從 Prompt 到 Harness:AI 編程真正缺的是工程紀律
整理版優先睇
AI編程真正缺嘅係工程紀律,唔係更勁嘅prompt。呢篇整理《Harness Engineering橙皮書》嘅方法論,教你建立指令、回饋、記憶同編排系統,令AI穩定產出。
呢篇文章係《Harness Engineering橙皮書:AI編程時代嘅工程方法論》嘅讀書筆記整理。作者最近讀完呢本書,覺得乾貨好多,決定整理出嚟方便自己同他人。本書表面係講Harness Engineering——幫AI agent設計指令、約束、工具、記憶、回饋同編排,令佢唔止係識傾偈,仲能夠喺真實工程環境穩定開工。佢真正想解決嘅問題唔係「點樣令AI更聰明」,而係「喺AI已經夠強但仲未穩定嘅情況下,人應該點樣重新設計工作系統」。
作者嘅處境係已經唔再單純「用AI」,而係用AI做開發、寫作、產品文檔同長期項目。佢發現真正影響結果嘅唔係某次對話質量,而係有冇將經驗沉澱成規則、工具、知識庫同回饋循環。本書嘅核心判斷係:AI編程時代,人嘅核心價值唔係親手寫更多代碼,而係設計一個能夠令AI持續產出、持續糾錯、持續積累嘅工作環境。作者從書中提煉出四個核心概念——Harness、回饋層、記憶層同編排層,並畀出每個概念嘅適用場景、誤用風險同實踐步驟。
最後,作者總結咗四個最有用嘅洞察:唔好發佈自己唔理解嘅代碼、規則應該從錯誤度生出來、評估者要獨立、上下文唔係越多越好。佢仲指出最反直覺嘅一點:AI越強,越需要工程紀律。模型能力提升唔會自動帶嚟可靠產出,反而令人更容易過度信任。文章結尾提供咗可執行清單同未來應該避免嘅陷阱。
- 結論:AI編程嘅瓶頸係缺乏工程紀律,而唔係模型能力;人應該設計系統,而唔係追求一次性提示詞。
- 方法:為每個長期項目建立輕量入口文件(如AGENTS.md),只記錄構建命令、測試方式、禁止事項同常犯錯誤,規則從錯誤度生出來。
- 差異:回饋層要求可執行嘅驗證手段(測試、lint、截圖等),而唔係AI自評;評估者必須獨立於生成者。
- 啟發:上下文唔係越多越好,連續兩次走偏就應該重開會話;記憶要控制喺100行以內,只記錄高頻錯誤同穩定偏好。
- 可行動點:今日就試一個小實驗——用三個會話完成一個功能(規劃、執行、審查);每週做Harness垃圾回收,刪除過時規則,補齊真實錯誤。
建立AI協作Harness系統
為每個長期項目創建AGENTS.md入口文件,只記錄構建命令、測試命令、項目禁區同常犯錯誤;每週維護規則,刪除AI能自己推斷嘅內容;同時建立MEMORY.md記錄高頻錯誤同寫作口味,每兩週壓縮一次。
從Prompt到Harness:重新定義AI工作環境
本書想解決嘅問題唔係「點樣令AI更聰明」,而係「喺AI已經夠強但仲唔穩定嘅情況下,人應該點樣重新設計工作系統」。以前我哋將注意力放喺prompt度,後來放喺context度,但真實項目嘅問題更硬:AI會誤解、偷懶、幻覺、重複犯錯、寫出自己都冇驗證過嘅代碼。靠一句提示詞管唔住呢啲問題。
AI編程時代,人嘅核心價值唔係親手寫更多代碼,而係設計一個能讓AI持續產出、持續糾錯、持續積累嘅工作環境
呢個就係Harness嘅概念:模型係腦子,Harness係手腳、護欄同儀表盤。作者提出要俾AI一個可以行動嘅殼——能讀文件、改代碼、跑測試、查資料、調用工具,仲有規則、邊界同回饋。
打造回饋閉環:讓錯誤變成複利
回饋層唔係叫AI講「我檢查過啦」,而係俾佢可執行嘅驗證手段:測試、lint、截圖、日誌、Playwright、DevTools、CI。呢點喺所有會產生結果嘅任務都適用,例如寫代碼、改UI、寫文章。
誤用係讓生成者自評,AI好容易滿足於「睇落可以」
作者建議每次改動後必須跑最小驗證;寫作時每篇文章用獨立會話審稿;產品設計用截圖同用戶路徑驗證,唔好剩係睇代碼。
- 1 畀項目列出3個最小驗證命令
- 2 喺規則文件寫清楚「改完必須跑邊啲檢查」
- 3 UI改動一定要睇截圖,唔好剩係睇源碼
- 4 複雜任務開全新會話做Reviewer
- 5 驗證失敗時先修Harness,再修單點輸出
記憶層同樣係複利機制。作者話記憶唔係資料庫,而係決策偏好同歷史教訓。要建立項目級MEMORY.md,只記錄「AI無法從文件推斷嘅信息」,每條記憶對應一個真實錯誤或穩定偏好,每兩週壓縮一次,刪除過時內容。
記憶要控制喺100行以內
編排層與評估獨立性
編排層係任務拆分同角色安排:Planner負責計劃,Generator負責實現,Evaluator負責挑錯。多agent嘅關鍵唔係數量,而係角色邊界。作者強調唔好畀同一個AI自己做自己審,因為佢會偏愛自己第一個方案。
評估者要獨立
呢點可以遷移到寫作:寫完文章後唔好喺同一個context度「潤色一下」,而係開新會話專門揾邏輯漏洞、廢話同唔成立嘅判斷。作者建議寫作流程分成三步:結構會話、正文會話、審稿會話。審稿只允許指出問題,唔可以直接改成一篇更「順」嘅廢話。
- 複雜任務先讓Planner寫計劃
- 實現會話只負責執行,唔擴展需求
- 審查會話必須係全新上下文
- 並行開發時每個任務用獨立worktree
- 合併前由人判斷結構、取捨同風險
反直覺與常見誤區
最反直覺嘅係:AI越強,越需要工程紀律。模型能力提升唔會自動帶嚟可靠產出,反而令人更容易過度信任佢。容易忽略嘅係基礎設施——冇測試同發佈清單,AI只會將混亂放大。
唔好發佈自己唔理解嘅代碼
作者提醒,AI可以寫實現,但責任唔可以外包。真正危險嘅係因為省事接受咗自己解釋唔到嘅嘢。架構邊界、數據流、狀態管理必須自己睇得明;睇唔明就唔合併。另外,規則應該從錯誤度生出來,提前寫500行規則通常係製造噪音。
多agent並行唔係同時開好多窗口,而係任務可隔離、結果可驗證、衝突可合併
仲要避免將規則文件寫成百科:語言慣例、框架常識、AI能從代碼讀出嘅嘢,唔值得佔用上下文。未來應該避免嘅仲有:唔好將時間花喺收藏提示詞上;唔好接受自己睇唔明嘅實現;唔好喺一個失敗context度無限糾正。
立即行動:建立可持續嘅Harness系統
今日就可以做一個小實驗:揀一個小功能或一篇短文,用三個會話完成——第一個淨係規劃,第二個淨係執行,第三個淨係審查。唔好讓同一個會話包辦到底。睇下最終返工次數係咪下降。
每週做一次Harness垃圾回收
長期堅持嘅習慣:每週刪除過時規則、合併重複規則、補充真實錯誤、壓縮記憶文件。記錄文件行數同重複錯誤次數。一句話總結:呢本書真正改變作者嘅,係將「使用AI」嘅問題,改成「設計一個令AI不斷變可靠嘅系統」嘅問題。
## 每週Harness垃圾回收步驟
1. 檢查AGENTS.md:刪除AI能自己推斷嘅規則
2. 合併重複規則,補齊近期錯誤
3. 壓縮MEMORY.md,刪除過時記憶
4. 記錄文件行數同重複錯誤次數
5. 檢查回饋層:最小驗證命令是否仍然有效呢篇文係《Harness Engineering橙皮書:AI編程時代嘅工程方法論》讀書筆記整理。
最近睇完呢本書,覺得乾貨好多,整理嚇,方便自己,方便人哋。

一、呢本書真正想解決啲乜問題
本書表面係講 Harness Engineering:畀 AI agent 設計指令、約束、工具、記憶、回饋同編排,令佢唔止係識得傾偈,而係喺真實工程環境裏面穩定咁做嘢。
佢真正想解決嘅問題唔係「點樣令 AI 更聰明」,而係「喺 AI 已經夠強但仲未穩定嘅情況下,人應該點樣重新設計工作系統」。以前我哋將注意力放喺 prompt 度,後來放喺 context 度,但真實項目嘅問題更加硬:AI 會誤解、偷懶、幻覺、重複犯錯、寫出自己都未驗證過嘅 code。靠一句提示詞管唔住呢啲問題。
呢本書同我而家最相關嘅一點係:我已經唔係單純「用 AI」,而係用 AI 做開發、寫作、寫產品相關文檔,同埋做長期項目。真正影響結果嘅,唔係某次對話嘅質素,而係我有冇將經驗沉澱成規則、工具、知識庫同回饋循環。
如果淨係帶走一個判斷:AI 編程時代,人嘅核心價值唔係親手寫更多 code,而係設計一個可以令 AI 持續產出、持續糾錯、持續累積嘅工作環境。
二、核心概念
1. Harness:AI 嘅工作環境,唔係提示詞
呢個係乜
Harness 係 AI 可以行動嘅果套殼:識得讀文件、改 code、跑測試、查資料、調用工具,仲有規則、邊界同回饋。模型係腦,Harness 係手腳、護欄同儀錶板。
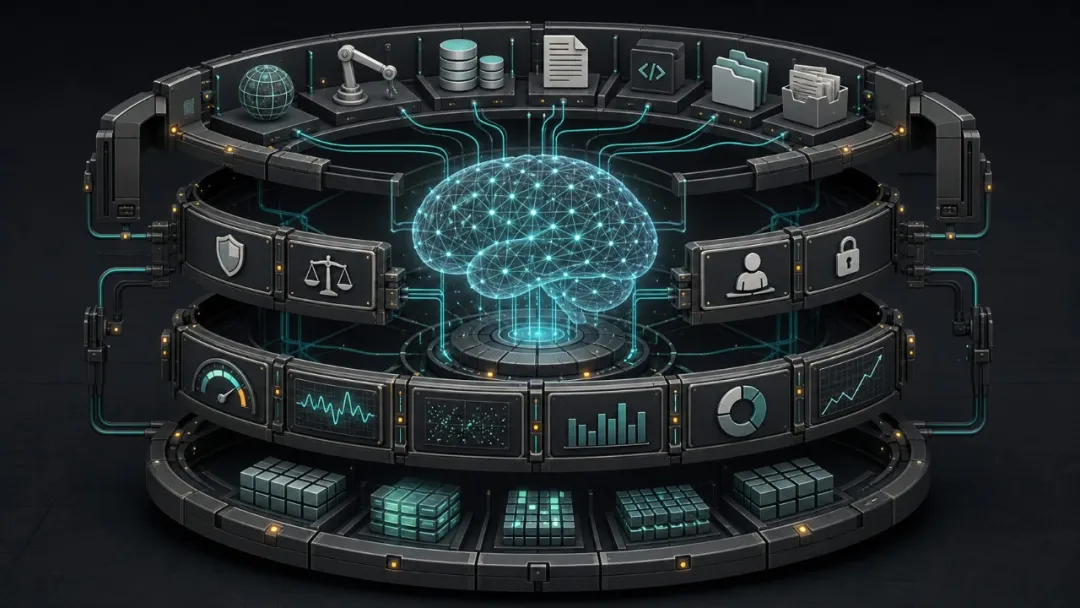
用喺咩場景
適合真實項目:iOS App、AI 工具、寫作工作流、獨立產品迭代。唔適合一次性傾偈或者簡單問答。誤用係將 Harness 當成「更長嘅 prompt」,將所有規則塞入一個文件,最後反而污染咗 context。
怎麼用
每個長期項目都建立一個輕量入口文件,例如 AGENTS.md / CLAUDE.md:淨係寫 AI 從 code 睇唔出嘅資訊,例如構建命令、測試方式、項目禁區、發佈流程、成日犯嘅錯。
實踐步驟
- 1. 由空文件開始,唔好預設一堆規則。
- 2. 每次 AI 犯錯,淨係加一條可以防止翻發嘅規則。
- 3. 每星期刪除 AI 可以自己從 code 推斷出嘅規則。
- 4. 將複雜規範拆成獨立文檔,入口文件淨係做地圖。
- 5. 規則有冇效,用「同類錯誤有冇翻發」嚟判斷。
2. 回饋層:令 AI 必須驗證自己嘅工作
呢個係乜
回饋層唔係叫 AI 話「我 check 咗㗎」,而係畀佢可執行嘅驗證手段:測試、lint、截圖、日誌、Playwright、DevTools、CI。

用喺咩場景
適合所有會產生結果嘅任務:寫 code、改 UI、寫文章、做產品頁。唔適合純概念討論。誤用係叫生成者自己評分,AI 好容易滿足於「睇落好似得」。
怎麼用
開發中,每次改動之後一定要跑最小驗證;
寫作中,每篇文章用獨立會話審稿;
產品設計,就用截圖同用戶路徑驗證,而唔係淨係睇 code。
實踐步驟
- 1. 為項目列出 3 個最小驗證命令。
- 2. 喺規則文件裏面寫清楚「改完一定要跑邊啲檢查」。
- 3. UI 改動一定要睇截圖,唔好淨係睇源碼。
- 4. 複雜任務開一個全新會話做 Reviewer。
- 5. 驗證失敗嘅時候先修 Harness,再修單點輸出。
3. 記憶層:令錯誤變成複利
呢個係乜
記憶層解決「今次踩過嘅坑,下次唔好再踩」。佢可以係 MEMORY.md、項目知識庫、覆盤日誌,或者係規則文件裏面新增嘅約束。
用喺咩場景
適合長期項目、系列文章、App 迭代、AI 工作流。唔適合短期一次性任務。誤用係將記憶當垃圾桶,乜都掉入去,最後 AI 揾唔到重點。
怎麼用
應該將 AI 協作入面嘅高頻錯誤、項目背景、寫作口味、發佈步驟沉澱落嚟,但係控制喺 100 行以內。記憶唔係資料庫,記憶係決策偏好同歷史教訓。
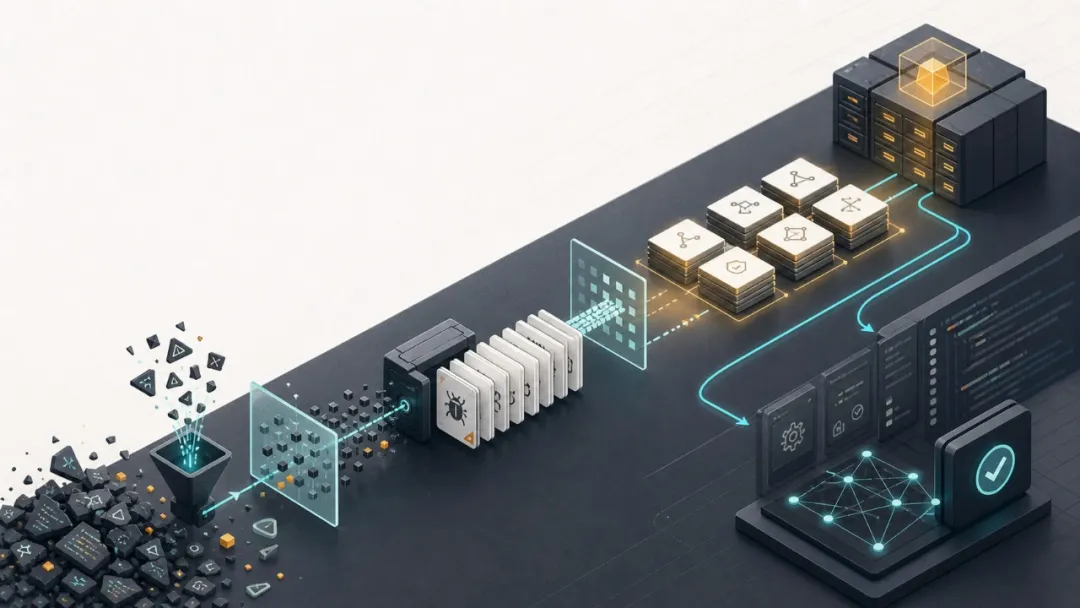
實踐步驟
- 1. 建立一個項目級
MEMORY.md。 - 2. 淨係記錄「AI 冇辦法從文件推斷嘅資訊」。
- 3. 每條記憶都對應一個真實錯誤或者穩定嘅偏好。
- 4. 每兩星期壓縮一次,刪除過時嘅內容。
- 5. 觀察 AI 係咪減少重複解釋嘅成本。
4. 編排層:由一個 AI 做嘢到多個 AI 協作
呢個係乜
編排層係任務拆分同角色安排:Planner 負責計劃,Generator 負責實現,Evaluator 負責捉錯。多 agent 嘅關鍵唔係數量,而係角色邊界。

用喺咩場景
適合複雜功能、長文章、重構、調研、上線前檢查。唔適合簡單任務。誤用係同時開好多會話但冇隔離工作區同明確目標,最後衝突更多。
怎麼用
獨立開發場景,一個會話寫需求,一個會話實現,一個新會話審查;
寫作場景,一個會話出結構,一個會話寫正文,一個會話捉邏輯漏洞。
實踐步驟
- 1. 複雜任務先叫 Planner 寫計劃。
- 2. 實現會話淨係負責執行,唔好擴充需求。
- 3. 審查會話一定要係全新 context。
- 4. 並行開發時每個任務用獨立 worktree。
- 5. 合併之前由人判斷結構、取捨同風險。
三、對我真正有用嘅 4 點
1. 唔好發佈自己唔理解嘅 code
Insight
AI 可以寫實現,但責任唔可以外判。真正危險嘅唔係 AI 寫錯,而係我因為貪方便接受咗自己解釋唔到嘅嘢。
我嘅理解
我可以叫 AI 寫 iOS App、Java 工具類、腳本、測試,但架構邊界、數據流、狀態管理一定要自己睇得明。睇唔明就唔合併,呢條線唔可以鬆。
點樣用喺我身上
我嘅開發工作入面,AI PR 合併之前一定要答到三個問題:改咗啲乜、點解咁改、壞咗點樣回滾。答唔到就繼續拆細。
2. 規則應該由錯誤度生出來
Insight
預先寫 500 行規則通常係製造噪音。真正有價值嘅規則嚟自真實失敗。
我嘅理解
我以前成日將「理想嘅工作方式」寫成規範,但 AI 唔會因為規範靚就遵守。更好嘅做法係等佢犯錯,然後將錯誤工程化成約束。
點樣用喺我身上
我每個新項目都從一個空 AGENTS.md 開始:構建命令、測試命令、禁止事項,然後每次踩坑就補一條。
3. 評估者要獨立
Insight
叫同一個 AI 自己寫、自己審,自然會漏嘢。佢會偏愛自己第一個方案。
我嘅理解
呢點可以搬去寫作。我寫完文章之後,唔應該喺同一個 context 度「潤色嚇」,而係開新會話叫佢專登揾邏輯漏洞、廢話同唔成立嘅判斷。
點樣用喺我身上
寫作流程改成三步:結構會話、正文會話、審稿會話。
審稿淨係允許指出問題,唔允許直接改成一篇更「順」嘅廢話。
4. context 唔係越多越好
Insight
context 太長會腐爛,失敗方案會污染之後嘅判斷。改兩次都仲錯,繼續補丁式糾正往往更差。
我嘅理解
我需要更加果斷咁清空重來。尤其係 debug、寫複雜邏輯、做 UI 嘅時候,如果 AI 連續兩次走歪,就應該重開 context,畀佢一個乾淨嘅狀態同更窄嘅問題。
點樣用喺我身上
我嘅開發同寫作都可以採用「二次失敗重啟規則」:同一個問題糾正超過兩次,就生成當前狀態摘要,重開會話繼續。
四、經驗、反直覺點同被忽略嘅細節
最反直覺係:AI 越強,就越需要工程紀律。模型能力提升唔會自動帶嚟可靠嘅產出,反而會令人更容易過度信任佢。
容易忽略嘅係基礎設施。Stripe 嘅個案說明,AI PR 行得鬱,唔止係模型強,而係團隊本身就有測試、部署、回滾同審查信號。個人開發都一樣,冇測試同發佈清單,AI 只會將混亂放大。
一個容易誤用嘅觀點係「多 agent 並行」。並行唔係同時間開好多視窗,而係任務可以隔離、結果可以驗證、衝突可以合併。否則只係將 context 切換嘅成本轉嫁畀自己。
另外,我哋仲要保持懷疑:書入面好多高產案例證明咗速度,但係冇完全證明長期可維護性。AI 寫出嘅 code 半年後仲可唔可以繼續演進,仍然要靠架構、測試同人嘅判斷嚟兜底。
五、睇完本書,接下來需要做嘅嘢 - 可執行清單
一個可以即刻試嘅小實驗
今日揀一個細功能或者一篇短文,用三個會話完成:第一個淨係規劃,第二個淨係執行,第三個淨係審查。唔好俾同一個會話由頭包到尾。睇嚇最終返工次數係咪下降。
一個長期可以堅持嘅習慣
每星期做一次 Harness 垃圾回收:刪除過時規則、合併重複規則、補充真實錯誤、壓縮記憶文件。記錄文件行數同重複錯誤次數。
六、未來應該避免啲乜
避免將時間花喺收藏 prompt 度。真正影響長期產出嘅,唔係某句神奇嘅 prompt,而係項目自己嘅規則、回饋同記憶。
避免叫 AI 寫完之後淨係睇解釋唔睇結果。AI 嘅解釋通常好順,但結果要靠測試、截圖、日誌同 diff 嚟判斷。
避免將規則文件寫成百科。語言慣例、框架常識、AI 可以從 code 讀到嘅嘢,唔值得佔用 context。
避免接受自己睇唔明嘅實現。短期好似慳時間,長期會變成冇辦法維護嘅債務。
避免喺一個失敗嘅 context 入面無限糾正。連續兩次走歪,就應該重開,而唔係繼續將錯誤路徑加厚。
七、一句話總結
呢本書真正改變我嘅,係將「用 AI」嘅問題,改成「設計一個令 AI 不斷變可靠嘅系統」嘅問題。
2026.05.06 19:58
滬·趙巷
📌 聲明:本文由 AI 輔助完成
此文是《Harness Engineering橙皮書:AI編程時代的工程方法論》讀書筆記整理。
最近讀完這本書,感覺乾貨滿滿,整理一下,方便自己,方便他人。
一、這本書真正想解決什麼問題
這本書表面上在講 Harness Engineering:給 AI agent 設計指令、約束、工具、記憶、反饋和編排,讓它不只是會聊天,而是能在真實工程環境裏穩定幹活。
它真正想解決的問題不是「怎麼讓 AI 更聰明」,而是「在 AI 已經足夠強但還不穩定的情況下,人應該怎樣重新設計工作系統」。以前我們把注意力放在 prompt 上,後來放在 context 上,但真實項目的問題更硬:AI 會誤解、偷懶、幻覺、重複犯錯、寫出自己也沒驗證過的代碼。靠一句提示詞管不住這些問題。
這本書和我現在最相關的一點是:我已經不是單純在“使用 AI”,而是在用 AI 做開發、寫作、寫產品相關文檔,以及做長期項目。真正影響結果的,不是某次對話質量,而是我有沒有把經驗沉澱成規則、工具、知識庫和反饋循環。
如果只帶走一個判斷:AI 編程時代,人的核心價值不是親手寫更多代碼,而是設計一個能讓 AI 持續產出、持續糾錯、持續積累的工作環境。
二、核心概念
1. Harness:AI 的工作環境,不是提示詞
這是什麼
Harness 是 AI 可以行動的那套殼:能讀文件、改代碼、跑測試、查資料、調用工具,也有規則、邊界和反饋。模型是腦子,Harness 是手腳、護欄和儀表盤。
用在什麼場景
適合真實項目:iOS App、AI 工具、寫作工作流、獨立產品迭代。不適合一次性閒聊或簡單問答。誤用是把 Harness 當成“更長的 prompt”,把所有規則塞進一個文件,最後反而污染上下文。
怎麼用
給每個長期項目建一個輕量入口文件,比如 AGENTS.md / CLAUDE.md:只寫 AI 從代碼裏看不出來的信息,例如構建命令、測試方式、項目禁區、發佈流程、常犯錯誤。
實踐步驟
- 1. 從空文件開始,不預設一堆規則。
- 2. 每次 AI 犯錯,只加一條能防止復發的規則。
- 3. 每週刪除 AI 能自己從代碼推斷出的規則。
- 4. 把複雜規範拆到獨立文檔,入口文件只做地圖。
- 5. 規則是否有效,用“同類錯誤有沒有復發”判斷。
2. 反饋層:讓 AI 必須驗證自己的工作
這是什麼
反饋層不是讓 AI 說“我檢查過了”,而是給它可執行的驗證手段:測試、lint、截圖、日誌、Playwright、DevTools、CI。
用在什麼場景
適合所有會產生結果的任務:寫代碼、改 UI、寫文章、做產品頁。不適合純概念討論。誤用是讓生成者自評,AI 很容易滿足於“看起來可以”。
怎麼用
開發中,每次改動後必須跑最小驗證;
寫作中,每篇文章用獨立會話審稿;
產品設計,則用截圖和用戶路徑驗證,而不是隻看代碼。
實踐步驟
- 1. 給項目列出 3 個最小驗證命令。
- 2. 在規則文件裏寫清楚“改完必須跑哪些檢查”。
- 3. UI 改動必須看截圖,不只看源碼。
- 4. 複雜任務開一個全新會話做 Reviewer。
- 5. 驗證失敗時先修 Harness,再修單點輸出。
3. 記憶層:讓錯誤變成複利
這是什麼
記憶層解決“這次踩過的坑,下次別再踩”。它可以是 MEMORY.md、項目知識庫、覆盤日誌,也可以是規則文件裏的新增約束。
用在什麼場景
適合長期項目、系列文章、App 迭代、AI 工作流。不適合短期一次性任務。誤用是把記憶當垃圾桶,什麼都往裏丟,最後 AI 找不到重點。
怎麼用
應該把 AI 協作中的高頻錯誤、項目背景、寫作口味、發佈步驟沉澱下來,但控制在 100 行以內。記憶不是資料庫,記憶是決策偏好和歷史教訓。
實踐步驟
- 1. 建一個項目級
MEMORY.md。 - 2. 只記錄“AI 無法從文件推斷的信息”。
- 3. 每條記憶都對應一個真實錯誤或穩定偏好。
- 4. 每兩週壓縮一次,刪除過時內容。
- 5. 觀察 AI 是否減少重複解釋成本。
4. 編排層:從一個 AI 幹活到多個 AI 協作
這是什麼
編排層是任務拆分和角色安排:Planner 負責計劃,Generator 負責實現,Evaluator 負責挑錯。多 agent 的關鍵不是數量,而是角色邊界。
用在什麼場景
適合複雜功能、長文章、重構、調研、上線前檢查。不適合簡單任務。誤用是同時開很多會話但沒有隔離工作區和明確目標,最後衝突更多。
怎麼用
獨立開發場景,一個會話寫需求,一個會話實現,一個新會話審查;
寫作場景,一個會話出結構,一個會話寫正文,一個會話挑邏輯漏洞。
實踐步驟
- 1. 複雜任務先讓 Planner 寫計劃。
- 2. 實現會話只負責執行,不擴展需求。
- 3. 審查會話必須是全新上下文。
- 4. 並行開發時每個任務用獨立 worktree。
- 5. 合併前由人判斷結構、取捨和風險。
三、對我真正有用的 4 個點
1. 不要發佈自己不理解的代碼
Insight
AI 可以寫實現,但責任不能外包。真正危險的不是 AI 寫錯,而是我因為省事接受了自己無法解釋的東西。
我的理解
我可以讓 AI 寫 iOS App、Java 工具類、腳本、測試,但架構邊界、數據流、狀態管理必須自己看懂。看不懂就不合並,這條線不能松。
如何用在我身上
我的開發工作裏,AI PR 合併前必須能回答三個問題:改了什麼、為什麼這樣改、壞了怎麼回滾。答不上來就繼續拆小。
2. 規則應該從錯誤里長出來
Insight
提前寫 500 行規則通常是在製造噪音。真正有價值的規則來自真實失敗。
我的理解
我以前容易把“理想工作方式”寫成規範,但 AI 不會因為規範漂亮就遵守。更好的方式是等它犯錯,然後把錯誤工程化成約束。
如何用在我身上
我的每個新項目都從一個空 AGENTS.md 開始:構建命令、測試命令、禁止事項,然後每次踩坑補一條。
3. 評估者要獨立
Insight
讓同一個 AI 自己寫、自己審,天然會漏。它會偏愛自己的第一個方案。
我的理解
這點可以遷移到寫作。我寫完文章後,不應該讓同一個上下文“潤色一下”,而應該開新會話讓它專門找邏輯漏洞、廢話和不成立的判斷。
如何用在我身上
寫作流程改成三步:結構會話、正文會話、審稿會話。
審稿只允許指出問題,不允許直接改成一篇更“順”的廢話。
4. 上下文不是越多越好
Insight
上下文太長會腐爛,失敗方案會污染後續判斷。修兩次還錯,繼續補丁式糾正往往更差。
我的理解
我需要更果斷地清空重來。尤其是調 bug、寫複雜邏輯、做 UI 時,如果 AI 連續兩輪走偏,就應該重開上下文,給它乾淨的狀態和更窄的問題。
如何用在我身上
我的開發和寫作都可以採用“二次失敗重啓規則”:同一個問題糾正超過兩次,就生成當前狀態摘要,重開會話繼續。
四、經驗、反直覺點和被忽略的細節
最反直覺的是:AI 越強,越需要工程紀律。模型能力提升不會自動帶來可靠產出,反而會讓人更容易過度信任它。
容易忽略的是基礎設施。Stripe 的案例說明,AI PR 能跑起來,不只是模型強,而是團隊本來就有測試、部署、回滾和審查信號。個人開發也一樣,沒有測試和發佈清單,AI 只會把混亂放大。
一個容易誤用的觀點是“多 agent 並行”。並行不是同時開很多窗口,而是任務可隔離、結果可驗證、衝突可合併。否則只是把上下文切換成本轉嫁給自己。
此外,我們還要保持懷疑:書裏很多高產案例證明了速度,但沒有完全證明長期可維護性。AI 寫出的代碼是否能在半年後繼續演進,仍然需要靠架構、測試和人的判斷來兜底。
五、讀完此書,接下來需要做的事 - 可執行清單
一個可以立刻嘗試的小實驗
今天選一個小功能或一篇短文,用三個會話完成:第一個只規劃,第二個只執行,第三個只審查。不要讓同一個會話包辦到底。看最終返工次數是否下降。
一個長期可以堅持的習慣
每週做一次 Harness 垃圾回收:刪掉過時規則、合併重複規則、補充真實錯誤、壓縮記憶文件。記錄文件行數和重複錯誤次數。
六、未來應該避免什麼
避免把時間花在收藏提示詞上。真正影響長期產出的,不是某句神奇 prompt,而是項目自己的規則、反饋和記憶。
避免讓 AI 寫完後只看解釋不看結果。AI 的解釋經常很順,但結果要靠測試、截圖、日誌和 diff 判斷。
避免把規則文件寫成百科。語言慣例、框架常識、AI 能從代碼裏讀出來的東西,不值得占上下文。
避免接受自己看不懂的實現。短期像省時間,長期會變成無法維護的債務。
避免在一個失敗上下文裏無限糾正。連續兩次走偏,就應該重開,而不是繼續把錯誤路徑加厚。
七、一句話總結
這本書真正改變我的,是把“使用 AI”的問題,改成了“設計一個讓 AI 不斷變可靠的系統”的問題。
2026.05.06 19:58
滬·趙巷
📌 聲明:本文由 AI 輔助完成