從零手把手教你寫一個簡易版 Claude Code:基礎篇
整理版優先睇
Claude Code 核心就係一個 ReAct 循環,用 100 行 Python 手搓出嚟,讓 AI Agent 自己思考、行動、驗證,完成複雜任務如寫貪食蛇或總結網頁。呢個內核簡單到爆,讀完即跑即改,唔使啃十幾萬行源碼。
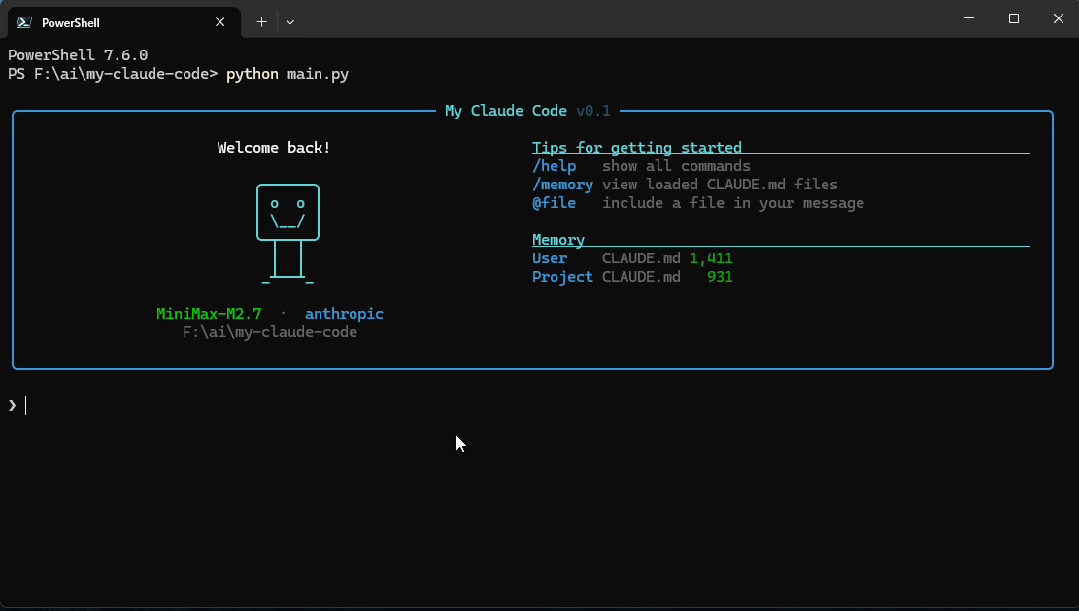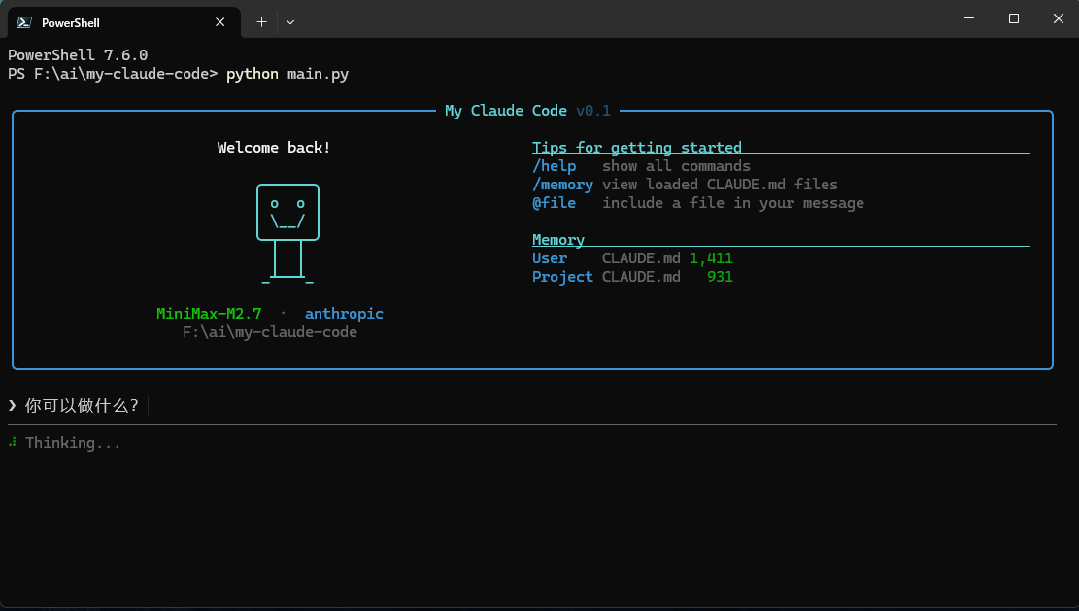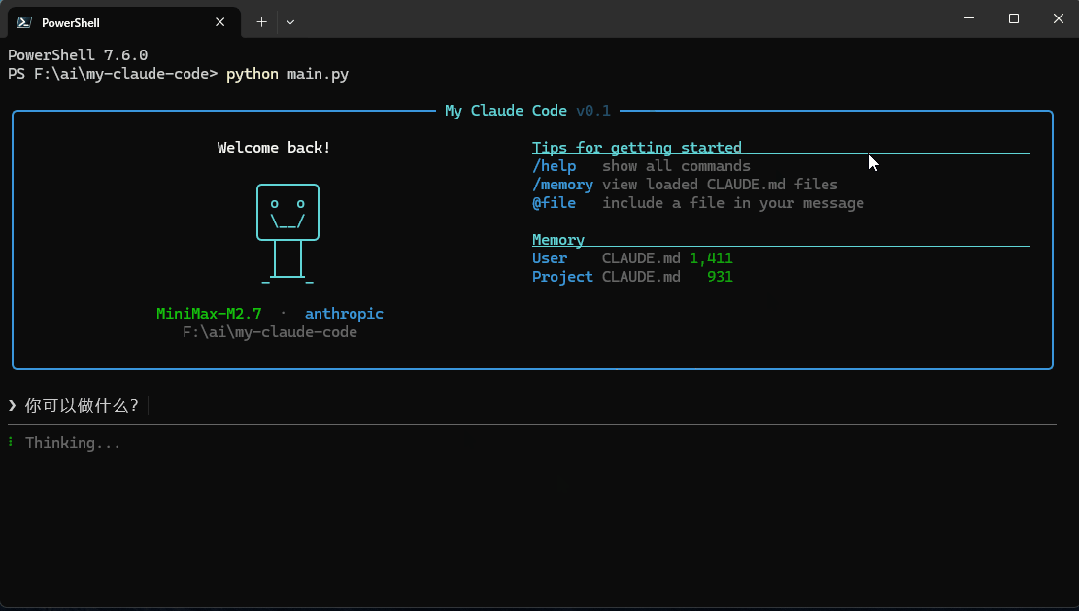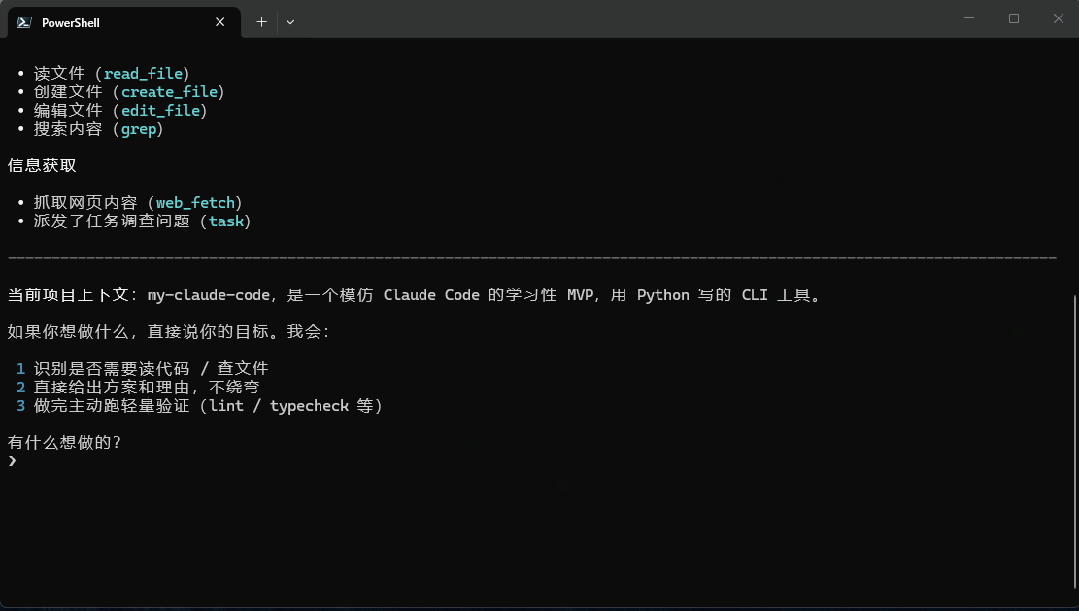
呢篇文章係 developerchengang 寫嘅,背景係 Claude Code 源碼最近洩露,全網熱扒佢嘅設計思想,但源碼十幾萬行近兩千文件,對新手嚟講太難啃,只記得幾個名詞。作者想解決呢個問題,用 100 行 Python 復刻核心內核,讓讀者即刻跑起嚟、改得動,之後再加編輯文件、搜索、子 Agent 等外圍功能。整體結論係 Agent 就係一個 while 循環加 try/except,包埋工具調用,萬變不離其宗。
作者用自身經驗同實戰代碼,詳細解釋 Agent 原理:大模型唔夠力做嘢(如上網、讀文件),就靠 Agent 做中間層,構建上下文、調工具、循環驗證,直到生成最終答案。以搜索 Hacker News 為例,展示三輪 ReAct(Reason + Act):先 Think 缺日期,用工具 get_current_date;再 Think 缺內容,用 search_web;最後 Respond 總結乾淨結果。呢個循環係 Claude Code、Cursor 等工具底層邏輯。
文章高潮係手搓代碼:裝 OpenAI SDK、定義 read_file 同 run_bash 工具、寫 TOOL_SCHEMAS、改 loop 成 agent_turn 內循環。跑起嚟試「睇目錄 Python 文件,講最大嗰個係做乜」,佢自己 ls、讀文件、總結。作者強調錯誤要喂返模型,唔崩 loop,後續倉庫有完整版加子 Age…
- 結論:Agent 核心就係 ReAct 循環(Think-Act-Verify),大模型負責思考同決定工具,框架負責執行同喂結果,簡單到 while True 加工具調用。
- 方法:用 OpenAI SDK 兼容 DeepSeek 等模型,定義工具如 read_file/run_bash 同 schema,內循環處理多輪工具呼叫,直到無 tool_calls 先回 content。
- 差異:普通 chat loop 一問一答,ReAct loop 多輪內循環,messages 只增不改,模型讀全歷史自己推理,錯誤當輸入繼續。
- 啟發:所有 AI 編程工具如 Claude Code、Cursor 底層都係呢個循環,讀源碼只問「while 裏多塞咗乜」。
- 可行動點:裝 pip install openai,抄 100 行 mini.py 跑起嚟試工具,之後自己加 edit_file/grep 等,倉庫有完整 my-claude-code。
my-claude-code 倉庫
完整 my-claude-code 實現,包括 mini.py 100 行核心、編輯文件、子 Agent、Memory 等,後續文章更新。
先睇效果同目標
最近 Claude Code 源碼洩露,全網扒設計,但對新手唔友好。作者用 100 行 Python 復刻內核,讓你即跑即改。效果圖顯示,一句「寫貪食蛇」就自動建文件、寫碼、debug;總結網頁都得。完整功能如子 Agent、Hooks 在倉庫。
Agent 係乜嚟?ReAct 循環點運作
Agent 係中間層,幫大模型用工具完成任務,如搜索 Hacker News:模型先 Think 缺「今天」,Act 調 get_current_date;再 Think 缺內容,Act 調 search_web;最後 Respond 總結。
呢個係 Claude Code 等工具底層,所有框架分工明確:模型 Think + Act,Agent 執行 + Verify。
手搓 100 行核心代碼
先裝 openai SDK,用 DeepSeek 模型。搭基本 chat loop,之後加工具 read_file 同 run_bash。
TOOL_SCHEMAS = [
{
"type": "function",
"function": {
"name": "read_file",
"description": "讀取一個本地文件的全部內容",
"parameters": {
"type": "object",
"properties": {"path": {"type": "string"}},
"required": ["path"],
},
},
},
{
"type": "function",
"function": {
"name": "run_bash",
"description": "在本機執行一條 shell 命令,返回 stdout+stderr",
"parameters": {
"type": "object",
"properties": {"command": {"type": "string"}},
"required": ["command"],
},
},
},
]def agent_turn(messages):
while True:
resp = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=TOOL_SCHEMAS,
)
msg = resp.choices[0].message
messages.append(msg.model_dump(exclude_none=True))
if not msg.tool_calls:
return msg.content or ""
for call in msg.tool_calls:
args = json.loads(call.function.arguments or "{}")
print(f" [tool] {call.function.name}({args})")
try:
result = str(TOOLS[call.function.name](**args))
except Exception as e:
result = f"[error] {type(e).__name__}: {e}"
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": result,
})外層 main loop 接上,system prompt 叫佢用工具。跑「睇 Python 文件最大嗰個做乜」,佢自動 ls、讀、總結。錯誤喂返模型,唔崩。
之後點玩?
核心就係呢個循環,之後加子 Agent、Memory、Hooks、Skills、多工具如 edit_file/grep/web_fetch,都係枝葉。自己試改進,或者去倉庫完整版。
Agent = while 循環 + try/except,就咁簡單!
前言: 近排 Claude Code 源碼洩露,全網都喺度拆解佢嘅代碼設計理念。但直接硬食源碼對新手唔友好,十幾萬行、近兩千個檔案,一開始就被各種設計模式淹死,睇完只記得幾個名詞。其實 Claude Code 嘅核心超簡單,簡單到可以濃縮成一句話——不過呢句話我放文章最後講。本文嘅目標:用 100 行 Python 重現呢個核心,讓你睇完就跑得起、改得動。至於編輯檔案、搜索、子 Agent 呢啲外圍功能,會喺我嘅
my-claude-code倉庫入面畀完整實現,有興趣自己去翻。
而家只係開頭,之後我仲會寫系列文章,嚟解構 Claude Code 嘅設計細節,同埋佢點樣實現各種功能。
一、先睇下效果
Claude Code 效果圖
畀我寫嘅 my-claude-code 整咗個貪食蛇:

就一句「幫我寫一個貪食蛇網頁版小遊戲」,佢自己決定建邊啲檔案、每個檔案寫乜、跑緊出錯自己返轉頭改。全程我一行代碼都冇碰過。
後面啲章節會話你知——讓佢跑成咁嘅核心,究竟係乜。
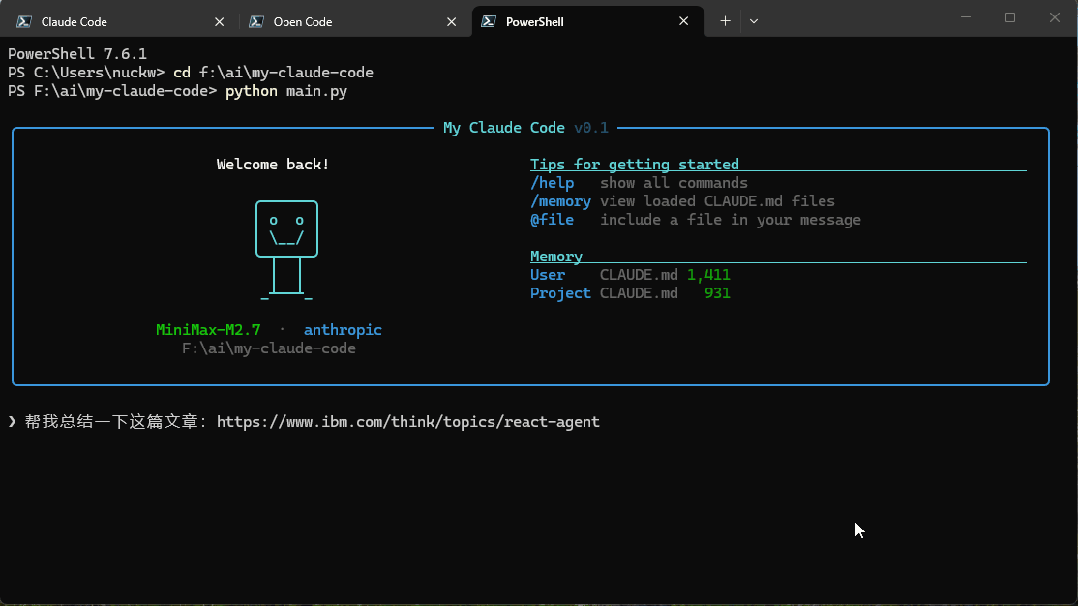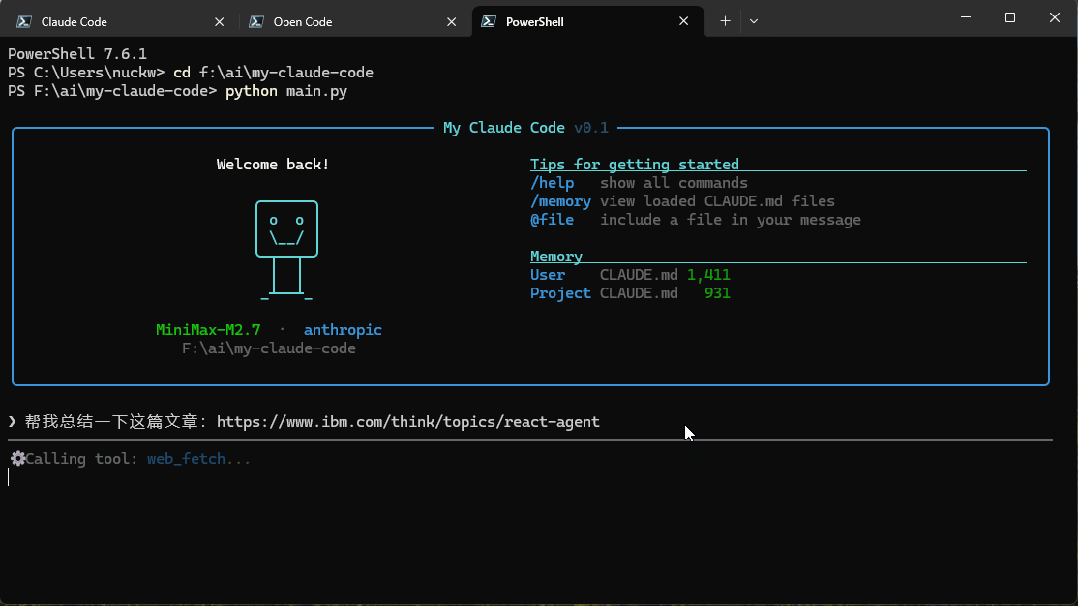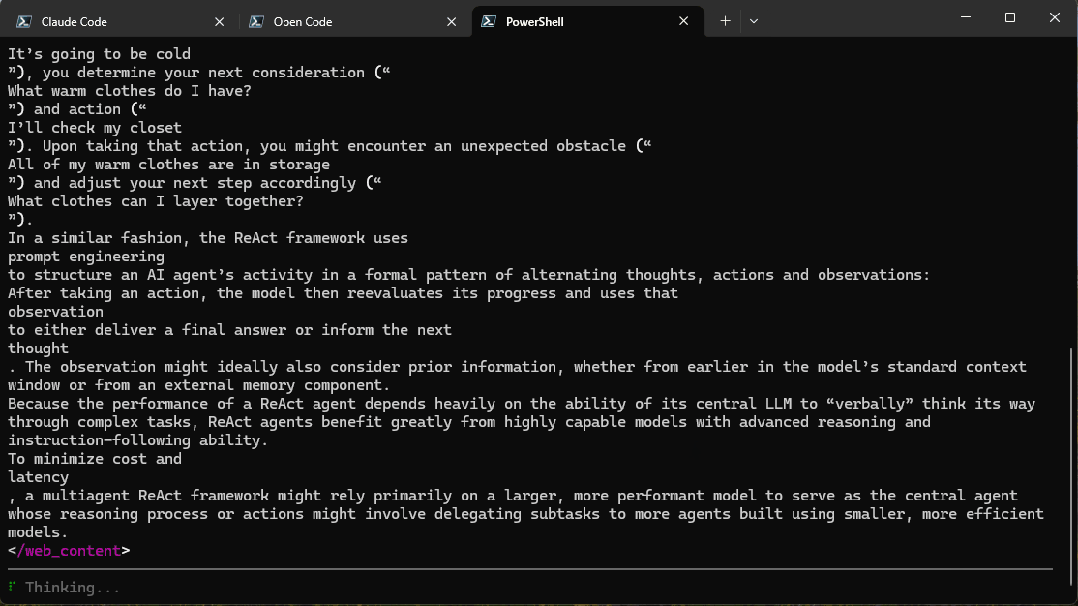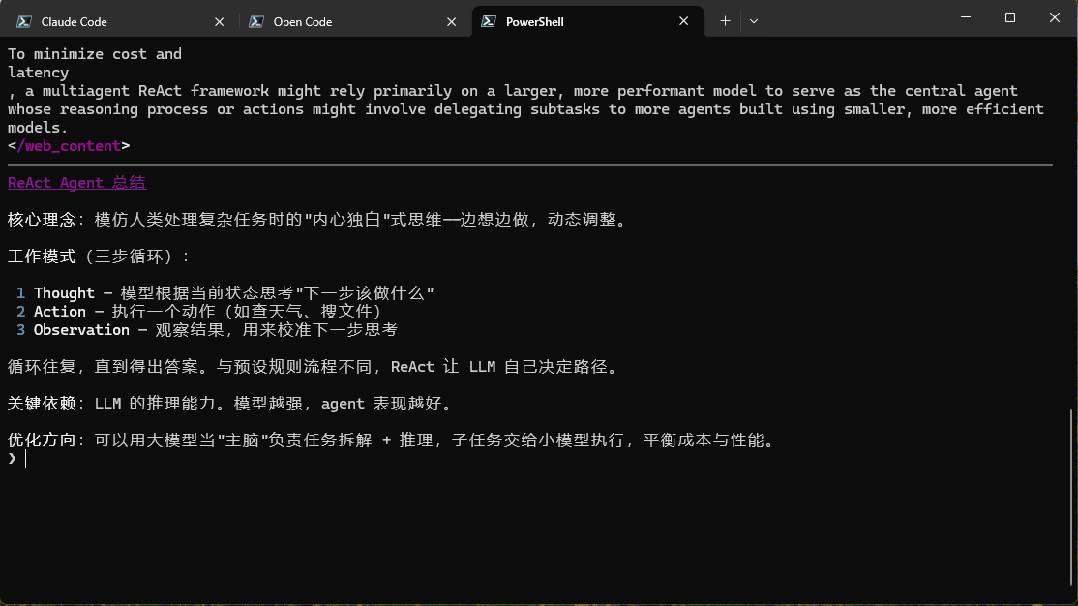
再嚟一張讓佢總結指定網頁內容嘅效果圖:
當然,仲有好多功能。子 Agent、Memory、Hooks、edit_file / grep / web_fetch 等完整工具箱,以及 /compact、/resume、/clear 呢啲 slash 命令——整體架構同 Claude Code 已經好似,實現細節當然有出入,但思路一脈相承。
但呢啲唔係而家嘅重點。完整功能實現會喺後續文章詳細講。而家我哋先把核心嘅循環跑起來,呢個循環先係 Agent 真正嘅內核。
二、乜嘢係 Agent?
假設我哋要完成咁一個任務:
任務: 幫我搜今日 Hacker News 嘅熱門新聞。
如果我哋直接畀呢個任務一個語言模型,可能會得到咁嘅回覆:
回覆: 唔好意思,我唔能夠直接上網搜最新 Hacker News 熱門新聞。
點解會咁呢?因為語言模型本身冇上網能力。而且,佢都唔知今日係乜日期,佢只可以根據訓練數據生成回覆,唔能夠執行實際操作。
呢個時候,我哋就需要一個中間層,嚟幫語言模型執行實際操作。呢個中間層就係 Agent。
你可以將 Agent 想像成一個醒目嘅指揮官,佢負責協調各種工具嚟完成用戶任務。佢會根據用戶輸入,揀啱嘅工具,並將工具輸出結果返畀用戶。
喺上面嘅例子,我哋睇下 Agent 點樣運作:
當你向 Agent 輸入指令:「幫我搜今日 Hacker News 嘅熱門新聞」嘅時候,Agent 唔會即刻將呢句話發畀大模型,而係先喺後台拼一次上下文。
佢會喺後台整一個龐大嘅上下文環境(Context),你可以將佢理解為畀大模型嘅輸入數據。呢個上下文環境入面包含系統設定、工具箱、用戶指令等等資訊。
發畀大模型嘅完整數據大概長咁:
大模型收到呢個上下文環境之後,會根據系統設定同工具箱嘅資訊,嚟理解用戶指令,並揀啱嘅工具嚟執行。
喺呢個例子入面:
第一輪
大模型會先推理(Think)分析用戶指令,發現咗一個變數——「今日」。佢心諗:「作為語言模型,我冇內置時間,但見到工具箱入面有個叫 get_current_date() 嘅工具,正好用得着!」
發出行動指令 (Act):咁,大模型就暫停咗文字回覆,轉而向 Agent 發返一段標準 JSON 格式指令,要求執行工具呼叫:
框架執行 (Verify/Observe):Agent 收到呢個指令之後,會解析工具名同參數,然後呼叫對應工具函數嚟執行操作。例如,佢會呼叫
get_current_date()函數嚟攞今日日期。工具執行完之後,會將結果發返畀 Agent。例如,get_current_date()可能回傳咗「2026-04-20」。Agent 靜靜將呢個結果加到對話歷史記錄入面,準備發返畀大模型。到呢個時候,發返畀大模型嘅上下文環境就變成咗:
第二輪
大模型再推理(Think)分析用戶指令,今次佢已經知「今日」嘅具體日期。大模型結合新上下文,確認目標:「好啦,而家我知道要搵 2026 年 4 月 20 日嘅 HN 新聞。下一步,我要呼叫搜索(search_web)工具
發出行動指令 (Act):咁,大模型再向 Agent 框架發返一段標準 JSON 格式指令,要求執行工具呼叫:
框架執行 (Verify/Observe):Agent 收到呢個指令之後,會解析工具名同參數,然後呼叫對應工具函數嚟執行操作。例如,佢會呼叫
search_web("2026-04-20 Hacker News 熱點新聞")函數嚟搜尋互聯網內容。工具執行完之後,會將結果發返畀 Agent。例如,search_web()可能回傳咗一個包含熱點新聞標題同連結嘅列表。Agent 將呢個結果加到對話歷史記錄入面,準備發返畀大模型。到呢個時候,發返畀大模型嘅上下文環境就變成咗:
留意睇呢兩段「上下文快照」嘅變化——[用戶指令] 由頭到尾都係同一句「幫我搜索今天 Hacker News 嘅熱點新聞」,冇改寫過。日期同搜索結果都係向下追加嘅新條目。呢個係 ReAct 嘅硬性契約:歷史只讀、只增唔改。模型係喺讀晒累積落嚟嘅完整歷史之後、自己腦海入面將「今日 ≈ 2026-04-20」連繫起嚟,而唔係某個環節將用戶原話替換咗。呢個不變量後面 3.4 嘅代碼入面仲會再遇到一次——全程 messages.append,冇任何地方動過舊消息。
第三輪
大模型再推理(Think)分析用戶指令,今次佢已經知「今日」嘅具體日期,又攞到搜索結果。大模型結合新上下文,確認目標:「好啦,30 條原始數據喺手。下一步,我要喺呢堆 JSON 入面揀出熱度最高嘅幾條、拋走
rank/points/comments/snippet呢啲用戶唔關心嘅欄位,用人話重新排版發返去。」大模型生成回答 (Respond):咁,大模型根據新上下文環境,將原始搜索結果過濾、去噪、重排之後,生成咗一個乾淨嘅回答:
Agent 將呢個回答發返畀用戶,完成咗整個任務。
睇完上面呢個 Hacker News 抓取例子,恭喜你——你已經掌握咗而家幾乎所有 AI 編程工具嘅底層核心邏輯。無論係 Claude Code、Cursor、opencode、Cline,定係 OpenAI 嘅 Codex CLI、Google 嘅 Gemini CLI,佢哋喺最底層跑嘅都係同一個閉環:ReAct(Reason + Act),即係「感知-思考-行動-驗證」四步循環。你會發現,大模型(大腦)同 Agent 框架(外骨骼)喺呢度有極其明確嘅分工:
感知 (Perceive):唔單止「聽指令」,仲係「讀環境」。大模型喺每一步都感知緊當前上下文環境,包括用戶指令、工具箱資訊、系統設定、工具呼叫結果等等。佢需要不斷更新自己嘅認知模型,嚟理解當前任務同目標。
思考 (Think):呢個係大模型嘅「主場」。佢喺每一步都做邏輯判斷——「我缺時間」、「我缺聯網能力」、「數據攞到可以排版」。佢清楚自己嘅邊界喺邊度。
行動 (Act):當大模型發現自己做唔到嘅時候,佢會輸出呼叫工具嘅指令(Tool Calling)。畀外圍嘅 Agent 真係去執行 get_date 或 search_web。
驗證 (Verify):工具呼叫完唔算完,Agent 一定要將呼叫結果(無論成功定報錯)攞返嚟驗證。就好似查日期嗰一步,有咗真實日期作為驗證結果,循環先可以繼續推前。
呢個循環不斷進行,直至大模型生成咗一個完整回答,或者達到某個終止條件。呢個過程就係 Agent 嘅核心工作原理,亦係 Claude Code 嘅核心設計思路。
三、手搓 Claude Code
接落嚟,我會一步步帶你手搓一個簡易版 Claude Code。
但我唔打算由零講到一個功能完整嘅版本——Claude Code 源碼漏咗出嚟就十幾萬行、接近兩千個文件,我自己寫嘅呢個簡化版都有將近三千行,文章入面塞唔落,你都冇心機睇。
所以呢一章嘅目標得一個:用 100 行代碼重現第二章嗰個 ReAct 循環。淨係做工具呼叫,別嘅乜都唔做。等你真係跑起一次,後面再睇 Claude Code 源碼、或者我倉庫入面嗰個稍微完整啲嘅版本,就冇乜障礙。
完整代碼喺倉庫嘅 mini.py 入面,100 行出頭,文末畀連結。下面一段一段拆。
3.1 先裝好環境
一個 Python 環境,一個 OpenAI SDK,一個模型嘅 API key。就呢三樣。
等等——Claude Code 不是 Anthropic 家的嗎,怎麼用 OpenAI SDK? 因為 OpenAI 的
chat.completions早就是工具調用事實上的行業標準,DeepSeek、GLM、Kimi、本機 Ollama 全都兼容它,換模型只改base_url就行。真想用 Anthropic 原生 API 也可以,把openai換成anthropic包就是——ReAct 循環的邏輯一字不變,變的只是 SDK 怎麼調。本文只是挑了最通用的那條路。
這裏我用的是 DeepSeek,便宜,跑工具調用夠用。你想用 OpenAI 官方、通義、或者本機 Ollama 都行——只要它兼容 OpenAI 的 chat.completions 接口,改個 base_url 就能切。
3.2 先搭一個最普通的對話 loop
加工具之前,我們先寫個最普通的命令行 chatbot。這一步和 Agent 半毛錢關係都沒有,但它是後面一切東西的骨架。
這時候你跑起來,和它說"你好",它會回你"你好"。但你問它"我的 config.json 裏寫了啥"——它會回你"抱歉,我無法直接訪問你的文件系統來讀取 config.json 的內容。"。這時候你就知道了——它只能說,不能做。
因為模型沒有"手"。它看不到你的文件,也跑不了你的命令。我們接下來要做的,就是給它裝一雙手。
3.3 給它兩個工具
挑兩個最小的:讀文件 和 跑命令。
為什麼是這兩個?因為它們已經足夠讓模型"摸清"你的項目——能讀文件意味着能看代碼,能跑命令意味着能 ls / grep / git log。Claude Code 自己的 Edit / Grep / Glob 這些工具,本質上都是在這兩個能力的基礎上再包一層。
光有函數不夠,還得告訴大模型"你有這些工具、每個工具怎麼調"。這部分是標準的 OpenAI function calling schema,照着寫就行:
這段 JSON 寫着煩,但你可以把它想成:就是第二章那個"工具箱"介紹文本換成了機器可讀的格式。大模型之所以知道該怎麼調 read_file("foo.py"),就是因為它看到了這段 schema。
3.4 把 while loop 改成 ReAct loop
這一節是全文的關鍵,慢一點看。
3.2 的 loop 是"用戶說一句、模型回一句"。現在我們要改成——"用戶說一句、模型可能來回用好幾次工具、最後給用戶一個答案"。
差別就在中間多了一個內循環:
你仔細看,這段代碼和第二章那個"三輪推理"的故事是一一對應的:
client.chat.completions.create(...)—— 大模型思考if not msg.tool_calls: return—— 模型覺得夠晒,直接答for call in msg.tool_calls—— 模型要求行動TOOLS[...](**args)—— Agent 真係去執行messages.append({"role": "tool", ...})—— 將驗證結果餵返去外層 while True—— 循環到模型話「我夠晒」
Claude Code 成個核心,就係呢20幾行。之後所有功能,都係喺呢個循環基礎上添枝加葉。你將呢段代碼搞掂晒,以後再睇任何 Agent 框架嘅源碼,你都只係問同一問題:佢嘅 while 循環入面,多塞咗啲乜?
另外有個好易畀人忽略嘅細節:工具出錯,唔可以畀 loop 崩潰。所以 try/except 入面我哋冇拋異常,而係將錯誤字串當工具輸出餵返畀模型,畀佢自己判斷呢個工具呼叫成功定失敗,下一步點做。
呢點反直覺但好重要——錯誤係 agent 下一個輸入,唔係終止條件。
3.5 將外殼拼埋一齊
最後將 3.2 嘅外循環接上 3.4 嘅內循環,就變成一個完整嘅 Agent 啦:
試跑一次睇下:
你淨係講咗一句,它自己決定先 ls 睇下、睇到邊個最大、再 read_file 讀入嚟、最後畀你總結。
呢就係 Agent。 就係咁。
3.6 跟住點?
到呢度,呢篇嘅核心任務已經完咗——你有咗一個跑得動嘅 Agent。剩下嘅都係喺呢100行外面加功能、加穩健性、加用戶體驗嘅工作。你完全可以停喺度,自己諗下仲可以加啲乜功能,或者改進邊度唔夠好,然後自己試下。
但核心,始終係你啱啱寫嘅呢100行。
四、寫在最後
如果呢篇文章淨係畀你帶走一句,我希望係呢句:
Agent = 一個 while 循環 + 一個 try/except。
真係,就咁簡單。你聽過嘅啲——Tool Use、ReAct、Multi-step、Agentic Workflow——全部都係從呢個結構長出嚟嘅枝葉。等你將 mini.py 呢 100 行食透,以後再去睇任何 Agent 框架嘅源碼,你都只係問同一條問題:佢嘅 while 循環裏,多塞咗啲乜?
呢篇只講咗最核心嘅循環。真正令 Claude Code 從「能跑」變成「好用」嘅啲嘢,呢篇裏我一個都冇提。例如:
子 Agent:讓模型喺主 Agent 裏再開一個細 Agent 專門處理某個子任務,主 Agent 同子 Agent 之間都係透過同樣嘅工具調用接口嚟通訊嘅。
Memory:讓模型可以將啲重要資訊(例如用戶嘅偏好、之前嘅對話內容、工具調用嘅結果)存落一個專門嘅記憶庫,之後需要嘅時候再拎出來用。
Hooks:喺工具調用前後,或者模型生成回答前後,插入啲自定義邏輯嚟加強功能或者改寫輸入輸出。
Skills:將啲複雜功能(例如寫代碼、總結資訊、分析日誌)封裝成一個個技能。
更多工具:例如
edit_file讓模型直接改代碼,grep讓模型喺文件裏搜尋關鍵字,web_fetch讓模型直接攞網頁內容……呢啲都係喺上面嗰個循環基礎上加嘅功能啫。
但佢哋都係喺嗰個 while 循環基礎上加嘅功能啫。你完全可以先將呢個循環食透,之後再去睇我倉庫裏嗰個比較完整嘅版本,睇下我點樣加呢啲功能。
完整代碼同後續功能更新都喺呢個倉庫裏: my-claude-code:https://github.com/developerchengang/my-claude-code
前言: 最近 Claude Code 源代碼泄露,全網都在扒它的代碼設計思想。但直接啃源碼對初學者不友好,十幾萬行、近兩千個文件,一上來被各種設計模式淹死,看完只記得幾個名詞。其實 Claude Code 的內核極其簡單,簡單到可以濃縮成一句話——不過這句話我放文章最後講。本文的目標:用 100 行 Python 復刻出這個內核,讓你看完就能跑起來、改得動。至於編輯文件、搜索、子 Agent 這些外圍功能,會在我的
my-claude-code倉庫裏給到完整實現,有興趣自己翻。
今天只是開篇,後續我還會寫系列文章,來解讀 Claude Code 的設計細節,和它是怎麼實現各種功能的。
一、先看效果
Claude Code 效果圖
讓我寫的 my-claude-code 寫了一個的貪吃蛇:
就一句「幫我寫一個貪吃蛇網頁版小遊戲」,它自己決定建哪些文件、每個文件寫什麼、跑起來報錯了自己回頭改。全程我一行代碼都沒碰過。
後面的章節會告訴你——讓它跑成這樣的核心,到底是什麼。
再來一張讓它總結指定網頁內容的效果圖:
當然,還有很多功能。子 Agent、Memory、Hooks、edit_file / grep / web_fetch 等完整工具箱,以及 /compact、/resume、/clear 這些 slash 命令——整體架構和 Claude Code 已經很接近了,實現細節當然有出入,但思路一脈相承。
但這些不是今天的重點。完整功能實現會在後續文章中詳細介紹。今天我們先把核心的循環跑起來,這個循環才是 Agent 的真正內核。
二、什麼是 Agent?
假設我們需要完成這樣一個任務:
任務: 幫我搜索今天 Hacker News 的熱點新聞。
如果我們直接把這個任務交給一個語言模型,可能會得到這樣的回答:
回答: 抱歉,我無法直接訪問互聯網來搜索最新的 Hacker News 熱點新聞。
為什麼會這樣呢?因為語言模型本身沒有訪問互聯網的能力。而且,它也不知道今天是什麼日期,它只能根據訓練數據來生成回答,而不能執行實際的操作。
這時候,我們就需要一箇中間層,來幫助語言模型執行實際的操作。這個中間層就是 Agent。
你可以把 Agent 想象成一個智能的指揮官,它負責協調各種工具來完成用戶的任務。它會根據用戶的輸入,選擇合適的工具,並且把工具的輸出結果返回給用戶。
在上面的例子中,我們看看 Agent 是怎麼工作的:
當你向 Agent 輸入指令:“幫我搜索今天 Hacker News 的熱點新聞” 時,Agent 並沒有立刻把這句話發給大模型,而是先在後台做了一次拼上下文。
它會在後台構建一個龐大的上下文環境(Context),你可以把它理解為給大模型的輸入數據。這個上下文環境裏包含了系統設定、工具箱、用戶指令等等信息。
發給大模型的完整數據大概長這樣:
大模型在接收到這個上下文環境後,會根據系統設定和工具箱的信息,來理解用戶的指令,並且選擇合適的工具來執行。
在這個例子中:
第一輪
大模型會先推理(Think)分析用戶的指令,發現了一個變量——“今天”。它心想:“作為語言模型,我沒有內置時間,但我看到了我的工具箱裏有一個叫 get_current_date() 的工具,我正好需要它!”
下達行動指令 (Act): 於是,大模型暫停了文本回復,而是向 Agent 返回了一段標準的 JSON 格式指令,要求執行工具調用:
框架執行 (Verify/Observe):Agent 接收到這個指令後,會解析出工具名稱和參數,然後調用對應的工具函數來執行操作。比如,它會調用
get_current_date()函數來獲取當前日期。工具執行完成後,會把結果返回給 Agent。比如,get_current_date()可能返回了“2026-04-20”。Agent 默默把這個結果加到了對話歷史記錄中,準備發回給大模型。這時,發回給大模型的上下文環境就變成了:
第二輪
大模型再次推理(Think)分析用戶的指令,這次它已經知道了“今天”的具體日期了。大模型結合新的上下文,確認了目標:“好,現在我知道要找 2026 年 4 月 20 日的 HN 新聞了。下一步,我需要調用搜索(search_web)工具
下達行動指令 (Act):於是,大模型再次向 Agent 框架返回了一段標準的 JSON 格式指令,要求執行工具調用:
框架執行 (Verify/Observe):Agent 接收到這個指令後,會解析出工具名稱和參數,然後調用對應的工具函數來執行操作。比如,它會調用
search_web("2026-04-20 Hacker News 熱點新聞")函數來搜索互聯網內容。工具執行完成後,會把結果返回給 Agent。比如,search_web()可能返回了一個包含熱點新聞標題和連結的列表。Agent 把這個結果加到了對話歷史記錄中,準備發回給大模型。這時,發回給大模型的上下文環境就變成了:
注意看這兩段「上下文快照」的變化——[用戶指令] 從頭到尾是同一句「幫我搜索今天 Hacker News 的熱點新聞」,沒有被改寫過。日期和搜索結果都是往下追加的新條目。這是 ReAct 的一個硬性契約:歷史只讀、只增不改。模型是在讀完整條累加下來的歷史之後、自己在腦子裏把「今天 ≈ 2026-04-20」連起來的,而不是某個環節把用戶原話替換掉了。這個不變量後面 3.4 的代碼裏還會再遇到一次——全程 messages.append,沒有任何地方動過舊消息。
第三輪
大模型再次推理(Think)分析用戶的指令,這次它已經知道了“今天”的具體日期了,也拿到了搜索結果了。大模型結合新的上下文,確認了目標:“好,30 條原始數據在手了。下一步,我要從這堆 JSON 裏挑出熱度最高的幾條、扔掉
rank/points/comments/snippet這些用戶不關心的字段,用人話重新排版發回去。”大模型生成回答 (Respond):於是,大模型根據新的上下文環境,把原始搜索結果過濾、去噪、重排後,生成了一個乾淨的回答:
Agent 把這個回答發回給用戶,完成了整個任務。
看完了上面這個 Hacker News 的抓取例子,那麼恭喜你——你已經掌握了當下幾乎所有 AI 編程工具的底層核心邏輯。無論是 Claude Code、Cursor、opencode、Cline,還是 OpenAI 的 Codex CLI、Google 的 Gemini CLI,它們在最底層跑的都是同一個閉環:ReAct(Reason + Act),也就是“感知-思考-行動-驗證”四步循環。你會發現,大模型(大腦)和 Agent 框架(外骨骼)在這裏面有着極其明確的分工:
感知 (Perceive): 不僅僅是“聽指令”,更是“讀環境”。大模型在每一步都在感知當前的上下文環境,包括用戶指令、工具箱信息、系統設定、工具調用結果等等。它需要不斷地更新自己的認知模型,來理解當前的任務和目標。
思考 (Think): 這是大模型的“主場”。它在每一步都在做邏輯判斷——“我缺時間”、“我缺聯網能力”、“數據拿到了可以排版了”。它清楚自己的邊界在哪裏。
行動 (Act): 當大模型發現自己做不到時,它會輸出調用工具的指令(Tool Calling)。讓外圍的 Agent 真正去執行 get_date 或 search_web。
驗證 (Verify): 工具調完了沒算完,Agent 必須把調用的結果(無論成功還是報錯)拿回來驗證。就像查日期那一步,有了真實日期作為驗證結果,循環才能繼續推進。
這個循環不斷地進行,直到大模型生成了一個完整的回答,或者達到了某個終止條件。這個過程就是 Agent 的核心工作原理,也是 Claude Code 的核心設計思路。
三、手搓 Claude Code
接下來,我會一步步帶你手搓一個簡易版的 Claude Code。
但我不打算從零講到一個功能完整的版本——Claude Code 源碼泄露出來就十幾萬行、接近兩千個文件,我自己寫的這個簡化版也有將近三千行,文章裏塞不下,你也沒耐心看。
所以這一章的目標只有一個:用 100 行代碼復現第二章那個 ReAct 循環。只做工具調用,別的什麼都不做。等你真的跑起來一次,後面再去看 Claude Code 源碼、或者我倉庫裏那個稍微完整點的版本,就沒什麼障礙了。
完整代碼在倉庫的 mini.py 裏,100 行出頭,文末給連結。下面一段一段拆。
3.1 先把環境裝好
一個 Python 環境,一個 OpenAI SDK,一個模型的 API key。就這三樣。
等等——Claude Code 不是 Anthropic 家的嗎,怎麼用 OpenAI SDK? 因為 OpenAI 的
chat.completions早就是工具調用事實上的行業標準,DeepSeek、GLM、Kimi、本機 Ollama 全都兼容它,換模型只改base_url就行。真想用 Anthropic 原生 API 也可以,把openai換成anthropic包就是——ReAct 循環的邏輯一字不變,變的只是 SDK 怎麼調。本文只是挑了最通用的那條路。
這裏我用的是 DeepSeek,便宜,跑工具調用夠用。你想用 OpenAI 官方、通義、或者本機 Ollama 都行——只要它兼容 OpenAI 的 chat.completions 接口,改個 base_url 就能切。
3.2 先搭一個最普通的對話 loop
加工具之前,我們先寫個最普通的命令行 chatbot。這一步和 Agent 半毛錢關係都沒有,但它是後面一切東西的骨架。
這時候你跑起來,和它說"你好",它會回你"你好"。但你問它"我的 config.json 裏寫了啥"——它會回你"抱歉,我無法直接訪問你的文件系統來讀取 config.json 的內容。"。這時候你就知道了——它只能說,不能做。
因為模型沒有"手"。它看不到你的文件,也跑不了你的命令。我們接下來要做的,就是給它裝一雙手。
3.3 給它兩個工具
挑兩個最小的:讀文件 和 跑命令。
為什麼是這兩個?因為它們已經足夠讓模型"摸清"你的項目——能讀文件意味着能看代碼,能跑命令意味着能 ls / grep / git log。Claude Code 自己的 Edit / Grep / Glob 這些工具,本質上都是在這兩個能力的基礎上再包一層。
光有函數不夠,還得告訴大模型"你有這些工具、每個工具怎麼調"。這部分是標準的 OpenAI function calling schema,照着寫就行:
這段 JSON 寫着煩,但你可以把它想成:就是第二章那個"工具箱"介紹文本換成了機器可讀的格式。大模型之所以知道該怎麼調 read_file("foo.py"),就是因為它看到了這段 schema。
3.4 把 while loop 改成 ReAct loop
這一節是全文的關鍵,慢一點看。
3.2 的 loop 是"用戶說一句、模型回一句"。現在我們要改成——"用戶說一句、模型可能來回用好幾次工具、最後給用戶一個答案"。
差別就在中間多了一個內循環:
你仔細看,這段代碼和第二章那個"三輪推理"的故事是一一對應的:
client.chat.completions.create(...)—— 大模型思考if not msg.tool_calls: return—— 模型覺得夠了,直接回答for call in msg.tool_calls—— 模型要求行動TOOLS[...](**args)—— Agent 真的去執行messages.append({"role": "tool", ...})—— 把驗證結果喂回去外層 while True—— 循環直到模型說"我夠了"
Claude Code 整個核心,就是這 20 來行。後面所有的功能,都是在這個循環的基礎上往外加枝加葉。你把這段代碼吃透了,以後再去讀任何 Agent 框架的源碼,你都只是在問同一個問題:它的 while 循環裏,多塞了點什麼?
另外有個很容易被忽略的細節:工具報錯,不能讓 loop 崩掉。所以 try/except 裏我們沒有拋異常,而是把錯誤字符串當成工具輸出喂回給模型,讓它自己去判斷這個工具調用成功了還是失敗了,下一步該怎麼辦。
這一點反直覺但非常重要——錯誤是 agent 的下一個輸入,不是終止條件。
3.5 把外殼拼起來
最後把 3.2 的外循環接上 3.4 的內循環,就成了一個完整的 Agent 了:
跑一把試試:
你只說了一句話,它自己決定先 ls 一下、看到哪個最大、再 read_file 讀進來、最後給你總結。
這就是 Agent。 就這麼回事。
3.6 然後呢?
到這兒,這篇的核心任務已經結束了——你有了一個能跑的 Agent。剩下的都是在這 100 行外面往外加功能、加健壯性、加用戶體驗的工作了。你完全可以停在這裏,自己想想還能加點什麼功能,或者改進哪裏不夠好,然後自己動手試試。
但核心,始終是你剛剛寫的這 100 行。
四、寫在最後
如果這篇文章只讓你帶走一句話,我希望是這句:
Agent = 一個 while 循環 + 一個 try/except。
真的,就這麼簡單。你聽過的那些——Tool Use、ReAct、Multi-step、Agentic Workflow——全都是從這個結構上長出來的枝葉。等你把 mini.py 這 100 行吃透,以後再去讀任何 Agent 框架的源碼,你都只是在問同一個問題:它的 while 循環裏,多塞了點什麼?
這篇只講了最核心的循環。真正讓 Claude Code 從"能跑"變成"好用"的那些東西,這篇裏我一個都沒提。比如:
子 Agent:讓模型能在主 Agent 裏再開一個小 Agent 去專門處理某個子任務,主 Agent 和子 Agent 之間也是通過同樣的工具調用接口來通信的。
Memory:讓模型能把一些重要信息(比如用戶的偏好、之前的對話內容、工具調用的結果)存到一個專門的記憶庫裏,後續需要的時候再調出來用。
Hooks:在工具調用前後、或者模型生成回答前後,插入一些自定義的邏輯來增強功能或者改寫輸入輸出。
Skills:把一些複雜的功能(比如寫代碼、總結信息、分析日誌)封裝成一個個技能。
更多工具:比如
edit_file讓模型直接改代碼,grep讓模型在文件裏搜索關鍵詞,web_fetch讓模型直接抓取網頁內容……這些都是在上面那個循環的基礎上加的功能而已。
但它們都是在那個 while 循環的基礎上加的功能而已。你完全可以先把這個循環吃透了,後面再去看我倉庫裏那個稍微完整點的版本,看看我是怎麼加這些功能的。
完整代碼和後續功能更新都在這個倉庫裏: my-claude-code:https://github.com/developerchengang/my-claude-code