從零生成一份教程包:主題到高質量教程包的完整工作流
整理版優先睇
yao-tutorial-skill:一條自然語言驅動嘅完整教程生成工作流,將數日工作縮短到幾分鐘
呢篇文章係開發者姚金剛分享佢設計嘅 yao-tutorial-skill,一套用自然語言驅動、能自我完善嘅教程生成系統。佢嘅核心唔係「AI 生成」本身,而係「資料優先」嘅設計哲學:高質量輸出必須建基於高質量輸入。開發者將傳統需要研究員、編輯、設計師、排版員多個人協作嘅流程,壓縮成一個可複用嘅 AI 編排,由你畀主題同種子材料,AI 完成研究、大綱、配圖、排版,最終輸出 PDF/DOCX/HTML 三種格式嘅學習包。
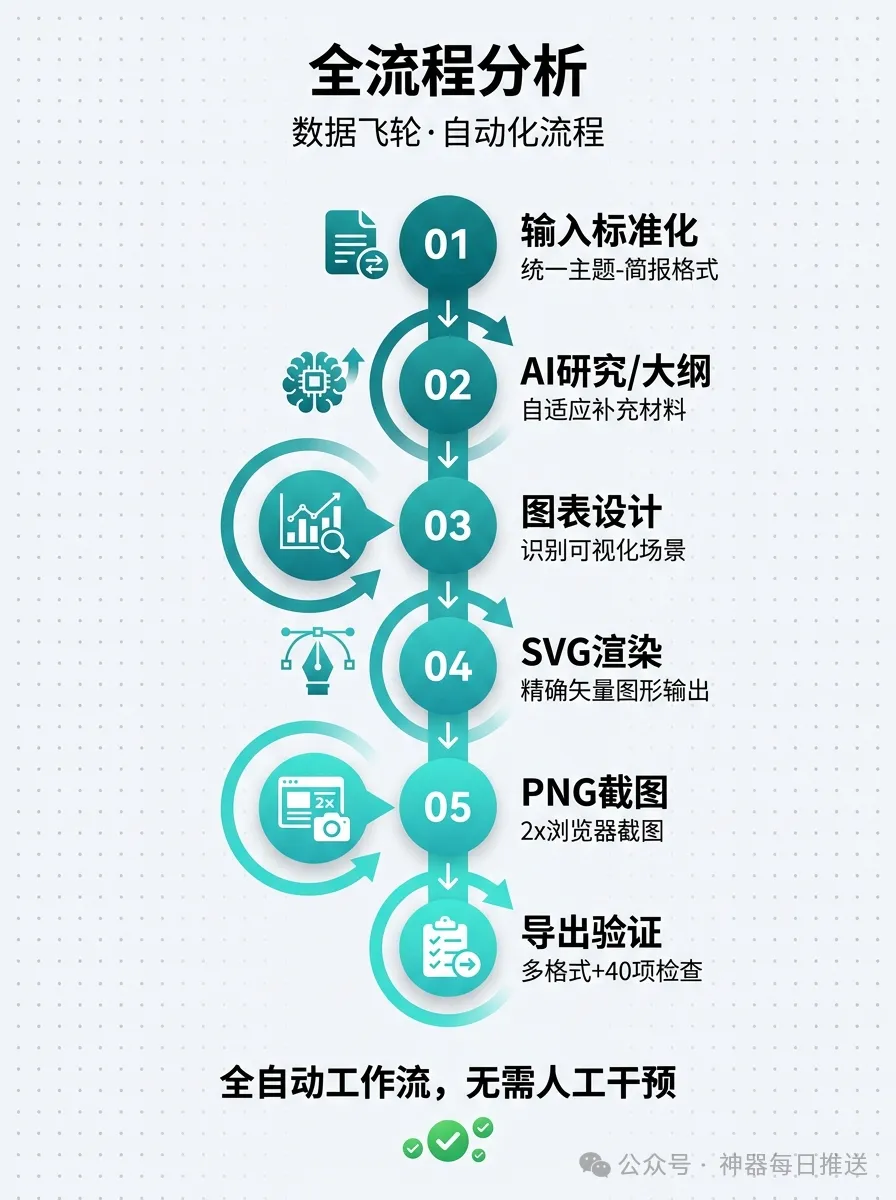
呢套工作流嘅真正價值,唔係承諾「讀完你就全會」,而係幫你用最短時間搭好主幹——每個階段做咩、點解咁做、點驗證自己真係識,同埋後續點自訂。開發者仲融入《課程營銷學》底層邏輯同 Kami 排版規範,令生成嘅教程有敍事張力同質感。佢設計咗 5 階段 Pipeline(輸入歸一化、內容生成、視覺設計、圖表捕獲、導出渲染),每個階段都有獨立質檢,總共有 40+ 檢查項。
整體結論係:呢個 Skill 喺工程主義細節上落咗好多功夫,唔係一堆工具嘅拼湊,而係一條由輸入到輸出嘅完整管道。當然,最終可靠性仲係取決於你提供嘅種子材料質素同人工監督介入點。如果你需要批量製作系統性教程,呢套工作流值得一試。
- 核心結論:高質量教程必須建基於高質量輸入,呢套 Skill 用「資料優先」代替隨機採樣,結構化輸出 PDF/DOCX/HTML 三種格式。
- 方法:5 階段 Pipeline——輸入歸一化、內容生成、視覺設計、圖表捕獲、導出渲染,每個階段有自動質檢,確保品質。
- 差異:唔係普通 AI 生成,而係融入《課程營銷學》同 Kami 排版規範,令教程有學習動機設計同高質感排版。
- 啟發:數據飛輪嘅邏輯——你先提供種子材料,AI 按需補充;類似訓練時先清洗數據集,再餵畀模型。
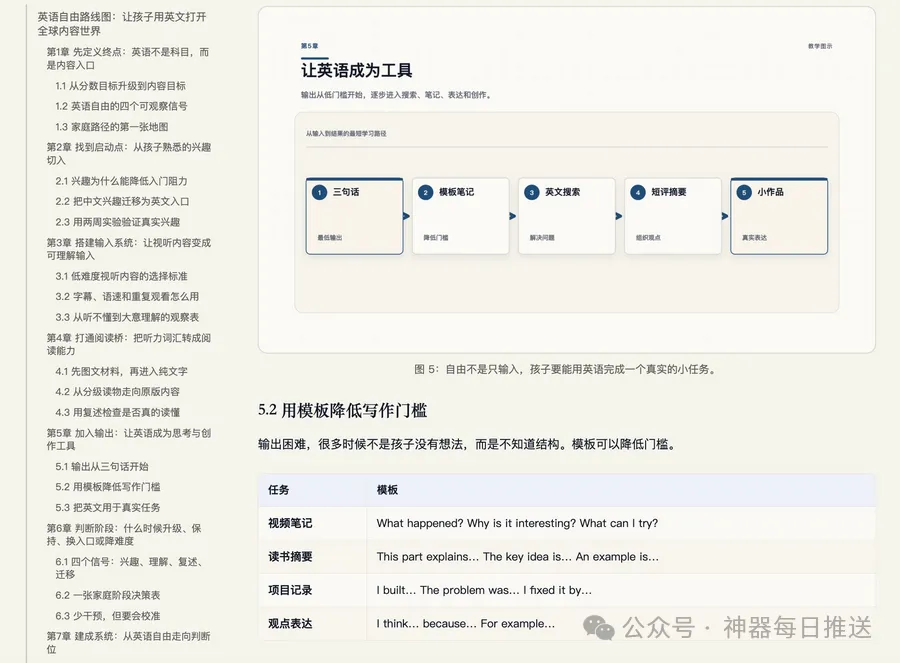
- 可行動點:你可以直接攞開發者提供嘅 topic-brief 模板,填入主題、受眾、深度等參數,幾分鐘內生成完整教程包。
教程 Skill 嘅 GitHub 倉庫
yao-tutorial-skill 原始碼同完整文檔,包括 9 個設計原則文檔同 3 個完整示例。
優化好嘅 Skill 下載
開發者提供嘅優化版本,可以直接導入 WorkBuddy 使用。
核心哲學:資料優先,唔係 AI 生成
呢個 Skill 最聰明嘅位,唔係「AI 生成」本身,而係數據飛輪嘅構造邏輯——參考資料為核心,唔係叫 AI 從互聯網垃圾隨機採樣,而係從你把關嘅材料出發,再叫 AI 按需補充。門檻好清楚:你要先提供有價值嘅種子材料。
三格式輸出(PDF/Word/HTML)唔係炫技,而係實際使用場景嘅細節覆蓋——PDF 適合打印同學習筆記,HTML 適合在線查閲同搜尋,Word 適合二次編輯。章節化配自動圖表亦唔係「AI 識畫圖」,而係「AI 知道邊個位要圖、配邊種圖類」。
5 階段 Pipeline:由 topic-brief 到驗證報告
整個工作流分 5 個階段,每個階段都有獨立質檢,確保最終質素唔會斷層。
- 1 Phase 1:輸入歸一化 + 自適應研究——讀取你提供嘅 topic-brief.json 同參考資料,計算材料充足性,唔夠就自動補充外部來源,輸出 reference-doc.md。
- 2 Phase 2:內容生成 + 大綱設計——AI 根據 9 個原則文檔生成完整草稿,每章只講一個核心概念,字數 200-500,必須有來源標記。
- 3 Phase 3:視覺設計 + 圖表渲染——自動識別教程中需要圖表嘅位,生成 flow/layer/comparison 等 8 種圖表類型嘅 SVG,再經特定渲染引擎輸出。
- 4 Phase 4:圖表捕獲——用 headless 瀏覽器將 SVG 截圖做 2x 高清 PNG,萬一冇瀏覽器就保留 SVG 畀 HTML 直接用。
- 5 Phase 5:導出渲染——用 Pandoc 同自訂樣式模板輸出 PDF/DOCX/HTML,最後用 40+ 檢查項驗證,列出 passed/failed 同 warnings。
9 大設計原則:令教程唔再係死板文字堆砌
呢個 Skill 唔係求其生成,而係紮根喺一套方法論。9 個原則文檔(約 4500 字)分別來自《課程營銷學》、Kami 排版系統同獨立教程包概念,解決咗 AI 生成常見嘅「平、散、無來源、不可離線」問題。
- frontend-slides-first:每章只講一個核心概念,字數 200-500,避免信息堆砌。
- source-backed:每個事實必須有 [source: 路徑] 標記,唔準冇來源。
- standalone:教程唔依賴外部連結,所有資料內嵌或隨包分發,確保離線可用。
- learning sufficiency:深度由「用戶能否獨立完成任務」決定,唔係字數。
- visual teaching:8 種圖表類型覆蓋 90% 教學場景,遵循 Kami 排版規範(DPI 300、暖灰 #F5F3EF)。
- provenance hygiene:引用格式統一、避免 dead links、版權聲明 CC-BY-NC-SA 4.0。
呢啲原則一齊用,令生成嘅教程有結構化表現:你唔會見到「第一…第二…第三…」一大段,而係列表、圖表、練習題交替出現,讀者掃讀已經見到重點。
自訂擴展:由樣式到研究深度都可以改
開發者留低咗多個自訂接口,你可以唔改原始碼就調整視覺風格、研究強度、圖表類型等。
- 改 tutorial-style.css 嘅 CSS 變量就可以換主題色、字型、頁面寬度。
- 喺 CHART_TYPES 字典加新圖表類型,例如 sankey 圖,只需定義 renderer 同 required_fields。
- 改 RESEARCH_INTENSITY 配置可以控制 light/intermediate/deep 嘅補充來源數量同字數上限。
- 喺 topic-brief.preferences.chapter_structure 完全自訂章節,優先級最高,AI 會嚴格跟住行。
- 輸出格式都有得微調:DOCX 用 reference-doc 控制樣式,PDF 改 page size 同 margin,HTML 用自訂 CSS。
{
"topic": "GitHub Copilot 實戰指南:從安裝到高效使用",
"audience": "有一定編程基礎,想學習使用 Copilot 提高編碼效率的開發者",
"goal": "學完後能獨立在項目中配置 Copilot,並掌握常用提示詞技巧",
"depth": "intermediate",
"format": ["pdf","docx","html"],
"references": ["C:\\Users\\admin\\Desktop\\copilot-docs\\README.md","https://docs.github.com/en/copilot"],
"preferences": {
"chapter_structure": [
{"chapter":1,"title":"Copilot 概述與安裝","content":"介紹 Copilot 是什麼,如何安裝和激活"},
{"chapter":2,"title":"基本使用姿勢","content":"自動補全、內聯聊天、斜槓命令"},
{"chapter":3,"title":"提示詞工程","content":"如何寫高質量的 Copilot 提示"},
{"chapter":4,"title":"實際工作流","content":"在真實項目中如何與 Copilot 協作"},
{"chapter":5,"title":"常見坑與最佳實踐","content":"注意事項、安全邊界、效率技巧"}
]
}
}常見問題同快速排查
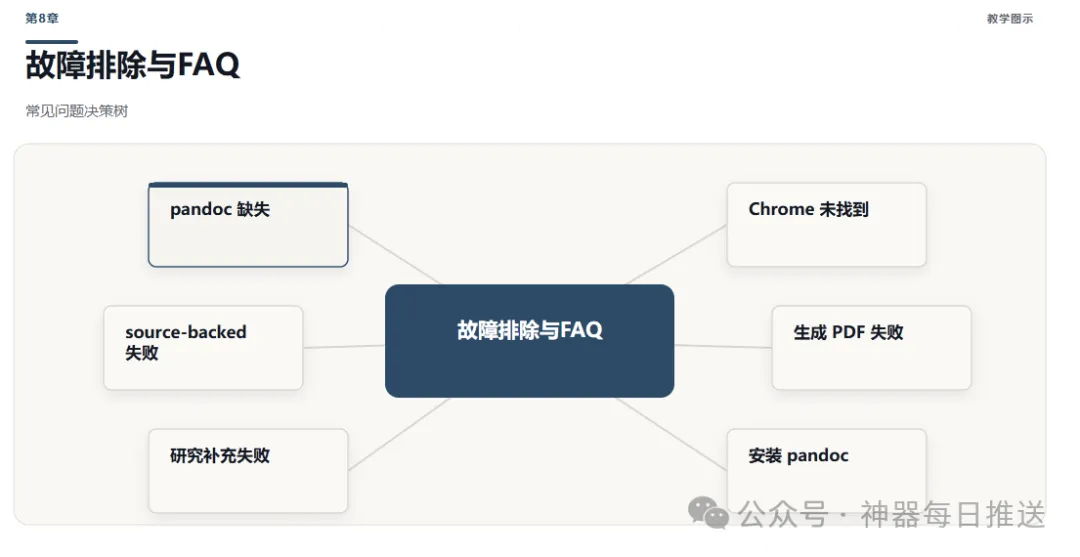
開發者整理咗 7 個常見問題,涵蓋依賴缺失、圖表生成失敗、PDF 導出錯誤、來源標記缺失等。以下係幾個最常撞到嘅情境:
- 1 pandoc: command not found——安裝 Pandoc 並確認 PATH,最簡單係用 package manager 裝。
- 2 SVG 未生成 PNG——檢查 Chromium 是否安裝,或者改 <code>FALLBACK_TO_SVG=true</code> 用 SVG 代替。
- 3 PDF 導出失敗——技能會自動回退用到嘅渲染引擎(Weasyprint -> Chrome print),最穩定係裝 xelatex。
- 4 來源標記缺失——檢查 build_reference_doc.py 嘅 source attribution 邏輯,確保每個段落都有 [source:] 標記。
- 5 學習充分性評分過低——將 depth 改成 deep,或者手動喺 preferences 加更多內容期望。
今日分享一個可以自動生成高質量教程嘅skill,呢個係一套用自然語言驅動、可以自我完善教程生成嘅系統。開發者姚金剛將佢設計成資料優先嘅研究引擎,核心思想係:高質量輸出一定要建立喺高質量輸入之上。

呢個設計裏面最聰明嘅部分,唔係「AI生成」本身,而係數據飛輪嘅構造邏輯:
- 參考資料為核心——唔係叫 AI 喺互聯網垃圾裏面隨機採樣,而係由你把關嘅材料出發,再叫 AI 按需要補充。呢個就好似訓練之前先清洗數據集,唔係直接掟俾模型原始信息。門檻喺呢度:你需要先提供有價值嘅種子材料。
- 三格式輸出(PDF/Word/HTML)——聽落簡單,但呢個係部署可靠性嘅體現。唔同場景需要唔同格式:PDF 適合打印同學習筆記,HTML 適合在線查閲同搜尋,Word 適合二次編輯。呢個唔係炫技,係實際使用場景嘅細節覆蓋。
- 章節化 + 自動配圖——教程嘅結構化輸出。呢度嘅關鍵唔係「AI識畫圖」,而係「AI知道幾時需要圖,同埋配喺邊個章節嘅邊個部分」。呢個係內容理解嘅體現,唔係簡單嘅模板填充。
- 融入《課程營銷學》底層邏輯——呢個說明開發者有產品思維。教程唔單止係知識傳遞,仲涉及學習動機、節奏控制同情緒設計。AI生成嘅嘢容易「平」,呢本書嘅融入可能係為咗令教程有敍事張力。
- 借鏡kami嘅排版規範——細節決定質感。技術內容最怕粗糙,好嘅排版可以降低認知負荷。呢個skill喺工程主義嘅細節上落咗功夫。
佢唔係一堆工具嘅拼湊,而係一個從輸入到輸出嘅完整管道:你俾主題同材料,AI完成研究、大綱、配圖、排版,最終輸出一個即刻用得嘅學習包。
呢份教程嘅價值,唔係喺承諾「讀完你就全會了」——嗰啲通常係營銷話術。佢嘅真實目標係:幫你搭好主幹。你會清楚睇到由零到用得嘅路徑:每個階段做啲乜、點解要咁做、點樣驗證自己真係識咗、同埋之後點樣自訂。呢個符合構建即理解嘅原則——真正嘅學習唔係被動接收,而係主動重建。
呢套工作流用自然語言作為程式語言,將傳統上需要多個人協作(研究員、編輯、設計師、排版員)嘅流程,壓縮成一個可重用嘅 AI 編排。當然,最終可靠性仲要睇數據質素同人工監督嘅介入點。
第1章 技能概述與核心價值
1.1 佢可以解決啲咩問題?
你可能遇過呢啲情況:
想為一個複雜主題(例如某個 AI 工具、編程框架、學習方法)製作一份系統性教程 手頭有啲散亂嘅筆記、URL 同文件,但唔知點樣組織成結構化嘅學習材料 需要生成 PDF、DOCX、HTML 三種格式,分別用嚟打印、編輯、在線發佈 希望教程唔係乾爭爭嘅文字,而係每章都有合適嘅圖表輔助理解 擔心自己寫嘅教程唔夠系統,或者排版粗糙
yao-tutorial-skill 就係為呢啲場景設計嘅。佢將「教程製作」呢個通常要幾日嘅任務,縮短到幾分鐘。
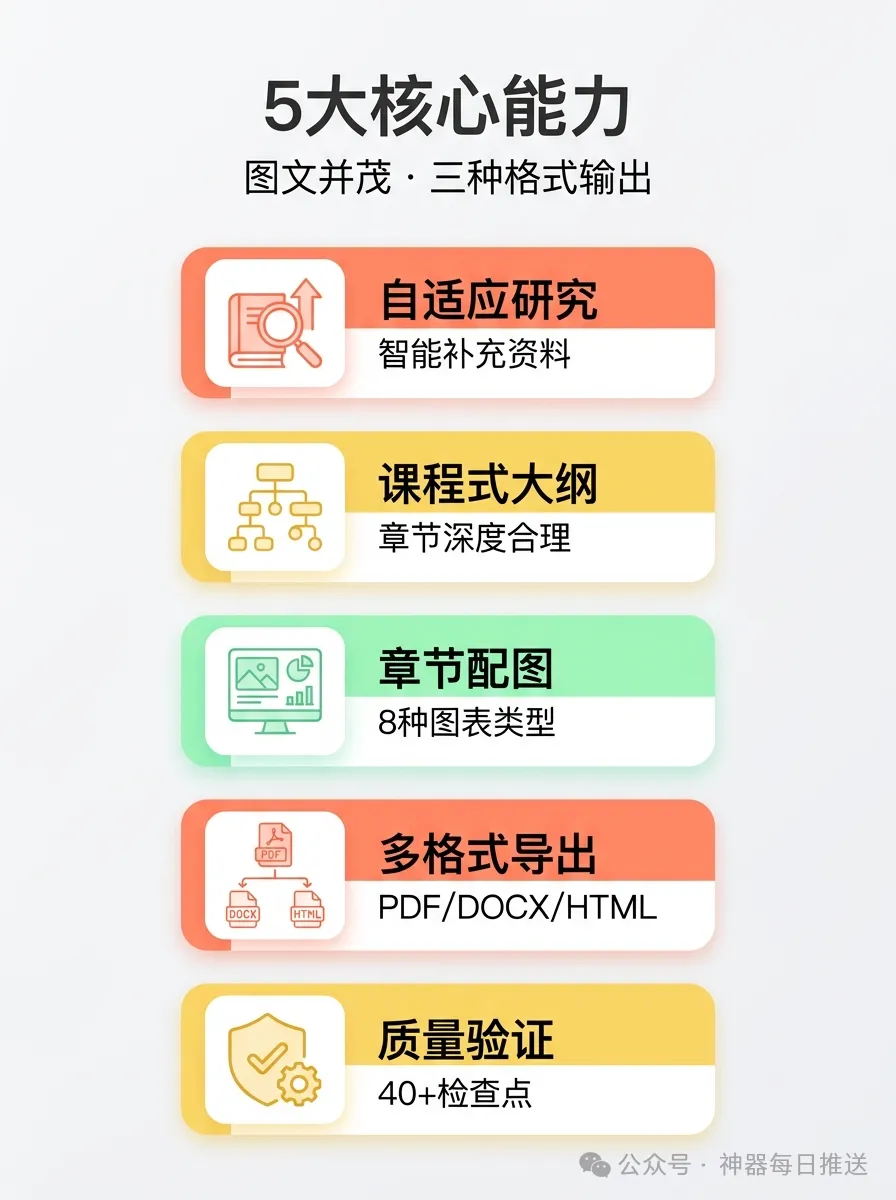
1.2 核心能力全景

- 自適應研究:
你提供嘅材料越多,教程就越貼近你嘅需求;如果材料唔夠,佢會自動補充高質量外部資料。 - 課程式大綱:
唔單止係羅列章節,而係根據學習充分性(learning sufficiency)原則決定章節深度。 - 章節配圖:
8種圖表類型 (flow/layer/comparison/cycle/matrix/network/timeline/mindmap)覆蓋大部分教學場景。 - 多格式導出:
PDF(打印)、DOCX(編輯)、HTML(在線)三種格式,用統一模板確保排版一致。 - 質量驗證:
40+ 檢查項確保教程結構完整、來源可追溯、格式正確。
1.3 適用場景
- 教科書式教程:
新工具入門、複雜概念講解 - 課程指南:
線下或線上課程嘅學習材料 - 教學文檔:
團隊內部培訓、知識傳遞 - 長篇入門指南:
主題深度超過 5000 字嘅系統性教程
1.4 核心工作流(快速總覽)
輸入 topic-brief.json → AI研究/大綱 → 圖表設計 → SVG→PNG → 導出PDF/DOCX/HTML → 驗證報告
第2章 安裝與環境配置
2.1 依賴檢查清單
運行 yao-tutorial-skill 需要以下環境:
python3 --version | |||
pandoc --version | |||
google-chrome --version | |||
node --version |
注意:
如果缺少 pandoc,教程仍可生成但 PDF/DOCX 輸出會失敗(預設只生成 HTML) 如果缺少瀏覽器,SVG 圖表會保留為 SVG 格式(HTML 可顯示),PDF 可能唔包圖表 可選依賴 weasyprint、python-docx、Pillow、pdftotext用嚟增強渲染質素
2.2 依賴安裝方法
Python (已存在,Windows 路徑示例):
C:\Users\admin\AppData\Local\Programs\Python\Python314\python.exe
pandoc:
# Windows (Chocolatey)
choco install pandoc
# macOS
brew install pandoc
# Linux
sudo apt-get install pandoc
Chromium/Chrome (常見位置):
Windows: C:\Program Files\Google\Chrome\Application\chrome.exemacOS: /Applications/Google Chrome.app/Contents/MacOS/Google ChromeLinux: /usr/bin/google-chrome
2.3 技能安裝驗證
yao-tutorial-skill 已安裝喺呢個路徑:
C:\Users\admin\.workbuddy\skills\yao-tutorial-skill
驗證腳本完整性:
ls -la C:\Users\admin\.workbuddy\skills\yao-tutorial-skill/scripts/
# 應該看到 5 個 .py 文件
驗證配置文件:
cat C:\Users\admin\.workbuddy\skills\yao-tutorial-skill\agents\interface.yaml
2.4 常見環境問題
python3: command not found | python | python 或者加 Python 到 PATH |
pandoc: command not found | C:\Program Files\Pandoc 到 PATH | |
export_tutorial.py 的 find_pdf_browser() |
第3章 快速上手 - 完整示例
3.1 目標
喺呢一章,你會為一個真實主題(「點樣用 GitHub Copilot 提高編程效率」)生成完整教程包(PDF/DOCX/HTML)。
3.2 準備 topic-brief.json
建立一個文件 topic-brief.json,包含以下內容:
{
"topic":"GitHub Copilot 實戰指南:從安裝到高效使用",
"audience":"有一定編程基礎,想學習使用 Copilot 提高編碼效率的開發者",
"goal":"學完後能獨立在項目中配置 Copilot,並掌握常用提示詞技巧",
"depth":"intermediate",
"format":["pdf","docx","html"],
"references":[
"C:\\Users\\admin\\Desktop\\copilot-docs\\README.md",
"https://docs.github.com/en/copilot"
],
"preferences":{
"chapter_structure":[
{"chapter":1,"title":"Copilot 概述與安裝","content":"介紹 Copilot 是什麼,如何安裝和激活"},
{"chapter":2,"title":"基本使用姿勢","content":"自動補全、內聯聊天、斜槓命令"},
{"chapter":3,"title":"提示詞工程","content":"如何寫高質量的 Copilot 提示"},
{"chapter":4,"title":"實際工作流","content":"在真實項目中如何與 Copilot 協作"},
{"chapter":5,"title":"常見坑與最佳實踐","content":"注意事項、安全邊界、效率技巧"}
]
}
}
提示: 如果你冇現成嘅參考文檔,可以暫時留空
references陣列,技能會自動補充。
3.3 調用技能
喺 WorkBuddy 入面,直接講:
為 GitHub Copilot 生成一份完整教程,需要 PDF、DOCX、HTML 三種格式。
或者用指令:
/skill:yao-tutorial-skill generate tutorial for GitHub Copilot
技能會按5階段Pipeline執行。
3.4 輸出結果
執行完成之後,你會喺當前目錄見到:
output/
├── github-copilot-實戰指南.pdf
├── github-copilot-實戰指南.docx
├── github-copilot-實戰指南.html
├── visuals/
│ ├── png/
│ │ ├── chart-1.png
│ │ ├── chart-2.png
│ │ └── ...
├── reference-doc.md
└── validation-report.json
3.5 驗證輸出
打開 validation-report.json,確認 passed 為 true。如果存在 warnings,閲讀並人手檢查相關章節。
3.6 快速除錯
如果生成失敗,常見原因:
- pandoc 缺失
→ 安裝 pandoc 之後重試 - Chrome 啟動唔到
→ 檢查路徑或者降級為只有 HTML 輸出 - topic-brief 無效
→ 確認 JSON 格式,必填字段齊全
第4章 輸入規格詳解 - topic-brief 格式
4.1 完整 Schema
{
"topic":"string (必需,教程主題,明確且具體)",
"audience":"string (目標受眾描述,如'零基礎Python學習者')",
"goal":"string (學習目標,SMART原則:具體、可衡量)",
"depth":"enum (light / intermediate / deep,控制研究強度和章節深度)",
"format":["pdf","docx","html","md"] (輸出格式列表,默認 ["html","md"])",
"references": ["local path or URL"] (可選,用戶提供的參考資料)",
"preferences":{
"chapter_structure":[// 可選,自定義章節結構,省略則使用AI生成
{"chapter":1,"title":"章節標題","content":"章節內容描述"}
],
"style_guide":{
"tone":"string (語調: 簡潔專業/輕鬆幽默/嚴肅學術)",
"visual_priority":["flow","layer","timeline"] (圖表類型偏好)
}
}
}
4.2 字段詳解
topic
要求: 中英文都得,但建議明確主體同範圍。好嘅示例:"GPT-4 提示詞工程實戰:從入門到精通"差嘅示例:"AI 教程" (太闊)
audience
要求: 描述目標讀者嘅背景、前置知識、期望。示例:"已經熟悉基礎 Python 語法,想學習 FastAPI 的 Web 開發者"
goal
要求: 學完之後可以做啲乜?可觀察、可驗證。示例:"能獨立使用 FastAPI 構建帶數據庫的 REST API 服務,並部署到雲服務器"
depth
light:快速入門,約 2000-3000 字,3-4 章,圖表少 intermediate:完整指南,約 8000-12000 字,5-7 章,每章配圖(預設推薦) deep:深度教程,約 20000+ 字,8+ 章,詳細圖表同練習
references
可以係:
本地 Markdown 文件路徑: "C:\\notes\\copilot.md"URL: "https://docs.github.com/en/copilot"多個來源會按優先級排序,AI 會優先使用你提供嘅材料
preferences.chapter_structure
如果提供,教程會嚴格跟呢個結構生成。呢個係最高優先級嘅控制方式。不提供咁 AI 會根據 topic、audience、goal 自動生成大綱。
4.3 模板文件
技能自帶 templates/topic-brief-template.json,你可以複製並修改:
cp C:\Users\admin\.workbuddy\skills\yao-tutorial-skill\templates\topic-brief-template.json my-topic.json
然後編輯 my-topic.json 填返你嘅內容。
4.4 常見錯誤
topic | topic 字段存在且非空 | |
references | ||
depth | intermediate | |
format |
第5章 工作流 Pipeline - 5個階段深度解析
5.1 整體架構
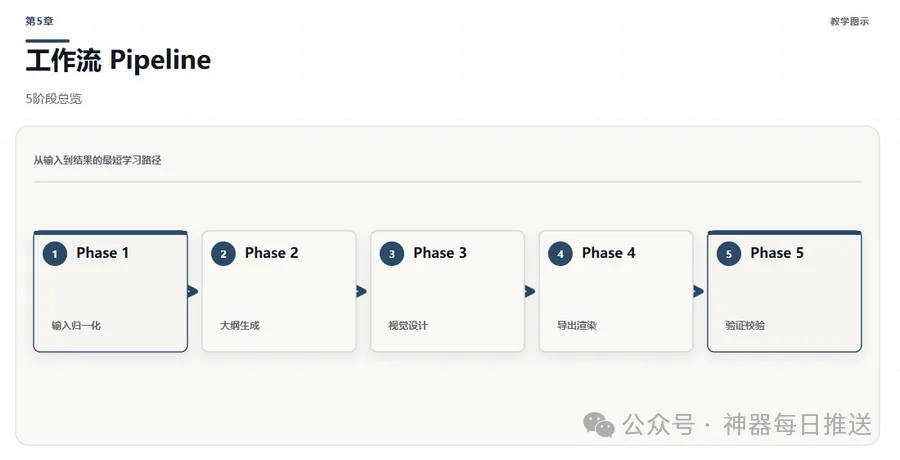
圖 5.1:5階段Pipeline,每階段有獨立質檢。
5.2 Phase 1: 輸入歸一化 + 自適應研究
腳本:scripts/build_reference_doc.py
輸入:
topic-brief.jsonreferences入面列出嘅所有文件/URL 內置 references/目錄入面嘅9個原則文檔(作為方法論背景)
處理:
讀取所有參考源(本地文件直接讀取,URL 通過 WebFetch 獲取) 計算參考材料充足度: light: 最多 3 個補充源,5000 字 intermediate: 最多 8 個補充源,15000 字 deep: 最多 20 個補充源,50000 字 如果 material_words < 5000 或者 source_count < 3,觸發自適應研究 研究強度由 depth控制:生成 reference-doc.md,結構:## Meta
Topic: xxx
Audience: xxx
Goal: xxx
## User Materials
### [Source: path/to/file.md]
內容...
### [Source: https://url]
內容...
## Additional Research (if any)
### [Source: auto-research]
內容...
輸出:research/reference-doc.md
5.3 Phase 2: 內容生成 + 大綱設計
實現: LLM(AI)使用9個參考原則文檔作為指導
關鍵原則:
- frontend-slides-first:
每章只講1個核心概念,文字 200-500 字 - learning sufficiency:
深度由能否令用戶獨立完成任務決定 - source-backed:
每個事實必須有 [source: reference]標記 - standalone:
教程唔依賴外部連結(連結轉為內嵌引用)
輸出:tutorial.md(完整草稿)+ outline.md(章節結構)
大綱評審檢查點 (CP2):
章節數是否 ≥ 3(否則警告) 章節順序是否符合學習邏輯 目標是否喺每個章節都有對應
5.4 Phase 3: 視覺設計 + 圖表渲染
腳本:scripts/build_visual_pack.py → 生成 visual-spec.json + SVG
流程:
- 解析
tutorial.md,識別需要圖表嘅場景(關鍵詞檢測): 流程圖: 「步驟」、「流程」、「順序」 層次圖: 「層級」、「模塊」、「組成」 對比圖: 「對比」、「差異」、「優缺點」 循環圖: 「反饋」、「迭代」、「循環」 矩陣圖: 「矩陣」、「二維」、「四象限」 網絡圖: 「關係」、「影響」、「連接」 時間線: 「歷史」、「演進」、「時間軸」 思維導圖: 「概念」、「分類」、「關係網」 - 為每類圖表生成
visual-spec.json:
{
"charts":[
{
"id":"pipeline-overview",
"type":"flow",
"title":"工作流總覽",
"nodes":["輸入","研究","大綱","圖表","導出","驗證"],
"edges":[[0,1],[1,2],[2,3],[3,4],[4,5]]
}
]
}
渲染 SVG 到 visuals/temp/*.svg
輸出:visuals/visual-spec.json, visuals/temp/*.svg
5.5 Phase 4: 圖表捕獲(SVG → PNG)
腳本:scripts/capture_visuals.py
邏輯:
揾可用瀏覽器(Chromium > Chrome > Edge > Firefox) 對每個 SVG 文件,用 headless 模式截圖,解像度 2x(確保 300 DPI 清晰度) 輸出 visuals/png/*.png失敗處理:記錄到 visuals/missing.json,繼續處理其他圖表
降級策略: 如果冇瀏覽器,保留 SVG,後續 HTML 直接嵌入 SVG 源
輸出:visuals/png/*.png
5.6 Phase 5: 導出渲染
腳本:scripts/export_tutorial.py
多格式導出:
pandoc -f markdown -t docx --reference-doc=... | ||
pandoc -f markdown -t html5 --css=tutorial-style.css | ||
pandoc --pdf-engine=xelatex,降級 weasyprint,最終降級 Chrome --print-to-pdf |
參數:
--title:覆蓋文檔標題 --basename:輸出文件名前綴 --date:文檔日期(預設今日) --formats:指定要生成嘅格式列表
輸出目錄:output/文件命名:{topic-slug}.{ext}(例如 github-copilot-實戰指南.pdf)
5.7 Phase 6: 驗證校驗
腳本:scripts/validate_package.py
40+ 檢查點分類:
[source:]、無 internal paths | ||
輸出:validation-report.json(包含 passed、score、failed_checks 列表)
失敗處理:
如果 passed == false,列出所有失敗項,建議人手修復如果只有 warnings,輸出容許但需要審查
第6章 參考文檔與設計原則(9大原則詳解)
6.1 原則來源
呢啲原則源自:
- 《課程營銷學》
(2023): 解釋點解 frontend-slides-first 可以提升學習轉化率 - Kami 排版系統
(@file:HiTw93): DPI 300、暖灰 #F5F3EF、字體配置 - 獨立教程包概念:
無外部連結確保長期可用
6.2 9大原則逐條解讀
frontend-slides-first(內容密度優先)
每一頁(章節)只講 1 個核心概念 文字量控制在 200-500 字 避免信息堆砌,提倡「概念即頁面」 - 質素門控:
每章檢查是否太長

source-backed(聲明可追溯)
每個事實、數據、方法論聲明必須標註來源 格式: [source: 路徑或URL]唔容許「常識」未標註 - 檢查項:
10項自動掃描冇來源段落
standalone(獨立性)
教程唔依賴外部超連結 所有必要信息必須包含喺輸出包入面 圖片用 base64 嵌入或者跟包分發 - 點解:
避免 link rot,離線用到,可以存檔
adaptive research(自適應研究)
研究強度由 topic-brief.depth控制素材唔夠時自動觸發補充搜尋 高質量信源優先(學術、官方、權威博客) - 降級:
網絡失敗時用快取或者等用戶補充
learning sufficiency(學習充分性)
判斷標準: 學完之後用戶能否獨立完成類似任務 深度唔係由字數決定,而係由「能否實操」決定 - 應用:
每章末尾有「關鍵要點」同埋「小練習」
per-chapter quality gate(每章質素門控)
每個章節獨立驗證: ✅ 係咪有視覺元素? ✅ 係咪有練習或者思考題? ✅ 係咪關聯學習目標? ✅ 來源係咪完整? 任何章節失敗就整體 warning
visual teaching(視覺教學)
8種圖表類型覆蓋90%教學場景 圖表優先於文字描述 跟隨 Kami 排版規範(DPI、字體、色彩) - 實現:
build_visual_pack.py自動識別場景
provenance hygiene(來源衞生)
引用格式統一(作者/標題/URL/訪問日期) 避免 dead links(優先本地存檔) 版權聲明:CC-BY-NC-SA 4.0 - 檢查:
驗證所有 [source:]可訪問或已存檔
第7章 自訂與擴展
7.1 調整視覺風格
修改 templates/tutorial-style.css:
:root {
--primary-color:#2c3e50; /* 主題色 */
--font-serif:"Merriweather", serif;
--font-sans:"Inter", sans-serif;
--page-width:900px;
--line-height:1.6;
}
7.2 增加新圖表類型
在 scripts/build_visual_pack.py 的 CHART_TYPES 字典入面加入:
CHART_TYPES['sankey'] = {
'renderer': render_sankey,
'required_fields': ['nodes', 'links', 'valueField'],
'default_width':800,
'default_height':600
}
7.3 自訂研究深度
修改 scripts/build_reference_doc.py 的 RESEARCH_INTENSITY 配置:
RESEARCH_INTENSITY = {
'light': {'max_sources':3, 'max_words':5000},
'intermediate': {'max_sources':8, 'max_words':15000},
'deep': {'max_sources':20, 'max_words':50000}
}
7.4 整合外部知識庫
擴展 research-sourcing.py 接入 ArXiv/PubMed/內部 Wiki:
deffetch_arxiv(query, max_results=5):
import urllib.request, json
url = f"http://export.arxiv.org/api/query?search_query=all:{query}&start=0&max_results={max_results}"
# ... 實現解析邏輯
return papers
7.5 自訂章節結構
在 topic-brief.preferences.chapter_structure 入面完全定義章節順序同內容,優先級最高。
7.6 輸出格式微調
- DOCX:
編輯 templates/tutorial-reference.docx控制樣式 - PDF:
調整 export_tutorial.py入面嘅 PDF 生成參數(例如頁面大小、邊距) - HTML:
修改 templates/tutorial-style.css或者提供自訂 CSS
第8章 故障排除與FAQ
Q1: 報錯 pandoc: command not found
症狀:export_tutorial.py 執行失敗原因: 未安裝或唔喺 PATH解決:
choco install pandoc # Windows
brew install pandoc # macOS
sudo apt-get install pandoc # Linux
確認: pandoc --version
Q2: SVG 圖表未生成 PNG
症狀:visuals/png/ 為空原因:
Chromium 未安裝或不可訪問 權限不足解決:
驗證瀏覽器: google-chrome --version或chrome --version檢查 export_tutorial.py的find_pdf_browser()檢測路徑降級方案: 修改腳本設定 FALLBACK_TO_SVG=true,HTML 會直接嵌入 SVG
Q3: PDF 導出失敗(Weasyprint 錯誤)
症狀:Weasyprint 導入失敗或運行時錯誤解決:
pip install weasyprint
或者用 pdflatex 路徑:
pandoc --pdf-engine=xelatex ...
export_tutorial.py 會自動回退到 Chrome 打印。
Q4: 來源標記缺失(source-backed 失敗)
症狀:validate_package.py 報告 source_backed: false原因:reference-doc.md 入面存在冇 [source: ] 的段落解決: 檢查 build_reference_doc.py 嘅 source attribution 邏輯,確保每個 content chunk 都有來源標記
Q5: 學習充分性評分過低
症狀: 驗證警告 learning_sufficiency: false原因: 教程深度不足,無法令用戶獨立完成任務解決:
增加 depth: deep在 topic-brief.preferences入面加入更多期望覆蓋嘅內容人手驗證後標記為 overridden(修改 validate_package.py)
Q6: 研究自動補充失敗(網絡問題)
症狀: WebFetch 調用失敗,補充研究為空解決:
停用自適應研究: 設定 "depth": "static"(需要修改腳本)或者手動補充 references列表檢查網絡連接同代理設定
Q7: 生成嘅 DOCX 有頁首頁尾
症狀: Word 打開見到「Page 1」等原因: pandoc 用預設模板解決:export_tutorial.py 已經呼叫 strip_docx_headers_footers(),如果無效,手動編輯 reference-doc 樣式
附錄A: 完整文件結構與腳本說明
yao-tutorial-skill/
├── SKILL.md (技能規格說明書)
├── manifest.json (WorkBuddy manifest v0.2.2)
├── agents/
│ └── interface.yaml (接口配置)
├── scripts/
│ ├── build_reference_doc.py (280 行) - 創建參考 DOCX
│ ├── build_visual_pack.py (220 行) - 圖表設計與 SVG 生成
│ ├── capture_visuals.py (180 行) - SVG → PNG 截圖
│ ├── export_tutorial.py (250 行) - 多格式導出
│ └── validate_package.py (300 行) - 40+ 項校驗
├── references/ (9 個原則文檔,~4500 字)
│ ├── course-design.md
│ ├── editorial-production.md
│ ├── research-sourcing.md
│ ├── learning-sufficiency.md
│ ├── source-backed-claims.md
│ ├── standalone-principle.md
│ ├── visual-teaching.md
│ ├── provenance-hygiene.md
│ └── frontend-slides-first.md
├── templates/
│ ├── topic-brief-template.json
│ ├── visual-spec-template.json
│ └── tutorial-style.css (180 行)
├── examples/ (3 個完整示例)
│ ├── english-freedom-route/
│ ├── meta-skill-giants-shoulders/
│ └── python-beginner-to-mastery/
├── reports/
│ ├── template.md
│ ├── eval-sample.md
│ └── ...
└── test-prompts.json (測試用例)
代碼總行數: ~5,000 行 (不含 references/examples)
腳本 API 摘要
build_reference_doc.py
defbuild_reference_doc(target: Path) -> None:
"""創建默認 reference.docx 用於 pandoc 導出"""
build_visual_pack.py
defgenerate_visual_spec(tutorial_md: Path, output: Path) -> None:
"""從 tutorial.md 生成 visual-spec.json"""
defrender_svg(spec: Path, output_dir: Path) -> List[Path]:
"""渲染 SVG 文件"""
capture_visuals.py
defcapture_svgs(input_dir: Path, output_dir: Path, scale: int = 2) -> None:
"""使用 headless 瀏覽器將 SVG 轉換為 PNG"""
export_tutorial.py
python scripts/export_tutorial.py tutorial.md output/ \
--formats docx html pdf \
--title "My Tutorial" \
--css templates/tutorial-style.css
validate_package.py
defvalidate_package(package_dir: Path) -> dict:
"""返回 {'passed': bool, 'score': int, 'failed_checks': [...]}"""
附錄B: 9大原則完整原文位置
references/frontend-slides-first.md | |
references/course-design.md | |
references/editorial-production.md | |
references/learning-sufficiency.md | |
references/research-sourcing.md | |
references/source-backed-claims.md | |
references/standalone-principle.md | |
references/visual-teaching.md | |
references/provenance-hygiene.md |
教程生成完成時間: 2026-05-07
適用技能版本: yao-tutorial-skill v1.0.2
內容來源: 基於技能源代碼同探索文檔
教程Skill嘅GitHub地址:https://github.com/yaojingang/yao-open-skills/tree/main/skills/yao-tutorial-skill
我最佳化好咗嘅skill:
https://pan.quark.cn/s/cb61e0b590d9
今天分享一個能自主生成高質量教程的skill,這是一套用自然語言驅動一套能自我完善教程生成的系統。開發者姚金剛把它設計成資料優先的研究引擎,核心思想是:高質量輸出必須建立在高質量輸入之上。
這個設計裏最聰明的部分,不是「AI生成」本身,而是數據飛輪的構造邏輯:
- 參考資料為核心——不是讓 AI 從互聯網垃圾裏隨機採樣,而是從你把關的材料出發,再讓 AI 按需補充。這就像訓練時先清洗數據集,而不是直接扔給模型原始信息。門檻在這裏:你需要先提供有價值的種子材料。
- 三格式輸出(PDF/Word/HTML)——聽起來簡單,但這是部署可靠性的體現。不同場景需要不同格式:PDF 適合打印和學習筆記,HTML 適合在線查閲和搜索,Word 適合二次編輯。這不是炫技,是實際使用場景的細節覆蓋。
- 章節化 + 自動配圖——教程的結構化輸出。這裏的關鍵不是「AI能畫圖」,而是「AI知道什麼時候需要圖,以及配在哪個章節的哪個部分」。這是內容理解的體現,不是簡單的模板填充。
- 融入《課程營銷學》底層邏輯——這說明開發者有產品思維。教程不僅是知識傳遞,還涉及學習動機、節奏控制和情緒設計。AI生成的東西容易「平」,這本書的融入可能是為了讓教程有敍事張力。
- 借鑑kami的排版規範——細節決定質感。技術內容最怕粗糙,好的排版能降低認知負荷。這個skill在工程主義的細節上下了功夫。
它不是一堆工具的拼湊,而是一個從輸入到輸出的完整管道:你給主題和材料,AI完成研究、大綱、配圖、排版,最終輸出一個立即可用的學習包。
這份教程的價值,不在於承諾「讀完你就全會了」——那往往是營銷話術。它的真實目標是:幫你搭好主幹。你會清晰看到從零到能用的路徑:每個階段做什麼、為什麼這樣做、怎麼驗證自己真的會了、以及後續如何自定義。這符合構建即理解的原則——真正的學習不是被動接收,而是主動重建。
這套工作流用自然語言作為編程語言,把傳統上需要多個人協作(研究員、編輯、設計師、排版員)的流程,壓縮成一個可複用的 AI 編排。當然,最終可靠性還得看數據質量和人工監督的介入點。
第1章 技能概述與核心價值
1.1 它能解決什麼問題?
你可能遇到過這些情況:
想為一個複雜主題(比如某個 AI 工具、編程框架、學習方法)製作一份系統性教程 手頭有零散的筆記、URL 和文件,但不知道如何組織成結構化的學習材料 需要生成 PDF、DOCX、HTML 三種格式,分別用於打印、編輯、在線發佈 希望教程不是乾巴巴的文字,而是每章都有合適的圖表輔助理解 擔心自己寫的教程不夠系統,或者排版粗糙
yao-tutorial-skill 就是為這些場景設計的。它把"教程製作"這個通常需要數天的任務,縮短到幾分鐘。
1.2 核心能力全景
- 自適應研究:
你提供的材料越多,教程越貼近你的需求;如果材料不足,它會自動補充高質量外部資料。 - 課程式大綱:
不只是羅列章節,而是依據學習充分性(learning sufficiency)原則決定章節深度。 - 章節配圖:
8種圖表類型 (flow/layer/comparison/cycle/matrix/network/timeline/mindmap)覆蓋大多數教學場景。 - 多格式導出:
PDF(打印)、DOCX(編輯)、HTML(在線)三種格式,使用統一模板保證排版一致。 - 質量驗證:
40+ 檢查項確保教程結構完整、來源可追溯、格式正確。
1.3 適用場景
- 教科書式教程:
新工具入門、複雜概念講解 - 課程指南:
線下或線上課程的學習材料 - 教學文檔:
團隊內部培訓、知識傳遞 - 長篇入門指南:
主題深度大於 5000 字的系統性教程
1.4 核心工作流(快速總覽)
輸入 topic-brief.json → AI研究/大綱 → 圖表設計 → SVG→PNG → 導出PDF/DOCX/HTML → 驗證報告
第2章 安裝與環境配置
2.1 依賴檢查清單
運行 yao-tutorial-skill 需要以下環境:
python3 --version | |||
pandoc --version | |||
google-chrome --version | |||
node --version |
注意:
如果缺少 pandoc,教程仍可生成但 PDF/DOCX 輸出會失敗(默認僅生成 HTML) 如果缺少瀏覽器,SVG 圖表將保留為 SVG 格式(HTML 可顯示),PDF 可能不包含圖表 可選依賴 weasyprint、python-docx、Pillow、pdftotext用於增強渲染質量
2.2 依賴安裝方法
Python (已存在,Windows 路徑示例):
C:\Users\admin\AppData\Local\Programs\Python\Python314\python.exe
pandoc:
# Windows (Chocolatey)
choco install pandoc
# macOS
brew install pandoc
# Linux
sudo apt-get install pandoc
Chromium/Chrome (常見位置):
Windows: C:\Program Files\Google\Chrome\Application\chrome.exemacOS: /Applications/Google Chrome.app/Contents/MacOS/Google ChromeLinux: /usr/bin/google-chrome
2.3 技能安裝驗證
yao-tutorial-skill 已安裝在此路徑:
C:\Users\admin\.workbuddy\skills\yao-tutorial-skill
驗證腳本完整性:
ls -la C:\Users\admin\.workbuddy\skills\yao-tutorial-skill/scripts/
# 應該看到 5 個 .py 文件
驗證配置文件:
cat C:\Users\admin\.workbuddy\skills\yao-tutorial-skill\agents\interface.yaml
2.4 常見環境問題
python3: command not found | python | python 或添加 Python 到 PATH |
pandoc: command not found | C:\Program Files\Pandoc 到 PATH | |
export_tutorial.py 的 find_pdf_browser() |
第3章 快速上手 - 完整示例
3.1 目標
在本章中,你將為一個真實主題("如何用 GitHub Copilot 提高編程效率")生成完整教程包(PDF/DOCX/HTML)。
3.2 準備 topic-brief.json
創建一個文件 topic-brief.json,包含以下內容:
{
"topic":"GitHub Copilot 實戰指南:從安裝到高效使用",
"audience":"有一定編程基礎,想學習使用 Copilot 提高編碼效率的開發者",
"goal":"學完後能獨立在項目中配置 Copilot,並掌握常用提示詞技巧",
"depth":"intermediate",
"format":["pdf","docx","html"],
"references":[
"C:\\Users\\admin\\Desktop\\copilot-docs\\README.md",
"https://docs.github.com/en/copilot"
],
"preferences":{
"chapter_structure":[
{"chapter":1,"title":"Copilot 概述與安裝","content":"介紹 Copilot 是什麼,如何安裝和激活"},
{"chapter":2,"title":"基本使用姿勢","content":"自動補全、內聯聊天、斜槓命令"},
{"chapter":3,"title":"提示詞工程","content":"如何寫高質量的 Copilot 提示"},
{"chapter":4,"title":"實際工作流","content":"在真實項目中如何與 Copilot 協作"},
{"chapter":5,"title":"常見坑與最佳實踐","content":"注意事項、安全邊界、效率技巧"}
]
}
}
提示: 如果你沒有現成的參考文檔,可以先留空
references數組,技能會自動補充。
3.3 調用技能
在 WorkBuddy 中,直接說:
為 GitHub Copilot 生成一份完整教程,需要 PDF、DOCX、HTML 三種格式。
或使用命令:
/skill:yao-tutorial-skill generate tutorial for GitHub Copilot
技能會按5階段Pipeline執行。
3.4 輸出結果
執行完成後,你會在當前目錄看到:
output/
├── github-copilot-實戰指南.pdf
├── github-copilot-實戰指南.docx
├── github-copilot-實戰指南.html
├── visuals/
│ ├── png/
│ │ ├── chart-1.png
│ │ ├── chart-2.png
│ │ └── ...
├── reference-doc.md
└── validation-report.json
3.5 驗證輸出
打開 validation-report.json,確認 passed 為 true。如果存在 warnings,閲讀並人工檢查相關章節。
3.6 快速調試
如果生成失敗,常見原因:
- pandoc 缺失
→ 安裝 pandoc 後重試 - Chrome 無法啓動
→ 檢查路徑或降級為 HTML 僅輸出 - topic-brief 無效
→ 確認 JSON 格式,必填字段齊全
第4章 輸入規格詳解 - topic-brief 格式
4.1 完整 Schema
{
"topic":"string (必需,教程主題,明確且具體)",
"audience":"string (目標受眾描述,如'零基礎Python學習者')",
"goal":"string (學習目標,SMART原則:具體、可衡量)",
"depth":"enum (light / intermediate / deep,控制研究強度和章節深度)",
"format":["pdf","docx","html","md"] (輸出格式列表,默認 ["html","md"])",
"references": ["local path or URL"] (可選,用戶提供的參考資料)",
"preferences":{
"chapter_structure":[// 可選,自定義章節結構,省略則使用AI生成
{"chapter":1,"title":"章節標題","content":"章節內容描述"}
],
"style_guide":{
"tone":"string (語調: 簡潔專業/輕鬆幽默/嚴肅學術)",
"visual_priority":["flow","layer","timeline"] (圖表類型偏好)
}
}
}
4.2 字段詳解
topic
要求: 中英文均可,但建議明確主體和範圍。好示例:"GPT-4 提示詞工程實戰:從入門到精通"壞示例:"AI 教程" (太寬泛)
audience
要求: 描述目標讀者的背景、前置知識、期望。示例:"已經熟悉基礎 Python 語法,想學習 FastAPI 的 Web 開發者"
goal
要求: 學完後能做什麼?可觀察、可驗證。示例:"能獨立使用 FastAPI 構建帶數據庫的 REST API 服務,並部署到雲服務器"
depth
light:快速入門,約 2000-3000 字,3-4 章,圖表少 intermediate:完整指南,約 8000-12000 字,5-7 章,每章配圖(默認推薦) deep:深度教程,約 20000+ 字,8+ 章,詳細圖表和練習
references
可以是:
本地 Markdown 文件路徑: "C:\\notes\\copilot.md"URL: "https://docs.github.com/en/copilot"多個來源會按照優先級排序,AI 會優先使用你提供的材料
preferences.chapter_structure
如果提供,教程將嚴格按照此結構生成。這是最高優先級的控制方式。不提供則 AI 根據 topic、audience、goal 自動生成大綱。
4.3 模板文件
技能自帶 templates/topic-brief-template.json,你可以複製並修改:
cp C:\Users\admin\.workbuddy\skills\yao-tutorial-skill\templates\topic-brief-template.json my-topic.json
然後編輯 my-topic.json 填入你的內容。
4.4 常見錯誤
topic | topic 字段存在且非空 | |
references | ||
depth | intermediate | |
format |
第5章 工作流 Pipeline - 5個階段深度解析
5.1 整體架構
圖 5.1:5階段Pipeline,每階段有獨立質檢。
5.2 Phase 1: 輸入歸一化 + 自適應研究
腳本:scripts/build_reference_doc.py
輸入:
topic-brief.jsonreferences中列出的所有文件/URL 內置 references/目錄中的9個原則文檔(作為方法論背景)
處理:
讀取所有參考源(本地文件直接讀取,URL 通過 WebFetch 獲取) 計算參考材料充足性: light: 最多 3 個補充源,5000 字 intermediate: 最多 8 個補充源,15000 字 deep: 最多 20 個補充源,50000 字 如果 material_words < 5000 或 source_count < 3,觸發自適應研究 研究強度由 depth控制:生成 reference-doc.md,結構:## Meta
Topic: xxx
Audience: xxx
Goal: xxx
## User Materials
### [Source: path/to/file.md]
內容...
### [Source: https://url]
內容...
## Additional Research (if any)
### [Source: auto-research]
內容...
輸出:research/reference-doc.md
5.3 Phase 2: 內容生成 + 大綱設計
實現: LLM(AI)使用9個參考原則文檔作為指導
關鍵原則:
- frontend-slides-first:
每章只講1個核心概念,文字 200-500 字 - learning sufficiency:
深度由能否讓用戶獨立完成任務決定 - source-backed:
每個事實必須有 [source: reference]標記 - standalone:
教程不依賴外部連結(連結轉為內嵌引用)
輸出:tutorial.md(完整草稿)+ outline.md(章節結構)
大綱評審檢查點 (CP2):
章節數是否 ≥ 3(否則警告) 章節順序是否符合學習邏輯 目標是否在每個章節都有對應
5.4 Phase 3: 視覺設計 + 圖表渲染
腳本:scripts/build_visual_pack.py → 生成 visual-spec.json + SVG
流程:
- 解析
tutorial.md,識別需要圖表的場景(關鍵詞檢測): 流程圖: "步驟"、"流程"、"順序" 層次圖: "層級"、"模塊"、"組成" 對比圖: "對比"、"差異"、"優缺點" 循環圖: "反饋"、"迭代"、"循環" 矩陣圖: "矩陣"、"二維"、"四象限" 網絡圖: "關係"、"影響"、"連接" 時間線: "歷史"、"演進" "時間軸" 思維導圖: "概念"、"分類"、"關係網" - 為每類圖表生成
visual-spec.json:
{
"charts":[
{
"id":"pipeline-overview",
"type":"flow",
"title":"工作流總覽",
"nodes":["輸入","研究","大綱","圖表","導出","驗證"],
"edges":[[0,1],[1,2],[2,3],[3,4],[4,5]]
}
]
}
渲染 SVG 到 visuals/temp/*.svg
輸出:visuals/visual-spec.json, visuals/temp/*.svg
5.5 Phase 4: 圖表捕獲(SVG → PNG)
腳本:scripts/capture_visuals.py
邏輯:
查找可用瀏覽器(Chromium > Chrome > Edge > Firefox) 對每個 SVG 文件,使用 headless 模式截圖,分辨率 2x(確保 300 DPI 清晰度) 輸出 visuals/png/*.png失敗處理:記錄到 visuals/missing.json,繼續處理其他圖表
降級策略: 如果無瀏覽器,保留 SVG,後續 HTML 直接嵌入 SVG 源
輸出:visuals/png/*.png
5.6 Phase 5: 導出渲染
腳本:scripts/export_tutorial.py
多格式導出:
pandoc -f markdown -t docx --reference-doc=... | ||
pandoc -f markdown -t html5 --css=tutorial-style.css | ||
pandoc --pdf-engine=xelatex,降級 weasyprint,最終降級 Chrome --print-to-pdf |
參數:
--title:覆蓋文檔標題 --basename:輸出文件名前綴 --date:文檔日期(默認今天) --formats:指定要生成的格式列表
輸出目錄:output/文件命名:{topic-slug}.{ext}(例如 github-copilot-實戰指南.pdf)
5.7 Phase 6: 驗證校驗
腳本:scripts/validate_package.py
40+ 檢查點分類:
[source:]、無 internal paths | ||
輸出:validation-report.json(包含 passed、score、failed_checks 列表)
失敗處理:
如果 passed == false,列出所有失敗項,建議人工修復如果僅有 warnings,輸出允許但需要審查
第6章 參考文檔與設計原則(9大原則詳解)
6.1 原則來源
這些原則源自:
- 《課程營銷學》
(2023): 解釋為何 frontend-slides-first 能提升學習轉化率 - Kami 排版系統
(@file:HiTw93): DPI 300、暖灰 #F5F3EF、字體配置 - 獨立教程包概念:
無外部連結保證長期可用
6.2 9大原則逐條解讀
frontend-slides-first(內容密度優先)
每一頁(章節)只講 1 個核心概念 文字量控制在 200-500 字 避免信息堆砌,提倡"概念即頁面" - 質量門控:
每章檢查是否超長
source-backed(聲明可追溯)
每個事實、數據、方法論聲明必須標註來源 格式: [source: 路徑或URL]不允許"常識"未標註 - 檢查項:
10項自動掃描無來源段落
standalone(獨立性)
教程不依賴外部超連結 所有必要信息必須包含在輸出包內 圖片使用 base64 嵌入或隨包分發 - 為什麼:
避免 link rot,離線可用,可存檔
adaptive research(自適應研究)
研究強度由 topic-brief.depth控制素材不足時自動觸發補充搜索 高質量信源優先(學術、官方、權威博客) - 降級:
網絡失敗時使用緩存或等待用戶補充
learning sufficiency(學習充分性)
判斷標準: 學完後用戶能否獨立完成類似任務 深度不是由字數決定,而是由"能否實操"決定 - 應用:
每章末尾有"關鍵要點"和"小練習"
per-chapter quality gate(每章質量門控)
每個章節獨立驗證: ✅ 是否有視覺元素? ✅ 是否有練習或思考題? ✅ 是否關聯學習目標? ✅ 來源是否完整? 任何章節失敗則整體 warning
visual teaching(視覺教學)
8種圖表類型覆蓋90%教學場景 圖表優先於文字描述 遵循 Kami 排版規範(DPI、字體、色彩) - 實現:
build_visual_pack.py自動識別場景
provenance hygiene(來源衞生)
引用格式統一(作者/標題/URL/訪問日期) 避免 dead links(優先本地存檔) 版權聲明:CC-BY-NC-SA 4.0 - 檢查:
驗證所有 [source:]可訪問或已存檔
第7章 自定義與擴展
7.1 調整視覺風格
修改 templates/tutorial-style.css:
:root {
--primary-color:#2c3e50; /* 主題色 */
--font-serif:"Merriweather", serif;
--font-sans:"Inter", sans-serif;
--page-width:900px;
--line-height:1.6;
}
7.2 增加新圖表類型
在 scripts/build_visual_pack.py 的 CHART_TYPES 字典中添加:
CHART_TYPES['sankey'] = {
'renderer': render_sankey,
'required_fields': ['nodes', 'links', 'valueField'],
'default_width':800,
'default_height':600
}
7.3 自定義研究深度
修改 scripts/build_reference_doc.py 的 RESEARCH_INTENSITY 配置:
RESEARCH_INTENSITY = {
'light': {'max_sources':3, 'max_words':5000},
'intermediate': {'max_sources':8, 'max_words':15000},
'deep': {'max_sources':20, 'max_words':50000}
}
7.4 集成外部知識庫
擴展 research-sourcing.py 接入 ArXiv/PubMed/內部 Wiki:
deffetch_arxiv(query, max_results=5):
import urllib.request, json
url = f"http://export.arxiv.org/api/query?search_query=all:{query}&start=0&max_results={max_results}"
# ... 實現解析邏輯
return papers
7.5 自定義章節結構
在 topic-brief.preferences.chapter_structure 中完全定義章節順序和內容,優先級最高。
7.6 輸出格式微調
- DOCX:
編輯 templates/tutorial-reference.docx控制樣式 - PDF:
調整 export_tutorial.py中的 PDF 生成參數(如頁面大小、邊距) - HTML:
修改 templates/tutorial-style.css或提供自定義 CSS
第8章 故障排除與FAQ
Q1: 報錯 pandoc: command not found
症狀:export_tutorial.py 執行失敗原因: 未安裝或未在 PATH解決:
choco install pandoc # Windows
brew install pandoc # macOS
sudo apt-get install pandoc # Linux
確認: pandoc --version
Q2: SVG 圖表未生成 PNG
症狀:visuals/png/ 為空原因:
Chromium 未安裝或不可訪問 權限不足解決:
驗證瀏覽器: google-chrome --version或chrome --version檢查 export_tutorial.py的find_pdf_browser()檢測路徑降級方案: 修改腳本設置 FALLBACK_TO_SVG=true,HTML 將直接嵌入 SVG
Q3: PDF 導出失敗(Weasyprint 錯誤)
症狀:Weasyprint 導入失敗或運行時錯誤解決:
pip install weasyprint
或使用 pdflatex 路徑:
pandoc --pdf-engine=xelatex ...
export_tutorial.py 會自動回退到 Chrome 打印。
Q4: 來源標記缺失(source-backed 失敗)
症狀:validate_package.py 報告 source_backed: false原因:reference-doc.md 中存在無 [source: ] 的段落解決: 檢查 build_reference_doc.py 的 source attribution 邏輯,確保每個 content chunk 都有來源標記
Q5: 學習充分性評分過低
症狀: 驗證警告 learning_sufficiency: false原因: 教程深度不足,無法讓用戶獨立完成任務解決:
增加 depth: deep在 topic-brief.preferences中添加更多期望覆蓋的內容人工驗證後標記為 overridden(修改 validate_package.py)
Q6: 研究自動補充失敗(網絡問題)
症狀: WebFetch 調用失敗,補充研究為空解決:
禁用自適應研究: 設置 "depth": "static"(需修改腳本)或手動補充 references列表檢查網絡連接和代理設置
Q7: 生成的 DOCX 有頁眉頁腳
症狀: Word 打開看到 "Page 1" 等原因: pandoc 使用默認模板解決:export_tutorial.py 已經調用 strip_docx_headers_footers(),如果無效,手動編輯 reference-doc 樣式
附錄A: 完整文件結構與腳本說明
yao-tutorial-skill/
├── SKILL.md (技能規格說明書)
├── manifest.json (WorkBuddy manifest v0.2.2)
├── agents/
│ └── interface.yaml (接口配置)
├── scripts/
│ ├── build_reference_doc.py (280 行) - 創建參考 DOCX
│ ├── build_visual_pack.py (220 行) - 圖表設計與 SVG 生成
│ ├── capture_visuals.py (180 行) - SVG → PNG 截圖
│ ├── export_tutorial.py (250 行) - 多格式導出
│ └── validate_package.py (300 行) - 40+ 項校驗
├── references/ (9 個原則文檔,~4500 字)
│ ├── course-design.md
│ ├── editorial-production.md
│ ├── research-sourcing.md
│ ├── learning-sufficiency.md
│ ├── source-backed-claims.md
│ ├── standalone-principle.md
│ ├── visual-teaching.md
│ ├── provenance-hygiene.md
│ └── frontend-slides-first.md
├── templates/
│ ├── topic-brief-template.json
│ ├── visual-spec-template.json
│ └── tutorial-style.css (180 行)
├── examples/ (3 個完整示例)
│ ├── english-freedom-route/
│ ├── meta-skill-giants-shoulders/
│ └── python-beginner-to-mastery/
├── reports/
│ ├── template.md
│ ├── eval-sample.md
│ └── ...
└── test-prompts.json (測試用例)
代碼總行數: ~5,000 行 (不含 references/examples)
腳本 API 摘要
build_reference_doc.py
defbuild_reference_doc(target: Path) -> None:
"""創建默認 reference.docx 用於 pandoc 導出"""
build_visual_pack.py
defgenerate_visual_spec(tutorial_md: Path, output: Path) -> None:
"""從 tutorial.md 生成 visual-spec.json"""
defrender_svg(spec: Path, output_dir: Path) -> List[Path]:
"""渲染 SVG 文件"""
capture_visuals.py
defcapture_svgs(input_dir: Path, output_dir: Path, scale: int = 2) -> None:
"""使用 headless 瀏覽器將 SVG 轉換為 PNG"""
export_tutorial.py
python scripts/export_tutorial.py tutorial.md output/ \
--formats docx html pdf \
--title "My Tutorial" \
--css templates/tutorial-style.css
validate_package.py
defvalidate_package(package_dir: Path) -> dict:
"""返回 {'passed': bool, 'score': int, 'failed_checks': [...]}"""
附錄B: 9大原則完整原文位置
references/frontend-slides-first.md | |
references/course-design.md | |
references/editorial-production.md | |
references/learning-sufficiency.md | |
references/research-sourcing.md | |
references/source-backed-claims.md | |
references/standalone-principle.md | |
references/visual-teaching.md | |
references/provenance-hygiene.md |
教程生成完成時間: 2026-05-07
適用技能版本: yao-tutorial-skill v1.0.2
內容來源: 基於技能源代碼和探索文檔
教程Skill的GitHub地址:https://github.com/yaojingang/yao-open-skills/tree/main/skills/yao-tutorial-skill
我優化好的skill:
https://pan.quark.cn/s/cb61e0b590d9