你寫的AI Agent Skill,可能正在幫倒忙
整理版優先睇
AI Agent Skill嘅核心係教AI「教AI」:提取比執行難,直覺信唔過,本質係重塑策略
呢篇文章整合咗微軟研究院最新論文《From Raw Experience to Skill Consumption》同埋Huashu Design作者花叔嘅實戰經驗,揭示咗AI Agent Skill系統嘅三個反直覺真相。作者發現,好多開發者以為寫Skill好簡單,但其實Skill嘅提取、評估同消費都有深層陷阱。整體結論係:Skill系統嘅本質唔係幫AI更快完成任務,而係幫AI將經驗轉化為可複用嘅知識。
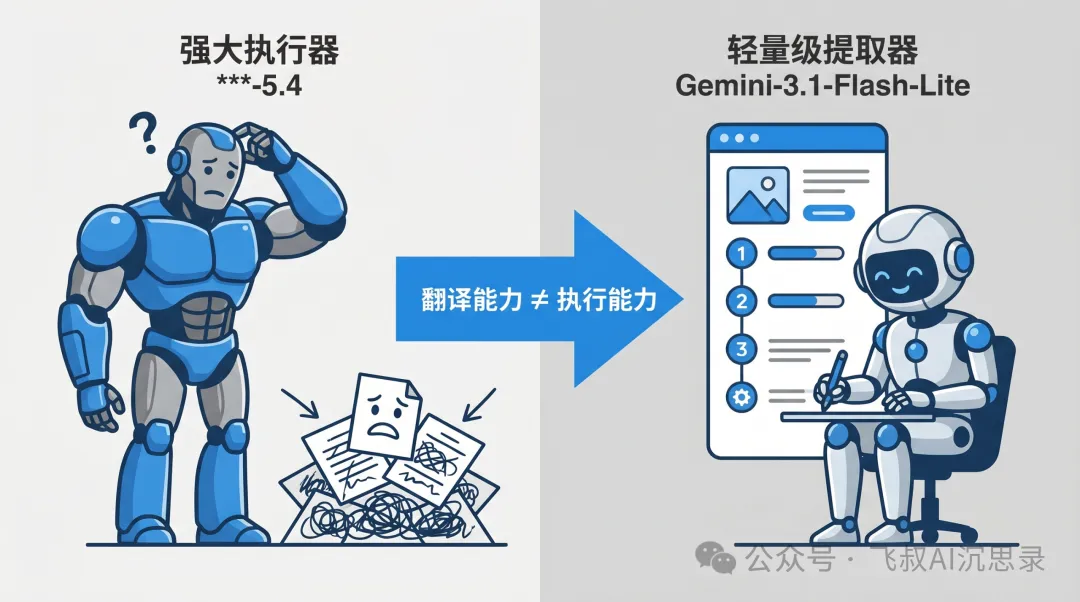
論文通過實驗指出,更好嘅執行器未必係更好嘅提取器——GPT-5.4執行最強但提取最弱,反而輕量模型Gemini-3.1-Flash-Lite提取效能最高,因為提取係「翻譯」能力而唔係「執行」能力。同時,人類直覺認為流暢完整嘅Skill,實際表現往往更差,例如低ΔSkill「編碼前解決合約」看似完美但冇用,高ΔSkill「當宿主引擎唔評估公式字符串時預先計算靜態值」先真正有效。花叔嘅「撞、借、請」三套邏輯同樣係逼AI跳出舒適區,而唔係俾多啲選項。
最後,Skill消費唔係加載工具,而係重塑模型嘅默認策略:同一Skill喺GPT-5.4同Qwen3.5-9B上會產生完全唔同嘅行為模式。經驗池嘅構成亦需要因應領域設計——失敗案例喺ALFWorld中有用,成功案例喺SpreadsheetBench先關鍵。作者提醒實戰者:唔好信直覺要信A/B測試,經驗池要精心設計,Skill適配係每目標屬性。
- 結論:Skill提取需要「翻譯」能力,唔係「執行」能力,揀提取器要揀會講清楚步驟嘅人,而唔係最強執行者。
- 方法:用A/B測試驗證Skill效果,關注三個維度:失敗機制編碼、可執行具體性、高風險動作黑名單;避免只睇「讀起嚟順唔順」。
- 差異:讀起嚟好嘅Skill往往表現更差——流暢完整同解決問題係兩回事,通用建議會降低性能。
- 啟發:Skill唔係附加插件,而係操作系統,會重塑模型嘅默認策略,所以要針對唔同模型調整表達方式。
- 可行動點:經驗池要根據領域特性設計,例如調試任務要多啲失敗案例,設計任務要強制探索多樣性(如花叔嘅「撞、借、請」)。
真相一:執行高手唔等於提取高手
微軟團隊喺SpreadsheetBench任務上做咗個實驗,結果好反直覺:GPT-5.4作為執行器表現最強,但作為提取器排名最後;相反,輕量級模型Gemini-3.1-Flash-Lite實現咗最高提取效能。點解會咁?因為Skill提取同任務執行係兩種唔同能力——執行器要「完成任務」,提取器要「將過程翻譯成說明書」。
花叔嘅Huashu Design都印證呢個邏輯:俾AI「執行」設計唔難,難嘅係令AI將設計過程「翻譯」成可複用嘅Skill。AI好容易俾啲通用建議(「要做個好設計」),而唔係具體補救措施(「Excel引擎唔評估公式字符串時要預先計算靜態值」)。微軟論文驗證咗:通用建議往往無效,具體補救措施先真正有用。
真相二:睇起嚟順眼嘅Skill,往往最冇用
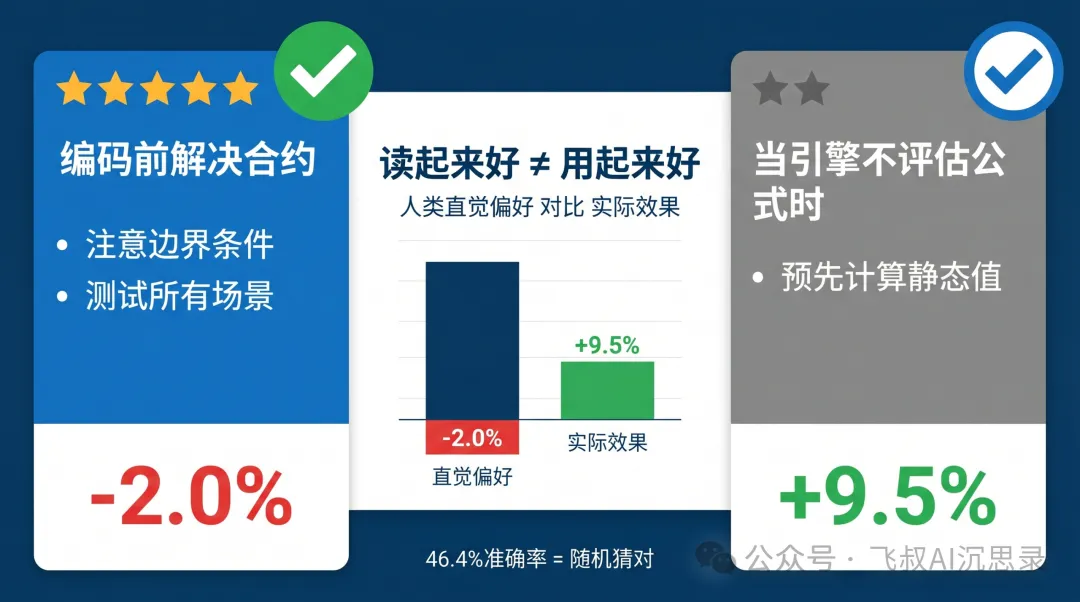
另一個震驚數據:微軟團隊用GPT-5.4做「評委」判斷兩個Skill文本嘅質量,準確率得46.4%,同隨機掟銀仔冇分別。更誇張嘅係,當兩個Skill真實性能差距超過5%時,評委反而揀中讀起嚟更好但實際更差嘅Skill,準確率得15.8%。
原因係:人類同AI嘅直覺傾向「流暢、完整、邏輯清晰」,但呢啲特徵同「能解決問題」係兩回事。論文舉例:低ΔSkill「編碼前解決合約,注意邊界條件」——讀起嚟完美,但係空話;高ΔSkill「當宿主引擎唔評估公式字符串時,預先計算靜態值」——讀起嚟具體,針對性極強。花叔嘅「圖片前置」都係呢個邏輯:唔係話「要做高質量內容」,而係具體指出「鸚鵡科普網站冇鸚鵡圖就係失敗」。
真相三:Skill係操作系統,唔係插件
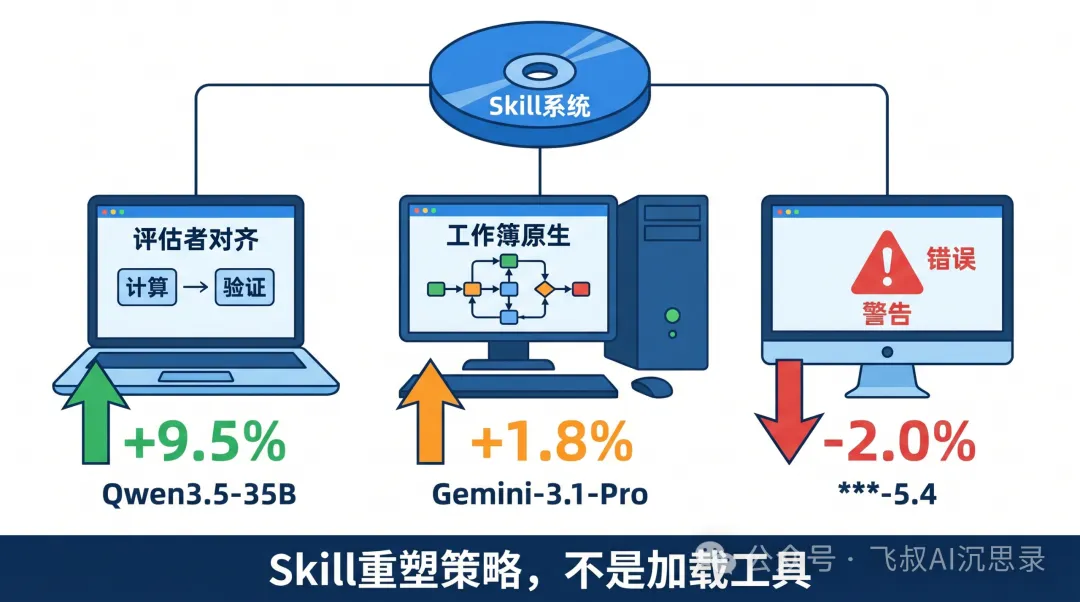
同一份Skill喺唔同模型上效果天差地別:強池Skill喺Gemini-3.1-Pro提升+1.8%,喺Qwen3.5-35B提升+9.5%;弱池Skill喺GPT-5.4反而-2.0%。點解?因為Skill消費唔係「加載一個工具」,而係「重塑默認策略」。
論文分析兩個模型:GPT-5.4消費Skill後,策略變成「評估者對齊的計算和驗證」;Qwen3.5-9B消費Skill後,策略變成「複雜的工作簿原生工作流」。同一份Skill,喺唔同模型嘅「操作系統」裏被解釋成完全唔同嘅行為。花叔嘅「撞、借、請」都係呢個邏輯:唔係俾AI三個新工具,而係改變AI嘅「操作系統」——從「揀最安全風格」變成「主動探索三種可能性」。
經驗池嘅陷阱:食譜唔啱,技巧再好都冇用
微軟團隊測試咗五種經驗池(成功率100%到0%),發現唔同領域嘅「有用經驗」完全唔同:ALFWorld呢啲具身規劃任務,失敗案例揭示無效動作同死衚衕——失敗本身就係信息;SpreadsheetBench呢啲表格任務,成功軌跡展示可行計算路徑——成功先係信息。但有一點共通:全失敗嘅池始終最差,因為成功軌跡提供「點樣行」,失敗軌跡提供「唔好行邊度」,得知道「點樣行」先真正前進。
花叔嗰套「撞、借、請」點解有效?因為佢針對「設計」呢個領域——設計需要多樣性,所以強制AI探索三種可能性。如果係代碼調試,經驗策略就應該完全相反:需要更多失敗案例去揭示bug模式。
前言
問題出喺邊?
真相一:更好嘅執行器,唔一定係更好嘅提取器
數據講反話
點解?
實戰啟示
選擇提取器 ≠ 選擇最強模型
真相二:睇起嚟越好嘅Skill,表現往往越差
一個令人震驚嘅數據
點解?
實戰啟示
唔好信直覺,要信A/B測試
失敗機制編碼:明確指出咩會失敗 可執行具體性:俾出嘅係鬱得手嘅具體步驟 高風險動作黑名單:話俾用戶知唔好掂咩
真相三:Skill唔係附加插件,而係操作系統
點解同一個Skill,喺唔同模型上效果差天共地?
點解?
實戰啟示
Skill適配係每個目標屬性
最大嘅陷阱:經驗池嘅構成,決定咗Skill嘅天花板
經驗唔係越多越好
點解?
實戰啟示
唔好用同一套經驗策略應對所有領域
最後嘅洞察:Skill系統嘅本質
俾實戰者嘅三個建議
1. 唔好迷信「讀起嚟好」
2. 經驗池要精心設計
3. Skill適配係每個目標屬性
前言
問題出在哪?
真相一:更好的執行器,不一定是更好的提取器
數據說反話
為什麼?
實戰啓示
選擇提取器 ≠ 選擇最強模型
真相二:讀起來越好的Skill,往往表現越差
一個令人震驚的數據
為什麼?
實戰啓示
不要相信直覺,要相信A/B測試
失敗機制編碼:明確指出什麼會失敗 可執行具體性:給的是能動手的具體步驟 高風險動作黑名單:告訴用戶別碰什麼
真相三:Skill不是附加插件,而是操作系統
為什麼同一Skill,在不同模型上效果天差地別?
為什麼?
實戰啓示
Skill適配是每目標屬性
最大的陷阱:經驗池的構成,決定了Skill的天花板
經驗不是越多越好
為什麼?
實戰啓示
不要用同一套經驗策略對付所有領域
最後的洞察:Skill系統的本質
給實戰者的三個建議
1. 不要迷信"讀起來好"
2. 經驗池要精心設計
3. Skill適配是每目標屬性