從 Prompt 到 Harness:如何理解 LLM Engineering 的三次範式遷移
整理版優先睇
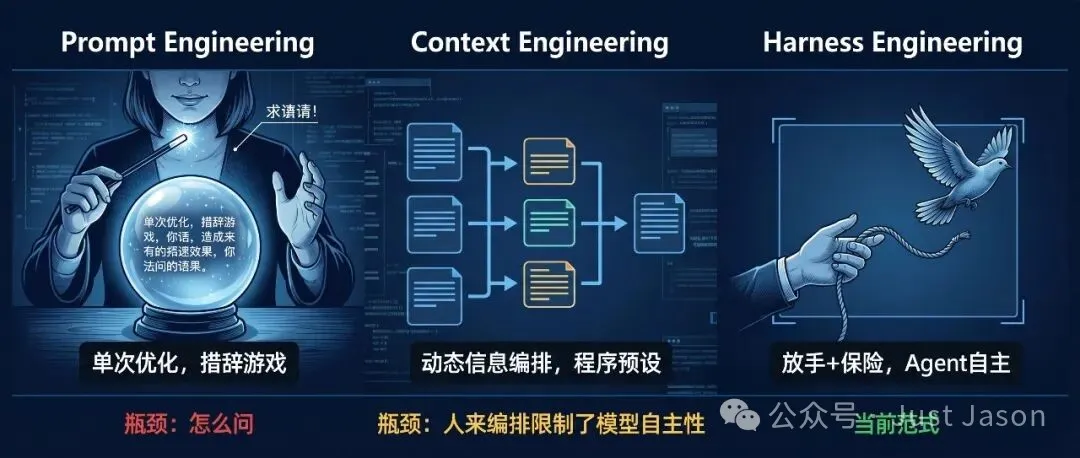
LLM工程從Prompt到Harness嘅三次範式遷移:唔好再盲目調prompt,要識得放手同埋上保險。
呢篇文章係由獨立AI產品創業者Jason寫嘅,佢透過自己做Zaokit嘅經驗,拆解LLM工程點樣由最初嘅Prompt Engineering進化到Context Engineering,再到而家嘅Harness Engineering。佢想解決嘅問題係:點解好多人在調prompt上花好多時間但效果唔好?整體結論係每一次範式遷移都係被前一個階段嘅限制逼出嚟嘅,理解呢個脈絡可以幫你決定而家應該將時間擺喺邊度。
文章指出,Prompt Engineering係單次任務嘅優化框架,但真實世界嘅任務多數係動態展開嘅,所以會撞牆。跟住Context Engineering嘗試管理多步任務之間嘅信息流轉,但又有context rot問題。最後Harness Engineering出現:放手俾agent自己攞資訊,同時劃好邊界。作者用Stripe Minions、Anthropic SDK、OpenAI Codex三個案例驗證呢個框架,強調「先放手、再上保險」嘅順序。最值得留意嘅係,佢提出螺旋發展嘅觀點:模型愈來愈強,人愈放得手,但同時新嘅可靠性問題會出現,需要新嘅工程實踐去兜底。
對獨立Builder嚟講,如果仲喺Prompt階段就要知道上限喺邊,如果已經進入Context階段就要諗點樣過渡到Harness。而家Cursor、Claude Code已經內置咗成熟嘅harness,但理解背後邏輯可以幫你喺工具唔夠用嘅時候知點做。
- LLM工程經歷咗三次範式遷移:Prompt Engineering(靜態單次優化)→ Context Engineering(動態多步信息流轉)→ Harness Engineering(自主運行+邊界兜底)。
- Prompt Engineering嘅根本限制係單次任務框架,唔適合多步任務;Context Engineering嘅限制係人硬編碼信息流程,反而成為瓶頸。
- Harness Engineering嘅核心係「放手」同「上保險」:俾agent工具自主獲取資訊,再從失敗模式倒推出能力邊界。
- 三個案例(Stripe Minions、Anthropic SDK、OpenAI Codex)驗證咗呢個框架:先放手發現失控模式,再針對性加約束。
- 螺旋發展:模型能力提升、人放更多手、新可靠性問題出現,三者互相驅動;而家下一層瓶頸係Eval同Governance。
引言:從一個撞牆經歷講起
作者Jason喺做Zaokit早期pipeline嘅時候,為咗一個prompt耗咗將近兩星期——換措辭、加示例、調結構,好似同一個脾氣唔穩定嘅合作者磨合咁。但磨完之後任務形態變咗,由「寫一段文案」變成「理解用戶意圖→檢索參考→生成初稿→多輪迭代」,佢先至醒覺嗰兩星期嘅調教根本對唔上號。
呢篇文章係Jason綜合自身經驗同行業研究嘅整理,目標係幫你睇清成個脈絡,而家唔使再重複行冤枉路。
從Prompt到Context再到Harness:三次瓶頸驅動嘅範式轉移
第一階段係Prompt Engineering。嗰陣時大家摸索Few-shot示例、Chain-of-Thought推理、角色指定呢啲技巧,好似交換咒語咁。但限制好明顯:佢係單次任務嘅優化框架,一遇上多步任務就唔掂。
第二階段Context Engineering係因為模型開始支援工具調用,任務由「問一個問題」變成「跑一個流程」。重點係管理步與步之間嘅信息流轉:上一步結果點樣流入下一步?環境反饋點樣注入?對話歷史點樣壓縮?但佢都有天花板——Microsoft同Salesforce研究發現,多輪對話後模型性能平均下降39%,呢個叫context rot。
第三階段Harness Engineering嘅前提係模型已經強到人類編排信息反而係瓶頸。Khan嘅研究顯示,喺gpt-5上,精心設計嘅Sculpting prompt準確率反而不及簡單CoT——模型越強,人類技巧反而變成約束。所以Harness Engineering第一步係放手:俾agent自主獲取資訊;第二步係上保險:劃定沙箱、權限、輪數限制等邊界。
三個案例驗證:Stripe、Anthropic同OpenAI
Stripe Minions每星期合併超過1000個PR,全部由agent寫,人類只做review。放手方面:agent可以自己決定用lint、測試、Sourcegraph等工具;上保險方面:agent跑喺隔離devbox,最多跑兩輪CI,MCP連接嘅內部工具只可訪問經過篩選嘅子集。
Anthropic做咗個實驗,讓agent自主構建完整web應用,發現咗三種失敗模式:一口氣做太多、過早宣佈完成、假裝測試通過。佢哋針對每種模式加保險:每個session只做一個feature、用JSON格式約束狀態記錄、強制用Puppeteer做端對端驗證。
OpenAI Codex團隊最極端——3-7人,5個月,100萬行代碼。工程師唔寫產品代碼,全部精力投入環境設計、意圖明文化、反饋循環構建。最值得借鑑嘅係「垃圾回收」設計:持續掃描代碼庫,發現架構drift就自動生成修復任務。
對獨立Builder嘅啟示同螺旋展望
如果你仲喺Prompt Engineering階段,要知道呢個框架上限好低,一旦任務複雜就唔夠用;如果你已經進入Context Engineering階段,開始做信息流轉嘅髒活,就要諗點樣過渡到Harness——直接俾agent工具同邊界,而唔係再替佢編排每一步。
而家Cursor同Claude Code已經內置咗成熟harness,你可以直接用。但理解背後邏輯,可以令你喺工具唔夠用或者想自建嘅時候,知道由邊度入手,而唔係盲目調prompt。
螺旋仲喺度轉緊。下一層瓶頸已經浮現:Eval(LLM-as-judge bias)、Governance(多agent互相認證審計)。NIST已經啟動咗AI Agent Standards Initiative,預計2026年Q4發佈初版Agent Interoperability Profile。呢啲就係下一個範式嘅開端。
做 Zaokit 早期 pipeline 嘅時候,我喺一個 prompt 上面搞咗差唔多兩星期。換措辭、加示例、調整結構——好似同一個脾氣好難捉摸嘅合作夥伴不斷磨合咁。
搞完之後,任務嘅形態變咗。由「寫一段文案」變成「理解用戶意圖→檢索參考→生成初稿→多輪迭代」。我先至意識到,嗰兩星期嘅調整根本對唔上號——佢解決嘅係一個假問題。
呢件事喺行業層面已經演進咗三輪。每一輪都唔係有人坐低設計出嚟,而係俾上一輪撞咗牆之後逼出嚟。要理解 LLM Engineering,最好嘅方法係回到每次轉移嘅現場:究竟撞咗乜嘢牆,同埋有乜嘢喺度等緊。

ChatGPT 上線冇幾耐,所有人都在摸索:換措辭、加前綴、調整語氣,睇下邊種講法可以換到更好嘅輸出。
呢個摸索期沉澱咗一套工程實踐:Few-shot 示例、Chain-of-Thought 推理、角色指定、輸出格式約束。GitHub 上面湧現咗大量 prompt 模板庫,大家交換 prompt 嘅方式好似交換咒語——呢條可以召喚好代碼,嗰條可以令翻譯更地道。「喺 prompt 尾加一句『呢個對我嘅職業生涯好重要』,輸出質素會提升」呢類發現,當時係真實有效嘅經驗。
呢啲技巧的確有用。CoT 喺當時可以將推理任務嘅準確率拉高十幾個百分點,一個精心設計嘅 prompt 同隨手寫嘅 prompt,輸出質素可能差兩個等級。
我自己都完整經歷過呢個階段:喺 prompt 裏面窮舉曬所有邊界情況,嘗試將每個細節都事先話俾模型知,希望佢跟住我想像嘅方式輸出。有時有效,有時完全隨機,根本摸唔清背後嘅規律。
但 Prompt Engineering 有一個根本限制:佢係單次任務嘅優化框架。 寫一封電郵、翻譯一段話、解釋一個概念——你喺發出 prompt 嗰一刻就完整知道需要乜嘢,亦都完整知道模型應該睇乜嘢。
然後模型開始支援工具調用。任務由「問一個問題」變成「跑一個流程」。你發現,措辭再完美,如果模型見到嘅資訊係錯嘅或者唔夠,輸出就係錯嘅。瓶頸從怎麼問移到了俾佢睇乜嘢。
二、Context Engineering:當任務唔再係一句話講得清
Prompt Engineering 時代,任務係靜態嘅。但真實世界嘅任務好少係靜態嘅。
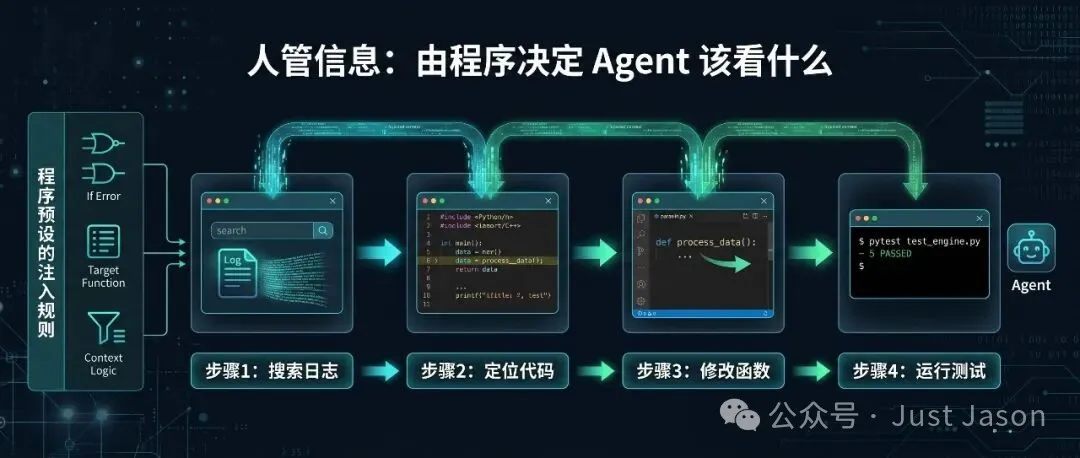
你叫 agent 修理一個 bug。一開始淨係知「用戶報咗一個 bug」。Agent 搜咗日誌,發現係支付模組嘅問題;睇咗支付模組嘅 code,定位到具體函數;改咗函數,LSP 報咗三個新嘅 type error;跑測試,兩個 pass 一個 fail,先知仲有邊界情況未處理。每一步嘅輸出決定咗下一步要做啲乜、要睇啲乜。任務嘅全貌唔係一開始可以定義到,佢係喺執行過程中逐步展開。
呢個就係 Prompt Engineering 撞嘅牆:你冇辦法喺一次 prompt 裏面將所有資訊組織好,因為嗰啲資訊要等前面步驟執行完先會浮現出嚟。
Context Engineering 真正做嘅新嘢係:喺一個動態展開嘅多步任務裏面,管理步與步之間嘅資訊流轉。具體回答嘅問題:
• 上一步嘅結果點樣流入下一步嘅 context? • 環境反饋(LSP 報錯、測試失敗)點樣注入? • 對話歷史越來越長,邊啲壓縮、邊啲保留? • 外部檢索嘅資訊,喺邊一步注入、注入幾多?
我用 Cursor 同 Claude Code 做 Zaokit 開發嘅感覺就係咁——喺一個大型任務裏面,最難頂嘅唔係模型唔夠聰明,而係資訊流轉出咗問題:前一步生成嘅檔案冇俾正確引用入嚟,測試報嘅錯誤冇注入到下一步嘅 context,模型靠估而唔係靠見到真實結果嚟做決定。
Cursor 係呢套邏輯嘅典型產品。你改咗一個函數簽名,佢唔係將整個 codebase 都塞入 context,而係動態檢索相關嘅調用方注入;你改完呢啲檔案,測試報咗新錯誤,佢再將測試檔案同錯誤資訊拉入嚟。每一步見到啲乜,取決於上一步發生咗啲乜。Lovable、Bolt 都係同一路數——編輯器、LSP、構建系統產生嘅環境反饋,被程序自動注入到下一輪 context。
2025 年 6 月,Karpathy 出咗個 post 俾呢套實踐一個名:
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
14k likes。留意佢用嘅動詞:filling。係由外部去填,唔係模型自己揾。呢啲實踐喺命名之前已經存在,Karpathy 嘅貢獻係準確捉住本質:任務動態展開,但管理呢個過程嘅規則係靜態嘅、人預設嘅。
Context Engineering 都有天花板。 Microsoft 同 Salesforce 嘅研究發現,隨住多輪對話推進,模型性能平均下降 39%,即使係最強嘅 o3 都從 98.1% 跌到 64.1%——呢個叫做 context rot。資訊管理本身會去到極限。
但更根本嘅問題唔係 context rot,而係:當模型能力已經超過人類硬編碼嘅規則時,人類做資訊編排反而變咗瓶頸。模型有能力判斷邊啲資訊重要、下一步要睇啲乜,但 context engineering 嘅框架唔俾佢呢個權力。 佢將一個已經夠聰明嘅 agent 當成被動嘅資訊接收者。
瓶頸再次移動:由「人類點樣幫 agent 編排資訊」到「點樣令 agent 自主編排,同時確保佢唔失控」。
三、Harness Engineering:放手,然後上保險
Harness Engineering 唔係有人坐低設計出嚟嘅新範式,而係 agent 大規模運行之後,工程師被現實教育出嚟嘅經驗。
前提:模型已經強到人類編排資訊反而係瓶頸。
Khan 嘅 Prompting Inversion 研究俾咗一個直接證據:一種叫 Sculpting 嘅精細 prompt 技法,喺 gpt-4o 上準確率 97%,超過 standard CoT 嘅 93%。但去到 gpt-5 上面反轉咗——standard CoT 96%,Sculpting 反而跌到 94%。模型越強,人類精心設計嘅技巧反而變咗約束。 你以為喺幫佢,其實係阻住佢。
所以 harness engineering 嘅第一步係放手:唔再幫 agent 做資訊決策,而係俾工具佢,等佢自己去攞需要嘅資訊。可以跑 lint、跑測試、睇瀏覽器狀態、檢索 codebase。Agent 自己決定幾時用呢啲工具、用邊個、用幾深。
第二步係上保險:俾 agent 畫清楚嘅能力邊界。沙箱隔離、CI 輪數限制、檔案權限、架構約束——邊界嘅形態取決於場景。
呢兩步嘅順序好重要。唔係先畫好框再放手,而係先睇佢自己可以跑到邊度,再喺失控嘅地方劃線。邊界係從現實反推返嚟,唔係坐喺白板前面憑空設計。
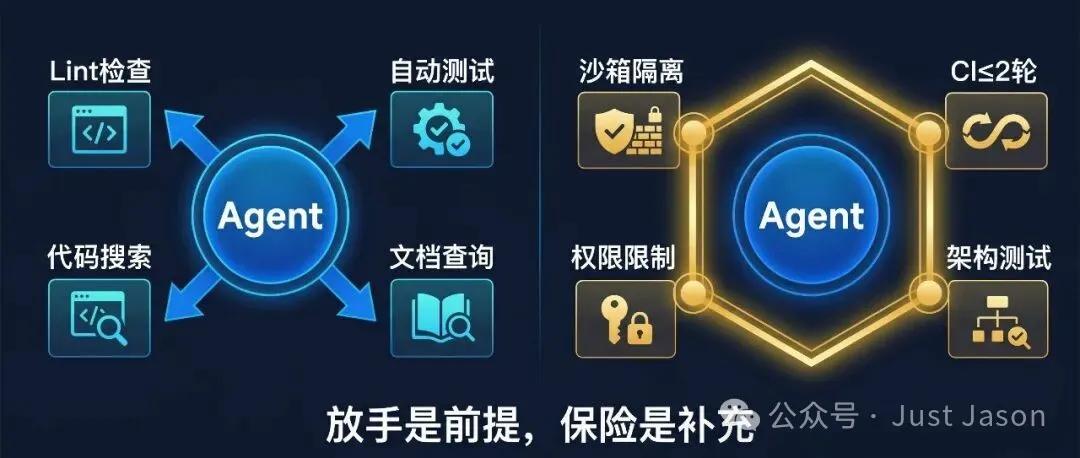
將呢兩步擺埋一齊:
Harness Engineering 係為 agent 構建運行環境嘅工程實踐。放手:俾 agent 工具同反饋通道,等佢自主攞資訊、自主判斷。上保險:幫 agent 框定能力邊界,確保自主運行唔失控。能力邊界唔係對模型嘅不信任,而係對非確定性系統嘅工程紀律。
四、三個案例驗證
Stripe Minions:1000 PR/星期,全靠 Agent 寫
Stripe 自己整咗一套叫 Minions 嘅無人值守 coding agent,每星期合併超過 1000 個 PR,全部 agent 寫嘅,人類只做 review。
放手嘅部分: Agent 可以跑 lint、跑測試、透過 Sourcegraph 搜 code、經 MCP 查內部文檔。呢啲工具唔係程序喺背後幫 agent 調用,而係 agent 自己決定幾時用、用邊個。Stripe 工程師總結咗一條設計原則:「shift feedback left」——可以喺本地攔住嘅唔等 CI。Agent 每次 push 之後,5 秒內就跑完一輪 lint 檢查。反饋嚟得越快,agent 自我糾正嘅成本就越低。
上保險嘅部分: Agent 跑喺隔離嘅 devbox 入面,唔可以 access 生產環境同外網。最多跑兩輪 CI,無論結果點都停低。MCP 連接咗 400 幾個內部工具,但每個 agent 淨係可以訪問經過篩選嘅子集。
值得一提:Stripe 按子目錄條件自動加載嘅 rule files,唔係 harness,而係 context engineering——規則加載邏輯係程序預設嘅,agent 冇選擇權。呢個都睇到螺旋嘅積層:harness 內部,context engineering 嘅 pipeline 仍然喺度運作。
Anthropic Claude Agent SDK:從失敗模式反推邊界
Anthropic 做咗一個實驗:叫 agent 自主構建一個完整嘅 web 應用。Agent 擁有完整開發工具鏈(檔案系統、bash、Puppeteer 瀏覽器控制)。放手之後,即刻暴露咗三種失敗模式:
1. 一次過做太多——嘗試一次實現所有功能,context 用曬留低一堆半製成品 2. 過早宣佈完成——見到有進度就話「搞掂咗」 3. 假裝測試通過——標記 feature 完成,但實際冇驗證
見到呢三條我笑咗,因為呢個幾乎係我自己用 Claude Code 跑複雜任務時遇到嘅同款問題。唔係 bug,而係 agent 喺冇約束嘅情況下嘅默認行為模式。
Anthropic 針對每種失敗模式加保險:
• 每個 session 淨係做一個 feature,硬約束,唔係建議 • feature_list.json 裏面 200+ 個 feature 全部都標為 failing,agent 淨可以將 passes 字段由 false 改成 true,唔可以刪 feature、唔可以改描述。用 JSON 而唔用 Markdown,因為模型比較唔會亂改 JSON 結構——數據格式本身已經係約束 • 必須用 Puppeteer 做端到端驗證,唔可以剩係靠 unit test 就話「通過咗」
呢度有一個推進關係值得記低:先放手,發現失控嘅模式,再針對性加保險。能力邊界係從失敗模式反推出嚟,唔係坐喺度憑空劃線。
OpenAI Codex 團隊:最極端嘅案例
OpenAI Codex 團隊 3-7 個人,5 個月,100 萬行 code,1500 個 PR。工程師唔再寫產品 code,全部精力投入三件事:環境設計、意圖明文化、反饋循環構建。
先講放手嘅部分。
工具鏈方面,agent 可以跑完整測試套件、調用自定義 linter、讀寫檔案系統、執行 bash 命令。工具唔係事先揀好餵俾佢,而係隨任務需要自主調用。
任務入口設計咗一個關鍵細節——issue 格式係強約束嘅。每個任務都有機器可解析嘅結構化驗收標準(acceptance criteria),唔係自然語言描述。Agent 開始工作之前已經知「乜嘢叫搞掂」,唔使估。
「垃圾回收」係 Codex 團隊最有意思嘅設計之一。唔係等 agent 提交先檢查,而係持續掃描成個 codebase,發現架構 drift(模組邊界俾侵蝕、重複 code 積累、依賴關係跨層)時,自動生成修復任務分配俾 agent。環境主動將要處理嘅問題推到 agent 面前,agent 自己決定點樣修。 呢個將「codebase 健康」由人手週期性審查變成持續自動化治理。
再講意圖明文化。
呢個係成個案例裏面最易被忽略、但我覺得最值得參考嘅部分。
當工程師唔再寫產品 code,佢哋花咗大量時間令 codebase「對 agent 可讀」——唔單止係註釋,而係架構決策嘅顯式文檔化:點解呢個模組嘅邊界劃喺度?點解呢個函數唔可以調用嗰個服務?呢啲喺人類團隊入面靠口耳相傳嘅隱形契約,全部要變成 agent 可以解析嘅文字。
翻譯成白話:以前人類靠默契運作,而家要將默契全部寫出嚟。 呢件事其實一早應該做,只不過以前求其過咗去。agent 嘅出現逼到團隊將隱性知識顯性化——意外地,呢個亦令 codebase 對新人工程師更友善。
上保險:三層硬攔截,淨係最後一層需要人。
第一層:自定義 linter,每次提交自動運行,檢查 code 風格、命名規範、禁用 API 調用。唔過就唔可以合入,冇人手豁免通道。
第二層:structural tests,專門驗證分層架構完整性。Agent 唔可以寫出跨越模組邊界嘅調用——唔係靠 prompt 入面寫「請遵守架構」,而係測試直接 fail。呢道攔截令架構約束由「建議」變成「物理規律」。
第三層:人手 review gate。1500 個 PR,每一個都要經工程師 review 先可以合併。呢個係唯一需要人參與嘅環節。前兩層自動化,反而令呢道門嘅價值更高——工程師 review 時,低級問題已經俾攔截咗,佢哋只需要判斷意圖同方向係咪正確。
負責人 Ryan Lopopolo 總結咗一句被廣泛引用嘅話:
"Agents aren't hard; the Harness is hard."
最後嘅結論同樣值得抽出來:
"Our most difficult challenges now center on designing environments, feedback loops, and control systems."
唔係模型唔夠強,而係環境設計唔夠好。呢句話我自己用 Claude Code 時深有體會——同一個模型,有冇好嘅工具鏈同約束機制,結果可以差好遠。最難嘅工作,已經由「訓練更好嘅模型」轉移咗去「搭建更好嘅運行環境」。
五、對 Builder 嚟講意味住啲乜
呢三個階段嘅演進,唔單止係大廠嘅工程問題。如果你用緊 Claude Code、Cursor,或者緊係將 AI 接入自己嘅產品,呢個脈絡直接影響你而家應該將時間放喺邊度。
仲喺 Prompt Engineering 階段嘅你,為每個任務精心寫 system prompt,調措辭、加示例、反覆測試。呢個係起點,亦都係上限。一旦任務複雜起嚟,呢套嘢唔夠用——唔係你寫得唔好,而係框架本身唔適合多步任務。
進入 Context Engineering 階段嘅你,開始關心資訊流轉:用咩框架管理多步任務?點樣將工具調用嘅結果注入到下一步?點樣壓縮對話歷史?呢個階段嘅工作會令 agent 嘅穩定性明顯提升,但你會越來越明顯感覺到自己做緊「管資訊」嘅 dirty work——而且模型往往比你更清楚佢需要啲乜。
企喺 Harness Engineering 門口嘅你,思考嘅問題變咗:唔係「點樣寫 prompt」,而係「俾佢咩工具、點樣驗證佢做嘅嘢係啱嘅、如果失控咗從邊度兜底」。呢個階段更加似係搭運行環境,而唔係同模型對話。
對獨立 Builder 嚟講,呢三個階段唔需要全部自己從頭行一次。Cursor、Claude Code 已經內置咗相當成熟嘅 harness——你可以直接用。但理解背後嘅邏輯,可以令你喺工具唔夠用嘅時候知道從邊度入手,而唔係盲目調 prompt。
六、回頭睇:一個螺旋嘅三圈
三個階段行落嚟,有一個 pattern 好清楚:每一次演化都唔係設計出嚟,而係上一階段嘅做法唔夠用,新實踐先俾逼出嚟。
每轉一圈,三件事一齊發生:模型更強咗少少,可以做更長更複雜嘅任務;人敢放多啲手,由全程在場變成剩係睇結果;新嘅可靠性問題暴露,催生新嘅工程實踐嚟兜底。三者唔係線性因果,而係互相驅動嘅螺旋。
前一圈唔會消失,佢變成基礎設施。Harness 入面仲行緊 context engineering 嘅 pipeline,pipeline 入面仲寫緊精心設計嘅 system prompt。Harness 嘅約束最終要落地到 agent 理解到嘅地方,而 prompt 仍然係嗰個載體。
定量數據支撐呢個判斷:Epsilla 嘅實驗顯示,同一個模型、同一個 prompt、同一份數據,淨係換 harness 配置,任務成功率由 42% 跳到 78%。LangChain 喺 Terminal Bench 2.0 嘅測試驗證咗類似結論:同一個 Opus 4.6,喺唔同 harness 下嘅 solve rate 差異超過 60%。模型冇變,變嘅係佢有冇俾賦予自主獲取反饋嘅能力,同埋有冇合理嘅邊界兜底。
螺旋仲喺度轉。Harness engineering 之後,下一層瓶頸已經喺度露出嚟:
• Eval:agent 跑完之後,結果到底好唔好?LLM-as-judge 本身有 bias,「評估評估系統」係一個遞迴問題。Cisco/Splunk 喺 2026 年收購咗專注 eval 嘅公司 Galileo,eval 嘅產業化正在發生。 • Governance:多個 agent 之間點樣互相認證、點樣審計、點樣管權限?NIST 已經啟動咗 AI Agent Standards Initiative,計劃 2026 年 Q4 發佈 Agent Interoperability Profile 初版。
但嗰個係螺旋嘅下一圈喇。
資訊來源
核心定義與框架
• Andrej Karpathy, Context Engineering 定義, Twitter/X, 2025.06.25 • Birgitta Böckeler, Harness Engineering for Coding Agent Users, martinfowler.com, 2026.04.02 • Ryan Lopopolo, Harness Engineering: Leveraging Codex in an Agent-First World, openai.com, 2026.02.11 • LangChain, The Anatomy of an Agent Harness, blog.langchain.com, 2026.03.10
產品案例
• Stripe Engineering, Minions: Stripe's One-Shot, End-to-End Coding Agents, stripe.dev, 2026.02.09 • Anthropic, Effective Harnesses for Long-Running Agents, anthropic.com, 2025.11.26
研究數據
• Khan, Prompting Inversion, arXiv, 2025 • Laban et al., LLMs Get Lost In Multi-Turn Conversation, Microsoft + Salesforce, 2025 • Epsilla, Harness Engineering: Evolution from Prompt to Context to Autonomous Agents, 2026
我係 Jason,一個獨立打造 AI 產品嘅創業者。如果呢篇文章對你有啟發,歡迎轉發俾關注 AI 工程嘅朋友。
我一個人打造嘅 Zaokit AI 產品(https://zaokit.app)正在內測,2026年5月31日前1000名用戶贈送價值150RMB嘅Pro計劃,幫大家高效完成圖文創作同PPT生成,唯一網站:https://zaokit.app
最後,如果你認同 Zaokit AI 嘅產品理念,歡迎後台留言加入我哋嘅社羣。我哋唔賣課、唔割韭菜,淨係聚焦 ToB 企業場景嘅 AI 落地實戰。 希望喺度,可以帶俾你唔一樣嘅思維火花同真實嘅商業碰撞。
相關閲讀:
做 Zaokit 早期 pipeline 的時候,我在一個 prompt 上耗了將近兩週。換措辭、加示例、調結構——像在跟一個脾氣捉摸不定的合作者反覆磨合。
磨完之後,任務形態變了。從"寫一段文案"變成了"理解用戶意圖→檢索參考→生成初稿→多輪迭代"。我才意識到那兩週的調教根本對不上號——它解決的是個假問題。
這件事在行業層面已經演進了三輪。每一輪都不是有人坐下來設計的,而是被上一輪撞了牆之後逼出來的。理解 LLM Engineering 的最好方式,是回到每次遷移的現場:是什麼撞了牆,又是什麼在等待。
ChatGPT 上線之初,所有人都在摸索:換措辭、加前綴、調語氣,看哪種說法能換來更好的輸出。
這個摸索期沉澱出了一套工程實踐:Few-shot 示例、Chain-of-Thought 推理、角色指定、輸出格式約束。GitHub 上湧現大量 prompt 模板庫,大家交換 prompt 的方式像交換咒語——這條能召喚出好代碼,那條能讓翻譯更地道。"在 prompt 末尾加一句'這對我的職業生涯非常重要',輸出質量會提升"這類發現,當時是真實有效的經驗。
這些技巧確實有用。CoT 在當時能把推理任務準確率拉高十幾個百分點,一個精心設計的 prompt 和隨手寫的 prompt,輸出質量可能差兩個等級。
我自己也完整走過這個階段:在 prompt 裏窮舉所有邊界情況,試圖把每個細節都事先告訴模型,希望它按照我想象的方式輸出。有時候有效,有時候完全隨機,根本摸不清背後的規律。
但 Prompt Engineering 有一個根本侷限:它是單次任務的優化框架。 寫一封郵件、翻譯一段話、解釋一個概念——你在發出 prompt 的那一刻就完整地知道需要什麼,也完整地知道模型該看什麼。
然後模型開始支持工具調用了。任務從"問一個問題"變成了"跑一個流程"。你發現,措辭再完美,如果模型看到的信息是錯的或不夠的,輸出就是錯的。瓶頸從怎麼問移到了給它看什麼。
二、Context Engineering:當任務不再是一句話能說清的
Prompt Engineering 時代,任務是靜態的。但真實世界的任務很少是靜態的。
你讓 agent 修一個 bug。一開始只知道"用戶報了個 bug"。Agent 搜了日誌,發現是支付模塊的問題;讀了支付模塊代碼,定位到具體函數;改了函數,LSP 報了三個新的 type error;跑測試,兩個 pass 一個 fail,才知道還有邊界情況沒處理。每一步的輸出決定了下一步該做什麼、該看什麼。任務的全貌不是一開始能定義的,它在執行過程中逐步展開。
這就是 Prompt Engineering 撞的牆:你沒法在一次 prompt 裏把所有信息組織好,因為那些信息要等前面步驟執行完才會浮現。
Context Engineering 真正做的新事是:在一個動態展開的多步任務裏,管理步與步之間的信息流轉。具體回答的問題:
• 上一步的結果怎麼流入下一步的 context? • 環境反饋(LSP 報錯、測試失敗)怎麼注入? • 對話歷史越來越長,哪些壓縮、哪些保留? • 外部檢索的信息,在哪一步注入、注入多少?
我用 Cursor 和 Claude Code 做 Zaokit 開發的體感就是這樣——在一個大型任務裏,最難受的不是模型不夠聰明,而是信息流轉出了問題:前一步生成的文件沒有被正確引用進來,測試報的錯誤沒有注入到下一步的 context,模型靠猜而不是靠看到真實結果做決定。
Cursor 是這套邏輯的典型產品。你改了一個函數簽名,它不是把整個代碼庫都塞進 context,而是動態檢索相關調用方注入;你修完這些文件,測試報了新錯誤,它再把測試文件和錯誤信息拉進來。每一步看到什麼,取決於上一步發生了什麼。Lovable、Bolt 是同樣的路數——編輯器、LSP、構建系統產生的環境反饋,被程序自動注入到下一輪 context。
2025 年 6 月,Karpathy 發推給了這套實踐一個名字:
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
14k likes。注意他用的動詞:filling。是外部在填,不是模型自己在找。這些實踐在命名之前就已經存在了,Karpathy 的貢獻是精確抓住了本質:任務動態展開,但管理這個過程的規則是靜態的、人預設的。
Context Engineering 也有天花板。 Microsoft 和 Salesforce 的研究發現,隨着多輪對話推進,模型性能平均下降 39%,即使是最強的 o3 也從 98.1% 掉到 64.1%——這被叫做 context rot。信息管理本身會到達極限。
但更根本的問題不是 context rot,而是:當模型能力已經超過人類硬編碼的規則時,人來做信息編排反而成了瓶頸。模型有能力判斷哪些信息重要、下一步該看什麼,但 context engineering 的框架不給它這個權力。 它把一個已經足夠聰明的 agent 當成了被動的信息接收者。
瓶頸再次移動:從"人怎麼替 agent 編排信息"到"怎麼讓 agent 自主編排,同時確保它不失控"。
三、Harness Engineering:放手,然後上保險
Harness Engineering 不是某人坐下來設計出來的新範式,是 agent 大規模跑起來之後,工程師被現實教育出來的經驗。
前提:模型已經強到人來編排信息反而是瓶頸了。
Khan 的 Prompting Inversion 研究給了一個直接證據:一種叫 Sculpting 的精細 prompt 技法,在 gpt-4o 上準確率 97%,超過 standard CoT 的 93%。但到了 gpt-5 上反轉了——standard CoT 96%,Sculpting 反而降到 94%。模型越強,人類精心設計的技巧反而成了約束。 你以為在幫它,其實在礙事。
所以 harness engineering 的第一步是放手:不再替 agent 做信息決策,而是給它工具,讓它自己去獲取需要的信息。能跑 lint、能跑測試、能查看瀏覽器狀態、能檢索代碼庫。Agent 自己決定什麼時候用這些工具、用哪個、用多深。
第二步是上保險:給 agent 畫明確的能力邊界。沙箱隔離、CI 輪數限制、文件權限、架構約束——邊界的形態取決於場景。
這兩步的順序很重要。不是先畫好框再放手,而是先看它自己能跑到哪裏,再從失控的地方劃線。邊界是從現實裏倒推出來的,不是坐在白板前憑空設計的。
把這兩步合在一起:
Harness Engineering 是為 agent 構建運行環境的工程實踐。放手:給 agent 工具和反饋通道,讓它自主獲取信息、自主判斷。上保險:給 agent 框定能力邊界,確保自主運行不失控。能力邊界不是對模型的不信任,而是對非確定性系統的工程紀律。
四、三個案例驗證
Stripe Minions:1000 PR/周,全靠 Agent 寫
Stripe 自建了一套叫 Minions 的無人值守 coding agent,每週合併超過 1000 個 PR,全部 agent 寫的,人只做 review。
放手的部分: Agent 可以跑 lint、跑測試、通過 Sourcegraph 搜代碼、通過 MCP 查內部文檔。這些工具不是程序在背後替 agent 調,是 agent 自己決定何時用、用哪個。Stripe 工程師總結了一條設計原則:"shift feedback left"——能在本地攔住的不等 CI。Agent 每次 push 後,5 秒內就能跑完一輪 lint 檢查。反饋來得越快,agent 自我糾正的成本越低。
上保險的部分: Agent 跑在隔離的 devbox 裏,不能訪問生產環境和外網。最多跑兩輪 CI,不管結果如何都停下來。MCP 連接了 400 多個內部工具,但每個 agent 只能訪問經過篩選的子集。
值得一提:Stripe 按子目錄條件自動加載的 rule files,不是 harness,是 context engineering——規則加載邏輯是程序預設的,agent 沒有選擇權。這也能看出螺旋的積層:harness 內部,context engineering 的 pipeline 仍然在運轉。
Anthropic Claude Agent SDK:從失敗模式倒推邊界
Anthropic 做了一個實驗:讓 agent 自主構建一個完整的 web 應用。Agent 擁有完整開發工具鏈(文件系統、bash、Puppeteer 瀏覽器控制)。放手之後,立刻暴露出三種失敗模式:
1. 一口氣做太多——試圖一次實現所有功能,context 用完留下一堆半成品 2. 過早宣佈完成——看到已有進度就說"做完了" 3. 假裝測試通過——標記 feature 完成,但實際沒有驗證
看到這三條我笑了,因為這幾乎是我自己用 Claude Code 跑複雜任務時碰到的同款問題。不是 bug,是 agent 在不受約束的情況下的默認行為模式。
Anthropic 針對每種失敗模式加保險:
• 每個 session 只做一個 feature,硬約束,不是建議 • feature_list.json 裏 200+ 個 feature 全標為 failing,agent 只能把 passes 字段從 false 改成 true,不能刪 feature、不能改描述。用 JSON 不用 Markdown,因為模型更不容易亂改 JSON 結構——數據格式本身就是約束 • 必須用 Puppeteer 做端到端驗證,不能只靠 unit test 就宣稱"通過了"
這裏有一個推進關係值得記住:先放手,發現失控的模式,再針對性加保險。能力邊界是從失敗模式倒推出來的,不是坐在那裏憑空畫線。
OpenAI Codex 團隊:最極端的案例
OpenAI Codex 團隊 3-7 人,5 個月,100 萬行代碼,1500 個 PR。工程師不再寫產品代碼,全部精力投入三件事:環境設計、意圖明文化、反饋循環構建。
先說放手的部分。
工具鏈方面,agent 可以跑完整的測試套件、調用自定義 linter、讀寫文件系統、執行 bash 命令。工具不是事先選好餵給它的,而是隨任務需要自主調用。
任務入口設計了一個關鍵細節——issue 格式是強約束的。每個任務都有機器可解析的結構化驗收標準(acceptance criteria),不是自然語言描述。Agent 開始工作之前就知道"什麼叫做完了",不需要猜。
"垃圾回收"是 Codex 團隊最有意思的設計之一。不是等 agent 提交才檢查,而是持續掃描整個代碼庫,發現架構 drift(模塊邊界被侵蝕、重複代碼積累、依賴關係跨層)時,自動生成修復任務分配給 agent。環境主動把需要處理的問題推到 agent 面前,agent 自己決定怎麼修。 這把"代碼庫健康"從人工週期性審查變成了持續自動化治理。
再說意圖明文化。
這是整個案例裏最容易被忽視、但我覺得最值得借鑑的部分。
當工程師不再寫產品代碼,他們把大量時間花在了讓代碼庫"對 agent 可讀"上——不只是註釋,而是架構決策的顯式文檔化:為什麼這個模塊的邊界劃在這裏?為什麼這個函數不能調用那個服務?這些在人類團隊裏靠口耳相傳的隱形契約,全部需要變成 agent 能解析的文本。
翻譯成大白話:過去人類靠默契運作,現在得把默契都寫出來。 這件事其實早就應該做,只是以前湊合過去了。agent 的出現逼着團隊把隱性知識顯性化——意外地,這也讓代碼庫對新人工程師更友好了。
上保險:三層硬攔截,只有最後一層需要人。
第一層:自定義 linter,每次提交自動運行,檢查代碼風格、命名規範、禁用 API 調用。不過就是不能合入,沒有人工豁免通道。
第二層:structural tests,專門驗證分層架構完整性。Agent 不能寫出跨越模塊邊界的調用——不是靠 prompt 裏寫"請遵守架構",而是測試直接 fail。這道攔截讓架構約束從"建議"變成了"物理規律"。
第三層:人工 review gate。1500 個 PR,每一個都經過工程師 review 才能合併。這是唯一一道需要人蔘與的環節。前兩層的自動化,反而讓這道門的價值更高——工程師 review 時,低級問題已經被攔掉了,他們只需要判斷意圖和方向是否正確。
負責人 Ryan Lopopolo 總結了一句被廣泛引用的話:
"Agents aren't hard; the Harness is hard."
最後的結論同樣值得摘出來:
"Our most difficult challenges now center on designing environments, feedback loops, and control systems."
不是模型不夠強,是環境設計不夠好。這句話我自己用 Claude Code 時深有體會——同一個模型,有沒有好的工具鏈和約束機制,結果差距巨大。最難的工作,已經從"訓練更好的模型"轉移到了"搭更好的運行環境"。
五、對 Builder 意味着什麼
這三個階段的演進,不只是大廠的工程問題。如果你在用 Claude Code、Cursor,或者在給自己的產品接 AI,這個脈絡直接影響你現在該把時間花在哪裏。
還在 Prompt Engineering 階段的你,在為每個任務精心寫 system prompt,調措辭、加示例、反覆測試。這是起點,也是上限。一旦任務複雜起來,這套東西不夠用——不是你寫得不好,而是框架本身就不適合多步任務。
進入 Context Engineering 階段的你,開始關心信息流轉:用什麼框架管理多步任務?怎麼把工具調用的結果注入到下一步?怎麼壓縮對話歷史?這個階段的工作會讓 agent 的穩定性顯著提升,但你會越來越明顯地感受到自己在做"管信息"的髒活——而且模型往往比你更清楚它需要什麼。
站在 Harness Engineering 門口的你,思考的問題變了:不是"怎麼寫 prompt",而是"給它什麼工具、怎麼驗證它乾的事是對的、如果失控了從哪裏兜底"。這個階段更像在搭運行環境,而不是在跟模型對話。
對獨立 Builder 來說,這三個階段不需要全部自己從頭走。Cursor、Claude Code 已經內置了相當成熟的 harness——你可以直接用。但理解背後的邏輯,能讓你在工具不夠用的時候知道從哪裏着手,而不是盲目調 prompt。
六、回頭看:一個螺旋的三圈
三個階段走下來,有一個 pattern 很清楚:每一次演化都不是設計出來的,是上一階段的做法不夠用了,新實踐才被逼出來。
每轉一圈,三件事同時發生:模型更強了一點,能做更長更復雜的任務;人敢多放手一點,從全程在場到只看結果;新的可靠性問題暴露,催生新的工程實踐來兜底。三者不是線性因果,是互相驅動的螺旋。
前一圈不會消失,它變成基礎設施。Harness 裏還在跑 context engineering 的 pipeline,pipeline 裏還在寫精心設計的 system prompt。Harness 的約束最終要落地到 agent 能理解的地方,而 prompt 仍然是那個載體。
定量數據支撐這個判斷:Epsilla 的實驗顯示,同一模型、同一 prompt、同一份數據,只換 harness 配置,任務成功率從 42% 跳到 78%。LangChain 在 Terminal Bench 2.0 的測試驗證了類似結論:同一個 Opus 4.6,在不同 harness 下的 solve rate 差異超過 60%。模型沒變,變的是它有沒有被賦予自主獲取反饋的能力,以及有沒有合理的邊界兜底。
螺旋還在轉。Harness engineering 之後,下一層瓶頸已經在露出來:
• Eval:agent 跑完了,結果到底好不好?LLM-as-judge 本身有 bias,"評估評估的系統"是一個遞歸問題。Cisco/Splunk 在 2026 年收購了專注 eval 的公司 Galileo,eval 的產業化正在發生。 • Governance:多個 agent 之間怎麼互相認證、怎麼審計、怎麼管權限?NIST 已經啓動了 AI Agent Standards Initiative,計劃 2026 年 Q4 發佈 Agent Interoperability Profile 初版。
但那是螺旋的下一圈了。
信息來源
核心定義與框架
• Andrej Karpathy, Context Engineering 定義, Twitter/X, 2025.06.25 • Birgitta Böckeler, Harness Engineering for Coding Agent Users, martinfowler.com, 2026.04.02 • Ryan Lopopolo, Harness Engineering: Leveraging Codex in an Agent-First World, openai.com, 2026.02.11 • LangChain, The Anatomy of an Agent Harness, blog.langchain.com, 2026.03.10
產品案例
• Stripe Engineering, Minions: Stripe's One-Shot, End-to-End Coding Agents, stripe.dev, 2026.02.09 • Anthropic, Effective Harnesses for Long-Running Agents, anthropic.com, 2025.11.26
研究數據
• Khan, Prompting Inversion, arXiv, 2025 • Laban et al., LLMs Get Lost In Multi-Turn Conversation, Microsoft + Salesforce, 2025 • Epsilla, Harness Engineering: Evolution from Prompt to Context to Autonomous Agents, 2026
我是 Jason,一個獨立打造 AI 產品的創業者。如果這篇文章對你有啓發,歡迎轉發給關注 AI 工程的朋友。
我一個人打造的 Zaokit AI 產品(https://zaokit.app)正在內測,2026年5月31日前1000名用戶贈送價值150RMB的Pro計劃,助力大家高效完成圖文創作和PPT生成,唯一網站:https://zaokit.app
最後,如果你認可 Zaokit AI 的產品理念,歡迎後台留言加入我們的社羣。我們不賣課、不割韭菜,只聚焦 ToB 企業場景的 AI 落地實戰。 希望在這裏,能給你帶來不一樣的思維火花和真實的商業碰撞。
相關閲讀: