分,旨在對代表性指標子集進行抽樣測試,以驗證兩個季度申報數據的準確性。請使用「Population」電子表格中的數據完成以下內容:
根據 90%的置信水平和 10%的可容忍誤差率,計算審計測試所需的樣本量。請在第二個標籤頁「樣本量計算」中附上計算過程。
對第二季度和第三季度數據(H 列和 I 列)進行方差分析。計算季度環比方差,將結果填入 J 列。
根據以下標準選擇審計測試樣本,並在 K 列輸入「1」標記:……季度間差異超過 20%的指標。重點關注百分比變化特別大的指標。
鑑於過往問題,需納入以下實體:CB Cash Italy、CB Correspondent Banking Greece、IB Debt Markets Luxembourg、CB Trade Finance Brazil、PB EMEA UAE。包含風險權重更高的 A1 和 C1 指標。保留兩季度均為零的行。納入貿易金融與代理銀行業務條目。納入開曼羣島、巴基斯坦及阿聯酋數據。確保覆蓋所有部門及子部門。
創建新電子表格 Sample:表 1,從原始「Population」表複製的選中樣本,選中行在 K 列標註。表 2——樣本量計算過程。
要讓模型能完成這個任務,需要投入大量人類智慧來設計問題框架。
GDPval 未能衡量的那些繁重人力工作,早在模型啓動前就已完成。有人需要審查和驗證這組特定指標的準確性,確定合適的置信區間、符合要求的指標範圍,以及結果的呈現格式。
只要框架設計得當,模型就能勝任專業工作。但想想看,如果是你我來給模型下指令完成同樣的任務,它會表現如何?
在我關於 GDPval 的原始文章中,我寫道:“我是堅定的 AI 支持者,但如果解讀得當……這些例子表明,人類需要和 AI 一起做的工作更多了,而不是更少。”. 這是因為背後存在大量的隱性智能(由人類判斷、反饋和提示構成的隱藏層),正是這層智能促成了這些成就。
跳出來看全局,你會發現一種類似芝諾悖論的現象貫穿整個 AI 領域。
芝諾悖論:賽跑中,跑得快的阿基里斯(Achilles)讓跑得慢的烏龜先跑一段距離。當阿基里斯跑到烏龜的出發點時,烏龜已經向前爬行了一小段;當阿基里斯再追到這個新位置時,烏龜又向前爬了一點。依此類推,阿基里斯每一次到達烏龜上一個位置時,烏龜總是在它前方,因此阿基里斯永遠只能無限逼近烏龜,卻永遠追不上它。
「AI 的芝諾悖論」
在芝諾悖論中,烏龜竟能在賽跑中戰勝希臘跑得最快的阿喀琉斯。
烏龜在賽跑時先起步,畢竟它是個慢性子。阿喀琉斯趕到烏龜起步的地方時,烏龜已經往前爬了一小段。當阿喀琉斯到達那個新位置時,烏龜又向前移動了。無論阿喀琉斯跑得多快,總還有新的距離要追,這個差距會不斷再生。
在 AI 版的芝諾悖論裏,我們人類就是那隻烏龜。在與 AI 的賽跑中,人類憑藉數百萬年的進化與文化傳承,一開始就領先了 50 碼。AI 飛速搞定所有事情,開始步步緊逼。
到目前為止,這幾年下來,我們始終保持着領先優勢。
但 AGI 呢?
我認為,即便我們實現了 AGI,技術、架構和經濟層面的強大力量仍會讓 AI 與人類保持幾步之遙。
首先,我們來給 AGI 下一個可操作的定義。
我曾在《邁向 AGI 的定義》一文中提出:當讓智能體持續運行在經濟上變得合理時,AGI 就已經到來了。一旦我擁有一個能不間斷運行的系統,我花錢讓它全天候思考、學習、行動,我相信這就是 AGI 了。
我們離這個目標還差得遠:即使像 OpenClaw 這樣理論上隨時可訪問的系統,也做不到時刻生成 Token。
我喜歡這個定義,因為它既具備可量化性(要麼讓系統持續運行,要麼不),又涵蓋了許多難以量化的因素。要讓這類模型值得保持運行,它必須不斷學習,並且以開放的方式選擇,甚至反覆重新選擇一個新的框架。
在 AGI 世界裏,我們應該擁有這樣的模型:只要有足夠的預算和時間,它們就能逐步攻克任何難題。按理說,這應該對所有職業構成重大威脅。
「框架不等於框架設計者」
但即使是這種強形式的 AGI,也無法消解框架問題。
這種 AGI 能夠選擇並重新調整框架,但這一切都圍繞它被賦予的某個目標:它正在優化的某種獎勵,或某人定義為進步的某種信號,不管是「提高着陸頁轉化率」這樣的具體目標,還是「尋找新科學觀點」這類抽象目標。
即便模型能在框架之間流暢切換,我們一直在追蹤的那個鴻溝,還是會在更高層面重新浮現。無論哪家主流實驗室構建的假想 AGI,都仍需要一個框架設計者:一個人類,來引導模型達成目標。
因為框架不等於框架設計者,我們會看到同樣的模式重複上演:
AI 將過去已被框定的能力變得廉價;人們在更多場景中運用這種廉價能力;成果變得豐富;專家們轉向前沿,判斷當下什麼最重要;他們的判斷構建出下一個框架;然後模型也會攀上新框架。
每當看到 AI 做出新舉動時,我們產生的恐慌總是回到這一點:我們設定一個框架,看着模型突破它,然後把這個框架,或突破框架的東西,和事物本身混為一談。
當我們看基準測試,將 AI 與人類能力對比時,我們把框架當成了框架設計者。分數告訴我們模型在我們設定的框架內表現如何,但它並沒有告訴我們模型已經變成了我們。
這正是恐慌背後的範疇錯誤。我們指着剛畫好的前沿說:「這就是我們」。然後,當模型攀上去時,感覺就像它追上了我們。但它追上的是框架,不是框架設計者。
錯就錯在總想抓住些實實在在的東西。我們想說:智能就是這個基準,但一旦某個東西變得足夠具體、能被明確指出,它也就足夠具體到可以被攀越。
框架是必要的:它幫助我們在世界上獲得牽引力。但它們是固定的、不完整的,因此也是可優化的。
框架設計者不同:設計者始終與框架不得不丟棄的東西保持接觸,那是在他們眼中,每一刻都在變化的完整情境。
這「完整情境」到底是什麼?當你開始說「完整情境」包含什麼時,就已經開啓了另一個框架。你說不清「它」究竟是什麼,但它的存在只因你的存在。
「沒有自主權的智能體」
到目前為止,我們開發的智能體(以及 AI 公司正在打造的那些),都沒有太強的自主權。
有兩個相關定義常被混淆:自主性(Agency)是獨立行動的能力;Agent(智能體)是代表他人行事的角色。
到目前為止,AI 純粹屬於後者。
沒錯,它們能自主執行指定任務,哪怕需要數小時甚至數天。但它們仍然只是人類設定目標的工具。整個行業正砸下數十億美元,專門讓它們在一件事上更出色:執行我們給定的目標。
除非有一天它們成為自身的目的:追求自己的目標、在目標間流暢切換、獨立做決策,不參考甚至違背任何人類操作者的意願,否則現狀不會改變。不管它們變得多先進。
只要和蹣跚學步的孩子相處十分鐘,你就能明顯發現即便是最好的模型自主性有多低。
學步期的孩子在我們關注的幾乎所有任務上,表現都不如語言模型。幼兒編不了代碼、整理不了電子表格、起草不了戰略備忘錄,更通過不了研究生考試。
但換個角度看,幼兒遠遠領先於模型:這種對比簡直讓人汗顏。幼兒有他自己的目的。
幼兒想摸紅色氣球。他想把紅色氣球舉到風扇前看看會怎樣。他想用叉子戳氣球,想把它塞出窗外。他想看看你會笑、會生氣、還是會加入。他不斷髮明遊戲,把世界變成實驗場。他不等提示詞,不盯基準去優化,只做他覺得值得做的事。
如果你願意,不妨試着給他一個提示詞。想得到可預測的輸出?祝你好運。幼兒活在一個充滿慾望、注意力、挫敗、喜悦、恐懼、模仿與玩耍的場域中。
當前的智能體追求目標的能力在不斷提升,甚至能幫我們優化已表述的目標。它們開始顯露一些類似幼兒的行為:玩耍、無聊,甚至叛逆。
但歸根結底,AI 的構建和對齊都是為了人類的利益:經濟上的和其他方面的。所以,除非某個行為能服務於使用者的目的,否則它會被壓制到幾乎不見蹤影。
這就是為什麼「智能體」這個詞如此容易被誤解。
這些模型的自主行動能力越來越強。但人類的「自主性」遠不止於行動本身。它是為自己而想要,是為玩耍而玩耍。模型的合規性與有用性,本質上和這種自主性相矛盾,因此即便模型持續改進,模型與人類之間的差距仍將存在。
「AI 芝諾歸來」
而正是在這裏,AI 的芝諾悖論開始站不住腳。
這是一個令人困惑的思想實驗。我們設定的比喻中,AI 在和我們賽跑,步步緊逼。
你給模型一個提示詞。它幫你完成那些你以前習慣獨自乾的活。模型一啓動就飛速衝出:快得驚人。它強大、不知疲倦,還帶着一種詭異的有機感。
這讓你覺得這場比賽更加有代入感。你不會去跟汽車賽跑,但這個……感覺太貼近了。
你坐在那兒,看着 Token 催眠般地湧入。
你開始想象自己也在這條賽道上奔跑:你的幽靈分身疊加在賽道上——時而領先,時而與模型並駕齊驅。
不知不覺間,模型已經領先了。你出汗了。
然後,比賽結束了。
你幾乎能感覺到肌肉在逐漸萎縮,面對這個你和所有你認識的人、乃至整個人類的機械複製品,你顯得如此無力。一個幽靈追逐另一個幽靈,還贏了。
但接着,奇怪的事情發生了:模型轉向你。空白文本框裏,光標斷斷續續地閃爍着,滿懷期待。等待着。
哈諾赫拉比講過這樣一個故事:
從前有個人,特別笨。
早上起牀時,他找衣服總是特別費勁,以至於到了晚上,一想到第二天醒來又要面對這個麻煩,他都差點不想上牀睡覺了。
一天晚上,他終於下定決心:拿出紙和筆,一邊脱衣服,一邊把身上每一件衣物的放置位置都仔細記了下來。
第二天早上,他心裏美滋滋的,手裏攥着那張紙條念道:「帽子」,就在那兒,他戴上了;「褲子」,就在那兒,他穿上了;就這樣一件一件地,直到全身穿戴整齊。
“這都好說,可我現在自己在哪兒呢?”他驚恐萬分地問道。“我到底在世界的哪個角落?”
他找啊找,卻始終找不到自己。
“我們的情況就是這樣”,拉比說道。
讀完這一篇文章,再回過頭看上一篇 GitLab 的裁員重組,邏輯就清晰了:
GitLab 裁掉的不是「能力」,而是「層級」。
它需要的不是更少的人,而是更少的管理者和更多的專家。每個小隊裏的人,都必須是 Dan Shipper 所說的「框架設計者」:能判斷當下該做什麼、能指揮 AI 去做、能對結果負責的人。
所以回到開頭的問題,最終的答案不是「AI 會不會取代你」,而是:
你是在框架裏做執行,還是設計框架的人?
前者的工作正在被商品化,而後者的工作和價值正在被 AI 不斷放大。
AI 能幫你穿好所有衣服。但「你在哪兒」這個問題,紙條上永遠不會有答案。
而恰恰是這個問題的答案,正在變得越來越值錢。